Context-aware Embedding for Targeted Aspect-based Sentiment Analysis
Bin Liang, Jiachen Du, Ruifeng Xu, Binyang Li, Hejiao Huang

TL;DR
This paper introduces a novel embedding refinement method for targeted aspect-based sentiment analysis that enhances context-dependent representations of targets and aspects, leading to improved performance.
Contribution
It proposes a sparse coefficient-based embedding refinement technique specifically designed for TABSA, addressing the limitations of context-independent embeddings.
Findings
Achieved state-of-the-art results on two benchmark datasets.
Demonstrated significant performance improvements over existing methods.
Validated the effectiveness of context-aware embedding refinement.
Abstract
Attention-based neural models were employed to detect the different aspects and sentiment polarities of the same target in targeted aspect-based sentiment analysis (TABSA). However, existing methods do not specifically pre-train reasonable embeddings for targets and aspects in TABSA. This may result in targets or aspects having the same vector representations in different contexts and losing the context-dependent information. To address this problem, we propose a novel method to refine the embeddings of targets and aspects. Such pivotal embedding refinement utilizes a sparse coefficient vector to adjust the embeddings of target and aspect from the context. Hence the embeddings of targets and aspects can be refined from the highly correlative words instead of using context-independent or randomly initialized vectors. Experiment results on two benchmark datasets show that our approach…
Click any figure to enlarge with its caption.
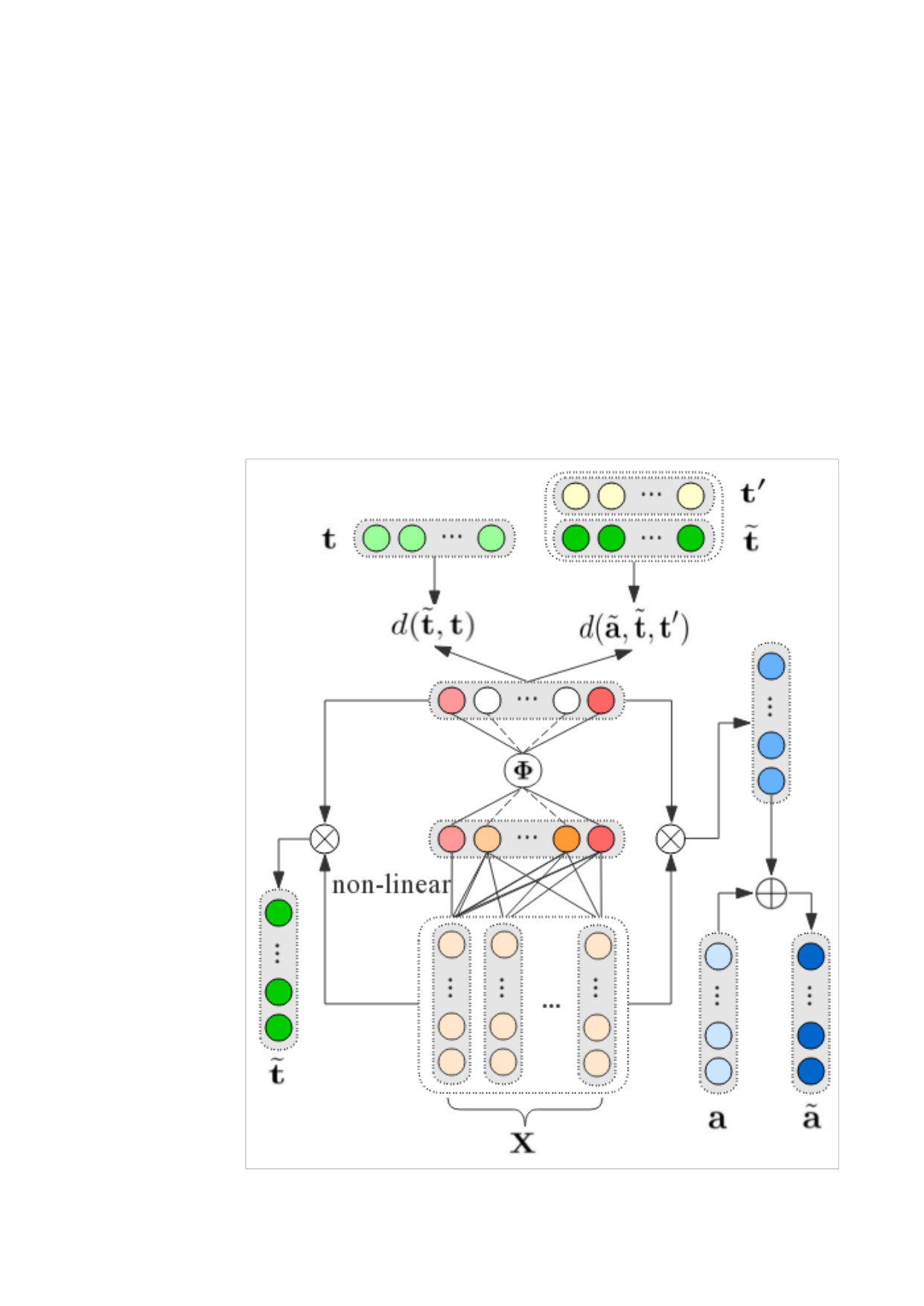 Figure 2
Figure 2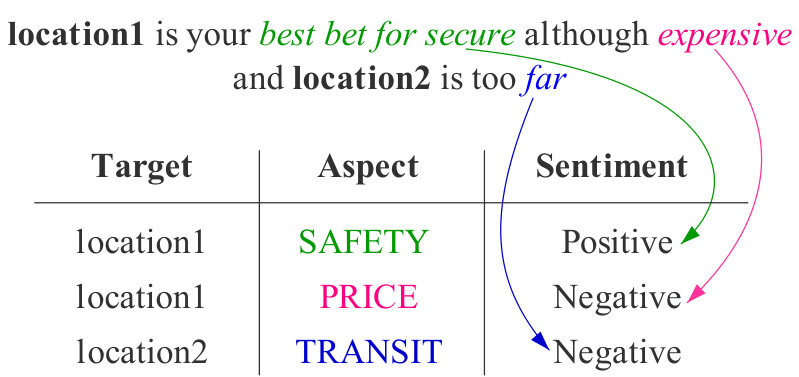 Figure 0
Figure 0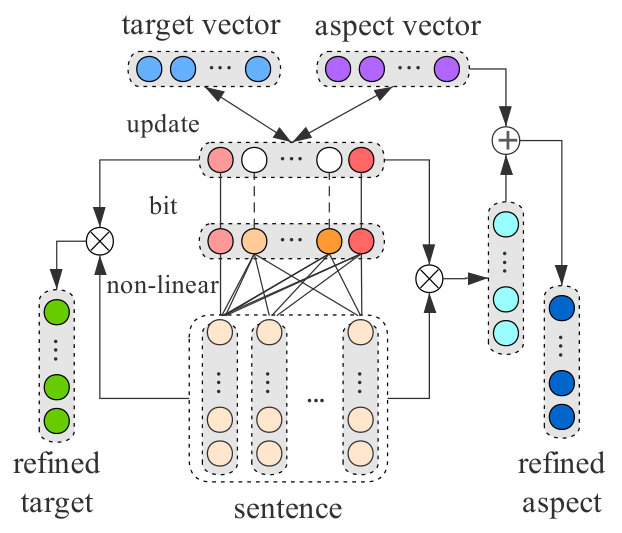 Figure 1
Figure 1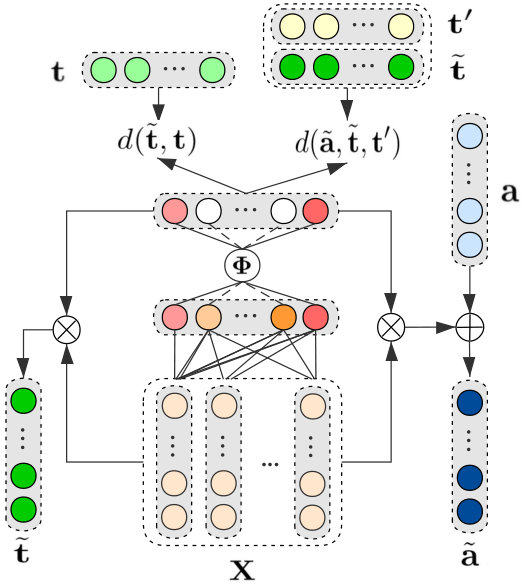 Figure 1
Figure 1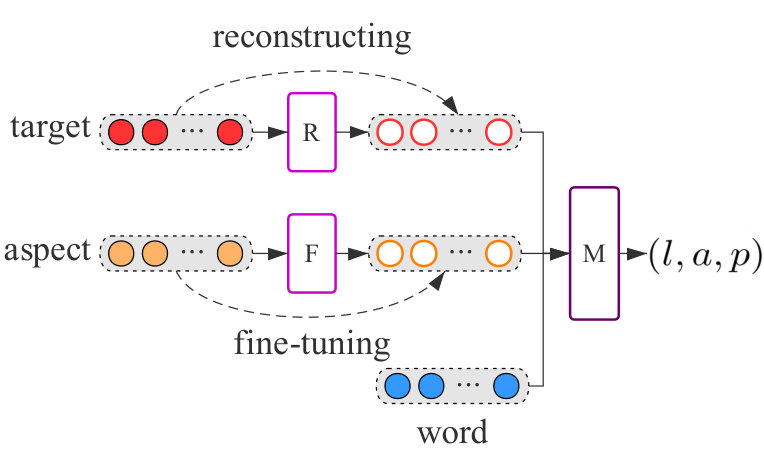 Figure 1
Figure 1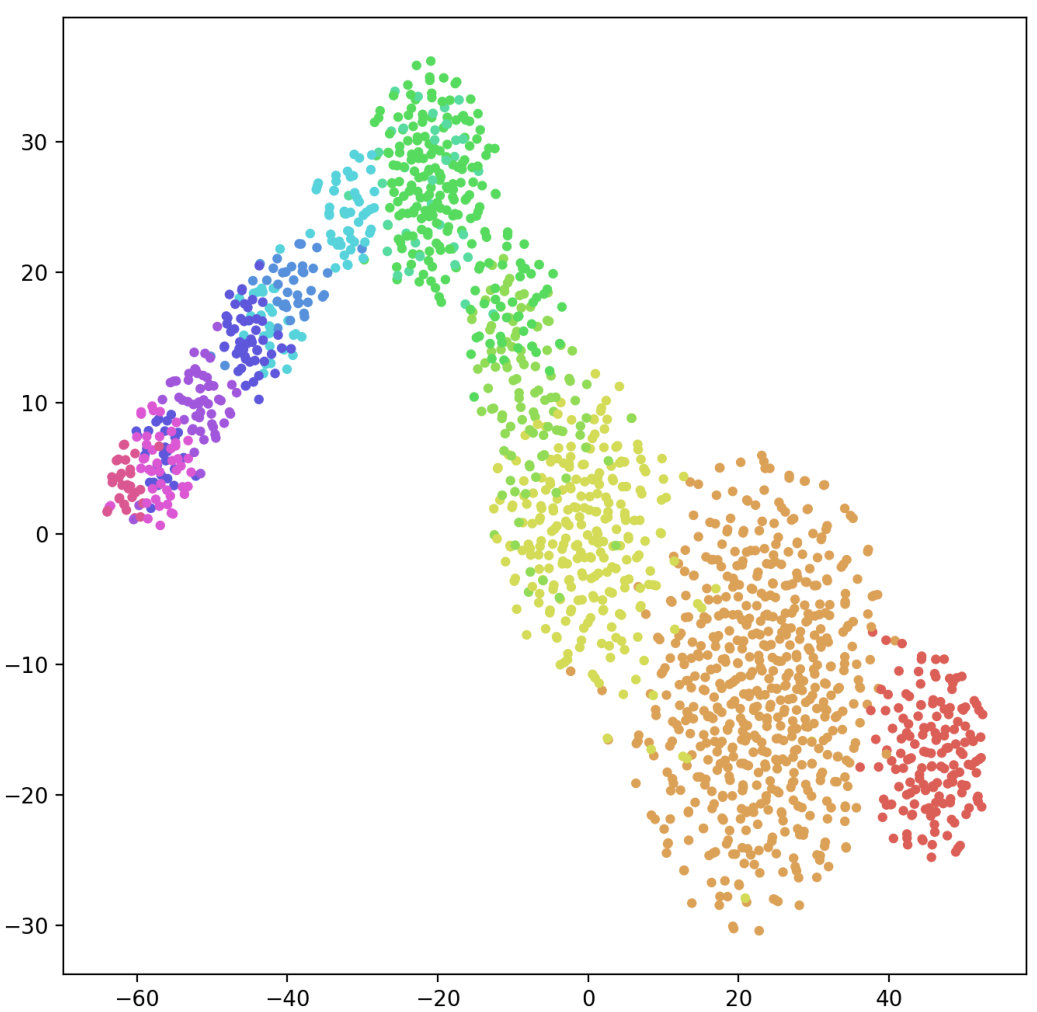 Figure 2
Figure 2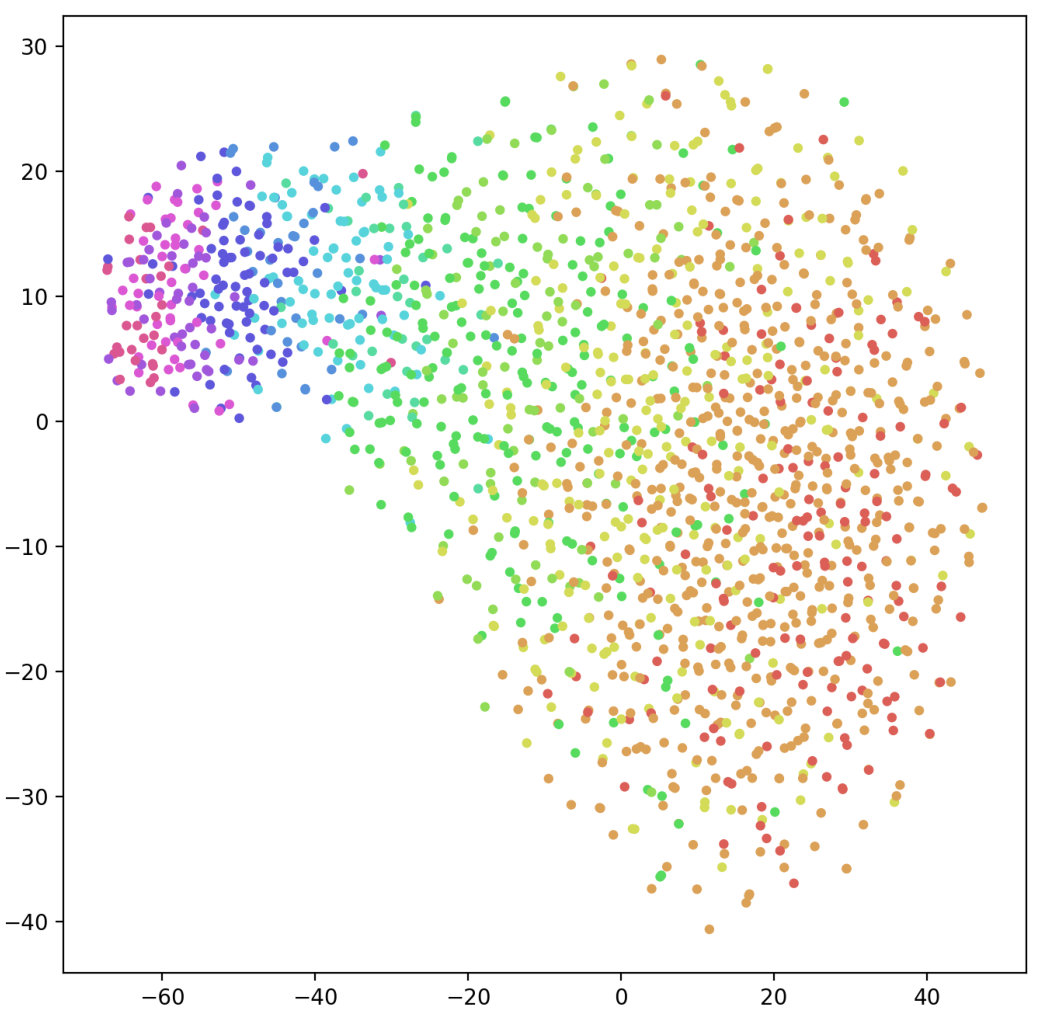 Figure 2
Figure 2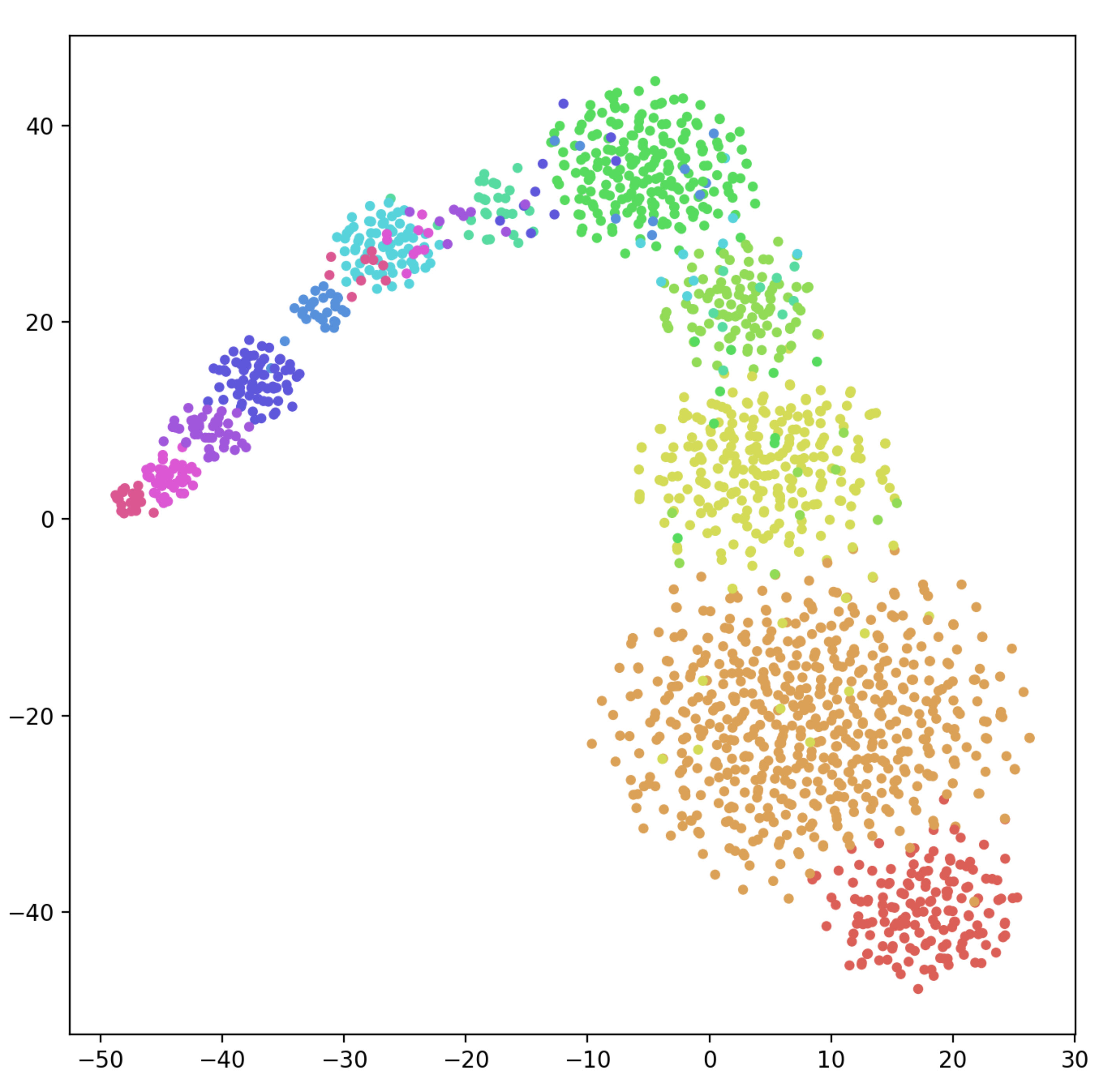 Figure 2
Figure 2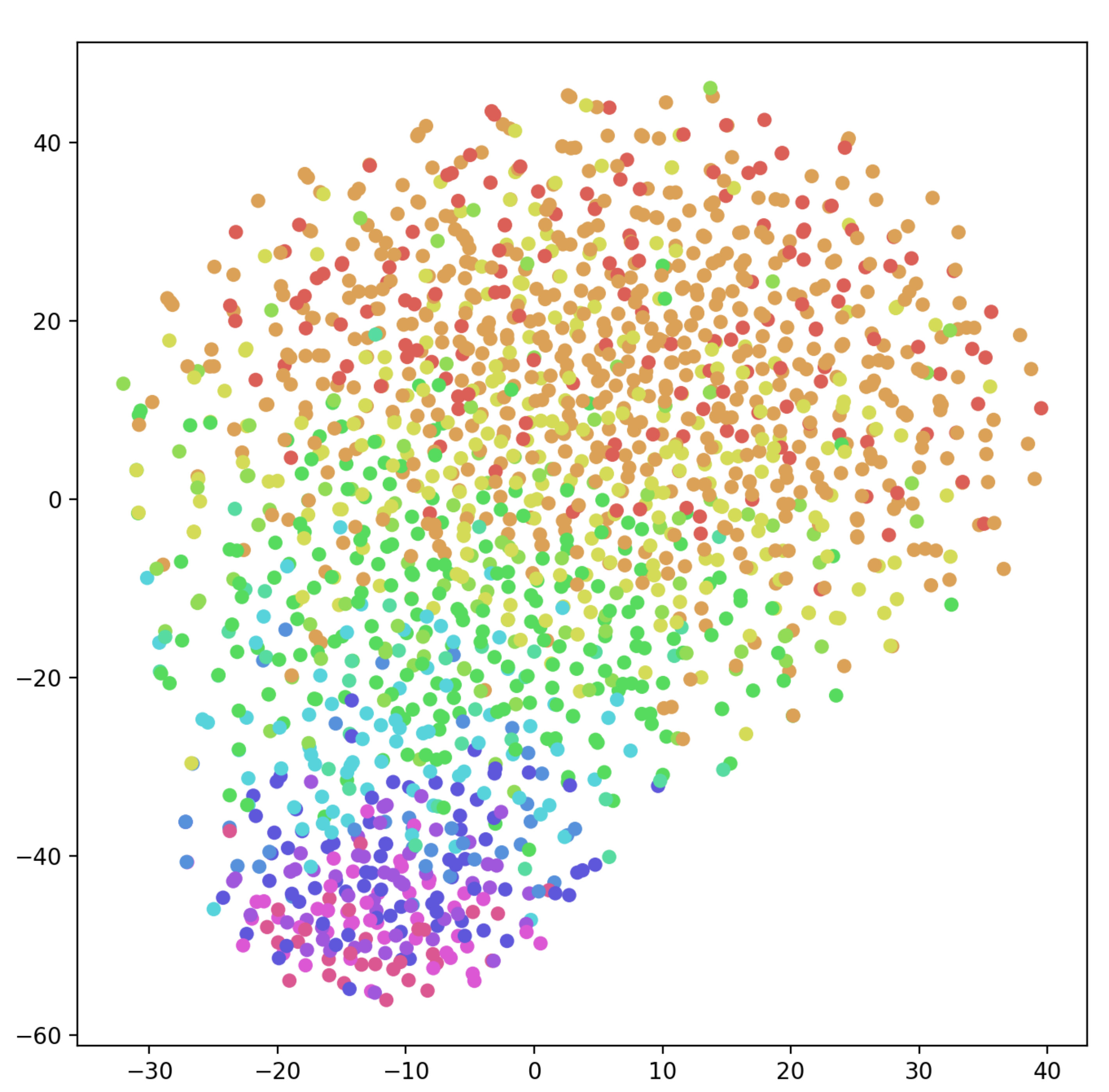 Figure 2
