TL;DR
This paper introduces a novel fidelity term based on back-projection for ill-posed linear inverse problems, demonstrating its advantages over traditional least squares in certain conditions and validating its effectiveness with various priors.
Contribution
The paper proposes a new back-projection based fidelity term for inverse problems, providing theoretical analysis and empirical validation against standard least squares methods.
Findings
The back-projection fidelity term performs better with badly conditioned operators.
Theoretical analysis shows advantages of the new term in specific scenarios.
Empirical results confirm improved performance with complex priors.
Abstract
Ill-posed linear inverse problems appear in many image processing applications, such as deblurring, super-resolution and compressed sensing. Many restoration strategies involve minimizing a cost function, which is composed of fidelity and prior terms, balanced by a regularization parameter. While a vast amount of research has been focused on different prior models, the fidelity term is almost always chosen to be the least squares (LS) objective, that encourages fitting the linearly transformed optimization variable to the observations. In this paper, we examine a different fidelity term, which has been implicitly used by the recently proposed iterative denoising and backward projections (IDBP) framework. This term encourages agreement between the projection of the optimization variable onto the row space of the linear operator and the pseudo-inverse of the linear operator…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16 Figure 17
Figure 17 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23 Figure 24
Figure 24 Figure 25
Figure 25 Figure 26
Figure 26 Figure 27
Figure 27 Figure 28
Figure 28 Figure 29
Figure 29 Figure 30
Figure 30 Figure 31
Figure 31 Figure 32
Figure 32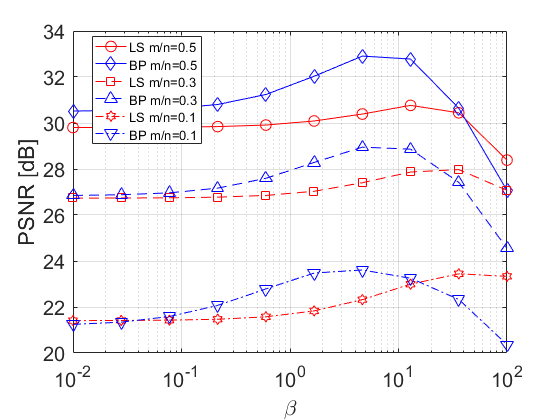 Figure 33
Figure 33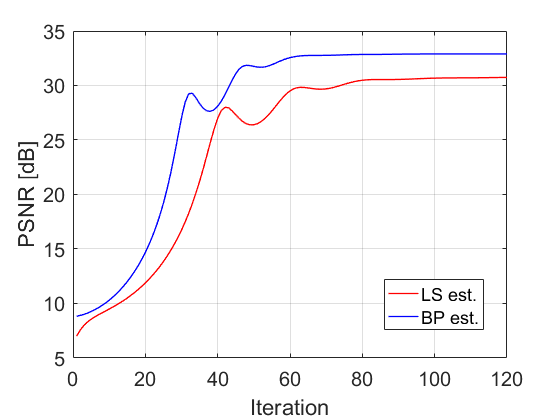 Figure 34
Figure 34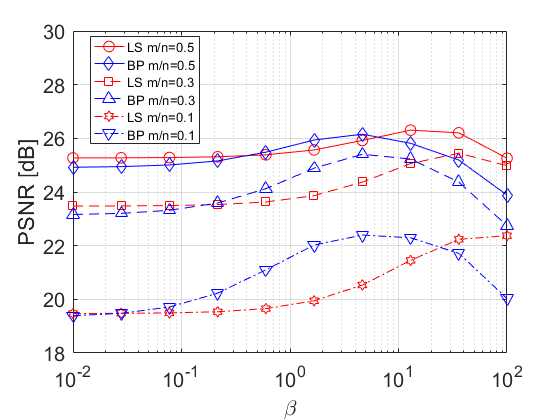 Figure 35
Figure 35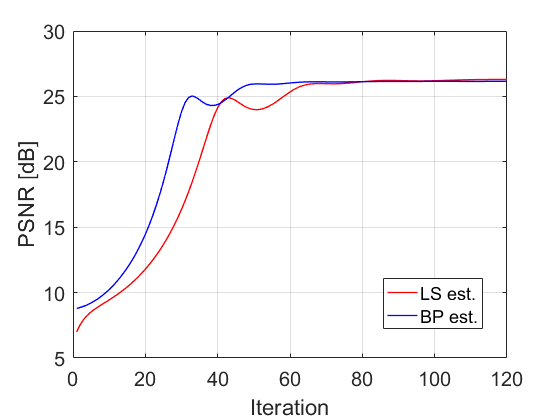 Figure 36
Figure 36 Figure 37
Figure 37 Figure 38
Figure 38 Figure 39
Figure 39 Figure 40
Figure 40| Bicubic | LS est. | BP est. | |
| SR x3 | 23.04 | 23.02 | 23.77 |
| Naive | LS est. | BP est. | |
|---|---|---|---|
| CS | 12.07 | 22.78 | 22.80 |
| CS | 13.22 | 23.55 | 23.62 |
| CS | 14.71 | 23.67 | 23.82 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Back-Projection based Fidelity Term for Ill-Posed Linear Inverse Problems
Tom Tirer and Raja Giryes This work was supported by the European research council (ERC starting grant 757497 PI Giryes). The authors are with the School of Electrical Engineering, Tel Aviv University, Tel Aviv 69978, Israel. (email: [email protected], [email protected])
Abstract
Ill-posed linear inverse problems appear in many image processing applications, such as deblurring, super-resolution and compressed sensing. Many restoration strategies involve minimizing a cost function, which is composed of fidelity and prior terms, balanced by a regularization parameter. While a vast amount of research has been focused on different prior models, the fidelity term is almost always chosen to be the least squares (LS) objective, that encourages fitting the linearly transformed optimization variable to the observations. In this paper, we examine a different fidelity term, which has been implicitly used by the recently proposed iterative denoising and backward projections (IDBP) framework. This term encourages agreement between the projection of the optimization variable onto the row space of the linear operator and the pseudo-inverse of the linear operator (”back-projection”) applied on the observations. We analytically examine the difference between the two fidelity terms for Tikhonov regularization and identify cases (such as a badly conditioned linear operator) where the new term has an advantage over the standard LS one. Moreover, we demonstrate empirically that the behavior of the two induced cost functions for sophisticated convex and non-convex priors, such as total-variation, BM3D, and deep generative models, correlates with the obtained theoretical analysis.
