Scalable Distributed Subtrajectory Clustering
Panagiotis Tampakis, Nikos Pelekis, Christos Doulkeridis, Yannis, Theodoridis

TL;DR
This paper presents a scalable distributed approach for subtrajectory clustering that dynamically discovers significant patterns in large mobility datasets using MapReduce, improving over existing methods.
Contribution
It introduces a novel distributed framework for subtrajectory clustering that handles dynamic pattern discovery and demonstrates superior scalability and effectiveness.
Findings
Efficiently clusters large-scale mobility data in distributed environments.
Outperforms state-of-the-art subtrajectory clustering algorithms.
Validated on synthetic and real maritime and urban datasets.
Abstract
Trajectory clustering is an important operation of knowledge discovery from mobility data. Especially nowadays, the need for performing advanced analytic operations over massively produced data, such as mobility traces, in efficient and scalable ways is imperative. However, discovering clusters of complete trajectories can overlook significant patterns that exist only for a small portion of their lifespan. In this paper, we address the problem of Distributed Subtrajectory Clustering in an efficient and highly scalable way. The problem is challenging because the subtrajectories to be clustered are not known in advance, but they need to be discovered dynamically based on adjacent subtrajectories in space and time. Towards this objective, we split the original problem to three sub-problems, namely Subtrajectory Join, Trajectory Segmentation and Clustering and Outlier Detection, and deal…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1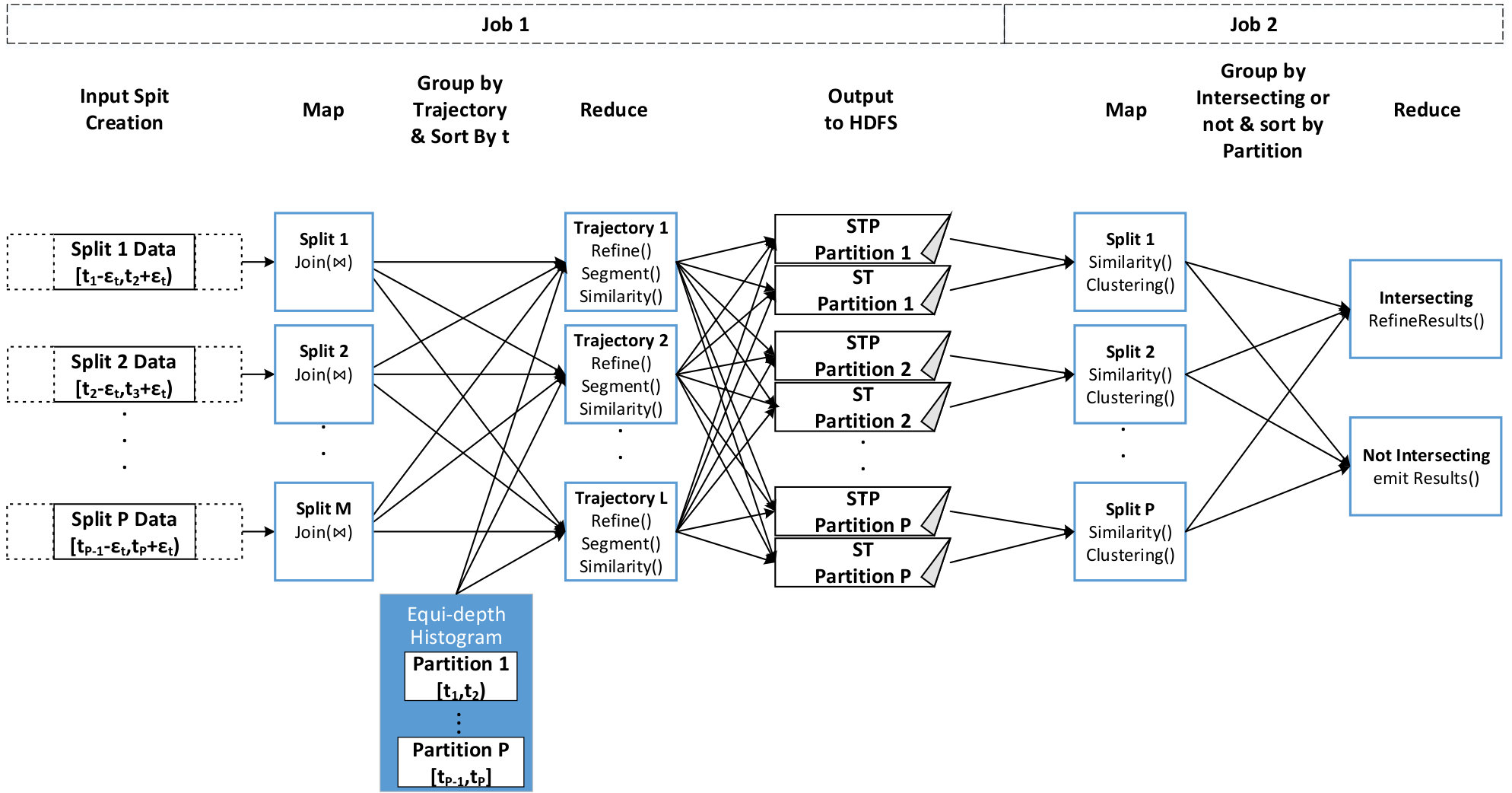 Figure 2
