A gray-box approach for curriculum learning
Francesco Foglino, Matteo Leonetti, Simone Sagratella, Ruggiero Seccia

TL;DR
This paper introduces a gray-box formulation for curriculum learning in deep reinforcement learning, providing a structured approach with efficient numerical methods and promising initial results on benchmark tasks.
Contribution
It proposes a novel gray-box reformulation of curriculum learning, along with efficient numerical methods to solve it, advancing beyond heuristic solutions.
Findings
Preliminary results show the approach's viability.
The method effectively addresses the curriculum scheduling problem.
Initial benchmarks indicate promising performance improvements.
Abstract
Curriculum learning is often employed in deep reinforcement learning to let the agent progress more quickly towards better behaviors. Numerical methods for curriculum learning in the literature provides only initial heuristic solutions, with little to no guarantee on their quality. We define a new gray-box function that, including a suitable scheduling problem, can be effectively used to reformulate the curriculum learning problem. We propose different efficient numerical methods to address this gray-box reformulation. Preliminary numerical results on a benchmark task in the curriculum learning literature show the viability of the proposed approach.
Click any figure to enlarge with its caption.
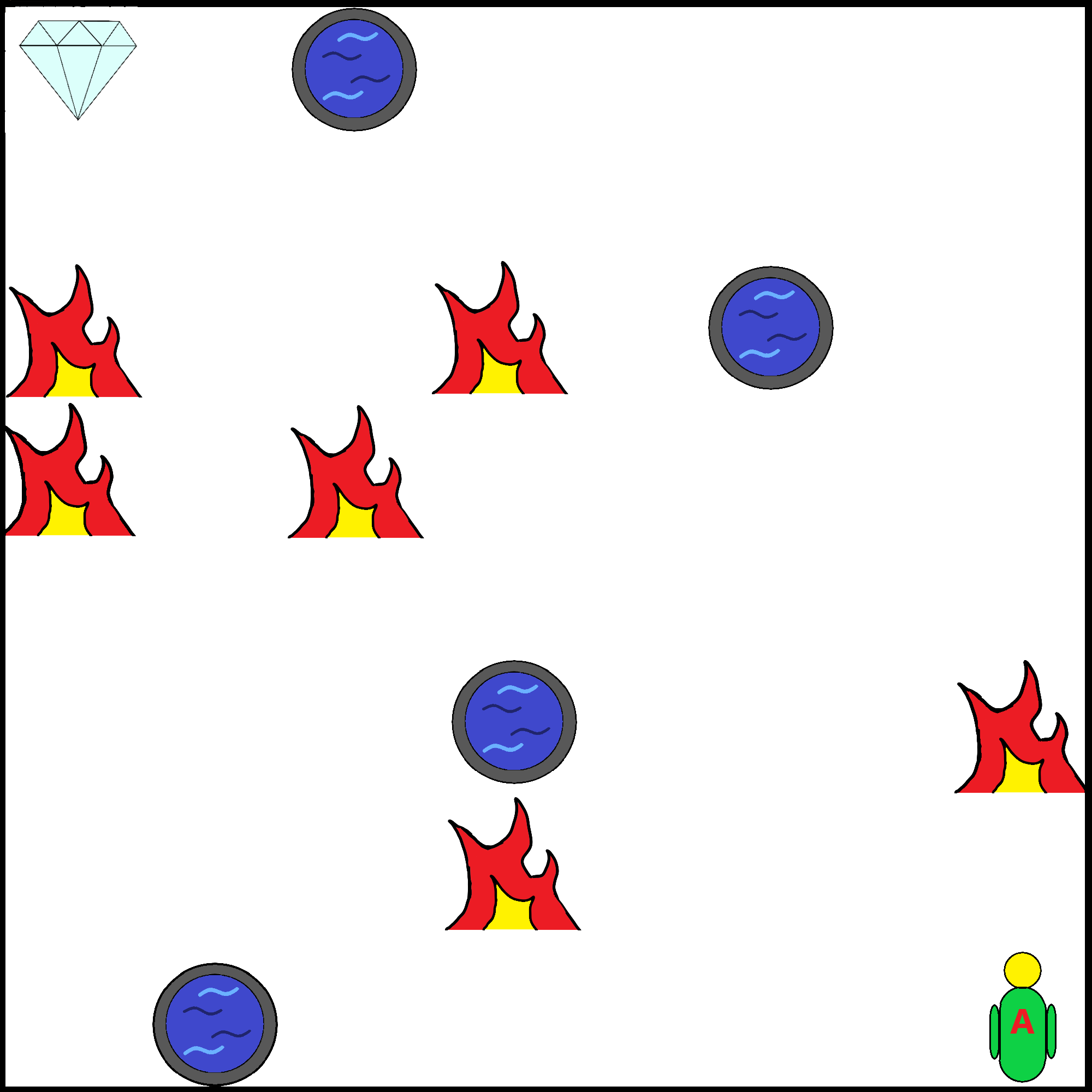 Figure 1
Figure 1| n = 12, L = 4 | n = 7, L = 7 \bigstrut[b] | |||||
|---|---|---|---|---|---|---|
| Algorithm | rank | rank \bigstrut | ||||
| C0 | -0,6389 | 11499 | -0,5051 | 4535 \bigstrut | ||
| GREEDY Par | -0,7765 | 144 | -0,6113 | 260 \bigstrut | ||
| GP | -0,7882 | 32 | -0,6511 | 38 \bigstrut | ||
| Heuristic | -0,7773 | 121 | -0,5966 | 417 \bigstrut | ||
| TPE | -0,8025 | 4 | -0,6697 | 14 \bigstrut | ||
| , | , | |||||
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
11institutetext: School of Computing, University of Leeds, Leeds, UK
11email: {scff,M.Leonetti}@leeds.ac.uk 22institutetext: Department of Computer, Control and Management Engineering Antonio Ruberti, Sapienza University of Rome, Via Ariosto 25, 00185 Roma, Italy 22email: {sagratella,seccia}@diag.uniroma1.it
A gray-box approach for curriculum learning
Francesco Foglino 11
Matteo Leonetti 11 0000-0002-3831-2400
Simone Sagratella 22 0000-0001-5888-1953
Ruggiero Seccia 22 0000-0001-5292-1774
Abstract
Curriculum learning is often employed in deep reinforcement learning to let the agent progress more quickly towards better behaviors. Numerical methods for curriculum learning in the literature provides only initial heuristic solutions, with little to no guarantee on their quality. We define a new gray-box function that, including a suitable scheduling problem, can be effectively used to reformulate the curriculum learning problem. We propose different efficient numerical methods to address this gray-box reformulation. Preliminary numerical results on a benchmark task in the curriculum learning literature show the viability of the proposed approach.
