Designing Test Information and Test Information in Design
David E. Jones, Xiao-Li Meng

TL;DR
This paper introduces a Bayesian framework for measuring information in hypothesis testing, emphasizing experimental design by focusing on data regions where models differ most, extending previous Fisher information results, and demonstrating practical utility through simulations and astronomy applications.
Contribution
It develops a new framework for test information measures in hypothesis testing, extending DeGroot's estimation framework and generalizing Fisher information equivalence.
Findings
Test information measures outperform variance-based measures in design contexts.
Simulation studies validate the proposed measures.
Application in astronomy illustrates practical benefits.
Abstract
DeGroot (1962) developed a general framework for constructing Bayesian measures of the expected information that an experiment will provide for estimation. We propose an analogous framework for measures of information for hypothesis testing. In contrast to estimation information measures that are typically used for surface estimation, test information measures are more useful in experimental design for hypothesis testing and model selection. In particular, we obtain a probability based measure, which has more appealing properties than variance based measures in design contexts where decision problems are of interest. The underlying intuition of our design proposals is straightforward: to distinguish between models we should collect data from regions of the covariate space for which the models differ most. Nicolae et al. (2008) gave an asymptotic equivalence between their test…
Click any figure to enlarge with its caption.
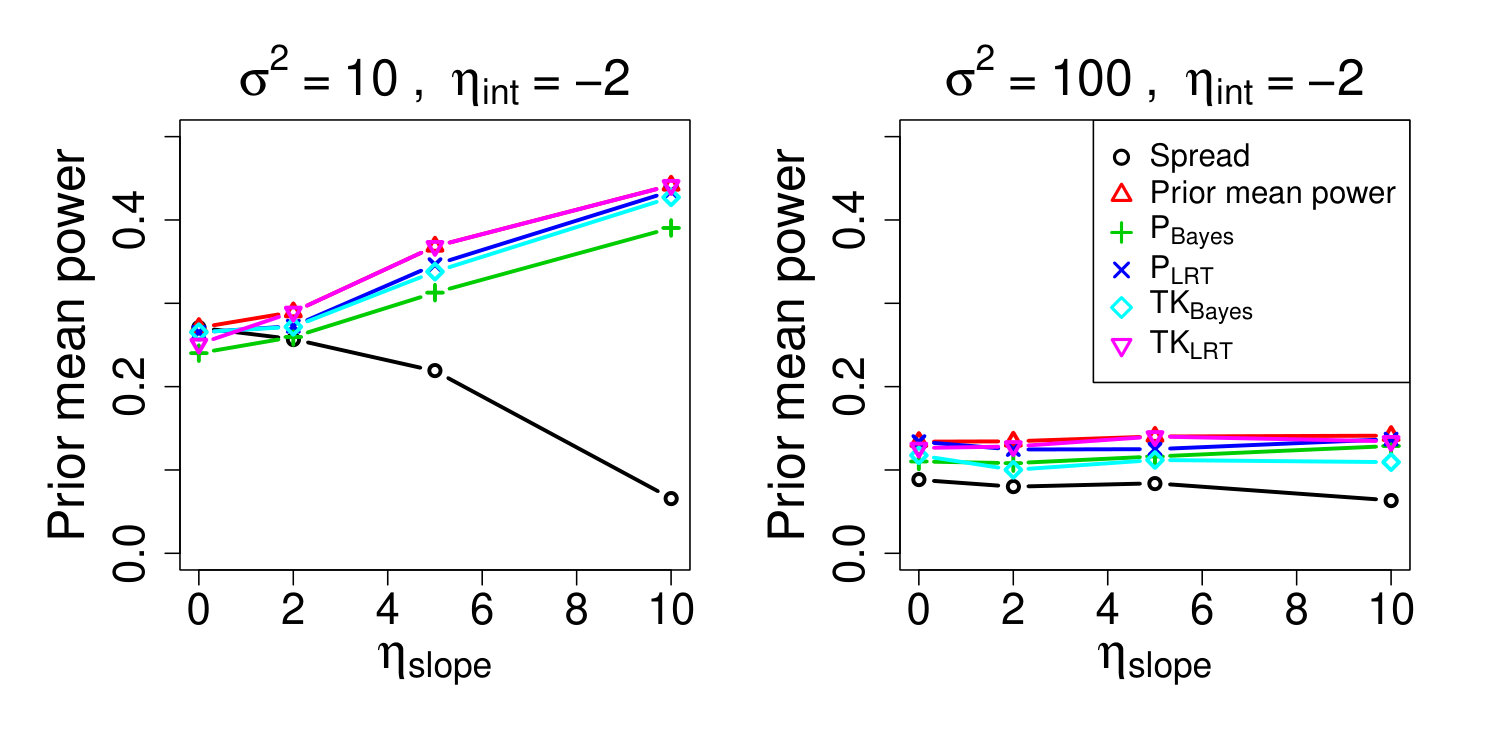 Figure 2
Figure 2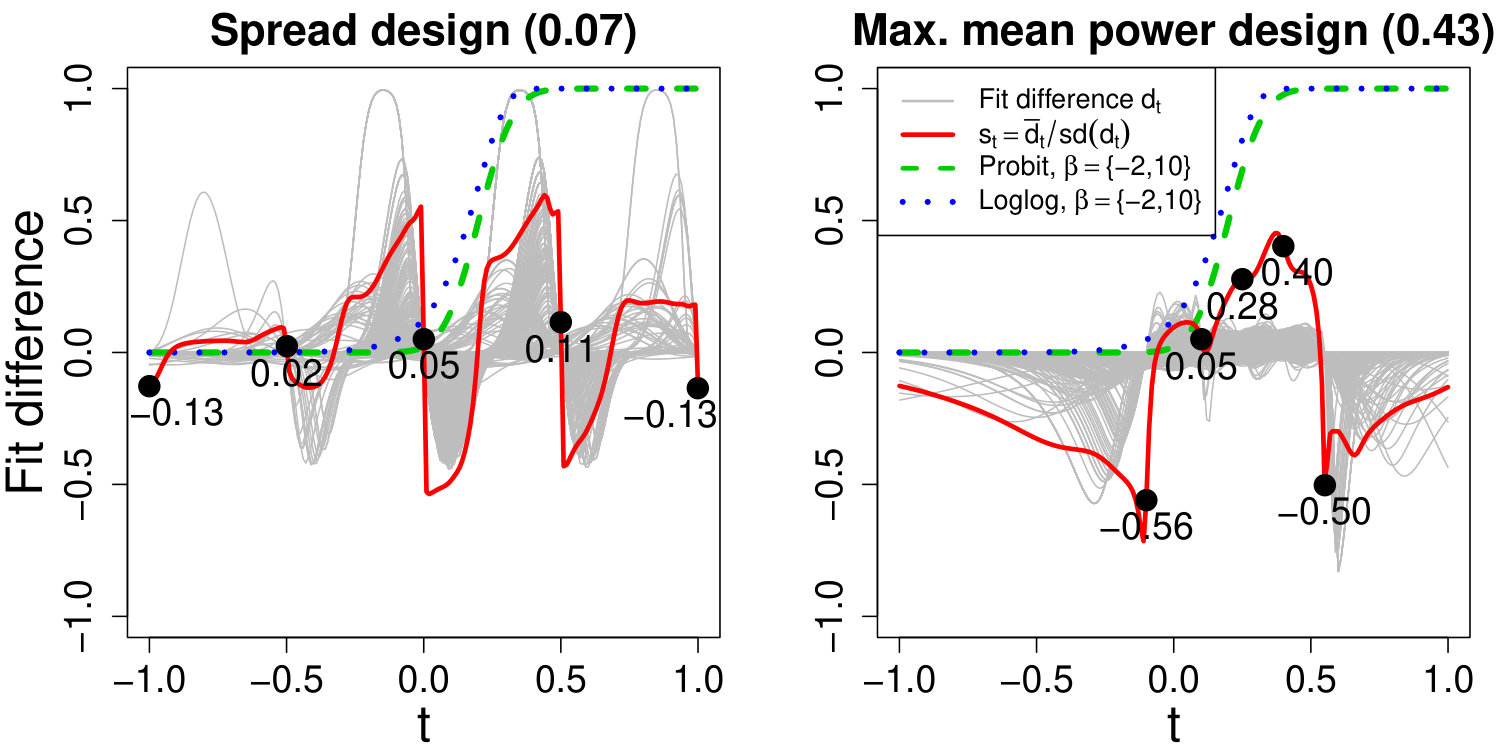 Figure 3
Figure 3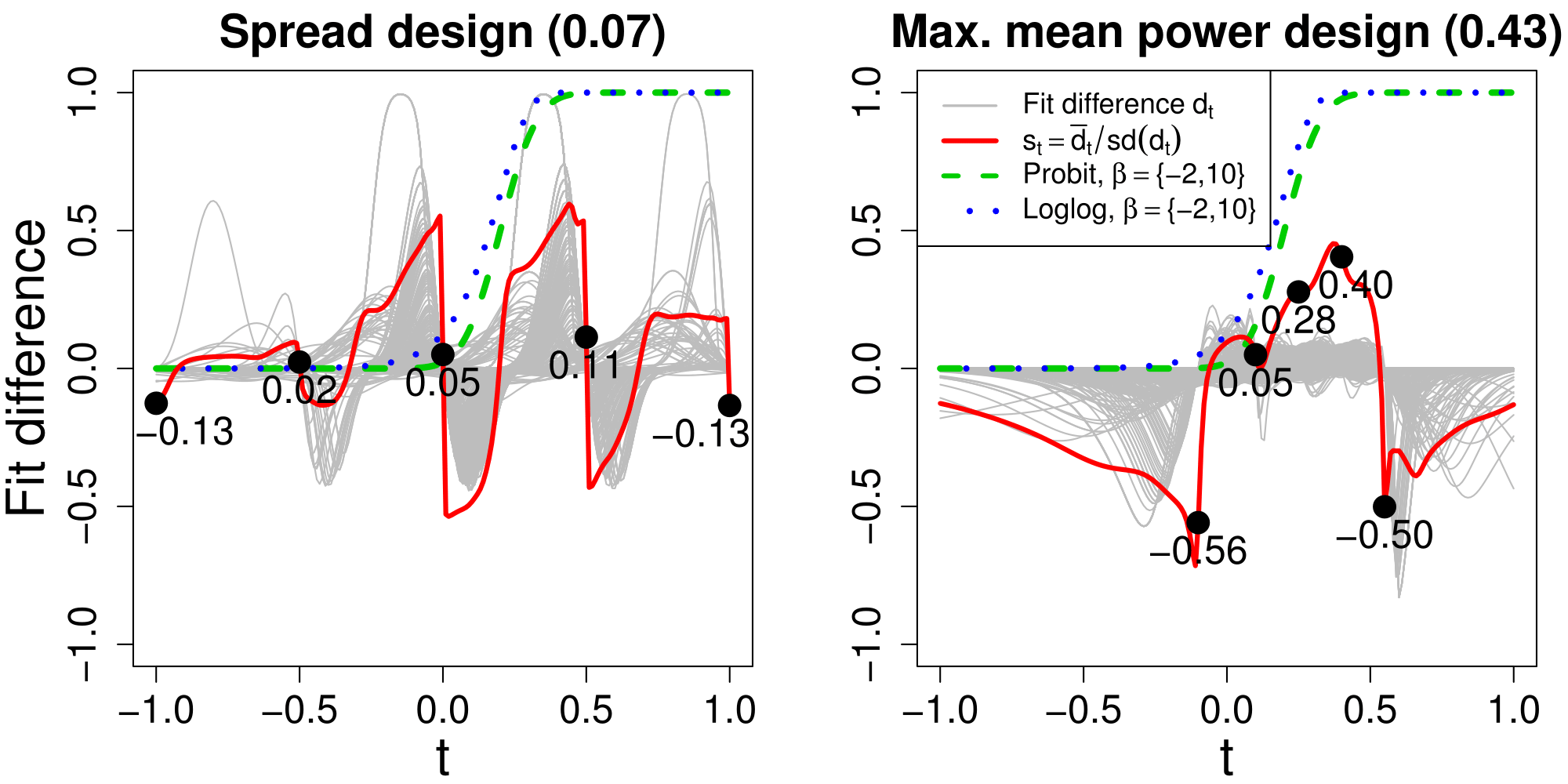 Figure 3
Figure 3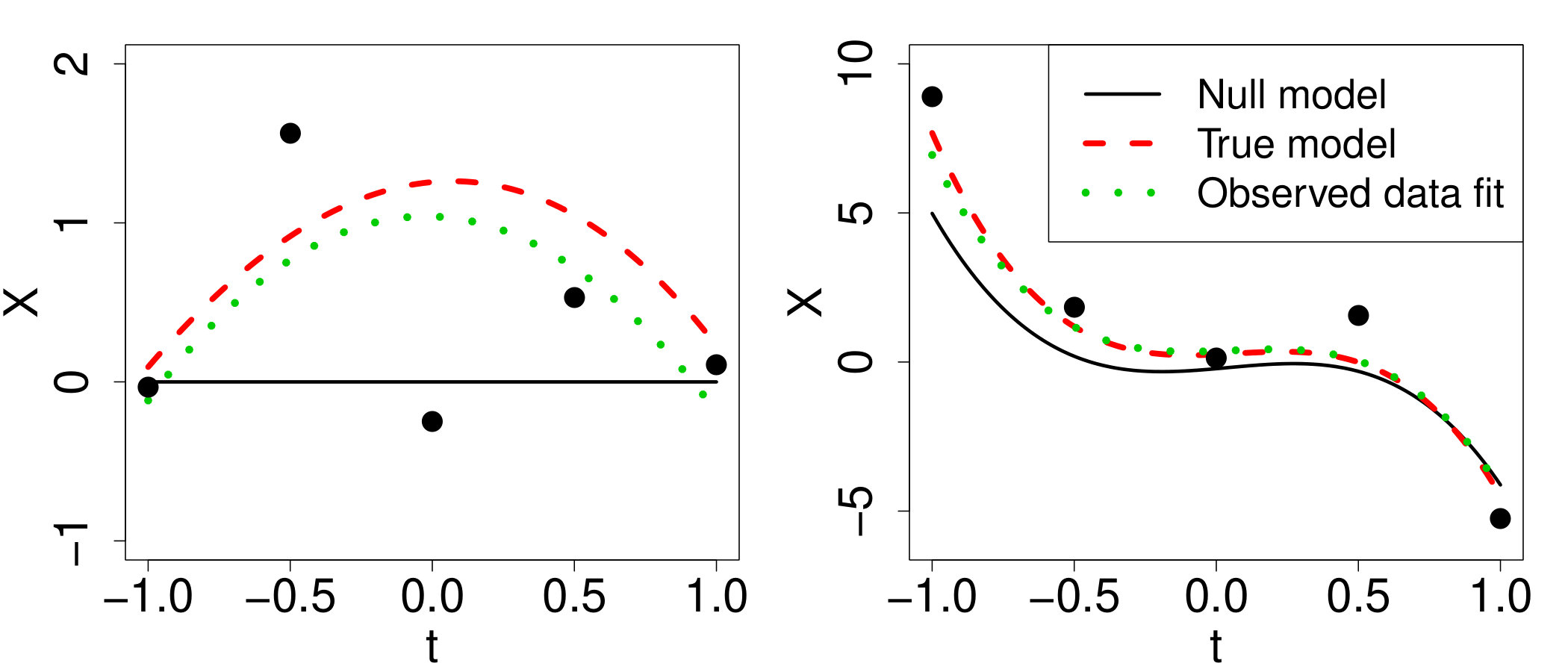 Figure 4
Figure 4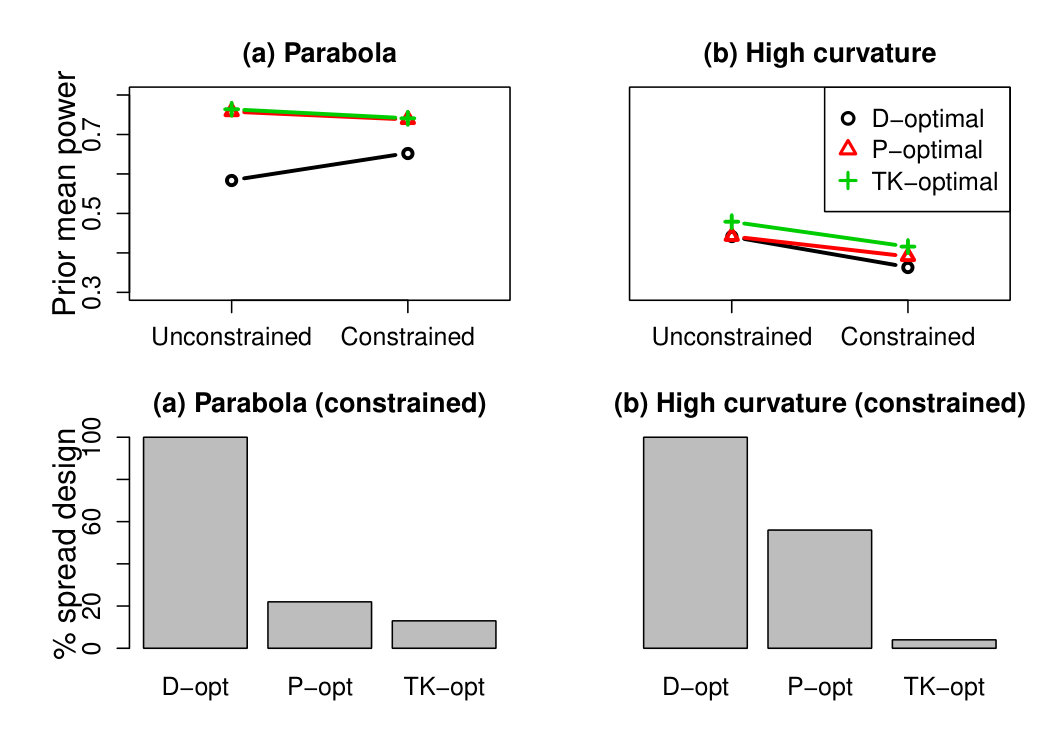 Figure 5
Figure 5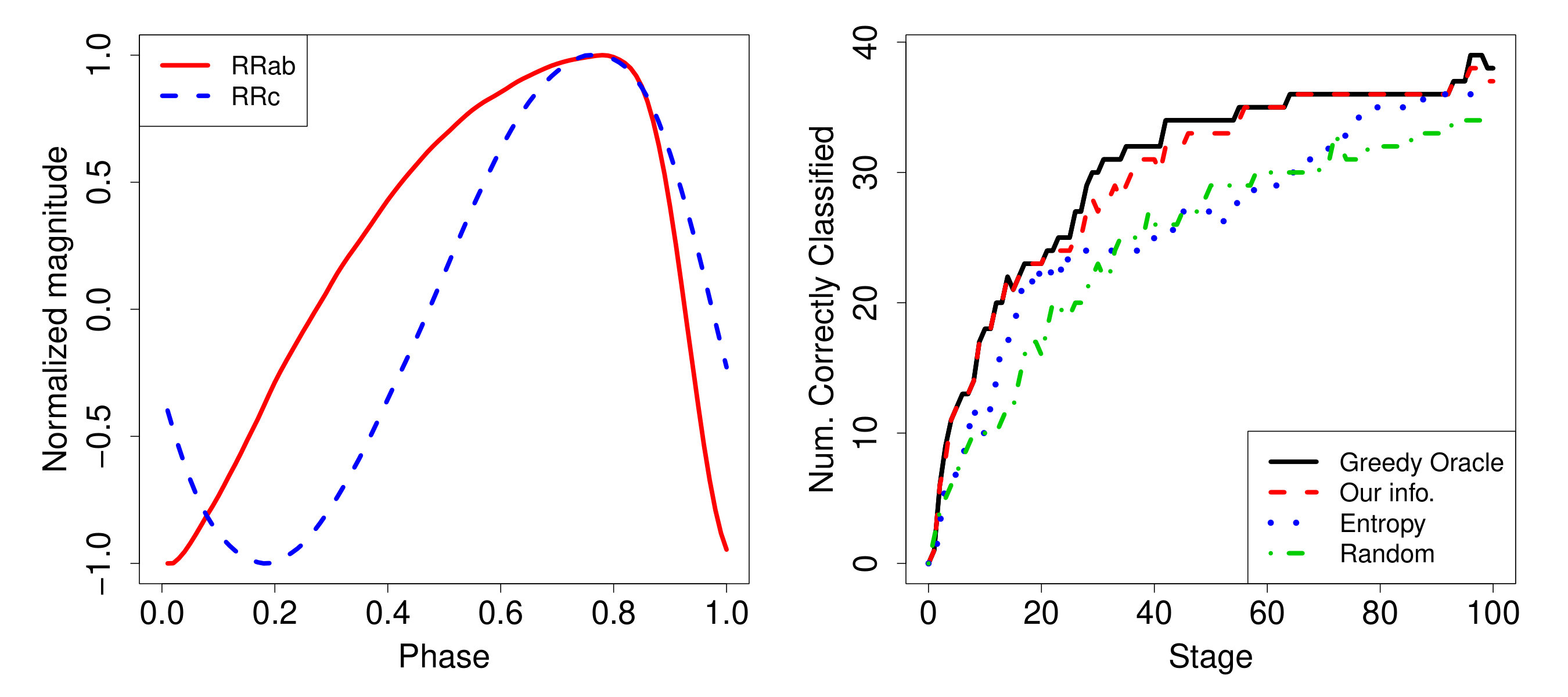 Figure 6
Figure 6Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsOptimal Experimental Design Methods · Advanced Statistical Methods and Models · Advanced Multi-Objective Optimization Algorithms
Designing Test Information
and Test Information in Design
David E. Jones1 and Xiao-Li Meng2
Texas A&M University1 and Harvard University2
Abstract
DeGroot (1962) developed a general framework for constructing Bayesian measures of the expected information that an experiment will provide for estimation. We propose an analogous framework for measures of information for hypothesis testing. In contrast to estimation information measures that are typically used for surface estimation, test information measures are more useful in experimental design for hypothesis testing and model selection. In particular, we obtain a probability based measure, which has more appealing properties than variance based measures in design contexts where decision problems are of interest. The underlying