A Temporal Sequence Learning for Action Recognition and Prediction
Sangwoo Cho, Hassan Foroosh

TL;DR
This paper introduces a novel approach for human action recognition and prediction by representing videos as sequences of words and applying a Temporal CNN to learn their temporal order, achieving high accuracy with low latency.
Contribution
The work presents a new method that models videos as sentences of visual words and uses a Temporal CNN to effectively predict and recognize actions with partial video sequences.
Findings
Achieves 95% accuracy with half the video frames on UCF101 and HMDB51.
Demonstrates low-latency prediction capability.
Attains state-of-the-art performance at full sequence completion.
Abstract
In this work\footnote {This work was supported in part by the National Science Foundation under grant IIS-1212948.}, we present a method to represent a video with a sequence of words, and learn the temporal sequencing of such words as the key information for predicting and recognizing human actions. We leverage core concepts from the Natural Language Processing (NLP) literature used in sentence classification to solve the problems of action prediction and action recognition. Each frame is converted into a word that is represented as a vector using the Bag of Visual Words (BoW) encoding method. The words are then combined into a sentence to represent the video, as a sentence. The sequence of words in different actions are learned with a simple but effective Temporal Convolutional Neural Network (T-CNN) that captures the temporal sequencing of information in a video sentence. We…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1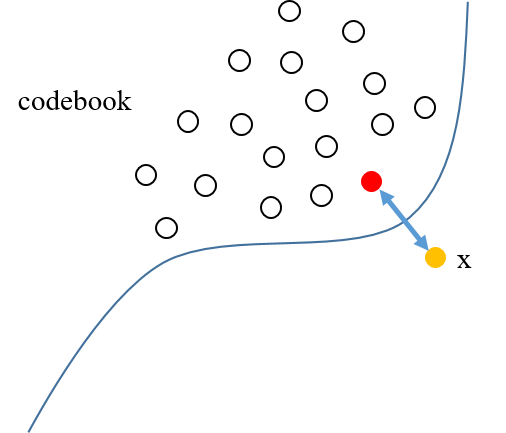 Figure 2
