TL;DR
This paper presents a high-resolution depth evaluation benchmark for realistic driving scenarios, enabling assessment of depth estimation robustness under various weather conditions and comparing stereo, monocular, and lidar methods.
Contribution
It introduces a novel evaluation benchmark with high-resolution depth data for automotive scenarios, addressing limitations of existing sparse datasets.
Findings
Stereo methods outperform monocular in adverse weather.
The benchmark reveals robustness differences among depth sensing techniques.
Current methods vary significantly in stability across conditions.
Abstract
This work introduces an evaluation benchmark for depth estimation and completion using high-resolution depth measurements with angular resolution of up to 25" (arcsecond), akin to a 50 megapixel camera with per-pixel depth available. Existing datasets, such as the KITTI benchmark, provide only sparse reference measurements with an order of magnitude lower angular resolution - these sparse measurements are treated as ground truth by existing depth estimation methods. We propose an evaluation methodology in four characteristic automotive scenarios recorded in varying weather conditions (day, night, fog, rain). As a result, our benchmark allows us to evaluate the robustness of depth sensing methods in adverse weather and different driving conditions. Using the proposed evaluation data, we demonstrate that current stereo approaches provide significantly more stable depth estimates than…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1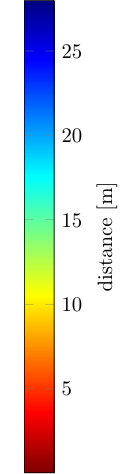 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16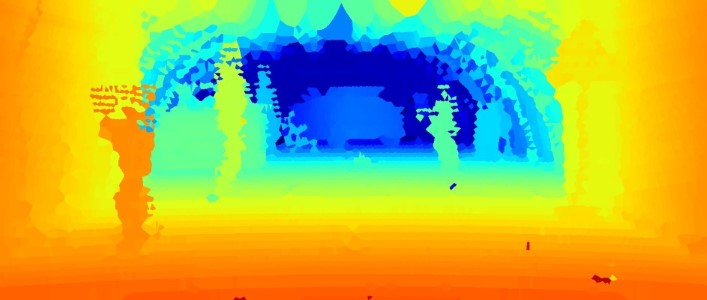 Figure 17
Figure 17 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23 Figure 24
Figure 24 Figure 25
Figure 25 Figure 26
Figure 26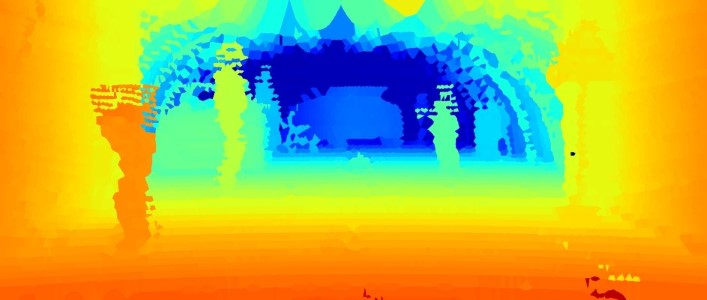 Figure 27
Figure 27 Figure 28
Figure 28 Figure 29
Figure 29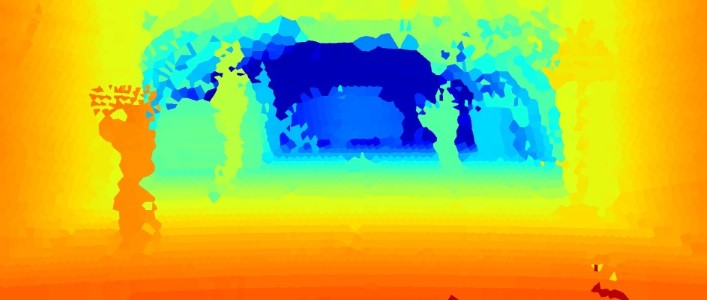 Figure 30
Figure 30 Figure 31
Figure 31 Figure 32
Figure 32 Figure 33
Figure 33 Figure 34
Figure 34 Figure 35
Figure 35 Figure 36
Figure 36 Figure 37
Figure 37 Figure 38
Figure 38 Figure 39
Figure 39 Figure 40
Figure 40| absolute | relative | scale-invariant | full-depth | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | RMSE | tRMSE | MAE | tMAE | logRMSE | SRD | ARD | SIlog | SSIM | PSNR | rPSNR | |||||
| Day | not binned | Lidar (int.) | 1.89 | 1.36 | 0.70 | 0.59 | 0.13 | 0.23 | 4.79 | 12.60 | 93.62 | 98.13 | 99.36 | 0.49 | 19.67 | 15.05 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
ALE average log error ARD absolute relative distance CNN convolutional neural network GPS global positioning system ICP iterative closest point IMU inertial measurement unit logRMSE logarithmic root-mean-squared error MAE mean-absolute error ppm parts per million PPS pulse per second PSNR peak signal-to-noise ratio rPSNR relative peak signal-to-noise ratio RMSE root-mean-squared error ROS robot operating system SfM structure from motion SGM semi-global matching SIlog scale invariant logarithmic error SRD squared relative distance SSIM structural similarity tMAE mean-absolute thresholded error ToF time-of-flight tRMSE root-mean-squared thresholded error
