Recursive Style Breach Detection with Multifaceted Ensemble Learning
Daniel Kopev, Dimitrina Zlatkova, Kristiyan Mitov, Atanas Atanasov,, Momchil Hardalov, Ivan Koychev, Preslav Nakov

TL;DR
This paper introduces a supervised, ensemble learning method for detecting and locating style changes in text documents, utilizing recursive analysis to improve accuracy, and achieving top results in a competitive challenge.
Contribution
It proposes a novel recursive style change detection approach combining diverse classifiers and engineered features, winning the PAN@CLEF 2018 challenge.
Findings
Achieved state-of-the-art performance in style change detection
Effectively locates precise change positions within texts
Demonstrates the effectiveness of ensemble and recursive methods
Abstract
We present a supervised approach for style change detection, which aims at predicting whether there are changes in the style in a given text document, as well as at finding the exact positions where such changes occur. In particular, we combine a TF.IDF representation of the document with features specifically engineered for the task, and we make predictions via an ensemble of diverse classifiers including SVM, Random Forest, AdaBoost, MLP, and LightGBM. Whenever the model detects that style change is present, we apply it recursively, looking to find the specific positions of the change. Our approach powered the winning system for the PAN@CLEF 2018 task on Style Change Detection.
Click any figure to enlarge with its caption.
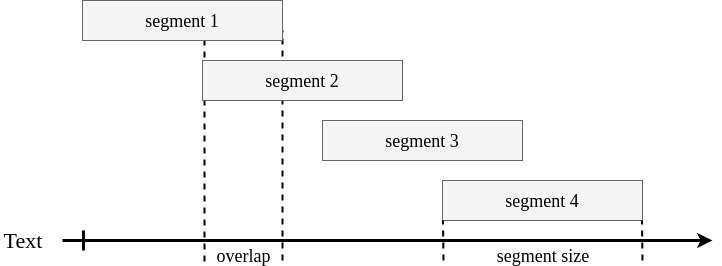 Figure 1
Figure 1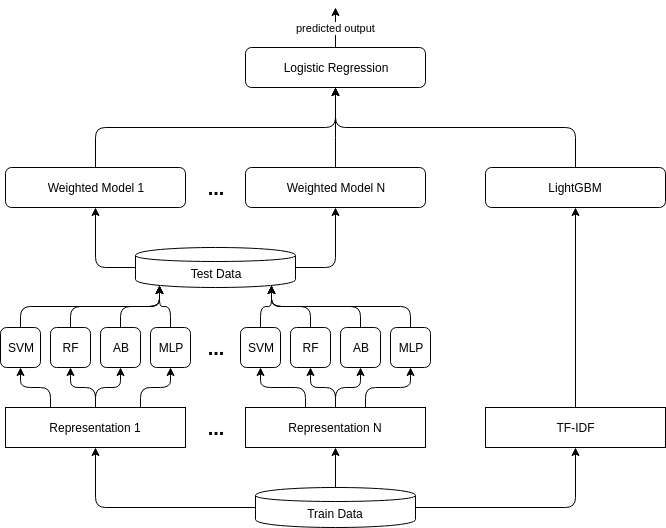 Figure 2
Figure 2| Features | Dimensionality |
|---|---|
| Tautology | 5 |
| Grammar contractions | 29 |
| Beginning and ending of author statements | 1 |
| Quotation marks | 1 |
| Readability | 9 |
| Frequent words | 415 |
| Lexical | 34 |
| Vocabulary richness | 2 |
| Named entity spellings | 2 |
| Word | Rescaled Counts |
|---|---|
| however | |
| one | |
| note | |
| edit | |
| first | |
| yes | |
| also | |
| another | |
| finally | |
| since | |
| update | |
| let |
| Word | Rescaled Counts |
|---|---|
| however | |
| one | |
| note | |
| edit | |
| first | |
| yes | |
| also | |
| another | |
| finally | |
| since | |
| update | |
| let |
| Word | Rescaled Counts |
|---|---|
| etc | |
| time | |
| well | |
| question | |
| way | |
| god | |
| p | |
| example | |
| work | |
| war | |
| though | |
| answer |
| Representation | Coefficient | Accuracy |
|---|---|---|
| Tautology | 1.50 | 67.4 |
| Grammar Contractions | 1.25 | 61.0 |
| Quotation Marks | 0.05 | 55.8 |
| Readability | -0.25 | 61.0 |
| Frequent Words | 0.81 | 63.3 |
| Lexical | 0.27 | 64.9 |
| Vocabulary Richness | -1.46 | 51.0 |
| LightGBM with TF-IDF | 5.01 | 88.5 |
| Classifier | Hyper-parameter | Value |
|---|---|---|
| Support Vector Machine | kernel | Radial basis function |
| penalty | 1.0 | |
| tolerance | 0.001 | |
| class weight | balanced | |
| Random Forest | estimators | 300 |
| with replacement | Yes | |
| AdaBoost Trees | base estimator | Decision tree |
| estimators | 300 | |
| Multi-layer Perceptron | layers | 1 |
| layer size | 100 | |
| activation | ReLU | |
| optimization | Adam | |
| regularization | L2 | |
| regularization term | 0.0001 | |
| learning rate | 0.001 | |
