TL;DR
Mo"ET is a novel mixture of expert trees model that enhances interpretability and safety in machine learning, especially in reinforcement learning, by enabling logical rule extraction and outperforming previous verifiable models.
Contribution
Introduces Mo"ET, a mixture of decision tree experts with a generalized linear model gating function, and a hard thresholding variant Mo"ETH for improved interpretability and safety guarantees.
Findings
Mo"ET outperforms decision tree-based methods in reinforcement learning tasks.
Mo"ETH enables easy logical rule extraction for predictions.
The models excel in real-world supervised problems, surpassing existing verifiable ML approaches.
Abstract
Rapid advancements in deep learning have led to many recent breakthroughs. While deep learning models achieve superior performance, often statistically better than humans, their adoption into safety-critical settings, such as healthcare or self-driving cars is hindered by their inability to provide safety guarantees or to expose the inner workings of the model in a human understandable form. We present Mo\"ET, a novel model based on Mixture of Experts, consisting of decision tree experts and a generalized linear model gating function. Thanks to such gating function the model is more expressive than the standard decision tree. To support non-differentiable decision trees as experts, we formulate a novel training procedure. In addition, we introduce a hard thresholding version, Mo\"ETH, in which predictions are made solely by a single expert chosen via the gating function. Thanks to that…
Click any figure to enlarge with its caption.
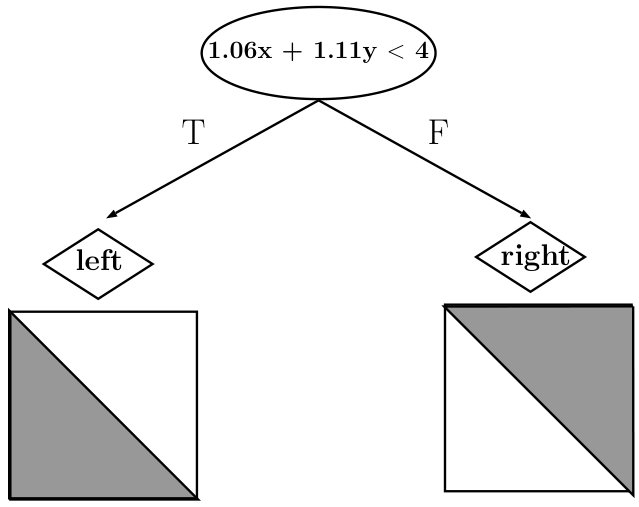 Figure 1
Figure 1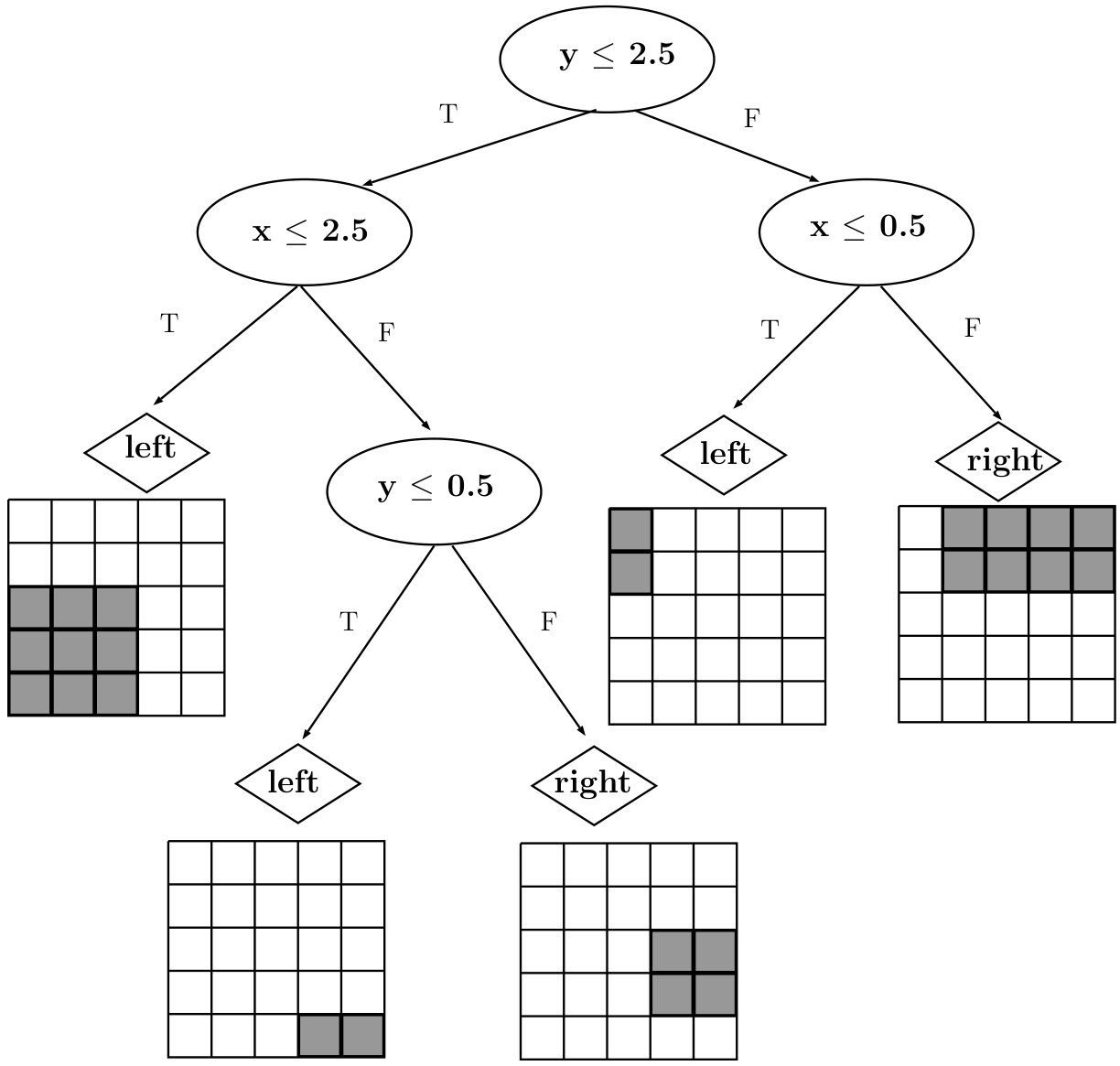 Figure 2
Figure 2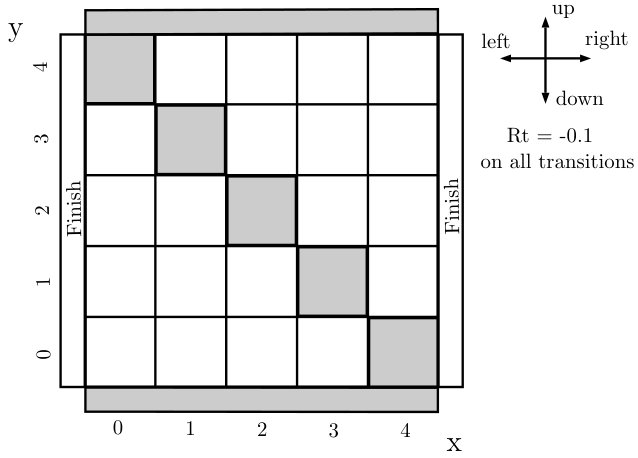 Figure 3
Figure 3 Figure 4
Figure 4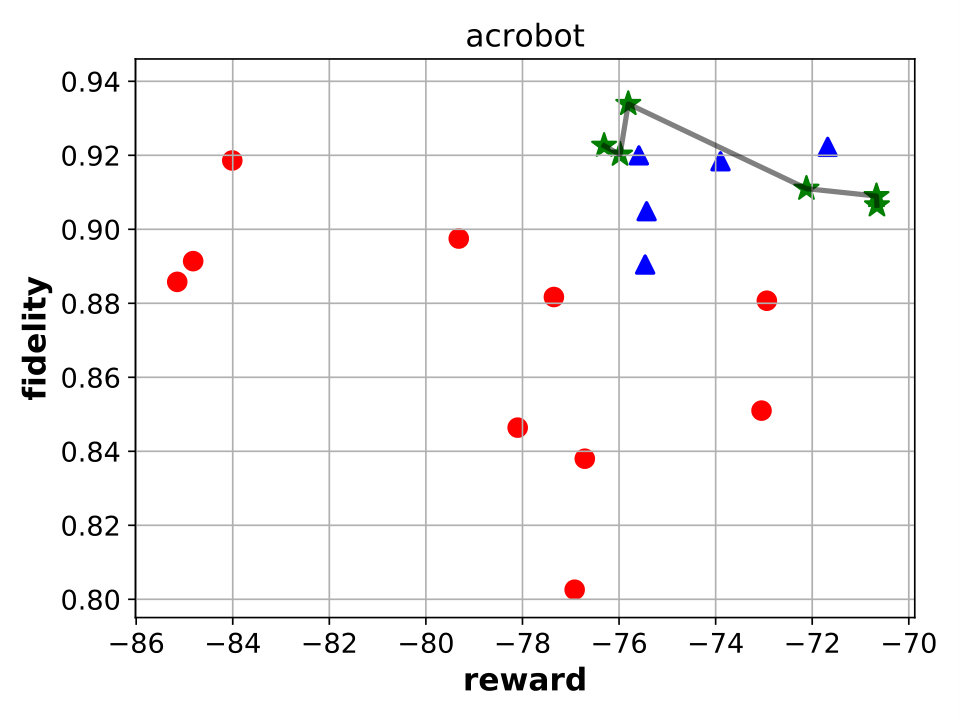 Figure 5
