Structured Pruning of Recurrent Neural Networks through Neuron Selection
Liangjian Wen, Xuanyang Zhang, Haoli Bai, Zenglin Xu

TL;DR
This paper introduces a structured pruning method for RNNs using neuron selection, significantly reducing model size and inference time without performance loss, suitable for edge device deployment.
Contribution
The paper proposes a novel structured pruning approach with neuron gates, optimizing the L0 norm to achieve practical speedup in RNNs.
Findings
Achieved nearly 20x inference speedup on Penn TreeBank.
Reduced RNN model sizes by pruning neurons effectively.
Maintained performance levels after pruning.
Abstract
Recurrent neural networks (RNNs) have recently achieved remarkable successes in a number of applications. However, the huge sizes and computational burden of these models make it difficult for their deployment on edge devices. A practically effective approach is to reduce the overall storage and computation costs of RNNs by network pruning techniques. Despite their successful applications, those pruning methods based on Lasso either produce irregular sparse patterns in weight matrices, which is not helpful in practical speedup. To address these issues, we propose structured pruning method through neuron selection which can reduce the sizes of basic structures of RNNs. More specifically, we introduce two sets of binary random variables, which can be interpreted as gates or switches to the input neurons and the hidden neurons, respectively. We demonstrate that the corresponding…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1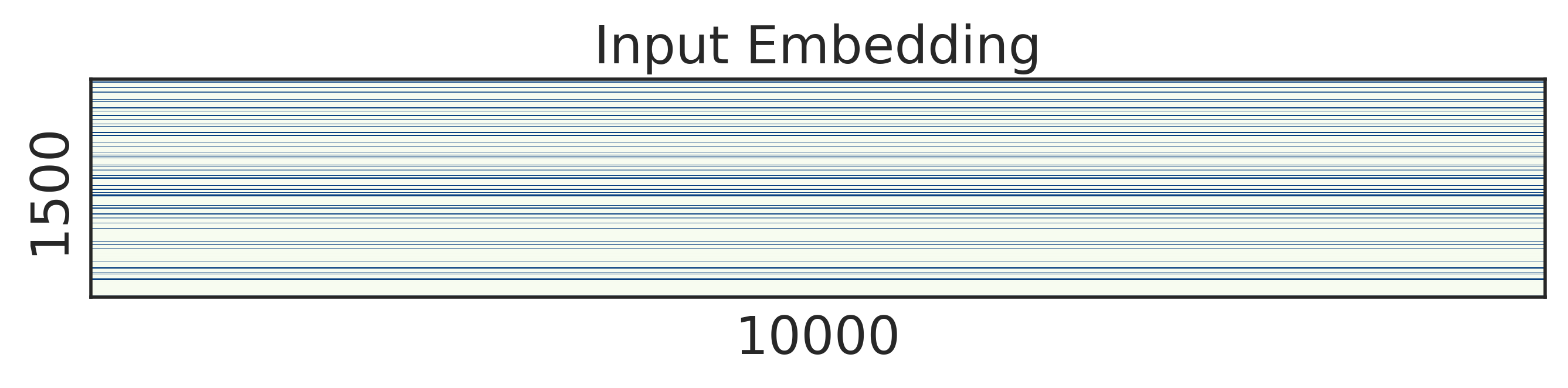 Figure 2