| mini-batch size | 200 | |
| maximum iterations | 10000 | |
| LightGBM | learning rate | 0.1 |
| number of leaves | 31 | |
| feature fraction | 0.6 | |
| L1 regularization term | 1.0 | |
| L2 regularization term | 1.0 | |
| minimum data in leaf | 20 | |
| Logistic Regression (meta-classifier) | optimization | liblinear |
| regularization | L2 | |
| penalty C | 1.0 | |
| tolerance | 0.0001 | |
| maximum iterations | 100 |
| windowDiff | winP | winR | winF | |
|---|---|---|---|---|
| BASELINE-rnd | 0.6088 | 0.2779 | 0.5477 | 0.2366 |
| BASELINE-eq | 0.6345 | 0.3326 | 0.6368 | 0.2907 |
| Stacking | 0.5719 | 0.3395 | 0.6132 | 0.3302 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
MethodsSupport Vector Machine
11institutetext: FMI, Sofia University “St. Kliment Ohridski”, Sofia, Bulgaria
11email: {dkopev, dvzlatkova, kmmitov, amitkov}@uni-sofia.bg
11email: {hardalov, koychev}@fmi.uni-sofia.bg 22institutetext: Qatar Computing Research Institute, HBKU, Doha, Qatar
22email: [email protected]
Recursive Style Breach Detection
with Multifaceted Ensemble Learning
Daniel Kopev Equal Contribution11
Dimitrina Zlatkova11footnotemark: 1 11
Kristiyan Mitov11footnotemark: 1 11
Atanas Atanasov11footnotemark: 1 11
Momchil Hardalov 11
Ivan Koychev 11
Preslav Nakov 22
Abstract
We present a supervised approach for style change detection, which aims at predicting whether there are changes in the style in a given text document, as well as at finding the exact positions where such changes occur. In particular, we combine a TF.IDF representation of the document with features specifically engineered for the task, and we make predictions via an ensemble of diverse classifiers including SVM, Random Forest, AdaBoost, MLP, and LightGBM. Whenever the model detects that style change is present, we apply it recursively, looking to find the specific positions of the change. Our approach powered the winning system for the PAN@CLEF 2018 task on Style Change Detection.
Keywords:
Multi-authorship Stylometry Style change detection Style breach detection Stacking ensemble Natural Language Processing Gradient boosting machines
1 Introduction
There are numerous tasks related to authorship attribution, but most of the research has been concentrated on large documents. An interesting problem to tackle for smaller texts is the one of style change detection: given a text document, identify whether style change occurs anywhere in it. This formulation usually entails a uniform distribution of text segments from multiple authors. A version of it is the intrinsic plagiarism detection problem, in which it is considered that there is a dominant author of the document being examined. Another variation is the task of detecting style change positions: determine the exact location of style breaches in the text. Historically, this has proven to be a difficult but interesting task, and performance in terms of accuracy has been low, leaving a lot of room for potential improvements over the state-of-the-art. Here, we target two tasks: (i) predicting whether style change occurs (Style Change Detection111http://pan.webis.de/clef18/pan18-web/author-identification.html), and (ii) finding the exact position of the change (Style Breach Detection222http://pan.webis.de/clef17/pan17-web/author-identification.html).
