A Generic Approach for Accelerating Belief Propagation based DCOP Algorithms via A Branch-and-Bound Technique
Ziyu Chen, Xingqiong Jiang, Yanchen Deng, Dingding Chen, Zhongshi He

TL;DR
This paper introduces FDSP, a branch-and-bound based method that accelerates belief propagation algorithms for large-scale DCOPs by reducing search space and maintaining solution quality.
Contribution
The paper proposes FDSP, a generic method that speeds up belief propagation algorithms for DCOPs using branch-and-bound with proven bounds and significant search space reduction.
Findings
FDSP reduces search space by at least 97%.
FDSP accelerates Max-Sum algorithm significantly.
FDSP maintains solution quality while speeding up computation.
Abstract
Belief propagation approaches, such as Max-Sum and its variants, are a kind of important methods to solve large-scale Distributed Constraint Optimization Problems (DCOPs). However, for problems with n-ary constraints, these algorithms face a huge challenge since their computational complexity scales exponentially with the number of variables a function holds. In this paper, we present a generic and easy-to-use method based on a branch-and-bound technique to solve the issue, called Function Decomposing and State Pruning (FDSP). We theoretically prove that FDSP can provide monotonically non-increasing upper bounds and speed up belief propagation based DCOP algorithms without an effect on solution quality. Also, our empirically evaluation indicates that FDSP can reduce 97\% of the search space at least and effectively accelerate Max-Sum, compared with the state-of-the-art.
Click any figure to enlarge with its caption.
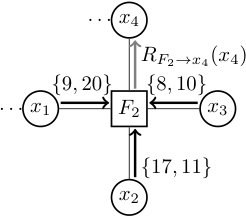 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3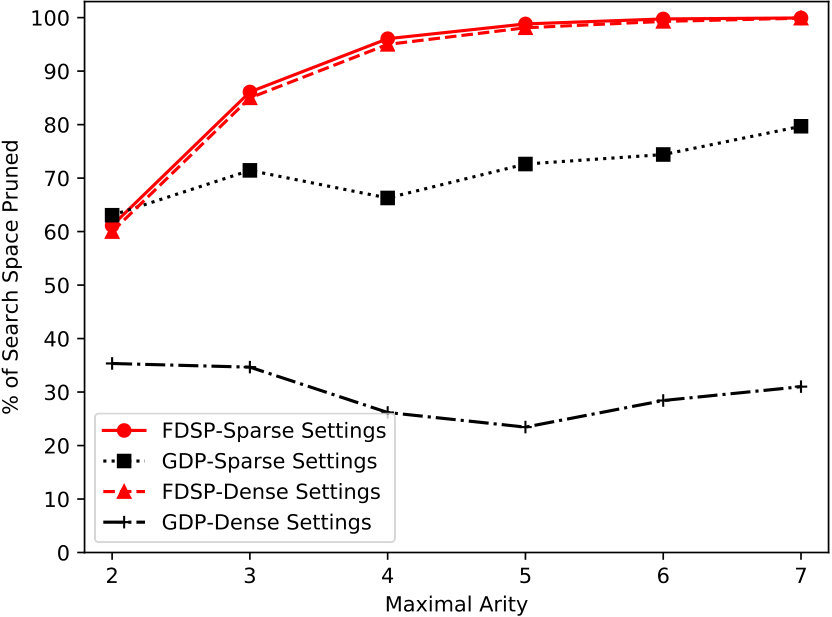 Figure 4
Figure 4 Figure 5
Figure 5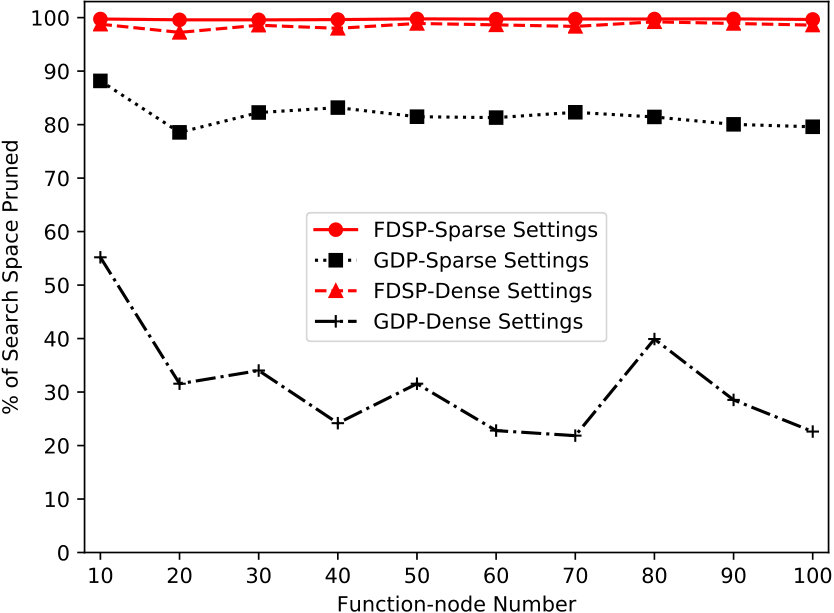 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8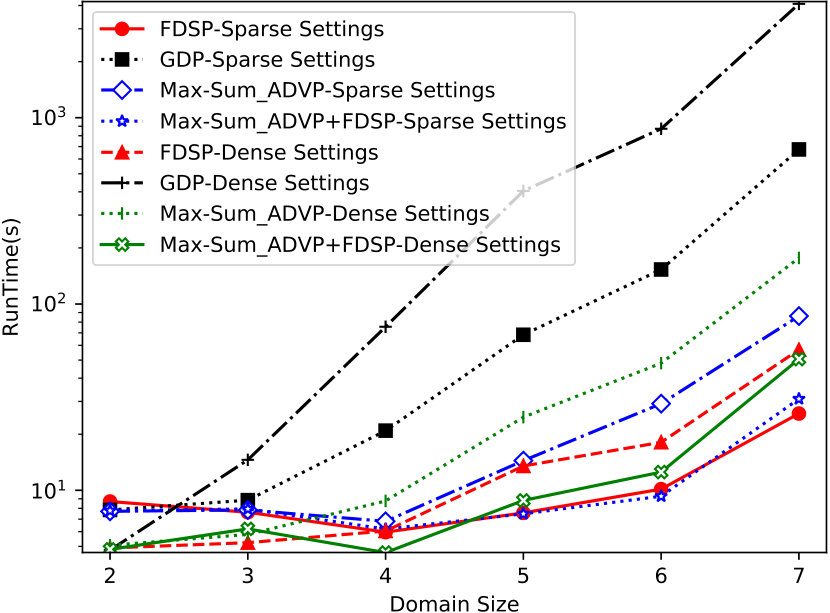 Figure 9
Figure 9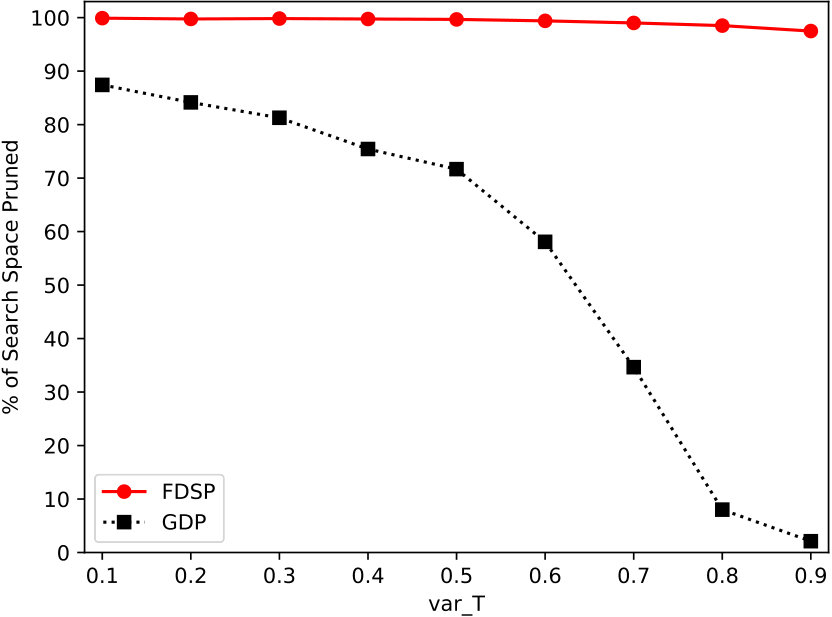 Figure 10
Figure 10Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsConstraint Satisfaction and Optimization · Data Management and Algorithms · Bayesian Modeling and Causal Inference
A Generic Approach to Accelerating Belief Propagation based Incomplete Algorithms for DCOPs via A Branch-and-Bound Technique
Ziyu Chen,1Xingqiong Jiang,1Yanchen Deng2, Corresponding author.
