TL;DR
This paper introduces Deep Recurrent Quantization (DRQ), a novel method that generates sequential binary codes with adjustable length, reducing training costs and increasing flexibility for image retrieval tasks.
Contribution
The paper presents the first quantization approach that trains once and produces variable-length binary codes using a deep recurrent architecture.
Findings
Achieves comparable or better retrieval performance than state-of-the-art methods.
Requires fewer parameters and less training time.
Demonstrates flexibility in code length adjustment without retraining.
Abstract
Quantization has been an effective technology in ANN (approximate nearest neighbour) search due to its high accuracy and fast search speed. To meet the requirement of different applications, there is always a trade-off between retrieval accuracy and speed, reflected by variable code lengths. However, to encode the dataset into different code lengths, existing methods need to train several models, where each model can only produce a specific code length. This incurs a considerable training time cost, and largely reduces the flexibility of quantization methods to be deployed in real applications. To address this issue, we propose a Deep Recurrent Quantization (DRQ) architecture which can generate sequential binary codes. To the end, when the model is trained, a sequence of binary codes can be generated and the code length can be easily controlled by adjusting the number of recurrent…
Click any figure to enlarge with its caption.
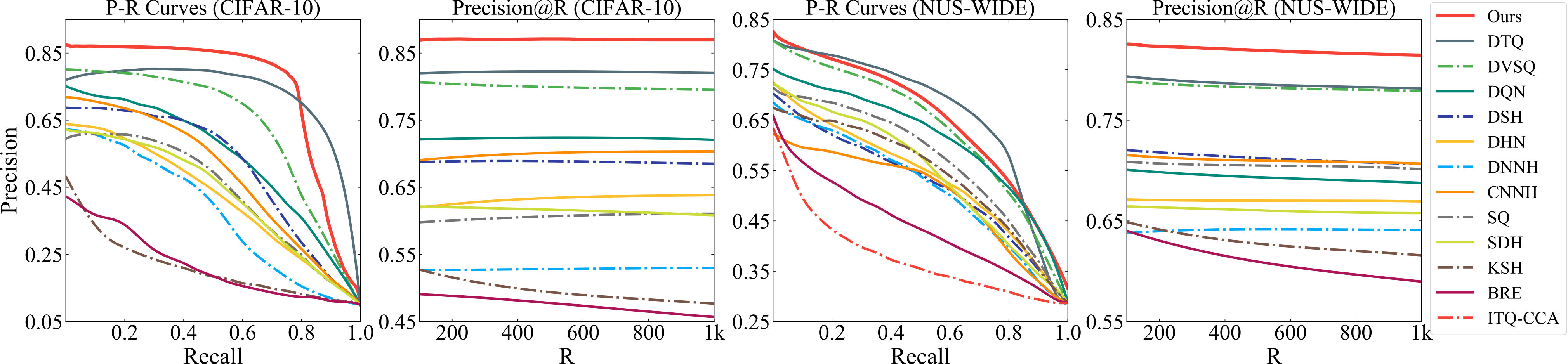 Figure 1
Figure 1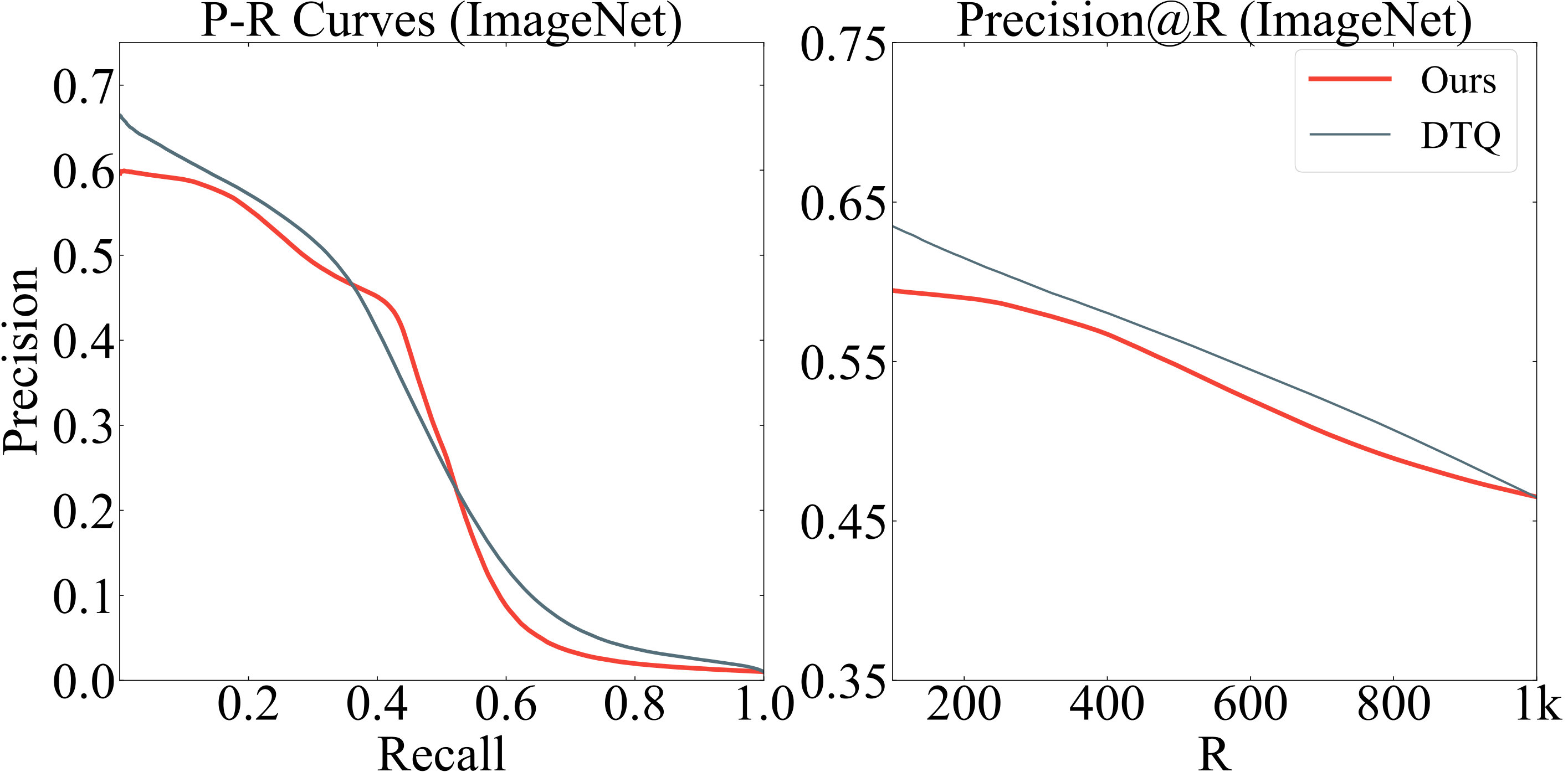 Figure 2
Figure 2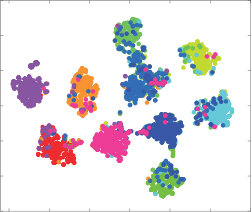 Figure 3
Figure 3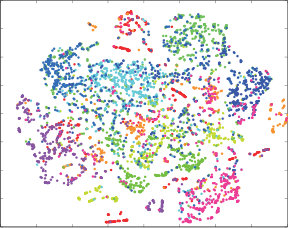 Figure 4
