TL;DR
This paper introduces entropy-based exploration (EBE), a novel method for reinforcement learning that adaptively explores the state space based on learning progress, leading to faster and more efficient training.
Contribution
The paper proposes EBE, an entropy-based exploration strategy that uses state-dependent action values to guide exploration without hyperparameter tuning.
Findings
EBE enables more efficient exploration in diverse environments.
Agents using EBE learn faster compared to traditional heuristics.
The method does not require hyperparameter tuning.
Abstract
Effective and intelligent exploration has been an unresolved problem for reinforcement learning. Most contemporary reinforcement learning relies on simple heuristic strategies such as -greedy exploration or adding Gaussian noise to actions. These heuristics, however, are unable to intelligently distinguish the well explored and the unexplored regions of state space, which can lead to inefficient use of training time. We introduce entropy-based exploration (EBE) that enables an agent to explore efficiently the unexplored regions of state space. EBE quantifies the agent's learning in a state using merely state-dependent action values and adaptively explores the state space, i.e. more exploration for the unexplored region of the state space. We perform experiments on a diverse set of environments and demonstrate that EBE enables efficient exploration that ultimately results in…
Click any figure to enlarge with its caption.
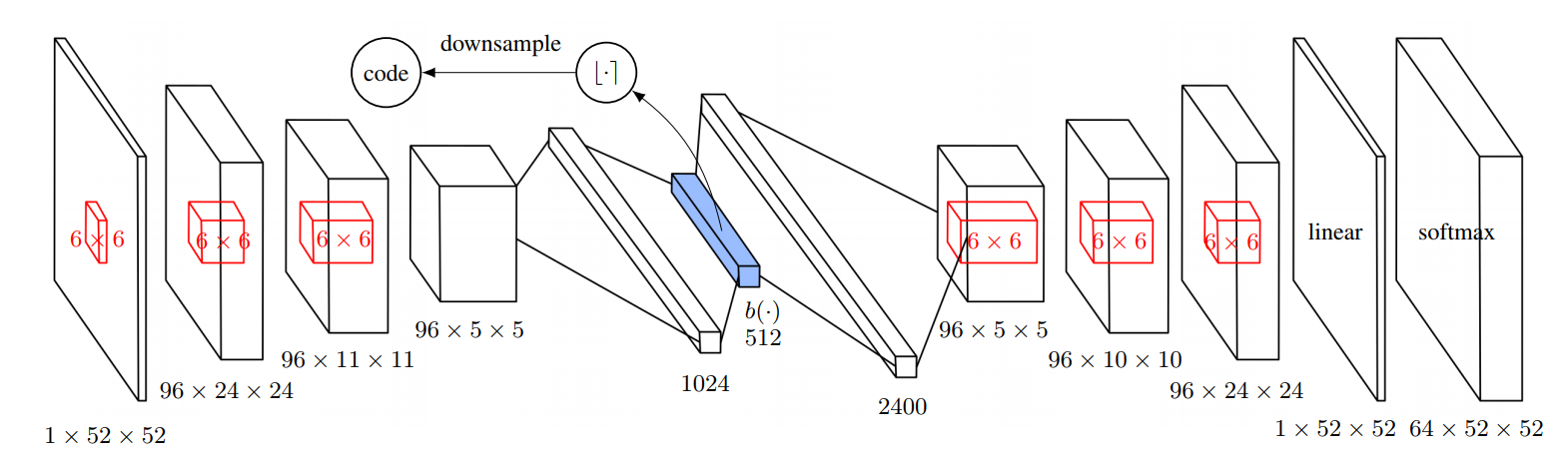 Figure 1
Figure 1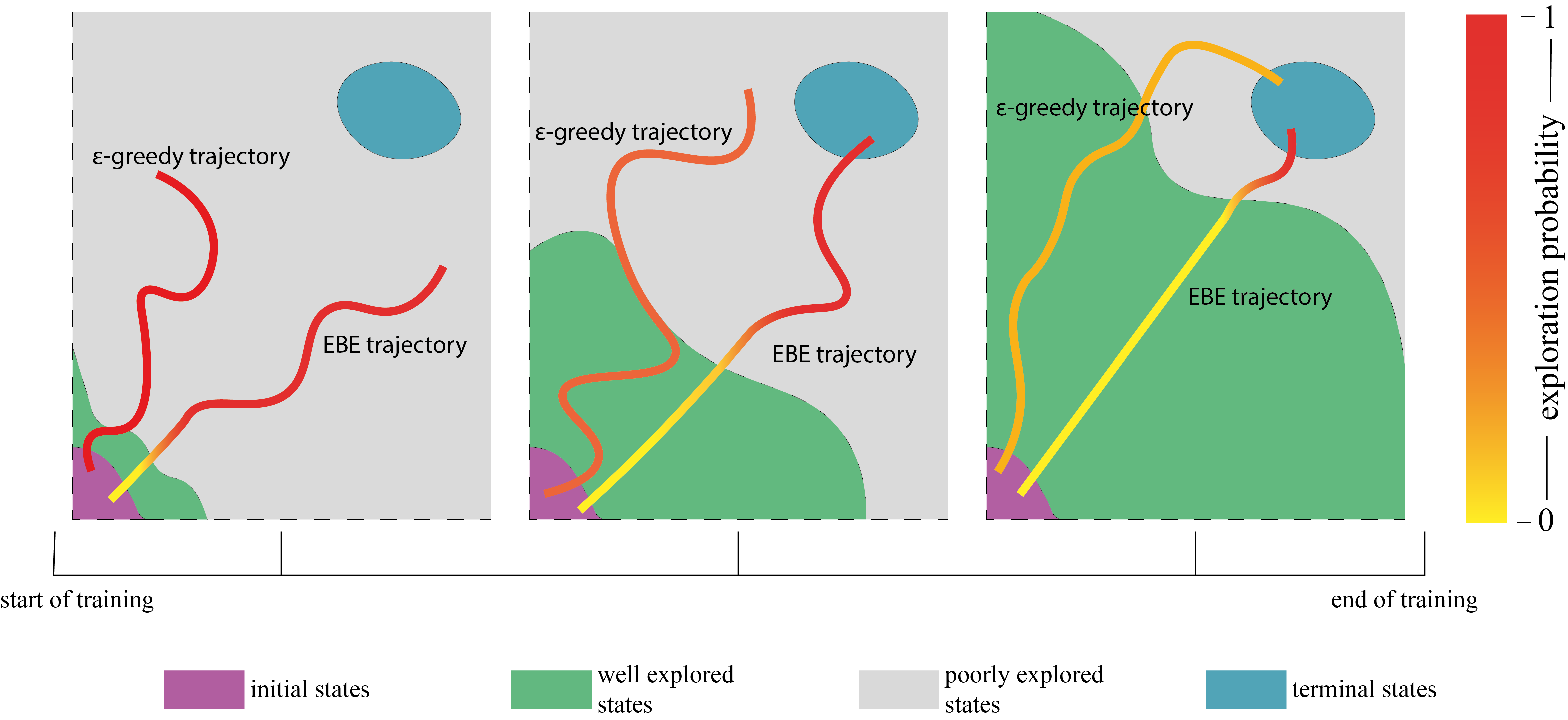 Figure 2
Figure 2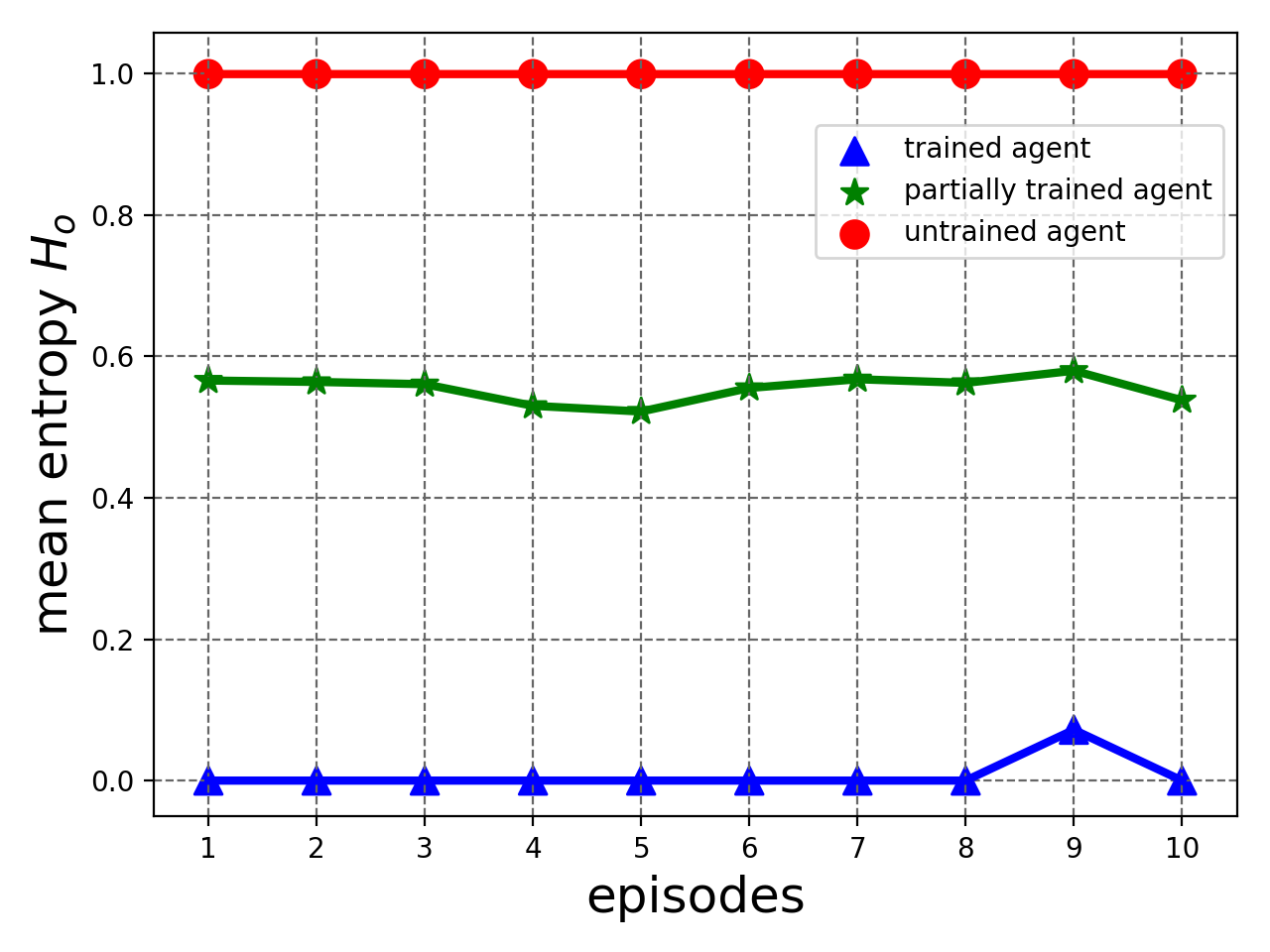 Figure 3
Figure 3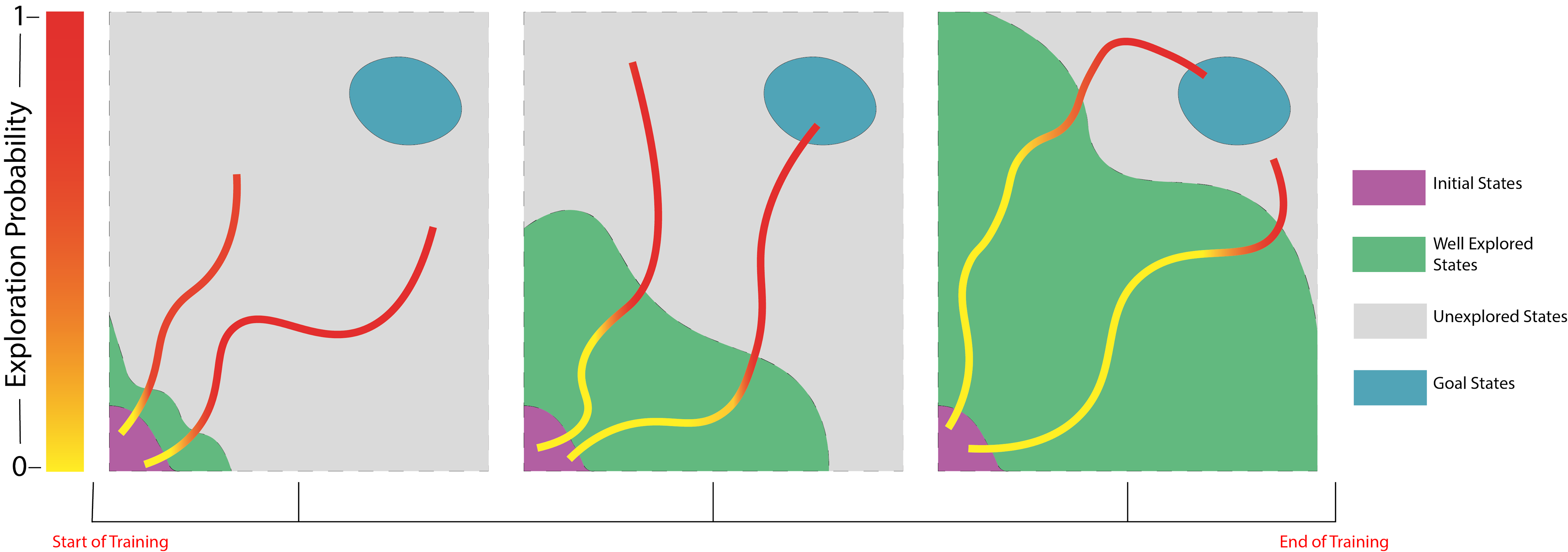 Figure 4
Figure 4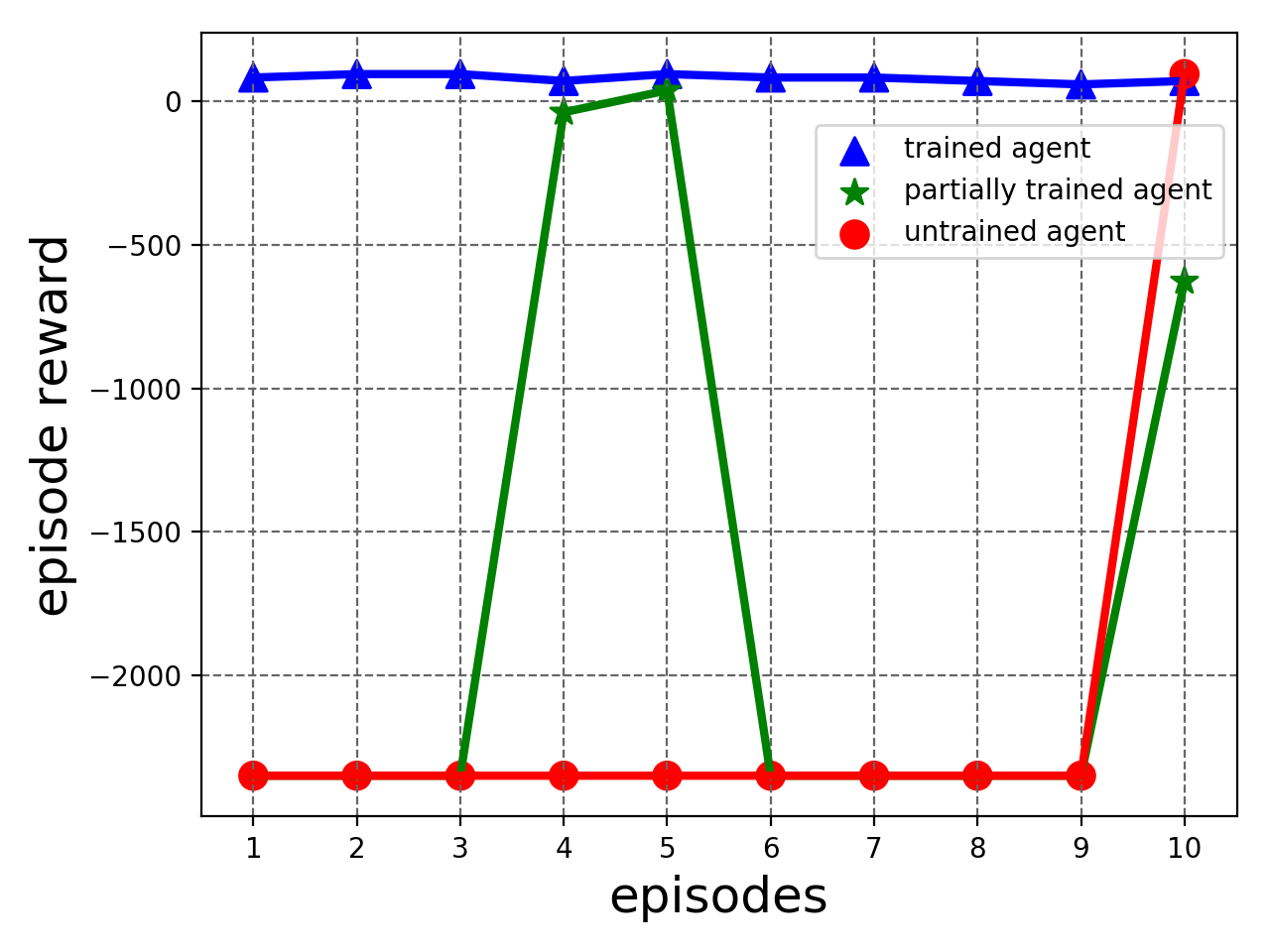 Figure 5
