Newswire versus Social Media for Disaster Response and Recovery
Rakesh Verma, Samaneh Karimi, Daniel Lee, Omprakash Gnawali, Azadeh, Shakery

TL;DR
This paper compares Twitter and newswire sources during the 2015 Nepal Earthquakes, evaluating their timeliness, content, and potential to provide comprehensive disaster situational awareness through summarization and linkage techniques.
Contribution
It introduces a method to link tweets and newswire articles, evaluates summarization techniques, and demonstrates their complementary roles in disaster response analysis.
Findings
Tweets often appear earlier than newswire articles.
Tweets and newswire provide complementary perspectives.
Unsupervised summarization can effectively capture key content.
Abstract
In a disaster situation, first responders need to quickly acquire situational awareness and prioritize response based on the need, resources available and impact. Can they do this based on digital media such as Twitter alone, or newswire alone, or some combination of the two? We examine this question in the context of the 2015 Nepal Earthquakes. Because newswire articles are longer, effective summaries can be helpful in saving time yet giving key content. We evaluate the effectiveness of several unsupervised summarization techniques in capturing key content. We propose a method to link tweets written by the public and newswire articles, so that we can compare their key characteristics: timeliness, whether tweets appear earlier than their corresponding news articles, and content. A novel idea is to view relevant tweets as a summary of the matching news article and evaluate these…
Click any figure to enlarge with its caption.
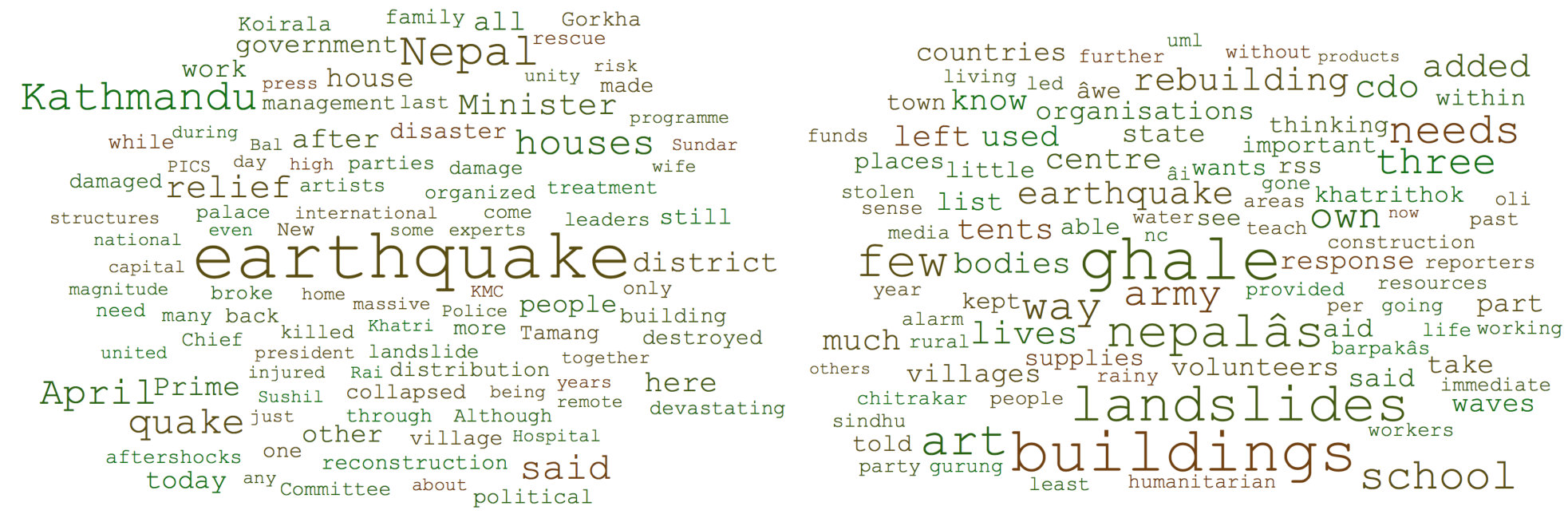 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7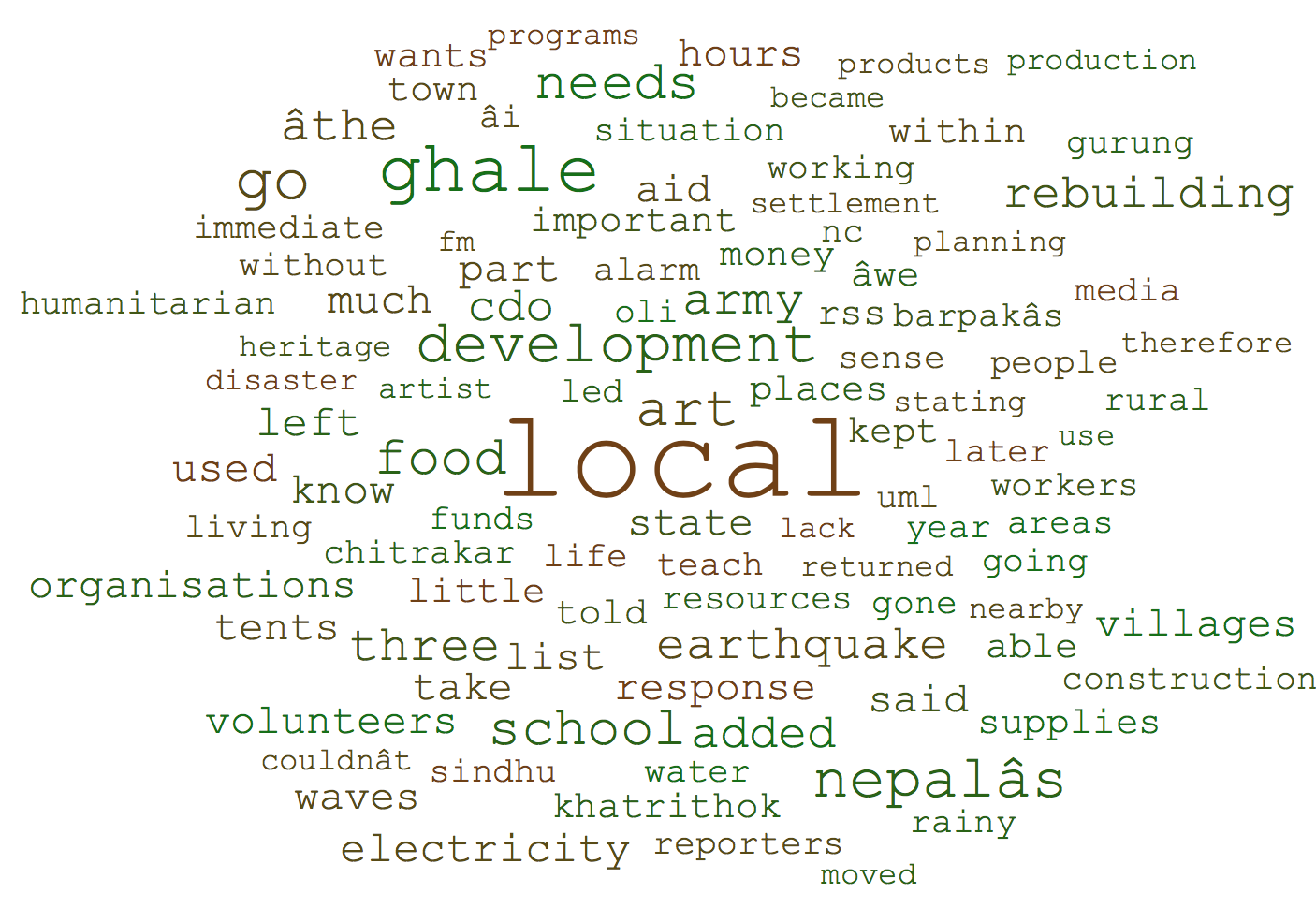 Figure 8
Figure 8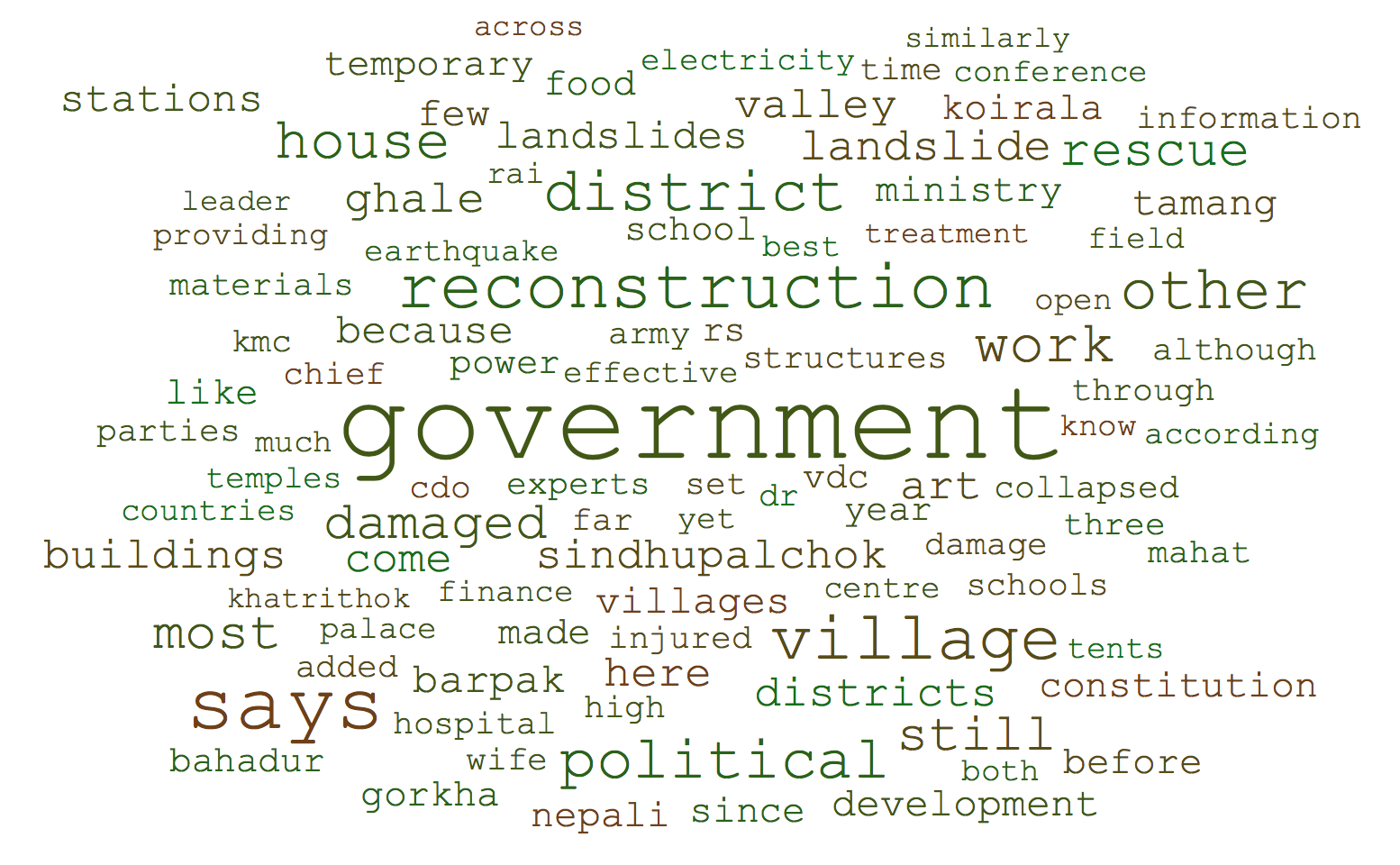 Figure 9
Figure 9 Figure 10
Figure 10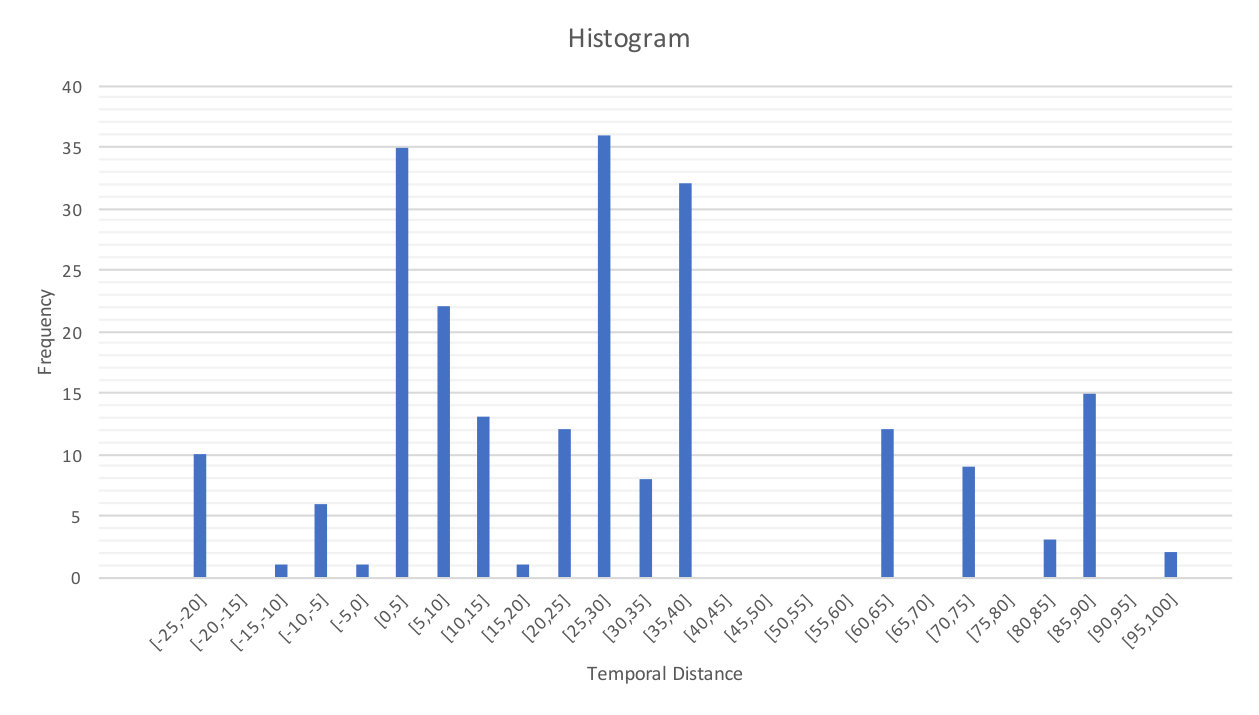 Figure 11
Figure 11 Figure 12
Figure 12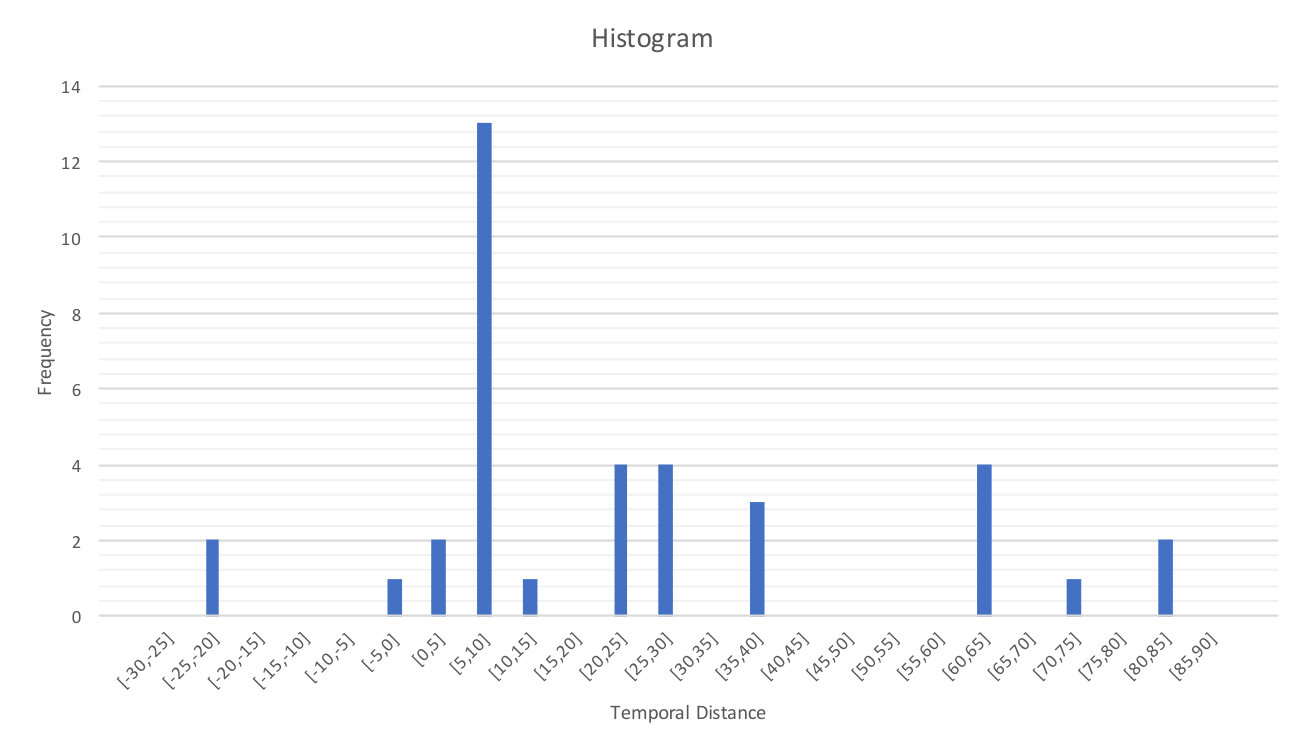 Figure 13
Figure 13 Figure 14
Figure 14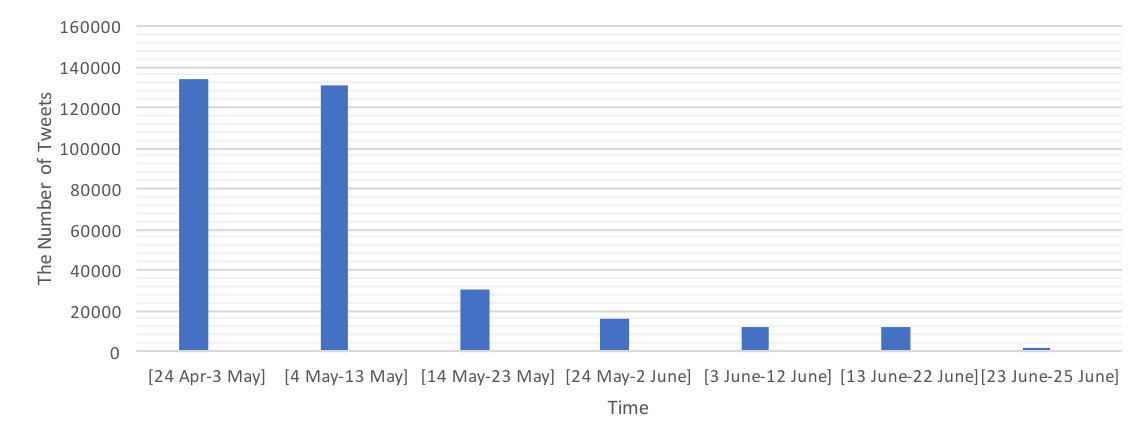 Figure 15
Figure 15 Figure 16
Figure 16| Word | Frequency |
|---|---|
| nepal | 329,836 |
| earthquake | 312,721 |
| help | 31,012 |
