A fast tunable blurring algorithm for scattered data
Gregor Robinson, Ian Grooms

TL;DR
This paper introduces a linear-time, tunable blurring algorithm for scattered data that enhances data analysis and assimilation by effectively separating spatial scales in geophysical observations.
Contribution
The paper presents a novel, efficient blurring method based on Gaussian interpolation and multiresolution convolution, generalizing traditional algorithms to scattered data and enabling new applications.
Findings
Efficient linear-time algorithm for scattered data blurring.
Effective separation of large-scale and small-scale spatial components.
Potential to improve data assimilation and analysis in geophysics.
Abstract
A blurring algorithm with linear time complexity can reduce the small-scale content of data observed at scattered locations in a spatially extended domain of arbitrary dimension. The method works by forming a Gaussian interpolant of the input data, and then convolving the interpolant with a multiresolution Gaussian approximation of the Green's function to a differential operator whose spectrum can be tuned for problem-specific considerations. Like conventional blurring algorithms, which the new algorithm generalizes to data measured at locations other than a uniform grid, applications include deblurring and separation of spatial scales. An example illustrates a possible application toward enabling importance sampling approaches to data assimilation of geophysical observations, which are often scattered over a spatial domain, since blurring observations can make particle filters more…
Click any figure to enlarge with its caption.
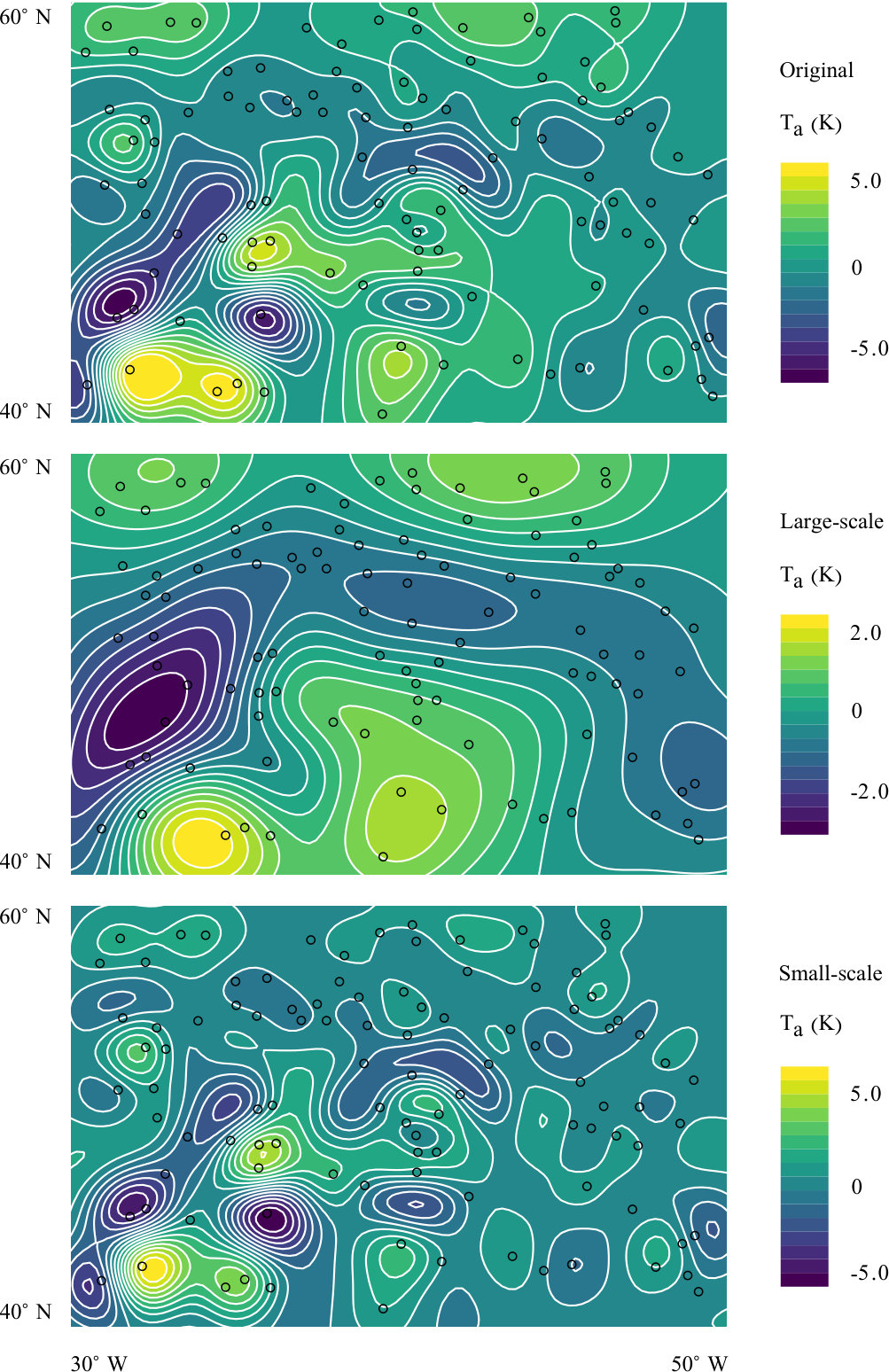 Figure 1
Figure 1 Figure 2
Figure 2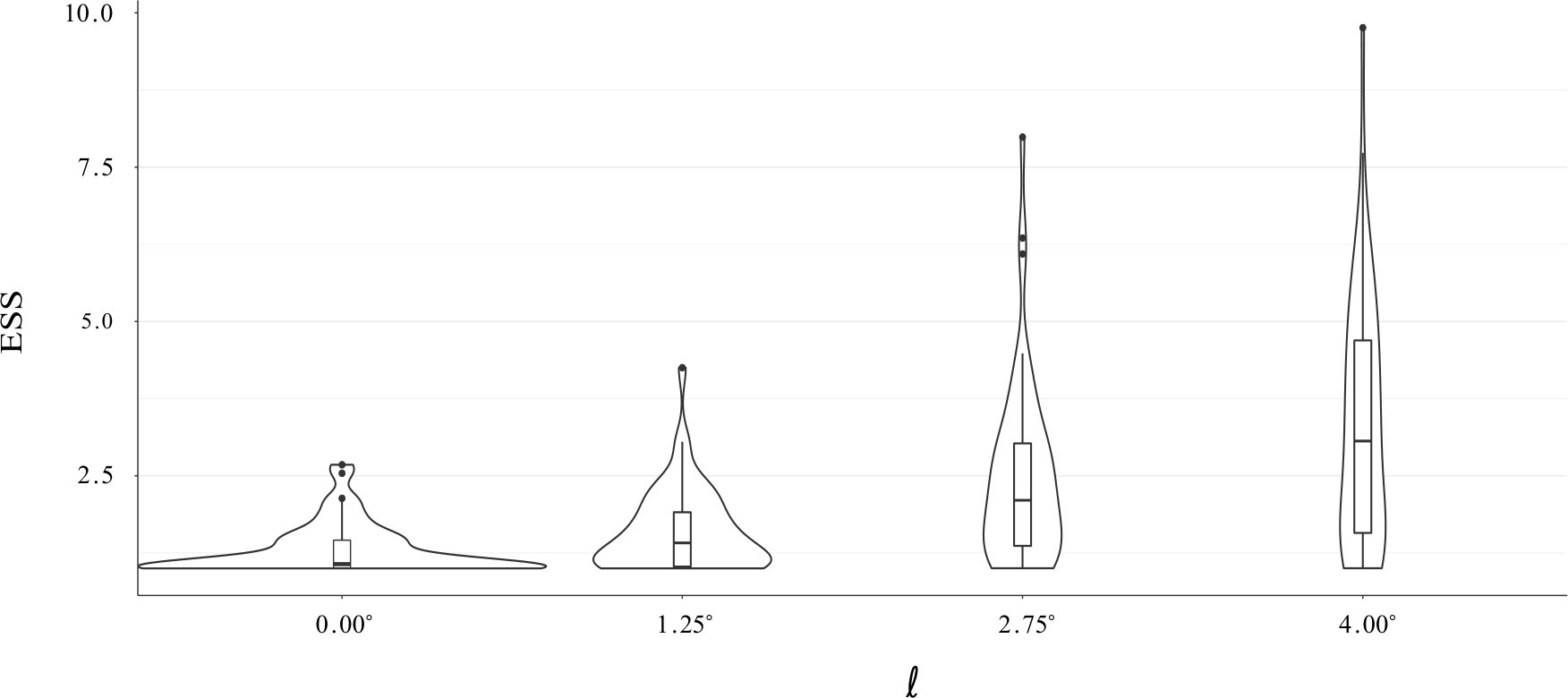 Figure 3
Figure 3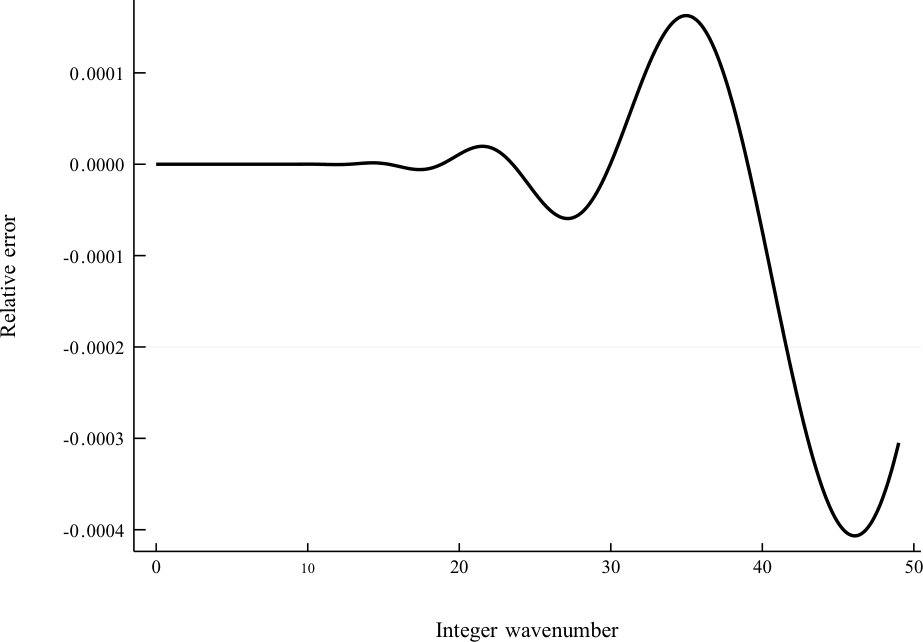 Figure 4
Figure 4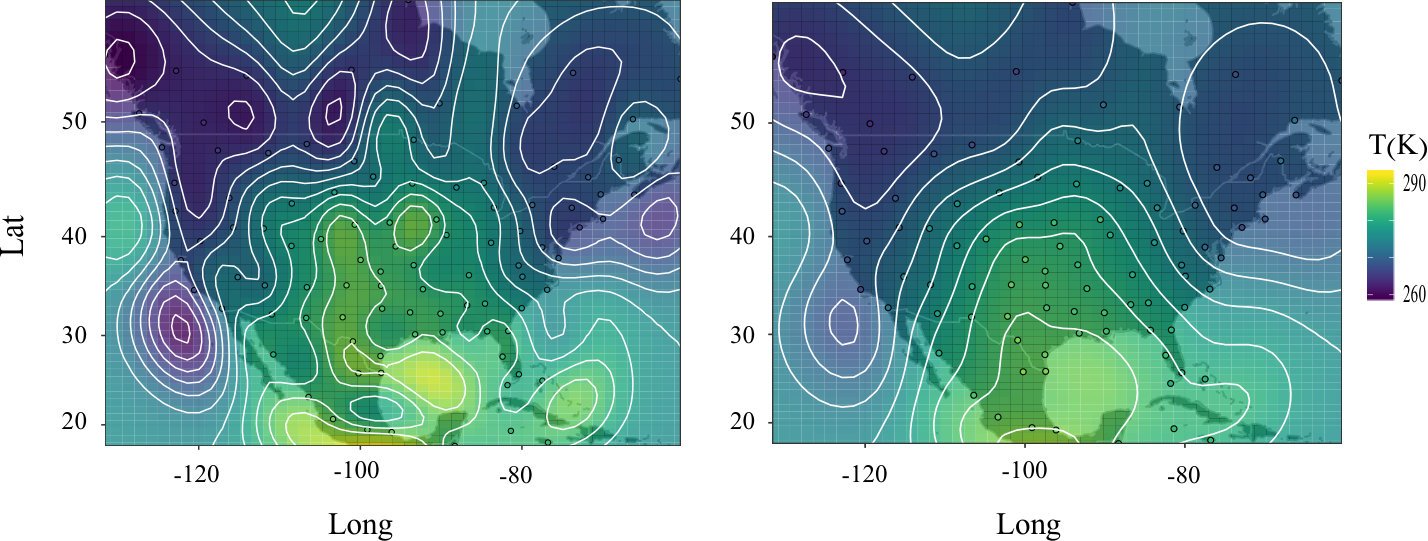 Figure 5
Figure 5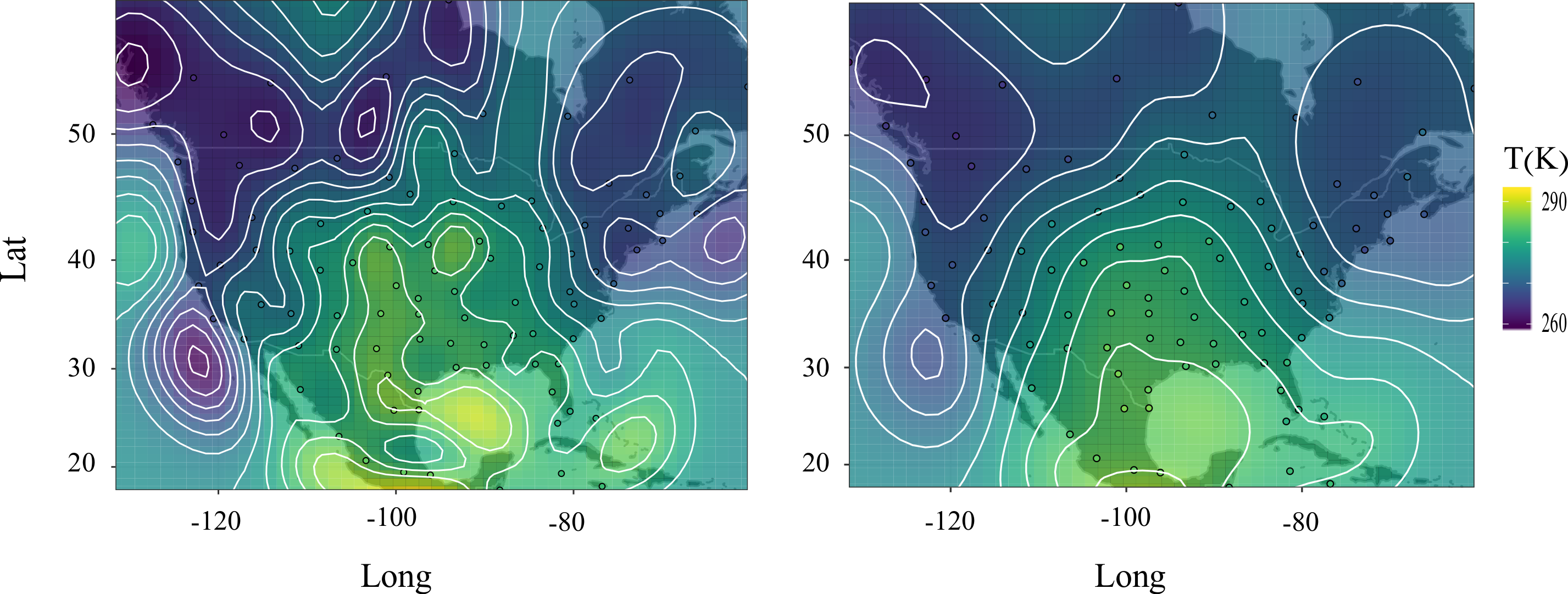 Figure 6
Figure 6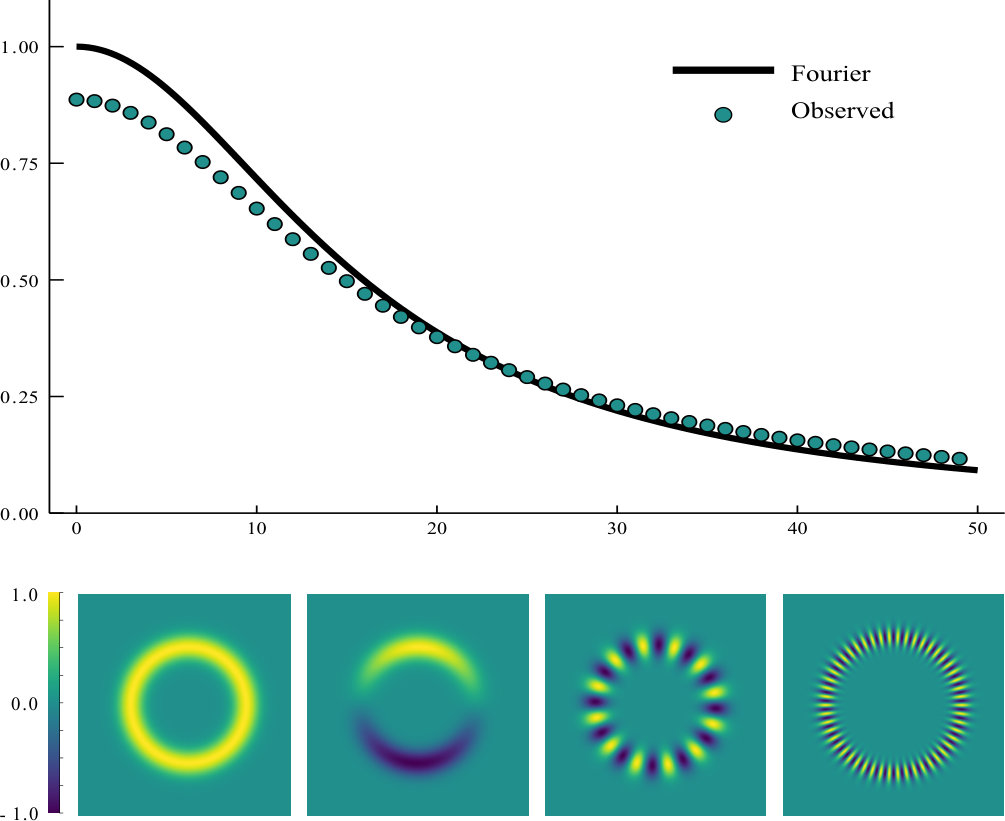 Figure 7
Figure 7Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
\newsiamremark
remarkRemark \newsiamremarkhypothesisHypothesis
\newsiamthmclaimClaim \headersFast tunable blurring algorithm for scattered dataG. Robinson & I. Grooms
A fast tunable blurring algorithm
for scattered data ††thanks: Submitted to the editors June 16, 2019. \fundingThis work was funded by the National Science Foundation under award no. 1821074.
