Lattice Coding for Downlink Multiuser Transmission
Min Qiu

TL;DR
This thesis explores lattice coding schemes for downlink multiuser communication, aiming to approach theoretical capacity limits by leveraging lattice structures to manage interference among users.
Contribution
It provides a systematic design approach for lattice coding and modulation in downlink multiuser systems, addressing a gap in practical coding scheme development.
Findings
Proposes lattice coding schemes that exploit interference structure.
Demonstrates potential to approach capacity limits.
Offers systematic design methodology for practical implementation.
Abstract
In this thesis, we mainly investigate the lattice coding problem of the downlink communication between a base station and multiple users. The base station broadcasts a message containing each user's intended message. The capacity limit of such a system setting is already well-known while the design of practical coding and modulation schemes to approach the theoretical limit has not been fully studied and investigated in the literature. This thesis attempts to address this problem by providing a systematic design on lattice coding and modulation schemes for downlink multiuser communication systems. The main idea is to exploit the structure property of lattices to harness interference from downlink users.
Click any figure to enlarge with its caption.
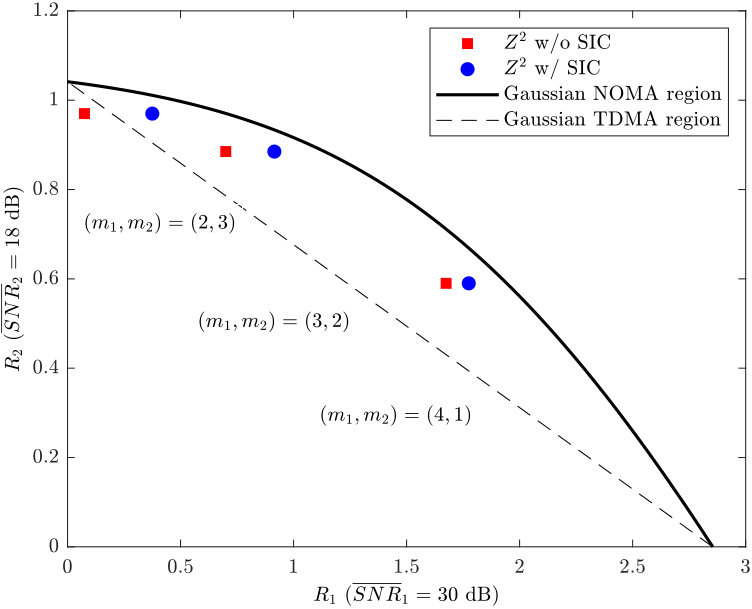 Figure 1
Figure 1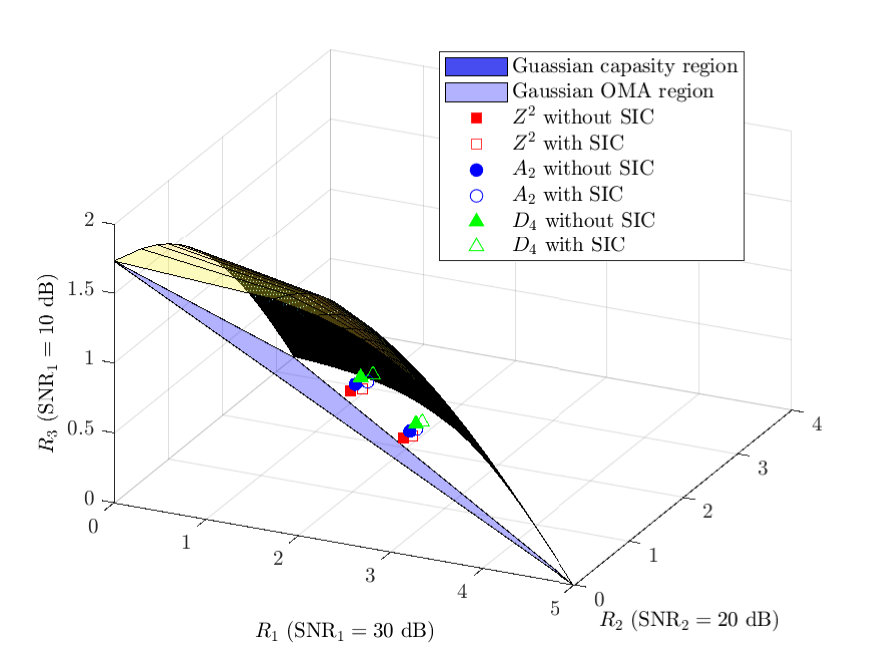 Figure 2
Figure 2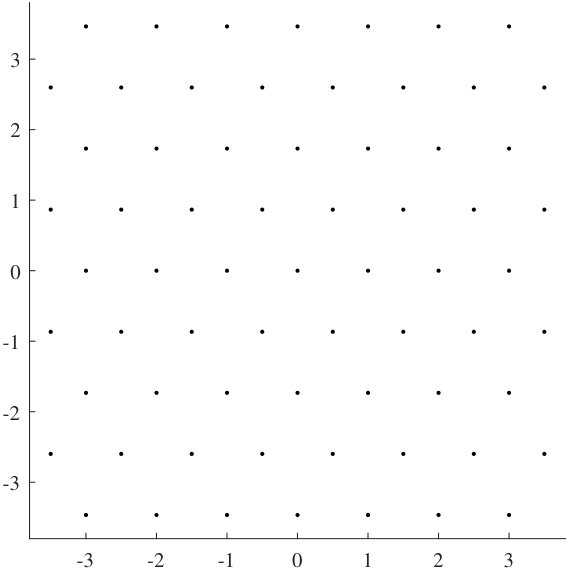 Figure 3
Figure 3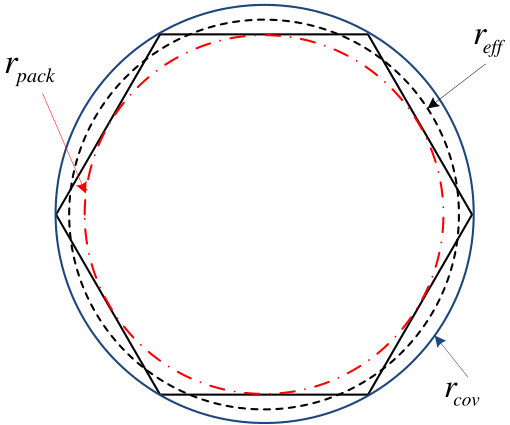 Figure 4
Figure 4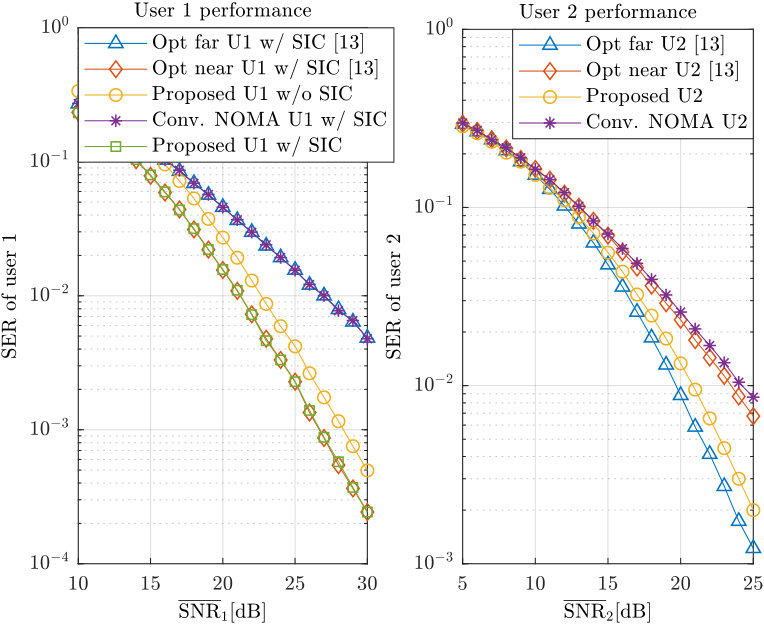 Figure 5
Figure 5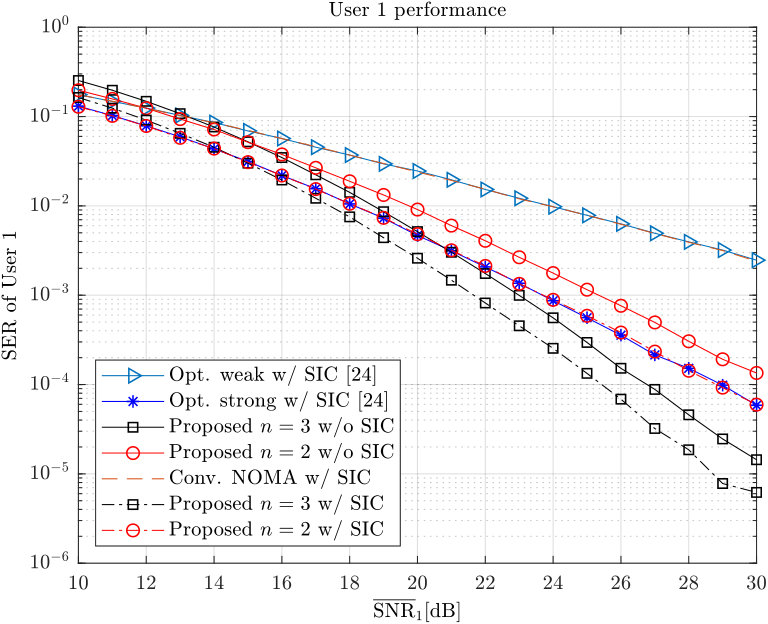 Figure 6
Figure 6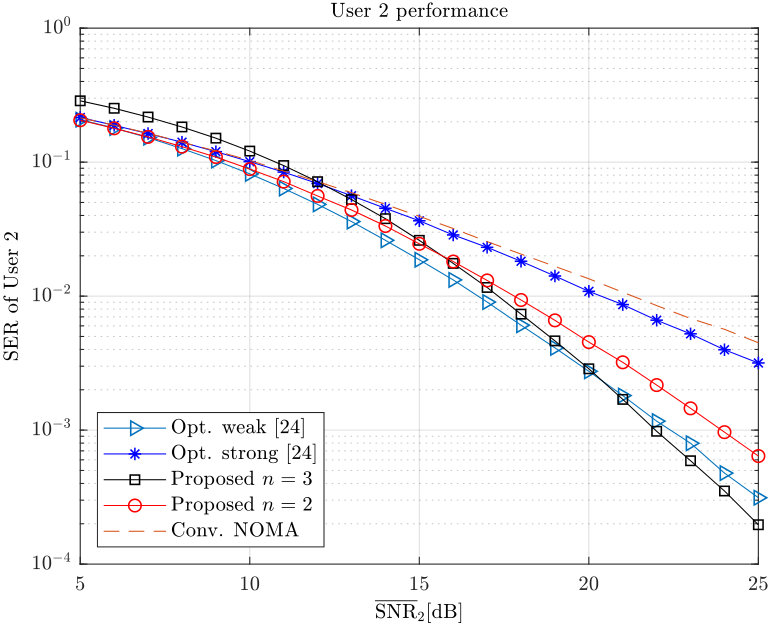 Figure 7
Figure 7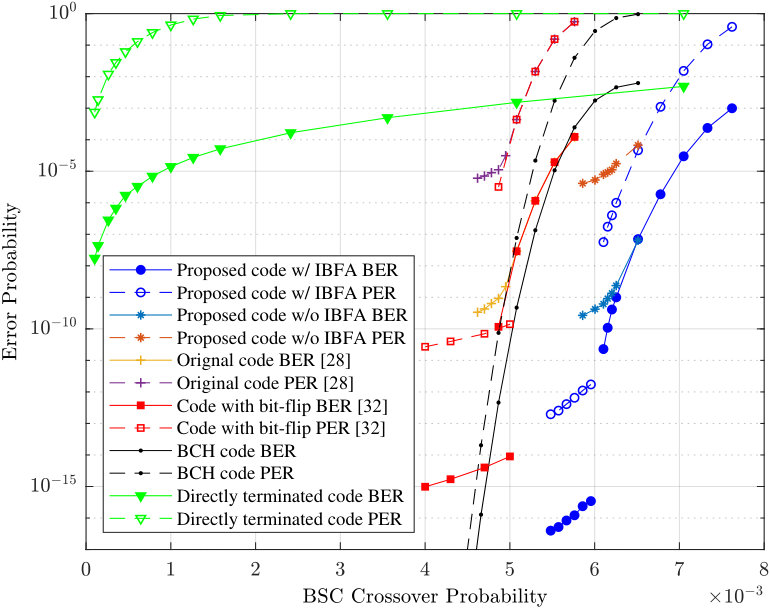 Figure 8
Figure 8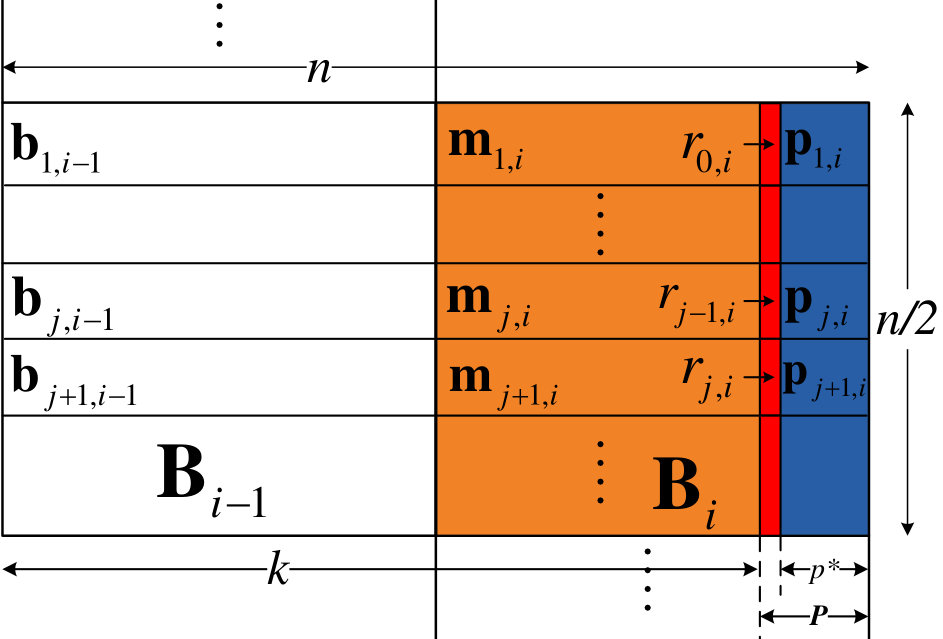 Figure 9
Figure 9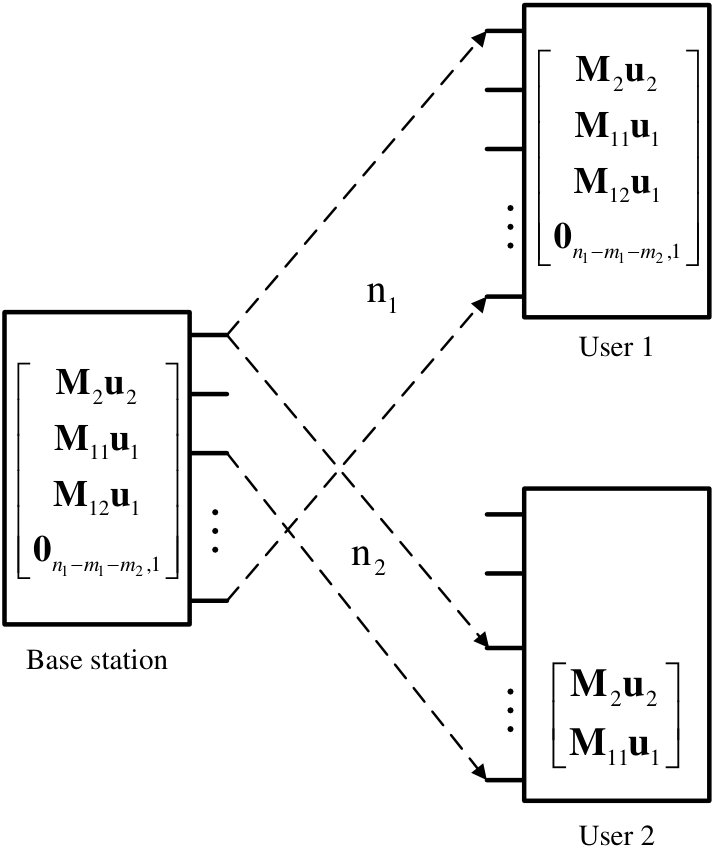 Figure 10
Figure 10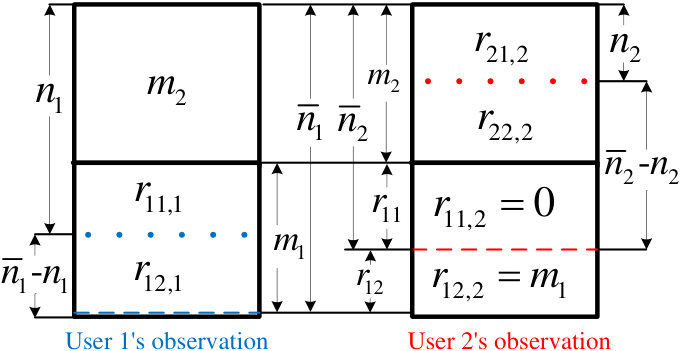 Figure 11
Figure 11 Figure 12
Figure 12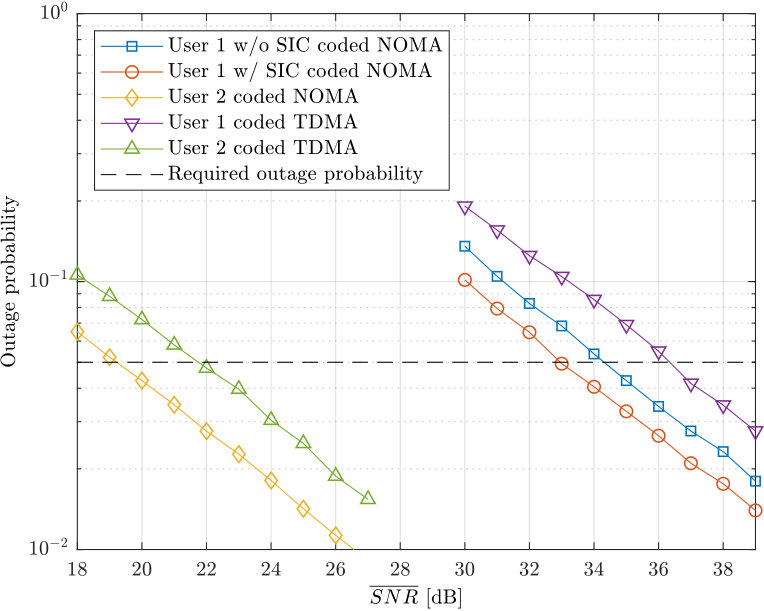 Figure 13
Figure 13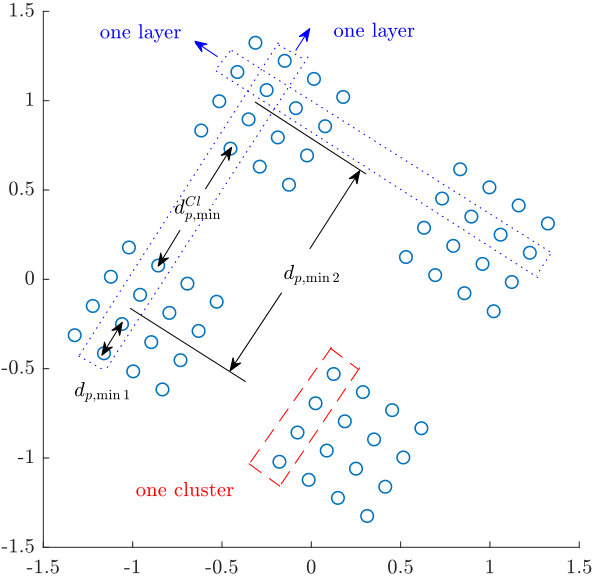 Figure 14
Figure 14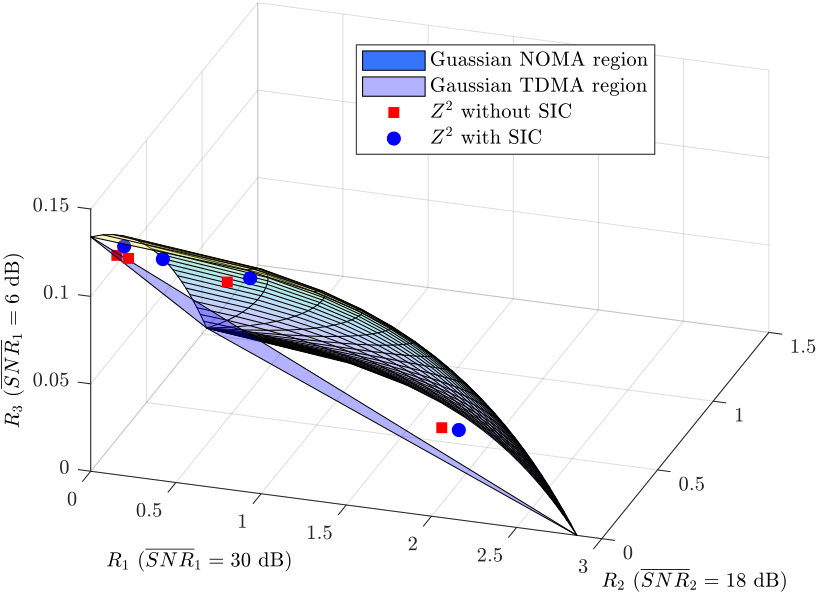 Figure 15
Figure 15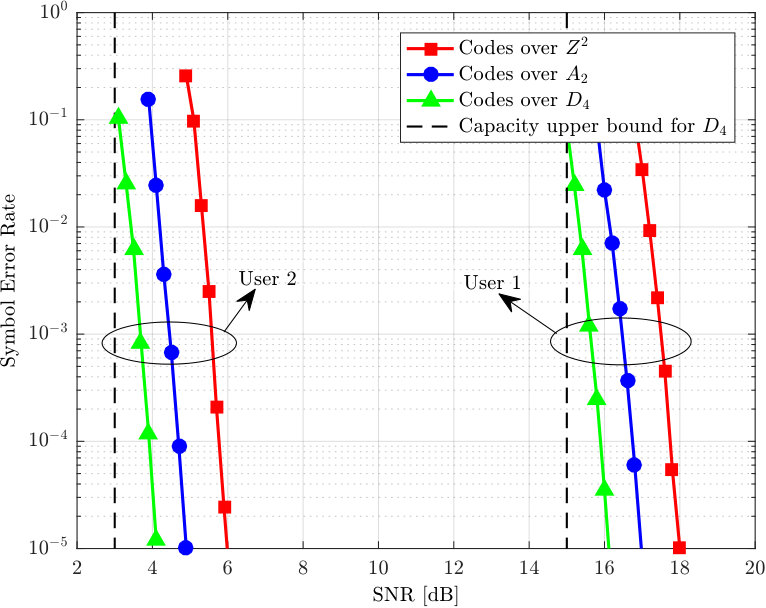 Figure 16
Figure 16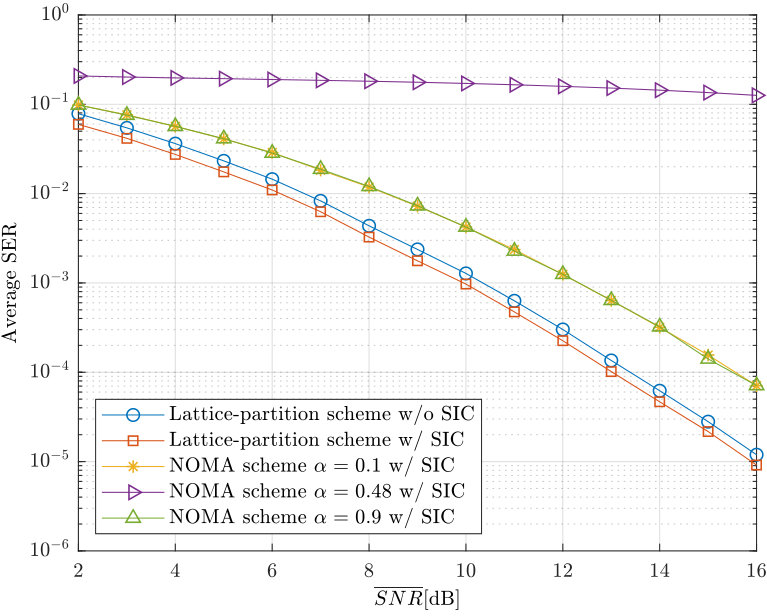 Figure 17
Figure 17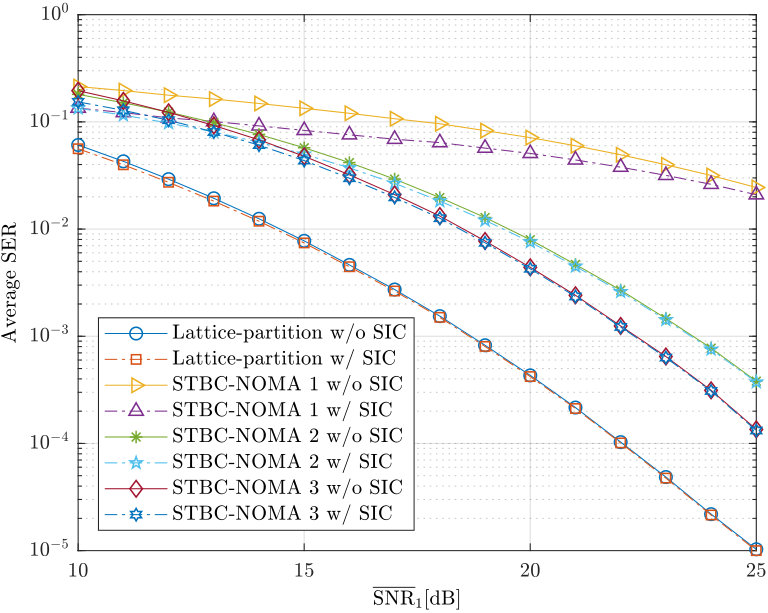 Figure 18
Figure 18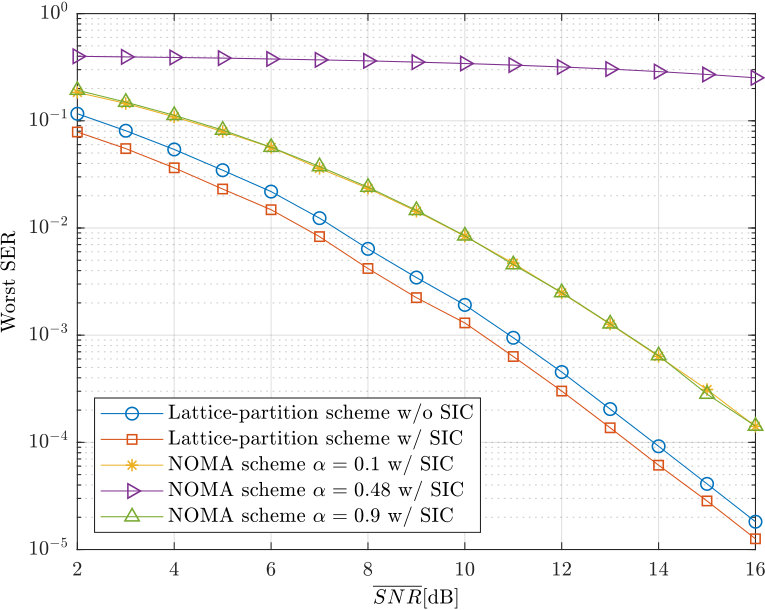 Figure 19
Figure 19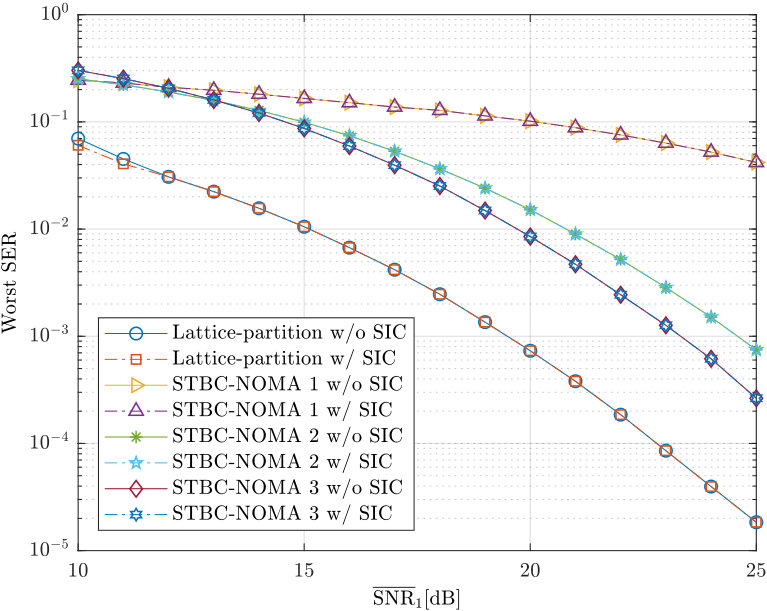 Figure 20
Figure 20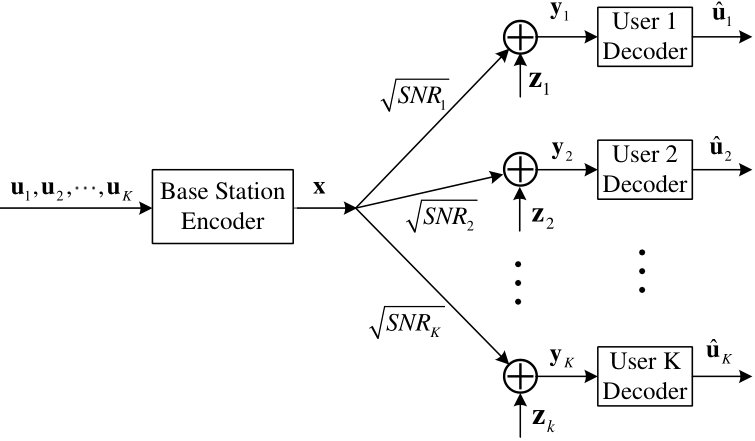 Figure 21
Figure 21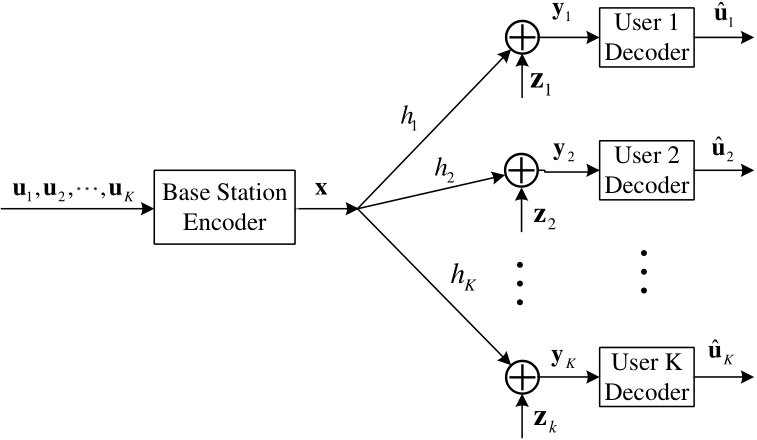 Figure 22
Figure 22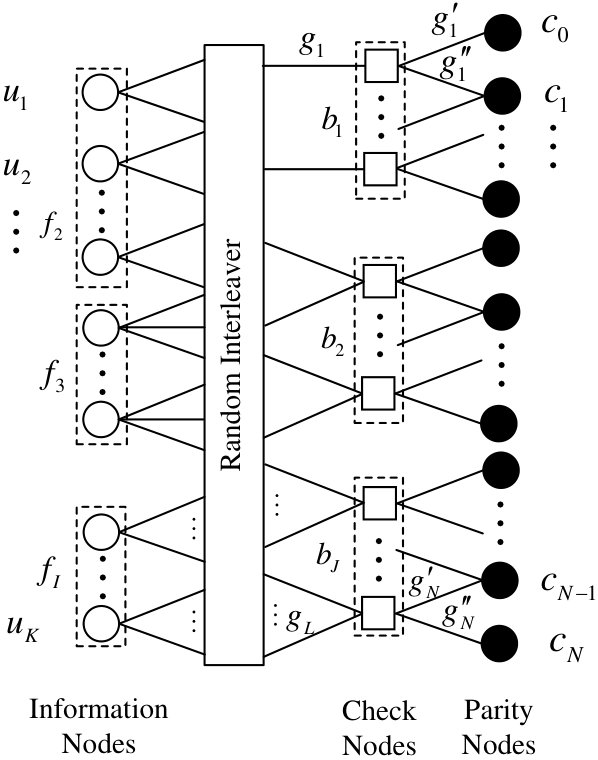 Figure 23
Figure 23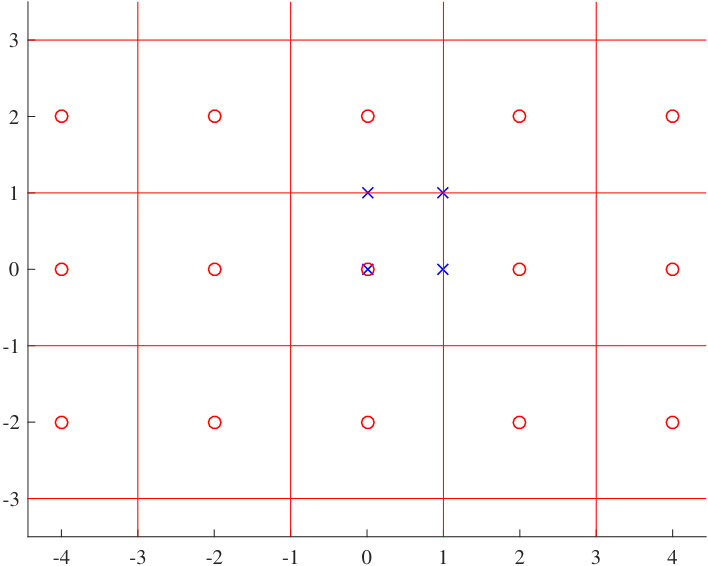 Figure 24
Figure 24 Figure 25
Figure 25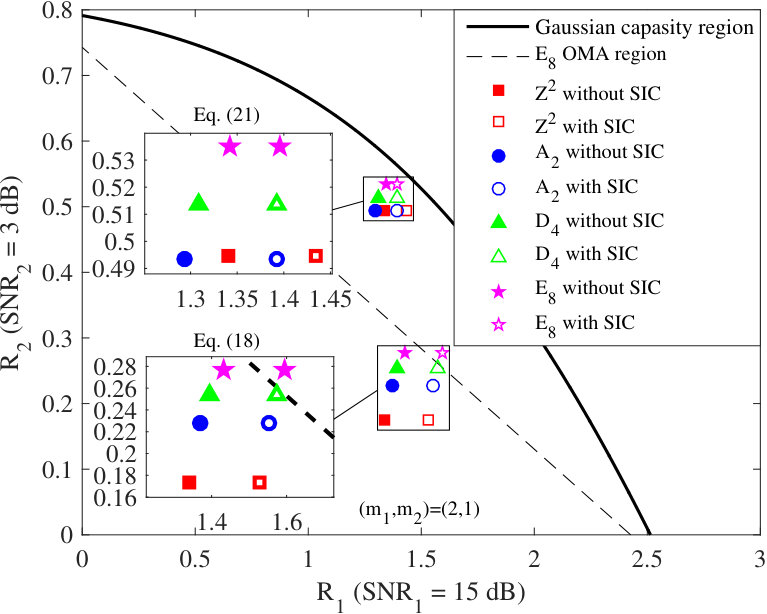 Figure 26
Figure 26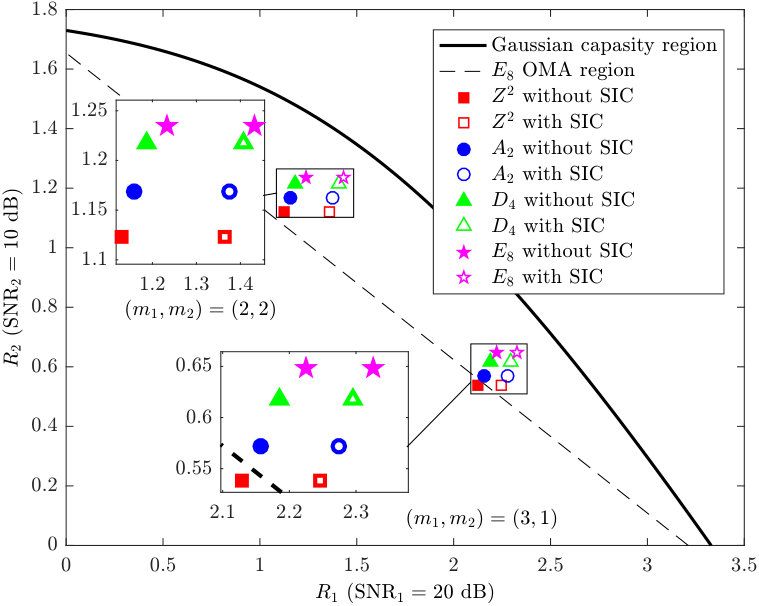 Figure 27
Figure 27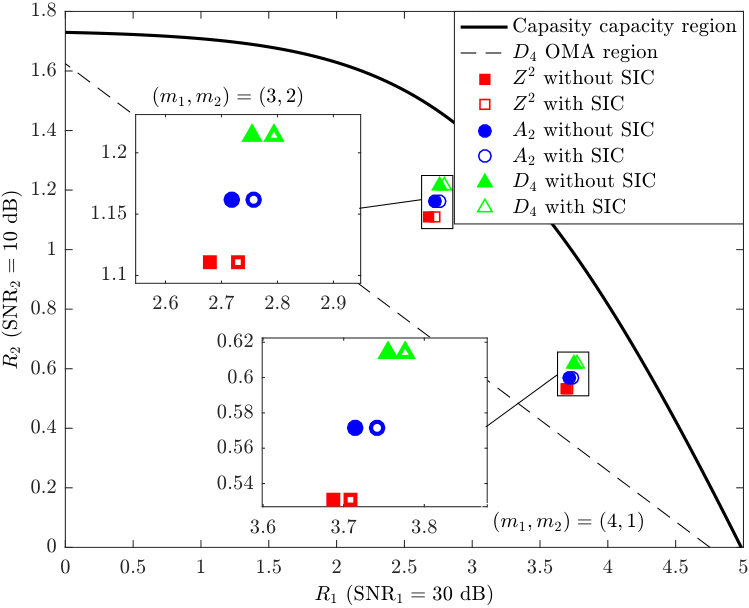 Figure 28
Figure 28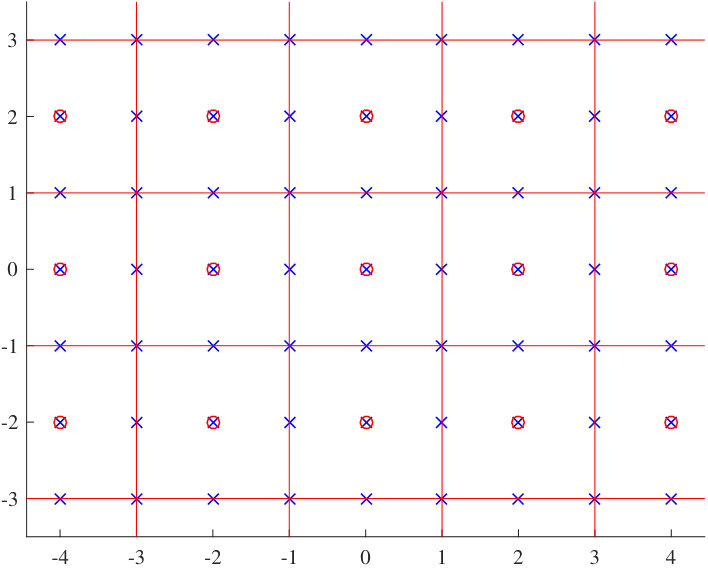 Figure 29
Figure 29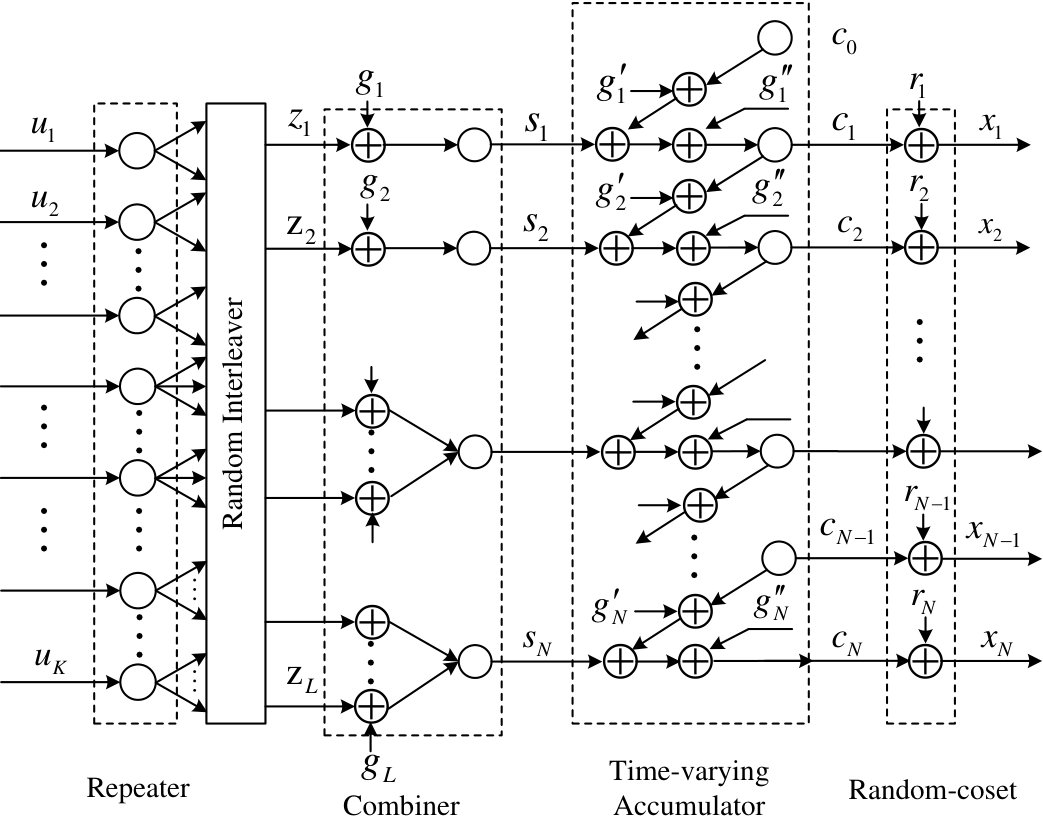 Figure 30
Figure 30 Figure 31
Figure 31 Figure 32
Figure 32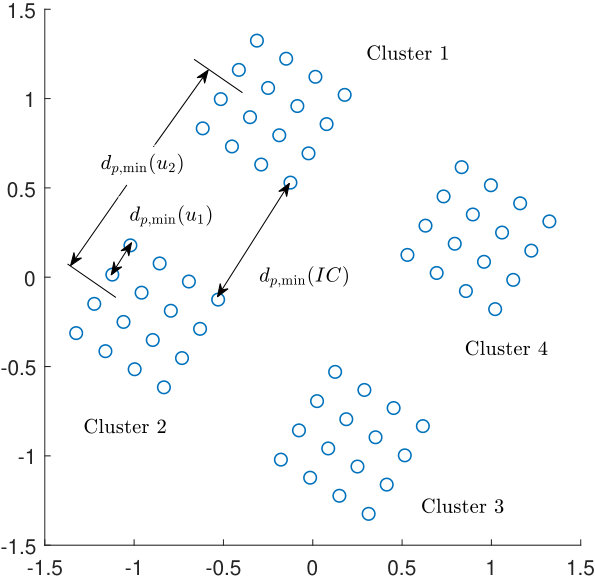 Figure 33
Figure 33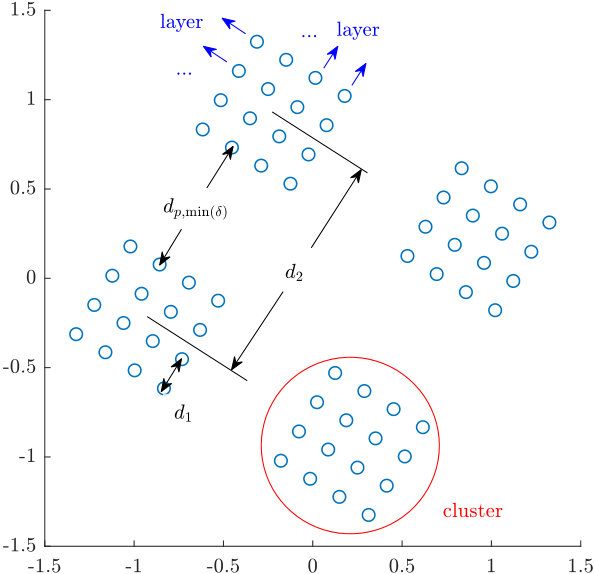 Figure 34
Figure 34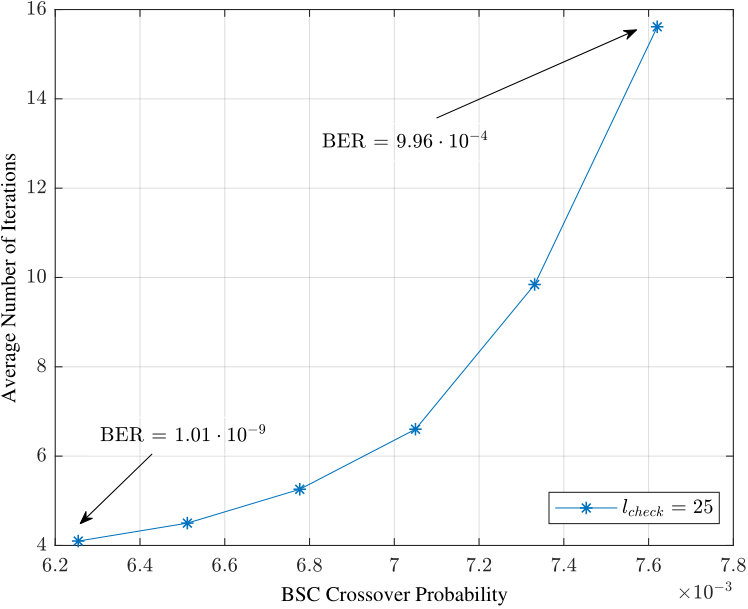 Figure 35
Figure 35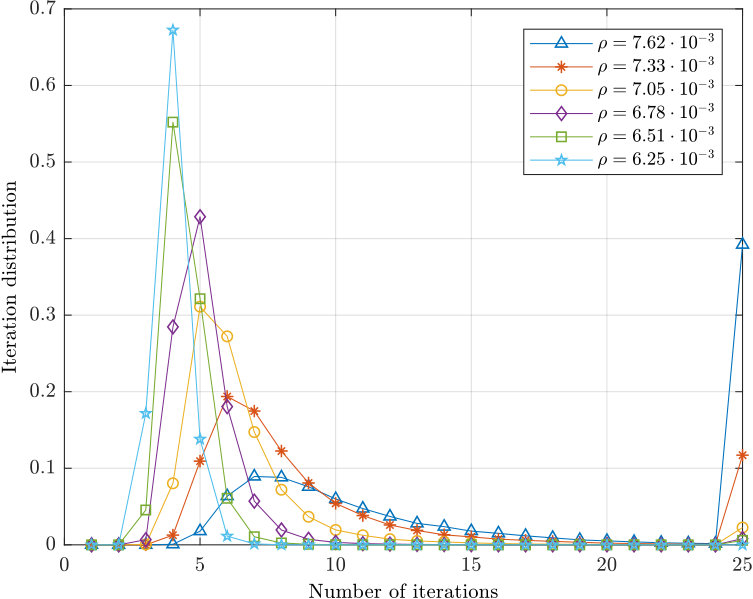 Figure 36
Figure 36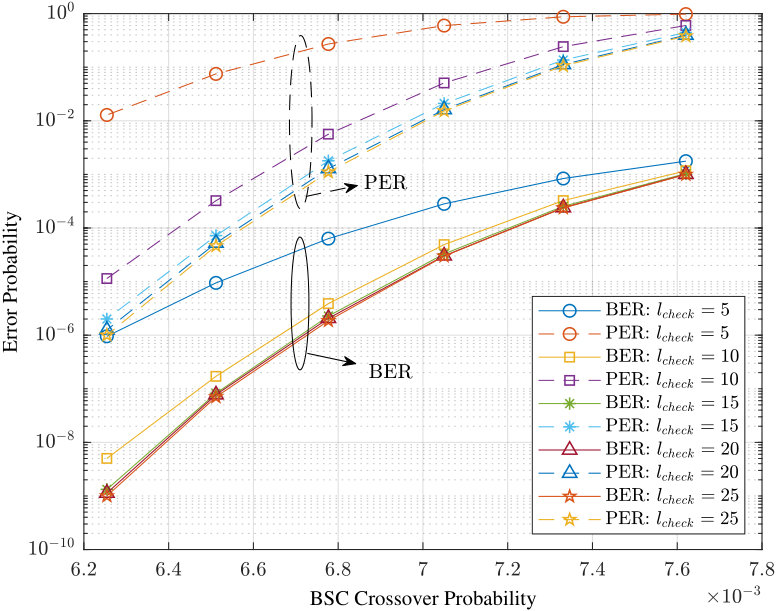 Figure 37
Figure 37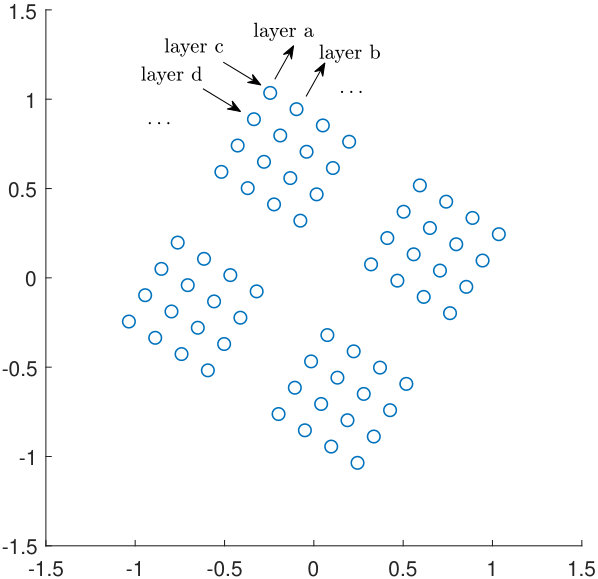 Figure 38
Figure 38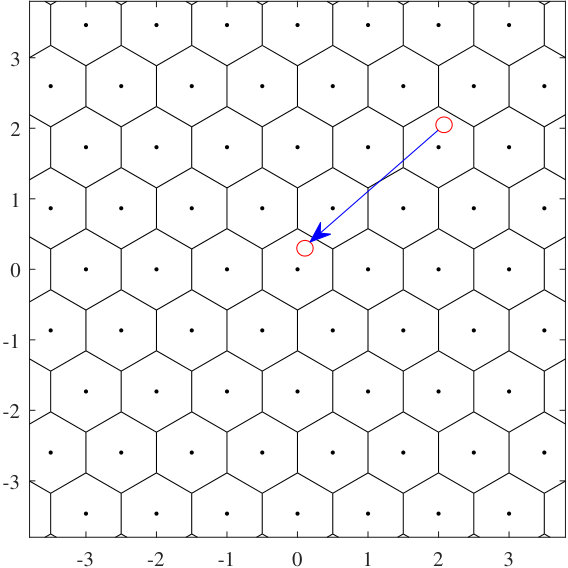 Figure 39
Figure 39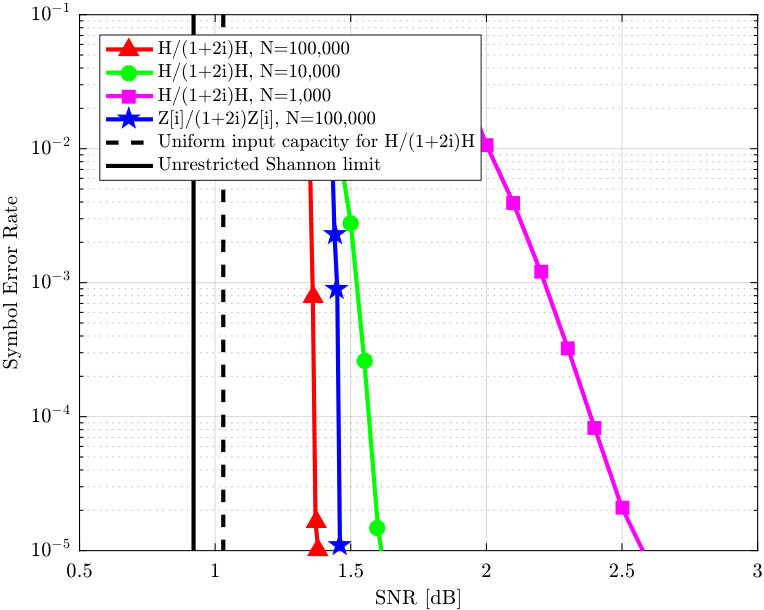 Figure 40
Figure 40| 3GPP | 3rd Generation Partnership Project |
| 4G | The Fourth-generation |
| 5G | The Fifth-generation |
| APP | A priori probability |
| AWGN | Additive white Gaussian noise |
| BCH | Bose-Chaudhuri-Hocquengham |
| BDD | Bounded distance decoding |
| BEC | Binary erasure channel |
| BER | Bit error rate |
| BI-AWGN | Binary input additive white Gaussian noise |
| BS | Base station |
| BSC | Binary symmetric channel |
| CDMA | Code-division multiple access |
| CLC | Convolutional lattice codes |
| CN | Check node |
| CRC | Cyclic redundant check |
| CSI | Channel state information |
| dB | Decibel |
| ECC | Error-correction code |
| eMBB | Enhanced mobile broadband |
| EXIT | Extrinsic information transfer |
| GF | Galois field |
| GLD | General low-density |
| FD | Full-duplex |
| FDMA | Frequency-division multiple access |
| FFT | Fast Fourier Transform |
| i.i.d. | Independent and identically distributed |
| ISI | Inter-symbol interference |
| I/Q | In-phase/Quadrature |
| IoT | Internet-of-things |
| IRA | Irregular repeat-accumulate |
| LDLC | Low-density lattice codes |
| LDPC | Low-density parity-check |
| LDA | Low-density Construction A |
| LLR | Log-likelihood ratio |
| LTE | Long-term evolution |
| MAP | Maximum a posterior |
| mMTC | Massive machine type communications |
| mmWave | Millimeter wave |
| MIMO | Multiple-input multiple-output |
| MMSE | Minimum mean square error |
| ML | Maximum-likelihood |
| MRC | Maximal-ratio combining |
| MRT | Maximal-ratio transmission |
| MSE | Mean squared error |
| NMSE | Normalized mean squared error |
| NOMA | Non-orthogonal multiple access |
| OFDM | Orthogonal frequency-division multiplexing |
| OFDMA | Orthogonal frequency-division multiple access |
| OMA | Orthogonal multiple access |
| OSTBC | Orthogonal space-time block code |
| PAM | Pulse amplitude modulation |
| Probability density function | |
| PER | Page error rate |
| QAM | Quadrature amplitude modulation |
| QoS | Quality-of-service |
| RA | Repeat-accumulate |
| RS | Reed-Solomon |
| SDN | Software defined networks |
| SER | Symbol error rate |
| SIC | Successive interference cancellation |
| SNR | Signal-to-noise ratio |
| SINR | Signal-to-interference-plus-noise ratio |
| SPA | Sum-product algorithm |
| SSD | solid-state storage device |
| TDMA | Time-division multiple access |
| uRLLC | Ultra reliable and low latency communications |
| VN | Variable node |
| Transpose of | |
| Conjugate transpose of | |
| Inverse of | |
| The element in the row and the column of | |
| Determinant of | |
| Trace of | |
| Absolute value (modulus) of the complex scalar | |
| The Euclidean norm of a vector | |
| The Frobenius norm of a matrix | |
| A lattice | |
| The field of real number | |
| The field of complex number | |
| The Euclidean space | |
| The finite field of size | |
| The ring of integers | |
| The ring of positive integers | |
| The ring of Gaussian integers | |
| The ring of Eisenstein integers | |
| The ring of Hurwitz integers | |
| The probability of event occurs | |
| Probability density function of the random variable | |
| Conditional distribution of given | |
| Joint distribution of and | |
| Rounds a real number to the nearest integer greater than or | |
| equal to if or rounds to 0 for all | |
| The real part of a complex number | |
| The imaginary part of a complex number | |
| The cardinality of a set | |
| The all-zero vector | |
| dimension identity matrix | |
| Statistical expectation | |
| The volume of a bounded region in the Euclidean space | |
| The -dimensional sphere centered at the origin with radius : | |
| Real Gaussian random variable with mean and variance | |
| Circularly symmetric complex Gaussian random variable: | |
| the real and imaginary parts are i.i.d. | |
| Circularly symmetric Gaussian random vector with | |
| mean zero and covariance matrix | |
| Natural logarithm | |
| Logarithm in base | |
| A diagonal matrix with the entries of on its diagonal | |
| Limit | |
| Maximization | |
| Minimization | |
| Natural exponential function | |
| Hyperbolic tangent function | |
| Hamming distance | |
| Hamming weight | |
| Minimum Euclidean distance | |
| Minimum Product distance | |
| Modulo lattice addition | |
| Modulo lattice subtraction | |
| The mutual information between and | |
| The entropy of a continous random variable | |
| The entropy of a discrete random variable | |
| Obtain the elements that only belong to set | |
| The computational complexity is the order of operations |
| Rates | Thresholds | Degree Distributions: for VNs, for CNs | |||
| 4.47 dB |
|
||||
| 3.31 dB |
|
||||
| 1.26 dB |
|
| Coding schemes | n [symbols] | Coding loss [dB] | Gap [dB] |
| GLD lattices [Boutros14] | 1,000 | 1.3 | N/A |
| LDA lattices [8122043] | 1,000 | 1.36 | N/A |
| 10,000 | 0.7 | N/A | |
| LDA lattices [Boutros16] | 10,008 | 0.55 | 1.05 |
| 100,008 | 0.36 | 0.9 | |
| 1,000,008 | 0.3 | 0.8 | |
| LDLCs [4475389] | 1,000 | 1.5 | N/A |
| 10,000 | 0.8 | N/A | |
| 100,000 | 0.6 | N/A | |
| QC-LDPC lattices [Khodaiemehr17] | 1,190 | 2 | N/A |
| 30,000 | 1.5 | N/A | |
| IRA lattices | 1,000 | 1.5 | 1.7 |
| 10,000 | 0.6 | 0.8 | |
| 100,000 | 0.3 | 0.46 |
| (bits) | (bits) | ||
| 2.4156 | 2.5471 | ||
| 2.3878 | 2.5193 | ||
| 2.3548 | 2.4864 | ||
| 2.3069 | 2.4385 | ||
| 2.1620 | 2.2925 |
| SIC | |||
| (0.903, 0.405) | NO | ||
| (0.714, 0.343) | YES | ||
| (0.783, 0.343) | NO | ||
| (2, 1) | (0.598, 0.279) | YES | |
| (0.711, 0.307) | NO | ||
| (0.532, 0.246) | YES | ||
| (0.634, 0.274) | NO | ||
| (0.471, 0.216) | YES |
| SIC | |||
| (0.588, 0.446) | NO | ||
| (0.470, 0.363) | YES | ||
| (0.518, 0.392) | NO | ||
| (3, 1) | (0.401, 0.311) | YES | |
| (0.432, 0.328) | NO | ||
| (0.322, 0.250) | YES | ||
| (0.354, 0.269) | NO | ||
| (0.252, 0.195) | YES | ||
| (0.785, 0.376) | NO | ||
| (0.551, 0.285) | YES | ||
| (0.678, 0.319) | NO | ||
| (2, 2) | (0.459, 0.233) | YES | |
| (0.570, 0.261) | NO | ||
| (0.350, 0.174) | YES | ||
| (0.488, 0.226) | NO | ||
| (0.291, 0.144) | YES |
| SIC | |||
| (0.683, 0.495) | NO | ||
| (0.609, 0.483) | YES | ||
| (4, 1) | (0.605, 0.437) | NO | |
| (0.579, 0.421) | YES | ||
| (0.511, 0.369) | NO | ||
| (0.491, 0.357) | YES | ||
| (0.870, 0.377) | NO | ||
| (0.821, 0.362) | YES | ||
| (3, 2) | (0.740, 0.314) | NO | |
| (0.702, 0.302) | YES | ||
| (0.605, 0.250) | NO | ||
| (0.565, 0.237) | YES |
| Detectable | |||
| Detectable | |||
| Detectable | |||
| Undetectable | |||
| Undetectable |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsCooperative Communication and Network Coding · Advanced Wireless Communication Technologies · Wireless Communication Security Techniques
**Lattice Coding for
Downlink Multiuser Transmission
Min Qiu**
A thesis submitted to the Graduate Research School of
The University of New South Wales
in partial fulfillment of the requirements for the degree of
**Doctor of Philosophy
**
**School of Electrical Engineering and Telecommunications
Faculty of Engineering
The University of New South Wales
** February 2019
Copyright Statement
I hereby grant The University of New South Wales or its agents the right to archive and to make available my thesis or dissertation in whole or part in the University libraries in all forms of media, now or hereafter known, subject to the provisions of the Copyright Act 1968. I retain all proprietary rights, such as patent rights. I also retain the right to use in future works (such as articles or books) all or part of this thesis or dissertation.
I also authorise University Microfilms to use the abstract of my thesis in Dissertation Abstract International (this is applicable to doctoral thesis only).
I have either used no substantial portions of copyright material in my thesis or I have obtained permission to use copyright material; where permission has not been granted I have applied/will apply for a partial restriction of the digital copy of my thesis or dissertation.
Signed
Date
Authenticity Statement
I certify that the Library deposit digital copy is a direct equivalent of the final officially approved version of my thesis. No emendation of content has occurred and if there are any minor variations in formatting, they are the result of the conversion to digital format.
Signed
Date
Originality Statement
I hereby declare that this submission is my own work and to the best of my knowledge it contains no material previously published or written by another person, or substantial portions of material which have been accepted for the award of any other degree or diploma at UNSW or any other educational institute, except where due acknowledgment is made in the thesis. Any contribution made to the research by others, with whom I have worked at UNSW or elsewhere, is explicitly acknowledged in the thesis. I also declare that the intellectual content of this thesis is the product of my own work, except to the extent that assistance from others in the project’s design and conception or in style, presentation and linguistic expression is acknowledged.
Signed
Date
Dedicated to my parents and wife.
Abstract
In this thesis, we mainly investigate the lattice coding problem of the downlink communication between a base station and multiple users. The base station broadcasts a message containing each user’s intended message. The capacity limit of such a system setting is already well-known while the design of practical coding and modulation schemes to approach the theoretical limit has not been fully studied and investigated in the literature. This thesis attempts to address this problem by providing a systematic design on lattice coding and modulation schemes for downlink multiuser communication. The main idea is to exploit the structure property of lattices to harness interference from downlink users. The research work of this thesis can be divided into five parts.
In the first part of our research, we focus on designing a class of lattice codes to approach the capacity of the classical point-to-point communication channel before we address the multiuser systems in the later chapters. A novel encoding structure of our multi-dimensional lattice codes is introduced and this approach is proved to allow our designed codes exhibit symmetry and permutation-invariance properties. By exploring these two properties, the degree distributions and the decoding thresholds of our codes are optimized by using one-dimensional extrinsic information transfer (EXIT) charts, which were mainly used for designing binary linear codes previously.
After the success in point-to-point communications, we move on to multiuser communications based on discrete and finite channel inputs. The second part of our research is to design practical lattice coding schemes for downlink non-orthogonal multiple access (NOMA) without successive interference cancellation (SIC) at the receiver. We first consider the case where the transmitter and receiver have full channel knowledge and propose a framework based on lattice partitions. The individual achievable rate of the proposed framework based on any lattice is derived and its gap to the multiuser capacity is upper bounded by a constant that is only related to the normalized second moment of the underlying lattice.
Next in the third part of our research, we investigate the slow fading scenario where the transmitter does not have full channel state information (CSI). For such a case, the generalization from our previous design with full CSI is non-trivial. Thus, we propose a new scheme for downlink NOMA without SIC by designing coding and modulation schemes based on statistical CSI while the power allocation factors are naturally induced by the design. The individual outage rate is analyzed and its gap to the multiuser outage capacity is proved to be upper bounded by a constant that is universal to the base station power, channel gain, and the number of downlink users.
In the fourth part of our research, we study the problem of downlink communication through block fading channels where the base station does not have CSI. Realizing that our previous two designs in this channel achieve no diversity gain, we propose a class of NOMA schemes by mapping all the users’ messages to the same -dimensional algebraic lattices constructed from algebraic number fields. The minimum product distance of the superimposed constellation is analyzed in detailed as it is closely related to the error performance. We show that, even without SIC at the receiver, our scheme can still offer full diversity to each user and provide high coding gain.
Finally, in the last part of our research, we conduct an additional work by designing error-correction codes for ultra-reliable applications such as fibre-optic communication systems and data-storage systems. For this work, we develop a class of product codes with high code rate and low error floor. The unique encoding structure allows the decoder to easily detect and correct more error patterns that contribute to the error floor. Moreover, an efficient post processing technique is proposed to enhance the decoding performance by further lowering the error floor. Theoretical analysis of the error pattern occurrence and the decoding performance is provided.
Acknowledgments
First of all, I would like to thank my supervisor, Professor Jinhong Yuan, who has provided me endless support and guidance from the beginning of my Ph.D. study. His deep understanding of the topics, his enthusiasm for the research and his dedication to his students have been a source of inspiration for me. In particular, he always provides me with constructive feedback and insightful suggestions on my work. Most importantly, he taught me how to become an independent researcher. It has truly been fortunate for me to pursue my Ph.D. degree under his supervision.
Second, I would like to thank my co-supervisor, Dr. Lei Yang, for his guidance, many fruitful discussions and technical support on channel coding knowledge and programming. I would never forget that he gave me countless valuable advice when I was struggling in my first year. I would like to thank Dr. Yixuan Xie, who has been supportive to me and provided me a variety of resources to study channel coding techniques. His valuable input on a number of problems which we discussed together, was really helpful in the early stage of my research study. I would also like to thank Dr. Derrick Wing Kwan Ng, for his suggestions on my research and journal writing.
Lots of thanks to Professor Yu-Chih Huang, who had been my host supervisor when I was a visiting Ph.D. student at the National Taipei University. I am very impressed by his immense knowledge on lattices and information theory as well as his endless motivation. I have learned tremendously from his continuous advice and guidance. I am really appreciate his support on both my study and life in Taiwan. We have built long-term research collaboration and we are really enjoy working together.
Many thanks to my colleagues in the wireless communication group of the University of New South Wales. Especially, I want to thank Zhuo Sun, Zhiqiang Wei, Peng Kang, Bryan Liu, Xiaowei Wu, Ruide Li, Yihuan Liao and Shuangyang Li. We have studied together, shared our happiness and frustration together, and helped each other. You really make the Ph.D. journey funny and interesting.
Finally, my deepest appreciation goes to my beloved family for their unconditional love and support. My parents have always been there to help when I had hard time in my study or in my life. I especially would like to thank my beloved wife, Jing Tao, for her unwavering love, encouragement and support. Without her love, all my achievements would be meaningless.