intuition of our design proposals is straightforward: to distinguish between models we should collect data from regions of the covariate space for which the models differ most. Nicolae et al. (2008) gave an asymptotic equivalence between their test information measures and Fisher information. We extend this result to all test information measures under our framework. Simulation studies and an application in astronomy demonstrate the utility of our approach, and provide comparison to other methods including that of Box and Hill (1967).
Keywords: Statistical information; Optimal design; Bayes factors; Hypothesis testing; Model selection; Power
1 Motivation and Overview
1.1 Test information framework: foundations and developments
Nicolae et al. (2008) highlighted that the amount of information provided by an experiment depends on our goals, and in particular the amount of information for hypothesis testing can be different from that for estimation. Nonetheless, the importance of information measures and the need for a framework for constructing and understanding them is common to both the testing and estimation scenarios. Indeed, Ginebra (2007) emphasized that flexible information measures are essential because information is a “highly multi-dimensional concept” that cannot be adequately captured by a narrow definition. In statistics, the most common appeal to information is the use of Fisher information to determine the asymptotic variance of the maximum likelihood estimator (MLE). However, the key to the importance of information measures is that they quantify what it is possible to learn on average given a data generating model (for the data to be used), and thus they go beyond detailing the properties of a specific procedure. This is illustrated by the fact that the Fisher information is not merely related to the asymptotic variance of the MLE, it also appears in the Cramér-Rao lower bound for the variance of all unbiased estimators. Given such requirements, it is natural that for Bayesian inference, estimation information measures should be based on the posterior distribution, which captures all available information. Furthermore, it should be no surprise that the fundamental component of our test information measures is the Bayes factor or likelihood ratio.
General development of the existing estimation information framework began with the concept of statistical entropy introduced by Shannon (1948):
[TABLE]
Entropy measures the information gained by observing the random variable with density , with respect to the measure . Lindley (1956) defined the expected information about a parameter provided by an experiment as the difference between the prior entropy and the expected posterior entropy. This measure has seen many applications, such as defining D-optimality (see the review by Chaloner and Verdinelli, 1995) and reference priors (e.g., Berger et al., 2009). DeGroot (1962) generalizes Lindley’s framework by replacing Shannon’s entropy by a general measure of uncertainty.
