Intermediate efficiency of some weighted goodness-of-fit statistics
Bogdan \'Cmiel, Tadeusz Inglot, Teresa Ledwina

TL;DR
This paper compares weighted goodness-of-fit tests, like Anderson-Darling and Eicker-Jaeschke, to the classical Kolmogorov-Smirnov test, focusing on tail detection and providing a quantitative, analytic evaluation of their efficiency.
Contribution
It introduces a tractable method for comparing weighted tests to the classical test and proposes a modified statistic within the Eicker-Jaeschke class as a competitive alternative.
Findings
Weighted tests show improved tail detection over classical tests.
Analytic comparison confirms the efficiency of proposed modifications.
Finite sample results support theoretical conclusions.
Abstract
This paper compares the Anderson-Darling and some Eicker-Jaeschke statistics to the classical unweighted Kolmogorov-Smirnov statistic. The goal is to provide a quantitative comparison of such tests and to study real possibilities of using them to detect departures from the hypothesized distribution that occur in the tails. This contribution covers the case when under the alternative a moderately large portion of probability mass is allocated towards the tails. It is demonstrated that the approach allows for tractable, analytic comparison between the given test and the benchmark, and for reliable quantitative evaluation of weighted statistics. Finite sample results illustrate the proposed approach and confirm the theoretical findings. In the course of the investigation we also prove that a slight and natural modification of the solution proposed by Borovkov and Sycheva (1968) leads to a…
Click any figure to enlarge with its caption.
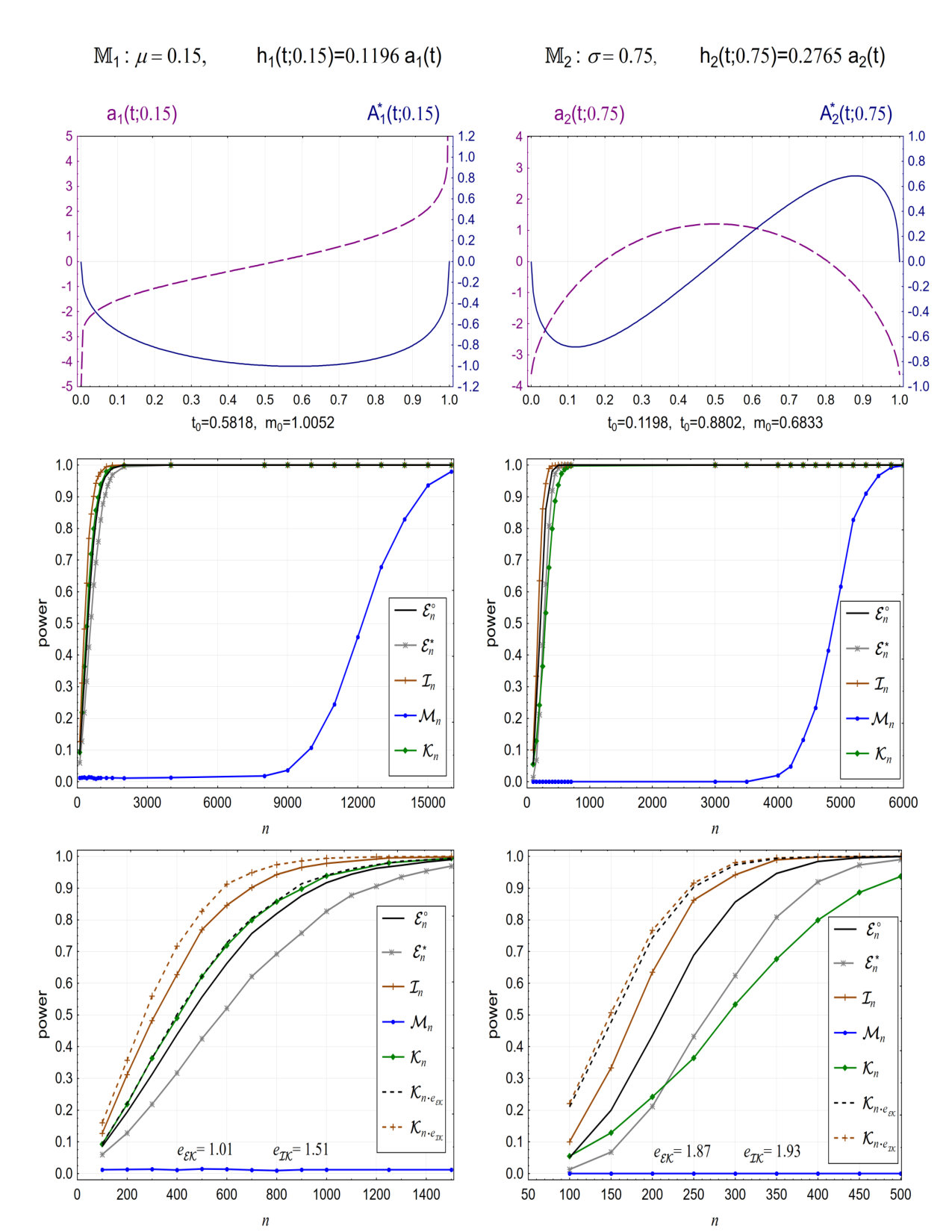 Figure 1
Figure 1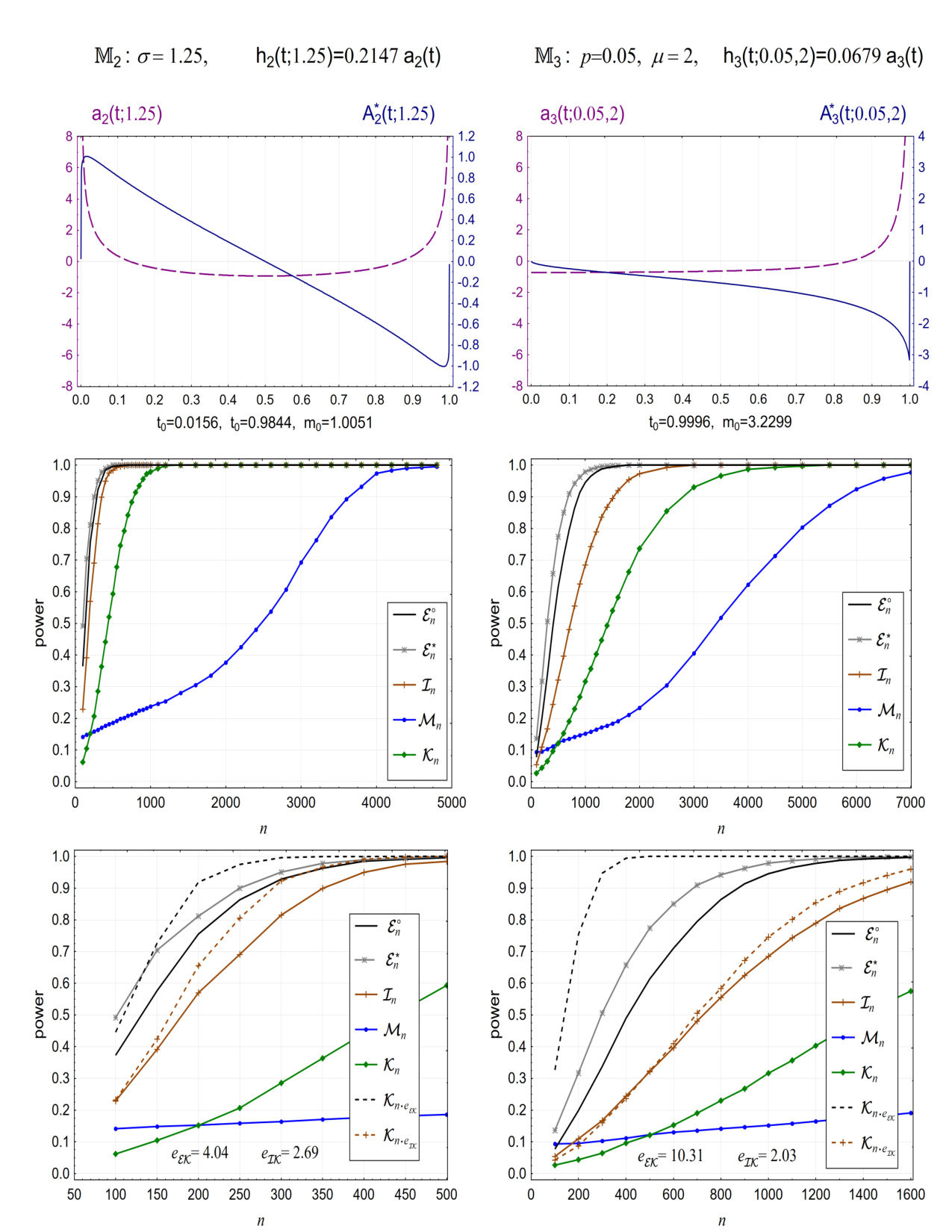 Figure 2
Figure 2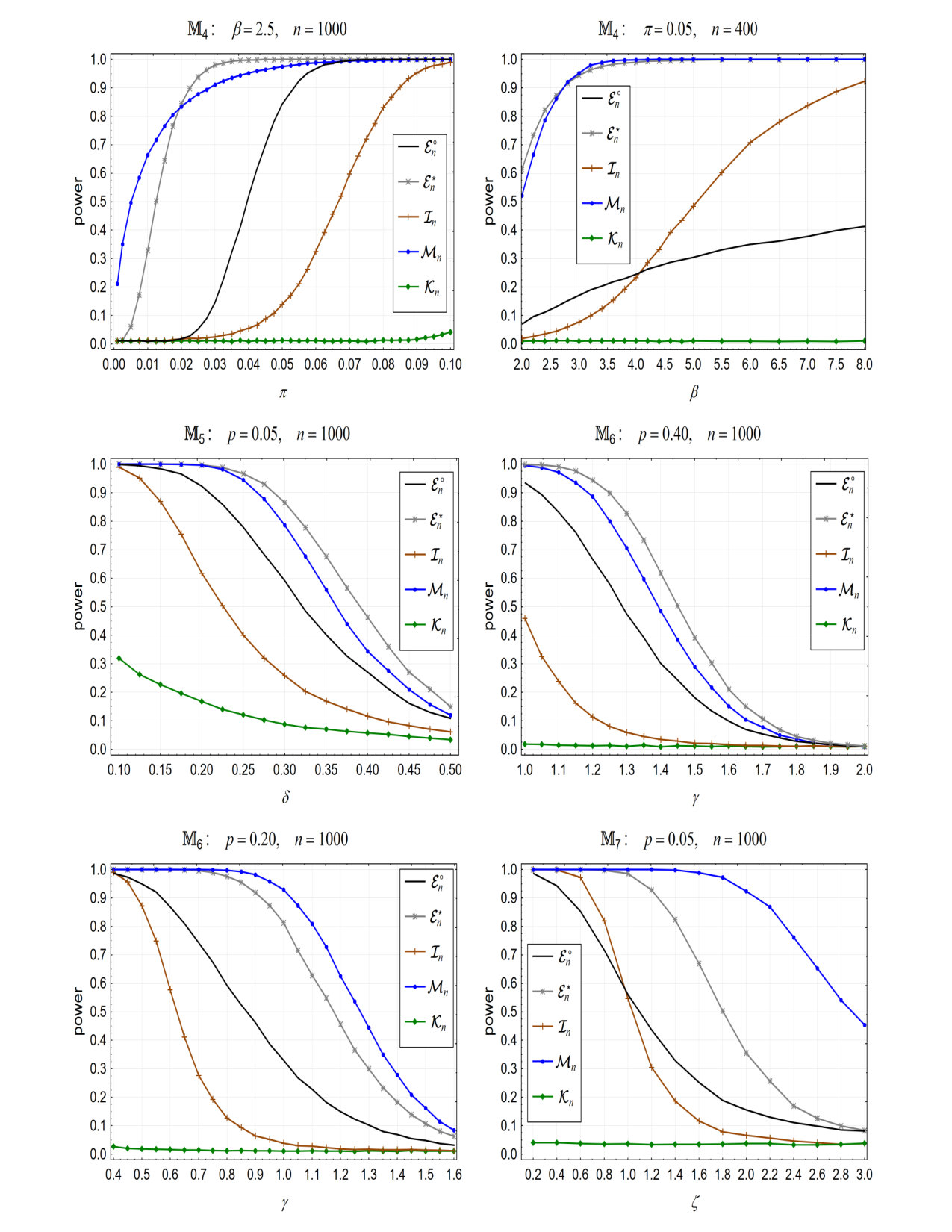 Figure 3