Figure 4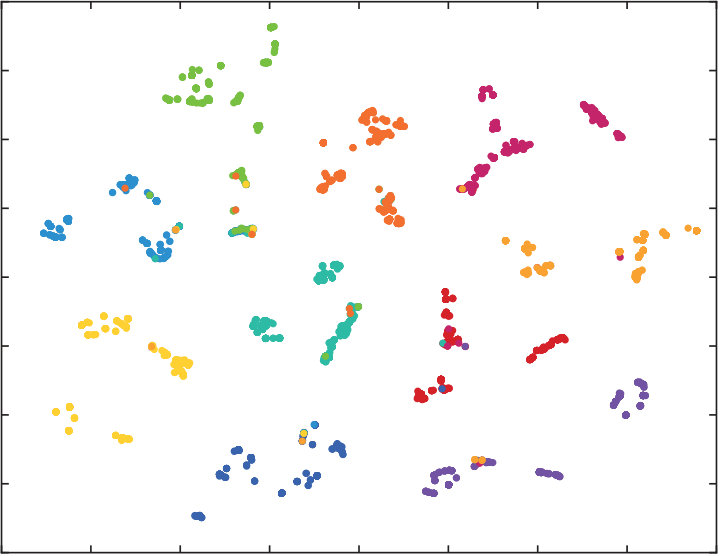 Figure 5
Figure 5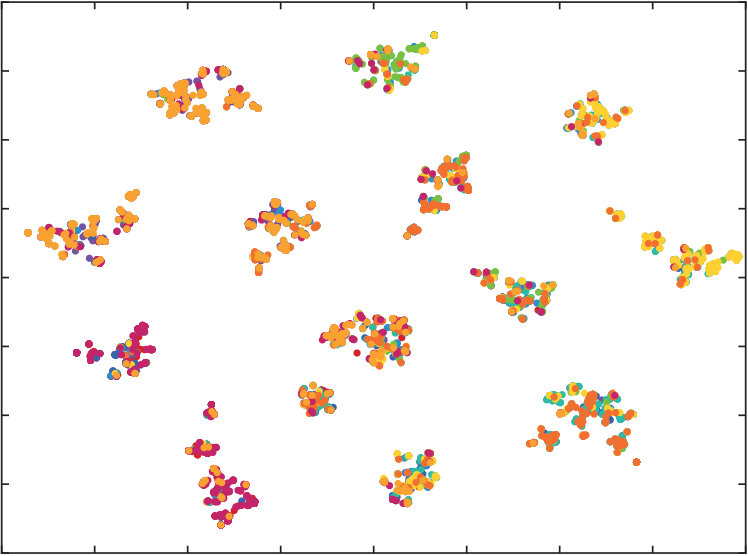 Figure 6
Figure 6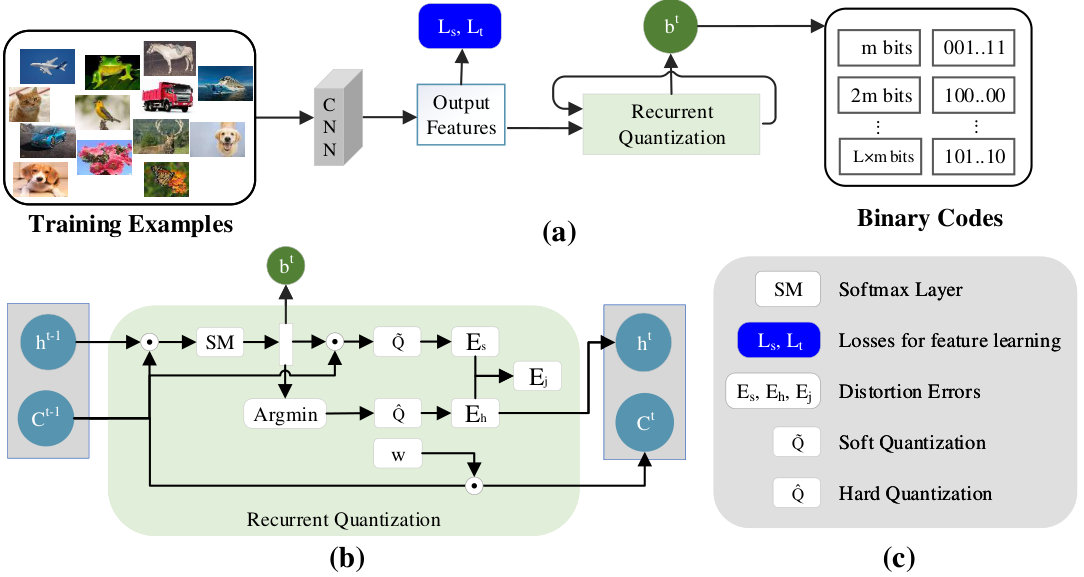 Figure 7
Figure 7 Figure 8
Figure 8| Method | 16 bits | 24 bits | 36 bits | 48 bits |
|---|---|---|---|---|
| DRSCH | 0.615 | 0.622 | 0.629 | 0.631 |
| DSCH | 0.609 | 0.613 | 0.617 | 0.686 |
| DSRH | 0.608 | 0.611 | 0.617 | 0.618 |
| VDSH | 0.845 | 0.848 | 0.844 | 0.845 |
| DPSH | 0.903 | 0.885 | 0.915 | 0.911 |
| DTSH | 0.915 | 0.923 | 0.925 | 0.926 |
| DSDH | 0.935 | 0.940 | 0.939 | 0.939 |
| PQNet | 0.947 | 0.947 | 0.946 | 0.947 |
| DRQ | 0.942 | 0.943 | 0.943 | 0.943 |
| Method | 12 bits | 24 bits | 36 bits | 48 bits |
|---|---|---|---|---|
| SH | 0.621 | 0.616 | 0.615 | 0.612 |
| ITQ | 0.719 | 0.739 | 0.747 | 0.756 |
| LFH | 0.695 | 0.734 | 0.739 | 0.759 |
| KSH | 0.768 | 0.786 | 0.790 | 0.799 |
| SDH | 0.780 | 0.804 | 0.815 | 0.824 |
| FASTH | 0.779 | 0.807 | 0.816 | 0.825 |
| NINH | 0.674 | 0.697 | 0.713 | 0.715 |
| DHN | 0.708 | 0.735 | 0.748 | 0.758 |
| DQN | 0.768 | 0.776 | 0.783 | 0.792 |
| DPSH | 0.752 | 0.790 | 0.794 | 0.812 |
| DTSH | 0.773 | 0.808 | 0.812 | 0.824 |
| DSDH | 0.776 | 0.808 | 0.820 | 0.829 |
| PQNet | 0.795 | 0.819 | 0.823 | 0.830 |
| DRQ | 0.772 | 0.838 | 0.840 | 0.843 |
| Method | CIFAR-10 | NUS-WIDE | ImageNet | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8 bits | 16 bits | 24 bits | 32 bits | 8 bits | 16 bits | 24 bits | 32 bits | 8 bits | 16 bit | 24 bits | 32 bits | |
| ITQ-CCA | 0.315 | 0.354 | 0.371 | 0.414 | 0.526 | 0.575 | 0.572 | 0.594 | 0.189 | 0.270 | 0.339 | 0.436 |
| BRE | 0.306 | 0.370 | 0.428 | 0.438 | 0.550 | 0.607 | 0.605 | 0.608 | 0.251 | 0.363 | 0.404 | 0.453 |
| KSH | 0.489 | 0.524 | 0.534 | 0.558 | 0.618 | 0.651 | 0.672 | 0.682 | 0.228 | 0.398 | 0.499 | 0.547 |