Index Terms:
Inverse problems, image restoration, image deblurring, image super-resolution, compressed sensing, total variation, non-convex priors, BM3D, deep generative models.
I Introduction
Inverse problems appear in many fields of science and engineering, where the goal is to recover a signal from its observations that are obtained by some acquisition process. In image processing, the observations are usually a degraded version of the latent image, which may be noisy, blurred, downsampled, or all together. Such observation models, and others, can be formulated by a linear model
[TABLE]
where represents the unknown original image, represents the observations, is an degradation matrix (sometimes also referred to as the measurement matrix) and is a noise vector. For example, this model corresponds to the problem of denoising [1, 2, 3, 4] when is the identity matrix ; inpainting [5, 6, 7] when is an sampling matrix (i.e. a selection of m rows of ); deblurring [8, 9] when is a blur operator; super-resolution [10, 11] if is a composite operator of blurring (e.g. anti-aliasing filtering) and down-sampling; and compressed sensing when is a (random) measurement matrix () and the signal is sparse under some basis representation [12, 13, 14] or resides in a general union of low-dimensional subspaces [15, 16].
The inverse problems represented by (1) are usually ill-posed, i.e. the measurements do not suffice for obtaining a successful reconstruction. Therefore, a vast amount of research has focused on designing good prior models for natural images. In fact, many of the methods for the problems mentioned above differ only in their prior assumptions and not in the way that they enforce fidelity to the observations.
To be more formal, a common strategy for recovering aims at minimizing a cost function of the form
[TABLE]
where is a fidelity term, is a prior term (can be also referred to as the regularizer), is a positive scalar that controls the level of regularization, and is the optimization variable. Many different prior functions are used in the literature, whether explicitly, e.g. total-variation (TV) [1], or implicitly, e.g. BM3D [4] and deep generative models [17]. Yet, most of the works use a typical least squares (LS) fidelity term
[TABLE]
where stands for the Euclidean norm. The frequent usage of this term is probably also motivated by the fact that it can be derived from the negative log-likelihood function, under the assumption that the noise is a vector of i.i.d. Gaussian random variables . However, note that, in general, maximum likelihood estimation has optimality properties only when the number of measurements is much larger than the number of unknown variables, which is obviously not the case in ill-posed problems.
In this paper, we examine a different fidelity term, which has been implicitly used by the recently proposed iterative denoising and backward projections (IDBP) framework [18] (we elaborate on this method in the appendix). Under the practical assumptions that and , we examine the fidelity term
[TABLE]
where is the pseudoinverse of the full row-rank matrix . Note that is an orthogonal projection onto the row space of 111In row space of , we mean the subspace spanned by the rows of ., and that can be interpreted as a ”back-projection” (BP) from back to . Therefore, the fidelity (4) encourages agreement between —the projection of onto the row space of , and —the back-projection of the measurements. In general, this is different than that encourages agreement between and . Note that in the noiseless case, i.e. when , the terms in (3) and (4) are translated to fitting to and to , respectively.
Note that for some inverse problems and may coincide. For example, in image inpainting, where is a selection of rows of , we have that is an matrix that merely pads with zeros the vector on which it is applied, and so . Therefore, we specifically focus on three popular inverse problems: super-resolution, deblurring and certain compressed sensing scenarios, where the two fidelity terms, and , are indeed very different.
Contribution. This work makes a first attempt towards characterizing for which observation model and prior it is better to use each of the following objectives:
[TABLE]
Particularly, for being the Tikhonov regularization (the prior), where closed-form solutions exist, we derive analytical expressions for the estimations’ mean square error (MSE) that allow to examine which fidelity term is preferable. For example, we show that in the noiseless case yields provably better restoration than
if the condition number of (i.e. the ratio between the largest and smallest squared singular values of ) is large, e.g. in typical super-resolution problems.
For sophisticated convex and non-convex priors, such as TV [1], BM3D [4], and DCGAN [19], analytical analysis is intractable. Therefore, we perform an intensive empirical study, where we use the same optimization method (FISTA [20] or ADAM [21]) to minimize each of the two different cost functions. Interestingly, we demonstrate that the behavior for the sophisticated priors strongly correlates with properties for which we establish concrete mathematical reasoning in the case of priors.
Another contribution of the paper that is deferred to the appendix is showing that IDBP framework [18], which has achieved excellent results for deblurring [18, 22] and super-resolution [23] is in fact the proximal gradient method [20, 24] (popularized under the name ISTA) applied on . This derivation of IDBP is completely different, and arguably simpler, than the way it is developed in [18].
The paper is organized as follows. Section II includes mathematical analysis of the two cost functions for the case of -type priors. The analytical results are verified in Section III. In Section IV the two cost functions are empirically examined for different sophisticated priors. Section V concludes the paper.
II Mathematical Analysis for Priors
In this section, we analyze the performance of the new cost function (6) and compare it to (5) for a type of prior functions, for which the closed-form solutions of (5) and (6) lead to a tractable performance analysis. We start with specifying the required assumptions, then we derive the estimators and expressions for their expected mean square error. Finally, the error expressions are compared and several observations are stated.
