Total variation vs L1 regularization: a comparison of compressive sensing optimization methods for chemical detection
Elin Farnell, Henry Kvinge, Julia R. Dupuis, Michael Kirby, Chris, Peterson, Elizabeth C. Schundler

TL;DR
This paper compares L1 and total variation regularization methods in compressive sensing for chemical detection, demonstrating that L1 regularization generally outperforms TV in real-world datasets at high compression rates.
Contribution
The study provides a comprehensive comparison of L1 and TV regularization in CS for chemical detection, highlighting the superiority of L1 in practical hyperspectral data scenarios.
Findings
L1 regularization outperforms TV in chemical detection accuracy.
Both methods achieve successful detection at 90% compression.
L1 regularization results in fewer false positives in reconstructed data.
Abstract
One of the fundamental assumptions of compressive sensing (CS) is that a signal can be reconstructed from a small number of samples by solving an optimization problem with the appropriate regularization term. Two standard regularization terms are the L1 norm and the total variation (TV) norm. We present a comparison of CS reconstruction results based on these two approaches in the context of chemical detection, and we demonstrate that optimization based on the L1 norm outperforms optimization based on the TV norm. Our comparison is driven by CS sampling, reconstruction, and chemical detection in two real-world datasets: the Physical Sciences Inc. Fabry-P\'{e}rot interferometer sensor multispectral dataset and the Johns Hopkins Applied Physics Lab FTIR-based longwave infrared sensor hyperspectral dataset. Both datasets contain the release of a chemical simulant such as glacial acetic…
Click any figure to enlarge with its caption.
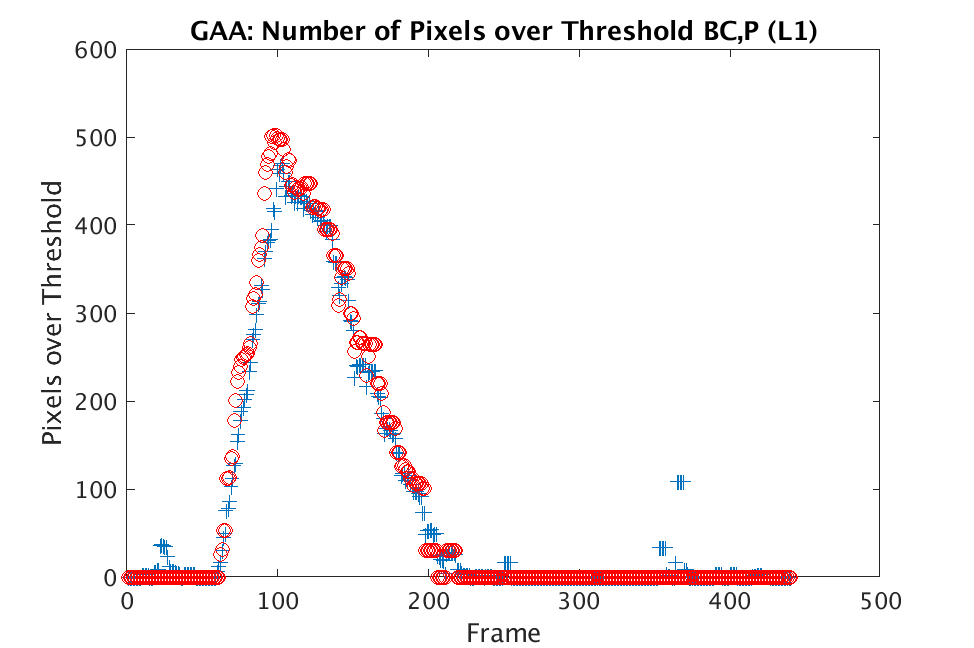 Figure 1