Gregor Robinson & Ian Grooms Department of Applied Mathematics, University of Colorado Boulder, Boulder, CO (, ). [email protected]
Abstract
A blurring algorithm with linear time complexity can reduce the small-scale content of data observed at scattered locations in a spatially extended domain of arbitrary dimension. The method works by forming a Gaussian interpolant of the input data, and then convolving the interpolant with a multiresolution Gaussian approximation of the Green’s function to a differential operator whose spectrum can be tuned for problem-specific considerations. Like conventional blurring algorithms, which the new algorithm generalizes to data measured at locations other than a uniform grid, applications include deblurring and separation of spatial scales. An example illustrates a possible application toward enabling importance sampling approaches to data assimilation of geophysical observations, which are often scattered over a spatial domain, since blurring observations can make particle filters more effective at state estimation of large scales. Another example, motivated by data analysis of dynamics like ocean eddies that have strong separation of spatial scales, uses the algorithm to decompose scattered oceanographic float measurements into large-scale and small-scale components.
keywords:
signal processing, data assimilation, multiresolution algorithms
{AMS}
65D15, 68U10, 65D10, 62M20, 93E11, 60G35
1 Introduction
We present a linear-time blurring algorithm that works for data measured at scattered points in , for arbitrary dimension , and that permits choice in shaping its response to different length scales. This algorithm is equivalent to solving a positive definite self-adjoint elliptic partial differential equation.
By blurring, we mean the process of attentuating small-scale content of a dataset. Doing so offers a way to denoise and simplify spatial data whose large features are of primary relevance. Blurring is also a mechanism for isolating small-scale content by simply subtracting the blurred version from the original. We show an example of each of these use cases.
Applications of blurring in scientific computing generally benefit from having control over the blurring spectrum, i.e. the factor by which it attenuates inputs of different spatial scales. This concept is made more rigorous in 2. Regularly-spaced data on a periodic domain would enable straightforward application of Fourier methods to implement a blurring algorithm that obeys a desired spectrum. But applications in geophysics, and remote sensing in general, often involve measurements made at irregularly scattered locations in a spatially-extended domain. It is therefore desirable not to require a regular grid.
The paper is organized as follows. Our blurring method is described in Section 2; an illustrative synthetic example is shown in Section 3; an example of separating large and small scales of scattered oceanographic data is presented in Section 4; how this blur can be applied in its original motivating context of meteorological data assimilation is described in Section 5 along with a connection to generalized Gaussian random fields that led to our algorithm’s discovery; another example using real meteorological data is in Section 6 to show the blur has the desired effect on particle filtering; algorithmic complexity and generalizations toward practical application of our method are discussed in Section 7; and conclusions follow in Section 8.
2 Method
Let be a vector of data at locations for each , where is the number of observations. The proposed blur works by solving for a discrete approximation of , where is an elliptic differential operator described in the next paragraph and is a continuous-domain interpolant of the data expressed as a sum of Gaussians. This obtains by approximating the Green’s function of as a multiresolution sum of Gaussians, computing the convolution of that approximation with , and evaluating the result at the locations .
Define to be the fractional bound-state Helmholtz operator:
[TABLE]
where is the formal Laplacian operator, is a tuning parameter with dimensions of length, and is a dimensionless tuning parameter that controls the rate of growth of eigenvalues. Eigenfunctions of are Fourier modes of wavenumber and corresponding eigenvalues . The characteristic scale of this operator is , in the sense that eigenfunctions with length scales longer than this have corresponding eigenvectors close to 1.
A drawback of this approach is that convolution with attenuates all but constant functions on , so even a constant data vector will be attenuated to some degree. We will discuss a way to mitigate this effect in Section 3.
To represent the data in a continuous form that allows convolution with , we choose radial basis function (RBF) interpolation [4]. RBF interpolation of the observations requires us to choose a kernel that is used as the radial basis in which the interpolant will represent the data. The interpolant takes the form
[TABLE]
where are interpolation weights such that
[TABLE]
In matrix form, this linear system becomes
[TABLE]
We take the RBF kernel to be , where is the density of a -variate Gaussian random variable with mean and covariance
[TABLE]
This notation is used as a convenient description of Gaussian functions even though we will not use them to describe any random variables.
One may worry that this method is hardly fast, despite using a fast PDE solver, since a naive approach to solving for requires operations. Computational complexity of our algorithm, including faster alternatives to solving for , is discussed in Section 7.
The multiresolution Gaussian approximation of the Green’s function begins by writing the Fourier transform of the inverse of Eq. 1 as an inverse-power function where . Exponential approximations of inverse power functions like this are studied in [3, 12]. The approach therein is to write a finite trapezoid-type discretization of an integral representation of . With the change of variables introduced by McLean [12], the integral representation to be discretized is
[TABLE]
where
[TABLE]
The finite trapezoid rule discretizes this into
[TABLE]
where is the Gamma function and
[TABLE]
Ref. [12] Lemma 4 shows that the total required number of terms scales as to achieve uniform relative error bounded by in the limit .
The approximation in Eq. 8 can now be rewritten in terms of normalized multivariate isotropic Gaussian functions of . Given weights and exponential rates from the exponential approximation above, we can derive the multiplicative factors required of this equivalent formulation:
[TABLE]
The second line obtains from simultaneously multiplying and dividing by the constant required to normalize the Gaussian term in large parentheses, which is written in that manner to ease visual comparison to the standard form of an isotropic -variate Gaussian probability density function of mean [math] and variance . Combining Eq. 8-Eq. 13 yields
[TABLE]
A plot of the relative error committed by this approximation is shown in Fig. 1.
Taking the inverse Fourier transform and combining terms finally yields the desired approximation of the Green’s function in physical space in terms of normalized Gaussians:
[TABLE]
With approximations of the data and the Green’s function now constructed in terms of -variate isotropic normalized Gaussians, convolution of which is trivial, applying a discrete version of the integral operator that inverts is just:
[TABLE]
Evaluating this quantity at the observation locations yields the output of our blur. The last line in the manipulation above shows that the continuous function we evaluate to arrive at outputs can be interpreted as an RBF interpolant of the blurred data in terms of a new blurred basis function , given by
[TABLE]
The weights of the blurred interpolant are identical to the weights of the input interpolant, which will be valuable later in this section.
We now describe our blurring algorithm more concretely. Algorithm 2.1 ties together pieces of the Green’s function approximation specified in Eq. 6-Eq. 17. Algorithm 2.2 combines RBF interpolation of the data with the output of Algorithm 2.1 with a convolution and evaluates the result at the data locations. These algorithms, used together, are a complete description of our blur.