2 Related Work
Authorship attribution
Previous work on authorship attribution and related problems (e.g., author obfuscation [3, 4, 12, 15]) used primarily term frequencies [5, 9] and features from stylometry [8, 9, 18]. We borrowed ideas for traditional features from [2, 13], but we also designed some new ones, related to tautology, grammar contractions, quote use discrepancies, beginning and ending author statement words, and named entity spellings (see Section 3.4).
Style breach detection.
See [19] for a summary of previous work on style breach detection and related tasks. Here we outline some of the most relevant work. Karaś et al. [5] used TF.IDF, POS tags, stop words and punctuation to represent paragraphs in the text, and applied a Wilcoxon Signed Rank test to check whether two segments are likely to come from the same distribution. They moved a sliding window over the sentences, computing similarity statistics and using dictionaries with common English words and sentiment. Then, they used a predefined threshold to determine whether a style breach between two sentences was likely. Safin and Kuznetsova [16] explored techniques typically used for intrinsic plagiarism detection. They vectorized sentences using pre-trained skip-thought models and looked for outliers using cosine-based distance between vectors.
3 Style Change Detection
Here, we describe our approach, which powered the winning system [20] for the PAN@CLEF 2018 task on Style Change Detection [7].
3.1 Data
We used data provided by the organizers of the CLEF-2018 PAN task on Style Change Detection333http://pan.webis.de/clef18/pan18-web/author-identification.html [7], which was based on user posts from StackExchange covering different topics with 300–1,000 tokens per document. It included a training set of 3,000 documents and a validation set of 1,500 documents.
3.2 Preprocessing
We pre-process the data in two phases. The first phase is applied before any feature extraction has taken place, and it replaces URLs and long numbers with specific tokens. The second phase is applied during feature computation. It filters the stream of words and replaces file paths, long character sequences and very long words with special tokens. Additionally, an attempt is made to split long hyphenated words (with three or more parts) by checking whether most of the sub-words are present in a dictionary of common words (from the NLTK words corpus [11]). The objective of all these steps is to reduce the impact of long words, which could adversely affect features that take word length into account. Such features are those from the lexical group and preprocessing is applied to them only, since it might have undesirable effect on the rest of the features.
3.3 Text Segmentation
Style changes in text documents entail that parts of the text would differ in some way. In an attempt to spot such differences, we split the document into four segments of roughly equal length (measured in terms of word tokens), we calculated the feature vectors for each of the segments, and we found the maximum difference between the values for each feature for any pair of segments. We chose the number of segments (namely, four) based on the distribution of the number of style changes across the entire training dataset. In order to obtain more potential data points, we applied a sliding window across each document with an overlap of one third of the segment size (see Figure 1). We applied this segmentation procedure for four of the feature groups, three of which used a sliding window. See Section 3.4 for more details.
3.4 Text Representation
Below, we describe the features we engineered specifically for the task of discovering style changes. The dimensionality of each of them is shown in Table 1.
Tautology: At a grammatical and, one might say, psychological level, writers attempt to avoid using repetitive statements. We account for this by looking at the average number of occurrences of each one to five word-grams in the entire document, and we use a vector of size five with the respective averages for text representation.
Grammar Contractions: Another viewpoint we look at is based on the discrepancies in words, which have contracted forms or shortened version of words such as I will (I’ll), are not (aren’t), and they are (they’re). Because most people favor one or the other, contraction apostrophes are suitable discriminative features (even more so in formal contexts) for identifying whether a piece of text is likely to be single- or multi-authored.
Frequent Words: Frequent words include stop words (taken from NLTK [11]) and function words (compiled from three separate lists444http://semanticsimilarity.files.wordpress.com/2013/08/jim-oshea-fwlist-277.pdf555http://www.sequencepublishing.com/1/academic.html666http://www.edu.uwo.ca/faculty-profiles/docs/other/webb/essential-word-list.pdf). Each frequent word is counted per text segment.