Our first contribution is to synthesize the test information measures suggested by Nicolae et al. (2008) to develop an analogous framework to that of DeGroot (1962) for test information. The general measures of expected test information that we propose use the -divergence introduced by Csiszár (1963) and Ali and Silvey (1966), and we extend the concept to define observed and conditional test information because these are of great importance in sequential design. This construction and the parallels with estimation information are summarized in Figure 1. The testing and estimation scenarios differ because the hypotheses to be compared must be incorporated into test information measures, and in computing expected test information we must choose a hypothesis to condition on. This last feature suggests that every expected test information measure should have a dual which conditions on the other hypothesis. Previous authors, including López-Fidalgo et al. (2007), have identified a similar phenomenon, but have not resolved the issue of two differing measures. Here, we demonstrate that there exists an appealing subclass of our measures which give the same expected test information as their duals, thereby resolving the conflict.
Our second contribution is to establish further connections between test and estimation information measures. These connections concern an important quantity for sequential design discussed by Nicolae and Kong (2004) and Nicolae et al. (2008), namely the fraction of information contained in the observed data relative to that contained in the intended complete data, which is not fully observed. Nicolae et al. (2008) established an asymptotic equivalence between their measures of the fraction of observed test information and the fraction of observed Fisher information (for estimation), as the distance between the null parameter and the MLE goes to zero. We show that, by allowing different weighting of observed and missing Fisher information, the equivalence can be extended to hold for all test information measures under our framework. This result identifies an appealing class of test information measures that weight observed and missing estimation information equally (in the limit considered).
With the basic foundations of our test information framework in place, we consider its practical implications. Nicolae and Kong (2004) and Nicolae et al. (2008) put forward their measures of the fraction of observed (or missing) test information with the purpose of informing data collection decisions in genetic linkage studies. We now build on this by illustrating specifically how test information measures may be used in experimental design, both in model selection and coefficient testing scenarios. In the design for model selection scenario, it is often not clear how to use estimation information measures, but the use of test information measures is intuitive. We demonstrate this advantage by finding optimal designs for choosing between the complementary log-log and Probit link functions for binary linear regression.