List of Publications
Journal Articles:
M. Qiu, L. Yang, Y. Xie and J. Yuan, “On the design of multi-dimensional irregular repeat-accumulate lattice codes,” IEEE Trans. Commun., vol. 66, no. 2, pp. 478–492, Feb. 2018. 2. 2.
M. Qiu, Y.-C. Huang, S.-L. Shieh, and J. Yuan, “A lattice-partition framework of downlink non-orthogonal multiple access without SIC,” IEEE Trans. Commun., vol. 66, no. 6, pp. 2532–2546, Jun. 2018. 3. 3.
M. Qiu, L. Yang, Y. Xie, and J. Yuan, “Terminated staircase codes for NAND flash memories,”IEEE Trans. Commun., vol. 66, no. 12, pp. 5861-5875, Dec. 2018. 4. 4.
M. Qiu, Y.-C. Huang, J. Yuan and C.-L. Wang, “Lattice-partition-based downlink non-orthogonal multiple access without SIC for slow fading channels,” IEEE Trans. Commun., vol. 67, no. 2, pp. 1166-1181, Feb. 2019. 5. 5.
M. Qiu, Y.-C. Huang, and J. Yuan, “Downlink non-orthogonal multiple access without SIC for block fading channels: An algebraic rotation approach,” IEEE Trans. Wireless Commun., accepted, Jun. 2019.
Conference Articles:
M. Qiu, L. Yang, and J. Yuan, “Irregular repeat-accumulate lattice network codes for two-way relay channels” in Proc. IEEE Global Commun. Conf. (GLOBECOM), Washington, D.C., Dec. 2016, pp. 1-6. 2. 2.
M Qiu, L. Yang, Y. Xie, and J. Yuan, “On the design of multi-dimensional irregular repeat-accumulate lattice codes,” in Proc. IEEE Symp. Inf. Theory (ISIT), Aachen, Jul. 2017, pp. 2598-2602. 3. 3.
M Qiu, Y.-C. Huang, S.-L. Shieh, and J. Yuan, “A lattice-partition framework of downlink non-orthogonal multiple access without SIC,” in Proc. IEEE Global Commun. Conf. (GLOBECOM), Singapore, Dec. 2017, pp. 1-6. 4. 4.
M Qiu, Y.-C. Huang, J. Yuan and C.-L. Wang, “Downlink lattice-partition- based non-orthogonal multiple access without SIC for slow fading channels,” in Proc. IEEE Global Commun. Conf. (GLOBECOM), Abu Dhabi, Dec. 2018, pp. 1-6. 5. 5.
M Qiu, Y.-C. Huang, and J. Yuan, “Downlink NOMA without SIC for fast fading channels: Lattice partitions with algebraic rotations,” in Proc. IEEE Intern. Commun. Conf. (ICC), May 2019, pp. 1-6.
Abbreviations
List of Notations
Scalars, vectors and matrices are written in italic, boldface lower-case and upper-case letters, respectively, e.g., , and . Random variables are written in uppercase Sans Serif font e.g., .
Contents
-
1.2.3 Designing New Coding Schemes With Ultra-High Reliability
-
4 Design of Multi-Dimensional Irregular Repeat-Accumulate Lattice Codes
-
4.3 Design and Analysis of Multi-dimensional IRA Lattice Codes
-
5 A Lattice-Partition Framework of Downlink NOMA without SIC
-
5.3 Downlink NOMA based on Multi-dimensional lattices without SIC
-
5.3.2 Proposed Lattice Framework for Downlink NOMA without SIC
-
5.4 Analysis of Achievable Rates and their Gaps to the Multiuser Capacity Region
-
6 Lattice-Partition-Based Downlink NOMA without SIC for Slow Fading Channels
-
6.3.1 Deterministic Model for Two-User Downlink NOMA over Fading Channels
-
6.4 Analysis of the Outage Rates and Their Gaps to Multiuser Outage Capacity
-
8.5.2 Analysis of the Proposed Iterative Bit Flipping Algorithm
-
C.2.1 Proof of User 1’s Achievable Rate for a Channel Realization
List of Figures
- 2.1 Two-dimensional square lattice .
- 2.2 Two-dimensional hexagonal lattice .
- 2.3 Example showing the modulo lattice operations.
- 2.4 Lattice cosets .
- 2.5 Lattice coset leaders .
- 2.6 Covering radius, effective radius and packing radius of a lattice. The solid hexagon is the Voronoi region of the lattice.
- 4.1 Uniform input capacities of and .
- 4.2 Block diagram of the IRA lattice encoder.
- 4.3 Tanner graph of the IRA lattice codes.
- 4.4 EXIT Chart of optimized degree distributions for the rate multi-dimensional IRA lattice code.
- 4.5 Symbol error rate performance of rate codes.
- 4.6 Symbol error rate performance of rate codes.
- 4.7 Symbol error rate performance of rate codes.
- 5.1 The system model of the downlink NOMA.
- 5.2 The deterministic model for two-user case.
- 5.3 The achievable rate pairs of downlink NOMA based on , , and with dB and dB.
- 5.4 The achievable rate pairs of downlink NOMA based on , , and with dB and dB.
- 5.5 The achievable rate pairs of downlink NOMA based on , and with dB and dB.
- 5.6 The achievable rate tuples of downlink NOMA based on , and with dB.
- 5.7 Symbol error rate performance of coded system for bits/real dim.
- 6.1 The system model of the -user downlink NOMA over slow fading channels.
- 6.2 An illustration of the defined parameters in (6.9)-(6.14).
- 6.3 The outage rate pairs of downlink NOMA with dB and .
- 6.4 The outage rate tuples of downlink NOMA with dB and .
- 6.5 Outage performance comparison between NOMA and TDMA.
- 7.1 An example of a superimposed constellation with being a two-dimensional ideal lattice and .
- 7.2 Minimum product distances of the scheme considered in Example 7.1 with various .
- 7.3 An example of a layer in Case I.
- 7.4 Minimum determinant of Alamouti coded two-dimensional superimposed constellation from
- 7.5 Simulation results for user 1’s SER.
- 7.6 Simulation results for user 2’s SER.
- 7.7 Simulation results for average SER among two users.
- 7.8 Simulation results for worst SER among two users.
- 8.1 Terminated staircase code block structure.
- 8.2 Structure of a staircase code block.
- 8.3 A stall pattern.
- 8.4 The stall pattern after row flipping.
- 8.5 The stall pattern after restoration and all-flipping.
- 8.6 Simulation results for BER(solid line) and PER(dash line).
- 8.7 Error performance of our code with .
- 8.8 Average number of iterations when .
- 8.9 Iteration distribution for various BSC crossover probabilities.
Chapter 1 Introduction
In this chapter, we first introduce the motivation of the research for this thesis before summarizing the principal research problems and the main contributions of the thesis.
1.1 Overview of 5G
With the increasing demands of network access and the explosive growth of smart devices connected to the cellular networks, higher data rate, better quality-of-service (QoS) and more conductivities are required to support these needs. In particular, it is expected that the number of connected devices would reach to about 31.4 billion while the amount of mobile data traffic would rise to 107 exabytes (1 exabytes bytes) per month in 2023 [EricssonJun18Report]. However, the current fourth generation (4G) cellular network systems have reached their limits and cannot satisfy the future requirements.
The fifth generation (5G) wireless systems are commonly regarded as the enormous breakthrough innovations to the current 4G systems, and thus will revolutionize the way of communication. Most notably, the 5G systems will have three main new features: enhanced mobile broadband (eMBB) offering much higher data rates for data-intensive applications across a wider mobile coverage area, ultra-reliable low latency communications (uRLLC) providing extremely highly reliable communications for strictly latency-sensitive services, and massive machine type communications (mMTC) providing massive connectivity to a massive number of Internet of Things (IoT) devices in a small area [ITUR, TR38.802]. The research and development of 5G technologies have drawn increasingly interests from both academia and industry [DerrickNG17, 6824752]. On the path to 5G, a number of techniques such as millimeter wave (mmWave), massive multiple-input multiple-output (MIMO), full-duplex (FD) relaying, software defined networks (SDN) and etc. have been identified as the key technologies by researchers [6736746]. Apart from the aforementioned techniques, new multiple access techniques are also required to support the increasing number of mobile users and to offer better QoS as well as higher spectral efficiency. As such, this thesis aims to give a contribution to new multiple access and coding techniques, addressing the communication problems over multiuser channels.
1.2 Motivation
1.2.1 Designing New Channel Coding Schemes
Most communication theories are built from the basic point-to-point communication where the backbone is channel coding. Channel coding is an essential part to provide reliability to all sorts of communications by protecting the transmitted messages from transmission errors due to noise and interference. The history of channel coding started with Claude Shannon’s landmark paper [6773024] in 1948, where the channel capacity was established by means of communication at the highest possible rate with arbitrarily small errors. However, during that time, the channel capacity was thought to be only achieved by using random Gaussian coding, which could arguably be infeasible for practical wireless systems. After six decades of efforts made by many researchers, there are a number of well-known practical coding schemes such as turbo codes [397441, Vucetic:2000:TCP:352869], low-density parity-check (LDPC) codes [748992, 1057683] and polar codes [5075875] that can be easily designed to approach the point-to-point channel capacity. All of these coding schemes have now become parts of the modern communication standards.
Despite the progress being made by those capacity-approaching codes, there are still many important and unsolved problems in coding [7265214]. First, all the codes adopted in current communication standards are binary codes and the most commonly used modulation are quadrature amplitude modulation (QAM) or pulse amplitude modulation (PAM). Although some of the codes have been shown to approach or achieve the capacity of the binary erasure channel (BEC), binary symmetric channel (BSC) and binary additive white Gaussian noise (BI-AWGN) channel, it is difficult for them to approach the unconstrained Shannon limit for which the capacity is not restricted to any signal constellation. Specifically, for high order modulations that are directly coded and mapped into by binary codes, the information loss in demodulation process is unavoidable. The loss can be compensated by using multi-level coding scheme [771140], however, with high computational complexity and large processing delay. For non-binary codes, there is no loss in the demodulation process since each non-binary coding alphabet is directly mapped into a modulation symbol. Therefore, non-binary codes generally outperform binary codes in the same spectral efficiency. That being said, designing capacity achieving non-binary codes are more challenging compared to binary codes. Second, coding over QAM and PAM modulations exhibit a shaping loss of 1.53 dB [4282117], corresponding to 0.25 bits/s/Hz/dim loss in the transmission rate. This loss would become more significant when the data rate is higher. Thus, efficient shaping is necessary in order to further improve the spectral efficiency without increasing the channel bandwidth.
It is known that lattices are good for the purposes of both channel coding and shaping [1512416]. Lattice codes, built from lattices, are the Euclidean counterpart of binary linear codes. Lattices are infinite and discrete sets of points. They processes with many nice properties and elegant mathematical structures [conway1999sphere]. The theory behind lattices was born and developed long before they being applied to the realms of communication and signal processing. The idea of employing lattices in channel coding is due to the fact that many nice properties of the lattices can be carried over to solve practical engineering problems. Most notably, it has been proved in [1337105] that there exists a sequence of lattice codes that can achieve the capacity of AWGN channels. This encouraging result illustrates that the ultimate Shannon limit can be achieved with structure codes as opposed to random Gaussian codes. That said, the complexities of the optimal shaping and decoding algorithm therein are formidable and the problem of construct practical capacity-achieving lattice codes are still challenging. Motivated by the success of applying lattices in channel coding, the first part of this thesis is to design practical lattice codes that can approach the unconstrained AWGN channel capacity with moderate decoding complexity.
1.2.2 Designing New Multiple Access Schemes
Different from the point-to-point communication, multiple access techniques are designed to share the channel resources among multiple users. Looking back at the history of mobile network [Goldsmith:2005:WC:993515], multiple access has changed significantly from frequency-division multiple access (FDMA) in the first generation (1G) network, time-division multiple access (TDMA) in the second generation (2G) network, code-division multiple access (CDMA) in the third generation (3G) network and orthogonal frequency division multiple access (OFDMA) in the current 4G network. These kinds of techniques are all known as orthogonal multiple access (OMA) because the channel resources are divided into orthogonal blocks based on frequency/time/codeword domain and each user is served in one orthogonal resource block exclusively. The benefit of doing so is that the inter-user interference can be avoided. As a result, the multiuser communication problem can be converted into parallel point-to-point communication problems where single-user coding/decoding techniques suffice. However, OMA has low spectral efficiency and cannot reliably operate at the multiuser capacity region in general [tse_book]. Another major drawback of OMA is that the number of served users is strictly limited by the number of orthogonal resources. Thus, it is difficult for conventional OMA to meet the future demands with the explosive growth of mobile users and traffic.
Recently, non-orthogonal multiple access (NOMA) has been proposed [6692652] and is expected to provide higher spectral efficiency, better user fairness, and allows the base station to serve more users [Dai15, DerrickNG17, wei2017fairness]. Unlike OMA, the key idea of NOMA is to allow multiple users to share a given channel resource slot e.g., time/frequency/code and use advanced multiuser detection technique at the receiver to distinguish different users. In addition, it is also possible that NOMA can be integrated with existing multiple access techniques [7510794, 7503854, 7999275]. For example, a NOMA scheme can be implemented on top of OFDMA where a subcarrier can be allocated to more than one users such that the non-orthogonal transmission occurs in a subcarrier. Although the application of NOMA in cellular networks is relatively new, the principle of NOMA has already been studied in information theory for a long time. Typically, a single-antenna downlink NOMA can be regarded as a case of scalar Gaussian broadcast channel where the transmitter performs superposition coding and the receiver performs successive interference cancellation (SIC) [Cover:2006:EIT:1146355]. In this way, NOMA is capable to operate at the multiuser capacity region. Although the theoretical performance limits of NOMA are well understood, much is still lacking when it comes to practical schemes that are able to approach these limits. In particular, the problem of designing practical downlink NOMA schemes with finite and discrete inputs has received much less attention. Moreover, SIC can introduce a large decoding burden, a long latency and error propagation to the receivers of mobile devices. The problem would be even more pronounced when the number of users participating in the transmission is large. Motivated by the advantages of NOMA and after realizing many successful applications of lattice coding in different communication scenarios [6034734, 5605356, Natarajan15], the main focus of this thesis is dedicated to address the aforementioned limitations to design practical downlink NOMA schemes suitable for different wireless communication scenarios and with performance analysis.
1.2.3 Designing New Coding Schemes With Ultra-High Reliability
For applications that have high reliability and tight delay-constraint requirements, coding with low error floor is often required in order to reduce the number of retransmissions. Typical examples for this scenario can be backhaul communications with optical fibers or data storage systems. For these systems, the error probability requirement is much lower than that for common wireless communication scenario. In general, these systems are required to provide bit error rates (BERs) below . Moreover, these systems are also required to support higher data rate and with lower latency. Compared to the channel codes used in long-term evolution (LTE) systems, the rates of the underlying channel codes in theses systems are usually very high, e.g., about 0.9. These requirements have led to a renewed interest in designing new coding schemes suitable for high data rate, low latency and high reliability applications.
It is well known that LDPC codes and turbo codes are capacity-approaching codes. As such, these codes can be considered for the use in future wireless communications, optical communications and storage as they are able to provide much stronger error-correction capability than the conventional linear block codes, e.g., Hamming codes and Bose-Chaudhuri-Hocquengham (BCH) codes. However, these codes with irregular degree distributions often exhibit high error floor due to poor minimum codeword distances. On the other hand, LDPC codes with regular degree distributions have better error floor performance but with degraded decoding performance compared to irregular LDPC codes. Recently, spatially coupled (SC) codes such as SC-LDPC codes [5571910, 5695130] and SC-turbo codes [8002601, 8368318] have been proposed and shown to have remarkable performance in terms of better error floor than their uncoupled counterparts while promising the close-to-capacity performance. Due to the nature of spatial coupling, these codes can be efficiently decoded by using a window decoder, i.e., to decode a portion of coupled codewords by using the component code decoder. In such a way, the latency caused by decoding can be lower than that of decoding a whole codeword block. Despite their capacity-approaching performance, the hardware complexity for implementing these error control systems could limit their applications. First, these codes rely on iterative soft-decision decoding to attain the near-capacity performance. The internal data flow of the iterative decoder, i.e., the rate of routing/storing messages, can exceed the maximum data rate supported by the optical fibre systems. For example, a standard sum-product algorithm can have a 48 Tb/s data flow while an optical transport network can only support 100 Gb/s [Smith12]. Second, soft-decision channel output, i.e., log-likelihood ratios (LLRs), is crucial for the iterative decoder. For solid-state storage devices (SSDs) based on NAND flash memories, the channel representing NAND flash memory is unique in that only hard-decision channel outputs are available. Soft-decision results can be indirectly acquired by reading hard-decision outputs multiple times with different sensing reference voltages. The acquisition of soft channel output is a costly operation in terms of power consumption and processing latency.