Figure 5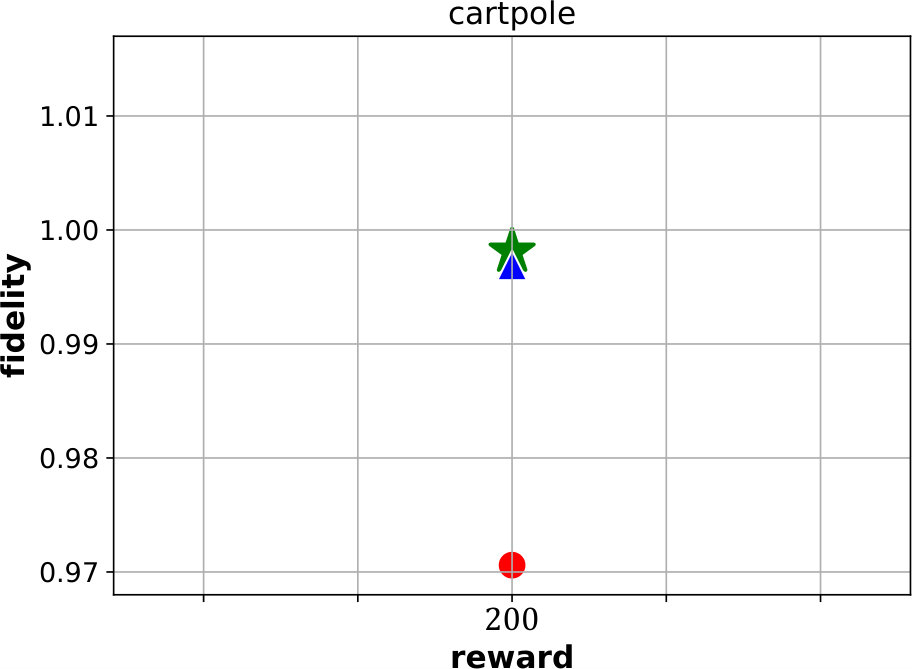 Figure 6
Figure 6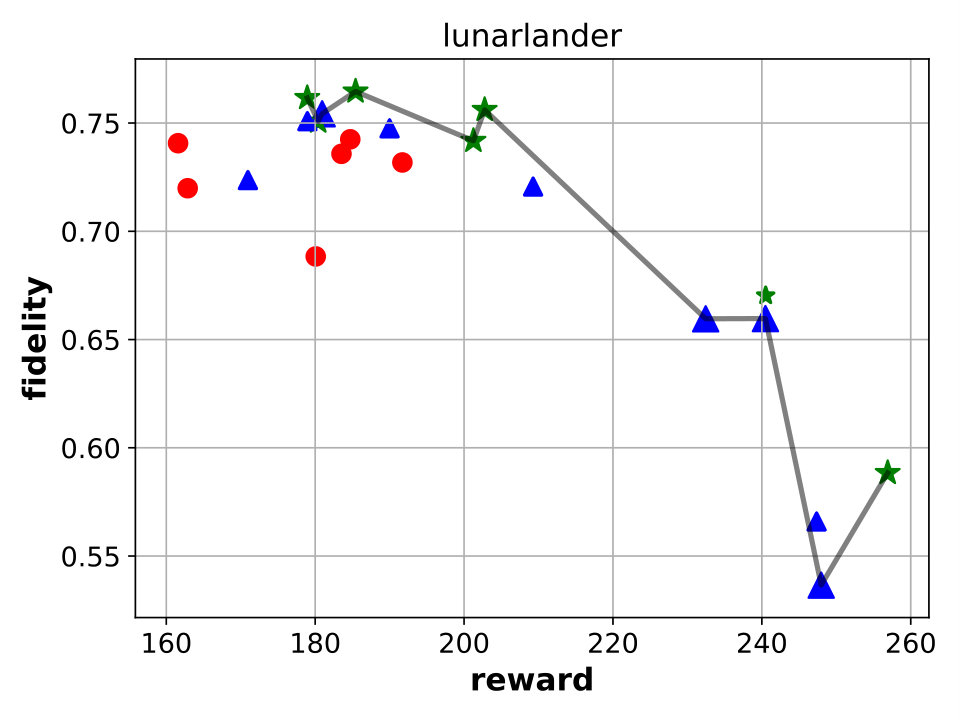 Figure 7
Figure 7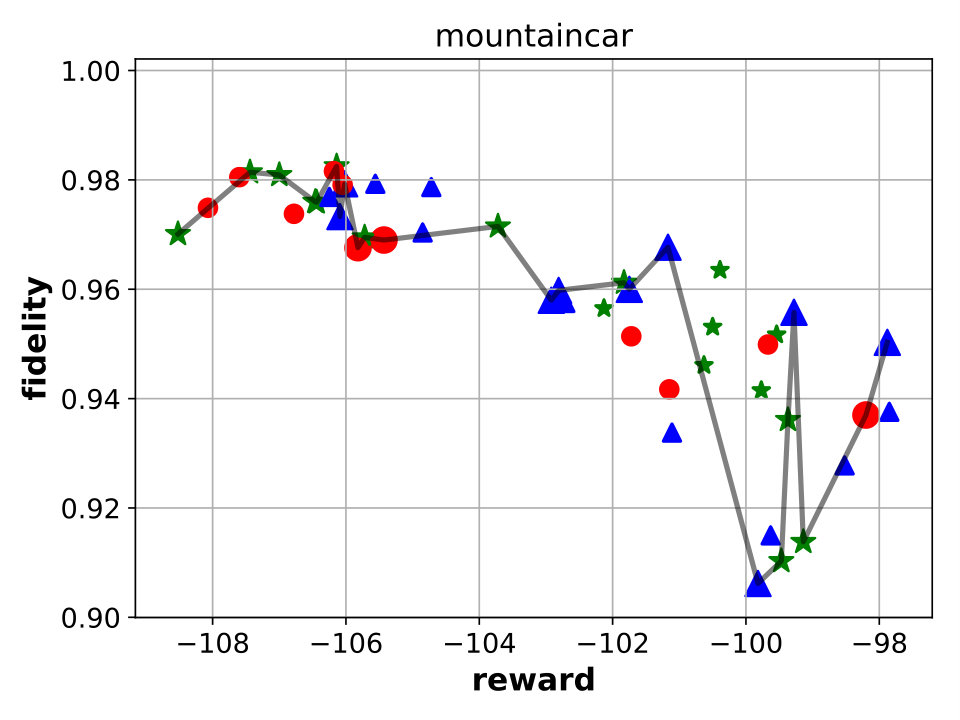 Figure 8
Figure 8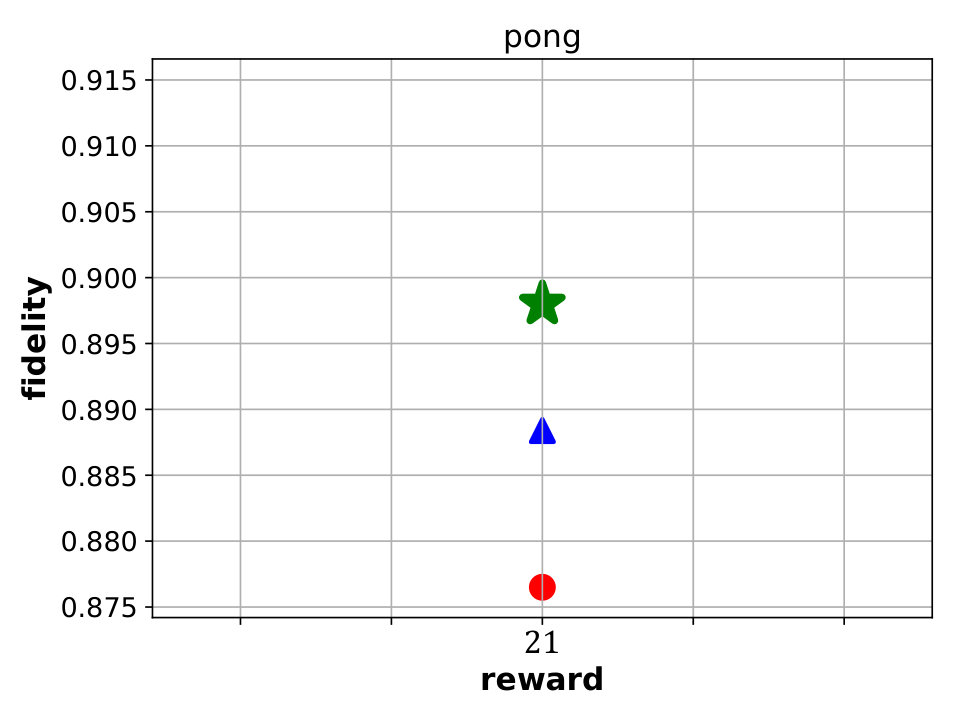 Figure 9
Figure 9 Figure 10
Figure 10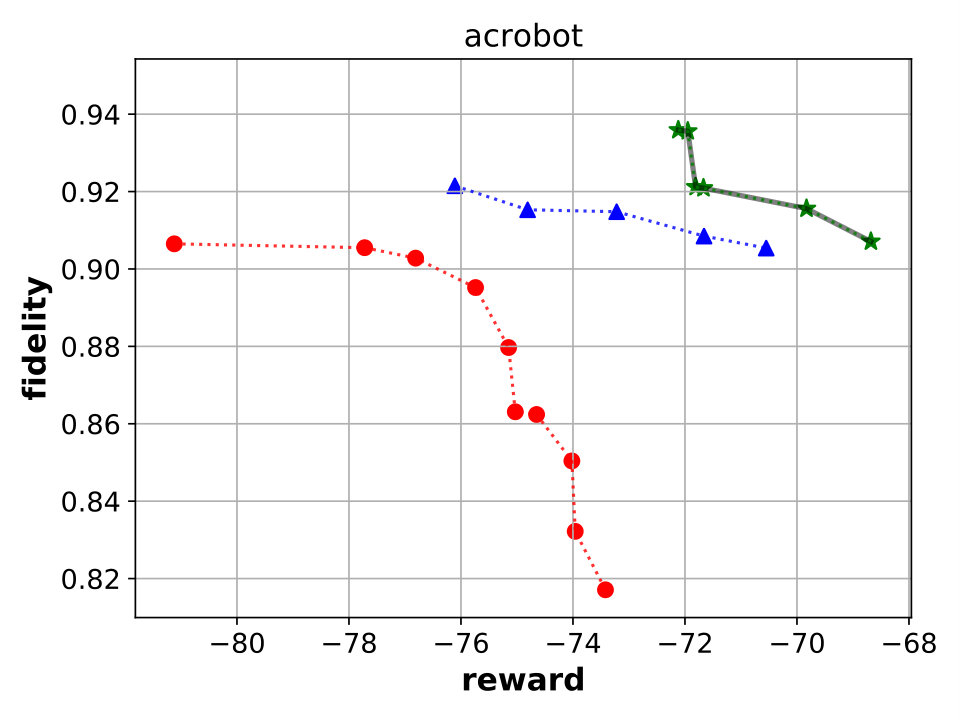 Figure 11
Figure 11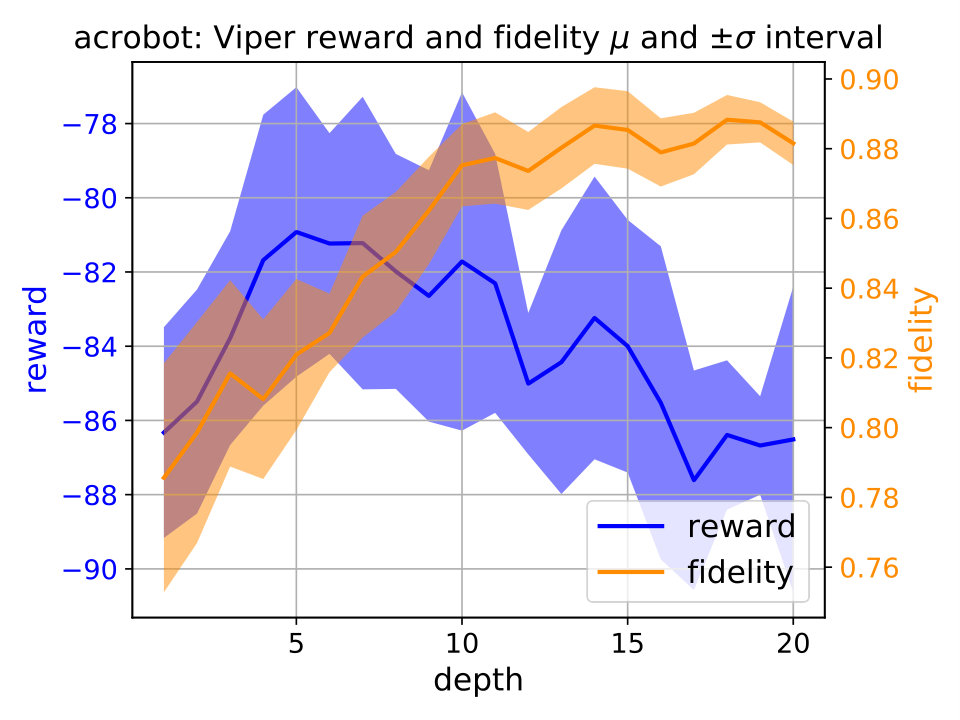 Figure 12
Figure 12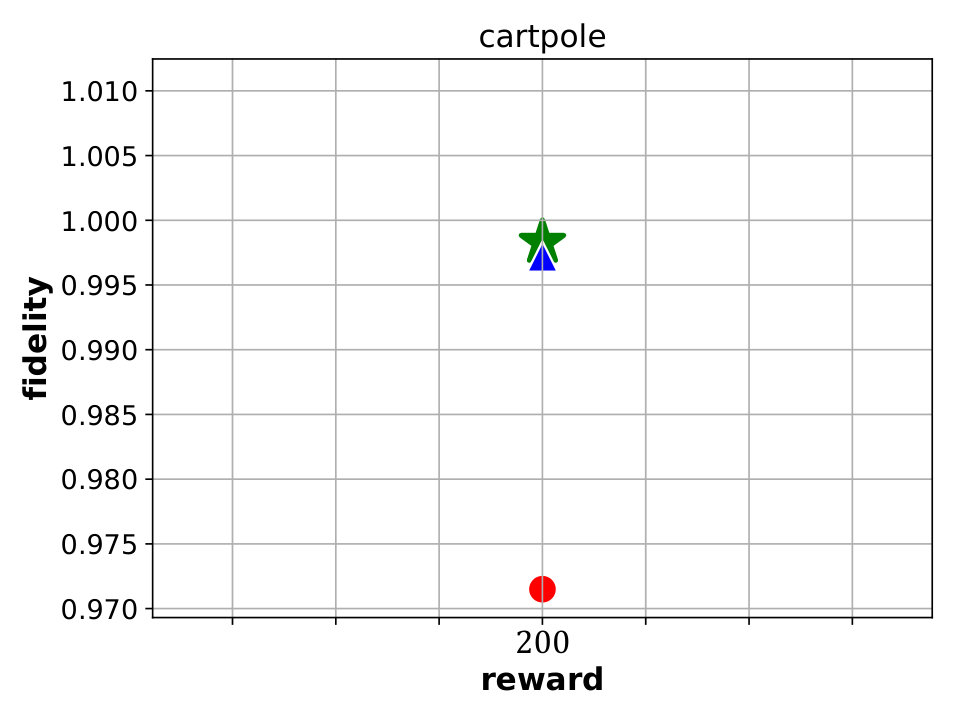 Figure 13
Figure 13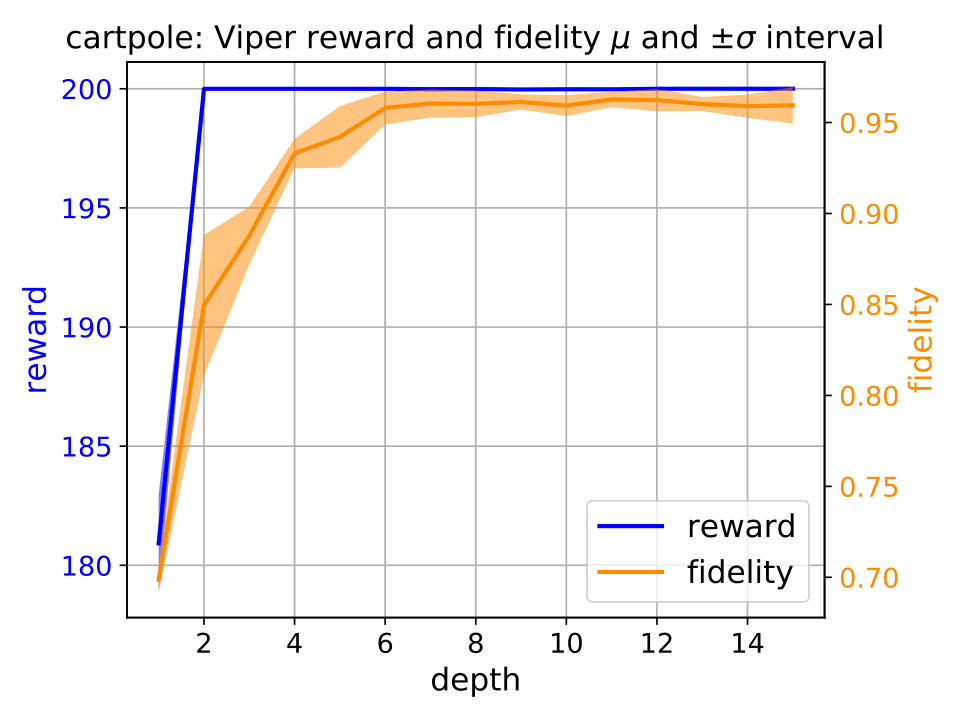 Figure 14
Figure 14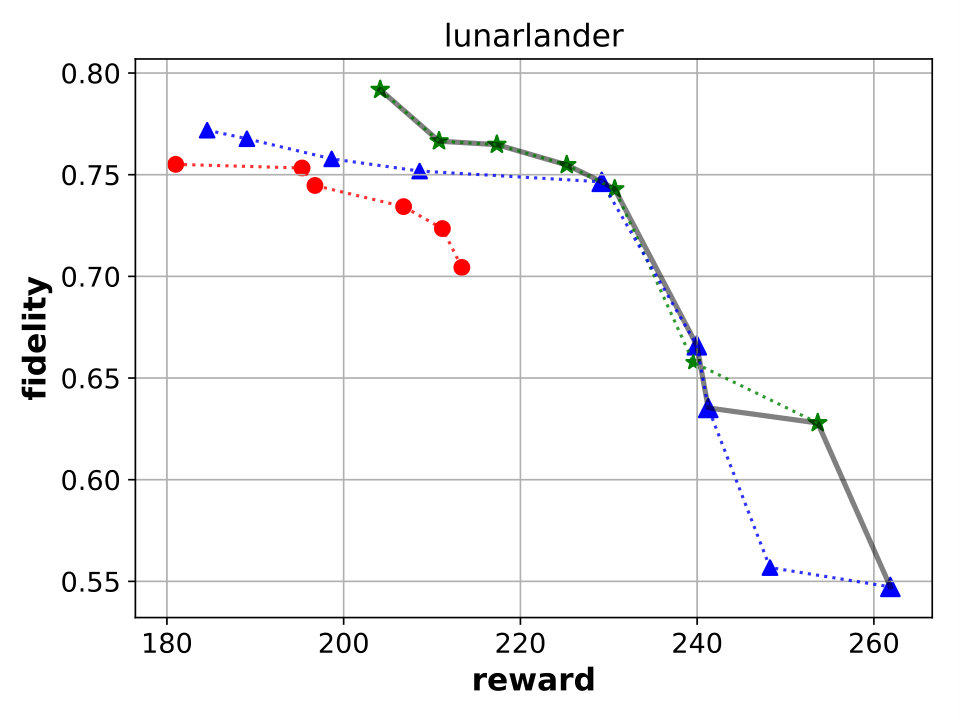 Figure 15
Figure 15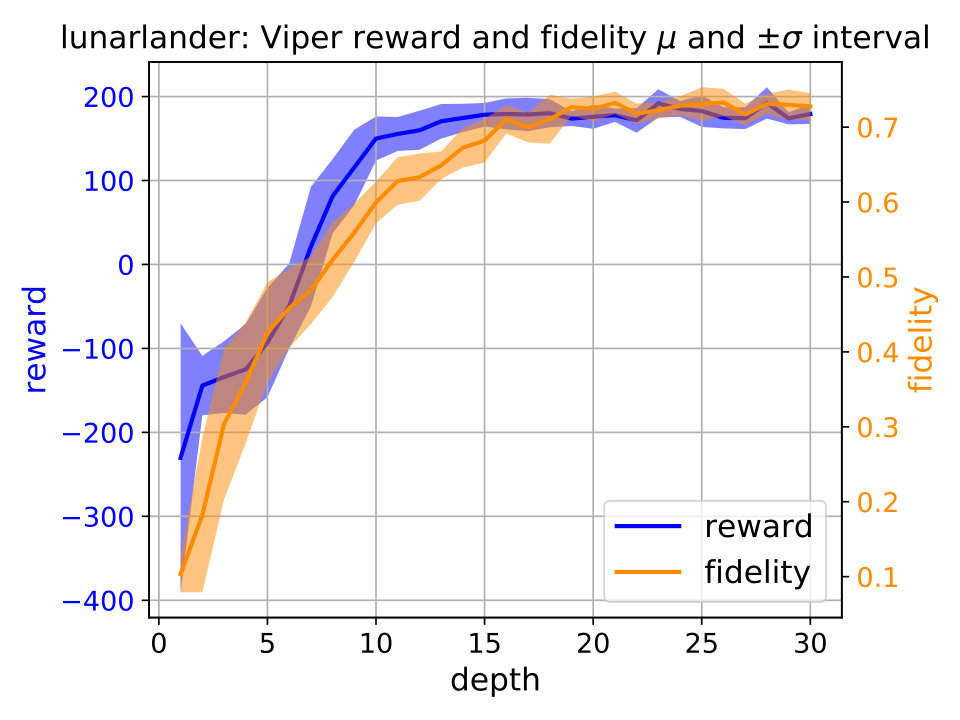 Figure 16
Figure 16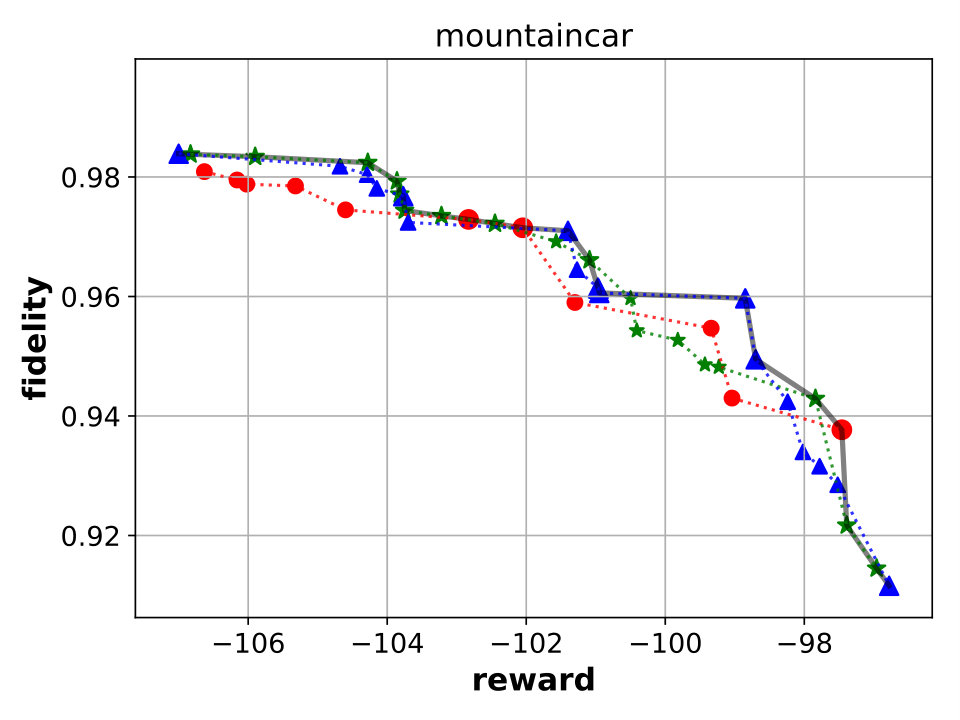 Figure 17
Figure 17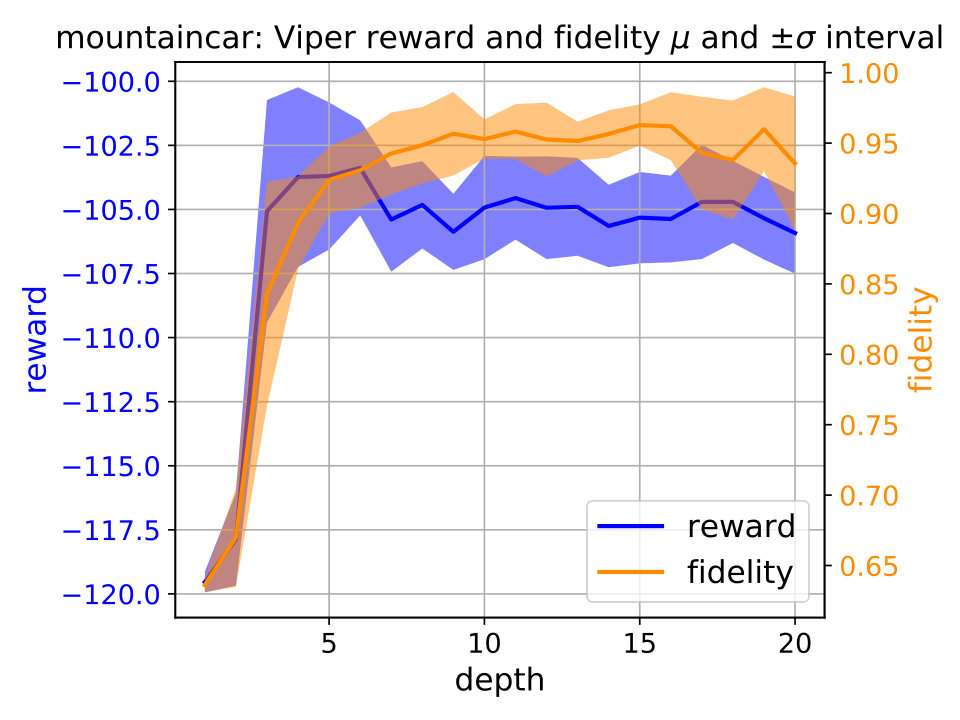 Figure 18
Figure 18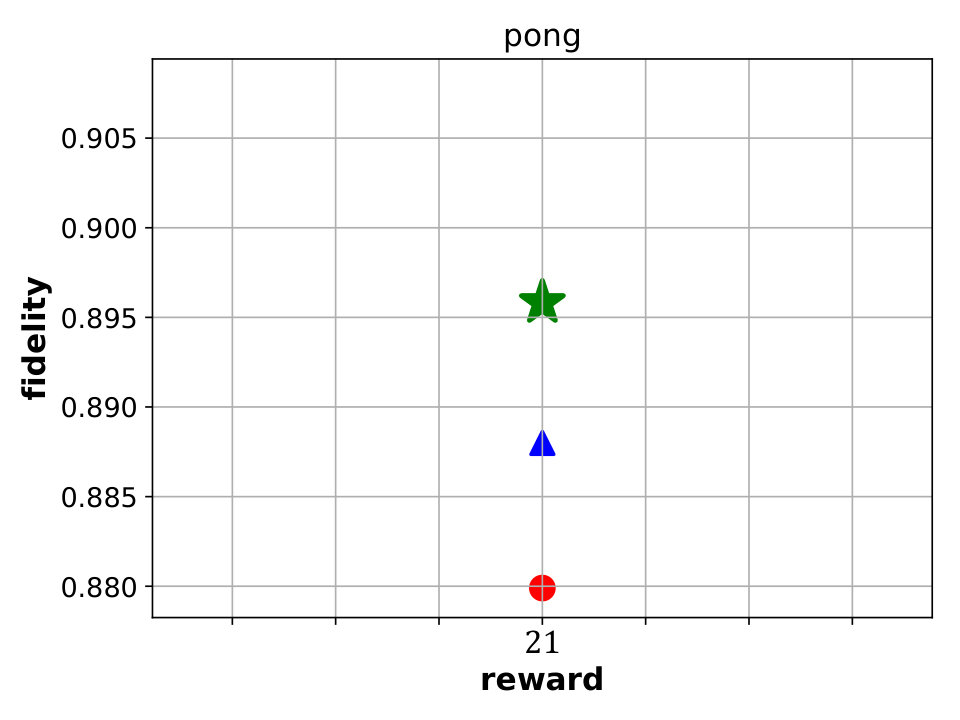 Figure 19
Figure 19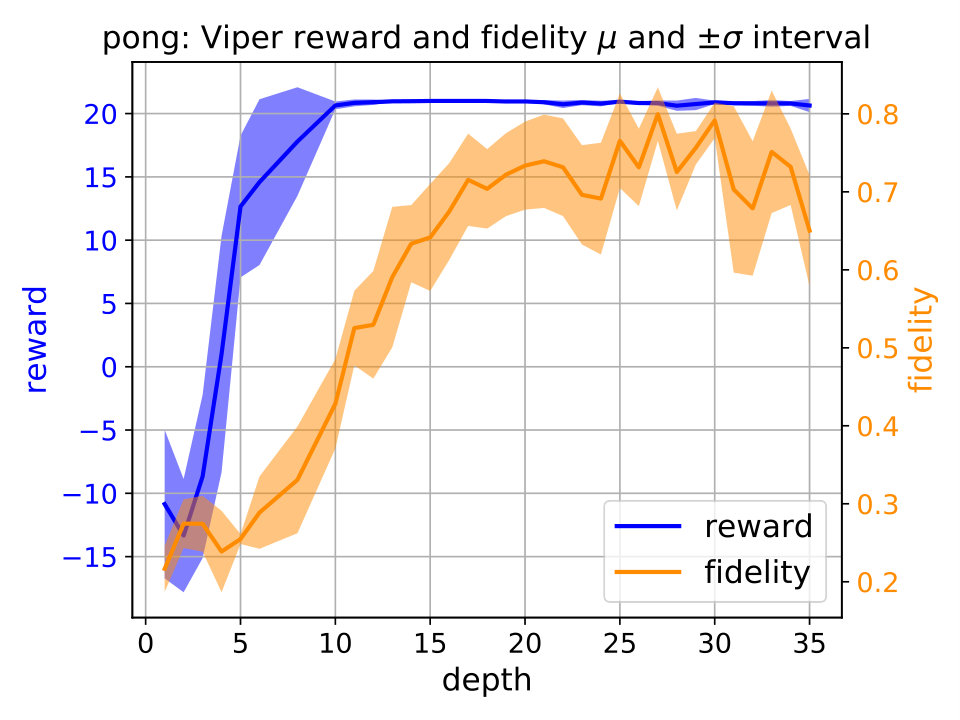 Figure 20
Figure 20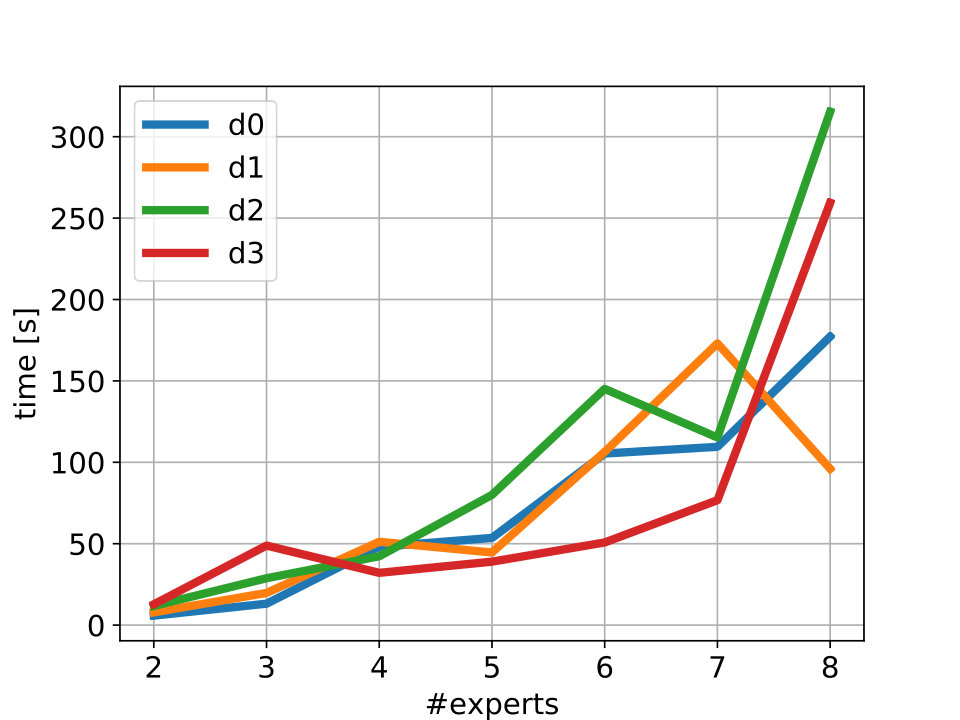 Figure 21
Figure 21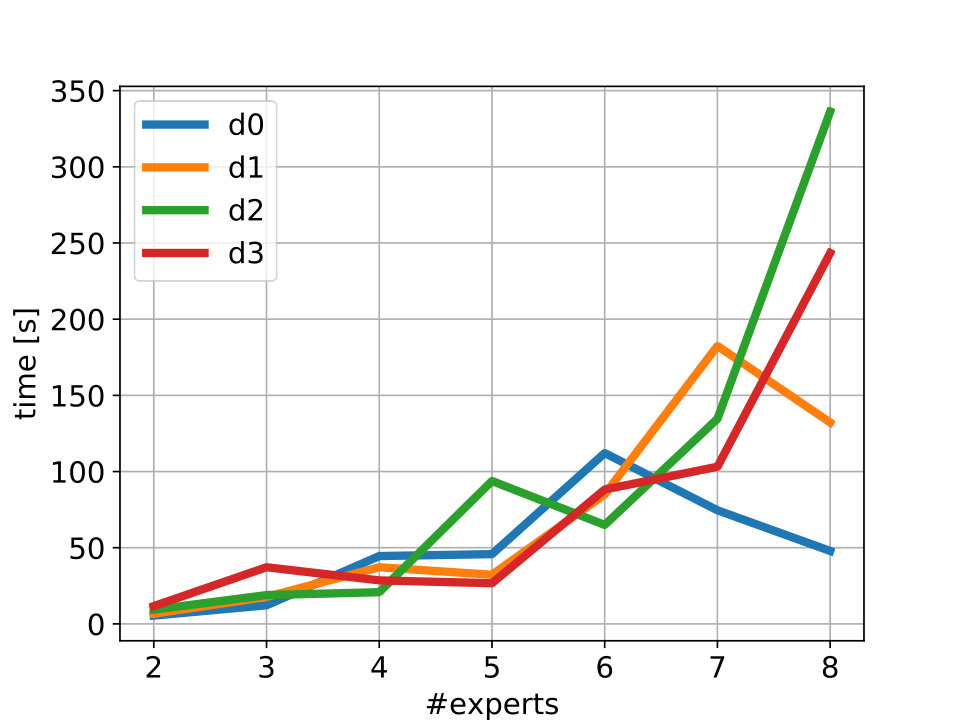 Figure 22
Figure 22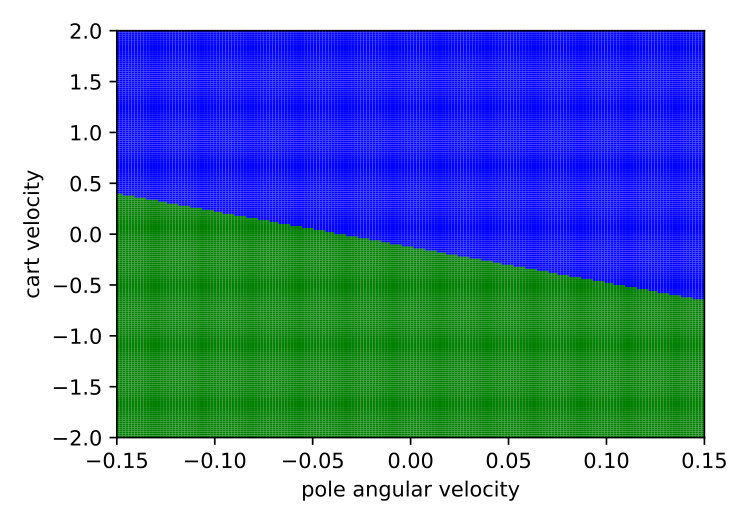 Figure 23
Figure 23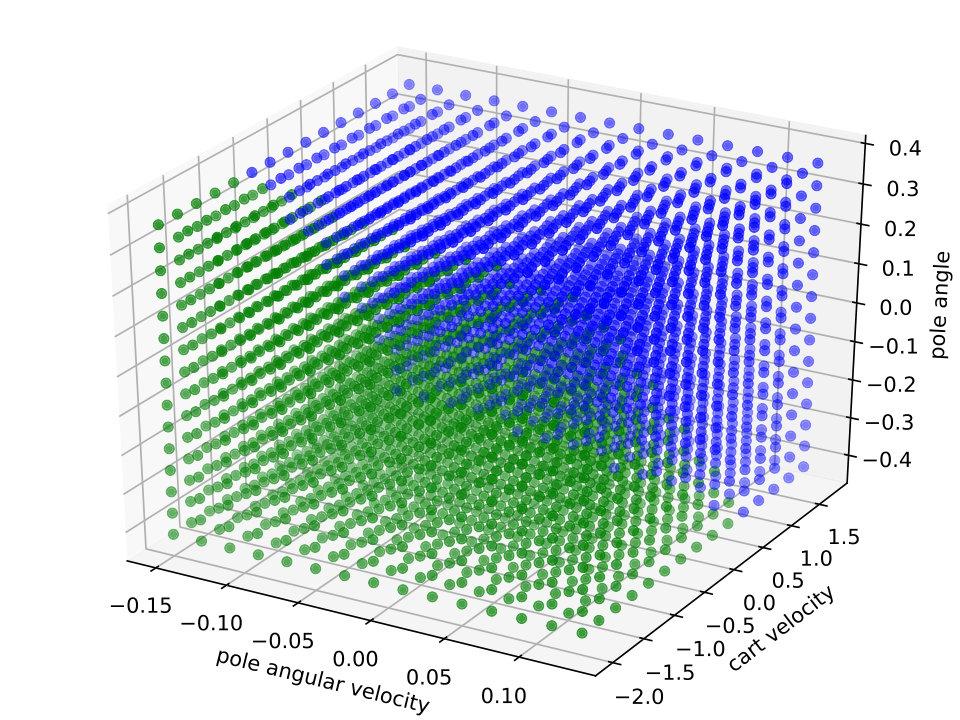 Figure 24
Figure 24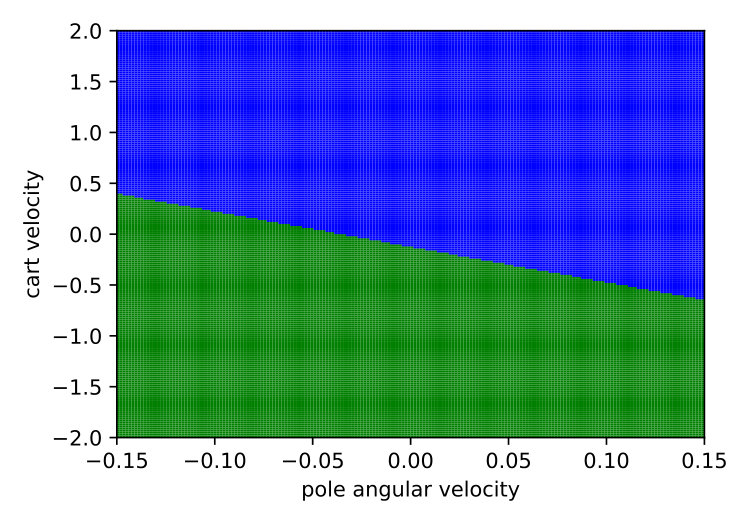 Figure 25
Figure 25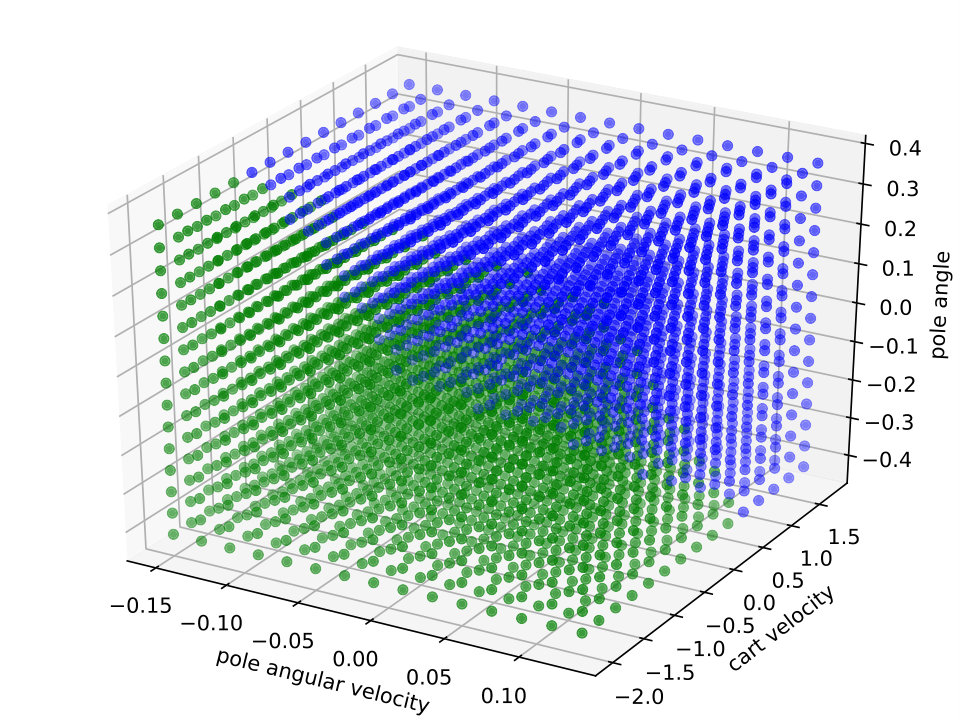 Figure 26
Figure 26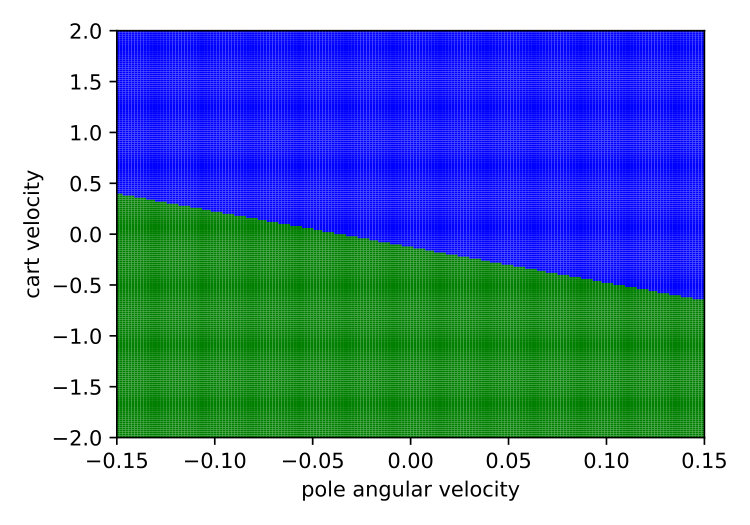 Figure 27
Figure 27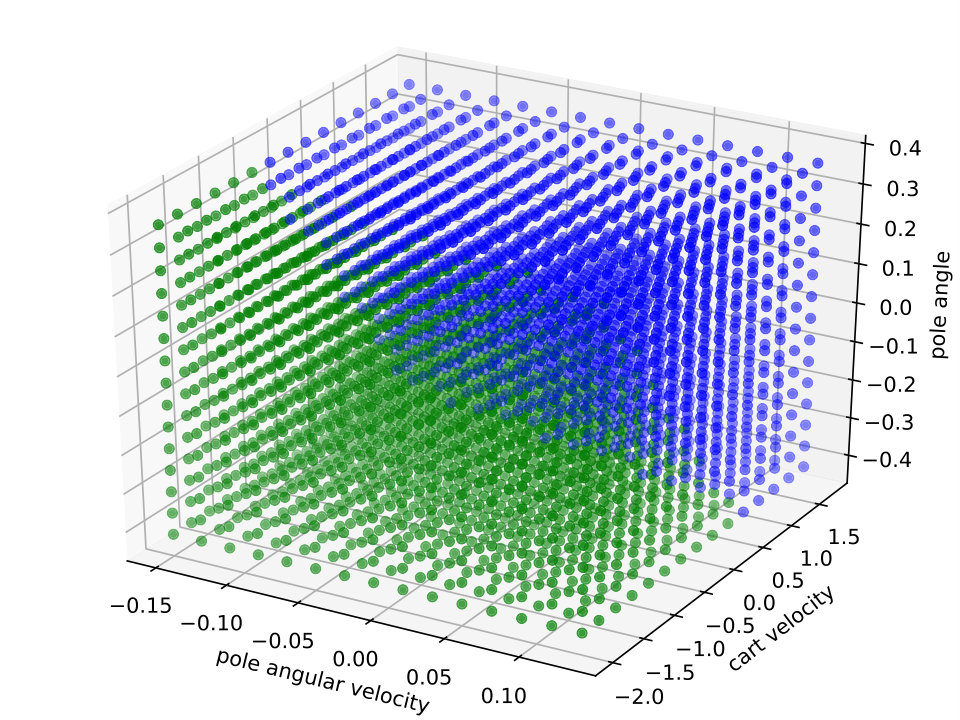 Figure 28
Figure 28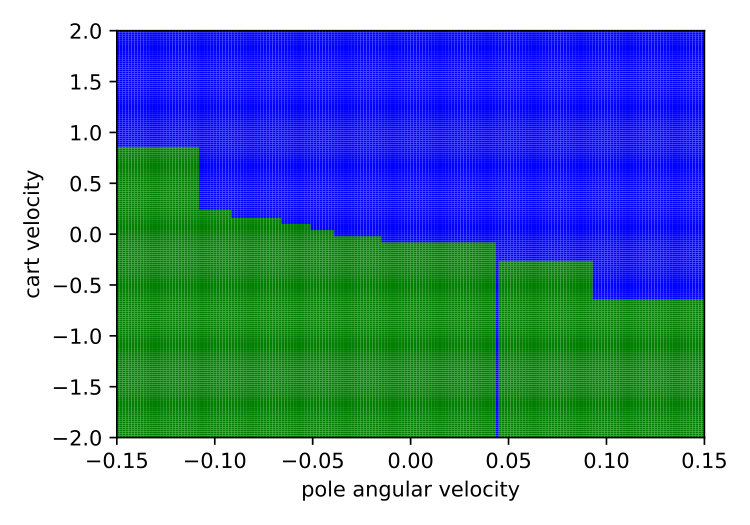 Figure 29
Figure 29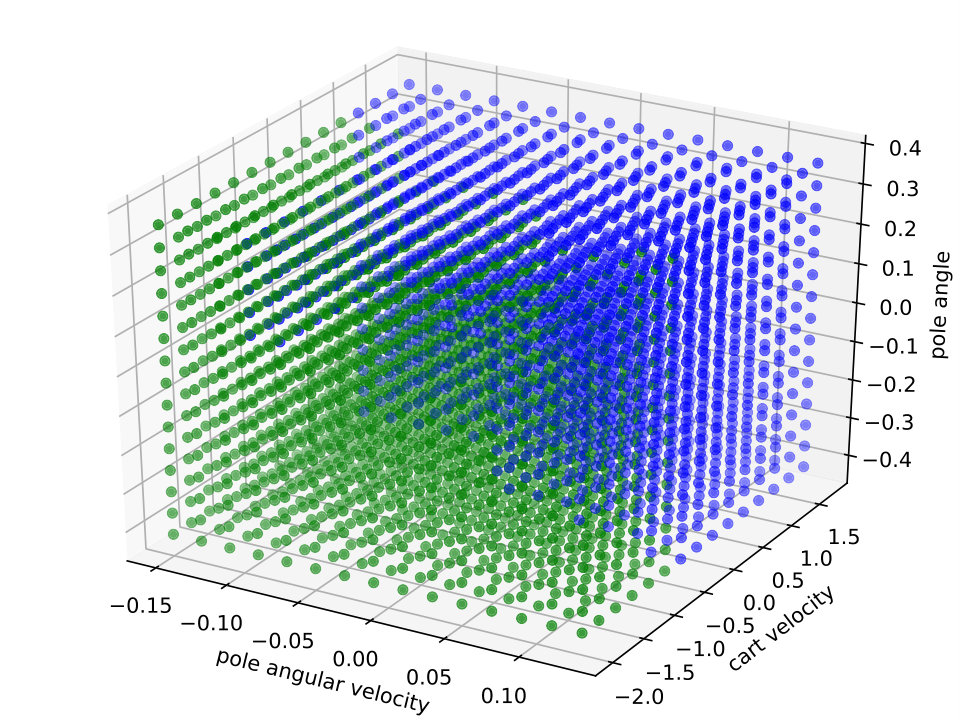 Figure 30
Figure 30| Depth | Nodes | |||
|---|---|---|---|---|
| N | MoËT | Viper DT | MoËT | Viper DT |
| 5 | 1 | 3 | 3 | 9 |
| 6 | 1 | 4 | 3 | 11 |
| 7 | 1 | 4 | 3 | 13 |
| 8 | 1 | 4 | 3 | 15 |
| 9 | 1 | 4 | 3 | 17 |
| 10 | 1 | 5 | 3 | 21 |
| Dataset | Size | Split (train/test/val) | Features |
|---|---|---|---|
| Adult income | 48,842 | 34,189 / 16,783 / 16,784 | 14 |