| SDH | 0.356 | 0.461 | 0.496 | 0.520 | 0.645 | 0.688 | 0.704 | 0.711 | 0.385 | 0.516 | 0.570 | 0.605 |
| SQ | 0.567 | 0.583 | 0.602 | 0.615 | 0.653 | 0.691 | 0.698 | 0.716 | 0.465 | 0.536 | 0.592 | 0.611 |
| CNNH | 0.461 | 0.476 | 0.465 | 0.472 | 0.586 | 0.609 | 0.628 | 0.635 | 0.317 | 0.402 | 0.453 | 0.476 |
| DNNH | 0.525 | 0.559 | 0.566 | 0.558 | 0.638 | 0.652 | 0.667 | 0.687 | 0.347 | 0.416 | 0.497 | 0.525 |
| DHN | 0.512 | 0.568 | 0.594 | 0.603 | 0.668 | 0.702 | 0.713 | 0.716 | 0.358 | 0.426 | 0.531 | 0.556 |
| DSH | 0.592 | 0.625 | 0.651 | 0.659 | 0.653 | 0.688 | 0.695 | 0.699 | 0.332 | 0.398 | 0.487 | 0.537 |
| DVSQ | 0.715 | 0.727 | 0.730 | 0.733 | 0.780 | 0.790 | 0.792 | 0.797 | 0.500 | 0.502 | 0.505 | 0.518 |
| DTQ | 0.785 | 0.789 | 0.790 | 0.792 | 0.795 | 0.798 | 0.800 | 0.801 | 0.641 | 0.644 | 0.647 | 0.651 |
| DRQ | 0.803 | 0.824 | 0.832 | 0.837 | 0.748 | 0.810 | 0.817 | 0.821 | 0.551 | 0.583 | 0.585 | 0.587 |
| Methods | 8 bits | 16 bits | 24 bits | 32 bits | 40 bits | 48 bits |
|---|---|---|---|---|---|---|
| PQ (PQNet) | 524k | 524k | 524k | 524k | 524k | 524k |
| OPQ | 4.72M | 4.72M | 4.72M | 4.72M | 4.72M | 4.72M |
| AQ (DTQ) | 524k | 1.05M | 1.57M | 2.10M | 2.62M | 3.15M |
| DRQ | 524k | |||||
| Structure | 8 bits | 16 bits | 24 bits | 32 bits |
|---|---|---|---|---|
| Unsupervised | 0.582 | 0.630 | 0.629 | 0.626 |
| Remove | 0.750 | 0.759 | 0.761 | 0.762 |
| Remove | 0.629 | 0.672 | 0.678 | 0.680 |
| only | 0.654 | 0.725 | 0.731 | 0.734 |
| Remove | 0.604 | 0.628 | 0.628 | 0.628 |
| Remove concat | 0.544 | 0.569 | 0.571 | 0.575 |
| DRQ | 0.748 | 0.810 | 0.817 | 0.821 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Deep Recurrent Quantization for Generating Sequential Binary Codes
Jingkuan Song1
Xiaosu Zhu1
Lianli Gao1
Xin-Shun Xu2