Dingding Chen1
Zhongshi He1
College of Computer Science, Chongqing University, Chongqing, China
1 {chenziyu, jxq, dingding, zshe}@cqu.edu.cn, 2 [email protected]
Abstract
Belief propagation approaches, such as Max-Sum and its variants, are important methods to solve large-scale Distributed Constraint Optimization Problems (DCOPs). However, for problems with -ary constraints, these algorithms face a huge challenge since their computational complexity scales exponentially with the number of variables a function holds. In this paper, we present a generic and easy-to-use method based on a branch-and-bound technique to solve the issue, called Function Decomposing and State Pruning (FDSP). We theoretically prove that FDSP can provide monotonically non-increasing upper bounds and speed up belief propagation based incomplete DCOP algorithms without an effect on solution quality. Also, our empirically evaluation indicates that FDSP can reduce 97% of the search space at least and effectively accelerate Max-Sum, compared with the state-of-the-art.
Introduction
Distributed Constraint Optimization Problems (DCOPs) which require agents to coordinate their decisions to optimize a global objective, are a fundamental framework for modeling multi-agent coordination in multi-agent systems (?). Thus, DCOPs are widely deployed in some real world coordination tasks including meeting scheduling (?), sensor networks (?), power networks (?), etc.
Algorithms for DCOPs can be classified into two categories: complete and incomplete, according to whether they guarantee to find the optimal solution. Complete algorithms (?; ?; ?; ?; ?; ?) can get the optimal solutions but incur exponential communication or computation overheads since DCOPs are NP-hard. In contrast, incomplete algorithms (?; ?; ?; ?; ?; ?) trade accuracy for computation time and memory so that they can be applied to large-scale problems. As a kind of incomplete algorithms based on belief propagation, Max-Sum (?) and its variants (?; ?; ?) have drawn a lot of attention since they can easily be deployed to any DCOP setting. Moreover, they can explicitly handle -ary constraints and more variables per agent (?). In more detail, agents in Max-Sum propagate and accumulate beliefs through the whole factor graph. And each agent only holds its belief about the utility for each possible assignment and continuously updates its belief based on the messages received from its neighbors.
In spite of many advantages of belief propagation approaches, they suffer from a huge challenge in scalability. Specifically, they perform maximization operations repeatedly to locally accumulate beliefs for the involved variables, given the local utility function and a set of incoming messages. The computation complexity of this step grows exponentially as the number of constraint arities. In other words, when a constraint function holds variables and the domain size of each variable is , Max-Sum needs to perform maximization operations to yield the best assignment for each variable.
To address the issue, two kinds of methods were proposed to improve the scalability of belief propagation approaches. The first kind is the algorithms based on a branch-and-bound technique including BnB-MS (?) and BnB-FMS (?) which both consist of a preprocessing phase and a pruning phase. In the preprocessing phase, the two algorithms use localized message-passing to simplify DCOPs. Specifically, BnB-MS reduces the number of moves that each agent needs to consider in coordinating mobile sensors while BnB-FMS removes tasks that an agent should never perform in dynamic task allocations. In the pruning phase, both algorithms reduce the search space using a branch-and-bound technique to speed up maximization operations. Unfortunately, these algorithms require to exchange a lot of messages in their preprocessing phases. Moreover, the bounds in these algorithms are computed by either brute force or domain-specific knowledge, which limits their applicability.
