TL;DR
This paper demonstrates a neural machine translation system with online learning that adapts in real-time to translator corrections, aiming to reduce post-editing effort in professional translation workflows.
Contribution
It introduces an end-to-end platform integrating online learning into neural machine translation within a popular translation interface, enabling continuous adaptation to user corrections.
Findings
System successfully integrates online learning with SDL Trados Studio.
Continuous learning reduces post-editing effort over time.
The platform adapts to specific domains and user styles.
Abstract
We introduce a demonstration of our system, which implements online learning for neural machine translation in a production environment. These techniques allow the system to continuously learn from the corrections provided by the translators. We implemented an end-to-end platform integrating our machine translation servers to one of the most common user interfaces for professional translators: SDL Trados Studio. Our objective was to save post-editing effort as the machine is continuously learning from human choices and adapting the models to a specific domain or user style.
Click any figure to enlarge with its caption.
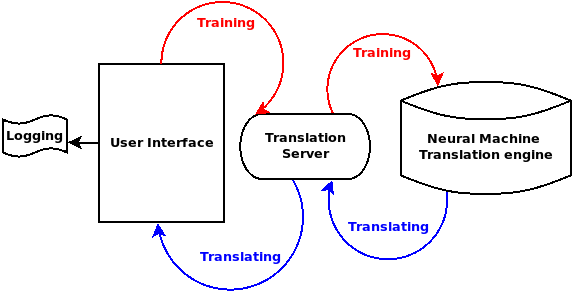 Figure 1
Figure 1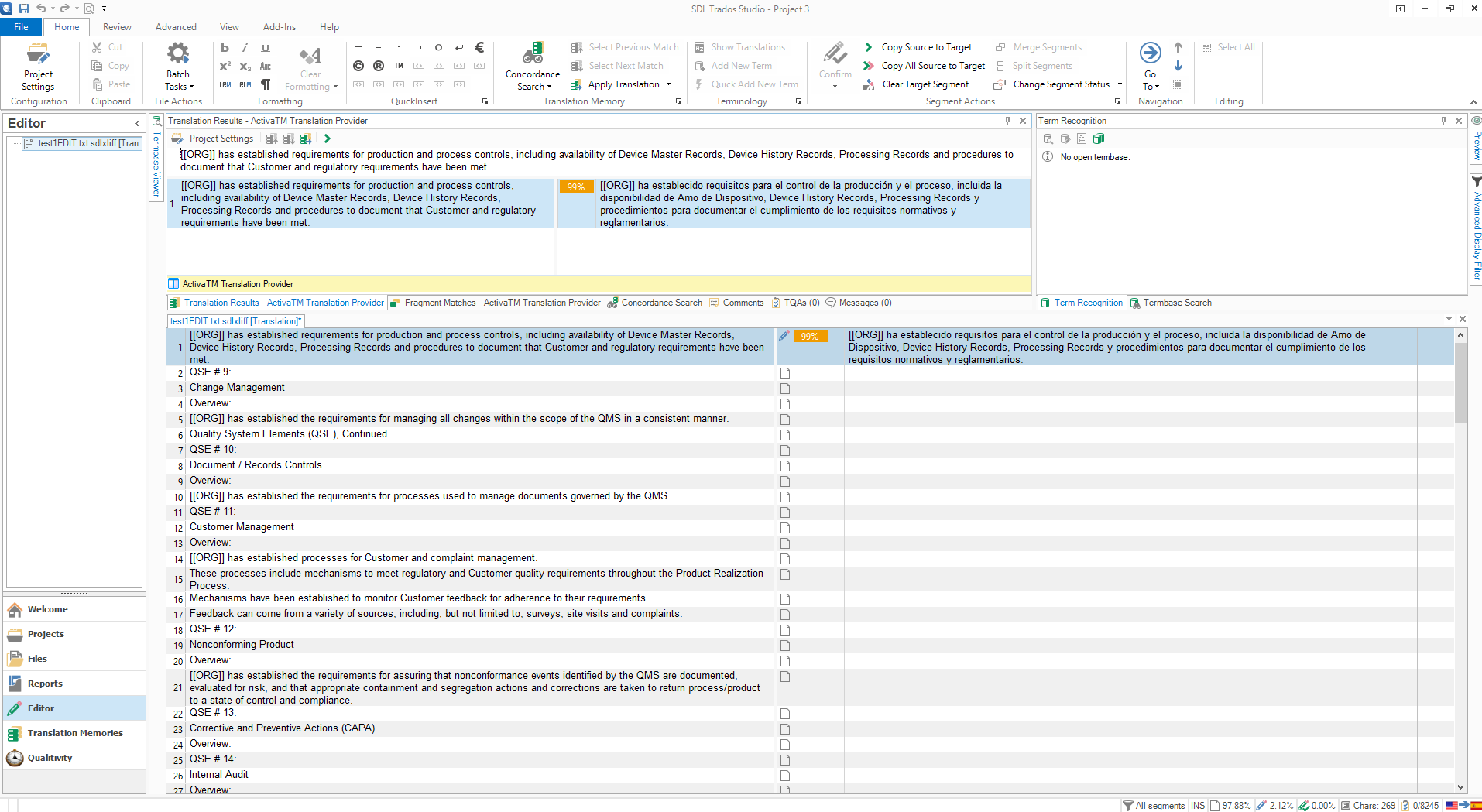 Figure 2
Figure 2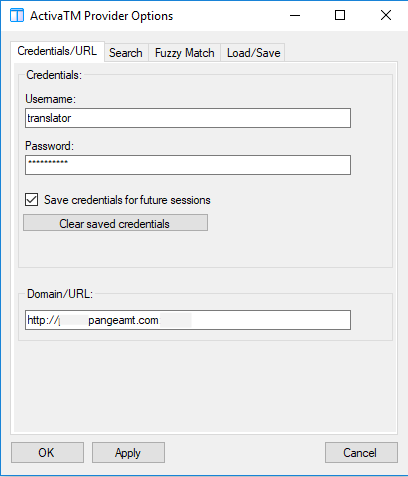 Figure 3
Figure 3 Figure 4
Figure 4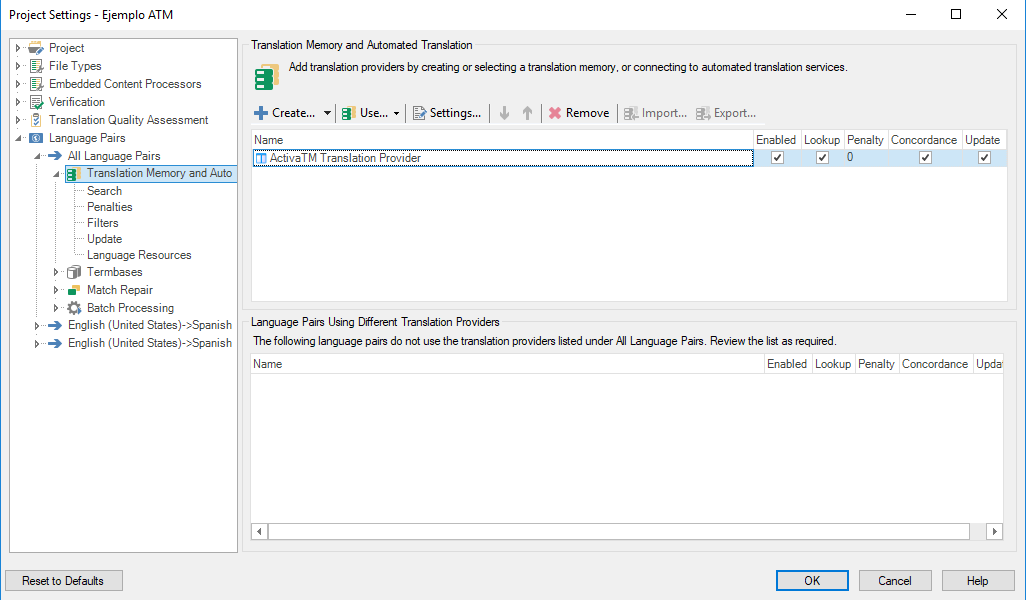 Figure 5
Figure 5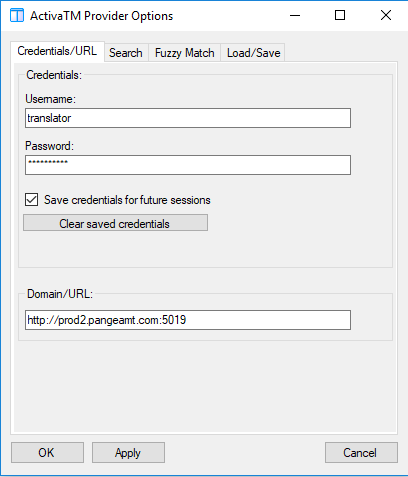 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8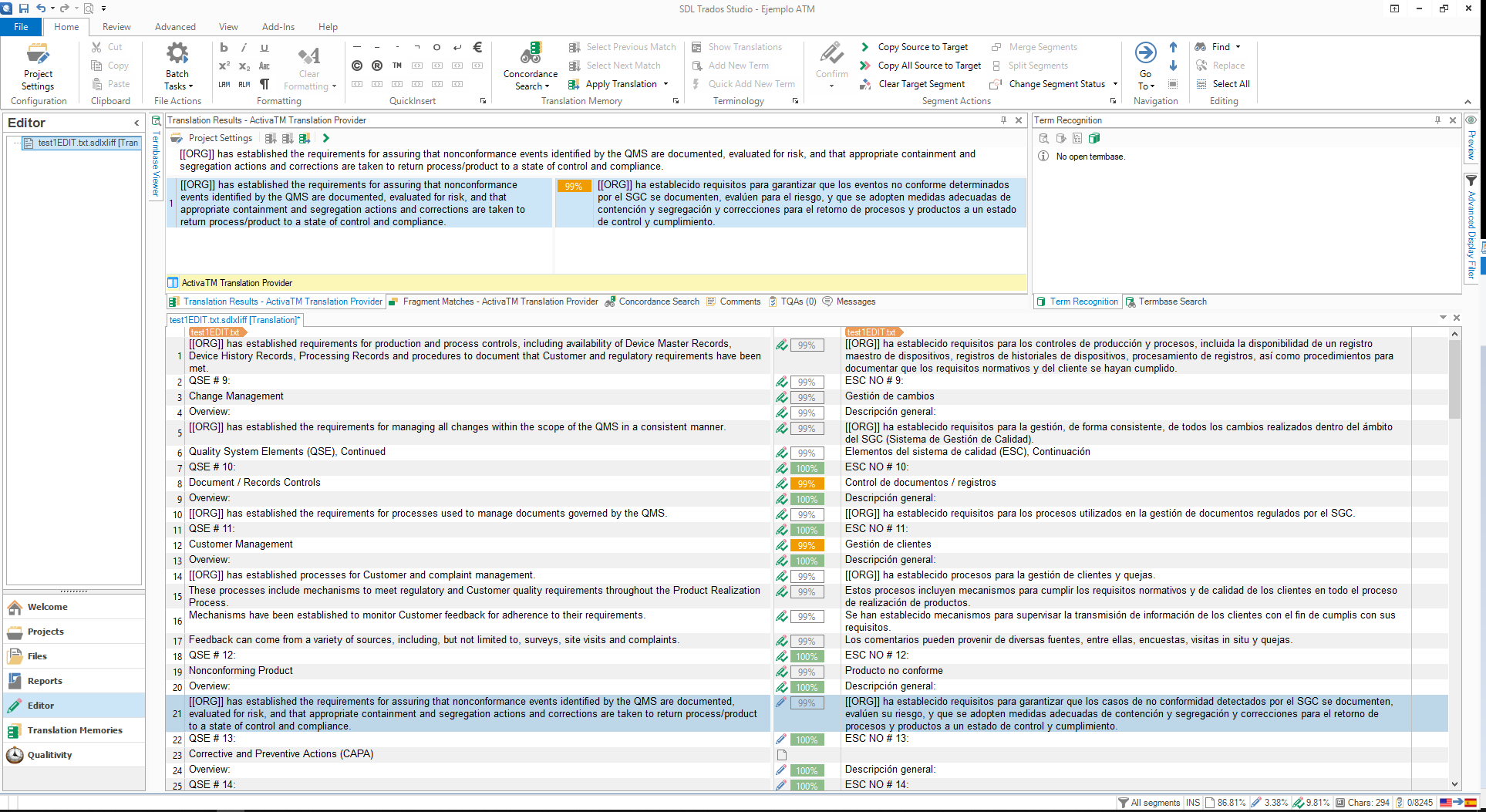 Figure 9
Figure 9Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Demonstration of a Neural Machine Translation System with Online Learning for Translators
Miguel Domingo
PRHLT Research Center - Universitat Politècnica de València
{midobal, lvapeab, fcn}@prhlt.upv.es
Mercedes García-Martínez
Pangeanic / B.I Europa - PangeaMT Technologies Division
{m.garcia, a.helle, a.estela, l.bie, m.herranz}@pangeanic.com
Amando Estela
Pangeanic / B.I Europa - PangeaMT Technologies Division
{m.garcia, a.helle, a.estela, l.bie, m.herranz}@pangeanic.com
Laurent Bié
Pangeanic / B.I Europa - PangeaMT Technologies Division
{m.garcia, a.helle, a.estela, l.bie, m.herranz}@pangeanic.com
Alexandre Helle
Pangeanic / B.I Europa - PangeaMT Technologies Division
{m.garcia, a.helle, a.estela, l.bie, m.herranz}@pangeanic.com
Álvaro Peris
PRHLT Research Center - Universitat Politècnica de València
