TL;DR
This paper presents a rank-order based, nonparametric method for extracting signals from noisy data, effectively handling outliers and heavy-tailed noise, with broad applications including nonlinear parameter estimation.
Contribution
The paper introduces a novel rank-order transform method that is insensitive to outliers, capable of distinguishing signals from noise, and applicable to nonlinear and heavy-tailed noise scenarios.
Findings
Successfully distinguishes chaos from white noise.
Outperforms least squares in radioactive decay parameter estimation.
Excels in trend extraction from heavy-tailed noise.
Abstract
We introduce an ordinate method for noisy data analysis, based solely on rank information and thus insensitive to outliers. The method is nonparametric, objective, and the required data processing is parsimonious. Main ingredients are a rank-order data matrix and its transform to a stable form, which provide linear trends in excellent agreement with least squares regression, despite the loss of magnitude information. A group symmetry orthogonal decomposition of the 2D rank-order transform for iid (white) noise is further ordered by principal component analysis. This two-step procedure provides a noise "etalon" used to characterize arbitrary stationary stochastic processes. The method readily distinguishes both the Ornstein-Uhlenbeck process and chaos generated by the logistic map from white noise. Ranking within randomness differs fundamentally from that in deterministic chaos and…
Click any figure to enlarge with its caption.
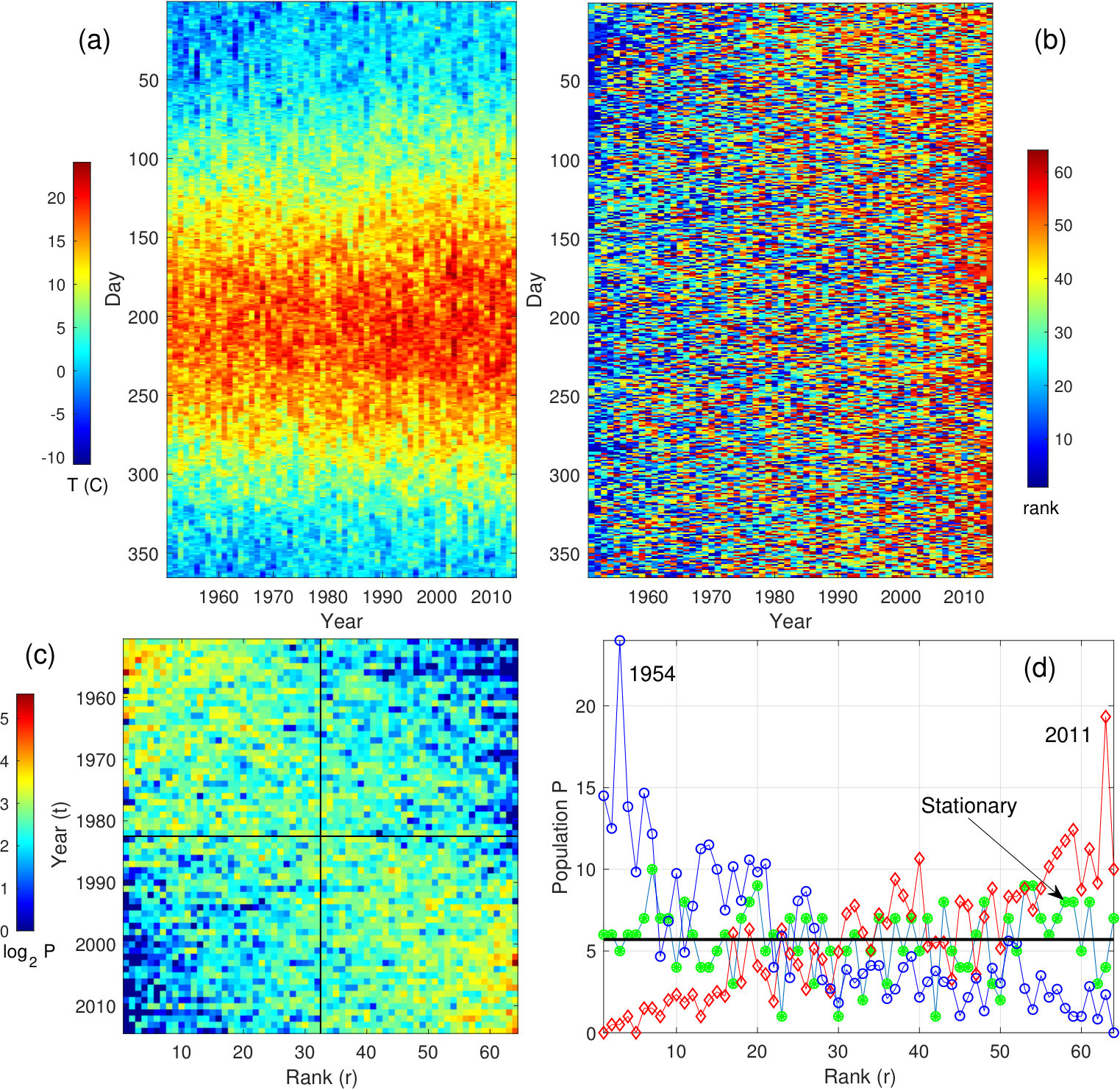 Figure 1
Figure 1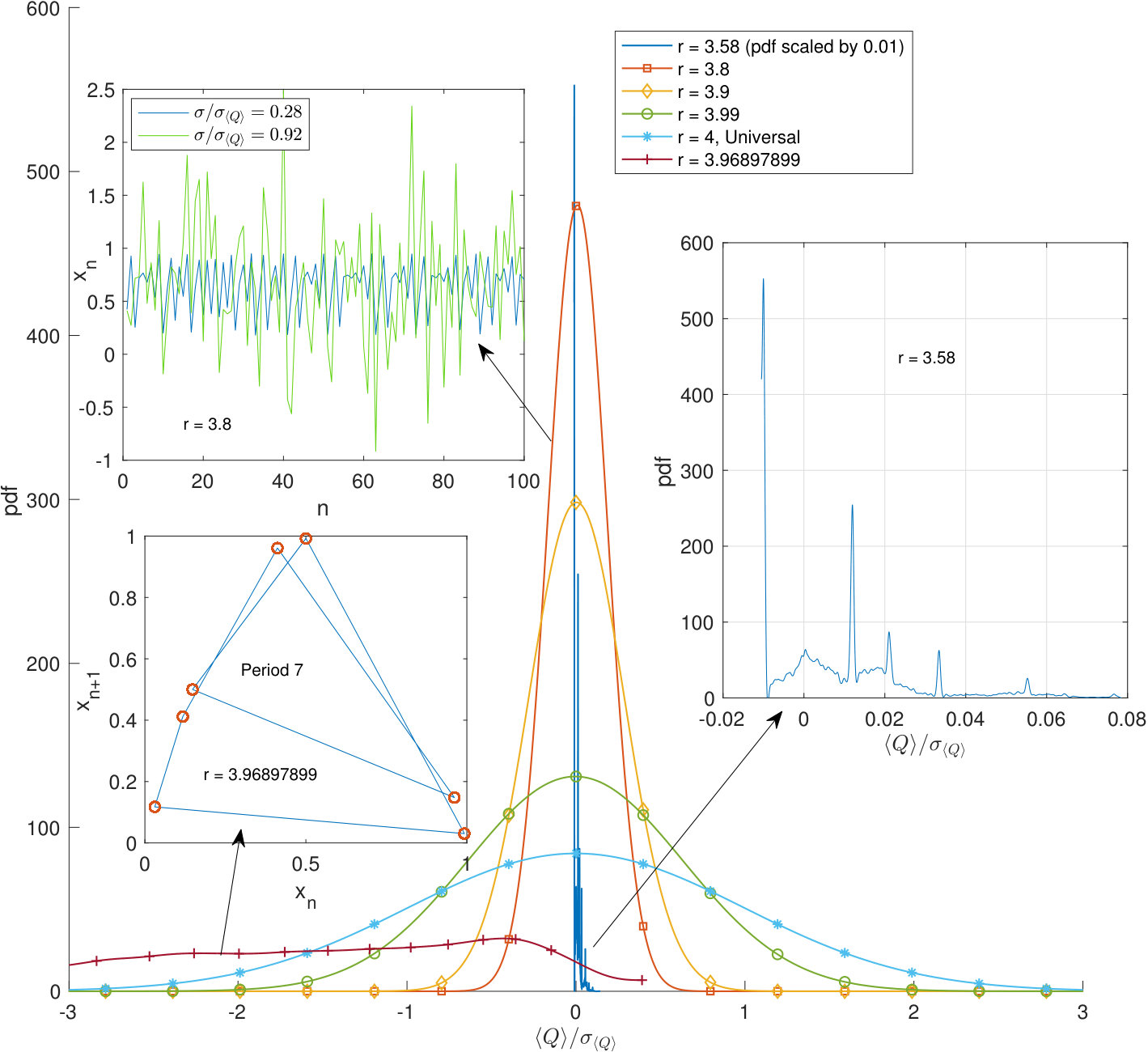 Figure 10
Figure 10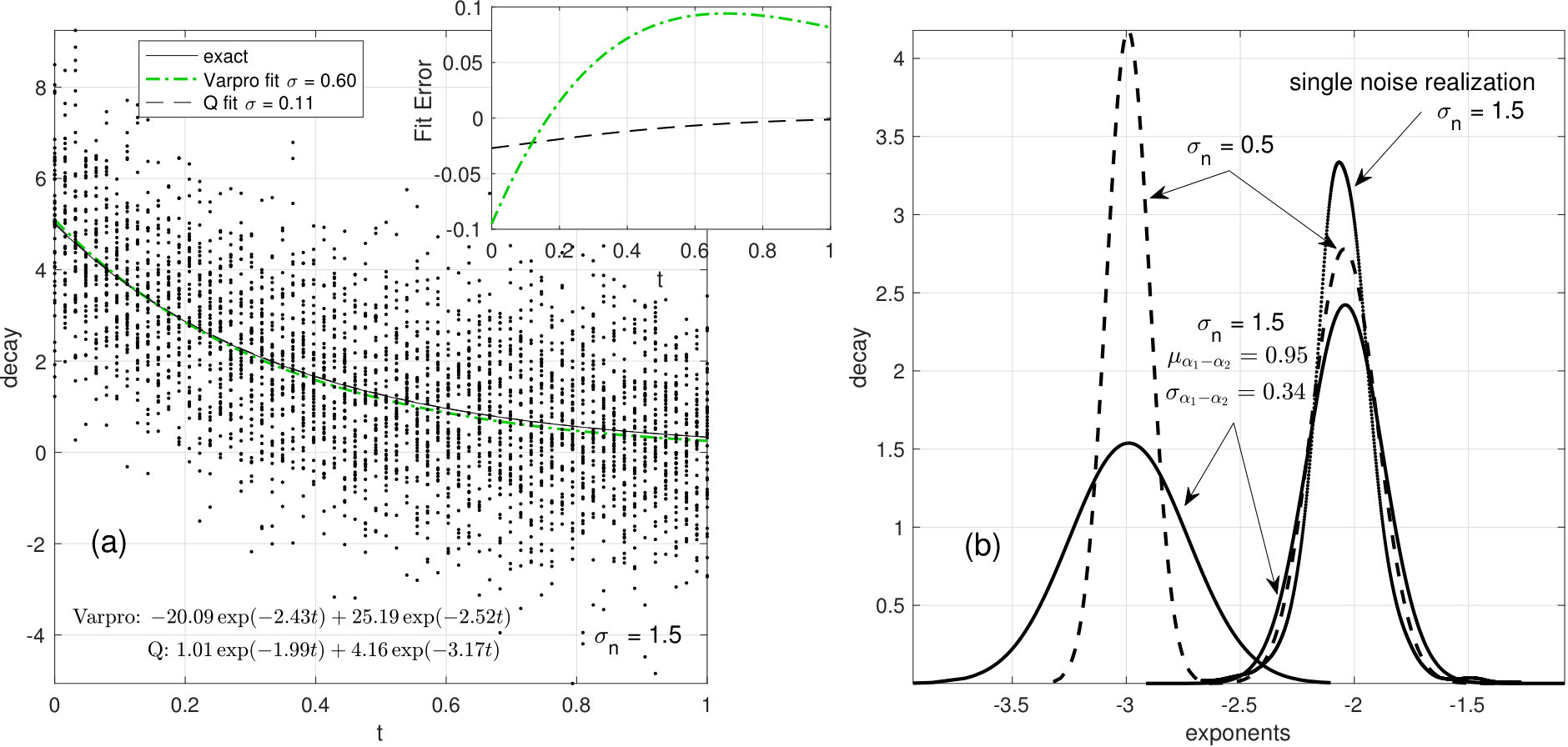 Figure 11
Figure 11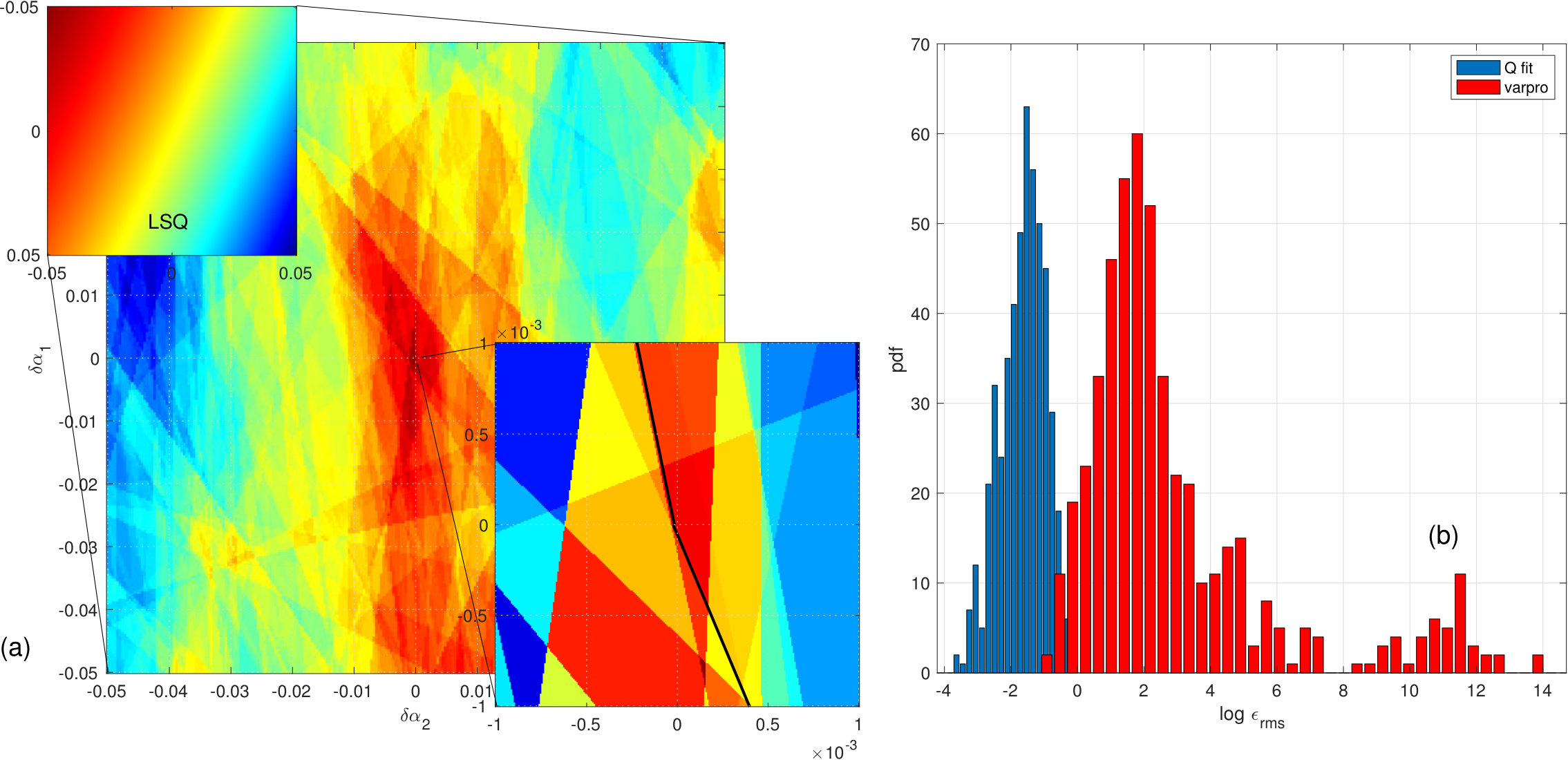 Figure 12
Figure 12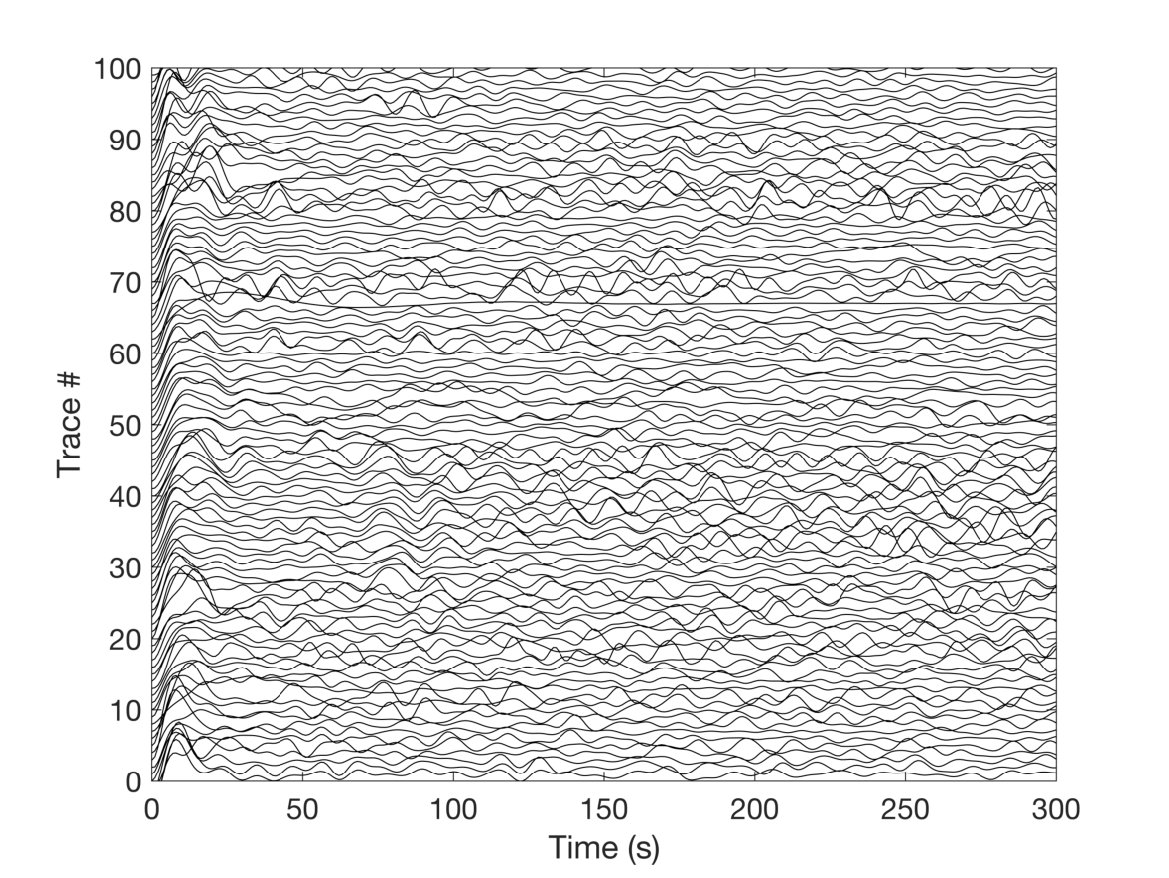 Figure 13
Figure 13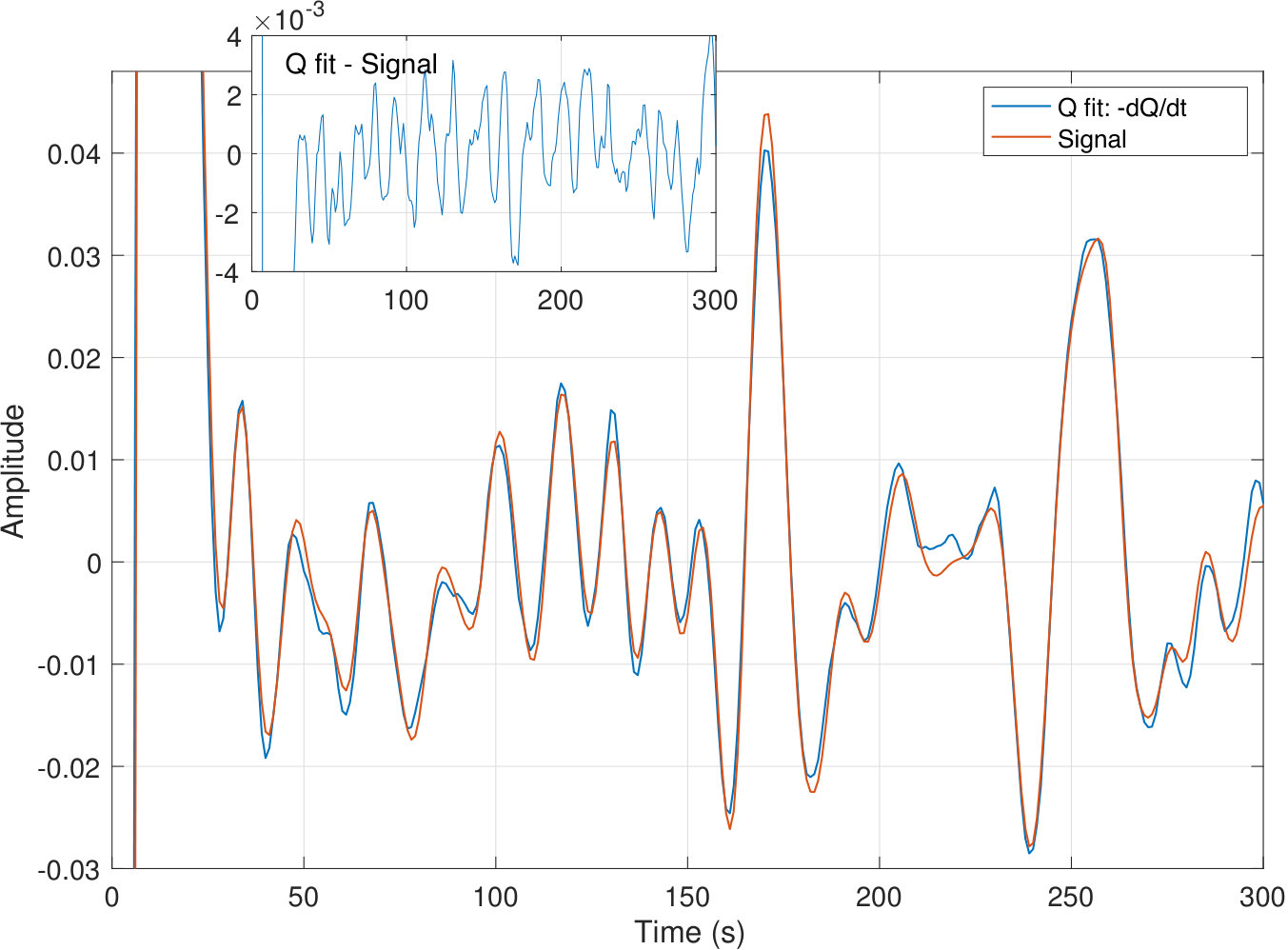 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16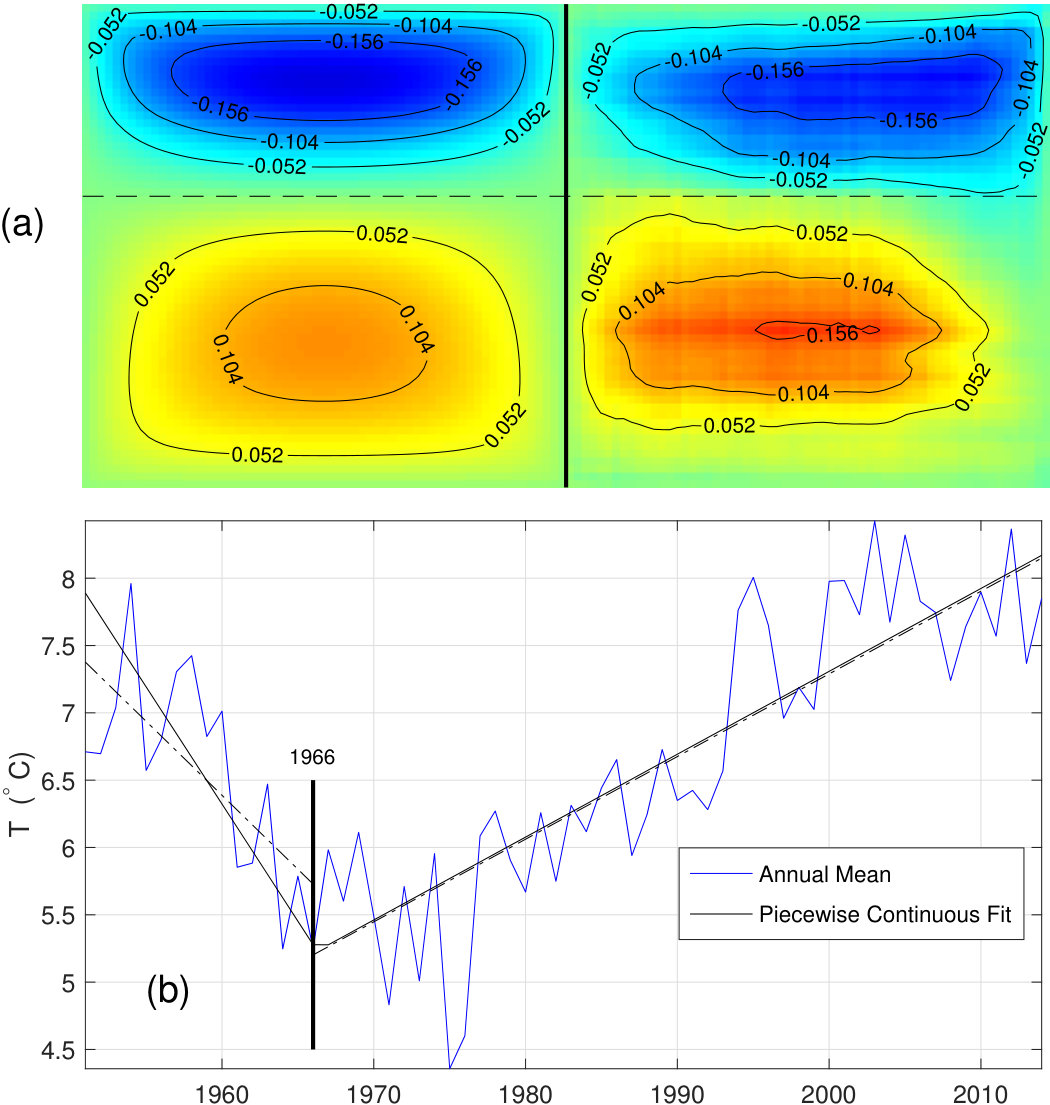 Figure 17
Figure 17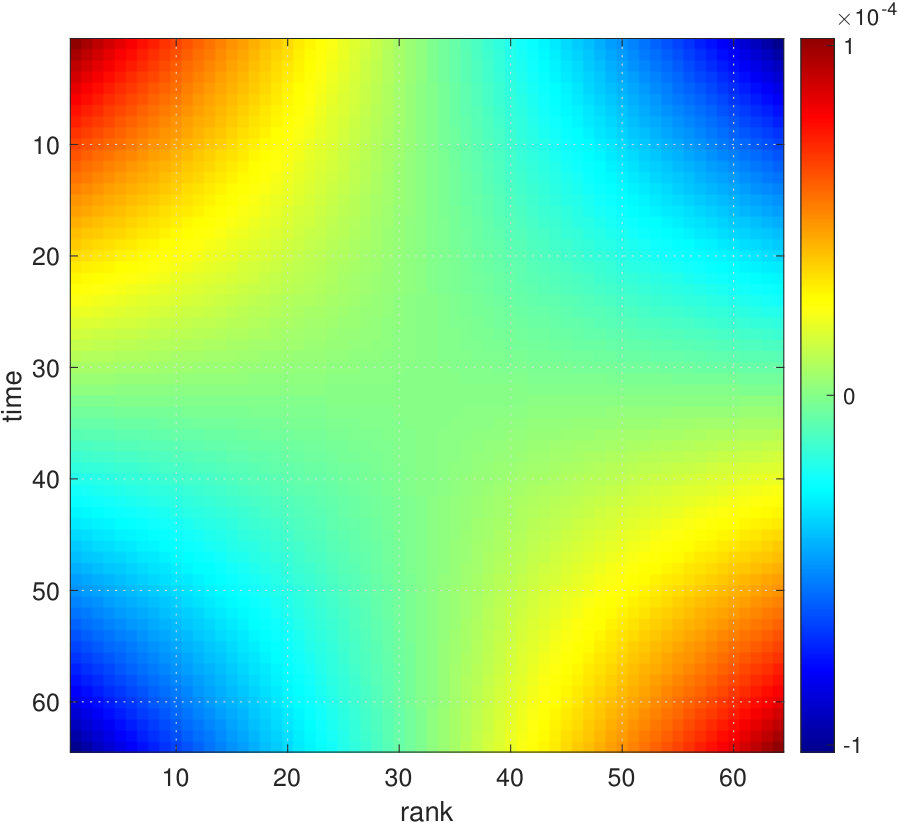 Figure 18
Figure 18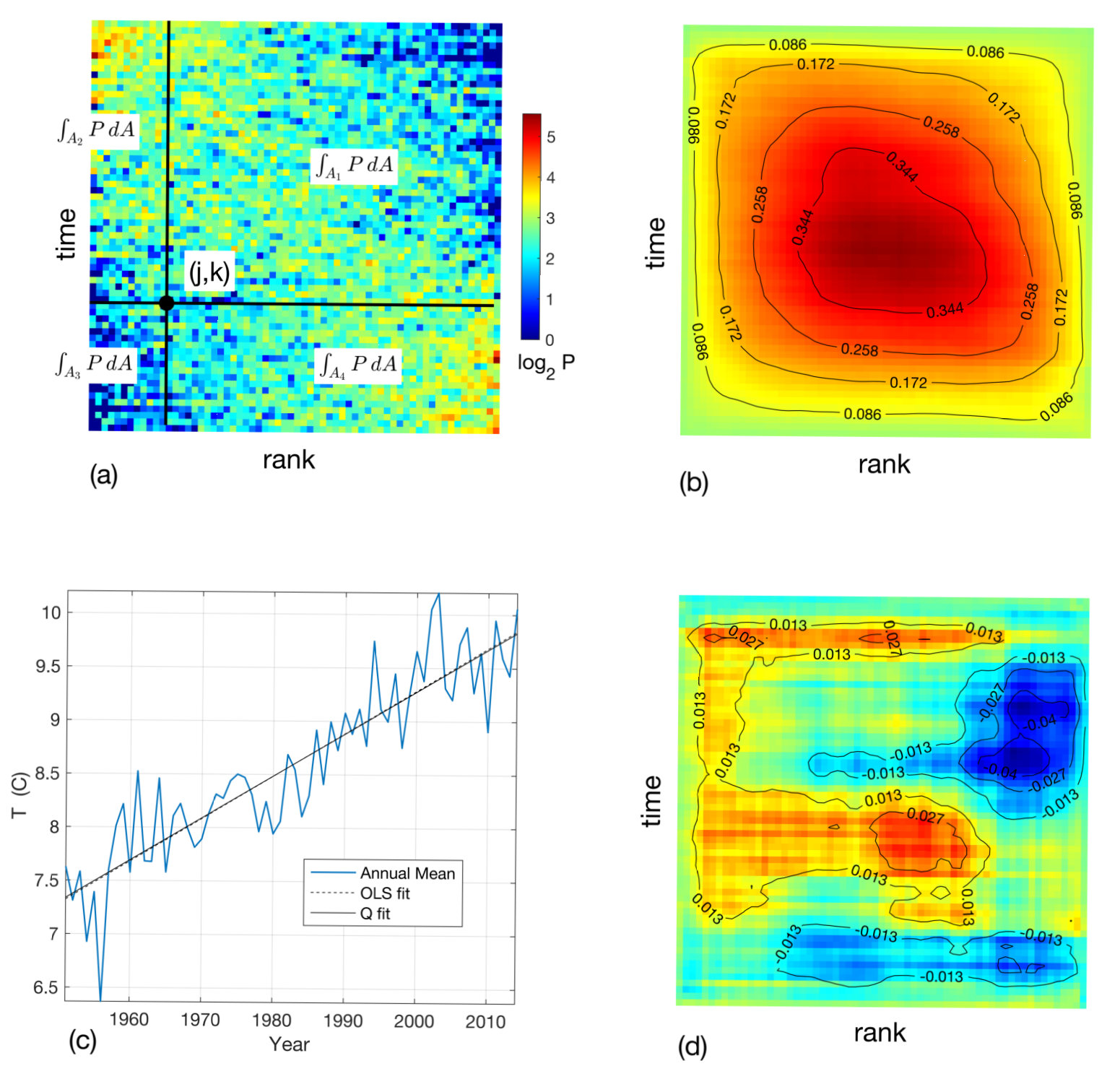 Figure 2
Figure 2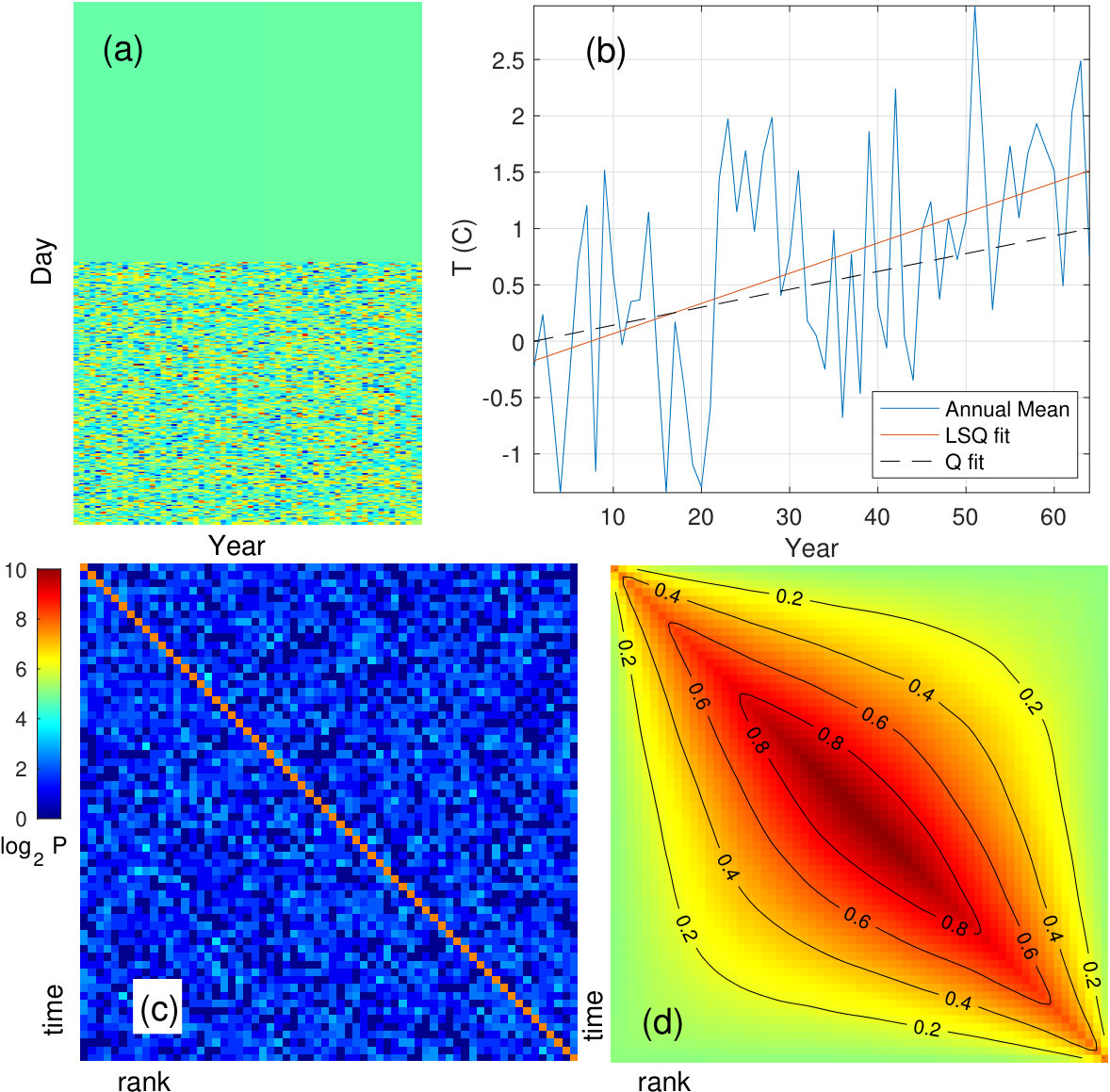 Figure 3
Figure 3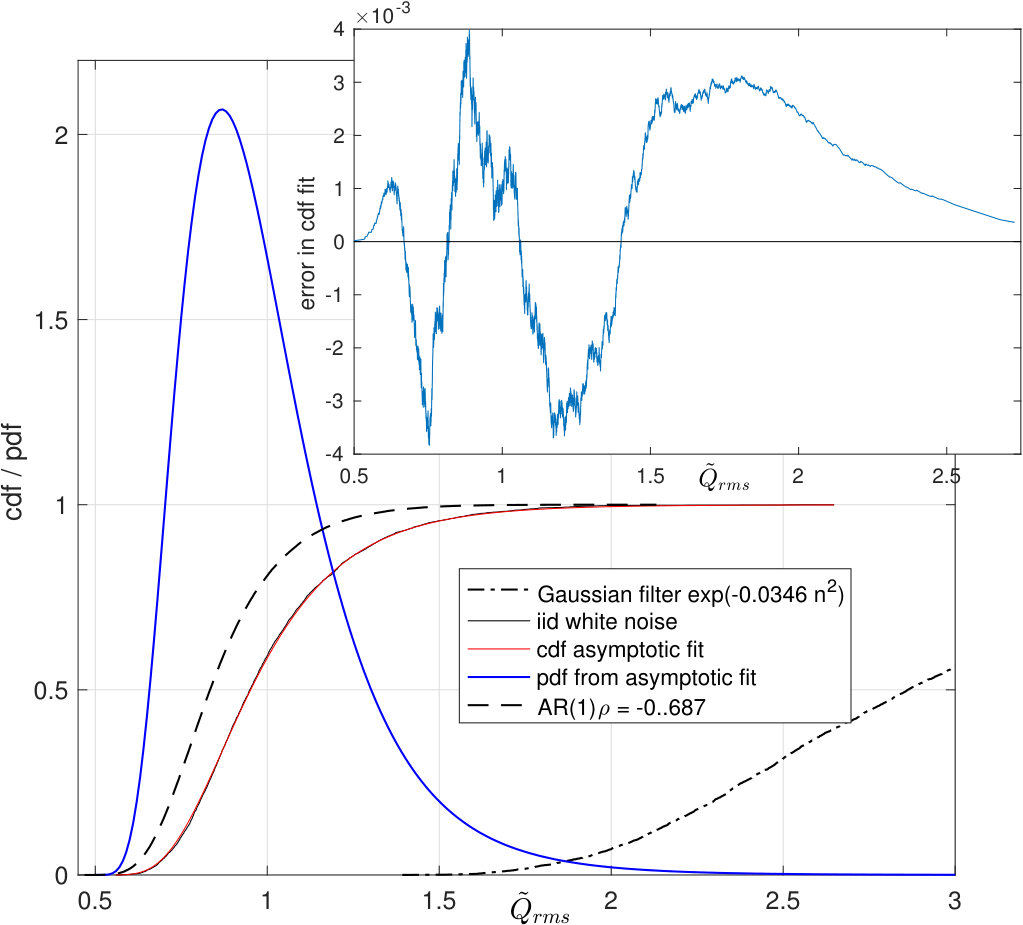 Figure 4
Figure 4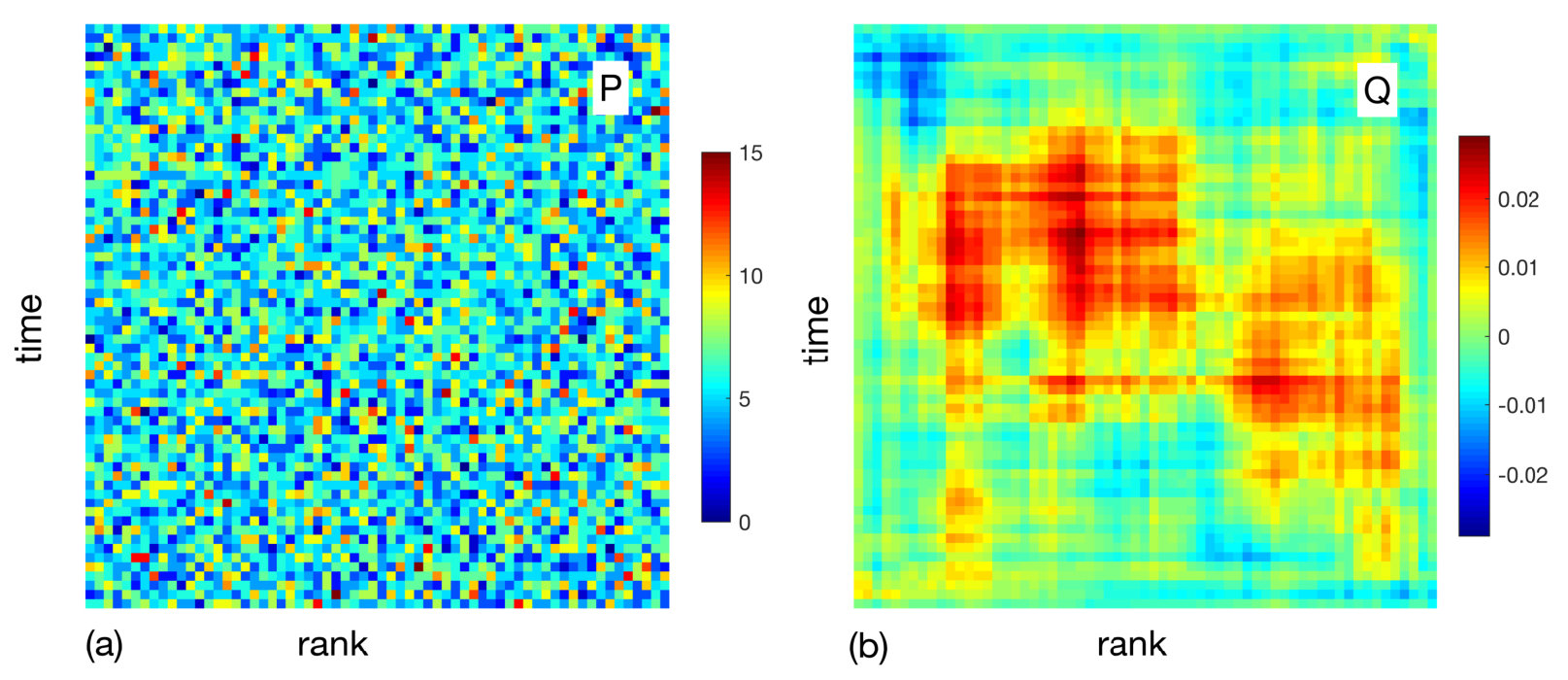 Figure 5
Figure 5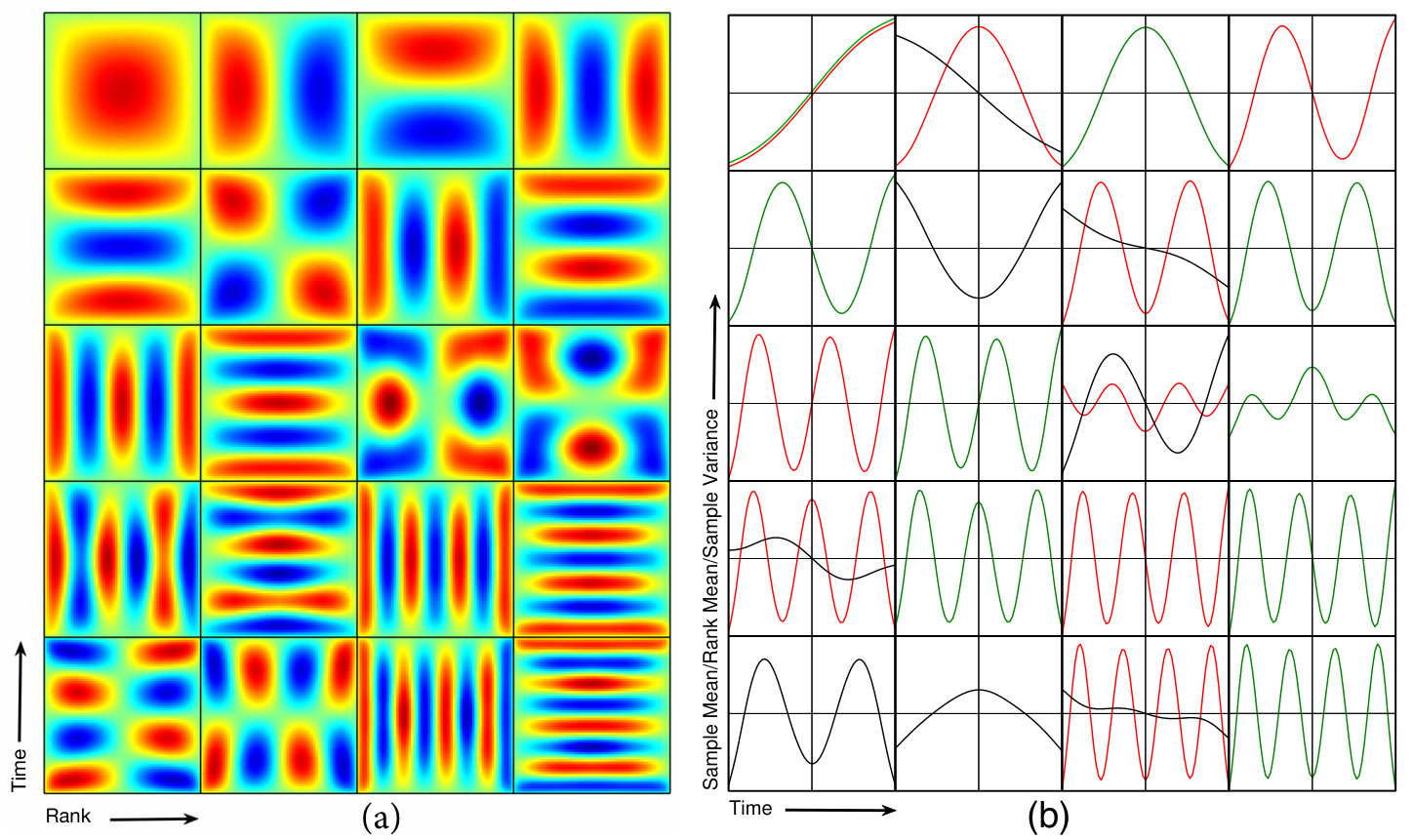 Figure 6
Figure 6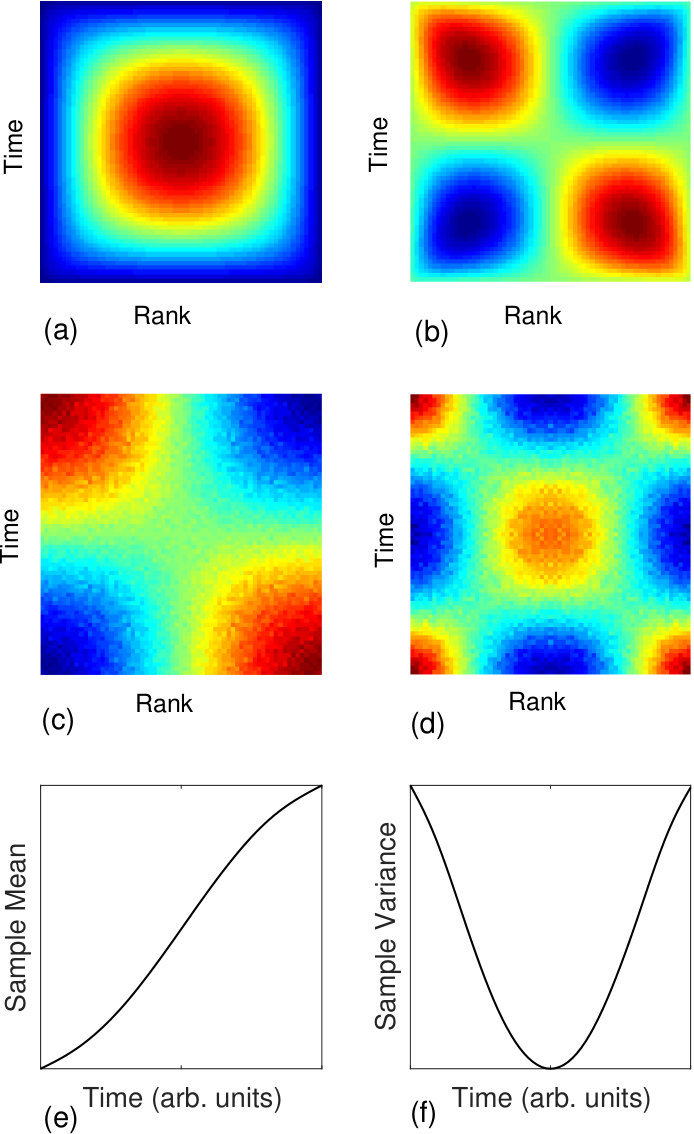 Figure 7
Figure 7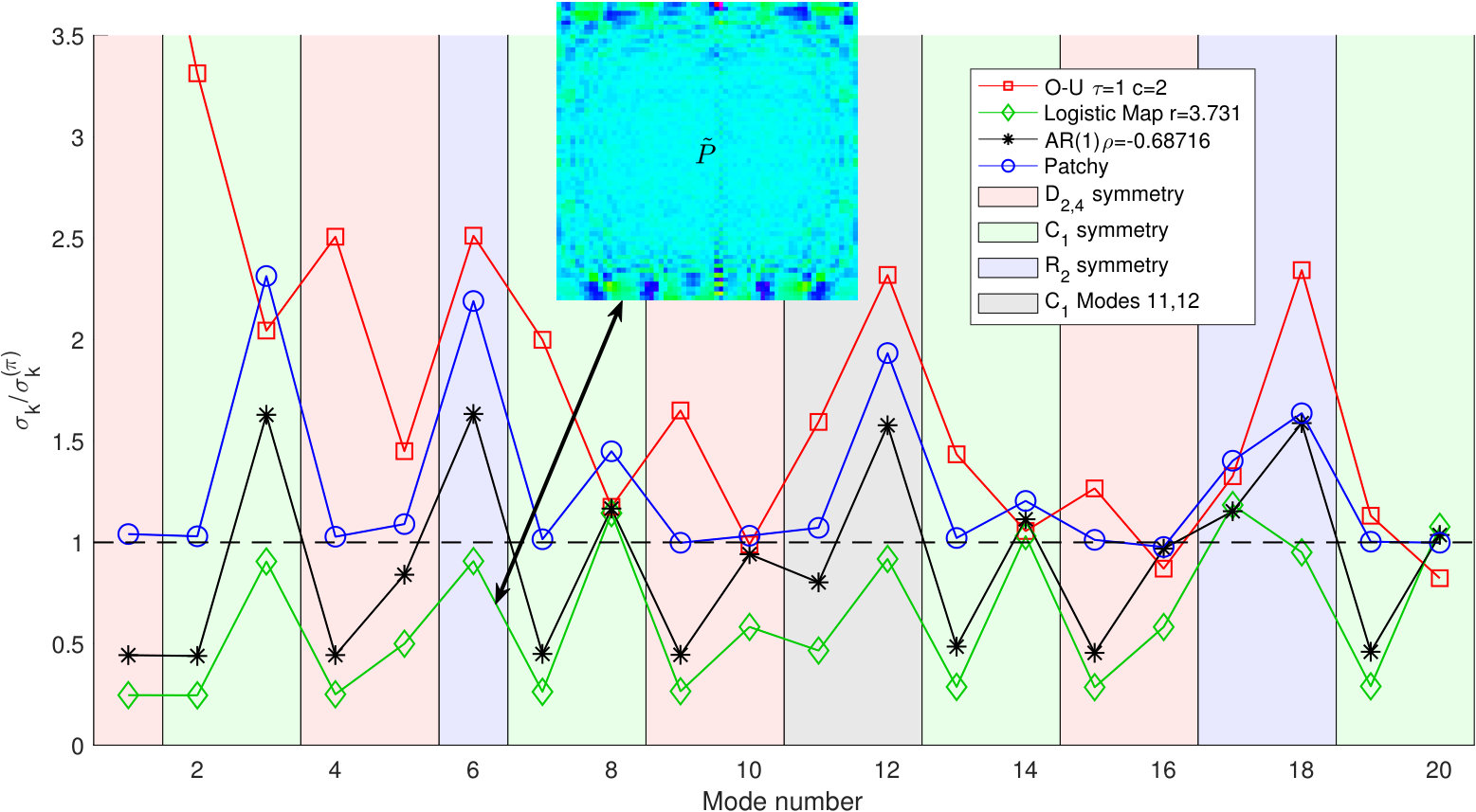 Figure 8
Figure 8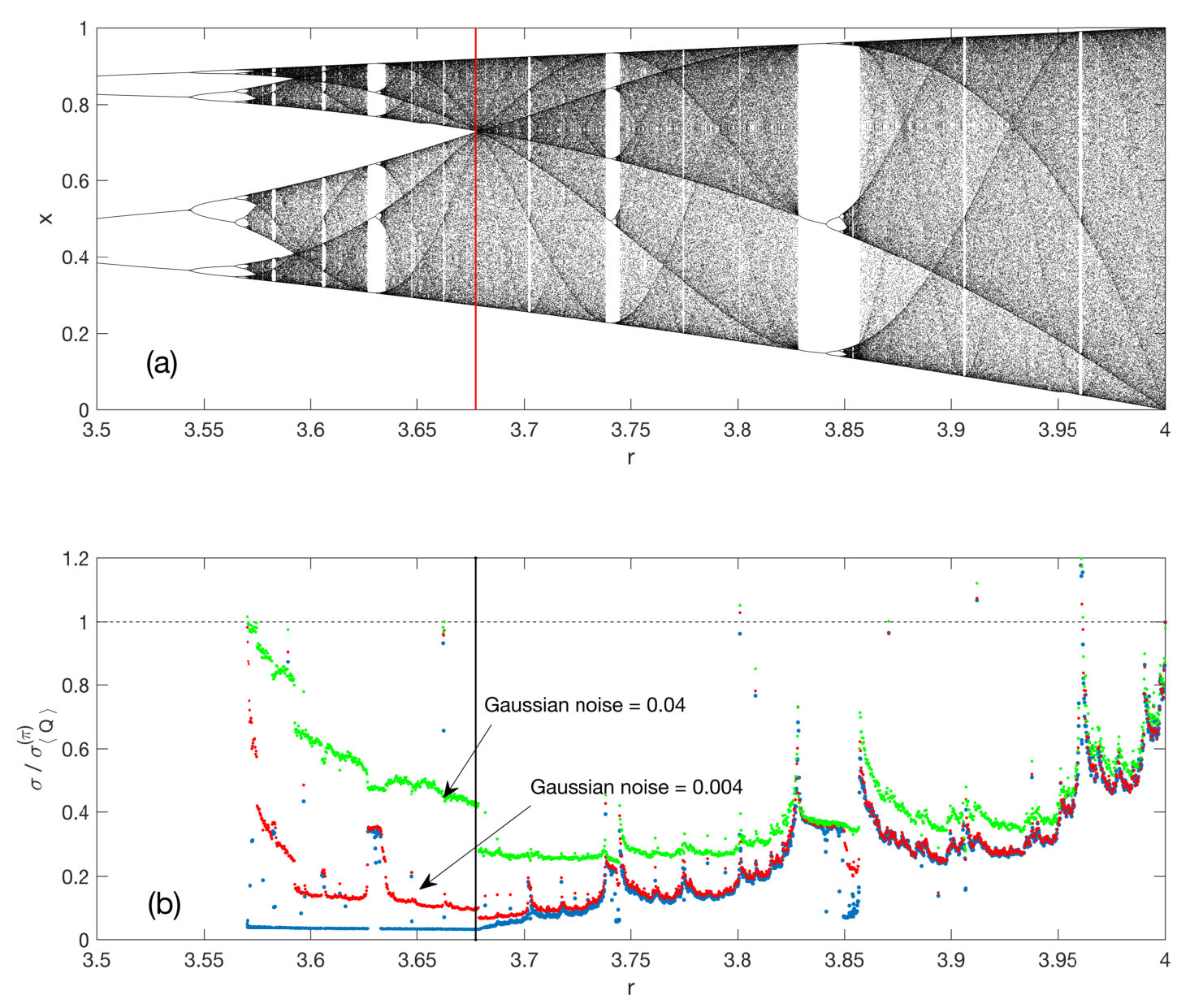 Figure 9
Figure 9| Planform | sym | sym | Null Projection |
|---|---|---|---|
| Distribution | LS | Theil-Sen | |
|---|---|---|---|
| Uniform | 0.012 | 0.007 | — |
| Gaussian | 0.023 | 0.023 | — |
| Cauchy | 0.042 | 0.038 | — |
| Pareto | 0.022 | 0.068 | 0.023 |
| GEV | 0.016 | 27.84 | 0.018 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
A universal rank-order transform to extract signals from noisy data
Glenn Ierley
Mathematics Department, Michigan Technological University
1400 Townsend Drive, Houghton MI 49931
Scripps Institution of Oceanography, UC San Diego (emeritus)
Alex Kostinski
Physics Department, Michigan Technological University