Figure 3Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Intermediate efficiency of some weighted goodness-of-fit statistics
**Bogdan Ćmiel
***Faculty of Applied Mathematics, AGH University of Science and Technology,
Al. Mickiewicza 30, 30-059 Cracov, Poland
e-mail: [email protected]
**Tadeusz Inglot
***Faculty of Pure and Applied Mathematics, Wrocław University of Science and Technology,
Wybrzeże Wyspiańskiego 27, 50-370 Wrocław, Poland
e-mail*: [email protected]
**Teresa Ledwina
***Institute of Mathematics, Polish Academy of Sciences,
ul. Kopernika 18, 51-617 Wrocław, Poland
e-mail*: [email protected]
Abstract: This paper compares the Anderson-Darling and some Eicker-Jaeschke statistics to the classical unweighted Kolmogorov-Smirnov statistic. The goal is to provide a quantitative comparison of such tests and to study real possibilities of using them to detect departures from the hypothesized distribution that occur in the tails. This contribution covers the case when under the alternative a moderately large portion of probability mass is allocated towards the tails. It is demonstrated that the approach allows for tractable, analytic comparison between the given test and the benchmark, and for reliable quantitative evaluation of weighted statistics. Finite sample results illustrate the proposed approach and confirm the theoretical findings. In the course of the investigation we also prove that a slight and natural modification of the solution proposed by Borovkov and Sycheva (1968) leads to a statistic which is a member of Eicker-Jaeschke class and can be considered an attractive competitor of the very popular supremum-type Anderson-Darling statistic.
MSC 2010 subject classifications: Primary 62G10; secondary 62G20, 60E15.
Key words and phrases: Anderson-Darling tests, asymptotic relative efficiency, Eicker-Jaeschke statistics, higher criticism, local alternatives, moderate deviations.