The second kind of approaches is sorting based, such as G-FBP(?) and GDP(?), which is applicable to all DCOP settings. G-FBP uses partially sorted lists to adapt FBP. Specifically, it selects and sorts the top values of the search space, presuming that the maximum value can be found from the selected range. Here, is a constant. However, G-FBP will incur additional computation once the maximum value cannot be found within the selected range. Different from G-FBP, the main idea of GDP is to explore only the rows that can cover the differences between the sum of the maximal utility of each message and the message utility corresponding to the assignment that produces the largest local utility. Thus, GDP needs to sort the local utilities of all function-nodes independently by each assignment of each variable in the preprocessing phase and is the sorted result of each assignment . Then, GDP returns a pruned range or according to whether , where , and . Here, is the summation of the maximum value for each received message from other variable-nodes and is the summation for the corresponding values of from the incoming messages of a function-node. However, GDP needs additional time to perform sorting operations in the preprocessing phase. More importantly, GDP is an one-shot pruning procedure that cannot use the learned experience from the assignment combinations explored to dynamically prune the search space.
Given the background, we devote to develop a generic and fast method for belief propagation based on a branch-and-bound technique, called Function Decomposing and State Pruning (FDSP). In more detail, we propose a domain-independent approach based on dynamic programming to effectively evaluate the upper bound of a given partial assignment, which overcomes the aforementioned drawbacks of BnB-MS and BnB-FMS. We further enforce the upper bounds by exploiting the fact that the assignment of the target variable is given. Finally, we prune the search space whenever the upper bound of a partial assignment is no greater than the best lower bound explored so far. The experimental results show the effectiveness of FDSP which can prune at least 97% of the search space when solving complex problems.
Background
Distributed Constraint Optimization Problems
A distributed constraint optimization problem can be represented by a tuple such that:
- •
is a set of agents.
- •
is a set of variables.
- •
is a set of finite and discrete domains, variable taking an assignment value in .
- •
is a set of constraints, where each constraint denotes how much utility is assigned to each possible combination of assignments of the involved variables .
Thus, a constraint function denotes the utility for each possible assignment combination of the variables in , represents the arity of , and denotes the domain size of variable . Note that the variables in are ordered according to their own indices, where a variable is ordered before a variable if .
Given this, the goal for a DCOP is to find the joint variable assignment such that a given global objective function is maximal. Generally, the objective function is described as the sum over :
[TABLE]
Max-Sum Algorithm
As a belief propagation approach, Max-Sum is a message-passing inference-based algorithm operating on factor graphs which comprise variable-nodes and function-nodes. Function-nodes which represent the constraints in a DCOP are connected to variable-nodes they depend on, while variable-nodes which represent the variables in a DCOP are connected to function-nodes they are involved in. As shown in Fig. 1, and are two function-nodes, , , , and are variable-nodes, where , , and are connected to , and , and are connected to . Here, (i.e., , where ) is a -ary constraint and (i.e., , where ) is a -ary one.
In Max-Sum, beliefs are propagated and accumulated through the whole factor graph via the messages exchanged between variable-nodes and function-nodes. The message from a variable-node to a function-node , called the query message. It is defined by
[TABLE]
where is a scalar set such that , and is a set of neighbors of except the target function-node . The response message sent from a function-node to a variable-node is given by
[TABLE]
When a variable-node makes its decision, it first accumulates the belief for each possible assignment from all messages it receives. Then, it selects a value to maximize the total utilities. The procedure can be formalized by:
[TABLE]
In this paper, we use the term ”target variable” to denote the destination variable-node of the outgoing message being computed, and represents the message from variable .
Proposed Method
Motivation
The maximization operation in Eq. (2) is the most computationally expensive operation in Max-Sum. For a -ary DCOP, the complexity of computing the response message is . Take Fig. 2 as an example. Assume that each variable takes a value in and the function-node has received the messages , and from , and , respectively. Then, requires operations to generate the message since its domain size and arity . Obviously, the complexity of this step grows exponentially as and scale up. Therefore, this is a huge challenge for scalability of belief propagation algorithms.