Figure 2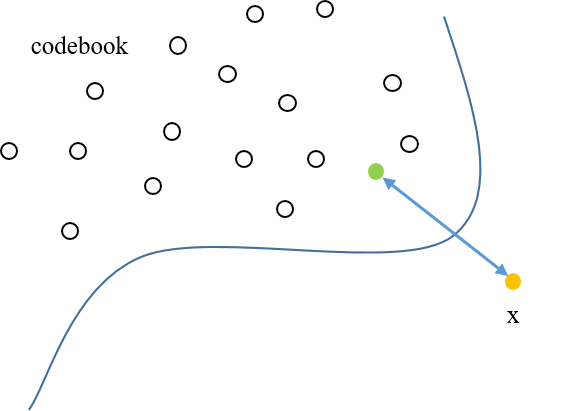 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5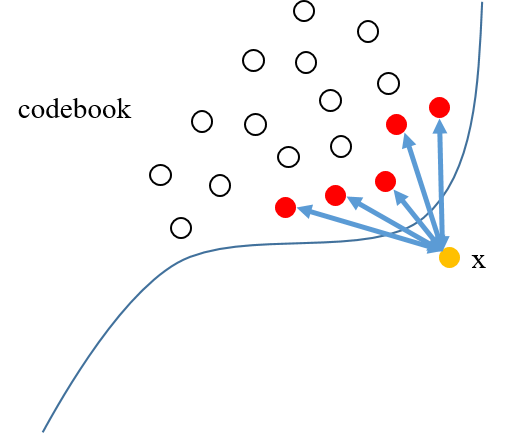 Figure 6
Figure 6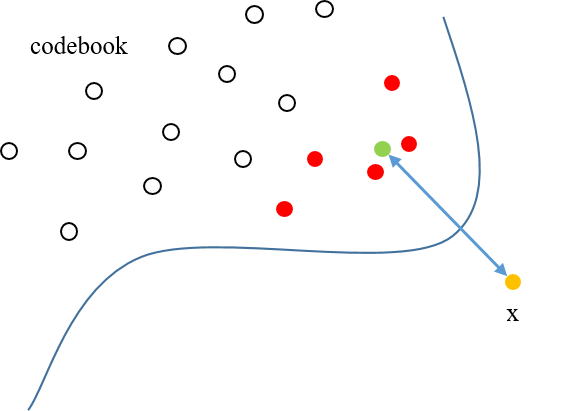 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11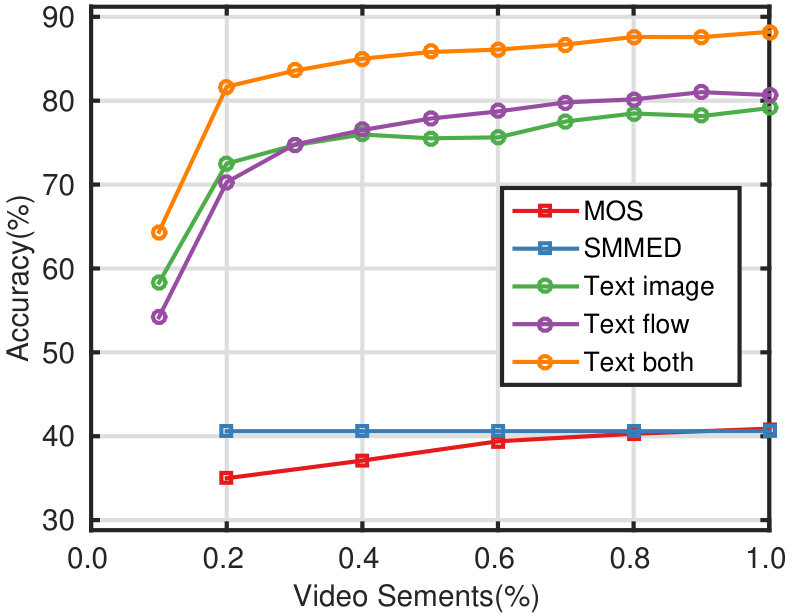 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15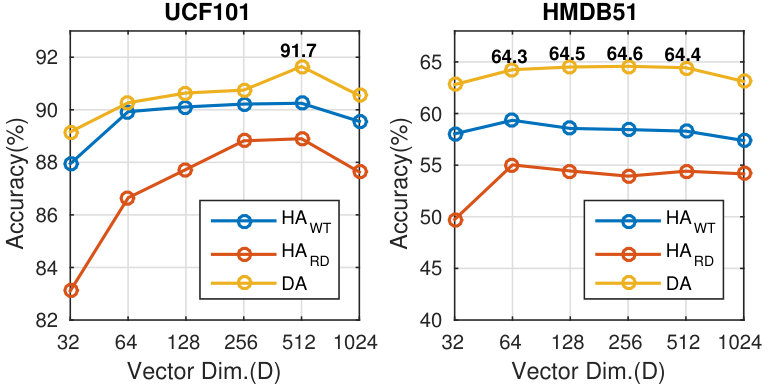 Figure 16
Figure 16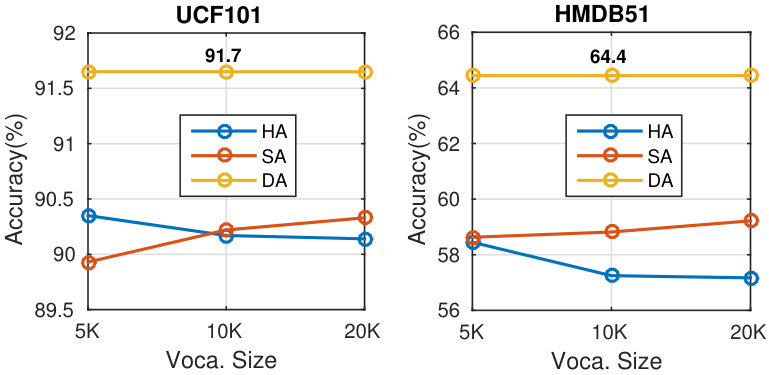 Figure 17