Keywords:
Curriculum learning Reinforcement learning Black-box optimization Scheduling problem.
1 Introduction
Curriculum learning is gaining popularity in (deep) reinforcement learning, see e.g. [8] and references therein. It can provide better exploration policies through transfer and generalization from less complex tasks. Specifically, curriculum learning is often employed to let the agent progress more quickly towards better behaviors, thus having the potential to greatly increase the quality of the behavior discovered by the agent. However, at the moment, creating an appropriate curriculum requires significant human intuition, e.g. curricula are mostly designed by hand. Moreover, current methods for automatic task sequencing for curriculum learning in reinforcement learning provided only initial heuristic solutions, with little to no guarantee on their quality.
After a brief introduction to reinforcement learning, see e.g. [10, 11], we define the curriculum learning problem. This is an optimization problem that cannot be solved with standard methods for nonlinear programming or with derivative-free algorithms. We define a new gray-box function that, including a suitable scheduling problem, can be effectively used to reformulate the curriculum learning problem. This gray-box reformulation can be addressed in different ways. We investigate both heuristics to estimate approximate solutions of the gray-box problem, and derivative-free algorithms to optimize it. Finaly, preliminary numerical results on a benchmark task in the curriculum learning literature show that the proposed gray-box methods can be efficiently used to address the curriculum learning problem.
2 Reinforcement learning background
Consider an agent that acts in an environment according to a policy . The policy is a function that given a state and a possible action returns a number in representing the probability that the agent executes the action in state . The environment is modeled as an episodic Markov Decision Process (MDP), that is, a tuple , where both and are nonempty and finite sets, for which is the state dimension, is a transition function, is a reward function, is the maximum length of an episode, and is a parameter used to discount the rewards during each episode. At every time step , the agent perceives the state , chooses an action according to , and the environment transitions to state . We assume for simplicity for the transition function , where denotes the projection operator over the set . Every episode starts at state , where can depend both on the environment and the episode. During an episode, the agent receives a total reward of
[TABLE]
Note that is used to emphasize the rewards that occur early during an episode. We say that is an absorbing state if for all , and for any action , that is, the state can never be left, and from that point on the agent receives a reward of [math]. Absorbing states effectively terminate an episode before the maximum number of time steps is reached.