As mentioned earlier, some efforts have been made to optimize this maximization operation. Nevertheless, the improved algorithms based on a branch-and-bound technique including BnB-MS and BnB-FMS require a number of messages to be passed in the preprocessing phase. And, these algorithms were proposed for the exact application, which makes it difficult to directly solve general DCOPs. Besides, the algorithms based on sorting, such as G-FBP and GDP, suffer from some drawbacks although they are generic. Specifically, G-FBP cannot guarantee that the maximum value can be found in the selected range, which can lead to a complete traverse to all the possible combinations in the worst case, while GDP requires sorting for each value in the domain of each variable in the preprocessing phase, which makes its use prohibitively expensive. Additionally, GDP cannot use the learned knowledge from the combinations explored to dynamically prune the search space. In other words, GDP is actually an one-shot pruning method. Taking Fig. 2 for example, according to GDP, the local utilities of are sorted independently by each value of the domain. When computing the pruned range of value , there are , and the base case . Hence, . Accordingly, GDP returns a fixed pruned range for value . Obviously, the pruned range contains the entire search space of value , and cannot be reduced in the subsequent search process.
Under such circumstances, we propose a generic, fast and easy-to-use approach based on a branch-and-bound technique, called FDSP that can use the learned experience from the combinations explored to dynamically prune the search space.
FDSP
FDSP generally consists of two components: estimation to provide upper bounds and pruning to reduce the search space. To provide the optimal upper bound for a partial assignment, the estimation must return the upper bounds for both the local function and the incoming messages. FDSP computes the function estimations in the preprocessing phase, called Function Decomposing (FD), while the message estimations are (re)constructed once the messages have changed. Pruning is implemented by a procedure called State Pruning (SP) which is based on a branch and bound technique. That is, the algorithm does not expand any partial assignment whose upper bound is less than the known lower bound. FDSP can be easily applied to any belief propagation based incomplete algorithms to deal with DCOPs with -ary constraints.
Function Decomposing
serves in a preprocessing phase to compute the function estimation for each variable of a function-node . Given a partial assignment to variables , the upper bound of the local function is maximization of over the remaining unassigned variables. That is
[TABLE]
Here, is the uninformed function estimation for the -th variable in , which provides optimistic upper bounds on the utilities of the subsequent search spaces of . Macarthur et al. (?) tried to compute the estimation by using brute force, which incurs exponential operations for each partial assignment. They also suggested that the domain characteristics can be used to compute the estimation, which has a limited generalization and cannot guarantee the tightness. In contrast, our proposed FD is an one-shot preprocessing procedure that uses dynamic programming to compute the estimation, which can significantly reduce the computation efforts. Specifically, the estimations are computed recursively according to Eq. (5).
[TABLE]
That is, the estimation for a variable is maximization of the one for the next variable. Particularly, the estimation for the last variable is the function itself. Note that, compared to the exponential overhead for each partial assignment in BnB-MS, our proposed FD only requires operations to compute the function estimation for each variable in the preprocessing phase.
In fact, the uninformed function estimation for could provide a tighter upper bound if we know the assignment of a variable such that . In this way, we can compute a tight upper bound even if there are many unassigned variables between the last assigned variable and the target variable in a partial assignment. By considering all the possible assignments of each variable ordered after , we further reinforce the upper bound and propose the informed function estimations. Eq. (6) gives the formal definition to the informed function estimation for in terms of where .
[TABLE]
Similar to the uninformed function estimations, the informed function estimations are computed in a recursive fashion by maximizing the estimation for the next variable. And the estimation for the last variable before is the corresponding uninformed function estimation with a given assignment .
Fig. 3 gives the sketch of FD. The procedure begins with computing the uninformed function estimation for each variable in according to Eq. (5) from the last one to the first one (line 1-3). Then, for every possible assignment of each variable, we compute the informed function estimation for each variable whose index is smaller than the current variable according to Eq. (6) (line 4-6).
Taking Fig. 2 for example, we can compute the uninformed function estimations for variable , , and as follows:
[TABLE]
These estimations can provide the upper bounds for the partial assignments with respect to their variables. Besides, the informed function estimations in terms of are computed as follows:
[TABLE]
State Pruning
is geared towards speeding up the computation of the messages from function-nodes to variable-nodes by branch and bound. That is, when the upper bound of a partial assignment is no greater than the lower bound, the search space corresponding to the partial assignment will be discarded. Fig. 4 gives the pseudo code of SP.