Figure 2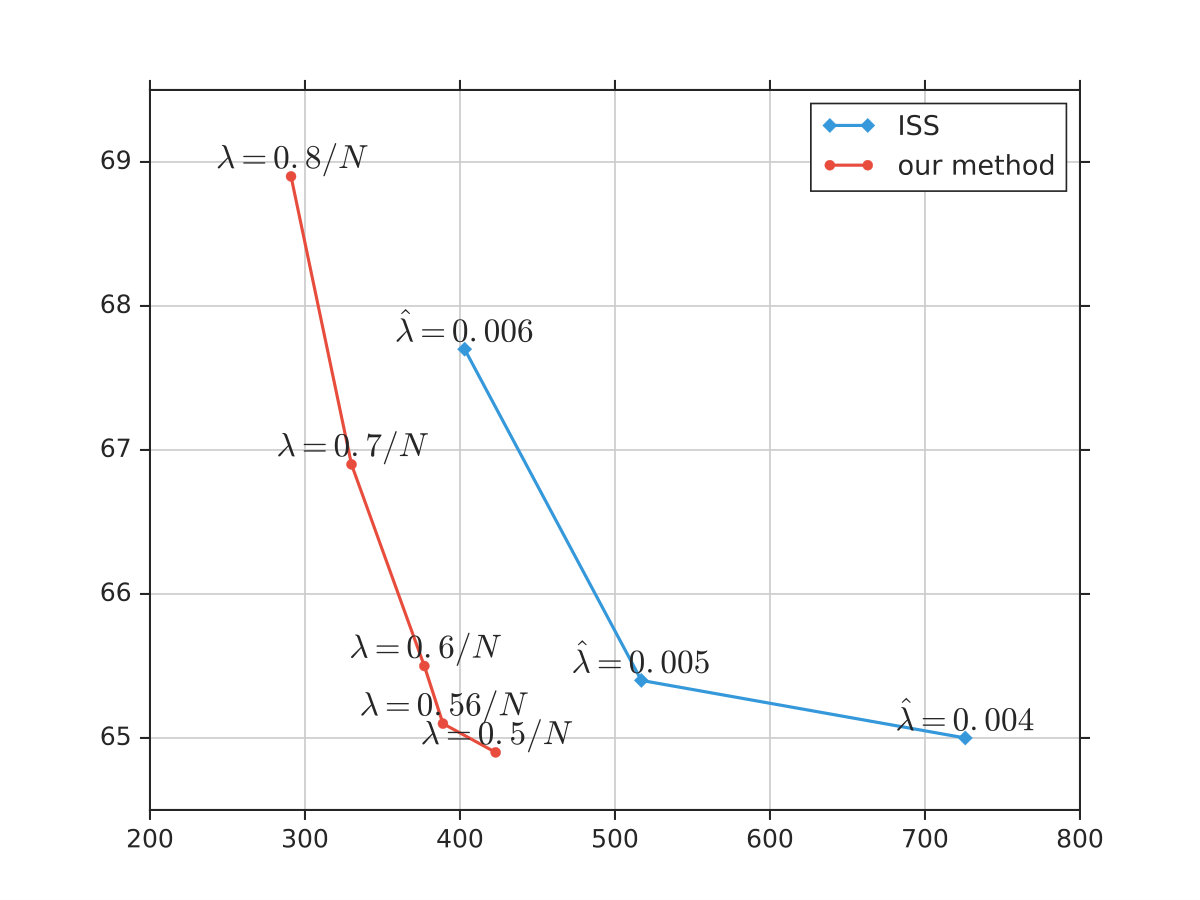 Figure 3
Figure 3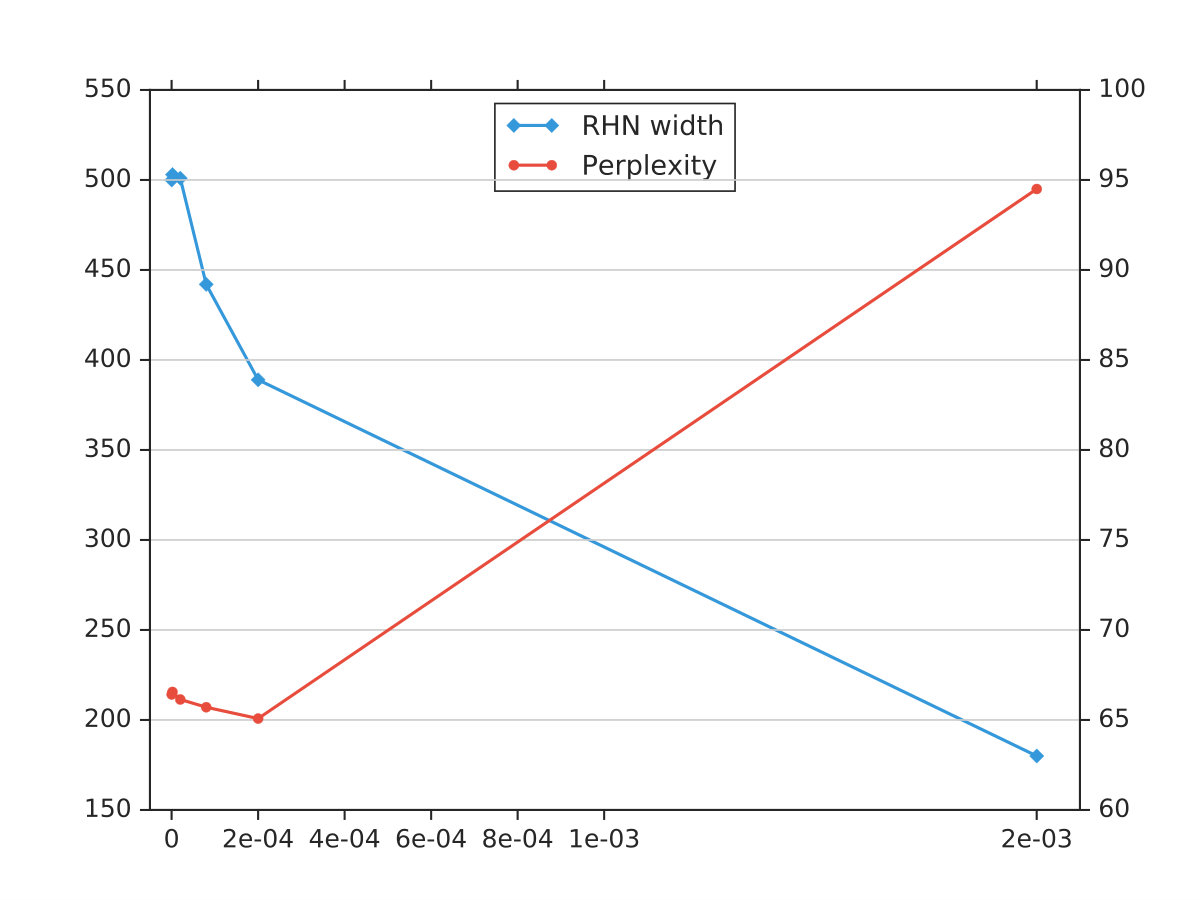 Figure 4
Figure 4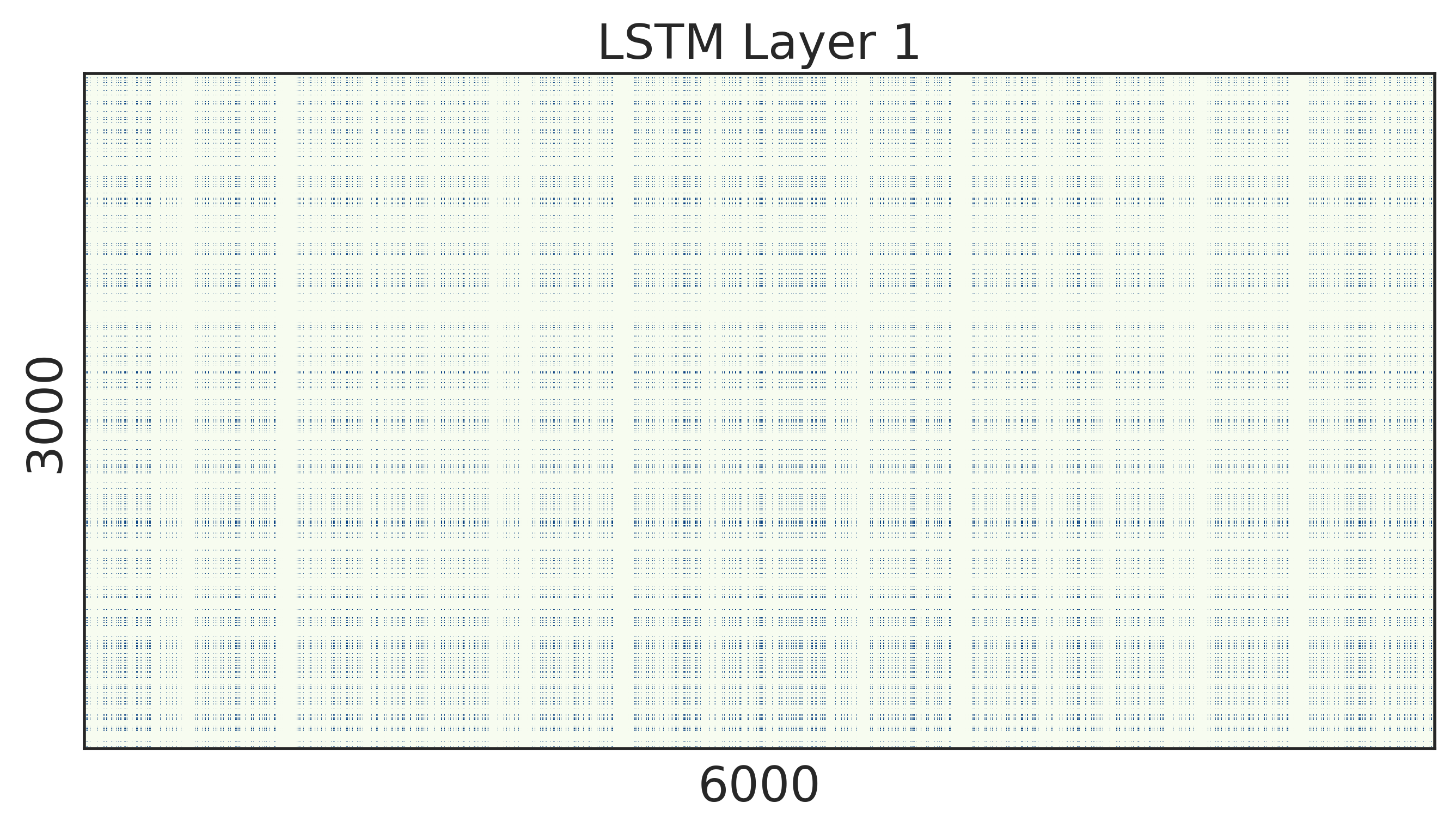 Figure 5
Figure 5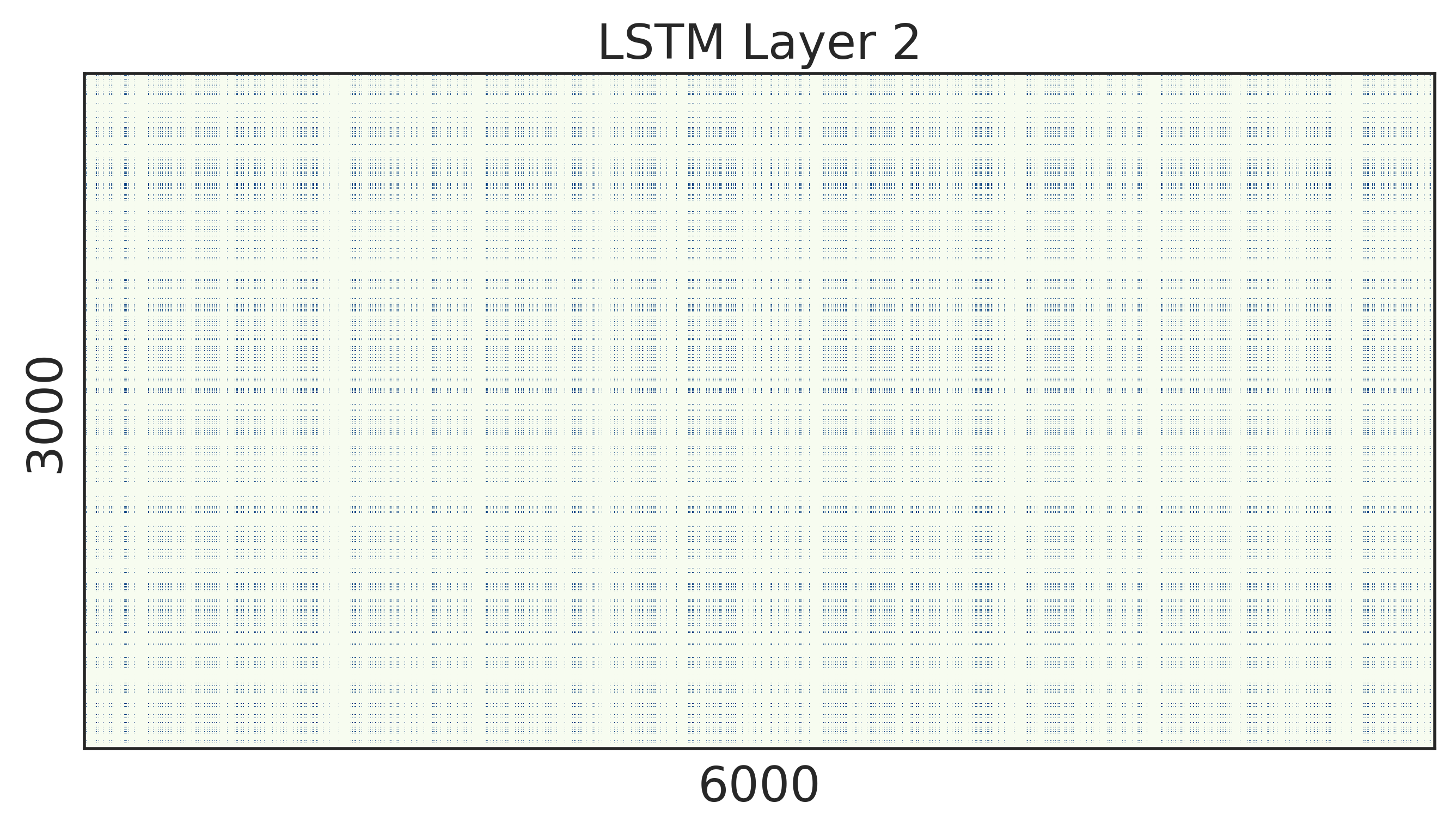 Figure 6
Figure 6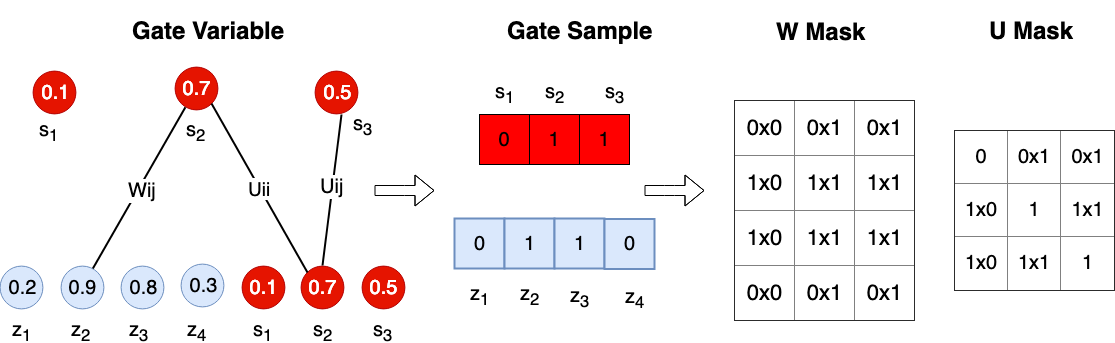 Figure 7
Figure 7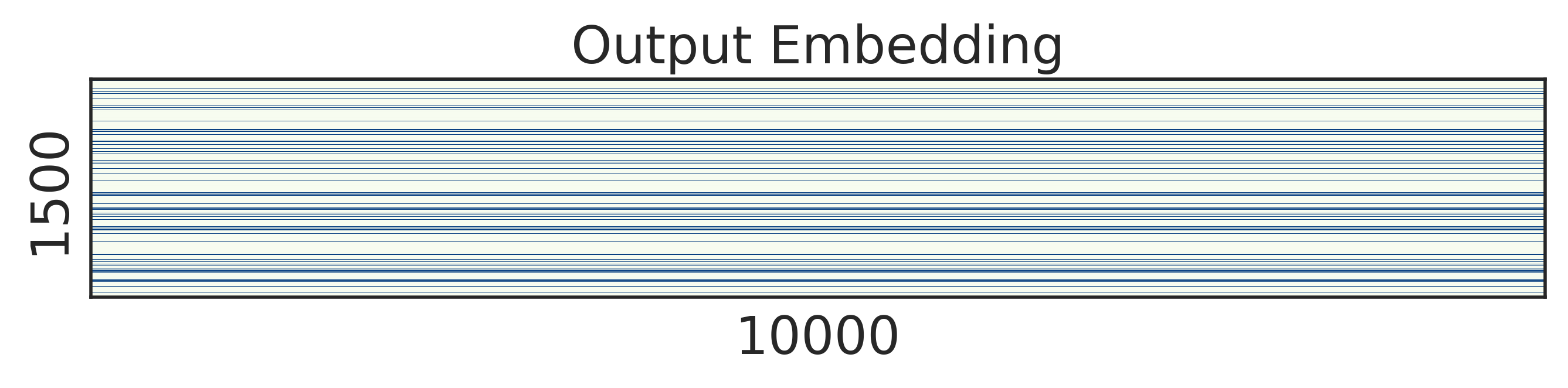 Figure 8
Figure 8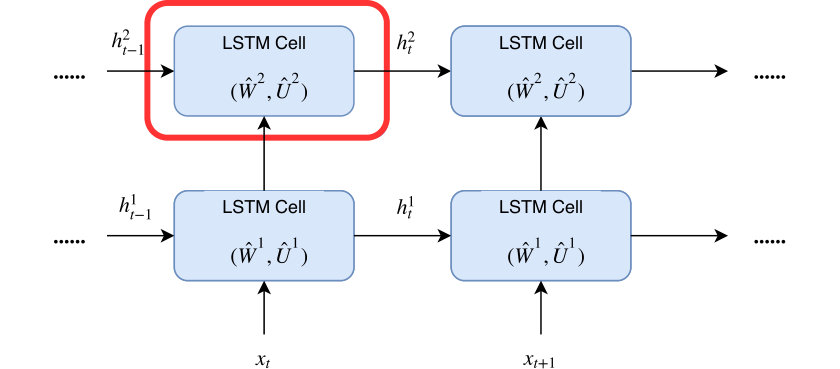 Figure 9
Figure 9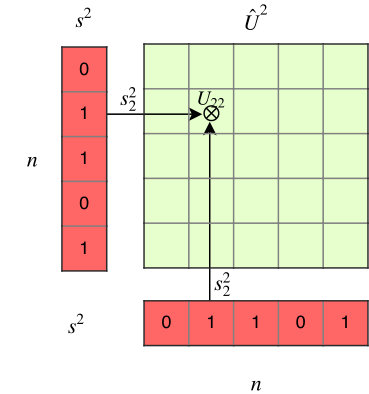 Figure 10
Figure 10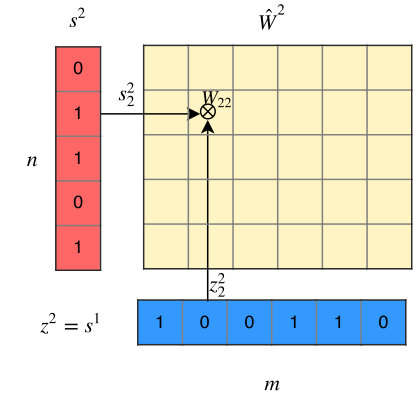 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16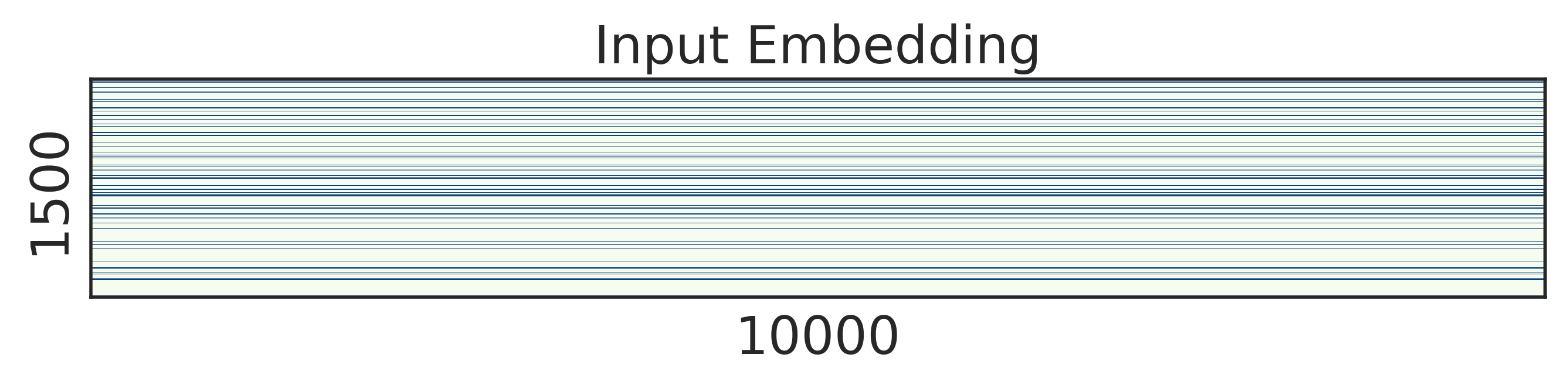 Figure 17
Figure 17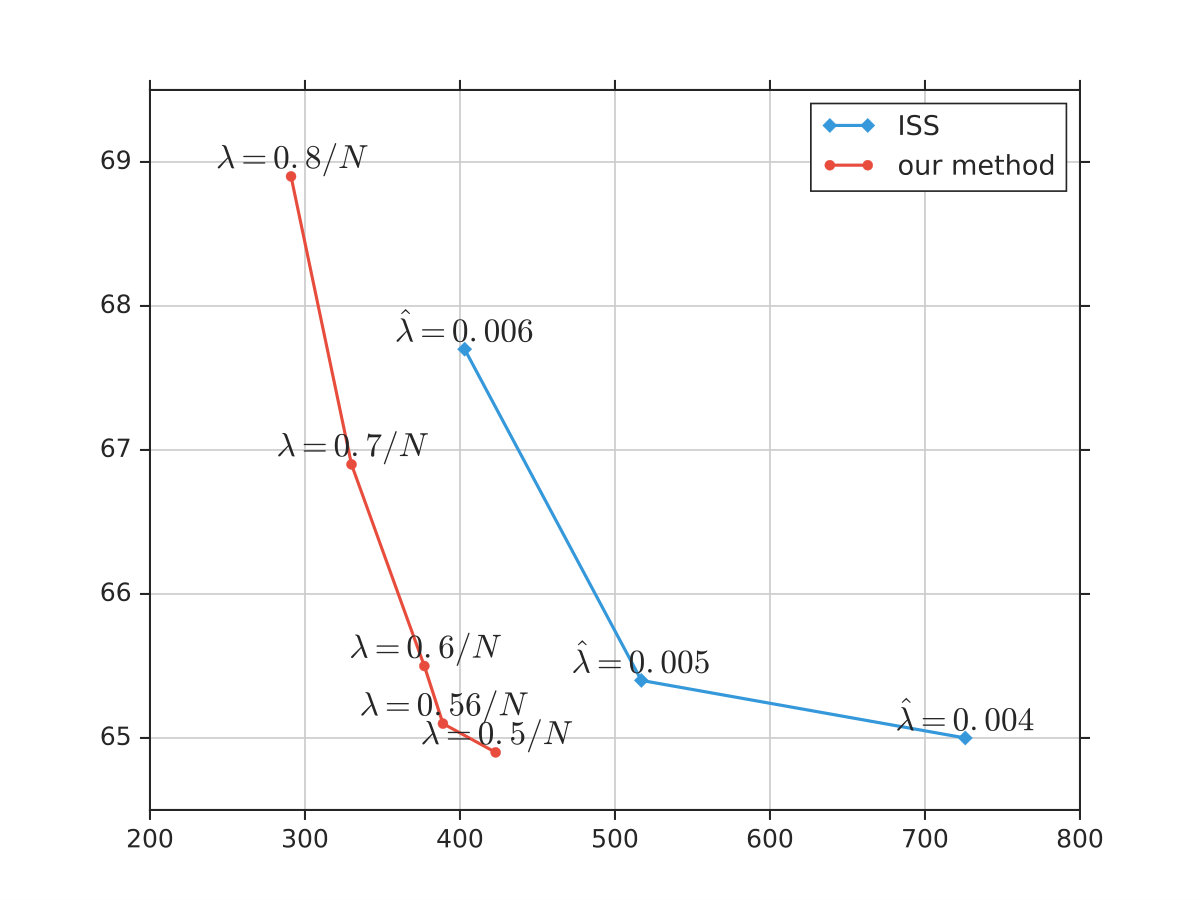 Figure 18
Figure 18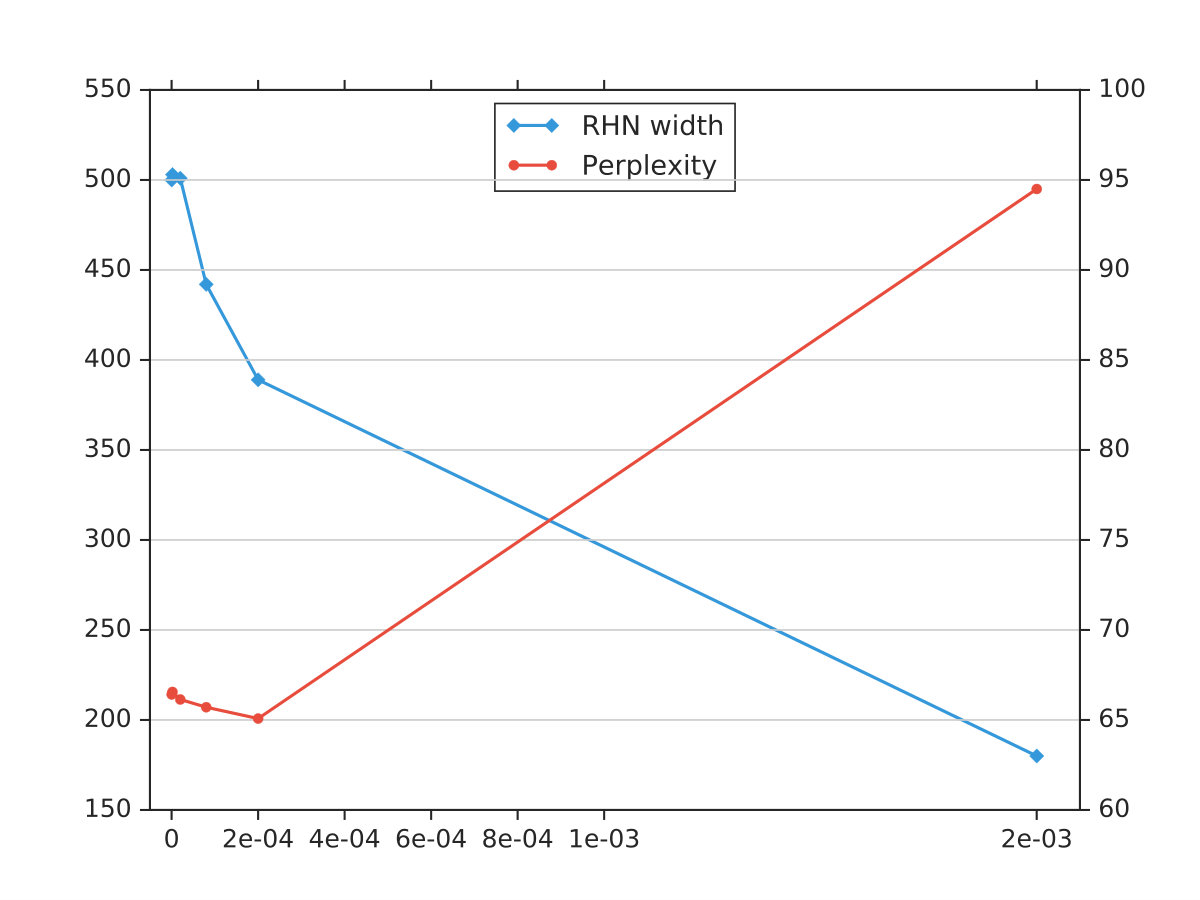 Figure 19
Figure 19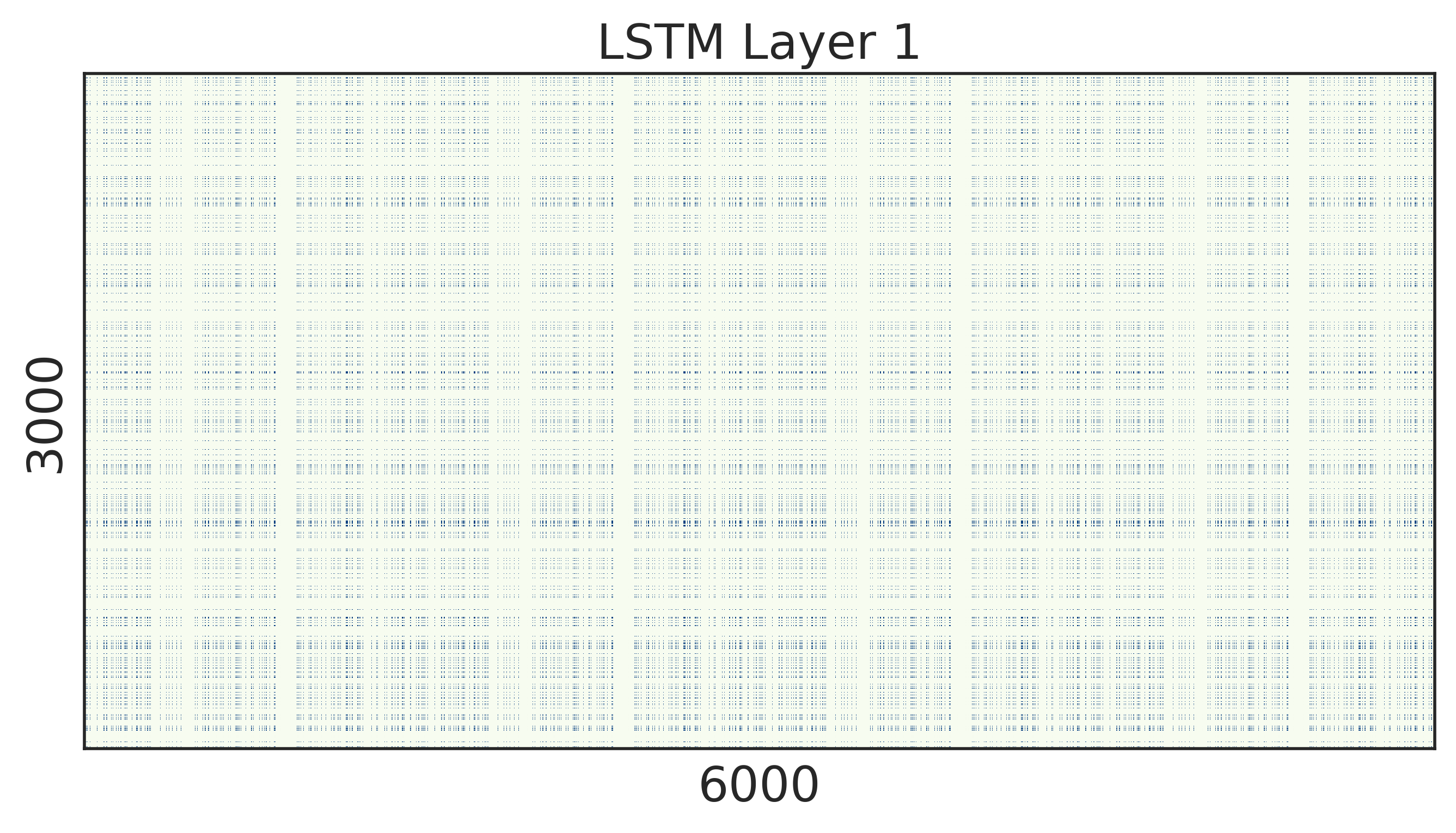 Figure 20
Figure 20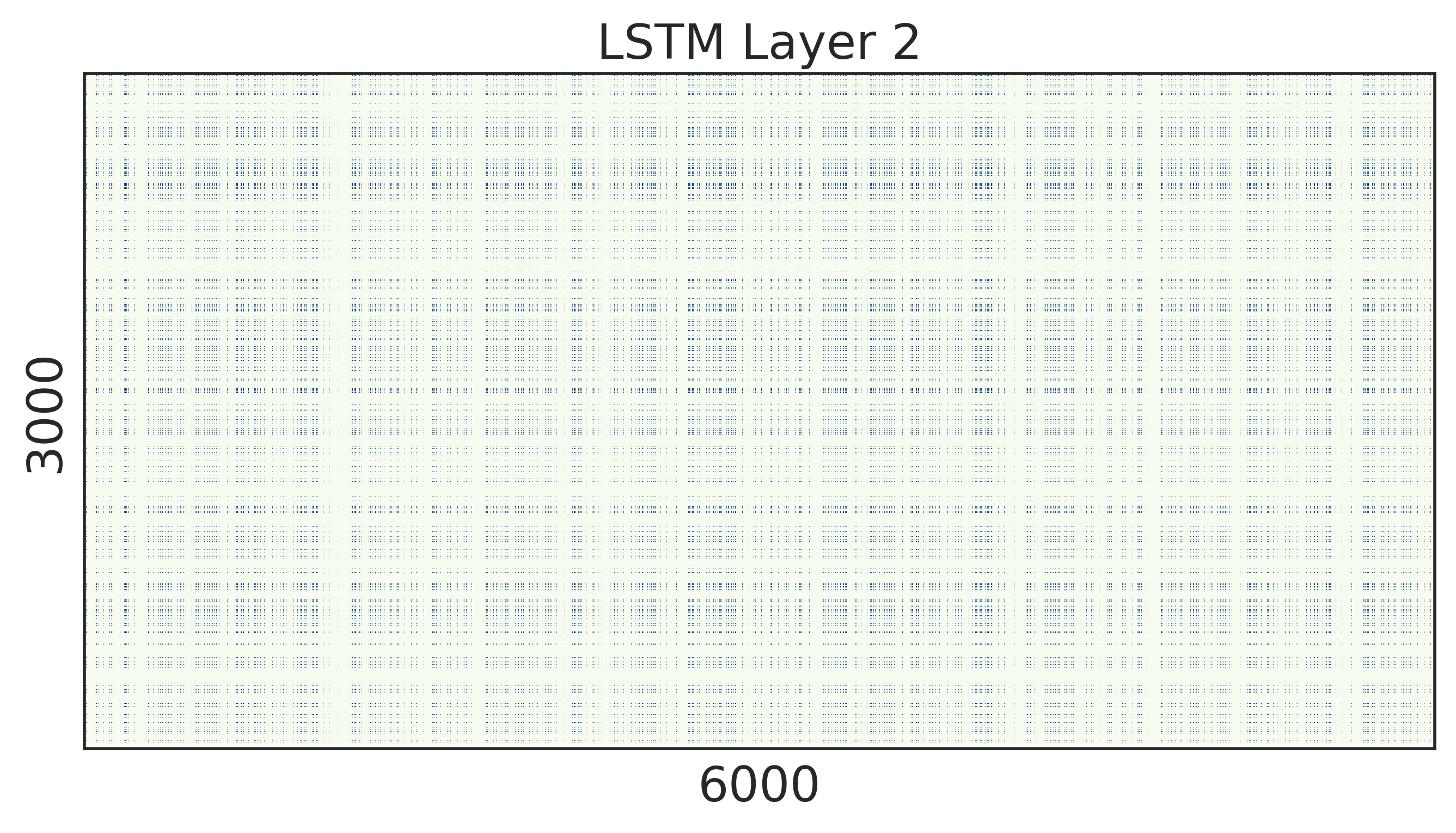 Figure 21
Figure 21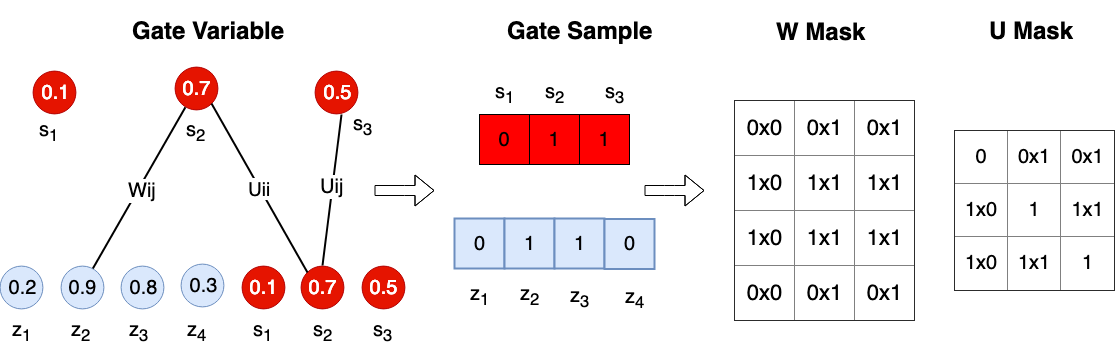 Figure 22
Figure 22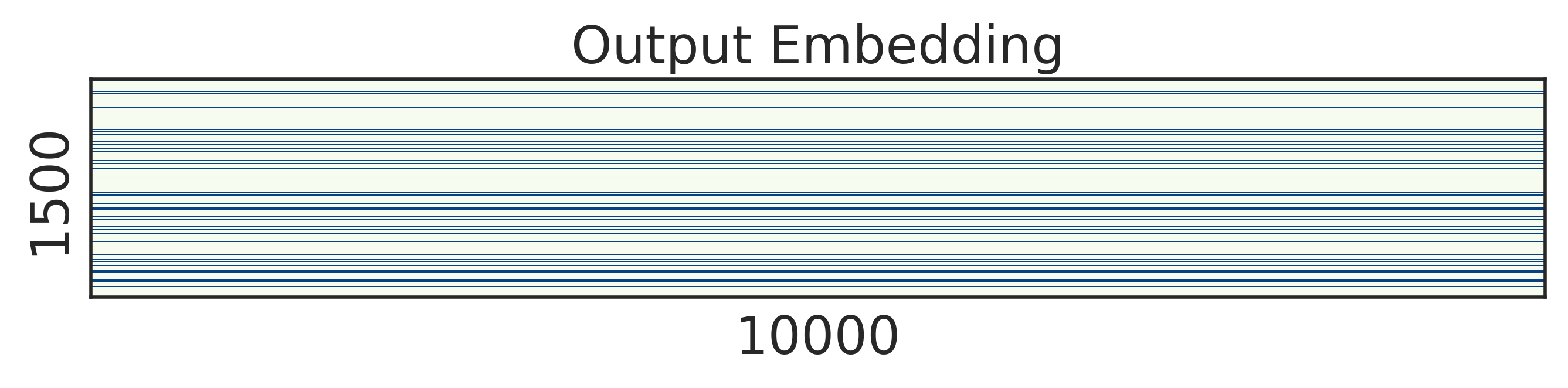 Figure 23
Figure 23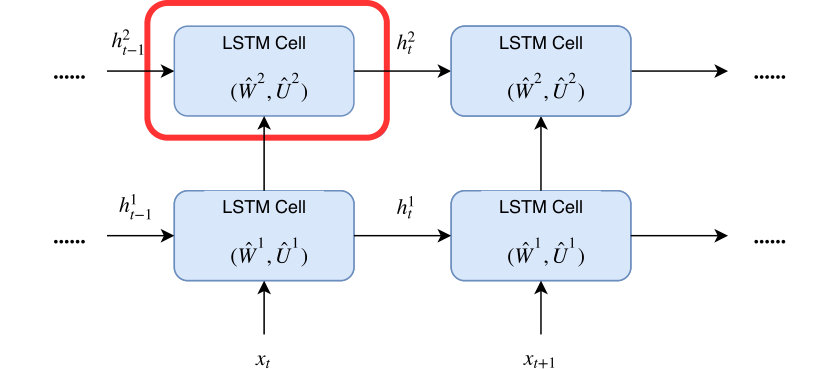 Figure 24
Figure 24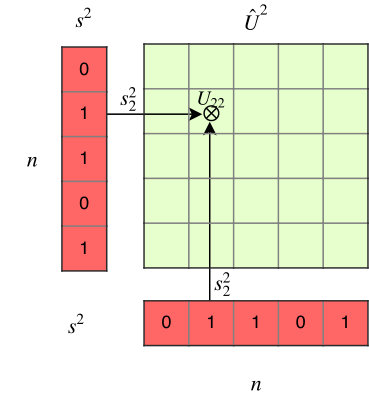 Figure 25
Figure 25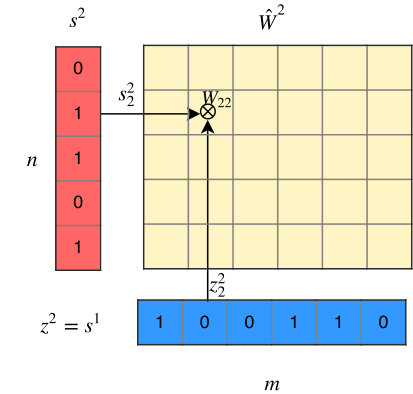 Figure 26
Figure 26 Figure 27
Figure 27 Figure 28
Figure 28 Figure 29
Figure 29 Figure 30
Figure 30| Method |
|
|
|
Size | Time (ms) | Speedup |
|
||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Vanilla Model | 0.35 | (82.57,78.57) | (1500, 1500, 1500) | 66.0M | 365.92 10.3 | 1.00 | 1.00 | ||||||||
| ISS | 0.60 | (82.59, 78.65) | (1500, 373, 315) | 21.8M | 39.88 0.7 | 9.17 | 7.48 | ||||||||
| our method | 0.65 | (81.62, 78.08) | (251, 296, 247) | 6.16M | 18.87 0.3 | 19.39 | 13.95 |