Another family of codes known as product codes have also been considered for storage and optical systems. In particular, product codes with algebraic block codes as component codes are more attractive as they can be encoded and decoded with low-complexity algorithms. Most importantly, these codes with iterative hard-decision decoding can be designed to perform well over the BSC, which is the channel model of many fibre-optic communication systems and storage systems [Smith12, Cho14]. However, the task of designing high rate codes with low error floor is still challenging. Furthermore, it is unclear whether the error floor of general product codes can be analytically and precisely estimated. Motivated by the advantages of the product codes, an additional aim of this thesis is to design a class of product codes along with a new decoder and efficient post processing techniques to offer enhanced error performance and provide a method to compute the error floor of the designed codes [8425763].
1.3 Literature review
In this section, the related works of this thesis surrounding lattice coding, non-orthogonal multiple access and coding for ultra-reliable applications are discussed and reviewed.
1.3.1 Lattice Codes
Extensive research has been conducted on the analytical proving of the capacity- achieving properties of lattice codes from the information-theoretic perspective. The central line of development in the application of lattices for the AWGN channel originated in the work [29612] and was partially corrected in [259668]. It was proved in these works that lattice codes can attain the capacity of the AWGN channel under the maximum-likelihood (ML) decoding, with shaping determined by “thin” spherical shells. This peculiar shaping region actually makes the code lose most of its lattice structure and look similar to a random code on a sphere. Moreover, the decision regions of ML decoding are not fundamental regions of the lattices and thus are unbounded. In contrast, lattice decoding amounts to finding the closest lattice point, ignoring the decision boundary of the code. Such an unconstrained search preserves the lattice symmetry in the decoding process and saves complexity. When restricted to lattice decoding, however, it was shown in [641543, 651040] that lattice codes can transmit reliably only at rates up to . The loss of “one” in this rate formula means significant performance degradation in the low SNR regime. It has been finally proved in [1337105] that the full capacity of the Gaussian channel can be achieved by lattice encoding and decoding. Although the theoretical problem of whether structured codes can achieve capacity was solved, the design of practical lattice codes with close-to-capacity performance is still challenging.
In general, there are two main approaches to construct lattice codes. The first one is to construct lattice codes directly in the Euclidean space. There are two well-known examples: low-density lattice codes (LDLC) [4475389] and convolutional lattice codes (CLC) [5961819]. Another approach is to adapt modern capacity approaching error correction codes to construct lattices, i.e., construct lattices from convolutional codes [6516165, 6582523], LDPC codes [1705007, Tunali15, Boutros16, 8122043] and from polar codes [8492454]. Their constructions involve some well-known methods such as Construction [conway1999sphere] (constructing lattices based on a linear code), Construction [conway1999sphere] (constructing lattices based on the generator matrices of a series of nested linear codes), and Construction [conway1999sphere] (constructing lattices based on the parity check matrices of a series of nested linear codes). These methods allow one to construct lattice codes not only with good error performance inherited from capacity-achieving linear codes, but also having relatively lower construction complexity compared with LDLCs and CLCs. To sum up, most of the aforementioned designs have been shown to approach the Poltyrev limit [312163] (i.e., the channel capacity without either power limit or restrictions on signal constellations) within 1 dB when the codeword length is long enough. In addition, all of these lattices can be decoded with efficient iterative decoding algorithms.
However, for LDLCs, in order to attain the best possible decoding performance, the decoder would have to take the whole probability density functions (PDFs) for processing. This would require a significant amount of memory. As reported in [5961819], the symbol error rate (SER) of the CLCs is higher than that of LDLCs. Both of these two lattice coding schemes are still difficult to implement in practice due to the use of non-integer lattice constellations. Moreover, the LDPC lattices in [1705007] and the polar lattices in [8492454] involve multilevel coding and multistage decoding due to their construction methods. This poses a much higher delay in encoding and decoding than that of low-density Construction (LDA) lattices in [8122043].
Since most of the available designs are based on infinite lattice constellations, their error performances are compared against Poltyrev limit. To put these lattice codes into practice, a power constraint must be satisfied. Moreover, most lattice codes built from LDPC codes have high complexity encoding structures due to the sparseness of their parity-check matrices which in general can lead to high-density generator matrices. Furthermore, most of the Construction , Construction and Construction lattice codes are designed based on one or two-dimensional (real dimension) lattice partitions [6516165, 6584536, 7124694]. It is understood that this can result in a shaping loss in error performance compared with using higher-dimensional lattice partitions [Shum15]. Constructing codes over multi-dimensional lattices have been considered in [Kositwattanarerk15, Oggier13, Kositwattanarerk13, Khodaiemehr16]. In [Kositwattanarerk15] and [Kositwattanarerk13], the authors proposed a method for constructing lattices over number fields and have studied their application in wiretap block fading channels. In [Oggier13], the authors have proposed a lattice construction method to allow Construction A lattices equipped with multiplication, which has potential application in nonlinear distributed computing over a wireless network. In [Khodaiemehr16], the authors have designed lattices to obtain diversity orders in block fading channels. However, [Kositwattanarerk15, Oggier13, Kositwattanarerk13, Khodaiemehr16] mainly focused on constructing lattices over algebraic number fields with applications to block fading channels while designing lattice codes to approach the unconstrained Shannon limit was not taken into account.
Recently, we have designed irregular repeat-accumulate (IRA) lattice network codes with finite constellations for two-way relay channels (TWRC) in [Qiu16]. The lattice codes are constructed via Construction A on non-binary IRA codes. We have used the extrinsic information transfer (EXIT) charts to optimize the degree distributions of our code ensembles in a bid to minimize the required decoding SNRs. However, this scheme is based on two-dimensional lattice partitions and thus still has a non-negligible performance gap to the unconstrained Shannon limit.
1.3.2 Non-Orthogonal Multiple Access
According to the literature [weisurvey16, Ding17J, 8114722, 8085125, 7676258], the designs of NOMA are generally categorized into power-domain and code-domain schemes. The main idea of power-domain schemes [6692652, 7676258] is that the transmitter superimposes different users’ signals sharing the same resource block and the receiver employs SIC to partially or fully cancel out interference. Due to its simplicity and efficiency, the 3rd Generation Partnership Project (3GPP) has proposed a preliminary version of power-domain NOMA terms multiuser superposition transmission (MUST) [TR36.859] for LTE networks. Code-domain NOMA is evolved from the conventional CDMA where low-density sequences are used as signatures of users and efficient message passing algorithms are adopted for joint decoding. Some code-domain NOMA schemes such as low density spreading (LDS) [Beek09], sparse code multiple access (SCMA) [Nikopour13], and pattern division multiple access (PDMA) [8352623] have become potential candidates for future uplink multiple access schemes [8316582]. Both power-domain and code-domain NOMA schemes have demonstrated significant gains over conventional OMA schemes and each category has its advantages and disadvantages. For downlink multiuser communications, power-domain NOMA is often considered due to its low decoding complexity as compared to code-domain NOMA.
For power-domain NOMA, extensive research has been conducted to further enhance the performance. This includes designing efficient user pairing [ding17pair], user scheduling algorithms [di16, Hsu2018VTC], power allocation optimization for paired users [8345745, Wei17] and system throughput analysis [wei2017performance, WeiCOML, wei2018multiICC]. The benefits of NOMA in various communication scenarios such as MIMO systems [7236924] and physical layer security [7812773] have also been investigated.
Very recently, there have been several designs for power-domain NOMA where discrete inputs over finite constellations are considered. For example, [Choi2016] and [Dong17] investigate the power allocation of two-user NOMA with QAM inputs. In [Fang16], a downlink multiuser transmission scheme named lattice partition multiple access (LPMA) is proposed, where the concept of Construction [7962201] is adopted to partition a two-dimensional lattice into individual constellations. Although it is shown that such scheme can perform well even when the difference between two channel gains is small, the requirement of coding over prime fields makes it less attractive in practice. A simple -user NOMA scheme based on PAM inputs is proposed in [Shieh16] to substantially reduce the burden of decoding at NOMA receivers. In such a scheme, the input distributions are deliberately chosen to be uniformly distributed over some PAM such that the decoder can directly treat interference as noise without severely degrading performance. Theoretical results therein show that this scheme can operate at rate pairs close to the capacity region regardless of the channel parameters, and simulation results further indicate that the actual gaps to the capacity region are much smaller than the theoretical guarantee. However, all the above works assume that the instantaneous channel state information (CSI) is available at the transmitter while the channel gain is constant over a transmission frame. When the transmitter does not have full CSI, the design of NOMA becomes challenging since the optimal user ordering and power allocation all depend on accurate CSI. Although some existing works in the literature [Wei2016NOMA, 7361990, 7438933, Wei17, 7959198, 8063934, 8327866] have considered NOMA with only statistical CSI at the transmitter, continuous Gaussian inputs are still adopted. To the best of our knowledge, systematic designs of practical NOMA schemes based on discrete and finite input without transmit CSI have not been reported in the literature yet. For block fading channels, the idea of constellation rotation has been adopted in [7880967] to design a two-user downlink NOMA system. More specifically, their design is to optimize the error performance of either one of the two users and only the user whose constellation is optimized can enjoy the diversity gain. Moreover, their approach is based on exhaustive search and thus is of high complexity. In addition, the diversity order they obtained is at most 2 for two users.
1.3.3 Channel Coding With Ultra-Reliable Requirements
In this subsection, we review the previous works on coding for ultra-reliable applications such as flash memories.
Conventional single-level cell (SLC) NAND flash memories only required mild error-correction capabilities for which Hamming codes were sufficient and acceptable in industries [TN-29-63]. Later, stronger error-correction codes (ECCs) such as BCH codes have been widely used for error correction in NAND flash memories [Dolecek17]. With the well-established algebraic coding theory [Lin:2004:ECC:983680], BCH codes can be explicitly designed to meet the specific requirements including information length requirements, rate requirements and the required number of correctable errors. However, the decoding complexity for BCH codes with length and error correction capability is of . When the code rate is fixed, the complexity grows quadratically with and [Cho14]. A special case of BCH codes, i.e., Reed-Solomon (RS) codes have also been applied in flash memories [4671744, 6804935]. As RS codes are non-binary and defined over , they can correct multiple symbols where each symbol contains a number of bits. However, RS codes have a higher computational complexity than binary BCH codes due to the operations in encoding and decoding. Note that all the above coding schemes do not have error floor, which is desirable for storage systems.
While BCH codes with existing hard-decision decoding algorithms are still popular in the current design practice [7553563], some capacity-approaching channel codes such as the LDPC codes [Gallager63low-densityparity-check, 6364973, 6804932, 7416649, 7553579, 7553518] have been adopted in some flash memory controllers. To attain the best possible performance for LDPC codes, soft information is required for their soft-decision iterative decoding. However, soft reading signals off the NAND flash memory chips would require multiple reads with varying sensing levels. Compared to the hard-decision memory sensing, soft-decision memory sensing introduces longer system latency and more power consumption [5629456]. In addition, the obtained and processed soft information requires more memory space than that for hard information to store. Furthermore, most capacity-approaching LDPC codes exhibit high error floor (bit error rate between and ) [Richardson03error-floorsof]. Thus, the use of LDPC codes in NAND flash memories poses significant challenges in both code design and hardware implementations.
In order to satisfy the requirements for current NAND flash memory design practice as well as to obtain a higher coding gain than the baseline BCH codes, product codes based on linear block codes are proposed and developed [6118315]. These coding techniques with iterative hard-decision decoding have been shown to provide comparable performance to LDPC codes with hard-input. It has been proved in [7954697] that product codes with BCH component codes can approach the capacity at high-rate regime. Some design examples such as block-wise concatenated BCH codes proposed in [Cho14] and [7192620] have demonstrated strong error-correction capabilities under hard-decision decoding and a low error floor (page error rate (PER) below ). Other product code schemes for flash memories such as concatenated Raptor codes [Yu14] and Hamming product codes [5645968] also show better performance than their stand-alone counterparts. Another type of product codes called half product codes was investigated in [Emmadi15, 8362743] and are shown to have better minimum distance properties than full product codes. Compared to stand-alone BCH codes with the same design code length, these product code schemes with iterative hard-decision decoding have a lower implementation complexity.
Recently, a new class of product codes known as staircase codes was proposed in [Smith12] for high-speed fibre-optic communications. The codes are unterminated and constructed via recursive convolutional coding and block coding while the component codes can be chosen from any conventional ECCs, e.g., Hamming, BCH, RS, etc. The unterminated nature ensures that all the information blocks are protected by both row and column codewords. The staircase code decoder features a sliding-window decoding with hard-decision decoding in each window. Most notably, the simulation result therein shows that the staircase codes with BCH component codes can operate about 0.56 dB away from the BSC limit when BER is at . It has been reported in [6787025] that the net coding gain of the staircase codes is competitive with the best known hard-decision decodable codes over a range of overheads. It is also worth mentioning that the error floor can be accurately estimated and analyzed by the proposed union bound technique in [Smith12]. The error floor is mainly due to the error patterns known as stall patterns that cannot be resolved by the decoder with no updated information (similar to the trapping sets in LDPC codes). Extensive research has been carried out to improve the performance of staircase codes. In [hager2017approaching], an iterative decoding algorithm was developed to reduce the event of miscorrection due to the underlying component code without cyclic redundant check (CRC) and thus improve the net coding gain. A post-processing technique based on exhaustive pattern search was proposed in [7905932] to handle stall patterns in order to reduce the error floor. Very recently, an improved staircase code decoder with a low complexity bit-flip algorithm was proposed in [Holzbaur17]. The numerical results therein show that the error floor can be lowered by resolving some of the stall patterns. However, certain stall patterns cannot be solved by their purposed decoding algorithm. Moreover, it is still unclear which stall patterns can be solved definitely by the decoder. Although these unterminated staircase codes demonstrate superior error performance, the unterminated nature is not suitable for general storage applications, such as flash memory devices because an error propagation could cause severe data corruption. Furthermore, direct termination of the staircase codes will leave the last information block only protected by row or column codewords, which results in performance degradation.
1.4 Thesis Outline and Main Contributions
1.4.1 Thesis Organization
In this subsection, the outline of each chapter in this thesis is given. There are nine chapters in total, including an overview of 5G communication scenarios, the motivation of the research conducted in this research, related works on channel coding and multiuser communications, background information on lattices and wireless communications, details of the conducted research and the conclusion of this thesis.
Chapter 1
This chapter provides an overview of 5G communication scenario and the future requirements. Then, the motivation of this thesis and the relevant works are stated. It also presents the outline and the main contributions of this thesis.
Chapter 2
In this chapter, all the fundamental background knowledge of lattices are presented. Examples with relevant figures are provided to help understand the concept. The materials presented in this chapter will be used throughout the rest of this thesis.
Chapter 3
The basics of modern digital communication systems encompass channel coding, digital modulation, detection are described in this chapter. In addition, different channel models from point-to-point communication to multiuser communication as well as their corresponding channel capacities are also presented.
Chapter 4
In this chapter, we address the problem of communication over classical point- to-point AWGN channels by designing practical multi-dimensional lattice codes over finite constellations to approach the unconstrained Shannon limit. Full descriptions of how to optimize the decoding threshold and relevant simulation results are presented.
Chapter 5
In Chapter 5, we introduce the proposed lattice-partition framework of downlink NOMA scheme without SIC where the underlying input is based on any -dimensional lattice. Detailed design of coding and constellation for downlink NOMA and the theoretical analysis on the individual achievable rates and their gaps to multiuser capacity are presented in this chapter.
Chapter 6
In Chapter 6, we consider the problem of downlink multiuser communication through NOMA over slow fading channels where the transmitter only has statistical CSI. A novel lattice-partition based downlink NOMA scheme is presented. Detailed explanation on how to design the input distributions for each user based on the average channel condition as well as the theoretical and numerical analysis for the performance of the proposed scheme without SIC are also presented in this chapter.
Chapter 7
In this chapter, we investigate the problem of downlink multiuser communication via NOMA over block fading channels with the transmitter having statistical CSI only. An algebraic rotation approached is adopted to design efficient and practical NOMA scheme to allow each user to obtain higher coding gain and full diversity gain. Theoretical analysis on the performance of the proposed scheme and relevant simulation results are provided in this chapter.
Chapter 8
In this chapter, we present the additional work on designing staircase codes for storage systems. In particular, the proposed code structure and the proposed decoding algorithm to provide enhanced error floor performance are described in detailed. Both theoretical and simulation results are also provided.
Chapter 9
This chapter concludes the thesis by summarizing the main ideas of each chapter and the contributions of all the works conducted during my Ph.D research.
1.4.2 Research Contributions
In what follows, a detailed list of the research contributions in chapters 4-8 are presented.
Chapter 4 presents the design of lattice codes built from Construction A lattices where the underlying linear codes are non-binary irregular repeat-accumulate (IRA) codes. Most importantly, our codes are based on multi-dimensional lattice partitions with finite constellations. We propose a novel encoding structure that adds randomly generated lattice sequences to the encoder’s messages, instead of multiplying lattice sequences to the encoder’s messages because most multi-dimensional (more than two dimensions) lattice partitions only form additive quotient groups and lack multiplication operations. We further prove that our approach can ensure that the decoder’s messages exhibit permutation-invariance and symmetry properties. With these two properties, the densities of the messages in the iterative decoder can be modeled by Gaussian distributions described by a single parameter. With Gaussian approximation, EXIT charts for our multi- dimensional IRA lattice codes are developed and used for analyzing the convergence behavior and optimizing the decoding thresholds. Simulation results are provided and show that our codes can approach the unconstrained Shannon limit within 0.46 dB and outperform the previously designed lattice codes with two-dimensional lattice partitions and existing lattice coding schemes for large codeword length.
The results in Chapter 4 have been presented in the following publications:
- •
M. Qiu, L. Yang, Y. Xie and J. Yuan, “On the Design of Multi-Dimensional Irregular Repeat-Accumulate Lattice Codes,” IEEE Trans. Commun., vol. 66, no. 2, pp. 478–492, Feb. 2018.
- •
M. Qiu, L. Yang, and J. Yuan, “Irregular repeat-accumulate lattice network codes for two-way relay channels” in Proc. IEEE Global Commun. Conf. (GLOBECOM), Washington, D.C., Dec. 2016, pp. 1–6.
- •
M Qiu, L. Yang, Y. Xie, and J. Yuan, “On the design of multi-dimensional irregular repeat-accumulate lattice codes,” in Proc. IEEE Symp. Inf. Theory (ISIT), Aachen, Jul. 2017, pp. 2598–2602.
In Chapter 5, a novel lattice-partition-based downlink non-orthogonal multiple access framework is presented. This framework is motivated by recognizing the algebraic structure behind the scheme recently proposed by Shieh and Huang in [Shieh16] as a lattice partition in ; and is in fact a generalization of the scheme in [Shieh16] to any base lattice. The schemes in the proposed framework enjoy many desirable properties such as explicit and systematic design and discrete input distributions. Moreover, the proposed method only requires a limited knowledge of channel parameters. The rates achieved by the proposed scheme with any base lattice and with single-user decoding (i.e., without successive interference cancellation) are analyzed and a universal upper bound on the gap to the multiuser capacity is obtained as a function of the normalized second moment of the base lattice. Since the proposed framework has a substantially larger design space than that of [Shieh16] whose base lattice is a one-dimensional lattice, one can easily find instances in larger dimensions that can provide superior performance. Design examples with the base lattices , , , and Construction A lattices, respectively, are provided and both theoretical and simulation results exhibit smaller gaps to the multiuser capacity as dimensions increase.
The results in Chapter 5 have been presented in the following publications:
- •
M. Qiu, Y.-C. Huang, S.-L. Shieh, and J. Yuan, “A Lattice-Partition Framework of Downlink Non-Orthogonal Multiple Access without SIC,” IEEE Trans. Commun., vol. 66, no. 6, pp. 2532–2546, Jun. 2018.
- •
M Qiu, Y.-C. Huang, S.-L. Shieh, and J. Yuan, ““A lattice-partition framework of downlink non-orthogonal multiple access without SIC,” in Proc. IEEE Global Commun. Conf. (GLOBECOM), Singapore, Dec. 2018, pp. 1–6.
In Chapter 6, the problem of downlink non-orthogonal multiple access over slow fading channels is studied. Full channel state information is assumed at the receivers, while only statistical CSI is assumed to be available at the transmitter. A novel lattice-partition-based scheme is proposed which, according to statistical CSI, employs discrete inputs from appropriately designed constellations carved from a lattice, rather than continuous Gaussian inputs as used in most existing works. Theoretical analysis shows that for any outage probability smaller than , which covers almost all the cases of practical interest, the proposed scheme with single-user decoding, i.e., without successive interference cancellation is able to approach the NOMA outage capacity region within a constant gap, independent of the signal-to-noise ratio and the number of users. Simulation results fortify the effectiveness of the proposed scheme by showing that the approach without SIC can achieve outage rates that are very close to the outage capacity region and the gap becomes even smaller when SIC is employed.
The results in Chapter 6 have been presented in the following publications:
- •
M. Qiu, Y.-C. Huang, J. Yuan and C.-L. Wang, “Lattice-Partition-Based Downlink Non-Orthogonal Multiple Access without SIC for Slow Fading Channels,” IEEE Trans. Commun., vol. 67, no. 2, pp. 1166-1181, Feb. 2019.
- •
M Qiu, Y.-C. Huang, J. Yuan and C.-L. Wang, “Downlink lattice-partition- based non-orthogonal multiple access without SIC for slow fading channels,” in Proc. IEEE Global Commun. Conf. (GLOBECOM), Abu Dhabi, Dec. 2018, pp. 1–6.
In Chapter 7, we investigate the problem of downlink NOMA over block fading channels. For the single antenna case, we propose a class of NOMA schemes where all the users’ signals are mapped into -dimensional constellations corresponding to the same algebraic lattices from a number field, allowing every user attains full diversity gain with single-user decoding, i.e., no successive interference cancellation. The minimum product distances of the proposed scheme with arbitrary power allocation factor are analyzed and their upper bounds are derived. Within the proposed class of schemes, we also identify a special family of NOMA schemes based on lattice partitions of the underlying ideal lattices, whose minimum product distances can be easily controlled. Our analysis shows that among the proposed schemes, the lattice-partition-based schemes achieve the largest minimum product distances of the superimposed constellations, which are closely related to the symbol error rates for receivers with single-user decoding. Simulation results are presented to verify our analysis and to show the effectiveness of the proposed schemes as compared to benchmark NOMA schemes. Extensions of our design to the multi-antenna case are also considered where similar analysis and results are presented.
The results in Chapter 7 have been presented in the following publications:
- •
M. Qiu, Y.-C. Huang, and J. Yuan, “Downlink Non-Orthogonal Multiple Access without SIC for Block Fading Channels,” IEEE Trans. Wireless Commun., accepted, Jun. 2019.
- •
M Qiu, Y.-C. Huang, and J. Yuan, “Downlink NOMA without SIC for fast fading channels: Lattice partitions with algebraic rotations,” in Proc. IEEE Intern. Commun. Conf. (ICC), May 2019, pp. 1-6.
In Chapter 8, we propose novel terminated staircase codes for ultra-reliable applications such as NAND flash memories. Specifically, we design a rate 0.89 staircase code whose component code is a BCH code, for flash memories with page size of 16K bytes. Different from most conventional unterminated staircase codes, we propose a novel coding structure by performing CRC encoding and decoding on each component codeword including information bits and parity bits. The CRC bits are protected by both row and column codewords. Furthermore, a novel iterative bit flipping algorithm is developed to solve stall patterns and lower the error floor. Based on our design, we perform an improved analysis on the error floor. We prove and show that our proposed decoding algorithm can solve more stall patterns which leads to a lower error floor compared to conventional staircase codes. Numerical results show that our terminated staircase codes outperform the stand-alone BCH codes and the conventional staircase codes.
The results in Chapter 8 have been presented in the following publication:
- •
M. Qiu, L. Yang, Y. Xie, and J. Yuan, “Terminated Staircase Codes for NAND Flash Memories,”IEEE Trans. Commun., vol. 66, no. 12, pp. 5861-5875, Dec. 2018.
Chapter 2 Background on Lattices
2.1 Introduction
In this part, we first introduce the basic concept of lattices and lattice codes. Then, we introduce algebraic number theory that is useful and essential for constructing lattices. We summarize the most important definitions and results without proofs. More details about lattices, lattice codes [conway1999sphere, huang13phd, dipietro:tel-01135575, Zamir15] and algebraic number theory can be found in [Oggier:2004:ANT:1166377.1166378, Oggier:33651, costa2018lattices], respectively, and the references therein. Here, we also fix most of the notation that will be employed later on. For our purposes, all the concepts below are introduced based on real-dimensional lattices.
2.2 Lattices
An -dimensional lattice is a discrete set of points in . It is a discrete subgroup that is closed under addition and reflection. That is, for any pair of lattice points, , we have .
In Fig. 2.1 and Fig. 2.2, we provide two examples of two-dimensional lattices, namely square lattice and hexagonal lattice , respectively. In algebraic number theory, these two lattices are referred to as the ring of Gaussian integer and the ring of Eisenstein integer , respectively. Now, we present the fundamental concepts of lattices.
2.2.1 Lattice Basics
Definition 2.1**.**
(Lattice): An -dimensional lattice is the set of all the linear combinations of linearly independent vectors such that:
[TABLE]
By the above definition, a lattice always contain the all-zero point . Moreover, we have restricted our definition to full-rank lattices (that is, -dimensional lattices in an -dimensional Euclidean space) because we do not need to treat lower-rank lattices for the purposes of our work.
Definition 2.2**.**
(Generator Matrix): A generator matrix of a lattice is a matrix whose rows generate
[TABLE]
Definition 2.3**.**
(Cartesian Product): The Cartesian product of two lattices and of dimensions and is an dimensional lattice :
[TABLE]
The generator matrix of this product lattice is a block-diagonal matrix
[TABLE]
with the component generator matrices on its diagonal, hence its determinant is the product of the component determinants
[TABLE]
Definition 2.4**.**
(Lattice Quantizer): A lattice quantizer (or the nearest neighbor quantizer) with respect to maps a point to its closest lattice point of as
[TABLE]
Definition 2.5**.**
(Fundamental Voronoi Region/Cell): Given a lattice , the fundamental Voronoi region/cell of this lattice is defined as
[TABLE]
In other words, is the set of all the real vectors that are closer (or as close) to the all-zero lattice point than to any other lattice point.
Definition 2.6**.**
(Voronoi Region/Cell): Given a lattice , the Voronoi region/cell of this lattice is defined as
[TABLE]
Similar to the above definition, is the set of all the real vectors that are closer (or as close) to the lattice point than to any other lattice point.
Clearly, the Voronoi cell have the following three properties:
- •
Each Voronoi cell is a shift of the fundamental Voronoi cell by , i.e., .
- •
The cells do not intersect with each other, i.e., for all .
- •
The union of the cells covers the whole Euclidean space, i.e., .
Definition 2.7**.**
(Modulo Operation): The modulo-lattice operation with respect to is defined as
[TABLE]
One example that explains the above operations can be found in Fig. 2.3 where the lattice is considered and the circle in the upper right corner represents a vector . The nearest neighbor quantizer associated with will quantize to the lattice point inside the same hexagon with . The hexagon circumventing the origin is the fundamental Voronoi region of . Moreover, the modulo operation will map to the corresponding position inside the fundamental Voronoi region as the circle shown in the middle of this figure.
Definition 2.8**.**
(Volume): The volume of a lattice with generator matrix is defined by
[TABLE]
Note that the volume of is sometimes written as , namely the volume of the fundamental Voronoi region of .
Definition 2.9**.**
(Minimum Euclidean Distance): The minimum Euclidean distance of a lattice is
[TABLE]
This quantity is closely related to the performance of a lattice for the transmission of information over a real channel with Gaussian noise, which is similar to the minimum distance of a linear code.
Definition 2.10**.**
(Kissing Number): The Kissing number of a lattice is the number of lattice points whose norm is the minimum Euclidean distance of
[TABLE]
One may also be interested in counting the number of lattice points that have any fixed norm and not only the minimum one. These numbers are collected by the so-called theta series.
Definition 2.11**.**
(Theta Series): Let for some with ; let be the number of points of a certain lattice whose squared Euclidean norm is . Then the theta series of is defined by
[TABLE]
It can be observed that according to the above two definitions.
Definition 2.12**.**
(Equivalence): A lattice is equivalent to another lattice if , where is a positive scalar and is an orthogonal matrix such that and is an identity matrix with size .
Definition 2.13**.**
*(Sublattice): A lattice is a sublattice of (nested in) another lattice if . *
Definition 2.14**.**
(Lattice Partition): A lattice partition is formed by
[TABLE]
where is the fine lattice and is the coarse lattice such that is nested in : .
Note that the lattice partition above forms a quotient group.
Definition 2.15**.**
(Coset): Given the lattice partition and for each , the set is a coset of in .
An example of the cosets from lattice partition is shown in Fig. 2.4. The fine lattice points are represented by the crosses and the coarse lattice points are represented by the circles. There are four cosets in the Voronoi region of the coarse lattice .
Definition 2.16**.**
(Coset leader): Given the lattice partition , the point is called the coset leader of coset .
An example of the coset leaders of lattice partition is shown in Fig. 2.5. The coset leaders are the fine lattice points that lie inside the fundamental Voronoi region of the coarse lattice. For this case, the coset leaders form a shift version of 4QAM.
Definition 2.17**.**
(Nesting Ratio): Given the -dimensional lattice partition , the nested ratio is precisely calculated as
[TABLE]
For a pair of nested lattice , we denote the modulo-lattice addition with respect to by “” where
[TABLE]
Similarly, we denote the modulo-lattice subtraction by “” where
[TABLE]
Definition 2.18**.**
(Nested Lattice Code): Given an -dimensional fine lattice and an -dimensional coarse lattice , where , an -dimensional nested lattice code (Voronoi code), which we refer to as , is the set of all coset leaders in that lie in the fundamental Voronoi region of the coarse lattice
[TABLE]
Due to this geometry property, the fundamental Voronoi region is also called the shaping region. Shaping is essential in designing practical lattice codes because a finite section of the lattice points must be selected to satisfy a transmission power constraint for a communication system. The code rate of this nested lattice code in bits/s/Hz/real dimension is given by
[TABLE]
The fine lattice and the coarse lattice need to be carefully chosen in order to construct reliable lattice coding schemes. In what follows, we provide some definitions on the figures of merit of lattices in terms of packing, covering, quantization, and channel coding.
2.2.2 Figures of Merit
Definition 2.19**.**
(Packing Radius): For a given lattice , a radius is said to be a packing radius if the set is a packing in Euclidean space for all distinct lattice points , we have
[TABLE]
That is, the spheres do not intersect. The packing radius of the lattice is defined by the largest balls the lattice can pack
[TABLE]
Definition 2.20**.**
(Effective Radius): The effective radius of a lattice , which we denote by , is defined as the radius such that the corresponding sphere has the same volume as that of the lattice
[TABLE]
Definition 2.21**.**
(Covering Radius): For a given lattice , a radius is said to be a covering radius if the set is a covering of Euclidean space such that
[TABLE]
That is, each point in space is covered by at least one sphere. The covering radius of the lattice is defined as
[TABLE]
We depict the packing radius, effective radius and covering radius of the lattice in Fig. 2.6. In this figure, it is obvious that .
Definition 2.22**.**
(Packing Efficiency): The packing efficiency of a lattice is defined as
[TABLE]
The packing efficiency always satisfies
[TABLE]
Definition 2.23**.**
(Goodness for Packing): A sequence of lattices is good for packing if it satisfies
[TABLE]
This is the best known lower bound given by the Minkowski-Hlawka theorem [Roger64].
Definition 2.24**.**
(Covering Efficiency): The covering efficiency of a lattice is defined as
[TABLE]
The covering efficiency is by definition not less than 1. However, it goes above 1 for all .
Definition 2.25**.**
(Goodness for Covering): A sequence of lattices is good for covering if it satisfies
[TABLE]
Definition 2.26**.**
(Second moment): The second moment the lattice is defined as the average energy per dimension of a uniform distribution over the fundamental Voronoi region of
[TABLE]
Definition 2.27**.**
The normalized second moment (NSM) of the lattice is given by
[TABLE]
which is invariant to scaling or rotation of .
Definition 2.28**.**
(Goodness for Quantization): A sequence of lattices is good for quantization if it satisfies
[TABLE]
These lattices are also commonly referred to as Rogers good, since it was first shown by Rogers that such lattices exist [Roger57].
Definition 2.29**.**
(Shaping Gain): The shaping gain is defined as the energy gain by achieving the reduction of the average energy of a lattice constellation compared with the constellation points that form an -dimensional cube. It can be calculated as
[TABLE]
where is the NSM of an -dimensional cubic lattice. A lattice with a smaller normalised second moment is always desirable as its shaping gain is higher. When the dimension approaches infinite, there exists a sequence of lattices that can achieves the optimal shaping gain:
[TABLE]
Definition 2.30**.**
(Goodness for Coding): Consider an -dimensional lattice . A lattice point is transmitted through an AWGN channel:
[TABLE]
where is the received signal vector and is an -dimensional independent and identically distributed (i.i.d) Gaussian noise vector with each element . We define the effective radius of the noise vector by
[TABLE]
The lattice decoder attempts to decodes to the nearest lattice point . An error would occur only if is outside the Voronoi region of . Due to the lattice symmetry, this is equivalent to leaving the fundamental Voronoi region . As such, the error probability can be written as
[TABLE]
A sequence of lattices is good for coding if for any , the error probability satisfies
[TABLE]
These lattices are also commonly referred to as Poltyrev good [312163]. The existence of such lattices are shown by Loeliger in [641543].
Definition 2.31**.**
(Dithering): In quantization theory, as well as in some non-linear processing systems, the term “dithering” corresponds to intentional randomization aimed at improving the perceptual effect of the quantization. In the context of lattice quantization or shaping, dither is an effective means of guaranteeing desired distortion or power levels, independent of the input statistics. Specifically, let be a random dither statistically independent of a lattice codeword , known to both the transmitter and the receiver, uniformly distributed over . The dithered codeword
[TABLE]
is also uniformly distributed over and is statistically independent of . As a result,
[TABLE]
Introducing the random dither variable is just a tactic to prove many theorems related to the capacity achieving property of lattice codes [Forney03]. This is analogous to the tactic used in [Elias55] to prove that binary linear block codes can achieve the capacity of a binary input-symmetric channel, namely the introduction of a random translate of a binary linear block code of length , where is a random binary -tuple which is uniform over . Very recently, it is shown that lattice codes can achieve the capacity of Gaussian channels without dithering when [8122043]. On the other hand, dither is still necessary in the low SNR regime [Yona10].
2.3 Lattices from Codes
Lattices can be seen as the generalization of linear codes over a finite field (Hamming space) to the Euclidean space. In this perspective, we will present some classical ways of constructing lattices from linear codes. These strategies are employed in the literature for the achievement of both theoretical and practical results. Among those construction methods, Construction , Construction and Construction are the most three common approaches.
2.3.1 Construction
Let be a linear code over of length , dimension , and rate . The code is generated via
[TABLE]
where is the generator matrix of code .
The lattice obtained by Construction is
[TABLE]
Moreover, let be the natural embedding of into . Specifically,
[TABLE]
Another way of describing Construction is
[TABLE]
For this lattice, it can be easily seen that
[TABLE]
The above relationship shown in (2.45) also that
[TABLE]
The volume of the lattice is given by
[TABLE]
It is also possible to build the Construction lattices in and domain by using the embedding of and , respectively.
2.3.2 Construction
Construction involves chains of nested binary linear codes and is employed to build lattices with a low-complexity iterative decoding algorithm.
Consider the chain of nested binary linear codes
[TABLE]
where is a length dimension code for and is a length dimension code. We denote by the vectors of that generate the -th code. The construction lattice with levels is obtained from
[TABLE]
Another way of describing Construction lattices is
[TABLE]
Note that Construction over with is a particular case of Construction with .
2.3.3 Construction
Construction is dual to Construction . The construction is described by using the parity-check matrices of the component linear codes.
Consider the chain of nested binary linear codes as in (2.48). Every one of the codes is generated by parity-check equations for . Let be the equations that generate the smallest code and suppose that is generated by . This guarantees that the inclusions in (2.48) are respected.
The construction lattice with levels is obtained from
[TABLE]
2.4 Algebraic Number Theory
In this section, we introduce the basic concepts of algebraic number theory. We will present only the relevant definitions and results which lead to algebraic lattice constructions.
Let be the set of rational integers and let be the set of rational number .
2.4.1 Elementary Concepts
In this subsection, we introduce some elementary concepts of algebraic number theory. We will present only the relevant definitions and results which lead to algebraic lattice constructions.
Definition 2.32**.**
(Group): Let be a set equipped with an internal operation (here we use addition which is enough for the purpose of our work) that combines any two elements and to form another element, denoted . The set is a group if
- •
For all , the result of the operation .
- •
The operation is associative, i.e., for all .
- •
There exists a neutral element 0, such that for all .
- •
For all , there exists an inverse such that .
The group is said to be Abelian if for all , i.e., the internal operation is commutative.
Definition 2.33**.**
(Subgroup): Let be a group and be a non-empty subset of G. We say that is a subgroup of if is a group, where is the internal operation inherited from .
Definition 2.34**.**
(Ring): Let be a set equipped with two internal operations and . The set is a ring if
- •
* is an Abelian group.*
- •
The operation is associative, i.e., for all and has a neutral element 1 such that for all .
- •
The operation is distributive over , i.e., and for all .
- •
There exists a neutral element 0, such that for all .
The ring is commutative if for all .
Definition 2.35**.**
(Field): Let be a commutative ring. The set is a field if for all , there exists a multiplicative inverse such that .
Definition 2.36**.**
(Algebraic Number): Let be an element of a field containing , we say that is an algebraic number if it is a root of a monic polynomial (whose leading coefficient is 1) with coefficients in .
Definition 2.37**.**
(Algebraic Integer): We say that is an algebraic integer if it is a root of a monic polynomial (whose leading coefficient is 1) with coefficients in .
Definition 2.38**.**
(Field Extension): Let and be two fields. If , we say that is a field extension of . We denote it .
Definition 2.39**.**
(Degree): Let be a field extension. The dimension of as vector space over is called the degree of over and is denoted by . If is finite, we say that is a finite extension of .
Definition 2.40**.**
(Number Field): A number field is a field extension of of finite degree, where is an algebraic number and also a primitive element, such that the -vector space is generated by the powers of . If this number field has degree , then is a basis for .
2.4.2 Embedding
In this subsection, we will see how a number field can be represented, we say embedded, into .
Definition 2.41**.**
(Ring of Integers): Let be a number field of degree . The ring of integers of , denoted by , is the set of all algebraic integers in number field and has rank (that is, there exists a basis of elements over ).
Definition 2.42**.**
(Integral Basis): Let be a basis of . If for any element of can be uniquely expressed as a linear combination of the basis element, i.e., with for , we say that is an integral basis of .
Definition 2.43**.**
(Ring Homomorphism): Let and be two field extensions of . We call a –homomorphism if is a ring homomorphism that satisfies for all , i.e., that fixes . Recall that if and are rings, a ring homomorphism is a map that satisfies the following for all .
- •
.
- •
.
- •
.
Definition 2.44**.**
(Embedding): For the number field with digree , there are distinct -homomorphisms which is also called the embedding of into . The embedding is defined by , where are the distinct zeros in of the minimum polynomial of over .
For any , the embedding of into is given by
[TABLE]
Definition 2.45**.**
(Discriminant): Let be an integral basis of . We define the discriminant of as
[TABLE]
Definition 2.46**.**
(Signature): The signature of is denoted by if among those -homomorphisms, there are real -homomorphisms, i.e., , and pairs of complex -homomorphisms, i.e., , where is the conjugate of for .
Definition 2.47**.**
(Totally Real Number Field): A number field is said to be totally real if it has signature , i.e., .
Definition 2.48**.**
(Totally Complex Number Field): A number field is said to be totally complex if it has signature , i.e., .
Definition 2.49**.**
(Algebraic Norm): The algebraic norm of given above is given by .
Definition 2.50**.**
(Canonical Embedding): The canonical embedding is a ring homomorphism defined by
[TABLE]
If we identify with , the canonical embedding can be rewritten as
[TABLE]
The canonical embedding gives a geometrical representation of a number field, the one that will serve our purpose.
2.4.3 Algebraic Lattices
We are now ready to introduce algebraic lattices. The definition of canonical embedding (Definition 2.50) establishes a one-to-one correspondence between the elements of an algebraic number field of degree and the vectors of the -dimensional Euclidean space. The final step for constructing an algebraic lattice is given by the following result.
Definition 2.51**.**
(Algebraic Lattice): Let be an integral basis of . An algebraic lattice is a lattice in with a generator matrix
[TABLE]
The volume of the lattice is given by
[TABLE]
where is the discriminant of . Before going further, let us take some time to emphasize the correspondence between a lattice point and an algebraic integer in . A lattice point is of the form
[TABLE]
for some with for .
Definition 2.52**.**
(Ideal): Let be a number field of degree and its ring of integers. An ideal is that for every and we have , briefly and .
