Demonstration-Guided Deep Reinforcement Learning of Control Policies for Dexterous Human-Robot Interaction
Sammy Christen, Stefan Stevsic, Otmar Hilliges

TL;DR
This paper introduces a deep reinforcement learning approach for training control policies enabling humanoid robots to perform natural human-like hand interactions, using a parameterizable reward function based on motion capture data.
Contribution
It presents a novel parameterizable reward function for learning diverse human-robot hand interactions without changing the reward structure.
Findings
Policies produce natural-looking motions
Large-scale user study confirms human-like perception
Method successfully applied to handshake, hand clap, finger touch
Abstract
In this paper, we propose a method for training control policies for human-robot interactions such as handshakes or hand claps via Deep Reinforcement Learning. The policy controls a humanoid Shadow Dexterous Hand, attached to a robot arm. We propose a parameterizable multi-objective reward function that allows learning of a variety of interactions without changing the reward structure. The parameters of the reward function are estimated directly from motion capture data of human-human interactions in order to produce policies that are perceived as being natural and human-like by observers. We evaluate our method on three significantly different hand interactions: handshake, hand clap and finger touch. We provide detailed analysis of the proposed reward function and the resulting policies and conduct a large-scale user study, indicating that our policy produces natural looking motions.
Click any figure to enlarge with its caption.
_figures_arm_and_hand.png) Figure 1
Figure 1_figures_arm_and_hand_cropped.png) Figure 2
Figure 2_figures_experiment_1_squeeze.png) Figure 3
Figure 3_figures_final_cost_comparison_new.png) Figure 4
Figure 4_figures_first_fig_2.png) Figure 2
Figure 2_figures_imitation_qual_clap.png) Figure 6
Figure 6_figures_robustnes_new.png) Figure 7
Figure 7_figures_robustnes_new_2.png) Figure 8
Figure 8_figures_system_2.png) Figure 9