Figure 2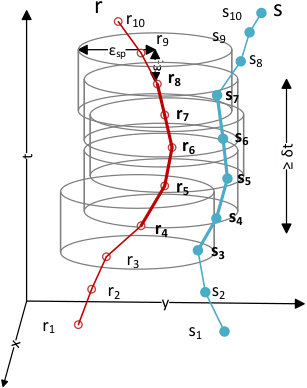 Figure 3
Figure 3 Figure 4
Figure 4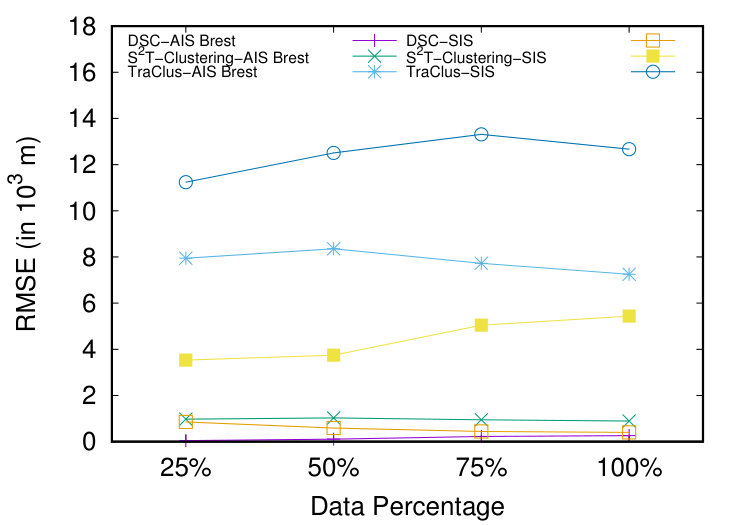 Figure 5
Figure 5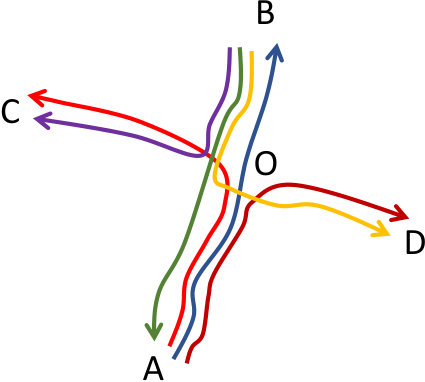 Figure 6
Figure 6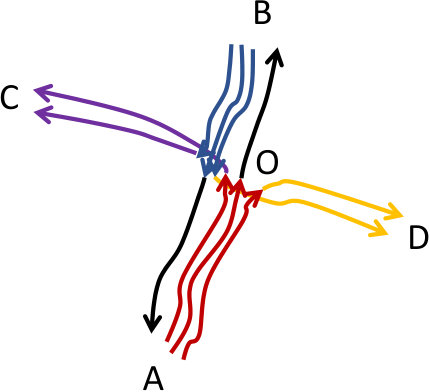 Figure 7
Figure 7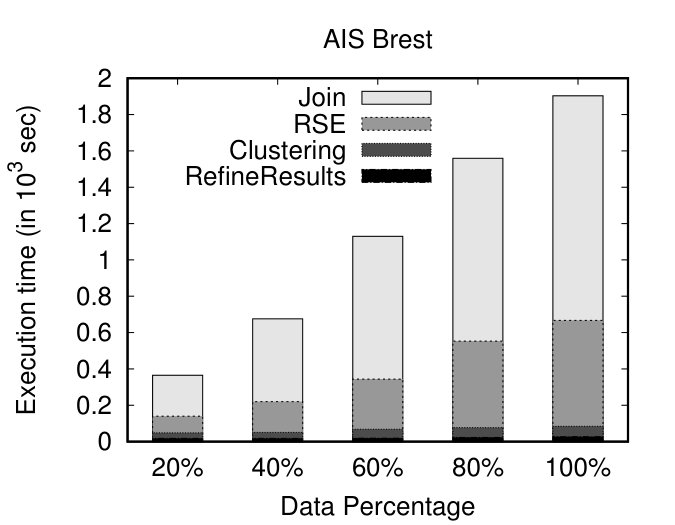 Figure 8
Figure 8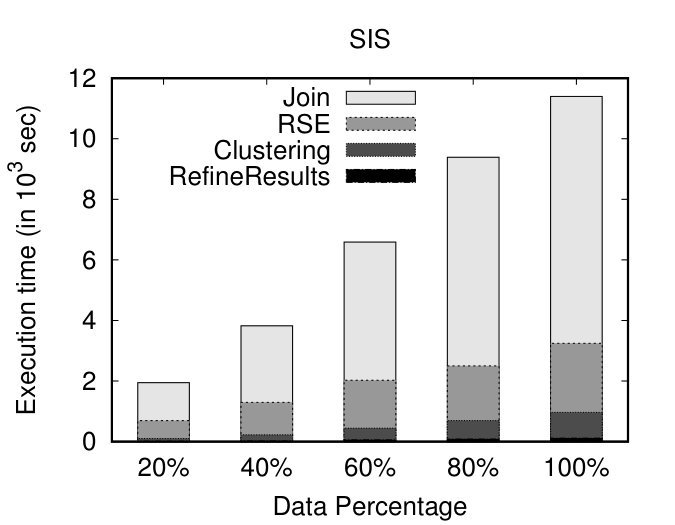 Figure 9
Figure 9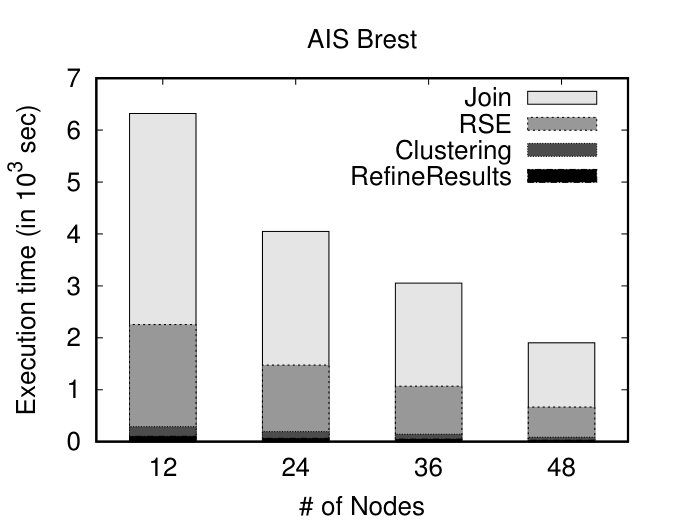 Figure 10
Figure 10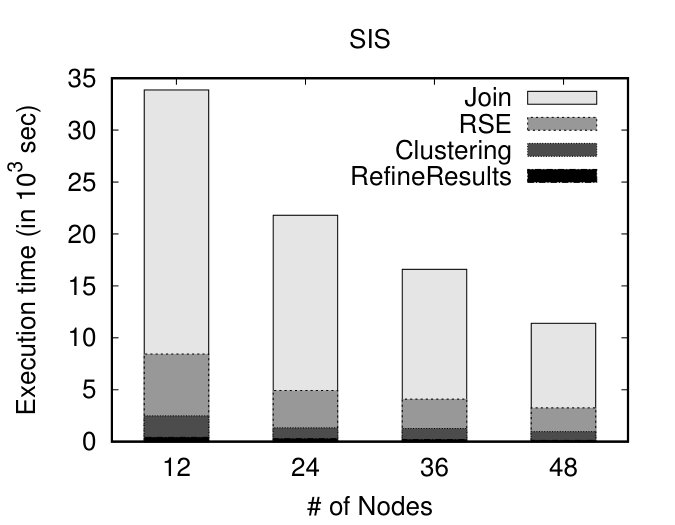 Figure 11
Figure 11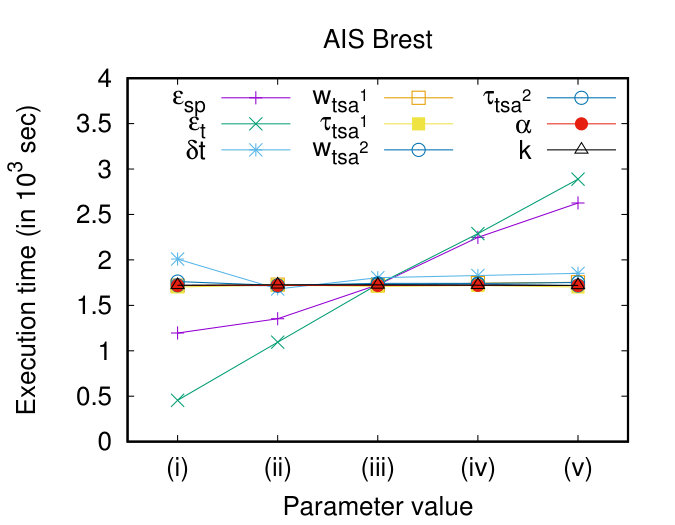 Figure 12
Figure 12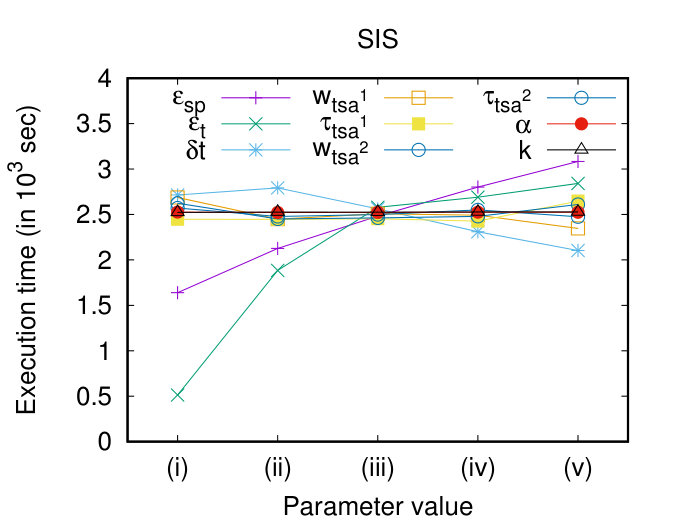 Figure 13
Figure 13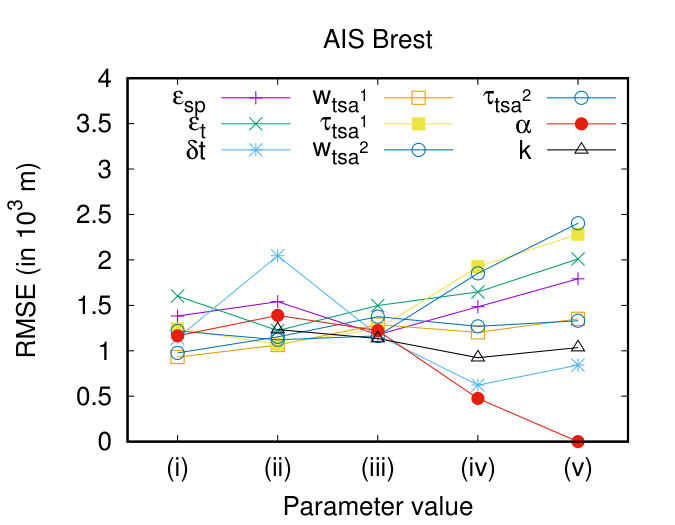 Figure 14
Figure 14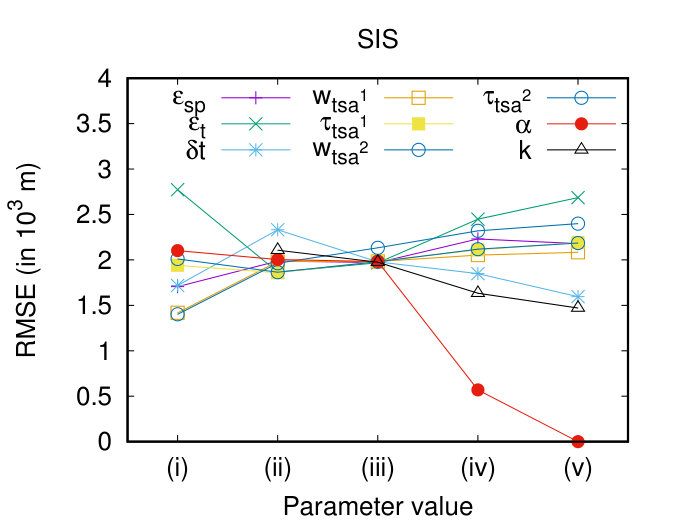 Figure 15
Figure 15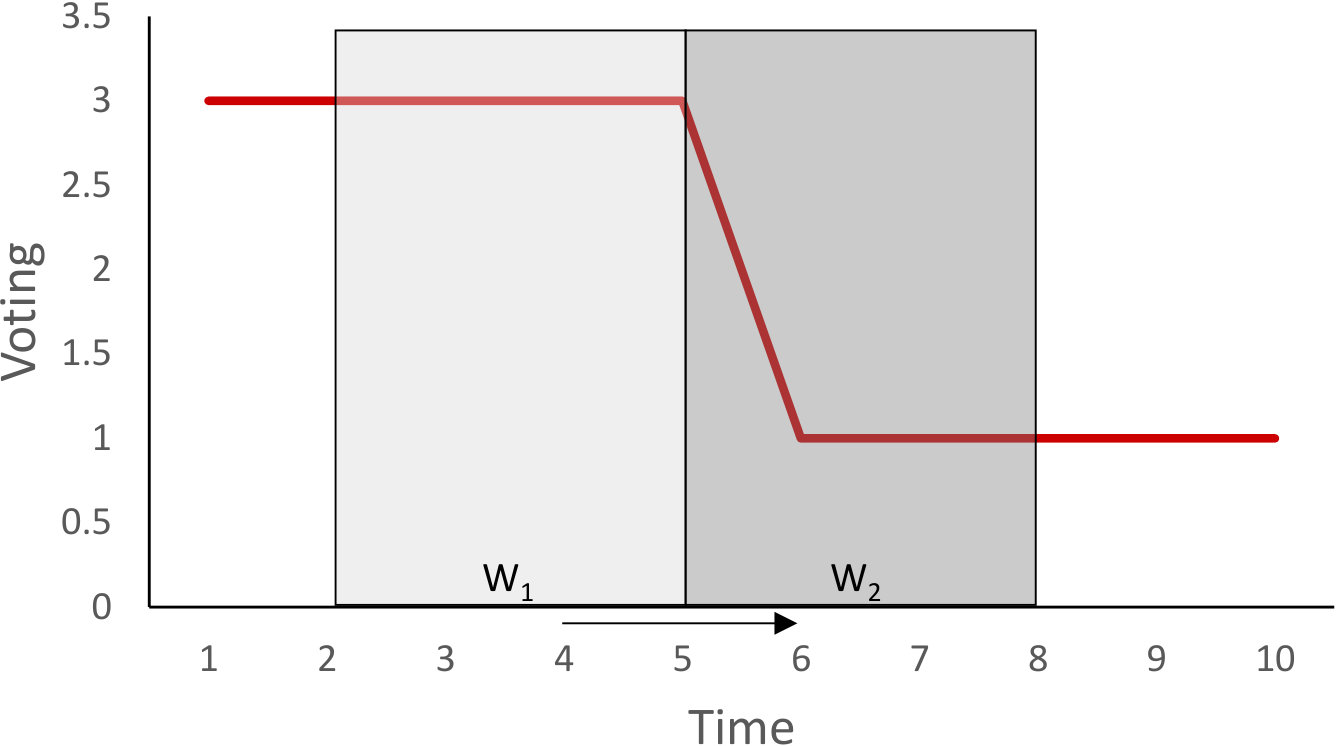 Figure 16
Figure 16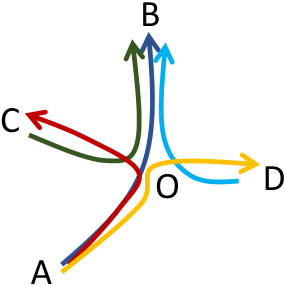 Figure 17
Figure 17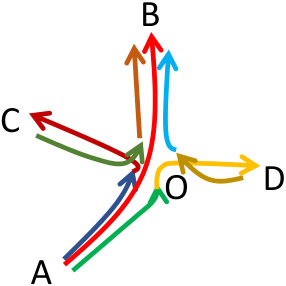 Figure 18
Figure 18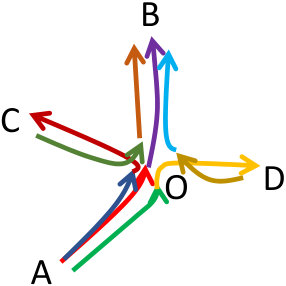 Figure 19
Figure 19| Parameter | Values | ||||
|---|---|---|---|---|---|
| (i) | (ii) | (iii) | (iv) | (v) | |
| (%) | 10% | 15% | 20% | 25% | 30% |
| (%) | 0% | 25% | 50% | 75% | 100% |
| (%) | 0% | 25% | 50% | 75% | 100% |
| 10 | 15 | 20 | 25 | 30 | |
| 0.2 | 0.4 | 0.6 | 0.8 | 1 | |
| (in ) | -2 | -1 | 0 | 1 | 2 |
| (in ) | -2 | -1 | 0 | 1 | 2 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Scalable Distributed Subtrajectory Clustering
Panagiotis Tampakis1, Nikos Pelekis2, Christos Doulkeridis3 and Yannis Theodoridis1
1Department of Informatics
2Department of Statistics & Insurance Science
3Department of of Digital Systems
University of Piraeus
Piraeus, Greece
{ptampak,npelekis,cdoulk,ytheod}@unipi.gr
Abstract