{midobal, lvapeab, fcn}@prhlt.upv.es
Francisco Casacuberta
PRHLT Research Center - Universitat Politècnica de València
{midobal, lvapeab, fcn}@prhlt.upv.es
Manuel Herranz
Pangeanic / B.I Europa - PangeaMT Technologies Division
{m.garcia, a.helle, a.estela, l.bie, m.herranz}@pangeanic.com
Abstract
We introduce a demonstration of our system, which implements online learning for neural machine translation in a production environment. These techniques allow the system to continuously learn from the corrections provided by the translators. We implemented an end-to-end platform integrating our machine translation servers to one of the most common user interfaces for professional translators: SDL Trados Studio. Our objective was to save post-editing effort as the machine is continuously learning from human choices and adapting the models to a specific domain or user style.
1 Introduction
Productivity is crucial in the translation industry. Nowadays, translation companies must be more competitive than ever and meet fast commercial demands. Thus, they need to produce high quality translations in shorter periods of time. Machine translation (MT) can help them to achieve this goal: instead of a linguist thinking out or “creating” translations from scratch, “humanizing” automatic translations has become a common process in the industry. This is known as post-editing (PE) and it has been shown to be effective in many cases (Arenas, 2008; Hu and Cadwell, 2016). As MT systems are continuously improving their capabilities (e.g. Hassan et al., 2018; Wu et al., 2016), this workflow has become of major relevance in the translation industry. Nonetheless, MT technology is still far from perfect (Dale, 2016; Koehn and Knowles, 2017), and there is still room for improvement.
Inherently to the PE process, new bilingual data is continuously generated (the post-edited samples). This data is typically used for the creation of domain-specific corpora, useful for adapting systems from a broader domain into a specific domain, client or style. The online learning (OL) paradigm aims to perform this adaptation during the PE process: each time the user validates a post-edited translation, the system is updated as this data is taken into account. Therefore, when the next translation is produced, the system will consider the previous post-editions. It is assumed that better translations (or translations more suited to the human post-editor preferences) will be produced.