|
|
|
||||||
|---|---|---|---|---|---|---|---|---|
| (1, 1, 1, 1) | (81.73, 78.33) | (1020, 215, 250) | ||||||
| (2, 1, 1, 1) | (82.87, 79.25) | (635, 146, 247) | ||||||
| (3, 1, 1, 1) | (85.49, 81.82) | (438, 110, 244) | ||||||
| (4, 1, 1, 1) | (87.37, 84.22) | (333, 88, 242) | ||||||
| (5, 1, 1, 1) | (90.83, 84.22) | (273, 70, 237) |
| Method | EM | F1 | ModFwd1 | ModBwd1 | ModFwd2 | ModBwd2 | outFwd | outBwd | Weight |
|---|---|---|---|---|---|---|---|---|---|
| Vanilla BiDAF | 67.98 | 77.85 | 100 | 100 | 100 | 100 | 100 | 100 | 2.69M |
| ISS [19] | 65.36 | 75.78 | 20 | 33 | 40 | 38 | 31 | 16 | 0.95M |
| our method | 65.67 | 75.69 | 26 | 33 | 36 | 36 | 33 | 15 | 0.96M |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMultimodal Machine Learning Applications · Domain Adaptation and Few-Shot Learning · Advanced Neural Network Applications
MethodsPruning
Structured Pruning of Recurrent Neural Networks through Neuron Selection
Liangjian Wen
Xuanyang Zhang
Haoli Bai
Zenglin Xu
SMILE Lab, School of Computer Science and Engineering
University of Electronic Science and Technology of China
Chengdu 610031, China.
Department of Computer Science and Engineering
The Chinese University of Hong Kong
Shatin NT 999077, Hong Kong SAR
Center of Artificial Intelligence
Peng Cheng Lab
Shenzhen, Guangdong, China
Abstract
Recurrent neural networks (RNNs) have recently achieved remarkable successes in a number of applications. However, the huge sizes and computational burden of these models make it difficult for their deployment on edge devices. A practically effective