Trajectory clustering is an important operation of knowledge discovery from mobility data. Especially nowadays, the need for performing advanced analytic operations over massively produced data, such as mobility traces, in efficient and scalable ways is imperative. However, discovering clusters of complete trajectories can overlook significant patterns that exist only for a small portion of their lifespan. In this paper, we address the problem of Distributed Subtrajectory Clustering in an efficient and highly scalable way. The problem is challenging because the subtrajectories to be clustered are not known in advance, but they need to be discovered dynamically based on adjacent subtrajectories in space and time. Towards this objective, we split the original problem to three sub-problems, namely Subtrajectory Join, Trajectory Segmentation and Clustering and Outlier Detection, and deal with each one in a distributed fashion by utilizing the MapReduce programming model. The efficiency and the effectiveness of our solution is demonstrated experimentally over a synthetic and two large real datasets from the maritime and urban domains and through comparison with two state of the art subtrajectory clustering algorithms.
K****eywords Mobility data, trajectories, subtrajectory clustering, big mobility data mining, distributed clustering, mapreduce
1 Introduction
Nowadays, the unprecedented rate of trajectory data generation, due to the proliferation of GPS-enabled devices, poses new challenges in terms of storing, querying, analyzing and extracting knowledge from big mobility data. One of these challenges is cluster analysis, which aims at identifying clusters of moving objects (thus, unveil hidden patterns of collective behavior), as well as detecting moving objects that demonstrate abnormal behaviour and can be considered as outliers.