| German credit | 1,000 | 11,700 / 11,150 / 11,150 | 10 |
| Fetal health | 2,126 | 11,488 / 11,319 / 11,319 | 21 |
| model/metrics | F1 score | Accuracy |
|---|---|---|
| Decision tree | 0.852 0.004 | 0.939 0.004 |
| Lasso logistic regression | 0.797 0.000 | 0.915 0.000 |
| MoËTh | 0.880 0.001 | 0.950 0.001 |
| MoËT | 0.891 0.001 | 0.955 0.001 |
| Ridge logistic regression | 0.739 0.000 | 0.903 0.000 |
| SVC | 0.762 0.000 | 0.906 0.000 |
| model/metrics | F1 score | Accuracy |
|---|---|---|
| Decision tree | 0.759 0.000 | 0.637 0.000 |
| Lasso logistic regression | 0.797 0.000 | 0.667 0.000 |
| MoËTh | 0.759 0.003 | 0.638 0.004 |
| MoËT | 0.808 0.003 | 0.687 0.004 |
| Ridge logistic regression | 0.792 0.000 | 0.660 0.000 |
| SVC | 0.799 0.000 | 0.693 0.000 |
| model/metrics | F1 score | Accuracy |
|---|---|---|
| Decision tree | 0.661 0.003 | 0.852 0.001 |
| Lasso logistic regression | 0.536 0.000 | 0.820 0.000 |
| MoËTh | 0.676 0.000 | 0.854 0.000 |
| MoËT | 0.674 0.004 | 0.860 0.001 |
| Ridge logistic regression | 0.529 0.000 | 0.819 0.000 |
| SVC | 0.406 0.000 | 0.805 0.000 |
| Model | Configuration | Reward | Fidelity |
|---|---|---|---|
| MoËT | E2-D0 |
| Model | Configuration | Reward | Fidelity |
|---|---|---|---|
| MoËT | E16-D11 | ||
| MoËT | E15-D11 | ||
| MoËT | E15-D11 | ||
| MoËT | E16-D9 | ||
| MoËT | E16-D0 | ||
| MoËT | E16-D0 |
| Model | Configuration | Reward | Fidelity |
|---|---|---|---|
| MoËTh | E6-D9 | ||
| MoËT | E6-D7 | ||
| MoËT | E16-D7 | ||
| MoËT | E7-D8 | ||
| MoËT | E3-D7 | ||
| MoËT | E3-D10 | ||
| MoËTh | E3-D6 | ||
| MoËT | E7-D5 | ||
| MoËT | E3-D7 | ||
| Viper | D12 | ||
| MoËT | E2-D8 | ||
| Viper | D11 | ||
| MoËTh | E4-D4 | ||
| MoËT | E5-D5 | ||
| MoËTh | E8-D5 | ||
| MoËTh | E4-D5 | ||
| MoËTh | E2-D8 | ||
| MoËTh | E4-D5 | ||
| MoËTh | E4-D5 | ||
| MoËT | E4-D4 | ||
| Viper | D5 | ||
| MoËT | E7-D2 | ||
| MoËT | E4-D2 | ||