II-A Assumptions
In order to allow a concrete mathematical comparison between and , in the theoretical analysis we restrict our discussion to prior functions of the form s(\tilde{\bm{x}})={\color[rgb]{0,0,0}\frac{1}{2}}\|\bm{D}\tilde{\bm{x}}\|_{2}^{2}={\color[rgb]{0,0,0}\frac{1}{2}}\tilde{\bm{x}}^{T}\bm{D}^{T}\bm{D}\tilde{\bm{x}}, where is a positive-definite matrix. This prior is often referred to as Tikhonov regularization and is one of the most widely used methods to solve ill-posed inverse problems. Yet, for obtaining analytical results, we further focus on a more specific type of this prior—we require that both and have the same right singular vectors. Let us define the singular value decomposition (SVD) of the matrix , where is an orthogonal matrix whose columns are the left singular vectors, is an rectangular diagonal matrix with nonzero singular values on the diagonal, and is an orthogonal matrix whose columns are the right singular vectors. The property that are strictly positive follows from our assumptions in Section I, that and . For , essentially, we assume that , where is an diagonal matrix of nonzero eigenvalues .
The assumption above is required because, as far as we know, currently there is no known analytical expression for the eigen-decomposition of arbitrary matrices which is required for our analysis [25]. Yet, this assumption holds in some practical cases, e.g. if and are circulant matrices (and thus diagonalized by the discrete Fourier transform), or if (i.e. least-norm regularization).
II-B Performance analysis
Let us start with obtaining closed-form expressions for the estimators and , which minimize and , respectively. Due to the convexity of the cost functions, this is done simply by equating their gradients to zero
[TABLE]
[TABLE]
In (II-B) we use the properties and .
We turn to compute the expected mean square errors (MSEs) of the estimators, conditioned on , under the assumptions that and . To ease formulations, we define the zero eigenvalues of (i.e. zeros in the diagonal of ) by .
The computation of the MSE of is given by
[TABLE]
The second equality follows from substituting (1) in (II-B), the fourth equality uses and the cyclic property of trace, the fifth equality uses , the sixth equality is obtained by substituting the eigen-decompositions of and , and the last equality follows from the fact that is an orthogonal matrix. Therefore, by defining the (squared) bias and variance terms as
[TABLE]
we may write the error as
[TABLE]
Note that the bias depends on the original image and not on the noise, and the opposite holds for the variance. Yet, both terms are affected by the structure of . The regularization parameters introduce a tradeoff: increasing them reduces the variance but increases the bias.
To ease the computation of the MSE of , let us also define an indicator function that is equal to 1 if and 0 otherwise, and an diagonal matrix with on its diagonal. The following identities are used
[TABLE]
Now, we get
[TABLE]
The second equality follows from substituting (1) in (II-B), the fourth equality uses and the cyclic property of trace, the fifth equality uses , the sixth equality is obtained by substituting the eigen-decompositions of , and , and the last equality uses the orthogonality of . Therefore, by defining
[TABLE]
we have that
[TABLE]
Comparing (II-B) and (II-B) we may notice the following. First, the term handles small (i.e. singular values of that are smaller than 1) better than . However, handles such small singular values worse than . The opposite holds for singular values that are greater than 1. This behavior can be formulated as the following observation.
Observation 1**.**
For we have that but . And, for we have that but .
Notice that in the noiseless case , implying that and . This leads us to the following observation for the noiseless case.
Observation 2**.**
In a noiseless scenario, the relation between and , dictates the relation between and . In particular, if all the singular values of are smaller than 1, then , and if all the singular values of are greater than 1, then .
Note that Observation 2 holds for any given setting of that is used by the two estimators. Therefore, these relations between and hold also when is tuned for best performance of each estimator.
In practice, a different value of can be preferred for the different cost functions. Let us denote by and the regularization parameter in and , respectively, and let the singular values of be indexed in a descending order, i.e. . Comparing and with leads to an additional observation for the noiseless case, which is in favor of the BP cost.
Observation 3**.**
*In a noiseless scenario, for any and , we have that . If in addition for some indices , then unless for all these indices. *
Proof.
Since , we have that . Therefore,
[TABLE]
If for some indices , it is easy to see that the inequality is strict unless for these indices. Finally, recall that in the noiseless case the relation between and , dictates the relation between and .
∎
Even though Observation 2 and Observation 3 consider the noiseless case, note that they cover events where the gap between and may be substantial enough to dictate the relationship between the MSEs also when the noise level is moderate. For example, if and all the singular values are much smaller than 1 then the ’in particular’-part in Observation 2 implies that is much smaller than . Another example, if and the condition number of , i.e. the ratio , is very large, then Observation 3 implies that is much smaller than .
II-C Discussion and implications for priors beyond
As can be seen in (II-B) and (II-B), for the discussed Tikhonov regularization the bias term of each estimator is minimized if , and in this case tends to . This means that the performance gap in the noiseless case, which is stated in Observation 2 and Observation 3, tends to zero for . However, note that we consider here priors mainly as a surrogate to complex priors which are hard to analyze. As we demonstrate in Section IV, the results that are obtained for sophisticated priors, such as TV, BM3D and DCGAN, indeed strongly correlate with the observations above
(especially with Observation 3 that implies an advantage of BP for badly conditioned ).
For such priors, the optimal value of for each fidelity term is significantly above 0 even in the noiseless case (contrary to priors), and the gap between the best recoveries is significant as well.
Another motivation for connecting the above analysis to other priors comes from recognizing attributes that distinguish between the LS and BP fidelity terms regardless of the prior used with them.
Let us focus on the noiseless case, where . In this case, (5) and (6) can be written as
[TABLE]
Under our SVD notations, we have and , where is the right singular vector of associated with the singular value . Therefore, we get
[TABLE]
Note that equally weighs all , contrary to that weighs them according to . As in inverse problems one (typically) cares about minimizing the MSE, an intuition that minimizing (20) may have an advantage over minimizing (19) for general priors, comes from the similarity between the BP fidelity term and formulating the MSE as (note that the sum here goes over all the basis vectors in ). For priors, we indeed have shown in Section II-B that this “equal weighting” strategy translates to the fact that do not depend on , contrary to , which later yields the MSE advantage of BP over LS in Observation 3. For priors, we have obtained analytical results and tradeoffs also for the noisy case. For other priors, we empirically show in Section IV correlation to the above analytical findings.