Definition 2.53**.**
(Principal ideal): An ideal is called principal if for some algebraic integer , in this case we also denote .
For a principal ideal of , its norm is computed as . Otherwise, if it is not principal, the norm is the cardinality .
Definition 2.54**.**
(Ideal Lattice): For a totally real number field of degree and an ideal with an integral basis , the corresponding ideal lattice is given by which has the generator matrix
[TABLE]
We can think of the diagonal matrix in (2.59) as a pre-fading, used to stretch an algebraic lattice into another, such as the lattice.
Definition 2.55**.**
(Diversity): A scheme is said to achieve a diversity order of if the average error probability satisfies
[TABLE]
The diversity of an -dimensional lattice is defined by
[TABLE]
Definition 2.56**.**
(Minimum Product Distance): Let be a lattice in . If has diversity , we define its minimum product distance by
[TABLE]
or equivalently, since we may consider the distance of from the origin, by
[TABLE]
where both products are taken over the non-zero components of the vectors.
It is shown in [485720, 681321] that codes carved from ideal lattices of totally real number fields attain the full diversity. Moreover, the minimum product distance of the codes thus can be easily guaranteed by the norm of the ideal .
2.5 Summary
In this chapter, we present the background materials on lattices. The main points presented in this chapter are summarized as follows.
- •
We quickly overview basic lattice definitions and some properties, with the main intention of giving some simple examples and getting used with some objects which will be used in the later chapters.
- •
We introduce the figures of merit of lattices to show how “good” a lattice can be.
- •
We present several classical methods of constructing lattices from linear codes.
- •
We provide some basic knowledge and definitions on algebraic number theory related to lattice construction.
- •
We also show the construction for several families of lattices that based on algebraic number field.
Chapter 3 Wireless Communications and Channel Coding
3.1 Introduction
In this chapter, we first introduce some basics of wireless communications, including different types of channel models, channel characteristics and the capacity. We then introduce the fundamental background of coding theories and techniques from point-to-point channels to multi-antenna channels. The materials in this chapter serve as the technical guidelines to provide the necessary background to understand the works in the later chapters. The contents are summarized from [Cover:2006:EIT:1146355, tse_book, Richardson:2008:MCT:1795974, johnson_2009, Lin09] and no new results are presented.
3.2 Binary Input Memoryless Channels
We start with the point-to-point communication channel model with binary channel inputs.
Definition 3.1**.**
(Discrete Channel): A discrete channel is one that transmits a symbol from a discrete set , known as the source alphabet, and returns a symbol from another (possibly different) discrete alphabet, .
A communication channel can be modeled as a random process. For a given symbol transmitted at time , such that is one of the symbols from the set , i.e. , the channel transition probability gives the probability that the returned symbol at time is the symbol from the set , i.e. .
Definition 3.2**.**
(Memoryless Channel): A channel is said to be memoryless if the channel output at any time instant depends only on the input at that time instant, not on previously transmitted symbols. More precisely, for a sequence of transmitted symbols and received symbols , a memoryless channel is therefore completely described by its input and output alphabets and the conditional probability distribution for each input– output symbol pair.
[TABLE]
The discrete memoryless channels are considered in this thesis.
3.2.1 Binary Erasure Channel
In the BEC, the channel input at time is binary, i.e., . The corresponding channel output takes on values in the alphabet , where indicates an erasure. Each transmitted bit is either erased with probability , or received correctly: and . Erasure occurs for each independently.
It is easy to see that the capacity of the BEC is [Richardson:2008:MCT:1795974, Chapter 3.1]
[TABLE]
in bits per channel use.
The BEC can be used to model data networks, where packets either arrive correctly or are lost due to buffer overflows or excessive delays [Richardson:2008:MCT:1795974, Chapter 3].
3.2.2 Binary Symmetric Channel
In the BSC, the channel input at time is binary, i.e., . The corresponding channel output is also binary, i.e., . Each transmitted bit is either flipped with probability , or received correctly. The parameter is called the crossover probability of the channel. Moreover, the output-symmetric property leads to
[TABLE]
The capacity of the BSC is [johnson_2009, Chapter 1.2.3]
[TABLE]
in bits per channel use.
The BSC channel can be used to model the communication channel in optical fibre [Smith12] as well as general storage systems where the channel outputs are in the form of hard-decision results [Cho14, Section II]. This model will appear in the work of designing product codes for storage systems in Chapter 8.
3.2.3 Binary Additive White Gaussian Noise Channel
In the BI-AWGN channel, the channel input at time is . The corresponding channel output is real-valued. More precisely, the input-output relationship is described by
[TABLE]
where is a Gaussian random variable with zero mean and variance . Each transmitted bit is corrupted by AWGN. The probability density function for is
[TABLE]
The capacity of the BI-AWGN chanel is [Richardson:2008:MCT:1795974, Example 4.38]
[TABLE]
in bits per channel use.
3.2.4 Unconstrained Additive White Gaussian Noise Channel
In contrast to the BI-AWGN channel, we define the unconstrained AWGN channel as follows. In the unconstrained AWGN channel, the input is not restricted to any signal constellation. Given the power constraint of the input signal , the capacity is [tse_book, Summary 5.1]
[TABLE]
in bits per channel use.
This model is the channel model considered in Chapter 4.
3.3 Fading Channels
We now look some general channel models beyond the above basic models. In a typical wireless communication scenario, the transmitted signal will be affected by both AWGN and fading attenuations. The general term fading is used to describe fluctuations in the envelope of a transmitted radio signal. Based on the variations of the channel strength over time and over frequency, it is generally divided into two types [tse_book, Chapter 2]:
- •
Large-scale fading, due to path loss of signal as a function of distance and shadowing by large objects such as buildings and hills. This occurs as the mobile moves through a distance of the order of the cell size, and is typically frequency independent.
- •
Small-scale fading, due to the constructive and destructive interference of the multiple signal paths between the transmitter and receiver. This occurs at the spatial scale of the order of the carrier wavelength, and is frequency dependent.
Large-scale fading is more relevant to issues such as cell-site planning. Small-scale multipath fading is more relevant to the design of reliable and efficient communication systems, which is considered in this thesis.
Now we introduce some important characteristics of the wireless channel.
Definition 3.3**.**
(Coherence Bandwidth): Coherence bandwidth is a statistical measurement of the range of frequencies such that the approximate maximum bandwidth or frequency interval over which two frequencies of a signal are likely to experience comparable or correlated fading [Goldsmith:2005:WC:993515, Chapter 3.3.2].
Definition 3.4**.**
(Coherence Time): The coherence time of a channel is defined as the time interval after which the channel impulse response decorrelates [Goldsmith:2005:WC:993515, Chapter 3.3.3].
Based on the coherence bandwidth, the wireless channel model can be further divided into frequency-selective channels and flat fading channels.
3.3.1 Frequency-Selective Fading Channel
If the bandwidth of the transmitted signal is larger than the channel coherence bandwidth, then the channel amplitude values of the received signal at frequencies separated by more than the coherence bandwidth are roughly independent. Thus, the channel amplitude varies widely across the signal bandwidth. In this case, the channel is called frequency-selective [Goldsmith:2005:WC:993515, Chapter 3.3.2]. When this occurs, the received signal includes multiple versions of the transmitted waveform which are attenuated (faded) and delayed in time, and hence the received signal is distorted. As a result of that, the channel induces inter symbol interference (ISI). The input-output relationship of the frequency-selective channel is given by
[TABLE]
where in this case the channel has taps.
3.3.2 Flat Fading Channel
If the wireless channel has a constant channel gain and the bandwidth of the transmitted signal is less than channel coherence bandwidth, the channel is usually referred to as flat fading [tse_book, Chapter 2.3.2]. In other words, fading across the entire signal bandwidth is highly correlated, i.e. the fading is roughly equal across the entire signal bandwidth. The input-output relationship of the channel is given by
[TABLE]
where is the fading coefficient at time . Here, we do not specify the dependence between the fading coefficients at different times .
Based on the channel coherence time, the wireless channel model can be further divided into slow fading channels, block fading channels and fast fading channels [tse_book, Chapter 2.3.1].
3.3.3 Slow Fading Channel
Slow fading arises when the coherence time of the channel is much larger than the delay requirement of the application. In this regime, the amplitude and phase change imposed by the channel can be considered constant over the transmission duration of the packet [tse_book, Chapter 5.4.1]. This channel is also sometimes referred to as quasi-static fading. The input-output relationship is given by
[TABLE]
where the channel coefficient remains constant for , i.e., the whole data packet length.
Slow fading is considered when we design new multiple access scheme in Chapter 5.
3.3.4 Fast Fading Channel
Fast fading occurs when the coherence time of the channel is much smaller than the delay requirement of the application. In this case, the amplitude and phase change imposed by the channel varies considerably over the period of use [tse_book, Chapter 5.4.5]. The channel model at time is given by
[TABLE]
3.3.5 Block Fading Channel
Block fading occurs when the channel coherence time is smaller than the data packet length. However, the channel is constant for a number of symbol interval. The channel model is given by
[TABLE]
where remains constant over the -th coherence period of symbols and is i.i.d. across different coherence periods [tse_book, Chapter 5.4.5].
This model is considered in our research work in Chapter 7.
3.4 Non-Orthogonal Multiple Access
In this section, we introduce multiuser communications. In particular, we will focus on the downlink communication scenario where a single transmitter (the base-station) attempts to communication information simultaneously to multiple users. The fundamental concept of NOMA is to realize the downlink multiple access technologies from the power domain. The key enabling technologies for current power-domain NOMA is based on two principles, namely, superposition coding and SIC [Cover:2006:EIT:1146355, Chapter 15.6.3].
3.4.1 Superposition Coding
At the transmitter side, the transmit signal is the (linear) superposition of the signals of all the users. It was first proposed in [1054727] and was proved to be optimal compared to time-sharing. It is one of the fundamental building blocks of coding schemes to achieve the capacity on the scalar Gaussian broadcast channel. In fact, it has been shown that superposition coding is capable of achieving the capacities of general degraded broadcast channel [Cover:2006:EIT:1146355].
Definition 3.5**.**
(Degraded Broadcast Channel): Consider a broadcast channel with one input alphabet and two output alphabets, and . This broadcast channel is said to be physically degraded if the channel transition probability satisfies [Cover:2006:EIT:1146355, Chapter 15.6.2]
[TABLE]
Compared to orthogonalization schemes, superposition coding can provide a very reasonable rate to the strong user, while achieving close to the single-user bound for the weak user. Intuitively, the strong user, being at a high SNR, is degree-of-freedom limited and superposition coding allows it to use the full degrees of freedom of the channel while being allocated only a small amount of transmit power, thus causing small amount of interference to the weak user. In contrast, an orthogonal scheme has to allocate a significant fraction of the degrees of freedom to the weak user to achieve near single-user performance, and this causes a large degradation in the performance of the strong user.
3.4.2 Successive Interference Cancellation
SIC plays an important role in achieving the capacities of downlink NOMA. For an SIC receiver, it first decodes other users’ signals one by one based on a decoding order before decoding its own signal. Upon finishing decoding one user’s signal, the receiver subtracts it from the received signal. As a result, the interference can be successfully removed and the achievable data rate is improved. In general, users with better channel conditions can perform SIC to mitigate the inter-user interference. Due to its advantages, SIC is also employed in practical systems such as CDMA [298053] and vertical-bell laboratories layered space-time (V-BLAST) [738086].
However, there are several potential practical issues in using SIC in a wireless system [tse_book, Discussion 6.1].
- •
Complexity scaling with the number of users: In the downlink, the use of SIC at the mobile means that it now has to decode information intended for some of the other users. Then the complexity at each mobile scales with the number of users in the cell.
- •
Error propagation: Capacity analysis assumes error-free decoding. However, with actual codes, decoding errors do occur. Once an error occurs for a user, this error can propagate to the decoders for all the users later in the SIC decoding order. This will affect the decoding error probabilities of the network.
- •
Imperfect channel estimation: SIC order heavily relies on accurate channel estimation. Imperfect channel estimation will affect the SIC ordering and may lead to SIC failure. In such a case, error propagation will also occur.
- •
Analog-to-digital quantization error: When the received powers of the users are very disparate, the analog-to-digital (A/D) converter needs to have a very large dynamic range, and at the same time, enough resolution to quantize accurately the contribution from the weak signal.
3.4.3 Multiuser Capacity Region
Consider a -user scalar Gaussian broadcast channel where both the transmitter and receivers have full CSI. The baseband channel model is
[TABLE]
where is the -th user’s received signal at time ; is the channel coefficient of the channel between the base station and the -th user; is the superposition coded message broadcasted by the base station and satisfies the total power constraint at the base station, i.e., ; and is the i.i.d. AWGN experienced at user . Without loss of generality, we assume that the channel gain follows
[TABLE]
The multiuser capacity region is the closure of the rate tuple [Goldsmith:2005:WC:993515, Chapter 14.5]
[TABLE]
in bits/s/Hz/real dimension for all possible splits of the total power at the base station, where is the power allocation for user .
In contrast to OMA such as TDMA, the rate region is given by
[TABLE]
where is the time-sharing parameter for user and = 1. The TDMA region is strictly inside the capacity region of the broadcast channel.
3.5 Linear Deterministic Model
Here, we introduce the linear deterministic model [Avestimehr11] which is used for modeling our downlink broadcast channel. The deterministic model allows us to characterize the capacity region of the broadcast channel approximately by considering an appropriate finite-field model of the broadcast channel. Coding schemes can then be designed according to the insight obtained from this relatively simple model. As we will see later that the deterministic model is employed for solving complex downlink communication problems in Chapter 5 and Chapter 6.
3.5.1 Modeling Signal Strength
Consider the real scalar Gaussian model for a point to point link
[TABLE]
where correspond to the channel input, output and the channel gain, respectively; is the noise; and the transmitter has the power constraint . Note that here both of the transmit power and noise power are normalized to 1. The channel gain is related to SNR, i.e., .
The model in (3.20) can be written as
[TABLE]
where follows by assuming the noise has a peak power equal to 1 and follows that
[TABLE]
If the 1 bit of the carry-over from the second summation to the first summation in (3.23) is ignored, the point-to-point Gaussian channel can be approximated as a pipe that only passes the bits above the noise level and truncates the bits below the noise level. Therefore, think of the transmitted signal as a sequence of bits at different signal levels, with the highest signal level in being the most significant bit and the lowest level being the least significant bit. As such, the receiver can see the most significant bits of without any noise and the rest are not seen at all.
The capacity of this deterministic channel is thus described by (3.24). This capacity is within -bit approximation of the capacity of the AWGN channel in (3.9). In the case of complex Gaussian channel, and the approximation is within 1-bit of the true AWGN capacity [Avestimehr11].
3.5.2 Modeling Broadcast
Consider the real scalar Gaussian broadcast channel with two receivers. The received SNR at receiver is denoted by for and we assume without loss of generality. The Gaussian broadcast channel is deterministically modeled as follows:
- •
Receiver 2 (weak user) receives only the most significant bits of .
- •
Receiver 1 (strong user) receives only the most significant bits of , and .
The bits in the deterministic model can be decoded by both users while the remaining bits can only be decoded by the strong user. The capacity of this model is then given by [Avestimehr11]
[TABLE]
The gap between the capacity region of the deterministic model and that of the Gaussian broadcast channel model (3.18) is within 1 bit for each user. However, this is only the worst-case gap and in the typical case where channel difference is large, the gap is much smaller than 1 bit.
3.6 Channel Coding
Shannon’s 1948 work shows that it is possible to transmit digital data with arbitrarily high reliability, over noise-corrupted channels, by encoding the digital message with an error correction code prior to transmission and subsequently decoding it at the receiver [6773024]. The transmitted symbols may be corrupted in some way by the channel, and it is the function of the error correction decoder to use the added redundancy to determine the transmitted message despite the imperfect reception. In this section, we introduce some codes design for the AWGN channel.
First, we give some useful definitions [Richardson:2008:MCT:1795974, Chapter 1.4] in the following.
Definition 3.6**.**
(Code): A code of length and cardinality over a field is a collection of elements from , i.e.,
[TABLE]
The code is linear if for any , we have . The code rate is given by
[TABLE]
It is measured in bits per transmitted symbol.
For this thesis, we only consider linear codes.
Definition 3.7**.**
(Hamming Weight) The Hamming weight of a codeword , which we denote by , is equal to the number of non-zero symbols in , i.e., the cardinality of the support set.
Definition 3.8**.**
(Hamming Distance) Given two codewords and , the Hamming distance of a pair , which we denote by , is the number of positions in which differs from . We have
[TABLE]
Further, and , with equality if and only if .
In what follows, we give some specific codes related to the work in this thesis.
3.6.1 BCH Codes
BCH codes are a class of cyclic codes such that a cyclic shift of a codeword is still a valid codeword [Lin09, Chapter 3.3]. BCH codes are specified in terms of the roots of their generator polynomials in finite fields.
Given two positive integers and such that , a primitive narrow-sense BCH code over the Galois field with code length and minimum distance at least is constructed by the following method.
Let be a primitive element of . For any positive integer , let be the minimal polynomial of . The generator polynomial of the BCH code is defined as the least common multiple (LCM)
[TABLE]
The error correction capability is [Lin:2004:ECC:983680, Chapter 6.2].
For any information sequence , the polynomial representation of is
[TABLE]
The polynomial representation of codeword is then generated by
[TABLE]
where is the codeword.
BCH codes can be efficiently decoded by Berlekamp–Massey algorithm [Berlekamp:2015:ACT:2834146], which realizes the bounded distance decoding (in Section 3.7.1).
3.6.2 Low Density Parity-Check Codes
LDPC codes are a class of linear block codes with near-capacity performance [Richardson:2008:MCT:1795974, Lin09, johnson_2009]. As their name suggests, LDPC codes are block codes with parity-check matrices that contain only a very small number of non-zero entries. This sparseness is essential for an iterative decoding complexity that increases only linearly with the code length [Lin09, Chapter 5]. The parity-check matrix of an LDPC code can be represented by a Tanner graph [1056404].
Definition 3.9**.**
(Tanner Graph): The Tanner graph consists of two sets of nodes: nodes for the codeword bits (called variable nodes (VNs)), and nodes for the parity -check equations (called check nodes (CNs)). An edge joins a variable node to a check node if that bit is included in the corresponding parity-check equation and so the number of edges in the Tanner graph is equal to the number of 1s in the parity-check matrix.
An parity-check matrix can be represented by a Tanner graph with VNs and CNs.
An LDPC code parity-check matrix is called -regular if each code bit is contained in a fixed number of of parity checks and each parity-check equation contains a fixed number of code bits. In other words, the parity-check matrix has column weights for each column and row weights for each row. The code rate for a regular LDPC code is bounded as [Lin09, Chapter 5.1.1]
[TABLE]
with equality when the parity-check matrix is full rank.
For irregular LDPC codes, the parameters and vary with the columns and rows. It is more useful to specify the degree distribution of the VN and the CN, denoted by and , respectively. The polynomials have the form [Lin09, Chapter 5.1.2]
[TABLE]
where denotes the fraction of all edges connected to degree- VNs; denotes the fraction of all edges connected to degree- CNs; is the maximum VN degree; and is the maximum CN degree. The code rate for an irregular LDPC code is bounded as [Lin09, Chapter 5.1.2]
[TABLE]
The irregular LDPC codes have better decoding threshold than their regular counterparts. The decoding is generally performed by sum-product decoding described in Section 3.7.4.
3.6.3 Repeat-Accumulate Codes
Repeat-accumulate (RA) codes are a specific class of serially concatenated codes in which the outer code is a rate- repetition code (repeating times) and the inner code is a convolutional code with generator . A convolutional code simply outputs the sum of the current input bit and the previous output bit over , i.e. it provides a running sum of all past inputs and so is often called an accumulator. These two component codes give repeat-accumulate codes their name. RA codes are a simple class of turbo-like codes [divsalar1998coding] as they are built from fixed convolutional codes interconnected with random interleavers. Here, the interleaver is placed between the inner and outer codes to improve the minimum Hamming distance and provide an interleaver gain for the turbo-like codes [Vucetic:2000:TCP:352869].
The irregular repeat-accumulate (IRA) codes generalize the RA codes in that the repetition rate may differ for each of the information bits and that the repeated bits are combined by a combiner and then are sent through the accumulator. IRA codes provide two important advantages over RA codes. First, they allow flexibility in the choice of the repetition rate for each information bit so that high-rate codes may be designed. Second, their irregularity allows operation closer to the capacity limit [Jin00].
Similar to LDPC codes, the family of RA codes can be represented by a Tanner graph. The code rate can also be determined from the degree distributions of VN and CN. The advantage of RA codes is that they have a much lower encoding complexity than LDPC codes while achieving comparable performance to LDPC codes. RA codes can also be decoded by using either sum-product algorithm or BCJR algorithm [johnson_2009, Chapter 6.2].
3.6.4 Extended Codes and Subcodes
Code extension is commonly used to provide a better minimum Hamming distance at the cost of lowering the code rate. Take an BCH code as an example, where is the codeword length, is the length of the bits to be encoded, is the error correction capability and denotes the minimum Hamming distance of the code. A singly-extended BCH code is obtained through an additional parity bit , formed by adding all coded bits over . In this case, the original codeword becomes . The singly-extended BCH code has the new parameters . On the other hand, a doubly-extended BCH code has two additional parity bits, denoted by and , such that
[TABLE]
i.e., the parity bits perform checks separately on odd and even bit positions. The doubly extension yields an BCH code.
As an alternative to extending the code, one may employ a subcode of the original BCH code. For example, the singly-extended BCH code behaves similarly to the even weight subcode of the BCH code, which is obtained by multiplying its generator polynomial by . As such, the resultant code has the parameters . The doubly-extended BCH code behaves similarly to the BCH subcode where odd and even coded bits separately sum to zero. This subcode is obtained by multiplying the generator polynomial by and becomes . Note that this subcode is not cyclic [hager2017approaching, Remark 1]. Compared to the code extension, subcodes have more rate loss because
[TABLE]
for any , where represents the change in the number of bits.
3.6.5 Product Codes
Let be a binary linear block code, and be a binary linear block code, where , , and represent code ’s length, dimension, and minimum distance, respectively for . A code with symbols can be constructed by making a rectangular array of columns and rows in which every row is a codeword in and every column is a codeword in . One code array or code block consists of information symbols and parity-check symbols. Since the rows (or columns) are codewords in (or ), the sum of two corresponding rows (or columns) in two code arrays is a codeword in (or in ). The resultant product code form a two-dimensional linear block code [Lin09, Chapter 3.5.1].
Let be the parity-check matrix of the binary linear code for . The product code based on and is defined as
[TABLE]
where each column and row of the codeword is a valid codeword of and , respectively.
3.7 Decoding
In this section, we introduce some common decoders for decoding linear block codes. We only present the main idea of the decoder while the detailed decoding algorithm is omitted.
3.7.1 Bounded Distance Decoding (BDD)
Consider the transmission of a -error correcting code codeword over a binary channel. The error vector introduced by the channel is denoted by . Applying BDD to the received word results in
[TABLE]
Note that the second case in (3.42) corresponds to an undetected error or miscorrection. If the channel is BEC, the second case will not happen. The BDD decoder is also known as the hard-decision decoder for decoding conventional linear block codes such as Hamming codes and BCH codes.
3.7.2 Maximum-Likelihood (ML) Decoding
The ML decoder always choose the codeword that is most likely to have produced the received vector . Specifically, given a received vector and a codebook , the ML decoder will choose the codeword that maximizes the probability . The ML decoder returns the decoded codeword according to the rule [Richardson:2008:MCT:1795974, Chapter 1.5]
[TABLE]
In the AWGN channel, the ML decoding is equivalent to finding the codeword that has the minimum Euclidean distance to the received codeword
[TABLE]
where denotes the demodulation function. The Viterbi decoding algorithm [1054010] was later shown to be an ML decoding algorithm [1450960].
3.7.3 Maximum A Posteriori (MAP) Decoding
Given a received vector and a codebook , a MAP decoder or block-MAP decoder chooses the codeword that maximizes the a posteriori probability for . The MAP decoding rule is given by [Richardson:2008:MCT:1795974, Chapter 1.5]
[TABLE]
where is the a priori probability of choosing codeword and follows that can be treated as a normalizing constant. If each codeword is equally likely to have been sent, then the MAP decoding rule is equivalent to the ML decoding rule
[TABLE]
The MAP decoding can also be done on a symbol by symbol basis. The symbol-MAP decoder will choose the most probable symbol, in our case bit, for each transmitted symbol (even if the set of chosen bits does not make up a valid codeword). A symbol-MAP decoder chooses the symbol according to the rule:
[TABLE]
An efficient algorithm for performing symbol-MAP decoding is the BCJR algorithm [1055186].
3.7.4 Sum-Product Decoding
The sum-product algorithm (SPA) [910572] is also sometimes called the belief-propagation (BP) algorithm [PEARL1986241]. It is an iterative soft-input and soft-output decoder which accepts the probability for each received bit as input and compute the probability of each received bit being one or zero after each decoding iterations by exchanging extrinsic information.
For the code that can be represented by a Tanner graph with VN and CN on each side, it can be thought of as a collection of VN decoders concatenated through an interleaver to a collection of CN decoders. The VN and CN decoders work cooperatively and iteratively to estimate the log-likelihood ratio (LLR) for each code bit. The LLR of a binary value is defined as
[TABLE]
The VNs process their inputs and pass extrinsic information up to their neighboring CNs; the CNs then process their inputs and pass extrinsic information down to their neighboring VNs; and the procedure repeats, starting with the VNs. After a preset maximum number of iterations of this VN/CN decoding round, or after some stopping criterion has been met (e.g., the parity-check equations are satisfied), the decoder computes (estimates) the LLRs from which decisions on the codeword bits are made. When the cycles in the code graph are large or the graph is cycle free, the estimates will be very accurate and the decoder will have near-optimal (MAP) performance [Lin09, Chapter 5.4].
Let denote the message sent from node of VN to node of CN in the operation of the SPA. Let denote the message sent from node of CN to node of VN. Also, let denote the set of neighbors of a given node in a Tanner graph. The message computations performed by the SPA can be expressed as follows [910572]:
VN to CN update:
[TABLE]
where is the set of neighboring nodes to , which excludes node .
CN to VN update:
[TABLE]
where is the set of neighboring nodes of without node ; is the set of arguments of the probability mass function ; and means the summation is taken over all nodes without node .
In contrast with the error-rate curves for classical codes – e.g., BCH codes with a BDD decoder, the error-rate curves for iteratively decoded codes generally have a region in which the slope decreases as the channel SNR increases (or, for a BEC, as the input erasure probability decreases). The sharp transition region on the curve is generally referred to as the waterfall region of the error-rate curve [Richardson:2008:MCT:1795974, Chapter 1.9].
3.8 Performance Analysis of Channel Coding
For a given code and decoder, one would like to know for which channel noise levels the decoder will be able to correct the errors and for which it will not. In most cases, the ensemble [Richardson:2008:MCT:1795974, Definition 1.15] of all possible codes with certain parameters (for example, a certain degree distribution) will be evaluated rather than a particular choice of code having those parameters.
Definition 3.10**.**
(Ensemble): Consider the code is over the field . We denote by the ensemble of codes of length and cardinality . There ere are degrees of freedom in choosing a code, one degree of freedom for each component of each codeword. The ensemble consists of all possible codes of length and cardinality .
In what follows, we describe two techniques to design and analyze the performance of a modern code ensemble, such as LDPC code ensembles and turbo-like code ensembles [Vucetic:2000:TCP:352869, Richardson:2008:MCT:1795974].
3.8.1 Density Evolution
When very long codes are considered, the extrinsic LLRs passed between the component decoders can be assumed to be independent and identically distributed. Under this assumption, the expected iterative decoding performance of a particular ensemble can be determined by tracking the evolution of these PDFs through the iterative decoding process, a technique called density evolution (DE) [Richardson:2008:MCT:1795974, Chapter 3.9].
DE can be used to find the maximum level of channel noise which is likely to be corrected by a particular code ensemble. A recursive function is used to track the expected residual graph evolution throughout the iterative decoding process. The decoding threshold is the point over which the error probability cannot drop to zero even after an infinite number of iterations. The derivation of the DE based on the following properties [johnson_2009, Chapter 7.2].
- •
Symmetry: The output of the channel is symmetric, e.g. for binary input, if then . As such, the LLRs output by the iterative decoder are also symmetric.
- •
All-zeros codeword: Using the symmetric condition above, the iterative decoding performance can be shown to be independent of the codeword transmitted. This result allows the performance of a code-decoder pair to be modelled by sending only the all-zeros codeword.
- •
Cycle-free graphs: As the codeword length goes to infinity, the ensemble average performance of the iterative decoder approaches that of decoding on a cycle-free graph.
- •
Concentration: With high probability, a randomly chosen code from an ensemble will have an iterative decoding performance close to the average performance of that ensemble.
To find the optimal degree distributions in the sense of the minimum threshold for a fixed code rate, a global optimization algorithm that searches the space of degree polynomials, is required on top of the DE algorithm.
3.8.2 Extrinsic Information Transfer Chart
As an alternative to DE, the EXIT chart technique is a graphical tool for estimating the decoding threshold of a code ensemble [957394]. The technique not only simplifies the DE process by representing the extrinsic information transferred between component codes by a single parameter, but also provides some intuition regarding the dynamics and convergence properties of an iteratively decoded code.
The idea behind EXIT charts begins with the fact that the VN decoders and CN decoders work cooperatively and iteratively to make bit decisions, with the metric of interest generally improving with each half-iteration. A transfer curve plotting the input metric versus the output metric can be obtained both for the VN decoders and for the CN deciders. Further, since the output metric for one processor is the input metric for its companion decoder, one can plot both transfer curves on the same axes, but with the abscissa and ordinate reversed for one decoder. Such a chart aids in the prediction of the decoding threshold of the ensemble of codes characterized by given VN and CN degree distributions: the decoding threshold is the or at which the transfer curve of the VN decoders just touches the curve of the CN decoders, precluding convergence of the two decoders. Similar to DE, decoding-threshold prediction via EXIT charts assumes a graph with no cycles, an infinite codeword length, and an infinite number of decoding iterations.
We will employ the EXIT chart technique in our code design in Chapters 4-5.
3.9 Summary
In this chapter, we present some basic background materials on wireless communications and channel coding which are closely related to and required by the research work in the thesis. The main points presented in this chapter are summarized as follows.
- •
We start with the introduction of point-to-point binary memoryless channel, including BEC, BSC, BI-AWGN and unconstrained AWGN channels. These channels are basic models for many coding designs.
- •
We provide some basic knowledge of different kinds of fading channels and their characteristics.
- •
We give background knowledge on NOMA, a promising way of downlink multiuser transmission. Two essential ingredients of NOMA as well as its performance limit, namely multiuser capacity region are also presented.
- •
We briefly describe different types of channel coding schemes, ranging from conventional algebraic codes and the modern capacity-approaching iterative decoded codes.
- •
For the above coding schemes, we also introduce the corresponding decoders by presenting the main ideas behind them.
- •
We briefly introduce two techniques DE and EXIT chart that are used for analyzing the average decoding performance of a code ensemble.
Chapter 4 Design of Multi-Dimensional Irregular Repeat-Accumulate Lattice Codes
4.1 Introduction
Lattice are effective arrangements of equally spaced points in Euclidean space. They have attracted considerable attentions in the coding community because their appealing algebraic structures can be efficiently exploited for encoding and decoding. In this chapter, we present our detailed design for a class of multi-dimensional lattice codes to attain the near-capacity performance for power constrained point-to-point channels, before we focus on the coding scheme design for multiuser downlink channels in the next few chapters.
4.1.1 Problem Statement
In light of the previous work mentioned in Section 1.3.1, we aim to design new multi-dimensional lattice codes to further approach the unconstrained AWGN channels. That being said, directly extending our previous design in [Qiu16] where the codes are based on two-dimensional lattice partitions to multi-dimensional lattice partitions is very challenging. There are two fundamental reasons why this is the case. First, in the previous setting, we employed a two-dimensional lattice partition to form a quotient ring which is isomorphic to a finite field. However, most multi-dimensional lattice partitions form additive quotient groups where addition is the only group operation. If we use multi-dimensional lattice partitions in our previous design, the multiplication between two lattice points cannot be performed on additive groups. Second, simply removing the multiplication in the encoding structure will prevent us from analysing and optimizing the multi-dimensional IRA lattice codes effectively. In the previous design, the encoder’s messages are multiplied by some randomly generated sequences so that the permutation-invariant property [Bennatan06] can be obtained. Under this property, the analysis and optimization of our lattice codes can be significantly simplified. It is possible to remove all the operations of multiplying random sequences to allow the use of multi-dimensional lattice partitions. However, the permutation-invariance property will not hold in this case. As a result, the densities of the messages in the iterative decoder can only be represented by a multivariate Gaussian distribution. This will lead to an extremely high complexity for our design and analysis.
4.1.2 Main Contributions
For this work, we aim to design multi-dimensional IRA lattice codes with finite constellations to further approach the unconstrained Shannon limit. This is different from most lattice codes which are based on infinite constellations in the literature. Even though these codes have been shown to approach the Poltyrev limit within 1 dB, it is still unclear whether these codes with power constraint can approach the unconstrained Shannon limit within 1 dB. In order to practically approach the unconstrained Shannon limit, we must optimize the degree distribution of our codes based on constellations, detection methods and decoding algorithms. Furthermore, we continue to use Construction A as it has been proved to be a simple and powerful tool for constructing capacity-achieving lattice codes according to the literature. The main contributions of our work are summarized as below:
- •
We designed a class of lattice codes with finite constellations based on multi- dimensional lattice partitions. More specifically, we proposed a novel encoding structure that adds random lattice sequences to the encoder’s messages (output of the interleaver, combiner and accumulator). In addition, we introduced a constraint on the random lattice sequences in our encoder and proved that the constraint can lead to linearity of our codes. Since no multiplication is required in our encoder, our design can be directly applied to any lattices of any dimensions.
- •
We investigated the optimal degree distributions of our lattice codes, aiming at approaching the unconstrained Shannon limit. We proved and showed that our encoding structure can produce permutation-invariant and symmetric effects in the densities of the decoder’s messages (soft information propagated in the iterative docoder). These two properties enable to use a Gaussian distribution characterised by a single parameter to model the soft information propagated inside the iterative decoder. Under this condition, we used a two-dimensional EXIT chart to analyse the convergence behaviour of the iterative decoder. With EXIT charts, we designed a set of lattice codes for different target code rates with the minimum decoding threshold.
- •
Numerical results are provided and show that our designed and optimised lattice codes can approach the unconstrained Shannon limit within 0.46 dB. We demonstrate that our lattice codes not only outperforms previously designed lattice codes in [Qiu16] with two-dimensional lattice partitions, but also have less coding loss compared with the existing lattice coding schemes in [Boutros14, Boutros16, Khodaiemehr17, 8122043, 4475389] for large codeword length, i.e., a codeword has more than 10,000 symbols.
4.2 Multi-Dimensional IRA Lattice Codes
In this section, we present the proposed multi-dimensional IRA lattice codes. We consider the channel to be a complex AWGN channel where the input is non-binary, which means asymmetric-output in general. For this channel, different transmitted symbols have different error resistance to the non-binary AWGN noise. Thus the decoding errors for different symbols are different.
4.2.1 IRA Lattices Construction
We begin with the construction of our lattice codes. The lattice codes are constructed via Construction A [conway1999sphere]. The error performance of Construction A lattices heavily depends on the underlying error correction codes. Thus, we choose IRA codes as they have been shown to have capacity-approaching performance in AWGN channels and has lower encoding complexity than that of general LDPC codes [Jin00, Chiu10, 7008249, 7124694, Yang15, Qiu17].
In this work, we use the conventional Construction A method to a more generic case which is not merely limited to two-dimensional lattices. Denote a non-binary IRA codes over by , where is a prime number and is a positive integer. The IRA encoder takes length input messages and produces length codewords. Here, and all the encoding operations are over . We denote the Construction A lattice by . It is generated via:
[TABLE]
where and is a lattice; is a homomorphism mapping function that maps each codeword component to the elements in the lattice partition:
[TABLE]
Note that in (4.1) should be a multiple of in (4.2).
It is also noteworthy that in conventional Construction A, can be any principal ideal domains (PID) such as rational integers and Gaussian integers . In that case, the lattice partition forms a quotient ring that is isomorphic to a finite field. In most cases where is a multi-dimensional lattice, the lattice partition forms a quotient group [Oggier13].
In (4.2), the -lattice is partitioned into numbers of cosets where each coset has a coset leader. For designing finite constellations, only coset leaders are used in transmission to satisfy the power constraint requirement. Therefore, using (2.19), the information rate for this Construction A lattice is
[TABLE]
where is the dimension of the -lattice.
We now present a specific design example of using the lattice via Construction A. According to [conway1999sphere], the lattice is a four-dimensional lattice which has the highest sphere packing density in the four-dimensional space. It is defined as:
[TABLE]
It has the generator matrix in the integer lattice form:
[TABLE]
As explained in Section 2.2.2, we use the NSM as the goodness to measure the shaping performance of the lattices. By (2.31), we calculate the NSM for is about . Then using (2.33) we can see that can provide a shaping gain about dB over the four dimensional cubic lattice.
According to [Natarajan15]. the lattice can be identified as Hurwitz quaternion integers:
[TABLE]
where is the basis of the number system for representing Hurwitz integers. Addition in is component wise whereas multiplication is non-commutative and defined based on the following relations:
[TABLE]
Given , the norm of is:
[TABLE]
Consider the following example. In (4.2), if we let , then the homomorphism mapping function becomes:
[TABLE]
Note that this lattice partition can be further expressed as:
[TABLE]
where (a) follows Eq. (2.9) and (b) follows [Zamir15, Eq. (2.43)]. The multiplication and division here should follow quaternion arithmetic [Smith03]. For the quantizer , we follow the approach in [Conway82] to develop the quantization algorithm of finding the closest lattice point to an arbitrary point in . The quantization algorithm has a lower computational complexity compared with ML decoding. It is very useful in the scenario where we perform the lattice partitions. The cardinality of this partition can be calculated by using (4.8) as . In this way, the lattice is partitioned into 25 cosets. Even though is a PID [Huang17], we only have the group homomorphism as the multiplication for is non-commutative.
Now we compare the mutual information of the uniform input distribution over the coset leaders of the lattice partition with that of a two-dimensional lattice to see the performance gain introduced by the multi-dimensional lattices. In this work, the two-dimensional square lattice is set to be a benchmark for performance comparison. Note that a finite portion of the lattice is known as a quadrature amplitude modulation (QAM). The lattice can be identified as Gaussian integers . For fair comparison, we partition both lattices in a way such that the information rates for both lattice partitions are the same.
We consider the examples of lattice partitions and , where both partitions yield the same information rate. This is because using (2.19) we can obtain the information rates for and as and , respectively. Here the lattice can be deemed as a two-dimensional complex lattice while the lattice is a one-dimensional complex lattice. Therefore the dimensions in (2.19) for both lattices are 2 and 1, respectively. In other words, the lattice requires one time slot to transmit its lattice point where the lattice requires two time slots to transmit a lattice point.
Given SNR values, the unconstrained Shannon limit for the AWGN channel is plotted in Fig. 4.1 along with the capacities of the lattice and the lattice. As observed from Fig. 4.1, the curve for the lattice always lies above that for the lattice. Therefore, under the same information rate, we can construct lattice partition based IRA lattice codes that require lower decoding SNR than any IRA lattice codes based on the lattice partitions. This is due to the advantage of shaping gain.
4.2.2 IRA Lattice Encoder
Here we show our proposed encoder design. The block diagram of the IRA lattice encoder is depicted in Fig. 4.2.
First of all, the input to the encoder is a length message , where each element for is taken from the set of coset leaders . This message is then fed into a repeater and repeated according to a discrete distribution of , where for and . The number represents the fraction of message symbols are repeated by times. The maximum repeating times is times, where , thus . After repeating, the total number of symbols becomes .
Next, the repeated symbols are passed into a random interleaver. We denote the interleaved sequence by . A randomly generated sequence with the same length is added to the interleaved sequence via in an element-wise manner, where “” is the modulo-lattice addition defined in (2.16). Note that each element of is randomly and uniformly chosen from the set of coset leaders such that a linear code constraint is met, which will be introduced later.
The resultant symbols are combined according to a discrete distribution of , where for and . Here the number represents the fraction of message symbols that are obtained from combining symbols from the output of the interleaver and the corresponding addition factors in . After combining, the message sequence becomes a length sequence denoted by , where . For , each symbol is calculated as:
[TABLE]
where and represent the first and last interleaved symbols input to the -th combiner, respectively; and are the addition factors with respect to and ; represents the number of symbols to be combined at the -th combiner; is the index of the first interleaved symbol input to the -th combiner. Note that the combiner is to combine the interleaved messages in order to satisfy the code rate requirement.
The combined message sequence is passed into a time-varying accumulator which features a time-varying transfer function determined by two randomly generated lattice sequences and . All the elements in both sequences are uniformly distributed over the set of coset leaders such that a linear code constraint is met, which will be introduced later. The output message of the time-varying accumulator is denoted by . The -th symbol , where , is generated by
[TABLE]
where the initial condition is given as . Here is a dummy parity that is fixed to [math] and will not be transmitted. It is also noteworthy that the random vectors , and in the encoding structure introduce and realize the permutation-invariance property on all edges of a Tanner graph as shown in Fig. 4.3 and will be discussed in Section 4.3.1.
Finally, the output of the accumulator adds a random-coset vector with length and become the coded lattice sequence :
[TABLE]
Elements of are uniformly distributed over the set of coset leaders . Before transmission, the average energy of codeword symbols is normalised to 1.
Note that although the four lattice sequences , , and are random, they are assumed to be known at both transmitters and receivers prior to transmission. Furthermore, the underlying linear codes for our Construction A lattices can be either systematic or nonsystematic non-binary IRA codes.