Algorithm 2.2 defines a linear operator on . We will prove that is positive definite in Theorem 2.1, which will be useful in Section 5. The theorem is more general than the specific algorithm so far presented, which will set the stage for potential variants to be described in Section 7. To ease into the theorem, we will summarize the preceding development of and connect it to a briefer alternative formulation that is easier to treat analytically.
We described a sequence of mappings between vector spaces, with blurring taking place most explicitly in the function space of interpolants by way of the convolution , where denotes an operator that performs convolution with the Gaussian approximation of , and is defined as the interpolation basis function centered at location .
Taken literally, that conceptual development prescribes the following composition of linear operations:
[TABLE]
Nodes in this diagram represents the various vector spaces found along the way of describing our blurring algorithm:
- •
is the space of input data,
- •
is the space of interpolant weights in the basis ,
- •
is the space of interpolants,
- •
is the space of blurred interpolants,
- •
is the space of blurred interpolant weights in the basis , and
- •
is the space of blurred data.
Arrows in the diagram represent the action of the operators superscribed on them:
- •
maps input data to RBF weights,
- •
maps RBF weights to interpolated functions,
- •
maps interpolated functions to blurred functions,
- •
maps blurred functions to weights in a blurred RBF basis, and
- •
maps blurred weights to blurred data.
The complicated sequence of steps above can simplify greatly; observe in Eq. 20 that the weights in the blurred basis are always identical to the weights in the unblurred basis . Therefore , leaving just where is the RBF matrix in the blurred RBF basis:
[TABLE]
This alternative perspective demonstrates that is equivalent to finding weights for an RBF interpolant of the unblurred data using a basis , and then evaluating an RBF interpolant of the blurred data using the same weights that now act as coefficients on a blurred basis . The following theorem is stated in terms of this simplified perspective.
Theorem 2.1**.**
*Let be an interpolating radial basis function and let be a convolution kernel. Suppose and each have positive Fourier transforms, and define . Then the matrices with entries and with entries are symmetric positive definite, and the product is positive definite. *
Proof 2.2**.**
A standard theorem of RBF interpolation (e.g. Section 3 of [4]) states that is positive definite under the assumption that the Fourier transform of is positive.
The Convolution Theorem guarantees that has a positive Fourier transform if and both have positive Fourier transforms, so is positive definite for the same reason that is positive definite.
*Observe that and are symmetric by construction, and that is symmetric positive definite since it is the inverse of a symmetric positive definite matrix. Theorem 7.6.3 in [7] states that the product of a positive definite matrix and a Hermitian matrix is a matrix with the same number of negative, zero, and positive eigenvalues as . It follows that the product of two Hermitian positive definite matrices is also positive definite. Therefore, since and are Hermitian positive definite matrices, is positive definite. *
The coefficients in the multiresolution approximation Eq. 15 are all positive, and the Fourier transform of a positive Gaussian is also a positive Gaussian. Therefore , as defined by Algorithm 2.2 together with Algorithm 2.1, is positive definite as a corollary of Theorem 2.1.
3 Example 1: circular measurement locations embedded in a 2-plane
We want to verify that the blur’s effect resembles what we would expect of a discrete approximation to . To that end, we blur equally-spaced data on a circle embedded in to provide insight into the spectral properties of the blur in practice. This example will also describe heuristics in choosing parameters , , and . In the course of this example we will also demonstrate an undesirable phenomenon whereby attenuates even the largest scales, and suggest a workaround.
Locations were chosen to encircle the origin in with distinct locations separated by unit distance from nearest neighbors, i.e.
[TABLE]
The interpolation kernel was chosen to be the isotropic Gaussian PDF with standard deviation . The convolution kernel is the multiresolution Gaussian approximation Eq. 15 to the fractional bound-state Helmholtz kernel with and , using approximation parameters , , and . These parameters yield an approximation of with relative error up to , the Nyquist number for the one-dimensional problem that this example simulates embedded in two dimensions. Recall that Fig. 1 shows this relative error as a function of .
The blur thus constructed defines a linear operator on . For the purpose of inspecting the effect of blurring at different scales we numerically constructed a matrix representation of (though for practical application of the blurring algorithm it is inadvisable to actually construct ). Due to the rotational symmetry of observation locations, the matrices and are circulant. The class of circulant matrices is stable under inversion, transposition, and matrix multiplication, so is also circulant. Therefore eigenvectors of are discrete Fourier vectors. This connection provides a rationale for comparing eigenvalues of to the spectrum of , whose eigenfunctions are Fourier modes. However, it is important to recognize that the comparison is imprecise because the interpolant Eq. 3 represents these discrete Fourier eigenvectors as functions that differ from Fourier modes on .
Eigenvalues of are plotted in Fig. 2 as circles, and some examples of eigenfunctions of are visualized beneath the plot for . Eigenfunctions of are defined here as continuous interpolants of the matrix’s eigenvectors found by the RBF interpolation scheme utilized in the blur. This figure also shows a solid trace labelled “Fourier” that plots , which is the spectrum of that corresponds to Fourier modes. Since eigenvectors of do not correspond to Fourier modes, this trace of the Fourier spectrum is only a rough comparison rather than an analytical prediction that we are trying to match. The observed spectrum of behaves as expected, with gradual blurring of small scale features.
Recall from Section 2 that this method has a drawback of attenuating large scales. That behavior is evident in the eigenvalues plotted in Fig. 2, which are all less than 1. Eigenvalues less than 1 correspond to attenuation, so the blur attenuates even the largest scale (eigenmode index 0). This over-attenuation occurs because convolution with attenuates every Fourier eigenmode of except constant functions in . Since a finite Gaussian approximation can never fully describe a nonzero spatial constant, even the largest-scale function in the space of possible RBF interpolants will be attenuated by our blur. The largest-scale eigenfunctions in this example are thin in the direction transverse to the circle, causing those modes to be blurred more than continuous Fourier modes in with the same wavenumber (i.e. Fourier modes with planar length scale equal to the circumferential length scale of eigenfunctions)
For a similar reason that large scales are attenuated too much, the blur does not suppress the smallest-scale eigenmodes as much as would suppress a true Fourier mode of the same wavenumber. This is because the RBF interpolants of the most highly-oscillatory eigenvectors in this example have more large-scale content than Fourier modes with the same length scale.
Over-attenuation can be mitigated, so that the largest scales are closer to unity, by rescaling the operator by replacing , where is a unit-norm vector with all entries identical. The eigenvectors of are usually not discrete Fourier vectors like they are in this symmetric example, so the largest-scale eigenvector is not necessarily . Therefore this mitigation technique is only a heuristic, which derives from the idea that an input with identical entries contains little small-scale information.