An important factor that is not taken into account in the above analysis is optimization, since for priors there is a closed-form solution. Yet, for sophisticated priors iterative optimization schemes are inevitable, and the regularization parameter has an effect which is similar to the step size in these schemes. In such cases, extremely low value of inherently results in a massive slowdown in the convergence for convex priors [26, 27] and/or bad local minima for non-convex priors. Taking a numerical optimization point of view, in the sequel we empirically show that is superior to even for priors with , if few iterations of conjugate gradients are used instead of the closed-form expressions (II-B) and (II-B). This implementation choice may be preferable in high-dimensional problems when it is not possible to invert the matrices. The advantage of BP in this case follows from the fact that the eigenvalues of are only 1 (in the row space of ) and 0 (in the null space of ), while may have very different eigenvalues in general, and conjugate gradients (among other methods) performs better when the eigenvalues are clustered [28]. In Section IV we provide empirical evidence that BP requires less iterations than LS also for other optimization schemes and priors.
III Experiments with Priors
In this section, we discuss the implications of the analytical results from Section II and verify them for specific observation models: super-resolution and compressed sensing. In the first, all the singular values of are smaller than 1 and the condition number of is large, while in the latter it is possible that all singular values are greater than 1 and that the condition number is very moderate. We also discuss the typical deblurring problem, which is highly ill-conditioned. In this case, in has to be regularized due to the large number of near zero singular values, and (II-B) needs to be modified accordingly.
Throughout this section, we use the closed-form estimators in (II-B) and (II-B) to restore the images. The empirical performance of these two estimators is presented by markers, while the analytical expressions from (11) and (15) are plotted in solid curves. Different colors are used to distinguish between the two fidelity terms that are used for the estimation.
III-A Super-resolution
Let us consider the super-resolution (SR) task, where is a composite operator of blurring (e.g. anti-aliasing filtering) followed by down-sampling. Note that the largest singular value of a typical low-pass filtering operation is 1, and it is associated with the DC (i.e. the magnitude of the Fourier coefficient that is associated with zero frequency). The rest of the singular values are smaller than 1. The subsequent operator is subsampling, which inevitability reduces the energy of the signal (as ). Therefore, essentially, all the singular values of are smaller than 1. Accordingly, the condition number of is large. These properties are demonstrated in Fig. 1(a) for SR with scale factor 3 and Gaussian filter of size and standard deviation 1.6 (used in many works, e.g. [11, 23, 29]), which is performed on a image (thus and ). We consider such a small image to allow computing the SVD of (our analytic expressions require both and ).
We verify our analytical results for the SRx3 scenario mentioned above, and two cases: and Gaussian noise with . The experiments are performed on the cameraman image, resized to pixels. In the noisy case, we average the results over 5 noise realizations. We have observed similar results for other images as well. We use the prior , which satisfies the assumptions ( and ).
The PSNR222The PSNR for a recovery of a uint8 image is computed as 10\mathrm{log}_{10}\Big{(}\frac{255^{2}}{\frac{1}{n}\|\hat{\bm{x}}-\bm{x}\|_{2}^{2}}\Big{)}. results are presented in Fig. 3 and validate the analytical expressions. For , is better than for any value of the parameter , as implied by Observation 2 since all the singular values of are smaller than 1 (Fig. 1(a)).
The rather large gap in favor of BP also agrees with Observation 3 that predicts it when the ratio is large. The fact that BP at outperforms LS at , further verifies Observation 3. For , the gap between the estimators is reduced because is worse than at handling the small singular values, as mentioned in Observation 1.
To demonstrate the numerical optimization advantage of the BP cost over the LS cost for (where the gap between the bias terms in (II-B) and (II-B) tends to 0), we repeat the experiments above for very small values of . However, this time instead of inverting the matrices in (II-B) and (II-B) we obtain the estimators using the conjugate gradient method. The results are presented in Fig. 3. Remarkably, a single iteration is enough for obtaining the exact BP estimator (for prior).
III-B Compressed sensing
Contrary to SR scenarios, in compressed sensing (CS) the condition number of is moderate and the singular values of may be larger than 1. Consider the commonly examined scenario where is the multiplication of an Gaussian measurement matrix (whose i.i.d. entries are drawn from ) with an Haar wavelet basis. We have observed that for high compression, e.g. , all the singular values are larger than 1 and the condition number is very small, as demonstrated in Fig. 1(c). However, for lower compression, e.g. , there are also singular values smaller than 1 and the condition number increases, as demonstrated in Fig. 1(d).
We verify our analytical results for these two compression ratios (both with ). The experiments are performed on the same version of cameraman image, and we use again the prior . The results are presented in Fig. 5 and validate the analytical expressions. For , is better than for any value of , as implied by Observation 2 since all the singular values of are greater than 1 (Fig. 1(c)).
To verify Observation 3 in this case, see that BP at has (slightly) higher PSNR than LS at , e.g. for . We have verified this also for very large values of (not presented here)—both curves decrease and reach a similar plateau at high , yet BP at indeed has higher PSNR than LS at , but the difference is extremely small. Interestingly, for , where some singular values of are smaller than 1 (Fig. 1(d)), gets better results than .
Also in this scenario, it can be verified that BP at has higher PSNR than LS at , as implied by Observation 3. The fact that the gap between BP and LS for and has been changed in favor of BP in the latter agrees with the derivation of Observation 3 in (II-B) that links the advantage of BP to an increased ratio.
We demonstrate again the numerical optimization advantage of the BP cost over the LS cost by repeating the experiments above for very small values of , while using the conjugate gradient method instead of matrix inversion. The results are presented in Fig. 5. It can be seen again that for the prior a single iteration is enough for obtaining the exact BP estimator.
We find it necessary to emphasize that compressed sensing scenarios require a sparsity-inducing prior, e.g. or TV prior, rather than an prior, for which both estimators exhibit poor results (i.e. very low PSNR). However, our purpose here is merely to validate our analysis, which applies only to priors, for a case in which all the singular values are greater than 1 and/or the condition number is small.