Wu Liu3&Heng Tao Shen1111Contact Author
1Center for Future Media, University of Electronic Science and Technology of China
2Shandong University
3JD AI Research
[email protected], [email protected], [email protected], [email protected], [email protected], [email protected]
Abstract
Quantization has been an effective technology in ANN (approximate nearest neighbour) search due to its high accuracy and fast search speed. To meet the requirement of different applications, there is always a trade-off between retrieval accuracy and speed, reflected by variable code lengths. However, to encode the dataset into different code lengths, existing methods need to train several models, where each model can only produce a specific code length. This incurs a considerable training time cost, and largely reduces the flexibility of quantization methods to be deployed in real applications. To address this issue, we propose a Deep Recurrent Quantization (DRQ) architecture which can generate sequential binary codes. To the end, when the model is trained, a sequence of binary codes can be generated and the code length can be easily controlled by adjusting the number of recurrent iterations. A shared codebook and a scalar factor is designed to be the learnable weights in the deep recurrent quantization block, and the whole framework can be trained in an end-to-end manner. As far as we know, this is the first quantization method that can be trained once and generate sequential binary codes. Experimental results on the benchmark datasets show that our model achieves comparable or even better performance compared with the state-of-the-art for image retrieval. But it requires significantly less number of parameters and training times. Our code is published online: https://github.com/cfm-uestc/DRQ.