4.2.3 The Linearity of IRA Lattice Codes
It can be noticed that our proposed lattice encoding structure is different from previous designs. More specifically, instead of using the modulo-lattice multiplication between encoder messages and random lattice sequences in [Qiu16], we use a different approach by introducing the “” operation in the encoding process. However, this difference introduced non-linearity to our codes if , and are totally independent, which is not appealing for low complexity decoding. To address this issue, we introduce a constraint on these random sequences to ensure the codes are linear.
Proposition 4.1**.**
The multi-dimensional IRA lattice codes are linear if the -th output element from the encoder satisfies the following conditions:
[TABLE]
* Proof: * Please refer to Appendix A.1.
Note that this equation has elements. We randomly choose any elements out of these elements to be random and uniformly distributed over the set of coset leaders . The last element is then determined by Eq. (4.14). One can also notice that the linearity condition excludes the random-coset vector . This is because the random-coset vector is independent of the encoder’s messages and is always removed before decoding. If the random-coset vector is included in the condition, the output-symmetric effect in the non-binary AWGN channel will vanish.
4.2.4 Tanner Graph
Similar to conventional binary IRA codes in [Jin00], our multi-dimensional IRA lattice codes can be represented by a Tanner graph as shown in Fig. 4.3.
The Tanner graph is a bipartite graph with variable nodes and check nodes. In the figure, variable nodes are represented by circles while check nodes are represented by squares. There are variable nodes on the Tanner graph. The variable nodes that placed on the left, are called information nodes. They represent the repeaters in the encoder. The degree distribution of information nodes with degree is denoted by in the figure. This means that the fraction of information nodes are connected to check nodes. Note that the random interleaver here introduces randomness in the edges between information nodes and check nodes. This randomness can prevent short cycles in the Tanner graph which leads to a better decoding performance [Johnson05]. On the right of the Tanner graph, there are variable nodes which are called parity nodes, representing the output from the time-vary accumulator. In the middle of the Tanner graph, there are check nodes, representing combiners. The degree distribution of check nodes with degree is denoted by which represents the fraction of check nodes connected to information nodes and 2 parity nodes. Note that the random-coset vector is removed before performing decoding, thus it is not shown in the Tanner graph.
Now consider the -th check node with degree , according to (4.11), (4.12) and the Tanner graph in Fig. 4.3, the parity-check equation at the -th check node is
[TABLE]
where . Note that in the Tanner graph, is a dummy bit and will not be transmitted.
We decompose the elements on the left hand side of Equation (4.2.4) into two vectors:
[TABLE]
[TABLE]
The first vector represents the symbols coming from the variable nodes connected to the -th check node. More specifically, are from information nodes while and are from parity nodes. The second vector represents the addition factors on the corresponding edges of the -th check nodes as shown in Fig. 4.3.
4.2.5 IRA Lattice Decoder
As shown in Section 4.2.4, the multi-dimensional IRA lattice codes have a Tanner graph representation. Therefore, we can employ a modified belief prorogation (BP) decoding algorithm to decode our lattice codes.
The decoder attempts to recover the source message from the noisy observation of the AWGN channel output , where denotes the complex AWGN noise. Before decoding, we first need to calculate the symbol-wise a posterior probability (APP) of each coset leader and for each lattice codeword component , which is written as:
[TABLE]
For the sake of simplicity, We let
[TABLE]
where and is the -th coset leader. Since the transmitted codeword symbol is , where is uniformly distributed over , thus the distribution for is also uniform over . Therefore, Eq. (4.19) can be written as
[TABLE]
where
[TABLE]
In this way, we have .
In (4.21), and both are vectors with length equal to the dimension of the lattice. In our design example, is a lattice point with four dimensions. We perform the symbol-wise maximum-likelihood detection. Considering that practical systems can only transmit and receive one two-dimensional signal at each time slot, the detection is a joint detection for two two-dimensional signals.
We denote the APP vector by where
[TABLE]
Then the above APP vectors are fed into a coset remover to obtain the APP vectors with respect to in (4.13) as the message before adding the random-coset vector . We denote the APP vector after removing coset by :
[TABLE]
where is defined in (2.17). The resultant APP vector is then passed into a BP decoder.
The decoder updates the information between check nodes and variable nodes in an iterative manner. We denote the message from the -th variable node to the -th check node by . The message passed from the -th check node to the -th variable node is denoted by . Both vectors are probability vectors with dimension . Use the Tanner graph in Fig. 4.3, we let and represent the set of check nodes connected to the -th variable node and the set of variable nodes adjacent to the -th check node, respectively. Without the loss of generality, let the index of information nodes be from to and the index of parity nodes be from to of the variable nodes. The decoding steps can be summarized in the following.
1) Initialization step: According to the Tanner graph in Fig. 4.3, the channel output must go through the parity nodes first. Thus for all edges between the parity nodes and the check nodes in the Tanner graph, the initial message is the channel APP in (4.2.5):
[TABLE]
For all edges between the information nodes and the check nodes in the Tanner graph, we let
[TABLE]
2) Update the check nodes to variable nodes messages: For all edges that connected to the -th check node, generate the probability vector with its -th element given by
[TABLE]
where is the summation performed by ; is the degree of the -th check node; are the incoming messages from all the connected variable nodes except the -th variable node, i.e., ; are the lattice symbols from the associated variable nodes; are the addition factors on the corresponding edges and denotes the addition factor for the edge . Note that the calculations of the check node messages are different from that in conventional IRA decoding as the parity-check equations and the associated arithmetic are different.
*3) Update the variable nodes to check nodes messages: * For all edges between the variable nodes and the check nodes in the Tanner graph, generate the probability vector with the -th element given by
[TABLE]
where denotes the degree of the -th variable node; denote the incoming messages from all the connected check nodes except the -th check node, i.e., ; in (4.2.5) for when the messages are from parity nodes to the -th check node and in (4.2.5) for when the messages are from information nodes to the -th check node.
*4) Stopping condition: * For each iteration, make the hard decision on the -th variable node by calculating
[TABLE]
for . It contains information from all the connected edges. If the hard decision results satisfy the parity-check equations in (4.2.4) or a predetermined maximum number of iterations is reached, then stop; otherwise go to Step 2).
The calculation in (4.26) has a very high computational complexity if the cardinality of the lattice partition is very large. We follow [Richardson01] to employ DFT and IDFT in our lattice decoding process to reduce the complexity.
First we need to introduce some important notations which will be used in the rest of this chapter. Define a probability vector as representing the probability of a lattice point being . In addition, the probability vector must satisfy and . Given a probability vector and , we define the operation as the following
[TABLE]
Now consider the expression in (4.26), an equivalent expression can be written as
[TABLE]
where is the vector that contains elements , in (4.26) and the “” operator performs the modulo-lattice convolution between two vectors. It produces a vector whose -th component is:
[TABLE]
This convolution can be evaluated by using -dimensional DFT and IDFT [Dudgeon84]. In this way, (4.30) can be evaluated as
[TABLE]
where the multiplication of the DFT vectors is performed in a component-wise manner. A further reduction in complexity of implementation can be obtained by using fast Fourier transform and inverse fast Fourier transform algorithms.
4.2.6 Complexity of IRA lattice codes
In this subsection, the complexity of our multi-dimensional IRA lattice codes will be investigated and compared to that of the IRA lattice codes with two-dimensional lattice partitions. Note that both lattice codes are built from Construction A. The underlying linear code for our design is over while the linear codes for the design with two-dimensional lattices is over [Qiu16].
For encoding, the computational complexity is the same as that of our previous design. As it can be seen from Fig. 4.2, the computational complexity of repeating, interleaving, combining and accumulating process does not change with the cardinality of the coset leaders. However, the storage is of for storing the lookup table for the modulo lattice operation while for [Qiu16] is .
Next, we focus on the complexity of symbol-wise detection. For an ML detector, the detection is based on the entire constellation. Thus, for a two-dimensional constellation with size , the computational complexity is in the order of . In our design, we have a four-dimensional constellation with size , the computational complexity is . The “2” here is due to the joint detection for two two-dimensional symbols. The computational complexity of the nonbinary BP decoding is in the order of when FFT is employed for check node calculations [Ganepola08]. For our decoder to decode lattice codes with four-dimensional lattice partitions, the complexity is . Compared with our previous coding scheme with two-dimensional lattice partitions, the complexity of the code design in this work is times higher. Note that here we do not include the discussion of complexity contribution of check nodes and variable nodes since they will be optimized and varied in our designed and are not fixed. Furthermore, the memory usage is associated with the non-zero elements of the parity-check matrix. Thus, the required memory can only be determined specifically case by case.
For Construction A lattices, it has been shown in [1337105] that the finite field size of the underlying linear code has to be large enough to achieve the capacity. Therefore, we have traded the complexity to attain better performance by introducing multi-dimensional lattice partitioned in our design.
4.3 Design and Analysis of Multi-dimensional IRA Lattice Codes
In this work, the analysis of our multi-dimensional IRA lattice codes focus on the average behaviour of randomly selected codes from an ensemble of codes. First, let be the fraction of interleaver’s edges that connected to the information nodes with degree and let be the fraction of interleaver’s edges that are connected to the check nodes with degree . Recall in Section 4.2.2 that and . The additional “2” here means every check node has two deterministic connections from the connected parity nodes as shown in Fig. 4.3. Following [Jin00], the edge degree distributions of our multi-dimensional IRA lattice codes can be written as
[TABLE]
[TABLE]
Given , , the type of lattice and the scaling factor in (4.2), we define an ensemble as the set of our multi-dimensional IRA lattice codes obtained via Construction A.
4.3.1 Modeling the Decoder’s Message Distributions
In our multi-dimensional IRA lattice codes, the soft information propagated in the iterative decoder can be modeled by a multi-dimensional LLR vector. Even though APP is used in our iterative decoder, it is common to use LLR in EXIT chart analysis. Note that APP and LLR are different but equivalent representations of the decoder’s soft information. In order to track the convergence behaviour of the iterative decoding, multi-dimensional EXIT charts may be required. However, developing these EXIT chart functions can be very difficult. To deal with this challenge, the new encoding structure is proposed. We will prove that using this structure, the densities of the messages in BP decoder can attain permutation-invariance and symmetry properties. With these two properties, the densities of the decoder’s messages can be represented as a single parameter. In this way, our method only needs to track one-dimensional variables rather than the true densities of the multi-dimensional LLR vectors. In addition, the symmetry property enables to use all-zero lattice codeword assumption in the EXIT chart analysis. As such, the expression of mutual information in the EXIT chart analysis can be simplified.
We first introduce some useful definitions and notations in the following.
4.3.2 Preliminaries
Following the definition in [Li03], we define the LLR values for a given probability vector as
[TABLE]
It is intuitive that .
The -dimensional LLR vector is then defined as . Note that unlike most LLR definitions, we include the element in the LLR vectors as it is associated with our analysis of permutation-invariance which will be introduced shortly. When we apply the operation defined in (4.29) on the LLR value , we have:
[TABLE]
Following from above, a -dimensional probability-vector random variable is defined as that only takes valid probability values. The associated -dimensional LLR-vector random variable is defined as .
Now we introduce the definitions of the symmetry and permutation-invariance properties and explain how we can achieve these properties.
4.3.3 Symmetry
Recall in Section 4.2.2, we add a random-coset vector at the end of the encoder. The random-coset elements are randomly chosen and uniformly distributed over the set of coset leaders . Thus we have the following theorem.
Theorem 4.1**.**
Adding a random-coset vector to the encoder output , where is uniformly distributed over , can produce the output-symmetric effect in non-binary input AWGN channels.
* Proof: * Please refer to Appendix A.2.
Similar to the non-binary LDPC codes in [Bennatan06], the LLR random vectors are symmetric under the output-symmetric effect. The symmetry property of an LLR random vector is defined as follows.
Definition 4.1**.**
Given an LLR random vector and an , is symmetric if and only if satisfies
[TABLE]
for all LLR vectors and all .
With this property, the probability of decoding error is equal for any transmitted codeword [Bennatan06]. In other words, the symmetry property removes the dependence of the decoder’s LLRs on transmitted codewords [Richardson01]. Therefore, we can use all-zero lattice codewords in our EXIT chart analysis.
4.3.4 Permutation-Invariance
We start with the definition of permutation-invariance [Severini05, Section 2.6] on a probability-vector random variable. Then we will show that our approach can achieve this property under our proposed structure.
Definition 4.2**.**
A probability-vector random variable is permutation-invariant if for any permutation of the indices such that the random vector is distributed identically with .
Under this property, all the random variables in are identically distributed (but may not be independent). Therefore, changing the order of the elements in will not change the distribution of .
Recall in Section 4.2.2, our codes have three randomly generated sequences added to the encoder’s messages. This leads to a symbol level permutation (the permutation from a coset leader to another coset leader) on the messages. The densities of these messages can be shown to have the permutation-invariance property. Now, we have the following theorem:
Theorem 4.2**.**
Given a -dimensional probability-vector random variable and a , the random vector is identically distributed with . Therefore is permutation-invariant.
* Proof: * Please refer to Appendix A.3.1.
This theorem can be carried over straightforwardly to LLR representation. Thus we have the following lemma:
Lemma 4.1**.**
Let be an LLR-vector random variable such that . If is permutation-invariant, then is also permutation-invariant.
* Proof: * Please refer to Appendix A.3.2.
Therefore, under the BP decoding, the messages passed within the Tanner graph of our codes satisfy all the symmetry and permutation-invariance properties.
4.3.5 Gaussian Approximation
With the symmetry and permutation-invariance properties, the -dimensional LLR can be modeled using a multivariate Gaussian distribution [Bennatan06]:
[TABLE]
with mean vector and covariance matrix given by
[TABLE]
More specifically, for , and if and otherwise. As a result, the density of the -dimensional LLR is completely described by a single parameter . It is worth mentioning that our definition of LLR random vector is -dimensional rather than in the literature. This is because the operation will change the position of . Thus we need to use a -variate Gaussian distribution to model the -dimensional LLR.
4.3.6 Convergence Analysis
EXIT charts track the mutual information between the transmit lattice symbol and the LLR random vector . With the all-zero lattice codeword assumption, the mutual information can be evaluated according to [Bennatan06]
[TABLE]
where is modeled by (4.38) and (4.39). Thus, the mutual information is a function of the single parameter . For simplicity, we let as every value of corresponds to a value of . Since the mapping is bijective, we can also define the inverse function to obtain when given .
In the EXIT chart analysis, variable nodes are treated as a component decoder while the combiners and the time-varying accumulator together is treated as another decoder. As such, we compute the variable-node decoder (VND) curve and the check-node decoder (CND) curve. The argument of each curve is denoted as and the value of the curve is denoted as , representing a priori input and the extrinsic output of each component decoder. The details of obtaining the transfer functions will be explained next.
4.3.7 EXIT Function for VND
For a variable node with degrees, the output mutual information of the VND for this type of variable nodes is given by [Brink03]:
[TABLE]
For a given VN degree distribution , the EXIT function for the VND of the entire IRA code is:
[TABLE]
4.3.8 EXIT Function for CND
For a check node with degree , we use a numerical method to obtain the approximated EXIT functions as there is no closed-form expression in the literature.
For a given , we obtain the corresponding parameter using . Then the input a priori LLR vectors are generated according to (4.38) and (4.39). For a given SNR, generate the all-zero lattice codeword, three random sequences , , , a random-coset vector and an AWGN channel noise sequence with variance of . We calculate the channel APPs by following (4.18) to (4.2.5) and then substitute the results into (4.35) to obtain the channel input LLR . Given , , , , and , we perform BP decoding with one iteration to produce the output LLR. The associated with the check node degree is obtained by substituting the output LLR into (4.40).
For a given CN degree distribution , the EXIT function for the CND of the entire IRA code can be obtained by:
[TABLE]
4.3.9 Design Examples
Based on our EXIT functions, we now employ the EXIT chart curve fitting technique [Brink03] to find the optimal CN and VN degree distributions such that the area between the CN curve and the VN curve is minimized. First, we carefully select an appropriate CN degree distribution. Then, we fit the EXIT curve of VND to CND by using linear programming to optimize the degree distribution for VN. Next, we update the CN degree distribution based on the optimized VN degree distribution. The optimization for the degree distribution of CN and VN are carried out in an iterative manner. Note that we have set the minimum gap between the VND curve and the CND curve to be greater than zero but not too large, e.g., 0.0001. In this way, the produced VND curve do not intersect with the CND curve and both curves create a narrow tunnel. The number of optimization iteration is set to 10 as more iterations does not improve the optimization results further.
An example of an EXIT chart for our multi-dimensional IRA lattice codes over with code rate of is illustrated in Fig. 4.4.
In our design, the portion of degree 1 CN must not be too small in order to ensure the decoder works in the first few iterations because our codes are nonsystematic [Brink03]. From Fig. 4.4, we can see that the VND curve literally touches the CND curve for the range , which guarantees successful convergence and accurate decoding threshold.
We have adopted the proposed approach in designing the -lattice ensemble with three code rates , and . The degree distributions and the decoding thresholds are shown in Table 4.1.
As shown in the table, the optimized CN distributions are degree 1 and degree 3 because this pair of CN distributions have the lowest optimization complexity and the minimum decoding threshold for the three code rates. We have also designed our codes with other pairs of CN distributions, but their performance is not much better than the code with only degree 1 and degree 3 CNs.
4.4 Simulation Results
In this subsection, we present our simulation results for our multi-dimensional IRA lattice codes over . In order to evaluate the average behavior of our codes, we randomly generated a codeword from the ensemble and randomly select the values for , , and in every channel realization. Since our coding scheme is based on finite constellations with power constraint, the performance for three designed code rates , and is measured in terms of symbol error rate (SER) versus SNR, which are depicted in Fig. 4.5, Fig. 4.6 and Fig. 4.7, respectively. Based on these designed code rates, the corresponding information rates are calculated by using (4.3) as bits/s/Hz, bits/s/Hz and bits/s/Hz, respectively. The corresponding unconstrained Shannon limit and uniform input capacity for each information rate are plotted in each figure. Additionally, we also show the SER performance for the previously designed IRA lattice codes over in all the figures for comparison because both partitions result in the same information rate. In our simulations, we set the codeword length to be 1,000, 10,000 and 100,000 symbols whereas the corresponding step sizes for SNR are 0.1 dB, 0.05 dB and 0.01 dB, respectively. The maximum number of decoding iterations was set to be 200.
In Fig. 4.5, the unconstrained Shannon limit for is 3.70 dB. In this case, we observe that the gap to the unconstrained Shannon limit at the SER of is 0.90 dB for our rate -partition-based lattice code and 1.28 dB for the code in [Qiu16]. Thus, our newly designed four-dimensional IRA lattice code is 0.38 dB better than the lattice code with two-dimensional lattice partitions. The unconstrained Shannon limit for is 2.84 dB. As shown in Fig. 4.6, the gap between our lattice code and the unconstrained Shannon limit is 0.62 dB. For the code in [Qiu16], the gap is 0.88 dB. Therefore, the proposed lattice code is 0.26 dB better. Fig. 4.7 shows that the gap to the unconstrained Shannon limit is further reduced to 0.46 dB for our rate four-dimensional IRA lattice code. Our code is 0.1 dB better than the rate two-dimensional lattice code in [Qiu16]. To this end, our proposed codes have lower decoding thresholds than that of the codes in [Qiu16] but with higher encoding and decoding complexities.
Now we compare our designed lattice codes with the lattice coding schemes from [Boutros14, Boutros16, Khodaiemehr17, 8122043, 4475389] for the same codeword length. Since these schemes are based on infinite constellations, their performances are measured in terms of gap to the Poltyrev limit which can be considered as coding loss [Boutros16, Section VI-B]. To obtain the coding loss in our lattice coding scheme, we measure the gap to uniform input capacity. The comparisons are listed in Table 4.2, showing the simulation results which are reported for each scheme in the appropriate reference, including codeword length, coding loss and the gap to unconstrained Shannon limit when SER is at .
From Figs. 4.5-4.7, one can observe that our code with rate have the smallest coding loss. To be more specific, the coding loss for our lattice codes with , and when SER is at is about 0.3 dB, 0.6 dB and 1.5 dB. From Table 4.2, it can be seen that our coding scheme outperforms all of these schemes for large codeword length, i.e., . When the codeword length is 1,000, our code is about 0.2 dB worse compared with LDA lattices [8122043] and GLD lattices [Boutros14] because of the probability of short cycles are higher when the codeword length is small. Since our goal is to design capacity-approaching lattice codes, thus we mainly focus on the codes with large codeword length, i.e., . Note that the direct comparison of encoding and decoding complexities for lattice codes with infinite constellations and our codes with finite constellations may not be fair and thus is omitted.
It is also worth noting that the waterfall regions of our multi-dimensional lattice codes are within 0.14 dB to the predicted decoding thresholds as shown in Table 4.1 for various code rates. Therefore, it is evident that the proposed EXIT chart analysis for our multi-dimensional lattice codes is effective.
4.5 Summary
In this chapter, we designed new multi-dimensional IRA lattice codes with finite constellations. Most compellingly, we proposed a novel encoding structure and proved that our codes can attain the permutation-invariance and symmetry properties in the densities of the decoder’s messages. Under these properties, we used two-dimensional EXIT charts to analyze the convergence behavior of our codes and to minimize the decoding threshold. Our design can employ any higher-dimensional lattice partitions. Numerical results show that our designed and optimized lattice codes can achieve within 0.46 dB of the unconstrained Shannon limit and outperform existing lattice coding schemes for large codeword length.
Chapter 5 A Lattice-Partition Framework of Downlink NOMA without SIC
5.1 Introduction
In the previous chapter, we discuss how to design multi-dimensional lattice codes for power constrained point-to-point channels. In this chapter, we start dealing with the design and analysis of lattice coding schemes for downlink multiuser communication systems.
With the increasing demands of network access and the continuous growth of smart devices connected to the cellular networks, the current fourth generation systems have reached their limit and cannot meet the future requirements such as higher data rates, massive connectivity, and/or higher spectral efficiency. To this end, it is imperative to develop new multiple access techniques. Recently, non-orthogonal multiple access has drawn considerable attention due to its capability of providing high system throughput and massive connectivity while maintaining user fairness. As such, NOMA has been recognized as a promising technique for the next generation wireless communications [Saito13, DerrickNG17, Dai15, Ding17, Ding17J, Lien17].
5.1.1 Main Contributions
In this work, we continue the quest of designing downlink NOMA schemes that can be efficiently decoded with low decoding complexity and latency. In particular, we follow the footsteps of [Shieh16] to devise coding schemes that can be decoded with single-user decoding i.e., without SIC, for downlink NOMA. Our scheme exploits the structural property of the lattices to harness inter-user interference while taking advantage of higher shaping gains from multi-dimensional lattices. The main contributions of our work are summarized as follows.
- •
We generalize the scheme in [Shieh16] to a general lattice partition framework for downlink NOMA without SIC. This is done by revisiting the two-step approach adopted in [Shieh16]. In the first step, the corresponding linear deterministic model [Avestimehr11] is investigated and an optimal input distribution is derived. This optimal distribution is then translated into a uniform distribution over a properly chosen PAM constellations for the original model. Our generalization is based on the observation that a PAM constellation can be regarded as isomorphic to a lattice partition of the one-dimensional lattice . With this algebraic structure, we propose a general lattice partition framework which allows us to use a lattice partition of any lattice in any dimension as constellation. This substantially enlarges the design space and subsumes the scheme in [Shieh16] as a special case.
- •
The achievable rate of the proposed scheme is then analyzed and its gap to multiuser capacity region is upper bounded by a function of the normalized second moment (which will be defined later) of the base lattice. This upper bound is universal in the sense that it is independent of the channel parameter and the number of users participating in the transmission. We would like to emphasize that similar to the scheme in [Shieh16], the proposed framework only requires a limited knowledge of channel parameters (which will be clearly defined in Chapter 5.2) rather than full channel state information. In addition, we extend our design to -user downlink NOMA as well as provide its capacity gap analysis and prove that the upper bound of the capacity gap does not scale with .
- •
Based on the derived bound, we compute the gap to the capacity of the proposed scheme with the base lattice chosen from some well-known lattices such as , , , , and Construction A lattices. While generating these design examples, for handling the crucial issue of breaking ties, an efficient method is also discussed. The results show that as the dimension increases, one can find good lattices such that the gap shrinks. We then provide simulation results to show that the actual gap to the capacity region can be much smaller than the upper bound, which confirms that the proposed framework is capable of operating very close to the multiuser capacity region with only single user decoding at each user.
5.2 System Model
In this work, we consider a downlink NOMA system that operates in a narrow band of frequencies and all the users in the system are assumed to be experiencing flat fading. For wideband systems, this model can be obtained by employing orthogonal frequency division multiplexing that efficiently transforms a frequency-selective fading channel into multiple flat fading ones. According to [1054727], the problem of downlink NOMA can be modeled as the Gaussian broadcast channel where a base station would like to broadcast messages to users , respectively, as shown in Fig. 5.1.
In our system setting, the base station and all users are equipped with a single antenna111For extension to multiple antenna case, one may use a zero-forcing beamforming scheme to null out interference and convert the problem into multiple single antenna problems as in [Geraci16]. and work in a half-duplex mode. In addition, we assume that each receiver knows the phase of its channel and can compensate the phase, i.e., we consider coherent detection in [tse_book, Chapter 3]. In this way, the complex channel model can be transformed into two real channels with real channel gains and real noise (i.e., our channel model with ). Hence, our channel model encompasses the one with complex inputs and outputs as a special case. As shown in Fig. 5.1, the base station first encodes into a codeword with power constraint , i.e., we use real channel jointly. The received signals arrive at user is given by
[TABLE]
where is the additive white Gaussian noise (AWGN) experienced at the -th user and is the -th user’s signal-to-noise ratio (SNR), representing the real channel gain. This models a general communication problem over a flat fading channel where each receiver knows its own channel state information. In our setting, the full channel state information is not available at the transmitter; instead, only a quantized version of , i.e., for are available at the transmitter. Upon receiving, user attempts to decode from . The achievable rate and the capacity region are defined in the usual information-theoretic manner (see [Cover:2006:EIT:1146355] for example).
Although the goal of this work is to develop transmission schemes for the -user case, in what follows, we first discuss and analyze the proposed scheme for the two-user case for the sake of simplicity. Despite being a special case, the code design and the analysis for the two-user case captures all the essences of the proposed framework and provide significant insights about the main concepts of the proposed framework, which allows us to substantially simplify the discussion for the -user case presented in Section 5.3.3.
5.3 Downlink NOMA based on Multi-dimensional lattices without SIC
In this section, we first review the deterministic model in [Avestimehr11] for a two-user downlink NOMA and the scheme in [Shieh16]. We then propose our general framework for downlink NOMA without SIC. Some design examples and analysis of achievable rates are then presented.
5.3.1 The Deterministic Approach to Downlink NOMA
The deterministic model is used for modeling downlink NOMA for two-user case. The analysis for the linear deterministic model will provide guidance and significant insights into to the original downlink NOMA model. By applying the deterministic model, the original Gaussian broadcast channel can be modeled as a pipe with two links. As shown in Fig. 5.2, the essential idea is that the pipe only passes the bits above the noise level while truncating the bits below the noise level. We define for and we know . Note that we have assumed so that the “” sign in [Avestimehr11, Eq. (10)] can be dropped. The base station broadcasts bits to both users. The maximum number of bits that user 1 can successfully receive and decode is while user 2 can only receive and decode up to bits as there are bits which are below the noise level and get shifted out at user 2.
We denote the number of transmitted bits intended for user by for , which must be a non-negative integer. As no SIC is employed in our scheme, even though user 1 can receive bits information, it will treat the other bits as interference. Therefore, the deterministic rate pair must satisfy the following:
[TABLE]
A capacity-achieving scheme in [Shieh16] for the deterministic model is given as follows. Following the notation defined in Chapter “List of Notations” of this thesis, we denote the message vectors and . The message vector where , is passed into encoding matrix of size and becomes the encoded message via . We define
[TABLE]
and
[TABLE]
where and . Considering the rate pair satisfying (5.2) and (5.3), we choose
[TABLE]
and
[TABLE]
where , , and are full rank binary matrices with size , , and , respectively. In this way, the transmitted codeword becomes a length column vector
[TABLE]
where all the operations above are over . One can follow the derivation in [Shieh16] to show that this scheme is capacity achieving for the downlink NOMA channel. From the second equality of (5.8), it can be noticed that the signals of two users are assigned to different rows of , representing different power levels in the original downlink NOMA model. Under this assumption, is considered as under the noise level and thus it is not received by user 2. In this case, there are bits get truncated.
In [Shieh16], Shieh and Huang translate the above scheme from the deterministic model into the coding scheme for the Gaussian model. The scheme therein translates each , into a pulse amplitude modulation (PAM) scheme and scales each user’s signal by a power allocation factor. They show that this simple scheme can approach the capacity region of the downlink NOMA channel within a constant gap even without SIC.
5.3.2 Proposed Lattice Framework for Downlink NOMA without SIC
We first note that the scheme in [Shieh16] corresponds to the superposition of properly scaled PAM constellations with size , and . Since an -ary PAM constellation is isomorphic to the coset decomposition , it is not difficult to show that the scheme in [Shieh16] is in fact isomorphic to the one-dimensional lattice partition chain . However, the hypercube shaping induced by this partition chain provides no shaping gain and it is well known that lattices with better shaping gain exist in higher dimensions. We therefore consider jointly modulating signals onto constellations with real dimensions.
For any pair satisfying (5.2) and , our scheme makes use of any lattice partition chain . The restriction of having partition orders being powers of 2 is merely for practical purpose and it can be lifted. In our proposed scheme, we choose a complete set of coset leaders of to be the constellation for user 1. This gives us the constellation which is isomorphic to and has cardinality . Similarly, we choose a complete set of coset leaders of to form the constellation of user 2. This constellation is isomorphic to and has cardinality .
Following (5.8), the proposed scheme first encodes a length signal into a codeword via the encoding function and then bijectively maps every bits from the codeword onto constellation to obtain . The transmitted signal is then given by
[TABLE]
where is a deterministic dither222In the literature of lattice codes, the dither could be random or deterministic vectors known at both the transmitter and receiver. For the proposed framework, deterministic dithers suffice. Typically, in practice, the dither is a deterministic vector such that the overall constellation is zero mean and has the minimum transmit power., is the combined constellation, and is to ensure . We note that
[TABLE]
corresponds to a complete set of coset leaders of . Thus, the combined constellation has the cardinality and preserves the structure of lattice .
We emphasis here that following the definition in (5.4) and (5.5), can be further decomposed into and as opposed to and , which will come in handy when analyzing the achievable rates. More specifically, let us consider the lattice partition chain where and are isomorphic to and , respectively. can then be represented as
[TABLE]
Remark 5.1**.**
From (5.3.2), one can see that the proposed scheme naturally induces a power allocation scheme from the lattice partition. Unlike power allocation schemes adopted by conventional NOMA schemes, the power allocation induced by our proposed scheme makes sure that the overall constellation preserves a lattice structure. In this way, our scheme can exploit the lattice structure to harness inter-user interference.
Remark 5.2**.**
It is worth noting that our proposed scheme in fact belongs to a larger framework in which one picks a complete set of coset leaders of as the overall constellation. The above choice, , ensures that the overall constellation has the smallest power within this family; therefore, after normalization for fitting the power constraint, it will have the largest minimum distance for user 1’s signal. Another reasonable choice is to simply let the overall constellation be , which resembles the conventional superposition coding.
[TABLE]
This constellation will have a larger power than and hence will result in a smaller minimum distance for user 1 after normalization. However, since we do not perform modulo , the distance between cluster centers (each corresponds to an element in ) will be larger than that in . Therefore, this choice will result in a better performance for user 2 by sacrificing the performance of user 1. In what follows, we analyze the performance of solely for simplicity and leave the exploration of other choices of coset leaders as future work.
5.3.3 An Extension to K-User Case
Similar to [Shieh16], we can generalize the proposed framework to the -user case. We first investigate the corresponding deterministic model in the following.
We denote to be the channel capacity from the base station to user , respectively. In this model, we assume . We define and denote the number of transmitted bits intended for user by for . The deterministic rate tuple must satisfy the following constraints:
[TABLE]
We start with the analysis for the first (strongest) user. From (5.13) and (5.14), we combine users into a super-user demanding bits and with channel capacity . Now the problem is reduced to a two-user case. Therefore, to analyze the achievable rate for user 1, one can directly follow our approach as described in Section 5.3.1.
Now we analyze the achievable rate for user . At user ’s channel, we have the capacity constraint as follows:
[TABLE]
For this case, we treat users as a super-user demanding bits and users as another super-user demanding bits. The problem can again be deemed as a two-user case. We thus choose the rate pairs that satisfies:
[TABLE]
In this way, the same approach from Section 5.3.1 can be used for analyzing this case. We then define
[TABLE]
and
[TABLE]
where and . According to the deterministic model, for user , there are number of bits are considered as under noise level and thus get truncated. Similarly, we can follow the steps in (5.6) and (5.7) to obtain the capacity-achieving scheme and for generating capacity-achieving input distributions.
Similar to our two-user case in Section 5.3.2, we translate the scheme from the deterministic model into the scheme for the Gaussian model. For any rate tuple within the capacity region of the -user linear deterministic model, we construct a lattice partition chain where is an -dimensional lattice. For each , the individual constellation is isomorphic to and has cardinality . The transmitter first encodes the message into a codeword via the encoding function and then bijectively maps every bits from the codeword onto constellation to obtain and then transmit
[TABLE]
where is a dither and is a normalize factor to ensure . Similar to the two-user case, the combined constellation has the cardinality and preserves the structure of lattice .
5.4 Analysis of Achievable Rates and their Gaps to the Multiuser Capacity Region
In this section, we analyze the achievable rates of the proposed scheme under single-user decoding (without SIC) and their gaps to the capacity region. We first present the main result of this work as follows.
Proposition 5.1**.**
In the -user downlink NOMA, regardless of the channel SNR, the gap between the individual rate achieved by the proposed scheme and the multiuser capacity region in bits per real dimension is upper bounded by
[TABLE]
Moreover, this gap only depends on the NSM of the base lattice and does not scale with .
In what follows, we provide the proof for the case. This simplest case will allow us to explain all the important ingredients of our analysis. The proof for the general -user case will be deferred to Appendix B.3. After proving the results, we then provide some analysis for the proposed scheme constructed over some well-known lattices and compare the required complexity with some existing NOMA schemes.
5.4.1 Analysis of the Two-User Case
We first consider . Let and be random variables uniformly distributed over and , respectively, and corresponding to the channel input random variable. Following the relationship given in (5.1), we define and to be the random variables corresponding to the received signal at users 1 and 2, respectively.
To analyze the achievable rate of the strong user without SIC, we define and bound the mutual information as follows,
[TABLE]
where is because the mapping between and is bijective, follows from the independence of and , and follows from the lower bound of the mutual information between a discrete random input and its noisy observation , which is established in Appendix B.1.
Since the gap between the achievable rate pairs in (5.2) and (5.3) and the multiuser capacity region is at most 1 bit per real dimension [Avestimehr11], we have the gap of user 1’s achievable rate to the multiuser capacity is at most
[TABLE]
bits per real dimension, where we have used the fact that is invariant to scaling.
To bound , we first need to find the analytical expression of the overall scaling factor . Lemma B.2 in Appendix B.1 establishes an upper bound on the power required by lattice constellation, which shows that there exists a fixed dither such that the resulting has
[TABLE]
where outputs the cardinality of following from (2.15). We then establish a lower bound for the scaling factor for user 1 as
[TABLE]
in (B.2.1) in Appendix B.2.1. By plugging this bound into (5.25), we conclude that the gap between user 1’s achievable rate and the multiuser capacity in bits per real dimension is lower bounded by
[TABLE]
which completes the proof of (5.22) in Proposition 5.1. The detail is shown in (B.2.1) in Appendix B.2.1.
For the weak user, we can write by following (5.11). The choice of parameters and suggested in the deterministic model ensures that is under the noise level. This leads to
[TABLE]
where is due to the bijective mapping between and , and again follows from the independence of and .
To further bound , we note that the effective noise is . We thus scale by
[TABLE]
to make the effective noise with . The equivalent communication channel then becomes where
[TABLE]
and . One can then again apply the lower bound of the mutual information between a discrete random input and its noisy version shown in Appendix B.1 to obtain
[TABLE]
where .
We again establish a lower bound for the scaling factor for user 2 as
[TABLE]
in (B.2.2) from Appendix B.2.2 and plug this into (B.18) to obtain
[TABLE]
which completes the proof of (5.23) for in Proposition 5.1. The detail is in (B.2.2) in Appendix B.2.2.
Remark 5.3**.**
From the derived results, one can see that the gaps to the capacity region can be upper-bounded by a function proportional to the logarithm of the NSM of the base lattice. This indicates that better results can be obtained by using lattices with smaller NSM. This is not surprising at all since smaller NSM means that the shape of the fundamental Voronoi region is closer to an -dimensional ball, which results in better shaping. Moreover, it is well-known that the NSM reduces as the dimension increases [Zamir15]; hence, it is beneficial to construct codes with large dimension. Additionally, we have used for dropping the dependency of . The gap can be shrunk if one tailors the bounds specifically for the actual . For example, when is a power of 2, by following similar steps above, one obtains and bits. Moreover, the 1 bit we added in both and is for bounding the difference between the Gaussian capacity region and the capacity region of the linear deterministic model for any () universally. Note that the capacity difference between the two models is a function of the parameters and cannot be larger than 1 bit [Avestimehr11]. Therefore, we consider the worst-case scenario to attain an upper bound for any parameters universally. In most of the cases, this capacity difference is much smaller than 1 bit and thus the gap can be further shrunk. Our simulation in Chapter 5.5 will confirm this observation that the actual gaps are usually much smaller than and derived here. This observation also applies to the -user case presented in Appendix B.3.
5.4.2 Analysis of the Capacity Gap for Certain Lattices
In this subsection, we first compute the gaps to the capacity region for the proposed scheme constructed over some well-known lattices including , , and . is a two-dimensional lattice corresponding to the Cartesian product of two . Plugging the corresponding NSM into (B.2.1) and (B.2.2) results in the gap upper bounds as shown in Table 5.1. We note that since and have the same algebraic structure, the gap in bit per real channel for is going to be identical to that for , which has been analyzed in [Shieh16]333When comparing the results obtained here and that in [Shieh16], one observes that the gaps for user 1 are indeed identical. However, there is a slight difference in the gaps for user 2. In fact, the analysis for user 2 in [Shieh16] contains a typo and thus the gap should again be identical to here.. We then compute the gap for the hexagonal lattice (the densest packing lattice in ), the checkerboard lattice (the densest packing lattice in ), and the Gosset lattice (the densest packing lattice in ). Their NSM and the gap upper bounds are shown in Table 5.1.
We then choose the base lattice from the family of Construction A lattices and provide an analysis on the gap of the achievable rate to the multiuser capacity region. Construction A is known for its ability to produce optimal lattices in many senses including packing, covering, channel coding, and shaping [1512416].
Definition 5.1**.**
(Construction A [conway1999sphere]): Let denote a non-binary linear code over , where is a prime number. The Construction A lattice is then generated via:
[TABLE]
where is the natural mapping that maps each codeword component to an element in .
In our analysis, we focus on using lattices from a random Construction A lattice ensemble specified by . This ensemble is obtained via Construction A by lifting a random -ary linear code to the Euclidean space. The random linear code is generated via a generator matrix where the entries are i.i.d. and uniformly distributed over . It is shown in [1512416] that within this ensemble, there exists a sequence of lattices that can attain the smallest NSM. In what follows, we use such lattices as base lattices for our proposed scheme and compute the capacity gap.
Given an -dimensional sphere with radius , the volume of the sphere is given by , where is the volume of an -dimensional sphere with unit radius. We define the effective radius as the radius of an -dimensional sphere which has the same volume as such that
[TABLE]
We know that the sphere has the smallest second moment of all -dimensional lattices with volume . Thus, the second moment of the Construction A lattice can be lower bounded by:
[TABLE]
The NSM of the Construction A lattice is then lower bounded by:
[TABLE]
We know that (see for example [Ordentlich16] and [8122043]) when the dimension is large enough, there exists a sequence of Construction A lattices whose Voronoi region is arbitrarily close to an -dimensional sphere where almost all the points of the constellation lie with close to the surface of the sphere. In this case, the second moment of the Construction A lattices can be arbitrarily close to the second moment of the sphere . Therefore, the NSM of our Construction A lattice becomes
[TABLE]
where (d) follows from
[TABLE]
Now using this sequence of lattices as our base lattices and substituting our results into (B.2.1) and (B.2.2) result in and , respectively. Similar to Remark 5.3, when and are powers of 2, the capacity gaps and can be further reduced.
5.4.3 Complexity Comparison
Now we compare the complexity on transmitters and receivers of our proposed scheme to that of the conventional NOMA with SIC. Specifically, we focus on the complexity at the transmitter and receiver. However, most of the work on NOMA is based on the achievable rate by assuming Gaussian inputs, which is by no means practical [arXiv:1706.08805]. We thus consider the downlink multiuser superposition transmission (MUST) in [TR36.859] as a conventional NOMA that adopts the current LTE standard modulation, e.g., QAM modulation. Compared to MUST, our scheme has a lower complexity at the receiver as SIC is removed. Most importantly, when the number of users increases, the complexity at the receiver grows with the number of users for conventional NOMA while our scheme still maintains single user decoding complexity. Compared to a recently proposed power domain NOMA scheme in [Shieh16], both the schemes do not involve SIC but our scheme has a higher decoding complexity due to the fact that larger dimensional constellations are considered. Note that the proposed framework subsumes the scheme in [Shieh16] as a special case with .
At the transmitter, the complexity for our scheme is higher than that of [TR36.859] and [Shieh16]. We would like to emphasize that there is no shaping gain in the schemes of [TR36.859] and [Shieh16] while our scheme is constructed over higher-dimensional lattices with a higher shaping gain. There is always a price to pay in having a shaping gain and our scheme is with no exception. In other words, as compared to [TR36.859] and [Shieh16], our scheme trades the complexity for better performance by introducing multi-dimensional lattice partitioned in our design.