| MoËTh | E6-D1 |
| Model | Configuration | Reward | Fidelity |
|---|---|---|---|
| MoËT | E8-D17 | ||
| MoËT | E7-D17 | ||
| MoËT | E8-D17 | ||
| MoËT | E8-D17 | ||
| MoËTh | E8-D17 | ||
| MoËT | E6-D17 | ||
| MoËTh | E7-D0 | ||
| MoËTh | E7-D0 | ||
| MoËT | E6-D3 | ||
| MoËTh | E7-D0 |
| Model | Configuration | Reward | Fidelity |
|---|---|---|---|
| MoËT | E16-D21 |
| Model | Configuration | Reward | Fidelity |
|---|---|---|---|
| MoËT | E8-D16 | ||
| MoËTh | E7-D17 | ||
| MoËT | E4-D15 | ||
| MoËT | E6-D13 | ||
| MoËTh | E2-D12 |
| Model | Configuration | Reward | Fidelity |
|---|---|---|---|
| MoËT | E2-D0 |
| Model | Configuration | Reward | Fidelity |
|---|---|---|---|
| MoËT | E15-D11 | ||
| MoËT | E15-D11 | ||
| MoËT | E16-D11 | ||
| MoËT | E16-D9 | ||
| MoËT | E16-D0 | ||
| MoËT | E16-D0 |
| Model | Configuration | Reward | Fidelity |
|---|---|---|---|
| MoËT | E3-D7 | ||
| MoËT | E7-D8 | ||
| MoËT | E16-D7 | ||
| MoËT | E3-D7 | ||
| MoËT | E3-D10 | ||
| MoËT | E6-D7 | ||
| MoËTh | E3-D6 | ||
| MoËTh | E6-D9 | ||
| Viper | D11 | ||
| MoËT | E2-D8 | ||
| Viper | D12 | ||
| MoËT | E7-D5 | ||
| MoËTh | E8-D5 | ||
| MoËTh | E2-D8 | ||
| MoËT | E5-D5 | ||
| MoËTh | E4-D5 | ||
| MoËTh | E4-D4 | ||
| MoËTh | E6-D1 | ||
| MoËT | E4-D2 | ||
| MoËT | E4-D4 | ||
| MoËTh | E4-D5 | ||
| MoËT | E7-D2 | ||
| Viper | D5 | ||
| MoËTh | E4-D5 |
| Model | Configuration | Reward | Fidelity |
|---|---|---|---|
| MoËT | E8-D17 | ||
| MoËT | E6-D17 | ||
| MoËTh | E8-D17 | ||
| MoËT | E8-D17 | ||
| MoËT | E7-D17 | ||
| MoËT | E8-D17 | ||
| MoËTh | E7-D0 | ||
| MoËTh | E7-D0 | ||
| MoËTh | E7-D0 | ||
| MoËT | E6-D3 |
| Model | Configuration | Reward | Fidelity |
|---|---|---|---|
| MoËT | E16-D21 |
| Model | Configuration | Reward | Fidelity |
|---|---|---|---|
| MoËTh | E2-D12 | ||
| MoËTh | E7-D17 | ||
| MoËT | E4-D15 | ||
| MoËT | E6-D13 | ||