**1. Introduction
**
Weighted Kolmogorov-Smirnov-type goodness-of-fit tests have received a renewed interest in recent years; cf. Jager and Wellner (2004, 2007), Chicheportiche and Bouchaud (2012), Greenshtein and Park (2012), Charmpi and Ycart (2015), Gontscharuk et al. (2016), and Stepanova and Pavlenko (2018) for some illustration. A renaissance in research has to a large extent been driven by an application of a supremum version of the Anderson-Darling statistic in detecting sparse heterogenous mixtures, invented and developed by Donoho and Jin (2004, 2015). Obviously, weighted statistics of supremum-type are useful in many other problems as well. The renewed interest raises many unsolved questions for such structures; cf. the list of open problems on p. 2032 in Jager and Wellner (2007), and Section 5 in Ditzhaus (2018), for example. One of the questions concerns the power behavior of the considered statistics under nearby alternatives. Another one involves better understanding of the advantages and limitations of popular classes of nonparametric statistics, reconsidered recently in the context of detection of some mixtures. The aim of the present paper is to provide some tools and at least partial answers to these challenging questions.
For an exemplification of our approach, we study some selected Eicker-Jaeschke-type statistics and compare them with the classical Kolmogorov-Smirnov and the integral Anderson-Darling statistics. We focus on uniformity testing and restrict our attention to two representatives of the class:
[TABLE]
and its truncated variant
[TABLE]
where is the empirical distribution function of independent random variables with values in (0,1). was proposed by Anderson and Darling (1952) while is a consistent variant of the statistic
[TABLE]
introduced and studied by Borovkov and Sycheva (1968).
Borovkov and Sycheva (1968) have shown that if the type I error tends to 0 slower than exponentially, as , then the uniform weight function ensures that is asymptotically uniformly most powerful, in a certain sense, in some class of weighted statistics. A similar result for an exponentially decreasing type I error is contained in Borovkov and Sycheva (1970). Eicker (1979) and Jaeschke (1979) have obtained Darling-Erdös-type results for and , under the null model, and suggested that is sensitive in detecting moderate tails while, in contrast, the classical unweighted Kolmogorov-Smirnov test, say , is asymptotically sensitive in detecting changes in the central range of the null distribution. Révész (1982) provided some illustrative results supporting such statements, while Mason and Schuenemeyer (1983, 1992) defined and studied some formalization of the ability to detect central and local tail departures. They also studied a class of Rényi-type tests, being also weighted statistics, but with heavier weights than the uniform one. Jager and Wellner (2007) studied, among others, the optimal detection boundary of for a sparse heterogenous mixture model. Ditzhaus (2018) extended the results in Jager and Wellner (2007) in many directions. Based on the findings of the two above mentioned papers, one sees that from the point of view of complete detectability of specific signals, a very large class of tests was shown to achieve the same completely detectable region, under very general signal models, as the very popular higher criticism test, related to the supremum-type Anderson-Darling statistic. It should be also strongly emphasized that all the above mentioned results on different forms of detectability were phrased in terms of the presence or absence of a power consistency under some convergent sequences of alternatives.
We would like to propose some quantitative results to study local power of some representatives of currently popular statistics from another perspective. Namely, an interesting question is how many observations are needed for these tests to attain a given power lying in the interval . Therefore, we shall compare the related numbers of observations via an appropriate asymptotic relative efficiency (ARE) notion. Moreover, we would like to show that careful introduction of the uniform weight, in a way proposed in (1.2), results in a stable and highly efficient solution. Surprisingly enough, this member of the Eicker-Jaeschke class has thus far received much less attention than . To complete the picture of the sup-type Anderson-Darling statistic, we also consider its integral variant.
Our approach to computing the efficiency of the considered statistics relies on a pathwise variant of Kallenberg’s intermediate ARE. The variant, elaborated in Inglot et al. (2018), is flexible enough to be applicable to some cases which lack high regularity. Weighted goodness-of-fit statistics, based on the classical empirical process, fall into this category. The characteristic features of the intermediate efficiency are: type I error tending to 0 slower than exponentially; local alternatives converging to the null distribution slower than ; and, in contrast to the above mentioned developments on different forms of distinguishability, and non-degenerate asymptotic powers under local alternatives. The efficiency shares the advantages of Bahadur’s and Pitman’s approaches, but is much more widely applicable. In particular, the intermediate efficiency exploits moderate deviations of test statistic under the null model, instead of large deviations inherent in Bahadur’s theory. For many weighted statistics large deviations are degenerate while moderate deviations are not. For a more detailed discussion, see Inglot et al. (2018).
In our efficiency calculations the classical unweighted Kolmogorov-Smirnov statistic shall play the role of a benchmark with respect to which other statistics shall be compared. Basically, to get the efficiency, one has to guarantee non-degenerate asymptotic powers of test statistics under a given sequence of alternatives and non-degenerate moderate deviations under the corresponding null model. The last question calls for example for using in place of . Sequences of alternatives are described in Section 2. In principle, they are defined via a fixed alternative distribution and a sequence of real parameters shrinking it to the null distribution. The efficiency allows for tractable analytic comparisons between two tests.
We give a sufficient condition on tails of local sequences under which the intermediate efficiency of with respect to exists and is positive. Under this condition, is always at least as efficient as and the efficiency of with respect to is always greater or equal to the efficiency with respect to . Moreover, we provide a sufficient condition, slightly stronger than that needed for , under which the efficiency of with respect to exists and is 0. In such situations, does much better than , as a rule. Both sufficient conditions define local alternatives which do not shift too much mass towards one or two ends of and provide clear hints on which departures from the null model can or can not be detected by and , respectively. Besides, the values of the efficiency nicely reflect the finite sample powers. We illustrate this in Section 8, where testing for the standard Gaussian distribution is considered. In Section 9 we study the case when the tails of the alternative are more heavy than they were assumed in Section 8. We compare there the above mentioned tests via simulations and state the result saying that so-called weak variant of the intermediate efficiency of with respect to is infinite. The outcomes, along with the results of Section 8, show that with a relatively small smoothing parameter is a well balanced solution working nicely under different kinds of tails of alternatives.
The structure of the paper is as follows: In Section 3 we restate slightly generalized results of Inglot and Ledwina (2006) related to the Kolmogorov-Smirnov statistic . Sections 4 and 5 collect necessary technical results on and . Section 6 presents respective results on the integral Anderson-Darling statistic . Section 7 gives analytical formulas for the Kallenberg efficiencies of , , and with respect to , and discusses the results. Section 8 reports outcomes of some simulation experiments. Section 9 contains some preliminary study of efficiency of with respect to under heavy-tailed alternatives. We close with Section 10 containing some discussion of our results. All proofs are collected in the Appendix.
**2. Testing problem and sequences of alternatives
**
Throughout we rely on the setup and results of Inglot et al. (2018). As typical in the one-sample case, we denote the sample size by instead of , as it was done in the general problem considered ibidem. Let be independent random variables with continuous distribution function . Denote by the null distribution function. Consider testing
[TABLE]
against the unrestricted alternative
[TABLE]
To introduce a class of sequences of alternatives approaching to , consider first a fixed alternative , a parameter , the combination and its transformation to (0,1) via . This yields the following alternative to the uniform distribution on (0,1)
[TABLE]
The function is called the comparison distribution function or the ordinal dominance curve. If is absolutely continuous with respect to then the density, say , of with respect to the Lebesgue measure on exists. The density is labeled as the comparison density, the relative density or the grade density. In terms of densities, (2.1) reads as , where stands for the uniform density on . See Handcock and Morris (1999), and Thas (2010) for details.