The research so far has focused mainly in methods that aim to identify specific collective behavior patterns among moving objects, such as [8, 7, 6, 15, 11, 10, 24, 27, 5]. However, this kind of approaches operate at specific predefined temporal “snapshots” of the dataset, thus ignoring the route of each moving object between these sampled points. Another line of research, tries to identify patterns that are valid for the entire lifespan of the moving objects [13, 18, 3, 21]. However, discovering clusters of complete trajectories can overlook significant patterns that might exist only for some portions of their lifespan. The following motivating example shows the merits of subtrajectory clustering.
Example 1**.**
(Subtrajectory clustering)* Figure 1(a) illustrates six trajectories moving in the xy-plane, where each one of them has a different origin-destination pair. More specifically, these pairs are , , , , and . These six trajectories have the same starting time and similar speed. A typical trajectory clustering technique would fail to identify any clusters. However, the goal of a subtrajectory clustering method is to identify 4 clusters ( (red), (blue), (purple), (orange)) and 2 outliers ( and (black)), as depicted in Figures 1(b).*
The problem of subtrajectory clustering is shown to be NP-Hard (cf. [1]). In addition, the objects to be clustered are not known beforehand (as in entire-trajectory – from now on – clustering algorithms), but have to be identified through a trajectory segmentation procedure. Efforts that try to deal with this problem in a centralized way do exist. More specifically, an approach that segments the trajectories based on their geometric features, and then clusters them by ignoring the temporal dimension is presented in [9]. Instead, the authors in [20] take into account the temporal dimension, and the segmentation of a trajectory takes place whenever the density of its spatiotemporal “neighborhood” changes significantly. The segmentation phase is followed by a sampling phase, where the most representative subtrajectories are selected and finally the clusters are built “around” these representatives. A similar approach is adopted in [1], where the goal is to identify common portions between trajectories,with respect to some constraints and/or objectives, thus taking into account the “neighborhood” of each trajectory. These common subtrajectories are then clustered and each cluster is represented by a pathlet, which is a point sequence that is not necessarily a subsequence of an actual trajectory.
Unfortunately, applying centralized algorithms for subtrajectory clustering (e.g., [20, 9, 1]) over massive data in a scalable way is far from straightforward. This calls for parallel and distributed algorithms that address the scalability requirements. In this context, one challenge is how to partition the data in such a way so that each node can perform its computation independently, thus minimizing the communication cost between nodes, which is a cost that can turn out to be a serious bottleneck. Another challenge, related to partitioning, is how to achieve load balancing, in order to balance the load fairly between the different nodes. Yet another challenge is to minimize the iterations of data processing, which are typically required in clustering algorithms. Interestingly, there have been some recent efforts towards mining mobility data in a distributed way, such as mining co-movement patterns [5], identifying frequent patterns [21] or adapting already existing distributed solutions to trajectory data [3], yet no approach for distributed subtrajectory clustering exists as of now.
Motivated by these limitations, we study the Distributed Subtrajectory Clustering (DSC) problem, which has not been addressed yet in a scalable and efficient way. Moreover, salient features of our approach include: (a) the discovery of clusters of subtrajectories, instead of whole trajectories, (b) spatio-temporal clustering, instead of spatial only, and (c) support of trajectories with variable sampling rate, length and with temporal displacement.
Our main contributions are the following:
- •
We formally define the problem of Distributed Subtrajectory Clustering, investigate its properties and discuss the main challenges.
- •
We propose two neighborhood-aware trajectory segmentation algorithms, which are tailored to DSC problem, covering different application requirements.
- •
We design an efficient and scalable solution for the problem of Distributed Subtrajectory Clustering.
- •
We perform an extensive experimental study, where the performance and the effectiveness of the proposed algorithms is evaluated by using a synthetic and two large, real trajectory datasets from different domains (urban and maritime). The merits of our solution are demonstrated with respect to two state of the art subtrajectory clustering algorithms, [20] and [9].
The rest of the paper is organized as follows. In Section 2 we provide an overview of the relevant literature. Subsequently, in Section 3 we introduce the DSC problem, in Section 4 we present our proposed solution and in Section 5 we perform a complexity analysis of the algorithms that constitute our solution. Then, in Section 6, we present the results of our experimental study. We conclude the paper in Section 7.
2 Related Work
In recent years, an increased research interest has been observed in knowledge discovery out of mobility data. Towards this direction, several mining methods have been proposed, which can be categorized to co-movement pattern discovery, trajectory clustering, sequential patterns and periodic patterns. In this section, we focus in the first two categories of patterns that are directly related to our work.
Co-movement patterns. One of the first approaches for identifying such collective mobility behavior is the so-called flock pattern [8, 25]. Inspired by this, a less “strict” definition of flocks was proposed in [7] where the notion of a moving cluster was introduced. There are several related works that emerged from the above ideas, like the approaches of convoys [6, 15], swarms [11], platoons [10], traveling companion [24] and gathering pattern [27].
However, all of the aforementioned approaches are centralized and cannot scale to massive datasets. In this direction, the problem of efficient convoy discovery was studied both in centralized [15] and distributed environment by employing the MapReduce programming model [14]. An approach that defines a new generalized mobility pattern is presented in [5]. In more detail, the general co-movement pattern (GCMP), is proposed, which models various co-movement patterns in a unified way and is deployed on a modern distributed platform (i.e., Apache Spark) to tackle the scalability issue. Even though all of these approaches provide explicit definitions of several mined patterns, their main limitation is that they search for specific collective behaviors, defined by respective parameters. Nevertheless, none of the above techniques tackles the subtrajectory clustering problem.
Trajectory clustering. Most of the aforementioned approaches operate at specific predefined temporal “snapshots” of the dataset, thus ignoring the route of each moving object between these “snapshots”. Another line of research, tries to discover groups of either entire or portions of trajectories considering their routes. A typical strategy in dealing with trajectory clustering is to transform trajectories to a multi-dimensional space and then apply well-known clustering algorithms such as OPTICS [2] and DBSCAN [4]. Alternatively, another approach is to define an appropriate similarity function and embed it to an extensible clustering algorithm. In this direction, there are several approaches whose goal is to group whole trajectories, including T-OPTICS [13], that incorporates a trajectory similarity function into the OPTICS [2] algorithm. CenTR-I-FCM [18], a variant of Fuzzy C-means, proposes a specialized similarity function that aims to tackle the inherent uncertainty of trajectory data.
Nevertheless, trajectory clustering is a computationally intensive operation and centralized solutions cannot scale to massive datasets. In this context, [3] introduces a scalable GPU-based trajectory clustering approach which is based on OPTICS [2]. Moreover, [21] attempts to identify frequent movement patterns from the trajectories of moving objects. More specifically, they propose a MapReduce approach by employing quadtree-based hierarchical grid in order to discover complex patterns of different granularity.
Subtrajectory clustering. Nonetheless, discovering clusters of complete trajectories can overlook significant patterns that might exist only for portions of their lifespan. To deal with this, another line of research has emerged, that of Subtrajectory Clustering. The predominant approach here is TraClus [9], a partition-and-group framework for clustering 2D moving objects (i.e. TraClus ignores the time dimension) that enables the discovery of common subtrajectories. The algorithm first partitions trajectories to directed segments (i.e., subtrajectories) whenever the shape of a trajectory changes significantly, by employing the minimum description length (MDL) principle. Subsequently, the resulting subtrajectories are clustered by employing a modified version of the DBSCAN algorithm, which is applicable to directed segments. Finally, for each identified cluster the algorithm calculates a “fictional” representative trajectory that best describes the corresponding cluster.