| MoËT | E8-D16 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
MoËT: Mixture of Expert Trees and its Application to Verifiable Reinforcement Learning
Marko Vasic
Andrija Petrovic
Kaiyuan Wang
Mladen Nikolic
Rishabh Singh
Sarfraz Khurshid
The University of Texas at Austin, USA
Singidunum University, Serbia
Google, USA
University of Belgrade, Serbia
Google Brain, USA
Abstract
Rapid advancements in deep learning have led to many recent breakthroughs. While deep learning models achieve superior performance, often statistically better than humans, their adoption into safety-critical settings, such as healthcare or self-driving cars is hindered by their inability to provide safety guarantees or to expose the inner workings of the model in a human understandable form. We present MoËT, a novel model based on Mixture of Experts, consisting of decision tree experts and a generalized linear model gating function. Thanks to such gating function the model is more expressive than the standard decision tree. To support non-differentiable decision trees as experts, we formulate a novel training procedure. In addition, we introduce a hard thresholding version, MoËTh, in which predictions are made solely by a single expert chosen via the gating function. Thanks to that property, MoËTh allows each prediction to be easily decomposed into a set of logical rules in a form which can be easily verified. While MoËT is a general use model, we illustrate its power in the reinforcement learning setting. By training MoËT models using an imitation learning procedure on deep RL agents we outperform the previous state-of-the-art technique based on decision trees while preserving the verifiability of the models. Moreover, we show that MoËT can also be used in real-world supervised problems on which it outperforms other verifiable machine learning models.