Figure 5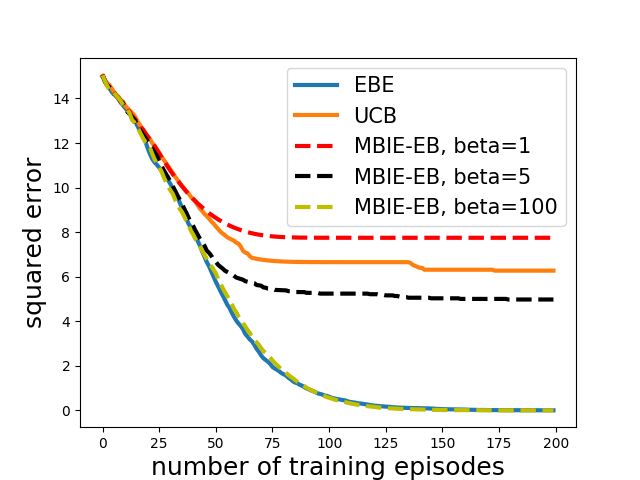 Figure 6
Figure 6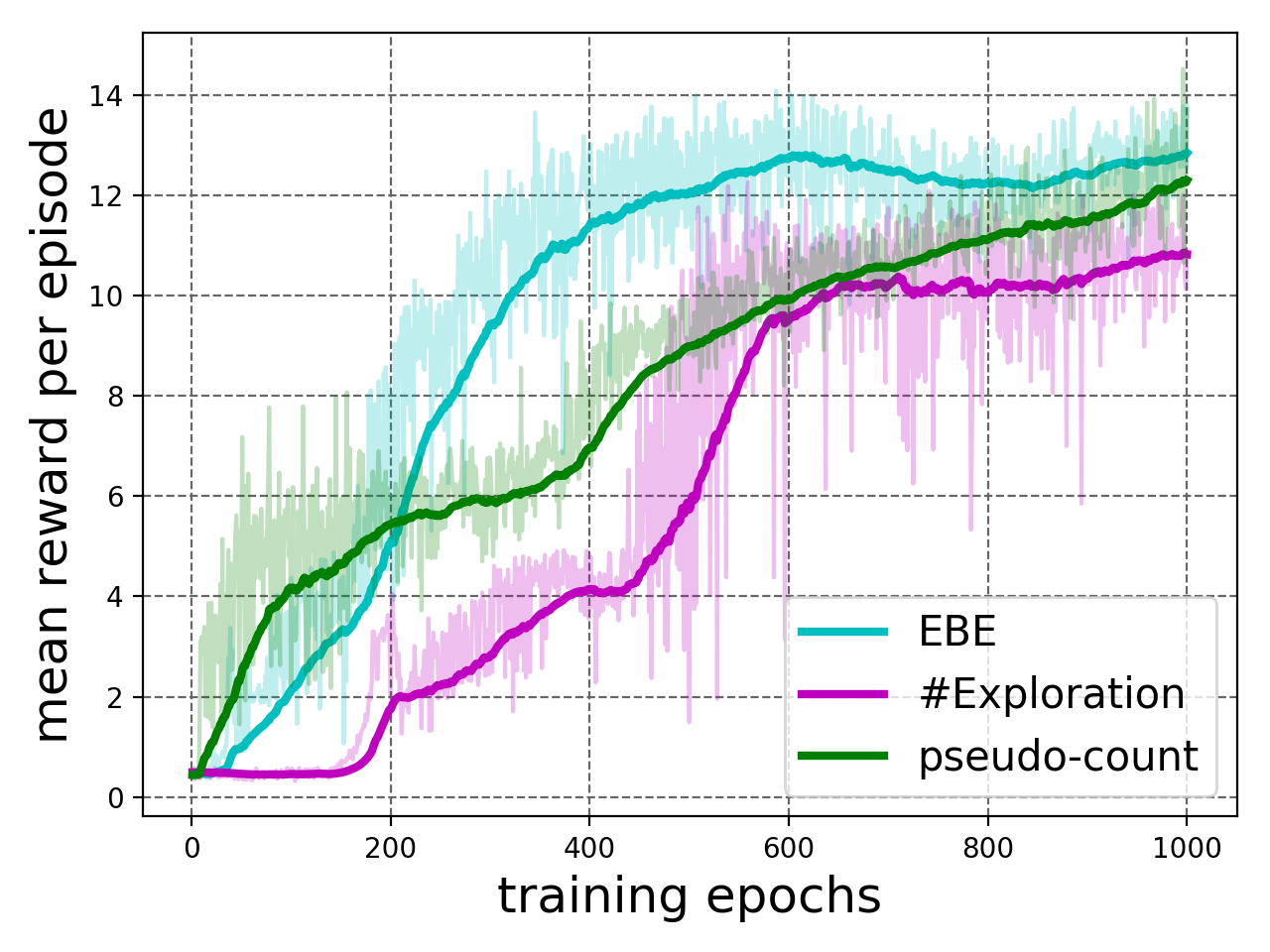 Figure 7
Figure 7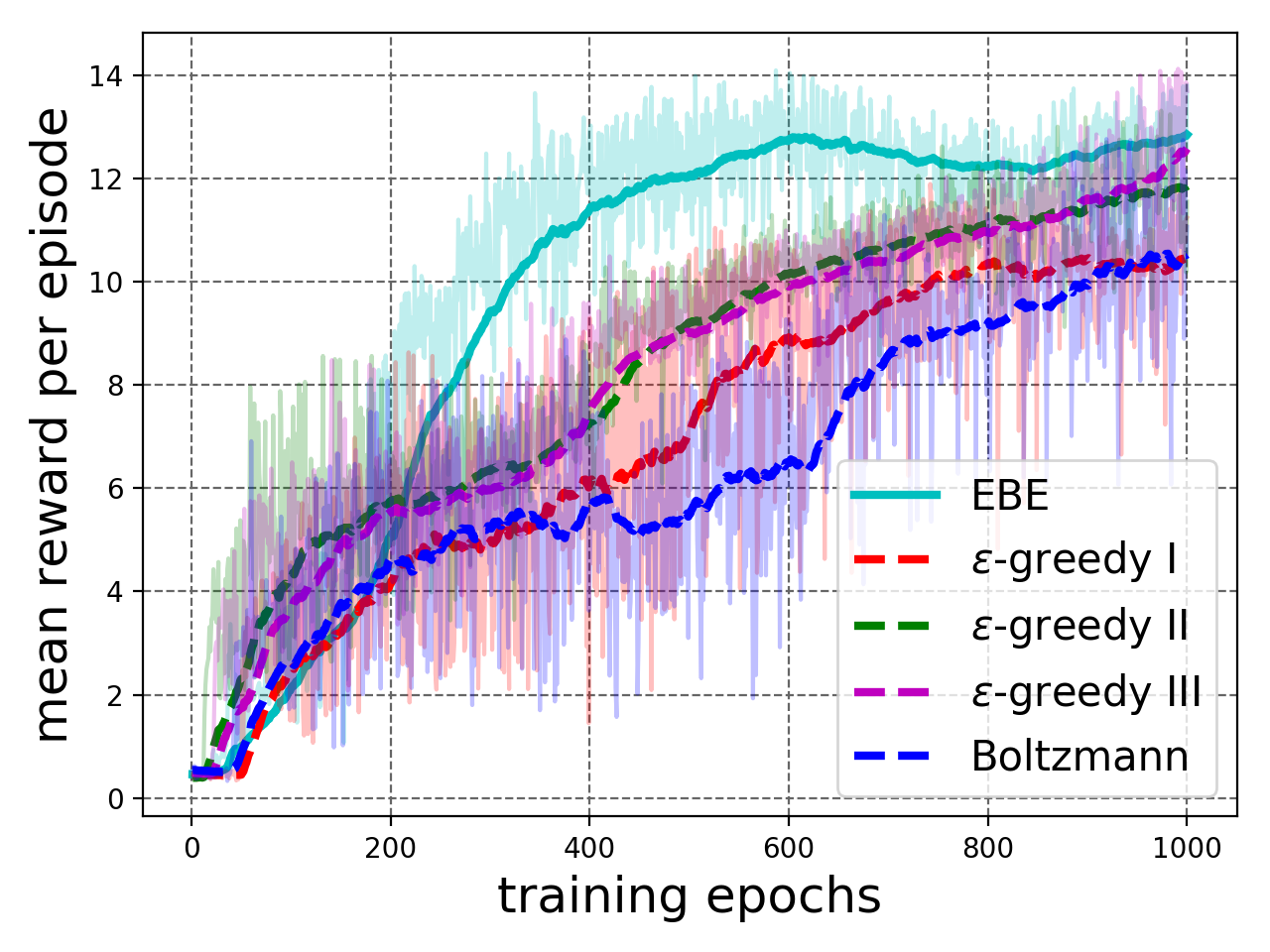 Figure 8
Figure 8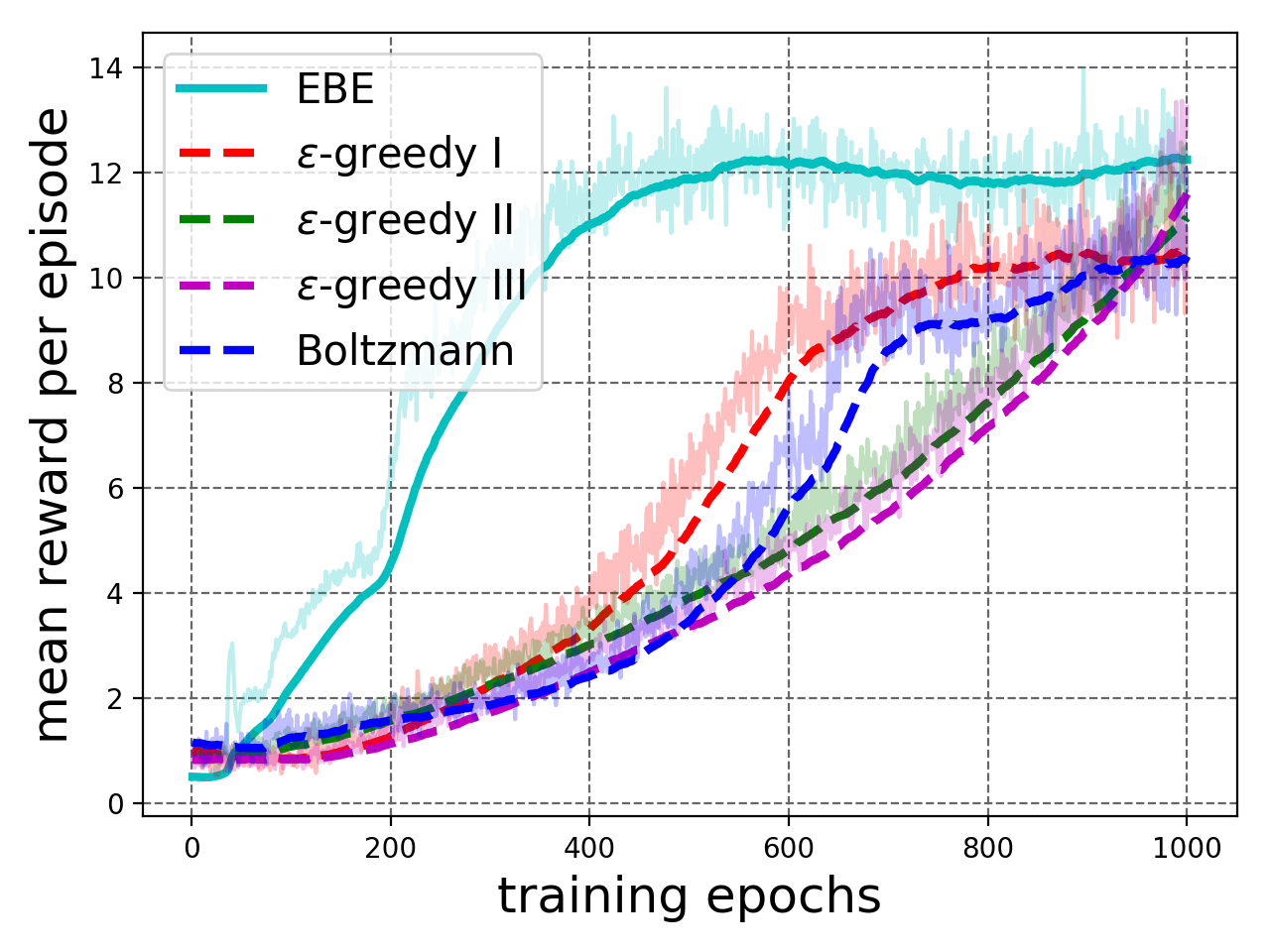 Figure 9
Figure 9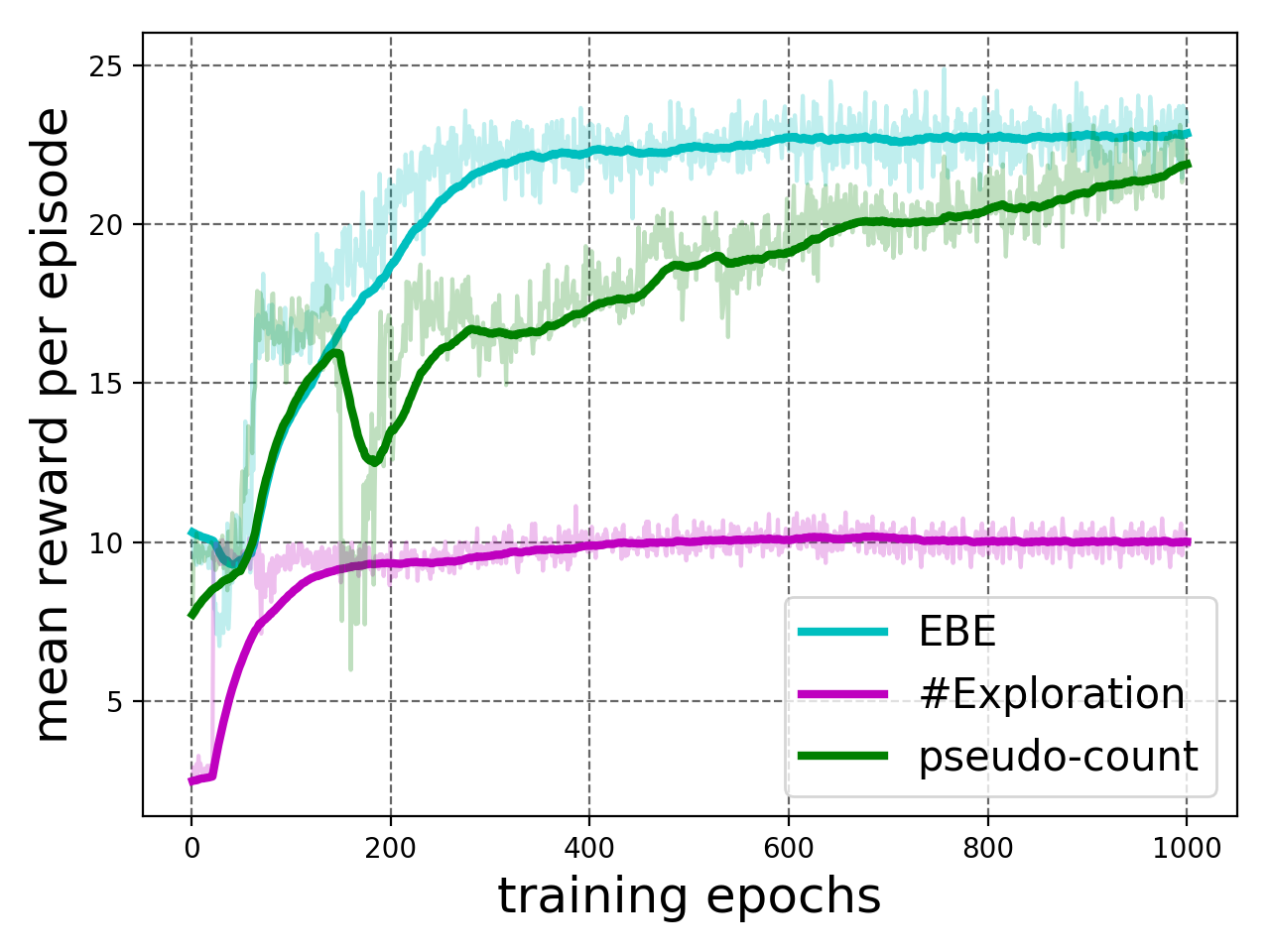 Figure 10
Figure 10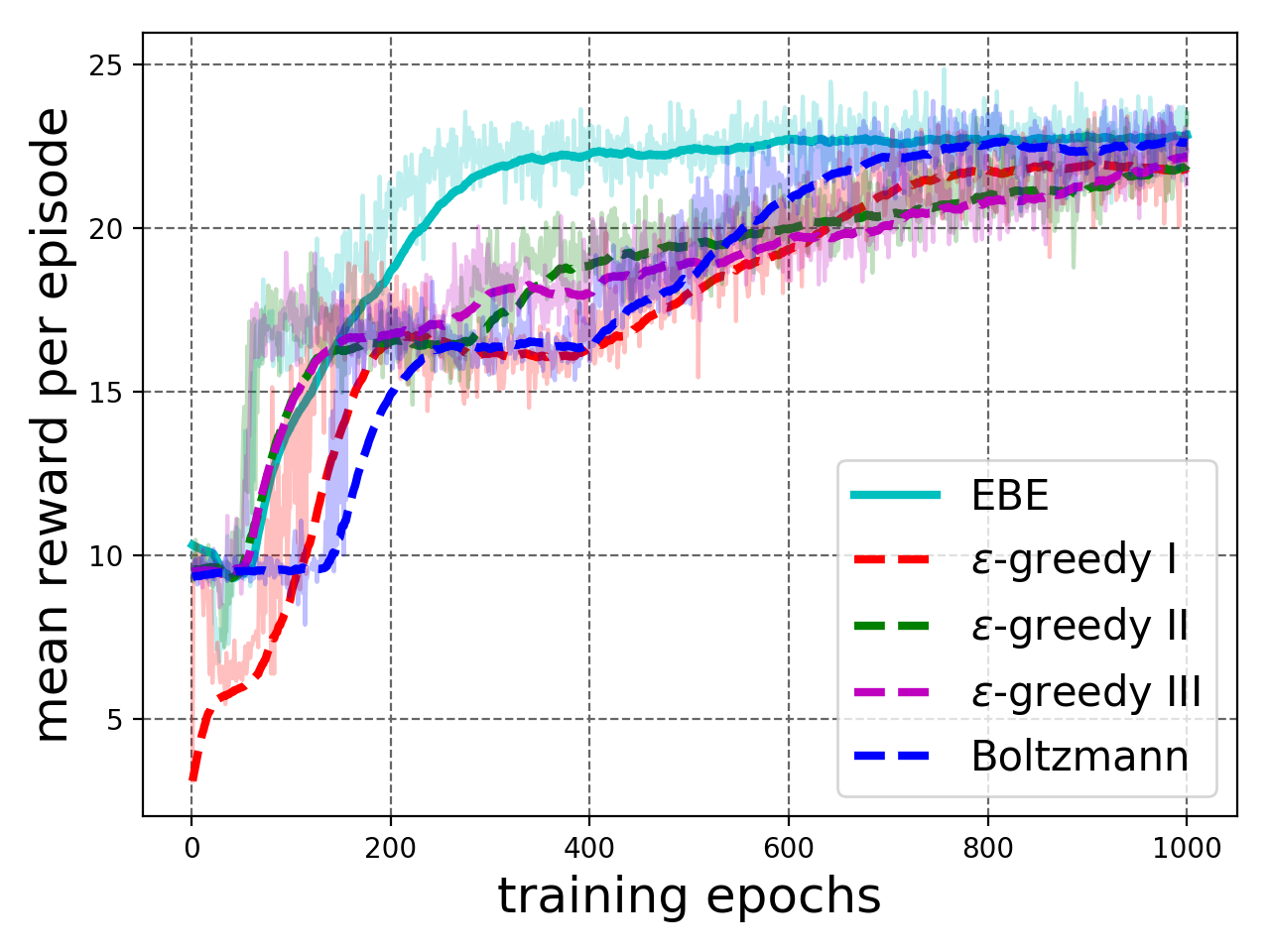 Figure 11
Figure 11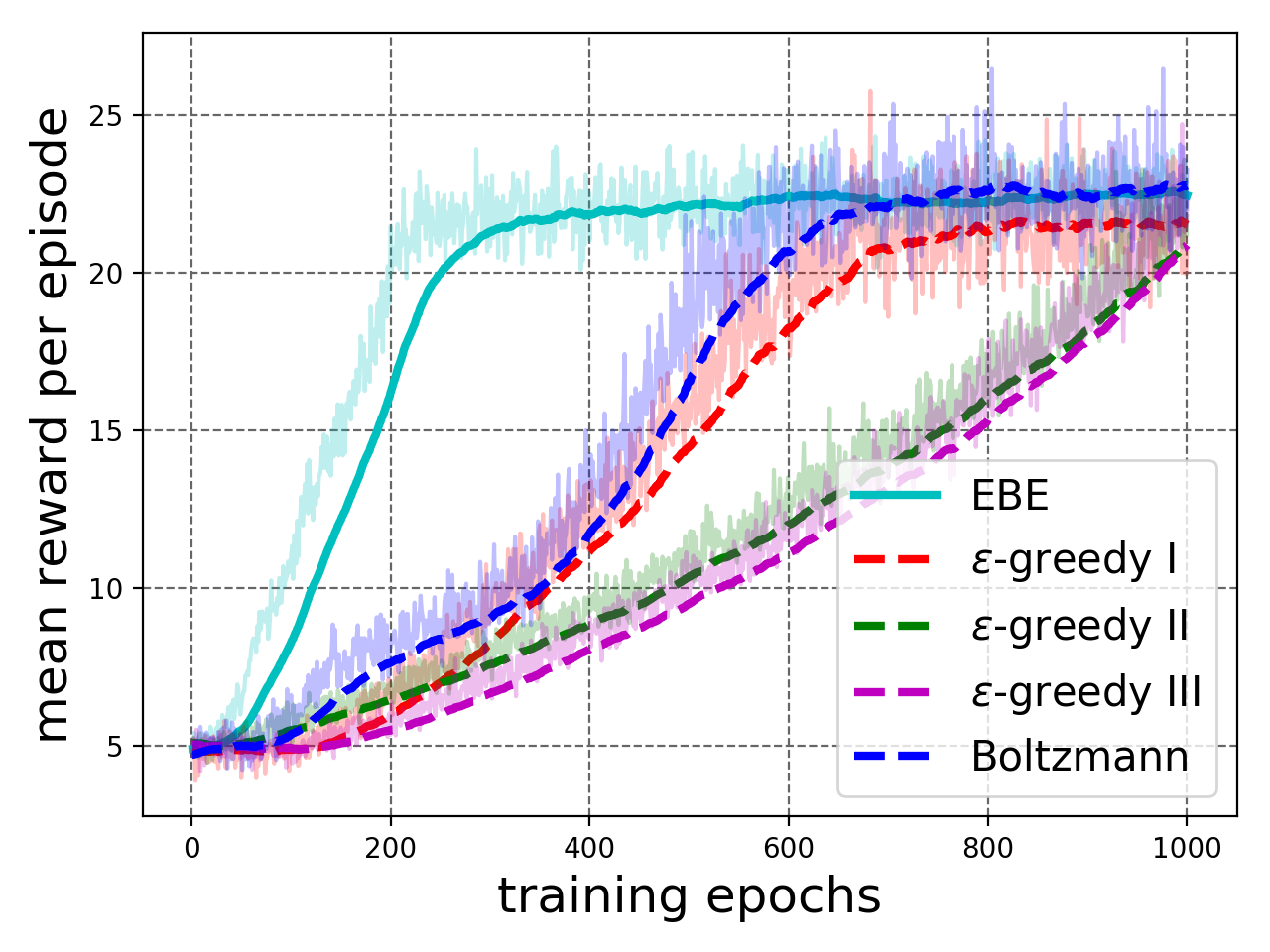 Figure 12
Figure 12 Figure 13
Figure 13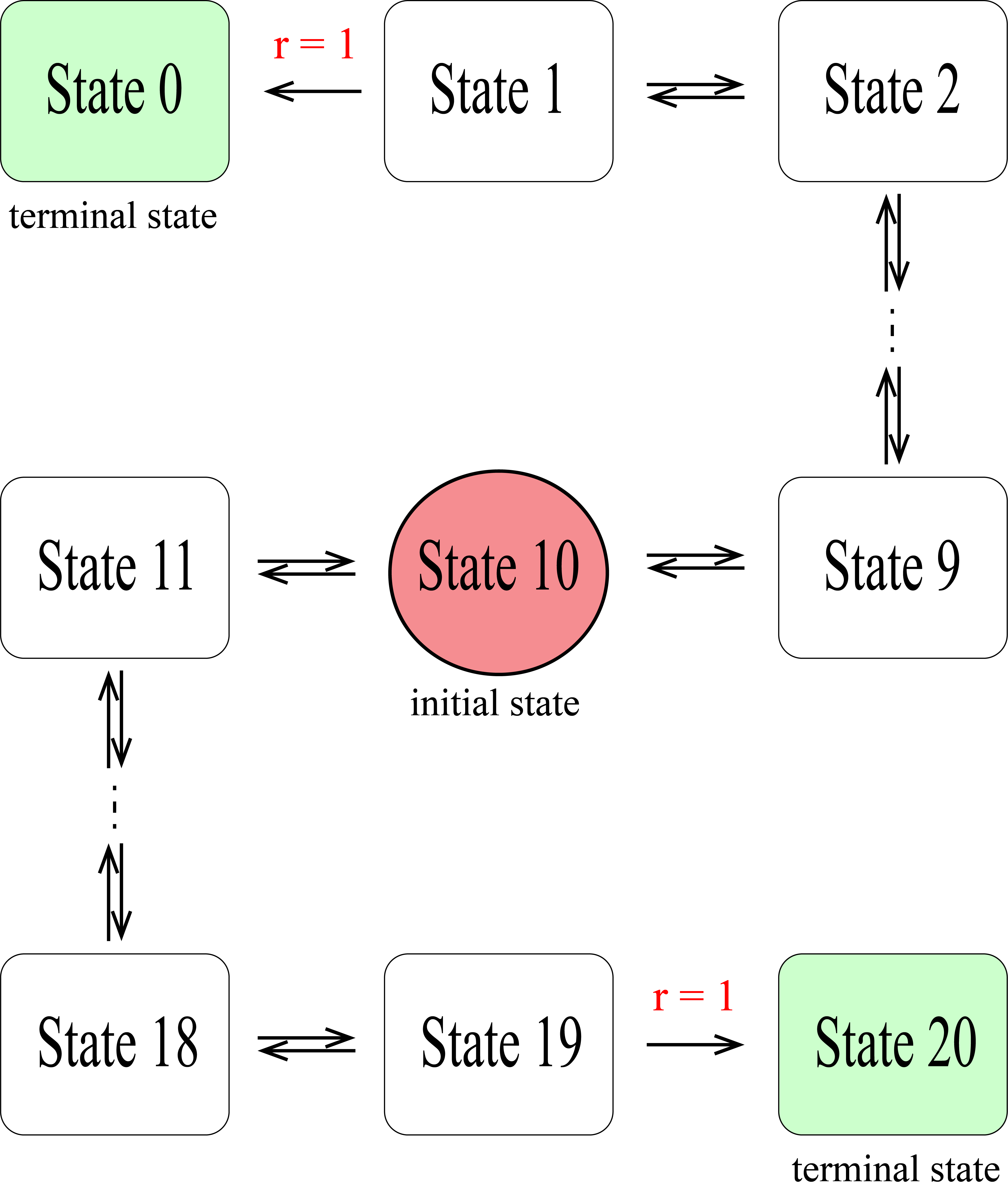 Figure 14
Figure 14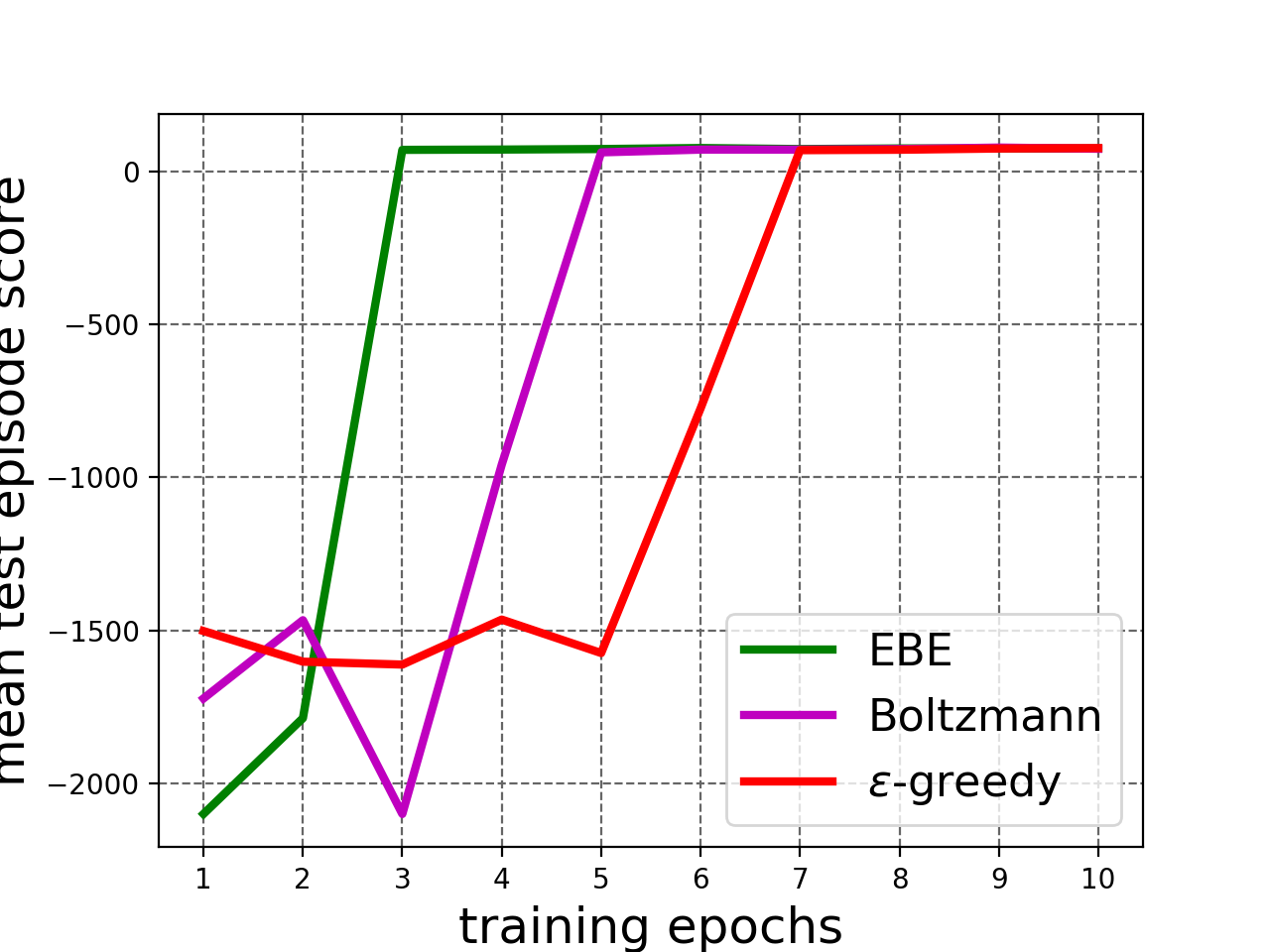 Figure 15
Figure 15 Figure 16
Figure 16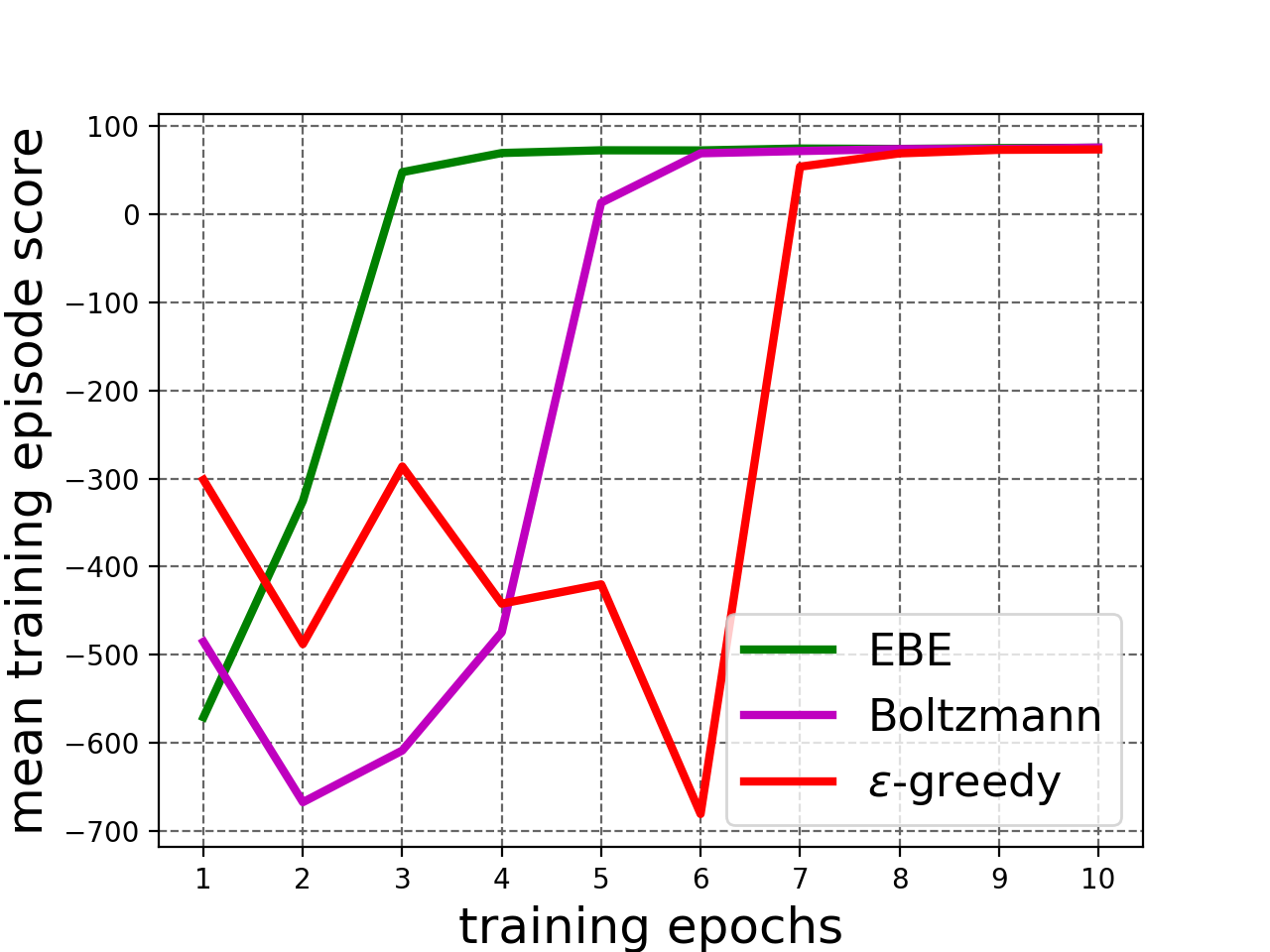 Figure 17
Figure 17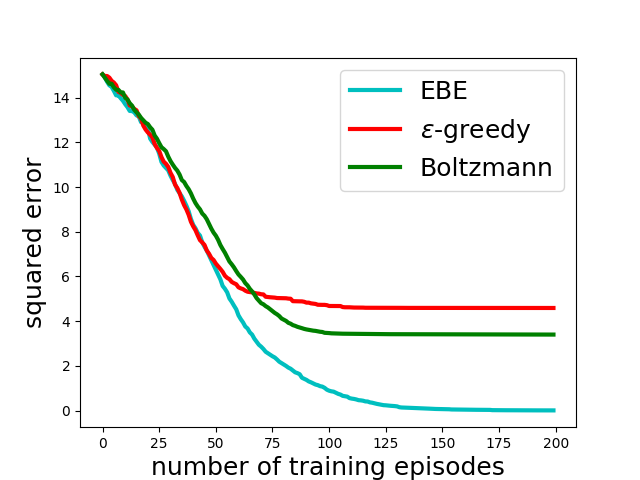 Figure 18
Figure 18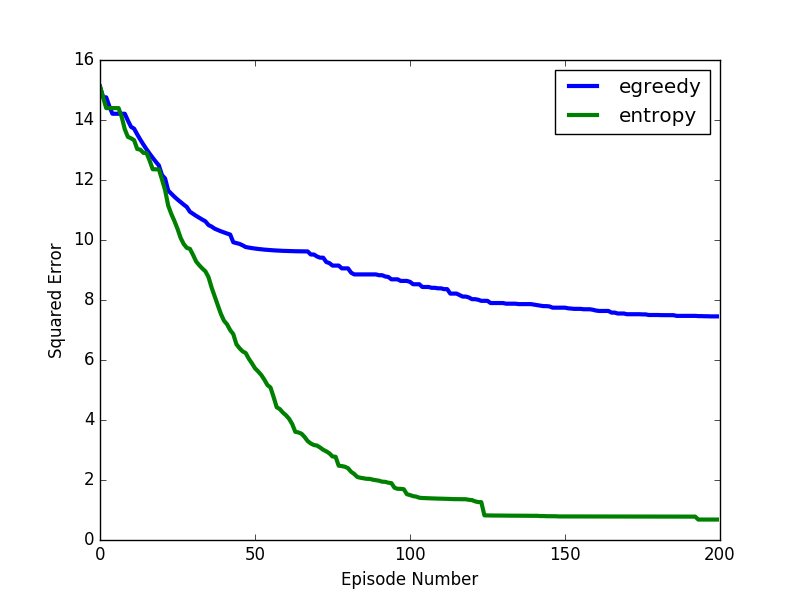 Figure 19
Figure 19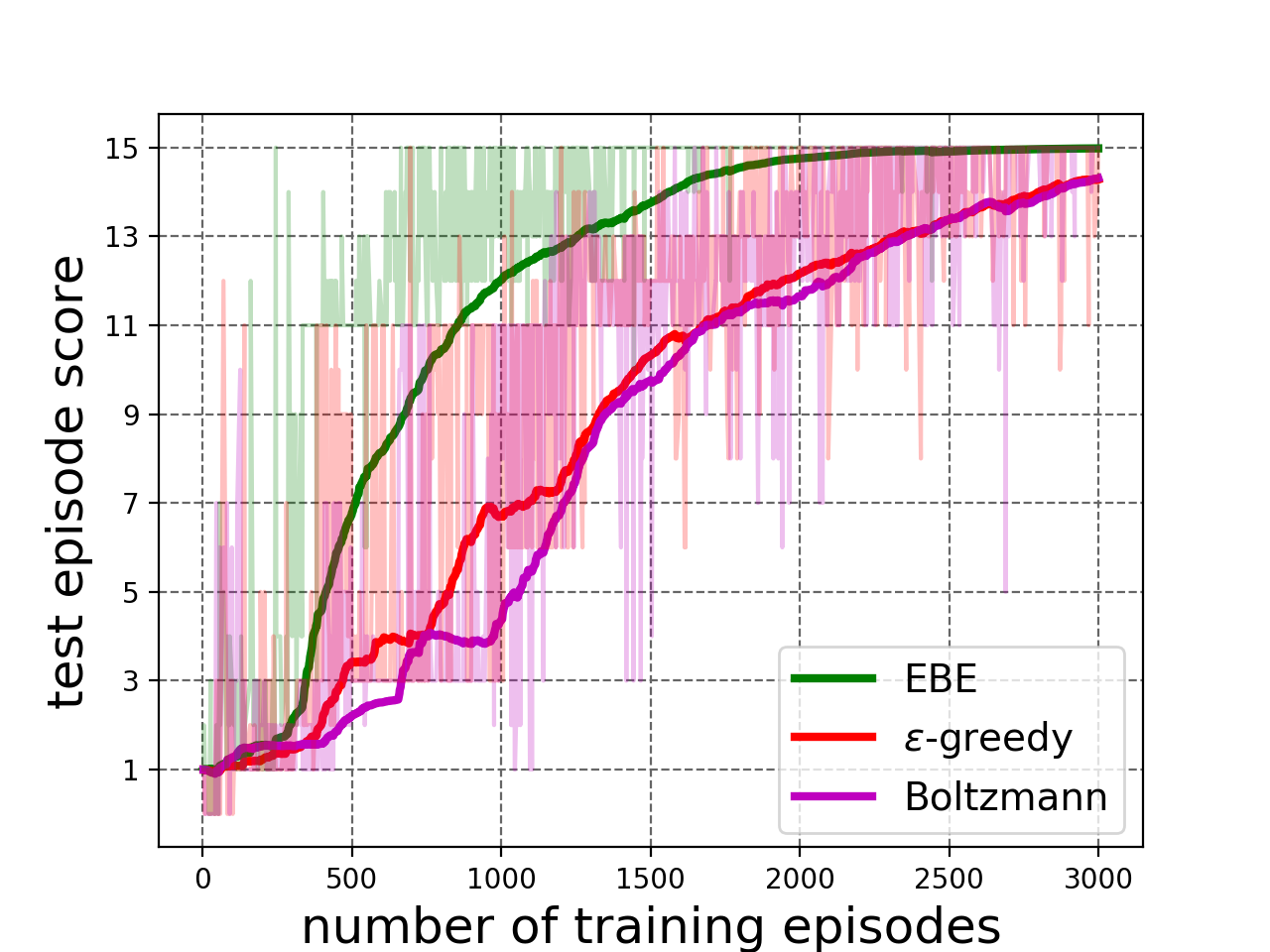 Figure 20
Figure 20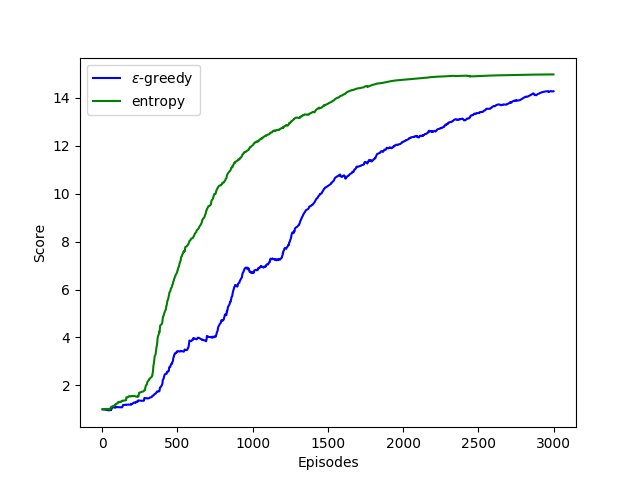 Figure 21