1400 Townsend Drive, Houghton MI 49931
Abstract
We introduce an ordinate method for noisy data analysis, based solely on rank information and thus insensitive to outliers. The method is nonparametric, objective, and the required data processing is parsimonious. Main ingredients are a rank-order data matrix and its transform to a stable form, which provide linear trends in excellent agreement with least squares regression, despite the loss of magnitude information. A group symmetry orthogonal decomposition of the 2D rank-order transform for iid (white) noise is further ordered by principal component analysis. This two-step procedure provides a noise “etalon” used to characterize arbitrary stationary stochastic processes. The method readily distinguishes both the Ornstein-Uhlenbeck process and chaos generated by the logistic map from white noise. Ranking within randomness differs fundamentally from that in deterministic chaos and signals, thus forming the basis for signal detection. To further illustrate the breadth of applications, we apply this ordinate method to the canonical nonlinear parameter estimation problem of two-species radioactive decay, outperforming special-purpose least square software. It is demonstrated that the method excels when extracting trends in heavy-tailed noise and, unlike the Thiele-Sen estimator, is not limited to linear regression. Lastly, a simple expression is given that yields a close approximation for signal extraction of an underlying generally nonlinear signal.
pacs:
Valid PACS appear here
††preprint: APS/123-QED
I Preview and Introduction
We report on a discovery of a rank-based method that appears remarkably versatile and robust with respect to the nature of noise. This is so because the method is ordinal, nonparametric, and therefore distribution-independent. Throughout the paper, the performance of the method is compared to leading nonparametric tests and software, using real as well as synthetic data, where exact results are known. As new results abound, but the most important ones appear in later sections (V and on), we begin with the slightly unconventional device of an annotated table of contents to orient the reader.
In Section II we introduce and motivate the initial construction of our method (dubbed there the transform) in a simple setting: we begin by solving for the long term warming trend buried in a fluctuating time series of daily low temperature. The same quantity later identified as a diagnostic for signal detection is simultaneously here used for signal extraction by means of parameter estimation (here, the slope). Agreement with the least squares method is excellent. This is quite surprising, given that the method retains no magnitude information whatsoever, only rank. This is a setting with few outliers, where the two approaches generally agree.
In Section III we propose a continuous approximation for , in terms of which one can understand as a simple 2-D integral transform. This formulation facilitates accurate approximation of various basic results (Figs. 2, 3, 7, and 17) with algebraic forms that are more transparent in meaning than the equivalent discrete forms.