Choosing the RBF standard deviation parameter is not to be taken lightly. We recommend choosing it to be roughly on the order of the nearest-neighbor distance between measurements. A value too small prevents the RBF interpolation step from resolving gradual transitions from location to location, causing the interpolant to appear as a rugged set of “spikes” that are overly suppressed by the convolution step on account of their inappropriately small scale. Choosing an interpolation kernel that is too large, however, can cause numerical problems related to ill-conditioning of the linear system we must solve to arrive at RBF coefficients. Choosing to be as large as possible, balanced against insurmountable instability due to ill-conditioning, is considered a best practice in RBF literature [4].
4 Example 2: scale separation of ocean temperature measurements
The application of our algorithm is demonstrated with data from Argo, an international instrumentation project to measure the world’s oceans [16]. Argo uses an array of approximately 3600 profiling floats. Every 10 days, these devices sink to a depth of 2000 meters to capture a depth-wise profile of measurements as they float back to the surface.
We apply our blurring algorithm to Argo sea surface temperature measurements to decompose the data into large-scale and small-scale components. Physical oceanographers are interested in how ocean heat content varies across spatial and temporal scales, and the Argo data set is an invaluable tool [23]. Given the irregularity of the Argo data in space and time, it is usually interpolated to a regular grid before use [15]. Our blurring algorithm enables extraction of the large-scale (blurred) part of the data without the need to first interpolate onto a grid. The data used in this example, accessed on February 13, 2020, were taken from the region N–N and –W over the time period February 1, 2020 through February 10, 2020.
A small number of data points were removed to maintain a minimum nearest-neighbor separation of 50 kilometers. A least-squares linear fit is subtracted from the remaining data to arrive at deviations. These deviations are blurred with Algorithm 2 using RBF length scale kilometers, kilometers, and exponent . Subtracting the linear fit to obtain deviations avoids rapid variation of the interpolant that could otherwise happen near the boundaries due to the basis functions’ rapid decay.
The original field of sea surface temperature deviations, as interpolated by RBF stage of our algorithm, is depicted in the top panel of Fig. 3. The center panel shows the large-scale component, which is the result of blurring the temperature deviations. The small scale component, plotted in the bottom panel, is the difference of the unblurred and blurred temperature deviations.
5 Application to particle filtering
The blur described above was originally motivated by an effort to mitigate the dimensional curse of particle filtering, which we will refer to as sequential importance sampling with resampling (SIR) hereinafter.111Sequential importance sampling (SIS) is also known as particle filtering. In this paper we specialize on SIS with resampling (SIR), the most famous variety of particle filter, though the dimensional curse and presumably our applications also extend to other particle filter varieties. This section will describe how the blur was derived from the motivating considerations about SIR, in terms of an observation error covariance matrix.
SIR begins by running an ensemble of forecasts; each ensemble member is a particle. A set of observations of the true system is then taken; the observations are corrupted by instrument errors, whose distribution defines a likelihood. This likelihood is used to compute weights for each particle so that the weighted ensemble approximates the Bayesian posterior.
SIR is susceptible to a phenomenon called collapse, characterized by essentially all the ensemble weight accumulating on a single ensemble member that is closest to the observations, causing the filter to catastrophically underestimate posterior dispersion. The number of ensemble members required to avoid SIR collapse depends on system covariance and observation error covariance, scaling exponentially in an effective system dimension.
Specific estimates of ensemble size required to avoid collapse, provided in [21, 22], suggest one can reduce the required ensemble size by increasing eigenvalues of the observation error covariance.222Decreasing eigenvalues of the system covariance has the same effect, for the same reasons. However, it is harder to justify changes to a dynamical model, and to implement those changes, than to modify the observation model as we propose. Doing so carefully can also improve uncertainty quantification for a fixed number of ensemble members. Ref. [14] suggests inflating the observation error variance at small scales, letting variance grow in wavenumber, since small scales have very limited predictability in geophysical flows [10, 17, 8].
To be more precise, consider an observing system
[TABLE]
where is the observation at location , is a function-valued observation operator acting on , which describes the scalar system state as a function of location, can be imagined as the standard deviation of the observation error at , and is the random observation error.
It is natural to think of as a random field. But letting the spectrum grow in wavenumber precludes pointwise definition of , with probability 1, so it is not a random field in the traditional sense. The idea of imposing a correlation structure with a growing spectrum can instead be understood in the framework of generalized random fields. In this case can be treated as a random process with realizations taking the form of tempered distributions, i.e. elements of the topological dual to a Schwartz space of rapidly decaying functions on .
Since realizations of with a growing spectrum cannot be described pointwise, instead interpret the spatially parametrized terms in Eq. 24 as averages with respect to a Schwartz function that is closely concentrated near . For example,
[TABLE]
Narrowing our attention within the scope of generalized random fields, let be a mean-zero stationary Gaussian generalized random field (GGRF). Then the vector is a multivariate normal random variable with zero mean and a covariance matrix with entries that depend only on . Hence the vector of observations conditioned on is a multivariate normal random variable with mean and covariance
[TABLE]
where is a diagonal matrix of the discrete observation standard deviations that can be treated as instrument errors and is an observation operator acting on the discrete vector that characterizes the underlying system state. The discrete observing system can be summarized in the form
[TABLE]
In the spirit of [9, 18], a connection between elliptic stochastic partial differential equations and random fields enables us to make use of fast algorithms for PDEs in the context of solving for the likelihood under GGRF models, rather than naively developing a dense approximation of and then solving the associated linear system. In seeking to build a GGRF error model with a likelihood that is cheap to evaluate in high dimensions, it was this connection that led to the development of the more generally-applicable blurring algorithm presented in this paper.
We specifically treat the continuous field of observation error as , where acts on a spatial white noise with mean zero and unit pointwise variance. As in Eq. 1, is the formal Laplacian operator, is a tuning parameter with dimensions of length, and is a dimensionless tuning parameter that controls the rate of growth of eigenvalues. Recall that eigenfunctions of are Fourier modes of wavenumber and corresponding eigenvalues . Recall also that the characteristic scale of this operator is , in the sense that eigenfunctions with length scales longer than this have corresponding eigenvalues close to 1. Modeling the observation error in this manner therefore ascribes a variance to large scales that is commensurate with instrument error, but it also progressively and unboundedly inflates variance for small scales at a rate controlled by . The GGRF description of observation error is thus a kind of surrogate model for the assumption of uncorrelated observations at large scales, but with inflated variance at small scales that are of lesser concern in geophysical forecasting.