Figure 17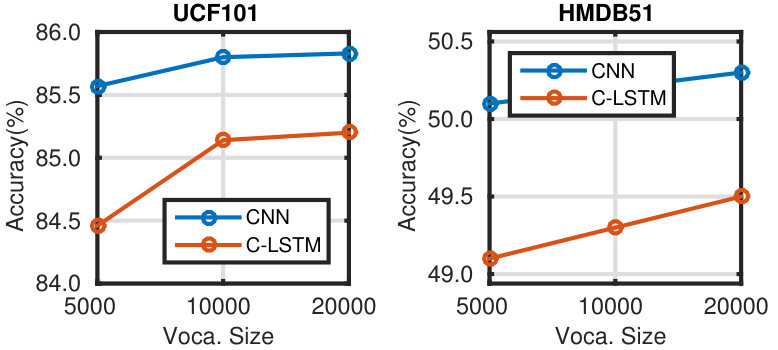 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22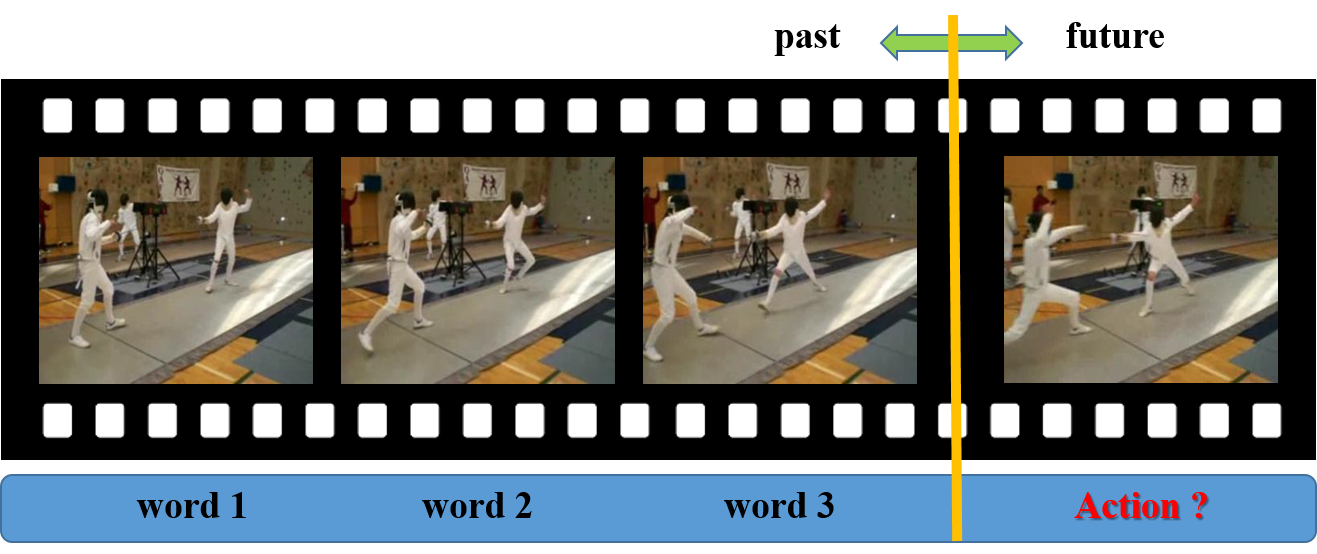 Figure 23
Figure 23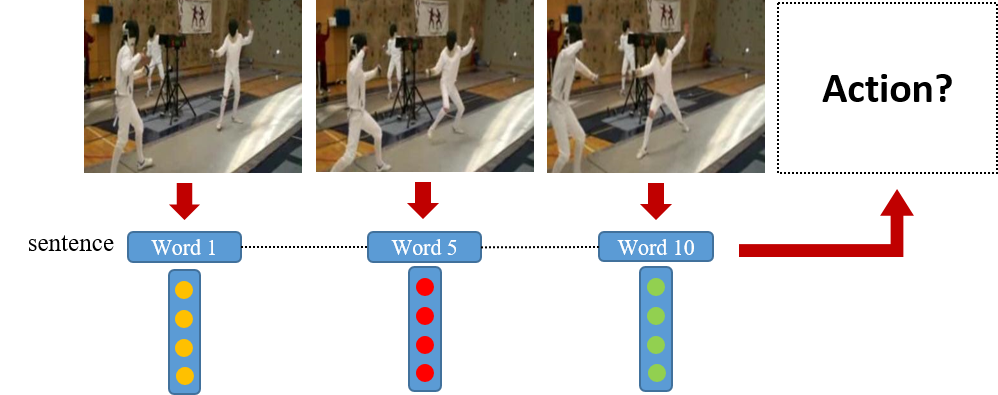 Figure 24
Figure 24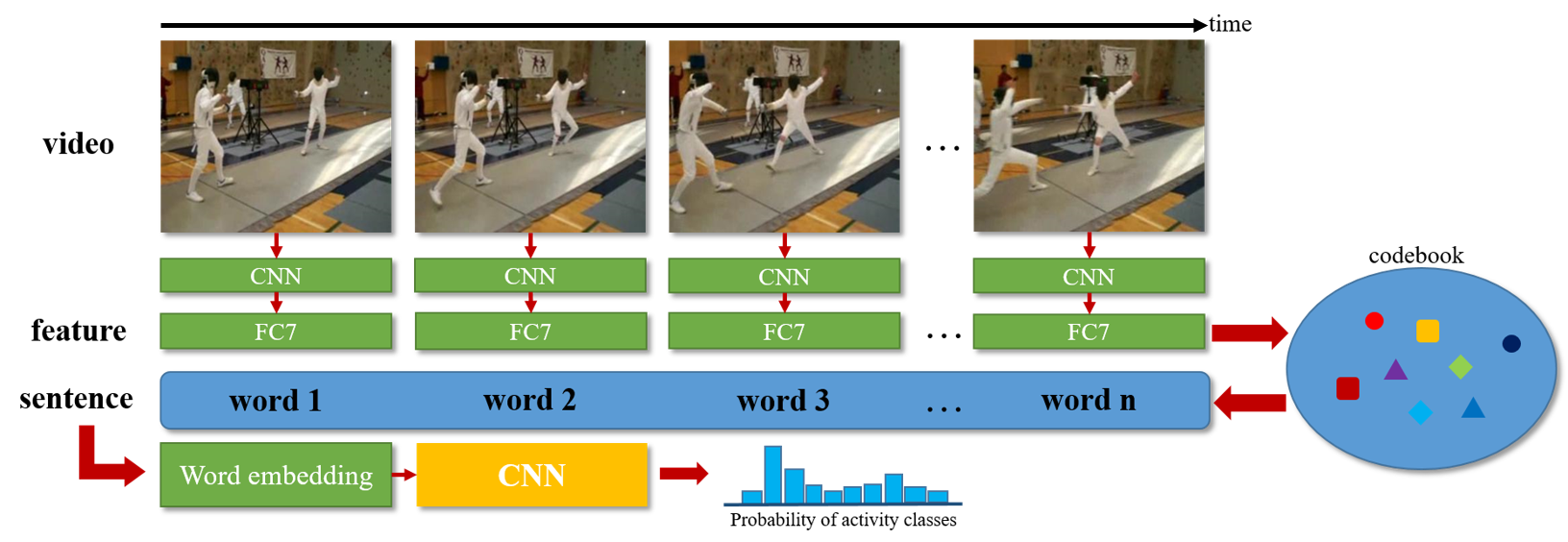 Figure 25
Figure 25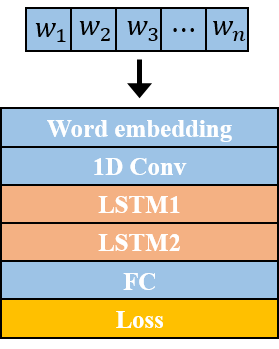 Figure 26
Figure 26 Figure 27
Figure 27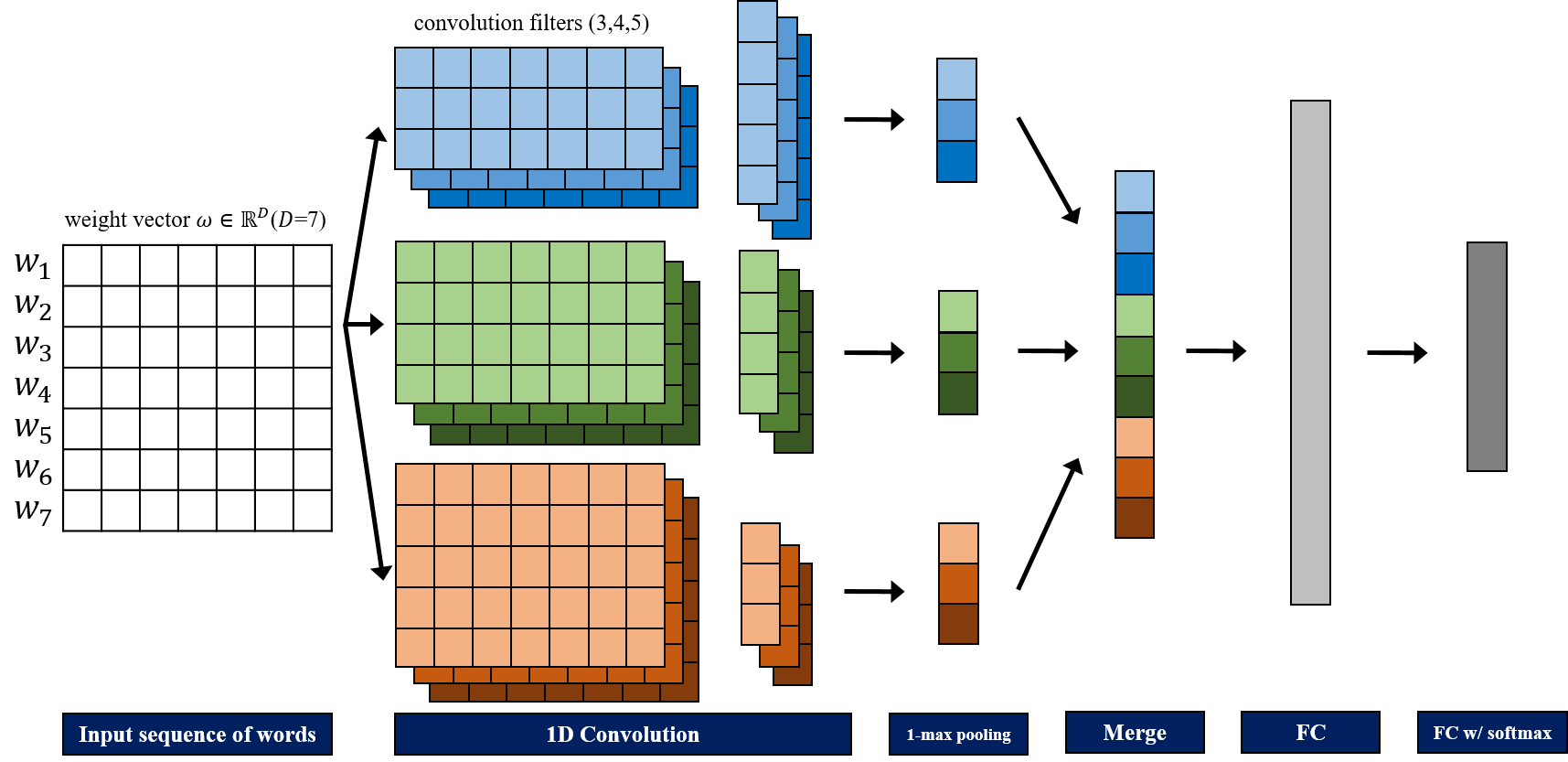 Figure 28
Figure 28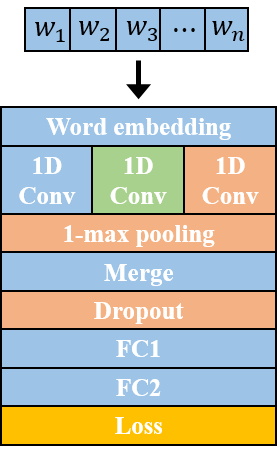 Figure 29
Figure 29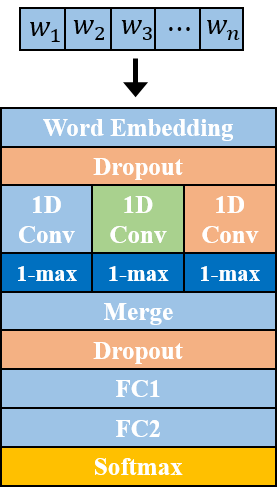 Figure 30
Figure 30Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.