A more recent approach to the problem of subtrajectory clustering, is S2T-Clustering [20], where the goal is to partition trajectories into subtrajectories and then form groups of similar ones, while, at the same time, separate the ones that fit into no group, called outliers. It consists of two phases: a Neighborhood-aware Trajectory Segmentation (NaTS) phase and a Sampling, Clustering and Outlier (SaCO) detection phase. In NaTS the trajectories are split to subtrajectories by applying a voting and segmentation process that detects homogenized subtrajectories w.r.t. the density of their neighborhood, in contrast with TraClus where the splitting is performed based on the geometric attributes of the trajectories. In SaCO the most representative subtrajectories are selected to serve as the seeds of the clusters, around which the clusters are formed (also, the outliers are isolated). A slightly different approach is presented in QuT-Clustering [19] and [23], where the goal is, given a a temporal period of interest , to efficiently retrieve the clusters and outliers at subtrajectory level, that temporally intersect . In order to achieve this, a hierarchical structure, called ReTraTree (for Representative Trajectory Tree) that effectively indexes a dataset for subtrajectory clustering purposes, is built and utilized.
An alternative viewpoint to the problem of subtrajectory clustering is presented in [1], where the goal is to identify “common” portions between trajectories, w.r.t. some constraints and/or objectives, cluster these “common” subtrajectories and represent each cluster as a pathlet, which is a point sequence that is not necessarily a subsequence of an actual trajectory. A pathlet can be viewed as a portion of a path that is traversed by many trajectories. In order to solve this problem, the authors in [1] prove that this problem is NP-Hard and propose some approximation algorithms with theoretical guarantees, concerning the quality of the solution and the running time. Similarly, in [28] the goal is to identify corridors, which are frequent routes traversed by a significant number of moving objects. As already mentioned, all of the above subtrajectory clustering approaches are centralized and cannot scale to the size of today’s trajectory data.
3 Problem Formulation
Given a set of moving object trajectories, a trajectory is a sequence of timestamped locations . Each represents the -th sampled point, of trajectory , where denotes the length of (i.e. the number of points it consists of). Moreover, denotes the spatial location (2D or 3D) and the time coordinate of point , respectively. A subtrajectory is a sub-sequence of which represents the movement of the object between and where and . Let denote the spatial distance between two points , . In our case we adopted the Euclidean distance, however, other metric distance functions might be applied. Also, let denote the temporal distance, defined as . Furthermore, let symbolize the duration of trajectory (similarly for subtrajectories).
3.1 Similarity between (sub)trajectories
Subtrajectory clustering relies on the use of a similarity function between subtrajectories. Although various similarity measures have been defined in literature, our choice of similarity function is motivated by the following (desired) requirements:
- Variable sampling rate and lack of alignment. We make the realistic assumption that the trajectories do not have a fixed sampling rate and that different trajectories might not report their position at the same timestamp.
- Variable trajectory length. We also assume that different trajectories might have different length (i.e. number of samples). This specification excludes euclidean-based similarity measures which deal with trajectories of equal length.
- Temporal displacement. A property that a desired similarity measure for (sub)trajectory clustering should hold, is to allow trajectories that have some temporal displacement to participate to the same cluster.
- Symmetry. Given a pair of (sub)trajectories and , an appropriate similarity measure between and should have the property of symmetry (i.e. =).
- Efficiency. The computation of the similarity should be efficient enough in order to be able to deal with massive volumes of data, without compromising the quality of the results.
In order to meet with the aforementioned specifications we utilize the Longest Common Subsequence (LCSS) for trajectories, as defined in [26]. However, other trajectory similarity functions, which meet with the specifications set, are also applicable. More specifically, the LCSS utilizes two parameters, the parameter indicating the temporal range wherein the method searches to match a specific point, and the parameter which is a distance threshold to indicate whether two points match or not. Hence, the similarity between two (sub)trajectories and is defined as:
[TABLE]
where is the length of the longest common subsequence. Moreover, it holds that .
However, LCSS returns the length of the longest common subsequence, which means that for a given point that is matched with a specific point the LCSS will consider the similarity between and as 1, regardless of their actual distance , which could vary from 0 to . Put differently, LCSS considers as equally similar all the points that exist within an range from , which is a fact that might compromise the quality of the clustering results. Ideally, given two matching points and , (, respectively) should contribute to , proportionally to the distance . For this reason, we propose a “weighted” LCSS similarity between trajectories, that incorporates the aforementioned distance proportionality. In more detail, for each discovered longest common subsequence the similarity is defined as:
[TABLE]
where is a pair of matched points.
3.2 A Closer Look to the Subtrajectory Clustering Problem
Our approach to subtrajectory clustering splits the problem in three steps. The first step is to retrieve for each trajectory , all the moving objects, with their respective portion of movement, that moved close enough in space and time with , for at least some time duration. Actually, this first step is a well-defined problem in the literature of mobility data management, known as subtrajectory join, and more specifically the case of self-join. In detail, the subtrajectory join will return for each pair of (sub)trajectories, all the common subsequencies that have at least some time duration, which are actually candidates for the longest common subsequence. Formally:
Problem 1**.**
(Subtrajectory Join) Given a temporal tolerance , a spatial threshold and a time duration , retrieve all pairs of subtrajectories such that: (a) for each pair , (b) there exists at least one so that and , and (c) there exist at least one so that and .
Figure 2 illustrates two trajectories and and their respective matching subtrajectories (). Each point of a trajectory defines a spatiotemporal ’neighborhood’ area around it, i.e. a cylinder of radius and height . In order for a pair of subtrajectories to be considered matching, each point of a subtrajectory must have at least one point of the other subtrajectory in its neighborhood, thus making the result symmetrical. Furthermore the duration of the match should be at least .
The second step takes as input the result of the first step, which is actually a trajectory and neighboring trajectories and aims at segmenting each trajectory into a set of subtrajectories. The way that a trajectory is segmented into subtrajectories is neighbourhood-aware, meaning that a trajectory will be segmented every time its neighbourhood changes significantly, so as to result in homogeneous subtrajectories (w.r.t. their surrounding moving objects). Returning to Example 1, trajectory should be segmented to and , since at the cardinality and the composition of its neighbourhood changes significantly. The problem of trajectory segmentation can now be formulated as follows.
Problem 2**.**
(Trajectory Segmentation) Given a trajectory , identify the set of timestamps (cutting points), where the density (or alternatively the composition) of the neighborhood of changes significantly. Then according to , is partitioned to a set of subtrajectories , where is the number of subtrajectories for a given trajectory , such that and .
Given the output of Problem 1, applying a trajectory segmentation algorithm for the trajectories will result in a new set of subtrajectories .
The third step takes as input and the goal is to create clusters (whose cardinality is unknown) of similar subtrajectories and at the same time identify subtrajectories that are significantly dissimilar from the others (outliers). More specifically, let denote the clustering, where is the number of clusters, and for every pair of clusters and , with , it holds that . Now, let us assume that each cluster is represented by one subtrajectory, called Representative, denoted as . Actually, the problem of clustering is to discover clusters of objects such that the intra-cluster similarity is maximized and the inter-cluster similarity is minimized. Therefore, the problem of subtrajectory clustering can be formulated as an optimization problem as follows.
Problem 3**.**
(Subtrajectory Clustering and Outlier Detection) Given a set of subtrajectories , partition into a set of clusters and a set of outliers , where , in such a way so that the Sum of Similarity between Cluster members and cluster Representatives (SSCR) is maximized:
[TABLE]
However, trying to solve Problem 3 by maximizing Equation (3) is not trivial, since the problem to segment trajectories to subtrajectories, select the set of representatives and its cardinality that maximizes Equation (3), has combinatorial complexity.
3.3 Distributed Subtrajectory Clustering
In this paper, we address the challenging problem of subtrajectory clustering in a distributed setting, where the dataset is stored distributed in different nodes, and centralized processing is prohibitively expensive.
Problem 4**.**
(Distributed Subtrajectory Clustering) Given a distributed set of trajectories, , where is the number of partitions of , perform the subtrajectory clustering task in a parallel manner.
Actually, Problem 4 can be broken down to solving Problems 1, 2 and 3 (in that order) in a parallel/distributed way. In the following, we adopt this approach and outline a solution that is based on MapReduce.