Figure 1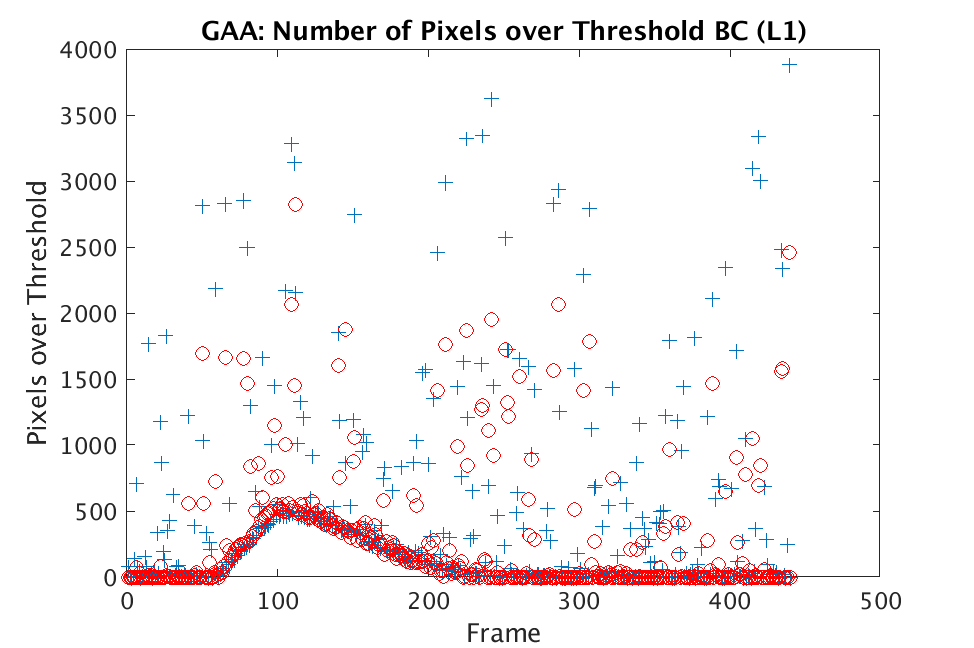 Figure 2
Figure 2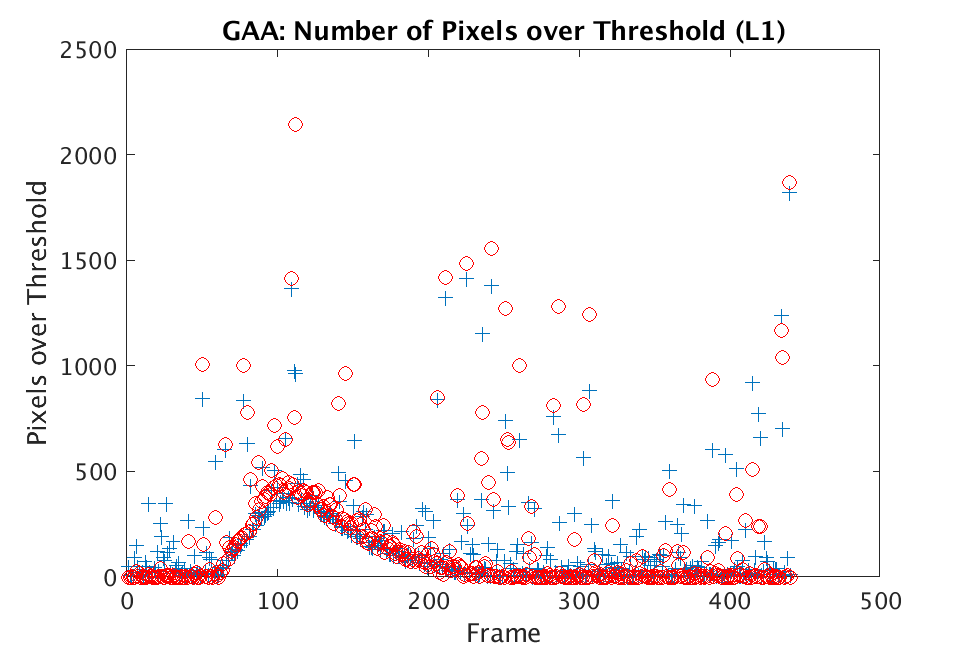 Figure 3
Figure 3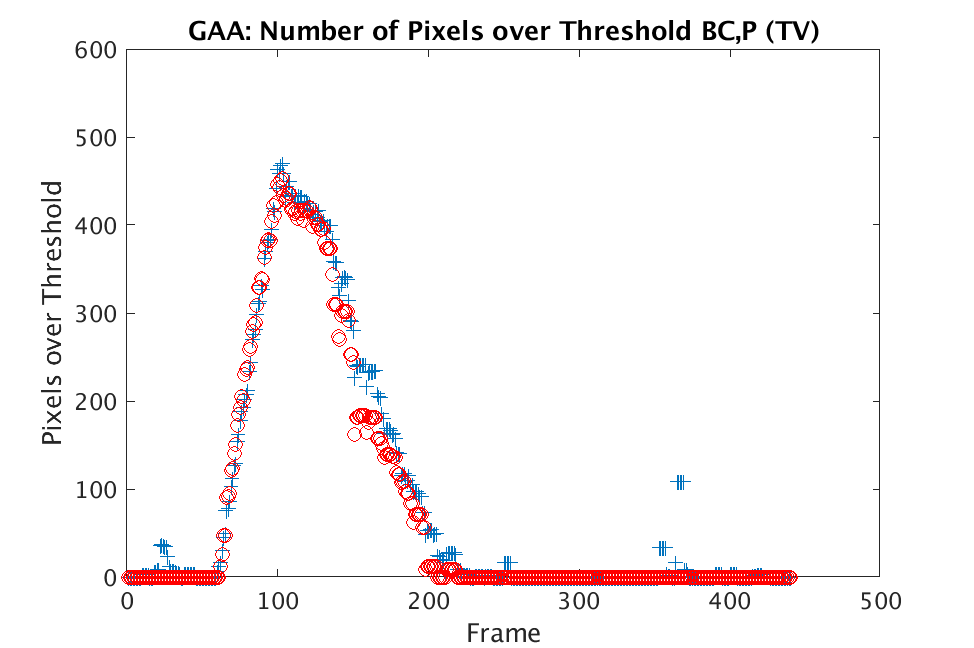 Figure 4
Figure 4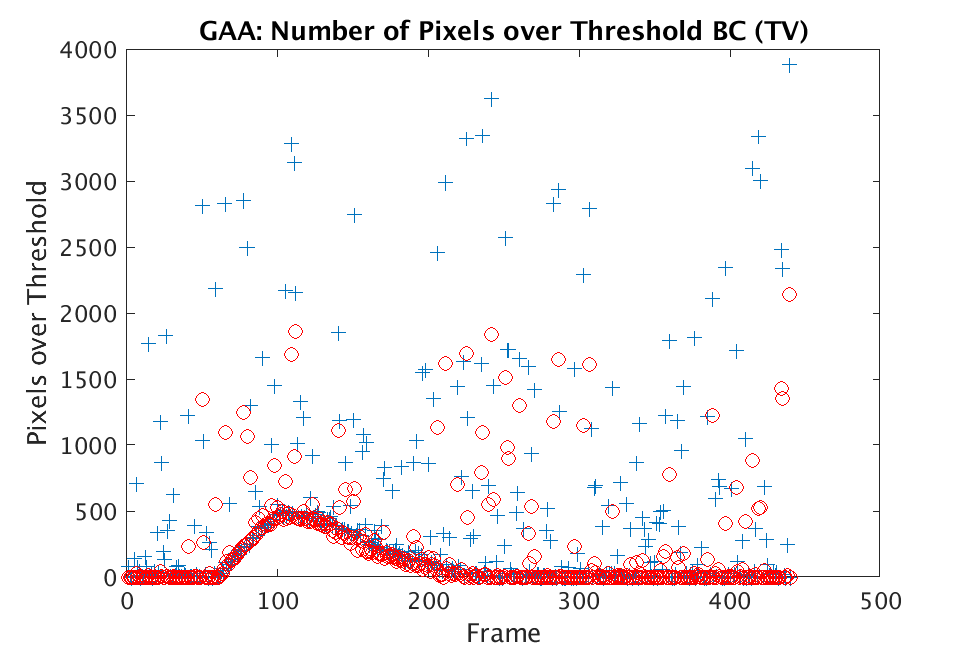 Figure 5
Figure 5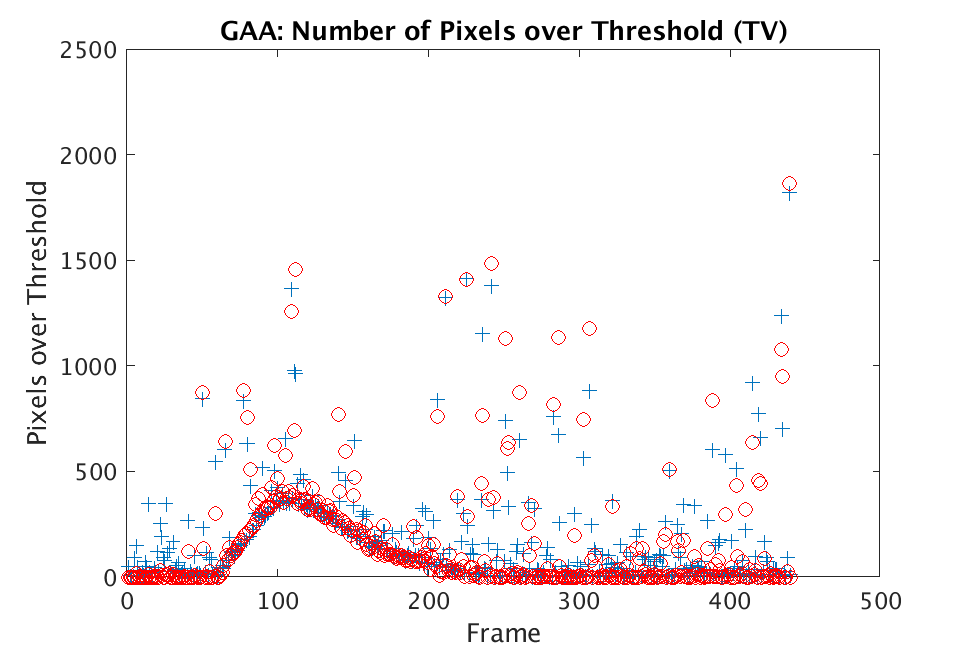 Figure 6
Figure 6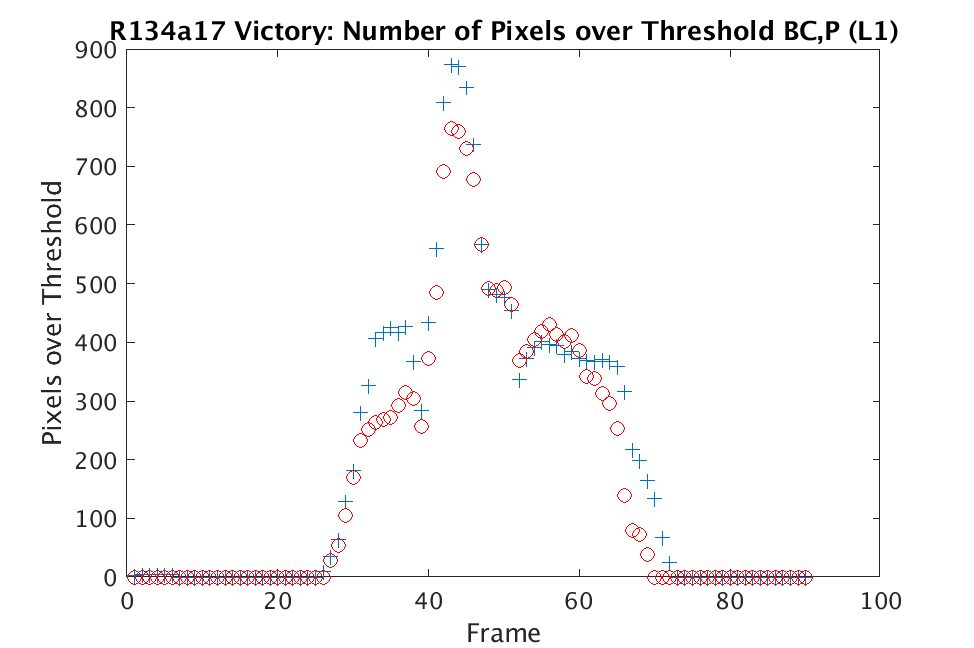 Figure 7
Figure 7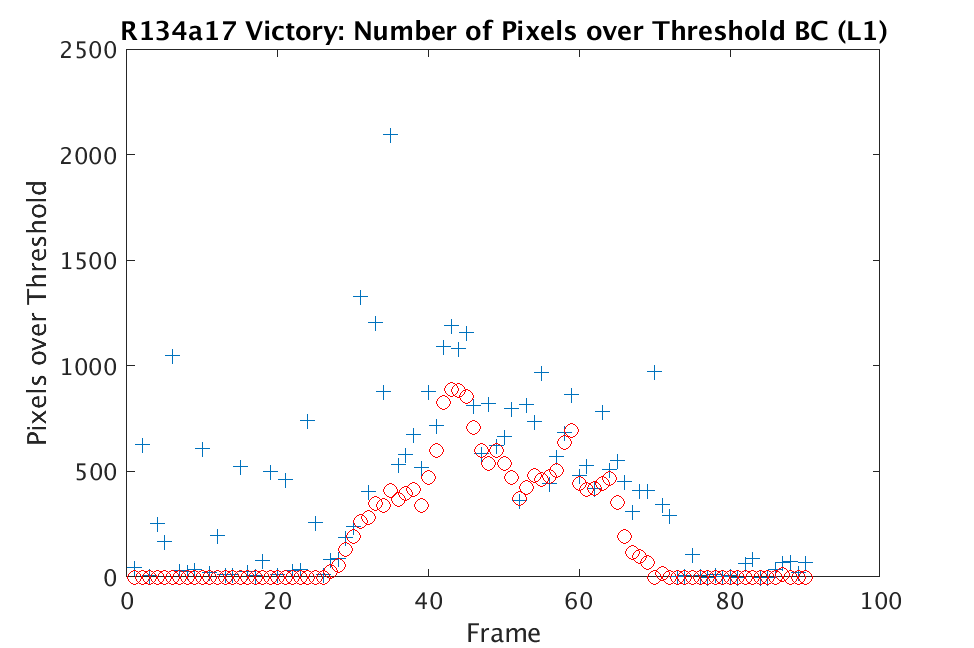 Figure 8
Figure 8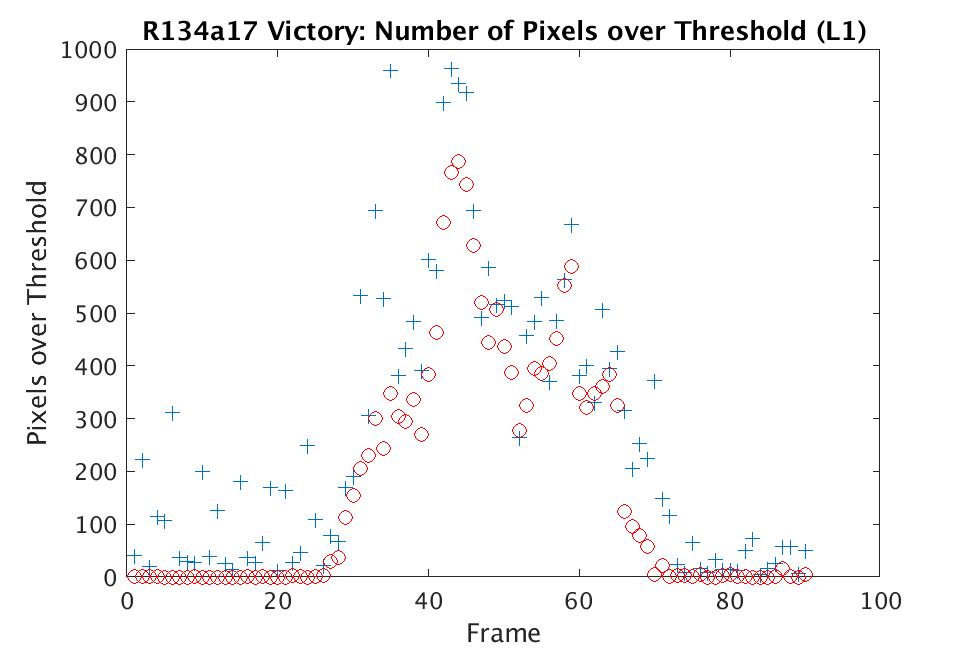 Figure 9
Figure 9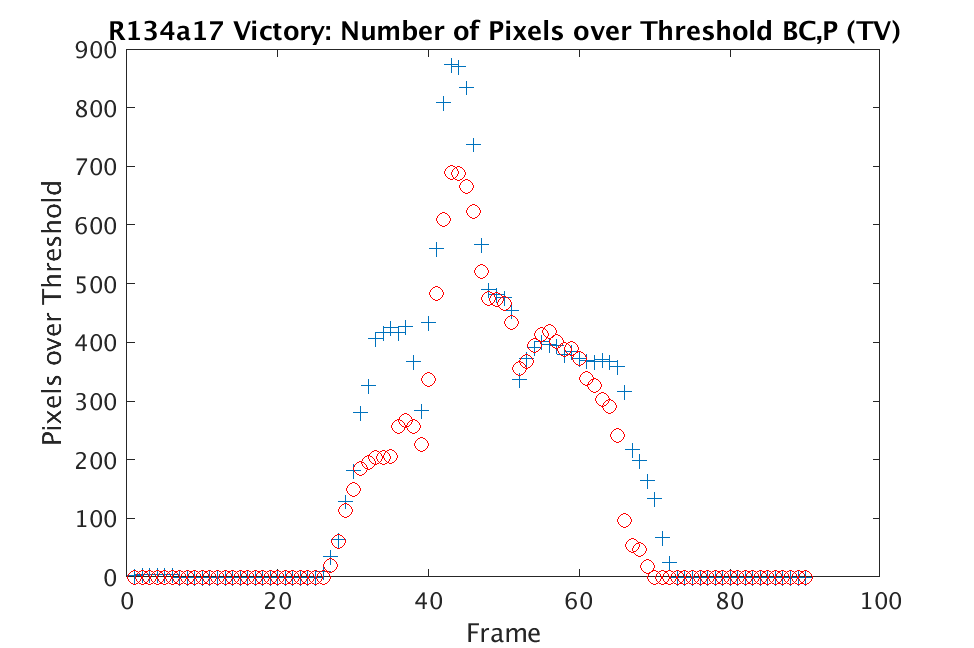 Figure 10
Figure 10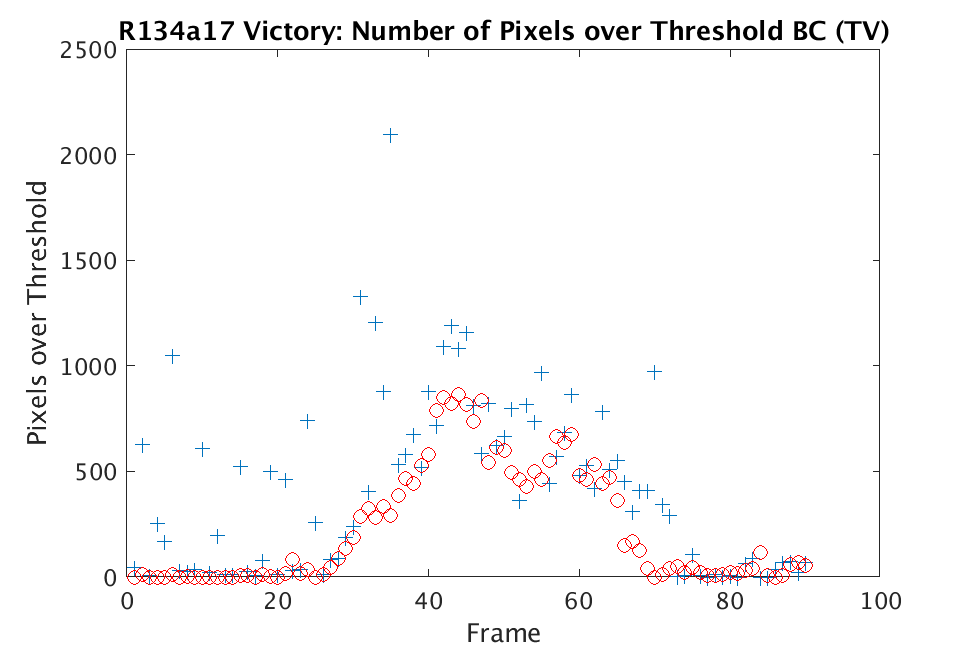 Figure 11
Figure 11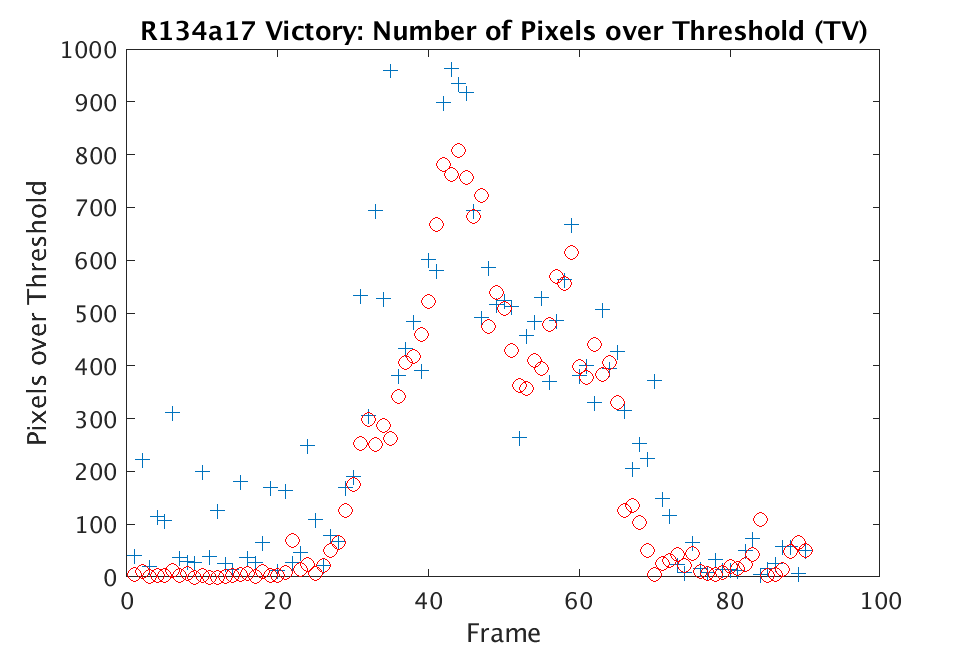 Figure 12
Figure 12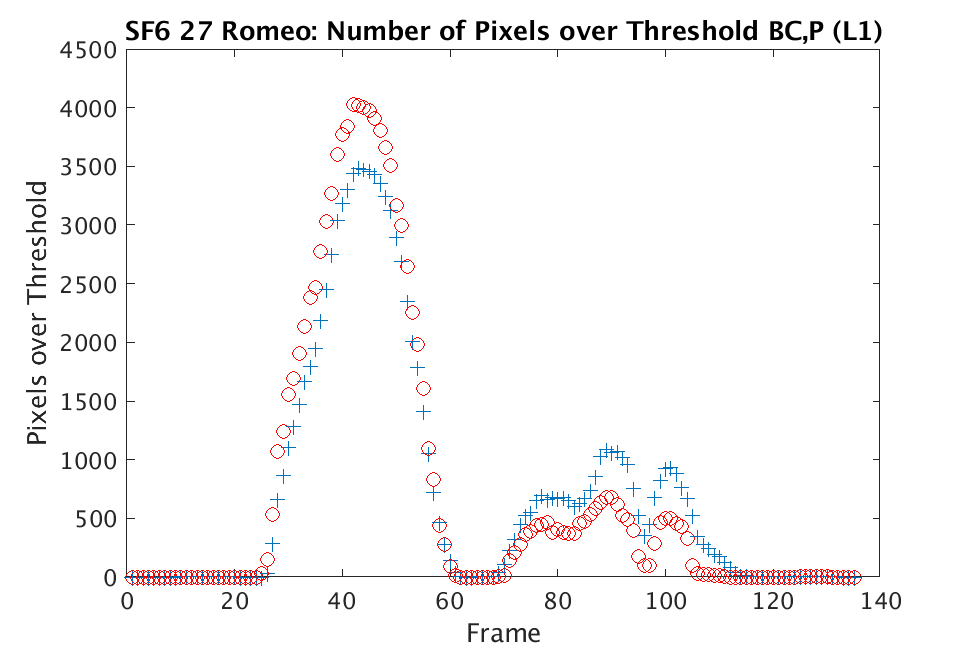 Figure 13
Figure 13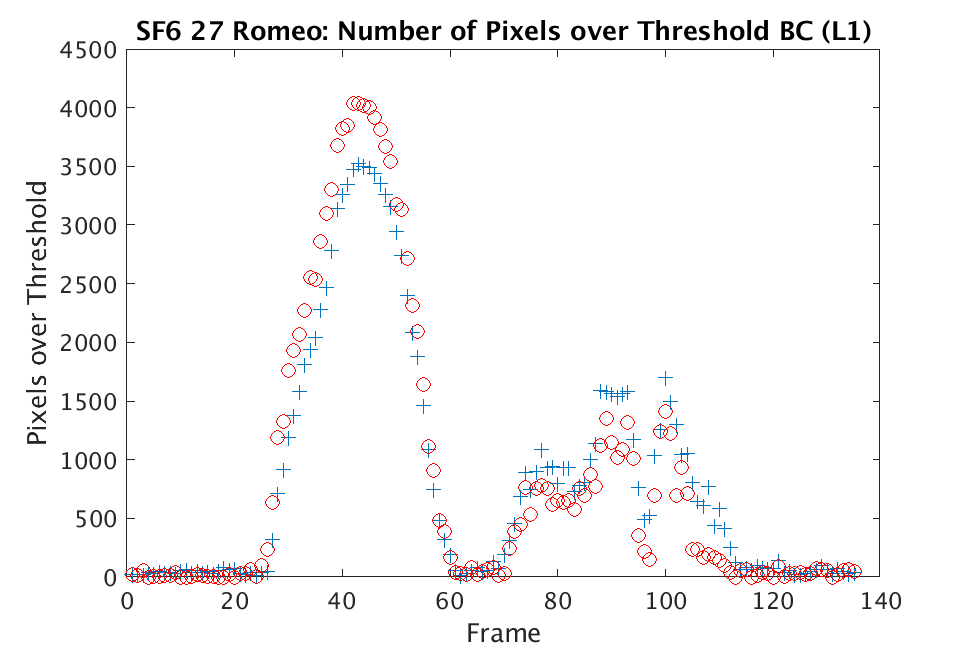 Figure 14
Figure 14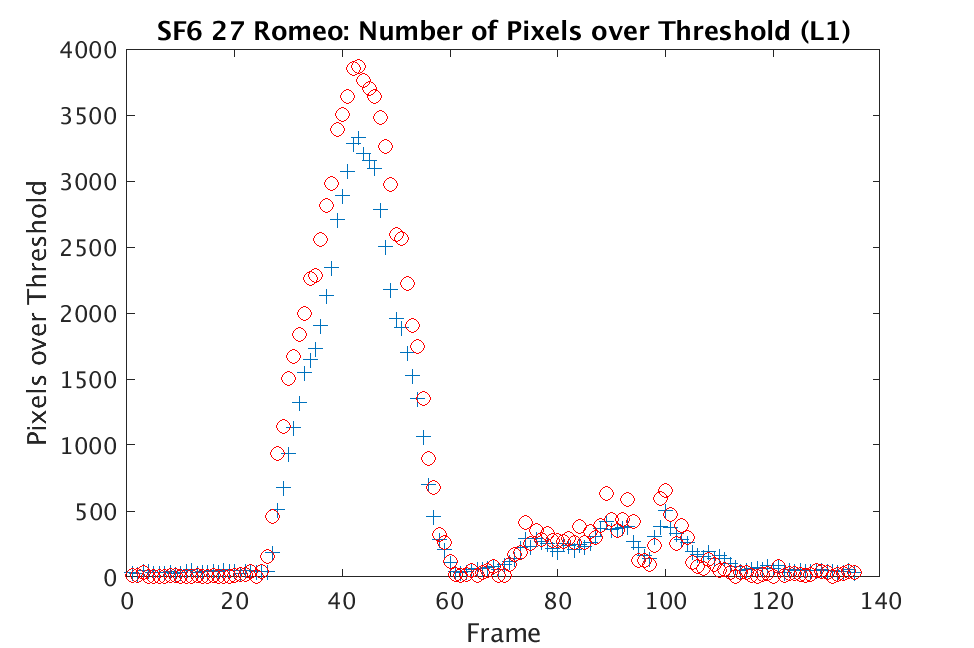 Figure 15
Figure 15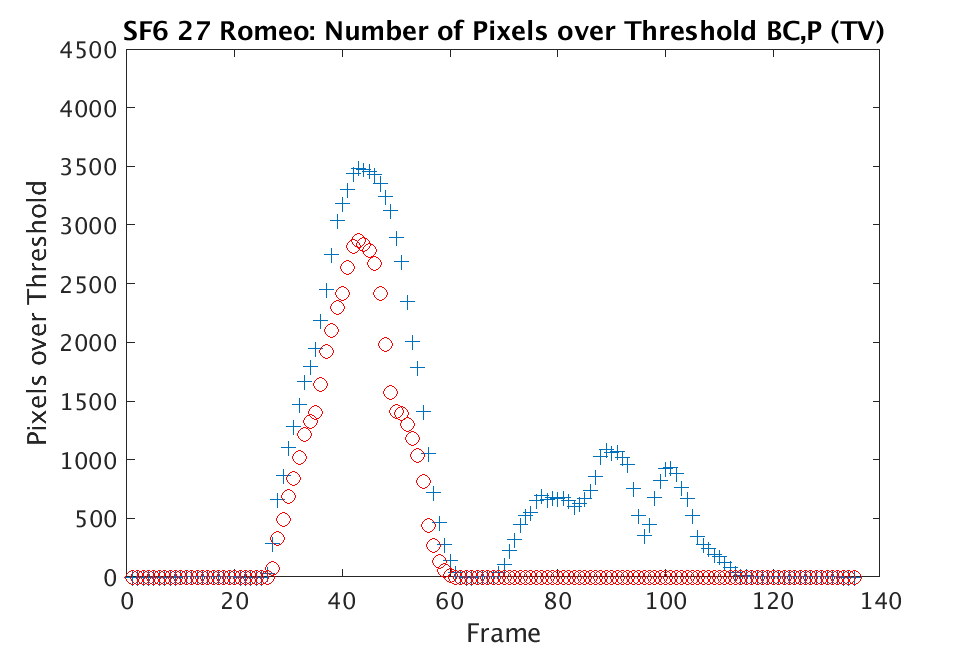 Figure 16
Figure 16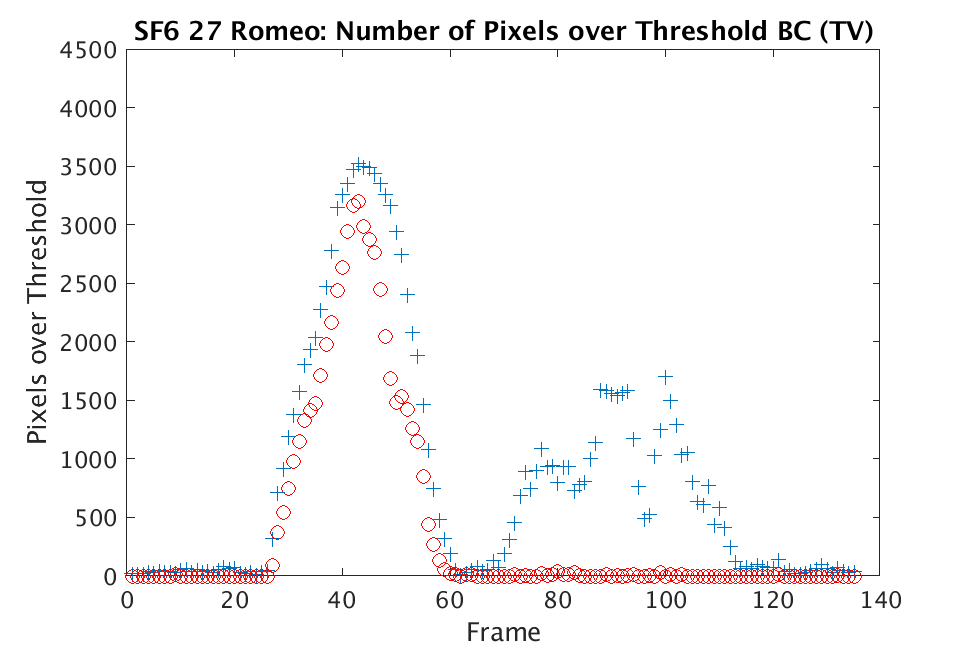 Figure 17
Figure 17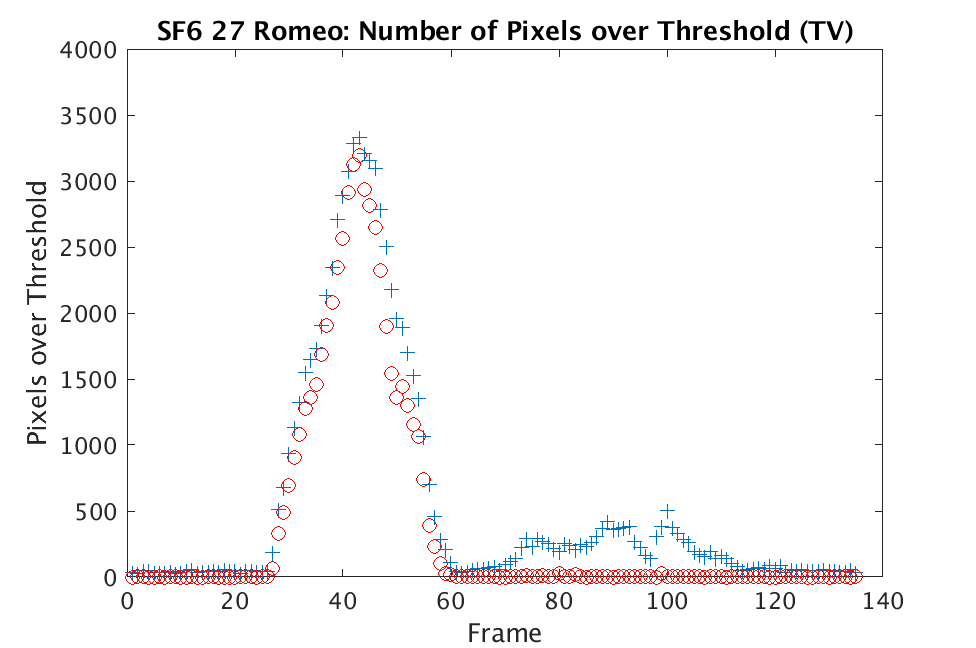 Figure 18
Figure 18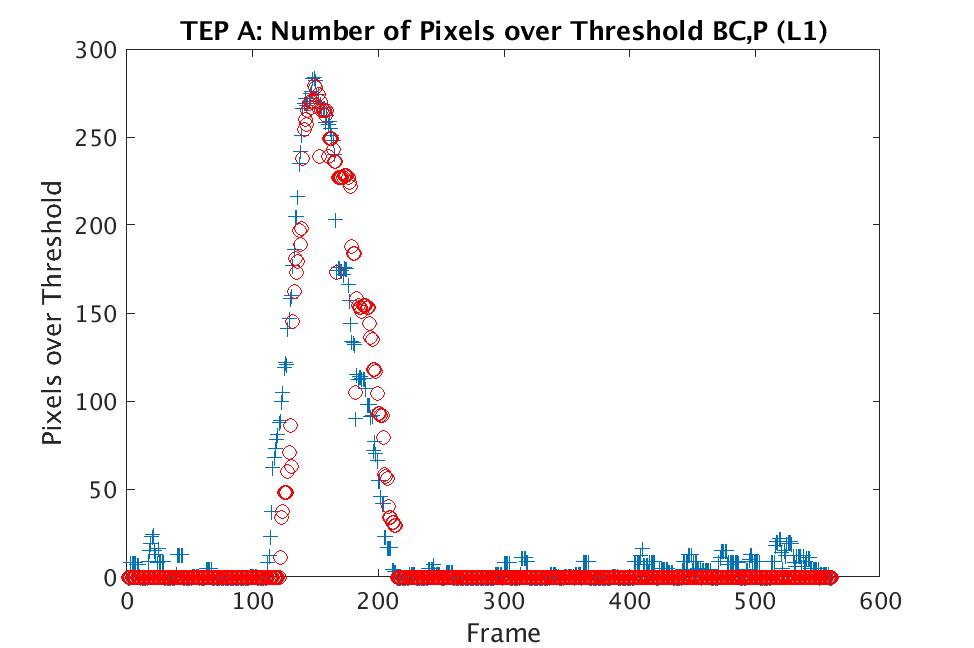 Figure 19
Figure 19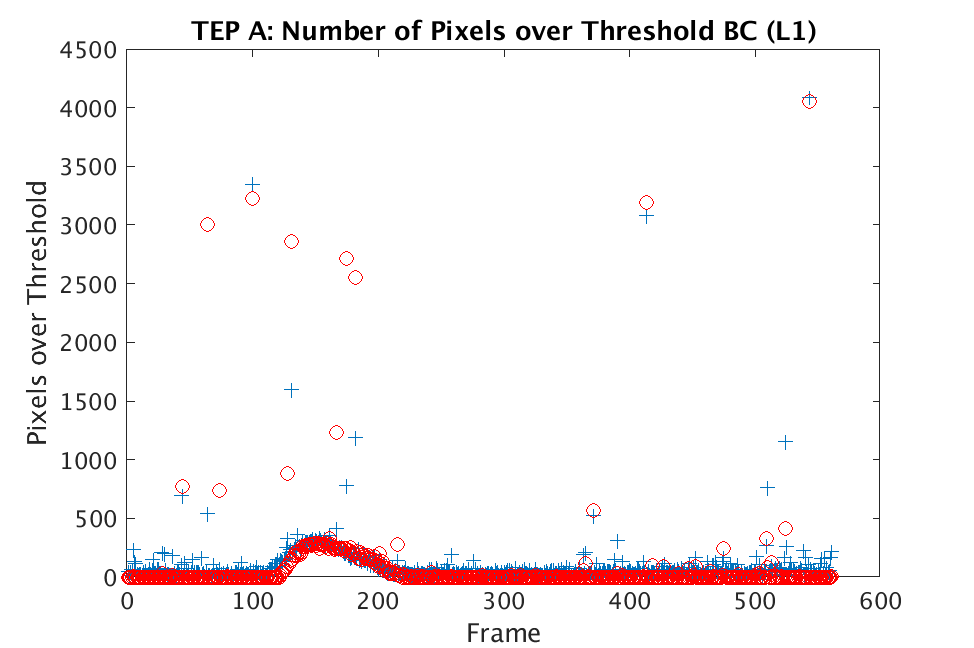 Figure 20
Figure 20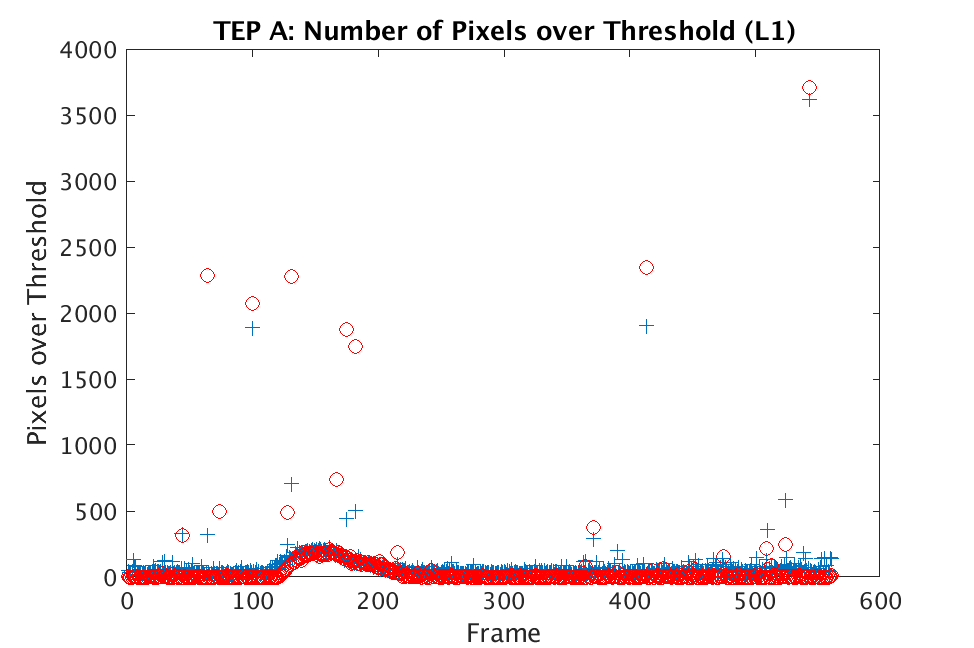 Figure 21
Figure 21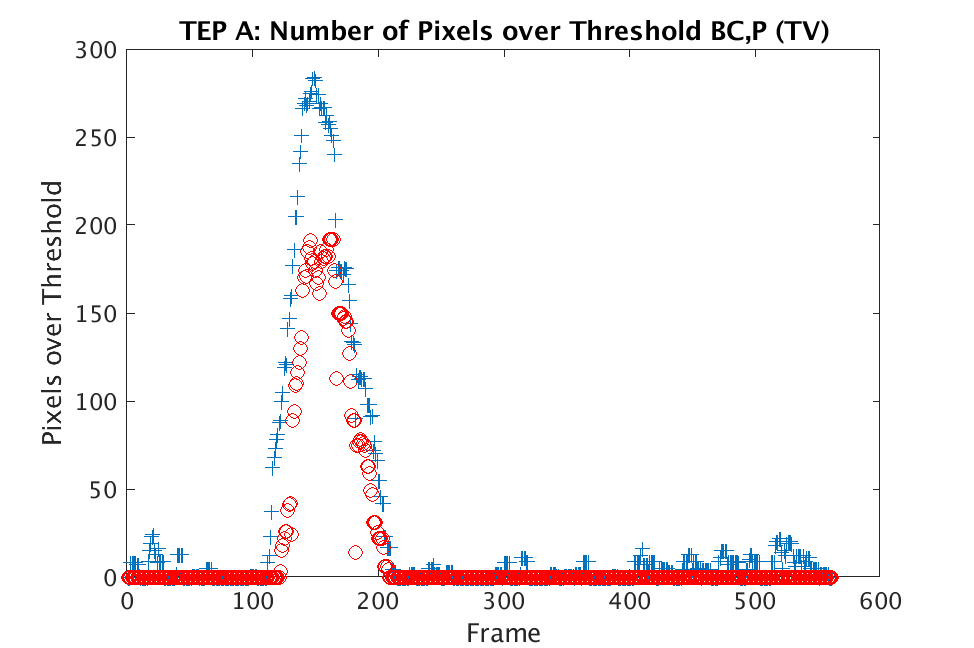 Figure 22
Figure 22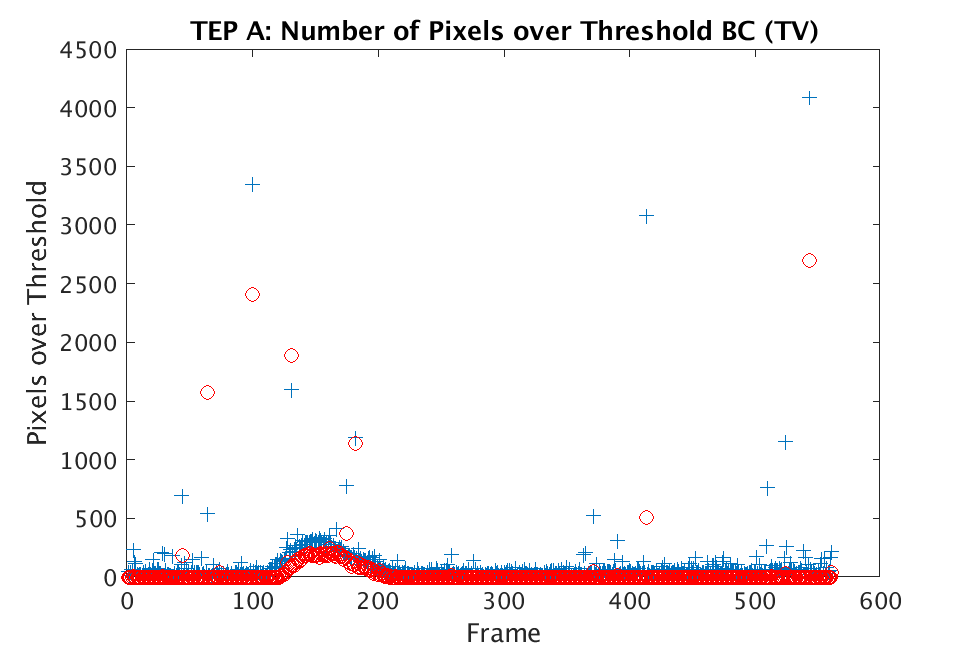 Figure 23
Figure 23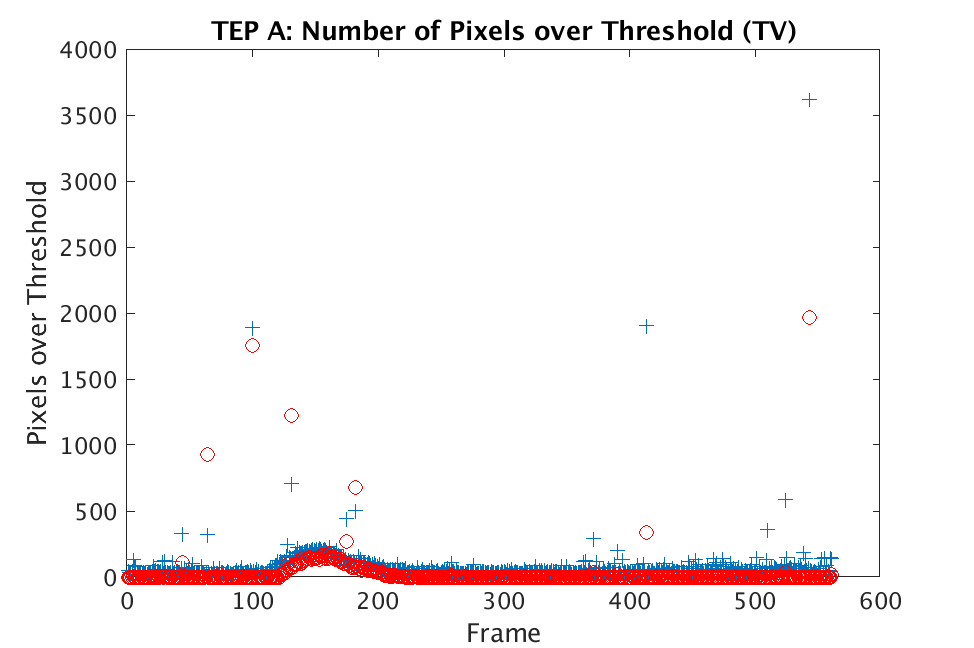 Figure 24
Figure 24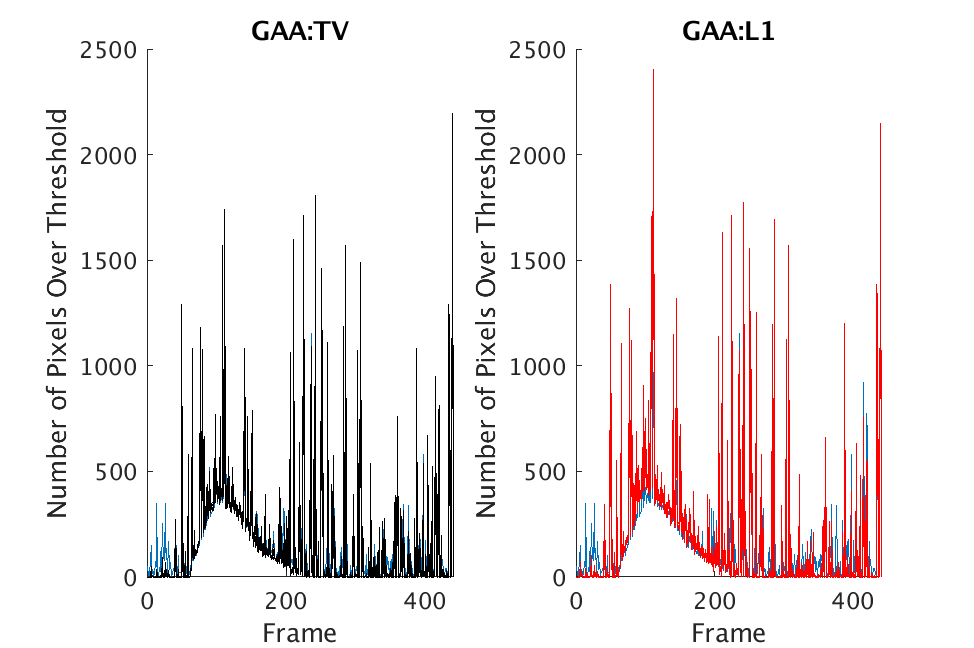 Figure 25
Figure 25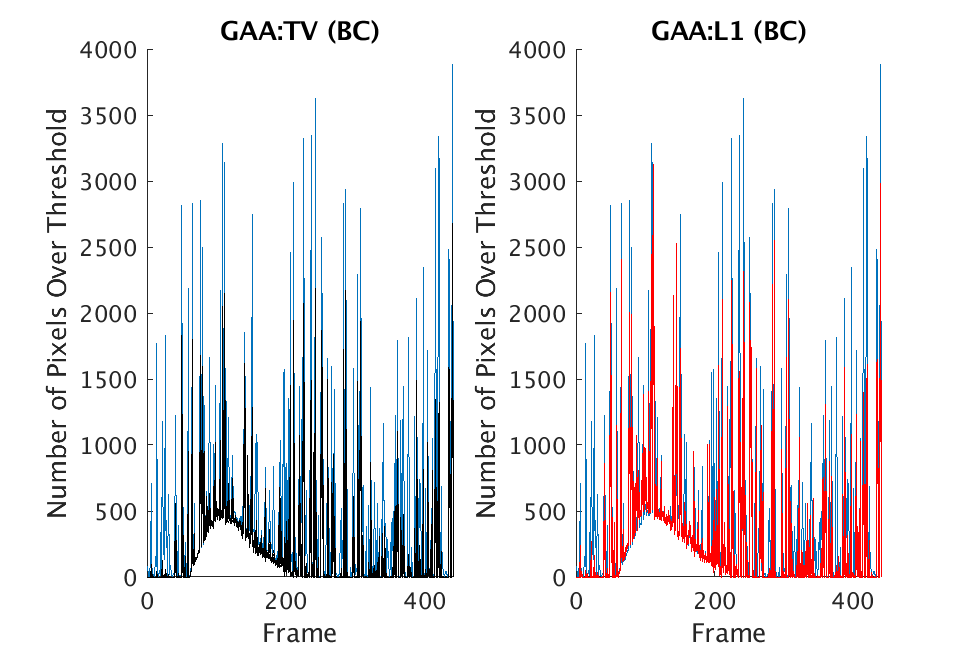 Figure 26
Figure 26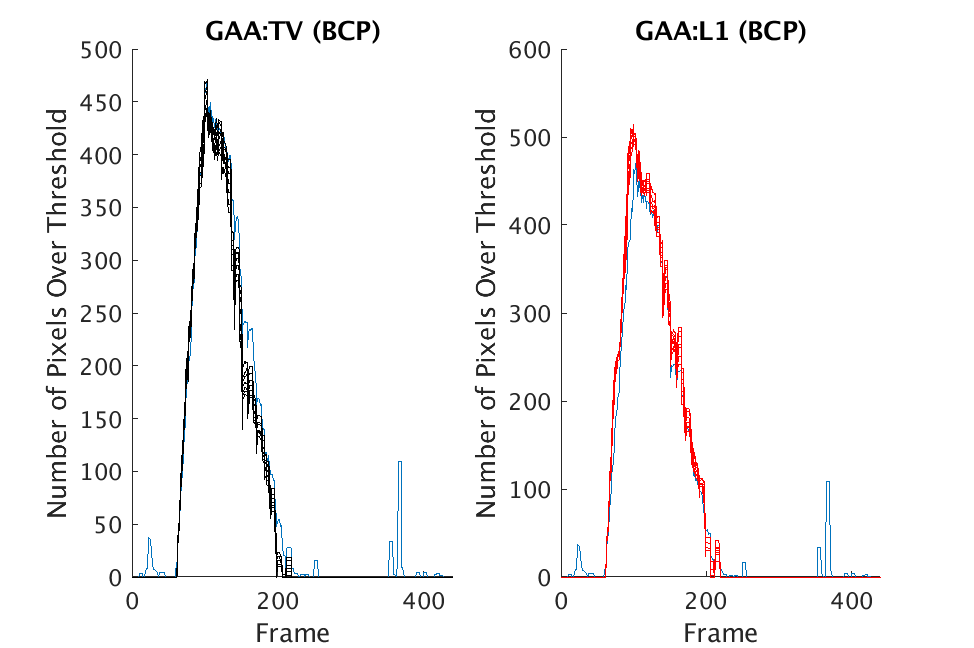 Figure 27
Figure 27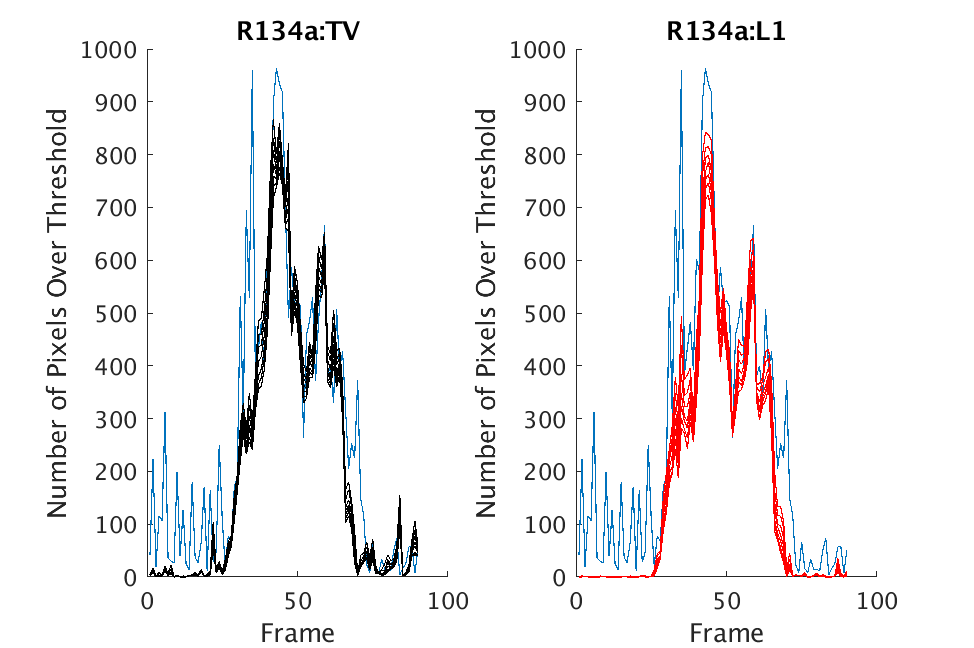 Figure 28
Figure 28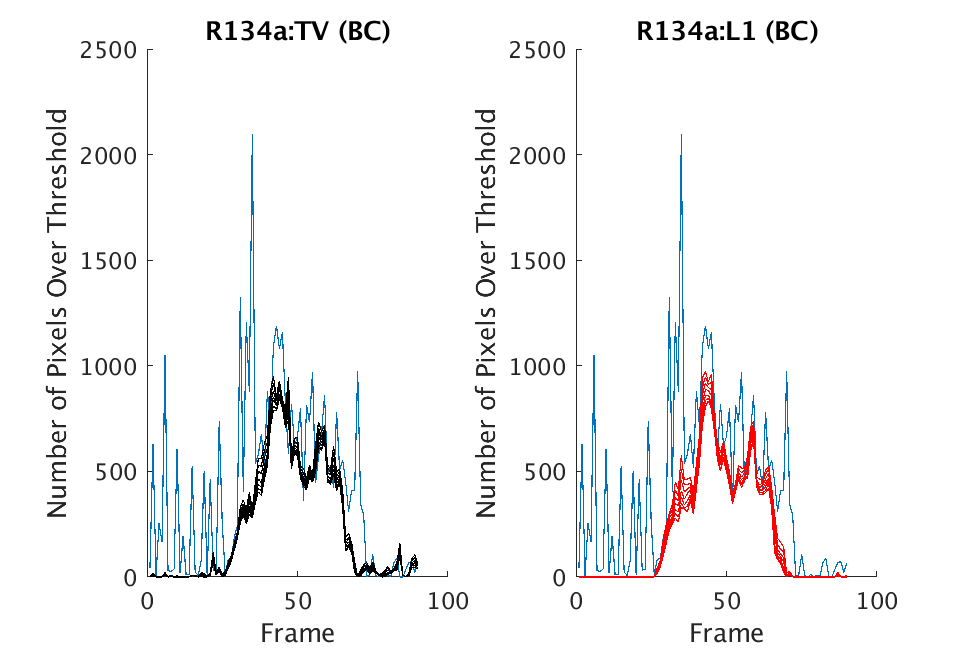 Figure 29
Figure 29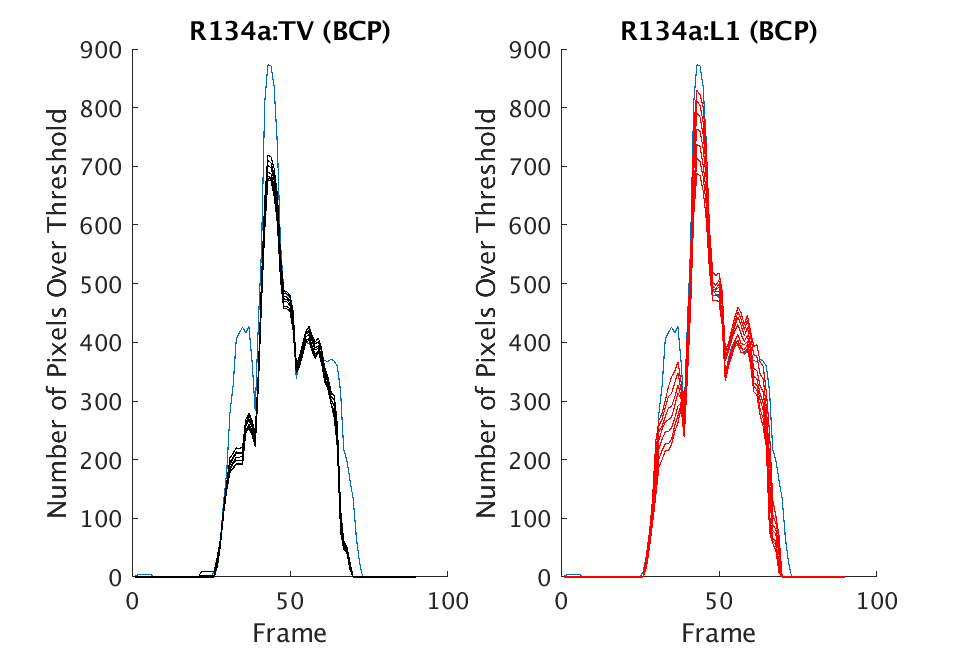 Figure 30
Figure 30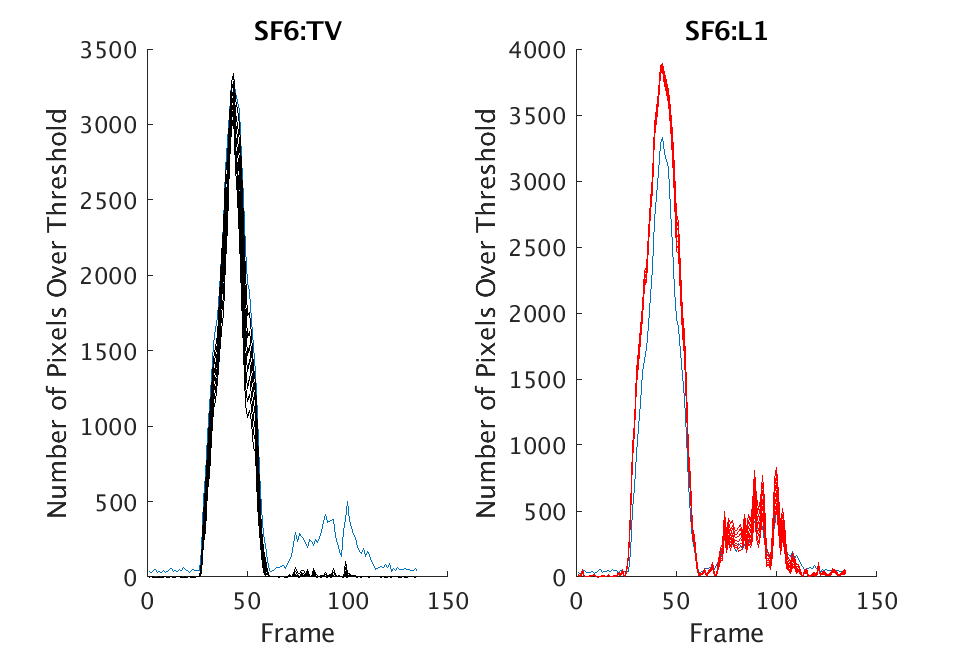 Figure 31
Figure 31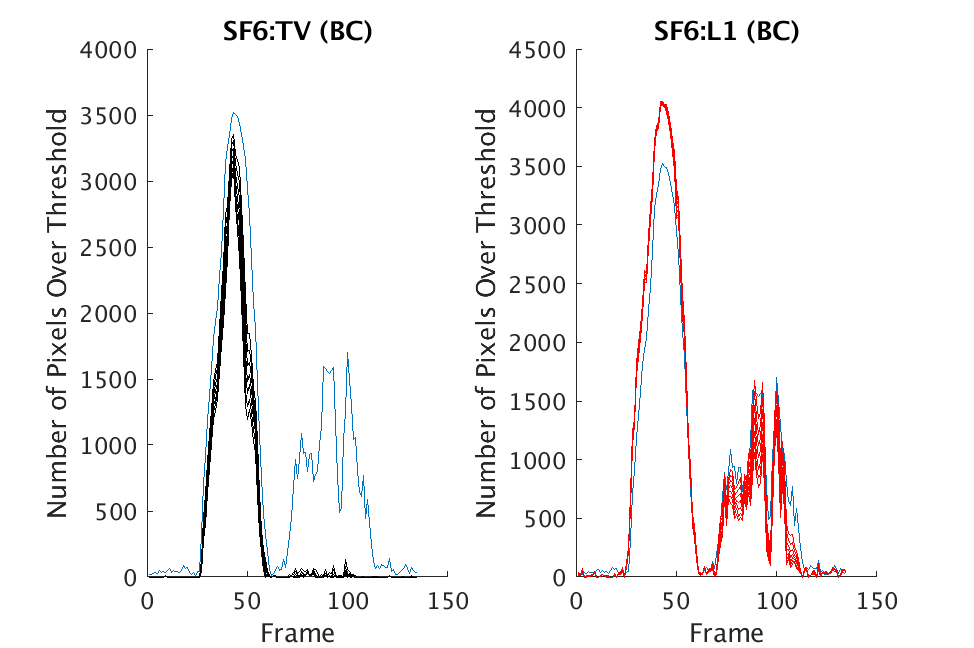 Figure 32