Lexical: The lexical features are computed as ratios per text segment using a sliding window and can be divided into the following three types:
Character-based: Spaces, digits, commas, colons, semicolons, apostrophes, quotes, parenthesis, number of paragraphs, and punctuation in general.
Word-based: We POS-tag the segment using NLTK, and we extract features such as ratios of pronouns, prepositions, coordinating conjunctions, adjectives, adverbs, determiners, interjections, modals, nouns, personal pronouns and verbs. Other word-based features include words with 2 or 3 characters, words with over 6 characters, average word length, all-caps words, and capitalized words.
Sentence-based: Those include ratios of question, period, exclamation sentences, short and long sentences, and average sentence length.
Quotation Marks: Normally used in pairs, different people might consistently prefer using either single or double quotation marks. We first exclude every shortened word with apostrophe (from a grammar contraction words dictionary), and then we use the variance in the number of single and double quotes as a single-feature representation of the documents.
Vocabulary Richness: Similarly to [2], vocabulary richness is represented by averaged word frequency class. Using the Google Books common words list,777http://norvig.com/google-books-common-words.txt the frequency class of a word is computed as , where is the frequency function and is the most frequent word in the corpus, in our case the. Two features are extracted per segment: the average frequency class of all words in it, and the ratio of unknown words (words not present in the common words list).
Readability: The following readability features are computed per text segment via the Textstat888http://github.com/shivam5992/textstat Python package: Flesch reading ease, SMOG grade, Flesch-Kincaid grade, Coleman-Liau index, automated readability index, Dale-Chall readability score, difficult words, Linsear write formula, and Gunning fog.
Beginning and Ending of Author Statements: As can be seen in Table 2, author statements begin and end with very different types of words. This can be used to locate points in documents where word clusters of small size contain high amount of these terms. We tried two approaches, applied after stopword removal, and we experimented with word phrases of sizes 1, 2 and 3, with single-terms yielding the best results. The first approach assigns scores to words to be rescaled (min-max normalized): it counts the number of times the target word is at a beginning or at an ending position relative to the author statement. A bit more sophisticated approach scores words based on how close they are to such a position. Each word is processed using a very steep half-sigmoid function (Equation 1, with k denoting the steepness), taking its relative position and rewarding those that are extremely close to a beginning or to an ending. Then, each word list of position scores is averaged across all documents.
[TABLE]
Finally, the document feature vector is represented by looking at local document clusters of three words, containing multiple high-scored words, indicating there may be an end of author statement immediately followed by a beginning of a new one. This document representation was not added as part of the stacking classifier (Section 3.5.2), but nevertheless has a strong performance on its own, yielding 65% accuracy.
Named Entity Spellings: Different named entity spellings can reflect personal preferences, rather than cultural ones. We use Damerau-Levenshtein string-edit distance [1, 10] to find inconsistencies in the wording of the same named entities within an edit distance of 1. The feature vector consists of the minimum counts between the different spellings for each found named entity.
3.5 Classification
3.5.1 LightGBM
Our gradient boosting approach combines LightGBM [6] with Logistic Regression and TF.IDF vector representation. Note that we use the test data when calculating the IDF statistics. This is not cheating as we do not use the labels for the examples, we only calculate word frequencies. Then, we use feature importance weights with a Logistic Regression estimator to select the best TF.IDF features; moreover, we only select features with weight greater than 0.1. We tune the Logistic Regression hyper-parameters using cross-validation. The best results are achieved with Stochastic Average Gradient descent, and inverse of the regularization strength C of 2. We trained using bagging with five folds. A simple LightGBM baseline achieved 73% accuracy on the validation set. Tuning the LightGBM hyper-parameters increased the accuracy to 86%, supported by a CV score of 85%. These parameters can be seen in Table 4.