1 Introduction
With the significant increase of the mass media contents, image retrieval has become the highly-concerned spot. Image retrieval concentrates on searching similar images from large-scale database. The direct way is to use reliable kNN (k-nearest neighbor) techniques, which usually perform brute-force searching on database. ANN (approximate nearest neighbor) search is an optimized algorithm which is actually practicable against kNN search. The main idea of ANN search is to find a compact representation of raw features i.e. a binary code with fixed length, which can retain structure of raw feature space and dramatically improve the computation speed.
Recently, hashing methods have been widely used in ANN search. They usually learn a hamming space which is refined to maintain similarity between features Liu et al. (2016); Zhu et al. (2016); Song et al. (2018c, b, a). Since the computation of hamming distance is super fast, hashing methods have huge advantages on ANN search. However, hashing methods lack accuracy on feature restoration. Methods based on quantization require a codebook to store some representative features. Therefore, the main goal of quantization is to reserve more information of feature space in codebook. Then, they try to find a combination of codewords to approximate raw features and only to store indexes of these codewords.
Quantization is originated from -means algorithm, which first clusters data points and uses the clustering centers as codebook. Each data point is represented by index of its corresponding center. In order to decrease computation cost of -means, product quantization Jegou et al. (2011) and optimized product quantization Ge et al. (2013) split whole feature space into a set of sub-regions and perform similar algorithm on each subspace respectively. Such initial quantization methods construct restrictions and well-designed codebooks to accelerate calculation. In the deep learning era, people proposed some end-to-end deep neural networks to perform image feature learning and quantization together. Deep quantization network Cao et al. (2016) use AlexNet to learn well-separated image features and use OPQ to quantize features. Deep visual-semantic quantization Cao et al. (2017) and deep triplet quantization Liu et al. (2018) quantize features by CQ. Different from these works, product quantization network Yu et al. (2018) proposed a differentiable method to represent quantization as operations of neural network, so that gradient descent can be applied to quantization. Despite their successes, PQ and its variants have several issues. First, to generate binary codes with different code lengths, a retraining is usually unavoidable. Second, it is tricky for the decomposition of high-dimensional vector space. Different decomposition strategies may result in huge performance differences. To tackle these issues, we propose a deep quantization method called deep recurrent quantization, which constructs codebook that can be used recurrently to generate sequential binary codes. Extensive experiments show our method outperforms state-of-the-art methods even though they use larger codebooks.
2 Preliminaries
Quantization-based image retrieval tasks are defined as follows: Given a set of images which contain images of height , width and channel . We first use a CNN, e.g. AlexNet and VGG to learn a hyper representation of images, where is the dimension of feature vectors. Then we apply quantization on these feature vectors, to learn a codebook which contains codewords and each of them has dimensions. Feature vectors are then compressed to compact binary codes where indicates the code length.
2.1 Integrate Quantization To Deep Learning Architectures
During the procedure of quantization, to pick a closest codeword from feature representation is to compute the distance between codewords and features and find the minimum one, which can be described as:
[TABLE]
where x are the features of a data point, and is the -th codeword, is quantization function and is quantized feature. Therefore, is the approximation of x. Meanwhile, we collect the index of codeword as the quantized code, which is described as:
[TABLE]
Since b is in the range of -, then all the codes can be binarized to a code length of . Then, the original feature x can be compressed to an extremely short binary code.
However, the formulation of codeword is non-differentiable, i.e. does not exist. It cannot be directed integrated into deep learning architectures. To tackle this issue, we use a convex combination of codewords to approximate features, which is defined as follows:
[TABLE]
Here, indicates the confidences of each codewords w.r.t. x, i.e. the closer one codeword is to a feature x, the higher will be. Then, is approximated by , which is the weighted sum of all codewords. We define as hard quantization and as soft quantization.
3 Proposed Method
The whole network architecture of our deep recurrent quantization (DRQ) is demonstrated in Fig. 1. DRQ contains two main parts: feature extraction module and quantization module. In feature extraction module, we apply intermediate supervision on top of CNN, to guide the learning of semantic-embedded visual features. In quantization module, we design a recurrent quantization block and integrate it into deep learning architecture which can be trained end-to-end.