Figure 9_paper_drl.jpg) Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13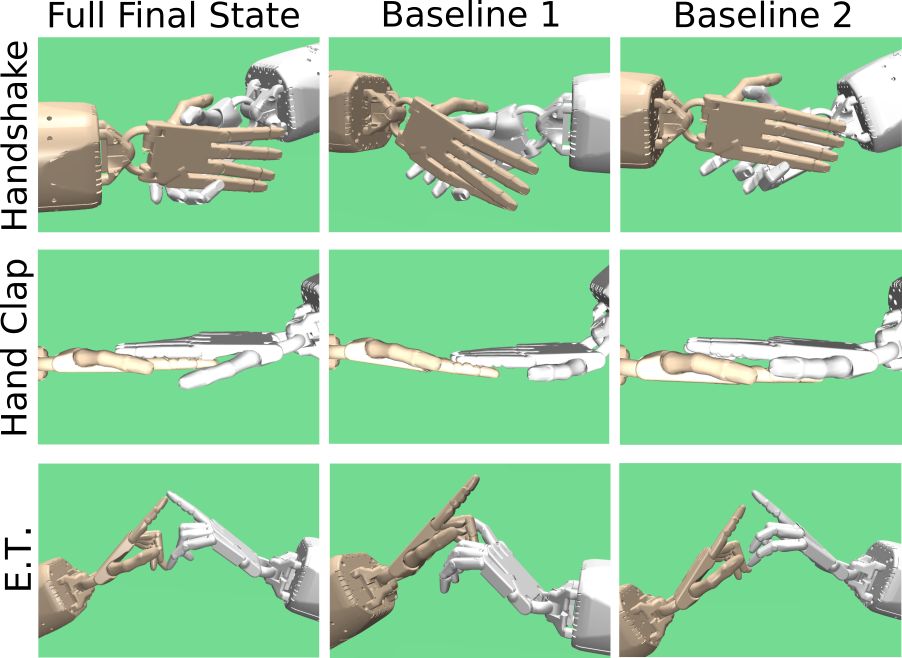 Figure 14
Figure 14 Figure 2
Figure 2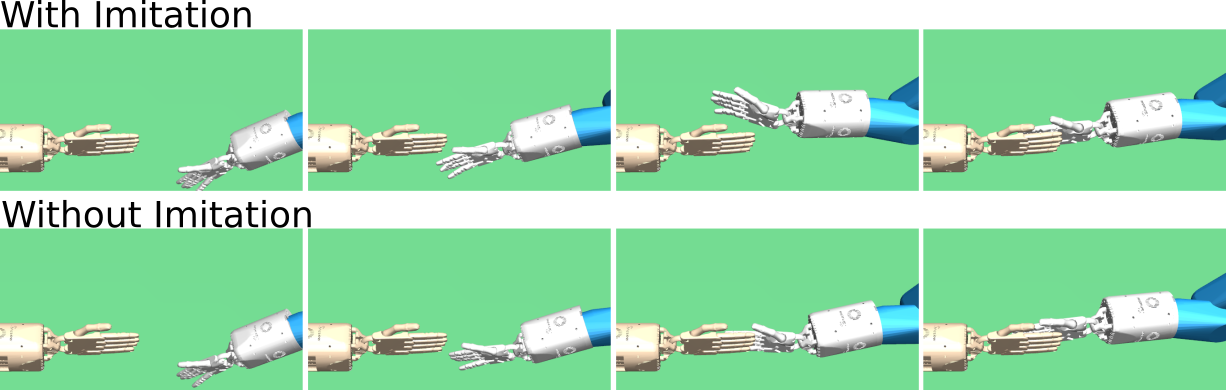 Figure 16
Figure 16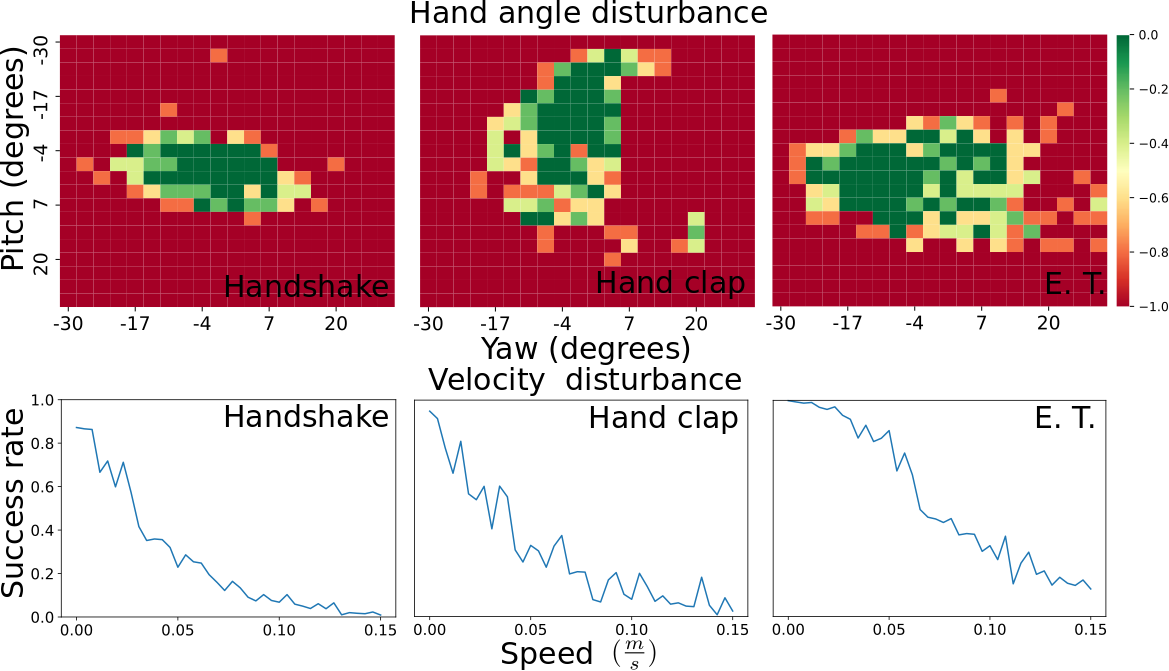 Figure 17
Figure 17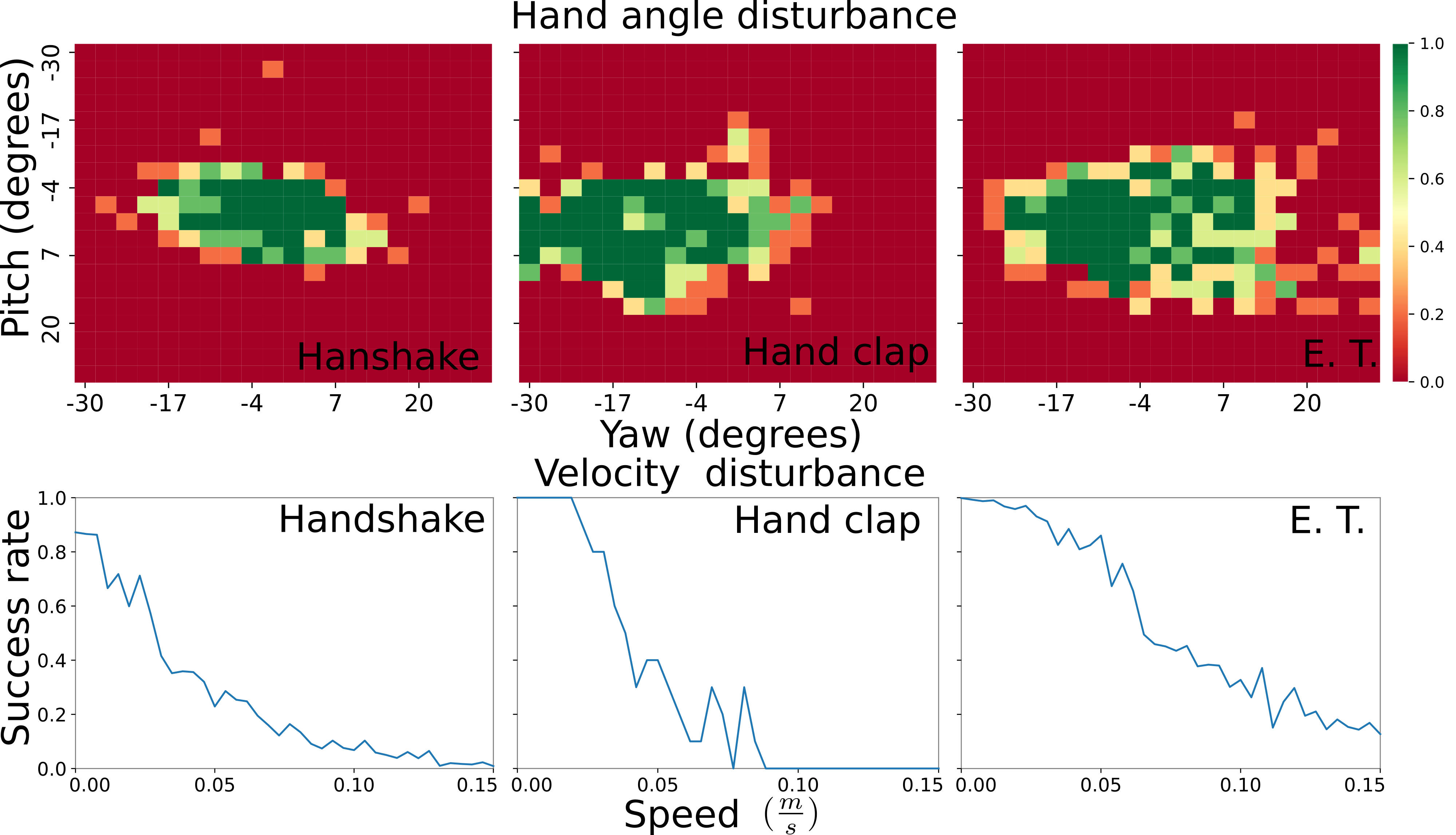 Figure 18
Figure 18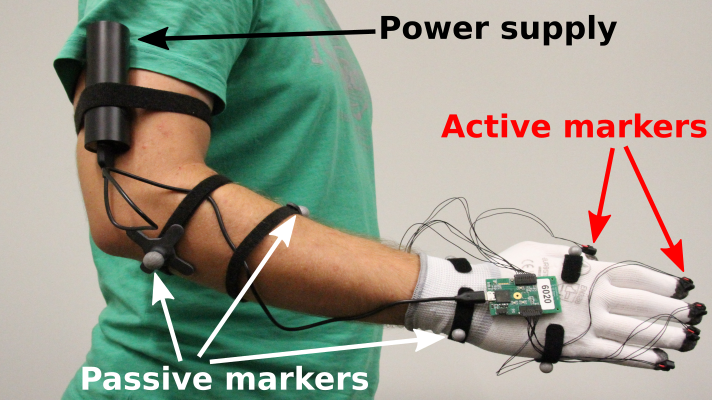 Figure 19
Figure 19 Figure 20
Figure 20| Score | mean | |||||
| Handshake | ||||||
| Hand clap | ||||||
| E.T. | ||||||
| Handshake non-smooth | ||||||
| Hand clap non-smooth |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Dexterous Humanoid Hand Control for Human-Robot Interactions Using Deep Reinforcement Learning and Imitation
Sammy Christen1, Stefan Stevšić1, Otmar Hilliges1 1AIT Lab, Department of Computer Science, ETH Zurich, 8092 Zurich, Switzerland sammy.christen | stefan.stevsic | otmar.hilliges @inf.ethz.ch This work was supported in parts by the Swiss National Science Foundation (UFO 200021L_153644). We thank the NVIDIA Corporation for the donation of GPU servers used in this work.