| relief | 26,062 |
| victims | 24,823 |
| Username | Description | Number of |
|---|---|---|
| Tweets | ||
| dlnepalnews | Link you with news in Nepal. | 1,601 |
| gcmcEarthquake | We tweet about Crisis, Disaster and | 1,078 |
| Emergency Management related to | ||
| Earthquakes. | ||
| crowdtrendies | The latest uber great campaigns from | 752 |
| all your favourite crowd funding websites. | ||
| wilayah_news | Breaking news and information from | 673 |
| the Muslim world. |
| Percentage of tweets with mentions | 17.3% |
| Percentage of tweets with URLs | 77.3% |
| Percentage of tweets containing disaster keywords | 40.6% |
| Percentage of tweets with hashtags | 32.1% |
| Filter | Articles Remaining | Extra Info |
|---|---|---|
| English-Only | 799 | 5 were empty files |
| 1000 character minimum | 517 | 414 avg. words per article |
| 10 sentence minimum | 349 | 519 avg. words per article |
| Emergency | Exigency | Hurricane | Tornado | Twister |
| Tsunami | Earthquake | Quake | Seism | Temblor |
| Tremor | Flood | Storm | Crest | Extreme weather |
| Forest fire | Brush fire | Ice | Stranded | Avalanche |
| Hail | Wildfire | Magnitude | Shelter-in-place | |
| Typhoon | Stuck | Disaster | Snow | Blizzard |
| Sleet | Mud slide | Mudslide | Erosion | Power outage |
| Brown out | Warning | Watch | Lightening | Lightning |
| Aid | Assistance | Help | Relief | Closure |
| Closedown | Closing | Shutdown | Interstate | Burst |
| Emergency Broadcast System | Tsunami Warning Center | |||
| The number of | The number of | Precision |
| relevant pairs | partially relevant pairs | |
| 37 | 218 | 0.47 |
| Annotator Pair | Jaccard Index |
|---|---|
| a and e | 0.3213 |
| b and d | 0.1877 |
| c and k | 0.1384 |
| f and g | 0.2783 |
| h and i | 0.2299 |
| j and l | N/A |
| Method | R1/R2 F1 | R1/R2 Prec. |
|---|---|---|
| Abstractive | Extractive | |
| PKUSUMSUM - Lead | 0.58618 / 0.47536 | 0.68469 / 0.55647 |
| PKUSUMSUM - Centroid | 0.42837 / 0.20766 | 0.72431 / 0.58853 |
| PKUSUMSUM - LexRank | 0.39544 / 0.14940 | 0.58085 / 0.32428 |
| PKUSUMSUM - TextRank | 0.41164 / 0.16862 | 0.64032 / 0.42380 |
| PKUSUMSUM - Unsup. Submod. | 0.42699 / 0.18426 | 0.62063 / 0.41153 |
| DocSumm - Greedy TFIDF | 0.39928 / 0.17318 | 0.66867 / 0.52939 |