3.1 Intermediate Supervision for Features
To get the feature representation of images, we use AlexNet to extract features from the last linear layer. To leverage the clustering performance i.e., to let the images with the same label have higher similarity and vice versa, we apply two losses with intermediate supervision. Specifically, we first collect a triplet in dataset which contains an anchor image , a positive sample and a negative sample w.r.t. anchor (for multi-label images, we define a positive image as one which shares at least one label with anchor, and a negative image as one which does not share any label with an anchor), and feed them into AlexNet to obtain the 4096-d features from layer. Then we add two linear layers of 1748-d and of 300-d. We concatenate and to get a final feature x of 2048-d. Since we feed the triplet into the network, the output features are represented as .
We apply two supervised objective function on these layers: 1) Adaptive margin loss , which is from DVSQ Cao et al. (2017) and applied to outputs of triplet, and 2) Triplet loss defined to final feature x, which is a concatenated feature of and . is defined as:
[TABLE]
Triplet loss can adjust features to adapt to clustering, which uses the triplet of . It is defined as:
[TABLE]
3.2 Recurrent Quantization Block
In recurrent quantization model, we adopt a shared codebook that contains codewords. We denote the level of quantization code as , which indicates how many iterations the codebook is reused. For each level, we pick a proper codeword as the approximation of feature vectors, and we take the index of picked codeword as the quantization code. For example, if we set , the index range of each level quantization code is , represented as a binary code of = bits. The total length of quantization code is . The position is the index of first level codeword, is the index of second level, etc. Therefore, the feature vector can be approximated by a combination of a few codewords in the codebook.
As we described in Sec. 2.1, to perform a quantization, input x and codebook C are necessary. Output is the code b. Inspired by the hierarchical codebooks in stacked quantizer Martinez et al. (2014), we observe the residual of x can be used as an input to the next quantizer. Therefore, a basic idea is to perform quantization step-by-step:
[TABLE]
Specifically, is quantized feature explained above, and are residuals of x. We put to the next quantization to get the which approximates . Therefore, can be described as an approximation of x, which is much preciser than . Notice that processing of is similar. If we use a shared codebook, the computation in Eq. 7 can be rewritten recurrently:
[TABLE]
And the soft and hard quantization of is defined as:
[TABLE]
The unfolded structure of recurrent quantization is depicted in Fig. 2. Here, is the raw features and initial codebook. is a shared learnable parameter with random initialization. In iteration , we compute to find the best-fitted codeword, then we use to compute residual of and treat residual as next input . Since the residual is one or more order of magnitudes lower than , the next input should be much smaller than codewords in codebook, so we use as a scale factor to adjust the norm of codebook in order to fit the new input. In next iteration , we use the scaled codebook to complete another similar computation. Finally, we learn a codebook C, a scale factor and sequential binary codes . The hard and soft quantization of x can be computed as:
[TABLE]
By reusing codebook C, we can reduce the number of parameters by times.
3.2.1 Objective Function
Since and are approximation of feature x, we define a distortion error as:
[TABLE]
where is the distortion error between and x at iteration and is the distortion error between and x. We sum distortions for each level and the total distortion error is:
[TABLE]
We also design a joint central error to align and :
[TABLE]
3.3 Optimization
In DRQ, there are two main losses: 1) and which refine features, 2) , which control the quantization effectiveness. We split the training procedure into three stages. Firstly, we minimize together to pre-train our preceding neural network. Then, we add recurrent quantization block into network but only perform one recurrent iteration i.e. set and optimize together. This is to get an initial codebook which are optimized for short binary codes. Finally, we set to a specified value and optimize the whole network with all losses, until it converges or we reach the max number of training iterations.
4 Experiments
To validate the effectiveness and efficiency of our adopted deep recurrent quantization, we perform extensive experiments on three public datasets: CIFAR-10, NUS-WIDE and ImageNet. Since existing methods use different settings, to make a thorough comparison with them, we follow these works and compare with them using separate settings. We implement our model with Tensorflow, using a pre-trained AlexNet and construct intermediate layers on top of the layer. Meanwhile, we randomly initialize codebook with specified and , which will be described below. We use Adam optimizer with for training.