Figure 32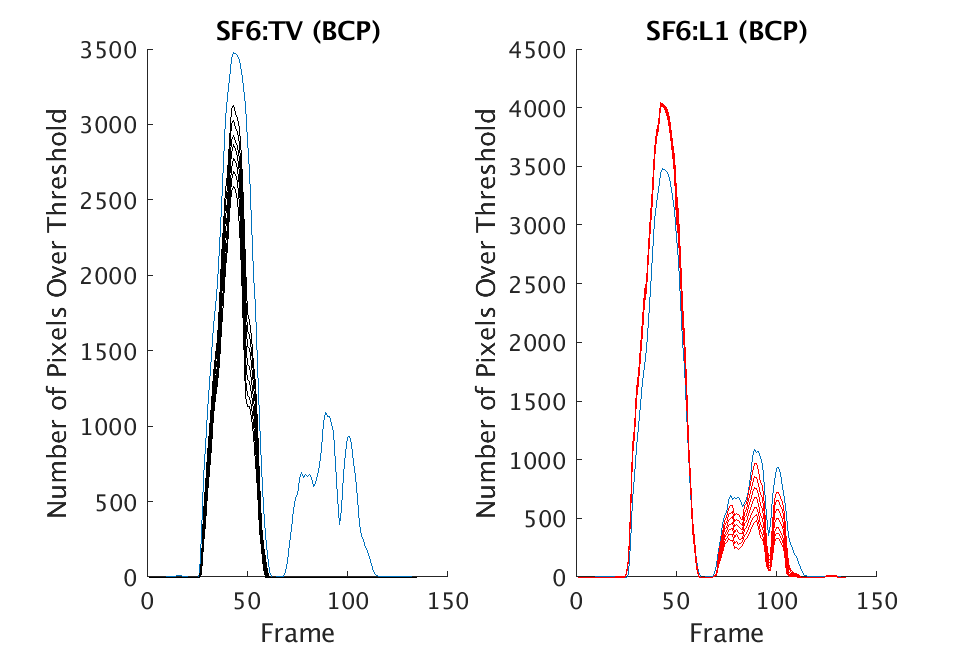 Figure 33
Figure 33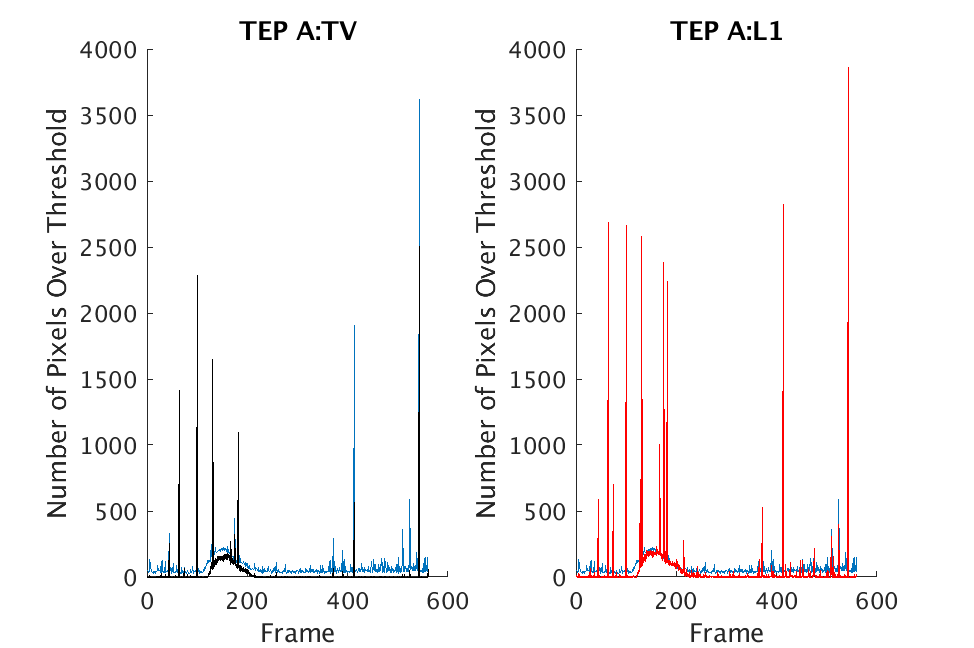 Figure 34
Figure 34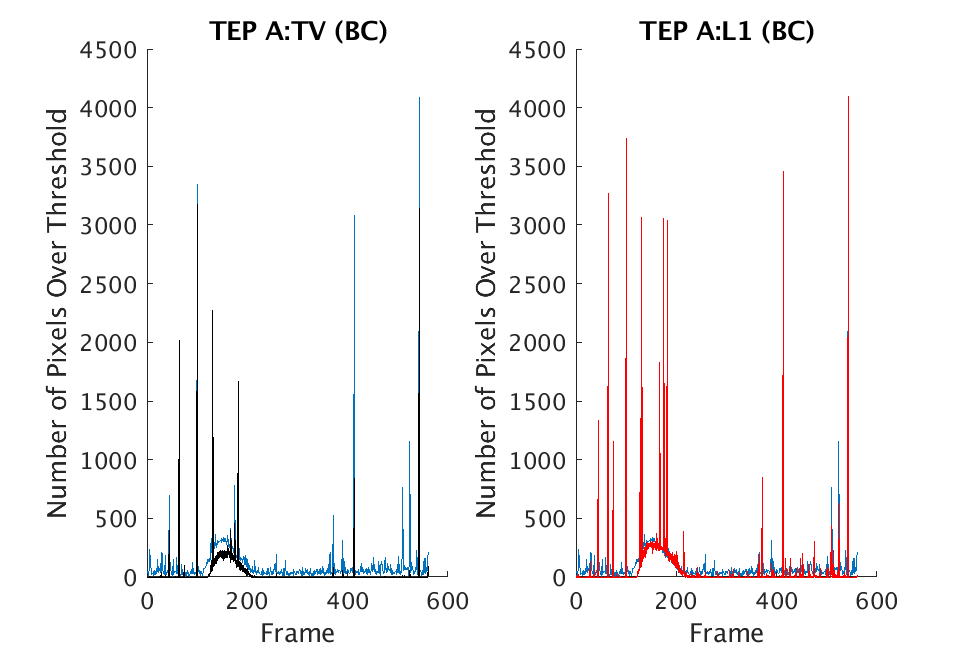 Figure 35
Figure 35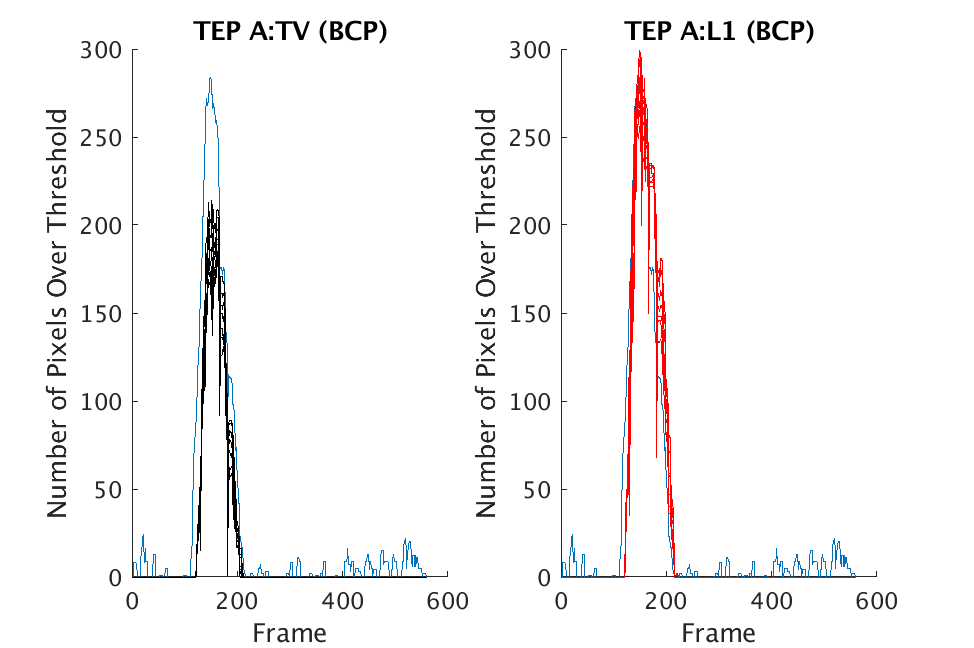 Figure 36
Figure 36Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
\authorinfo
Further author information (E-mail): (Send correspondence to E.F.)
E.F.: [email protected]; H.K.: [email protected]; M.K.: [email protected];
C.P.: [email protected]; J.R.D.: [email protected]; E.C.S.: [email protected]
Total variation vs L1 regularization: a comparison of compressive sensing optimization methods for chemical detection
Elin Farnell
Colorado State University, Department of Mathematics, 1874 Campus Delivery, Fort Collins, CO 80523-1874, USA
Henry Kvinge
Colorado State University, Department of Mathematics, 1874 Campus Delivery, Fort Collins, CO 80523-1874, USA
Julia R. Dupuis
Physical Sciences Inc., 20 New England Business Center, Andover, MA 01810-1077, USA
Michael Kirby
Colorado State University, Department of Mathematics, 1874 Campus Delivery, Fort Collins, CO 80523-1874, USA
Chris Peterson
Colorado State University, Department of Mathematics, 1874 Campus Delivery, Fort Collins, CO 80523-1874, USA
Elizabeth C. Schundler
Physical Sciences Inc., 20 New England Business Center, Andover, MA 01810-1077, USA
Abstract
One of the fundamental assumptions of compressive sensing (CS) is that a signal can be reconstructed from a small number of samples by solving an optimization problem with the appropriate regularization term. Two standard regularization terms are the L1 norm and the total variation (TV) norm. We present a comparison of CS reconstruction results based on these two approaches in the context of chemical detection, and we demonstrate that optimization