TL;DR
This paper introduces a robust zero-shot cross-domain slot filling method that leverages slot descriptions and example values, improving transferability and performance in low-data scenarios for dialog systems.
Contribution
It proposes a novel approach combining slot descriptions with example values to enhance zero-shot slot filling robustness across misaligned schemas.
Findings
Outperforms state-of-the-art models on multi-domain datasets.
Effective in low-data and schema-misalignment scenarios.
Demonstrates improved transferability of slot representations.
Abstract
Task-oriented dialog systems increasingly rely on deep learning-based slot filling models, usually needing extensive labeled training data for target domains. Often, however, little to no target domain training data may be available, or the training and target domain schemas may be misaligned, as is common for web forms on similar websites. Prior zero-shot slot filling models use slot descriptions to learn concepts, but are not robust to misaligned schemas. We propose utilizing both the slot description and a small number of examples of slot values, which may be easily available, to learn semantic representations of slots which are transferable across domains and robust to misaligned schemas. Our approach outperforms state-of-the-art models on two multi-domain datasets, especially in the low-data setting.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1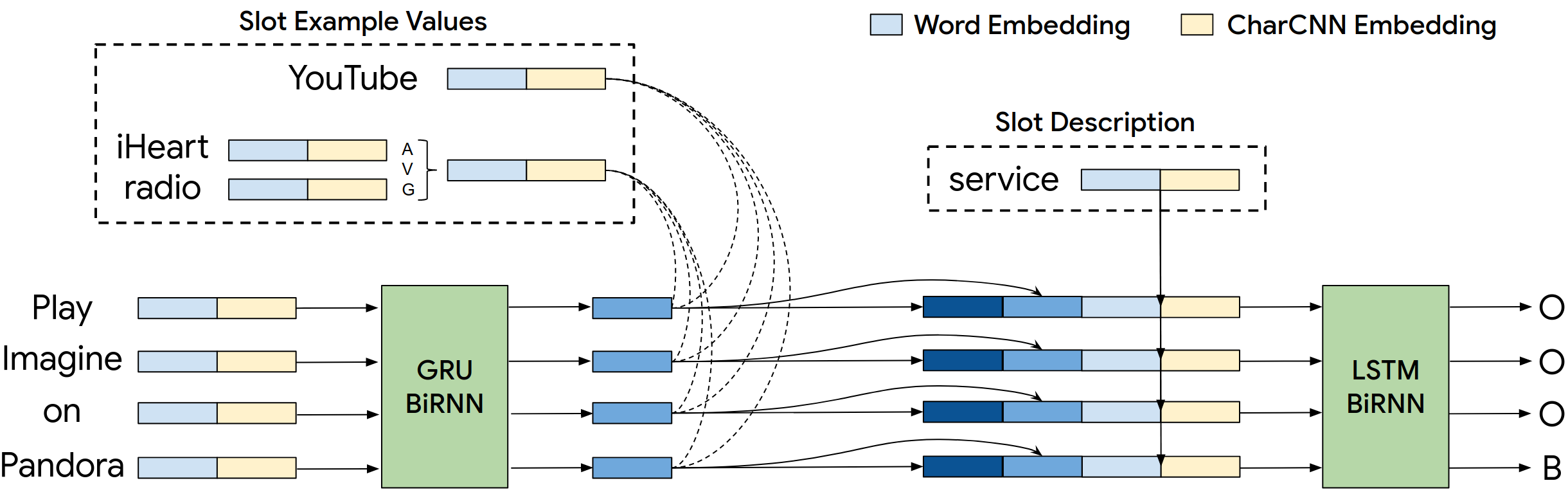 Figure 4
Figure 4 Figure 3
Figure 3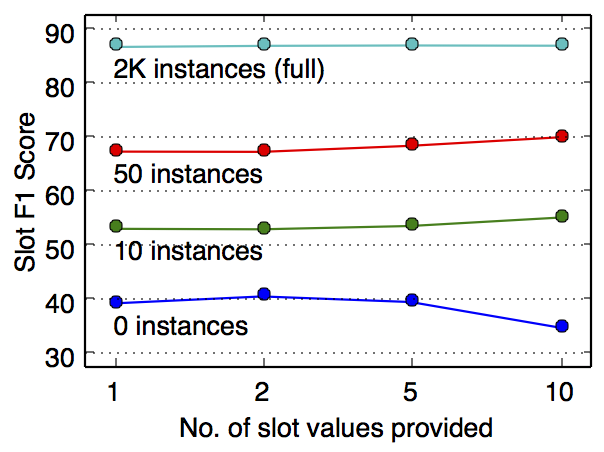 Figure 2
Figure 2| Intent | Slot Names (Training and Evaluation) |
|---|---|
| AddToPlaylist | artist, entityName, musicItem, playlist, playlistOwner |
| BookRestaurant | city, cuisine, partySizeNumber, restaurantName, restaurantType, servedDish, spatialRelation, state… |
| GetWeather | city, conditionDescription, country, geographicPoi, spatialRelation, state, timeRange… |
| PlayMusic | album, artist, genre, musicItem, playlist, service, sort, track, year |
| RateBook | bestRating, objectName, objectPartOfSeriesType, objectSelect, objectType, ratingUnit, ratingValue |
| SearchCreativeWork | objectName, objectType |