Pixel-Accurate Depth Evaluation in Realistic Driving Scenarios
Tobias Gruber1,3 Mario Bijelic1,3 Felix Heide2,4 Werner Ritter1 Klaus Dietmayer3
1Daimler AG 2Algolux 3Ulm University 4Princeton University
Abstract
This work introduces an evaluation benchmark for depth estimation and completion using high-resolution depth measurements with angular resolution of up to (arcsecond), akin to a 50 megapixel camera with per-pixel depth available. Existing datasets, such as the KITTI benchmark [13], provide only sparse reference measurements with an order of magnitude lower angular resolution – these sparse measurements are treated as ground truth by existing depth estimation methods. We propose an evaluation methodology in four characteristic automotive scenarios recorded in varying weather conditions (day, night, fog, rain). As a result, our benchmark allows us to evaluate the robustness of depth sensing methods in adverse weather and different driving conditions. Using the proposed evaluation data, we demonstrate that current stereo approaches provide significantly more stable depth estimates than monocular methods and lidar completion in adverse weather. Data and code are available at https://github.com/gruberto/PixelAccurateDepthBenchmark.git.
1 Introduction
3D scene understanding is one of the key challenges for safe autonomous driving, and the critical depth measurement and processing methods are a very active areas of research. Depth information can be captured using a variety of different sensing modalities, either passive or active. Passive methods can be classified into stereo methods [5, 19, 23, 42], which, inspired by the human visual system, extract depth from parallax in intensity images, structure from motion (SfM) [24, 31, 57, 59, 65], and monocular depth prediction [6, 10, 15, 28, 46]. Monocular depth estimation methods attempt to extract depth from cues such as defocus [56], texture gradient and size perspective from a single image only. All of these passive sensing systems suffer in low light and at night, when the measured intensity is too low to robustly match image content. Active sensing methods, such as lidar systems and time-of-flight (ToF) cameras, overcome this challenge by relying on active illumination for depth measurements. Specifically, lidar systems [50] achieve large distances by focusing light into multiple beams which are mechanically scanned. This sequential acquisition fundamentally limits the angular resolution by the scanning mechanics, prohibiting semantic scene understanding at large distances where only a coarse sample distribution is available. As a result, a variety of algorithms for depth completion [7, 22, 32] have been proposed recently. Existing correlation ToF cameras [17, 25, 29] or structured light cameras [1, 37, 38, 49], provide accurate high-resolution depth for close ranges indoors but suffer at long ranges in outdoor scenes due to strong ambient illumination and modulation frequency limitations.