5.5 Design Examples and Simulation Results
In this section, we provide numerical and simulation results for the proposed schemes constructed over the lattices discussed in Chapter 5.4.2. While constructing constellations from lattice partition chains, the first crucial issue one may encounter is to handle ties when a coset of in has more than one minimum-norm element. In this case, the mapping between source information and lattice constellations is not bijective, resulting in ambiguity in decoding. In what follows, we first introduce an algorithm for handling ties and then present simulation results.
5.5.1 Handling the Ties of Cosets
Consider a pair of nested lattice . Applying (2.9), (2.14), and [Zamir15, Eq. (2.43)], we have
[TABLE]
Thus, the problem boils down to quantizing the lattice points to the fine lattice. We follow the approach in [Conway82] to develop a modified algorithm for quantizing , , and . As partition algorithms design is not the focus of this work, we thus omit the detail algorithms here but only point out the main difference for ties handling.
A tie occurs when an arbitrary point is close to more than one coarse lattice points. Let us consider for example. To find the closest lattice point in to , we have
[TABLE]
The quantization for each dimension is independent. Now we have a rule to handle the tie as follows. For a random integer and ,
[TABLE]
We can directly apply this rule for quantizing . Note that following [Conway82], quantization for , and can be done through finding the closest point to , thus the ties are already handled in that step.
We adopt the developed lattice quantizers in our lattice partitions and perform simulation which is shown in Section 5.5.2 and Section 5.5.3.
5.5.2 Achievable Rate Simulation: Two-User Case
We first present some simulation results for our downlink NOMA scheme of two-user case in Figs. 5.3-5.5. Different from our theoretical analysis, when constructing the transmitted signal in (5.3.2), we use a fixed dither to reduce the overall power consumption of the underlying constellation. This is a common approach in practical simulation. We evaluate rate pairs achieved by our scheme with SIC, and that without SIC for two users by performing Monte Carlo simulation with averaging over at least channel realizations. The corresponding choices of are shown in the figures. Note that the achievable rate pairs for either or are not included as these are considered as single user cases. We also plot the capacity region which is obtained by Gaussian input distributions and the OMA time-sharing region obtained by time-sharing between two practical schemes with constellations carved from lattices in all the figures. The actual gaps between the achievable rates obtained from the simulations and the capacity regions in Figs. 5.3-5.5, are given in Tables 5.2-5.4, respectively, where denotes the pair of the actual gaps to the multiuser capacity region.
From Tables 5.2-5.4, it can be seen that the simulated gaps to multiuser capacity are smaller than the theoretical results in Table I. This is because the theoretical gaps are upper bounds derived to drop the dependency of the actual parameters. The actual gaps are obtained by Monte-Carlo simulations which involve actual parameters. As a result, the actual gap varies with the parameters. Moreover, as discussed in Remark 5.3, we have added 1 bit in our derived theoretical gaps to bound the capacity differences between the linear deterministic model and the downlink NOMA model. Therefore, the simulated gaps are usually much smaller than the theoretical bounds.
In Fig. 5.3, we consider the low SNR regime where dB and dB, which correspond to and , respectively. Here, we can see that the actual gaps between the capacity region and the rates achieved by our proposed are much smaller than the derived upper bounds. For example, the proposed scheme with , which can be regarded as applying the scheme in [Shieh16] independently twice, can operate within 1 bit to the capacity region. Moreover, our scheme with , and achieve rate pairs better than that achieved by . In particular, the proposed scheme constructed over has the highest achievable rates due to the fact that has the highest shaping gain compared with , and . Simulation results for the case of dB and dB are provided and shown in Fig. 5.4 and Fig. 5.5, respectively. Similar observations can be made for these settings. Here, we can see that our scheme employing lattice partition can approach the multiuser capacity region within 0.5 bits. Apart from that, another observation in Fig. 5.4 is that, the gap in between our scheme with and without SIC becomes larger when is larger. This is due to the fact that user 2 introduces strong interference to user 1, which leads to rate loss in . However, when the channel conditions are in huge difference as shown in Fig. 5.5, our scheme without SIC can operate very closed to the schemes with SIC even though user 2 has strong interference, i.e., the case of . This result is even more favourable for NOMA as NOMA can attain higher gain when the channel difference is large. Note that the scheme with is not shown in Fig. 5.5 mainly due to the larger constellations size that introduces high computational complexity in the simulation.
Note that in Fig. 5.3, we have considered two instances in our proposed framework. These two cases have the same target rate pairs, i.e., . The only difference is that the first case has the modulo operation after superposition coding as described in (5.3.2) while the second case directly sends the superimposed signal as described in (5.12). Interestingly, for this case, the rate pairs achieved by these two designs are quite different and deserve some discussions.
First of all, we would like to emphasize that the second design also belongs to our proposed framework. It just corresponds to a different choice of coset leaders as discussed in Remark 5.2. Secondly, comparing in (5.3.2) to in (5.12), the modulo operation in ensures that the overall combined constellation has less power and thus the scaling is going to be larger than for , resulting in a larger minimum distance for user 1’s signal. This is confirmed by noting that in Fig. 5.3, the rate pairs corresponding to the first design have larger (roughly 0.2 bit larger) than that corresponding to the second design. On the other hand, directly performs superposition without modulo operation provides a larger distance between cluster centers (each cluster corresponds to an element in ), resulting in a larger minimum distance for user 2’s signal. This is confirmed again by noting that in Fig. 5.3, the rate pairs corresponding to the second design have larger (roughly 0.2 bit larger) than that corresponding to the first design. Thirdly, from Fig. 5.3, one observes that the second design is able to provide rate pairs outside the OMA region while the first one cannot. However, in the high SNR regime, the aforementioned rate difference becomes negligible and both designs are able to outperform OMA. Thus, in Fig. 5.4 and Fig. 5.5, we only plot the first design for the sake of brevity. Last but not least, we note that the rate loss in for case 1 can be reduced by properly selecting coset leaders. A typical example is the performance achieved by . Since there is no power saving by performing modulo operation on [Forney03, footnote 9], the performance differences are only caused by coset leader selections that affects the Euclidean distance between each coset. The selection of coset leaders within our proposed framework is itself an interesting problem that deserves a full investigation and is beyond the scope of this work. In this work, we analyze the performance of the proposed framework with design corresponding to (5.3.2) to show that there exists at least one design within our proposed framework that can operate very close to the capacity region and leave the coset leader selection problem as a potential future work.
5.5.3 Achievable Rate Simulation: Three-User Case
Now we present the simulation result for three-user case to demonstrate the performance of our design for -user downlink NOMA. We consider the three-user case with dB, dB and dB, which corresponds to . We again use Monte Carlo simulation to evaluate some of the achievable rate tuples for our scheme with and without SIC based on , and lattices. When SIC decoder is applied, the strong users (users 1 and 2) first decode and subtracts the signals of the user having smaller SNR than itself, starting from the weakest user. Note that the achievable rate tuples for the proposed scheme with lattices are not simulated due to the huge computational complexity. The results are shown in Fig. 5.6 along with the Gaussian capacity region and Gaussian OMA time-sharing region.
Akin to the two-user case, it can be seen that among the considered designs, achieves the highest rate tuples. In addition, all the achievable rate tuples of our proposed schemes lie outside the OMA region, indicating that even without SIC, our scheme outperforms any OMA scheme. Furthermore, the results show that our scheme can approach the multiuser capacity region within a small gap even though the number of users increases.
5.5.4 Error Probability Simulation
Now we build the coded system for our downlink NOMA scheme. In our simulation, each encoding function mentioned in Section 5.3.2 consists of two parts, namely a linear code over followed by a bijective mapping that maps each onto . We note that other popular coded modulation techniques such as bit interleaved coded modulation and multilevel coding can also be adopted. In this work, we adopt coding over due to its best performance among these techniques. The codes over used in the following simulations are constructed via the code design technique proposed in [8066336].
To give an illustration on the performance of our scheme with coded systems, we select one rate pair that is achievable by our scheme and design the codes based on it. More specifically, we choose the case in Fig. 5.3 and select the target rate pair to be the achievable rate pair of lattices, that is bits per real dimension. This results in the code rates and for user 1 and user 2, respectively. Then we use extrinsic information transfer (EXIT) charts to design length 10,000 non-binary irregular repeat-accumulate (IRA) codes over the lattice partitions of , , , , and , respectively. The design details can be found in [8066336] and thus are omitted here. Note that the codes are optimized particularly for point-to-point AWGN channel and have been shown to have the near-capacity performance in [8066336]. However, it is entirely possible that the codes are not optimal for downlink NOMA where interference is present. The code design problem for downlink NOMA where the structure of the interference is taken into account is an interesting problem in its own right and is clearly beyond the scope of this work.
To perform the simulation, the source message is encoded into the non-binary codes via the encoding function described in Section 5.3.2 and then bijectively mapped the codeword element onto the constellation. The corresponding SER versus SNR results are presented in Fig. 5.7. The Shannon limit for using the proposed constellation carved from lattice is also plotted by dash line in the figure. No SIC is performed.
From Fig. 5.7, we can see that it would require about 3 dB more power for codes over to achieve the same rate as for when the SER is at . Codes over are about 1 dB better than codes over . Most notably, codes over require 1 dB less power to attain the achievable rate of . The SER results agree with the achievable rate results, showing that better performance can be attained by using constellations carved from lattices with smaller NSM. The performance loss shown in the figure is mainly due to finite codeword length and the suboptimal code design in the sense that the codes are in fact optimized for point-to-point AWGN channels rather than downlink NOMA.
5.6 Summary
Guided by the corresponding linear deterministic model, we have developed a general lattice framework of downlink NOMA without SIC. We have analyzed the rates achieved by the proposed framework with any lattice as base lattice and provided an upper bound on the gap between the rates and the capacity region as a function of the NSM of the base lattice. For some well-known lattices such as , , , and Construction A lattices, the gap upper bounds have been evaluated and have been shown to shrink as the dimension increases. Simulation results have shown that the actual gaps can be much smaller than the derived theoretic bounds, which have further demonstrated the capability of our proposed scheme to achieve the near-capacity performance in downlink NOMA.
Chapter 6 Lattice-Partition-Based Downlink NOMA without SIC for Slow Fading
Channels
6.1 Introduction
For power-domain NOMA, it has been known for quite a while [Cover:2006:EIT:1146355] that the capacity region can be achieved by superimposing codewords with Gaussian distribution at the transmitter and adopting SIC at the receivers. Hence, most of the works in the literature assume the above capacity-achieving scheme and focus largely on determining user pairing and power allocation among paired users and among resource blocks for maximizing system throughput, see for example [7542601, 7937794, 7959169, 7972963, 7971899, 7974731, 8352621]. However, Gaussian signalling is deemed impractical (if not impossible) and SIC imposes a burden on receivers as each receiver has to (partially) decode others’ codewords before decoding its own codeword, which increases decoding complexity and latency.
In chapter 5, we have introduced several works on NOMA with practical discrete inputs [Choi2016, Dong17, Fang16, Shieh16, 8254176, 8291591]. However, having instantaneous CSI (or AWGN channel) as assumed in these works is unlikely to be realistic for scenarios where the feedback links may be costly and limited [tse_book]. Statistical CSI is a more appropriate assumption for such cases and can be deemed as the worst case scenario for these applications [5208539, Section I]. Although some existing works in the literature [7361990, 7438933, Wei17, 7959198, 8063934, 8327866] have considered NOMA with only statistical CSI at the transmitter, continuous Gaussian inputs and SIC are still adopted. To the best of our knowledge, the designs and analyses for NOMA without SIC based on discrete inputs with statistical CSI have not been reported in the literature yet. Hence, further investigation on this case is called for.
6.1.1 Main Contributions
In this work, we consider the problem of designing practical schemes for NOMA systems under slow fading channel where only statistical CSI is available at the transmitter and full CSI is available at the receivers. We focus on bridging the gap between theory and practice. In particular, we develop a lattice-partition-based downlink NOMA scheme which adopts discrete inputs according to statistical CSI and can be efficiently decoded with single-user decoding, i.e., without SIC. The main contributions of our work are summarized as follows.
- •
We propose a novel scheme for the -user downlink NOMA system over slow fading channels. Similar to [Shieh16, 8291591], we first look into the corresponding linear deterministic model [Avestimehr11] and then translates the results back to the NOMA model. As a result, the proposed scheme is a systematic design which determines the modulation, coding rate, and power allocation for each user, according to the statistical CSI and the target outage probability. Our scheme adopts discrete constellations carved carefully from lattices, and hence admits discrete input distributions. By leveraging the structure of interference induced by the proposed signalling, the proposed scheme can be efficiently decoded with single-user decoding, i.e., no SIC is required. We would like to emphasize that this is a non-trivial generalization of [Shieh16, 8291591] since in the present work, the transmitter only has statistical CSI while the schemes in [Shieh16, 8291591] hinge entirely on (quantized) instantaneous CSI. To overcome this, we design the constellations according to average channel condition and derive suitable code rates as a function of outage probabilities.
- •
We rigorously show that for any outage probability below and any rate tuple lying inside the NOMA outage capacity region, there is an instance of our proposed scheme that can achieve that rate tuple to within a constant gap. Specifically, the derived upper bound of the gap is universal for every signal-to-noise ratio (SNR) and any number of users, and this upper bound is found to be a function of the base lattice adopted in construction only. To the best of our knowledge, this is for the first time that the NOMA outage capacity region can be closely approached with discrete inputs and single-user decoding.
- •
Monte Carlo simulation is conducted to demonstrate that the achievable outage rate tuples of our scheme is very close to the NOMA outage capacity region, even with single-user decoding at each user. The gap to the NOMA outage capacity region is shown to be even smaller if SIC is adopted at each strong user. Furthermore, we also provide simulations for a practical set-up of our scheme where off-the-shelf LDPC codes are employed on top of the underlying lattice constellations. The results reaffirm that our proposed scheme without SIC significantly outperforms OMA-type schemes.
6.2 System Model
In this work, we consider a downlink NOMA system where a base station wishes to broadcast messages to users, each of which experiences independent slow fading. The base station and all users are equipped with a single antenna and work in a half-duplex mode.
As depicted in Fig. 6.1, the base station first jointly encodes the binary messages intended for users into a codeword where each codeword symbol is with power constraint , i.e., we use real channels jointly. We denote by the instantaneous channel coefficient from the base station to user , where is a realization of whose channel gain has an inverse cumulative distribution function (ICDF) for . The received signal arrives at user is then given by
[TABLE]
where is the total power constraint at the base station and is AWGN experienced at user . We assume that the transmitter only has the knowledge of statistical CSI of , , while each user knows the realization , i.e., instantaneous CSI. Hence, each receiver can compensate the phase of the channel by coherent detection [tse_book, Ch. 3.1.2], justifying the real channel model in (6.1).
An outage event occurs at user when this user cannot successfully decode its own message . We denote by the required outage probability for user and a rate is said to be achievable with outage if under this rate, the outage probability for user is not greater than . The outage capacity region under is then defined as the closure of the set of all outage rate tuples under the input power constraint. Without loss of generality, we assume that the user ordering follows throughout this work. The outage capacity has been characterized in [5208539] and is summarized as follows.
Theorem 6.1**.**
[5208539, Th. 1]* Given the required outage probability vector , the -th user’s outage capacity in bits per real dimension contains every rate tuple such that there exist power allocation factors satisfying results in where*
[TABLE]
for all .
It should be noted that the outage capacity region based on the user ordering by sorting the value of such that is larger than any outage capacity region based on an arbitrary user ordering [5208539].
In this work, we consider that each user’s channel follows a Rayleigh distribution for demonstration and therefore for , where for . Although the analysis is based on Rayleigh fading, our proposed scheme in fact will work for any fading channel whose channel gain has a finite mean.
6.3 Proposed Lattice-Partition-Based Downlink NOMA Scheme
In this section, we present the proposed lattice-partition-based scheme for downlink NOMA over slow fading channel. In particular, we use the deterministic model [Avestimehr11] as a tool to approximate our downlink NOMA model. We first investigate the corresponding linear deterministic model for the two-user case in Chapter 6.3.1 and then generalize the discussion to the -user case in Chapter 6.3.2. The schemes and observations made for the deterministic model provide significant insights into designing schemes for the original model, which is presented in Chapter 6.3.3.
Before proceeding, we note that unlike existing work in the literature adopting this deterministic approach, here the noise level at each receiver is determined by its fading realization, which is oblivious to the transmitter. To overcome this, we design the constellations according to statistical CSI and rely on the analysis in Chapter 6.4 or simulations in Chapter 6.5 for picking appropriate code rates.
6.3.1 Deterministic Model for Two-User Downlink NOMA over Fading Channels
We use the linear deterministic model [Avestimehr11] to approximate the two-user downlink NOMA for a given fading channel realization. The main idea behind the linear deterministic model is to model the broadcast channel links as bit pipes that only pass to each user the bits above its noise level and truncate the bits below the noise level.
First, we define user ’s average signal-to-noise power ratio (SNR) including the base station power, average channel gain and noise variance as
[TABLE]
We emphasize that as slow fading is considered, user will only get to experience one channel realization of . Since the transmitter only has the knowledge of statistical CSI, our scheme will particularly make use of the statistical CSI through . Let for and assume that . Here, is the maximum number of bits that user expects to receive as if the instantaneous SNR is . The base station broadcasts bits to both users. Let non-negative integers and represent the number of transmitted bits intended for user 1 and user 2, respectively, satisfying
[TABLE]
Since , the base station treats user 2 as the weak user and thus places user 2’s bits above user 1’s bits in the deterministic model. Note that the bits in a higher level in the deterministic model means that the corresponding signals get allocated more power in the original downlink NOMA model.
When the instantaneous SNR of user 1 is , user 1 can receive bits and hence the noise level observed by user 1 is below . When the instantaneous SNR of user 2 is , the noise level observed by user 2 is below . As is placed below in the deterministic model, user 1’s bits can be decomposed into two parts based on the noise level observed by user 2. Specifically, we let where
[TABLE]
are the number of bits that are above and below the noise level of user 2, respectively. Thus, user 2 can receive bits in total.
The above case illustrates the expected performance when the instantaneous channel gain equals to the average channel gain. We now consider the case for a given channel realization . We define for , where is the normalized channel gain such that
[TABLE]
Here, is the maximum bits that user can receive under the channel realization . Thus, represents the number of bits that are overtransmitted for user . Based on the noise level observed by user 1, we decompose where
[TABLE]
are user 1’s message bits above and under its observed noise level, respectively. The channel fading first starts to affect the least significant bits corresponding to the signals with the lowest signal power, i.e, those corresponding to .
For user 2’s channel, we similarly decompose with
[TABLE]
where and represent user 1’s message bits above and under the noise level, respectively, from user 2’s observation. Since the noise level can be above , we also decompose with
[TABLE]
where and represent user 2’s message bits above and under the noise level, respectively, observed by user 2.
To better understand the relationships between the above variables, an example for the case where and is provided in Fig. 6.2.
In this figure, the dotted lines represent the noise levels based on an instant channel while the dash lines represent the noise levels based on the statistical CSI. For user 1, the total number of bits will be treated as under the noise level, is exactly the number of overtransmitted bits in this instantaneous fading channel. Since , user 1’s message bits that are above the noise level is precisely as indicated in (6.9). For user 2, the channel fading starts affecting the least significant bits from to . In this case, user 1’s bits are all under the noise level and hence as it is placed under in the deterministic model. The number of bits that can be received by user 2 is limited by , i.e., as indicated in (6.13).
Based on the above definitions, the following relationships can be easily verified.
- i)
;
- ii)
;
- iii)
, when ;
- iv)
, , , , when ;
- v)
, , , , when .
The fact i) shows the total number of bits that user 2 can successfully receive; ii) shows the total number of bits that will be treated as noise and get truncated at user 2; iii) shows the number of overtransmitted bits for user 2 when the instantaneous SNR is smaller than ; iv) means that only bits are above the noise level when the intended bits for user 2 is larger than ; and finally v) means that user 2 can receive the whole when its intended rate is smaller than .
6.3.2 The -User Case
Similar to the two-user case, we define the average SNR for user as in (6.3) and denote to be the maximum number of bits received by user for when the instantaneous SNR equals to the average SNR. Without loss of generality, we assume throughout Chapter 6. We then denote the number of transmitted bits intended for user by for . The deterministic rate tuple must satisfy the following constraints:
[TABLE]
We start with the analysis for the first (strongest) user. From (6.15) and (6.16), we can reduce the problem into a two-user case by combining users into a super-user, demanding bits and the maximum number of bits received is . Therefore, to analyze the received bits for user 1, one can directly follow our approach as described in Section 6.3.1.
Now we analyze the received bits and interference for user . At user ’s channel, we have the rate constraint as follows:
[TABLE]
For this case, we treat users as a super-user, demanding bits and users as another super-user demanding bits. The problem can again be deemed as a two-user case. We thus choose the rate pairs that satisfies:
[TABLE]
In this way, the same approach from Section 6.3.1 can be used for analyzing this case. As is placed below in the deterministic model, it can then be decomposed into based on the noise level observed by user , where
[TABLE]
are the number of bits above and below noise level, respectively. Thus, user can receive bits in total.
To analyze the case for a random channel realization, we similarly define and as in (6.8) for . For user 1 and user , the analysis can be followed from (6.9)-(6.14) by treating the rest of the users as a superuser.
For user , we treat users as a super-user demanding like the above case but treat users as another super-user demanding bits. Based on the noise level observed by user , we decompose , where
[TABLE]
are the first super-user’s message bits above and under noise level, respectively, from user ’s observation. Since the noise level can be above , we also decompose , where
[TABLE]
are user ’s message bits above and under noise level, respectively, observed at user .
Based on the above definitions, the following facts can be easily verified.
- vi)
;
- vii)
;
- viii)
, when ;
- ix)
, , , , when ;
- x)
, , , , when .
The fact vi) shows the total number bits that user can successfully receive; vii) shows the total number of bits that will be treated as noise and get truncated at user ; viii) shows that the number of overtransmitted bits for user when the instantaneous channel gain is smaller than the average channel gain; ix) means that all bits are below noise level when the number of intended bits for users is larger than ; and finally x) means that user can receive the whole when the sum of the intended rates of users is smaller than .
6.3.3 Translating Back to the Downlink NOMA Model
We now translate the above scheme for the deterministic model into the coding scheme for the -user downlink NOMA over slow fading channels.
For any rate tuple satisfying (6.15)-(6.17), our scheme makes use of the lattice partition chain with any base lattice . The restriction of having partition orders being powers of 2 is merely for practical purpose and it can be lifted. We emphasize here that the selections of are based on the statistical CSI at the transmitter. In the proposed scheme, we use the coset leaders from the above lattice partitions as constellations and code over uses of the constellations in order to establish reliable communication. Specifically, the encoding and decoding process are summarized as follows.
6.3.4 Encoding
For , the binary source messages of length is encoded into a length binary codeword via the channel encoding function . The modulated signal is of length where each entry is obtained by bijectively mapping every bits from user ’s codeword onto user ’s constellation which is a complete set of coset leaders of the lattice partition with cardinality . Note that we assume that each user has the same packet size as users with the smaller packet size can use zero padding. The overall transmission rate in bits per real dimension is
[TABLE]
The transmitted signal is then given by
[TABLE]
where is a deterministic dither known at both transmitter and the receiver and it is to ensure that the overall constellation is zero-mean and has the minimum transmit power; and is a normalize factor to ensure .
6.3.5 Decoding
Consider the decoding procedure at user , with its received signal given in (6.1). The decoder attempts to decode from the received signal via a decoding function by treating other users’ signals as noise, i.e., a single-user decoder. An outage occurs when the decoded signal . We note that the received signal can also be decoded via a SIC decoder which first decodes users ’s codewords before decoding its own codeword. Both single-user decoding and SIC decoding will be included in simulations for comparison. However, the analysis in what follows focuses solely on single-user decoding as it is one of the main motivation of this work.
An example of the proposed scheme is presented as follows.
Example 6.1**.**
We provide an illustrative example for our proposed coding scheme. Consider a two-user downlink NOMA where the average SNRs are dB, which result in . Assume that the intended rates for users 1 and 2 are , satisfying (6.4) and (6.5). When the base lattice is a two-dimensional , the modulations and are and , which correspond to 256-QAM and 4-QAM, respectively.
Remark 6.1**.**
It is noteworthy that the overall constellation corresponds to a complete set of coset leaders of the coarse lattice because . In addition, the proposed scheme naturally induces power allocation factors from the lattice partition chain which is determined based on statistical CSI. Similar to [8291591], the power allocation induced by our proposed scheme ensures that the combined constellation still preserves the structure of lattice . In this way, our scheme can exploit the lattice structure to harness inter-user interference.
6.4 Analysis of the Outage Rates and Their Gaps to Multiuser Outage Capacity
Guided by the linear deterministic model, we first analyze the individual achievable rate of the proposed scheme without SIC for a fading channel realization. The lower bound on the individual outage rate for a given outage probability, is then obtained based on the individual achievable rate. Finally, the gaps between our outage rates and the multiuser outage capacity are investigated. Throughout the chapter, unless otherwise specified, we use the term “outage rate” to denote the outage rate achieved by the proposed scheme for brevity.
We now present the main results of this work as follows.
Proposition 6.1**.**
In the user downlink NOMA over slow fading channel, given the statistical CSI at the transmitter, the outage rate tuple of our scheme without SIC is lower bounded by
[TABLE]
where and it is determined by the NSM of the base lattice.
The proof is given in Section 6.4.1. One can see that the lower bound of the outage rate is a function of the required outage probability. In practice, the acceptable outage probabilities are typically not very large. Hence, we restrict our discussion to the outage probabilities smaller than , which cover almost all the cases of practical interest. As shown in Appendix C.1 and Lemma C.1, by choosing this number, the multiuser outage capacity is bounded away from for a given SNR and a required outage probability, which is useful when we analyze the capacity gap in Section 6.4.2. Under this assumption, we can show that for any rate tuple lying inside the outage capacity region given in Theorem 6.1, there is an instance of our proposed scheme that can achieve that rate tuple to within a constant gap. In particular, we have the following proposition whose proof is in Section 6.4.2.
Proposition 6.2**.**
Given a required outage probability satisfying for , for any lying on the boundary of the NOMA outage capacity region, one can always find an outage rate tuple achieved by our scheme such that where
[TABLE]
Remark 6.2**.**
First, the upper bounds shown above are universal for all and does not scale with . Interestingly, one observes that the bounds for users 1 and are also universal for all outage probabilities. In addition, similar to the results in [Shieh16, 8291591], one can also see that the upper bound is also a function proportional to the logarithm of the NSM of the base lattice, indicating that smaller gaps can be obtained by using lattices with better shaping. For example, for a 3-user case with , are and by using lattice and the optimal lattice whose NSM are and , respectively. Last but not least, we stress that as evident in the proofs in what follows, many loose bounds based on the worst case scenario are used for making the results universal. Our simulation results in Section 6.5 will show that the gaps are usually much smaller than the derived upper bound.
6.4.1 Analysis of the Individual Outage Rate
For user 1, we follow the definition in (6.9) and (6.10) to decompose into and as opposed to and . Let us consider the lattice partition chain where and are isomorphic to and , respectively. Thus, can then be represented as
[TABLE]
Similarly, for user , the super-user’s constellation and its own constellation can be decomposed according to (6.11)-(6.14) and (6.23)-(6.26).
[TABLE]
Let be random variables uniformly over , respectively, and let be the input random variable. Following the relationship given in (6.1), we define to be the random variables corresponding to the received signal at users , respectively.
*1): * For user 1, we can write according to (6.35). As user 1 treats users as a super-user, we can define as the random variable associated with the super-user. To analyze the achievable rate of our scheme without SIC for an instant channel realization , we bound the mutual information as follows.
[TABLE]
where is indeed the parts above the noise level for user 1 according to the deterministic model; is a fixed dither decomposed from ; (\ref{eqn:rate_1_GBC}.a) is due to the bijective mapping between and , and (\ref{eqn:rate_1_GBC}.b) follows the independence between each for . To further bound , we note that the effective noise can be written as , where is a fixed dither to minimize energy of constellation . Note that we can always find such a pair by fixing that minimizes the energy of and let . We then scale the effective noise by
[TABLE]
In this way, the scaled effective noise has power . The equivalent communication channel then becomes where
[TABLE]
and . We then apply the established lower bound of the mutual information between a discrete random input and its noisy version shown in [8291591, Lemma 6] to obtain the following
[TABLE]
where .
We then establish the lower bound for the scaling factor of in (C.2.1) and for in (C.2.1)-(C.10) in Appendix C.2.1. By plugging these bounds into (6.4.1), we obtain the lower bound for user 1’s achievable rate in bits per real dimension for a given channel realization as
[TABLE]
where here follows the constraint in (6.9).
As our scheme does not invoke SIC at each receiver, the outage probability of user is calculated as , where is user ’s target transmission rate. Given user 1’s rate and the required outage probability , we have
[TABLE]
The lower bound for user 1’s the outage rate is
[TABLE]
where here follows (6.9). This completes the proof for (6.29).
*2): * For user , we define by treating users as a super-user and by treating users as another super-user. Then, we decompose and according to (6.36) and (6.37), respectively.
We bound the mutual information for user for a channel realization as follows,
[TABLE]
where is a fixed dither decomposed from , (\ref{eqn:rate_k_GBC}.a) is due to a bijective mapping between the lattice and the term , and (\ref{eqn:rate_k_GBC}.b) follows
[TABLE]
To further bound (6.4.1), we note that effective noise is , where is a fixed dither decomposed from and to minimize the energy of constellation . We thus scale the effective noise by
[TABLE]
such that . In this way, we can similarly apply the lower bound of the mutual information between a discrete random input and its noisy version shown in [8291591, Lemma 6] to obtain
[TABLE]
where , and
[TABLE]
is the scaling factor for the minimum distance of the constellation . The effects of changing of on the constellation are illustrated in facts ix) and x) given in Section 6.3.2. We then follow the similar step as in user 1’s case to obtain the lower bound on user ’s outage rate
[TABLE]
where here follows from (6.13) and the detail derivation is in Appendix C.2.2. This completes the proof for (6.30).
3): For user , we define by treating users as a super-user. We then similarly decompose and according to (6.36) and (6.37), respectively. The mutual information for user is bounded by:
[TABLE]
where is the fixed dither decomposed from , (\ref{eqn:rate_2_GBC}.a) follows from the existence of a bijective mapping between and , and (\ref{eqn:rate_2_GBC}.b) follows from
[TABLE]
We follow the steps as in user and ’s cases to further bound (6.4.1) and leave the detail process in Appendix C.2.3. The lower bound of user ’s outage rate is
[TABLE]
where here follows (6.13). This completes the proof for (6.31).
6.4.2 Outage Capacity Gap Analysis
In this subsection, we investigate the gap between the outage rate of our scheme and the NOMA outage capacity region. We assume that for . Otherwise, the problem can be reduced to that with less users.
*1): * When , the output of function in (6.44) is smaller than . That is:
[TABLE]
The gap of user 1’s outage rate to multiuser outage capacity is upper bounded by
[TABLE]
where follows from (6.54); follows from
[TABLE]
by letting (for , the gap is at most bits, i.e., because ) and follows from the fact that given a power allocation vector , one can always pick a rate tuple satisfying (6.15)-(6.17), resulting in at most 1 bit gap from the corresponding multiuser capacity such that [Avestimehr11]. This completes the proof for (6.32).
*2): * For user , we let . When , we have . Thus, since according to (6.56). For , we need to consider two cases as the output of function in (6.50) cannot be determined even with the constraint .
When in (6.50), the gap of user ’s outage rate to multiuser outage capacity is upper bounded by
[TABLE]
where the first inequality is true for outage probabilities within our chosen range (see Lemma C.1) and the second inequality follows from (6.4.2.b).
When in (6.50), user ’s gap is bounded by
[TABLE]
where (\ref{eq:gap_k_c2}.a) is due to treating users as a super-user and then applying the gaps in ; (\ref{eq:gap_k_c2}.b) follows the fact that is monotonically increasing in because its first derivative is
[TABLE]
(\ref{eq:gap_k_c2}.c) follows from that
[TABLE]
and (\ref{eq:gap_k_c2}.d) follows from the fact that is monotonically decreasing for because its first derivative is
[TABLE]
This completes the proof for (6.33).
*3): * For user , let (since will result in gap at most bit), when in (6.53), the gap of user ’s outage rate to multiuser outage capacity is upper bounded by
[TABLE]
where the first inequality is due to (C.1) in Lemma C.1. For the other case, the gap is upper bounded by
[TABLE]
This completes the proof for (6.34).
6.4.3 Complexity Comparison
We now discuss the complexity of our NOMA scheme with SIC and that without SIC. Consider a -user downlink NOMA system, to perform SIC, the strong users have to decode other users’ messages before decoding their own messages. However, each user has some probability to become the strongest channel user and may have to decode other users’ messages in order to perform SIC. As a result, the decoding and detection delay introduced by SIC at the receiver can be as large as times of the decoding and detection time for our scheme without SIC. Furthermore, another encoding and modulation delay is also introduced as a result of re-encoding the decoded message and then re-mapping the codeword to the modulation. In contrast, our scheme does not require any re-encoding and re-mapping process. In addition, the detection complexity heavily depends on the dimensions of the underlying lattices. In general, the higher lattice dimension, the higher detection complexity. This is also true for any conventional power-domain NOMA scheme with high dimensional constellations. When the dimension of the underlying lattice becomes higher, our scheme can use efficient lattice decoders such as the sphere decoder [771234] for detection as the superimposed constellation still preserves the nice lattice structure. Last but not least, allowing users to decode others’ messages may result in a significant security problem while this can be easily avoided by using dithers for our scheme (note that the same trick cannot be used for NOMA with SIC since SIC by nature requires users to know each other’s codebooks). To sum up, we have significantly reduced the complexity caused by SIC while still maintaining considerable performance in terms of individual outage rates.
6.5 Simulation Results
Simulation results are provided to demonstrate the effectiveness of the proposed scheme. In Chapter 6.5.1, we use the Monte-Carlo method for simulating achievable outage rates. In Chapter 6.5.2, we implement off-the-shelf LDPC codes to realize our proposed scheme for simulating outage probability performance.
6.5.1 Outage Rate Simulation
We construct proposed scheme over two-dimensional lattice , which is purely for practical purposes as is associated with QAM modulations. In our simulations, we test channel realizations drawn from Rayleigh distribution with unit mode, i.e., . For each realization, we evaluate the achievable rates by the Monte Carlo method with samples. The required outage probability is set to be 0.05111Note that we can set the outage rate to a very small value such as 0.001. However, in such cases, the achievable rate pairs for every scheme are going to be very small (at the order of 0.01 bit per real dimension or smaller), which do not seem to be interesting.. In Fig. 6.3, we consider two-user NOMA with dB, which corresponds to . In Fig. 6.4, a three-user NOMA example is simulated with dB such that . In both figures, the achievable outage rates of the proposed scheme with SIC, that without SIC, the TDMA outage capacity region (with Gaussian input distributions), and the NOMA outage capacity region (with Gaussian input distributions) are plotted.
In both figures, one can see that the actual gaps between the outage capacity region and the outage rates achieved by our scheme are much smaller than the theoretical upper bounds. Specifically, the theoretical upper bounds are calculated as bits and bits for two-user case and three-user case, respectively, while the simulated gaps from both figures are within 1 bit to the NOMA outage capacity region for both cases. This is because in our analysis, in order to obtain theoretic guarantees that are universal for all average SNR, many loose bounds are adopted for covering the worst case scenario. When decoded by a SIC decoder, the proposed scheme can operate at outage rate pairs that are very close to the outage capacity region. The loss is mainly due from the shaping loss incurred by having discrete input distributions. Moreover, even with single-user decoding, the proposed scheme can achieve outage rate pairs that are within 1 bit to the NOMA outage capacity region. It is worth noting that the performance of the OMA-type scheme (Gaussian TDMA region) is obtained by time-sharing between two single-user scheme with impractical Gaussian inputs. Despite that, some of the outage rate pairs of our proposed scheme with practical discrete inputs are still outside the Gaussian TDMA region, which indicates that the proposed scheme is capable of outperform OMA-type scheme even without SIC.
6.5.2 Outage Probability Simulation
Now we employ practical channel coding on top of our modulation for our proposed NOMA scheme. For illustrative purposes, we perform the simulation for a two-user case. To approach the rate pair shown in Fig. 6.3 for and , we adopt and in Example 6.1. In addition to the modulation, we adopt off-the-shelf DVB-S2 LDPC codes with block length 64800 [DVBS214] and group multiple coded bits for mapping to the proposed constellations. Specifically, we choose the codes with rates , for users 1 and 2, respectively, such that the actual transmission rate pair is , which is fairly close to the target outage rate pair. When performing SIC, we assume that user 2’s message is perfectly known at user 1. Note that this assumption is for obtaining the benchmark performance only while in practice SIC failure is deemed as an outage event. In addition, we assume that user 1 and user 2’s messages are of the same length. If the lengths are different, we pad the uncoded modulated signals from the user with longer message length to the message with shorter length in order to make all the bits with interference. For a TDMA scheme to reach the rate pair of , the required transmission rate pair is with time-sharing factor . To approximate these target rates, we use rate , DVB-S2 LDPC codes in conjunction with and , respectively. With time-sharing factor , the resultant transmission rate is . The simulation is performed for channel realizations where the outage probability is averaged for outage samples in each realization.
From Fig. 6.5, we can see that user 1 without SIC saves about 2 dB power while user 2 saves about 2.5 dB power when compared with TDMA schemes. With perfect SIC, another 1 dB gain can be obtained for user 1. Note that for TDMA, user 1’s transmission rate is smaller than the target rate while user 2’s rate is larger than the target rate, i.e., and . Thus, the gap between the rate differences for user 2 is larger than that of user 1. One may also notice that user 1 requires more power to reach than user 2. This is because user 1’s constellation is large, i.e., with size 256, and using binary linear codes on top of larger-size constellations will lead to significant performance loss. Although better channel codes tailored specifically for downlink NOMA can be designed to enhance the outage performance, they are beyond the scope of this work.
6.6 Summary
In our previous work [8291591], it has been shown that lattice partition is a powerful tool for constructing coded modulation schemes for downlink NOMA with instantaneous CSIT under single-user decoding. In this work, we have further extended this result to the case where only statistical CSIT is available by 1) modifying the deterministic model; 2) analyzing the modified deterministic model; 3) proposing new lattice-partition-based schemes based on the insights obtained from the modified deterministic model. As a result, we have derived the outage rates achieved by our scheme with any base lattice. Moreover, for any outage probability below 63.21%, we have proved that for any rate tuple lying inside the NOMA outage capacity region, there exists an instance of our scheme that is able to achieve this rate tuple within a constant gap even without SIC. Simulation results have demonstrated that the actual gaps can be much smaller than the analytic upper bounds, reaffirming that the proposed scheme is capable of achieving the near-capacity performance of downlink NOMA with only statistical CSI at the transmitter and without SIC at the receivers.
Chapter 7 Downlink NOMA without SIC for Block Fading Channels
7.1 Introduction
In this chapter, we continue the study of constructing practically implementable downlink NOMA schemes that perform well even under single-user decoding. In particular, we consider the scenario where the signal received at each user experiences a block fading channel [MinICC19, DBLP:journals/corr/abs-1905-09514]. We again assume that the base station only has statistical CSI. For such a channel, an important performance metric is the diversity, measuring the decay rate in error probability with respect to SNR [1256737, Caire06]. All the schemes [Choi2016, Dong17, Fang16, Shieh16, 8291591, Qiu18Globecom, 8517129] previously mentioned in Chapter 6, however, achieve no diversity gains in block fading channels. To achieve full diversity order for point-to-point communication over block fading channels, it has been known for quite a while [485720] that properly rotated QAM constellations will do the job. Therefore, in this chapter, we will further investigate the proposed lattice based schemes such that they can achieve diversity gains and good reliability for downlink NOMA systems over block fading channels.
7.1.1 Main Contributions
In this work, the problem of achieving full diversity order for every user in the downlink multiuser transmission over block fading channels is addressed. The main contributions of the work are summarized as follows.
- •
We propose a class of downlink NOMA schemes without SIC for block fading channels with only statistical CSI at the transmitter and full CSI at the receiver. Specifically, the proposed scheme constructs an -dimensional ideal lattice from algebraic number fields and carves its coset leaders to form the constellation for each user. This class of schemes is the first attempt to use algebraic methods to provide high reliability solutions to downlink multiuser communications. Within the proposed class, we also identify a special family of schemes that are closely related to lattice partitions of the base ideal lattice.
- •
To evaluate the error performance of the proposed scheme under single-user decoding, we analyze the minimum product distance of the composite constellation of the proposed scheme. We first show the equivalence between the superimposed -dimensional constellation carved from any ideal lattice and the Cartesian product of identical rotated superimposed one-dimensional constellation. As a result, we then rigorously prove that the minimum product distance of the -dimensional composite constellation can be upper bounded by the minimum product distance of the equivalent one-dimensional superimposed constellation and derive the analytical expression for the upper bound as a function of all users’ power allocation factors and spectral efficiencies. Moreover, our bound closely captures the actual minimum product distance in the sense that all the local maximums of the actual distance coincide with our upper bound. Furthermore, it is shown numerically that the special family of schemes corresponding to lattice partition can achieve the maximal minimum product distance among all the proposed schemes.
- •
We then extend our analysis to the MIMO-NOMA system with orthogonal space-time block codes (OSTBC). For such codes, the probability of error is largely determined by the minimum determinant, which can be further simplified as a function of the minimum Euclidean distance of the underlying composite constellation. Following similar steps in our analysis in the single antenna case, we obtain the exact analytical expression of the minimum determinant of the superposition coded space-time codeword with arbitrary power allocation factors and spectral efficiencies. Again, a special family of schemes corresponding to lattice partition is identified and it achieves the maximal minimum determinant.