Finally, note that for Gaussian there is no efficient way to implement the operators and for large dimensions. Therefore, in practice, taking to be the subsampled Fourier transform is more common, e.g. in sparse MRI [30]. However, note that for this acquisition model is simply the Hermitian transpose of (this property follows from the fact that the subsampled Fourier transform is a tight frame [31]), which together with the unitarity of the Fourier transform leads to . This means that the two cost functions coincide, which is also implied by the fact that in this case all the singular values of are 1 and thus (II-B) is identical to (II-B). Therefore, we do not make a comparison for this case.
III-C Deblurring
In the deblurring problem, is a square () ill-conditioned matrix that performs blurring (i.e. filtering by a blur kernel). Typically, the blur kernel coefficients are normalized such that their sum is 1. Thus, the largest singular value of is 1 (associated with the DC), and many other singular values are near 0. Accordingly, the condition number of is extremely large. These properties are demonstrated in Fig. 1(b) for uniform kernel of size (used in many works, e.g. [8, 9, 18]).
Note that if one uses , exactly as defined in (II-B), both Observation 2 and Observation 3 imply an advantage of over in the noiseless case due to small singular values and a large condition number, respectively. However, since in the deblurring problem is not rank-deficient but rather (very) ill-conditioned, deblurring scenarios always assume that the measurements are noisy (typically with low noise levels). Therefore, it is required to regularize the inversion of in in order to mitigate the effect of near zero on the variance of . A common regularized inversion is diagonal loading: inverting instead of , where is a parameter. This is equivalent to replacing with in the eigen-decomposition of .
For with such a regularized inversion, it is not hard to repeat the computations in (II-B) and obtain a very similar result, where is replaced with and is replaced with . Formally, we get
[TABLE]
Therefore, as could be expected, increasing the amount of regularization reduces the variance of but increases its bias. As a sanity check, observe that for we get that (III-C) coincides with (II-B) (recall ). Since in this case the performance of depends on the couple , we cannot obtain clear properties like the observations in Section II-B that hold uniformly for any parameter setting. Yet, as demonstrated below and in the sequel, we have empirically observed that it is possible to find settings of that balance the bias and variance of and therefore lead to very good results despite the observed noise.
We verify (III-C) for the uniform blur kernel mentioned above, and two levels of Gaussian noise: and . The experiments are performed on the version of cameraman image, and we use again the prior. The results are presented in Fig. 6. They show that with good tuning of can outperform , especially when the noise level is low. This implies that ”well-tuned” handles the badly conditioned (Fig. 1(b)) better than .
III-D The effect of the joint right singular vectors assumption
In this section, we compare the empirical MSE and the analytical formulas in (11), (15) and (III-C) in cases where the condition is violated (recall that the columns of are the right singular vectors of and is a diagonal matrix, as defined in Section II-A). Since our formulas require the diagonal of (i.e. ), we compute it as the diagonal of , which is exact under the analysis assumption and can be regarded as an approximation when .
We start with examining the case of , where is the 2D finite difference operator and the diagonal loading is required to make . Note that for the deblurring task we have that both and are circulant matrices that can be diagonalized by the DFT matrix. Therefore, the condition holds for that equals the (inverse) DFT matrix. However, for the SR task cannot be singularly decomposed by a Fourier basis. Therefore, the condition cannot be satisfied.
We repeat previous deblurring and SR experiments with the examined . The results are presented in Figs. 7(a) and 7(c). For deblurring we see perfect agreement between the empirical results and the analytical formulas (as expected). For SR we see that violating the condition has led to a small gap between the empirical results and the formulas.
Now, we further increase the violation of the condition by breaking the circularity property of . We do it by replacing with a non-circulant operator that performs finite difference only on every 8th pixel (and identity on the rest). We repeat the previous deblurring and SR experiments and present the results in Figs. 7(b) and 7(d). It is easy to see that the deviation of the empirical results from the formulas further grows for both tasks.
The experiments demonstrate that the deviation between the empirical MSE and the analytical expressions is proportional to how much the condition on is violated. Yet, the overall trend in the curves still shares similarity with the analytical results, which motivates considering the observations obtained by the analytical analysis for practical sophisticated priors.
III-E Incorporating prior knowledge on with the results
The analytical MSE formulas in (11) and (15) are conditioned on the latent image , as the expectations are taken only with respect to the noise . These expressions have led to observations in Section II
that depend only the singular values of (i.e. ) and do not require prior knowledge on (recall that accurately modeling natural images is difficult). The usefulness of these observations for preferring one fidelity term over the other for sophisticated priors is demonstrated in Section IV.
However, a natural question arises: How can one leverage prior knowledge on to improve the criterion for choosing the fidelity term?
In this section we briefly demonstrate, using a controlled experiment, how the observations in Section II can be polished given a constraint that resides in the orthogonal complement of a known subspace . Note that for low-dimensional such that , we still have an ill-posed linear inverse problem.
We consider the compressed sensing scenario from Section III-B where , and . In this case has (more than 1000) singular values that are larger than 1 and (slightly more than 500) singular values that are smaller than 1 (see Fig. 1(d)). Therefore, the events in the ’in particular’-part in Observation 2 do not occur. Indeed, observe that in Fig. 4(b) none of the estimators is consistently (i.e. for any ) better than the other when is the cameraman image.
Now, let us use the notation from Section II, where the columns of , that is, the right singular vectors of , are ordered according to a descending order of the singular values (from 1 to ), and the last columns span the null space of . Suppose that is the subspace spanned by the columns of , where we use Matlab notation, and that . Due to the orthogonality of , we have that for any . Substituting this property in (II-B) and (II-B), we get
[TABLE]
Therefore, for the considered CS scenario, we have that for any (because for all ). Since , this implies that for any .