approach is to reduce the overall storage and computation costs of RNNs by network pruning techniques. Despite their successful applications, those pruning methods based on Lasso either produce irregular sparse patterns in weight matrices, which is not helpful in practical speedup. To address these issues, we propose a structured pruning method through neuron selection which can remove the independent neuron of RNNs. More specifically, we introduce two sets of binary random variables, which can be interpreted as gates or switches to the input neurons and the hidden neurons, respectively. We demonstrate that the corresponding optimization problem can be addressed by minimizing the norm of the weight matrix. Finally, experimental results on language modeling and machine reading comprehension tasks have indicated the advantages of the proposed method in comparison with state-of-the-art pruning competitors. In particular, nearly 20 practical speedup during inference was achieved without losing performance for the language model on the Penn TreeBank dataset, indicating the promising performance of the proposed method.
keywords:
Feature Selection, Recurrent Neural Networks , Learning Sparse Models, Model Compression
††journal: Neural Networks
1 Introduction
Recurrent neural networks (RNNs) have recently achieved remarkable successes in multiple fields such as image captioning [1, 2], action recognition [3, 4], music segmentation [5], question answering [6, 7], machine translation [8, 9, 10], and language modelling [11, 12, 5]. These successes heavily rely on huge models trained on large datasets, especially for those RNN variants such as Long Short Term Memory (LSTM) networks [13] and Gated Recurrent Unit (GRU) networks [14]. With the increasing popularity of edge computing, a recent trend is to deploy these models onto end devices so as to allow off-line reasoning and inference. However, these models are generally of huge sizes and bring expensive computation and storage costs during inference, which makes the deployment difficult for those devices with limited resources. In order to reduce the overall computation and storage costs of these models, model compression on recurrent neural networks has been widely concerned.
Network pruning is one of the prominent approaches to tackle the compression of RNNs. [15] presents a connection pruning method to compress RNNs efficiently. However, the obtained weight matrix via connection pruning has random and unstructured sparsity. Such unstructured sparse formats are unfriendly for efficient computation in modern hardware systems [16, 17] due to irregular memory access in modern processors. Previous studies [18, 19] have shown that speedup obtained with random sparse matrix multiplication on various hardware platforms is lower than expected. For example, varying the sparsity level in weight matrices of AlexNet in the range of 67.6%, 92.4%, 94.3%, 96.6%, and 97.2%, the speedup ratio was 0.25, 0.52, 1.36, 1.04, and 1.38, respectively. A practical remedy to this problem is structured pruning where pruning individual neurons can directly trim weight matrix size such that structured sparse matrix multiplication efficiently utilizes the hardware resources.