Figure 21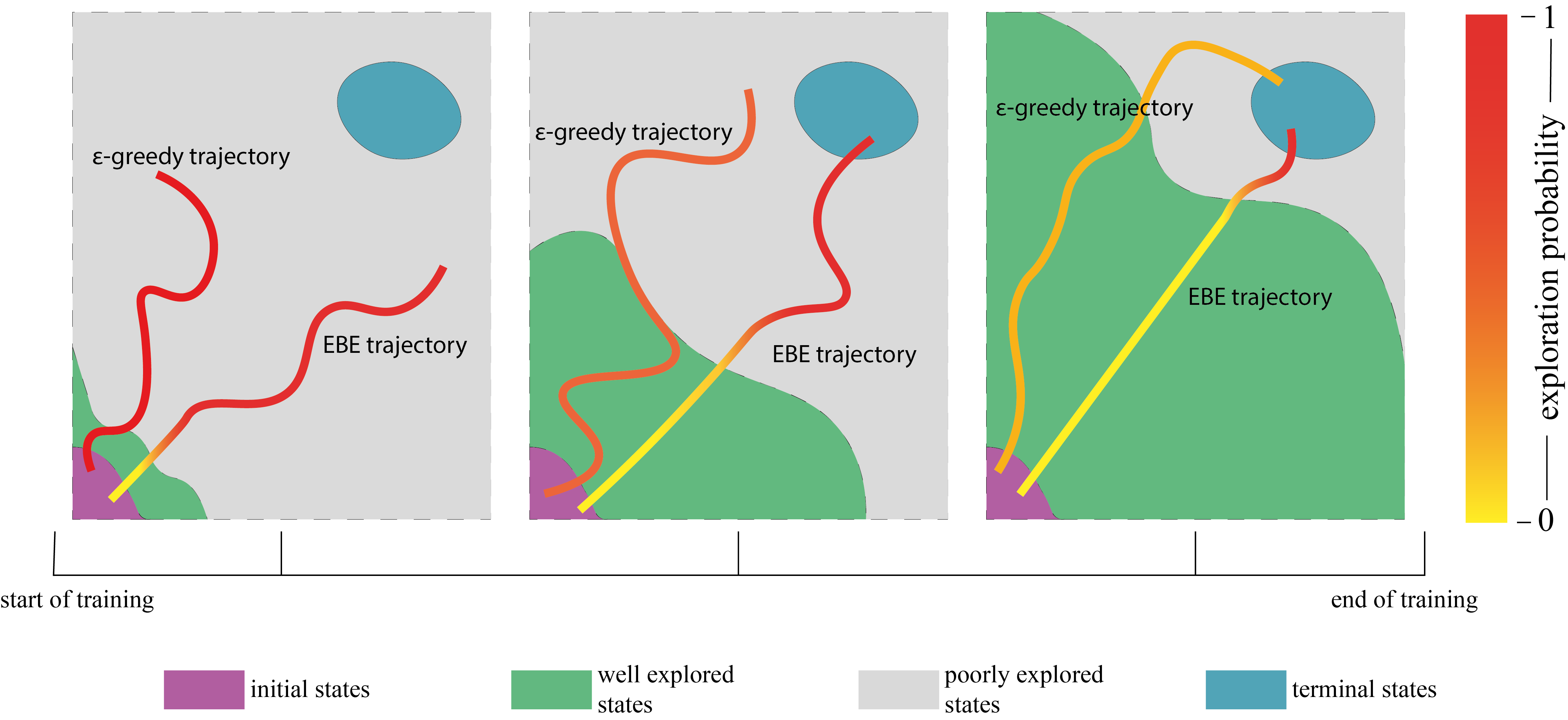 Figure 22
Figure 22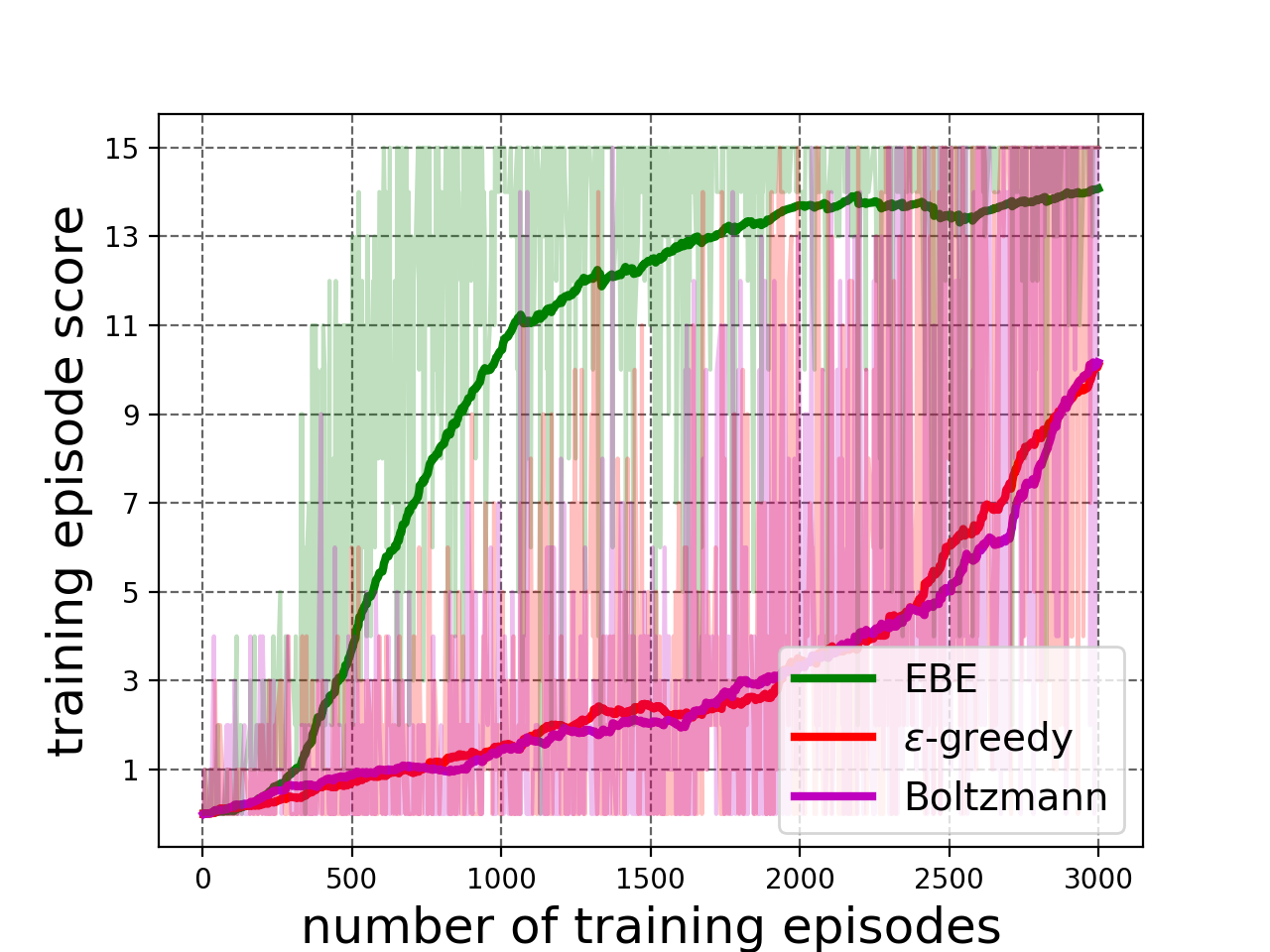 Figure 23
Figure 23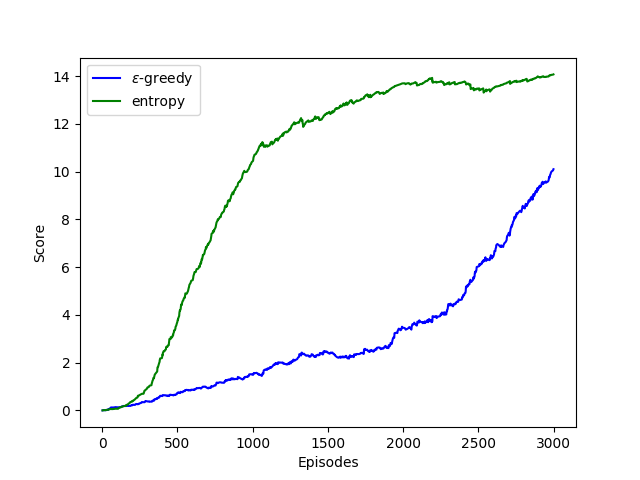 Figure 24
Figure 24 Figure 25
Figure 25| variant | details |
|---|---|
| -greedy I | 1.0 is used for first 100 epochs, then it is linearly annealed to 0.01 till 600 epochs. Afterwards 0.01 is used. |
| -greedy II | is linearly annealed from 1.0 to 0.01 over the entire training process. |
| -greedy III | is used for first 100 epochs. is then linearly annealed from 1.0 to 0.01 over the remaining training process. |
| Boltzmann | temperature is linearly annealed from 1.0 to 0.01. |
| game | EBE | -greedy | Boltz. | #Expl. | pseudo-count |
|---|---|---|---|---|---|
| DTC | 39 | 38 | 42.5 | 64 | 51.5 |
| DTL | 40 | 38 | 44 | 61.5 | 52 |
| Layer | input size | filter size | stride | no. of filters/neurons | activation | output size |