The policy function is obtained from an estimate of the value function
[TABLE]
for any state and action . The value function is the expected reward for taking action in state at any possible time step and following thereafter until the end of the episode. We linearly approximate the value function in a parameter :
[TABLE]
where are suitable basis functions mapping the pair into . The policy function for any point and any parameter , is given by
[TABLE]
During the reinforcement learning process the policy is optimized by varying the parameter over in order to obtain greater values of the environment specific total reward . In this respect, we introduce the black-box function , which takes the parameter and returns the expected total reward obtained with the policy . It is reasonable to assume that is bounded from above over . Then, a global optimal policy for the environment is given by satisfying
[TABLE]
In practical reinforcement learning optimization, at any time step of a finite number of episodes the policy parameter is updated by using a learning algorithm that exploits the value of both the reward and the current estimate of the value function , aiming at computing a point satisfying (1). Certainly, the better the point from which the learning procedure starts, the faster the global optimum is achieved. In general, due to the limited number of iterations granted, we say that the learning algorithm is able to compute a local optimal satisfying
[TABLE]
where is related to and is the starting guess.
3 The curriculum learning problem
We want the agent to quickly obtain great values of in a specific environment that we call the final task. To do this, it is crucial to ensure that the reinforcement learning phase in the final task starts from a good initial point ideally close to a global maximum of over . Curriculum learning is actually a way to obtain a good starting point computed by sequentially learning the policy on a subset of possible tasks (i.e. environments) different from the final task , see e.g. [8] and references therein. The curriculum is the sequence of these tasks in which the policy of the agent is optimized before addressing the final task . Specifically, given a starting , the point is obtained by (approximately) maximizing over , the point is obtained by (approximately) maximizing over , and so on. At the end of this process we get a point ready to be used as starting guess for the optimization of the policy in the final task . Clearly, the obtained depends on the specific sequence of tasks in the curriculum . To underline this dependence, we write .
We denote with the set of available tasks. The tasks in must be included in the curriculum of length less than in a specific order and without repetitions. The quality of the curriculum is given by that is obtained by executing learning updates with respect to for a finite number of episodes and starting from . A practical performance metric of great interest is given by the so called regret function, which takes into account both the expected total reward that is obtained for the final task at the end of the learning process, and how fast it is achieved:
[TABLE]
where is a given good performance threshold (which can be the total reward obtained with the optimal policy when known), and is the point obtained with the learning algorithm at the end of the th episode. Given the curriculum , the function sums the gaps between the threshold and the total reward actually achieved at every episode. Clearly the aim is to minimize it
[TABLE]
where is the set of all feasible curricula obtained from .
Problem (3) presents two main drawbacks: (i) having a black-box nature, its objective function has not an explicit definition and it is in general nonsmooth, nonconvex, and even discontinuous; (ii) it is a constrained optimization problem, whose feasible set is combinatorial. With the aim of solving problem (3), drawback (i) does not allow us to resort to methods for general Mixed-Integer NonLinear Programs (MINLP), see e.g. [2], while (ii) makes it difficult to use standard Derivative-Free (DF) methods, see e.g. [6, 7]. See [8] and the references therein for possible numerical procedures to tackle problem (3). As we show in section 6, the methods proposed in [8] constitute only a preliminary step in order to solve efficiently the curriculum learning problem.
In the next section we define a new gray-box reformulation for problem (3) that incorporates a scheduling problem. Afterwards, we propose different practical techniques to address this gray-box reformulation.
4 The scheduling problem to minimize regret
Let us introduce the variables and . Any indicates the presence of the th task of in the curriculum , specifically, if and only if the th task of is in the curriculum . Any , with , is an indicator variable used to model the order of the task in the curriculum: if and only if the th task of is in the curriculum and it is scheduled before the th task of . All the tasks not included in the curriculum are considered scheduled after all the ones included.
Minimizing the regret is equivalent to maximizing the merit function given by
[TABLE]
We make the following assumption:
(A1)
Every task in contributes to the value of with a fixed individual utility . Moreover, considering all pairs with , if the th task of is in the curriculum and it is scheduled before the th task of , then there is a penalty in equal to .
This concept of penalty in assumption (A1) is useful to model the fact that a task can be preparatory for another task . In this sense, if the policy is not optimized in the preparatory task before it is optimized in task , then the utility given by task has to be reduced by the corresponding penalty.