Next, in the specific case of testing for linear regression parameters, we give a closed form design criterion that is related to the familiar Bayesian alphabet optimality criteria, and demonstrate its use in sequential design. We also propose a posterior probability based expected test information measure, which has many appealing properties, including the aforementioned duality (and can be applied more widely than the linear regression context). Our approach to design for testing linear regression parameters differs from that of Toman (1996), which minimizes Bayes risk, because we instead maximize the expected probabilistic information for distinguishing hypotheses.
Among the existing literature on measuring design information for hypothesis testing and model selection, the approach of Box and Hill (1967) is perhaps most similar to ours. They chose designs that maximize the expected change in entropy of the posterior probability mass function on the model indicator, but did not provide a general framework for test information measures and design. In terms of mathematical justification, our framework benefits from the work of Ginebra (2007), which reviewed and synthesized previous theory including that of Blackwell (1951), Sherman (1951), Stein (1951), and Le Cam (1964). Specifically, our expected test information measures satisfy (up to aesthetics) the three basic requirements identified in Ginebra (2007). Our framework adds the concept of coherent dual test information measures, and our observed test information measures have fewer restrictions than those suggested by Ginebra (2007) (who focused on the estimation case). Furthermore, we demonstrate that, in practice, test and estimation information measures behave very differently, despite their common mathematical roots described by Ginebra (2007).
Other important design approaches for model discrimination include the -optimal designs introduced by Stigler (1971) and Studden et al. (1980), and the -optimal designs introduced by Atkinson and Fedorov (1975a) and Atkinson and Fedorov (1975b). The former approach focuses on nested models and the latter on the squared differences between mean functions, and both differ somewhat to our more general framework. The KL-optimality criterion of López-Fidalgo et al. (2007) is closely related to the likelihood ratio test and therefore some specific measures falling under our framework, though we principally consider the Bayes factor. Connections between T-optimal, -optimal, and KL-optimal designs have been established by a number of authors including Dette et al. (2009) and López-Fidalgo et al. (2007). However, connections between designs for estimation and these model discrimination designs are rarer, partly because optimal designs for the distinct goals of estimation and model discrimination are usually different.
A key limitation of designs optimized for distinguishing between a set of models is their inherent sensitivity to these hypothesized models. In particular, if none of the hypothesized models reasonably capture reality, then the design selected by any model-based measure can be seriously sub-optimal. Furthermore, designs for model discrimination tend to have only a small number of unique design points and therefore model checking beyond the intended discrimination can be difficult, e.g., it may not even be possible to estimate the parameters of the hypothesized models under the optimal design, see for instance Dette et al. (2009). These issues are almost unavoidable and can perhaps only be mitigated by generic space filling designs sometimes used in estimation scenarios for similar reasons, with the familiar trade-off between robustness and efficiency. With that in mind, test information measures are valuable design tools when scientific investigations are of a confirmatory nature, meaning that there is some reason to believe that the proposed models adequately capture accepted scientific phenomena (physics is one area where this quite often holds). In summary, the information measures we propose are beneficial whenever an investigator seeks to compare several reasonable competing models.
Our paper is organized as follows. The remainder of Section 1 gives three categories of scientific problems where test information measures are useful, briefly reviews the estimation information framework proposed by DeGroot (1962), and discusses the parallels with the test information measures introduced by Nicolae et al. (2008). The main body of the paper is divided between Sections 2 and 3, which deal with expected and observed test information, respectively. These sections finish with illustrations of the practical use of test information in design and sequential design for decision problems, respectively. Section 2 also introduces a fundamental symmetry condition that defines an appealing class of test information measures. Section 4 presents our main result linking test and estimation information. In Section 5 we apply our approach to a problem in astronomy, and Section 6 concludes with discussion and open challenges.
1.2 Uses of test information
We now describe three experimental design problems, representing broad categories of scientific questions.
Classification and model selection. In astronomy, the intensity of some sources (e.g., Cepheid stars) varies periodically over time, thus creating a continuous function of time called a lightcurve. Such sources can be classified by features of their lightcurves, e.g., the period or characteristic shape. Since telescope time is limited for any group of researchers, the lightcurve of a source is observed at a number of time points and then a classifier is applied. For example, some modern techniques use random forest classifiers, e.g., Richards et al. (2011) and Dubath et al. (2011). Intuitively, given some lightcurve observations, the design problem is to pick the time of the next observation that will maximize the probability of correct classification.
Screening and follow-up. In genetic linkage studies it is of interest to test if markers (or genes) located close together on the same chromosome are more likely to be inherited together than if markers are inherited independently (the null hypothesis). This is a screening process because the magnitude of the linkage (i.e., dependence) is ultimately of interest. In the case of too much missing information, a follow-up study could choose between increasing the number of markers in potential regions of linkage or collecting samples from additional individuals. To assess which option is likely to have greater power, for example, we must take the models under the two hypotheses into account, as studied in Nicolae and Kong (2004) and Nicolae et al. (2008).
Robust design. Test information measures can also be useful in applications at the interface of testing and estimation. In chemical engineering, it is often of interest to estimate the mean yield of a product under different conditions, and ultimately to model the yield. In this situation, space filling designs are usually preferred because it is unknown where the regions of high (and low) yield will be. However, space filling designs can vary in their efficiency for distinguishing specific models, and test information measures can be used to select the ones that best separate important candidate models.
1.3 Bayesian information for estimation
We briefly review the framework of DeGroot (1962) to help make clear both distinctions and parallels between test and estimation information. Suppose that we are interested in a parameter and our prior distribution is . Information about is gained through an experiment whose future outcome is , the set of possible outcomes of the experiment. For example, may specify the design points at which data are to be collected. We denote by a measure of the expected information to be gained by conducting . The measure should have basic properties such as non-negativity and additivity. To specify the meaning of additivity we need the notion of conditional information: if is an experiment composed of two sub-experiments, then we denote by the expected conditional information to be gained by conducting after conducting , i.e., the expected new information that will be gained from . Additivity can now be formalized.
Definition 1**.**
An information measure is additive if, for any composite experiment and any proper prior , the following relation holds
[TABLE]
DeGroot (1962) chose to be the difference between the prior uncertainty and the expected posterior uncertainty about . He defined the prior uncertainty to be , where the uncertainty function is a concave functional of , i.e., for any two densities and and . Similarly, DeGroot (1962) defined the expected posterior uncertainty to be , where the expectation is with respect to . Thus, we have the following.
Definition 2**.**
The expected Bayesian estimation information provided by an experiment , under a proper prior , is
[TABLE]
Lindley (1956) suggested should be the entropy function given in (1). DeGroot (1962) showed that (3) satisfies non-negativity for all priors and experiments if and only if is concave. To generalize further, we follow the logic of Definition 2 and define the expected conditional estimation information contained in the second of two sub-experiments as
[TABLE]
where , and is the outcome of , . The desired additivity then follows trivially by definition. However, it is not generally true that , even when and are independent.
1.4 Test information measures proposed by Nicolae
et al. (2008)
For the sharp test hypotheses and , Nicolae et al. (2008) (implicitly) proposed the very natural frequentist expected test information measure
[TABLE]
where the superscript indicates the testing context, and
[TABLE]
is the likelihood ratio. We observe that (5) is the Kullback-Leibler (KL) divergence between the data models and , and thus it is closely connected to the entropy based measure proposed by Lindley (1956). (The KL divergence between two densities and , will be denoted , and is defined as , where the support of is assumed to be a subset of the support of .) Nonetheless, there is a good reason why Nicolae et al. (2008) did not simply use Definition 2 to construct measures of test information; namely, it does not take the hypotheses into account. Indeed, the presence of the two parameter values, and , in (5) clearly distinguishes test information from the estimation information we have considered so far. This difference makes intuitive sense because it represents the difference between gaining evidence for distinguishing two hypotheses and neutrally gaining knowledge about the parameter.
In practice, the alternative hypothesis is often composite and in the Bayesian context we then write , for some prior . One of the Bayesian measures of expected test information (implicitly) suggested by Nicolae et al. (2008) is
[TABLE]
Variance and entropy are both measures of spread and hence (7) is also connected to the measure proposed by Lindley (1956), although no logarithm is taken in (7). The key distinction with Definition 2 is again due to the appearance of the null hypothesis . In summary, these examples have connections with the estimation information measures reviewed in Section 1.3, but also have common features distinguishing test information from estimation information. Based on these parallels and distinctions, the next section proposes our general framework for constructing test information measures, which is summarized in the grey box on the left of Figure 1.