In Section IV we introduce two statistical metrics used for confidence tests, characterize their distributions, and give an asymptotic approximation for the scaling of each. The case of correlated noise is also considered.
In Section V we give a universal representation of the transform for all distributions of iid (white) noise. Key is a five term exact orthogonal decomposition based on planar group character, applied to all realizations of in an ensemble. Principal component analysis (PCA) is used on each of the resulting group ensembles. The lifting of the original 1D time series to the 2D rank-order space of – “order” here taken as time-like, but generally representing any serial independent variable – establishes a link between modes and corresponding ordered patterns of (sample) nonstationarity in mean and variance. As a consequence, -based slope estimates from Section II for long term trends are unaffected by trends in variance. These ideas are further developed in Section VI, where a new metric is developed for characterizing stochastic processes, offering a prejudice-free means of selecting a model for experimental data.
In Section VII we address a detection problem where the signal is a chaotic series generated by the logistic map. Our method, which makes no assumptions about the functional form of the underlying signal, readily distinguishes the presence of chaotic signals, whether alone or in combination with white noise.
In Section VIII we consider the canonical nonlinear parameter estimation problem for noisy two-species radioactive decay (Bevington and Robinson, 1992, Chapter 8). In this problem of quantitative signal extraction our method outperforms special-purpose least square software by stably retrieving both decay rates.
In Section IX we introduce a heuristic approximation for extracting a complex signal up to within a linear re-scaling by simple differentiation of the transformed field.
In Section X two data sets with distributions of infinite mean and variance noise are explored. For such distributions, the Theil-Sen nonparametric method is commonly used, but is limited to linear regression. Our transform also succeeds for the linear problem but extends to arbitrary functional forms and multilinear settings as well.
In Section XI we close with an extension of the method to unequally spaced time series. We develop the theoretical basis for error analysis and apply it to linear regression, hence accounting for the otherwise enigmatic agreement of the linear fits exhibited in Section II.
Signal Detection
To place the transform within the existing literature on time-series analysis, consider signal detection first where statistical signal processing is, perhaps, the natural setting. Here one devises a test statistic and selects an operating threshold Kay (1998). Performance as judged by false positives/negatives is typically characterized with, e.g., a receiver operating characteristic curve. If used in the time domain, most such detectors are local; they use a single realization consisting of short segment of the signal to evaluate the test statistic and assign a score. The resulting sequence of statistics for the entire time series identifies discrete intervals where signal is likely present. In Bandt and Pompe (2002) information entropy was proposed as such a test statistic. Initially applied to detection for speech and deterministic chaos, it has been widely used, e.g., Garland et al. (2018); Fischer et al. (2017).