Figure 2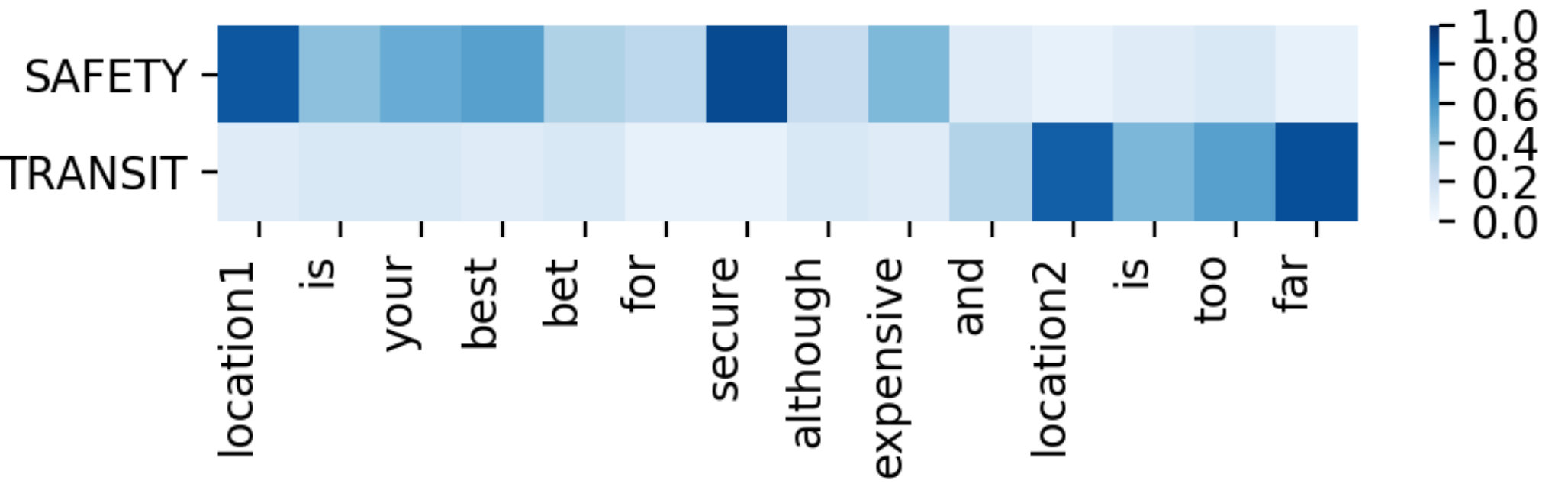 Figure 2
Figure 2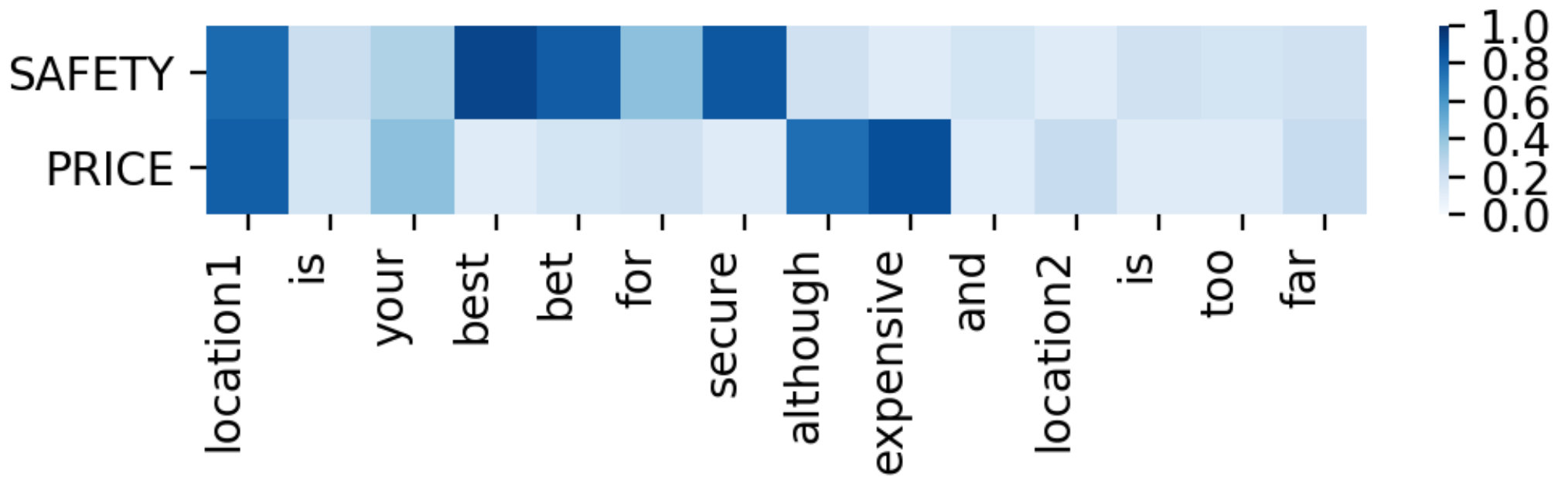 Figure 3
Figure 3| Model | Aspect Detection | Sentiment Classification | |||
|---|---|---|---|---|---|
| Acc. (%) | F1 (%) | AUC (%) | Acc. (%) | AUC (%) | |
| LSTM-Final | — | 68.9 | 89.8 | 82.0 | 85.4 |
| LSTM-Loc | — | 69.3 | 89.7 | 81.9 | 83.9 |
| SenticLSTM | 67.4 | 78.2 | — | 89.3 | — |
| RE+SenticLSTM (ours) | 73.8 | 79.3 | — | 93.0 | — |
| Delayed-memory | 73.5 | 78.5 | 94.4 | 91.0 | 94.8 |
| RE+Delayed-memory (ours) | 76.4 | 81.0 | 96.8 | 92.8 | 96.2 |
| Model | Aspect Detection | Sentiment Classification | |||
|---|---|---|---|---|---|
| Acc. (%) | F1 (%) | AUC (%) | Acc. (%) | AUC (%) | |
| SenticLSTM | 67.3 | 76.4 | — | 76.5 | — |
| RE+SenticLSTM(ours) | 71.2 | 78.6 | 89.5 | 76.8 | 82.3 |
| Delayed-memory | 70.3 | 77.4 | 90.8 | 76.4 | 83.6 |
| RE+Delayed-memory(ours) | 71.6 | 79.1 | 91.8 | 77.2 | 84.6 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSentiment Analysis and Opinion Mining · Text and Document Classification Technologies · Topic Modeling