Note that for that is the subspace spanned by the columns of and (i.e. in a subspace spanned by columns of that are either associated with singular values that are greater than 1 or with the null space of ), similar arguments lead to for any . Fig. 9 verifies both results for a test image that is the projection of the cameraman image onto (i.e. , where is the cameraman image).
Note that the behavior in Fig. 9 cannot be predicted by the ’in particular’-part in Observation 2 that considers all the singular values of , regardless of . We believe that a detailed study with constraints on that better fit images is an interesting direction for future research.
IV Experiments with Sophisticated Priors
In this section we empirically demonstrate that the behavior of and (the minimizers of and ) for sophisticated convex and non-convex priors (for whom mathematical analysis is hard or even intractable) strongly correlates with properties for which we have established concrete mathematical reasoning in the case of priors. Specifically, for super-resolution and deblurring tasks (where the condition number of is very large) BP cost function can lead to significantly improved results compared to the LS cost function, yet, there is inverse proportion between the performance gap and the noise level (since the singular values of are small in these tasks).
For Gaussian compressed sensing with low ratio (where the condition number is small and the singular values are greater than 1) is not significantly better than , but it is quite robust to noise. However, when the ratio increases (then the condition number increases and some singular values are smaller than 1) the advantage of BP is more significant, but inversely proportional to the noise level.
IV-A TV prior
We start with the widely-used (isotropic) total-variation (TV) prior [1], which is given by
[TABLE]
for a two-dimensional signal . The factor 0.1 is used to achieve good performance for in case of denoising (). Obviously, it does not affect the comparison between the methods, since is multiplied by that can be set arbitrarily. Note that is convex, and thus and are also convex functions. We choose to minimize them by the same method: 100 iterations of FISTA [20], which is basically a variant of ISTA (see (32) in the appendix) that is incorporated with Nesterov’s accelerated gradient [32]. The step size is the typical 1 over the Lipschitz constant of , which in our case can be computed as 1 over the spectral norm of the constant Hessian matrix , i.e. for BP recovery and (computed by the power method) for LS recovery. This common choice of step size is known to ensure convergence in the convex setting [20]. Several methods for performing proximal mapping of (i.e. Gaussian denoising associated with the TV prior) exist [33, 34]. Here, we choose to apply split Bregman method [33]. The experiments are performed on the following eight classical test images: cameraman, house, peppers, Lena, Barbara, boat, hill and couple.
IV-A1 Super-resolution
We compare the performance of and for SR with Gaussian anti-aliasing kernel (defined in Section III-A) and scale factor of 3. We consider the noiseless case , as well as the case of Gaussian noise with . For both estimators we initialize FISTA with the bicubic upsampling of . For BP, the operator has fast implementation using the conjugate gradient method [35]. Fig. 11 shows the PSNR of the reconstructions, averaged over all images, for different values of the regularization parameter . Fig. 11 shows the average PSNR as a function of the iteration number, where for each estimator we use the value of which has led to its best results in Fig. 11 (0.25 for LS and 16 for BP in Fig. 10(c); 0.5 for LS and 46 for BP in Fig. 10(d)). It can be seen that converges somewhat faster than . In Figs. 21(c) and 21(d) we also display the results for cameraman image in the noiseless case.
Note the agreement of the obtained results with the observations from Section II, even though they have been established for a much simpler convex prior. In the noiseless case, outperforms for any value of , while in the noisy scenario, this does not hold. However, even in the latter case, (with good tuning of ) outperforms (with good tuning of ). Yet, the gap between them (for optimal tuning) is smaller than in the noiseless case.
IV-A2 Deblurring
We compare the two estimators for the widely examined uniform blur kernel mentioned in Section III-C. We make the common assumption of circular shift-invariant blur operator, which allows very fast implementation of the gradient steps in the optimization of both cost functions using Fast Fourier Transform (FFT). We consider two levels of Gaussian noise: and . For both estimators we initialize FISTA with , and for we use . Fig. 13 shows the average PSNR for different values of , and Fig. 13 shows the average PSNR as a function of the iteration number, where each estimator uses the best from Fig. 13 (0.3 for LS and 20.5 for BP in Fig. 12(c); 0.98 for LS and 19.5 for BP in Fig. 12(d)). Note that converges much faster than . The difference here for deblurring is more significant than for SR. Visual results for couple image in the case of are presented in Figs. 22(c) and 22(d).
The obtained results agree with the observations in Section III-C, in the sense that there exist settings of for which outperforms . Presumably, even for the more complex TV prior, this is due to a better handling of whose condition number is very large. As expected, the performance gap between the estimators (for optimal tuning) decreases when the noise level is higher. However, it is still highly in favor of .
IV-A3 Compressed sensing
We compare the performance of and for CS with Gaussian measurement matrix (i.e. ), for which the two cost functions differ (see the discussion in Section III-B). In these CS experiments (only) we decrease the size of the test images to 128128 pixels, as there is no efficient way to implement the operators and for large dimensions. We consider compression ratios of , , and . For each of them we examine the noiseless case and the case of Gaussian noise with signal-to-noise ratio (SNR) of 20 dB. For both estimators we initialize FISTA with zero and use 500 iterations. As we compute in advance, both estimators have similar computational cost per iteration. Fig. 15 shows the average PSNR for different values of . For we show in Fig. 15 the average PSNR vs. the iteration number, where each estimator uses the best from Fig. 15. Again, note that requires less iterations than . Visual results for house image in the noiseless case are presented in Fig. 16.
The results show correlation with the observations in Section II. In the noiseless case, when the ratio increases (and thus the condition number of increases, e.g. see Figs. 1(c) and 1(d)) the performance gap between BP and LS increases in favor of BP. In the noisy case, when the ratio increases the BP estimator becomes more sensitive to noise (due to the increase in the number of singular values that are smaller than 1, again, see Figs. 1(c) and 1(d)).