|---|---|---|---|---|---|---|
| CONV 1 | 1 | 32 | RELU | |||
| CONV 2 | 1 | 64 | RELU | |||
| FC 1 | 640 | - | - | 256 | RELU | 256 |
| FC 2 | 256 | - | - | 3 | LINEAR | 3 |
| Layer | input size | filter size | stride | no. of filters/neurons | activation | output size |
|---|---|---|---|---|---|---|
| conv 1 | 3 | 8 | RELU | |||
| conv 2 | 2 | 8 | RELU | |||
| FC 1 | 2880 | - | - | 128 | RELU | 128 |
| FC 2 | 128 | - | - | Linear |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Learning-Driven Exploration for Reinforcement Learning
Muhammad Usama and Dong Eui Chang 1The authors are with Control Laboratory, School of Electrical Engineering, Korea Advanced Institute of Science and Technology (KAIST), Daejeon, Republic of Korea. {usama, dechang}@kaist.ac.kr* corresponding author
Abstract
Effective and intelligent exploration has been an unresolved problem for reinforcement learning. Most contemporary reinforcement learning relies on simple heuristic strategies such as -greedy exploration or adding Gaussian noise to actions. These heuristics, however, are unable to intelligently distinguish the well explored and the unexplored regions of state space, which can lead to inefficient use of training time. We introduce entropy-based exploration (EBE) that enables an agent to explore efficiently the unexplored regions of state space. EBE quantifies the agent’s learning in a state using merely state-dependent action values and adaptively explores the state space, i.e. more exploration for the unexplored region of the state space. We perform experiments on a diverse set of environments and demonstrate that EBE enables efficient exploration that ultimately results in faster learning without having to tune any hyperparameter.