We will use the fact that preferentially inflating observation variance at small scales is equivalent to treating blurred innovations as uncorrelated.333The innovation of an ensemble member is the difference between observation and forecast. To see this equivalence, observe how the correlation matrix features in the Gaussian likelihood, the logarithm of which is proportional to
[TABLE]
Then consider preprocessing the “standardized innovations” with a linear operation
[TABLE]
If these blurred observations are now assimilated under the assumption that the errors in the blurred field are standard normal, then the log-likelihood is proportional to
[TABLE]
Any valid covariance matrix must be symmetric and positive definite. If is a positive definite blurring operator — i.e. a positive definite operator with a decaying spectrum toward small scales — then is a symmetric positive definite operator with a spectrum that grows toward small scales. In light of these considerations, take to be the algorithm presented in Section 2. Although Theorem 2.1 shows that is positive definite, it is typically not symmetric, and the symmetric part of is not necessarily positive definite. For this reason we must treat as a covariance matrix, rather than .
In summary, we propose blurring standardized innovations with in such a way that is a covariance for a discretized GGRF.
6 Example 3: SIR with radiosonde data
To demonstrate the behavior of our blurring algorithm on scattered data and its impact on SIR weights, we make use of data from the U.S. National Center for Atmospheric Research (NCAR) Convection Allowing Ensemble [19, 20]. The NCAR ensemble produced real-time 48 hour forecasts over the conterminous United States (CONUS) from April 7, 2015 to December 30, 2017. The ensemble forecasting system consisted of two components: an 80 member ensemble assimilation system operating at 15 km resolution and a 10 member ensemble forecast system operating at 3 km resolution. We make use of the 80 member ensemble data. The assimilation system used the Advanced Research version of the Weather Research and Forecasting (WRF) model; observations were assimilated in a 6 hour cycle via the Ensemble Adjustment Kalman Filter [2] implemented in the Data Assimilation Research Testbed software suite [1]. Every assimilation cycle processed between 66,000 and 70,000 observations from a variety of sources including radiosondes, aircraft measurements, satellite wind measurements, and Global Positioning System radio occultation data, among others. Further details are provided in [19].
To verify that our blurring algorithm performs as expected on scattered data, we apply it to radiosonde temperature measurements at a single pressure level. Every 12 hours, i.e. every other assimilation window, there are between 90 and 97 radiosonde measurements scattered across North and Central America and the Caribbean available at various pressure levels. An example of the locations of these observations at a pressure level of 70 kPa on May 15, 2017 is shown in Fig. 4. The left panel shows the locations of the measurements along with an interpolated temperature field obtained using Gaussian RBFs with standard deviation . The right panel shows the result of applying our blurring algorithm with blurring exponent and blurring length scale . Figure 4 provides visual evidence that our algorithm indeed blurs scattered data. Interpolating the raw data would leave strange regions of approximately zero Kelvins in the interpolants depicted. So for the purpose of visualization, we subtract the mean before applying the blur, and then add the mean back to the blurred data.
We next verify that the algorithm has a controllable degree of blurring with the desired effect on SIR weights, viz. that the effective sample size increases as the blurring length scale increases. To that end we use the 80 member ensemble forecast for temperature at the locations of the radiosonde temperature observations, assume that the forecast weights are all equal to , and update the weights based on mismatch to the observations using the standard SIR update formula.
To be precise, let be the vector of radiosonde temperature observations at a given time, let be the vector of forecast temperatures at the same time and locations for ensemble member , and let be a diagonal matrix whose diagonal contains the standard deviations of the observation errors. The un-normalized weight for the ensemble member is
[TABLE]
where is the matrix corresponding to the blurring operator and is a rescaling factor with a unit vector of identical entries. The normalized weights are
[TABLE]
and the effective sample size (ESS) is
[TABLE]
Figure 5 shows violin plots of the ESS computed twice daily over the entire month of May 2017 using radiosonde temperature data at a pressure level of 50 kPa. The standard particle filter (i.e. without blurring, or ) exhibits very poor performance with ESS only rarely rising much beyond 1.
As the blurring length scale increases from 0, the distribution of ESS also increases. With , the median ESS is approximately 3 and ESS occasionally rises beyond 5. We emphasize that these values of ESS are still quite small for an 80 member ensemble, but the goal here has not been to demonstrate the performance of the particle filter per se, but of the blurring algorithm for scattered data. That said, even a tiny increase of the ESS beyond its minimum possible value of 1 is promising because it offers hope that uncertainty quantification will improve faster upon increasing the ensemble size.
7 Computational considerations
The first step of our blur involves solving a dense linear system Eq. 3 for interpolation weights . A naive approach to doing so would require storage and operations. This would be highly undesirable, especially if the interpolation matrix changes between assimilation cycles due to changing observation locations. Happily, there exist algorithms to solve a Gaussian RBF problem much faster. These notably include PetRBF, which is based on GMRES iteration with a restricted additive Schwarz method preconditioner. PetRBF requires storage and operations in arbitrary dimension , and is scalable to many cores as implemented in PETSc [25].
Another potential bottleneck is evaluating the sum of Gaussians at target locations, with terms in the approximation of . A direct approach to evaluating this sum, as is written in Algorithm 2.2, has time complexity . This Gaussian sum approximation can be reduced to with the Fast Gauss Transform (FGT) [6]. The FGT has exponential time complexity in location dimensionality , so it often runs slower than direct evaluation when is greater than 2. The Improved Fast Gauss Transform (IFGT) exists to eliminate that exponential scaling that hinders the original FGT for large [24]. The IFGT can be challenging to use in practice, but there exist approaches to assist in automatic tuning such as [13]. Finally, ASKIT offers a new approach to the kernel summation problem that extends to non-Gaussian kernels and which may be less fragile in high dimensions [11].
Our algorithm uses an interpolation basis function whose width remains fixed throughout the domain. This may be problematic when the density of observation locations is highly heterogeneous, since an RBF standard deviation large enough to resolve smooth features in a sparsely-sampled region may be large enough that it causes numerical problems in densely-sampled regions. Those numerical problems may arise from ill-conditioning of or from insufficient data locality expected of some divide-and-conquer solvers like PetRBF. There is some extant literature on the use of nonuniform RBF width parameters to address this situation [5], so that the size of the basis function can adapt to the density of observations. Using adaptive width involves interpolation with a basis that is allowed to vary with . Adaptive width can be incorporated into our blur, just by modifying Eq. 3 and Eq. 18 to let vary with . Using nonuniform width parameters no longer comes with guaranteed nonsingularity, but [5] suggests that singularity is more of an exception than a rule.