Due to the promising properties of structured pruning, the structured pruning on deep neuron networks(DNNs) has been widely explored [20, 21, 22, 23]. However, compared with the structured pruning on DNNs, there is a vital challenge originated from recurrent structure of RNNs, which is shared across all the time steps in a sequence. Structured pruning methods used in DNNs cannot be directly applied to RNNs. The reason is that independently removing the links can result in a mismatch of feature dimensions and then induce invalid recurrent units. In contrast, this problem does not exist in DNNs, where neurons can be independently removed without violating the usability of the final network structure. Accordingly group sparsity [24] is difficult to be applied in RNNs.
To address this issue, we explore a new type of method along the line of structured pruning of RNNs through neuron selection. In detail, we introduce two sets of binary random variables, which can be interpreted as gates to the neurons, to indicate the presence of the input neurons and the hidden neurons, respectively. The two sets of binary random variables are then used to generate sparse masks for the weight matrix. More specifically, the presence of the matrix entry depends on both the presence of the -th input unit and the -th output unit, while the value of indicates the strength of the connection if . However, the optimization of these variables is computationally intractable due to the nature of possible states of binary gate variable vector . We then develop an efficient inference algorithm for inferring the binary gate variables, motivated from the work of pruning DNN weights[25, 24].
While previous efforts on structured pruning of RNNs resort to the group lasso (i.e., the norm regularization) for learning sparsity [19], the lasso based methods are shown to be insufficient in inducing sparsity for large scale non-convex problems such as the training of DNNs [25, 26]. In contrast, the expected minimization closely resembles spike-and-slab priors [27, 28, 29] used in Bayesian variable selection [25, 24]. The spike-and-slab priors can induce high sparsity and encourage large values at the same time due to the richer parameterization of these priors, while LASSO shrinks all parameters until lots of them are close to zero. And the -norm regularization explicitly penalizes parameters for being different than zero with no other restrictions. Hence compared with Intrinsic Sparse Structures (ISS) via Lasso proposed by [19], our neuron selection via the norm regularization can achieve higher adequate sparsity in RNNs.
In this paper, we propose a new type of method to prune individual neurons of RNNs. Our key contribution is that we introduce binary gates on recurrent and input units such that sparse masks for the weight matrix can be generated, allowing for effective neuron selection under sparsity constraint. For the first work of neuron selection in RNNs, we attempt to employ the smoothed mechanism for the regularized objective proposed in [24], motivated from [25].
We evaluate our structured pruning method on two tasks, i.e., language modeling and machine reading comprehension. For example, in the case of language modeling of the word level on the Penn Treebank dataset, our method achieves the state-of-the-art results, i.e., the model size is reduced by more than 10 times, and the inference of the resulted sparse model is nearly 20 times faster than that of the original model. We also achieve encouraging results for the recurrent highway networks [30] on language modeling and BiDAF model [31] on machine reading comprehension.
2 Related Work
Despite model compression has achieved impressive success in DNNs(e.g., CNNs) [32, 33, 34], it is difficult to directly apply this technology of compressing DNNs to the compression of RNNs due to the recurrent structure in RNNs. There are some recent efforts on the compression of RNNs. Generally, the compression techniques on RNNs can be categorized into the following types: pruning [15, 35, 19], low-rank matrix/tensor factorization [36, 3, 30] and quantization [37, 38]. [39] introduces several strategies including gate activation sparsity, top-k pruning schemes and mixed quantization schemes to compress LSTMs. Our work lies in the branch of pruning.
Pruning approaches can be further divided into non-structured pruning and structured pruning. For non-structured pruning, elements of the weight matrices can be removed based on some criteria. For example, [15] presents a magnitude-based pruning approach for RNNs, i.e., at every iteration, the top-k elements of the weights are set as 0. While such an approach can achieve over 90% sparsity in RNNs of Deep Speech 2 model with a minor decrease of accuracy, the obtained non-structured sparse matrices cannot efficiently accelerate the computation in modern computing platforms due to the irregular memory access. To improve this, [35] further proposed block-structured pruning in RNNs via the group lasso regularization. It extends the approach in [15] to prune blocks of a matrix instead of individual weights. [19] also proposed Intrinsic Structured Sparsity (ISS) for LSTMs by collectively removing the columns and rows for the weight matrices. ISS reduces the sizes of basic structures within LSTM units and is more hardware-friendly for acceleration compared with block structure in [35]. Similar to [35], ISS also relies on group lasso for sparsity learning. Nevertheless, lasso regularization is shown to be insufficient for large non-convex problems, e.g., the training of DNNs [26]. To alleviate this challenge in [19, 35], we instead present a structured sparsity learning method through regularization, which not only reduces the size of basic structures of LSTMs but also achieves higher sparsity for non-convex RNN training in a tractable way.
3 Structured pruning of LSTMs through neuron selection
Without loss of generality, we focus on the compression of LSTMs [13], a common variant of RNN that learns long-term dependencies. Note that our method can be readily applied to the compression of GRUs and vanilla RNNs. Before presenting the proposed sparsification methods, we first introduce the LSTM network.
[TABLE]
where is the sigmoid function, denotes the element-wise multiplication and is the hyperbolic tangent function. denotes the input vector at the time-step , denotes the current hidden state, and denotes the long-term memory cell state. , and correspond to the input gate, the forget gate and the output gate, respectively. For notation simplicity, we let be the input-to-hidden weight matrices, and be the hidden-to-hidden weight matrices.
3.1 Neuron Selection via Binary Gates
To prune individual neurons in LSTMs, which can simultaneously reduce the size, FLOPs of LSTMs, we introduce neuron selection mechanisms into the design of LSTMs. As illustrated in Figure 1 (b) and (c), we introduce two auxiliary sets of binary ”gate” or ”switch” variables: one set of variables (denoted by ) controls the presence of the input neuron , where and is the number of input neurons the other set of binary gate switch variables (denoted by ) controls the presence of the hidden neuron , where and is the number of hidden neurons. In this way, controls the strength of the link from the input neuron to the hidden neuron , while and control the presence of neurons, and the mask on can be calculated by . In particular, such a gating mechanism can induce structured sparsity on the weight matrices. If , all hidden neurons connected to will be switched off meaning that the -th column of will be all zeros; and will turn off each row of . Therefore, by sharing the binary masks across all the gates, we can obtain structured sparsity on the weight matrices. For convenience, we re-parameterize the original parameter matrices and to and as follows,
[TABLE]
where denotes the element-wise product operation. In this way, controls the strength of the link from the input neuron to the hidden neuron , while and control the presence of neurons. Furthermore, our proposed switch mechanism can be directly applied to stacked LSTMs. As illustrated in Figure 1(a), since the output of the -th layer is the input of the -th layer, we have .
To model the uncertainty of each random “gate” variable and , we let and , where and are the parameters of the Bernoulli distributions, and denote the probability of random variable and taking value 1, respectively. We can optimize this objective function with and by minimizing the norm of the weight matrix to achieve neuron selection. The norm regularization can explicitly penalize no-zero parameters of models without further restrictions [24], and it demonstrates superior advantages over the norm regularization in the sparse learning. A naive idea in learning sparsity is to directly utilize the -norm regularization on the weights of LSTMs, which leads to the following objective function:
[TABLE]
Here denotes the -norm, and follows a similar pattern. is the indicator function, and and denote the number of input units and hidden units, respectively. represents the loss on the dataset , and and are penalty parameters for the sparsity regularization.
Neuron selection via binary random variables generates masks for the weight matrix. With the gating mechanism, the norm in Equation 3.1 can be further specified as and . Hence we can seek to penalize the number of parameters appearing in LSTM on average. The expectation of Equation (3.1) over the auxiliary masks is reformulated as follows,
[TABLE]
The item in denotes the mask of weight parameters . The term only depends on the presence of the -th recurrent units. Hence the expectation of is . Note that to avoid quadratic terms on , we write as the summation of two terms as shown in Equation (3.1). Since the binary gates are shared across layers in stacked RNNs, it may result in an extremely unbalanced sparse structure in different layers to penalize the gate variables of different layers with the same penalty factor. For this reason, we specify independent regularization for different layers.
3.2 Optimization
It is intractable to learn sparse parametric models by minimizing the norm based on gradient optimization. The optimization of the objective in Equation (3.1) is problematic due to the discrete nature of and . In principle, the REINFORCE estimator [40] can be used to compute the gradients, but it suffers from high variance and slow convergence. On the other hand, the straight-through estimator (STE) [41] can also be used, however, the mismatch of the parameters between the forward and backward pass in the optimization leads to biased gradients and updates.
A more appealing method is to continuously relax discrete random binary variables by a hard-sigmoid rectification of continuous random variable with a distribution [24], as follows:
[TABLE]
where the corresponds to the continue distribution with parameter . Then the probability of the discrete random binary variables being non-zero is computed by the cumulative distribution function(CDF) of , as follow:
[TABLE]
Then it can not only enable gradient-based optimization of a generic loss by smoothing the binary gate variables , but also allow the variables to be exactly zero. We can write the continuous distribution by using the the reparameterization trick [42, 43], where is a deterministic and differentiable function and denotes the uniform or Gaussian free noise. Since is independent of the parameters of models, we can directly take the gradient of the optimization target over the parameters of the distributions of random variables.
Similarly, we can apply the same procedure to smooth gate variables with which denotes the parameters of the correlative continuous distribution. Armed with the above approach, we can generate and via the differentiable transformation in Equation (3.2), and therefore shift the optimization over and in Equation (3.1) to and in the hard concrete distributions. The original objective function in Equation (3.1) can be reformulated as
[TABLE]
As shown in [24], an efficient choice of the smoothing continuous distribution is as following; the binary concrete distribution [44, 45] with the parameters and , where and are the location and temperature parameters respectively, is stretched from the (0,1) interval to the (,) interval,with and . Then we apply a hard-sigmoid on its random samples. More specific, the procedure to smooth gate variables is as following:
[TABLE]
where is the sigmoid function as introduced before. The probability of the being non-zero can be computed by the cumulative density function of as follows:
[TABLE]
where denotes the parameters of the hard concrete distribution. Similarly, we can apply the same procedure to smooth gate variables .