Like the transform, this information entropy is also rank-based and nonparametric. However, it is a “local” measure whereas is “global”. By global we mean that evaluation of relies on a significant number of trials to accumulate sufficient statistics about the parent noise distribution. This global approach performs well for detection at a poor signal-to-noise-ratio (SNR) when local methods would fail. The weakness is that cannot be obtained from a single trial. One can liken the global character of the approach to a spectrogram-based signal detection in the frequency domain (see e.g. Helble et al. (2012)) but, where the latter are usually energy detectors (or other power-law), detection is based solely upon rank.
Signal Extraction
Turning to the subsequent problem of signal extraction, this is often accomplished by some variant of a least squares minimization, and a vast literature supports this approach. For example, when errors are identically and independently distributed (iid) Gaussian random variables, ordinary least squares is the maximum likelihood estimator, e.g., see Lupton (1993); Bevington and Robinson (1992). However, nonstationary variance is ubiquitous in data analysis and so is lack of independence. These complications could be addressed with generalized least squares using a weight matrix equal to the inverse of the covariance matrix, , when the covariance of the fluctuations is known. In practice must be estimated. For this “feasible generalized least squares” it is difficult to assess the effect of error with empirical weights. Correlated non-stationary noise is often heavy-tailed, e.g. see Bardou et al. (2002) for numerous examples in atomic physics, and outliers are then a serious problem for least squares. Rank-based methods need no empirical weights for such complications. Two species radioactive decay is a case where the least square error itself – nonlinear in the parameters – may fail as a penalty function, while our rank-based measure proves robust.
For parameter estimation, one chooses a representation for the solution, either specific to the application, as with exponential decay, or a generic form such as a polynomial expansion. The coefficients in the functional form are determined by a minimization procedure.
For non-parametric signal extraction, we make no assumption about form apart from spectral separation. The natural comparison for a deterministic signal buried in noise is a moving average convolution, with the stencil of weights ranging from a simple boxcar to a precisely designed filter for impulse response. Such filters are applied to single realizations whereas needs an ensemble.
In summary: in the realms of both detection and extraction, to the best of our knowledge there are no methods that are rank-based, nonparametric, and global in the sense defined above.