| FindScreeningEvent | locationName, movieName, movieType, objectLocationType, objectType, spatialRelation, timeRange |
| Target training e.g. | 0 | 50 | |||||
|---|---|---|---|---|---|---|---|
| Intent Model | CT | ZAT | +2Ex | LSTM | CT | ZAT | +10Ex |
| AddToPlaylist | 53.3 | 46.8 | 55.2 | 59.4 | 74.4 | 73.4 | 76.2* |
| BookRestaurant | 45.7 | 46.6 | 48.6* | 57.5 | 63.8 | 63.5 | 63.6 |
| GetWeather | 63.5 | 60.7 | 66.0* | 75.7 | 72.1 | 71.1 | 77.5* |
| PlayMusic | 28.7 | 30.1 | 33.8* | 49.3 | 56.4 | 56.0 | 58.8 |
| RateBook | 24.5 | 31.0 | 28.5 | 85.1* | 82.9 | 83.8 | 82.2 |
| SearchCreativeWork | 24.7 | 26.7 | 26.2 | 52.9 | 62.8 | 63.7 | 65.9 |
| FindScreeningEvent | 23.7 | 19.7 | 25.5* | 60.8 | 64.9 | 64.6 | 67.0* |
| Average | 37.7 | 37.4 | 40.6* | 62.8 | 68.2 | 68.0 | 70.1* |
| Target training e.g. | 0 | 50 | ||||
|---|---|---|---|---|---|---|
| Intent Model | CT | ZAT | +10Ex | CT | ZAT | +10Ex |
| BookBus | 70.9 | 70.1 | 74.1* | 86.8 | 85.2 | 89.4 |
| FindFlights | 43.5 | 44.8 | 53.2* | 62.3 | 59.7 | 69.2* |
| BookRoom | 23.6 | 23.4 | 33.0* | 49.7 | 52.1 | 58.7* |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Robust Zero-Shot Cross-Domain Slot Filling with Example Values
Darsh J Shah*
MIT CSAIL, Cambridge, MA
Raghav Gupta*
Google Research, Mountain View, CA
Amir A Fayazi
Google Research, Mountain View, CA
Dilek Hakkani-Tür
Amazon Alexa AI, Sunnyvale, CA
Abstract
Task-oriented dialog systems increasingly rely on deep learning-based slot filling models, usually needing extensive labeled training data for target domains. Often, however, little to no target domain training data may be available, or the training and target domain schemas may be misaligned, as is common for web forms on similar websites. Prior zero-shot slot filling models use slot descriptions to learn concepts, but are not robust to misaligned schemas. We propose utilizing both the slot description and a small number of examples of slot values, which may be easily available, to learn semantic representations of slots which are transferable across domains and robust to misaligned schemas. Our approach outperforms state-of-the-art models on two multi-domain datasets, especially in the low-data setting.