We intend to approximate with the following function that is linear with respect to :
[TABLE]
If assumption (A1) holds, then certainly is a good approximation of . In general cases, given the utilities and the penalties , our idea is to maximize by modifying the indicator variables and corresponding to feasible curricula in . We introduce additional variables indicating the order of the tasks in the curriculum ; if the th task of is not in then . We are ready to define the scheduling problem for curriculum learning.
[TABLE]
Problem (4) is an Integer Linear Program (ILP) that can be solved by resorting to many algorithms in the literature.
The following properties hold:
- •
Let be an optimal point of the scheduling problem (4) with . Let be such that, for all , with and , where the operator ord() returns the index of the task in . Then , i.e. is a feasible curriculum.
- •
Let be any curriculum in , then parameters exist such that solving problem (4) with gives such that and , for all . That is, any curriculum in can be computed by solving problem (4) with suitable parameters .
We introduce the gray-box function , which takes the parameters , computes a curriculum by solving problem (4) with parameters , and returns the regret . By using the gray-box function , problem (3) can be equivalently reformulated as
[TABLE]
5 Numerical methods for the gray-box
The gray-box function can be used in different ways in order to solve the curriculum learning problem efficiently. Here we consider three of them.
- •
Problem (5) is a black-box optimization problem whose feasible set includes only lower bounds. Therefore we can resort to many DF algorithms in order to compute (approximate) optimal points of (5). A potential solution is represented by Sequential Model-Based Optimization (SMBO) methods which consider the information obtained by all the previous iterations to build a surrogate probabilistic model of . At each iteration a new point is drawn by maximizing an acquisition function and the information gained with this new sample is used to update the surrogate model [9, 14, 13].
- •
We can compute a good estimate for and then evaluate in order to have a good value of the regret.
- •
We can use a good estimate for as a reference point to define a trust region for the feasible set of problem (5). The resulting furtherly constrained black-box optimization problem can be solved with many DF algorithms such as a Tree-structured Parzen Estimator (TPE), see e.g. [5], which allows us to define a distribution of probability of the parameters () to optimize.
Computing a good estimate for can be critical for obtaining good numerical performances. Here we propose a method that is justified by the assumption (A1). In that, if the assumption (A1) holds, then we have for any with :
[TABLE]
where is an unknown constant. That implies
[TABLE]
We observe that computing this estimate requires evaluations of .
In the following section we adapt these ideas to a benchmark task in the curriculum learning literature.
6 Experimental evaluation
In order to evaluate the effectiveness of the proposed framework, we implemented it on the GridWorld domain. In this section, we describe the GridWorld’s setting and all the libraries adopted for the definition of the framework.
6.1 GridWorld
GridWorld is an implementation of an episodic grid-world domain used in the evaluation of existing curriculum learning methods, see e.g. [15]. Each cell can be free, or occupied by a fire, pit, or treasure. The aim of the game is to find the treasure in the least number of possible episodes, avoiding both fires and pits. An example of GridWorld is shown in Figure 1.
**States : **
The state is given by the agent position, that is .
**Actions and transition function : **
The agent can move in the four cardinal directions, and the actions are deterministic.
**Reward function : **
The reward is -2500 for entering a pit, -500 for entering a fire, -250 for entering the cell next to a fire, and 200 for entering a cell with the treasure. The reward is -1 in all other cases.
**Episodes length , absorbing states, discount parameter : **
All the
episodes terminate under one of these three conditions: the agent falls into a pit, reaches the treasure, or executes a maximum number of actions (). We use .
**Basis functions : **
The variables fed to tile coding are the distance from, and relative position of, the treasure (which is global and fulfills the Markov property), and distance from, and relative position of, any pit or fire within a radius of 2 cells from the agent (which are local variables, and allow the agent to learn how to deal with these objects when they are close, and transfer this knowledge from a task to another).
We consider tasks of dimensions similar to Figure 1 and with a variable number of fires and pits. The number of episodes for all the tasks is the same.
6.2 Algorithms and implementation details
We analyse different optimization techniques to solve the curriculum learning problem. In particular, we compare five different methods:
- •
C0: where no curriculum learning is performed, i.e. , but the agent is trained directly to solve the final task with starting point .
- •
**GREEDY Par: ** Greedy algorithm which constructs the curriculum incrementally by considering at each iteration the tasks which mostly improve the final performance [8]. This is used as benchmark.