- •
Simulation results are provided to illustrate that our scheme can provide a systematic design that each user employs the same ideal lattice and same rotation is sufficient to attain full diversity with single-user decoding (i.e., without SIC). Moreover, the special family of schemes based on lattice partitions provides substantially better error performance than the benchmark NOMA schemes.
7.2 System Model
In this work, we consider a downlink NOMA system where a base station wishes to broadcast messages to users, one for each user. For , the message is a binary sequence of length , where is the dimension of the code and is the spectral efficiency of user in bits/s/Hz/real dimension. We emphasize here that due to the delay requirements, the channel between the transmitter and each user experiences independent block fading with a finite number of realizations within each data packet transmission duration, which is different from the slow fading model considered in [8517129] where each user only gets to experience one realization within each data packet transmission duration. For now, we assume that every device in the network is equipped with a single antenna and works in a half-duplex mode.
The base station encodes all users’ messages into a codeword of the codebook , satisfying the power constraint . We denote by the instantaneous channel coefficient vector from the base station to user . Here, each fading coefficient is drawn i.i.d. from Rayleigh distribution. The received signal at user is denoted by with
[TABLE]
where is the total power constraint at the base station and is the Gaussian noise experienced at user . Each user is assumed to have full CSI, i.e., , while the transmitter only has the statistical CSI, i.e., the distributions of each . We note that this channel model is quite standard and can be easily obtained by interleaving the codeword across multiple channel coherence time periods and applying de-interleaving and coherent detection to the received signals [tse_book, Chapter 3.2].
We measure the reliability by the pairwise error probability (PEP). Following [tse_book, Chapter 3.2], for any two codewords and , user ’s error probability without SIC is upper bounded by the average PEP of the composite constellation over all pairs, which is
[TABLE]
where is the product distance of from that differs in components and is the average SNR. It can be seen that in the high SNR regime, the overall error probability decreases exponentially with the order of , which is known as the diversity order. The code has full diversity when . Moreover, one would like to maximize the minimum product distance in a bid to minimize the overall PEP, which provides additional coding gain on top of the diversity gain. The diversity order and the minimum product distance are important metrics for improving the reliability of communication through block fading channels. Note that although we focus solely on Rayleigh fading channels in this paper, the diversity order and product distance criterion are generalizable to other fading channels, e.g., Rician fading [tse_book, Chapter 3.2], [Vucetic:2003:SC:861866, 1256737].
In this work, we focus on the case of only as it is more practical for multi-carrier NOMA where each subcarrier is allocated to two users [7273963, 8449119]. This is also a common assumption in many works in the NOMA literature, see for example [Wei17, 8345745, Choi2016, Dong17]. We would like to emphasize that the schemes proposed in this work are not limited to the two-user case and can be generalized to the general -user case in a straightforward manner. However, the analysis becomes quite messy for and is thus left for future study. Throughout Chapter 7, without loss of generality, we also assume that and thus users 1 and 2 are commonly referred to as the strong and weak users, respectively.
7.3 Downlink NOMA over Block Fading Channels
In this section, we first introduce the proposed class of NOMA schemes based on superpositions of codes from -dimensional ideal lattices. We then identify, within the proposed class of schemes, a special family of schemes corresponding to lattice partitions of the underlying ideal lattices. The minimum product distance of the proposed schemes will be analyzed in Chapter 7.4.
7.3.1 Proposed Downlink NOMA Schemes from Ideal Lattices
Encouraged by the success of using ideal lattices for point-to-point communications over block-fading (see [Oggier:2004:ANT:1166377.1166378]), we construct rotated version of multi-dimensional QAM (corresponding to lattices) from a totally real ideal lattice. It is worth noting that the rotated versions of many other well-known lattices such as , , and that are good for block fading channels can also be constructed. Our choice of using rotated is mainly for encoding/decoding complexity and for achieving full diversity order.
Throughout Chapter 7, we use the cyclotomic construction [Oggier:2004:ANT:1166377.1166378, Chapter 7.2] to construct ideal lattices that are equivalent to . Consider the -th primitive root of unity for some prime number . Construct the maximal real sub-field of the -th cyclotomic field . This is totally real and has degree . A set of integral basis is given by . The embeddings of into are given by
[TABLE]
Then, the generator matrix is given by
[TABLE]
where is an upper triangular matrix with entries for ; is to ensure that is equivalent to ; and is to normalize the volume of such that .
The minimum product distance of this family of ideal lattices is
[TABLE]
Having constructed the considered ideal lattice, we now introduce the encoding and decoding steps of our proposed NOMA scheme at the transmitter and the receiver, respectively.
7.3.2 Transmitter Side
For user , a subset of the ideal lattice is carved to form the constellation of the user . Specifically, has cardinality and is the complete set of coset leaders (see Chapter 2.2 for the definition) of the lattice partition . User ’s message is mapped into . The transmitter then sends the superimposed signal , where
[TABLE]
where , , and are length dither vectors to ensure the constellations , , and , respectively, to have zero mean; is a normalize factor for ensuring power constraint ; and are the power allocation factors for users 1 and 2, respectively. Here, the normalization factor is computed by using Lemma D.1 in Appendix D.1 as
[TABLE]
7.3.3 Receiver Side
Recall that the received message at user is denoted by and is given in (7.1). There are two options for the decoder, depending on the implementation and application. If a single-user decoder is adopted (i.e., without performing SIC), the decoder of user attempts to recover from by treating the other user’s signal as noise. If an SIC decoder is adopted, user 2 remains the same decoding procedure, while user 1 first decodes , subtracts it out, and then decodes its own message. Both single-user decoding and SIC decoding will be included in simulations for comparison. However, our design and analysis focus solely on the case with single-user decoding as it is one of the main motivation of this work.
Remark 7.1**.**
Similar to most works considering block Rayleigh fading channels (see [Oggier:2004:ANT:1166377.1166378] and reference therein), we focus solely on diversity order and minimum product distance. It is worth mentioning that standard channel coding can be employed on top of the modulation schemes of this work to obtain additional coding gain at the cost of further lowering the spectral efficiency.
Remark 7.2**.**
Consider a -user downlink NOMA system. For the conventional power-domain NOMA, each user would have to decode other users’ messages to perform SIC because each user has some probability to potentially become the strongest channel user. Thus, the demodulation and decoding delay can be as large as times of that for our proposed scheme without SIC. Moreover, encoding delays are introduced by SIC as a result of re-encoding the decoded message and then re-mapping the codeword to the modulation. In contrast, re-encoding and re-mapping are not required in our scheme without SIC.
7.3.4 Proposed Schemes based on Lattice Partitions
Now, we identify a special family of the proposed schemes within the proposed class of schemes. In this family of schemes, after the mapping process from to for , the transmitted signal is given by
[TABLE]
where is a deterministic dither to ensure the composite constellation have zero mean and
[TABLE]
is the normalization factor to ensure the power constraint . To see that is indeed the correct normalization factor, we use Lemma D.1 in Appendix D.1 to obtain that . Here, the power allocation is . When substituting this power allocation into (6) and decomposing , it can be easily verified that this family of schemes described in (7.8) is a special case of the proposed class of schemes in (7.3.2).
The beauty of this family of schemes is that the composite constellation corresponds to the lattice partition because for equivalent to . Moreover, the relationship among , , and closely follows the lattice partition chain and hence many nice properties of the underlying ideal lattice naturally carry over to the individual and composite constellations. For example, since the superimposed constellation still preserves the nice lattice structure, efficient lattice decoders such as the sphere decoder [771234] can be used at each receiver for decoding. Also, the minimum product distance of a scheme within this family can be precisely computed as shown in the following proposition.
Proposition 7.1**.**
The lattice-partition scheme with ideal lattices as the base lattice can provide full diversity to each user and the composite constellation has a minimum product distance
[TABLE]
* Proof: * Since corresponds to the lattice partition , the minimum product distance of the composite constellation can be derived as
[TABLE]
where is obtained by plugging from (7.9).
Now, since , full diversity is thus guaranteed according to (7.2).
7.4 Performance Analysis
In this section, we analyze , the minimum product distance of the normalized and dithered composite constellation defined in (7.3.2) for any parameters , , , . We emphasize that under block fading, the symbol error rate (SER) performance of the whole downlink system is closely related to according to (7.2). Moreover, the analytical results of the minimum product distances will provide insights into the relationship between spectral efficiency, power allocation factor and the error performance of the proposed scheme.
7.4.1 Preparations and Definitions
we first introduce a few preparations and definitions in the following chapter.
7.4.2 Layer
We define a layer of in (7.3.2) to be the collection of points constituting a shifted version of a rotated and dithered one-dimensional superimposed constellation
[TABLE]
where is a complete set of the coset leaders of the one-dimensional lattice partition , is a scalar dither for , and is an rotation matrix such that the shifted and rotated one-dimensional constellation becomes a subset of . In other words, a layer is given by for some fixed . Examples of all the layers for the case of and are illustrated in Fig. 7.1 where each circle represents a constellation point of and there are 16 layers in total.
7.4.3 Intra-Layer Minimum Product Distance
We denote by the intra-layer minimum product distance as the minimum product distance between any pair of two distinct constellation points within a layer, i.e., within the shifted version of the (rotated) one-dimensional constellation .
7.4.4 Cluster
We define a cluster to be all the points in a shifted version of user 1’s constellation in one layer, i.e., for a fixed . Each layer has clusters. In the example shown in Fig. 7.1, there are 2 clusters inside a layer. With a slight abuse of notation, we define the minimum product distance between two distinct clusters and as
[TABLE]
7.4.5 Inter-Cluster Minimum Product Distance
The inter-cluster minimum product distance is then defined as
[TABLE]
An example of can also be found in Fig. 7.1.
7.4.6 Minimum Product Distance Notations
We denote by and the minimum product distance of users 1 and 2’s constellations in one layer, respectively. To be specific, they are computed as
[TABLE]
Examples of and are shown in Fig. 7.1.
7.4.7 Main Result
The minimum product distance of the proposed NOMA scheme with arbitrary power allocation is upper bounded as follows.
Proposition 7.2**.**
The minimum product distance of the proposed NOMA scheme with ideal lattices as the base lattice and with arbitrary power allocation is upper bounded by
[TABLE]
where
[TABLE]
and denotes the inter-cluster minimum product distance for the case of for any . The upper bound for can be obtained by switching the roles of and and substituting into from (7.2).
The proof of this proposition is described in details in Section 7.4.8. Before that, we would like to emphasize that one can find the exact minimum product distance of for a given by numerically calculating all the product distances between all pairs of two constellation points in and find the minimum value among them. However, the computational complexity will dramatically increase with , and increasing. We use the following example to demonstrate the effectiveness of our analytical upper bound.
Example 7.1**.**
Consider and . Both and are rotated 64-QAM constellations and becomes a superimposed constellation with 4096 constellation points. In Fig. 7.2, we evaluate the upper bound of in (7.2) and the exact values of by computer search for . The minimum product distance achieved by our scheme based on lattice partition is also plotted.
It can be observed that the derived upper bound well captures the trend of the changes in and fits all the local maximum points (peak values in the figure). Most notably, the proposed scheme based on lattice partition achieves the largest value (the first peak value in the figure), which shows the optimality of this scheme. Although we have not rigorously proved that this scheme is always optimal for a general pair of , it is optimal for all the cases that we have tested, including every for (each user’s constellation ranging from rotated 4-QAM to rotated -QAM).
7.4.8 Proof of Proposition 7.2
We now derive the upper bound for the minimum product distance of the superimposed constellation . In what follows, we first prove in Lemma 7.1 that the -dimensional superimposed constellation is an -fold cartesian product of a one-dimensional superimposed constellation. Then, we show in Lemma 7.2 that can be upper bounded by the minimum product distance of this one-dimensional superimposed constellation. With these lemmas, we then bound the minimum product distance of by analyzing the minimum product distances of the one-dimensional superimposed constellation.
Lemma 7.1**.**
Consider the constellation defined in (7.3.2) for and the base lattice is equivalent to . The constellation is the rotated -fold Cartesian product of the one-dimensional constellation in (7.12).
* Proof: * Following (7.3.2), we write the superimposed constellation as
[TABLE]
where follows that is obtained by multiplying the dithered coset leaders of to the rotational matrix while these coset leaders are generated by with and for ; follows that since , thus and for ; is due to that each component of follows for and because , the coset leader of , is precisely the -fold Cartesian product of the coset leader of ; and follows that for because
[TABLE]
Thus, is the -fold Cartesian product of one-dimensional constellation with rotation.
With Lemma 7.1, we prove an upper bound on in the following.
Lemma 7.2**.**
Consider a normalized and dithered superimposed constellation defined in (7.3.2) for and is equivalent to . The minimum product distance of is upper bounded by
[TABLE]
where is the one-dimensional constellation defined in (7.12); and is an rotation matrix such that when or 1.
* Proof: * Given the definition of layer in Section 7.4.2 and based on Lemma 7.1, it is worth noting that all the layers have the same Euclidean distance profiles and thus their minimum Euclidean distances, denoted by , are the same regardless of any rotation . Thus, we have
[TABLE]
When or 1, the superimposed constellation becomes a single user’s constellation. In this case, the following relationship always holds
[TABLE]
Based on the above relationships and Lemma D.2 in Appendix D.1, there exists at least one layer such that the minimum product distance of this layer satisfies
[TABLE]
for some rotation matrix . By using (7.33)-(7.36) and the relationship between minimum product distances in two different layers established in Lemma D.3 in Appendix D.1, we conclude that
[TABLE]
Now, we denoted by the minimum of the set of all product distances between all pairs of two distinct constellation points in any two different layers. It is obvious that
[TABLE]
where the normalize factor does not affect the equality and inequality here.
With the upper bound in Lemma 7.2, we now restrict the problem of bounding the minimum product distance of an -dimensional constellation to analyzing the intra-layer minimum product distance . This approach turns out to be sufficient for our purpose as it captures the trends of the change of the and fits perfectly with many local maximum values, as already shown in Example 7.1.
Remark 7.3**.**
When analyzing the minimum product distance of the superimposed constellation , we only need to analyze the case for . Specifically, the superimposed constellation for is equivalent to for . Thus, the later case is analyzed when we let and such that , where corresponds to the complete set of coset leaders of and for .
Based on the definitions given in Section 7.4.1, the intra-layer minimum product distance is
[TABLE]
Since and can be easily computed as in (7.23) and (7.24), respectively, what is left is to analyze . To perform the analysis, we first consider the case of and and then use the result to analyze the general case of .
1) Case I: () For this case, there are two clusters, each of which contains number of constellation points. Before the constellation points from two clusters start to overlap, the inter-cluster minimum product distance is the product distance between two constellation points at the edge of each cluster. This scenario is illustrated in the example shown in Fig. 7.1. The inter-cluster minimum product distance is given by
[TABLE]
where we have used the relationship of product distances in two line segments in established in Lemma D.4 in Appendix D.1. We emphasize that Lemma D.4 will be frequently used in the rest of the proof. Since for according to (7.23) and (7.24), the intra-layer minimum product distance is thus determined by comparing and . To have , the necessary condition to satisfy this inequality is
[TABLE]
Thus, when , we have
[TABLE]
Then, for , the intra-layer minimum product distance becomes the inter-cluster minimum product distance such that
[TABLE]
where follows that for . Thus, we can now focus on analyzing for this range.
To simplify the description for the subsequent analysis, we label two clusters as clusters 1 and 2, respectively, from the left to the right of a layer. Moreover, we refer to the Voronoi cell of an element with respect to the underlying rotated lattice in cluster 1 as a cell of cluster 1. For each cluster, there are cells which are labelled cell to , respectively, from the left to the right of a cluster. With increasing, two clusters are moving toward each other. When the left constellation point on cell in cluster 1 overlaps with the right constellation point on cell 1 in cluster 2, . From (7.40), this happens when . After the overlapping, the inter-cluster minimum product distance is bounded by
[TABLE]
where is due to the fact that the maximum of the inter-cluster product distance happens when a constellation point from cluster 2 is located in the center of a cell in cluster 1.
Consider the scenario where the leftmost constellation point of cell 1 of cluster 2 is in between the center and the right edge of cell in cluster 1. To have a clear view on this, we plot this scenario in Fig. 7.3.
By counting the number of cells within clusters and inspecting the relationship between different product distances as shown in Fig. 7.3, the inter-cluster minimum product distance is derived as
[TABLE]
Similarly, for the case where the left constellation point in cell 1 of cluster 2 is located in between the center of cell and cell in cluster 1, the inter-cluster minimum product distance is
[TABLE]
By combining the right hand side of (7.44), (7.46), the boundary of corresponding to the in (7.46) can be computed as
[TABLE]
Summarizing the above results, we obtain the inter-cluster minimum product distance for case I in (7.29) for .
2) Case II: () First, it is obvious that the intra-layer minimum product distance is the same as in (7.42) of Case I when . However, (7.29) does not hold anymore when multiple clusters start to intercept. Since there are clusters, different constellation points from multiple clusters can be located in a cell of any cluster. Similar to Case I, we label all the clusters as from the left cluster to the right cluster in a layer to simplify the description in the following analysis.
We denote by the number of clusters intercept with each other, i.e., there are different constellation points from different clusters, respectively, intercept with the cells of cluster 1. When , the scenario becomes identical to Case I and the same analysis on the minimum product distance applies. For , the inter-cluster minimum product distance takes into account that the cells of clusters intercepting with each other. Thus, it can be bounded by
[TABLE]
where comes from the same reason that we have in (7.44). Now consider any two clusters and we assume without loss of generality. In the following, for the ease of presentation, we refer to in case I as . It can be easily seen that when , and coincide. For , to determine , we first need to find a set of product distances between cluster 1 and for as follows. Suppose that there are constellation points from cluster that have intercepted with the cells of cluster 1. By applying Lemma D.4 multiple times, we obtain the product distance between a point in cluster 1 and the -th constellation point from cluster intercepting with the cells of cluster 1 (called ) as
[TABLE]
The minimum product distance is then computed as
[TABLE]
where follows from Lemma D.4 and follows from the fact that is the spacing between cluster and in terms of and is the maximum spacing because
[TABLE]
For , the inter-cluster minimum product distance for the scenario where the cells of clusters intercept with each other, is obtained by finding the minimum of the product distances based on all combinations of clusters and
[TABLE]
where follows from that .
The only thing left is to find the boundary of , called , such that when , the bound in (7.48) is valid. This happens when the minimum product distance between cluster 1 and cluster satisfies the condition of . Otherwise, the above scenario is reduced to the scenario of the cells of clusters intercepting with each other because leads to
[TABLE]
where follows from that and follows from (7.4.8) that if for any . Thus, the corresponding is derived by using the above condition as
[TABLE]
Note that we only needs to look at according to Remark 7.3. This completes the proof.
7.5 Extension to MIMO-NOMA
In this part, we extend the main idea and analysis to MIMO-NOMA over block fading channels for constructing good MIMO-NOMA schemes without SIC. We restrict our attention to a very popular class of codes for MIMO channel named OSTBC. Some advantages of using OSTBC include achieving full transmit diversity and efficiently detection by turning the MIMO channel into a set of non-interfering parallel subchannels. We note that a scheme of NOMA with two transmit antennas and one receive antenna for each user combined with Alamouti code [730453] has been reported in [8392409] where the closed form expressions for outage probabilities under Nakagami-m fading channels are derived. However, the analysis is based on Gaussian inputs. In this section, we adapt the techniques used in the previous section to analyze the error performance of MIMO-NOMA scheme with general OSTBC [Vucetic:2003:SC:861866].
7.5.1 MIMO-NOMA system model
Consider a two-user MIMO-NOMA where the base station and each user have and sufficient-spacing antennas, respectively. We again assume that the transmitter has statistical CSI while the receiver has full CSI for its own channel. The base station encodes all users’ messages into a superimposed codeword from the codebook and broadcasts it to each user, where means the codeword spreads time slots and for . We denote by the channel matrix for user with i.i.d. entries. Here, we assume that is constant during one codeword block while a transmit packet contains multiple blocks. The received signal at user for time slots is denoted by and is given by
[TABLE]
where is the total power constraint at the base station and is a circular-symmetric AWGN experienced at user with i.i.d. entries .
The reliability is again measured by PEP. Consider the channels with i.i.d. entries . Following [Vucetic:2003:SC:861866, Chapter 2.5.1], for any two codewords and , user ’s error probability is upper bounded by its average PEP given by
[TABLE]
where denotes the conjugate transpose, is user ’s average SNR; are the non-zero eigenvalues of with being the codeword difference matrix with . The diversity order of is . For , the code has full rank such that and . In this case, the code achieves full diversity, i.e., the diversity order is . To further minimize the PEP, it is important to maximize the minimum determinant . It is noteworthy that the design criterion is generalizable to other fading channels, e.g., Rician fading [Vucetic:2003:SC:861866, 1256737]. Without loss of generality, we assume that and user 1 is considered as the strong user. Note that this user ordering is also adopted in [8392409].
7.5.2 Proposed Scheme and Main Result
We first briefly describe the scheme of space-time coded MIMO-NOMA in the following.
7.5.3 Transmitter Side
A superimposed signal sequence is encoded into a OSTBC codeword , where can be expressed by (7.3.2) for and is applied to to ensure . Here is an additional normalization for the space-time code on top of the normalization of the superimposed constellation and it depends on the specific space-time code (for example, Alamouti code has ).
7.5.4 Receiver Side
Upon receiving given in (7.55), the maximum-ratio combining and the space-time decoding are employed for decoding. By using the orthogonality of pairwise rows of the transmission matrix [Vucetic:2003:SC:861866, Chapter 3.6], the decoder attempts to minimize the following metric
[TABLE]
where is the estimated superimposed symbol of . If single-user decoding is adopted, each user directly decodes their own messages from for in a symbol-wise manner. For user 1 with SIC user 2’s message will be decoded from first and the corresponding codeword will be re-encoded and subtracted from the received signal.
For lattice-partition based MIMO-NOMA scheme, the superimposed signal with can be expressed by (7.8), which corresponds to the lattice partition chain described in Section 7.3.4. As a result, many nice properties of the underlying lattice carry over to the individual and the superposition coded space-time codewords.
The analytical expression of the minimum Euclidean distance is similar to that of the minimum product distance given in (7.2)-(7.29). We summarize the main result here and the proof is presented in Chapter 7.5.5.
Proposition 7.3**.**
For arbitrary power allocation, the minimum determinant is , where is obtained by replacing from (7.61) to and from (7.62) to and substituting them into (7.2)-(7.29) and setting . For the lattice-partition based scheme, the minimum determinant is , where and is given in (7.9).
We would like to emphasize that although we present the results for the complex OSTBC over complex MIMO setting, the above results are valid for real OSTBC.
We now give an example in the following to show the analytical results. We use the same setting as in Example 7.1 and employ Alamouti code. We then obtain the exact values for by exhaustive search and compute the analytical results in Proposition 7.3. The results are shown in Fig. 7.4, from which one can observe that the analytical results perfectly match with the exact values of . Moreover, the scheme based on lattice partition is again optimal in terms of minimum determinant.
7.5.5 Proof of Proposition 7.3
Consider the transmission scheme described in Section 7.5.2. According to the design criterion for OSTBC [Vucetic:2003:SC:861866, Chapter 3.5], the codeword matrix satisfies . Hence, the minimum determinant of codeword difference matrix is
[TABLE]
From this point onward, the problem of analyzing minimum determinant is reduced to that of analyzing the minimum Euclidean distance of the composite constellation . In what follows, we prove the following lemma about the exact minimum Euclidean distance, which in turn, gives us the exact minimum determinant.
Lemma 7.3**.**
Consider the constellation defined in (7.3.2) for and is equivalent to . Then the minimum Euclidean distance of is
[TABLE]
* Proof: * From Lemmas 7.1-7.2, we know that each layer has the same Euclidean distance profile and thus same minimum Euclidean distance regardless of rotation. Similar to Lemma 7.2, we have
[TABLE]
where denotes the minimum of the set of Euclidean distances between all pairs of two distinct constellation points in any two different layers.
For any pair of non-intercepting layers from , the minimum Euclidean distance between them is the length of the line segment that is orthogonal to these layers. The end points of this line segment are in fact the constellation points of a layer that is orthogonal to these layers. For any pair of intercepting layers within the composite constellation, the crossing point and two constellation points (each one is from different layer) form a right triangle. The Euclidean distance between these two constellation points is strictly larger than the Euclidean distance between the crossing point and either of those two constellation points, respectively. Thus, we conclude that . This completes the proof of (7.59).
With Lemma 7.3, we obtain by replacing the scalar with . To analyze this minimum Euclidean distance, we first denote by and the minimum Euclidean distance of constellation and , respectively, where
[TABLE]
Here, when the base lattice is equivalent to and , where is given in (7.3.2). Then, following the steps of our analysis in Section 7.4.8 completes the proof.
7.6 Simulation Results
In this section, we provide the simulation results of our proposed scheme introduced in Chapters 7.3 and 7.5 and compare them with the current state-of-the-art.
7.6.1 Single Antenna Case
In this subsection, we first provide simulation results of the lattice partitioned scheme for the single antenna case. The dimension of the underlying ideal lattice is set to . For illustrative purpose, we consider in order to make fair comparison with the scheme in [7880967]. We use the conventional NOMA (labelled Conv. NOMA) scheme which adopts square 4-QAM (not rotated) as a benchmark. The performance of strong user (user 1) and that of weak user (user 2) are measured in terms of SER versus their average SNRs and plotted in Fig. 7.5 and Fig. 7.6, respectively. In addition, the SER of the schemes in [7880967] are plotted in both figures. Note that [7880967] has two schemes corresponding to optimization for strong user and optimization for weak user, respectively. We also emphasize here that the power allocations for the conventional NOMA scheme, our schemes and the schemes in [7880967] are the same, i.e., . In all the curves in these figures, when SIC is adopted at user 1, we assume that user 2’s signals are perfectly decoded and subtracted.
It can be observed that for the proposed schemes with and 3, respectively, the full diversity orders of and 3, respectively, can be achieved for both users even without SIC. In particular, each user in our scheme for achieves comparable performance compared to the user whose constellation is optimized in [7880967]. Conversely, in [7880967], the performance at the user which is not optimized reveals no diversity gain as the conventional NOMA scheme. Furthermore, the maximum diversity order in scheme [7880967] is only 2 while our scheme can provide higher diversity order and coding gain to both users by choosing higher-dimensional ideal lattices as the base lattices. Last but not least, our proposed scheme based on lattice partition provides a systematic way to design downlink NOMA scheme that offers full diversity gain and high coding gain, while the scheme in [7880967] is based on exhaustive search.
7.6.2 Multiple Antennas Case
In this subsection, we provide the simulation results for the proposed MIMO-NOMA scheme where the base station and each user have two antennas and the underlying OSTBC is Alamouti code. We consider the case for and the channel is Rayleigh fading. The difference between and is 5 dB. Since we are unable to find a benchmark downlink MIMO-NOMA scheme with discrete inputs and with similar channel assumptions as ours, we thus compare the error performances of our lattice-partition scheme and a number of space-time block coded NOMA schemes with some power allocations. Specifically, we choose and 0.31 for three schemes (labelled as STBC-NOMA 1-3, respectively) and the corresponding minimum determinants are , and , respectively. The lattice partition scheme has a minimum determinant of . Here, the error performances are measured by average SER and worst case SER among two users versus user 1’s average SNR. These results are plotted in Fig. 7.7 and Fig. 7.8, respectively.
It can be seen that the scheme with larger minimum determinant has better error performance than that of the scheme with smaller minimum determinant. Another interesting observation is that the schemes with SIC only provide negligible gain for both average and the worst SER performance among two users. This is due to the fact that the average/worst SER performance is largely dominated by the performance of the user with much higher SER.
7.7 Summary
In this work, we have proposed a class of downlink NOMA scheme without SIC for block fading channels. In particular, we have used algebraic lattices to design modulations such that full diversity gain and large coding gain can be attained for all users at the same time. Moreover, the minimum product distance for the superimposed constellation for arbitrary power allocation has been thoroughly investigated. Within the proposed class, a family of schemes based on lattice partitions has then been identified. It has been shown via numerical result that schemes from this special family achieve the largest minimum product distances among the proposed class. An extension of the proposed scheme to the MIMO-NOMA system with OSTBC has then been introduced. The exact minimum determinant of the proposed scheme has been derived. Simulation results have been provided, which confirms our analytical results and also demonstrates that our schemes significantly outperform the current state-of-the-art.
Chapter 8 Terminated Staircase Codes For NAND Flash Memories
8.1 Introduction
In addition to addressing the problem of lattice coding designs for point-to-point systems (Chapter 4) and for downlink multiuser systems (Chapters 5-7), we also address the problem of designing powerful channel codes for storage systems such as NAND flash memories in this chapter. This is also relevant and important to ultra-reliable communications for future digital systems.
NAND flash memories are non-volatile storage devices where data can be saved and retained for a long time without continuous power supply. They have become immensely popular due to their attractive features such as higher data throughput and lower power consumption when compared to traditional hard disk drives (HDDs). However, the cost-per-bit associated with NAND flash memories is higher than that of HDDs. To reduce the bit cost, a range of techniques such as multi-level cell (MLC) [Micheloni17] and triple-level cell (TLC) have been developed to increase the storage capacity density of NAND flash memories. These storage techniques enable each memory cell to store more than 1 bit information. As such, high-capacity NAND flash memories have been widely deployed in mobile phones, digital cameras, solid state drives (SSDs) and other electronic devices [Huang11, Yu14].
It is known that a flash memory is an array of cells where data is stored as electric charges. In the event of charge leakage, read and write disturbance, aging and microprogramming [Li13], it is very likely that the stored data could be in errors or erased. In addition, the stored data are even more vulnerable to noise and cell-to-cell interference with the increase in storage density. This is due to the fact that the MLC, TLC and QLC techniques and scaling technology have led to reducing noise margin and strengthening interference from adjacent memory cells [Wang_Flash_11]. To overcome these issues and maintain the data integrity, i.e., reliable data storage and retrieval, it is necessary to deploy powerful error correction codes (ECCs) to protect the stored data in NAND flash memories. ECCs can be used for performing error recovery by detecting and correcting errors to ensure that the stored data can be read correctly.
In this chapter, we will introduce a class of staircase codes with improved decoding algorithm to achieve the required error floor performance for flash memory devices.
8.1.1 Main Contributions
Motivated by the success of unterminated staircase codes and in the quest of finding strong ECCs with hard-decision decoding for flash memories, we propose terminated staircase codes for flash memory devices in this work. Different from the conventional unterminated staircase codes in [Smith12, 6787025, Holzbaur17], we introduce a new design in the code structure and decoding algorithm to lower the error floor. The main contributions of our work are summarized as below:
- •
We purpose terminated staircase codes and design an example of rate 0.89 terminated staircase code for flash memories with page size of 16K bytes. Specifically, the codes are terminated in a way such that all the information blocks are protected by row and column encoding. The code structure not only allows our codes inherit the properties of the unterminated staircase codes but also makes the codes satisfy the length and rate requirements. In particular, we propose a novel coding structure by performing cyclic redundancy check (CRC) encoding and decoding on the whole codeword including information bits and parity bits. The CRC bits are protected by both row and column codewords in our construction.
- •
We improve the staircase code decoder. Specifically, we develop a novel CRC decoding process based on our encoding structure which allows our decoder to detect more stall patterns. A more accurate error floor estimation including the contributions of both detectable and undetectable stall patterns to the error floor, is provided based on our code structure and decoding algorithm.
- •
We propose a novel iterative bit flipping algorithm which is embedded in our decoder. Theoretical analysis on the performance for our decoder is provided. Specifically, we prove and show that our decoder has the capability to solve more stall patterns, resulting in a lower error floor than that of the conventional staircase codes. Our method can be implemented on any general staircase codes and some product codes. Our error floor analysis shows that our coding scheme can satisfy the BER requirements for flash memories by lowering the error floor below . Simulation results are provided and show that our design example can outperform the conventional staircase codes and the stand-alone BCH code.
8.2 Terminated Staircase Codes
In this section, we present the general framework of our proposed terminated staircase codes based on unterminated staircase codes [Smith12]. The code structure is depicted in Fig. 8.1.
It contains code blocks: . The component code for constructing our terminated staircase code is a linear block code whose codeword length is and the information length is . Note that the component code needs to be in a systematic form and its code rate should satisfy . As shown in Fig. 8.1, the information bits are in block for while the parity bits are in block for . The blocks in white are fixed to all-zero bit-values and are assumed to be known at the encoder-decoder pair and thus will not be stored. Under this setting, the code rate for our terminated staircase codes is:
[TABLE]
It is worth mentioning that these all-zero code blocks are used for protecting the first and the last code blocks. Although inserting zero blocks in our terminated staircase codes will lead to some code rate loss compared to direct termination of staircase codes (i.e., directly terminating the staircase codes such that code block is the last one), this approach can ensure that all the information blocks are protected by both row and column coding. However, direct termination of staircase codes will leave the last information block only protected by either row or column codewords. In this case, the error performance of the whole staircase codes would be degraded because the error rate is largely affected by the higher error rates at the code boundaries. In this work, we focus on this simple termination approach and leave the exploration of other termination mechanisms as future work. It is also noteworthy that the choice of highly depends on the requirements of the applications for our coding schemes. For the purpose of this work, we restrict all the elements in the code blocks to be binary, although the non-binary construction is analogous.
8.3 Terminated Staircase Codes for NAND Flash Memories
From now on, we will put into practice our coding scheme described in Section 8.2 with the goal of designing the terminated staircase codes for flash memories. We consider the data transmission channel to be BSC [Camp13] and only hard-decision channel output is available. Although more advanced noise models consider the asymmetric nature of the noise [7416649], we only focus on the BSC and leave the code design and optimization for the asymmetric channels in our future work.
In this work, we consider designing a 16K bytes staircase code for future flash memories with 16K bytes page size. Furthermore, we consider each page of the flash memories is protected by a single ECC. The code rate of the ECC should be at least around 0.89 so that a codeword can be stored in a single page. An example that can meet the above requirements it to choose a binary primitive narrow-sense BCH code with where denotes the number of correctable errors, as the component code. Furthermore, the number of information blocks is 2, which leads to such that the terminated staircase codes contain code block . Note that this is the only possible design of the terminated staircase codes that can satisfy the length, code rate and error floor requirements simultaneously when using BCH codes as component codes. Since the length of the component code is required to be even, the original BCH code is shortened by 1 bit, resulting in . In the information bits, 1-bit CRC with the generator polynomial is included. Thus, the component code now becomes an BCH code with 19 redundant bits including 18 BCH parity bits and 1 CRC bit. Each CRC bit is used for providing even parity check for a BCH codeword and is also protected by both row and column coding. The introduction of CRC bits is crucial for any product-like codes with small component codes [7352332] because the CRC can prevent additional error events that are caused by the component code decoder. In particular, it has been reported in [7352332] that the staircase codes without CRC have worse performance and higher error floor compared with the staircase codes with CRC. By plugging and into Eq. (8.1), our terminated staircase codes have information length bits and code rate . One may notice that the information length is not exactly 16K bytes which is 131072 bits. For illustrative purpose, we provide a design example for terminated staircase codes to demonstrate its superior performance. To have the exact information length, one can expand the size of the information matrices , while reducing the size of the all-zero block and . For other code designs such as 2K bytes, 4K bytes and 8K bytes codes, it is difficult to find a suitable BCH code such that the resultant staircase code satisfies both code rate and error floor requirements. For example, one can only pick a shortened BCH code and set to construct a 4K bytes staircase code with rate about 0.9. However, the error floor for this code occurs at due to according to (8.11) in the later analysis. Our proposed iterative bit flipping algorithm cannot provide a huge gain to allow the code to reach . Thus, the shortened BCH code with 1-bit CRC is unique for the 16K bytes staircase code such that it satisfies both rate and error floor requirements. If there is no restriction on the codeword length, it is possible for one to choose a component code with larger , and such that the constructed staircase code has better error floor performance and high code rate.
8.3.1 Encoding of Terminated Staircase Codes
Now consider the terminated staircase code in Fig. 8.1 for . The encoding is performed in a recursive manner by generating the code block for . Our encoding algorithm is modified according to our code construction and based on the encoder of original unterminated staircase codes [Smith12]. The code block of our proposed 16K bytes terminated staircase code is depicted in Fig. 8.2.
A staircase code block comprises three parts: , where are the orange portions and are the blue and red portions in Fig. 8.2. Let denote the row number in a code block. In this figure, for and , the -th row vector is a component code codeword, where is the -th row of block ; consists information bits; and is the redundant bits vector which comprises the parity bits and the CRC bit (which is highlighted in red in Fig. 4). Here, the 1-bit CRC is obtained by performing the CRC encoding on the -th row vector which excludes the CRC bit. Similarly, the CRC bit associated with the -th row is a result of applying CRC encoding on the CRC-excluded codeword vector as shown in Fig. 8.2. The detailed encoding steps for our terminated staircase codes are summarized in Algorithm 8.1 in the following.
Remark 8.1**.**
When encoding proceeds to block , the all-zero information block is encoded into multiple rows of all-zero codewords. However, in practice the all-zero codeword will not be stored and thus the encoding process does not include the encoding of all-zero information block. It is also note worthy that the code block with only parity bits, e.g., , is coded with all-zero information. The introduction of the extra parity bit matrix in block can yield to a better error performance than that of the terminated staircase codes without [7938011, Sec. III]. This is because any errors occur in the parity block will not be correctable if there are no column codewords to protect the parity block. That said, the additional parity block only results in negligible code rate loss when is high.
We also stress here that the way of using CRC in our design is different from that of conventional staircase codes designs. For example, in [Holzbaur17], the BCH component code is obtained by multiplying the generator polynomial of the shortened BCH codes to . Although their component codes provide the same error correction capability and error detection probability as that in our design with BCH component codes, their code generation methods can only be applied to cyclic code families. In contrast, our methods of using CRC can be applied to any general component codes, providing additional error detection mechanism. As an alternative way for having an additional error detection capability, one may suggest using an extended code [hager2017approaching, Sec. II-B] as the component codeword. However, for singly-extended codes, the additional parity bits are only encoded by column codewords. As a result, when these bits are in error, the errors can only be corrected by column decoding but without row decoding.
8.3.2 Decoding of Terminated Staircase Codes
The decoding of our terminated staircase codes is accomplished by using an iterative hard-decision decoder. We consider the terminated staircase code shown in Fig. 8.1 except the all-zero blocks to be the received codeword where all the received bits are corrupted by a BSC. During the iterative hard-decision decoding, bounded-distance decoding (BDD) [hager2017approaching, Sec. II-C] is applied to each row of block for . An example of BDD can be the Berlekamp-Massey decoder [Berlekamp:2015:ACT:2834146]. After the BDD decoding, the CRC decoding is performed on all the successfully decoded codewords. We let be the number of iterations and be the maximum number of iterations allowed. The parity-check matrix for the component code is denoted by . The decoding steps for our terminated staircase codes are summarized in Algorithm 8.2 in the following.
8.4 Error Floor Analysis
In this section, we first introduce the error patterns which are the main contributor of the error floor of staircase codes. We then present a method to evaluate the error floor performance for our proposed codes.
8.4.1 Stall Patterns
For staircase codes, the dominating contributions to the error floor are the error patterns that cannot be corrected by iterative decoding. These error patterns are referred to as stall patterns [Smith12].
Definition 8.1**.**
A stall pattern is a set of error positions in a stable state such that no updates are performed by the decoder. The stall pattern that occurs in a staircase code with -error-correcting component code, involves at least erroneous rows and columns, each of which has at least bits are in error.
All the stall patterns are assumed to be not correctable if we use the conventional staircase code decoder [Smith12]. It should be noted that even though some error events other than stall patterns can lead to failure of the iterative hard-decision decoder, these kinds of events occur less likely when the crossover probability of the BSC is low. Thus we do not count them as the cause of the error floor. When analyzing the error floor, we assume that our decoder can resolve all surrounding errors with only a stall pattern remains unsolved. Therefore, the BER of the error floor can be regarded as the probability that the stall patterns appear in the staircase code blocks. In [Smith12], a union bound technique was proposed to bound the probability of these stall patterns in order to estimate the error floor of the staircase codes. This technique has been widely accepted and adopted in [hager2017approaching, 7905932, Holzbaur17]. In what follows, we provide a modified error floor analysis for our 16K bytes terminated staircase codes based on this technique.
In our analysis, we consider that the stall patterns can span one block such as block or ; or span two blocks such as blocks and . Other blocks such as and are all-zero and are known at both encoder and decoder. For block , it is very unlikely that a stall pattern can occur in block . Even though a stall pattern may span , the errors in parity parts does not contribute to error rates of information parts. Thus, this kind of error event is not considered in the analysis.
8.4.2 General Stall Pattern Analysis
First, we denote the number of erroneous rows by and the number of erroneous columns by . The number of errors in the stall pattern is denoted by . According to Definition 8.1, we know that and . The number of bit errors in this stall pattern should satisfy
[TABLE]
The number of combinations of rows and columns that occur in is
[TABLE]
where is the number of erroneous columns in block . Note that this combination includes the case where the stall pattern occurs in a single block or because of the second equality in (8.3). This is different from the analysis for unterminated staircase codes [Smith12] where a stall pattern spanning in is not considered because the error probability is calculated on a single code block, e.g., . When the stall pattern spans , the multiplicity becomes
[TABLE]
Note that here we do not need to consider the case that a stall pattern spans a single block or , i.e., , because the case of spanning in has been covered in Eq. (8.3) and there is no contribution to error rate when the whole stall pattern is in .