| NewsSumm - ILP with Budget | 0.41619 / 0.18641 | 0.62037 / 0.44923 |
| NewsSumm - ScoreILP with TFIDF | 0.39358 / 0.16135 | 0.56496 / 0.36475 |
| NewsSumm - Title Reduction | 0.41717 / 0.17841 | 0.64739 / 0.48364 |
| Min | Max | Average | Mode of |
| cluster size | cluster size | Cluster size | the cluster sizes |
| 8 | 18 | 11.47 | 9 |
| Relevancy | R1/R2 F1 | R1/R2 Prec. | R1/R2 Prec. |
|---|---|---|---|
| Type | Abstractive | Extractive | Whole Article |
| Partially Relevant | 0.17021 / 0.01749 | 0.22569 / 0.02191 | 0.39487 / 0.05062 |
| Relevant | 0.11670 / 0.01150 | 0.36622 / 0.02676 | 0.51154 / 0.06385 |
| Set | Set | ||
|---|---|---|---|
| PRT | NA | 0.76239 | 0.93424 |
| RT | NA | 0.66994 | 0.96928 |
| PRT | AS | 0.88186 | 0.90919 |
| RT | AS | 0.81098 | 0.94268 |
| PRT | ES | 0.85351 | 0.92084 |
| RT | ES | 0.74424 | 0.95237 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Newswire versus Social Media for Disaster Response and Recovery
Rakesh Verma
Samaneh Karimi
Daniel Lee
Omprakash Gnawali
Azadeh Shakery
University of Houston
University of Tehran
Institute for Research in Fundamental Sciences (IPM)
Abstract
In a disaster situation, first responders need to quickly acquire situational awareness and prioritize response based on the need, resources available and impact. Can they do this based on digital media such as Twitter alone, or newswire alone, or some combination of the two? We examine this question in the context of the 2015 Nepal Earthquakes. Because newswire articles are longer, effective summaries can be helpful in saving time yet giving key content. We evaluate the effectiveness of several unsupervised summarization techniques in capturing key content. We propose a method to link tweets written by the public and newswire articles, so that we can compare their key characteristics: timeliness, whether tweets appear earlier than their corresponding news articles, and content. A novel idea is to view relevant tweets as a summary of the matching news article and evaluate these summaries. Whenever possible, we present both quantitative and qualitative evaluations. One of our main findings is that tweets and newswire articles provide complementary perspectives that form a holistic view of the disaster situation.