The above motivates us to consider the observations from , : , and nearly null distribution functions of the form
[TABLE]
where is continuous, , while as . In many standard situations the function is absolutely continuous with a derivative , which is unbounded. For an illustration see Section 8. This is in sharp contrast to the situation we considered in the two-sample problem, treated in Inglot et al. (2018).
In what follows, by we denote the probability measure related to in (2.2) while stands for the uniform distribution on . Moreover, and denote fold products of and , respectively.
- The intermediate slope of the classical Kolmogorov-Smirnov statistic
We have
[TABLE]
where is the empirical distribution function of the sample. The intermediate slope of , under (2.2) with in such a way that , can be deduced from Inglot and Ledwina (2006). However, it should be noted that in that paper the corresponding sequences of alternatives were defined via densities. This forced an unnecessary assumption that the related should be absolutely continuous. Moreover, for convenience, it was assumed that is bounded. Under (2.2) no extra assumptions are needed. For completeness, we restate here the corresponding results. In particular, (3.4), below, follows immediately from the proof of Theorem 6.1 in Inglot and Ledwina (2006).
Define
[TABLE]
Proposition 1. For any positive , such that and , as , it holds that
[TABLE]
and
[TABLE]
*for every . Consequently, the intermediate slope of is .
Note that for we have the moderate deviations (3.3) in the full range of ’s and (3.4) holds without any further assumptions on . As said before, shall play the role of a benchmark procedure in our comparisons.
In the next section we list some weighted variants of , which we shall further study, and present their moderate deviations under the null model. It should be emphasized that, in contrast to the benchmark procedure, the competitors do not need to have non-zero moderate deviations in the full range of ’s. This is very useful, as we shall see that it is a natural and an unavoidable restriction in the case of some weighted statistics.
To calculate the efficiencies of weighted statistics, with respect to , we need for them some results analogous to (3.3) and (3.4) and, additionally, we have to identify sequences of alternatives for which asymptotic powers of these competitors of are non-degenerate. These questions are solved in Sections 4 and 5. To get such asymptotic results, we shall consider some subclasses of functions in (2.2). The requirements are not very restrictive and many commonly used models fulfill them.
**4. Some weighted variants of and their moderate deviations under
**
In addition to the statistics and , which are central in our study, for the purpose of some discussion we consider two additional statistics: , defined in (1.3), and
[TABLE]
extensively investigated in the probabilistic literature; see Shorack and Wellner (1986) for some evidence.
For any of the above weighted statistics, say , we study for which sequences , such that and , the limit
[TABLE]
exists. The number is called the index of moderate deviations. Depending on whether or , we speak of non-degenerate or degenerate moderate deviations.
Obviously, the simplest solution is . For this statistic, similarly as for , moderate deviations exist and are non-degenerate in the whole range of ’s; cf. Lemma 1, below. As (3.3), the result is obtained by matching the KMT strong approximations and an asymptotic behavior of corresponding suprema of a weighted Brownian bridge. The last question is well studied, see Sec. II of Adler (1990) for some basic results and Lifschits (1995), Sec. 14, for further developments. The proof is skipped, as it is very similar to that for ; cf. Inglot and Ledwina (1990) for details on .
The statistic can be seen to be a refined variant of . In this case the situation is much more complex. Namely, if tends to 0 relatively slowly, then, using again the strong approximation technique, we get non-degenerate moderate deviations. However, if the rate of convergence of is too fast, then the index of moderate deviations is 0 for large class of sequences ; see Lemma 2. An even more extreme situation occurs in the case of , for which the moderate deviations are non-degenerate only for a very restricted class of sequences ; cf. (ii) of Lemma 4. For the index of moderate deviations is 0 for all allowable sequences ’s; see (i) of Lemma 3. In such circumstances, similarly as in the case of the Bahadur approach to an efficiency, one can search for a monotonic function (or a sequence of functions), which, after imposing on a given statistic, leads to tails commensurable with that of . Obviously, such a monotonic transformation gives an equivalent test. It turns out that in the case of the transformation does the job and
[TABLE]
exhibits a quantifiable moderate deviation behavior. The result is due to Mason (1985); cf. (ii) of Lemma 3, below. Similarly, the second statement in (i) of Lemma 4 is due to Mason (1985).
Lemma 1. *For any , and such that , it holds that *
[TABLE]
Lemma 2.
(i) Assume that . Then for any , and such that it holds
[TABLE]
(ii) *Suppose . Then for any , and such that and , it holds that *
[TABLE]
Lemma 3.
(i) If and then
[TABLE]
(ii) For any , and such that , we have
[TABLE]
**Lemma 4.
**(i) Suppose that and . Then for any
[TABLE]
(ii) For any , and such that , we have for
[TABLE]
Remark 1. With probability 1 it holds that
[TABLE]
where , , are order statistics of the sample while for convenience we additionally set . Lemma 2 (ii) and the above exhibit that abandoning some fraction of smallest and largest transformed observations in the sample allows for non-degenerate moderate deviations when using the uniform weight. The above shows also that the construction of the statistic follows a similar idea as the modified higher criticism statistic defined in Section 3 of Donoho and Jin (2004), where a slightly smaller fraction of smallest transformed observations was abandoned. Some simulated powers of are reported and discussed in Li and Siegmund (2015).
The proof of Lemma 2 is provided in the Appendix. Also there, we justify the index [math] appearing in Lemma 3 and 4. The statement (ii) of Lemma 4 is a consequence of Proposition 2.5 in Inglot and Ledwina (1993). As mentioned earlier, (4.5) and the moderate deviations for follow from Mason (1985). The above shows that even such standard weighted statistics behave very differently, and this illustrates the “irregularities”, we mentioned in Section 1. Anyway, for each of the considered examples there are sequences for which the respective index of moderate deviations is positive. This makes it possible to apply the pathwise variant of intermediate efficiency elaborated in Inglot et al. (2018). The next step in this direction is to study the asymptotic behavior of the statistics under sequences of alternatives. This question is studied below. To avoid repetitions of similar statements, we restrict our attention to presenting in full form only the respective results on and .
**5. An asymptotic behavior of and under sequences of alternatives and their intermediate slopes
**
We follow the scheme and notation of the definition of the pathwise variant of intermediate efficiency elaborated in Inglot et al. (2018). Therefore, we consider a particular sequence where , as , and the related in (2.2), is given by
[TABLE]
where is continuous and . As in Section 2, we set for the distribution of and for its -fold product. Additionally, introduce
[TABLE]
In the case of , assume that satisfies
[TABLE]
where is defined in (5.2). Then there exists such that
[TABLE]
Set
[TABLE]
Throughout , stands for the standard normal distribution function.
Theorem 1. *Consider (5.1) with satisfying (5.3) and , and . Then
(i) ;
(ii)
*where is the standard normal distribution function, is the distribution function of \;\sup_{[\delta,1-\delta]}\bigl{\{}|B(t)|/\sqrt{t(1-t)}\bigr{\}} with defined in (5.4), while is a Brownian bridge.
Hence*, , *and the intermediate slope of under has the form where
Remark 2. In the case of an analogue of Theorem 1 holds true for any in (2.2). The only difference is that in the description of one should use in the place of . Hence we get the following: For (5.1) with , and , the intermediate slope of , under , has the form where while . A comparison of with supports the statement that is a natural refinement of .