2 Expected Test Information: Theory and Applications
2.1 Test information: a synthesis
The two key properties of expected information measures are non-negativity and additivity. For simplicity, we develop our framework in the case of continuous densities and the Lebesgue measure. Theorem 2.1 of DeGroot (1962) establishes non-negativeness of the estimation information reviewed in Section 1.3. Writing the marginal density of as , the key formula underlying the theorem is
[TABLE]
That is, the expected posterior density with respect to the marginal density is the prior density. To see the corresponding key identity for hypothesis testing, we first observe that the expected test information (5) uses the likelihood ratio as the fundamental statistic for quantifying the information for distinguishing two values of . More generally, the hypotheses may be composite, say and , in which case we turn to the Bayesian perspective and replace the likelihood ratio with the Bayes factor
[TABLE]
where , for . (We assume throughout, for .) Thus, for hypothesis testing, the analogous formula to (8) is
[TABLE]
That is, the expected Bayes factor (or likelihood ratio), under the alternative, does not favor either hypothesis. For simplicity, we assume here and throughout that the support of is for all . Equation (10) allows us to apply Jensen’s inequality to ensure that the general expected test information given in Definition 3 (below) is non-negative. For test information, the parallel of the uncertainty function is the evidence function , which acts on the positive real numbers and in particular has the Bayes factor (or likelihood ratio) as its argument. The use of Jensen’s inequality to ensure non-negativity requires that the evidence function is concave, and we therefore assume concavity throughout. Note that what is measured by the evidence function is the evidence in support of the null hypothesis, and therefore, like DeGroot (1962), we are interested in a reduction, i.e., a reduction in the evidence supporting the null hypothesis.
Definition 3**.**
Under , the expected test information provided by the experiment for comparing the hypotheses and , for a given evidence function and a proper prior , is defined as
[TABLE]
where .
The prefix “expected” is necessary because the Bayesian approach generally assumes that data have been observed. Note that (11) is mathematically equivalent to the frequentist measure
[TABLE]
when and , for . (The frequentist perspective is also recovered if the prior is viewed as part of the data generating model.) Under (12), the measure (5) is given by choosing . The mathematical equivalence of Bayesian and frequentist measures of expected test information means that we can interchange the Bayes factor in (11) and the likelihood ratio as convenient. More generally, the Bayes factor in (11) can be replaced by any numerical comparison of the hypotheses, at least if the baseline is also adjusted. However, the main focus here will be on the Bayesian perspective because it is statistically coherent and is conceptually well suited to incorporating composite hypotheses (and nuisance parameters, see Section 2.3) when no data have been observed, as is often the case when we choose a design. We retain the argument in our notation as a reminder that (11) does depend on the prior , which we should therefore choose carefully, as with the specification of any part of our models. Also note that the parameter in Definition 3 can simply be a model indicator and hence our framework goes beyond parametric models.
The final term of (11) is the -divergence introduced by Csiszár (1963) and Ali and Silvey (1966), which generalizes KL divergence. Indeed, as mentioned in Section 1.4, the measure (5) is a KL divergence. The properties of KL divergence alert us to the important feature that expected test information is not necessarily symmetric in the two hypotheses. A class of evidence function that treat the hypotheses equally will be introduced in Section 2.2.
The baseline term ensures non-negativity of expected test information, and has common intuitive appeal because it represents no evidence for either hypothesis. Note that we have chosen a baseline that does not incorporate investigator specific quantities such as the frequentist size of a particular test, because a general information measure should appeal to many different researchers. Information measures with general appeal are typically maximal information measures, for example, Fisher information measures the maximal estimation information asymptotically available. Our test information measures are also implicitly maximal since they are functions of only the prior probabilities and Bayes factor (or likelihood ratio), which contain all the relevant information. For example, the KL divergence in (5) uses the expected log likelihood ratio to quantify the maximal probabilistic information for distinguishing the hypotheses, and leaves the choice of a specific decision rule to individual investigators.
From this point on, we will frequently write to mean and for similar notation will again drop the arguments after the semicolon when this causes no confusion. We complete our initial development of test information by specifying the form of , which is easily deduced from the expected conditional estimation information (4).
Definition 4**.**
The expected conditional test information provided by conducting the experiment after is
[TABLE]
where , for and .
That (13) is non-negative is again a consequence of Jensen’s inequality:
[TABLE]
where, to make the expressions easier to read, we have denoted the observed data by lower case letters, and unobserved data by upper case letters. Given Definition 4, the additivity property of Definition 1 holds trivially, i.e., .
2.2 Symmetry class and a probability based measure
The best choice of will to some extent depend on the particular context (see Section 4 for some theoretical guidance), but here we propose a class of evidence functions that have appealing properties. The class is those evidence functions that treat the hypotheses symmetrically and in particular satisfy the condition
[TABLE]
Naturally, represents the evidence for the alternative, since the roles of and have been swapped. Thus, setting , the symmetry condition (15) states that our choice of should preserve the Bayes factor. We include the arguments and in (15) because in general the evidence measures may be allowed to depend on the order of the hypotheses through prior probabilities as well as through the Bayes factor.
The symmetry condition (15) implies that the resulting expected test information measure satisfies the fundamental coherence identity
[TABLE]
The right hand of (16) swaps the hypotheses, indicating that the dual expected test information measure takes an expectation with respect to , rather than . Indeed, the dual test information measure quantifies the reduction in evidence for the alternative when data are collected under the null. The coherence identity (16) states that, before we observe any data, the expected amount of information in the data for distinguishing the two hypotheses is the same regardless of which is in fact true. This symmetry is intuitive because the probabilistic separation of the two marginal data models and should not depend on which hypothesis is true. This coherence requirement saves us from guessing which hypothesis is true when designing optimal experiments.
We can go further and consider what specific evidence functions satisfying (15) are particularly appealing. We want our evidence function to be probability based because hypothesis testing is fundamentally about seeking probabilistic evidence, usually in the form of *p-*values or posterior probabilities. Indeed, for the purposes of test information, the traditional estimation information focus on variance and spread is in general inadequate. From the Bayesian perspective, a sensible probability based evidence function is
[TABLE]
where and are the prior probabilities of and , respectively (for simplicity we assume ). When , (17) is just the posterior to prior probability ratio for . The resulting dual expected test information measures are
[TABLE]
where denotes the Bayes factor . The measure (18) is simply the expected difference between the prior and posterior probability of the null, relative to the prior probability, when the data are actually from the alternative. That is, (18) constitutes the relative loss in probability of the null. The measure (19) is the same but with the roles of and switched. Since (15) is satisfied, the coherence identity (16) tells us that . This and the straightforward Bayesian probability interpretation of (18) make (17) a particularly appealing choice of evidence function.
There are also other examples of evidence functions that satisfy (15), e.g.,
[TABLE]
For this evidence function, both sides of (16) equal . Historically, this symmetrized form of KL divergence is the divergence that Kullback and Leibler (1951) originally suggested (without scaling by a half). Intuitively, it can be interpreted as a measure of the expected test information when the two hypotheses are considered equally likely apriori. However, symmetrized KL divergence does not have a straightforward probability interpretation, and therefore we prefer (17)-(19).
2.3 Nuisance parameters
Many statistical problems come with nuisance parameters. In the frequentist setting, once data have been observed, estimates of the nuisance parameters can be inserted to give a point estimate of the expected test information (12). A confidence interval for (12) can be obtained by evaluating it for values of the nuisance parameters within a confidence interval. (Both could instead be done for observed test information, see Section 3.1.) In design problems, data are typically yet to be collected but (12) could be evaluated on a grid of values of the nuisance parameters.
In the Bayesian context, the nuisance parameters (under the null) and (under the alternative) are simply integrated out along with the parameters that define the hypotheses. That is,
[TABLE]
where the Bayes factor is now given by
[TABLE]
with being the support of the prior density of , for . Clearly, the mathematical properties of (21) are the same as those of (11).
As mentioned in Section 2.1, alternatives to the Bayes factor in Definition 3 can be used at the expense of the coherence of the Bayesian method and simplicity. For example, those intending to use the likelihood ratio test, may opt to mimic the likelihood ratio test statistic by calculating
[TABLE]
where \theta^{\text{\tinyH_{i}}}_{\text{\tiny MLE}} and are the MLEs of and , respectively, under hypothesis , for . In this work we focus on the expected test information given in Definition 3 (and (12)) and thus leave the theoretical investigation of measures such as (23) for future work. However, we include numerical results based on (23) in Section 2.4.
2.4 Probit and complementary log-log regression example
Consider the binary regression model
[TABLE]
where
[TABLE]
is the design matrix (i.e., essentially ), and , for the link function and . The sharp hypotheses of interest are and , where and are the familiar complementary log-log and Probit link functions, respectively ( is the standard Normal cumulative distribution function). In this model selection scenario, the coefficients and are nuisance parameters, and we assign the prior distribution
[TABLE]
for , with and to be determined. Our independent prior for is Bernoulli. The design problem is to choose the design which will provide the most information for distinguishing between the two link functions. Ponce de Leon (1992) previously considered a similar problem but formulated it as an estimation design problem by parameterizing a continuum of models between the logistic and complementary log-log binary regression models, as for example in McCullagh and Nelder (1989), page 378.