In order to evaluate the performance of such diverse sensing approaches for autonomous driving, empirical datasets under realistic road conditions and meaningful metrics are required. Captured with previous generation hardware, the NYUdepth v2 [54] and KITTI [13] datasets are established for developing and evaluating depth estimation methods. While NYUdepth v2 contains a large variety of close-range indoor scenes captured by a Microsoft Kinect RGB-D camera [64], the KITTI dataset provides real-world street view scenarios recorded with a stereo camera and a lidar sensor. Although the sparse depth measurements of the KITTI dataset have been accumulated over multiple laser scans [58], the resulting “ground truth” depth provides only horizontal and vertical angular sampling. To detect the legs of a pedestrian at 150 m distance an angular resolution of less than would be required. In this work, we present an evaluation framework with pixel-wise annotated ground truth depth, as visualized in Figure 1, at an angular resolution of . This resolution corresponds to a 50 mega-pixel camera (similar to KITTI [13]: 4.65 µm pitch, 4.4 mm focal length) which enables semantic understanding tasks at large distances, such as pedestrian detection. We also record and provide stereo and lidar measurements acquired with recent state-of-the-art automotive sensors.
The robustness of the sensing and processing chain is critical for autonomous driving, which mandates reliability in adverse weather situations such as rain, fog and snow. Note that the evaluation in these corner cases is particularly challenging because lidar sensors fail in severe adverse weather. For example, in dense fog or snow, the first peak lidar measurements are unusable due to severe back-scatter in these scenarios. As a result, existing driving datasets [13, 20, 61] do not cover these severe conditions. To acquire accurate depth in challenging weather situations, and with reproducible scenes and conditions, we record sensor data with the proposed sensor setup in a weather chamber [8] that provides reproducible fog and rain. Using pixel-wise ground truth depth from clear conditions, the proposed approach allows us to accurately evaluate the performance under varying fog visibilities and rain intensities.
Specifically, we make the following contributions:
- •
We introduce an automotive depth evaluation dataset (1,600 samples) in adverse weather conditions with high-resolution annotated ground truth of angular resolution – an order of magnitude higher than existing lidar datasets with angular resolution of .
- •
We evaluate the performance state-of-the-art algorithms for stereo depth, depth from mono, lidar and sparse depth completion, in reproducible, finely adjusted adverse weather situations.
- •
We demonstrate that stereo vision performs significantly more stable in fog than lidar and monocular depth estimation approaches.
2 Related Work
Depth Estimation and Depth Completion
Depth estimation algorithms can be categorized based on their input data. While SfM approaches [24, 31, 57, 59, 65] rely on sequentially captured image data, multi-view depth estimation [5, 19, 23, 42] uses at least two different views of a scene which are simultaneously captured. Monocular depth estimation methods [6, 10, 15, 28, 46] tackle the severely ill-posed depth reconstruction by monocular cues such as texture variation, gradients, object size, defocus, color or haze. Over the last years, convolutional neural networkss have been shown to be well-suited for both SfM, multi-view and monocular approaches, and they can be trained supervised by large RGB-D indoor datasets acquired by consumer ToF cameras. Since the acquisition of ground truth depth in large outdoor environments is challenging, semi-supervised [27] or even self-supervised approaches [2, 12, 15, 41] have been proposed, tackling this challenge by solving proxy tasks such as stereo matching. Another body of work focuses on completing sparse lidar point clouds. Existing depth completion methods rely on contextual information from RGB images to obtain high-resolution depth [7, 22, 32].