During testing, we use the following estimator for the final and under a hard concrete smoothness:
[TABLE]
4 Experiments
To compare with Intrinsic Sparse Structures (ISS) via Lasso proposed by [19], we also evaluate our structured sparsity learning method with regularization on language modeling and machine reading tasks. In the case of language modeling, we seek to sparsify a stacked LSTM model [46] and the state-of-the-art Recurrent Highway Networks (RHNs) [30]
on the Penn Treebank (PTB) dataset [47]. For the task of machine reading comprehension, we choose the Bi-Directional Attention Flow Model (BiDAF) [31] with a small hidden size of 100 on the SQuAD dataset [48]. While our structured norm imposes no shrinkage on the remaining components, the learned model could be over-fitted if weight decay is not assigned. Consequently, we follow a similar pattern in [24] to impose regularization on model parameters. For the setting of the hard concrete distribution, we follow the same pattern in [24] for all experiments, i.e., are taken as the hyper-parameters. For , it is updated by back-propagation of the network and initialized by samples from .
4.1 Language Modeling
For language modeling, we evaluate two models: stacked LSTMs and recurrent highway neural networks. Both models are trained from scratch. We use the word level PTB dataset for language modeling, which consists of 929k training words, 73k validation words and 82k test words with 10,000 unique words in its vocabulary.
4.1.1 Stacked LSTMs
Baselines. We compare our proposed method against two baselines, the vanilla two-layer stacked LSTM used in [46] and the ISS method [19], which is the state-of-the-art method in RNN compression. The dropout keep ratio is for the vanilla model. The vocabulary size, embedding size and hidden size of the stacked LSTMs are set as , and , respectively, which is consistent with the settings in [19]. The results of ISS are taken from the original paper.
Hyper-parameters Setting. We use NT-ASGD [49] for training with an initial learning rate equal to and the gradient clipping set to . Similar to ISS [19], we increase the dropout keep ratio to 0.65 due to the intrinsically structured sparsity in the network. We use the default initialization strategy provided in PyTroch111https://pytorch.org/ for the input and output word embedding as well as the parameters of the LSTM.
Results. We show the results of stacked LSTMs in Table 1. It can be observed that our method finds the most compact structure of the model, i.e. the numbers of the first and second hidden units are reduced from 1500 to 296 and 247 respectively, both of which are significantly smaller than the vanilla stacked model and the ISS method. Besides, the dimension of word embedding vectors also decreases from 1500 to 251. Overall, our method reduces the model size form to , which is more than 10 reduction comparing to the vanilla model. Theoretically, the computation is reduced by nearly 14 in terms of multi-add operations. Compared with ISS in [19], our structured sparsity learning method reduces the multi-add computation further by 1.86x and the model size further by . The results indicate that our structured regularization can indeed sufficiently sparse the model. Additionally, despite the model size being sharply shrunk, our method still achieves the lowest perplexity on the PTB dataset. The excellent performance of our method can be explained by the superiority of our structured regularization since it poses no penalization over the remained parameters, while for ISS, the group lasso method penalizes the norms of all groups collectively, and thereon could affect the model capacity.
In order to evaluate the practical speedup of the learned structures of our proposed method and all the baseline, we measure the speedup of inference on CPU222Intel CPU E5-2630 v4 @ 2.20GHz processor with a total of 40 cores. using TensorFlow with Intel MKL library333https://www.tensorflow.org/guide/performance/overview.. The time is measured with 10 batch size and 30 unrolled steps, and the result is averaged from times of inference with standard deviation reported. It can be seen from Table 1 that the practical inference time is 19.4 faster than the original model. The actual speedup is even higher than the theoretical result, and we conjecture that this could be due to some basic optimization in the MKL library.
To look into the learned structured sparsity, we further visualize the embedding and weights of the stacked LSTMs in Figure 2 after training 200 epochs. We can see that after structured regularization, the size of word embedding is highly reduced, and similarly, most rows and columns of the weight matrices are pruned away. Therefore, such matrices can be re-arranged to a small and compact structure, leading to practical speed up during inference.
Ablative Study. We used a two-layer stacked LSTM to verify the sensitivity of the penalty parameters in Equation (3.1). Experimentally, we find that setting all the penalty values to (where denotes the number of training data) can lead to good performance. For convenience, we use ,, and to denote the times to , e.g., denotes the penalty parameter to the input neuron the first layer. Here the super-index denotes the corresponding layer. Initially, we set all the parameters to the same value (i.e., ). We find that the numbers of the first-layer and second-layer hidden units are reduced from 1500 to 215 and 250 respectively, while the size of the input only decreases from 1500 to 1020.
Since the first input layer is usually much larger than the hidden layers, we increase the penalty value of to drop out more input neurons and to seek much smaller networks. From Table 2, we can find that with a larger value of , the sparser input layer can be obtained while with a significant increase in the perplexity.
4.1.2 Recurrent Highway Networks
Our method can be further extended to Recurrent Highway Networks (RHNs) [30]. Due to the structure of RHNs, we only introduce the binary mask and set its regularization as . During training, we impose regularization over so as to learn structured sparsity.
Baselines. To evaluate our structured sparsity learning method, we choose ”Variational RHN + WT” of [30] as our baseline model. The number of units per layer is defined as the width of RHNs. It has depth 10 and width 830, with totally parameters. The implementation of RHNs is available from its authors444https://github.com/jzilly/RecurrentHighwayNetworks. Aside from the vanilla RHNs, we also compare to the ISS method, and its results are taken from [19].
Hyper-parameters Setting. For our method, we use the same hyper-parameters as those in the baseline, except for that the parameters of models are initialized uniformly in , the dropout ratios are multiplied by , and we divide the learning rate by a factor of at every epoch after it reaches .
Results. Table 3 shows the results obtained by the baseline, ISS and our method. Comparing to the vanilla RHN and ISS method, our structured sparsity approach can significantly achieve a more compact model with width 387 without losing perplexity. The parameter size also decreases to , which is about reduction.
We further investigate the trade-off between perplexity and sparsity of our method and ISS, and the plot is shown in Figure 3. It can be observed that our method can achieve a higher reduction of RHNs width than ISS at the same perplexity. With the same width, our method can achieve lower perplexity as well. This again demonstrates the superiority of our structured regularization over group lasso methods in inducing sparsity for recurrent structures.
4.2 Machine Reading Comprehension
Machine Reading Comprehension (MRC) is one of the frontier tasks in the field of natural language processing. In MRC, the models answer a query about a given context paragraph, and Exact-Match (EM) and F1 scores are two major metrics for the evaluation (the higher the better). We use the benchmark Stanford Question Answering Dataset (SQuAD) [48], which consists of 100,000+ questions crowd-sourced on more than 500 Wikipedia articles.
Baselines. We use the BiDirectional Attention Flow Model (BiDAF)555We use the code from https://github.com/allenai/bi-att-flow. [31] as the backbone model to evaluate our structured sparsity learning method. The BiDAF is composed of bidirectional LSTMs, and our structured regularization method can be readily applied. We focus on sparsifying the two layers of the bidirectional LSTM denoted as ModFwd1, ModBwd1, ModFwd2, and ModBwd2, since they are shown to be most computationally expensive layers in [19].
Hyper-parameter setting. We penalize different layers of the model in a similar pattern to the two-layer LSTMs used language modeling. We also increase the dropout keep ratio to 0.9 as the structured sparsity itself can prevent over-fitting to some extent. All the rest training schemes are the same as those in the baseline.
Results. Table 4 shows the EM, F1, the number of remaining components and model sizes obtained by the baseline, ISS and our method. As is mentioned in [19], the scale of the vanilla BiDAF is compact enough on the SQuAD dataset, and it is thereon hard to reduce the hidden size of those LSTM layers in BiDAF without losing any EM/F1. Our structure sparsity method achieves competitive sparsity and performance comparing to the ISS method, both of which produce remarkably compressed models under acceptable degradation to the vanilla BiDAF. The result again demonstrates that our structured methods can be effectively used to discover the sparsity of recurrent neural networks.
5 Conclusion
In this paper, we propose a novel structured sparsity learning method for recurrent neural networks. By introducing binary gates on neurons, we penalize weight matrices through regularization, reduce the sizes of the network parameters significantly and lead to practical speedup during inference. We also demonstrate the superiority of our relaxed regularization over the group lasso used in previous methods. Our methods can be readily used in other recurrent structures such as Gated Recurrent Unit, and Recurrent Highway Networks.
For future work, we plan to explore the sparsity constraints for neuron selection for further reducing the number of model parameters, to exploit a more appealing unbiased, lower variance estimator(e.g., the unbiased ARMs-estimator recently proposed in [50]) for neuron selection. We also plan to combine neuron selection with quantization algorithms to further reduce model sizes and FlOPs of RNNs.
Acknowledgments
This work was partially supported by NSF China(No. 61572111), a Fundamental Research Fund for the Central Universities of China (No.ZYGX2016Z003), and Startup Funding (No.G05QNQR004).
References
- [1]
O. Vinyals, A. Toshev, S. Bengio, D. Erhan, Show and tell: Lessons learned from the 2015 mscoco image captioning challenge, IEEE transactions on pattern analysis and machine intelligence 39 (4) (2016) 652–663.
- [2]
P. Anderson, X. He, C. Buehler, D. Teney, M. Johnson, S. Gould, L. Zhang, Bottom-up and top-down attention for image captioning and visual question answering, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 6077–6086.
- [3]
J. Ye, L. Wang, G. Li, D. Chen, S. Zhe, X. Chu, Z. Xu, Learning compact recurrent neural networks with block-term tensor decomposition, in: 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18-22, 2018, 2018, pp. 9378–9387.
- [4]
Y. Pan, J. Xu, M. Wang, J. Ye, F. Wang, K. Bai, Z. Xu, Compressing recurrent neural networks with tensor ring for action recognition, in: The Thirty-Third AAAI Conference on Artificial Intelligence, AAAI 2019, Honolulu, Hawaii, USA, January 27 - February 1, 2019, 2019, pp. 4683–4690.
- [5]
H. Liu, L. He, H. Bai, B. Dai, K. Bai, Z. Xu, Structured inference for recurrent hidden semi-markov model, in: Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, IJCAI 2018, July 13-19, 2018, Stockholm, Sweden., 2018, pp. 2447–2453.
- [6]
T. Sagara, M. Hagiwara, Natural language neural network and its application to question-answering system, Neurocomputing 142 (2014) 201 – 208.