II Description of the transform and trend extraction
We chose climate as a setting to initially motivate and illustrate the method, but several other contexts will be provided throughout the paper. Nonparametric statistics have been used in climate physics, e.g., record-breaking statistics have been employed to infer a variety of trends from temperature time-series Benestad (2003, 2004); Meehl et al. (2009); Anderson and Kostinski (2010). Such nonparametric and distribution-free methods are, indeed, an alternative to the various least squares methods. However, to the best of our knowledge, up to now only record lows and record highs have been used in the climate context, e.g., Coumou and Rahmstorf (2012). Here, we are guided by the simple thought that the entire rank information and not just its first and last element, ought to be used in nonparametric analyses and our results buttress this claim. Throughout this paper, the th entry in a time-series, , is assigned rank if it is the lowest value of the entire sequence when sorted by magnitude. For example, the high or low daily temperature at a particular location, is sorted and ranked below, and we track the year of origin (order, ). Hence, the “rank-order” in the title. We note in passing that rank is not always uniquely defined as ties occur. The subject of ties merits a paper of its own paralleling considerations raised e.g. in Edery et al. (2013). To circumvent this problem we either assign fractional rank or add white noise. In this paper we examine data sets of daily high temperatures from the Global Historical Climatology Network (GHCN) and raw monthly mean temperatures from the Berkeley Earth repository.
As a specific example, consider the GHCN weather station SZ000009480 (Lugano, Switzerland). Color is used in Fig. 1(a) to display daily high temperature values as a day (row) and year (column) matrix. The seasonal variability is apparent, e.g., almost everything is red around day 180 (summer). In Fig. 1(b) we display the same data but with daily rank recorded in rows: all magnitude information has been discarded and all data are now integer-valued. The appearance is fine-grained, reminiscent of “salt-and-pepper” noise. The central finding of this paper is that the trend information content of 1(a) and 1(b) is almost identical (for a large data set), despite the total loss of magnitude data. This is appealing, as ranking is affected neither by outliers, nor any monotonic transformation of temperature data, e.g., a logarithm Thompson and Macdonald (1991), nor by occasional gaps in data as shown below. To introduce the approach, we begin by re-packaging the day/year rank matrix data.
Disregarding the dependence (for the moment), let us view the daily temperature values in Fig. 1(b) as independent random trials, indexed by year. For example, among the 365 trials during year 1951, nine record low (rank 1) values occurred, that is, lower than any of the 63 subsequent values (1952-2014) for that day. Given the independent trials perspective, the essential information can be distilled to just three numbers: only the year, the rank, and the “population” of that rank need be preserved. The order of occurrence of the nine “events” is superfluous as the events are indistinguishable (because the trials are independent and, for the moment, seasonality is not a concern). Therefore, the input data matrix of Fig. 1(b) can be condensed. Guided by this observation, we let the rank be an independent variable and construct a 64 x 64 rank-order square matrix as shown in Fig. 1(c) where each entry is the “occupation number” or the number of occurrences for that particular rank and year. The total population of the -matrix is . is integer-valued, invariant with respect to temperature offset, and the total population of each row and column is . More generally for the range is [] where is the number of trials (here days).
Note that the entries of are not evenly distributed among the quadrants defined by the cross-hairs in Fig. 1(c). Whereas the combined population of upper left and lower right quadrants is 14083, that of lower right and upper left is 9277. The expected population, given a stationary climate, is . This nonstationarity of is of overwhelming statistical significance, and we use this message in the data to work towards an objective, assumption-free definition of a warming signal. The extreme case of a pure warming trend with no variability results in a which is a multiple of the identity matrix, with a pre-factor . By contrast, consider an ensemble of stationary climate realizations. For a given time series of 64 years, any entry is equally like to be the hottest (record-breaking) and shuffling these entries does not change the statistics, because of independence Foster and Stuart (1954). Then, in the limit, ensemble-averaged populations of all ranks of a given row of (fixed time) should be equal and the matrix should approach perfect uniformity (all matrix elements equal, ).
To gain further insight into the meaning of the -signal consider an early and late year, namely, 1954 (order 4) and 2011 (order 61), displayed as a histogram versus rank in Fig. 1(d). Observe that, for a steady climate, rank occupation numbers, approximated as independent trials (akin to classical particles), obey Poisson statistics: , with being the average population per rank and the standard deviation. Hence, we expect as the green curve (labeled stationary) indicates. Not so for red (diamond) and blue (circle) curves. Note a near perfect reflection symmetry between these curves. This is another manifestation of warming. The 1954 and the 2011 population maxima occur at ranks 3 and 63, respectively. Hence, the statistically essential information for these years is stored in intermediate ranks (see Fig. 1 caption for further numerical illustration). On the other hand, high occupation of mid-rank, say rank 32, although significant, does not convey as much information about a warming trend as the high occupation of extreme, or near extreme, ranks.
Based on the above discussion, the notion of a warming signature emerges, characterized by the over-population of the lowest ranks in early years, i.e. red values in upper left and lower right corners, with the blue values predominant in the other two corners. But why limit one’s attention to only symmetric partition of into four quadrants? To that end, consider the general partitioning into (unequal) quadrants defined by the off-center cross-hairs in Fig. 2(a) and focus on the excess of records over the expected mean in quadrants 2 and 4, and the corresponding deficit in quadrants 1 and 3. For each quadrant pair we take the ratio of actual to expected populations and then form the difference of these two ratios. This difference vanishes (on average) for a steady climate. For the data of Fig. 1, the value of this difference at the centered cross-hairs is while a peak value of occurs at . When this partitioning is repeated with the cross-hairs traversing the entire grid, a new matrix is generated, denoted as , e.g. . To ensure the existence of the four quadrants, given that is , the difference of ratios is computed at grid points.111The row index of is a time-like coordinate. Its values lie at the midpoints of the original grid with points. The mathematical implementation for the above construction of is given by
[TABLE]
where is the number of years. This defines the discrete transform of . Note that , i.e. is the excess or deficit percentage for the partition of . If and are rearranged as vectors, (1) can be viewed as , where the matrix , augmented with the row and column sum constraints for , is well-conditioned and admits a stable inversion for given . Hence preserves, while reordering, the trend information stored in from the original temperature record.
For the weather station of Fig. 1, the corresponding is shown in Fig. 2(b). The complete trend information is stored in the set of partitions of and hence in the elements of . As illustrated above, positive elements of arise from partitions with a warming bias. Thus, for a stationary climate, one anticipates no sign preference for elements of . This motivates us to consider , the mean value of all matrix elements, defined as
[TABLE]
The angular brackets, from now on, denote the average over all matrix elements throughout this paper (as opposed to an ensemble average) so is a scalar, and it vanishes on average for a stationary random process.
Natural variability induces fluctuations in about zero. Once that probability distribution is characterized, one has a quantitative basis to decide whether a trend is actually present, as discussed below. Thus, we propose to quantify a trend by the linear function (temperature vs. time) whose slope is determined by annulling the mean value of . In other words, a single adjustable parameter, the slope, is chosen to annul the average matrix element of . To do this, a candidate linear function of is subtracted from the original time series (input data), row-by-row ranks recomputed, re-populated with revised values, the transform applied and its mean computed. The scalar is a monotone function of the trial slope and always has a single zero crossing.
To illustrate, we return to the data in Fig. 2. Remarkably, is positive definite, that is, positive for each and every partition of (each matrix element of ). Thus, the warming signature is exceptionally strong. Moreover, as Fig. 2(c) confirms, not only does annulling in the original record determine a unique linear trend, that trend is nearly indistinguishable from the LS fit. Similar close agreement between LS and linear trends is found in most cases. Nonetheless, while LS and fits of temperature trend commonly agree to C over periods of 50 years or more, a few larger discrepancies arise. These arise in cases with large seasonal variation in variance, which we shortly explore. A systematic cause of smaller discrepancies is that LS regression of the annual mean does not distinguish between a few large excursions in daily low temperature vs. numerous small excursions whereas is affected principally by the latter. Lastly, autocorrelation, common in temperature time series, can differentially affect the two.
The partitioning of temperature data in a matrix may seem a necessary condition for linear regression with . Not so. Dropping one calendar day to obtain points affords a wide number of factorizations. The set serves to make the point. Before detrending, values for this set consist of seven approximately equal low values, one intermediate, and two high. The last pair are the original , and subharmonic, , which averages two years of temperatures at a time. The superharmonic, averages every six months hence the signal has both a long term trend and a period two seasonality. Its initial is intermediate. The remaining seven, incommensurate with seasonality, all have a very irregular mean signal, though one still marked by the same long term trend. Each factorized form was detrended with exactly the same slope. All of them simultaneously have reduced to noise level (or, translated back to temperatures, differences averaging about C). So the choice of binning causes no meaningful disagreement about the trend required to annul on the assumption of a linear long term signal.
Note that the algorithm of obtaining the linear trend with is objective in the sense that a robot can be programmed to detrend the temperature data by simply annulling . A skeptical reader might wonder about extracting a dimensional quantitative trend in degrees/decade from the dimensionless rank input only. In fact, it is signal and noise that together conspire to give the quantitative information needed because ranks are scrambled by the noise indiscriminately while the signal affects them systematically. The key relation here is a proportionality constant that relates a dimensional change in slope to the dimensionless change induced in for a specified noise field. Unlike itself, that constant does depend upon the exact distribution. We revisit this point at the close of Section XI, where an error estimate for slope is derived.
As we shall see, the rank-order transform reveals the entire form of a signal and not just the linear trend, i.e. there is information in the residual shown in Fig. 2(d). One does not generally expect and least square fits to agree at all orders, particularly as ordinary least square fits are influenced by outliers, while is not, for which see the treatment of heavy tails in Section X, where empirically weighted least square fits can work up only to a point, while performs well without need of such measures. Note also that a monotone deformation of temperature data (e.g., a logarithmic one) affects the least squares fit but not .
To illustrate some remarkable properties of the transform, we consider a highly idealized synthetic data set both because the true answer is known, hence and LS errors can be assessed quantitatively, and because the idealization makes transparent the cause of the difference in comparative performance. Motivated by the data for Bethel Airport, AK where and (unweighted) LS trends for 1951-2014 differ by C, we consider the daily low temperature on Planet X, where the climate is so equable for the first half of the year as to have no variability in temperatures but solely a trend of C over 64 years. In contrast, during the second half of the year the same trend is overlain with large variance. Fig. 3(b) shows the corresponding and LS fits: C and C, respectively. Clearly, the LS fit is thrown off by the abrupt noise. Fig. 3(c) depicts the matrix (note the log scale), revealing the reason for the divergent estimates. The exact data for the first half of the year result in a perfectly diagonal population of entries while the second half of the year consists of nearly randomly distributed entries. Fig. 3(d) shows the resulting is resistant to noise; each partition sees a positive excess strongly dominated by the diagonal while the random entries largely average out. Hence, detrending this , (see (9) for an exact expression in the limit of zero noise), effectively yields an exact result. In real data, all cases of large discrepancies in trend estimates between and LS occur in locations that experience large excursions in seasonal variance. Conversely, and LS linear trends for stations with minimal variance excursions commonly agree within the previously indicated C per years.
III Simple Analytic Approximations for
Towards gaining an intuitive sense for we introduce here a continuous version of , denoted as and similarly for . For simplicity, the domain of each is taken as . Then
[TABLE]
and we require to satisfy the homogeneous constraints
[TABLE]
Making use of the latter constraints (3) can be simplified to
[TABLE]
The inversion yields
[TABLE]
Alternatively, we can write (3) in the form of a two-dimensional convolution as
[TABLE]
where denotes the Heaviside function.
The simplest possible algebraic form that satisfies (4) is and we choose the sign to reflect an excess in second and fourth quadrants and deficit in first and third, that is, a warming signal. From these assumptions results
[TABLE]
with a mean value of and root-mean-square value of . While the issue of normalization has been bypassed, this simple ansatz for is an excellent means to anticipate the form of a ubiquitous pattern in both for real data at numerous sites with warming, and the dominant mode of in a PCA decomposition, even for realistic correlated temperature fluctuations in a stationary climate, typically accounting for 25% of the variance in . While (8) reflects the form of for a wide range of SNR, the limiting form for zero noise is a diagonal matrix for . Translated to the continuous form, this results in
[TABLE]
whose diamond-shaped contours are those seen in Fig. 3. In this special case the formula above, if sampled on the unit interval at a spacing of with endpoints excluded, is identical to the discrete result for , regardless of the value of . Appendix A examines breaks in a series, based on this continuous approximation.
IV Metrics of , their statistical distributions and asymptotics
Reduction to a matrix is the basis for the transform, and the exact general result for the equilibrium form of for a given signal in the presence of uncorrelated noise can be obtained. This result is essential for deriving error bounds. However, because of numerical complexity for realistic arguments, and the need for development of its asymptotic expansion, we defer that discussion to Appendix B.
Here we extend our approach that began by consideration of in Section II. We aim to characterize the standard deviation for for iid noise. To this end we find an asymptotic expansion that clarifies parametric dependencies. Deeper meaning of such benchmarking emerges in the next section.
In Section II we proposed that a linear trend can be determined by setting the average matrix element . Such a trend is a combination of a long term signal plus some contribution from natural variability. Given but a single realization, one cannot disentangle these two. However, knowing the distribution of , one can set bounds on the contribution from natural variability to within any desired confidence level. For iid noise, the quantity follows a normal distribution and the standard deviation of can be characterized in general terms. Considering the disparate influence of and on that result, one expects the dependence on the former to be the same as that for a sum of normal variables, namely . It is plausible that an asymptotic expansion of in has the same leading order dependence, succeeded by an ordered progression of higher order corrections. Numerical experiment at varying and with realizations each time yields the following approximation in such a form:
[TABLE]
(The coefficients above are sensitive to errors in computed estimates of .) As is an ordinal method, asymptotic results such as (10), and also (12) below, are distribution-independent for white noise. The form above can be motivated by comparison to the derivation for a related expansion (see Appendix B). A sample run with 5000 trials using iid normal random variables, , and gave compared to the expected result from (10) of . Normalizing values of with the sample standard deviation yielded a distribution that passed the Kolmogorov-Smirnov test for normality at the % significance level with an asymptotic -value of .
Beyond linear trends, may reveal a general nonlinear signal and a suitable second benchmark is then the root-mean-square (rms) value of whose distribution must be characterized. The rms average is given by:
[TABLE]
The pair of mean and rms values of have the great advantage that they are readily computed, especially the first for which there is a fast explicit algorithm given in Appendix B. (There is also a fast algorithm for itself given .)
The quantity is observed to obey a generalized -distribution and collapses to a single curve as a function of the normalized variable , and where a similar asymptotic expansion holds, namely:
[TABLE]
An empirical expression for the cumulative distribution function (cdf) with uniform error can be written in terms of the incomplete gamma function222The incomplete gamma function used here is 8.2.2 of the Digital Library of Mathematical Functions. as
[TABLE]
One must qualify the use of results like (10) and (12) when the ambient noise is other than iid (white) noise. One common factor is autocorrelation. For example, it is a matter of common experience that weather has a persistence, typically 3 to 4 days. With the temperature data running vertically in the data matrix of Fig. 1(a), one has a resulting correlation between successive rows in that data matrix. For correlated identically distributed variables arranged in this fashion it remains true that follows a normal distribution, but the coefficients in (10) depend on the specific autocorrelation.
For not only the coefficients change but the generalized -distribution itself alters as seen in Fig. 4 where two examples make our point. The more conventional case is provided by convolving a Gaussian white noise sequence with a Gaussian filter of the form . As in Fig. 1(a), the data are stacked vertically in the input matrix to , hence successive rows are correlated. The resulting distribution of (dash-dot) is observed to be broader. A second example, with a narrower distribution, is an AR(1) model with , whose autocorrelation function has a pronounced dip of at one time lag. The cdf for the standard reference (solid black), along with its asymptotic fit (13), lies between the other two. The difference between empirical and asymptotic results for iid noise is shown in the inset figure, and also the pdf that follows from the asymptotic form (13).
All three cdf curves are scaled by the same iid noise value for . For these two correlated examples, a linear remapping of the form gives a curve fairly close to the original iid distribution. The parameters that achieve this are ) for the Gaussian filter, and for the AR(1) model. The first of these, a shrinking of scale, can be thought of as a decrease in the effective number of independent samples Koivunen and Kostinski (1999). That the second comparison distribution is narrower is attributable to the negative correlation, which disrupts, rather than reinforces, the tendency for transient nonstationarity. We draw upon this dynamic to great effect in Section VII, where we consider chaotic series generated by the logistic map, also generally characterized by negative correlation.
V Sample variability projected on the rank-order -plane characterizes stationary random processes.