We consider designs of 5 unique points in with 100 replications of each. Within this class, we optimize the expected test information under the posterior-prior ratio and log evidence functions, i.e., (17) and . Since and are nuisance parameters, we use the two measures in Section 2.3, i.e., the Bayes and MLE plug-in approaches. Under the posterior-prior ratio evidence function, we denote these two measures by and , respectively. Similarly, under the log evidence function the two measures are denoted and , respectively. The notation indicates a design criterion, indicates a connection to the expected posterior probability of , given by , and indicates the testing context and the KL divergence between the marginal data models. The criteria are computed using Monte Carlo simulation and the optimal design under each criterion is found using a single point exchange algorithm similar to that introduced by Fedorov (1972). The design matrix optimizing criterion is denoted , for , collectively called the P-optimal and TK-optimal designs.
We need a separate criterion by which we can evaluate and compare the optimal designs. Since power is a common quantity of interest, we choose the criterion to be the prior mean power of the likelihood ratio test, i.e.,
[TABLE]
where , and denotes the power of the likelihood ratio test under design matrix and given the parameters and (for a test size of 5%). Section 6.2 discusses reasons why (27) or similar summaries of power are not the only measures of expected test information, or even particularly good measures. Nonetheless, the relative familiarity of (27) makes it suitable for our current purpose of comparing the performance of the different optimal designs. Figure 2 shows the prior mean power under , for , given various specifications of the priors in (26). In all cases the covariance matrix and only and are indicated. Note that we tried several values of but the results were qualitatively very similar, so Figure 2 only shows results for .
Also shown is the prior mean power under and , the maximum prior mean power design and the spread of points (replicated 100 times), respectively. The P-optimal and TK-optimal designs all perform well in terms of prior mean power, and in some cases yield considerably greater prior mean power than . For example, when and (left panel of Figure 2), the design has prior mean power while the P-optimal and TK-optimal designs are all relatively close to achieving the maximum prior mean power of . The problem with in this case is that both inverse link functions practically go from 0 to 1 over a small range of the covariate and therefore spreading the design points over the whole interval is not an effective strategy.
To investigate the designs further, Figure 3 compares and . In each plot, the design is given by the x-coordinates of the large dots (100 binary observations are recorded at each). In this illustration, 500 datasets were simulated under each design with and . For reference, the Probit (dotted blue line) and complementary log-log (dashed green line) inverse link functions are plotted for . However, since , the actual value of and vary across the simulated datasets. Furthermore, for any given dataset, there is uncertainty associated with the MLE of and . These two sources of variation are captured by the spread of the solid thin grey lines in Figure 3; each corresponds to a single simulated dataset and traces the fit difference for , where are the MLEs of for dataset , for and . The distribution of the fit differences at any point indicates our ability to distinguish the two inverse link functions at that point based on maximum likelihood fits. The solid thick red line summarizes by tracing the relative mean fit difference , where and are the mean and standard deviation of over 500 simulations, respectively.
The y-coordinates of the large dots give the values of at the design points (as do the numbers below the large dots). As expected, is generally small at the design points, but for the variability in is low and thus is larger at the design points than under . The low variability is achieved by grouping the design points together near the important steep section of the reference inverse link functions. The complementary log-log and Probit regression models fit by maximum likelihood are known to differ principally in the tails, and hence is not largest at the design points in the central steep section. However, these points constrain the fits, thus reducing variability in so that the two design points in the tails have large values of . The designs and are almost identical to , which is to be expected because intuitively the prior mean power should increase as the expected negative log Bayes factor (or likelihood ratio) increases.
2.5 Normal linear regression coefficient tests
We now discuss the Normal linear regression model
[TABLE]
and the hypotheses and . The goal is to test the adequacy of a specific value of the regression coefficients, rather than treating them as nuisance parameters as we did in Section 2.4. Thus, is now playing the role of in the expected test information of Definition 3, and formally we restrict its support under to be . We again consider the criteria and which, since there are no nuisance parameters, are now simply given by Definition 3 under the posterior-prior ratio and log evidence function, respectively.
In the linear regression setting, has the closed form
[TABLE]
The first term of (29) confirms our intuition that the expected test information is large when and the mean of the alternative are well separated (with respect to ). Heuristically, the second term of (29) tells us to maximize the “ratios” of the prior (alternative) variance of each parameter to the regression estimate variance. This is intuitive because we need the estimation variance to be small in comparison to the prior variance in order to effectively distinguish and (and hence further distinguish from ). The final term penalizes the alternative for introducing uncertainty in , i.e., for avoiding exclusion of the true model by being vague.
The TK-optimality criterion (29) is closely related to the D-optimality criterion popular in estimation problems (e.g., see the review by Chaloner and Verdinelli 1995). The D-optimality criterion is derived from the expected estimation information suggested by Lindley (1956), and is given by
[TABLE]
where is the posterior covariance matrix of (for any value of ). The criteria and are both entropy based, but the dependence of on and distinguishes this criterion from and other estimation focused criteria.
To gain some intuition, let us consider a simple linear regression with
[TABLE]
In this scenario, it is well known that the D-optimal design places half of the design points , , at and the other half at (or, if is odd, points at one boundary and at the other). Let , where and are the mean intercept and mean slope of the alternative model, respectively. If , then the sign of tells us if the lines and have greater separation at or at . For any , it is easily shown that is optimized by placing all points at if , by placing them at if , and by any design dividing the points between the boundaries if . Generally, designs based on test information measures trade robustness for power in distinguishing particular models, and the behavior just described is an instance of the inevitable sensitivity to the hypotheses mentioned in Section 1.1. However, in the current context, we found that designs optimizing are slightly more robust than those optimizing in that they divide the points between both the boundaries, unless the hypotheses are far more separated at one boundary than at the other.
3 Observed Test Information in Theory and Applications
3.1 Observed test information: building blocks
Observed test information is key in practice when we observe some data and wish to know how much information they contain in order to decide if we should collect more. It is also important conceptually because it is the implicit building block for expected and conditional test information.
Consider the setting in Section 1.3. After an experiment is conducted, the observed estimation information gained is the reduction in uncertainty, , where is the observed outcome. Observed estimation information is not necessarily non-negative because, by chance, after observing we may have more uncertainty about as measured by , e.g., the posterior may be more diffuse than the prior due to likelihood-prior conflict; see Reimherr et al. (2019). (This posterior “dilation” can even be deterministic; see Seidenfeld and Wasserman (1993).) DeGroot (1962) did not explicitly mention observed information, but Lindley (1956) did define it (as above) when is the entropy function (1). Ginebra (2007) restricted all observed information measures to be non-negative and asserted that this allows them to be interpreted as capturing model checking information, in addition to information about . However, Ginebra (2007) did not explain why adding a non-negativity condition is necessary or sufficient to ensure that a model checking interpretation is reasonable. From a Bayesian perspective, the definition given by Lindley (1956) is valid, and we therefore take this as the basis of observed estimation information.
Following Lindley (1956), we define observed test information in Definition 5 (below) by simply removing the expectation appearing in the expected test information of Definition 3. However, the resulting relationship between observed and expected information is more subtle than in the estimation case. Indeed, Definition 3 conditions on to average over the unobserved data, but the actual data used in Definition 5 may be generated under .
Definition 5**.**
The observed test information provided by the experiment for comparing the hypotheses and , for a given evidence function and a proper prior , is defined as
[TABLE]
where is the observed outcome of , and .
Since Bayesians condition on observed data, the prefix ‘observed’ is redundant, but it is retained for clarity. The quantity defined by (32) is not necessarily non-negative. However, it is positive when is increasing and the Bayes factor favors , i.e., . Often, it seems sensible for to be increasing because we want (32) to increase as the Bayes factor decreases towards zero (since observed test information should be compatible with Definition 3 which assumes ). For increasing, a negative value of indicates that the evidence in the observed data supports , either because is in fact the more accurate hypothesis or due to chance. Since the data can support only one of the hypotheses, for increasing it follows that exactly one of the dual observed test information measures and will be positive (unless they are both zero). Also, usually only one of and will reasonably approximate the corresponding expected test information, and , respectively.
We highlight that, in the current observed data case, our use of dual measures is again key because it ensures a symmetric treatment of the hypotheses, which is not easily achieved by other means. For example, consider a that is concave, increasing, and passes through (for all non-zero prior probabilities and whose sum is one), then is also concave, it gives expected test information , and yields non-negative observed test information, as required by Ginebra (2007). However, in many cases, excluding the case of (20), this approach does not treat the hypotheses equally. For example, we can modify the evidence function to , but the resulting observed test information has a maximum of one for data supporting , and is unbounded for data supporting . Our approach using dual observed test information measures is therefore more appealing because and are symmetrically defined.
Next, in the same spirit, we define the observed conditional test information from experiment after observing of experiment to be
[TABLE]
This is simply the information given in Definition 4, but without an expectation over . In sequential design we require a version of the coherence identity (16) to hold for (33). In particular, given some observed data , we want the optimality of our design to be free of the validity of hypothesis or . The symmetry condition (15) implies that
[TABLE]
for all , where . The factor appears in (34) (but not in (15)) because the observed data already favors one of the hypotheses before any new data are collected. If (34) holds, then a design that optimizes (32) also optimizes . Hence we do not need to know which hypothesis is true when choosing .