based on the L1 norm outperforms optimization based on the TV norm. Our comparison is driven by CS sampling, reconstruction, and chemical detection in two real-world datasets: the Physical Sciences Inc. Fabry-Pérot interferometer sensor multispectral dataset and the Johns Hopkins Applied Physics Lab FTIR-based longwave infrared sensor hyperspectral dataset. Both datasets contain the release of a chemical simulant such as glacial acetic acid, triethyl phosphate, and sulfur hexafluoride. For chemical detection we use the adaptive coherence estimator (ACE) and bulk coherence, and we propose algorithmic ACE thresholds to define the presence or absence of a chemical of interest in both un-compressed data cubes and reconstructed data cubes. The un-compressed data cubes provide an approximate ground truth. We demonstrate that optimization based on either the L1 norm or TV norm results in successful chemical detection at a compression rate of 90%, but we show that L1 optimization is preferable. We present quantitative comparisons of chemical detection on reconstructions from the two methods, with an emphasis on the number of pixels with an ACE value above the threshold.
keywords:
Hyperspectral imaging, L1 norm, total variation norm, ACE, compressive sensing, optimization
1 INTRODUCTION
Hyperspectral imaging is a key tool for problems that require high-precision measurements across various spectral ranges. One such problem is the detection of specific chemicals in a scene of interest. More generally, hyperspectral imaging has been employed for a wide range of applications from food quality assessment to surface composition and mineralogy mapping [1, 2, 3].