The data shown in Fig. 2(c) exhibit an unmistakable linear trend. Yet, at least in principle, natural variability of a truly stationary climate could create such a trend. While strict stationarity is a theoretical property of a random process, finite samples (even large ones) never appear purely random and exactly stationary. Finite samples exhibit transient trends and the likelihood of such trends depends on the specific stationary process. But, while spurious trends in sample mean and variance can be a hindrance for deterministic signal detection, one can turn this around and use these same calculated trend likelihoods to characterize (or “fingerprint”) specific stationary stochastic processes.
As we demonstrate below, the “lifting” of a one-dimensional time series to the two-dimensional space of rank-order via the transform enables an application of group theory, delivering a universal characterization of transient trends for arbitrary stationary stochastic processes and sample sizes. In particular, encouraged by anonymous reviewers, we pay special attention to two models: the Ornstein-Uhlenbeck process and the logistic map, the latter explored further from the perspective of deterministic chaos in Section VII.
Towards the complete characterization of transient trends, we begin with the iid (stationary, -correlated or white) noise, which is the featureless “standard candle” of stochastic processes. Because the transform is ordinal, there is no need to limit our development to a Gaussian distribution; all white noise distributions are equivalent. The featureless spectrum of white noise suggests absence of features in any representation. Indeed, this featureless quality is so at the level of raw input data and remains true for matrix, e.g., see Fig. 5(a), devoid of apparent structure, appearing as salt-and-pepper noise. In fact, as all ranks have equal rights, ensemble-averaged tends to the perfect uniformity (constant ) for, not just iid, but more generally to all independent stationary processes because of the reshuffling argument (see Section II). This limit also holds for correlated (and hence, shuffling-breaking) stationary processes, aside from slight effects at the corners (see Appendix B.1).
In contrast, the ensemble average of the -transformed (distribution-invariant) white noise in the rank-order plane (hereafter dubbed noise [34]) is not uniform and even at a single realization level, deviates greatly from the salt-and-pepper noise, as illustrated by the patchiness (structure) in Fig. 5(b). We take advantage of such structure and decompose it in terms of dominant modes (planforms), linking these planforms to the types of transient patterns in time (see Fig. 6).
Group-based algorithm for the standard “etalon”
The desired correspondence between the planforms of and specific features in the generating time series emerges from an examination of symmetries and associated groups. Group character is central in the rank-order plane, e.g., time-reversal symmetry means the ensemble average of is invariant under a left-right flip. Just as any 1-D function can be written as the sum of even and odd terms, , an arbitrary function in dimensions has a unique, orthogonal group decomposition in terms (two terms for ). For the five term expansion assumes the form
[TABLE]
where
[TABLE]
[TABLE]
Here denotes the dihedral group, the reflection group, and the rotation group, with the third and fourth components on the right in (14) representing reflections about the and axes respectively. The applications of this expansion appear manifold, including an exploration of wallpaper groups as in Verberck (2012)333As commented in [20], “A more formal approach for deriving minimal symmetry-adapted functions for the wallpaper groups involves group theory; each wallpaper group should be decomposed into irreducible representations.” We note one result in this area, that the wallpaper group of graphene has a point group expansion from (14) in and only.. The first term is the only one in the decomposition with (in general) a nonzero mean value when integrated over the domain; all others vanish identically by anti-symmetry.444In higher dimension, the first term of this decomposition has symmetry , the hyperoctahedral group.
The expansion (14) can be applied in discrete form to the square matrix for each realization555Among the properties of (14) yet to be explored, for a square matrix populated by iid normal entries, the ensemble variances are evidently , as the matrix dimension tends to infinity, with the remainder apportioned in enigmatic proportion between and ., yielding five ensembles; one per group. Each of these ensembles is then characterized by principal component analysis (PCA). This expansion is driven by data (hence Lorenz’s term “empirical orthogonal functions” Lorenz (1956)), rather than pre-selected, as in a generalized harmonic analysis of noise. PCA is designed to decorrelate the signal by projecting the data onto orthogonal axes. Here it decomposes -noise variability in the group representation with modes in order of decreasing contribution to variance (, a quadratic metric) of each ensemble.
For numerical implementation, PCA is evaluated by singular value decomposition (Matlab routine svd). We used an ensemble of realizations populated by iid normal random variables of zero mean and unit variance though the ordinal results depend on neither choice, even from row to row. For -correlated noise, the lowest modes from the PCA decompositions of the resulting group ensembles rapidly approach their limiting forms as a function of , with the highest retained mode determining the needed grid resolution. We aim for well resolved structure, not just meeting the Nyquist limit. As a test of this, spline interpolation of for onto the coarser mesh of for gives a relative standard error for the mismatch of . The singular values (scaled by ) exhibit a similar relative error. The choice of will thus suffice for most applications and so one need not repeatedly compute this etalon for different but rather can rely on interpolation.
When searching for signal in noise, approaches a finite limiting form as . Here there is no signal and hence no structure which attains with increasing . Remarkably then, and quite in contrast with e.g. the temperature data for Lugano, the PCA results for iid noise with the minimum possible choice of are indistinguishable from those for . The reduction to saves CPU time for both generating the random realizations and their initial processing to obtain .
For each symmetry group, the PCA modes have an ordered set of singular values. The collected set of all group PCA modes is then re-sorted by singular value, with the corresponding symmetry group noted for each. In this merged set one encounters repeated mode pairs of symmetry and . In both cases transient nonstationarity is more compactly represented by forming sum and difference modes, i.e. , and similarly for the other pair. There are also unpaired modes of all three symmetries, particularly at higher order. But, of the first twenty modes, only two such exceptions occur: the first and sixth modes, to which we shortly turn.
Results: a universal characterization of transients for noise
Fig. 6(a) shows a set of oriented planforms, indexed as denoting a total of extrema in the direction and in . The case of corresponds to the above two unpaired modes while for we have pairs in the form of a matrix and its companion transpose. This then constitutes our “etalon” against which stochastic processes are to be compared.666The categorization used here breaks down at higher order when further bifurcations cause complex patterns but these are not of practical concern.
-noise variability falls into three main categories: nonstationarity of the sample mean, ; of sample variance, ; and departure from -correlation, described by the autocorrelation function (ACF) for stationary random processes Yaglom (2004). For reasons of symmetry in the rank-order plane, we also consider nonstationarity of (sample) mean rank, . These curves are obtained by conditional sampling in a long Monte Carlo run. Each realization with a mode projection for exceeding the level is captured. The means of the realizations thus isolated, mode-by-mode, are plotted in the matching tableaux of Fig. 6(b). These curves (time series) follow the group selection rules indicated in Table 1.777For simplicity, we have omitted modes for spurious trends in variance of rank, which would symmetrize the table with a complementary entry in the third line.
Tutorial on Fig. 6: Case studies for modes 1 & 6
Although PCA modes for are of little use, each mode can be inverted to discover its antecedent .888The magnitude of is arbitrary when this is done but has an upper bound which, if exceeded, induces negative elements in the resulting . In Fig. 7(c,d) we show the precursors for two modes, and , reproduced here from Fig. 6(a). These examples will demonstrate how separation of transient mean and transient variance arises from “lifting” to the rank-order plane. (Other similar separations are also seen in Fig. 6, e.g. modes and , associated solely with variance.)
The first mode is associated with an approximately linear trend in data, .999, with one inflection point, is not quite linear, hence an exactly linear trend in the data maps onto an expansion in odd modes, though dominated by the first. Note that and curves, each as a set, are not orthogonal, in contrast to the group PCA modes. How can one see this intuitively? Here proves essential. Imagine a realization for which Fig. 7(e) is, by chance, the mean trend. Record lows (and generally lower ranks) are more likely to occur at early times and, conversely, record highs at later times. Such an excess of record lows in the upper (early time) left (lower rank) corner of paints it red, and similarly for the lower right corner, paralleling the construction that lead to Fig. 2. Thus, a linear trend of the mean yields , odd in both its dimensions and corresponding an even/even (consistent with the mixed derivative in (6)). Not only linear, but anti-symmetric, trends lead in general to symmetry of and symmetry of .101010The link of an antisymmetric trend and pure symmetry of applies to stationary processes. (For iid white noise in particular it derives from (B1) perturbed about the vacuum state.) However, for finite SNR acquires lower symmetry components as well, e.g. in Figure 3(c). Nonetheless annulling remains valid. Also, for a measure of nonstationary mean of any form, but which excludes nonstationary variance, one can modify (11) by computing the rms value of the horizontal mean of .
The second mode is paired with a roughly quadratic profile in variance. Again, by appealing to , we can understand this relation by considering a realization with sample mean variance as in Fig. 7(f). Now both record highs and lows are more likely to occur at early and late times, thereby producing the red corner pattern of Fig. 7(d). Further, the over-population of middle ranks at intermediate times also paints the center of red. Then, because of the row and column sum constraints, necessarily all four middle edges must be under-populated (blue). A similar derivative argument applies for parity, and a general statement is that symmetric trends in variance lead to symmetry of and symmetry of .
Returning now to Fig. 6(b), note the consecutive identical pairs of mean rank (red) and mean data (green), that is for and respectively, and so on. Mode pair marks a planform bifurcation from to in lines 3 and 4 of Table 1, with a more subtle relation to and .
The only member of the odd/odd planform category here is , but the notation in Table 1 anticipates presence of a higher planform also of symmetry. Mode 21 from the merged PCA expansion is that planform. The leading four PCA modes of this merged set account for nearly half the total variance while the asymptotic decay rate is 111111The appearance of here suggests that binary decision underlying ranking can play a role. This is reminiscent of in the Landauer principle., in contrast to the “whitish” for raw input or .
Transient trends in (sample) variance are plotted in black. Note how modes of symmetry (6,17,18) are associated with spurious trends in sample variance alone, just as modes of and symmetry are linked to odd order trend of only the sample mean. It is the pairs where odd order variance and even order mean are linked.
The notation reminds one that these modes are zero-mean fluctuations. But ensemble means from conditional sampling are not zero-mean. Rather, the conditionally sampled modes for rank all have mean and similarly the modes for variance have a mean equal to that for a sum of values of a random variable from the particular distribution used, here unity. The negative values in the plots for Fig. 6(b) then are relative to these means. Both rank and variance themselves remain positive definite. For graphical purposes only a single re-scaling was applied to all curves in Fig. 6(b), so their relative magnitudes can be compared directly.
While results based on rank, as for any results from , are distribution-independent, transient dimensional fluctuations in mean and variance refer back to the raw data space and these necessarily reintroduce a dependence on the particular distribution in question. At issue is a constant of proportionality between, say, a given gradient in dimensional variables and the induced change in the dimensionless measure . We treat this for the specific case of Gaussian noise later in Section XI, where we derive an explicit error estimate for -based linear regression. The theoretical framework for making that link is given in Appendix B.
Note that automatically annihilates all modes except those of groups and . The latter group occurs in pairs. Each such mode pair can be rotated back to the original basis by . Only the recovered mode of symmetry then contributes to . The second – in which trends in rank and mean are anti-correlated – vanishes identically in integral.
Anti-correlation is forbidden at lowest order; the only mode present already is of group . Linear trend in rank must hence match trend in the data regardless of the loss of magnitude information. This is not obvious. One can try to construct a companion mode, necessarily of group , with rank and data linearly anti-correlated, e.g. in continuous form but inversion of any such form yields a of singular support, that is a set of measure zero for projections from the space of ranked white noise realizations. The problem is that one needs a form for which vanishes on the boundaries but at the same time satisfies (in the continuous version)
[TABLE]
and this is evidently not possible.
We can now give a precise statement of the meaning of annulling : The initial data yield a nonzero from the sum of projections on modes only (subject to the second rotation noted above).121212From the expansion in (14) for Lugano, accounts for 99.2% of the content of the matrix in Fig. 2(b), the highest fraction for any station observed. Adding a linear trend to the data modifies the contributions, principally from mode 1. The coefficient of that linear term is adjusted until the total sum from all terms vanishes. As explained in the discussion of Figure 7, this procedure is unaffected by nonstationary variance. The invariance of -derived trends of the mean with respect to variance thus holds unconditionally.
This is the crucial difference between least squares and . Least squares fits are strongly affected by non-stationary variance, as shown by our earlier toy model of Figure 3. One has then to resort to empirically determined weights to try to minimize this influence. For heavy-tailed noise however such weights prove ultimately ineffective, as we later document in Section X. No such empirical machinery is needed for .
Note that if the goal is merely to obtain a trend by annulling , then any functional form with nonzero antisymmetric component will also project on the modes and hence determine a unique amplitude for that function. Annulling , that is, does not confer any special status on a linear trend. Rather, that choice resides in the application and the onus is on the user to choose.
A second moment of interest is (where represents the Hadamard product). This selects for only the modes in group with parity , which are raised to and parity , and thus contribute in integral. This is the natural companion measure to detect even signals of nonstationary mean while detects odd.
Note the generality of these results: the response to an actual signal of low SNR results from combining the components in Fig. 6(a) weighted by the expansion coefficients for that signal when expressed in terms of the complete set in 6(b). Hence, whether considering the transient sample mean of a stationary process, or the real mean of a non-stationary one, detects them the same. The key distinction is that, for the case of -noise, the standard deviation for each of these modes is universal and fixed and their means vanish; for a signal, the amplitudes are arbitrary and unknown in advance.
VI Fingerprinting Stochastic Processes
The group PCA decomposition yields the -noise standard deviation for each of the first 20 modes, thus defining benchmarks. Stationary processes other than white noise will deviate in one or more of these measures, just as earlier observed in Section IV with the influence of autocorrelation on the distribution of . Although group PCA components represent apparent non-stationarity, spontaneously arising in a finite sample of a random process, each standard deviation for the parent distribution of individual mode coefficients has an asymptotic expansion of the same general form as (10) and (12). Hence the suite of ratios of such quantities (a “fingerprint”), approaches a well-defined limit as .
The four processes illustrated in Fig. 8 are: the Ornstein-Uhlenbeck (O-U) process with relaxation and (as in Lehle (2011)), the auto-regressive process AR(1) with Priestley (1981); Percival et al. (1993), a model for patchiness consisting of white noise with the standard deviation for each successive group of 13 samples chosen from a uniform distribution on the interval , and a chaotic series generated by the logistic map with .
This group-theoretic signature, consisting of the standard deviation for each mode normalized by the -noise values, is one way to detect and/or classify a specific stationary stochastic process. It is a function of (but not ) just, as in the correlation theory of random processes, the ACF is a function of the number of time lags, . But the fingerprint furnishes information over and above that available from the ACF. Distinct stochastic processes with nearly identical ACFs are shown in Fig. 8: (1) the -correlated (like noise“) patchy” process whose fingerprint oscillates about the -noise standard; (2) the model and the logistic map with distinct fingerprints.
The largest departures from -noise occur for the O-U process, with a long correlation, in contrast to the -correlated patchy process. This fingerprint of O-U can be compared to the approach to stochastic signal detection in Lehle (2011), but with the further development in Scholz et al. (2017), generalized there from a parametric to a non-parametric version based on higher moments of noisy data. Our method is also non-parametric, but deals only with rank and hence serves as a complementary approach to Scholz et al. (2017).
Fingerprints of stochastic processes should be compared at the same (or in the continuous case). As attains a value several times the longest expected correlation, the fingerprint attains its asymptotic limit. For three of the four processes in Fig. 8, is well into that regime. However, the continuous O-U process has a much longer correlation time and, for a step size of , one would need of order to reach that limit. Its fingerprint at , strongly dominated by the (offscale) peak mode 1, is nonetheless a perfectly fair point of comparison with any other stochastic process at the same .131313One case, not shown in Fig. 8, yields no discernible departure from -noise and that is the first billion decimal digits of . This holds for strings of , , , and digits after accounting for ties. Thus, perceives digits of as iid noise, hence the name.
Generality of results
The suppression of apparent linear trends (mode 1) by both the logistic map and AR(1) in Fig. 8 evidently reflects an inhibiting effect of the negative correlation at one time lag in the ACF. But the hallmark of true, rather than apparent sample, non-stationarity is the presence of structure in , as for any deterministic signal, buried in noise or not. This is in contrast to the constant (uniform) ensemble-averaged matrix that obtains for any stationary random process (but see Appendix B.1 for a small caveat which explains the removal of the component of as in Fig. 7, hence the in Fig. 8). Chaotic systems are deterministic and even the logistic map at , commonly thought to be random, has a structured . All chaotic systems exhibit intricate, and unique, ensemble-averaged patterns for . One of the discoveries of this paper is that ranking within randomness differs inherently from ranking in chaos (as well as more orderly deterministic systems) as reflected in rank portraits (analogous to phase portraits), e.g., in Fig. 8).