Demonstration-Guided Deep Reinforcement Learning of Control Policies for Dexterous Human-Robot Interaction
Sammy Christen1, Stefan Stevšić1, Otmar Hilliges1 1AIT Lab, Department of Computer Science, ETH Zurich, 8092 Zurich, Switzerland sammy.christen | stefan.stevsic | otmar.hilliges @inf.ethz.ch This work was supported in parts by the Swiss National Science Foundation (UFO 200021L_153644). We thank the NVIDIA Corporation for the donation of GPU servers used in this work.
Abstract
In this paper, we propose a method for training control policies for human-robot interactions such as handshakes or hand claps via Deep Reinforcement Learning. The policy controls a humanoid Shadow Dexterous Hand, attached to a robot arm. We propose a parameterizable multi-objective reward function that allows learning of a variety of interactions without changing the reward structure. The parameters of the reward function are estimated directly from motion capture data of human-human interactions in order to produce policies that are perceived as being natural and human-like by observers. We evaluate our method on three significantly different hand interactions: handshake, hand clap and finger touch. We provide detailed analysis of the proposed reward function and the resulting policies and conduct a large-scale user study, indicating that our policy produces natural looking motions.
I Introduction
Dexterous humanoid hands, such as the Shadow Dexterous Hand [1], are becoming very sophisticated. Improvements in mechatronics have enabled very compact systems that have more than twenty degrees of freedom (DoF). However, controller design remains very challenging and has been shown to be a very complex problem [2, 3]. Recently, model-free deep reinforcement learning (DRL) algorithms have been applied to the control of humanoid hands, albeit on relatively simple tasks such as grasping or door opening [2] and in simulation only. In [4], a controller trained in simulation has been transferred to a real humanoid hand. This opens up the door to learn policies for natural physical human-robot interactions. In particular, we are interested in learning a control policy for diverse hand interactions, such as handshakes or hand claps. The handshake is the most common greeting gesture throughout the world, therefore it has received a lot of attention in the robotics community [5, 6, 7, 8, 9]. In this paper, we present a method for training a control policy for human-robot hand interactions, using data from human demonstrations in combination with deep reinforcement learning. We test our method on the simulated model of the Shadow Dexterous Hand.
To train a control policy using a DRL algorithm, one of the main issues is the definition of a reward function. For simple tasks, like grasping or pick and place tasks, the goal is obvious and the reward can be easily shaped. For our task, however, it is not obvious how to shape a reward function. The reward needs to result in motions that are perceived as natural, the hand needs to reach a desired contact profile and precise position, while dealing with complex contact dynamics. To produce natural looking motions of animated characters in [10], the reward is based on tracking position and angle references from motion capture data. However, the authors only consider motions in open space and hence their reward function cannot be transfered to our task. Thus, we investigate important terms to construct a reward function and compare the influence of different reward terms in an ablation study. To enable generalization to different hand interactions, we define a parametrized reward function. We extract most of the reward function parameters from motion capture data, leading to only six parameters that are relatively easy to adjust. One could argue that the policy could be learned directly from data via Inverse Reinforcement Learning (IRL). However, state-of-the-art IRL methods [11, 12] have not been applied to tasks that require precise positioning or challenging contact dynamics. Furthermore, these methods can be unstable when applied to motion capture data [12]. To ensure training convergence, we propose a specialized training method. Standard DRL algorithms work out of the box on benchmark problems [13], but for more complex problems additional training details, such as randomization or early stopping are important [10, 14, 2]. We propose a training method which works in combination with DDPG, resulting in stable convergence properties.
This work presents a method for learning control policies for dexterous human-robot interaction. More specifically, we contribute the following:
(i) A multi-objective reward function for DRL algorithms. We show how reward function parameters are extracted from motion capture data and provide detailed analysis of how different parts of the reward influence the resulting control policy. (ii) A training method which works in combination with standard DRL algorithms.
(iii) A dataset of human hand interactions. (iv) A large-scale user study showing that adding imitation reward to the policy results in motions that are perceived as more natural.
II Related Work
II-A Human Hand Interaction
Different aspects of the human-robot handshake problem were investigated in the robotics community, e.g., force properties of a human handshake [5], the possibility to recognize personality and gender from a handshake [6], or the design of a compliant controller for handshakes [7]. Previous work mostly focuses on the handshake properties after the contact phase. However, producing a handshake movement is equally important [8, 9]. When humans establish a handshake, one person requests the handshake by holding out one hand, while the other person responds by grabbing the hand [9]. Based on this observation, [9] tries to model the appropriate time to request a handshake.