4.1 Comparison Results Using Setting 1
4.1.1 Settings
We first conduct results and make comparisons with state-of-the art methods on two benchmark datasets: CIFAR-10 and NUS-WIDE. CIFAR-10 is a public dataset labeled in 10 classes. It consists of 50,000 images for training and 10,000 images for validation. We follow Yu et al. (2018) to combine the training and validation set together, and randomly sample 5,000 images per class as database. The remaining 10,000 images are used as queries. Meanwhile, we use the whole database to train the network. NUS-WIDE is a public dataset consisting of 81 concepts, and each image is annotated with one or more concepts. We follow Yu et al. (2018) to use the subset of 195,834 images from the 21 most frequent concepts. We randomly sample 1,000 images per concept as the query set, and use the remaining images as the database. Furthermore, we randomly sample 5,000 images per concept from the database as the training set. We use mean Average Precision (mAP@5000) as the evaluation metric.
4.1.2 Results
On CIFAR-10, we compare our DRQ with a few state-of-the-art methods, including DRSCH Zhang et al. (2015), DSCH Zhang et al. (2015), DSRH Zhao et al. (2015), VDSH Zhang et al. (2016), DPSH Li et al. (2015), DTSH Li et al. (2015), DTSH Wang et al. (2016), DSDH Li et al. (2017) and PQNet Yu et al. (2018), using 16, 24, 36, 48 bits. We set and . The results on CIFAR dataset are shown in Table 1. Results show our network achieves comparable mAP performance against state-of-the-art methods, i.e. PQNet. Our mAP is only 0.3%-0.5% lower than PQNet. Results also show our performance is stable with variable bit-lengths. Our method only get 0.1% decrease when bit-length shrinks to 16 bits. Noticed that our recurrent quantization only use a single codebook with codewords, and therefore our method requires much less parameters compared with other methods, as shown in Tab. 4.
On NUS-WIDE dataset, we compare our method with a few shallow and deep methods. Shallow methods include SH Salakhutdinov and Hinton (2009), ITQ Gong et al. (2013), LFH Zhang et al. (2014), KSH Liu et al. (2012), SDH Shen et al. (2015), FASTH Lin et al. (2014). Deep methods include NINH Lai et al. (2015a), DHN Zhu et al. (2016), DQN Cao et al. (2016), DPSH Li et al. (2015), DTSH Wang et al. (2016), DSDH Li et al. (2017) and PQNet Yu et al. (2018). The results are generated in 12, 24, 36, 48 bits. We fix to generate 48 bits codes, and then slice these codes to get shorter binary codes. The results are shown in Table 2. On NUS-WIDE, our method achieves the highest mAP compared with state-of-the-art methods when the code length is longer than 12 bits. Noticed that our method uses a shared codebook for all code lengths, and it is trained once.
The codebook size w.r.t. code-length comparison between multiple methods is shown in Tab. 4. Our method obtains the smallest codebook size compared with the other methods. Also, to generate binary codes with different lengths, our methods is trained once.
4.2 Comparison Results Using Setting 2
4.2.1 Setting
Following DTQ Liu et al. (2018), on CIFAR-10, we combine the training and validation set together, and randomly select 500 images per class as the training set, 100 images per class as the query set. The remaining images are used as the database. On NUS-WIDE, we use the subset of 195,834 images from the 21 most frequent concepts. We randomly sample 5,000 images as the query set, and use the remaining images as the database. Furthermore, we randomly select 10,000 images from the database as the training set. On ImageNet, we follow Cao et al. (2017) to randomly choose 100 classes. We use all the images of these classes in the training set as the database, and use all the images of these classes in the validation set as the queries. Furthermore, we randomly select 100 images for each class in the database for training. We compare our method with 11 classical hash or quantization methods, including 5 shallow methods: ITQ-CCA Gong et al. (2013), BRE Kulis and Darrell (2009), KSH Liu et al. (2012), SDH Shen et al. (2015) and SQ Martinez et al. (2014), and 6 deep architecture: CNNH Xia et al. (2014), DNNH Lai et al. (2015b), DHN Zhu et al. (2016), DSH Liu et al. (2016), DVSQ Cao et al. (2017), DTQ Liu et al. (2018).
4.2.2 Results
We use mAP@54000 on CIFAR-10 and mAP@5000 on NUS-WIDE and ImageNet. We use 8, 16, 24, 32-bits codes by setting . We also use precision-recall curve and precision@R (returned results) curve to evaluate the retrieval quality. The results are shown in Table 3, Fig. 3 and Fig. 4.
It can be observed that: 1) Our DRQ significantly outperforms the other methods in CIFAR-10 and NUS-WIDE datasets. Specifically, it outperforms the best counterpart (DTQ) by 1.8%, 3.5%, 4.2% and 4.5% on CIFAR-10, and by 1.2%, 1.7% and 2.0% on NUS-WIDE dataset. DRQ is outperformed by DTQ on NUS-WIDE for 8-bit codes. The possible reason is that in DRQ, codebooks are shared by different code lengths, and may lose some accuracy especially for short binary codes. On ImageNet, our method is outperformed by DTQ, which may be caused by the random selection. Also, our DRQ requires much less parameters than DTQ, and our model is only trained once. 2) With the increase of code length, the performance of most indexing methods is improved accordingly. For our DRQ, the mAP increased by 3.4%, 7.3% and 3.6% for CIFAR-10, NUS-WIDE and ImageNet dataset respectively. This verifies our DRQ can generate sequential binary codes to gradually improve accuracy. 3) The performances of precision-recall curves for different methods are consistent with their performances of mAP. The precision curves represent the retrieval precision with respect to number of return results.