keywords:
Nepal Earthquake , newswire , social media , summarization , disaster response , disaster recovery
MSC:
[2010] 00-01, 99-00
††journal: Journal of Information Processing and Management
1 Introduction
When a disaster strikes, responders and relief agencies need to rapidly assess the damages to lives and infrastructures, and get a grip on the situation. Phone service and electricity supply may be disrupted in various parts of the affected region. Thus, there may not be direct sources of information available, e.g., calling (or messaging) the first responders in the affected region may not be possible. How to acquire important and reliable information quickly in such a fast-moving and chaotic situation? For this purpose, they may turn to indirect sources: the social networks, such as Twitter, or the newswire services.
Twitter has become a de facto standard domain for event detection [1], because of its real-time nature. Researchers have given some evidence to show that Twitter users break news before newswire. However, few studies have examined the content and timeliness of the two different sources, especially in the context of a major disaster.
In this paper, we examine the content and timeliness of the two different sources in the context of the 2015 Nepal Earthquakes. Since newswire articles are typically much longer than tweets, and first responders may not have much time to read multiple news articles before responding in a disaster situation, we also examine the effectiveness of summarization from several viewpoints. These considerations lead to the following research questions (RQ):
Does Twitter report news faster than traditional newswire, especially in the context of a rapidly changing situation such as a major disaster? (RQ1) 2. 2.
What type of information is reported earlier by Twitter, especially in the context of a rapidly changing situation such as a major disaster? (RQ2) 3. 3.
How effective is summarization of news articles with respect to Twitter content? (RQ3) 4. 4.
How effective is summarization of news articles for capturing the important information from human viewpoint? (RQ4) 5. 5.
How effective are some of the methods proposed for linking tweets with news articles? (RQ5) 6. 6.
How effective are tweets as summaries of news articles? (RQ6)
The rest of this paper is organized as follows. In the next section, we review the relevant related work. In Section 3, we describe the datasets. Section 4 describes the proposed method for linking tweets with news articles and its evaluation (RQ5). The summarization research questions (RQ3 and RQ4) are investigated in the following section. RQ1 and RQ2 are studied in Sections 6.1 and 6.2 and Section 7 concludes the paper.
2 Related Work
Twitter for emergency applications has been studied by several researchers, e.g., [2, 3, 4, 5, 6]. In [2], researchers concluded that Twitter was not yet ready for first responders. However, it was helpful for civilians. These were the early days of Twitter, as we find from [3] that individuals immediately posted specific information helpful to “early recognition and characterization of emergency events” in the case of the Boston marathon bombing. In [4], researchers found that tangible, useful information was found in the early period before storm system Sandy and it got buried in emotional tweets as the storm actually hit. However, we think more studies are needed on this issue, since the tweets collected were rather small, approximately 27,000, using just the hashtag #sandy. A bilingual analysis of tweets obtained over 84 days overlapping the Tohoku earthquake showed, among other results, the correlation between Twitter data and earthquake events [5]. A survey of this literature can be found in [6].
Several papers have examined Twitter data in the Nepal Earthquake context [7, 8, 9, 10, 11]. Relevance of tweets was examined by [7, 8]. However, note that our problem is different, viz., whether a tweet is relevant in the context of a given news article. The other papers examined different aspects such as public concerns and perceptions of disaster recovery efforts [9, 11] and public reaction to social media project of the police [10].
Researchers have examined the question of whether Twitter can replace newswire for breaking news [1]. They studied a period of 77 days in 2011 during which 27 events occurred. The biggest disasters in this event-set are: an airplane crash with 43 deaths, and a magnitude 5.8 earthquake in Virginia that caused infrastructural damage.111None of these disasters, bad as they are, rise to the level of the Nepal Earthquake(s) of 2015 in which almost 10,000 lives were lost. They collected a large dataset of tweets and news articles, but then eliminated a large collection of tweets based on clustering. More elimination of tweets led to only 97 linked tweet-news article pairs, which is a small dataset.
Thus, some researchers have focused on comparing the two sources of information, e.g., [1], some others utilize the joint information in them to improve the performance of news related tasks, and some papers try to discover the linkage between tweets and news articles [12, 13, 14, 15, 16, 17].
2.1 Tweet-News Linking
In this section, the previous works on these areas are reviewed.
The tweet-news linking method proposed by Guo et. al, [18] with the aim of enriching short text data in social networks is a graph based latent variable model. They extract text-to-text relations using hashtags in tweets and named entities in news articles along with their temporal similarity.
In [19], a framework for connecting news articles to Twitter conversations is proposed using Local cosine similarity, global cosine similarity, local frequency of the hashtag and global frequency of the hashtag as the classification features extracted for each article-hashtag pair. The task of linking tweets with related news articles is studied in another paper to construct user profiles [20]. The authors proposed two sets of strategies to find relevant news articles to each tweet in this paper. In addition to URL-based strategies, which is similar to the idea used in [21], they also proposed several content-based strategies that include computing the similarity between hashtag-based, entity-based and bag-of-word-based representations of tweets and news articles to discover the relation between them. In addition to user modeling, the tweet-news linking task has been employed in document summarization [22], sentiment analysis [23] and event extraction [24]
2.2 Tweet Assisted Summarization and Tweet Summarization
In [25], researchers proposed two methods that leverage tweets for ranking sentences in news articles for summarization: a voting method based on tweet hit counts of sentences, and a random walk on a heterogeneous graph (HGRW) consisting of tweets and news article sentences as nodes and the edge weights are defined by weighted idf-modified-cosine scores. The best ROUGE-1 F-score [26] is achieved by a version of HGRW that outputs both sentences from news articles and tweets in the summary, where the summary consists of top four sentences/tweets as highlights of the article.
Tweet summarization has also been studied, e.g., see [27] and references cited therein. Our problem is a little different, we consider tweets that are linked and found relevant (or partially relevant) to news articles from the perspective of summaries of those news articles. We then evaluate them to get an idea of how much content of the articles is captured by these tweets.
3 Datasets
We collected two datasets, a tweet dataset, and a newspaper article dataset, for our research questions. We describe these datasets below.
3.1 Twitter Dataset & Characteristics
There are some tweet datasets on the Nepal Earthquake released by other researchers, e.g., [28]. However, since the main goal in this paper is to use the linkage between tweets and news media content for disaster response and recovery, we need two contemporaneous datasets of news articles and tweets, relevant to the Nepal Earthquake. Therefore, we collected a set of tweets about the Nepal earthquake using “Nepal earthquake” as the search query and annotated them. We also collected a set of news articles as explained in section 3.2. The tweet collection consists of 336,140 tweets written from April 24, 2015 to June 25, 2015. In the rest of this section, some characteristics of the tweets generated in this time period is studied.