keywords:
Verification , Deep Learning , Reinforcement Learning , Mixture of Experts , Explainability
††journal: Neural Networks
\LetLtxMacro\todom\setabbreviationstyle
[acronym]long-short
1 Introduction
Deep learning has achieved many recent breakthroughs, in challenging domains such as Go [1], and healthcare [2, 3] to name a few. Encoding state representation via deep neural networks allows Deep Reinforcement Learning (DRL) agents to achieve superior performance. Also it enables development of performant radiology models [4, 5, 6]. However, the models learned do not provide safety guarantees and are hard to analyze, which hinders their use in safety-critical applications.
An effective recent approach, called Viper, follows the DAgger imitation learning procedure [7] to create a decision tree model mimicking a DRL agent [8]. The key advantage of such decision tree models is that they are amenable to verification. Moreover, they are shown to perform well on environments such as Pong. However, decision trees are limited to axis perpendicular decision boundaries, which can adversely impact the performance. In this paper, we alleviate this issue by proposing a model with less restrictions on the geometry of decision boundaries.
We present MoËT (Mixture of Expert Trees), a technique based on Mixture of Experts (MoE) [9, 10, 11]. MoËT consists of decision tree (DT) experts and a gating function that determines the weights with which experts are used. Standard MoE models can typically use any expert as long as it is a differentiable function of model parameters. In this paper we tackle the problem of using non-differentiable decision trees in MoE context, as a means of obtaining verifiable DRL agents. Similar to MoE training by Expectation-Maximization (EM) algorithm, we first observe that MoËT can be trained by interchangeably optimizing the weighted log likelihood for experts (independently from one another) and optimizing the gating function with respect to the obtained experts. Based on that, we propose a procedure for DT learning in the specific context of MOE. To the best of our knowledge we are first to combine standard non-differentiable DT experts with MoE approach.
For a gating function, we use a simple generalized linear model with softmax function, which provides a distribution over experts. While decision boundaries of DT s are axis-perpendicular, the softmax gating function supports boundaries with hyperplanes of arbitrary orientations, thus improving expressiveness. We also consider a variant of MoËT model that uses hard thresholding (MoËTh) which selects just one most likely expert tree. Since MoE training algorithm tends to assign a region of space to a single expert () anyway, this variant does not suffer in performance, as we empirically demonstrate. Benefits of MoËTh compared to the soft version of MoËT are that it (a) allows for decomposing a decision into a set of logical rules, thus providing means for interpreting the model decisions, and (b) allows translation to satisfiability modulo theories (SMT) 111Very roughly, SMT is the problem of determining whether a mathematical formula is satisfiable, and it generalizes the Boolean satisfiability problem (SAT) to more complex formulas. formulas [12], thus providing rich opportunities for formal verification using off the shelf SMT solvers 222SMT solvers are tools designed to solve SMT problems., as we demonstrate in the paper.
To employ MoËT in DRL setting we use the DAgger imitation learning procedure to mimic DRL agents. We evaluate our technique on six different environments: CartPole, Pong, Acrobot, Mountaincar, Lunarlander and Pendulum. We show that MoËT achieves better rewards and lower misprediction rates than Viper. Finally, we demonstrate how a MoËT policy for CartPole can be translated into an SMT formula to verify its properties using the Z3 theorem prover [13]. In addition we showed that MoËT can also be used in real-world supervised machine learning problems. We demonstrated that compared to the other verifiable machine learning models (logistic regression, decision trees and support vector classifiers with linear kernels) MoËT achieved much better results. By improving reliability of AI systems and to a degree improving their interpretability, our work aims at positive societal impact.
In summary, this paper makes the following key contributions:
We propose MoËT, a technique based on MoE with decision tree experts, and present a learning algorithm to train MoËT models. 2. 2.
We create MoËTh, MoËT version with hard thresholding and softmax gating function which can be translated to an SMT formula amenable for verification and is not hard to interpret in case of small models. 3. 3.
We apply MoËT models in the RL setting, evaluate it on different environments and show that they lead to more performant models compared to Viper decision trees. 4. 4.
We apply MoËT models in real-world supervised problems and show that MoËT achieved better results compared to the others verifiable machine learning models.
The remainder of the paper is structured as follows. In section 2 the related work is reviewed. Motivating example to showcase some of the key difference between Viper and MoËT is presented in section 3, whereas background methodology is presented in 4. Explanation of MoËT model is given in section 5. Experimental setup and results obtained on different RL environments and supervised datasets are presented in section 6. The conclusions are drawn in section 7. We open source our technique and make it available at: https://github.com/marko-vasic/MoET.
2 Related Work
Verifiable Machine Learning: RL algorithms are notoriously hard to debug and verify [14, 15]. A number of techniques has been proposed for enabling verification in RL setting [16, 17, 18, 19]. One existing approach synthesizes a program that approximates an RL policy [16]. The program acts as a shield, and their technique coordinates between using the shield program and original policy, which in combination provide safety guarantees. Instead of using a programmatic policy as a shield, another approach [18] creates a programmatic policy that can replace neural network policy altogether. Niu et al. [20] provide a general framework that leverages the success of verifiable and safe model-free RL in learning high performance controllers. Another system for verification of deep RL agents is presented in [17]. A hybrid RL agent framework that produces high-level autonomous verifiable behavior for unmanned vehicles is introduced in [21]. An abstraction approach, based on interval Markov decision processes, that yields probabilistic guarantees on accuracy of policy’s execution, and presents techniques to build and solve different kind of control problems using abstract interpretation, mixed-integer linear programming, entropy-based refinement, and probabilistic model checking is presented in [22].
Compared to the other approaches, in this paper we propose a pure machine learning technique that is verifiable and applicable even outside of the RL setting. There has also been recent work on verification of random forests and tree ensembles [23, 24]. Such approaches might be useful in our future work to extend verification from MoËTh to general MoËT models (which we describe later).
Explainable Machine Learning: There has been a lot of recent interest in explaining decisions of black-box models [25, 26, 27]. Nowadays, a large set of explainable RL literature is emerging, intended to provide ethical, responsible and trustable algorithms for explaining model outputs of DRL agents [28, 29, 30]. Shi et al. [31] proposed XPM – an explainable RL framework for portfolio management optimization that is based on application of class activation mappings for output explanation. Similarly, Ayala et al. [32] proposed the introspection-based method for transforming Q-values into probabilities of success, used as the base to explain the agent’s decision-making process. Besides of the explainable RL algorithms, the two most well known algorithms that are commonly used for deep learning models interpretation are LIME [33] and LORE [34]. LIME and LORE explain behavior of a black-box model locally, around an input of interest, by sampling the black-box model around the neighborhood of the input, and training a local DT (or a linear model) over the sampled points.
Another view at MoËT is that it explains behavior of a deep RL agent. MoËT combines local trees into a global policy by combining local decision trees via a gating function. Inspection of the trees and the gating might shed light on the agent’s decision making. However, we do not focus on this aspect in this paper.
Tree-Structured Models: Tree-Structured models are very attractive type of machine learning algorithms due to low complexity and interpretability [35, 36]. Irsoy et al. [37] propose a decision tree model with soft decisions at internal nodes where children are chosen with probabilities given by a sigmoid gating function. However, this reduces the tree’s interpretability. Binary tree-structured hierarchical routing mixture of experts (HRME) model, which has classifiers as non-leaf node experts and simple regression models as leaf node experts, was proposed in [38]. Hester and Stone [39] use random forests in RL setting to build a model of environment from which policy is inferred.
The form of our model can be related to these models, but it is designed with verifiability in mind and we also propose a novel training procedure suited to that specific model.
Knowledge Distillation and Model Compression: We rely on ideas already explored in fields of model compression [40] and knowledge distillation [41, 42, 43]. The idea is to use a complex well performing model to facilitate training of a simpler model which might have some other desirable properties (e.g., verifiability and interpretability). Such practices have been applied to approximate decision tree ensemble by a single tree [44]. In contrast, we approximate a neural network. Similarly, a neural network can be used to train another neural network [45], but neural networks are hard to interpret and even harder to formally verify. Such practices have also been applied in the field of reinforcement learning in knowledge and policy distillation [46, 47, 48, 49, 50], which are similar in spirit to our work, and imitation learning [8, 7, 51, 52], which provide a foundation for our work.
3 Motivating Example: Gridworld
We now present a simple motivating example to showcase some of the key differences between Viper and MoËT approaches. Consider the Gridworld problem shown in Figure 1 (for ). The agent is placed at a random position in a grid (except the walls denoted by filled rectangles) and should find its way out. To move through the grid the agent can choose to go up, left, right or down at each time step. If it hits the wall (gray cell) it stays in the same position (state). State is represented using two integer values ( coordinates) which range from —bottom left to —top right. The grid can be escaped through either left doors (left of the first column), or right doors (right of the last column). A negative reward of is received for each agent action (negative reward encourages the agent to find the exit as fast as possible). An episode finishes as soon as an exit is reached or if steps are made whichever comes first.
The optimal policy () for this problem consists of taking the left (right resp.) action for each state below (above resp.) the diagonal. We used as a teacher and imitation learning approach of Viper to train an interpretable DT policy that mimics . The resulting DT policy is shown in Figure 1. The DT partitions the state space (grid) using lines perpendicular to x and y axes, until it separates all states above diagonal from those below. This results in a DT of depth with nodes. On the other hand, the policy learned by MoËT is shown in Figure 1. The MoËT model with experts learns to partition the space using the line defined by a linear function (roughly the diagonal of the grid). Points on the different sides of the line correspond to two different experts which are themselves DT s of depth [math] always choosing to go left (below) or right (above).
We notice that DT policy needs much larger depth to represent while MoËT can represent it as only one decision step. Furthermore, with increasing (size of the grid), complexity of DT grows, while MoËT complexity stays the same; we empirically confirm this as follows. For Gridworld sizes , the depths of obtained DT s are and the numbers of their nodes are respectively. In contrast, MoËT models of the same complexity and structure as the one shown in Figure 1 are learned for all values of . We present these results in Table 1 for better readability (all policies learned are equivalent to ).
4 Background
In this section we provide description of two relevant methods we build upon: (1) Viper, an approach for interpretable imitation learning, and (2) MoE learning framework.