As a possible application, consider a time series of velocities measured in high Reynolds number, statistically stationary, turbulent flow. It is a standard assumption that the power spectrum of such a flow obeys the Kolmogorov scaling at intermediate wave numbers. Typically, a suitable log-log plot is used to test this and even to deduce small corrections to the power scaling, caused by fine-scale intermittency. Given the inevitable measurement noise, how clearly is this scaling distinguishable from, say, scaling? The latter is mimicked by the Lorenzian power spectrum whose ACF is exponential, i.e., a first order Markov process. This is where one could run the transform, to fingerprint the time series without prejudice, at the “machine learning” stage, before committing to a stochastic process model.
VII An illustration from deterministic chaos: the logistic map
In many physics applications, “noise” is fluctuations in the measurement or observation, e.g., Van der Ziel (1976), while “signal” has suggested deterministic components. Chaos produced, for example, by a nonlinear dynamical system is neither. Following a suggestion by an anonymous reviewer, we digress to test the transform on deterministic chaos generated by the famous “logistic map”
[TABLE]
and show that it compares favorably for detection with the highly regarded “permutation entropy” complexity measure of Bandt and Pompe Bandt and Pompe (2002).
While earlier we relied upon metrics such as rising above a threshold value dictated by the desired confidence level as the means for signal detection, with deterministic chaos the tables are turned. A chaotic trajectory is of course, in a loose sense, “noisy” but the implication for the pdf of is that it is not noisy enough; it fails to span the gamut of values that would be seen with, say, -noise. A general signature of this is that the standard deviation falls below the asymptotic estimate in (10). When this occurs, we conclude that deterministic chaos is present in the time series, either alone or in concert with stochastic noise.
The bifurcation sequence through which a chaotic map is reached at is discussed in, e.g. Cvitanović et al. . We take a time series from (15) with entries, and reconstitute it in matrix form again with the entries stacked vertically. The pdf for as a function of is instructive, as seen in Figures 9 and 10. For , immediately above onset at the pdf is extremely narrow and multi-peaked. These peaks are vestiges of the principal bifurcation branches at lower . But by all such evidence is absent; the pdf is normal with a standard error of . As anticipated, this chaotic data presents with a systematically narrower range of values than found for random noise which, based on (10), would have (the scale factor for the -axis here). But, with increasing , the width grows and, at the end point of , the pdf for coincides exactly with the earlier described “universal distribution” for noise. This general picture needs to be qualified as suggested by filamentary structure in Fig. 9.
The initial transition from a spiked pdf to a normal distribution occurs at , as marked by the vertical line in Fig. 9(a), where upper and lower branch families first meet. As noted by a referee, there is a parallel feature that pairs with this transition in the pdfs for ; below the pdf for itself is singular, above the pdf, still punctuated with singularities, has full support. Yet another representation of this stochastic “phase transition” is the fingerprint of Section VI, which for the logistic map has a discontinuity at .
However there are thereafter discrete departures again from the normal pdf, e.g. those associated with the gaps centered at and . There is a large isolated spike at with the indicated anomalously broad pdf, stemming from an orbit of period seven. It achieves a peak of , i.e., this represents normal signal detection by . Similar features punctuate the curve elsewhere. Each feature in Fig. 9(b) can be linked with associated structure in the logistic map above but the general pattern, again, consists of Gaussian pdfs of increasing standard deviation to the right.
Figures 9 and 10 depict the standard deviation for the distribution of with (10) used as the benchmark for -noise. By continuity, near the terminus at and bracketing the spike at must lie two adjacent values of at which . These are not the loci of -noise, however, as the coincidence with the value from (10) is a necessary, but not a sufficient condition. A practical sufficiency condition is that the pdf itself when also pass the Kolmogorov-Smirnov test for normality. This is true only at , not elsewhere.
The red and green traces in Fig. 9, show the displacement of the curves due to the addition of Gaussian noise of the indicated magnitude. Note the increasingly sharp discontinuity at the , with Gaussian (or smooth) pdfs only minimally disrupted by noise while the singular ones exhibit heightened sensitivity. Furthermore, the inset at top left in Fig. 10 shows two traces: the logistic map for , and the same output with added Gaussian noise of . Even for intense noise, a decrease in SNR of dB relative to the highest noise level used in Bandt and Pompe (2002) – this combination of signal plus noise remains distinguishable from pure noise as indicated by a standard error that expected from (10). Indeed as is a global method, for any in the chaotic range, approaches unity only when the stochastic contribution tends to infinity and so for any finite noise and a sufficiently long record, it is always possible to detect a presence of chaos. Thus, by sensing and transforming rank fluctuations, detects subtle aspects of disorder: the distinction between stochastic noise and deterministic chaos.
VIII A general (nonlinear) regression principle
With we have a general purpose, indeed with the extension in Section XI to general time series, a universal penalty function as an alternative to least square error. To illustrate this we consider the nonlinear parameter estimation problem of fitting two exponential functions. This is well known as an ill-posed problem for a least squares fit. The classical problem in physics for which this model arises is of course radioactive decay. Though we adopt this setting for its familiarity, multiple exponential fits arise in many other arenas, among them the fitting of transmission functions in radiative transfer and dwell time distributions for ion channels in biophysics. Many special-purpose routines have been written for applications of such multiple exponential fits (e.g., see Wiscombe and Evans (1977); Landowne et al. (2013)) and here we consider a representative package, the variable projection method “varpro” Oleary and Rust (2013), and show that outperforms it. But, unlike varpro and other software, e.g. implementation of the Padé-Laplace algorithm Yeramian and Claverie (1987), we change nothing. We minimize no differently than we would in fitting a noisy quadratic curve. There are no parameters to tune, no weights.141414One downside in compared with high order regressions of linear least square problems: the latter is solved by simple matrix inversion. Use of gives a nonlinear minimization problem, though a robust one for all cases we have explored.
Consider a signal of the form
[TABLE]
with and and the observations consist of 50 repeated “measurements” taken at 64 evenly spaced points on the interval . For so short an interval and given relatively close exponents, even the noise-free fitting problem can be challenging. Here we complicate the situation greatly by the addition of Gaussian noise with . As seen in Fig. 11(a), the raw data show only a general exponential decay; there is no immediate indication of two species. Varpro requires seed values for the exponent pair. Conservatively, (to give varpro maximum advantage), in all cases we seed with the exact values. Values for the coefficients and exponents based on proceed very much like the earlier process of detrending. One takes initial values for these, substitutes them into (16) and subtracts the resulting values of from each of the realizations in the data matrix. The of the residual is computed and then minimized by varying the vector of unknown parameters. We used the Nelder-Mead Matlab routine fminsearch for that minimization.
For the result of the single realization in Fig. 11(a), the regression also has been seeded with exact values. While the regression does fit the exact result better, the main point about exponential fits is that the varpro result is a fairly good fit as well. But, where the fit yields reasonably accurate coefficients and exponents, the varpro coefficients are wildly in error, of opposite signs, with a meaningless negative value.
In Fig. 11(b) we see the Gaussian pdfs for the standard error of each -determined exponent both for and also . Each of these is a projection from a four-dimensional pdf. One side effect of that projection is an apparent modest overlap of the two exponents around the value of . If one steps back to the two-dimensional pdf projection that obtains in the plane, near coincidence of values becomes a negligible fraction. The sample mean value of is with a standard deviation of , so near equality occurs only at the 3 sigma level. A final revealing (non-normal) pdf is that plotted with dots for . Here are the values obtained with repeated invocations of the Nelder-Mead routine using random perturbations of the starting seeds about their exact values. One does not obtain a single well-defined minimum, rather there are countless, nearly equal, local minima clustered in a small region leading to a pdf with sample mean of . From a slice through the 4-D volume of , taking in particular the plane, one sees in Fig. 12(a) a finely structured field with numerous overlapping wedge-shaped regions. (Maxima are more easily discerned with this color map so is plotted.) Optimization with this simplex structure needs an appropriate routine, and the Nelder-Mead algorithm proves well suited. In the magnified view (inset at lower right), one can see that, while the algorithm has settled on a simplex vertex that is a local maximum, it missed the better tiny simplex almost directly beneath. These issues are local; all the exponent values for found with the randomly perturbed initial seeds are reasonably accurate, moreover their standard error foreshadows the Monte Carlo simulation with independent realizations of noise. Note that optimization routines customarily allow for user set tolerances. One of these is the function tolerance; how small a change of is realizable. Given that derives from rank, this is a discrete value. The smallest possible change is found by perturbing the center of the matrix with the following matrix:
[TABLE]
This manifestly preserves the row and column sum identities and consists of a rank exchange of one in two adjacent entries. For the model problem here that leads to . Finally, in Fig. 12(b) we compare the varpro and results for the Monte Carlo simulation. The results of the former are so poor that one cannot compare exponent to exponent and coefficient to coefficient. Instead, we adopt a simple gross measure. We let and use to denote the vector with components given by their numerically determined values. We then compute as a measure of the error. The dynamic range is so large that we plot the distribution of the log this quantity. About 5% of the varpro results are slightly better than the single worst result, and can be sensibly associated with the expected values of coefficients and exponents. About 25% of the remainder consist of solutions similar to that listed in Fig. 11(a); two nearly equal exponents and coefficients that satisfy , with . For the remaining 75%, one exponent is about and the second is much larger in magnitude. The latter are evenly split between large positive values with coefficients of order and large negative values with coefficients of order one. All of these results, except the initial 5%, amount to the same conclusion about the data; that there is only a single exponent present.
We have assumed it is known that: (1) exponential decay is the correct model, and (2) two species are present. One could assume a state of complete ignorance, but we think it fair at least to assume exponential decay is understood to be the relevant model. But, one may well not know a priori the number of species. There is, as a reviewer noted, then no basis on which to prefer the Varpro or the result. As they use different metrics, all one can say is that each has minimized what was asked of it. But there is a difference. Varpro, or any other software that relies upon least square error for the penalty function, is incapable of stably fitting more than a single exponent for data with this level of noise. The fit, by contrast, offers a single exponent fit of , and a stable two exponent fit. However, the values of are essentially identical – (one species) and (two species) – so one cannot on that basis prefer one solution over the other. Other evidence is required.
No more is needed for the practical application of in a multitude of other problems. One simply replaces a routine that computes the least square error of a trial regression with one that returns for the trial. Error bounds are desirable in any application, but one cannot give a universal characterization for these, even for least square applications. For a linear trend, one can obtain a general form for the standard error of the slope and this is done for the fit in Section XI.
IX Signal extraction from noisy data without a priori knowledge of signal shape
The opening example in Section II established a surprising result: that rank data, lacking all magnitude information, can nonetheless predict linear trends in noisy data in excellent agreement with slopes found from the traditional (unweighted) least squares. In this section we argue for a far stronger result: the same rank information yields an assumption-free estimate for a general nonlinear signal with relative amplitude information intact.
Inspired by the close correspondence of undulations in the modes and oscillations in the companion , we propose that, up to a linear rescaling, the underlying signal is well approximated by , where the overbar denotes the mean over rank in (i.e., horizontal mean).151515Note a tentative parallel result for signal extraction of nonstationary variance, namely . The need of linear rescaling arises because rank is invariant under .
Evidently it is the differential impact of systematic rank arising from signal juxtaposed against random rank scrambling by the noise that allows for the signal magnitude recovery. But this depends upon a finite signal-to-noise ratio (SNR); the limit of a perfect input signal is singular and the recovered signal in that limit is (counterintuitively) less accurate.
We are indebted to Professor Peter Shearer of UCSD for the raw data from a forthcoming publicationShearer and Buehler , a sample of which is shown in Figure 13. The full set consists of S-wave reflections from the 410- and 660-km mantle discontinuities between 96 and 97 degree epicentral distance. Here , the data are uniformly spaced at s and the authors of Shearer and Buehler use the mean over 1192 traces as the signal proxy. In Figure 14 we compare that signal with the result from with the difference between the two shown in the inset. The two spikes centered at 171 and 255 seconds correspond to reflections at the above noted 410- and 660-km mantle discontinuities respectively. As noted in Shearer and Buehler , the oscillations are part of a signal rather than noise as these do not decrease as , (, # of traces), and the -approach confirms this independently, just as it distinguished chaos from noise in Section VII.
For this comparison, the free linear rescaling of was chosen to match the arithmetic mean most closely. (In a general application without a reference signal, the multiplicative scale can be set by minimizing . Here that dependence is fairly weak with a shallow minimum that gives a similar result.) The new result from shows excellent fidelity with the benchmark: the phase of all the oscillations is spot on, the differences are confined to small changes in peak amplitudes.
As with the initial result for Lugano, where we found a slope from annulling of C over 65 years, nearly identical to the standard LS fit of C per 65 years, so too here we obtain a result nearly identical to one previously found by more conventional methods. The initial message is, we reiterate, that this agreement is achieved based solely on rank information. Just as for Lugano where we expanded the reach of the transform to nonlinear parameter estimation and (in the next section) to data fitting in the presence of heavy tail noise, with results in each case unmatched by conventional methods, so too here we anticipate that signal extraction with offers comparable opportunities.
X performs well in heavy-tailed noise
So far mostly Gaussian white noise has been used but here we examine distributions with heavy tails, where outliers are ubiquitous. In the least square family these are often handled with the bisquare method, which excludes outliers adaptively by assigning them zero weight. However, for distributions with infinite mean and/or variance a more powerful approach is needed. We are grateful to an anonymous reviewer for suggesting a comparison with the Theil-Sen estimator, used exclusively to determine linear trends Balkema and Embrechts (2018). Its potential limitation is computation time for large data sets. For example each trial of data pairs for Table 2 required 20 seconds of CPU time on a 2.5 GHz Intel Core i7 laptop. The full implementation requires fitting slopes to all possible pairs of points, which takes operations. Several theoretical papers have proposed implementations but no public code, so far as we know, is available, although CPU time may not be a practical concern for small to medium scale applications.
In Table 2, the first two cases pose no problem, even for unweighted least squares, though we quote the bisquare result for consistency. The Cauchy distribution is the first point where the bisquare adaptive approach becomes critical; unweighted least squares is not useful. But then even the bisquare method begins to lag in performance for the Pareto distribution and finally is unusable for the generalized extreme value distribution. Both of the latter distributions have infinite mean and variance. By contrast, for Pareto and GEV, Theil-Sen performs admirably as expected. But so does detrending by simply setting , which is as earlier noted already a practical algorithm. While the GEV distribution may seem a far-fetched choice, in fact it arises in applications such as analysis of hydrometeorological data for maximum precipitation events El Adlouni et al. (2007).
One can generalize this problem slightly to the multilinear form, .161616Or, for that matter, . To take a practical example, set and for a grid. For the case of Pareto noise from the fit we obtain and . The bisquare algorithm reports and so, as in Table 2, it is beginning to fray. In contrast, there is no parallel procedure for the Theil-Sen test. There is an unpublished manuscript by Dang et al. Wang et al. for the multilinear case, but it remains an unrealized routine for general application. So, for the multilinear case with GEV noise, neither method offers a result to compare with the fit of and .
Note also about the general multilinear problem that the regression is unusual compared to one’s experience based on the least square formulation. We obtain and individually by setting twice; once for the data matrix in each orientation. This generalizes to a multilinear form in any number of variables with the slight modification that one has first to appropriately permute, and then to reshape, the matrix for each of the coefficients to be determined. This decomposition is possible because is invariant to a constant offset.
XI On the general application of
Although the transform was developed for regularly spaced data such as that in Fig. 1(a), it is flexible in application and here we touch upon the possibilities. For example, uniform spacing of the temperature data by day and year could be replaced by recording daily low temperature when first attained, i.e., by the continuous astronomical Julian date, including the hour, minute, and second. Then the abscissae are irregularly spaced.
A model data set is plotted in Fig. 15(a) consisting of 1500 pairs. The coordinates are generated from a uniform distribution on the interval . The values are given by
[TABLE]
where are noise values from a Cauchy distribution with mean and scale .
We need a data matrix from which to compute and . For this purpose we subdivide the into bins each with points, with . We choose comparable and . From the asymptotic formula at (10), to leading order there is no difference if these are reversed, and the numerics confirm it. But (10) is asymptotic and one cannot approach either extreme (e.g. 1500 bins and 1 experiment, or vice-versa) without a breakdown in the formalism. should be chosen with the Nyquist frequency in mind whenever information about the expected signal is available.