- [7]
X.-L. Mao, Y.-J. Hao, D. Wang, H. Huang, Query completion in community-based question answering search, Neurocomputing 274 (2018) 3 – 7.
- [8]
D. Bahdanau, K. Cho, Y. Bengio, Neural machine translation by jointly learning to align and translate, arXiv preprint arXiv:1409.0473.
- [9]
T. Luong, H. Pham, C. D. Manning, Effective approaches to attention-based neural machine translation, in: Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, EMNLP 2015, Lisbon, Portugal, September 17-21, 2015, 2015, pp. 1412–1421.
- [10]
Z. Yang, W. Chen, F. Wang, B. Xu, Generative adversarial training for neural machine translation, Neurocomputing 321 (2018) 146 – 155.
- [11]
W. Byeon, T. M. Breuel, F. Raue, M. Liwicki, Scene labeling with LSTM recurrent neural networks, in: CVPR, 2015, pp. 3547–3555.
- [12]
I. Sutskever, O. Vinyals, Q. V. Le, Sequence to sequence learning with neural networks, in: NIPS, 2014, pp. 3104–3112.
- [13]
S. Hochreiter, J. Schmidhuber, Long short-term memory, Neural computation 9 (8) (1997) 1735–1780.
- [14]
K. Cho, B. Van Merriënboer, C. Gulcehre, D. Bahdanau, F. Bougares, H. Schwenk, Y. Bengio, Learning phrase representations using rnn encoder-decoder for statistical machine translation, arXiv preprint arXiv:1406.1078.
- [15]
S. Narang, E. Elsen, G. Diamos, S. Sengupta, Exploring sparsity in recurrent neural networks, arXiv preprint arXiv:1704.05119.
- [16]
V. Lebedev, V. Lempitsky, Fast convnets using group-wise brain damage, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 2554–2564.
- [17]
Y. Zhao, L. Wang, W. Wu, G. Bosilca, R. W. Vuduc, J. Ye, W. Tang, Z. Xu, Efficient communications in training large scale neural networks, in: Proceedings of the on Thematic Workshops of ACM Multimedia 2017, Mountain View, CA, USA, October 23 - 27, 2017, 2017, pp. 110–116.
- [18]
W. Wen, C. Wu, Y. Wang, Y. Chen, H. Li, Learning structured sparsity in deep neural networks, in: NIPS 2016, December 5-10, 2016, Barcelona, Spain, 2016, pp. 2074–2082.
- [19]
W. Wen, Y. He, S. Rajbhandari, M. Zhang, W. Wang, F. Liu, B. Hu, Y. Chen, H. Li, Learning intrinsic sparse structures within long short-term memory, arXiv preprint arXiv:1709.05027.
- [20]
Z. Zhuang, M. Tan, B. Zhuang, J. Liu, Y. Guo, Q. Wu, J. Huang, J. Zhu, Discrimination-aware channel pruning for deep neural networks, in: Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, 3-8 December 2018, Montréal, Canada., 2018, pp. 883–894.
- [21]
Y. He, X. Zhang, J. Sun, Channel pruning for accelerating very deep neural networks, in: IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, October 22-29, 2017, 2017, pp. 1398–1406.
- [22]
X. Ding, G. Ding, Y. Guo, J. Han, Centripetal sgd for pruning very deep convolutional networks with complicated structure, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 4943–4953.
- [23]
Y. He, P. Liu, Z. Wang, Z. Hu, Y. Yang, Filter pruning via geometric median for deep convolutional neural networks acceleration, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 4340–4349.
- [24]
C. Louizos, M. Welling, D. P. Kingma, Learning sparse neural networks through regularization, CoRR abs/1712.01312.
- [25]
S. Srinivas, A. Subramanya, R. V. Babu, Training sparse neural networks, in: CVPR Workshops 2017, Honolulu, HI, USA, July 21-26, 2017, 2017, pp. 455–462.
- [26]
M. D. Collins, P. Kohli, Memory bounded deep convolutional networks, CoRR abs/1412.1442.
- [27]
T. J. Mitchell, J. J. Beauchamp, Bayesian variable selection in linear regression, Journal of the American Statistical Association 83 (404) (1988) 1023–1032.
- [28]
S. Zhe, Z. Xu, Y. Qi, P. Yu, Sparse bayesian multiview learning for simultaneous association discovery and diagnosis of alzheimer’s disease, in: Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, January 25-30, 2015, Austin, Texas, USA, 2015, pp. 1966–1972.
- [29]
Z. Xu, S. Zhe, Y. Qi, P. Yu, Association discovery and diagnosis of alzheimer’s disease with bayesian multiview learning, J. Artif. Intell. Res. 56 (2016) 247–268.
- [30]
J. G. Zilly, R. K. Srivastava, J. Koutník, J. Schmidhuber, Recurrent highway networks, in: Proceedings of the 34th International Conference on Machine Learning-Volume 70, JMLR. org, 2017, pp. 4189–4198.
- [31]
M. Seo, A. Kembhavi, A. Farhadi, H. Hajishirzi, Bidirectional attention flow for machine comprehension, arXiv preprint arXiv:1611.01603.
- [32]
S. Han, H. Mao, W. J. Dally, Deep compression: Compressing deep neural network with pruning, trained quantization and huffman coding, CoRR abs/1510.00149.
- [33]
M. F. Mohammed, C. P. Lim, A new hyperbox selection rule and a pruning strategy for the enhanced fuzzy minmax neural network, Neural Networks 86 (2017) 69 – 79.
- [34]
B. O. Ayinde, T. Inanc, J. M. Zurada, Redundant feature pruning for accelerated inference in deep neural networks, Neural Networks 118 (2019) 148–158.
- [35]
S. Narang, E. Undersander, G. Diamos, Block-sparse recurrent neural networks, arXiv preprint arXiv:1711.02782.
- [36]
R. Prabhavalkar, O. Alsharif, A. Bruguier, I. McGraw, On the compression of recurrent neural networks with an application to LVCSR acoustic modeling for embedded speech recognition, in: ICASSP 2016, Shanghai, China, March 20-25, 2016, 2016, pp. 5970–5974.
doi:10.1109/ICASSP.2016.7472823.
- [37]
I. Hubara, M. Courbariaux, D. Soudry, R. El-Yaniv, Y. Bengio, Quantized neural networks: Training neural networks with low precision weights and activations, CoRR abs/1609.07061.
- [38]
P. Wang, X. Xie, L. Deng, G. Li, D. Wang, Y. Xie, Hitnet: Hybrid ternary recurrent neural network, in: Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, 3-8 December 2018, Montréal, Canada., 2018, pp. 602–612.
- [39]
Z. Wang, J. Lin, Z. Wang, Hardware-oriented compression of long short-term memory for efficient inference, IEEE Signal Process. Lett. 25 (7) (2018) 984–988.
- [40]
R. J. Williams, Simple statistical gradient-following algorithms for connectionist reinforcement learning, Machine learning 8 (3-4) (1992) 229–256.
- [41]
Y. Bengio, N. Léonard, A. Courville, Estimating or propagating gradients through stochastic neurons for conditional computation, arXiv preprint arXiv:1308.3432.
- [42]
D. P. Kingma, M. Welling, Auto-encoding variational bayes, arXiv preprint arXiv:1312.6114.
- [43]
D. J. Rezende, S. Mohamed, D. Wierstra, Stochastic backpropagation and approximate inference in deep generative models, arXiv preprint arXiv:1401.4082.
- [44]
C. J. Maddison, A. Mnih, Y. W. Teh, The concrete distribution: A continuous relaxation of discrete random variables, arXiv preprint arXiv:1611.00712.
- [45]
E. Jang, S. Gu, B. Poole, Categorical reparameterization with gumbel-softmax, 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings.
- [46]
W. Zaremba, I. Sutskever, O. Vinyals, Recurrent neural network regularization, arXiv preprint arXiv:1409.2329.
- [47]
M. P. Marcus, M. A. Marcinkiewicz, B. Santorini, Building a large annotated corpus of english: The penn treebank, Computational linguistics 19 (2) (1993) 313–330.
- [48]
P. Rajpurkar, J. Zhang, K. Lopyrev, P. Liang, Squad: 100,000+ questions for machine comprehension of text, arXiv preprint arXiv:1606.05250.
- [49]
S. Merity, N. S. Keskar, R. Socher, Regularizing and optimizing lstm language models, arXiv preprint arXiv:1708.02182.
- [50]
M. Yin, M. Zhou, ARM: augment-reinforce-merge gradient for stochastic binary networks, ICLR.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] O. Vinyals, A. Toshev, S. Bengio, D. Erhan, Show and tell: Lessons learned from the 2015 mscoco image captioning challenge, IEEE transactions on pattern analysis and machine intelligence 39 (4) (2016) 652–663.
- 2[2] P. Anderson, X. He, C. Buehler, D. Teney, M. Johnson, S. Gould, L. Zhang, Bottom-up and top-down attention for image captioning and visual question answering, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 6077–6086.
- 3[3] J. Ye, L. Wang, G. Li, D. Chen, S. Zhe, X. Chu, Z. Xu, Learning compact recurrent neural networks with block-term tensor decomposition, in: 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18-22, 2018, 2018, pp. 9378–9387.
- 4[4] Y. Pan, J. Xu, M. Wang, J. Ye, F. Wang, K. Bai, Z. Xu, Compressing recurrent neural networks with tensor ring for action recognition, in: The Thirty-Third AAAI Conference on Artificial Intelligence, AAAI 2019, Honolulu, Hawaii, USA, January 27 - February 1, 2019, 2019, pp. 4683–4690.
- 5[5] H. Liu, L. He, H. Bai, B. Dai, K. Bai, Z. Xu, Structured inference for recurrent hidden semi-markov model, in: Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, IJCAI 2018, July 13-19, 2018, Stockholm, Sweden., 2018, pp. 2447–2453.
- 6[6] T. Sagara, M. Hagiwara, Natural language neural network and its application to question-answering system, Neurocomputing 142 (2014) 201 – 208.
- 7[7] X.-L. Mao, Y.-J. Hao, D. Wang, H. Huang, Query completion in community-based question answering search, Neurocomputing 274 (2018) 3 – 7.
- 8[8] D. Bahdanau, K. Cho, Y. Bengio, Neural machine translation by jointly learning to align and translate, ar Xiv preprint ar Xiv:1409.0473.