3.1.1 Most Frequent Words in Tweets
As shown in table 1, the top 10 most frequent words in the set of collected tweets are nepal, earthquake, help, relief and victims. The number of unique words in this dataset is 91,752.
3.1.2 The Number of Tweets about the Nepal Earthquake over Time
The number of tweets written about the Nepal earthquake varies in different points of time as shown in Figure 1. The higher number of tweets during the first two periods, i.e. from April 24 to May 23, is due to the occurrence of the earthquake on April 25, its aftershocks and all related issues that raised consequently.
3.1.3 Twitter Users Activity
The tweets of the collected tweet dataset is generated by 160,053 unique users. The top 4 users ranked based on the number of written tweets from April 24, 2015 to June 25, 2015 about the Nepal earthquake are shown in Table 2. According to their descriptions, the top ranked users are those who are active in news area in different related domains such as Nepal related news, natural disasters or Muslim world news.
3.1.4 The Descriptive Statistics of the Twitter Dataset
Table 3 shows some of the descriptive statistics of the collected tweet dataset including the fraction of tweets with URLs, mentions, hashtags and disaster keywords. To compute the fraction of tweets that contain a disaster keyword, a list of keywords about weather, disaster and emergency 222https://gist.github.com/jm3/2815378 is employed.
3.1.5 Annotation
To evaluate the performance of the proposed tweet-news linking method, a set of 310 pairs of tweet-news articles were selected to be annotated by a group of 10 researchers, such that each pair was annotated by two annotators. This set of 310 pairs is the result of pairing a set of 31 news articles and their top 10 most similar tweets based on their TFIDF similarity score. The set of 31 news articles is a subset of the news articles used for summarization annotation, explained in section 3.2.4, that are selected based on being relevant to the Nepal earthquake.They were asked to annotate each pair of tweet-news article according to the following instructions.
If the tweet is relevant to the news article, i.e. it is about a specific subject that is also mentioned in the news article, it should be labeled as relevant (label = 2).
- 2.
If the tweet is generally relevant to the topic of the news article, it should be labeled as partially relevant(label = 1).
- 3.
If the tweet doesn’t have a meaningful content or is totally irrelevant to the news article, it should be labeled as not relevant (label = 0).
One example of each type was also included to further clarify these categories.
3.2 News Articles Dataset & Characteristics
News articles were collected from five Nepali news sources: “Kantipur,” “Kathmandu Post,” “Nayaptika,” “Nepali Times” and “The Rising Nepal.” In total more than 700 articles were obtained in both English and Nepali, all of them published between April 2, 2015 and November 5, 2015. The English subset ranges from April 28, 2015 to August 19, 2015.
3.2.1 Some Challenges of the News Dataset
For the present paper, we focus only on the English language subset of the dataset. Hence, we first filter out any files that have Nepali filenames or content.
Because the articles were printed in Nepal, even the English language subset had encoding that was incompatible with standard English characters. So the articles were filtered further to include only those that can be decoded to ASCII characters.
After this, another round of filtering was done to ignore articles which contained less than 1000 characters (approx. 100 words). And the final dataset used for annotation required a minimum of 10 sentences.
3.2.2 Dataset of Human Annotations
The set of 349 news articles was used to make a smaller annotated set, by dividing into articles with less than 20 sentences and those with greater than 20 sentences. Then 36 were randomly selected from the set of those less than 20 sentences, and 24 from the set more than 20 sentences. There were 12 annotators and each annotated 10 articles: 6 smaller and 4 larger. For each set of ten articles was annotated by two annotators. This resulted in a set of 60 human annotated news articles with summaries. Annotators were asked to perform two annotation tasks for each article (Figure 2): (1) abstractive and (2) extractive 333Annotator H extractive summaries missing for 3 documents due to unforeseen issues.
3.2.3 Preprocessing
For consistency all data analyzed in conjunction with the News Dataset used the following preprocessing steps:
News article content was parsed into sentences, and then each sentence into word tokens.
- 2.
Stopwords (words with low information value) were removed.
- 3.
Stemming was done to allow words like “work,” “worked” and “working” to be considered as the same.
- 4.
During any comparison, the word tokens were always lowercased.
The preprocessing was done using the open-source package Natural Language Toolkit (NLTK) [29].
3.2.4 Annotation
To keep the task of creating summaries feasible, 60 documents were chosen for annotation. These were annotated by a group of 12 researchers with the following instructions. Each annotator was provided the same list of keywords.
Summarize each article in 100 words (or less).
- 2.
If a keyword is mentioned, then it must also be mentioned in the summary,
- 3.
In addition to the 100 word summary, select five sentences that best represent the document content.
For inter-annotation agreement tests, each document was annotated by two annotators. We separated the initial English-only subset into articles that were between 10-20 sentences long and articles with more than 20 sentences. Each set of ten documents included six from the former set and four from the latter. The same set of ten documents were reviewed by two annotators.
4 Linking Tweets with News Articles
To discover the linkage between tweets and news articles, a machine learning approach is proposed that explores the space of tweet-news article pairs. In this approach, each pair of tweet and news article is represented by a set of features, then a classification model is learned using a training set with matching labels. Finally, the trained model is applied on the tweet-news article pairs of the test set to find the matched ones. The features employed to represent each tweet-news article pair are as follows.
char Ngram similarity score: This feature measures the similarity between the char Ngrams of the tweet and the news article by counting the number of the matched char Ngrams normalized by the total number of possible matched character Ngrams. The main aim of defining and using this feature is to detect the similarities between tweet’s words, specially hashtags, written in camel case style and news article words. In this paper, this feature is computed for N = 2 and N = 3. Furthermore, the same feature is computed for the expanded versions of the tweet and news article datasets. For expansion, we add all WordNet synsets [30] of each word found in the text. Thus, four different features are computed for each tweet-news article pair including char2gramSim, char3gramSim, exp_char2gramSim and exp_char3gramSim.
Temporal distance: The difference between the publish date of the news article and the tweet is considered as a feature for each pair.
TFIDF score: The TFIDF similarity between the tweet and news article content is employed as another feature. The TFIDF similarity scores are calculated using the Lemur project 444 https://www.lemurproject.org.
Hashtag similarity: This feature is computed by counting the number of hashtags matched with any term in the news article, normalized by the total number of hashtags used in the tweet.
After obtaining the feature vectors of the training set and test set, the classification model should be learned. Since the pairs of tweet-news articles are used as the instances in this paper and the number of matched pairs are very few compared to all possible pairs of tweets and news articles in the training set, the training data is imbalanced. Therefore, a random undersampling method is employed to make the training data balanced before learning the classification model. In this paper, SVM is used as the classification method with parameters tuned using a validation set. We randomly selected one fifth of the training set and used it as the validation set for parameter tuning.
4.1 Experimental Results
4.1.1 Training and Test Sets
As mentioned in section 3.1, tweets related to the Nepal earthquake were collected. Then, the list of keywords about weather, disaster and emergency, mentioned in 3.1.4, is used to filter the tweets that contain at least one of the keywords. The final set of tweets is employed as the test set. We used another dataset of tweets and news articles with their matching labels [31] as the training set. The number of tweets in the training set is 34,888 and the number of news articles in the training set is 12,704. Both training and test sets are preprocessed by removing the non-ascii characters, punctuation, stop-words and URLs. We created the feature vectors for all pairs of tweets and their top (up to) 100 retrieved news articles, based on their TFIDF similarity score, for both training and test sets. In summary, the total number of instances, i.e. tweet-news pairs, in the training data is 759,971 and in the test data is 528,402.
4.1.2 Experiments
We used the Scikit-Learn and imblearn Python libraries for the implementation of the classification and undersampling methods respectively. We randomly selected one fifth of the training set and used it as the validation set for tuning gamma and C, the parameters of the SVM method. To tune the parameters, we performed 5-fold cross validation on the validations set using the GridSearchCV module of scikit-learn library.