We have also considered an analogue of Theorem 1 for with fixed . The result, together with Lemma 4 (ii), shows that the intermediate slope of is smaller than the related slope of . Hence, under fixed , is less efficient than . Therefore, we skip the presentation of the relevant details.
We have also derived the intermediate slope of a recent modification of introduced by Stepanova and Pavlenko (2018). The results do not differ substantially from these on . Therefore, we present here our results only for the classical case of .
For suppose that satisfies
[TABLE]
The assumption (5.6) implies that there exists such that
[TABLE]
where is defined in (5.2). In terms of an alternative in (2.1), the condition (5.6) means that
[TABLE]
Put
[TABLE]
Theorem 2. *Suppose that satisfies (5.6) with some . Consider (5.1) with and as Then
*(i) ;
(ii)
*where , is the distribution function of \;\sup_{[\delta,1-\delta]}\bigl{\{}|B(t)|/\sqrt{t(1-t)}\bigr{\}} with defined in (5.7), is defined in (5.5), while is a Brownian bridge.
Hence*, , *and the intermediate slope of under has the form where
Remark 3. The restriction (5.6) on , imposed in Theorem 2, is obviously stronger than the related condition (5.3) needed for . When is absolutely continuous with a derivative and for some it holds that and then the condition (5.6) is satisfied with . In particular, when is bounded then (5.6) holds with . The case admits unbounded .
Consider the alternative (5.1) with of the form . Then (5.3) and (5.6) do not hold. This corresponds to a heavy-tailed departure. When the null distribution is then such corresponds to the Lehmann (1953) alternative in (2.1). For further discussion of some examples see Sections 8 and 9.
**6. The integral Anderson-Darling statistic and the related asymptotic results
**
Set
[TABLE]
By Proposition 2.2 and Remarks 2.2-2.4 in Inglot and Ledwina (1993) we infer the following.
Lemma 5. *For any , and such that , it holds that *
[TABLE]
Now, consider alternatives of the form (5.1), with such that for some it holds that
[TABLE]
Observe that under (6.3) for defined in (5.2) it holds that
[TABLE]
Note that both conditions (5.3) and (5.6) imply (6.3). Asymptotic behavior of under the sequence of alternatives (5.1) with satisfying (6.3) is described below.
Theorem 3. Suppose satisfies (6.3). Consider obeying (5.1) with and such that , as . Then
[TABLE]
where
[TABLE]
Hence, the intermediate slope of has the form
[TABLE]
The result (6.4) was reported in Inglot et al. (2000) for the case of absolutely continuous with a bounded derivative . Its proof was very briefly sketched in Inglot et al. (1998). Here, for completeness, we provide detailed justification of (6.4). In fact, a result like (6.4) with the corresponding (6.3) can be immediately generalized to Hilbertian norms on imposed on the empirical process. We omit the details. Such a result, along with the technique developed in Inglot and Ledwina (1993), allows us to calculate intermediate slopes of a family of integral test statistics.
Remark 4. Assume that in (2.2) is absolutely continuous and . If for some then (6.3) holds. If then (5.3) is satisfied. In the case for some we have (5.6) with .
For testing consider the alternative distribution function , parametrized by , and given by , where if , if , and if . is a member of the symmetric Pareto family considered in Grabchak and Samorodnitsky (2010). Such an , via (2.1), corresponds to in (2.2). A simple calculation shows that (6.3) is satisfied for when while (5.3) does not hold for any . Moreover, for each it holds that for any . In such a sense, has the heaviest possible tails which can appear in (2.1) when .
**7. Intermediate efficiencies of and with respect to
**
Exploiting the results collected in Sections 2 - 6 and using Theorem 1 from Inglot et al. (2018), we immediately obtain the following results.
Theorem 4. *Consider a sequence of alternatives defined by (5.1) with .
(i) The intermediate efficiency of with respect to , under the sequence , exists and equals
[TABLE]
(ii) Suppose . If satisfies (5.3) and . Then the intermediate efficiency of with respect to under the sequence , exists and equals
[TABLE]
(iii) If satisfies (6.3) then the intermediate efficiency of with respect to under the sequence , exists and equals
[TABLE]
Theorem 5. *Consider a sequence of alternatives defined by (5.1) with satisfying (5.6) for some and .
Then the intermediate efficiency of with respect to , under the sequence , exists and equals*
[TABLE]
Remark 5. We have chosen as a benchmark since, first of all, it seems to be a natural reference statistic when some weighting is considered. Moreover, in view of the approach elaborated in Inglot et al. (2018), it is applicable in such a role since it obeys moderate deviations in the full range. Alternatively, in view of Lemmas 1 and 5, and can be used as benchmarks, as well. Perhaps the most natural candidate for a benchmark procedure could be the Neyman-Pearson test statistic for uniformity against , cf. (2.2), defined when is absolutely continuous with derivative . To justify such a choice, again one should know that moderate deviations for this statistic hold for all sequences such that and This is the case when is bounded. However, for unbounded such a question seems to remain open. Results of Merlevède and Peligrad (2009) suggest that for unbounded the speed , using their and our notations, needs to be adjusted to .
Remark 6. The results (7.1), (7.2) and (7.3) show that, under appropriate assumptions, the sample sizes needed for the Kolomogorov-Smirnov test to be, given , as good as the tests based on , and , respectively, are equal approximately to , respectively. Thus, they are approximately proportional to .
The relation (7.4) reveals that, under (5.6), for the Kolmogorov-Smirnov test the sample size sufficient to attain, given , the power as good as that of the test based on is of smaller order than . A similar result to (7.4) can be formulated on .
The statement (7.4) deserves some more detailed comments. First of all, it should be emphasized that the intermediate efficiency concerns the situation when asymptotic powers of the corresponding tests are kept in . Therefore, the result (7.4) does not contradict consistency of under fixed or convergent alternatives. Observe that our approach exhibits that the functions and , defining the intermediate slopes, are related to the respective shifts in the limiting theorems, which ensure non-degenerate asymptotic powers. Since , it can be expected that, in a finite sample comparison, the power function of should be much smaller than the corresponding power function of . This tendency is quantitatively measured by the intermediate slopes and the intermediate efficiency. Since in the intermediate approach the alternatives are not very close to the null one and the levels do not decrease very fast, we can expect that a similar tendency shall be seen in empirical powers under fixed alternatives, which satisfy (5.6). In Section 8.2 we present a small simulation study which confirms such intuitions.
Next, compare (7.4) with, consistent with it, findings of Lockhart (1991). In that paper it was shown that, under usual types of contiguous alternatives, the power and the level of have the same limit, and the related ARE of the test with respect to the corresponding Neyman-Pearson test (NP) is 0. The same conclusion holds true for the ARE of with respect to any other test with a nonzero asymptotic efficiency relative to the NP test. In our opinion, in this application, the intermediate approach, resulting in non-zero shift, explains better observed empirical powers of than the conclusion on the shift 0 under Pitman’s approach.
The results on in Lockhart (1991) were formulated in the case when is absolutely continuous and the corresponding function belongs to . This assumption is standard in the classical approach to investigation of an asymptotic power and the asymptotic relative efficiency of tests under alternatives of order . For an illustration see the insightful results on proved by Milbrodt and Strasser (1990), and Janssen (1995). On the other hand, note that we have shown that the intermediate slope of is well defined for any . This opens a possibility of comparisons of some competitors to for some interesting alternatives with . Typically, alternatives with heavy tails lead, via , to a corresponding . Tails heavier than Gaussian are common in many current applications. For related discussion, see Cont (2001). Examples of such alternatives along with some preliminary results on a weak variant of the intermediate efficiency are presented in Section 9. It turns out that in such a setting the asymptotic behavior of changes dramatically. Namely, the weak intermediate efficiency of with respect to is infinite. In light of recent results on the intermediate efficiency of the Neyman-Pearson statistic with respect to , in the case when contained in Inglot (2019), this is not surprising. It turns out that, in contrast to , is completely inefficient in such situations.