The algorithm begins with calculating the message estimation for each variable , which gives the maximal message utility with respect to all non-target variables after it given these variables unassigned, according to Eq. (7) (line 7-15).
[TABLE]
Here, is the target variable and denotes the upper bounds on the received messages from the variables after except . In order to reduce the unnecessary computation, recomputes the message estimations for each variable ordered before only when the message from changes. Besides, instead of directly computing message estimations according to Eq. (7), further reduces the computation efforts by recursively backing up the maximal message utilities from the last non-target variable to the first one. That is, the message estimation of a variable is the sum of the maximal message utility and the message estimation of the non-target variable next to it. Consider the function-node in Fig. 2(b). When we are computing the message for , the message estimations for , and are computed as follows:
[TABLE]
Then, computes the maximum utility of each assignment of the target variable in (line 16-22). Specifically, assigns assignment to according to the order of values in (line 19). Thus, the current partial joint state , where represents an unassigned variable (line 20). After that, FDSPRec is called for the variable which is the first unassigned variable to recursively expand the search space (line 21). Finally, stores to when for the current assignment is returned (line 22). The procedure (line 20 - 22) repeats until all the assignments of have been visited.
In FDSPRec, first finds that is the unassigned variable next to (line 24-26). Note that is an assigned variable. Then, decides to expand the search space or update the maximum utility and the lower bound (line 28-39). In more detail, expands the search space by appending the assignment of to the partial joint state (line 29). And then, computes the utilities contributed (i.e., ) by the incoming messages with respect to the current by summing the accumulated with the entry in terms of and assignment (line 30). Then, computes the current upper bound according to Eq. (8) (line 31).
[TABLE]
Specifically, if (i.e., is after ), which means the assignments of all variables before have been given, the current upper bound of the local function is provided by the uninformed function estimation of variable . Otherwise, the upper bound is computed by the informed function estimation. In other words, the informed function estimation is used to compute a tight upper bound whenever it is applicable.
Next, decides whether to expand the search space according to the lower bound (line 32-39). If the upper bound is greater than the current lower bound and is not the last variable, the algorithm proceeds by calling the recursive function FDSPRec to expand the search space (line 33-35). Otherwise, the search space corresponding to can be discarded. If is the last non-target variable, i.e., the search space has been fully expanded, computes the current utility of the complete assignment by adding the local utility and . Then, updates the maximum utility and the lower bound (line 36-39). Finally, when all the assignments of have been visited, the algorithm returns (line 40).
Fig. 5 shows an example for calculating the message from function to variable when (i.e., ) in Fig. 2, where the numbers with circles represent the trace of SP. Since is fixed to assignment , needs to compute the maximum utility by extending the partial assignment . Firstly, visits the first assignment of and computes by Eq. (8). Then, it expands by visiting the first assignment of since . Similarly, expands . At this point, since and is fully assigned, computes the utility of : , and updates and . Next, visits the next assignment of . Similarly, computes the current upper bound and the current utility corresponding to , and updates and . After that, visits the second assignment of since all assignments of have been exhausted. And, computes which is less than , so is discarded. Similarly, is also discarded. Finally, finds the maximum utility , i.e., .
As seen from the example, FDSP can prune at least 75% of the search space during computing the message from the function-node to variable-node , where and .
Theoretical Analysis
In this section, we will theoretically prove that FDSP can speed up belief propagation based incomplete algorithms without an effect on solution quality, i.e., FDSP can provide monotonically non-increasing upper bounds and never prunes the optimal assignment with the maximum utility .
Lemma 1**.**
For a function-node and a given partial assignment with in which is the last non-target entry, the upper bound of any direct subsequent partial assignment is at least as low as the one of , where is the variable next to such that .
Proof.
Recall that the upper bound of a given partial assignment is computed according to either the uninformed function estimation or the informed function estimation, depending on the index of the target variable. Thus, three cases need to be discussed: 1) all the upper bounds are computed according to the uninformed function estimations; 2) the upper bound of is computed according to the uninformed function estimation, while the one of is computed according to the informed function estimation; 3) all the upper bounds are computed according to the informed function estimations. Here, we only give the prove for case 2) (i.e., , ) due to the limited space. Similar analysis can be applied to case 1) and 3).