IV-B BM3D prior
We turn to compare the performance of the two cost functions for the BM3D prior [4], which is based on sparsifying a three-dimensional transformation applied to groups of nearest-neighbor (i.e. similar) patches. This prior is non-convex. In fact, it is also not clear how to precisely formulate its associated . Yet, when implementing proximal algorithms the proximal mapping of can be replaced with applying the BM3D denoiser as a ”black-box”. We use 200 iterations of FISTA to minimize the cost functions with typical step sizes as explained above, and the same eight classical test images.
IV-B1 Super-resolution
We repeat the two SR experiments of Section IV-A1. Fig. 18 shows the average PSNR for different values of , and Fig. 18 shows the average PSNR as a function of the iteration number, where each estimator uses the best from Fig. 18 (0.09 for LS and 16 for BP in Fig. 17(c); 0.5 for LS and 140 for BP in Fig. 17(d)). Again, note that converges much faster than . In Figs. 21(e) and 21(f) we display the results for cameraman image in the noiseless case.
Note the strong correlation between the obtained results and the observations from Section II, even though the prior is highly non-convex. In the noiseless case, outperforms for a large range of . For very small values of it is inferior to , but with only a small gap. From a practitioner point of view, the advantages of using the BP cost here are still clear, since when is well-tuned (for each of the cost functions) is significantly better. Note that in the examined noisy scenario, well-tuned is still better than well-tuned , but the gap decreases.
IV-B2 Deblurring
We repeat the two deblurring experiments of Section IV-A2. Fig. 20 shows the average PSNR for different values of , and Fig. 20 shows the average PSNR as a function of the iteration number, where each estimator uses the best from Fig. 20 (0.027 for LS and 25.5 for BP in Fig. 19(c); 0.5 for LS and 29.5 for BP in Fig. 19(d)). Figs. 22(e) and 22(f) present visual results for couple image in the case of . The observations that have been made for TV prior stay the same here for the BM3D prior: There exist settings of for which significantly outperforms and converges faster.
IV-C DCGAN prior
The developments in deep learning [36] in the recent years have led to significant improvement in learning generative models. Methods like variational auto-encoders (VAEs) [37] and generative adversarial networks (GANs) [38] have found success at modeling data distributions. This has naturally led to using pre-trained generative models as priors in imaging inverse problems [17]. Since in popular generative models [37, 38] a generator learns a mapping from a low dimensional space to the signal space , one can search for a reconstruction of only in the range of the generator. This can be formulated by the following non-convex prior
[TABLE]
Plugging (24) into the typical cost function (5), we get the objective
[TABLE]
Note that for this prior, a regularization parameter is not required. The recovery of the latent image is given by , where is a minimizer of (25), which can be obtained by backpropagation and standard gradient based optimizers.
The technique above has been examined recently in [17]. Here, we compare it with the one obtained by a similar approach that uses the BP cost function (6), i.e. we plug (24) into (6), to get the objective
[TABLE]
and recover by , where is a minimizer of (26).
We use the CelebA dataset [39] and Tensorflow package [40] to train a generator using DCGAN architecture [19] on the cropped version of the images (6464 pixels), as done in [17]. We use the first 200,000 images (out of 202,599) for training, and the training procedure follows the one in [19, 17]. At test time, all the optimizations with respect to are performed using: ADAM [21] with learning rate of 0.1 (as done in [17]), same 10 random initializations of , and 2000 iterations, which suffice for ensuring that the objectives (25) and (26) stop decreasing. The value of that gives the lowest objective is chosen.
IV-C1 Super-resolution
We compare the performance of and for SR with Gaussian anti-aliasing kernel (defined in Section III-A) and scale factor of 3. Table I shows the PSNR results for the different cost functions, averaged over the last 50 images in CelebA (these images are not included in the training data). Several visual results are shown in Fig. 23.
It can be seen that the BP fidelity yields higher average PSNR and perceptually better recoveries. In fact, in each of the 50 examined images has obtained higher PSNR than . This behavior agrees with the previous experiments that demonstrate the advantages of the BP cost for the noiseless SR problem. We also note that even though the results of the simple bicubic upsampling are always perceptually worse than the recoveries that use DCGAN, its PSNR is sometimes higher. This drawback of GAN-based priors is due to the limited representation capabilities of the generators (sometimes referred to as ”mode collapse”). A very recent work has suggested to mitigate this deficiency by image-adaptation and back-projections [41].
IV-C2 Compressed sensing
Due to the small image dimensions, we are able to compare the performance of and for CS with Gaussian measurement matrix (i.e. ), for which the two cost functions differ (see the discussion in Section III-B). We use compression ratios of , , and . Table II shows the PSNR results for the different cost functions, averaged over the last 50 images in CelebA. Several visual results are shown in Figs. 24 and 25.
The performance gap between and is negligible for , and increases in favor of BP when the ratio increases. This behavior correlates with the analysis in Section II (specifically with Observation 3), which explains such behavior for priors by the fact that when the ratio increases the condition number of increases as well.
V Conclusion
In this work we examined the BP fidelity term for ill-posed linear inverse problems. This term has only been used implicitly by the recently proposed iterative denoising and backward projections (IDBP) framework, and is an alternative to the least squares (LS) term, which is the common choice in most works. We showed that IDBP is essentially a specific optimization scheme, namely the proximal gradient method (known also as ISTA), for minimizing the cost function induced by the BP fidelity term. We analytically compared the two fidelity terms—BP and LS—for the case of -type prior functions, and obtained mathematically-backed observations in favor of the BP term when the condition number of is large (which is the case in many applications, such as super-resolution and deblurring). Furthermore, we showed that it is possible to leverage prior knowledge on to increase the coverage of the observations. Finally, we empirically demonstrated that the behavior for sophisticated priors, such as TV, BM3D and DCGAN, strongly correlates with the theoretically backed properties that we established for priors. While the mathematical performance analysis in this work is done only for priors, it provides a good characterization for the advantages of BP and LS compared to each other. Yet, we believe that there are other factors that should be explored with respect to the new fidelity term, such as its behavior with non-convex priors or its effect on the convergence speed of iterative optimization algorithms.