3.2 Sequential design for linear regression coefficient tests
Consider the linear regression model (28) introduced in Section 2.5 and the test of against (i.e., ). Given some initial observed data , the sequential design problem is to choose a design matrix for additional data . In our simulation study, we generate a parameter vector under and then simulate the initial observed data according to a cubic regression model of the form (28), i.e., the design matrix is
[TABLE]
where are the design points, for . Specifically, we set and the observed data design points , , are ,, [math], , . Examples of are plotted in Figure 4.
Given the observed data, new design points are chosen by optimizing the observed conditional test information (33) with respect to the design matrix , under the posterior-prior ratio and log evidence functions. That is, we optimize the conditional versions of the P-optimality and TK-optimality criteria discussed in Section 2.5. The conditional P-optimality criterion is the expected reduction in posterior probability of the null when we collect relative to its prior probability. We approximate it using a Monte Carlo estimate, under the prior probabilities . The conditional TK-optimality criterion is straightforwardly given by , where is specified in (29), and and are the observed data posterior mean and covariance matrix of under , respectively. For comparison, we also optimize the (deterministic) conditional D-optimality criterion with respect to . Often it is not clear how to use the D-optimality criterion and other estimation based criteria to choose designs for testing, but the current scenario is an exception because the hypotheses are nested.
To generalize beyond a single value of , we generate , for , and for each we generate observed datasets , for . Then, for each simulated dataset , we find the conditional P-optimal, TK-optimal, and D-optimal design for the missing data . To compare performance, we also calculate the prior mean power (27) of the likelihood ratio test under each of these three procedures. In our simulations, we set , and use various values of and . First, Figure 5 part (a) corresponds to simulations with and , i.e., the alternative mean model is parabola shaped. For these choices, the maximum separation between the null and true model is usually not at the boundaries of the interval ; see the example simulation given on the left of Figure 4. The top row of Figure 5 shows the prior mean power of the three procedures when all design points in are allowed (i.e., is unconstrained) and also when only two possibilities for are allowed (these latter results are for the constrained optimization example discussed shortly). For part (a), the conditional D-optimal procedure performs relatively poorly because it places all the new points at the boundaries, a good strategy for estimation but not for the current hypothesis test. The conditional P-optimality and TK-optimality procedures instead place the points near , and consequently are substantially superior in terms of prior mean power.
For the simulations corresponding to Figure 5 part (b), we generated and , and then set and drew , for . Under these settings, the maximum separation between the null curve and the observed data posterior mean fit tends to be at one of the boundaries, and therefore the conditional D-optimality procedure performs reasonably. Thus, in part (b) of Figure 5 the three procedures perform similarly.
We now briefly investigate how the three criteria perform if we impose some robustness to model misspecification. The points labeled “constrained” in the first row of Figure 5 show the prior mean power of the likelihood ratio test when the three criteria are used to choose between two missing data designs: (i) the spread of points ; (ii) the narrower spread of points , where is the location of maximum separation between the observed data posterior mean model and the null mode. If is near a boundary then all the points are shifted left or right to avoid any crossing the boundary, but they still cover an interval of length 0.4. The results follow a similar pattern to before, except that now the prior mean power is usually lower, principally because designs placing all the points at a single location have been excluded. The first row of Figure 5 shows that the constrained conditional P-optimality procedure has prior mean power almost as high as the constrained conditional TK-optimality procedure, but the second row indicates that it also selects the more robust design (i) far more often (usually when the posterior probability of is low). Thus, the conditional P-optimality procedure offers a compromise between power for distinguishing the hypotheses of interest and robustness.
4 Links between Test and Estimation Information
4.1 Fraction of observed test information
Nicolae et al. (2008) proposed several measures of the fraction of observed test information to guide data collection decisions in genetic studies (see Section 1.2). We provide the general mathematical form in Definition 6 (below) because the fraction of observed test information is important in sequential design and for establishing theoretical connections between test and estimation information.
Definition 6**.**
The fraction of observed test information provided by the first part of the composite experiment for comparing the hypotheses and , for a given evidence function and a proper prior , is defined as
[TABLE]
where is the observed outcome of , and .
If , then it follows that (36) is between 0 and 1. In practice, if is close to one then we may decide not to perform , particularly if it is expensive. The canonical example sets and thus takes the ratio of the observed data log Bayes factor and the expected complete data log Bayes factor. Similarly, in the frequentist case, Nicolae et al. (2008) suggested the measure
[TABLE]
where is the MLE of based on .
The decision whether to collect more data depends on which hypothesis is true, because if the observed data supports the false hypothesis then our need for additional data is greater. Thus, it is unsurprising that there is no general coherence identity for the fraction of observed test information. In practice, we suggest using if and otherwise. The resulting measure has a similar interpretation as (36) but takes account of which hypothesis is more likely, and is always between [math] and . In the special case where (and (15) is satisfied), we have , but this is not a coherence identity since the corresponding observed test information is negative on one side of the equality and positive on the other.
4.2 Connections between estimation and test information
Meng and van Dyk (1996) showed that the relative augmentation function
[TABLE]
converges to the fraction of observed Fisher information
[TABLE]
as . Here, is the usual observed Fisher information, and is the missing Fisher information given by
[TABLE]
As Nicolae et al. (2008) mentioned, replacing with gives us the same limit for the measure in (37). This result is intuitive in that we might expect test information to coincide with estimation information when the two hypotheses are both very close to . The following theorem generalizes the equivalence, and its proof is given in Appendix A.
Theorem 1**.**
Let the hypotheses be and , and suppose that the derivatives of the evidence function exist at 1. Then, for univariate and , we have
[TABLE]
under the uniform integrability condition given in the proof in the Appendix.
It is possible to extend Theorem 1 to avoid the univariate condition and sharp hypotheses (by using priors that converge to delta functions), but the current form suffices to illustrate the connection between test and Fisher information. The theorem tells us that if , then will exactly correspond to as . Otherwise, the relative conversion number indicates how much of the missing data estimation information is converted to test information in the limit, relative to the conversion of observed estimation information. For example, under the posterior-prior ratio evidence function (17) we have , and therefore the stronger our initial bias in favor of the null, the greater the importance of the missing data estimation information, relative to the observed estimation information.
This makes sense because Fisher information measures our ability to estimate the true parameter, and the value of successful estimation for testing depends on the strength of our prior separation of the hypotheses. If , then all estimation information will be helpful because the prior does not separate the hypotheses, hence and the fraction of observed test and estimation information coincide. When is close to [math], the posterior probability of (the hypothesis assumed true by Definition 6) will be close to one, even though the observed data provides no evidence. Thus, we have , because there is little to be gained by collecting more data. When is close to , the prior is in conflict with our assumption that is true, and therefore estimation information from new data not only has the potential to distinguish the hypotheses, but also to overcome misleading information from the prior. Hence, when is close to , the value of estimation information is inflated in the testing context, and we expect . In the current example , meaning that indeed , as anticipated, when is close to .
The relative conversion number has similar interpretations for other evidence functions. In each case it indicates the relative worth of the missing data estimation information for testing, when there is no evidence in the observed data. Thus, provides a characterization of the general approach to testing implied by the evidence function, i.e., whether we would be likely to collect additional data if the observed data does not separate the hypotheses.
5 Follow-up Observations of Astronomical Lightcurves
We now demonstrate how our methodology can be used to schedule follow-up telescope observations in order to better distinguish two subclasses of RR Lyrae stars. RR Lyrae stars pulsate, which leads to periodic changes in their brightness, and they are important objects because they allow astronomers to calculate distances to other galaxies and within our own galaxy. Our dataset consists of 200 RRab and 200 RRc lightcurves from the Catalina Real Time Transient Survey (CRTS), see Drake et al. (2009) and Drake et al. (2014). A lightcurve is a time series recording the brightness of a star over time, and different characteristic lightcurve shapes are associated with each type of star. The left panel of Figure 6 shows templates we constructed for RRab and RRc lightcurves from a large training dataset again from CRTS. The templates are plotted in phase space because the lightcurves of RR Lyrae are periodic (up to observation noise). The full CRTS catalog is available at http://crts.caltech.edu/.
Our dataset consist of 400 lightcurves, each with between 62 and 499 observations. Through initial screenings, we can assume they are either RRab or RRc. Given a statistical model for the two types, we can compute the posterior probability that a lightcurve is RRab. Sometimes the posterior probability will be close to 0.5 or favor the wrong lightcurve type (here we know the true types for practical purposes because experts have inspected each lightcurve individually and taken additional information into account). It is therefore of interest to know what follow-up observation times would allow us to better identify the true class. In practice, telescope time is limited and so we suppose that for each lightcurve there are 3 possible follow-up observation times to choose from. We will choose using our probability based information measure, which uses the evidence function (17), and make comparisons with several other methods.