One of the challenges associated with hyperspectral imaging is the high expense associated with sensing outside of the visible range. As a consequence, compressive sensing (CS) has become an important tool for hyperspectral imaging [4]. Using the CS framework, it is possible to build a hyperspectral imaging device with just a single sensor (a so-called single-pixel camera) [5]. Such devices make applications of hyperspectral imagery accessible at a significantly lower cost than traditional models.
In the context of CS, one begins with an ill-posed problem - there are infinitely many scenes that could produce a particular set of CS observations. The traditional approach is to solve a related optimization problem with a regularization term. There are many options for the particular optimization problem and regularization term, with -regularization and total variation (TV) regularization being standard choices [5, 6, 7]. In this paper, we seek to address the question of which of these two approaches is preferable in terms of chemical detection in reconstructed data. We focus specifically on the context of chemical detection in datasets that contain chemical releases or chemical simulant releases. In order to provide quantitative evidence, we simulate CS sampling on data so that we have an approximate ground truth for comparison.
To measure the accuracy of reconstructed hyperspectral data, we focus on the ability to detect the presence or absence of a target chemical signature in raw and reconstructed data. We use the adaptive coherence estimator (ACE) as our detector algorithm. While we wish to evaluate based on a binary choice between “chemical present” and “chemical absent” in each pixel, the output of the ACE algorithm is instead a real number between [math] and . To make this conversion, a threshold is necessary. In order to make a fair comparison between raw and reconstructed data we introduce a method of determining this threshold. To our knowledge this method is new.