Context-aware Embedding for Targeted Aspect-based Sentiment Analysis
Bin Liang1, Jiachen Du1, Ruifeng Xu1 , Binyang Li2, Hejiao Huang1
1Department of Computer Science, Harbin Institute of Technology (Shenzhen), China
2 School of Information Science and Technology,
University of International Relations, Beijing, China
[email protected], [email protected]
[email protected], [email protected]
[email protected] ∗ Corresponding Author
Abstract
Attention-based neural models were employed to detect the different aspects and sentiment polarities of the same target in targeted aspect-based sentiment analysis (TABSA). However, existing methods do not specifically pre-train reasonable embeddings for targets and aspects in TABSA. This may result in targets or aspects having the same vector representations in different contexts and losing the context-dependent information. To address this problem, we propose a novel method to refine the embeddings of targets and aspects. Such pivotal embedding refinement utilizes a sparse coefficient vector to adjust the embeddings of target and aspect from the context. Hence the embeddings of targets and aspects can be refined from the highly correlative words instead of using context-independent or randomly initialized vectors. Experiment results on two benchmark datasets show that our approach yields the state-of-the-art performance in TABSA task.
1 Introduction
Targeted aspect-based sentiment analysis (TABSA) aims at detecting aspects according to the specific target and inferring sentiment polarities corresponding to different target-aspect pairs simultaneously Saeidi et al. (2016). For example, in sentence “location1 is your best bet for secure although expensive and location2 is too far.”, for target “location1”, the sentiment polarity is positive towards aspect “SAFETY” but is negative towards aspect “PRICE”. While “location2” only express negative polarity about aspect “TRANSIT-LOCATION”. This can be seen in Figure 1, e.g., where opinions on the aspects “SAFETY” and “PRICE” are expressed for target “location1” but not for target “location2”, whose corresponding aspect is “*TRANSIT-LOCATION *”. Here, an interesting phenomenon is that, the opinion “Positive” towards aspect “SAFETY” is expressed for target “location1” will be change if “location1” and “location2” are exchanged. That is to say, the representation of target and aspect should take full account of context information rather than use context-independent representation.
Aspect-based sentiment analysis (ABSA) is a basic subtask of TABSA, which aims at inferring the sentiment polarities of different aspects in the sentence Ruder et al. (2016); Chen et al. (2017); Gui et al. (2017); Peng et al. (2018); Ma et al. (2018a). Recently, attention-based neural models achieve remarkable success in ABSA Fan et al. (2018); Wang et al. (2016); Tang et al. (2016). In TABSA task, the attention-based sentiment LSTM Ma et al. (2018b) is proposed to tackle the challenges of both aspect-based sentiment analysis and targeted sentiment analysis by incorporating external knowledge. For neural model improvement, a delayed memory is proposed to track and update the states of targets at the right time with external memory Liu et al. (2018).