Appendix A The Connection Between IDBP [18] and
A-A Background
The iterative denoising and backward projections (IDBP) framework [18] is inspired by the plug-and-play priors concept [42], which encourages the usage of existing Gaussian denoisers as ”black boxes” to implicitly dictate the prior when solving inverse problems. Such an approach allows one to use sophisticated denoising methods even when it is not clear how to formulate their associated priors, e.g. convolutional neural network (CNN) denoisers.
Several plug-and-play works have been published [42, 43, 44, 45, 46, 47, 29, 48, 49]. Most of them consider the typical cost function (5) and directly minimize it using existing iterative optimization schemes, such as FISTA [20], ADMM [50] or quadratic penalty method [51], that include steps in which the proximal mapping of is used (as explained below, this mapping is equivalent to Gaussian denoising under the prior ).
Recently, [18] has suggested, after several manipulations, to solve a different optimization problem
[TABLE]
where is the noise level and is a design parameter. This work has also proposed an adaptive strategy to set , which does not depend on the prior and, contrary to cross-validation, does not require a set of ground truth examples. It has been suggested in [18] to solve (27) using a simple alternating minimization scheme that possesses the plug-and-play property, where the prior term is handled solely by a Gaussian denoising operation with noise level . In this iterative method, is obtained by projecting onto
[TABLE]
and is obtained by
[TABLE]
The two repeating operations lends the method its name: Iterative Denoising and Backward Projections (IDBP). After a stopping criterion is met, the last is taken as the estimate of the latent . Note that in many cases the operation can be performed efficiently (e.g. the matrix inversion can be avoided using the conjugate gradient method [35]), and thus IDBP is dominated by the complexity of the denoising operation, similarly to other plug-and-play techniques. Using sophisticated denoisers, such as BM3D and CNNs, this algorithm has achieved excellent results for deblurring [18, 22] and super-resolution [23].
A-B Obtaining IDBP by applying ISTA on
Interestingly, there is another way to develop the exact algorithm, which is different from the way it is developed in [18]. First, note that (27) can be solved directly for . Similar to (A-A), we get
[TABLE]
Substituting (30) into (27), we reach with a specific value of the regularization parameter, i.e. . Therefore, IDBP is essentially a specific method to minimize the cost function. Let us show that this method coincides with applying the proximal gradient method [20, 24], popularized under the name ISTA333ISTA is the abbreviation of Iterative Shrinkage-Thresholding Algorithm, initially designed for [52]., on . Let us define the proximal mapping, which was introduced by Moreau [53] for convex functions. Here we do not limit this definition to convex functions, though, we emphasize that previous results for proximal mapping of convex functions do not apply to non-convex functions.
Definition 1**.**
The proximal mapping of a function at the point is defined by
[TABLE]
Clearly, given the same , Gaussian denoising and proximal mapping are tightly connected .
Assuming a differentiable fidelity term with a Lipschitz continuous gradient , applying ISTA on (2) involves iterations of
[TABLE]
where is a step-size, which ensures convergence for convex if it is equal to (or smaller than) 1 over the Lipschitz constant of [20].
Proposition 1**.**
The IDBP algorithm, given in (A-A) and (A-A), coincides with applying ISTA (32) on the cost function .
Proof.
Let us compute . Using the properties and , we get
[TABLE]
The Lipschitz constant of can be computed here as the spectral norm of the constant Hessian matrix . Therefore, can be chosen as
[TABLE]
where we use the fact that the spectral norm of a non-trivial orthogonal projection is 1. Now, due to the connection , (32) can be written as
[TABLE]
Finally, by plugging (A-B) and (34) into (35) and setting , we get the IDBP scheme, which is presented in (A-A) and (A-A).
∎
The connection between IDBP and ISTA, allows IDBP to adopt the theoretical results of the latter. Yet, note that the powerful global convergence (obtaining the optimal value of the objective) of ISTA holds only for denoisers that are associated with convex prior functions [20]. This limitation is shared also with ADMM-based plug-and-play schemes [43].
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] L. I. Rudin, S. Osher, and E. Fatemi, “Nonlinear total variation based noise removal algorithms,” Physica D: nonlinear phenomena , vol. 60, no. 1-4, pp. 259–268, 1992.
- 2[2] A. Buades, B. Coll, and J.-M. Morel, “A review of image denoising algorithms, with a new one,” Multiscale Modeling & Simulation , vol. 4, no. 2, pp. 490–530, 2005.
- 3[3] M. Elad and M. Aharon, “Image denoising via sparse and redundant representations over learned dictionaries,” IEEE Transactions on Image processing , vol. 15, no. 12, pp. 3736–3745, 2006.
- 4[4] K. Dabov, A. Foi, V. Katkovnik, and K. Egiazarian, “Image denoising by sparse 3-D transform-domain collaborative filtering,” IEEE Transactions on image processing , vol. 16, no. 8, pp. 2080–2095, 2007.
- 5[5] M. Bertalmio, G. Sapiro, V. Caselles, and C. Ballester, “Image inpainting,” in Proceedings of the 27th annual conference on Computer graphics and interactive techniques , pp. 417–424, ACM Press/Addison-Wesley Publishing Co., 2000.
- 6[6] A. Criminisi, P. Pérez, and K. Toyama, “Region filling and object removal by exemplar-based image inpainting,” IEEE Transactions on image processing , vol. 13, no. 9, pp. 1200–1212, 2004.
- 7[7] M. Elad, J.-L. Starck, P. Querre, and D. L. Donoho, “Simultaneous cartoon and texture image inpainting using morphological component analysis (MCA),” Applied and Computational Harmonic Analysis , vol. 19, no. 3, pp. 340–358, 2005.
- 8[8] J. A. Guerrero-Colón, L. Mancera, and J. Portilla, “Image restoration using space-variant Gaussian scale mixtures in overcomplete pyramids,” IEEE Transactions on Image Processing , vol. 17, no. 1, pp. 27–41, 2008.