††Asterisk (*****) denotes equal contribution. Research conducted when all authors were at Google Research.
1 Introduction
Goal-oriented dialog systems assist users with tasks such as finding flights, booking restaurants and, more recently, navigating user interfaces, through natural language interactions. Slot filling models, which identify task-specific parameters/slots (e.g. flight date, cuisine) from user utterances, are key to the underlying spoken language understanding (SLU) systems. Advances in SLU have enabled virtual assistants such as Siri, Alexa and Google Assistant. There is also significant interest in adding third-party functionality to these assistants. However, supervised slot fillers Young (2002); Bellegarda (2014) require abundant labeled training data, more so with deep learning enhancing accuracy at the cost of being data intensive Mesnil et al. (2015); Kurata et al. (2016).
Two key challenges with scaling slot fillers to new domains are adaptation and misaligned schemas (here, slot name mismatches). Extent of supervision may vary across domains: there may be ample data for Flights but none for Hotels, requiring models to leverage the former to learn semantics of reusable slots (e.g. time, destination). In addition, schemas for overlapping domains may be incompatible by way of using different names for the same slot or the same name for different slots. This is common with web form filling: two sites in the same domain may have misaligned schemas, as in Figure 1, precluding approaches that rely on schema alignment.
Zero-shot slot filling, typically, either relies on slot names to bootstrap to new slots, which may be insufficient for cases like in Figure 1, or uses hard-to-build domain ontologies/gazetteers. We counter that by supplying a small number of example values in addition to the slot description to condition the slot filler. This avoids negative transfer from misaligned schemas and further helps identify unseen slots while retaining cross-domain transfer ability. Besides, example values for slots can either be crawled easily from existing web forms or specified along with the slots, with little overhead.
Given as few as 2 example values per slot, our model surpasses prior work in the zero/few-shot setting on the SNIPS dataset by an absolute 2.9% slot F1, and is robust to misaligned schemas, as experiments on another multi-domain dataset show.
2 Related Work
Settings with resource-poor domains are typically addressed by adapting from resource-rich domains (Blitzer et al., 2006; Pan et al., 2010; Guo et al., 2018). General domain adaptation techniques such as multi-task learning Jaech et al. (2016); Goyal et al. (2018); Siddhant et al. (2018) and domain adversarial learning Liu and Lane (2017) have been adapted and applied to SLU and related tasks Henderson et al. (2014). Work targeting domain adaptation specifically for this area includes, modeling slots as hierarchical concepts Zhu and Yu (2018) and using ensembles of models trained on data-rich domains Gašić et al. (2015); Kim et al. (2017); Jha et al. (2018).
Zero-shot learning (Norouzi et al., 2013; Socher et al., 2013) by way of task descriptions has gained popularity, and is of interest for data-poor settings like ours. Particularly, work on zero-shot utterance intent detection has leveraged varied resources like click logs Dauphin et al. (2013) and manually-defined domain ontologies Kumar et al. (2017), as well as models such as deep structured semantic models Chen et al. (2016) and capsule networks Xia et al. (2018). Zero-shot semantic parsing is addressed in Krishnamurthy et al. (2017) and Herzig and Berant (2018) and specifically for SLU utilizing external resources such as label ontologies in Ferreira et al. (2015a, b) and handwritten intent attributes in Yazdani and Henderson (2015). Our work is closest in spirit to Bapna et al. (2017) and Lee and Jha (2018), who employ textual slot descriptions to scale to unseen intents/slots. Since slots tend to take semantically similar values across utterances, we augment our model with example values, which are easier to define than manual alignments Li et al. (2011).
3 Problem Statement
We frame our conditional sequence tagging task as follows: given a user utterance with tokens and a slot type, we predict inside-outside-begin (IOB) tags using 3-way classification per token, based on if and where the provided slot type occurs in the utterance. Figure 3 shows IOB tag sequences for one positive (slot service, present in the utterance) and one negative (slot timeRange, not present in the utterance) instance each.