3.5.2 Stacking
The basic idea behind our Stacking Ensemble classifier was to take into account different independent points of view in the context of distinguishing multi-authored documents and to learn dependencies between them. At the bottom level, we train four different non-linear classifiers — SVM, random forest, AdaBoost trees, multi-layer perceptron (described in Table 4) — for each feature vector derived from the representations in Section 3.4 on 75% of the training data. Then, each one of them predicts on the remaining 25% and is assigned a weight, based on its accuracy, relative to the remaining classifiers with the same input feature vectors. Those groups form a single vector each with prediction class probabilities, based on the weights and the outputs of its classifiers. These vectors, together with the predictions of the LightGBM classifier (see Section 3.5.1), serve as an input to a simple linear Logistic Regression meta-learner. The process of training is visualized in Figure 2.
Before predicting, each classifier is trained again on the whole dataset (except for LightGBM, which is not weighted across groups). For each new sample, the zero-level classifiers use the same weights learned in training to transform the given sample as an input vector of probabilities for the meta-learner. This yields accuracy of 87%. The coefficients learned by the meta-model for each text representation and their standalone accuracies can be seen in Table 3.
4 Style Breach Detection
In this section, we describe our approach to the more complex task of finding the positions where style breach occurs, which we address using the supervised model from the previous Section 3.
4.1 Data
We use the dataset from the PAN-2017 competition999http://pan.webis.de/clef17/pan17-web/author-identification.html [19], which consists of 187 documents each containing 1,000–2,400 word tokens. About 20% of the texts have no style changes and the rest have between 1 and 8 changes. Switches of authorships101010In this dataset, style change also means switch of authorship. may only occur at the end of sentences, not within. The exact positions of the style changes in the multi-authored documents are provided as part of the dataset, but we did not use them for training.
This dataset is hard due to its small size and to class imbalance. Applying our model from the previous section on it poses further challenges as we have originally developed the model to identify the presence of changes in shorter texts (300–1,000 tokens) and with fewer style breaches (up to 3).
4.2 Method
Given a document to analyze, we first apply our model from the previous Section 3 to predict whether there is style change in it. If style change is detected, we split the document in two: each half containing the same number of sentences. Then, we perform the same check for style change on each of the two parts, and if the results for both parts are negative then the exact position of the breach would be where the text was split in half. We repeat this procedure of splitting and searching for changes recursively until the length of the text fragment becomes less than 20 sentences, in which case, we return the middle point and we perform no more checks on the respective fragment.
Note that at training time, the model checks for the presence of changes on the full text, while at testing time it is applied to fragments of various sizes: starting with documents that are larger than those seen in training and going down to fragments whose size decreases exponentially. This discrepancy in the fragment sizes at training and testing makes the model’s task harder. In order to alleviate the problem, we chose a relatively large minimum size for the text fragments of 20 sentences, assuming that shorter texts would not be easily handled by the model; we later confirmed this suspicion experimentally.
The next issue is that due to class imbalance, the model is much more likely to predict the positive class, which results in a lot of false positive, i.e., many non-existent style breaches being predicted in a document. On many occasions, the recursive procedure predicted an unreasonable number of breaches in a single document in the range of 20 or even 30, considering that the maximum number of style changes in a document in the training data was only 8. This is not completely unexpected though, as during training the model was never told the exact number of changes, just that there should exist at least one. Our strategy to cope with this was to increase the threshold for predicting that there is a style breach from 50% to 75%. This resulted in a significant drop in the average number of breaches predicted by the model from over 10 to 3.265.
4.3 Results
We evaluated the performance of our model for predicting the location of the style breaches using the following two evaluation measures:
- •
WindowDiff [14], which is standard in general text segmentation evaluation, and returns an error rate between 0 and 1 (0 indicating perfect prediction) for predicting the exact location of the breaches by penalizing near-misses less severely compared to other/complete misses or to predicting more style breach locations than there are to be found.
- •
WinPR [17], which computes common information retrieval measures, precision (WinP) and recall (WinR), and thus makes a more detailed, qualitative statement about the model performance.
We assessed our results by comparing them to the two baselines from [19]:
BASELINE-rnd randomly places between 0 and 10 borders at arbitrary positions inside a document. 2. 2.