4 Problem Solution
4.1 Overview
An overview of our approach is presented in Algorithm 1. Initially, we Repartition the data into equi-sized, temporally-sorted partitions (files), which are going to be used as input for the join algorithm in order to perform the subtrajectory join in a distributed way (line 3). Note that this is actually a preprocessing step that only needs to take place once for each dataset . However, it is essential as it enables load balancing, by addressing the issue of temporal skewness in the input data. Subsequently, for each partition and for each trajectory we discover parts of other trajectories that moved close enough in space an time (line 5). Successively, we group by trajectory in order to perform the subtrajectory join (line 8). At this phase, since our data is already grouped by trajectory, we also perform trajectory segmentation in order to split each trajectory to subtrajectories (line 9). In turn, we utilize the temporal partitions created during the Repartition phase and re-group the data by temporal partition. For each we calculate the similarity between subtrajectories and perform the clustering procedure (line 12). At this point we should mention that if a subtrajectory intersects the borders of two partitions, then it is replicated in both of them. This will result in having duplicate and possibly contradicting results. For this reason, as a final step, we treat this case by utilizing the Refine Results procedure (line 14). Finally, a set of clusters and a set of outliers are produced.
4.2 Distributed Subtrajectory Join
As already mentioned, the first step is to perform the subtrajectory join in a distributed way. For this reason, we exploit the work presented in [22], coined DTJ, which introduces an efficient and highly scalable approach to deal with Problem 1, by means of MapReduce. More specifically, DTJ is comprised of a Repartitioning phase and a Query phase.
The Repartitioning phase is a preprocessing step that takes place only once and it is independent of the actual parameters of the problem, namely , , and . The idea is to construct an equi-depth histogram based on the temporal dimension, where each of the bins contain the same number of points and the borders of each bin correspond to a temporal interval . The histogram is constructed by taking a sample of the input data111In Hadoop, this is achieved using the InputSampler and TotalOrderPartitioner.. Then, the input data is partitioned to processing tasks based on the temporal intervals of the histogram bins. This guarantees temporal locality in each partition, as well as equi-sized partitions, thus balancing the load fairly.
In the Query phase, the actual join processing takes place. It consists of two steps, the Join and the Refine step, which are implemented as a Map and a Reduce function respectively. The output of this MapReduce job is for each trajectory all the moving objects, with their respective portion of movement, that moved close enough in space and time for at least some time duration. In more detail, the output of DTJ is per trajectory and the tuples are of the form , where is the i-th point of the reference trajectory, with and is a list of points of other trajectories that have been identified as join results by the DTJ query. In Figure 3, the DTJ query corresponds to Job 1 until the Refine() procedure.
For more technical details about the algorithms involved in DTJ and an extensive experimental study, we refer to [22].
4.3 Distributed Trajectory Segmentation
The Trajectory Segmentation algorithm (TSA) takes as input a single trajectory, along with information about its neighborhood, and partitions it to a set of subtrajectories. In this paper, we propose two alternative segmentation algorithms.
The first algorithm, coined , identifies the beginning of a new subtrajectory whenever the density of its neighborhood changes significantly. Such a segmentation algorithm is reminiscent of the flock definition [8], where the identified groups need to be composed of at least objects. For this purpose, we use the concept of voting as a measure of density of the surrounding area of a trajectory. For a given point and any trajectory , the voting is defined as:
[TABLE]
where, is the matching point of with , as emitted by the subtrajectory join procedure. For a trajectory that consists of points , we compute its normalized voting vector as follows:
[TABLE]
Finally, the voting of a trajectory (or subtrajectory) is defined as:
[TABLE]
The second segmentation algorithm, coined , identifies the beginning of a new subtrajectory whenever the composition of its neighborhood changes substantially. This segmentation algorithm is reminiscent of the moving cluster definition [7], where the identified groups need to share a sufficient number of common objects. Such an algorithm does not take as input the but instead, for each point , it takes as input a list of the trajectory ids that have been produced as output by the DTJ procedure.
The following example explains intuitively the difference between the two segmentation algorithms.
Example 2**.**
Consider the example of Figure 4(a) that illustrates five trajectories: , , , and . Figures 4(b) and (c) depict the result of and , respectively. In more detail, we can observe that both and segmented trajectory to subtrajectories and , due to the fact that after , both the density and the composition of the neighborhood changes. The same holds for trajectories , and , which are segmented to subtrajectories , , , , and . However, when it comes to trajectory , we can observe that while segments it to subtrajectories and , does not perform any segmentation. This is due to the fact that, after , even though the density of the neighborhood remains the same (i.e. 3 moving objects), the composition of the neighborhood changes completely. In a subsequent step this will drive the clustering algorithm to identify, in the case of a flock-like cluster from to , while in the case of two moving clusters from to and from to .
Both segmentation algorithms share a common methodology, which employs two consecutive sliding windows and of size (i.e. samples) to estimate the point (cutting point) where the “difference” between the two windows is maximized. This methodology has been successfully applied in the past on signal segmentation [17, 16]. To exemplify, let us consider trajectory of Example 2. For simplicity, we assume that the voting of the specific trajectory from to is 3 and from to is 1. Figure 5 illustrates the two sliding windows and that traverse the voting signal of trajectory .
Trajectory segmentation. Since the output of the DTJ algorithm is per trajectory, it is straightforward to give it as input to TSA which operates at the level of a trajectory. Moreover, the segmentation is performed in an embarrassingly parallel way, due to the fact that each trajectory can be processed by a different reduce task independently from others, as depicted in Figure 3. In more detail, for a given trajectory , first calculates the normalized voting vector and then performs the segmentation by utilizing it. Apart from , the input of the TSA algorithm is two additional parameters: and . The output is a vector , which keeps the starting position of each subtrajectory of .
In more detail, as presented in Algorithm 2, two consecutive sliding windows of size are created over , named and (line 4). These sliding windows move forward in time until is traversed. Here, is the number of points of trajectory . Then, for each window, the average normalized voting is computed (lines 5-6) and their absolute difference is stored in , which is an array that stores all the differences between the sliding windows (line 7). Subsequently, we examine whether the current difference is larger than the maximum difference and we update accordingly (line 8). Finally, if the difference is higher than a threshold and is locally maximized, then, at that point, we segment the trajectory and we store the starting position of the new subtrajectory to (lines 9-10).
On the other hand, the input of is a list of lists for each . Similarly, two consecutive sliding windows and of size are created (line 4). Then, for each window, the union of lists is computed and stored in and , respectively (lines 5-6). Successively, the Jaccard dissimilarity between and is computed and is stored to , which is an array that stores all the similarities between the sliding windows (line 7). From then on, the algorithm is identical to .
Similar subtrajectories. After trajectory segmentation, the next step is to calculate the similarity between all the pairs of subtrajectories, using Equation 2. This cannot be done completely after the segmentation at the Reducer phase of Job 1, illustrated in Figure 3, because at that point each reduce function has information only about the segmentation of the reference trajectory to subtrajectories. For this reason, at this point we cannot calculate the denominator of Equation 2. However, for each subtrajectory , where is the reference trajectory, we can calculate the similarity between the matching points (enumerator of Equation 2).
In more detail the output of each reduce function (Job 1 Figure 3) is a relation, called STP, which holds a set of key-value pairs of the form , where are the temporal first and last point, respectively, of trajectory that “matches” with subtrajectory . Moreover, in a separate relation, coined ST, we hold some extra information for each subtrajectory. More specifically, the tuples of are key-value pairs, where the key is the subtrajectory identifier and the value is of the form , where () is the starting time (ending time, respectively) of the subtrajectory, is the voting and is the number of points which constitute the specific subtrajectory. Due to the fact that these two relations can be pretty large, we need to partition them into smaller files. In order to achieve this, we broadcast the load balanced temporal partitions that were created during the Repartitioning phase of DTJ. As illustrated in Figure 3, each reducer loads these partitions and assigns each subtrajectory (tuple of ST and STP) to all the partitions with which it temporally intersects. Subsequently, the tuples are grouped by temporal partition and each group is fed to a Mapper.