To achieve a handshake with humanoid hands, usually the robot requests the handshake and closes the fingers when the human hand is in contact [7]. To the best of our knowledge, our method is the first that treats the problem in the case where the human requests the handshake. This case is harder from a control perspective, because it requires coordination with the human hand, the robot needs to produce natural looking motions and it still involves physical contact as in the previous case. The control of robotic arm movement is investigated in [8, 9], but these papers do not control humanoid hands and do not observe complex contact dynamics. Furthermore, we investigate the possibility of performing different hand interactions, such as hand claps or finger touches, which are relatively under-researched.
II-B Control of Dexterous Humanoid Hands
Dexterous humanoid hands are a highly complex mechanical systems [15]. Due to their high complexity, the control problem is shown to be very challenging [2, 3]. Most approaches therefore use trajectory optimization to provide a controller [3, 16, 17]. These approaches require a precise model of the system, which makes them hard to transfer to real robots. Leveraging real robot data for model learning was proposed in [18], but the method is limited to slow in-hand manipulation of a pole. Contrary, model-free DRL does not require a model of the robot dynamics, i.e., all information is obtained through multiple episodes of trial-and-error. The only input to the algorithm is a reward function. Recently, model-free DRL has been applied to the control problem of humanoid hands [2], achieving impressive results in a simulated environment. Furthermore, [4] demonstrates the possibility of transferring a policy trained in simulation to the real Shadow Dexterous Hand.
For non-linear control tasks, model-free DRL algorithms have shown impressive performance [19, 20, 21] on the OpenAI gym benchmark problems [13]. Furthermore, when applied to low degree of freedom robotic manipulators (7-10 DoF), like robotic hands with grippers, model-free DRL has been leveraged successfully [22, 14, 23]. However, the problem becomes more challenging when DRL is applied to systems with higher DoF. A hand control problem [2] or natural movement character control problem [10] deal with such systems. In [10], the authors carefully design and adjust the weights of the reward to achieve the desired performance. To improve convergence properties, the authors use two training techniques: setting the initial state on the demonstration trajectory and early stopping. Human demonstration can be used to accelerate the convergence rate [2]. In [2], a human operator provides demonstrations via teleoperation, which are used to initialize the policy. Alternatively, IRL methods [24, 25, 26] can learn the reward function from demonstration data. However, they require running the RL algorithm in the inner loop of an iterative method, which is not feasible with DRL algorithms. To overcome this issue, IRL is posed as an adversarial imitation problem [12, 11], but these methods are prone to instability.
Our method is inspired by previous DRL approaches, but our task requires significant changes of existing methods. In [2], the demonstrations are provided by teleoperating a simulated robot hand, operating in isolation. For our case, it is impractical to collect demonstrations this way because it requires interactions between two humans. Thus, we capture real interactions using a motion capture system. Our method is more similar to [10], which is not designed for humanoid hands. In [10], the authors use motion capture data directly in the reward function formulation. Contrary, we extract the final pose parameters from data, while we similarly use motion capture data to produce natural looking motions. Additionally, we add contact patterns as an objective to the reward function, and provide a different training method.
III Preliminaries
III-A Deep Reinforcement Learning
Our control problem can be formalized using Markov Decision Processes (MDP), defined as a tuple . We describe an environment with a set of states , a set of actions , a reward function , transition dynamics , an initial state distribution and a discount rate , where and . Model-free RL does not require knowledge of transition dynamics and requires only sampling from the transition dynamics probability distribution. We define the return as a discounted sum of future rewards:
[TABLE]
The controller is defined as a control policy , which maps states to actions . The goal of the reinforcement learning algorithm is to learn a policy which maximizes the expected return from the start distribution:
[TABLE]
We define the action-value or Q-function, which describes the expected return under a policy when taking action from state , also called state-action pair, as follows:
[TABLE]
To solve the given problem, we define the Q-function and policy as neural network function approximators parametrized with and . This is known as an actor-critic type of RL algorithm, since we learn both an actor function, i.e., the policy, and a critic function, i.e., the Q-function. More specifically, we use the DDPG algorithm [19] to compute the gradients for updating the neural network parameters. To update , we minimize the loss:
[TABLE]
To update the actor parameters , we compute the gradients:
[TABLE]
which are applied to the actor neural network. For both networks we use three fully connected layers with neurons and ReLu activation functions.
To ensure convergence of the policy, we apply all techniques from the DDPG paper to stabilize convergence properties. This includes a replay buffer, batch normalization and target networks. DDPG is an off-policy algorithm, thus we define the exploration policy as:
[TABLE]
where is a sample from zero mean Normal distribution. More implementation details can be found in [19].