BASELINE-eq also decides on a random basis how many borders should be placed (again 0–10), but then places these borders uniformly, i.e., so that all resulting segments are of equal size with respect to the tokens contained.
Table 5 shows the average results we achieved by applying our model using 5-fold cross-validation as well as the scores for the two baselines above. We can see that our stacking approach managed to outperform the two baselines on both evaluation measures. Our results are also close to the ones achieved at the PAN-2017 edition [5], although they cannot be compared directly, as the systems that participated in the PAN competition were evaluated on a different test dataset.
5 Conclusion and Future Work
Detecting style change in texts is a difficult task for humans: we, ourselves, found it hard to discern between texts with and without style change while exploring the dataset. Nonetheless, our experiments have shown that it is possible for machine learning algorithms to achieve good performance for this problem.
The idea of applying a model recursively to find the exact style breach positions came to us as a natural experiment after tackling the simplified binary task of style change detection, for which we achieved an accuracy of 89%. Our results for the more complex style breach position task are very close to the current state-of-the-art without the need for much adaptation of the original solution.
We believe that the results can be improved further if training is done on text pieces of different lengths, given that during validation, the recursive procedure has to be applied to smaller and smaller fragments of the original document. Tuning the model to work better for the case of imbalanced classes can also be a source of improvement. Another aspect we believe to be an important part of understanding the problem, and is yet to be explored, is the analysis and engineering of features based on the disparity between author takes on particular linguistic structures.
Acknowledgements.
This work was supported by the Bulgarian National Scientific Fund within the project no. DN 12/9, and by the Scientific Fund of the Sofia University within project no. 80-10-162/25.04.2018.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Damerau, F.J.: A technique for computer detection and correction of spelling errors. Commun. ACM 7 (3), 171–176 (1964)
- 2[2] Meyer zu Eissen, S., Stein, B., Kulig, M.: Plagiarism detection without reference collections. In: Advances in Data Analysis. pp. 359–366. Berlin, Heidelberg (2007)
- 3[3] Hagen, M., Potthast, M., Stein, B.: Overview of the author obfuscation task at PAN 2017: Safety evaluation revisited. In: Working Notes Papers of the CLEF 2017 Evaluation Labs. CLEF ’17, vol. 1866 (2017)
- 4[4] Karadzhov, G., Mihaylova, T., Kiprov, Y., Georgiev, G., Koychev, I., Nakov, P.: The case for being average: A mediocrity approach to style masking and author obfuscation - (Best of the Labs Track at CLEF-2017). In: Proceedings of the 8th International Conference of the CLEF Association: Experimental IR Meets Multilinguality, Multimodality, and Interaction. pp. 173–185. CLEF ’17, Dublin, Ireland (2017)
- 5[5] Karaś, D., Śpiewak, M., Sobecki, P.: OPI-JSA at CLEF 2017: Author Clustering and Style Breach Detection—Notebook for PAN at CLEF 2017. In: CLEF 2017 Evaluation Labs and Workshop – Working Notes Papers. CLEF ’17, Dublin, Ireland (2017)
- 6[6] Ke, G., Meng, Q., Finley, T., Wang, T., Chen, W., Ma, W., Ye, Q., Liu, T.Y.: Light GBM: A highly efficient gradient boosting decision tree. In: Proceedings of the 30th Annual Conference on Neural Information Processing Systems. pp. 3146–3154. NIPS ’17, Long Beach, California (2017)
- 7[7] Kestemont, M., Tschuggnall, M., Stamatatos, E., Daelemans, W., Specht, G., Stein, B., Potthast, M.: Overview of the author identification task at PAN-2018: Cross-domain authorship attribution and style change detection. In: Working Notes of CLEF 2018 - Conference and Labs of the Evaluation Forum. CLEF ’18, Avignon, France (2018)
- 8[8] Khan, J.: Style breach detection: An unsupervised detection model—notebook for PAN at CLEF 2017. In: CLEF 2017 Evaluation Labs and Workshop – Working Notes Papers. CLEF ’17, Dublin, Ireland (2017)