This paper is organized as follows. In Sec. 2, we provide background on CS, TV and -regularization, and methods for chemical detection. In Sec. 3, we propose a threshold for use with chemical detection methods that makes objective comparison possible. We then provide results that compare TV and -regularization as applied to two hyperspectral datasets. We further address robustness of the two regularization approaches to variation in the threshold choice. Finally, we summarize our findings and propose questions for future work in Sec. 4.
2 BACKGROUND
In this paper we will generally use upper case letters (for example , , , , and ) to denote matrices. We will use lower case letters (for example , , , and ) to denote vectors. Matrices being placed side by side always denotes standard matrix multiplication.
2.1 Compressive Sensing
Compressive sensing (CS) is a collection of methods that allow accurate reconstruction of certain classes of signals even when measurements are low-dimensional linear functionals of raw data [5]. In the language of linear algebra, CS can be equivalently formulated as being a set of methods for solving the ill-posed problem of finding from
[TABLE]
when is a matrix, , and . While in general there will be an infinite number of solutions such that , additional assumptions about allow us to choose a close approximation to among all . Thus, rather than solving the algebraic equation (1) we solve an optimization problem in which we minimize some functional on all satisfying . In this way our assumptions about inform a choice of regularization term. That is, instead of solving (1) we solve some variation of the optimization problem
[TABLE]
where is a functional measuring the extent to which satisfies some assumption about .