The code to reproduce the experiments is given at https://github.com/Usama1002/EBE-Exploration and the supplementary video is given at https://youtu.be/nJggIjjzKic.
I Introduction
Reinforcement learning (RL) is a sub-field of machine learning where an agent interacts with its environment to learn a policy that maximizes the cumulative reward over a horizon. Since the agent does not begin with perfect knowledge of the environment dynamics, it has to learn solving the task through the process of exploration, thus, giving rise to the fundamental trade-off between exploration vs exploitation. A long-standing problem in RL is to find ways to achieve better trade-off between exploration and exploitation.
In this work, we argue that state dependent action values can provide valuable information to the agent about its learning progress in a state. We use the concept of entropy from information theory to quantify agent’s learning in a state and the algorithm subsequently decides whether to explore in a state based on it. This minimizes the prospects of unnecessary exploration while still exploring the poorly explored regions of the state space.
II Preliminaries
II-A Reinforcement Learning
Reinforcement learning [1] is a sequential decision making process in which an agent, while in state of environment , at time step , chooses an action from set following a policy and receives a reward and transitions into next state following transition or dynamics model . The goal of any RL algorithm is to maximize the expected discounted return , where is the discount factor. Given a policy , the state dependent action and the state value functions are defined as and , respectively. We use a deep -network (DQN) [2] to approximate the high-dimensional action value function, .
II-B Entropy
The entropy of a discrete random variable with probability distribution is defined as
[TABLE]
III Entropy-Based Exploration (EBE)
In this section, first, we go through the motivation behind EBE and then we present the mathematical realization of the concept.
III-A Motivation
An efficient exploration strategy should adapt itself to explore more in poorly explored regions of the state space, which we refer to as learning-driven exploration. This allows the agent to explore deeper into the state space resulting in deep111the word deep is used here in different context from deep learning. exploration. Our definition of deep exploration is different from [3] where deep exploration means ”exploration which is directed over multiple time steps or far-sighted exploration” [3]. In our work, deep exploration concerns spatially extended exploration in the state space.
This concept is illustrated in Figure 1 where EBE and -greedy exploration are depicted by two separate trajectories at three different stages of the presumed training process. The redness of a trajectory indicates the exploration probability in that state. The exploration probability for EBE increases as we move towards an unexplored region of the state space. But for -greedy exploration where the value of is annealed from the start to the end of the training process, at a particular instant in training, the agent explores in all states with the same probability irrespective of the knowledge it already has acquired. Adaptive exploration by EBE enables the agent to allocate more resources towards exploring the relatively poorly understood regions of the state space, thus improving the learning progress.
III-B Entropy-Based Exploration (EBE): A Realization of Learning-Driven Deep Exploration
The agent quantifies the utility of an action in a state in the form of state-dependent -values. We use the difference between , where , in a state as an estimate of the agent’s learning progress in that state. Therefore, we use -values to define a probability distribution over actions in a state, i.e.
[TABLE]
Since may cause numerical overflow when is large, we use the so-called max trick in equation (1) to improve numerical stability.
We use to obtain the normalized state dependent entropy, , as follows
[TABLE]
The entropy in equation (2) quantifies the agent’s learning in state : the lower the entropy , the more learned the agent is as some actions are better than the others. Therefore, we use to guide exploration in a state. Given in a state from equation (2), the agent explores with probability i.e. it behaves randomly. In practice, EBE is similar to -greedy exploration method with replaced with the state dependent .
III-B1 How does entropy estimate agent’s learning in a state?
The state space can be broadly classified into two categories: states in which a choice of action is crucial and states in which a choice of action does not significantly impact what happens in the future [4]. For the former set of states, some actions are decisively better than the others. Quantitatively, it means that -values of the better actions are significantly higher than -values of the remaining actions. Therefore, the distribution defined in equation (1) is highly skewed towards better actions and by equation (2), the entropy of these states is low. Note that the lowest achievable entropy may be different for different states.
Consider, for example, the case where the agent is trained to play VizDoom game Seek and Destroy (see Section IV-C1 for details). We consider three cases consisting of an untrained agent222the -network was initialized using Kaiming Uniform method [5] and no further training was performed., a partially trained agent333the agent was trained using EBE for two epochs only. and a trained agent444the agent was trained using EBE for 20 epochs. Here, we define as entropy averaged over an entire episode, i.e.
[TABLE]
where is the number of steps in the episode, represents the state at step and is given in equation (2). We test the agents for 10 episodes. Figure 2 plots and the accumulated episode reward versus test episodes. We see that the trained agent has the lowest (Fig. 2(a)) and the highest accumulative reward (Fig. 2(b)) for all episodes. The partially trained agent still has significant for all episodes which reflects its incomplete learning while untrained agent has the highest and the lowest reward.
These results show that entropy is a good measure to estimate agent’s learning in a state, which in turn can be used to quantify the need for exploration. This forms the basis for our proposed entropy-based exploration strategy.
III-B2 How EBE is different from Boltzmann Exploration?
EBE uses entropy of a state , as defined in equation (2), to decide whether to explore in a state. Boltzmann exploration, on the other hand, does not use the entropy of a state and probabilistically explores in a state based on probability , where is the temperature.
IV Experiments
We demonstrate the performance of EBE on many environments including a linear environment, a simpler breakout game and multiple FPS games of Vizdoom [6]. Results shown are averaged over five runs.
IV-A Value Iteration on Simple Linear Environment
We start experiments on a simple value iteration task as this task is devoid of many confounding complexities and provides better insight into used methods. Moreover, exact optimal -values, for all , can be computed analytically which helps monitor the learning progress.
The environment is described in Figure 3(a). We use temporal difference based tabular Q-learning without eligibility traces to learn the optimal -values, for all .
As baselines, we use -greedy exploration where the value of is linearly annealed from 1.0 to 0.0 over the number of episodes and Boltzmann exploration where the temperature is linearly decreased from 0.8 to 0.1. The evaluation metric is the mean squared error between the actual -values, , and the learned -values, :
[TABLE]
The squared error is plotted in Figure 3(b). We see that -values learnt with EBE converge to the optimal -values while others fail. This is a very promising result as it indicates the ability of EBE to adequately explore the state space.
IV-B Breakout Game
Next, we experiment with breakout game complex enough to offer significant learning challenge as it uses a neural network as a function approximator and works on raw images as states. There are 15 bricks in total and the agent gets a reward of 1 point for breaking a brick. An episode ends when one of the following happens: all bricks are broken, the paddle misses the ball or the maximum number of steps has been reached. We use a stack of 2 images: the current image and the previous image, as our state observation. In a state, the agent opts to do nothing or move the paddle left or right. EBE is compared to -greedy exploration in which is linearly annealed from 1.0 to 0.0 over the number of episodes and Boltzmann exploration where temperature is linearly annealed from 1.0 to 0.01 over training process. See Appendix I-A for details regarding the experimental setup.
The results are shown in Figure 4. EBE results in faster learning than baselines (Figure 4(a)). As seen in Figure 4(b), the agent trained with EBE starts performing episodes with higher reward early on in the training process as compared to the other agents, which validates our hypothesis of deep exploration, in which the agent transitions quickly into the poorly explored region of the state space, which usually corresponds to the later states of a training episode.
IV-C VizDoom
We use the following environments from VizDoom platform [6] to conduct experiments.
IV-C1 Seek and Destroy
Here, the agent is tasked to shoot an attacking monster spawned randomly on the opposite wall of the room. The gun can only fire straight, so the agent must come in line with the monster before firing. The agent gets a reward of 101 point for shooting the monster, for firing each shot and for each step taken. The agent gets raw images as state observations. It can either move left, move right or fire a shot in a state. The episode ends when either the monster is dead, the player is dead or 300 time steps have passed.
We compare EBE with Boltzmann and -greedy exploration strategies. In Boltzmann exploration, the temperature parameter is linearly annealed from 1.0 to 0.01 over the training epochs. For -greedy exploration, is set to 1.0 for first epoch, then is linearly annealed to 0.01 till epoch 6. Thereafter, is used. See Appendix I-B for details about the training setup.
The results are shown in Figure 4. Mean test scores in Figure 4(c) show that EBE-trained agent outperforms the agents trained with baselines. Similarly, we see in Figure 4(d) that EBE exploration results in high reward training episodes considerably earlier in training manifesting deep exploration (Section III-A).
IV-C2 Defend the Center (DTC)
In this environment, the agent is tasked to shoot at attacking monsters spawned around it in a circle. It can only rotate about its position. The agent is provided with 26 ammo and it gets a reward of point for each kill and for getting killed itself. The episode ends when the agent is dead or 2100 steps (60 seconds) have passed. The agent observes the state using raw frames and can either attack, turn left and turn right in a state. An episode is considered successful if the agent kills at least 11 monsters before being dead itself, i.e. scores at least 10 points.
We compare EBE with baselines detailed in Table I. Details about the experimental setup are given in Appendix I-B.
The experimental results are shown in Figure 5. We see in Figure 5(a) that the agent trained with EBE exploration attains the maximum mean test reward per episode after about 60% of training epochs as compared to the other exploration strategies. Moreover, Figure 5(b) shows deep exploration, defined in Section III-A, where EBE was able to perform high reward training episodes early on in the training process. This result shows effectiveness of EBE on high-dimensional RL task that enables effective exploration without having to tune any hyperparameter.
IV-C3 Defend the Line (DTL)
This environment is similar to DTC except that the agent placed is on one side of the room and monsters are spawning on the opposite wall. The agent is rewarded one point for each kill and penalized one point for being dead. Here, the agent is provided with unlimited ammunition and limited health that decreases with each attack the agent takes from the monsters. The agent observes raw frames and can attack, turn left or turn right in a state. The episode ends when the agent is dead or episode times out with 2100 steps (60 seconds). The goal is to kill at least 16 monsters before the agent dies, i.e. to obtain at least 15 points in one episode. EBE is compared to the same baselines as considered in Section IV-C2, see Table I. Details about the experimental setup are given in Appendix I-B.
The experimental results are shown in Figure 5. Figure 5(c) shows that agent trained with EBE exploration attains the maximum mean test reward after about 30% of training epochs as compared to other exploration strategies. Moreover, Figure 5(d) shows deep exploration, defined in Section III-A, where EBE was able to perform high reward training episodes early on in the training process.