[TABLE]
Here, the second step holds since . Thus, according to Eq. (6) we have . Besides, the third step and the fourth step hold since (Eq. (5)) and , respectively.
Thus the lemma is proved. ∎
Theorem 1**.**
FDSP does not affect the optimality of Eq. (2).
Proof.
Prove by contradiction. For a function-node , assume that the optimal assignment of Eq. (2) is , and the corresponding utility value is . Assume that FDSP has missed that assignment. Thus, there must exist a partial assignment such that . According to Lemma 1, the upper bound is monotonically non-increasing, i.e., . Note that
[TABLE]
Here, . Thus, we have , which is contradict to the assumption. Therefore, the upper bound of a partial assignment cannot be less than the value of any subsequent full assignment and the optimality is hereby guaranteed. ∎
Complexity Analysis
Each variable needs to compute and stores an uninformed function estimation and informed function estimations in the preprocessing phase. Thus, the time and space of each variable require and , respectively, where the value of becomes smaller as FD performs. Thus, FDSP in the preprocessing phase needs a small overhead.
Besides, since each function-node needs to explore the search space with respect to the target variable, the time complexity in the worst case is . However, with SP, only the small search space needs to be explored. Therefore, the overall overhead is small. For this point, our empirical evaluation also verifies that FDSP only requires little time to run.
Empirical Evaluation
We empirically evaluate the performances of FDSP and GDP which are both applied to Max-Sum on four configurations of -ary random DCOPs. Since BnB-MS and BnB-FMS are not generic algorithms and G-FBP is inferior to GDP (?), we do not include them for comparison. The complexity of a -ary DCOP can be quantified by the number of function-nodes, the average/maximal arity and the domain size (?; ?). In addition to these parameters, we also find the number of variable-nodes can affect the complexity. Intuitively, given the number of function-nodes and the average arity per function-node, the graph density is actually determined by the number of function-nodes. Therefore, we introduce a new parameter called variable tightness (denoted as var_T ) to depict the complexity from another perspective, which is defined as follows.
[TABLE]
It can be concluded that given the function-node number and total arity number, the number of variable-nodes decreases as var_T increases, which will generate a denser and more complex problem since each variable-node has to connect more function-nodes.
For each configuration other than the first one, we generate sparse factor graphs and dense factor graphs by randomly selecting var_T from [0.1, 0.5] and (0.5, 0.9], respectively. In the first configuration, we set the number of function-nodes to 100 and the minimal arity to 2, and uniformly select the costs, the domain size and the maximal arity from [1, 100], [2, 10] and [2, 7], respectively. And, var_T varies from 0.1 to 0.9. In the second one, we vary the maximal arity from 2 to 7. In the third configuration, we vary the number of function-nodes from 10 to 100. In the last one, we set the number of function-nodes to 50 and vary the domain size from 2 to 7. Also, we benchmark Max-Sum_ADVP+FDSP to demonstrate the generalization of FDSP. To guarantee Max-Sum_ADVP to converge, we alternate its directions every 100 iterations. All the omitted parameters except var_T in each configuration are the same as the ones in the first configuration. For each of the setting, we generate 25 random instances and the results are averaged over all instances. The algorithms terminate after 200 iterations for each instance.
Fig. 6 gives the comparison under different var_T. It can be observed that FDSP clearly outperforms GDP under different var_T, and the gap is widen as var_T grows. Concretely, FDSP can prune at least 97% of the search space while GDP only prunes at most 87% of the search space when computing Eq. (2). Moreover, FDSP performs similarly as var_T grows, which indicates FDSP is less sensitive to the complexity of problems. On the other hand, the performance of GDP decreases as var_T increases, and GDP performs poorly when solving the problems with var_T. This is because the sum of the difference between the maximal value and the value corresponding to the maximal local utility in each message will increase when the graph density increases as var_T grows. As a result, GDP provides a large pruned range so as to prune only a small proportion of the search space.
Fig. 7 shows the performance comparison on different maximal arities. It can be concluded that FDSP outperforms GDP in both sparse and dense factor graphs, especially in dense factor graphs. FDSP prunes around 60%-99% of the search space in both sparse and dense factor graphs, while GDP can only prune at most 80% and 36%, respectively. That is because FDSP provides tighter bounds to make Max-Sum explore fewer combinations.