The OL paradigm has quickly attracted the attention of researchers and industry. The CasMaCat (Alabau et al., 2013) and MateCat (Federico et al., 2014) projects—where phrase-based statistical MT systems were adapted incrementally from the user post-edits—achieved many advances in this direction. More recently, OL techniques were also applied to neural machine translation (NMT) systems (Peris et al., 2017; Turchi et al., 2017; Kothur et al., 2018; Wuebker et al., 2018; Peris and Casacuberta, 2018).
In this paper, we introduce a demo system of our in-house OL framework, in which we integrated our translation servers with the translators user-friendly interface SDL Trados Studio.
The rest of this document is structured as follows: Section 2 introduces the online learning paradigm. Next, in Section 3, we describe in detail our in-house architecture in which this paradigm is implemented. Finally, Section 4 summarizes the demo system.
2 Adapting a NMT system via online learning
We are interested in benefiting from the post-edits generated by the user during the PE process. To that end, we update the system on-the-fly, i.e, as soon as a sentence has been validated by the post-editor. Right after the user confirms a post-edit, we update the models of our NMT system, using the source sentence and the post-edit as a training pair. This adaptation can be done following gradient descent, the regular training method for neural networks.
3 Architecture
Our in-house architecture of the OL framework is composed of three main modules: the MT engine, the user interface and the translation server which links both.
Moreover, we added a logging option to keep user tracking information as keystrokes, time and mouse movements. Fig. 1 illustrates this architecture.
The translation process consists of delivering machine translations to the user interface and the training process retrains the MT engine with the feedback provided by the user. Both processes are performed through client-server communication. Next, we describe each module in detail.
3.1 Machine Translation Engine
The core of the MT engine is composed by the models generating translations, which can be retrained when required. Each translation project has its own model, whose architecture is set according to the project’s need. All models are neural-based and are trained using OpenNMT-py (Klein et al., 2017).
Each MT model has its own configuration file, which contains personalized translation and OL options, such as tokenization, subword segmentation, learning rate, etc.
3.2 Translation Server
A translation server communicates with the MT models in order to generate translations and adapt the systems based on the user’s post editions. This server is based on OpenNMT-py’s REST server and uses the HTTP protocol to define the messages in order to serve user’s requests. The code of our translation server is open and available111https://github.com/midobal/OpenNMT-py/tree/OnlineLearning. We created a branch in OpenNMT-py that features this server and is compatible with all its different models.
The communication between the user interface and the MT engine is performed by means of GET and POST requests. The server waits for translation requests. When received, these requests are sent to the machine translation engine in a JSON format. When a machine translation segment is corrected by the user, the correction is sent to the translation engine.
3.3 User Interface
In the translation industry, the most common user interface for translators is SDL Trados Studio222https://www.sdl.com/es/software-and-services/translation-software/sdl-trados-studio/. Fig. 2 shows the user interface. The user gets the machine translation outputs automatically when the target part of the segment in the interface is clicked. Then, the user post-edits the segment and, when the translation is corrected, confirms it.
SDL allows the development of plugins for Trados Studio to enhance and extend the tool. Moreover, it has a large developer community333https://community.sdl.com/developers-more/developers/language-developers helping the software with add-ons and apps. We incorporated our adaptive framework as a Trados Studio plugin, that connected the user interface with Trados Studio with our translation server. As the user confirms a post-edit, the reviewed segment is sent back to the MT engine to be retrained with this new information.
In order to set up this plugin, the user fills the credentials with a username, password and URL pointing to the server (see Fig. 3 top left box). Also, the user fills the required languages and clicks in the “use machine translation” option (see Fig. 3 top right box). Finally, all the options have to be enabled in the translation provider plugin (see Fig. 3 bottom box) in the Trados Studio project settings.
3.4 Logging
In order to measure the productivity and effectiveness of OL during the PE process, we integrated tools to log the time, keystrokes and mouse movements involved in post-editing a given file. To achieve this, we incorporated the Qualitivity444https://community.sdl.com/product-groups/translationproductivity/w/customer-experience/2251.qualitivity plugin for Trados. This plugin generates an XML logging file, which contains all the keystrokes time information per segment. An example of this logging is shown in Figure 4.