- •
**GP: ** where problem (5) is modeled through a Gaussian Process and new points are drawn by maximizing an acquisition function, the Expected Improvement (EI), with a BFGS method (GPyOpt library). Since it is used without incorporating any a priori knowledge, it searches for the best values () on the box .
- •
Heuristic where a good estimate for is computed through formulas (6) and (7), with calculated such that and .
- •
TPE: where the surrogate model of problem (5) is defined by a Tree-structured Parzen Estimator and new points are drawn by maximizing the EI (hyperopt library). It is used as a local-search method by defining the distribution of () as a gaussian distribution centered in the values () returned by the heuristic and with a variance proportional to the mean of () respectively.
The proposed framework is implemented in Python 3.6 on a Intel(R) Core(TM) i7-3630QM CPU 2.4GHz. by means of the following libraries:
docplex (v 2.8.125):
version of Cplex used for solving the ILP (4). We set the running time to 60 seconds per iteration and the mipgap to .
GPyOpt (v 1.2.5):
used as black-box optimization algorithm for solving problem (5) when no information on good estimates of is available. It is a Sequential Model Based Optimization (SMBO) algorithm where the surrogate function is defined through a Gaussian Process and the new point is determined by the maximization of the EI [1, 12].
hyperopt (v 0.2):
used as black-box optimization algorithm for solving problem (5) when a good estimate of is available. It is an SMBO method where the surrogate function is defined by a Tree-structured Parzen Estimator and the new point is determined as in the previous case by maximizing the acquisition function [3, 4, 5].
Burlap:
used for the implementation of the GridWord domain along with the Sarsa() code as learning algorithm to update the policy and Tile Coding as the function approximator (http://burlap.cs.brown.edu).
6.3 Numerical results
We consider two different experiments on the GridWorld domain. In the first example, we define different tasks and we impose that at maximum tasks of them can be performed, obtaining 13345 potential curricula. For this example we set . In the second case, tasks are defined and all of them can be considered in the same curriculum , for a total of 13700 possible combinations of tasks. For this example we set . See [8] for futher details about these examples.
Algorithm C0 requires 1 curriculum evaluation, i.e. call of , while Heuristic needs curriculum evaluations. The number of curriculum evaluations granted to the other algorithms is 300.
In Table 1 for each algorithm we report:
- •
the best value of the regret found ()
- •
the ranking of the returned solution with respect to all the possible curricula (rank)
From the numerical results, it is evident how all the proposed optimization methods based on the gray-box are able to improve the performance value obtained when training the agent directly on the final task (algorithm C0). As a proof of the effectiveness of the proposed heuristic method from (6) and (7), we highlight how this procedure is always able to find better solutions than and similar solutions to those returned by GREEDY Par. Moreover, the definition of a surrogate function through a Gaussian Process seems to be a successful choice in order to further improve the solution found. Finaly, the local search performed by TPE around the tentative point leads to a remarkable improvement of the final performance by finding, in both the two scenarios, one of 15th best solutions out of the more than 13000 possible curricula.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Gpyopt: A bayesian optimization framework in python. http://github.com/Sheffield ML/G Py Opt (2016)
- 2[2] Belotti, P., Kirches, C., Leyffer, S., Linderoth, J., Luedtke, J., Mahajan, A.: Mixed-integer nonlinear optimization. Acta Numer. 22 , 1–131 (2013)
- 3[3] Bergstra, J.: Hyperopt: Distributed asynchronous hyperparameter optimization in python (2013)
- 4[4] Bergstra, J., Yamins, D., Cox, D.D.: Making a science of model search: Hyperparameter optimization in hundreds of dimensions for vision architectures (2013)
- 5[5] Bergstra, J.S., Bardenet, R., Bengio, Y., Kégl, B.: Algorithms for hyper-parameter optimization. In: Advances in neural information processing systems. pp. 2546–2554 (2011)
- 6[6] Custódio, A.L., Scheinberg, K., Nunes Vicente, L.: Methodologies and software for derivative-free optimization. Advances and Trends in Optimization with Engineering Applications pp. 495–506 (2017)
- 7[7] Di Pillo, G., Liuzzi, G., Lucidi, S., Piccialli, V., Rinaldi, F.: A DIRECT-type approach for derivative-free constrained global optimization. Computational Optimization and Applications 65 (2), 361–397 (2016)
- 8[8] Foglino, F., Leonetti, M.: An optimization framework for task sequencing in curriculum learning. ar Xiv preprint ar Xiv:1901.11478 (2019)