Viper. Viper algorithm (included in appendix) is an instance of DAgger imitation learning approach, adapted to prioritize critical states based on Q-values. Inputs to the Viper training algorithm are (1) environment which is an finite horizon (-step) Markov Decision Process (MDP) with states , actions , transition probabilities , and rewards ; (2) teacher policy ; (3) its Q-function and (4) number of training iterations . Distribution of states after steps in environment using a policy is (assuming randomly chosen initial state). Viper uses the teacher as an oracle to label the data (states with actions). It initially uses teacher policy to sample trajectories (states) to train a student (DT) policy. It then uses the student policy to generate more trajectories. Viper samples training points from the collected dataset giving priority to states having higher importance , where . This sampling of states leads to faster learning and shallower DT s. The process of sampling trajectories and training students is repeated for number of iterations , and the best student policy is chosen using reward as the criterion.
Mixture of Experts. MoE is an ensemble model [9, 10, 11] that consists of expert networks and a gating function. Gating function divides the input (feature) space into regions for which different experts are specialized and responsible. MoE is flexible with respect to the choice of expert models as long as they are differentiable functions of model parameters (which is not the case for DT s).
In MoE framework, probability of outputting given an input is given by:
[TABLE]
where is the number of experts, is the probability of choosing the expert (given input ), is the probability of expert producing output (given input ). Learnable parameters are , where are parameters of the gating function and are parameters of the experts. Gating function can be modeled using a softmax function over a set of linear models. Let consist of parameter vectors , then the gating function can be defined as .
In the case of classification, an expert outputs a vector of length , where is the number of classes. Expert associates a probability to each output class (given by ) using the gating function. Final probability of a class is a gate weighted sum of for all experts . This creates a probability vector , and the output of MoE is .
MoE is commonly trained using an EM algorithm, where instead of direct optimization of the likelihood one performs optimization of an auxiliary function defined in a following way. Let denote the expert chosen for instance . Then joint likelihood of and can be considered. Since is not observed in the data, log likelihood of samples cannot be computed, but instead expected log likelihood can be considered, where expectation is taken over . Since the expectation has to rely on some distribution of , in the iterative process, the distribution with respect to the current estimate of parameters is used. More precisely function is defined by [10]:
[TABLE]
where is the estimate of parameters in iteration . Then, for a specific sample , the following formula can be derived [10]:
[TABLE]
where it holds
[TABLE]
5 Mixture of Expert Trees
In this section we explain the adaptation of original MoE model to mixture of decision trees, and present both training and inference algorithms.
Considering that coefficients (Eq. 4) are fixed with respect to and that in Eq. 3 the gating part (first double sum) and each expert part depend on disjoint subsets of parameters , training can be carried out by interchangeably optimizing the weighted log likelihood for experts (independently from one another) and optimizing the gating function with respect to the obtained experts. The training procedure for MoËT, described by Algorithm 1, is based on this observation. First, the parameters of the gating function are randomly initialized (line 2). Then the experts are trained one by one. Each expert is trained on a dataset of instances weighted by coefficients (line 5), by applying specific DT learning algorithm (line 6) that we adapted for MoE context (described below). After the experts are trained, an optimization step is performed (line 7) in order to increase the gating part of Eq. 3. At the end, the parameters are returned (line 8).
Our tree learning procedure is as follows. Our technique modifies original MoE algorithm in that it uses DT s as experts. The fundamental difference with respect to traditional model comes from the fact that DT s do not rely on explicit and differentiable loss function which can be trained by gradient descent or Newton’s methods. Instead, due to their discrete structure, they rely on a specific greedy training procedure. Therefore, the training of DT s has to be modified in order to take into account the attribution of instances to the experts given by coefficients , sometimes called responsibility of expert for instance . If these responsibilities were hard, meaning that each instance is assigned to strictly one expert, they would result in partitioning the feature space into disjoint regions belonging to different experts. On the other hand, soft responsibilities are fractionally distributing each instance to different experts. The higher the responsibility of an expert for an instance , the higher the influence of that instance on that expert’s training. In order to formulate this principle, we consider which way the instance influences construction of a tree. First, it affects the impurity measure computed when splitting the nodes and second, it influences probability estimates in the leaves of the tree. We address these two issues next.
A commonly used impurity measure to determine splits in the tree is the Gini index. Let be a set of indices of instances assigned to the node for which the split is being computed and set of corresponding instances. Let categorical outcomes of be , and for let denote as a fraction of instances in for which it holds . More formally , where denotes indicator function of its argument expression and equals if the expression is true. Then the Gini index of the set is defined by: . Considering that the assignment of instances to experts are fractional as defined by responsibility coefficients (which are provided to tree fitting function as weights of instances computed in line 5 of the algorithm), this definition has to be modified in that the instances assigned to the node should not be counted, but instead, their weights should be summed. Hence, we propose the following definition:
[TABLE]
and compute the Gini index for the set as . Similar modification can be performed for other impurity measures (such as entropy) relying on distribution of outcomes of a categorical variable. Note that while the instance assignments to experts are soft, instance assignments to nodes within an expert are hard, meaning sets of instances assigned to different nodes are disjoint. Probability estimate for in the leaf node is usually performed by computing fractions of instances belonging to each class. Instead of such estimates, again, we use estimates defined by Eq. 5. Hence, the estimates of probabilities needed by MoE are defined. In Algorithm 1, function performs decision tree training using the above modifications.
We consider two ways to perform inference with respect to the obtained model. First one which we call MoËT, is performed by maximizing with respect to where this probability is defined by Eq. 1. The second way, which we call MoËTh, performs inference as , meaning that we only rely on the most probable expert.
Adaptation of MoËT to imitation learning. We integrate MoËT model into imitation learning approach of Viper by substituting training of DT with the MoËT training procedure.
Verifiability by translating MoËT to SMT. We define a translation of MoËTh models to SMT formulas, which opens a range of possibilities for validating and interpreting the model using automated reasoning tools. SMT formulas provide a rich means of logical reasoning, where a user can query the solver with questions such as: “What inputs do the two models differ on?”, or “What is the closest input to the given input using which model makes a different prediction?”, or “Are the two models equivalent?”, or “Are the two models equivalent in respect to the output class C?”. Answers to such questions can help better understand and compare models in a rigorous way. Also note that the symbolic reasoning of the gating function and decision trees allows construction of SMT formulas that are readily handled by off-the-shelf tools, whereas direct SMT encoding of neural networks do not scale for any reasonably sized network because of the need for non-linear arithmetic reasoning.
We show the translation of MoËT policy to SMT constraints for verifying policy properties. We present an example translation of MoËT policy on CartPole environment with the same property specification that was proposed for verifying Viper policies [8]. The goal in CartPole is to keep the pole upright, which can be encoded as a formula:
[TABLE]
where represents state after steps, is the deviation of pole from the upright position. In order to encode this formula it is necessary to encode the transition function which models environment dynamics: given a state and action it returns the next state of the environment. Also, it is necessary to encode the policy function that for a given state returns action to perform. There are two issues with verifying : (1) infinite time horizon; and (2) the nonlinear transition function . To solve this problem, Bastani et al. [8] use a finite time horizon and linear approximation of the dynamics. We make the same assumptions.
To encode we need to translate both the gating function and DT experts to logical formulas. Since the gating function in MoËTh uses exponential function, it is difficult to encode the function directly in Z3 as SMT solvers do not have efficient decision procedures to solve non-linear arithmetic. The direct encoding of exponentiation therefore leads to prohibitively complex Z3 formulas. We exploit the following simplification of the gating function that is sound when hard prediction is used:
[TABLE]
First simplification is possible since the denominators of the gating functions are same for all experts, and second is due to the monotonicity of the exponential function. We use the same DT encoding as in Viper. To verify that holds we need to show that is unsatisfiable. In the experimental evaluation we run the verification with our MoËTh policies and show that is indeed unsatisfiable.
Expressiveness. DT s make their decisions by partitioning the feature space into regions which have borders perpendicular to coordinate axes. To approximate borders that are not perpendicular to coordinate axes very deep trees are often necessary. MoËTh mitigates this shortcoming by exploiting hard softmax partitioning of the feature space using borders which are still hyperplanes, but need not be perpendicular to coordinate axes (see Section 3), which improves the expressiveness.
Interpretability. While we do not focus on interpretability in this work, it is useful to note that MoËTh models do exhibit some interpretability properties. A MoËTh model is a combination of a linear model and several decision tree models. Only a single DT is used for each prediction (instead of weighted average), which facilitates interpretability. If the models are small (e.g, depth ) and include small number of features, a person can easily simulate and understand the model. These observations resonate with several points about interpretability made in [53]
Limitations. Our work tries to strike a balance between expressiveness, which allows for more performant models, and verifiability, which allows for more reliable models. Therefore, while being more expressive than decision trees, MoËT still has limited expressiveness compared to deep learning models, which is a price paid for easier verifiability.
6 Evaluation
We first discuss DRL agents we use as a starting point in the imitation learning. Second, we explore the performance capabilities of Viper by finding decision tree depths at which the performance saturates—cannot be improved by increasing the depth further. Then, after ensuring that we explored the useful space of configurations for Viper, we pick the best performing Viper models and compare them with the best performing MoËT models to quantitatively compare the two. Finally, we re-evaluate performance of the models to evaluate how well they generalize. Also, we verify MoËTh policies on CartPole environment and visually compare the expressiveness of different policies. Eventually, we presented that MoËT can be also successfully applied in real-world supervised learning problems.
DRL** agents**. We use following OpenAI Gym environments in our evaluation: CartPole, Acrobot, Mountaincar, Lunarlander, Pong and Pendulum (description of the environments is included in the appendix). For DRL agents, we use a policy gradient model in CartPole, a deep Q-network (DQN) [54] in Pong, and dueling DQN [55] in the other environments (training hyperparameters provided in the appendix). We train MoËT and Viper policies by mimicking the agents. The rewards (total return during an episode) obtained by the DRL agents on CartPole, Acrobot, Mountaincar, Lunarlander, Pong and Pendulum are , , , , and , respectively. Rewards are averaged across ( in CartPole) runs (episodes).
Performance saturation of Viper. We first examine performance capabilities of Viper, i.e., answer the question of when the performance saturates, by examining performance of decision trees of gradually increased maximum depth (Figure 2). For each depth we train multiple Viper models and show performance trends in terms of reward and fidelity. By reward we mean cumulative reward achieved during an episode, while fidelity represents percent of times a student performs the same action as its teacher (DRL agent). Achieving high reward indicates that a student is performing well, while high fidelity indicates that the student policy is close to the teacher’s. We ensure to train at least different Viper models for each depth.333 We train at least Viper models for each subject and maximum depth value. Due to the computational limitations actual number of Viper models trained varies across environments: CartPole , Acrobot , Mountaincar , Lunarlander , Pong and Pendulum .
Using the performance trend plots we infer when Viper performance saturates, i.e., reaches a depth after which further increasing maximum depth does not help. Performance saturation depths for CartPole, Acrobot, Mountaincar, Lunarlander, Pong and Pendulum are , , , , and , respectively. Identifying the performance saturation points for Viper is helpful in identifying the overall best performing Viper model, thus giving confidence during comparison with MoËT models that we explored the useful space of Viper configurations.
Best performing Viper, MoËT and MoËTh models. We next compare Viper, MoËT and MoËTh models by visualizing their Pareto fronts with respect to the reward and fidelity (Figure 3). Pareto front of a set of models consists of all models from that set which are not dominated by any other model from the set in terms of reward or fidelity. In other words, every model dominated by another model in terms of both metrics is not considered. From the set of all Viper models trained for different maximum depths (from depth to the saturation depth) we select models on the Pareto front. Similar is done for MoËT and MoËTh which we trained for different number of experts and expert depths (information about configurations used is provided in the appendix). A global Pareto front (best models across all architectures) is shown with points connected by a black solid line.
By inspecting the results we notice that in the case of CartPole, all models achieve maximum reward (), however fidelity is significantly higher in the case of MoËT and MoËTh (over compared to ). Also, it is interesting to note that both MoËT and MoËTh models on the Pareto front consist of experts of depth [math], while the Viper model on the Pareto front is a decision tree of depth . In the case of Acrobot, we notice that MoËT models dominate MoËTh and Viper models, and that MoËTh models dominate Viper models. Thus, both MoËT and MoËTh models achieve higher reward and fidelity over Viper models. In the case of Mountaincar, the global Pareto front contains some Viper models, but mostly MoËT and MoËTh dominate. Furthermore, models exhibiting the highest reward as well as fidelity are MoËT and MoËTh models. In the case of Lunarlander, both MoËT and MoËTh dominate Viper models. A MoËTh model achieves the maximum reward of over while a Viper model achieves the maximum reward of around . Furthermore, both MoËT and MoËTh models achieve better fidelity compared to Viper. In the case of Pong, all models achieve maximum reward (), however fidelity is higher for MoËT and MoËTh. In the case of Pendulum, MoËT and MoËTh models achieve better maximum reward, while maximum fidelity is about equal for all the models. Note that for a given fidelity score, MoËT and MoËTh are advantageous to Viper. Scores of the points on the global Pareto front are presented in a tabular form in E.