III-B Simulation Environment
Our simulation environment consist of two robots: the agent, controlled by the policy, and the target hand. The agent consists of a 4 DoF robotic arm and the Shadow Dexterous Hand with 24 DoF. The Shadow Dexterous Hand is controlled by 20 actuators (cf. Fig. 2). We use the same hand model as stand-in for a human hand for convenience, since this model is easy to pose in different configurations. However, this model can be replaced with a human hand model, which should not influence the results of our experiments since the hand is not actuated, as usually assumed for a hand requesting an interaction [8, 9]. The robot models are taken from the OpenAI gym framework [13].
The input to the control policy are joint angles, joint velocities and contact sensor readings (cf. Fig. 2) of the agent hand. Additional inputs are the positions of the target hand links and the origin of each rigid body on the hand. The policy outputs are control signals that actuate the agent’s arm and hand. Control signals are setpoints for the joint angles scaled in the range from to .
IV Method
Our method is able to learn control policies of hand interactions using motion capture data of human demonstrations. We assume the following setting: the first participant requests the interaction while the second is executing the interaction sequence. In the example of a handshake, the first participant stretches out the hand to request the handshake, while the other responds by grabbing the hand. The robot learns to perform the behavior of the second participant. The goal is to produce the desired interaction and motions perceived as natural. We propose a single reward function that can be applied to various hand interactions. The parameters of the reward function are extracted directly from the motion capture dataset using Alg. 1. The policy is trained via a DDPG based training method, as explained in Sec. IV-B.
IV-A Reward Function
Our proposed reward function consists of two terms:
[TABLE]
where is the final state reward, which is used to reward the correct end configuration, and the imitation state reward , which provides trajectory guidance to make the interactions look more natural. The final state reward itself consists of four terms:
[TABLE]
where is a position reward, is an angle reward, is a contact reward, and penalizes high action inputs. Experimentally, we determined that the most important position features are the fingertip positions of the agent hand (total number ). Regarding the angles, we use all joint angles of the robot hand to compute the angle reward (total number ). Position and angle rewards are defined as a negative norm of position features and angle errors:
[TABLE]
The vector is the goal position of each position feature and is the current position of the respective feature. Similarly, is the goal joint angle and the current joint angle on the robot hand. The weights , determine the importance of the specific goal, which we define via algorithm described in Sec. IV-A1. When using only position and angle rewards, the robot hand only roughly reaches the desired end configuration (cf. Fig 4, Baseline 2). Our task requires accurate hand positioning, which is hard to achieve in tasks that involve contacts. We achieve the desired hand position by adding a contact reward , which forces the desired contact profile. For more details about the influence of the reward terms we refer to Sec. V-A. Additionally, a control input reward is added to prevent high control signals. Contact and input rewards are defined as:
[TABLE]
where the indicator function outputs in case the contact sensor is active and [math] otherwise. The weight determines the importance of each contact sensor. The system has contact sensors. is the control input signal for each actuator and is the respective weight. The system has control inputs.
The imitation reward consist of two further terms:
[TABLE]
The difference compared to the final state reward is that the goal position and goal angles depend on the timestep:
[TABLE]
These rewards are scaled with the weights and .
The final state reward function is often enough to complete the interaction, i.e., to reach the final pose. However, the most direct trajectory often does not look natural (cf. Fig. 6). We overcome this issue by adding an imitation reward. As shown in Sec. V-B, imitation reward significantly improves that the hand motion is perceived as natural. However, when the starting hand pose is far away from poses in demonstration examples, the policy may produce non-smooth motions. We evaluate these examples also in Sec. V-B.
IV-A1 Reward function parameters
To define the terms of the reward function, we use a motion capture dataset of an interaction sequence. The dataset provides positions of rigid bodies and joint angles of two human hand models at timestep : the target hand, denoted with superscript , which requests the interaction and the actor hand, denoted with superscript , which the robot imitates. From , we can calculate distances between the rigid bodies and the relative position calculated in the coordinate frame of the target hand body . We use fingertip positions on both hands, plus the palm position on the target hand. For the joint angles, we use all joints from the human data that have a corresponding joint on the robot hand. Based on the minimum distance, we set the reference frame and reference timestep , as shown in Alg. 1. Using these references, we compute the goal positions and goal angles. The position goals are defined in a goal centric way, which enables us to calculate them for a randomly positioned hand in the simulation , as shown in line 5 of Alg. 1, where is the rotation matrix of the target hand rigid body with index .
Position weights are calculated using the equation:
[TABLE]
The angle and control weights all have the same value . We set the contact weights to for all sensors that should be in contact. This can be done by asking participants where they feel the pressure during interactions. Alternatively, one could use the method from [5], which simply applies color to the target hand and measures contact area from paint marks.
To train the policy, we need to set just six weights in the reward function (). In all our experiments, is set to 1, while is roughly set to , where is the number of sensors that should be in contact.