Now we partition the data into the 30 bins; the first bin containing the 50 smallest values of , , up to the last bin with the 50 largest. Each is then paired with its corresponding , so bin #1 now contains 50 pairs, and so on. Finally, we assemble the 50 trials. For experiment 1, take element 1 (), from bin #1, element 1 () from bin #2, etc. Up to the 50th experiment: take the last remaining element from bin #1 () etc.
The resulting data matrix is shown in Fig. 15(b) along with a color scale to show the wide range of values associated with this noise distribution. From one row to the next, the coordinate in a given column is no longer constant (previously the calendar year) but, as each experiment is independent, nothing hinges upon that constancy; each row still represents a linear trend that we attempt here to estimate as a function of the horizontal coordinate. For the purposes of computing and , that horizontal coordinate is the (integer) bin number, while if a specific functional relation (trend) is to be tested, we appeal to the specific for that row and column.
Proceeding to enumeration of we obtain the matrix illustrated in Fig. 15(c). Although noisy, the matrix has a bias, with upper left and lower right overpopulated, indicating a positive trend. The matrix at right confirms this. Here and this can be compared to the noise benchmark at (10) on the assumption that the latter does indeed hold for all distributions. For the present and one obtains and here is well above the noise level; there is a signal. Moreover and the ratio is very close to the ratio of for a pure linear signal with no noise, evaluated at points, indicating that the signal, based on , has nearly the maximum trend possible based on .
We annul exactly as before taking care that, when the trend is computed, matrix entries must be computed individually since columns of the raw data matrix are no longer at fixed . The result is a slope estimate of hence an error of . The result is plotted as a solid line in Fig. 15, the exact result is dashed.
The generalized fits are insensitive to a constant offset and one has to find another tool for that purpose. For heavy-tailed distributions a local method of matching the estimated sample is preferable. On mild assumptions about noise statistics, one expects a fitted line to lie in the dense “middle” of a cloud of sample points. A simple method to estimate that middle is first to subtract the fit and then to count the sample points lying within a sliding window, fixing the intercept as the midpoint of the window location where the convolution peaks. We used the first member of a Slepian sequence Slepian (1978); Thomson (1982) for that window successfully, yielding the intercept for the solid line in Fig. 15(a).
This exercise repeated 1500 times gives an estimate for the mean slope error of , consistent with a limiting value of zero, that is, an unbiased estimator. It also gives an estimate for the standard deviation of the slope of . Note for this latter that
[TABLE]
consistent with the value of reported in Table 2.
Data matrix considerations & error estimates
We have constructed raw data matrices reflecting a variety of origins of noise and signal. The simplest circumstance is -correlated noise, with successive rows representing repeated trials, and convergence to the underlying signal scaling as . Typically would be determined by the expected signal duration or period. In most instances, either or would serve as the metric, and their general asymptotic expansions are as indicated in (10) and (12). Beyond this, from (23) and (24) we have the analytic foundation to demonstrate that for such noise in the absence of signal, the ensemble average is constant and hence vanishes.
Often, however, the noise is stationary but correlated. As shown in Appendix B.1, the ensemble average of is no longer constant and hence the mean is nonzero. But, since the induced has symmetry, the ensemble mean of is still zero. One must still compute the modified standard deviation to set appropriate thresholds for signal detection. While the mean of (10) is altered by the corner effects on , this diagnostic has anyway a nonzero mean in all cases, so Monte Carlo computations will automatically adjust for this correction. Still, in some cases it may make sense to use an altered based on , with its projection removed.
The raw data matrix in the introductory climate example manifests another phenomenon. Here the data was wrapped vertically in the matrix, that is, the end of column 1 then continues on at the top of column 2, and so on. Here not only do we have the vertical correlation whose effects were considered in Section IV but, from the theoretical perspective of Appendix B.1, one would need to model as well the cross-correlation as between columns. All the more must we rely upon numerical evidence. As first noted in Section II, the principal effect of (positive) vertical correlation is a reduction in the effective value of . Extensive numerical simulation further indicates that, in spite of cross-column correlation, the ensemble mean remains constant in the absence of signal provided the columns are long enough, relative to the correlation length, so that row elements are uncorrelated.
A variant of this issue arises if one seeks to extract not the long term, but the seasonal signal. Then the original data matrix for Lugano is turned 90 degrees so it is the end of one row which is correlated with the start of the next. Again the ensemble mean of for pure noise is not constant, and so the ensemble mean of is not zero. While this again represents a potential bias, numerical results suggest the ensemble mean still has symmetry and hence does not affect estimated trends in the mean, only estimated trends in variance.171717For chaos a nonvanishing ensemble mean of is general even with rows of independent trials. The deterministic nature of such processes invalidates a result like (23).
With this preamble, we turn to the practically important question of error analysis in the simplest case of iid noise. As remarked previously, when looking for estimated slope error, one has to restore the link between the rank-order space of and the dimensional space of the raw data. Now the underlying pdf of white noise – Gaussian, Cauchy, etc. affects the slope error. If the noise in (17) is replaced by Gaussian noise with standard deviation then for total sample points, the large limit of the standard deviation of the (unit) slope for an unweighted least squares fit is
[TABLE]
For the present procedure we can appeal to the leading term of (10), which must then be divided by the ensemble average of evaluated at to calibrate the change in the mean value of when perturbed by a signal . It is through this factor that the connection between the particular noise distribution and signal manifests itself, accounting for the variation of the entries in Table 2. In principle this derivative can be computed analytically by taking the mean value of the transform of the Fréchet derivative of (24). Short of that, direct numerical evaluation of that Fréchet derivative for leads to . This can be compared in a test of consistency to a numerical fit from Monte Carlo simulations for varying of
[TABLE]
which gives at . Taking the large limit of (19) and the leading term in (10) then gives the standard deviation of the slope estimate as
[TABLE]
hence LS and fits of slope are, for this Gaussian case, essentially identical. As noted in the introduction, LS is the maximum likelihood estimator for this case hence one cannot improve upon (18). That the constant in (20) is slightly smaller is not however a contradiction. Rather, it reflects a compounding of errors from two delicate estimations for asymptotic constants, namely (19) and (10).
Strictly speaking, (10) only applies for a discrete set of abscissae, not to the larger generalized set of points here. But for the above estimate we need only a leading order result and for that it suffices to use (10) with the abscissae chosen as the column-by-column means.
The procedure above extends readily to fitting an unknown signal by minimizing using an expansion in a basis set of the user’s choosing. One can extend the binning here to higher dimension and then parallel the development of Section VIII. Lastly, one can pursue the second half of the formalism, with , but this is beyond the scope of this paper.
Concluding Remarks
The ordinal nature of the -transform introduced in this paper gives it great versatility, extending to time series with different units and to imaging and rendering it robust with respect to gaps in data. The algorithm is simple, objective, and fast. It performs well in various types of noise, including heavy-tailed.
The unknown signal, whether deterministic or random, is defined by the departure from the “equality of ranks”, that is, uniformity (constancy) of the ensemble-averaged rank population matrix . At a single realization level, the departure is from the ‘salt-and-pepper” (Poisson process). The logic is reminiscent of the first law of thermodynamics: when introducing internal energy, one does not yet know what “heat” is, but understands its absence through heat insulation. Remarkably, this “not noise” definition readily distinguishes deterministic chaos from noise as illustrated on the data produced by the logistic map even in the presence of significant white noise. That same fingerprint which, for some, serves to detect signal can, for others, serve to revise the noise threshold against which some other signal is then judged.
For parameter estimation, even the linear model is on first glance surprising as annulling accurately recovers the slope despite having no magnitude information; only ranks, perturbed by noise. The keys to understanding emerge in the group PCA analysis of Section V and the error analysis of Section XI. With the extension to minimization of , one has then a general alternative for least square error as a penalty function. Success with the canonical nonlinear parameter estimation problem of two-species radioactive decay and excellent performance for heavy-tail noise without need of empirical weights are harbingers of promise for future applications.
Using the transform for nonparametric signal extraction without prior information on signal shape in a blind and distribution-independent manner is documented with the seismological data of Figure 13. The required, heuristic, form is quickly and easily computed. While more theoretical development is needed, exploratory applications will be of great interest.
We hope that the reader will try these ideas as the Matlab code is supplied in supplemental material.
Acknowledgements.
This work was supported by the NSF grant AGS-1639868. We thank anonymous reviewers for suggesting comparison with the Theil-Sen algorithm, and the logistic map and Ornstein-Uhlenbeck process as test cases.
Appendix A Detecting breaks in a time series
Another, more quantitative, prediction follows from (3) by noting that once a linear trend is removed from a data set, the residual is often a double-lobed horizontal structure of alternating sign. This is the signature of a correction to the temperature profile with alternate periods of cooling and warming, but no net trend. Similar bimodal patterns arise in after detrending either a quadratic temperature profile or a piecewise linear version, but with significant differences as shown in Fig. 16.
A simple algebraic representation of for the piecewise case may be taken as a trendless, zero mean, piecewise linear profile in with a node at , multiplied by . Application of (5) then yields
[TABLE]
A typical pattern for (21) is seen at top left in Fig. 17. To the right is the residual after removing the linear trend for station USW00023050 (Albuquerque Int’l Apt, NM). The dashed line is a zero contour of on the left, chosen to coincide with the zero of the horizontal mean of the at the right.
A self-consistent way to achieve a breakpoint is simultaneously to detrend each of , , and as well as possible, while requiring that the trend used for the third be the net slope of left and right segments joined as a continuous function. This imposes a jump condition. Each of the three mean values for is first weighted by to put them on an equal footing and their sum of squares then minimized. The dash-dot line in Fig. 17 shows the optimal result. The continuity constraint yields a jump of C for raw temperatures to the left of the break. We note a similar isolated nearby empirical breakpoint in 1961, with an estimated bias of C to the left, for the monthly mean data for this station in the Berkeley Earth series (#173069). While the coincidence of the bias estimates is striking, the onset date here has to be refined since the deduction based on (22) assumes a piecewise continuous profile. A simple trial confirms that a jump moves earlier.
From (21) follows the exact general result that
[TABLE]
where is the zero line of . It follows then that all zeros of a bimodal must always lie in the middle one-third of the domain. For a timespan of 64 years, that amounts to the middle 21. From a sample of 79 GHCN stations with unbroken temperature records, 40 exhibited an evident bimodal pattern after detrending. In all cases, the zero of the horizontal average of the residual observes this constraint, moreover the relation above then furnishes an objective location for the break point in a piecewise temperature correction, leaving only its amplitude to be determined. For the case illustrated, the zero of is at the beginning of 1976, in accord with the middle-third rule, and the indicated node is hence early in 1966.
Appendix B More on analytic results
B.1 An expression for the ensemble mean of
To gain a deeper understanding of transform properties (e.g., the signal extraction conjecture or normality of the distribution for , discussed in later sections), we note here an exact general result for the ensemble mean of in the case of uncorrelated iid variables with a secular component ( a year index from to ), namely:
[TABLE]
where pdf and cdf are the governing probability density and cumulative distribution functions on the interval with appropriate parameters as needed. Here is the binomial coefficient, is a matrix whose rows contain all possible choices of elements from the set and
[TABLE]
For the useful particular case of Gaussian random component with standard deviation , the element of is given by
[TABLE]
A test of this prediction for a linear against the mean from Monte Carlo trials with realizations gives a residual with rms error that decays as expected, like . The Fréchet derivative of these forms proves a central ingredient in error bounds for linear regression. We return to this point in Section XI, where the transform is broadened to general time series. It would be useful to generalize the equilibrium form (23) to correlated noise but even the uncorrelated Gaussian case in (24) is difficult, e.g., proving that in the absence of any signal is a complex task of integration and combinatorial identities. Moreover as it stands, owing to the factorial growth of terms, (23) and (24) are computationally feasible only out to , smaller than needed in practice. An asymptotic expansion is needed.
B.2 Effects of correlation: end effects on
Even for a stationary random process, correlation introduces a surprise: the ensemble average of is no longer constant. One can see the origin of this by considering a time series of exactly three entries, . If these are iid with the standard normal distribution (zero mean, unit variance), then the joint pdf for this set is given by
[TABLE]
From the symmetry of this form alone it follows that the probability for each variable being the lowest rank is . Numerical experiments suggest this conclusion holds for any iid distribution, a result which may be strengthened by appeal to the argument in Foster and Stuart (1954), which notes that reshuffling records destroys any rank correlation in a time series.
We introduce correlation in the simplest possible fashion. Let , , and where are iid normal variables as above. Now is correlated with , and with , but and are uncorrelated. Now the joint pdf is
[TABLE]
where
[TABLE]
and one sees in the last three forms the correlation relations stated above. And now the computation for lowest rank yields
[TABLE]
and
[TABLE]
with an overshoot at the ends and a low in the middle. The symmetry breaking here is that is correlated with two neighbors, and with only one. For an extended row of this same construction, that symmetry breaking remains confined to the ends. A similar result obtains for the highest rank.
In consequence, for correlated stationary noise, all four corner regions of are affected, while the interior approaches constancy. For progressively larger , the fractional area affected tends to zero and so also then the induced ensemble average of . This effect manifests as a pure contribution to and pure for and so leaves trends completely unaffected. In cases where a variance signal is sought, one could first simulate the noise in a Monte Carlo computation, obtain the ensemble average , and then remove its zero-mean projection on all realizations with variance signal present.
B.3 Analysis for asymptotics of
While a derivation of (10) is challenging, one can approach it with a simplified model developed from a computationally efficient observation about (2). Noting the earlier recasting of , if one is solely interested in , this is obtained by left multiplying on both sides by , a row vector of ones. We can pre-multiply at right, denoting the result as . The result for then obtains in flops and computation is dominated by flops for the sort operation needed for . It is instructive to reconstitute as a matrix, as shown in Fig. 18.181818It is even more instructive to examine the eigenvectors and eigenvalues of reconstituted as a matrix. The sum of the point-wise (Hadamard) product of this field with the noisy data in is the precise content expressed in , and so also then the meaning of setting . Recall that the entries in are correlated Poisson random variables. Specifically, to leading order any element has a correlation of with all other elements in the row and column. For typical values of , this is weak correlation, and so we consider instead a companion matrix populated by uncorrelated Poisson variables with the same parameter, . Half the elements in are positive, the other half are the negatives of these. Accordingly, we partition the contraction into the corresponding contributions. We can use a normal approximation for the sum of uncorrelated Poisson variables with positive definite coefficients. The variance of the resulting normal random variable is
[TABLE]
A second normal random variable from the sum with negative coefficients has exactly the same variance. Consequently, the variance of the final sum of these two is twice the above. (The means of the two are equal and opposite and so the mean of their sum is zero.) The standard deviation then follows directly. The elements could be expressed exactly by reference to (1) but the algebra would be formidable, to say nothing of the sum. But one can anyway observe that depends solely upon save for the overall prefactor of . Here the asymptotic result that follows is
[TABLE]
With less than a two percent change in the leading order coefficient, this result is very close to (10). The main distinction is the absence of a term of order . Such a term cannot arise from the algebra that generates . Rather it stems from the weak correlation of order for the full problem.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Bevington and Robinson (1992) P. R. Bevington and D. K. Robinson, Data reduction and error analysis for the physical sciences (Mc Graw-Hill, New York, 1992).
- 2Kay (1998) Steven M. Kay, Fundamentals of Statistical Signal Processing, Volume II: Detection Theory (Prentice, 1998).
- 3Bandt and Pompe (2002) Christoph Bandt and Bernd Pompe, “Permutation entropy: A natural complexity measure for time series,” Phys. Rev. Lett. 88 , 174102 (2002).
- 4Garland et al. (2018) J. Garland, T. Jones, M. Neuder, V. Morris, J. White, and E. Bradley, “Anomaly detection in paleoclimate records using permutation entropy,” Entropy 20 (2018).
- 5Fischer et al. (2017) Svenja Fischer, Andreas Schumann, and Alexander Schnurr, “Ordinal pattern dependence between hydrological time series,” J. Hydrology 548 , 536 – 551 (2017) . · doi ↗
- 6Helble et al. (2012) Tyler A. Helble, Glenn R. Ierley, Gerald L. D’Spain, Marie A. Roch, and John A. Hildebrand, “A generalized power-law detection algorithm for humpback whale vocalizations,” J. Acoust. Soc. Am. 131 , 2682–2699 (2012).
- 7Lupton (1993) R. Lupton, Statistics in Theory and Practice (Princeton University Press, 1993).
- 8Bardou et al. (2002) François Bardou, Jean-Philippe Bouchaud, Alain Aspect, and Claude Cohen-Tannoudji, Lévy statistics and laser cooling: how rare events bring atoms to rest (Cambridge University Press, 2002).
