Chi-squared Test for Binned, Gaussian Samples
Nicholas R. Hutzler

TL;DR
This paper analyzes the chi-squared test for binned Gaussian data, revealing that standard assumptions underestimate the expected value and variability of the test statistic when using sample standard deviations.
Contribution
It derives corrected formulas for the expected value and standard deviation of the chi-squared statistic accounting for sample standard deviation effects.
Findings
Expected chi-squared value is larger than standard estimates.
Standard deviation of chi-squared is also larger than previously reported.
Results improve accuracy of goodness-of-fit assessments for binned Gaussian data.
Abstract
We examine the test for binned, Gaussian samples, including effects due to the fact that the experimentally available sample standard deviation and the unavailable true standard deviation have different statistical properties. For data formed by binning Gaussian samples with bin size , we find that the expected value and standard deviation of the reduced statistic is \begin{equation} \frac{n-1}{n-3}\pm \frac{n-1}{n-3}\sqrt{\frac{n-2}{n-5}}\sqrt{\frac{2}{N-1}}, \end{equation} where is the total number of binned values. This is strictly larger in both mean and standard deviation than the value of reported in standard treatments, which ignore the distinction between true and sample standard deviation.
Click any figure to enlarge with its caption.
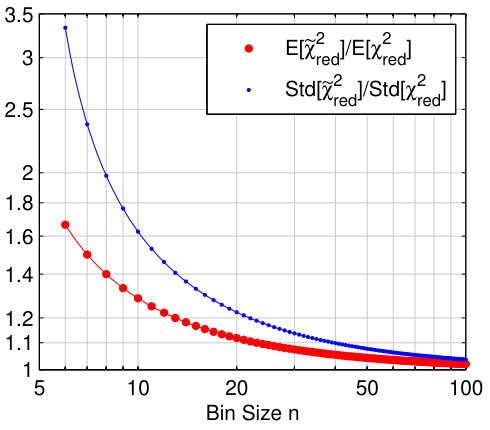 Figure 1
Figure 1Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Chi-squared Test for Binned, Gaussian Samples
Nicholas R. Hutzler
Division of Physics, Mathematics, and Astronomy
California Institute of Technology
Pasadena, CA 91125
Abstract
We examine the test for binned, Gaussian samples, including effects due to the fact that the experimentally available sample standard deviation and the unavailable true standard deviation have different statistical properties. For data formed by binning Gaussian samples with bin size , we find that the expected value and standard deviation of the reduced statistic is
[TABLE]
where is the total number of binned values. This is strictly larger in both mean and standard deviation than the value of reported in standard treatments, which ignore the distinction between true and sample standard deviation.
- June 2019
1 Introduction
Precision measurements of physical quantities typically require a very large number of individual measurements of the same quantity often taken under varying conditions, such as drifting signal-to-noise or many experimental configurations with different signal sizes. For this reason, as well as for simplification of data analysis and reduction of computational requirements, the data are typically binned together such that measurements in the same bin were taken within a time during which the conditions were similar. In order to check whether the binning is susceptible to the varying conditions, as well as to search for unknown sources of noise, a test [1, 2, 3] is commonly used. Regardless of whether or not it is an ideal choice of statistic for this case, it is fairly intuitive as a measure of whether the assigned error bars are correctly capturing the statistics of the data. However, some of the simplifying assumptions used to construct the standard can give results with a significant bias for large data sets. We discuss why the standard treatment underestimates both the mean and variance of the statistic, and then determine the appropriate correction factors.
2 Chi-squared test for binned, Gaussian samples
Consider a quantity of measurements without any assigned uncertainties. Say that the measurements are normally distributed with constant, true mean that is not known to the experimenter. We shall not assume that the data has a constant variance. Let us gather these data sequentially into groups with consecutive points each. Now compute the usual sample mean, standard deviation, and standard error of each group of points:
[TABLE]
We have now binned our data into a smaller set of mean values and uncertainties . As a check to see whether the assigned uncertainties are correctly capturing the statistical fluctuations of the data we can perform a test as outlined in many standard texts [1, 2, 3]. We will test the hypothesis that the are normally distributed about a constant (though this approach is easily extended to models with more degrees of freedom), and that the uncertainties correctly describe the statistical fluctuations of the data about the mean. The reduced- value of the data set is
[TABLE]
where is the weighted mean of the data, and is the true (unknown) standard deviation of the points , which need not be constant over different values of . If the fluctuations in the data are Gaussian in nature, and correctly accounted for by the uncertainties, then we have the usual result
[TABLE]
However, the experimenter does not know the true standard deviation, and therefore actually computes the statistic
[TABLE]
using as an estimator for . We wish to find the statistical properties of this quantity, which we shall find differ from . Intuitively, the sample standard deviation is computed from a finite number of measurements and therefore has some uncertainty associated with it, and that uncertainty should be propagated through when examining the statistic. This is a well-known effect when estimating parameters from finite data sets and has been previously explored in a number of contexts, for example Poisson distributions, counting experiments, weighted means, and histogram fitting [4, 5, 6, 7, 8, 9, 10].