IV-B Training
To train the policy, we first need to position the target hand. For a single training episode, the target hand stays fixed. Although we train the policy with a static hand, we experimentally show that our policy generalizes to moving hands (cf. V-C). The joint angles of the target hand are set according to the joints of the human target hand at a timestep which occurs prior to the interaction timestep . This ensures that the target hand is not closed, thus allowing the robot to interact. Our reward function is defined in a goal centric way. This enables randomization of the target hand position, performed at the beginning of each episode. To calculate the reward function parameters, we pick an interaction sequence uniformly at random.
We randomize the robot hand position additionally to target hand randomization. For imitation reward to be effective, the robot hand should be positioned in the same configuration as the human hand at the start of the imitation trajectory. Thus, we position the robot wrist to the position of the human wrist at timestep , augmented with random Gaussian noise. The timestep is selected uniformly at random from a set . We use a small offset because hands can collide in the last part of the trajectory. If this position is not reachable, we start from the closest reachable position. Contrary to [10], we cannot position the agent exactly in the human pose because of the configuration differences of the human and robot arms. Furthermore, our task is driven by a goal pose, which means that starting only from demonstration trajectories, as in [10], will result in poor generalization. After each steps, we update the network using the DRL algorithm described in Sec. III-A.
IV-C Data Collection
To collect data, we use the OptiTrack motion capture system. Each participant is equipped with markers as shown in Fig. 3. We only track the right hand of each participant. Hand tracking is prone to marker mislabeling, with fingertip markers being most problematic. We use active markers, which can be uniquely identified by their blinking pattern, on the fingertips. The OptriTrack software fits a model of the human hand to the markers, providing the position of each link and joint angle of the human hand. For each interaction, we recorded five demonstrations. We will release the dataset and simulation environment for further research (https://ait.ethz.ch/projects/2019/DRL-handshake/).
V Results
We conducted experiments in simulation to evaluate our method. We extensively test our policy on three different hand interactions: handshake, hand clap, and E.T. greeting (e.g. index finger touching), see Fig. 4. These three interactions are diverse: the handshake requires grasping of the target hand in a specific way, the hand clap has a characteristic motion prior to contact, while the E.T. greeting requires precise positioning of the index finger.
V-A Ablation Study on Reward Function
In a first experiment, we intend to show the influence of the different parts of our reward function on the resulting control policy. For this, we do an ablation study on our reward function. We compare the full final state reward with two baselines. Baseline 1 uses only the relative position of the palm instead of the fingertips as a goal position feature, while keeping angle, contact and input reward the same. In Baseline 2, we remove the contact reward from the reward function. Furthermore, we examine the influence of adding the imitation reward to the final state reward.
Our final state reward function shows overall better performance than both baselines (c.f. Fig. 5). The influence of the position reward can be seen by comparing Baseline 2 to Baseline 1 for handshake and E.T. interactions. Although both baselines have low success rates, Baseline 2 results in final configurations closer to the desired ones as shown in Fig. 4. Adding contact reward to Baseline 2, i.e. using our reward function, removes these errors. The importance of the contact reward can be also seen in Fig. 5 in case of the hand clap. Since precise positioning is less important here, Baseline 1 achieves high success rate because of the contact reward. After adding the imitation reward, we observe that the success rates do not significantly change.
V-B Evaluation of Imitation Training
To qualitatively assess the impact of the imitation reward, we conduct a large-scale user study (). We present 11 video sequences of policy outputs with and without imitation reward side-by-side . We keep the initial conditions for each sequence-pair the same and randomly assign videos to the left or right. The participants state which video is perceived as more natural on a forced alternative choice 5-point scale. The five responses are: ”Left sequence looks much more natural”, ”Left sequence looks more natural”, ”Both the same”, ”Right sequence looks more natural”, ”Right sequence looks much more natural”.
Assuming equidistant intervals, we mapped user responses onto a scale from -2 to 2, where positive values mean that the user prefers the policy generated with imitation reward and vice versa. The imitation policy can generate non-smooth motions when the starting pose is far away from the recorded human trajectory. To evaluate these examples, we compare two sequences including obvious non-smooth motions.
Generally speaking, participants favor policies generated with imitation reward (c.f. Table I). For hand claps, the differences are easy to spot (see Fig. 6). Hence, human raters strongly prefer the imitation based policy. For the handshake, the differences are harder to see, resulting in significant amount of participants selecting ”Both the same” (). However, the majority of the participants still prefer the imitation based policy. For the E.T. interactions, there are no observable differences. Thus, the majority of participants answered with ”Both the same” (). For non-smooth handshakes, the results indicate that participants prefer smooth motions. However, for non-smooth hand claps, participants prefer imitation features, although the mean score is lower than in the case of smooth hand claps.