For each news article, we ranked the tweets based on their class membership probabilities, namely the probabilities of being classified as relevant, estimated by SVM. We selected the top 10 tweets for each news article and annotated the resulting pairs as relevant, partially relevant or irrelevant for a subset of 31 news articles from the test set. To aggregate the two labels assigned by two annotators for each pair, we considered the ceiling of their arithmetic mean as the final annotation for that pair. In other words, if the sum of two labels is 0, the final annotation for that pair would be 0 (i.e. irrelevant pair), if the sum of two labels is either 1 or 2, the final annotation would be 1 (i.e. partially relevant pair) and if the sum of two labels is either 3 or 4, the final annotation would be 2 (i.e. relevant pair). After obtaining the aggregated annotations for each pair, the precision is calculated. To compute the precision, we considered the partially relevant examples as true positive with a weight of 0.5. The precision and aggregated annotation results on the set of 310 tweet-news pairs are shown in table 6.
We computed the actual agreement between the two annotators by considering a weight of 0.5 for which the annotations difference equals to one. The computed score for our annotations is 0.59 which means that there is a moderate agreement between the annotators.
4.2 Challenges of the Tweet-News Linking Task
Some of the challenges of the tweet-news linking task are:
The lack of published time information of news articles.
- 2.
The lack of geographic location information of tweets.
- 3.
Different time zones in tweets’ time information.
5 Summarization of News Articles
Summarization is used to paraphrase or represent a large document with a smaller set of sentences. Here we look at how summarization can be used to alleviate some of the information overload of articles related to the Nepal Earthquake. We analyze the datasets used and present some results of automatically generated summaries.
5.1 Evaluation of Annotation
There are many ways to evaluate the annotations of humans. One simple measure is the Jaccard Index. It computes the amount of common elements between two sets. In the case of our task, a set would be a single summary and the elements would be words of that summary. Table 7 reports the average Jaccard Index over the ten documents annotated by each annotator pair. Note that one set of 10 documents had only a single annotator so the Jaccard Index is not applicable. However, the annotations are still used in all relevant evaluations.
[TABLE]
5.2 Limits of Extractive Summaries
ROUGE will be the metric of choice for the evaluations of automatic summarizers. ROUGE is based on the word overlap between peer summary (i.e. generated summary) and an annotated summary. Since, annotator generated abstractive summaries will use words not in the vocabulary of the documents, even a perfect extractive summarizer will never achieve 100% recall.
We investigate this limit by using the articles themselves as a peer summary against their matching annotator summaries. Because we will be evaluating the whole article, the precision will be low. However, the recall value can show the upper limit of any extractive summarizer. Running ROUGE shows that the maximum achievable score is 89.8%. This puts into context the ROUGE F1 scores reported earlier, and reinforces a similar result of [32], where they also computed this limit for Document Understanding Conference (DUC) data.
5.3 Evaluating Automatic Summarizers
We created summaries of the English-only subset using the following approaches:
PKUSUMSUM an open source package that has algorithms for single-document, multi-document, and topic-based summarization [33]. 2. 2.
DocSumm is a Python package that has greedy and dynamic programming heuristics for approximating the summary based on sentences of original document (extractive summarization) [32]. 3. 3.
NewsSumm is a Python package that has several heuristics, including integer linear programming (ILP) and title-based reduction of a document before summarization, for extractive summarization.
The summaries of the human annotated articles are then evaluated using ROUGE software [34], since ROUGE needs reference summaries. We report the ROUGE 1-gram F1 score for summaries created by PKUSUMSUM, DocSumm, and NewsSumm in Table 8. For each generated summary we compare them against the human generated summaries (abstractive) and also the human selected representative sentences (extractive). Since extractive summaries are based on human selection of the five best sentences, of arbitary length, to represent the document, it would be better to evaluate ROUGE-1 without a 100-word limit on the human-annotated extractive summary. Therefore, precision is a better metric for comparison and those are the results presented in Table 8. We also report ROUGE-2 scores, because research has shown that in some cases this is a better suited metric [35, 36].
We see that all of the extractive summarizers are performing competitively against the “Lead” baseline. When comparing against human-annotated extractive summaries, we see two things. First, that summarizers are doing a good job capturing content that humans believe are important. Second, that when summarizers are compared against annotated extractive summaries they perform much better. From the small drop from R1 to R2 score of the Lead method, it is clear that most annotators’ generated abstractive summaries also included more sentences from the beginning of the article.
5.4 Qualitative Evaluation of Extractive Summarizers
Here we use word cloud representations to give an intuitive interpretation of the content in the generated extractive summarizers. We create word clouds for the two best methods in Section 5.3. In this paper, we used an online tool called WordItOut555https://worditout.com to generate the word cloud representations. In all word clouds presented in this paper, a filter is used to display only the words with minimum frequency of 2.
Figure 3 shows a word cloud made by the aggregation of all the summaries generated by the PKUSUMSUM-Centroid method. This gives a sense of the content in those summaries. For contrast, we also generate a word cloud for the original news articles without the content of the generated summaries. Specifically, common words are first removed completely and then the word clouds are built with frequencies of surviving words. In essence, this shows what information remains apart from the generated summaries.
The images clearly show a contrast of content. The summary wordcloud shows “earthquake” as its most prominent word. The image of the articles show less focus. If viewed alone, the reader would not quickly infer the gist of the original content. Similarly, Figure 4 represents “Lead” method. And here we see an even more stark difference.
6 Comparing Twitter and News Media information
6.1 News Reporting Speed
One of the aspects of comparing Twitter and traditional newswire is their speed in reporting news, specially during a disaster. To this aim, we used the set of tweets-news article pairs classified as matched by the proposed method and also annotated as relevant or partially relevant pairs by annotators. For these pairs, we calculated the temporal distance between the tweets and their corresponding news article by subtracting the news article publish date from tweet publish date. We computed the temporal distances for all matched pairs annotated as relevant and partially relevant separately. Figures 5 and 6 show the histograms of the temporal distances of the matched pairs annotated as relevant and partially relevant by bin. The size of the bins is 5.
As shown in Figures 5 and 6, in most cases the temporal distances are positive that means in most matched pairs of tweet-news, the news article publish date is older than its matched tweet date. Furthermore, the percentage of tweets that appeared before their matching news article are 91.8% and 91.7% in relevant and partially relevant pairs, respectively. This implies that the news are reported by tweets faster than news articles in both relevant and partially relevant pairs.
6.2 Clustering on Tweets
To investigate the second research question (RQ2), we used the same set of tweets that was used in 6.1 to compare the news reporting speed in Twitter and news media, then we removed the few number of tweets that were published after their matched news articles and employed the resulting tweet set for clustering. In other words, we obtained a set of tweet-news pairs that were classified as matched by our tweet-news linking method, annotated as relevant or partially relevant by annotators and were published before their matched news article to find that what type of information are reported earlier by Twitter through investigating the clusters found on the tweets.
For clustering, we used a short text clustering method called GSDMM which is a collapsed Gibbs Sampling algorithm for the Dirichlet Multinomial Mixture model [37]. In this experiment, the values of the GSDMMfls parameters are , , , where is the number of clusters, and are Dirichlet priors and is the number of iterations that the clustering algorithm repeats until convergence. The total number of tweets used as input in this experiment is 172. Table 9 contains some statistics about the clustering result. In this experiment, tweets are preprocessed by removing the non-ascii characters, punctuation, stop-words and URLs.
Some of the clusters obtained from applying GSDMM on the set of tweets mentioned above are shown in Figure 7. The word cloud representation is used to show the clusters. As Figure 7 shows, each of these clusters correspond to a separate topic relevant to the Nepal Earthquake. The topics corresponding to each of these clusters include a four month old baby being pulled form the rubble (the top left cluster), a man being pulled from the rubble 82 hours after the Nepal earthquake (the top right cluster), India’s effort to help the earthquake survivors (the bottom left cluster) and the health water crisis in Nepal after the earthquake (the bottom right cluster).