4 Model Architecture
Figure 2 illustrates our model architecture where a user utterance is tagged for a provided slot. To represent the input slot, along with a textual slot description as in Bapna et al. (2017), we supply a small set of example values for this slot, to provide a more complete semantic representation.111Note that the slot description is still needed since example slot values alone cannot distinguish slots which take semantically similar values (e.g. departDate vs returnDate). Detailed descriptions of each component follow.
Inputs: We use as input -dimensional embeddings for 3 input types: user utterance tokens \{u_{i}\in\mathbb{R}^{d_{wc}},\,1\scalebox{0.9}{\leq}i\scalebox{0.9}{\leq}T\}, input slot description tokens \{d_{i}\in\mathbb{R}^{d_{wc}},\,1\scalebox{0.9}{\leq}i\scalebox{0.9}{\leq}S\}, and example values for the slot, with the token embedding for the example denoted by \{e^{k}_{i}\in\mathbb{R}^{d_{wc}},\,1\scalebox{0.9}{\leq}i\scalebox{0.9}{\leq}N_{k}\}.
Utterance encoder: We encode the user utterance using a -dimensional bidirectional GRU recurrent neural network (RNN) Chung et al. (2014). We denote the set of per-token RNN hidden states by H=\{h_{i}\in\mathbb{R}^{d_{en}},\,1\scalebox{0.9}{\leq}i\scalebox{0.9}{\leq}T\}, which are used as contextual utterance token encodings.
[TABLE]
Slot description encoder: We obtain an encoding of the slot description by mean-pooling the embeddings for the slot description tokens.
[TABLE]
Slot example encoder: We first obtain encodings \{e_{k}^{x}\in\mathbb{R}^{d_{wc}},\,1\scalebox{0.9}{\leq}k\scalebox{0.9}{\leq}K\} for each slot example value by mean-pooling the token embeddings. Then, we compute an attention weighted encoding of all slot examples \{e^{a}_{i}\in\mathbb{R}^{d_{wc}},\,i\scalebox{0.9}{\leq}1\scalebox{0.9}{\leq}T\} for each utterance token, with the utterance token encoding as attention context. Here, denotes attention weights over all slot examples corresponding to the utterance token, obtained with general cosine similarity Luong et al. (2015).
[TABLE]
Tagger: We feed the concatenated utterance, slot description and example encodings to a -dimensional bidirectional LSTM. The output hidden states X=\{x_{i}\in\mathbb{R}^{d_{en}},1\scalebox{0.9}{\leq}i\scalebox{0.9}{\leq}T\} are used for a 3-way IOB tag classification per token.
[TABLE]
Parameters: We use fixed -dim pretrained word embeddings222https://tfhub.dev/google/nnlm-en-dim128/1 for all tokens. We also train per-character embeddings, fed to a 2-layer convolutional neural network Kim (2014) to get a -dim token embedding. For all inputs, the -dim final embedding is the concatenation of the word and char-CNN embeddings. The RNN encoders have hidden state size . All trainable weights are shared across intents and slots. The model relies largely on fixed word embeddings to generalize to new intents/slots.
5 Datasets and Experiments
In this section we describe the datasets used for evaluation, baselines compared against, and more details on the experimental setup.
Datasets:
In order to evaluate cross-domain transfer learning ability and robustness to misaligned schemas, respectively, we use the following two SLU datasets to evaluate all models.
- •
SNIPS: This is a public SLU dataset Coucke et al. (2018) of crowdsourced user utterances with 39 slots across 7 intents and training instances per intent. Since 11 of these slots are shared (see Table 1), we use this dataset to evaluate cross-domain transfer learning.
- •
XSchema: This is an in-house crowdsourced dataset with 3 intents ( training instances each). Training and evaluation utterances are annotated with different schemas (Table 1) from real web forms to simulate misaligned schemas.
Baselines:
We compare with two strong zero-shot baselines: Zero-shot Adaptive Transfer (ZAT) Lee and Jha (2018) and Concept Tagger (CT) Bapna et al. (2017), in addition to a 2-layer multi-domain bidirectional LSTM baseline Hakkani-Tür et al. (2016) for non-zero-shot setups. ZAT and CT condition slot filling only on slot descriptions, with ZAT adding slot description attention, char embeddings and CRFs on top of CT. Since labor-intensive long text descriptions are unavailable for our data, we use tokenized slot names in their place, as in Bapna et al. (2017).