In our application of CS to hyperspectral imagery we assume each data cube has bands and each band is of size (that is, as a 2-dimensional array, each band has size where ). When manipulating hyperspectral data for the experiments in this paper we generally flatten each band so that we can treat the whole hyperspectral cube as a matrix. Hence in our setting becomes and the problem is to try to reconstruct the matrix when we are only given a matrix such that . Analogously to above, this problem will be solved by making assumptions about the sparsity of the columns of under certain transformations.
2.2 Total Variation and L1 Regularization
Two of the most popular choices for in (2) are:
- •
-regularization: Here is the -norm, . While it is uncommon for images (hyperspectral or otherwise) to be sparse in their natural basis, it is well known that they are very often sparse in other bases such as wavelet bases. If are the -dimensional Haar wavelet transform and its inverse, respectively, then to require a solution to have sparsity in the wavelet basis we solve the modified optimization problem:
[TABLE]
where is a sampling matrix. Note that informally, this problem is asking us to find such that when we sample with we get , and that is maximally sparse in the Haar wavelet basis (i.e. is maximally sparse). In this paper all experiments are done with respect to the -dimensional Haar wavelet basis.
The specific version of (3) used to reconstruct a hyperspectral image from (given as an matrix) is
[TABLE]
Note that in this case , so that we are applying the inverse of a -dimensional Haar wavelet transform to each band independently, taken as a vector (or column) of . Now takes the form of a matrix (rather than just a vector) where each column is the set of samples obtained from a specific band (column) of . We define to be the usual -norm applied to as a length -vector.