IV-D Comparison of EBE with Count-Based Exploration
Some of the classic and theoretically-justified exploration methods are based on counting state-action visitations and turning this count into a bonus reward to guide exploration. In the bandit setting, the widely-known Upper-Confidence-Bound (UCB) [8] chooses the action that maximizes where is the estimated reward of executing and is the number of times the action was previously chosen. Similar algorithms for MDP setting select action at time that maximizes where is the number of visitations of . Here, is the exploration bonus that decreases with the increase in . Model Based Interval Estimation-Exploration Bonus (MBIE-EB)[9] proposed with constant. For MDPs, we can get .
We compare EBE with UCB and MBIE-EB on linear MDP environment considered in Section IV-A under the same experiment settings. As shown in Figure 6(a), EBE performs better than UCB in terms of convergence. The performance of MBIE-EB improves as the value of is increased and with , the performance of MBIE-EB becomes comparable to EBE.
MBIE-EB, UCB and related algorithms assume that the MDP is solved analytically at each timestep, which is only practical for small finite state spaces. Therefore, counting-based methods cannot be extended to high-dimensional, continuous state spaces where states are rarely visited more than once. [10] allows generalization of count-based exploration algorithms to the non-tabular case by deriving pseudo-counts from arbitrary density models over the state space. Exploration algorithm [11] uses hashing to discretize the high-dimensional state space which visitation counts using a hash table.
We compare EBE with pseudo-count based exploration algorithm[10] and #Exploration[11]. See Appendix II for implementation details of these baselines. Figure 6(b) shows the results for VizDoom game Seek and Destroy. EBE and #Exploration are able to learn solving the task with EBE learning much earlier while pseudo-count algorithm failed to solve the task. Similarly, Figure 6(c) and Figure 6(d) show comparison results for DTC and DTL, respectively. For both games DTC and DTL, EBE depicts efficient exploration by learning to solve the tasks with higher rewards much earlier than the baselines. However, #Exploration strategy settles at a much lower score for both the games. The following table provides the wall time (in hours) averaged across five runs for DTL and DTC.
-greedy exploration is the most efficient in terms of wall time, followed by EBE. #Exploration incurs needs training time due to online training of autoencoder used for hash codes [11] as well.
IV-E Swing-up Control of Rotary Inverted Pendulum
We compare EBE with Boltzmann and -greedy exploration to perform the swing-up control of a rotary inverted pendulum. We use Quanser Qube [12] as our experimental platform as shown in Figure 7(a). We use deep -learning with prioritized experience replay [13] to learn a policy to swing the pendulum up to its upright position and use a PD controller to balance it in its upright position. The state observation consists of angle of horizontal arm, angle of pendulum with respect to its upright position and angular velocities and . Angles and are shown in Figure 7(b). The reward function used for agent learning is given as
[TABLE]
where . The RL agent swings the pendulum upright and we switch to PD controller when . We perform training on the simulator provided by [14] and transfer the learnt policies to real system without any fine tuning.
We compare EBE exploration to the following two baselines: greedy exploration and Boltzmann exploration. For greedy exploration, we use , where , and for Boltzmann exploration we use temperature value of . For training setup details, see Appendix I-C. The results are shown in Figure 7(c) which plots the mean reward of five independent runs. We see that EBE learns higher reward episodes than any of the baselines. We also visualize the quality of learnt policies in our supplementary video provided at https://youtu.be/nJggIjjzKic.
V Related Work and Discussion
Existing entropy-based exploration strategies can be broadly divided into two categories [15]: entropy regularization [16] for RL and maximum entropy principle for RL. Entropy regularization methods, such as [17, 18, 19], attempt to alleviate the problem of premature convergence in policy search by imposing information-theoretic constraints on the learning process. [20] shows that entropy regularization yields better optimization properties. Maximum entropy principle methods for RL aim to encourage exploration by optimizing a maximum entropy objective. Authors in [21, 22, 23, 24, 25] simply augment the conventional RL objective with the entropy of the policy. [26, 27] used the maximum entropy principle to make MDPs linearly solvable while [28] employed the maximum entropy principle to incorporate prior knowledge into the RL setting.
Our proposed method belongs to the class of methods that use quantification of uncertainty for exploration. [29] maximizes the information that the most recent state-action pair carries about the future, while [30] maximizes the information gain about the agent’s belief of the environment dynamics. Using information gain for exploration can be traced to [31] and has been further explored in [29, 32, 33].
Another class of exploration methods, such as [34, 35, 36, 37], focusses on predicting the environment dynamics where prediction error is used as a basis of exploration. These methods, however, tend to suffer from the noisy TV problem [37] in stochastic and partially-observable MDPs.
Practical reinforcement learning algorithms often utilize simple exploration heuristics, such as -greedy exploration and Boltzmann exploration [1]. These methods, however, exhibit a random exploratory behavior, which can lead to exponential regret even in the case of simple MDPs.
Our proposed method differs from the existing entropy exploration methods for RL in the sense that unlike imposing entropy constraints on old and new policies in entropy regularization methods, we use the entropy to dictate the need for exploration in a state. Soft actor-critic (SAC) [22] augments the utility objective with the entropy of policy to motivate exploration while DIAYN [23] unsupervisedly learns skills optimizing maximum entropy objective alone. VIME [24] learns dynamics model using a Bayesian neural network and optimizes an objective based on an intrinsic reward obtained from the information gain of and some utility extrinsic reward. On the other hand, we focus on optimizing objective based on task utility alone unlike maximum entropy principle methods where the optimizable objective is altered to improve the exploratory behavior of the agent [21, 22, 23]. Also, unlike VIME [24], we do not need to learn the dynamics model . This allows the agent to exhibit efficient exploration while optimizing the task utility objective only, thus, maximizing the performance.
VI Conclusion
We have introduced a simple-to-implement yet effective exploration strategy that intelligently explores the state space based on agent’s learning. We show that the entropy of state-dependent action values can be used to estimate agent’s learning for a set of states. Based on agent’s learning, the proposed entropy-based exploration (EBE) is able to decipher the need for exploration in a state, thus, exploring more the unexplored region of state space. This results into what we call deep exploration which is confirmed by multiple experiments on diverse platforms. As shown by the experiments, EBE results into faster and better learning on tabular and high-dimensional state space platforms without having to tune any hyperparameter.
VII ACKNOWLEDGMENT
This research has been in part supported by the ICT R&D program of MSIP/IITP [2016-0-00563, Research on Adaptive Machine Learning Technology Development for Intelligent Autonomous Digital Companion].
APPENDIX
I Details about Experimental Setup
I-A Simpler Breakout Game
DQN is used as learning algorithm for this environment. Two most recent frames, the current one and the previous one, are used as current state information and fed to the -network to estimate action values for the state. The -network is a convolutional neural network whose architecture is detailed below:
We use Adam optimizer with the learning rate of . Agents are trained for 3000 episodes with a maximum of 200 steps per epoch and the target network update frequency of 100 steps. We use the minibatch size of 10, discount factor 0.95 and replay memory size of 1000.
I-B VizDoom Experiments
We use DQN as our learning algorithm. Raw gray scale input images of resolution are scaled down to resolution . These images are then processed by a deep -network. The -network architecture is shown in Table III.
Since the number of available actions for each considered VizDoom game is 3, we have in III. We do not use any target network for VizDoom experiments. Also we only use the current frame as state observation. Stochastic Gradient Descent (SGD) is used as optimizer with the learning rate of 0.00025. We use the minibatch size of 64 and the discount factor of 0.99.
For game Seek and Destroy, we use replay memory size of 10000 and train the agent for 10 epochs with 2000 steps per epoch. However, for games defend the center and defend the line, we train the agent for 1000 epochs with 5000 steps per epoch and use the replay memory size of 50000.
Experiments are performed with one NVIDIA TITAN Xp GPU and 12 gigabytes of RAM. It takes approximately 55 hours to complete 1000 epochs for Defend the Line and Defend the Center games while it takes approximately 15 minutes to complete 10 epochs for Seek and Destroy game.
I-C Swing-up Control of Rotary Inverted Pendulum Pendulum
The action space is discretized to get the following set . -values are approximated using deep neural network having one hidden layer of 128 neurons and relu as activation function and an output layer of neurons. The network is trained with batch size of 32, discount factor 0.99, learning rate 0.001, replay memory size 50000 and target network update frequency of 1000 steps. The first 10,000 steps are used for initial data collection and no learning is performed during this time. The episode ends when either 2048 steps have passed or . For balance control, we use a PD controller with and . The control law is given as
[TABLE]
where the control input is further clipped to range to prevent any hardware damage.
II Comparison of EBE with Count-Based Exploration Methods - Implementation Details
In this section, we explain the details about implementation of baselines in Section IV-D of the main paper.
II-A Pseudo-Count Based Exploration
We use a gated variant of PixelCNN++ [38] as the density model over the state space that is used to generate the exploration bonus. This bonus is then used to guide the exploration. The pseudo-count is computed as
[TABLE]
where and is the prediction gain and and are defined in [10]. The agent then selects the action that maximizes at step .
II-B #Exploration
Since our observations consist of raw images, an autoencoder (AE) from [11] is used to get the hash codes. See Figure 1 of [11] for the AE architecture. The solid block represents the dense sigmoidal binary code layer, after which noise with uniform distribution is injected to improve AE’s capability to reconstruct the distinct state inputs as explained in [11]. The code is then rounded to the nearest integer. Matrix , with entries drawn i.i.d. from the standard Gaussian distribution and and , is used to project the code to lower dimensional space via SimHash. See Algorithm 2 in [11] for more details. The AE is trained using loss function described in equation (3) in [11] where we use and . The rest of the implementation details are the same as in Appendix I-B.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] R. S. Sutton and A. G. Barto, Reinforcement learning - an introduction . Adaptive computation and machine learning, MIT Press, 1998.
- 2[2] V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, S. Petersen, C. Beattie, A. Sadik, I. Antonoglou, H. King, D. Kumaran, D. Wierstra, S. Legg, and D. Hassabis, “Human-level control through deep reinforcement learning,” Nature , vol. 518, pp. 529–533, Feb. 2015.
- 3[3] I. Osband, C. Blundell, A. Pritzel, and B. Van Roy, “Deep exploration via bootstrapped dqn,” in Advances in Neural Information Processing Systems 29 (D. D. Lee, M. Sugiyama, U. V. Luxburg, I. Guyon, and R. Garnett, eds.), pp. 4026–4034, Curran Associates, Inc., 2016.
- 4[4] Z. Wang, T. Schaul, M. Hessel, H. Van Hasselt, M. Lanctot, and N. De Freitas, “Dueling network architectures for deep reinforcement learning,” in Proceedings of the 33rd International Conference on International Conference on Machine Learning - Volume 48 , ICML’16, pp. 1995–2003, JMLR.org, 2016.
- 5[5] K. He, X. Zhang, S. Ren, and J. Sun, “Delving deep into rectifiers: Surpassing human-level performance on imagenet classification,” Co RR , vol. abs/1502.01852, 2015.
- 6[6] M. Kempka, M. Wydmuch, G. Runc, J. Toczek, and W. Jaskowski, “Vizdoom: A doom-based AI research platform for visual reinforcement learning,” Co RR , vol. abs/1605.02097, 2016.
- 7[7] W. Chargin and D. Moré, “Tensorboard smoothing implementation.” https://github.com/tensorflow/tensorboard/blob/f 801ebf 1f 9fbfe 2baee 1ddd 65714 d 0bccc 640fb 1/tensorboard/plugins/scalar/vz_line_chart/vz-line-chart.ts#L 704 , 2015.
- 8[8] T. L. Lai and H. Robbins, “Asymptotically efficient adaptive allocation rules,” Advances in Applied Mathematics , vol. 6(1):4-22, 1985.