Depth Datasets
The development and evaluation of depth estimation algorithms require a large amount of representative data, particularly for learned estimation methods. Scharstein and Szeliski [48] provided the Middlebury data set as an early testing environment for quantitative evaluation of stereo algorithms, where the ground truth was obtained by structured light. While the Middlebury dataset contained, in the first version, only two samples, subsequent datasets, such as Make 3D [47] provided around 500 samples with ground truth measured by a custom-build 3D scanner, though with lower resolution of 55x305. Facilitated by consumer depth cameras such as the Microsoft Kinect [64], a number of depth data sets for indoor scenes have been proposed [9, 52, 53, 54, 55]. In particular, the NYUdepth v2 data set [54] is a widely used dataset with around 1500 samples. However, due to the limitations of consumer depth cameras in severe ambient light and modulation frequency limitations, these data sets only include indoor scenarios with limited ranges. The KITTI Stereo 2015 benchmark [35] has introduced 400 images of street scenes with ground truth depth acquired by a lidar system. In order to mitigate the sparsity of raw ground truth depth (4 % coverage), 7 laser scans are registered and accumulated, and moving objects are replaced with geometrically accurate 3D models leading to 19 % coverage. In order to obtain sufficient data for learning algorithms, Uhrig et. al [58] presented a method to generate denser depth maps (16 % coverage) by automatically accumulating 11 laser scans and removing outliers by stereo comparison. Note that, even with accumulation, the resulting depth maps are still not providing depth at the resolution of the image sensor [35]. Synthetic data sets such as the New Tsukuba Stereo Data set [34], Virtual KITTI [11] and Synthia [44] offer the possibility to create a theoretically unlimited amount of data with dense and accurate ground truth depth. While these data sets are extremely valuable for pretraining algorithms [43], they cannot replace real recordings for performance evaluation of real-world applications due to the synthetic-to-real domain gap [39]. In this work, we aim to close the gap between range-limited indoor and ground-truth-limited outdoor scenarios.
Robust Perception in Adverse Weather
Robust environment perception is critical for enabling autonomous driving (without remote operators) over the world and in all environmental conditions. To this end, it is critical that self-driving cars should not stop working when being faced with unknown sensor distortions and situations that have not been in the training distribution. To characterize sensor distortions, previous methods have been focused on evaluating automotive sensors in challenging situations such as dust, smoke, rain, fog and snow [40]. For these evaluations, testing facilities such as Cerema [8] and Carissma [18] provide reproducible adverse weather situations with defined and adjustable severity. In particular, cameras suffer from reduced contrast because particles in the air cause scattering [4, 36]. Recently, the Robust Vision Challenge [14] promotes the development of robust algorithms benchmarked on a variety of datasets. However, the generalization and robustness to real adverse weather is significantly more difficult than dataset generalization because challenging weather conditions occur rarely and change quickly [60]. As a result, recent approaches evaluate robustness using synthetically extended datasets such as Foggy Cityscapes [45]. In this work, we depart from these synthetic datasets and instead propose a non-synthetic, but reproducible, benchmark for depth estimation in adverse weather conditions such as rain and fog under controlled conditions.
3 Sensor Setup and Calibration
To acquire realistic automotive sensor data, which serves as input for the depth evaluation methods assessed in this work, we equipped a research vehicle with a RGB stereo camera (Aptina AR0230, 1920x1024, 12bit) and a lidar (Velodyne HDL64-S3, 905 nm), see Figure 2. All sensors run in a robot operating system (ROS) environment and are time-synchronized by a pulse per second (PPS) signal provided by a proprietary inertial measurement unit (IMU). For the Velodyne lidar, both last and strongest return are recorded. Next, we describe the acquisition of the ground truth depth dataset that we use to evaluate the depth estimates obtained from the automotive sensor suite.
Ground Truth Acquisition
We acquire ground truth depth for static scenarios using a Leica ScanStation P30 laser scanner (360°/290° FOV, 1550 nm, with up to 1M points per second, up to angular accuracy, and 1.2 mm + 10 parts per million (ppm) range accuracy). To mitigate the effects of occlusions and to further increase the resolution, we accumulate multiple pointclouds at different overlapping positions. At least three white sphere lidar targets with a diameter of 145 mm at defined positions have to be detected for registration of the raw pointclouds. Each raw scan lasts about 5 min, which limits the proposed high-resolution acquision approach to static scenarios. Using the known positions of the targets in every raw pointcloud, transformations between these raw pointclouds are obtained by solving a linear least-squares problem. As a result, we obtain a dense pointcloud ( 50M points) with a uniformly distributed mean distance between neighboring points of only 3 mm, corresponding to an angular resolution of . We use the middle of the rear axis, identified by measuring the positions of the wheel hubs, as the origin of the target point clouds. All sensors of the automotive sensor suite from Figure 2 have been calibrated with respect to this ground truth pointcloud, which we describe in the following.