Remark 7. An easy calculation shows that , and for any satisfying (5.3). Moreover, can be arbitrarily close to 0 (take for small , where denotes the indicator of the set ). On the other hand, can take any positive value (for small take or ). Also can be arbitrarily close to (for small take ).
Remark 8. To give some insight into asymptotic levels of the tests considered in Theorems 1 - 3 and Remark 1, set where while is a positive constant. Recall that the Kallenberg efficiency is characterized by levels tending to 0 and asymptotic powers in . According to (i) of Theorem 1 in Inglot et al. (2018), for any of the statistics, say , being compared to , it holds that , where is the intermediate slope of .
For and any the allowable levels are of the form .
For take , and satisfying (5.3). Then (7.2) holds for any and the allowable levels take the form .
For take satisfying (5.6) with some . Then (7.4) holds true for any and the allowable levels take the form .
For the situation is much more regular. For any in and satisfying (6.3) the statement (7.3) holds and the allowable levels take the form .
As for the asymptotic power under with the above , we have the following situation, being a consequence of Lemma 1 of Appendix B in Inglot et al. (2018). In the case any fixed asymptotic power from (0,1) is attainable by an appropriate choice of in (6.4). In contrast, for and we do not show that asymptotic power exists and we can only say that taking, in the present Theorems 1 and 2, any the resulting sequences of powers are bounded away from 0 and 1.
Though the above conclusions, contained in Remark 8, may look to be complicated and abstract, it turns out that, under standard circumstances, the value of the efficiency nicely helps to predict the empirical power of a test being compared to a benchmark. The reason for this is that on not very extreme tails of the test statistic, which are characteristic to the intermediate approach, the asymptotics work well for relatively small sample sizes. Hence, the approach gives good approximation for standard significance levels. A similar conclusion can also be found in Ermakov (2004), p. 624. Below, we demonstrate to what extent, for selected statistics with non-zero intermediate efficiency with respect to , our results explain empirical powers under fixed levels and fixed alternatives.
**8. Simulation and efficiencies
**
**8.1. Examples of departures from the standard Gaussian model
**
We start with three simple classical situations related to detecting lack-of-fit to the standard normal distribution . To be specific, , and the alternatives are: and In all simulations here and in Section 9 we consider fixed alternatives. To clearly distinguish this case from the combination , used in theoretical considerations, we use the notation for the fixed alternative. This is especially useful in Section 9, where itself corresponds to some mixtures. For some simulated powers of under the shift and scale models see Moscovich et al. (2016). The location-contaminated alternative comes from the paper by Pearson et al. (1977). The alternative was exploited for comparison of powers in Li and Siegmund (2015). In recent years this model with , and , has been popularized under the label “sparse heterogeneous mixtures”; cf. Donoho and Jin (2004) and related papers.
After the transformation , these alternatives have some densities on which can always be written in the form , where Since we like to present ’s in our figures in some normalized form, we introduce the following parametrization. By we denote the norm on (0,1) with the Lebesgue measure, we put , and . This yields the following alternative models:
:
:
: \displaystyle h_{3}(t;p,\mu)=1+\theta^{[3]}a_{3}(t;p,\mu),\;\;\;\mbox{with}\;\;\;a^{[3]}(t;p,\mu)=p\Bigl{\{}\frac{\varphi(\Phi^{-1}(t)-\mu)}{\varphi(\Phi^{-1}(t))}-1\Bigr{\}},\\ \hskip 28.45274ptp\in(0,1),\;\mu\in\mathbb{R},\;\mu\neq 0.
The functions and are unbounded while is bounded for and unbounded otherwise. It holds that . Set We have The last relation implies that the intermediate efficiency of the mixture does not depend on . In contrast, the efficiency is influenced by a change of the “direction” of the noise in the mixture; i.e. in this particular case. More examples of mixtures are discussed in Section 9.
Similarly as in Section 5, given , set
[TABLE]
Note that for the functions and and all related parameters under consideration (5.6) holds with any and hence (5.3) and (6.3) hold, as well (cf. Remark 2). For , if then (5.6) holds with ; if then (5.6) holds with ; if then (5.3) holds while (5.6) does not. For all (6.3) is satisfied.
**8.2. Alternatives from , and satisfying (5.3), (5.6) and (6.3), corresponding efficiencies and simulated powers
**
We restrict our attention to , , , and two selected members of the class of statistics , indexed by satisfying (ii) of Lemma 2. It is intuitively clear that using a relatively small parameter can be profitable when under an alternative a considerable amount of a probability mass is shifted towards one or both tails, while a larger is expected to be more useful in detecting centrally located changes. For an illustration we took
[TABLE]
and
[TABLE]
In the simulation experiments the significance level was set to and the number of MC runs for estimating sizes was . Moreover, we used MC runs for estimating powers. The programs were written in C Sharp.
We have considered with , with and and with . For all the cases the assumptions (5.3), (5.6) and (6.3) are satisfied. Hence our theoretical results on the intermediate efficiencies are applicable.
The selected models, the corresponding efficiencies and the related empirical powers are presented in Figures 1 and 2. In the first row of the figures we display graphs of and , , and the corresponding values of , , where and .
The middle rows show empirical powers of , , , and , against .
The bottom rows show the above power curves for sample sizes not exceeding the first value for which the empirical power of attains the value in . We additionally display here the values of the efficiencies and . In all four cases as well as In the last row we also present the corresponding simulation results for and i.e. the empirical powers for the Kolmogorov-Smirnov test based on the corrected sample sizes and , respectively. The zoom applied here allows to see well the way in which the corrected sample sizes influence the empirical powers of .
The results show that the finite sample interpretation of the intermediate efficiency indeed reflects very well the behavior of empirical powers of . For very large values of the efficiency and relatively small sample sizes, as is the case for the model in Figure 2, the empirical powers of considerably overestimate the powers of and . However, it is hard to expect very accurate small sample results in such an extreme situation. In any case, the message is informative. The results of simulations also indicate that the 0 efficiency of with respect to should not be surprising. Shapes of empirical powers of , as functions of , are very different from those for . For the alternatives under consideration one needs a relatively huge number of observations to achieve a high power of the test based on . Similar pictures are expected to be valid for many other classical alternative distribution models.
**9. On the behavior of and when (5.3) is violated
**
The above part of the paper gives some quite reliable insight into the behavior of powers of the Kolmogorov-Smirnov test and the selected Eicker-Jaeschke statistics and , in the case when the tails of an alternative are relatively light; i.e. the conditions (5.3) and (5.6) are satisfied. Under these conditions and , respectively. From previous developments it follows that one should expect much worse power behavior of in the case of alternatives obeying relatively heavy tails. We shall study this question in the present section by contrasting the behavior of with , in the case when the condition (5.3) is violated. Since we are aware of an extension of Theorem 1 in this case, we are able to calculate only a so-called weak variant of the intermediate efficiency. Let us denote it by . This weak variant is defined as a limit of the ratio of the slopes, as tends to infinity. The difference between and resembles to some extent the difference between the approximate and the exact Bahadur efficiency. The weak variant of the intermediate efficiency was already studied in Ivchenko and Mirakhmedov (1995), and Inglot (1999).