Experimental Setup:
We use SNIPS to test zero/few-shot transfer: for each target intent , we train on all training instances from intents other than , and varying amounts of training data for , evaluating exclusively on . For XSchema, we train and evaluate on a single intent, specifically evaluating cross-schema performance.
We sample positive and negative instances (Figure 3) in a ratio of 1:3. Slot values input during training and evaluation are randomly picked from values taken by the input slot in the relevant domain’s training set, excluding ones that are also present in the evaluation set. In practice, it is usually easy to obtain such example values for each slot either using automated methods (such as crawling from existing web forms) or have them be provided as part of the slot definition, with negligible extra effort.
To improve performance on out-of-vocabulary entity names, we randomly replace slot value tokens in utterances and slot examples with a special token, and raise the replacement rate linearly from 0 to 0.3 during training Rastogi et al. (2018).
The final cross-entropy loss, averaged over all utterance tokens, is optimized using ADAM Kingma and Ba (2014) for 150K training steps. Slot F1 score Sang and Buchholz (2000) is our final metric, reported after 3-fold cross-validation.
6 Results
For the SNIPS dataset, Table 4 shows slot F1 scores for our model trained with randomly-picked slot value examples in addition to slot descriptions vis-à-vis the baselines. Our best model consistently betters the zero-shot baselines CT and ZAT, which use only slot descriptions, overall and individually for 5 of 7 intents. The average gain over CT and ZAT is in the zero-shot case. In the low-data setting, all zero-shot models gain over the multi-domain LSTM baseline (with the 10-example-added model further gaining on CT/ZAT). All models are comparable when all target data is used for training, with F1 scores of for the LSTM, and and for CT and our model with 10 examples respectively.
Table 4 shows slot F1 scores for XSchema data. Our model trained with 10 example values is robust to varying schemas, with gains of on BookBus, and on FindFlights and BookRoom in the zero-shot setting.
For both datasets, as more training data for the target domain is added, the baselines and our approach perform more similarly. For instance, our approach improves upon the baseline by on SNIPS when 2000 training examples are used for the target domain, affirming that adding example values does not hurt regular performance.
Results by slot type: Example values help the most with limited-vocabulary slots not encountered during training: our approach gains on slots such as conditionDescription, bestRating, service (present in intents GetWeather, RateBook, PlayMusic respectively). Intents PlayMusic and GetWeather, with several limited-vocabulary slots, see significant gains in the zero-shot setting.
For compositional open-vocabulary slots (city, cuisine), our model also compares favorably - e.g. vs slot F1 for unseen slot cuisine (intent BookRestaurant) - since the semantic similarity between entity and possible values is easier to capture than between entity and description.
Slots with open, non-compositional vocabularies (such as objectName, entityName) are hard to infer from slot descriptions or examples, even if these are seen during training but in other contexts, since utterance patterns are lost across intents. All models are within slot F1 of each other for such slots. This is also observed for unseen open-vocabulary slots in the XSchema dataset (such as promoCode and hotelName).
For XSchema experiments, our model does significantly better on slots which are confusing across schemas (evidenced by gains of on depart in FindFlights, roomType in BookRoom).
Effect of number of examples: Figure 4 shows the number of slot value examples used versus performance on SNIPS. For the zero-shot case, using 2 example values per slot works best, possibly due to the model attending to perfect matches during training, impeding generalization when more example values are used. In the few-shot and normal-data settings, using more example values helps accuracy, but the gain drops with more target training data. For XSchema, in contrast, adding more example values consistently improves performance, possibly due to more slot name mistmatches in the dataset. We avoid using over 10 example values, in contrast to prior work Krishnamurthy et al. (2017); Naik et al. (2018) since it may be infeasible to easily provide or extract a large number of values for unseen slots.