Camera Calibration
The intrinsic calibration of the stereo cameras is performed by detecting checkerboards with predefined field size [63]. We recorded these checkerboards at different distances and viewpoints in order to obtain the camera matrix and distortion coefficients. In order to register the very dense ground truth point clouds to the camera coordinate systems (extrinsic calibration), multiple black-white targets are placed at known 3D positions. By labeling the target positions in the images, an extrinsic calibration is obtained by solving the perspective-n-point problem using Levenberg-Marquardt non-linear least-squares optimization [30, 33].
Lidar Registration
While the resolution of scans from the Leica laser scanner facilitates the detection of the white sphere targets, it is challenging to detect these targets at larger distances in the Velodyne laser scan. Therefore, these lidar targets cannot be used for registration of both Leica and Velodyne pointclouds. We use generalized iterative closest point (ICP) [51] for registration by minimizing the difference between two pointclouds, with the initial iterate shifted to the manually measured mounting position.
4 Adverse Weather Dataset
We model the typical automotive outdoor scenarios from [13]. Specifically, we setup the following four realistic scenarios: pedestrian zone, residential area, construction area and highway. Real world examples of these scenarios are shown in Figure 3, while our setup scenes are shown in Figure 5. We used mannequins as pedestrians in order to fix the scene during all measurements. These scenarios are recorded under different controlled weather and illumination conditions in a weather chamber [8]. The visible back part of the weather chamber, see Figure 5, is constructed as greenhouse that is either transparent or covered by a black tarp and allows to achieve realistic daytime and night conditions. After acquiring reference measurements in clear conditions, the whole chamber is flooded with fog. The fog density is tracked by the meteorological visibility defined by , where is the atmospheric attenuation. As the fog slowly dissipates, visibility increases and the recordings are stopped after reaching . In order to obtain a larger number of samples, three dissipation runs have been performed. For measurements in rain, two particular intensities at 15 and 55 mm/h/ represent light and heavy rain. In total, this benchmark consists of 10 randomly selected samples of each scenario (day/night) in clear, light rain, heavy rain and 17 visibility levels in fog (20-100 m in 5 m steps), resulting in 1600 samples in total.
5 Benchmark
In this section, we introduce all quantitative metrics and visualization methods used as evaluation methods in the remainder of this paper. The evaluation is performed on 2.5D depth images because this domain allows for an immediate and intuitive comparison with the ground truth obtained by a depth camera or projected lidar points.
Metrics
We adopt established metrics for benchmarking depth estimation algorithms. Specifically, we use the metrics from the KITTI benchmark [58], that is scale invariant logarithmic error (SIlog) [10], squared relative distance (SRD), absolute relative distance (ARD) and root-mean-squared error (RMSE). In addition, we evaluate mean-absolute error (MAE) and the threshold metric for . Recently, Imran et al. [21] proposed root-mean-squared thresholded error (tRMSE) and mean-absolute thresholded error (tMAE) as variants of the established RMSE and MAE metrics which we also add to our evaluation framework. Moreover, as this work offers dense depth ground truth, we also assess depth map accuracy using dense image metrics, such as structural similarity (SSIM) and peak signal-to-noise ratio (PSNR). Since PSNR is based on absolute distances, we introduce a variant using relative depth relative peak signal-to-noise ratio (rPSNR), see supplemental document. We provide an in-depth description and formal definition of each metric in the supplemental document.