Despite the remarkable progress made by the previous works, they usually utilize context-independent or randomly initialized vectors to represent targets and aspects, which losses the semantic information and ignores the interdependence among specific target, corresponding aspects and the context. Because the targets themselves have no expression of sentiment, and the opinions of the given sentence are generally composed of words highly correlative to the targets. For example, if the words “price” and “expensive” are in the sentence, it probably expresses the “Negative” sentiment polarity about aspect “PRICE”.
To alleviate these problems above, we propose a novel embedding refinement method to obtain context-aware embedding for TABSA. Specifically, we use a sparse coefficient vector to select highly correlated words from the sentence, and then adjust the representations of target and aspect to make them more valuable. The main contributions of our work can be summarized as follows:
- •
We reconstruct the vector representation for target from the context by means of a sparse coefficient vector, hence the representation of target is generated from highly correlative words rather than using context-independent or randomly initialized embedding.
- •
The aspect embedding is fine-tuned to be close to the highly correlated target and be away from the irrelevant targets.
- •
Experiment results on SentiHood and Semeval 2015 show that our proposed method can be directly incorporated into embedding-based TABSA models and achieve state-of-the-art performance.
2 Methodology
In this section, we describe the proposed method in detail. The framework of our proposed method is demonstrated in Figure 2.
We assume a words sequence of a given sentence as an embedding matrix , where is the length of sentence, is the dimension of embedding, and each word can be represented as an -dimensional embedding including the embedding of target via random initialization and the embedding of aspect which is an average of its constituting word embeddings or single word embedding. The sentence embedding matrix is fed as input into our model to achieve the sparse coefficient vector via the fully connected layer and the step function successively. The hidden output is utilized to compute the refined representation of target and aspect . Afterwards, the squared Euclidean function and are used to iteratively minimize the distance to get the refined embeddings of target and aspect.
2.1 Task Definition
Given a sentence consisting of a sequence of words , where is a target in the sentence, there will be 1 or 2 targets in the sentence corresponding to several aspects. There are a pre-identified set of targets and a fixed set of aspects . The goal of TABSA can be regarded as a fine-grained sentiment expression as a tuple , where refers to the polarity which is associated with aspect , and the aspect belongs to a target . The objective of TABSA task is to detect the aspect and classify the sentiment polarity according to a specific target and the sentence .
2.2 Target Representation
The idea of target representation is to reconstruct the target embedding from a given sentence according to the highly correlated words in the context. By this means we can extract the correlation between target and context, the target representation is computed as:
[TABLE]
where is the representation of target, is a sparse coefficient vector indicating the importance of different words in the context, defined as:
[TABLE]
where is a step function given a real value:
[TABLE]
where is an average function, and the vector u can be computed by a non-linear function of basic embedding matrix :
[TABLE]
where is a non-linear operation function like sigmoid, and denote the weight matrix and bias respectively. The target representation is inspired by the recent success of embedding refinement Yu et al. (2017). For each target, our reconstruction operation aims to get a contextual relevant embedding by iteratively minimizes the squared Euclidean between the target and the highly correlative words in the sentence. The objective function is defined as:
[TABLE]
where aims to control the sparseness of vector . Through the iterative procedure, the vector representation of the target will be iteratively updated until the number of the non-zero elements of vector less than the threshold value: . Where is the number of the non-zero elements of vector and is a threshold to control the non-zero number of vector .
2.3 Aspect Representation
Generally, the words of aspects contain the most important semantic information. Coordinate with the aspect itself, the context information can also reflect the aspect, such as the word “price” in the sentence probably has relevant to aspect “PRICE”. To this end, we refine the aspect representation according to target representation. By incorporating highly correlated words into the representation of aspect, every element in the fine-tuned aspect embedding is calculated as:
[TABLE]
where is a parameter to control the influence between aspect and the context.
For each aspect, the fine-tuning method aims to move closer to the homologous target and further away from the irrelevant one by iteratively minimizes the squared Euclidean. The objective function is thus divided into two parts:
[TABLE]
where is the the homologous target and is the irrelevant one. is a parameter that controls the distance from the irrelevant target.
3 Experiments
This section evaluates several deep neural models based on our proposed embedding refinement method for TABSA.
Dataset.
Two benchmark datasets: SentiHood Saeidi et al. (2016) and Task 12 of Semeval 2015 Pontiki et al. (2015) are used to evaluate our proposed method. SentiHood contains annotated sentences containing one or two location target mentions. The whole dataset contains 5215 sentences with 3862 sentences containing a single location and 1353 sentences containing multiple (two) locations. Location target names are masked by and in the whole dataset. Following Saeidi et al. (2016), we only consider the top 4 aspects (“GENERAL”, “PRICE”, “TRANSIT-LOCATION” and “SAFETY”) when evaluate aspect detection and sentiment classification. To show the generalizability of our method, we evaluate our works in another dataset: restaurants domain in Task 12 for TABSA from Semeval 2015. We remove sentences containing no targets as well as NULL targets like the work of Ma et al. (2018b). The whole dataset contains 1,197 targets in the training set and 542 targets in the testing set.
Experiment setting.
We use Glove Pennington et al. (2014)111http://nlp.stanford.edu/projects/glove/ to initialize the word embeddings in our experiments, and target embeddings (location1 and location2) are randomly initialized. We initialize and with random initialization. The parameters of , and in our experiment are 4, 1 and 0.5 respectively. Given a unit of text , a list of labels is provided correspondingly, the overall task of TABSA can be defined as a three-class classification task for each pair with labels Positive, Negative, None. We use macro-average F1, Strict accuracy (Acc.) and AUC for aspect detection, and Acc. and AUC for sentiment classification ignoring the class of None, which indicates that a sentence does not contain an opinion for the target-aspect pair .
Comparison methods.