At this point, each Mapper has now all the information needed to calculate the similarity between all the pairs of subtrajectories (Equation 2), for each temporal partition separately. The similarity between subtrajectories is output in a new relation, called SP. Each tuple of this relation holds information about a subtrajectory and its similarity with all the other subtrajectories, whenever this similarity is larger than zero. More specifically, SP contains a set of key-value pairs where the key is the ID of the subtrajectory and the value is a list containing elements of the form , where is a subtrajectory for which it holds that .
4.4 Distributed Clustering
Clustering. After having calculated the similarity between all pairs of subtrajectories for each temporal partition, we can proceed to the actual clustering and outlier detection procedure. The output of the similarity calculation process, namely , is actually an adjacency list. The intuition behind the proposed solution to Problem 3 is to select as cluster representatives, highly voted subtrajectories (Equation 6) that are not similar with the already selected representatives . Then, we assign each subtrajectory to the (and hence ) with which it has the maximum similarity .
The input of the clustering algorithm is , and parameters and and the output is the set of clusters and the set of outliers . More specifically, is a threshold for setting a lower bound on the voting of a representative. This prevents the algorithm from identifying clusters with small support. Parameter is a similarity threshold used to assign subtrajectories to cluster representatives. It ensures that a subtrajectory assigned to a cluster has sufficient similarity with the representative of the cluster. This actually poses a lower bound to the average distance between the representatives and the cluster members and, consequently, guarantees a minimum quality in the identified clusters (intra-cluster distance).
Lemma 1**.**
The average distance , between a representative subtrajectory and a cluster member will always be at most .
[TABLE]
To begin with, we want to traverse the subtrajectories by their voting, in descending order (i.e. highly voted subtrajectories first). In order to achieve this, we need to sort by (line 3). Subsequently, for each subtrajectory we examine whether it is already assigned to cluster (line 5). If is not assigned to any cluster and the voting of is less than , then we add to the outliers set (line 21). Otherwise, we create a new cluster and consider as the representative (lines 6-7). Successively, we consult relation and retrieve the adjacency list of (line 8). Then, for each element that belongs to the adjacency list of , we examine if it is assigned to any cluster. If not, we investigate whether the similarity between and is greater or equal than the similarity threshold . If not, we add to the outlier set , otherwise we assign it to the cluster led by and remove it from the outliers , in case (lines 9-13). If is assigned to a cluster, we examine whether the similarity of with is greater than the similarity with the representative of the cluster that is currently assigned. If this is the case, then we remove from the current cluster and assign it to the cluster led by (lines 17-19). Finally, we concatenate with (line 22) so as to return, except from the outlier set , both cluster members and representatives.
Refinement of Results. At this point we successfully accomplished to deal with Problem 3 for each temporal partition. However, this might result in having duplicates due to the fact that each subtrajectory that temporally intersects multiple partitions is replicated to each one of them. The actual problem that lies here is not the duplicate elimination problem itself but the fact that the result for such a subtrajectory might be contradicting in different partitions. In more detail, for each partition, the clustering procedure will decide whether a subtrajectory is a Representative (), a Cluster Member () or an Outlier (). Hence, for each intersecting subtrajectory and for each pair of consecutive partitions with which intersects, can have the following pairs of states: (a) -, (b) -, (c) -, (d) - (-), (e) - (-) and (f) - (-).
In order to implement the above procedure we need to have all the information concerning the intersecting subtrajectories ( and ) for all the Partitions sorted in time. To do this, we group the trajectories according to whether they are intersecting or not. As illustrated in Figure 3, the non-intersecting are emitted, since they are not affected, while the intersecting subtrajectories get sorted by partition. Hence, a Reducer will receive all the required information to make the appropriate decisions. In more detail, we sweep through the temporal dimension and for each pair of consecutive partitions we make the appropriate decisions.
For each of the above cases, as depicted in Algorithm 5, a decision has to be made, in order to eliminate duplicates and provide the correct result according to the problem definition. More specifically, in case of (a), is marked as outlier in both partitions, hence, we only need to eliminate duplicates. In case of (b), the two clusters are “merged”, since all of the subtrajectories that belong to them are similar “enough” with , which is the representative of both clusters. In case of (c), let us assume that belongs to cluster in Partition and in Partition . Then, is assigned to the cluster with which it has the largest similarity with its representative. In case of (d), remains to be a cluster representative and is removed from the cluster in which it is a member. Finally, in case of (e) and (f), is removed from .
5 Complexity Analysis
The purpose of this section is to analyse and provide insight to the complexity of the different algorithms that are involved to the solution to the Distributed Subtrajectory Clustering problem, presented in this paper.
DTJ: The complexity of the Join algorithm is roughly , with being the average number of points per spatial index partition and . The complexity of the Refine algorithm is , where is the average number of points per trajectory, is the average number of points contained in a window, the average number of points contained in a window and is average the size of the list. For more details about the complexity of the algorithms involved in DTJ please refer to [22].
Segmentation: The complexity of the algorithm is , where is average the size of the “matching” list and is the average number of points per trajectory. The reason that we include to this analysis is that in order to perform , we first need to calculate the normalized voting vector. The complexity of the algorithm is also , since and are already sorted by trajectory id and the list intersection can take place in linear time to the size of the lists.
Clustering: The complexity of algorithm is , with being the number of subtrajectories, the average size of the adjacency list and is the sorting cost. Here, we should mention that . Furthermore, and are implemented as HashMaps, hence key search has an time complexity. The complexity of the algorithm is , where is the number of temporal partitions, is the average number of intersecting subtrajectories per partition and is the average size of the intersection. We should mention, here, that the intersection between two consecutive partitions is performed in linear time by utilizing HashSets sets.
6 Experimental Study
In this section, we present the findings of our experimental evaluation. The experiments were conducted in a 49 node Hadoop 2.7.2 cluster, provided by * okeanos*222IAAS service for the Greek Research and Academic Community https://okeanos.grnet.gr/home/. The master node consists of 8 CPU cores, 8 GB of RAM and 60 GB of HDD while each slave node is comprised of 4 CPU cores, 4 GB of RAM and 60 GB of HDD. Our configuration enables each slave node to launch 4 containers, thus up to 192 tasks (Map or Reduce) can be launched simultaneously. For our experimental study, we employed two real datasets that will assist us to evaluate the performance, scalability and effectiveness of our solution. Furthermore, we utilized a synthetic dataset that simulates the case of Figure 1 in order to verify that our solution operates as anticipated, given a dataset with a known ground truth. The real datasets are from two different domains, namely the urban and the maritime domain. In more detail, the first one, named SIS333This private dataset was kindly provided by Gruppo Sistematica SpA, is a 27GB proprietary insurance dataset of moving objects around Rome and Tuscany area, that contains approximately trajectories that correspond to points. The second one, coined Brest444https://zenodo.org/record/1167595#.XKHTyaRRVPa, is a 650MB publicly available AIS dataset of vessels moving in the wider Brest area, consisting approximately of trajectories that correspond points.
Our experimental methodology is as follows: Initially, in Section 6.2 we verify the correctness of our solution by applying it to a dataset with a known ground truth and compare our findings with T-OPTICS [13], a well-known entire trajectory clustering technique. Moreover, we compare our solution with TraClus [9] and S2T-Clustering [20], two state of the art subtrajectory clustering methods. Subsequently, in Section 6.3, we study the scalability of our solution by varying (a) the dataset size, and (b) the number of cluster nodes. Finally, in Section 6.4, we perform a sensitivity analysis in order to evaluate the effect of setting different values to the parameters of our solution, in terms of execution time and quality. Table 1 shows the experimental setting, where we vary the following parameters: , , , , , and and measure their effect in the performance and the effectiveness of our algorithms. We should mention that the default segmentation algorithm in our experimental study is .
6.1 Parameter Setting
Setting the different parameters for different datasets can turn out to be an arbitrary procedure, which, in turn, can jeopardise the quality of the clustering results. For this reason, we provide some simple rules for setting the parameters relatively to the dataset being clustered, that do not compromise the quality of the results. In more detail, can be set as a percentage of the dataset diameter. This, however, can be problematic when dealing with datasets having large spatial variation in their density (e.g. ports in the maritime domain). For this reason, we utilized the partitioning provided by the spatial index (QuadTree) of DTJ and calculated for each point, as a percentage of the diameter of the cell of the QuadTree to which it belongs. Moreover, and are calculated relatively to the average duration between two consecutive trajectory samples ( 1200 sec for SIS and 950 sec for AIS Brest).