To calculate for a local sequence of alternatives , when (5.3) is violated, set
[TABLE]
and denote by any point at which the supremum in (9.1) is attained.
Lemma 7. *Suppose that and or , as . Assume that , , and . Then one gets *
[TABLE]
Hence, the intermediate slope of under has the form .
Corollary 1. Under the assumptions of Lemma 7 it holds that
[TABLE]
The relation (9.3) suggests that perhaps the intermediate efficiency of with respect to equals , as well. However, verifying this would require non-trivial investigations of the question on non-degeneracy of the asymptotic power of under the above described local alternatives. This is a challenging open question. Note that non-degenerate asymptotic power of is needed to have the interpretation of the intermediate efficiency in terms of the limiting ratio of appropriate sample sizes; cf. Theorem 1 in Inglot et al. (2018).
We show below that even this weak variant of the efficiency gives a right indication on an empirical power behavior of and , when (5.3) fails.
We shall study an empirical behavior of , , , as well as and under the following alternative models
, where , and ,
where is the Lehmann distribution; cf. Remark 3,
where is the symmetric Subbotin distribution function obeying the density
where is the distribution function of the symmetric Pareto distribution with the parameter ; cf. Remark 4.
The model comes from Mason and Schuenemeyer (1983). If then has lighter tails than the uniform (0,1) distribution, say . When then has heavier lower and upper tails than . For the condition (5.3) does not hold if . defines alternatives with an allocation of the probability mass only on the tails.
- were chosen as mixtures. Detection of mixtures is of vital interest. Lehmann’s model, used in , is popular in the statistical literature. The Subbotin distribution is discussed in Donoho and Jin (2004). The mixture has been inspired by Jin et al. (2005), where an additive model with disturbances with algebraically decreasing tails was considered. For with , with , and with the condition (5.3) does not hold.
Each of the models can be equivalently rewritten in the form The functions , are symmetrical with respect to 1/2 and unbounded at 0 and 1 while is unbounded at 0. For close to 0 the functions behave like: , respectively. Note also that do not belong to for , accordingly.
In Figure 3 we plot empirical powers of the considered tests, under and some selected and , against the parameters and of the considered models. The outcomes show that, when (5.3) is violated, empirical behavior of is very poor and resembles the behavior of in previous figures. In contrast, now does very well. Obviously, the imposed lack of (5.3) implies the violation of (5.6), as well. Moreover, except for the cases when a very large amount of probability mass is shifted to the ends of , also works very well. In all situations shown in Figure 3 the variant dominates considerably. The empirical behavior of is not impressive in comparison to and .
It should be emphasized that we have not conducted an extensive search for and defining and . We simply took the two candidates which satisfy the assumption (ii) of Lemma 2, i.e. satisfying . In spite of this, from the outcomes in Figures 1 - 3, it can be seen that is a reasonably well balanced solution. At any rate, some search for a data-driven choice of the smoothing parameter would be very welcome.
10. Discussion
The present paper illustrates the advantages of using the pathwise variant of the Kallenberg efficiency to study goodness-of-fit to a completely known continuous distribution function. In Inglot et al. (2018) the paths were defined as mixtures of a big fraction of the null distribution and a small fraction of an alternative one. Consequently, we consider , where is the null distribution, represents the alternative, and as . For convenience, in this paper we have transformed the observations to (0,1) via , cf. (2.1), but it is not essential to the interpretation of the results. Moreover, to increase the readability of the results, we introduced (2.2). Anyway, in essence the pathwise variant of the efficiency evaluates the quality of tests by measuring their ability to detect (local) mixtures. On the other hand, the mixtures define “directions” along which we approach the null model and, as a rule, the corresponding results on the efficiency are valid for many “directions”. Moreover, in the intermediate approach decreases relatively slowly. The above implies that the resulting, asymptotic in nature, expression for the efficiency gives reliable results on empirical powers under fixed alternatives which are not necessarily mixtures, fixed sample sizes, and standard significance levels.
At first glance, our approach resembles detecting mixtures under the dense regime; cf. Cai et al. (2011) for the terminology and an insightful introduction to the problem. However, we are focused on a goodness-of-fit context and our goal is not to study if and when a procedure can detect or fail to detect a given mixture, but we would like to investigate how well a selected test can distinguish some classes of alternatives from the null model. Therefore, in contrast to the signal detection approach, we insist on having the error of the second kind in . Moreover, the distribution function is fixed, independent on . So, our setting differs from the typical approach in studies of detectable and undetectable regions, originated by Ingster (1997) and extensively developed in recent years; cf. Ditzhaus (2018) for the most general setting and historical details. Also, the outcomes of both approaches are qualitatively different. A typical feature of Ingster’s approach is that whole big classes of tests have the same detection boundaries; cf. Jager and Wellner (2007), and Ditzhaus (2018) for an illustration. In contrast, the Kallenberg efficiency allows for catching some subtle differences between test statistics. It seems that some further investigations on this approach could result in better understanding advantages and limitations of popular classes of modern goodness-of-fit statistics. In particular, some more work on the asymptotic distribution of test statistics under the regime and is necessary. Moreover, moderate deviations for the whole classes of test statistics, which were recently considered, should be developed. As illustrated by our analysis of and related discussion, for sufficiently smooth functionals of the weighted empirical process deriving the intermediate efficiency is relatively easy. Sup-type functionals are less regular and more difficult to handle. Anyway, in our opinion, the present paper shows that such work is worthy of further consideration. In particular, it would be interesting to close our investigations on and by showing if and when their intermediate efficiencies with respect to exist in the situation when (5.6) and (5.3), respectively, are violated.
**Appendix: Proofs
**
**A.1. Proof of Lemma 2
**
Let be independent uniform (0,1) random variables and let denote their order statistics.
(i) Let . Then, by the assumption , we have for sufficiently large
[TABLE]
[TABLE]
[TABLE]
[TABLE]
Since for all then
[TABLE]
Hence and from the relation for sufficiently large we get
[TABLE]
Moreover, since , then for sufficiently large it holds . On the other hand by being true for we have
[TABLE]
As for sufficiently large , the above inequality and the definition of imply for sufficiently large
[TABLE]
[TABLE]
Combining (A.1), (A.2) and (A.3), again by the definition of and the assumption , we obtain for sufficiently large
[TABLE]
Imposing the logarithm in (A.4), dividing by , and using again the assumption we get
[TABLE]
and the proof is complete.
(ii) Let be the uniform empirical process and denote
[TABLE]
Since , then the assumption on implies . Let , be such that and . Then for any fixed and sufficiently large we have
[TABLE]
and
[TABLE]
Moreover, from KMT inequality we have
[TABLE]
where are universal positive constants.
If we shall show that for any and such that it holds
[TABLE]
then by the choice of , the first component in the exponent on the right hand side of (A.7) dominates the second one and simultaneously the first component on the right side of (A.5) and (A.6) dominates the second one and (4.4) follows from (A.8).