We compare our method with several typical baseline systems Saeidi et al. (2016) and remarkable models Ma et al. (2018b); Liu et al. (2018) proposed for the task of TABSA.
(1) LSTM-Final Saeidi et al. (2016): A bidirectional LSTM model takes the final states to represent the information.
(2) LSTM-Loc Saeidi et al. (2016): A bidirectional LSTM model takes the output representation at the index corresponding to the location target.
(3) SenticLSTM Ma et al. (2018b): A bidirectional LSTM model incorporates external SenticNet knowledge.
(4) Delayed-memory Liu et al. (2018): A memory-based model utilizes a delayed memory mechanism.
(5) RE+SenticLSTM: Incorporating our proposed method into SenticLSTM.
(6) RE+Delayed-memory: Incorporating our proposed method into Delayed-memory.
3.1 Comparative Results of SentiHood
The experimental results are shown in Table 1. The classifiers based on our proposed methods (RE+Delayed-memory, RE+SenticLSTM) achieve better performance than competitor models for both aspect detection and sentiment classification. In comparison with the previous best-performing model (Delayed-memory), our best model (RE+Delayed-memory) significantly improves aspect detection (by 2.9% in strict accuracy, 2.5% in macro-average F1 and 2.4% in AUC) and sentiment classification (by 1.8% in strict accuracy and 1.4% in AUC) on SentiHood.
The comprehensive results show that by incorporating refined context-aware embeddings of targets and aspects into the neural models can substantially improve the performance of aspect detection. This indicates that the refined representation is more learnable and is able to extract the interdependence between aspect and the corresponding target in the context. On the other hand, the performance of sentiment classification is improved certainly in comparison with the remarkable models (Delayed-memory and SenticLSTM). It indicates that our context-aware embeddings can capture sentiment information better than the models using traditional embeddings even incorporating external knowledge.
3.2 Comparative Results of Semeval 2015
To illustrate the robustness of our proposed method, a comparative experiment was conducted on Semeval 2015. As shown in Table 2, our embedding refinement method achieves better performance for both aspect detection and sentiment classification than two original embedding-based models, for aspect detection in particular. Consequently, our method is capable of achieving state-of-the-art performance on different datasets.
3.3 Visualization
To qualitatively demonstrate how the proposed embedding refinement improves the performance for both aspect detection and sentiment classification in TABSA, we visualize the proposed context-aware aspect embeddings and original aspect embeddings which are learned with Delayed-memory and SenticLSTM models via t-SNE Maaten and Hinton (2008). As shown in Figure 3, compared with randomly initialized embedding, it is observed a significantly clearer separation between different aspects represented by our proposed context-aware embedding. This indicates that different representations of aspects can be distinguished from the context, and that the commonality of a specific aspect can also be effectively preserved. Hence the model can extract different semantic information according to different aspects, when detecting multiple aspects in the same sentence in particular. The results verify that encoding aspect by leveraging context information is more effective for aspect detection and sentiment classification in TABSA task.
4 Conclusion
In this paper, we proposed a novel method for refining representations of targets and aspects. The proposed method is able to select a set of highly correlated words from the context via a sparse coefficient vector and then adjust the representations of targets and aspects. Hence, the interdependence among specific target, corresponding aspect, and the context can be extracted to generate superior embedding. Experimental results demonstrated the effectiveness and robustness of the proposed method on two benchmark datasets over the task of TABSA. In future works, we will explore the extension of this approach for other tasks.
Acknowledgments
This work was supported by National Natural Science Foundation of China U1636103, 61632011, 61876053, U1536207, Key Technologies Research and Development Program of Shenzhen JSGG20170817140856618, Shenzhen Foundational Research Funding JCYJ20180507183527919, Joint Research Program of Shenzhen Securities Information Co., Ltd. No. JRPSSIC2018001.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Chen et al. (2017) Peng Chen, Zhongqian Sun, Lidong Bing, and Wei Yang. 2017. Recurrent attention network on memory for aspect sentiment analysis. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing , pages 452–461.
- 2Fan et al. (2018) Chuang Fan, Qinghong Gao, Jiachen Du, Lin Gui, Ruifeng Xu, and Kam-Fai Wong. 2018. Convolution-based memory network for aspect-based sentiment analysis. In The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, SIGIR 2018, Ann Arbor, MI, USA, July 08-12, 2018 , pages 1161–1164.
- 3Gui et al. (2017) Lin Gui, Yu Zhou, Ruifeng Xu, Yulan He, and Qin Lu. 2017. Learning representations from heterogeneous network for sentiment classification of product reviews. Knowledge-Based Systems , 124(C):34–45.
- 4Liu et al. (2018) Fei Liu, Trevor Cohn, and Timothy Baldwin. 2018. Recurrent entity networks with delayed memory update for targeted aspect-based sentiment analysis. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages 278–283.
- 5Ma et al. (2018 a) Dehong Ma, Sujian Li, and Houfeng Wang. 2018 a. Joint learning for targeted sentiment analysis. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages 4737–4742.
- 6Ma et al. (2018 b) Yukun Ma, Haiyun Peng, and Erik Cambria. 2018 b. Targeted aspect-based sentiment analysis via embedding commonsense knowledge into an attentive LSTM. In Proceedings of the Thirty-Second Conference on Artificial Intelligence,(AAAI-18) , pages 5876–5883.
- 7Maaten and Hinton (2008) Laurens van der Maaten and Geoffrey Hinton. 2008. Visualizing data using t-sne. Journal of machine learning research , 9(Nov):2579–2605.
- 8Peng et al. (2018) Minlong Peng, Qi Zhang, Yu-gang Jiang, and Xuanjing Huang. 2018. Cross-domain sentiment classification with target domain specific information. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages 2505–2513.