- •
TV-regularization: In this case is the TV functional . There are two different version of the TV functional. The isotropic TV functional was the version originally proposed [7]. The anisotropic version is slightly easier to minimize and hence we have used this version in this paper. If is an array, then
[TABLE]
where indices are taken modulo and modulo respectively. Note that if and are the gradient operators then we can write (5) as
[TABLE]
TV-regularization is also widely used for denoising. One advantage of this global approach is that it is much more likely to preserve features such as edges that would be smoothed by other denoising techniques. The optimization problem then solved to reconstruct in the TV case is:
[TABLE]
where is again a sampling matrix. In the case where is a hyperspectral image, we write
[TABLE]
Here is defined as
[TABLE]
where the -norm is applied to the matrices resulting from matrix multiplication in (8) by flattening them and treating them as length vectors.
Partly driven by interest in CS, efficient methods for solving (3) and (6) have been developed. In this paper we used the split Bregman method [8] to solve both (4) and (7).
2.3 Chemical Detection: ACE and Bulk Coherence
In this paper, we present a comparison of TV and approaches to CS reconstruction on datasets that contain observations of chemical explosions. Hence, we measure success in terms of chemical detection in reconstructed cubes. In this section, we provide brief descriptions of the standard approaches to chemical detection that we use.
The adaptive coherence estimator (ACE) [9, 10] is a well-known technique used for chemical detection. Let be a spectral signature for a target chemical and let be a spectral signature in a specific pixel within a hyperspectral cube (in the literature, is the pixel under test (PUT)). The ACE statistic is the square of the cosine of the angle between and relative to the background. To be precise, the ACE statistic is calculated in this setting as
[TABLE]
where is the maximum likelihood estimator for the covariance matrix of background data.
We additionally use a bulk coherence statistic for signal enhancement. This statistic is also called the multipulse coherence estimator (MPACE) [11, 12]. The motivation for using this statistic is to improve detection when there are neighborhoods of pixels that contain multiple high ACE values. Bulk coherence at a given pixel is defined by incorporating the ACE statistic values in that pixel and neighboring pixels: let be the -th pixel ACE value in a neighborhood of pixels. Then we compute bulk coherence as
[TABLE]
If several ACE values in a neighborhood are close to 1, then will be close to zero, thus giving a bulk coherence value near 1. In practice, we use to create a neighborhood centered on a pixel to compute bulk coherence.
In our experimental results, we observe improved chemical detection resulting from the use of bulk coherence. We additionally seek to reduce noise via a filter we refer to as persistence. Specifically, persistence defines a value for a pixel to be zero if its bulk coherence fails to remain above a threshold for at least five successive time frames.
3 COMPARISON: TOTAL VARIATION VS L1 REGULARIZATION
In the context of CS for hyperspectral imagery, an important application is chemical detection. We focus our comparison of TV and -regularization on this context and we emphasize quantitative aspects of this comparison on real-world datasets that contain chemical simulant releases. We begin by introducing a means of algorithmically-determining thresholds so that we can objectively compare the number of pixels in a hyperspectral cube that are deemed to have a particular chemical present. Then we present results on various datasets to demonstrate comparative performance on cubes reconstructed via the two methods.
3.1 Thresholds for ACE and MPACE
In this section, we propose a method of setting thresholds for the ACE statistic. By construction, the threshold definition is responsive to the device used for CS, the spectral signature of the chemical of interest, and the reconstruction optimization approach. The methodology described here for ACE thresholds can be applied in the same manner for bulk coherence thresholds.
We define the ACE threshold by using ACE values for a specific chemical of interest on a set of hyperspectral cubes that have been sampled and which do not contain an observation of that chemical. We call these background cubes. The motivation behind our threshold definition is that the threshold should be slightly larger than the ACE values generally observed in background cubes. The precise definition is as follows.
Choose parameters and In the results we present in this paper, we use we use for sampled and reconstructed data and for raw, uncompressed data. Consider a collection of reconstructed background cubes Compute the ACE statistic for a chemical of interest in all pixels in all cubes: let be the set of all ACE values computed in cube . For each define to be the smallest element in such that percent of the pixels in have values below Then we define the threshold to be
[TABLE]
Based on experimental evidence, this threshold definition appears to effectively capture the presence and absence of chemicals of interest.
3.2 Performance: Chemical Detection
We present results from two datasets: the Physical Sciences Inc. Fabry-Pérot interferometer sensor multispectral dataset and the Johns Hopkins Applied Physics Lab FTIR-based longwave infrared sensor hyperspectral dataset [13, 14]. These datasets contain chemical simulant releases and provide an ideal setting for comparison of the two optimization approaches to CS presented in this paper. In both cases, we compare the number of pixels with ACE (bulk coherence) values above a threshold in reconstructed cubes against the number of pixels with ACE (bulk coherence) values above a threshold in uncompressed cubes. By using the algorithmically determined threshold as described in Sec. 3.1, we make an objective comparison of the two methods. We present results from two chemical release datasets from the Fabry-Pérot data and two from the Johns Hopkins data.
All results presented in this paper are from simulated CS on raw data with 90% compression. We use shifted Walsh-Hadamard sampling with a fixed maximal-variance order [15]. In all cases, we restrict to a field of view that contains the chemical release.
In Figs. 1 and 2, we show the results of chemical detection on Fabry-Pérot GAA and TEP A datasets. In both figures, blue crosses correspond to the number of pixels over the threshold for uncompressed data, and red circles represent the number of pixels over the threshold for reconstructed data. Total variation results are shown in the left column and results are shown in the right column. Finally, the rows represent ACE results, bulk coherence results, and bulk coherence and persistence results, respectively. Notice that in both datasets, there is significant noise that results in spikes for both uncompressed and reconstructed data; the cleanest results appear in the final row where persistence has been implemented. Most importantly, cubes reconstructed with both methods exhibit chemical detection that is consistent with results on uncompressed data. And in both cases, there is slightly stronger detection that occurs on cubes reconstructed with -regularization.
In Figs. 3 and 4, we show similar results on Johns Hopkins data for R134a 17 Victory and SF6 27 Romeo. The organization of the results is the same as in Figs. 1 and 2. What is more, we observe similar behavior here: both methods appear to produce chemical detection that is consistent with that on uncompressed cubes, with slightly stronger detection occurring on the -reconstructed cubes. There is one striking difference that occurs on the SF6 data displayed in Fig. 4. In this data, the chemical is clearly present in the field of view during time frames 30-60, then the chemical re-enters the field of view in a weaker, dissipated form in frames 70-110 (presumably due to a change in wind direction). The cubes reconstructed with -regularization consistently detect the chemical in these later time frames, whereas those reconstructed with TV consistently fail to detect the chemical in these later frames. This dataset provides an example that speaks strongly to the recommendation of -regularization over TV.
3.3 Robustness to Threshold Variation
We now consider the robustness of the two approaches to variation in the algorithmically determined threshold Specifically, for each of the following datasets and corresponding chemical explosions, in addition to using to compare chemical detection, we consider a range of threshold values centered at :
[TABLE]
The point of these experiments is to demonstrate that it is very unlikely that our results on TV vs. are a function of the choice of threshold for detection. That is, locally the ROC curve for -minimization lies above the ROC curve for TV-minimization.
We present selected results from both the Fabry-Pérot and Johns Hopkins datasets. In Fig. 5, we provide results on the GAA and TEP A datasets for the various thresholds for both optimization methods. All GAA data is displayed in the left column and all TEP A data is in the right column of Fig. 5. Blue curves are produced from chemical detection on uncompressed data and show the number of pixels over the corresponding threshold in each time frame. For each figure, there are seven curves shown in black or red that correspond to the seven thresholds considered. Note that there are artifacts and noise that lead to large spikes in the number of pixels over the threshold for both the GAA and TEP A datasets. The top row shows results for ACE, the middle row shows results for bulk coherence, and the third row shows results for bulk coherence and persistence, respectively. The cleanest comparison arises in the bulk coherence, persistence setting (note that the scales differ for the various figures). For both TV and there are many pixels over the threshold when the chemical is present in the scene, with stronger detection occurring in the results.
Figure 6 contains similar information, but these are results on Johns Hopkins data (R134a 17 Victory and SF6 27 Romeo). The results in Figs. 5 and 6 suggest that both approaches consistently produce reasonable chemical detection, with slightly stronger detection arising from -regularization. The exception to this occurs in the Johns Hopkins SF6 dataset. In this case, no threshold choice in leads to clear chemical detection when the chemical reenters the scene on cubes reconstructed with TV; in contrast, all choices of threshold in lead to chemical detection on the same data reconstructed with -regularization.
4 CONCLUSION
Compressive sensing techniques are already appreciated as an important tool for hyperspectral sensing and chemical detection. We have presented evidence to make a quantitative comparison of two common approaches to reconstruction: use of an -regularization term and of a TV-regularization term. We focus on a specific context, that in which the hyperspectral data has been subsampled by a specific set of linear functionals derived from rows of a Walsh-Hadamard matrix. In this setting, we have compared results on Fabry-Pérot and Johns Hopkins data. Experimentally, we have shown that, while both approaches produce good results (even at 90% compression), optimization with -regularization is generally more effective for chemical detection and more robust to threshold choices for chemical detection. We thus recommend -regularization as a useful means of CS reconstruction of hyperspectral cubes for chemical detection.
An avenue for further work is to demonstrate a theoretical justification for the differences in chemical detection performance on reconstructed hyperspectral cubes. Other questions that would be useful directions for future work include the following: how does the choice of sampling matrix affect the comparative performance of and TV? Are these results consistent across different levels of compression? How does the choice of sparsity promoting basis affect performance?
Acknowledgements.
The authors would like to thank Louis Scharf for insightful discussions related to this work, especially with regard to content involving ACE and MPACE. This research was partially supported by Department of Defense Army STTR Compressive Sensing Flash IR 3D Imager contract W911NF-16-C-0107 and Department of Energy STTR Compressive Spectral Video in the LWIR contract W911SR-17-C-0012.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Gowen, A., O’Donnell, C., Cullen, P., Downey, G., and Frias, J., “Hyperspectral imaging–an emerging process analytical tool for food quality and safety control,” Trends in food science & technology 18 (12), 590–598 (2007).
- 2[2] Lorente, D., Aleixos, N., Gómez-Sanchis, J., Cubero, S., García-Navarrete, O. L., and Blasco, J., “Recent advances and applications of hyperspectral imaging for fruit and vegetable quality assessment,” Food and Bioprocess Technology 5 , 1121–1142 (May 2012).
- 3[3] Van der Meer, F. D., Van der Werff, H. M., Van Ruitenbeek, F. J., Hecker, C. A., Bakker, W. H., Noomen, M. F., Van Der Meijde, M., Carranza, E. J. M., De Smeth, J. B., and Woldai, T., “Multi-and hyperspectral geologic remote sensing: A review,” International Journal of Applied Earth Observation and Geoinformation 14 (1), 112–128 (2012).
- 4[4] Willett, R. M., Duarte, M. F., Davenport, M. A., and Baraniuk, R. G., “Sparsity and structure in hyperspectral imaging: Sensing, reconstruction, and target detection,” IEEE signal processing magazine 31 (1), 116–126 (2014).
- 5[5] Baraniuk, R. G., “Compressive sensing [lecture notes],” IEEE signal processing magazine 24 (4), 118–121 (2007).
- 6[6] Candès, E. J. and Wakin, M. B., “An introduction to compressive sampling,” IEEE signal processing magazine 25 (2), 21–30 (2008).
- 7[7] Rudin, L. I., Osher, S., and Fatemi, E., “Nonlinear total variation based noise removal algorithms,” Physica D: nonlinear phenomena 60 (1-4), 259–268 (1992).
- 8[8] Goldstein, T. and Osher, S., “The split Bregman method for L 1 𝐿 1 L 1 -regularized problems,” SIAM J. Imaging Sci. 2 (2), 323–343 (2009).