Binned Metrics
The depth in a depth map is typically not uniformly distributed, as shown in Figure 4. By calculating the mean error of a depth image, errors at shorter distances contribute more to the mean than errors at larger distances. For a fair comparison of algorithms, we also provide binned evaluations where metrics are calculated in bins of approximately 2 m and the mean of the bins gives the final result. This ensures that every distance contributes equally to the evaluation metric.
Top-Down View
As additional qualitative visualization, we provide top-down views generated by projecting 2.5D depth images into 3D. However, projecting all points to the ground plane does not provide any meaningful top-down view because in such a top-view, points from the ground, from the ceiling, and from objects in between cannot be distinguished. For improved visualization of the top-down view, we discretize the x-y plane into 10x10 cm grid cells and squeeze the height by counting the number of points in each grid cell [26, 62]. As the number of points in a cell is decreasing with distance (see Figure 4), we normalize the number of points according to their distance.
6 Evaluation
Evaluated Methods
A large body of work on depth estimation and depth completion has emerged over the recent years. For brevity, we focus in this benchmark on one algorithm per algorithm category. Specifically, we compare Monodepth [15] as a representative method for monocular depth estimation, semi-global matching (SGM) [19] as traditional stereo and PSMnet [5] as deep stereo algorithms, and Sparse2Dense [32] as a depth completion method for lidar measurements using RGB image data. We set all algorithms up to estimate full-resolution depth maps, except for Monodepth [15] where we observed a substantial drop in performance and therefore resized the images to the native size the model was trained on. Additionally, we finetuned the model on the training split of [16] where the same sensor setup has been utilized. For Sparse2Dense [32], we trained the network with 8000 points on KITTI in order to apply it to our projected lidar points. Similar to the KITTI Depth Prediction benchmark [58], we interpolate the results of methods that provide less than 100 % density with nearest neighbor interpolation. Additionally, we crop the images for 270 pixels from the top, 170 pixels from the left, 20 pixels from the right and 20 pixels from the bottom to avoid boundary artifacts, e.g. missing lidar points in the top part of the image.
Public Benchmark
We will make all sensor data and the high-resolution ground truth data publicly available. All code for calculating the error metrics and for generating qualitative results (color-coded depth map, error map and top-down view) will be provided. The dataset is high-resolution, and enables fine-grained evaluation in controlled adverse weather conditions.
Clear Weather Evaluation
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] S. Achar, J. R. Bartels, W. L. Whittaker, K. N. Kutulakos, and S. G. Narasimhan. Epipolar time-of-flight imaging. ACM Transactions on Graphics (To G) , 36(4):37, 2017.
- 2[2] F. Aleotti, F. Tosi, M. Poggi, and S. Mattoccia. Generative adversarial networks for unsupervised monocular depth prediction. In Proceedings of the IEEE European Conference on Computer Vision , 2018.
- 3[3] M. Bijelic, T. Gruber, and W. Ritter. A benchmark for lidar sensors in fog: Is detection breaking down? In IEEE Intelligent Vehicle Symposium , pages 760–767, Jun 2018.
- 4[4] M. Bijelic, T. Gruber, and W. Ritter. Benchmarking image sensors under adverse weather conditions for autonomous driving. In IEEE Intelligent Vehicle Symposium , pages 1773–1779, Jun 2018.
- 5[5] J.-R. Chang and Y.-S. Chen. Pyramid stereo matching network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages 5410–5418, 2018.
- 6[6] R. Chen, F. Mahmood, A. Yuille, and N. J. Durr. Rethinking monocular depth estimation with adversarial training. ar Xiv preprint ar Xiv:1808.07528 , 2018.
- 7[7] Z. Chen, V. Badrinarayanan, G. Drozdov, and A. Rabinovich. Estimating depth from RGB and sparse sensing. Proceedings of the IEEE European Conference on Computer Vision , Sep 2018.
- 8[8] M. Colomb, H. Khaled, P. André, J. Boreux, P. Lacôte, and J. Dufour. An innovative artificial fog production device improved in the european project FOG. Atmospheric Research , 87:242–251, Mar 2008.