Ablation: Slot replacement offsets overfitting in our model, yielding gains of for all models incl. baselines. Fine-tuning the pretrained word embeddings and removing character embeddings yielded losses of . We tried more complex phrase embeddings for the slot description and example values, but since both occur as short phrases in our data, a bag-of-words approach worked well.
Comparison with string matching: A training and evaluation setup including example values for slots may lend itself well to adding string matching-based slot fillers for suitable slots (for example, slots taking numeric values or having a small set of possible values). However, this is not applicable to our exact setting since we ensure that the slot values to be tagged during evaluation are never provided as input during training or evaluation. In addition, it is difficult to distinguish two slots with the same expected semantic type using such an approach, such as for slots ratingValue and bestRating from SNIPS intent RateBook.
7 Conclusions and Future Work
We show that extending zero-shot slot filling models to use a small number of easily obtained example values for slots, in addition to textual slot descriptions, is a scalable solution for zero/few-shot slot filling tasks on similar and heterogenous domains, while resistant to misaligned overlapping schemas. Our approach surpasses prior state-of-the-art models on two multi-domain datasets.
The approach can, however, be inefficient for intents with many slots, as well as potentially sacrificing accuracy in case of overlapping predictions. Jointly modeling multiple slots for the task is an interesting future direction. Another possible direction is to incorporate zero-shot entity recognition Guerini et al. (2018), thereby eliminating the need for example values during inference.
In addition, since high-quality datasets for downstream tasks in dialogue systems (such as dialogue state tracking and dialogue management) are even more scarce, exploring zero-shot learning approaches to these problems is of immense value in building generalizable dialogue systems.
Acknowledgements
We would like to thank Ankur Bapna for the insightful discussions that have notably shaped this work. We would also like to thank the Deep Dialogue team at Google Research for their support.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Bapna et al. (2017) Ankur Bapna, Gökhan Tür, Dilek Hakkani-Tür, and Larry P. Heck. 2017. Towards zero-shot frame semantic parsing for domain scaling . In Interspeech 2017, 18th Annual Conference of the International Speech Communication Association, Stockholm, Sweden, August 20-24, 2017 .
- 2Bellegarda (2014) Jerome R Bellegarda. 2014. Spoken language understanding for natural interaction: The siri experience. In Natural Interaction with Robots, Knowbots and Smartphones , pages 3–14. Springer.
- 3Blitzer et al. (2006) John Blitzer, Ryan Mc Donald, and Fernando Pereira. 2006. Domain adaptation with structural correspondence learning. In Proceedings of the 2006 conference on empirical methods in natural language processing , pages 120–128. Association for Computational Linguistics.
- 4Chen et al. (2016) Yun-Nung Chen, Dilek Hakkani-Tür, and Xiaodong He. 2016. Zero-shot learning of intent embeddings for expansion by convolutional deep structured semantic models. In Acoustics, Speech and Signal Processing (ICASSP), 2016 IEEE International Conference on , pages 6045–6049. IEEE.
- 5Chung et al. (2014) Junyoung Chung, Caglar Gulcehre, Kyung Hyun Cho, and Yoshua Bengio. 2014. Empirical evaluation of gated recurrent neural networks on sequence modeling. ar Xiv preprint ar Xiv:1412.3555 .
- 6Coucke et al. (2018) Alice Coucke, Alaa Saade, Adrien Ball, Théodore Bluche, Alexandre Caulier, David Leroy, Clément Doumouro, Thibault Gisselbrecht, Francesco Caltagirone, Thibaut Lavril, et al. 2018. Snips voice platform: an embedded spoken language understanding system for private-by-design voice interfaces. ar Xiv preprint ar Xiv:1805.10190 .
- 7Dauphin et al. (2013) Yann N Dauphin, Gokhan Tur, Dilek Hakkani-Tur, and Larry Heck. 2013. Zero-shot learning for semantic utterance classification. ar Xiv preprint ar Xiv:1401.0509 .
- 8Ferreira et al. (2015 a) Emmanuel Ferreira, Bassam Jabaian, and Fabrice Lefevre. 2015 a. Online adaptative zero-shot learning spoken language understanding using word-embedding. In 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages 5321–5325. IEEE.