To prove (A.8) recall that from the Darling-Erdös theorem (cf. Csörgő and Horvath, 1993, pp. 257-258) it follows that
[TABLE]
where . Denote by the median of . Then from the above relation , where is the median of the limiting distribution. Hence , and tends to infinity. By a straightforward application of the Borell inequality for (see e.g. van der Vaart and Wellner, 2000, p. 438) we get for every and
[TABLE]
Since by the assumption it follows then inserting into the last inequality we get
[TABLE]
On the other hand, for any and sufficiently large we have and consequently
[TABLE]
The last two relations complete the proof of (A.8).
**A.2. Proof of Lemma 4 (i)
**
The proof goes along the lines of that of Lemma 1 in Mason (1985). For any the function is increasing on and due to . This gives the following estimate
[TABLE]
[TABLE]
By the inequality holding for we infer that for some positive
[TABLE]
Taking logarithms of both sides of (A.9), dividing by and using the assumption we get
[TABLE]
which completes the proof.
**A.3. Proof of Lemma 3 (i)
**
Observe that for the above proof is valid. The only difference is that in (A.10) the first component on the right hand side vanishes and the assumption becomes superfluous. So, Lemma 3 (i) holds true.
**A.4. Proof of Theorem 1
**
Let , be the uniform empirical process and set . By (5.3) there exists such that .
(i) It holds that
[TABLE]
[TABLE]
When then (A.11) is majorized by converging to . If then the majorant of (A.11) converges to as well. This proves (i).
(ii). The key step is to show that for appearing in (5.4)
[TABLE]
Indeed, having (A.12), for positive the triangle inequality and (5.4) imply that
[TABLE]
[TABLE]
[TABLE]
Since converges in distribution to a Brownian bridge, then (ii) follows.
Now, by the definitions of and , using the triangle inequality we infer that
[TABLE]
[TABLE]
[TABLE]
[TABLE]
For we have
[TABLE]
So, by (5.3) and the assumption for and sufficiently large the right hand side of (A.14) can be estimated by
[TABLE]
Hence, for and sufficiently large we have
[TABLE]
and the right hand side in (A.13) is majorized by
[TABLE]
which, in view of the assumption , as , and an application of the main result of Mason (1985), tends to 0. This concludes the proof of (A.12).
**A.5. Proof of Theorem 2
**
As previously, let , be the uniform empirical process and set . By (5.6) there exists such that . We can write
[TABLE]
Proof of (i). Since
[TABLE]
[TABLE]
then we proceed exactly in the same way as in the proof of (i) in Theorem 1.
Proof of (ii). The key step is to show that for appearing in (5.7)
[TABLE]
Indeed, having (A.15), and arguing as in the proof of (ii) of Theorem 1, (5.7) imply that for positive
[TABLE]
Since converges in distribution to a Brownian bridge, then (ii) follows.
To prove (A.15) let be such that as . Let be a sequence such that and as . Let be order statistics of i.i.d. random variables. Set
[TABLE]
Then, due to (5.6) and the assumption ,
[TABLE]
Now, by the definitions of and in (5.7) and (A.16), we infer in the same way as in (A.13) that
[TABLE]
[TABLE]
On the event , for and sufficiently large, by (5.6) and , it holds that
[TABLE]
The same estimate holds on for . On the other hand, on the event , for and suficiently large, by (A.14) and (5.6),
[TABLE]
provided that is chosen in such a way that . The relations (A.18) and (A.19) allow to majorize the right hand side of (A.17) by
[TABLE]
In view of the assumption as , we have . An application of the main result of Mason (1985) concludes the proof of (ii).
By (i) and (ii), is bounded in the probability and, in consequence, . Hence, for it holds that . Therefore, for satisfying the assumptions of Theorem 2, we infer that .
**A.6. Proof of Theorem 3
**
Let us start with an useful elementary result.
Lemma A.1. Let be a sequence of non-negative random variables defined on a probability space with a measure which can depend on . Moreover, let be a sequence of positive numbers tending to infinity as .
Then the following conditions are equivalent:
*(i) ;
*(ii) ;
and each of them implies
Set and . Recall that under the empirical process has the same distribution as , where denotes the uniform empirical process. Hence
[TABLE]
where for
[TABLE]
[TABLE]
By the inequality we have for sufficiently large
[TABLE]
Applying the above estimate to and , by (6.3) and the Lebesgue Dominated Theorem it follows
[TABLE]
[TABLE]
Moreover, for any sequence converging in to it holds and . As the process has continuous trajectories a.s., then by Theorem 5.5 of Billingsley(1968) the above implies
[TABLE]
and
[TABLE]
The right hand side of (A.22) is a mean-zero Gaussian random variable with the variance . Using this, the assumption and (6.3) the proof follows from (A.20) - (A.22).
**A.7. Proof of Theorem 5
**
To prove (7.4) we shall exploit throughout the relation of and , and corresponding results for . Take any and define . Set . Since has continuous and increasing distribution function then is the critical value of corresponding to the level .
By the assumption we have and Lemma 3 implies that
[TABLE]
This yields and and means that is an admissible significance level and the assumptions of Theorem 1 in Inglot et al. (2018) hold with and .
On the other hand, the power of under equals . By Theorem 2 we have
[TABLE]
This proves that under the test has non-degenerate asymptotic power. By Proposition 1 of the present contribution and Theorem 1 in Inglot et al. (2018) the proof of (7.4) is concluded.
**A.8. Proof of Lemma 7
**
By (A.14) and the assumption we have for
[TABLE]
From the Chebyshev’s inequality and (A.23) we get for arbitrary
[TABLE]
[TABLE]
where is defined in (9.1). On the other hand, since , then by the triangle inequality for sufficiently large we have
[TABLE]
[TABLE]
[TABLE]
where is the normalizing sequence in the Darling-Erdős theorem. The last expression tends to 0 due to the assumption and the theorem of Jaeschke (1979). Combining (A.24) and (A.25) we obtain (9.2).
Acknowledgements. The work of B. Ćmiel was partially supported by the Faculty of Applied Mathematics AGH UST dean grant for PhD students and young researchers within subsidy of Ministry of Science and Higher Education.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Adler, R.J. (1990). An Introduction to Continuity, Extrema, and Related Topics for General Gaussian Processes . Institute of Mathematical Statistics. Lecture Notes-Monograph Series. Vol. 12, Hayward, California.
- 2[2] Anderson, T. W. and Darling, D. A. (1952). Asymptotic theory of certain “goodness of fit” criteria based on stochastic processes. Ann. Math. Statist. 23 193-212.
- 3[3] Billingsley, P. (1968). Convergence of Probability Measures . Wiley.
- 4[4] Borovkov, A. A. and Sycheva, N. M. (1968). On asymptotically optimal non-parametric criteria. Theory Probab. Appl. 13 359-393.
- 5[5] Borovkov, A. A. and Sycheva, N. M. (1970). On asymptotically optimal nonparametric criteria. In Nonparametric Techniques in Statistical Inference (M. L. Puri, ed.) 259-266. Cambridge Univ. Press.
- 6[6] Cai, T. T., J. Jeng and J. Jin (2011). Optimal detection of heterogeneous and heteroscedastic mixtures. J. R. Statist. Soc. B 73 629-662.
- 7[7] Chicheportiche, R. and Bouchaud, J.-F. (2012). Weighted Kolmogorov-Smirnov test: Accounting for the tails. Physical Review E 86 041115-1 - 041115-6.
- 8[8] Cont, R. (2001). Empirical properties of assets: stylized facts and statistical issues. Quant. Fin. 1 223-236.