6.3 Content Comparison
In this section, the word cloud representation is used to compare the textual content of news articles, their annotated summaries and also the tweets content for relevant and partially relevant annotated pairs as shown in figures 8, 9, 10 and 11.
One of the differences of news articles and tweets content, shown in their word clouds is the different choice of words in the two channels. As figures 9 and 8 show objective words such as ‘government,’ ‘people,’ ‘houses’ and ‘buildings’ have high weights in news articles and their summaries, while as shown in figures 10 and 11, more opinionated and subjective words such as ‘devastating,’ ‘massive’ and ‘suffering’ are used in tweets. Another observation is that the newspaper articles have a lot of locations, e.g., ‘Kathmandu,’ ‘Sindhupalchok,’ ‘Tamang,’ and ‘Barpak,’ but the tweets focus more on the human angle, e.g., ‘parents,’ ‘baby,’ ‘man,’ ‘month-old,’ ‘four-month-old,’ ‘year-old,’ ‘trapped,’ ‘pulled,’ and ‘rubble.’
6.4 Tweets as Summaries
The tweets deemed “relevant” can be grouped together and considered a summary. The relevancy was computed as explained in Section 4.1.2. Using these tweet summaries, we again use ROUGE to evaluate their content. Table 10 shows a weak representation of news articles. However, the precision of the tweets against extractive annotations shows that tweets are capturing pertinent information, within their tight size constraint.
Another approach to evaluating the content of these tweet summaries is to look at the “unique” information found only in the tweet summaries. If we view the words of tweet summaries as one set, , and represent the target comparison as another set of words, , the we can use the following to show “unique” words found:
[TABLE]
[TABLE]
Table 11 show that as expected the news articles themselves contain a lot of words not in the tweet summaries (93.4% and 96.9% for partial relevance and full relevance, respectively). But it also shows that tweet summaries contain unique words as well. This, in conjunction with the good precision values, reveals that the tweet summaries do contain some pertinent and some unique information.
From both Tables 10 and 11, we see that the human annotators are using their own words to describe the events and thus the overlap is lower and the difference is higher with respect to abstractive summaries. The relevant tweets have the highest precision with the whole news articles indicating that they meaningful precursors of events/information described in more detail in the articles. However, the tables clearly show a complementary situation, i.e., the tweets relevant or partially relevant have some but not all of the information in the news articles and vice versa.
6.5 The Extra Information in Tweets vs News
In our next investigation, we tried to find what new information is provided in tweets that is not available in news media about the Nepal Earthquake and vice versa, i.e. what new information is provided in news articles that is not available in tweets. In this experiment, we used the same 172 tweets and news articles used in Section 6.2. To this aim, we computed the difference of the aggregate of all tweets’ content, denoted by , from the aggregate of the matching news articles’ content (NAC), i.e. , and , and represented the resulting set of words by their word clouds. Precisely speaking, to compute , we find the common words between and and remove all of its occurrences from . We do the same for computing .
Comparing the two word clouds in Figures 12 and 13 shows that news articles mainly contain information about the Nepal earthquake from the agencies viewpoint. The use of terms such as ‘government’, ‘reconstruction’ and ‘political’ shows the formal and objective language employed by news agencies to describe the situation. In contrast, tweets content is more about the human angle, the content type that news articles lack. These word clouds reinforces that the two sources of information can complement each other to provide a comprehensive picture from two different angles about a major disaster like the Nepal Earthquake. The immediacy of tweets can be used by first responders for search and rescue operations.
7 Conclusion
In this paper, we studied, compared and analyzed newswire and Twitter from different viewpoints in the context of the 2015 Nepal Earthquakes. In this regard, we collected and annotated two datasets: A tweet dataset that contains 336,140 tweets related to the Nepal Earthquake written from April 24, 2015 to June 25, 2015 and a news dataset containing 700 news articles relevant to the Nepal Earthquakes and dated in the year 2015. We presented descriptive statistics of the collected tweets from different viewpoints: the most frequent words, the top most active users, the changes in the number of tweets over time and the use of hashtags, URLs and mentions in the collected tweets.
We also evaluated several methods of summarization of news articles against human ground truth and against Twitter content. Furthermore, using the tweet-news pairs classified as matched and annotated as relevant, we compared the speed of Twitter and newswire in news reporting (RQ1), the content generated in each of these two channels (RQ3, RQ4), and the effectiveness of the matched tweets to summarize their corresponding news articles (RQ6). We found that during the Nepal earthquake, most of the human news and earthquake related crises appear in Twitter before news media. Another finding is that during a major disaster, twitter contains more opinionated and subjective content in comparison with the news media content.
We have also shown that automatic summarization can be an effective method for quickly pulling the important information from news articles. All the methods investigated in this paper were unsupervised approaches, which means that they can be used as quick and efficient filters to combat the information overload present in news articles. We also show that twitter data holds data that is complementary to the content of relevant news articles. For consumers of information like first responders, it is paramount that all available information about a natural disaster can be quickly processed. Both automatic summarization of news articles as well as Twitter content, can be used to support this need. We also proposed a tweet-news linking method to find the matched tweets to each news article and evaluated its performance using our annotated datasets (RQ5). It gave a decent precision of on the annotated subset.
References
- [1]
S. Petrovic, M. Osborne, R. McCreadie, C. Macdonald, I. Ounis, L. Shrimpton, Can twitter replace newswire for breaking news?, in: Seventh international AAAI conference on weblogs and social media, 2013.
- [2]
A. Mills, R. Chen, J. Lee, H. Raghav Rao, Web 2.0 emergency applications: How useful can twitter be for emergency response?, Journal of Information Privacy and Security 5 (3) (2009) 3–26.
- [3]
C. A. Cassa, R. Chunara, K. Mandl, J. S. Brownstein, Twitter as a sentinel in emergency situations: lessons from the boston marathon explosions, PLoS currents 5.
- [4]
P. R. Spence, K. A. Lachlan, X. Lin, M. del Greco, Variability in twitter content across the stages of a natural disaster: Implications for crisis communication, Communication Quarterly 63 (2) (2015) 171–186.
- [5]
S. Doan, B.-K. H. Vo, N. Collier, An analysis of twitter messages in the 2011 tohoku earthquake, in: International conference on electronic healthcare, Springer, 2011, pp. 58–66.
- [6]
M. Martinez-Rojas, M. del Carmen Pardo-Ferreira, J. C. Rubio-Romero, Twitter as a tool for the management and analysis of emergency situations: A systematic literature review, International Journal of Information Management 43 (2018) 196–208.
- [7]
F. Alam, S. Joty, M. Imran, Graph based semi-supervised learning with convolution neural networks to classify crisis related tweets, in: Twelfth International AAAI Conference on Web and Social Media, 2018.
- [8]
A. Hürriyetoglu, C. Gudehus, N. Oostdijk, Using relevancer to detect relevant tweets: The nepal earthquake case, in: booktitle = Working notes of FIRE 2016 - Forum for Information Retrieval Evaluation, Kolkata, India, December 7-10, 2016., 2016, pp. 76–78.
- [9]
J. Radianti, S. R. Hiltz, L. Labaka, An overview of public concerns during the recovery period after a major earthquake: Nepal twitter analysis, in: 49th Hawaii International Conference on System Sciences, HICSS 2016, Koloa, HI, USA, January 5-8, 2016, 2016, pp. 136–145.
- [10]
R. Subba, T. Bui, Online convergence behavior, social media communications and crisis response: An empirical study of the 2015 nepal earthquake police twitter project, in: 50th Hawaii International Conference on System Sciences, HICSS 2017, Hilton Waikoloa Village, Hawaii, USA, January 4-7, 2017, 2017, pp. 1–10.
- [11]
Y. Su, Z. Lan, Y. Lin, L. K. Comfort, J. Joshi, Tracking disaster response and relief following the 2015 nepal earthquake, in: 2nd IEEE International Conference on Collaboration and Internet Computing, CIC 2016, Pittsburgh, PA, USA, November 1-3, 2016, 2016, pp. 495–499.