First we describe the lightcurve model. The templates in the left panel Figure 6 are mean lightcurve shapes and therefore we expect deviation from these shapes in actual observations due to both variability in the underlying lightcurve shapes and observation noise. To account for these sources of variability we model each lightcurve as a Gaussian process (GP) with the mean being the appropriate template and a nugget or additional variance term to account for observation noise. Specifically, let be the magnitude (brightness) observations for source , with corresponding observation phases , for . We use observation phases rather than times because for the lightcurve in our dataset it is possible to estimate the period accurately so we treat the period as known. If is the lightcurve period, then the phase at time is given by . (Note that sometimes period information alone can distinguish between types, but this is not always the case for RRab and RRc stars, which motivates our investigation.) Under class , we model the lightcurve observations by the GP
[TABLE]
where is a vector whose entries are the values of the template for class at the phases given by , and is an covariance matrix, for . The parameters and center and scale the lighcurve template. Let , for , be disjoint phase bins on which we assume fixed nugget terms , for . We then decompose as , where
[TABLE]
and is a diagonal matrix with diagonal entry given by , where is such that . For simplicity and computational reasons, for each lightcurve we find an initial estimate of the alignment and noise parameters , and then treat these parameters as known. However, the GP parameters are nuisance parameters to be fitted. We use a Laplace approximation for the observed Bayes factor (see (22)), where and .
At each stage , for each lightcurve , we randomly generate 3 phases , for follow-up observations and select one of them using four different methods: (i) an oracle method, (ii) the conditional test information under the probability based evidence function (17) (with ), (iii) the entropy based method of Box and Hill (1967), and (iv) random selection. The oracle method selects the observation phase that results in the highest expected posterior probability for the true class (which is otherwise treated as unknown). We use Monte Carlo approximations to perform the averaging needed for methods (i)-(iii). After choosing a future phase under each method, the follow-up observations at the new phases are simulated under the model described above, with set to the true class. We repeat this process for stages . At each stage, the simulations of the new observations are performed conditioning on the initial lightcurve and the data points collected up to that stage under the oracle method.
For the initial lightcurves, 61 of the 400 stars were misclassified when assigning them to the class with the highest posterior probability. In this example the stars that were initially correctly classified were still correctly classified when follow-up observations were collected, so for the purposes of evaluation it makes sense to focus on only the initially misclassified ones. The right panel of Figure 6 shows the number of the 61 misclassified lightcurves that were correctly classified at each of the 100 follow-up stages under each of the four scheduling methods. The random method performs worst because the dash-dot line is below the other lines at most stages, meaning that to achieve a given number of correct classifications the random method generally requires more follow-up observations. The oracle method (solid line) unsurprisingly performs the best, and our test information approach (dashed line) performs very similarly. In fact, our probability based test information should theoretically match the oracle method, due to the coherence identity (34), which ensures we do not need to know the true class to choose the optimal strategy. The discrepancy seen in Figure 6 is due only to numerical inaccuracies, i.e., we use a Laplace approximation to our test information under the null and under the alternative, but the two do not exactly match. The entropy method of Box and Hill (1967) (dotted line) performs better than the random approach but not as well as our test information. In Section 6 and Appendix B, we provide conceptual reasons to expect our information to offer improvement over the entropy method.
6 Discussion and Further Work
6.1 Philosophical considerations
Box and Hill (1967) proposed maximizing the change in the expected entropy of the posterior distribution on the model space. In the current context, their criterion is given by
[TABLE]
where is the design point, and is the posterior probability of , given the data (collected at the design point ). Importantly, the expectation in (43) is taken with respect to , where is the conditional probability density function of , given the hypothesis and the design point , for . A limitation of this approach is that there is an inconsistency in taking the expectation with respect to , which averages over the two hypotheses, because in most scientific scenarios it is assumed that only one of the hypotheses is true. From a Bayesian perspective, which assumes a distribution on the unknown true hypothesis, maximizing (43) is the right approach. However, the hypothesis testing questions posed in science are not Bayesian, and therefore optimizing (43) can lead to sub-optimal decisions. For example, it is possible to construct a situation where (43) favors one design but another design is uniformly better in terms of the probability of coming to the right conclusion (even if the conclusion is to be drawn based on the posterior probability of each hypothesis). See Appendix B for an example, which is somewhat contrived, but nevertheless proves the existence of this phenomenon.
Our information criteria avoid the above issue by exploiting the fundamental coherence identities given in (16) and (34), which allow us to average over the future data while conditioning on only one hypothesis and then make use of the symmetry between the hypotheses. In the application in Section 5, our probability based information criterion performs somewhat better than the Box and Hill (1967) criterion, and chose the same design points as the oracle method more often. It is possible that this superior performance is due to the use of the coherence identities to avoid the issues seen in Appendix B, though more investigation is clearly needed.
6.2 Additional benefit
Our general framework can also help to rule out undesirable measures of test information. For example, the variance of the log Bayes factor is essentially a measure that Nicolae et al. (2008) rejected after some trial and error, but our framework will reject it immediately because the corresponding evidence function is not concave. Perhaps the most notable quantity ruled out is power, which has no easy quantification in the presence of composite hypotheses or nuisance parameters. The second major problem is that there is not an intuitive measure of observed power, and it is therefore difficult to see how sequential design decisions (e.g., stopping rules) can be based on power. A further fundamental difficulty is that power does not have the maximal information interpretation discussed in Section 2.1 because it incorporates an investigator-specific critical region.
6.3 Future work
A natural future step is to investigate how test and estimation information measures can be combined to find designs that are good for both testing and estimation. Some work has been done along these lines by Borth (1975) in the special case of the entropy approach taken by Lindley (1956) and Box and Hill (1967). However, in general, test and estimation information are not related simply, and therefore trying to directly find designs that are good for both testing and estimation may not be an effective strategy. Instead, we can divide up the design points and construct two designs, one that is good for testing and one that is good for estimation. The overall design, composed of all the design points, should then have reasonable properties for both tasks. Future work will explore this approach and investigate methods for setting the proportion of the design points to be allocated to each task.
Another key direction is to deal with more than two hypotheses, a scenario which often arises in classification contexts. In preliminary investigations, we have extended many of the concepts in this paper to multiple hypotheses by using one-versus-all comparisons, but more work is needed to demonstrate the utility of our framework in this more general setting.
Appendix A Proof of Theorem 1
A Taylor expansion of in gives
[TABLE]
where , and is the standard Taylor expansion remainder term. If we set , then becomes
[TABLE]
Next, for a sequence such that , we assume uniform integrability for the sequence . Then, inserting for in (44), setting , and taking an expectation with respect to , we obtain
[TABLE]
The result (41) then follows after taking the ratio of (45) and (46) and letting .
Appendix B Entropy criterion example
Suppose there are two choices for a design point , say and . Here we show that it is possible to construct an example such that
[TABLE]
where is the entropy based criterion of Box and Hill (1967) given in (43), is the data to be sampled under , is the true hypothesis, and the (47)-(50) hold regardless of whether or . In other words, there are situations where the criterion favors even though the posterior probability of is more likely to be greater than 0.5 under than under for at least one choice of , and at least as likely for the other choice of (see (51) and (48)). Furthermore, (49) and (50) convey that the expected posterior probability for the true hypothesis and our probability based information criterion, respectively, are also larger under , which lends further support to favoring .
Example. Suppose that , regardless of . Under , let the distribution of depend on as follows:
[TABLE]
Setting , , and , the inequalities (47)-(50) hold for , for , and holds for . The key to this example is that is small despite the fact that the only possibility for occurs when and . It is easy to construct a similar example using Normal distributions.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Ali and Silvey (1966) Ali, S. and S. D. Silvey (1966). A general class of coefficients of divergence of one distribution from another. Journal of the Royal Statistical Society. Series B (Methodological) 28 , 131–142.
- 2Atkinson and Fedorov (1975 a) Atkinson, A. and V. Fedorov (1975 a). The design of experiments for discriminating between two rival models. Biometrika 62 (1), 57–70.
- 3Atkinson and Fedorov (1975 b) Atkinson, A. C. and V. V. Fedorov (1975 b). Optimal design: Experiments for discriminating between several models. Biometrika 62 (2), 289–303.
- 4Berger et al. (2009) Berger, J. O., J. M. Bernardo, and D. Sun (2009). The formal definition of reference priors. The Annals of Statistics 37 , 905–938.
- 5Blackwell (1951) Blackwell, D. (1951). Comparison of experiments. In Proceedings of the Second Berkeley Symposium on Mathematical Statistics and Probability , Volume 1, pp. 93–102. Univ. of California Press.
- 6Borth (1975) Borth, D. M. (1975). A total entropy criterion for the dual problem of model discrimination and parameter estimation. Journal of the Royal Statistical Society. Series B (Methodological) 37 , 77–87.
- 7Box and Hill (1967) Box, G. E. and W. J. Hill (1967). Discrimination among mechanistic models. Technometrics 9 (1), 57–71.
- 8Chaloner and Verdinelli (1995) Chaloner, K. and I. Verdinelli (1995). Bayesian experimental design: A review. Statistical Science 10 (3), 273–304.