Unfortunately, many fast solvers for the RBF problem are incompatible with basis functions that vary by location. One possibility to reduce the cost of solving for interpolation weights in this case is to choose compactly-supported basis functions so that is sparse. We are unaware of any compactly-supported radial basis functions with positive Fourier transforms that are simple to convolve with a Gaussian, particularly for arbitrary . But performing the interpolation in terms of compactly-supported bases can be made compatible with the rest of our blurring method, simply by approximating each with a sum of Gaussians. The resulting Gaussian approximation of the data will not be an interpolant, but careful construction can make it accurate. Therefore Theorem 2.1 does not apply, but we can still expect this substitution to yield a good approximation of the convolution acting on the original interpolant.
It is similarly possible to choose a different convolution kernel to approximate with a sum of Gaussians. This idea can be used to implement a blur of the form presented here with a wider variety of characteristics, such as a non-monotonic response in length scale. If the Guassian approximation kernel possesses a positive Fourier transform, and the RBF interpolation employs a uniform basis function, then Theorem 2.1 still applies to guarantee that is a valid covariance matrix in its application shown in Section 5.
To reduce the prefactor in the convolution step, we can apply a reduction algorithm based on Prony’s method with the suboptimal approximation Eq. 8 as a starting point [3]. Doing so yields an optimal multiresolution approximation of the integral kernel for given uniform relative error bounds, which may require substantially fewer terms to attain the same relative accuracy. This reduction method may be particularly helpful for different forms of (ergo ) that do not yield such a rapidly-convergent approximation as Eq. 15.
8 Conclusions
We have a described a method to blur data measured at locations that are arbitrarily scattered in , for arbitrary , by applying a discrete approximation to the integral equation that inverts the fractional bound state Helmholtz operator . The degree of attenuation for different length scales can be tuned by adjusting the parameters and ; large scales are attenuated little, but length scales shorter than are rapidly suppressed with a rate determined by .
The discrete approximation results from a multiresolution Gaussian approximation to the differential operator’s Green’s function. This readily permits convolution with a sum of Gaussians that approximate the data; we take the sum of Gaussians approximation to be a radial basis function (RBF) interpolant with a Gaussian kernel. The blur is shown to be a positive definite linear operator on in a more general context where the interpolation basis and the convolution kernel have positive Fourier transforms.
Spectral properties of our blur are examined with an example shown in Section 3. This example provides evidence that the algorithm operates as expected: attenuation gradually increases in wavenumber, roughly approximating the differential operator’s inverse spectrum, with a caveat that our blur attenuates even the largest scale. In order to preserve large scales, we propose dividing by , where is a unit vector with all entries identical.
Section 4 shows an example application of our blurring algorithm on sea surface temperature data measured by oceanographic floats in the Argo project. In contrast to the typical approach of decomposing these data into large-scale and small-scale components, our method circumvents the need for interpolating onto a regular grid.
Our blur is developed with application to Sequential Importance Sampling with Resampling (SIR) particle filters in mind. Section 5 describes how blurring observations with before assimilating them as if they have uncorrelated errors is equivalent to assuming that the observation errors have covariance , which gives observation errors the correlation structure of a stationary generalized Gaussian random field. Relative to an uncorrelated model, an observation error model of this type decreases the number of ensemble members required to achieve good uncertainty quantification from SIR for spatially-extended dynamical systems [14].
Section 6 demonstrates that this blur has the desired effect of helping balance SIR weights in an example with real meteorological data, which improves uncertainty quantification by reducing the tendency of SIR to produce underdispersed posterior distributions in high dimensions. This example is chosen to be provocative of potential future applications to geophysical fluid dynamics, but it is worth characterizing traits of applications that would be more appropriate. The extratropical temperature field in Section 6 probably features little dynamical nonlinearity at large scales, and its measurements are linear and Gaussian, so this corpus of data is an excellent candidate for assimilation with any one of the many variants of the Ensemble Kalman Filter. A more appropriate application of blurred-observation SIR would feature substantially non-Gaussian behavior at large scales. That can arise due to nonlinear dynamics of large scales or due to large dispersion of a non-negative state variable relative to its mean, or due to a nonlinear observation operator inducing a non-Gaussian posterior distribution. Moist convective systems, for example, have nonlinear dynamics and substantially skewed sign-definite variables. Examples of nonlinear observation operators that could be similar motivation for SIR include satellite radiance and precipitation measurements. Any of these features could provide motivation for accepting the computational challenge of SIR in exchange for provable convergence to the smoothed-observation surrogate model with its controllable bias. However, it remains to be seen whether a smoothed-observation SIR filter can beat methods in the EnKF family when applied to real atmospheric problems.
A naive implementation of Algorithm 2.1 requires memory and operations to solve for interpolant weights. However Section 7 describes how specialized kernel matrix solvers and fast kernel summation methods can reduce the asymptotic complexity of our algorithm to .
Acknowledgments
We are grateful to Jeff Anderson and Glen Romine for their help in accessing and using the NCAR ensemble data. We are grateful to Gregory Beylkin for pointing us towards a multiresolution Gaussian approximation of the blurring kernel. The Argo data used here (http://doi.org/10.17882/42182#70590) were collected and made freely available by the International Argo Program and the national programs that contribute to it (http://www.argo.ucsd.edu, http://argo.jcommops.org). The Argo Program is part of the Global Ocean Observing System.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] J. Anderson, T. Hoar, K. Raeder, H. Liu, N. Collins, R. Torn, and A. Avellano , The data assimilation research testbed: A community facility , B Am Metorol Soc, 90 (2009), pp. 1283–1296.
- 2[2] J. L. Anderson , A local least squares framework for ensemble filtering , Mon. Wea. Rev., 131 (2003), pp. 634–642.
- 3[3] G. Beylkin and L. Monzón , Approximation by exponential sums revisited , Appl Comput Harmon A, 28 (2010), pp. 131–149.
- 4[4] B. Fornberg and N. Flyer , A primer on radial basis functions with applications to the geosciences , SIAM, 2015.
- 5[5] B. Fornberg and J. Zuev , The Runge phenomenon and spatially variable shape parameters in RBF interpolation , Computers & Mathematics with Applications, 54 (2007), pp. 379–398.
- 6[6] L. Greengard and J. Strain , The fast gauss transform , SIAM Journal on Scientific and Statistical Computing, 12 (1991), pp. 79–94.
- 7[7] R. A. Horn and C. R. Johnson , Matrix analysis , Cambridge Univ. Press, Cambridge, 23. print ed., 1990.
- 8[8] F. Judt , Insights into atmospheric predictability through global convection-permitting model simulations , J. Atmos. Sci., 75 (2018), pp. 1477–1497.