- [12]
M. Tsagkias, M. De Rijke, W. Weerkamp, Linking online news and social media, in: Proceedings of the fourth ACM international conference on Web search and data mining, ACM, 2011, pp. 565–574.
- [13]
A. Mogadala, D. Jung, A. Rettinger, Linking tweets with monolingual and cross-lingual news using transformed word embeddings, arXiv preprint arXiv:1710.09137.
- [14]
J. Wang, W. Tong, H. Yu, M. Li, X. Ma, H. Cai, T. Hanratty, J. Han, Mining multi-aspect reflection of news events in twitter: Discovery, linking and presentation, in: Data Mining (ICDM), 2015 IEEE International Conference on, IEEE, 2015, pp. 429–438.
- [15]
T. Ahmad, A. Ramsay, Linking tweets to news: Is all news of interest?, in: International Conference on Artificial Intelligence: Methodology, Systems, and Applications, Springer, 2016, pp. 151–161.
- [16]
B. Mazoyer, J. Cagé, C. Hudelot, M.-L. Viaud, Real-time collection of reliable and representative tweets datasets related to news events, in: Proceedings of the first International Workshop on Analysis of Broad Dynamic Topics over Social Media: BroDyn, Vol. 18, 2018.
- [17]
X. Lin, Y. Gu, R. Zhang, J. Fan, Linking news and tweets, in: Australasian Database Conference, Springer, 2016, pp. 467–470.
- [18]
W. Guo, H. Li, H. Ji, M. Diab, Linking tweets to news: A framework to enrich short text data in social media, in: Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vol. 1, 2013, pp. 239–249.
- [19]
B. Shi, G. Ifrim, N. Hurley, Be in the know: Connecting news articles to relevant twitter conversations, arXiv preprint arXiv:1405.3117.
- [20]
F. Abel, Q. Gao, G.-J. Houben, K. Tao, Semantic enrichment of twitter posts for user profile construction on the social web, in: Extended semantic web conference, Springer, 2011, pp. 375–389.
- [21]
R. McCreadie, C. Macdonald, I. Ounis, News vertical search: when and what to display to users, in: Proceedings of the 36th international ACM SIGIR conference on Research and development in information retrieval, ACM, 2013, pp. 253–262.
- [22]
Z. Wei, W. Gao, Gibberish, assistant, or master?: Using tweets linking to news for extractive single-document summarization, in: Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, ACM, 2015, pp. 1003–1006.
- [23]
S. Kulcu, E. Dogdu, A scalable approach for sentiment analysis of turkish tweets and linking tweets to news, in: Semantic Computing (ICSC), 2016 IEEE Tenth International Conference on, IEEE, 2016, pp. 471–476.
- [24]
H. Li, H. Ji, Cross-genre event extraction with knowledge enrichment, in: Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2016, pp. 1158–1162.
- [25]
Z. Wei, W. Gao, Gibberish, assistant, or master?: Using tweets linking to news for extractive single-document summarization, in: Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’15, ACM, New York, NY, USA, 2015, pp. 1003–1006.
URL http://doi.acm.org/10.1145/2766462.2767835
- [26]
C. Lin, E. H. Hovy, Automatic evaluation of summaries using n-gram co-occurrence statistics, in: Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics, HLT-NAACL 2003, Edmonton, Canada, May 27 - June 1, 2003, 2003.
URL http://aclweb.org/anthology/N/N03/N03-1020.pdf
- [27]
K. Rudra, S. Banerjee, N. Ganguly, P. Goyal, M. Imran, P. Mitra, Summarizing situational tweets in crisis scenario, in: Proceedings of the 27th ACM Conference on Hypertext and Social Media, HT ’16, ACM, New York, NY, USA, 2016, pp. 137–147.
URL http://doi.acm.org.ezproxy.lib.uh.edu/10.1145/2914586.2914600
- [28]
F. Alam, S. Joty, M. Imran, Domain adaptation with adversarial training and graph embeddings, 2018.
- [29]
S. Bird, E. Klein, E. Loper, Natural language processing with Python, ” O’Reilly Media, Inc.”, 2009.
- [30]
G. A. Miller, Wordnet: A lexical database for english, Communications of the ACM 38 (11) (1995) 39–41.
- [31]
W. Guo, H. Li, H. Ji, M. Diab, Linking tweets to news: A framework to enrich short text data in social media, in: Proceedings of the 51th Annual Meeting of the Association for Computational Linguistics, 2013.
- [32]
R. M. Verma, D. Lee, Extractive summarization: Limits, compression, generalized model and heuristics, Computación y Sistemas 21 (4).
- [33]
J. Zhang, T. Wang, X. Wan, PKUSUMSUM : A java platform for multilingual document summarization, in: COLING 2016, 26th International Conference on Computational Linguistics, Proceedings of the Conference System Demonstrations, December 11-16, 2016, Osaka, Japan, 2016, pp. 287–291.
URL http://aclweb.org/anthology/C/C16/C16-2060.pdf
- [34]
C. Lin, ROUGE: A Package for Automatic Evaluation of Summaries, in: Proceedings of Workshop on Text Summarization Post-Conference Workshop, (ACL 2004) Barcelona, Spain, 2004.
- [35]
K. Owczarzak, J. M. Conroy, H. T. Dang, A. Nenkova, An assessment of the accuracy of automatic evaluation in summarization, in: Proceedings of Workshop on Evaluation Metrics and System Comparison for Automatic Summarization@NACCL-HLT 2012, Montrèal, Canada, June 2012, 2012, 2012, pp. 1–9.
URL https://aclanthology.info/papers/W12-2601/w12-2601
- [36]
Y. Graham, Re-evaluating automatic summarization with BLEU and 192 shades of ROUGE, in: Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, EMNLP 2015, Lisbon, Portugal, September 17-21, 2015, 2015, pp. 128–137.
URL http://aclweb.org/anthology/D/D15/D15-1013.pdf
- [37]
J. Yin, J. Wang, A dirichlet multinomial mixture model-based approach for short text clustering, in: Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining, ACM, 2014, pp. 233–242.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] S. Petrovic, M. Osborne, R. Mc Creadie, C. Macdonald, I. Ounis, L. Shrimpton, Can twitter replace newswire for breaking news?, in: Seventh international AAAI conference on weblogs and social media, 2013.
- 2[2] A. Mills, R. Chen, J. Lee, H. Raghav Rao, Web 2.0 emergency applications: How useful can twitter be for emergency response?, Journal of Information Privacy and Security 5 (3) (2009) 3–26.
- 3[3] C. A. Cassa, R. Chunara, K. Mandl, J. S. Brownstein, Twitter as a sentinel in emergency situations: lessons from the boston marathon explosions, P Lo S currents 5.
- 4[4] P. R. Spence, K. A. Lachlan, X. Lin, M. del Greco, Variability in twitter content across the stages of a natural disaster: Implications for crisis communication, Communication Quarterly 63 (2) (2015) 171–186.
- 5[5] S. Doan, B.-K. H. Vo, N. Collier, An analysis of twitter messages in the 2011 tohoku earthquake, in: International conference on electronic healthcare, Springer, 2011, pp. 58–66.
- 6[6] M. Martinez-Rojas, M. del Carmen Pardo-Ferreira, J. C. Rubio-Romero, Twitter as a tool for the management and analysis of emergency situations: A systematic literature review, International Journal of Information Management 43 (2018) 196–208.
- 7[7] F. Alam, S. Joty, M. Imran, Graph based semi-supervised learning with convolution neural networks to classify crisis related tweets, in: Twelfth International AAAI Conference on Web and Social Media, 2018.
- 8[8] A. Hürriyetoglu, C. Gudehus, N. Oostdijk, Using relevancer to detect relevant tweets: The nepal earthquake case, in: booktitle = Working notes of FIRE 2016 - Forum for Information Retrieval Evaluation, Kolkata, India, December 7-10, 2016., 2016, pp. 76–78.