Fig. 8 presents the results under different number of function-nodes. Similar to the first configuration, FDSP prunes at least 97% of the search space in both sparse and dense factor graphs, while GDP can only prune at most 88% and 55% of the search space in sparse and dense factor graphs, respectively. This is because GDP is an one-shot pruning procedure and cannot use the learned experience from the assignment combinations explored to dynamically prune the search space.
Fig. 9 gives the runtime under different domain sizes. It can be seen that our FDSP exhibits great superiority over GDP and Max-Sum_ADVP when solving the problems with large domain sizes, which indicates that FDSP can scale up well and only requires few computation efforts. GDP would perform even worse in practice since the runtime presented in Fig. 9 actually does not take sorting, which is quite expensive when the domain size is large, into consideration. Besides, one can easily observe that Max-Sum_ADVP+FDSP is superior to Max-Sum_ADVP when solving the problems with large domain sizes in sparse and dense factor graphs, which indicates that FDSP can also effectively accelerate the variants of Max-Sum.
Conclusion
In this paper, we propose FDSP, a generic, fast and easy-to-use method based branch and bound, which significantly accelerates belief propagation based incomplete DCOP algorithms. Specifically, we first propose function decomposing (FD) to effectively compute the function estimation, which dramatically reduces the overheads in computing an upper bound of a partial assignment. Then, we further present state pruning (SP) based on branch and bound to reduce the search space. Besides, we theoretically prove that our bounds are monotonically non-increasing during the search process and FDSP never prunes the assignment with the maximum utility. Our experimental results clearly show that FDSP can prune around 97%-99% of the search space and only requires little time, especially for the large and complex problems.
Acknowledgment
This research is funded by Chongqing Research Program of Basic Research and Frontier Technology (No. cstc2017jcyjAX0030), Fundamental Research Funds for the Central Universities (No. 2018CDXYJSJ0026) and Graduate Research and Innovation Foundation of Chongqing, China (Grant No. CYS18047).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[Arshad and Silaghi 2004] Arshad, M., and Silaghi, M. C. 2004. Distributed simulated annealing. Distributed Constraint Problem Solving and Reasoning in Multi-Agent Systems 112.
- 2[Cerquides et al . 2014] Cerquides, J.; Farinelli, A.; Meseguer, P.; and Ramchurn, S. D. 2014. A tutorial on optimization for multi-agent systems. Computer Journal 57(6):799–824.
- 3[Chen, Deng, and Wu 2017] Chen, Z.; Deng, Y.; and Wu, T. 2017. An iterative refined max-sum_ad algorithm via single-side value propagation and local search. In Proc. of the 16th Conference on AAMAS , 195–202.
- 4[Enembreck and Barthès 2012] Enembreck, F., and Barthès, J. P. A. 2012. Distributed constraint optimization with mulbs: A case study on collaborative meeting scheduling. Journal of Network & Computer Applications 35(1):164–175.
- 5[Farinelli et al . 2008] Farinelli, A.; Rogers, A.; Petcu, A.; and Jennings, N. R. 2008. Decentralised coordination of low-power embedded devices using the max-sum algorithm. In Proc. of the 7th Conference on AAMAS , 639–646.
- 6[Farinelli, Rogers, and Jennings 2014] Farinelli, A.; Rogers, A.; and Jennings, N. R. 2014. Agent-based decentralised coordination for sensor networks using the max-sum algorithm. Autonomous Agents and Multi-Agent Systems 28(3):337–380.
- 7[Fioretto et al . 2017] Fioretto, F.; Yeoh, W.; Pontelli, E.; Ma, Y.; and Ranade, S. J. 2017. A distributed constraint optimization (dcop) approach to the economic dispatch with demand response. In Proc. of the 16th Conference on AAMAS , 999–1007.
- 8[Gershman, Meisels, and Zivan 2009] Gershman, A.; Meisels, A.; and Zivan, R. 2009. Asynchronous forward bounding for distributed cops. Journal of Artificial Intelligence Research 34:61–88.