With all this log information, we can measure the effort required to post-edit a file using MT with OL. Preliminary experiments in simulated and real environments with professional translators (Domingo et al., 2019), reported significant improvements of the quality of the translations generated by the MT systems (up to 5.3 points according to hTER, and 7.8 points according to hBLEU), and a significant reduction of the PE time (up to 7.5 second per sentence).
4 Summary
We have introduced a demonstration of Pangeanic’s translation framework, which incorporates on-the-fly system adaptation via online learning. This paradigm allows human translators /post-editors to produce more human-quality text, that is, be more productive—a fundamental issue in the translation industry—since the system is continuously learning from the user post-edits, avoiding repetition of the same errors. We have integrated our MT servers into the SDL Trados Studio user interface which is one of the most used in the translation industry. This system aims to improve human translators’ work by saving time and effort.
Acknowledgments
The research leading to these results has received funding from the Spanish Centre for Technological and Industrial Development (Centro para el Desarrollo Tecnológico Industrial) (CDTI) and the European Union through Programa Operativo de Crecimiento Inteligente (Project IDI-20170964). We gratefully acknowledge the support of NVIDIA Corporation with the donation of a GPU used for part of this research.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Alabau et al. (2013) Vicent Alabau, Ragnar Bonk, Christian Buck, Michael Carl, Francisco Casacuberta, Mercedes García-Martínez, Jesús González-Rubio, Philipp Koehn, Luis A. Leiva, Bartolomé Mesa-Lao, Daniel Ortiz-Martínez, Hervé Saint-Amand, Germán Sanchis-Trilles, and Chara Tsoukala. 2013. CASMACAT: An open source workbench for advanced computer aided translation. The Prague Bulletin of Mathematical Linguistics , 100:101–112.
- 2Arenas (2008) Ana Guerberof Arenas. 2008. Productivity and quality in the post-editing of outputs from translation memories and machine translation. Localisation Focus , 7(1):11–21.
- 3Dale (2016) Robert Dale. 2016. How to make money in the translation business. Natural Language Engineering , 22(2):321–325.
- 4Domingo et al. (2019) Miguel Domingo, Mercedes García-Martínez, Álvaro Peris, Alexandre Helle, Amando Estela, Laurent Bié, Francisco Casacuberta, and Manuel Herranz. 2019. Incremental adaptation of NMT for professional post-editors: A user study. In Proceedings of the Machine Translation Summit . Under publication.
- 5Federico et al. (2014) Marcello Federico, Nicola Bertoldi, Mauro Cettolo, Matteo Negri, Marco Turchi, Marco Trombetti, Alessandro Cattelan, Antonio Farina, Domenico Lupinetti, Andrea Martines, Alberto Massidda, Holger Schwenk, Loïc Barrault, Frederic Blain, Philipp Koehn, Christian Buck, and Ulrich Germann. 2014. The matecat tool. In Proceedings of the 25th International Conference on Computational Linguistics: System Demonstrations , pages 129–132.
- 6Hassan et al. (2018) Hany Hassan, Anthony Aue, Chang Chen, Vishal Chowdhary, Jonathan Clark, Christian Federmann, Xuedong Huang, Marcin Junczys-Dowmunt, William Lewis, Mu Li, et al. 2018. Achieving human parity on automatic chinese to english news translation.
- 7Hu and Cadwell (2016) Ke Hu and Patrick Cadwell. 2016. A comparative study of post-editing guidelines. In Proceedings of the 19th Annual Conference of the European Association for Machine Translation , pages 34206–353.
- 8Klein et al. (2017) Guillaume Klein, Yoon Kim, Yuntian Deng, Jean Senellart, and Alexander M. Rush. 2017. Open NMT: Open-source toolkit for neural machine translation. In Proceedings of the Association for the Computational Linguistics , pages 67–72.