4.3 Ablation Study
In this subsection, we study the effect of each part in our architecture using the following settings. 1) Unsupervised quantization: we use raw output without additional . 2) Remove : we remove and , and change to 2048-d and apply on it directly, to validate the role of . 3) Remove : we remove and and change to 300-d with , to validate the role of . 4) only: we remove the construction of and associated losses, to validate the role of . 5) Remove : we remove to validate the effectiveness of joint central loss. 6) Intermediate supervision: we use only , which is 300-d and also apply to , to validate effectiveness of the concatenation of . We perform ablation study on NUS-WIDE and show results in Tab. 5. In general, DRQ performs the best, and ‘Remove ’ ranks the second. By removing , the supervision information is still utilized in , so mAP drop is not that significant. The unsupervised architecture also achieves good results, indicating the validity of pretrained AlexNet. Notice that if we remove any of the objective functions in the structure, mAP will have a huge loss. This indicates the effectiveness of each part of our DRQ. We get the worst result when we remove the concat, this may be of the significant information loss in 300-d features.
4.4 Qualitatively Results
To qualitatively validate the performance of quantization methods, we also perform t-SNE visualization on DTQ, DVSQ and DRQ, and show the results in Fig.5. Visualizations are created on CIFAR-10, we randomly sample 5,000 images from database and adopt 32 bits quantized features. Our DRQ has a similar performance to DTQ, and they both show distinct clusters in their visualization, which is much better than DVSQ. Our unsupervised structure also has a promising performance since data points are concretely clustered. However, some of the data points with different labels are wrongly clustered together. This indicates the importance of supervision information.
5 Conclusion
In this paper, we propose a Deep Recurrent Quantization (DRQ) architecture to generate sequential binary codes. When the model is trained once, a sequence of binary codes can be generated and the code length can be easily controlled by adjusting the number of recurrent iterations. A shared codebook and a scalar factor is designed to be the learnable weights in the deep recurrent quantization block, and the whole framework can be trained in an end-to-end manner. Experimental results on the benchmark datasets show that our model achieves comparable or even better performance compared with the state-of-the-art for image retrieval, but with much less parameters and training time.
Acknowledgements
This work is supported by the Fundamental Research Funds for the Central Universities (Grant No. ZYGX2014J063, No. ZYGX2016J085), the National Natural Science Foundation of China (Grant No. 61772116, No. 61872064, No. 61632007, No. 61602049).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Cao et al. [2016] Yue Cao, Mingsheng Long, Jianmin Wang, Han Zhu, and Qingfu Wen. Deep quantization network for efficient image retrieval. In AAAI , pages 3457–3463, 2016.
- 2Cao et al. [2017] Yue Cao, Mingsheng Long, Jianmin Wang, and Shichen Liu. Deep visual-semantic quantization for efficient image retrieval. In CVPR , volume 2, 2017.
- 3Ge et al. [2013] Tiezheng Ge, Kaiming He, Qifa Ke, and Jian Sun. Optimized product quantization for approximate nearest neighbor search. In CVPR , pages 2946–2953, 2013.
- 4Gong et al. [2013] Yunchao Gong, Svetlana Lazebnik, Albert Gordo, and Florent Perronnin. Iterative quantization: A procrustean approach to learning binary codes for large-scale image retrieval. IEEE Transactions on Pattern Analysis and Machine Intelligence , 35(12):2916–2929, 2013.
- 5Jegou et al. [2011] Herve Jegou, Matthijs Douze, and Cordelia Schmid. Product quantization for nearest neighbor search. IEEE transactions on pattern analysis and machine intelligence , 33(1):117–128, 2011.
- 6Kulis and Darrell [2009] Brian Kulis and Trevor Darrell. Learning to hash with binary reconstructive embeddings. In NIPS , pages 1042–1050, 2009.
- 7Lai et al. [2015 a] Hanjiang Lai, Yan Pan, Ye Liu, and Shuicheng Yan. Simultaneous feature learning and hash coding with deep neural networks. In CVPR , pages 3270–3278, 2015.
- 8Lai et al. [2015 b] Hanjiang Lai, Yan Pan, Ye Liu, and Shuicheng Yan. Simultaneous feature learning and hash coding with deep neural networks. In CVPR , pages 3270–3278, 2015.