More specifically, while is normally distributed, is not:
[TABLE]
the -distribution with degrees of freedom, which has larger tails for finite than a normal distribution. Notice that we are treating as a constant, which is valid in the limit , though for smaller the statistical properties of the weighted mean cannot be ignored [9, 11, 12, 13, 14, 15]. In particular, the weighted mean also has correction factors due to the difference between true and sample standard deviation, and has a non-trivial variance, both of which will impact the statistic. A good discussion of these complexities can be found in reference [15].
The square of is therefore distributed as , the -distribution with degrees of freedom, which has
[TABLE]
This is as opposed to the statistic, which has (appropriately) a distribution. is therefore distributed as a sum of -distributions, which is complicated [16]. However, the expectation value and variance are straightforward to calculate,
[TABLE]
This implies that the mean and standard deviation of the statistic are larger than those of the statistic by
[TABLE]
up to further corrections of order . A plot of these correction factors is shown in Figure 1. In the limit we recover the usual result, but for finite we will always expect larger values for both mean and standard deviation. We can also see that choosing is not advisable, since the statistic will have a non-convergent variance.
3 Conclusion
In summary, we find that the standard statistic computed from binning finite data sets underestimates the mean and variance for binned Gaussian samples, and derive simple, closed expressions for the biases. For very large data sets with finite bin sizes, such as those commonly found in precision physics measurements, these corrections can be significant and should not be neglected.
Acknowledgments. I would like to acknowledge helpful discussions with David Watson, and many helpful discussions with the ACME Collaboration, in particular David DeMille, John M. Doyle, and Brendon O’Leary.
Appendix: A simple example
We can see how the “usual” chi-squared statistic gives an incorrect result by performing a simple numerical test on some simulated data. Generate 1,000,000 points , bin into groups of , and then compute means , standard errors and the reduced chi-squared statistic (as described in the main text) for the resulting 100,000 binned points.
Nx = 1000000 //Number of x values nbin = 10 //Number of points to bin for j = 1:(Nx/nbin) //Step over bins x = randn(1,nbin) //Generate nbin normally distributed points y(j) = mean(x) //Means sigmayi(j) = std(x)/sqrt(nbin) //Standard errors end ybar = sum(y./sigmayi.^2)/sum(1./sigmayi.^2) //Weighted mean chi = (y-ybar)./sigmayi //chi chi2 = sum(chi.^2) //chi^2 dof = length(y)-1 //Degrees of freedom redchi2 = chi2/dof //Reduced chi^2 redchi2sigma = sqrt(2/dof) //‘‘Usual’’ uncertainty of chi^2
If we run this piece of code, we will find redchi2 = 1.2868 and redchi2sigma = 0.0045 (though of course the former will be different each time due to the random nature of the calculation.) This value differs considerably from the naïve expectation of based on the usual treatment that ignores the difference between sample and true standard deviations, but is quite close to the expected value of from equations (8) and (9).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Press W H, Teukolsky S A, Vetterling W T and Flannery B P 2007 Numerical Recipes 3rd ed (Cambridge University Press) ISBN 978-0521880688
- 2[2] Bevington P R and Robinson D K 2003 Data Reduction and Error Analysis for the Physical Sciences 3rd ed (Boston: Mc Graw-Hill)
- 3[3] Taylor J R 1996 An Introduction to Error Analysis 2nd ed (University Science Books) ISBN 978-0935702750
- 4[4] Baker S and Cousins R D 1984 Nucl. Instruments Methods Phys. Res. 221 437–442 ISSN 01675087
- 5[5] Jading Y and Riisager K 1996 Nucl. Instruments Methods Phys. Res. Sect. A Accel. Spectrometers, Detect. Assoc. Equip. 372 289–292 ISSN 01689002
- 6[6] Hammersley A and Antoniadis A 1997 Nucl. Instruments Methods Phys. Res. Sect. A Accel. Spectrometers, Detect. Assoc. Equip. 394 219–224 ISSN 01689002
- 7[7] Mighell K J 1999 Astrophys. J. 518 380–393 ISSN 0004-637X
- 8[8] Hauschild T and Jentschel M 2001 Nucl. Instruments Methods Phys. Res. Sect. A Accel. Spectrometers, Detect. Assoc. Equip. 457 384–401 ISSN 01689002