V-C Policy Evaluations
To evaluate the robustness of policies created with our method, we test the reaction to perturbations in orientation and velocity of the target hand. During training, we only randomize the position of the target hand, while the orientation stays the same. We position the target hand in the reachable workspace of the agent and measure the success rate, while changing the yaw and pitch angles of the target hand. In a realistic scenario, the human hand will not be perfectly still. Furthermore, the human can react when the contact is imminent by closing the hand or approaching the agent hand. Thus, we conduct a second experiment where the target hand is moving at constant speed, changing the direction at random every half second (see Fig. 7).
The experiments indicate that our method is robust to perturbations in orientation and velocity of the target hand. This shows that our reward function generates policies that generalize well to unseen scenarios. We also tested our policy with changing configurations of the target hand, i.e., closing fingers in a handshake policy, and did not observe any major changes. Demonstrations of these experiments can be seen in the accompanying video (https://youtu.be/ZSgEqyltaN4).
VI Discussion and Conclusion
Control of dexterous humanoid hands is a challenging problem, especially when it involves contact dynamics. In this paper, we demonstrate that a single parametrized reward function can be used for different hand interactions. To define parameters of the reward function, we use a simple algorithm to extract parameters from motion capture data. We show that policies generated with our method produce more natural looking trajectories, and generalize well to different orientations and velocities of the target hand.
Our results are shown only in simulation and with a static target hand as an initial step towards natural human-robot hand interactions. To achieve this level of performance on a real robot, transfer learning methods, such as the one suggested in [4], could be applied. We show that our policy reacts well to small velocity disturbances. However, humans can perform synchronous hand motions prior to interaction. This problem should be investigated in more detail. Our method only considers contacts, but we never investigated forces acting on the hand. [5] emphasizes the importance of forces applied during handshakes. According to our measurements, forces applied to the target hand are in the range of a normal handshake. Compliant behavior is important for hand interactions [7]. However, evaluation of the robot hand compliance is outside the scope of our work.
This paper shows how natural human-robot hand interaction can be learned using DRL. To the best of our knowledge, this is the first paper that uses a dexterous humanoid hand for human-robot hand interactions. This opens up the possibility to achieve natural hand interactions on a real humanoid robot.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] “Shadow dexterous hand,” https://www.shadowrobot.com/products/dexterous-hand/ , accessed: 2018-08-21.
- 2[2] A. Rajeswaran, V. Kumar, A. Gupta, J. Schulman, E. Todorov, and S. Levine, “Learning complex dexterous manipulation with deep reinforcement learning and demonstrations,” ar Xiv preprint ar Xiv:1709.10087 , 2017.
- 3[3] I. Mordatch, Z. Popović, and E. Todorov, “Contact-invariant optimization for hand manipulation,” in Proceedings of the ACM SIGGRAPH/Eurographics symposium on computer animation . Eurographics Association, 2012, pp. 137–144.
- 4[4] M. Andrychowicz, B. Baker, M. Chociej, R. Józefowicz, B. Mc Grew, J. Pachocki, A. Petron, M. Plappert, G. Powell, A. Ray, J. Schneider, S. Sidor, J. Tobin, P. Welinder, L. Weng, and W. Zaremba, “Learning dexterous in-hand manipulation,” ar Xiv preprint ar Xiv:1808.00177 , 2018.
- 5[5] E. Knoop, M. Bächer, V. Wall, R. Deimel, O. Brock, and P. Beardsley, “Handshakiness: Benchmarking for human-robot hand interactions,” in Intelligent Robots and Systems (IROS), 2017 IEEE/RSJ International Conference on . IEEE, 2017, pp. 4982–4989.
- 6[6] P.-H. Orefice, M. Ammi, M. Hafez, and A. Tapus, “Let’s handshake and i’ll know who you are: Gender and personality discrimination in human-human and human-robot handshaking interaction,” in Humanoid Robots (Humanoids), 2016 IEEE-RAS 16th International Conference on . IEEE, 2016, pp. 958–965.
- 7[7] M. Arns, T. Laliberté, and C. Gosselin, “Design, control and experimental validation of a haptic robotic hand performing human-robot handshake with human-like agility,” in Intelligent Robots and Systems (IROS), 2017 IEEE/RSJ International Conference on . IEEE, 2017, pp. 4626–4633.
- 8[8] T. Shu, X. Gao, M. S. Ryoo, and S.-C. Zhu, “Learning social affordance grammar from videos: Transferring human interactions to human-robot interactions,” ar Xiv preprint ar Xiv:1703.00503 , 2017.