Parameter sets the size of the windows and upon which some measure is calculated. Small values on can affect the robustness of the estimation, thus resulting to over-segmentation. On the other hand, large values of can result to overlooking some cutting points due to the large window size. It has been observed that for the robustness of the estimation is not affected and the size of the window is small enough so as not to overlook any cutting points. Concerning parameter , our experiments show that the best result in terms of quality is achieved for Finally, the values of and can be set “around” the mean value of the similarity and the voting of the temporal partition, respectively, in terms of standard deviation. In fact, it has been observed that the average similarity and voting can produce clustering results of good quality. For more details about the effect, in terms of quality, of setting different values to the parameters of our solution, please refer to Section 6.4
6.2 Comparison with related work
Initially, so as to verify that our solution operates as expected, we utilize a synthetic dataset555The original dataset was found in [12] that simulates the case of Figure 1. The only difference is that the two outliers mentioned there ( and ), will now form clusters. Hence, the ground truth for the synthetic cluster becomes , , , , and .
In fact, as depicted in Figure 6(a), T-OPTICS identifies the six original routes: (in red), (in blue), (in orange), (in yellow), (in light blue) and (in purple). On the other hand, DSC identifies, with and -, the six expected clusters of subtrajectories: (in red), (in yellow), (in blue), (in light blue), (in purple) and (in green).
Subsequently, we compare DSC with two state of the art subtrajectory clustering algorithms, S2T-Clustering and TraClus. The metric that we employ in order to evaluate the quality of the outcome of the clustering procedure is the well-known RMSE metric, which is actually a measure of intra-cluster distance between the representatives and the cluster members. Hence the larger the RMSE, the lower the intra-cluster distance and consequently the quality of the clustering. It is obvious that, under this definition, RMSE is equivalent to SSRC (Equation 3). In order to perform this experiment, we utilized the 20% of each dataset which was further partitioned in 4 portions (25%, 50%, 75%, 100%). This choice was necessary because the centralized implementations of S2T-Clustering and TraClus could not scale with the full size of the datasets that we utilized.
As illustrated in Figure 7, DSC outperforms, in terms of RMSE, both TraClus and S2T-Clustering. In more detail, TraClus presents the largest RMSE which is somehow anticipated, since the specific algorithm utilizes a density-based approach to cluster subtrajectories, which in turn, through cluster expansion, can lead to spatially extended clusters. On the other hand, S2T-Clustering presents smaller RMSE than TraClus, due to the fact that it adopts a distance-based approach and discovers more compact clusters. However, DSC results in smaller RMSE than S2T-Clustering, mostly due to the fact that in the latter, two trajectories might end-up in the same cluster even if they have small “matching portions”. However, in DSC this “matching portions” should have a minimum () duration.
6.3 Performance and Scalability
Initially, we vary the size of our datasets and measure the execution time of our algorithms. We show the impact of the individual steps: Join, RSE, Clustering and RefineResult using stacked bars. To study the effect of dataset size, we created 4 portions (20%, 40%, 60%, 80%) of the original datasets. RSE stands for the Refine and Segmentation procedure (Figure 3, Job 1, Reduce phase). As illustrated in Figures 8(a) and (b), as the size of the dataset increases, DSC appears to scale linearly. Subsequently, we keep the size of the datasets fixed (at 100%) and vary the number of nodes. As the number of nodes increases and the dataset size remains the same, it is expected that the execution time will decrease. Indeed, as depicted in Figures 8(c) and (d), as the number of nodes increases, DSC presents linear speedup. This linear behaviour, is somehow anticipated due to the fact that the DSC approach is dominated by DTJ, in terms of execution time, which presents linear speedup, as shown in [22].
Investigating further the performance of the different steps of our proposal, we can observe that, as expected, the execution time of the whole procedure is dominated by the Join step (Figure 3, Job 1, Map phase), followed by RSE. Finally, as anticipated, the Clustering and the RefineResults step (Figure 3, Job 2) present very good performance, since the computationally intensive part of the similarity matrix calculation has already been done as part of the previous steps.
6.4 Sensitivity Analysis
In this section, we perform a sensitivity analysis of all the involved parameters. More specifically, we vary each parameter presented in Table 1, while keeping the rest of them in their default value (bold), and we measure their effect in the execution time and the quality of the clustering results, in terms of RMSE. Figures 9(a) and (b) show that the parameters that appear to have a significant impact on execution time are and . This is justified from the fact that these parameters actually affect significantly the complexity of the Join step (Figure 3, Job 1, Map phase), which is the dominant cost of DSC. Another parameter that seems to have a perceivable effect on the execution time, is , which in fact “filters” the results of DTJ, thus fewer data reach the next steps.
Regarding the quality of the clustering results, as illustrated in Figure 9(c) and (d), all the parameters seem to have an effect over it. In more detail, the larger the values of and , the larger the RMSE. This behaviour is expected since we allow objects that are further away from a representative to participate to the same cluster. In contrast, as increases, the RMSE decreases, which is also anticipated since it sets a lower bound to the longest common subsequence. Furthermore, all the parameters that control the segmentation have the same effect on the RMSE, i.e. the smaller (in length) the subtrajectories, the smaller the RMSE. This shows that breaking trajectories to subtrajectories has a positive effect on the quality of the clustering and justifies the motivation of our work. Moreover, as increases the RMSE decreases, since for small values of , less similar objects are allowed to participate in a cluster. Finally, the larger the the smaller the RMSE, since it disallows the identification of clusters with small support.
7 Conclusions
In this paper, we addressed the problem of Distributed Subtrajectory Clustering by building upon a scalable subtrajectory join query operator in order to tackle the problem in an efficient manner. Subsequently, we proposed two alternative trajectory segmentation algorithms. Finally, we proposed a distributed clustering algorithm where the clusters are identified in a parallel manner and get refined as a final step. Our experimental study was performed on a synthetic and two large real datasets of trajectories from the urban and the maritime domain. As for future work, we plan to extend our solution with properties of density-based clustering algorithms. Furthermore, since our algorithm employs a single pass from the data we will investigate the possibility of addressing the same problem in a streaming environment.
8 Acknowledgements
This work was partially supported by projects datACRON (grant agreement No 687591), Track&Know (grant agreement No 780754) and MASTER (Marie Sklowdoska-Curie agreement N. 777695), which have received funding from the EU Horizon 2020 R&I Programme.
Appendix A Appendix
Proof of Lemma 1
Proof.
[TABLE]
∎
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] P. K. Agarwal, K. Fox, K. Munagala, A. Nath, J. Pan, and E. Taylor. Subtrajectory clustering: Models and algorithms. In PODS , pages 75–87, 2018.
- 2[2] M. Ankerst, M. M. Breunig, H. Kriegel, and J. Sander. OPTICS: ordering points to identify the clustering structure. In SIGMOD , pages 49–60, 1999.
- 3[3] Z. Deng, Y. Hu, M. Zhu, X. Huang, and B. Du. A scalable and fast OPTICS for clustering trajectory big data. Cluster Computing , 18(2):549–562, 2015.
- 4[4] M. Ester, H. Kriegel, J. Sander, and X. Xu. A density-based algorithm for discovering clusters in large spatial databases with noise. In KDD , pages 226–231, 1996.
- 5[5] Q. Fan, D. Zhang, H. Wu, and K. Tan. A general and parallel platform for mining co-movement patterns over large-scale trajectories. PVLDB , 10(4):313–324, 2016.
- 6[6] H. Jeung, M. L. Yiu, X. Zhou, C. S. Jensen, and H. T. Shen. Discovery of convoys in trajectory databases. PVLDB , 1(1):1068–1080, 2008.
- 7[7] P. Kalnis, N. Mamoulis, and S. Bakiras. On discovering moving clusters in spatio-temporal data. In SSTD , pages 364–381, 2005.
- 8[8] P. Laube, S. Imfeld, and R. Weibel. Discovering relative motion patterns in groups of moving point objects. IJGIS , 19(6):639–668, 2005.