Performance generalization of models. In the supervised learning setting, after the best models are selected based on their performance on a validation set, they are re-evaluated on a test set to get a better estimate of their performance on the new data. In RL setting there is no direct analogy to validation and test datasets, but the models can be re-evaluated after the selection is performed. After we identify the best models on the Pareto fronts (Figure 3), we re-evaluate their performance by running them again through the RL environment. Figure 4 shows the achieved performance of these models after re-evaluation. In the case of CartPole and Pong performance before and after re-evaluation are very similar. In the case of Acrobot, Mountaincar and Lunarlander, models that were on the global Pareto front are mostly still on the global Pareto front in the re-evaluation. Moreover, MoËT and MoËTh models dominate Viper models in most of the cases. Pendulum environment behaves more stochastically – evaluating policy (done across episodes) can exhibit significantly different reward from evaluation to evaluation, making results more inconclusive. However, all models achieve great fidelity level, and reward that is close to the DRL agent one. Considering high performance, differences in performance between models are minor. Scores of the points that were on the global Pareto front are presented in a tabular form in E.
Following the previous analysis, we conclude that MoËT and MoËTh models provide better performance (in terms of reward and fidelity) compared to Viper in most of the cases, demonstrating that MoËT is a valuable technique to be considered when looking for a verifiable RL policy.
Verification. We perform verification of MoËTh policies obtained in our experiments according to the procedure described in Section 5. All models considered in this experiment successfully pass the verification procedure. To better understand the scalability of our verification procedure, we report the verification times needed to verify policies for different number of experts and expert depths in Figure 5. The verification times generally increase with the number of experts. MoËTh policies with 2 experts take from s to s for verification, while the verification times for 8 experts can go up to as much as s. This corresponds to the complexity of the logical formula obtained with an increase in the number of experts. While the effect of expert depths on verification times is visible in a case of few experts, with the increase of experts it is less noticeable, thus indicating that the number of experts has more influence on the verification times than expert depths. We run the verification on Intel i7-7600, 2.80GHz, 16 GB LPDDR3. We show example SMT formula (of Viper and MoËTh policies) in D.
Expressiveness. We provide a simple qualitative comparison of best Viper and MoËTh policies, by contrasting them to DRL policy on a CartPole environment. The figure 6 visualizes these policies and demonstrates that MoËTh policy much more closely resembles the DRL policy thanks to its ability to represent hyperplanes of arbitrary orientation, while DT policy obtained by Viper approximates DRL policy by axis perpendicular hyperplanes. The MoËTh policy presented is equivalent to the following program: if then go right else go left, where and are cart position and velocity, and and pole angle and its angular velocity.
Supervised learning. We evaluated the performance of MoËT and MoËTh in the supervised regime on three real-world datasets. Two datasets (German credit and Adult income) come from the UCI ML repository [56], whereas the Fetal health dataset is a publicly available dataset that can be found on Kaggle. We summarize the properties of the datasets that we use in Table 2.
In the Adult income dataset [57] the goal is to predict whether an income is greater than 50K dollars. In the German credit dataset, the goal is to classify bank account holders into two classes – good or bad. In the Fetal health dataset, the goal is to predict whether a fetus is healthy or not based on the features extracted from cardiotocogram examination.
We compared MoËT with other supervised learning models which would require similar effort and tools to be verified: decision tree, support vector classifier (SVC) with linear kernel, ridge logistic regression and lasso logistic regression. The results are evaluated by F1 score and accuracy. The hyperparameters of compared models are tuned on validation set. The results evaluated on test set with 95% confidence intervals for Fetal health, German credit, and Adult income datasets are presented in Tables 3, 4, and 5, respectively. It can be observed that MoËT is the best performing model with exception of SVC being better on German credit data according to accuracy (but not F1 score). Therefore, it can be concluded that MoËT can also be successfully applied in the case of supervised learning problems.
7 Conclusion
We introduced MoËT, a technique based on MoE with decision trees as experts and formulated a learning algorithm to train MoËT models. To the best of our knowledge, this approach is the first to combine standard non-differentiable DT experts with MoE approach. Furthermore, we used MoËT in RL setting by mimicking DRL agents, in this way constructing RL policies that can be verified and are more interpretable than the DRL agents themselves. We showed a procedure to translate MoËT policies into SMT logic providing rich means for verification, and showed that MoËT models perform better than the previous state-of-the-art approach Viper and that they are also useful in the supervised regime.
ACKNOWLEDGMENTS. This work was supported by NSF grant CCF-1718903 to SK.
Appendix A Viper Algorithm
Viper algorithm is shown in Algorithm 2.
Appendix B Environments
In this section we provide a brief description of environments we used in our experiments. We used five environments from OpenAI Gym: CartPole, Acrobot, Mountaincar, Lunarlander, Pong and Pendulum.
B.1 CartPole
This environment consists of a cart and a rigid pole hinged to the cart, based on the system presented by Barto et al. [58]. At the beginning pole is upright, and the goal is to prevent it from falling over. Cart is allowed to move horizontally within predefined bounds, and controller chooses to apply either left or right force to the cart. State is defined with four variables: (cart position), (cart velocity), (pole angle), and (pole angular velocity). Game is terminated when the absolute value of pole angle exceeds , cart position is more than units away from the center, or after successful steps; whichever comes first. In each step reward of is given, and the game is considered solved when the average reward is over in over 100 consecutive trials.
B.2 Acrobot
This environment is analogous to a gymnast swinging on a horizontal bar, and consists of a two links and two joins, where the joint between the links is actuated. The environment is based on the system presented by Sutton [59]. Initially both links are pointing downwards, and the goal is to swing the end-point (feet) above the bar for at least the length of one link. The state consists of six variables, four variables consisting of and values of the joint angles, and two variables for angular velocities of the joints. The action is either applying negative, neutral, or positive torque on the joint. At each time step reward of is received, and episode is terminated upon successful reaching the height, or after steps, whichever comes first. Acrobot is an unsolved environment in that there is no reward limit under which is considered solved, but the goal is to achieve high reward.
B.3 Mountaincar
This environment consists of a car positioned between two hills, with a goal of reaching the hill in front of the car. The environment is based on the system presented by Moore [60]. Car can move in a one-dimensional track, but does not have enough power to reach the hill in one go, thus it needs to build momentum going back and forth to finally reach the hill. Controller can choose left, right or neutral action to apply left, right or no force to the car. State is defined by two variables, describing car position and car velocity. In each step reward of is received, and episode is terminated upon reaching the hill, or after steps, whichever comes first. The game is considered solved if average reward over consecutive trials is no less than .
B.4 Lunarlander
This environment consists of a space ship and a landing pad, to which the ship should land. Controller can choose when to turn on the left engine, right engine or the main engine, thus controlling the movement of the ship. State is defined by: and coordinates of the lander, and velocities in the and direction, angle of the lander, angular velocity, and two boolean values indicating if left or right leg is touching the ground. Episode finishes when lander crashes or comes to rest, after which it received appropriate reward. Firing main engine is points, and each leg contact is points. The game is considered solved if achieved reward is at least points.
B.5 Pong
This is a classical Atari game of table tennis with two players. Minimum possible score is and maximum is .
B.6 Pendulum
The environment consists of a pendulum, and the goal is to swing it up so it stays upright. State is defined by: —angle of the pendulum, and —angular velocity of the pendulum. Note that the OpenAI gym environment instead of the state feature contains two features: (which is equal to ) and (which is equal to ). Action available is applying torque to the pendulum. In OpenAI gym action can take any value in range . We discretize action space into possible actions corresponding to torque of , [math], or . In each step reward obtained is equal to . Thus, the maximum reward that can be obtained in a step is [math], which occurs when pendulum is upright, with zero velocity, and [math] torque is applied to the pendulum. Episode is of length .
Appendix C Model training parameters
C.1 DRL Agent Training
In this section we present the architectures and hyperparameters used to train DRL agents for different environments.
For CartPole, we use policy gradient model as used in Viper. While we use the same model, we had to retrain it from scratch as the trained Viper agent was not available. We use hidden layer with neurons. We set discount factor to , number of epochs to and batch size to .
For Pong, we use a DQN network [54] model that is already trained (the same as used in Viper). This model originates from the OpenAI baselines [61].
For Acrobot, Mountaincar and Lunarlander, we implement our own version of dueling DQN network following [55]. We use hidden layers with neurons in each layer for Mountaincar, and neurons in each layer for Acrobot and Lunarlander. We set the learning rate to , batch size to in Mountaincar, in Acrobot and Lunarlander, step size to and number of epochs to in Mountaincar, in Acrobot and Lunarlander. We checkpoint a model every steps and pick the best performing one in terms of achieved reward.
C.2 Viper and MoËT Training
We used iterations of DAgger, and as a maximum number of samples for training student policies. During evaluation, cumulative reward is averaged across runs in a given environment ( in a case of CartPole).
We trained Viper for varying value of the tree maximum depth. The values used are: in CartPole, in Acrobot, in Mountaincar, In Lunarlander, and in Pong.
We trained MoËT models for varying number of experts and their maximum depths. The number of experts used are: in CartPole, in Acrobot, in Mountaincar, in Lunarlander, and in Pong. The maximum depths of experts are: in CartPole, in Acrobot, in Mountaincar, in Lunarlander, and in Pong. We used following learning rates for training MoËT models: , while for the learning rate decay we used (no decay) and (learning rate is multiplied by this value after each epoch). As for the maximum number of epochs for MoËT training procedure we used values: .
C.3 Compute
To run our experiments we used a cluster with nodes of the following configuration: Xeon CPU E5-2650 v3 (Haswell): 10 cores per socket (20 cores/node), 2.30GHz, 128 GB DDR4-2133. We used up to 10 such nodes when scheduling our experiments.
Appendix D SMT translation example
The CartPole MoËTh policy presented in Figure 6 is shown in Figure 7. SMT formula that would encode the policy part (mapping input to a model decision) of CartPole verification formula would look as follows: If(2.18cp + 7.22cv + 20.64pa + 25.33pv > -1, 1, 0). This MoËTh policy consists of the gating expressed by the inequality and two trivial expert decision trees of depth [math]. Therefore, second and third part of the If formula are trivial. In case that decision trees were nontrivial, those parts of the formula would be expanded with nested if expressions.
A simple depth Viper policy for CartPole is shown in Figure 7. SMT formula that would encode the policy part of this formula would look like following: If(pv < -0.033, If(pa < 0.039, 0, 1), If(pa < -0.037, 0, 1))
The full formula for CartPole environment verification contains additional details, it is the conjunction of the formula encoding the policy, the safety requirements and the environment dynamics, as illustrated by the formula in Section 5.
Appendix E Evaluation Results
Tables 6, 7, 8, 9, 10, 11 show data about models on the global Pareto front presented in Figure 3 of Section 6.
Tables 12, 13, 14, 15, 16, 17 show data about the models on the global Pareto after reevaluation is performed. This corresponds to data presented in Figure 4 of Section 6.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] D. Silver, A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. Van Den Driessche, J. Schrittwieser, I. Antonoglou, V. Panneershelvam, M. Lanctot, et al., Mastering the game of Go with deep neural networks and tree search, Nature 529 (7587) (2016) 484.
- 2[2] R. Miotto, F. Wang, S. Wang, X. Jiang, J. T. Dudley, Deep learning for healthcare: review, opportunities and challenges, Briefings in bioinformatics 19 (6) (2018) 1236–1246.
- 3[3] A. Esteva, A. Robicquet, B. Ramsundar, V. Kuleshov, M. De Pristo, K. Chou, C. Cui, G. Corrado, S. Thrun, J. Dean, A guide to deep learning in healthcare, Nature medicine 25 (1) (2019) 24–29.
- 4[4] J.-Z. Cheng, D. Ni, Y.-H. Chou, J. Qin, C.-M. Tiu, Y.-C. Chang, C.-S. Huang, D. Shen, C.-M. Chen, Computer-aided diagnosis with deep learning architecture: applications to breast lesions in us images and pulmonary nodules in ct scans, Scientific reports 6 (1) (2016) 1–13.
- 5[5] M. Cicero, A. Bilbily, E. Colak, T. Dowdell, B. Gray, K. Perampaladas, J. Barfett, Training and validating a deep convolutional neural network for computer-aided detection and classification of abnormalities on frontal chest radiographs, Investigative radiology 52 (5) (2017) 281–287.
- 6[6] T. Kooi, G. Litjens, B. Van Ginneken, A. Gubern-Mérida, C. I. Sánchez, R. Mann, A. den Heeten, N. Karssemeijer, Large scale deep learning for computer aided detection of mammographic lesions, Medical image analysis 35 (2017) 303–312.
- 7[7] S. Ross, G. Gordon, D. Bagnell, A reduction of imitation learning and structured prediction to no-regret online learning, in: Proceedings of the fourteenth international conference on artificial intelligence and statistics, 2011, pp. 627–635.
- 8[8] O. Bastani, Y. Pu, A. Solar-Lezama, Verifiable reinforcement learning via policy extraction, in: Advances in Neural Information Processing Systems, 2018, pp. 2499–2509.