Among these errors, we consider that bits are received in error. The other bits of errors are caused by incorrect decoding from the component code decoder. We let denote the BSC crossover probability and let represent the probability of incorrect decoding. It has been reported in [Smith12] that is independent of . Thus, the probability that the stall pattern has bit errors is
[TABLE]
We let represent the number of ways to distribute errors in an stall pattern. As reported in [Holzbaur17], is overestimated in [Smith12] because it includes the cases that the number of errors in one or more than one erroneous rows/columns is less than . According to [Holzbaur17], the problem of finding is equivalent to finding the number of binary matrices with size and total weight . Most importantly, the minimum weight for each row and each column of these matrices should be . To solve this combinatorial problem, we have used a reduced precise number formula for counting the number of binary matrices given in [perez2002reduced], which has a lower computational complexity than that of the method introduced in [Holzbaur17]. The formula takes a vector of row weights and a vector of column weights , where outputs the weight and , represent the -th erroneous row and the -th erroneous column of the stall pattern, respectively. The formula then returns the number of unique binary matrices satisfying the row and column weight requirements. For each column and row weight, the following requirements have to be met:
[TABLE]
where follows that the maximum row/column weight cannot exceed the size of a stall pattern and follows from Definition 8.1. Since each error bit locates in one of the erroneous rows and columns, thus:
[TABLE]
The number of stall patterns with is
[TABLE]
where is the set of all pairs of and satisfying (8.6)-(8.8). However, it has been pointed out in [miller2013, Section 3] that is unchanged under the permutation of the entries of and . Thus, to avoid the time-consuming calculation for over all possible pairs of and , we can have the following
[TABLE]
where is a subset of ; is the number of rows with weight ; and is the number of columns with weight . The multipliers and are the number of permutations of entries inside a row vector and a column vector, respectively.
Combining (8.3)-(8.5) and (8.10), the contribution of the stall patterns to the BER and PER error floors can be calculated as
[TABLE]
where is the number of information bits of our terminated staircase codes. Here we consider the worst case such that all the error bits of a stall pattern are inside information blocks.
Now we need to evaluate the erroneous decoding probability before we can calculate the BER and PER for the error floor. As pointed out in both [Smith12] and [Holzbaur17], can only be estimated via simulations and it is related to . Here, we use a different approach to estimate . We run the simulation for our terminated staircase codes for a low crossover probability and record the for the minimal stall patterns with by using the number of decoding failures caused by the minimal stall patterns divided by the total number of transmissions. Note that in this case. Then can be evaluated using Eq. (8.12).
8.5 An Improved Method To Lower The Error Floor
In this section, we present and analyze our proposed method for handling stall patterns. We will show that our method can lead to a considerably error floor reduction. We assume that all the errors other than the errors in a stall pattern, are solved by our iterative hard-decision decoder in Algorithm 8.2.
First, we have to define two types of stall patterns which will be useful for our subsequent analysis.
Definition 8.2**.**
A stall pattern is detectable if all the erroneous rows and columns associated with the stall patterns can be detected by using the parity-check matrix of the component code or CRC.
Definition 8.3**.**
A stall pattern is undetectable if either the erroneous rows or columns or both associated with the stall patterns cannot be detected by using either the parity-check matrix of the component code or CRC.
Stall pattern detection is crucial for correcting stall patterns. The minimal stall pattern is an example of detectable stall patterns for a staircase code with double-error-correcting component codes. Since the component code has the minimum distance of 6, any stall pattern where each erroneous row/column has less than or equal to 5 errors, can always be detected. For example, a stall pattern is always detectable. However, when the number of row/column errors are larger than 5, i.e., , it may be undetectable. Furthermore, due to miscorrection, e.g., the BDD decoder outputs an incorrect codeword, some detectable stall patterns may become undetectable after some iterations. In the error floor estimation, we treat these kinds of stall patterns as undetectable stall patterns. Note that when analyzing the occurrence probability of undetectable stall patterns, the number of of rows and columns calculated in Section 8.4.2 are replaced by the number of codewords with weight and , respectively.
8.5.1 Iterative Bit Flipping Algorithm (IBFA)
We first review the low complexity bit-flip operation which was originally proposed in [Holzbaur17] to solve some of the stall patterns. After a stall pattern is detected and all the location information of erroneous rows and columns is available, the bit-flip operation flips all the bits in the intersections of the erroneous rows and columns associated with the stall pattern. For a staircase code with an BCH codes as component codes, the bit-flip operation in [Holzbaur17] can successfully solve the detectable stall pattern up to . For any stall pattern with larger values, the algorithm flips one erroneous column. However, this approach cannot guarantee to be successful all the time.
Based on the bit-flip operation in [Holzbaur17], we propose a new post processing technique called iterative bit flipping algorithm to improve the performance by solving more stall patterns. Later in this section we will prove that our approach can solve more stall patterns than the existing design in [Holzbaur17], leading to a significant error floor reduction.
Our iterative bit flipping operation is automatically triggered after a predefined number of decoding iterations have been completed. The proposed algorithm is embedded in Step 7 of Algorithm 8.2 in Section 8.3.2. For simplicity, we let represent the indices of erroneous rows/columns. The steps for our proposed iterative bit flipping algorithm are summarized in Algorithm 8.3 in the following.
Remark 8.2**.**
In [Holzbaur17], the bit-flip algorithm always flips an erroneous row when and for . Here, we consider flipping the erroneous column or row by comparing to . For example, if , there is a higher probability that the number of errors in one column is larger than the number of errors in one row. In this case, flipping one erroneous column has a higher probability to solve more errors than flipping one erroneous row. This will become clearer in Section 8.5.2. In Step 2 of Algorithm 8.3, the decoder does not correct any stall patterns with for . This is because the stall patterns with this size are less likely to appear and may not be solved successfully. In addition, when the crossover probability of the BSC is high, there exist non-stall-pattern error events with very large and applying the algorithm on these errors could introduce more errors. In Step 3, if the dimension of the stall pattern is not reduced after row/column flipping, it means the row/column flipping is not effective. We thus restore all code blocks in Step 3 and then perform the all-flipping operation. This approach has been proved to solve more stall patterns in Section 8.5.2. In addition, the restoration process can guarantee no extra errors are introduced when all decoding attempts fail. However, the bit-flip algorithm in [Holzbaur17] only repeat row flipping or all flipping twice, which may not be effective for stall patterns with larger size and larger value of .
Example 8.1**.**
Here we provide a simple example to illustrate how our decoder works. Assume that the underlying component code is with . Now consider a stall pattern shown in Fig. 8.3.
Our decoder flips the first erroneous row according to Step 3 of Algorithm 8.3. Then, three erroneous columns have weights reduced to 3 and the other three columns have weights increased to 4 as shown in Fig. 8.4.
None of the errors can be decoded by the BDD decoder since each erroneous row and column has weight larger than . As the size of this stall pattern is not reduced after row flipping, i.e., , the decoder restores the code block such that the stall pattern becomes the one in Fig. 8.3 and then applies all-flipping operation in Step 4 of Algorithm 8.3. The resultant stall pattern is shown in Fig. 8.5.
It can be seen that easily seen that all the errors in the first three erroneous columns (from left to right) can be corrected by the BDD decoder now. Then the stall pattern in Fig. 8.5 becomes a stall pattern and can be solved by all-flipping operation in Step 4 of Algorithm 8.3.
If using the bit-flip algorithm in [Holzbaur17] to decode this stall pattern, only one erroneous row will be flipped twice and the stall pattern still cannot be solved.
8.5.2 Analysis of the Proposed Iterative Bit Flipping Algorithm
In this subsection, we analyze our proposed iterative bit flipping algorithm and prove that our decoder is able to solve more stall patterns than the conventional staircase codes. There results are useful for estimating the error floor later on. First, the following lemma is useful.
Lemma 8.1**.**
(Theorem 1 in [Holzbaur17]) Consider a terminated staircase code whose component code can correct errors. The staircase code decoder using all-flipping operation can correct all the errors for any detectable stall pattern such that .
* Proof: * See Appendix E.1.
The above stall patterns only need a single all-flipping operation to correct. For any stall patterns with , both row/column flipping and all-flipping operations are required. Based on Algorithm 8.3, we present the main theorem of this work as follows.
Theorem 8.1**.**
*Consider a terminated staircase code whose component code can correct errors. Our decoder with the proposed iterative bit flipping algorithm can always correct the following detectable111Here we assume that the stall patterns remain detectable in each iteration of IBFA. The undetectable stall patterns will be treated separately in the analysis in Section 8.5.3. stall patterns:
-
stall patterns for any when ;
-
stall patterns for any when ;
-
stall patterns when ;
-
stall patterns for any when ;
-
stall patterns when .
Note that the value of and can be swapped.*
* Proof: * See Appendix E.2.1 for the proof of Theorem 8.1-1.
See Appendix E.2.4 for the proof of Theorem 8.1-2.
See Appendix E.2.5 for the proof of Theorem 8.1-3.
See Appendix E.2.9 for the proof of Theorem 8.1-4.
See Appendix E.2.10 for the proof of Theorem 8.1-5.
Remark 8.3**.**
We have rigorously proved that not only all the stall patterns in [Holzbaur17, Table 1] for , but also other some larger size stall patterns can always be successfully solved by using Algorithm 8.3. For the detectable stall patterns that are not included in the above theorems, our decoder can still solve them with some probability. The reason of decoding failure is mainly due to the fact that the errors in each erroneous row and column remain larger than even after row/column flipping and all-flipping operations. This can happen when the size of the stall pattern is large and the number of errors inside the stall pattern is relatively small.
We point out here that the maximum number of bit-flipping required for solving stall patterns is 6. Note that among those solvable stall patterns in Theorem 8.1, the stall patterns with the largest size are with . It will take up to 5 bit-flipping iterations to reduce the stall patterns with to stall patterns with . This is because our iterative bit-flipping algorithm can solve at least one erroneous row or one erroneous column in one iteration. Otherwise, if the size of the stall pattern is not reduced after one iteration of Algorithm 8.3, the decoder stops the iteration and outputs all the code blocks. And only one iteration of bit-flipping is required for solving the stall pattern with according to Lemma 8.1. That being said, 6 iterations only occur in the worst case while in practice the required number of iterations is smaller than that. For the bit-flip algorithm in [Holzbaur17], two iterations are required.
8.5.3 An Improved Error Floor Estimation
In this subsection, we estimate the error floor for our design example of the terminated staircase code with double-error-correcting BCH component code introduced in Section 8.2.
When estimating the error floor, we treat the detectable and undetectable stall patterns separately. Undetectable stall patterns have row/column errors larger than 6. For example, a stall pattern can be undetectable. If this stall pattern has fewer errors, e.g., , it can be successfully detected by parity-check. However, if the column errors are undetectable, this stall pattern cannot be solved by our Algorithm 8.3. This is because the erroneous columns whose weights are increased after the row flipping, will be incorrectly decoded to wrong codewords. In such a case, the column becomes undetectable after Step 3 of Algorithm 8.3. Therefore, we count this kind of stall pattern as undetectable stall patterns even though it is detectable before performing row/column flipping. As such, we calculate the contribution to the error floor from detectable and undetectable stall patterns separately.
We then adopt the analytical method shown in Section 8.4.2 to calculate the error floor for our proposed codes. We first run the simulation for our terminated staircase codes with Algorithm 8.2 (exclude Algorithm 8.3) for a various of crossover probability to collect the number of decoding failures caused by the minimal stall pattern and the total number of transmissions. Given the aforementioned information, we use Eq. (8.12) to obtain the incorrect decoding probability . According to Theorem 8.1, the detectable stall patterns that may not be solvable by Algorithm 8.3 include but not limited to , . The dominant undetectable stall pattern with the smallest size is . For the undetectable stall pattern, the number of errors satisfies . This is because if , the stall pattern can be detected in Step 2 of Algorithm 8.3 and then all the erroneous columns can be corrected after the all-flipping operations. Therefore, the next dominant undetectable stall pattern is with , . It should be noticed that when calculating the multiplicity term in Eq. (8.3) and Eq. (8.4) for undetected stall patterns, we replace the multiplier with the number of valid BCH codeword with weight . This number can be well approximated as by using Peterson Estimation [Micheloni:2012:ISS:2412028]. We then use Eq. (8.11) and Eq. (8.12) to compute the BER and PER contributions of the above dominant stall patterns. An example for the contribution to the error floor for the dominant stall patterns under the setting of and is shown in Table 8.1. We pessimistically assume that all of these stall patterns are uncorrectable. The stall patterns which have negligible contribution to the error floor are not taken into account.
When calculating for these stall patterns, we have to determine the set according to Eq. (8.10). It should be noticed that not all weight vector pairs in the set can produce an unsolvable stall patterns. Consider the stall pattern as an example. If the weight vector pairs are and , then it can always be corrected by Algorithm 8.3. This is because the erroneous row and column with weight 5 will become weight 2 after the all-flipping operation in Step 4 of Algorithm 8.3. This will result in a stall pattern with which can be successfully solved according to Theorem 8.1-1. Any permutations on this weight vector pairs will have the same result. Similarly, for stall pattern, any row weight or column with weight larger than or equal to 5 will be corrected after Step 4 of Algorithm 8.3, resulting in a stall pattern with in the worst case which can be successfully solved according to Theorem 8.1-2. For the stall pattern, any row with weight larger than or equal to 6 will be corrected after Step 4 of Algorithm 8.3. Thus it then becomes a stall pattern with which can be solved based on Theorem 8.1-4. Therefore, we only consider the vector pairs that are associated with uncorrectable stall patterns. In this way, the error floor contribution of stall patterns can be calculated more accurately as the number of uncorrectable stall patterns is not overestimated. These vector pairs are listed in the second column of Table 8.1. It can be seen that the smallest undetectable stall pattern has negligible contribution to the error floor. All other stall patterns has the BER contribution lower than . We then estimate the error floor via
[TABLE]
This gives a BER of and a PER of .
8.6 Complexity Analysis
In this section, we briefly discuss the encoding, decoding complexity and latency of the proposed code compared to the conventional staircase codes and other codes suitable for NAND flash memories.
8.6.1 Encoder Complexity
First, we investigate the encoding complexity, which includes implementation complexity, computational complexity and encoding latency of the proposed codes. Regarding the implementation complexity, our encoder requires a memory of bits to store a code block as the encoded block will be used in the encoding of . It also requires a component code encoder unit and a CRC encoder. Since the CRC is 1 bit, the CRC encoding can be performed by an adder. Compared with the conventional staircase codes [Holzbaur17] whose component codes are of the same size222We say both component codes are of the same size rather than the same code due to different ways of using CRC. The difference is explained in Remark 8.1. as ours, the implementation complexity is the same because both component code encoding and CRC encoding are required. Regarding the computational complexity, both codes require the same number of component code encoding and CRC encoding for one code block. Turning to the encoding latency, we denote the time required for one time component code encoding and CRC encoding by and , respectively. To produce one code block, the required time for our staircase codes is . For conventional staircase codes, the required time is between and . When parallel encoding is available, the conventional staircase code encoder can encode at most component codewords at the same time while our encoder still has to encode each component codeword one after one. This is because the encoded CRC bit associated with the -th row will be used in the encoding of the -th row in our design. Therefore, our terminated staircase codes have a higher encoding latency than conventional staircase codes in general. That being said, during the writing access, the encoder can output a single code block once the encoding process for this block is finished. This is more efficient than traditional linear block code encoding, e.g., encoding of BCH codes, where the encoder has to output the whole codeword only when all the information bits are encoded.
8.6.2 Decoder Complexity
We compare the decoding complexity, latency and the implementation complexity of the proposed code to those of conventional staircase codes.
Similar to the architecture of product code decoder in [Smith12], our decoder consists of a data storage unit for the product code array, a syndrome storage unit, and a BDD decoder unit and a CRC decoder. Unlike our encoder which has to encode information recursively, our decoder can decode multiple component codes simultaneously when parallel decoding is available. Thus, the computational complexity and the decoding latency of our codes are the same as that of the conventional staircase codes. However, with the proposed iterative bit flipping algorithm, additional storage is required to store the location of erroneous rows and columns associated with a stall pattern. The index of a row/column can be specified using bits. As a result, the extra storage for all the location information is bits. The factor “2” here is due to the storage for indices obtained from both parity-check and CRC check. Although in Step 3 of Algorithm 8.3 the code blocks are stored, the storage resource can be taken from that in Step 4 of Algorithm 8.2 while updating the code blocks. For the internal data flow, i.e., the rate of routing/storing messages, our terminated staircase decoder shown in Algorithm 8.2 has a similar data flow as that of the decoder in [Smith12]. This data flow is much lower than that of soft message-passing decoder [Smith12].
8.7 Simulation Results
8.7.1 Error Probability
In this subsection, we present the simulation results for our proposed terminated staircase codes. First, to illustrate the effectiveness of introducing our iterative bit flipping algorithm, we evaluate the performance for our codes with and without Algorithm 8.3. The performance is measured in terms of BER and PER versus the crossover probability of the BSC and is shown in Fig. 8.6. The error floor calculated in Section 8.5.3 is plotted in Fig. 8.6 and its curves are labelled with “w/ IBFA”. In the mean time, we simulate the error floor performance for our code without the iterative bit flipping algorithm whose curves are labelled with “w/o IBFA” in the figure. Moreover, the error probability of the staircase code with direct termination (i.e., the last code block is ) is also plotted in Fig. 8.6. To carry out performance comparisons, we plot the error performance of the conventional staircase codes, including the unterminated staircase codes with bit-flip operation [Holzbaur17] and the original staircase codes (i.e., without solving any stall patterns) [Smith12], in Fig. 8.6. Note that the error floor performance of the staircase codes with bit-flip [Holzbaur17] is estimated by using the method proposed in [Holzbaur17, Sec. 4] as the simulation therein only shows the expected error floor region. For fair comparison, we only consider that the conventional staircase codes and our proposed codes use the component codes which are of the same rate and size. We also plot the error performance for a stand-alone BCH code with the same information length and same rate. Note that the performance of this long BCH code is obtained by calculating the error probability analytically [Cho14, Sec. V-B].
From Fig. 8.6, it can be observed that our proposed 16K bytes terminated staircase code significantly outperforms the stand-alone BCH code with the same length and code rate. In particular, our code has a BER which is about six orders of magnitude lower than that of the BCH code under the same crossover probability. As more stall patterns are solved by our proposed decoder, our proposed code reaches an error floor about for BER and for PER which is more than one order of magnitude lower than the improved codes in [Holzbaur17]. Without the iterative bit flipping algorithm, our code has almost the same error floor performance as the original staircase codes [Smith12]. Thus, our staircase code with the proposed algorithm is superior to the original staircase code by reaching an error floor that is more than six orders of magnitude lower. This huge performance gain is achieved with slightly increased decoding complexity. For the staircase code with direct termination, its performance is severely degraded since it requires to allow the BER reaching below . We also compare our code to the SC-LDPC code in [7553579] with and with rate 0.8735 under the BSC. From [7553579, Fig. 3], it can be seen that to reach the BER below , the crossover probability needs to be larger than while for our code is less than . Hence, our code has better decoding performance than the SC-LDPC codes in [7553579] under the BSC. In addition, our code shows no error floor for BER lower than while the SC-LDPC code only shows no error floor for BER above .
We point out here that even using the same-size component codes, the unterminated staircase codes and our terminated staircase codes have different code rates. This is because our termination method introduces a rate loss in our codes. In the above example, our terminated staircase code has a code rate of 0.8899 while the unterminated staircase code whose component code is of the same size as ours, has a code rate of 0.9255 [Holzbaur17] (which is the same as that of the directly terminated staircase code). However, we emphasize that as one of the main contributions of this work is to lower the error floor of terminated staircase codes and therefore the comparisons in the error floor regime are meaningful. It might be possible to use efficient termination mechanisms to further reduce the rate loss. However, to the best of our knowledge, other termination techniques for staircase codes have not been reported in the literature yet. Hence, we only focus on this simple termination approach which is sufficient for the purpose of our work and leave the exploration of other termination mechanisms as future work.
8.7.2 Computational Complexity
The above simulations for our terminated staircase codes are performed under . We now plot the error performance for our code with different number of iterations, i.e., , in Fig. 8.7.
It can be observed that when , the performance loss is negligible. Note that in this work, we set in order to attain the best possible performance. In practice, we can set while the performance loss is still small according to Fig. 8.7. To further investigate the complexity and throughput of our decoder, we plot the average number of iterations versus the BSC crossover probability and the corresponding iteration distribution in Fig. 8.8 and Fig. 8.9, respectively.
Here, the number of iterations in Fig. 8.9 is the sum of the number of iterations of staircase code decoding and the number of iterations for bit-flipping. In addition, the range of the crossover probability corresponds to the BER from to . It can be observed that in the low BER region, the average number of total iterations converges to 4. Since the iterative bit flipping algorithm only starts working in the low BER regime, the extra iterations introduced by our iterative bit flipping algorithm is negligible because the occurrence probability of stall patterns is very small. As a result, the throughput decrease due to using the iterative bit flipping algorithm can be deemed negligible. Compared with the decoder in [Holzbaur17] when its maximum number of iterations is the same as ours, the average number of iterations is also the same as ours. This is because in the high BER regime, both decoders do not correct stall patterns while in the low BER regime the extra iteration introduced by our iterative bit flipping algorithm is negligible. Compared with other product code schemes such as the 8K bytes BCH product code in [Cho14] where the maximum number of iterations could be as large as 1024 [Cho14, Figs. 3-4], our decoder requires much less iterations to lower the error floor performance.
8.8 Summary
In this work, we proposed a class of staircase codes and designed an example of such code for NAND flash memories with 16K bytes page size. Most notably, we developed a new coding structure by performing CRC encoding and decoding to each component codeword, providing additional error detection capabilities. The CRC bits are protected by both row and column codewords. We then proposed a novel iterative bit flipping algorithm to handle stall patterns. Most compellingly, we proved and showed that the decoder with our proposed algorithm can solve more stall patterns, resulting in a lower error floor than that of the conventional staircase codes. A more accurate error floor estimation for our codes was presented. Theoretical analysis demonstrates that our proposed codes can satisfy the BER and code rate requirements for flash memory devices. Furthermore, simulation results show that our proposed codes can significantly outperform the stand-alone BCH codes and conventional staircase codes.
Chapter 9 Thesis Conclusions
In this thesis, the problems of point-to-point and downlink multiuser communications have been studied and addressed. Specifically, we have proposed practical lattice coding schemes to approach the capacity of the AWGN channel and the capacity of the downlink multiuser channel. In addition, we also have introduced powerful error-correction codes and a new decoding algorithm for digital systems that requires ultra-high reliability, such as optical fibre communications and data storage. We conclude this thesis in the following by summarizing our main contributions.
In Chapter 1, we have presented an overview of the future 5G communication networks followed by our motivations of this thesis. Previous works related to coding designs and downlink NOMA have been reviewed and discussed. Thesis organization and the main contributions of each work conducted in this thesis have also been provided.
In Chapter 2, we have introduced some fundamental knowledge of lattices that are useful in the later chapters. This includes many important definitions of lattices, the figures of merit and some well-known construction methods of lattices.
In Chapter 3, we have provided the necessary background knowledge on wireless communications and channel coding. In particular, we have introduced different types of wireless channel models and coding schemes that are related to our work.
In Chapter 4, we have given the detailed description of our first work: designing practical lattice codes to approach the unconstrained Shannon limit. By introducing a novel encoding structure for our multi-dimensional lattice codes, we have proved that the proposed lattice codes exhibit two properties: permutation-invariance and symmetry. These properties allow us to use one-dimensional EXIT charts to design and optimize the degree distribution of the underlying lattice codes. We have provided simulation results to show that the designed codes can approach the capacity of the AWGN channel within 0.46 dB.
In Chapter 5, we have described our proposed lattice-partition framework of -user downlink NOMA without SIC. The proposed framework has many desirable properties such as explicit and systematic design, using discrete and finite inputs, and has lower complexity than conventional NOMA with SIC receivers. The individual achievable rate of the proposed framework based on any -dimensional lattice has been analyzed the its gap to the multiuser capacity region has been derived. It has been proved that the upper bound of the gap is constant and universal to all SNR and . The gap can be further reduced by using multi-dimensional lattices that have higher NSM. Our simulation results have verified the correctness of our analysis and the effectiveness of the proposed framework.
In Chapter 6, we have presented a new lattice-partition scheme for -user downlink NOMA without SIC for slow fading channels without transmit CSI. In this work, the modulation and coding scheme have been carefully designed based on the statistical CSI. Most importantly, we have analyzed the individual outage rate of the proposed scheme based on any -dimensional lattice and have derived its gap to the multiuser outage capacity. The gap can be upper bounded by a constant independent of the channel gain and the number of users. Our simulation results presented in this chapter have shown that the scheme can attain the near-capacity performance even with single-user decoding for each receiver.
In Chapter 7, a class of NOMA schemes without SIC has been presented. Different from any of our schemes in the previous chapters, we aim to achieve full diversity gain for each downlink user in the presence of block fading by carefully designing the signal constellation for each user. Within the proposed class, a special family of NOMA schemes based on lattice partitions of the underlying ideal lattices has been identified. The analysis in this chapter have shown that the lattice-partition schemes achieve the largest minimum product distances of the superimposed constellations, which guarantees full diversity and better error performance. Moreover, our designs have been extended to the multi-antenna case where similar analysis the results are also presented.
In Chapter 8, we have presented an additional work to design a class of staircase codes with improved decoding performance for storage systems. Our new designs allow the decoder to detect and correct more stall patterns which may not be correctable in the previous staircase code designs. An improved staircase code decoder that iteratively detects and corrects the stall patterns have been proposed and presented. We have proved and shown that the new decoder can solve specific types of stall patterns, leading to lower error floor. Further to this, a more accurate method used for estimating the error floor performance of the proposed staircase code by using the proposed decoder has been introduced. Numerical results have confirmed the effectiveness of our design.
Appendix A Proof of Theories of Chapter 4
A.1 Proof of Proposition 4.1
We divide our encoder described in Section 4.2.2 into two parts: the first part is from the input of the repeater to the output of the interleaver; the second part is from the input of the combiner to the output of the accumulator. To prove that our codes are linear codes, we only need to show that the second part is a linear system. This is because the first part is already linear.
A linear code has the linear property such that the linear combination of two codewords is still a valid codeword. Now suppose we have two different codewords and with length . The linear combination of these two codewords is
[TABLE]
where is the modulo lattice addition. Now, we focus on the -th component of the codeword for . The encoding function for the -th component of the codeword is
[TABLE]
where and represent the first and last interleaved symbols to the -th combiner; is the -th output of the time-varying accumulator. Note that the random-coset is removed before iterative decoding, thus it is not considered as part of the codebook information. We can then rewrite the above equation as
[TABLE]
where and is the constant associated with . Note that the term can be extracted by using the associative law on the addition of Hurwitz integers.
Now for the -th codeword component in and , we have
[TABLE]
[TABLE]
Here is deterministic for a particular codeword position. The linear combination in Eq. (A.1) becomes Eq. (A.1) for .
[TABLE]
The deterministic part can contribute to non-linearity when . Therefore, when we let , our codes are linear.
A.2 Proof of Theorem 4.1
Consider the -th symbol. Let be the channel input. Let be the -th received signal with the input-output relationship given by
[TABLE]
where is the noise of the AWGN channel; follows Eq. (4.13); is the -th random variable of intended codeword before adding the random-coset and is the -th random variable of the random-coset.
To prove that adding the random-coset can produce the output-symmetric effect, we must have
[TABLE]
where outputs the maximum-likelihood decision region; and . In other words, the decoding error probability is the same for any transmitted codeword.
For the left term in Eq. (A.67), we have
[TABLE]
Since is independent of and is uniformly distributed over , we then have
[TABLE]
Similarly, for a different realisation of and , we have
[TABLE]
Since the ranges of and are , therefore we can obtain that
[TABLE]
Plugging Eq. (A.71) into Eq. (A.2) and Eq. (A.2), respectively, we obtain Eq. (A.67).
A.3 Proof of Permutation-Invariance
A.3.1 Proof of Theorem 4.2
First, we define a probability-vector random variable and let where is a random variable and uniformly chosen from . For the -th random variable in , we denote a probability event by
[TABLE]
Then for the -th random variable in , we have
[TABLE]
because is independent of .
Similarly, for the -th random variable in , where , we can obtain that:
[TABLE]
We know is a random variable and uniformly chosen from . Thus we have:
[TABLE]
Therefore, the distribution of any two random variables in is the same. If we let for any fixed , we obtain that:
[TABLE]
It can be seen that every random variable in is identically distributed. Therefore, we can conclude that is identically distributed with so is permutation-invariant.
A.3.2 Proof of Lemma 4.1
For the -th LLR random variable in , we denote a probability event by
[TABLE]
where is a random event. From (4.36), we know that , thus we can obtain that
[TABLE]
where denotes the joint pdf of and .
Similarly, for the -th LLR random variable in where , we have
[TABLE]
We know and have the same distribution as because is permutation-invariant. Thus, the joint distribution of and is the same as that of and . As a result, we can obtain that:
[TABLE]
This indicates that and have the same distribution for any . Therefore, is permutation-invariant.
Appendix B Proof of Theories of Chapter 5
B.1 Two useful lemmas
B.1.1 An extension of Theorem in [ozarow90]
In this appendix, we provide a lemma, which is key to our analysis of the gap to the capacity region. This lemma is an extension of the main Theorem in [ozarow90] (also Proposition 1 in [dytso15]) to the multi-dimensional setting.
Let be an -dimensional constellation carved from a shifted version of an -dimensional lattice and be the input random variable uniformly distributed over . We assume . Let be the received random variable with the input-output relationship given by
[TABLE]
where is the noise vector which is zero-mean and has independent of . We have the following lemma.
Lemma B.1**.**
The mutual information between and is lower-bounded as follows,
[TABLE]
* Proof: * Let with uniformly distributed over . Clearly, form a Markov chain in the following order
[TABLE]
Therefore, from the data processing inequality [Cover:2006:EIT:1146355], we have
[TABLE]
Note that
[TABLE]
for any valid distribution . We pick
[TABLE]
where and are the th elements of and , respectively. Plugging this choice into (B.1.1) gives
[TABLE]
Thus,
[TABLE]
Now, choosing , we have
[TABLE]
Hence, (B.8) becomes
[TABLE]
We choose to obtain
[TABLE]
Plugging (B.11) into (B.1.1) results in
[TABLE]
This completes the proof.
B.1.2 A corollary of Proposition 2 in [Forney89]
We now provide an upper bound on the required power of the proposed lattice constellation.
Lemma B.2**.**
Let be a discrete random variable uniformly distributed over the coset representatives of the lattice partition with any positive integer . There exists a dither such that has
[TABLE]
* Proof: * Let be a random dither that is uniformly distributed over . From [1337105, Eq. (23)], we have
[TABLE]
which says that the input power is equal to the second moment of the coarse lattice when averaged over the dither . Thus, there exists a fixed dither vector such that
[TABLE]
Combining (B.1.2) and (B.15) completes the proof for (B.13).
B.2 Proof of the 2-user case
B.2.1 Proof of user 1’s gap
We now bound the overall scaling factors for user 1. Recall that is to ensure . The scaling factor for user 1 can be lower bounded by:
[TABLE]
where in (b) we have used .
The gap between the user 1’s achievable rate and the multiuser capacity can be further bounded by plugging (B.2.1) into (5.25).
[TABLE]
B.2.2 Proof of user 2’s gap
Following (5.25), we again obtain an upper bound of the gap of user 2’s achievable rate to the multiuser capacity by using the invariant property of as
[TABLE]
bits per real dimension.
We then lower bound the scaling factor for user 2 as follows:
[TABLE]
Plugging (B.2.2) into (B.18), we have
[TABLE]
B.3 Proof of the K-user case
Let be random variables uniformly over , respectively, and let be the input random variable. For analyzing the first (strongest) user, we treat users as a super-user. One can thus obtain the same lower bound for the achievable rate as shown in (5.4.1) and the same capacity upper bound in (5.22).
For user , we treat users as a super-user whose constellation is and treat users as another super-user whose constellation is . Similar to the two-user case, and are corresponding to and , respectively. Note that is the constellation for users whose signals have less power than user ’s signal and thus may not be correctly decoded at the user . Following (5.3.3) and (5.3.3), we further decompose into and as
[TABLE]
It is worth mentioning that corresponds to the part that is under the noise level as predicted by the linear deterministic model and cannot be decoded at the user .
The channel output for user is then given by:
[TABLE]
where in (c) we have used corresponding to (B.21). Here and are randomly and uniformly distributed over and , respectively. From user ’s point of view, the strong super-user’s constellation can be decomposed into two parts such that can be successfully received while is considered under noise level.
We can now bound the achievable rate for user as follows,
[TABLE]
where (a) is due to a bijective mapping between and , and (b) follows the fact that is independent of , and . To further bound the first term in (B.3), we note that effective noise is . We thus scale by
[TABLE]
to form . The equivalent communication channel then becomes where
[TABLE]
and with . One can then again apply the lower bound in Appendix B.1 to get
[TABLE]
where .
Using the invariant property of , we again obtain the gap between user ’s achievable rate to the capacity upper bounded by
[TABLE]
bits per real dimension. After this, following the similar steps as those in Section 5.4.1, one can obtain the lower bound for the scaling factor for user as:
[TABLE]
The gap to the capacity is then given by:
[TABLE]
which completes the proof of (5.23) for in Proposition 5.1. From here we can see that the gap to capacity does not scale with the number of users.
Appendix C Proof of Theories of Chapter 6
C.1 A Useful Lemma
We note that the outage capacity in Theorem 6.1 becomes infinity as increases to 1. This is because continuous Gaussian inputs are allowed when deriving capacity results; thereby, if the receivers can accept ridiculously high outage probabilities, the transmitter can keep tuning up the rates unboundedly. In contrast, our scheme employs discrete inputs whose achievable rates are limited by the corresponding entropies. As a consequence, the gap between the outage capacity and our achievable rate can be unbounded as increases. However, such high outage probabilities are of no practical significance. In the following lemma, we characterize an upper bound on the outage probability so that the outage capacity in Theorem 6.1 is contained inside the capacity region of the AWGN network whose SNRs are exactly the average SNRs. We believe that this range covers almost all the cases that are of practical interest.
Lemma C.1**.**
When for , for any power allocation factors , the rate tuple on the boundary of the outage capacity region (6.2) is upper bounded by
[TABLE]
* Proof: * For user , leads to
[TABLE]
This completes the proof.
C.2 Proof of Individual Outage Rate
C.2.1 Proof of User 1’s Achievable Rate for a Channel Realization
We first bound the overall scaling factor for user 1’s lattice constellation. Recall that is to ensure . We then lower bound the scaling factor for user 1 as follows:
[TABLE]
where follows [8291591, Lemma 7], and follows from that for ; and follows from (6.4). Plugging (C.2.1) into (6.4.1) results in
[TABLE]
Now we wish to lower bound the term . When , the achievable rate for user 1 is lower bounded by
[TABLE]
as and in this case. The achievable rate will approach to with increasing.
We now consider the case for for the worst case scenario. If the channel gain is so small such that , then user 1 cannot decode its own signal. In this case, the achievable rate becomes zero. Thus, we consider the case such that , i.e., . The term in (C.2.1) can be bounded by
[TABLE]
where follows from (6.10); follows by substituting and then into
[TABLE]
The lower bound for user 1’s achievable rate for a channel realization is then obtained as
[TABLE]
Similarly, we can use (C.2.1) to bound the term when by using (C.7)
[TABLE]
Then the lower bound for user 1’s achievable rate in bits per real dimension for a channel instant is
[TABLE]
where here follows the constraint in (6.9). In order to obtain the true lower bound for the outage rate in the subsequent analysis, we use (C.10) rather than (C.5) to be lower bound for . This is because the term in (C.10) captures the major fading penalty on the achievable rate while (C.5) only shows a minor effect on the rate due to channel fading.
C.2.2 Proof of User ’s Outage Rate
We bound the scaling factor of in (C.2.2),
[TABLE]
where follows from (6.49); follows from [8291591, Lemma 7]; is obtained by using ; and follows by using (6.24) and (6.26) such that
[TABLE]
Plugging (C.2.2) into (6.4.1) results in
[TABLE]
where (\ref{eq:rate_k_GBC_final}.a) follows by using (C.7) and here is due form the constraint in (6.13).
Given a target transmission rate and the required outage probability for user , we have
[TABLE]
The lower bound for the outage rate of user is
[TABLE]
where here follows (6.13).
C.2.3 Proof of User ’s Outage Rate
To further bound , we note that the effective noise is , where is a fixed dither decomposed from and to minimize the decomposed lattice constellation. We then scale the effective noise by
[TABLE]
such that . In this way,
we can then again apply the lower bound of the mutual information between a discrete random input and its noisy version shown in [8291591, Lemma 6] to obtain
[TABLE]
where , and
[TABLE]
is the scaling factor of the minimum distance of the superimposed lattice . The effects of changing of on the constellation are illustrated in facts iv) and v) given in Section 6.3.1 by recognizing user as user 2 in the two-user case.
Then, the scaling factor for user can be bounded by directly following (C.2.2):
[TABLE]
Plugging (C.19) into (C.2.3) leads to
[TABLE]
where (\ref{eq:rate_2_GBC_final}.a) follows by applying (C.7) and is due from the constraint in (6.13).
Given a target transmission rate and the outage probability for user , we have
[TABLE]
The lower bound for user ’s outage rate is
[TABLE]
where here follows (6.13).
Appendix D Proof of Theories of Chapter 7
D.1 Useful lemmas
Lemma D.1**.**
Let be a discrete random variable uniformly distributed over the complete set of coset leaders of with any . Let be a dither vector such that has zero mean. When , the average power of is given by
[TABLE]
* Proof: * Let be a random variable that is uniformly distributed over the fundamental Voronoi cell and independent of . Then is a continuous random variable whose distribution is uniform over a region and has zero mean. The average power of is
[TABLE]
where the second equality is according to [1337105, Eqs (22)-(23)]. As , the region consists of numbers of Voronor cells , where the coset leader is in the cell center.
Let be a random dither that is uniformly distributed over . Then,
[TABLE]
Here, becomes a continuous random variable that is uniformly distributed over the fundamental Voronoi cell . We note that .
Since , the lattice partition is the -fold Cartesian product of the one-dimensional lattice partition . The fundamental Voronoi cell is the -fold Cartesian product of the fundamental Voronoi cell . Given that the fundamental Voronoi cell is , thus the region of is . The coset leaders of are the -fold Cartesian product of the one-dimensional coset leaders of , i.e., . After subtracting a fixed dither to ensure zero mean, the one-dimensional coset leaders become . We note that the union of the Voronoi cells of these coset leaders is exactly , same with the fundamental Voronoi cell . Hence, the Cartesian products of both the union cells and the fundamental Voronoi cell lead to the same support. Thus, the random variable uniformly distributed over these regions have the same average power, meaning that .
As a result, the average power of is therefore
[TABLE]
where and for .
Lemma D.2**.**
For the -dimensional ideal lattice constructed via cyclotomic construction, there exists at least a lattice point and satisfying both and .
* Proof: * We consider the lattice point generated from a length integer vector . Since the generator matrix of , is a rotated version of , i.e., the rotation matrix itself, it is obvious that because rotation does not affect the Euclidean distance.
Now, we write the analytical expression for as
[TABLE]
As is the -th root of unity of the polynomial
[TABLE]
thus,
[TABLE]
Substituting into gives
[TABLE]
where is due to shifting the periodic function to the right by and substituting . The product distance between and is then computed as
[TABLE]
where follows that as this is a necessary condition to obtain the ideal lattice [Oggier:2004:ANT:1166377.1166378, Eq. (7.4)] and follows from (D.1).
Lemma D.3**.**
*Consider any two layers: layer 1 and 2 in . Let and be two distinct points on layer 1 and and be two distinct points on layer 2, such that and , where and denote the Euclidean distance and product distance, respectively. Then for any two distinct points and on layer 1 and any two distinct points and on layer 2 satisfying , the following relation holds: . *
* Proof: * For layer 1 and 2, we can write the corresponding -dimensional line equations as and , respectively. Since points and is in layer 1, we have .
Similarly, for layer 2 with points and on it, we have . The product distance between points and is given by
[TABLE]
Similarly, the product distance point and is given by
[TABLE]
Since , we have
[TABLE]
where follows that . Since , and based on (D.1), we have , which implies that .
Lemma D.4**.**
*Let , and be three points on a line in . Assume that point is located in between points and . Then, the product distances of line segments , and satisfy *
[TABLE]
* Proof: * Let , and . The equation of the -dimensional line through point to point is . Here, the direction of the line is from to . Since point is also on this line, thus point satisfies
[TABLE]
Since point is located in between point and , we have to ensure that the directions from to and from to are the same. The -th square root of the product distance of line segment is given by
[TABLE]
The -th square roots of product distances of line segment is
[TABLE]
We also note that the -th square roots of product distances of line segment is
[TABLE]
Noting that (D.1)(D.1)(D.15) completes the proof.
Appendix E Proof of Theories of Chapter 8
E.1 Proof of Lemma 8.1
In this section, we prove that our decoder can solve any detectable stall pattern with for any .
We first consider a stall pattern. According to the condition in (8.2), the number of errors in the stall pattern should satisfy . This implies that for each erroneous column, the column weight should be at least . Thus we have the following property:
[TABLE]
Performing Step 4 of Algorithm 8.3 by flipping all the intersection bits of the stall pattern results in
[TABLE]
where denotes the -th erroneous column after the all-flipping operation. As a result, all the erroneous columns can now be decoded by the component code decoder. The proof for any stall pattern can be done by simply swapping with in the above argument.
E.2 Proof of Theorem 8.1
For notation simplicity, we define and .
E.2.1 Proof of Theorem 8.1-1
In this subsection, we prove that our decoder can solve any detectable stall pattern for any . The proof consists of two parts in the following.
E.2.2 Case 1
We first consider a detectable stall pattern. Since could be larger than the minimum number of errors , there could have some erroneous columns with weight larger than . Specifically, we have
[TABLE]
where outputs the set size; and represent the -th and -th erroneous columns, respectively, when no flipping operations have been performed on this stall pattern yet. According to Step 3 of Algorithm 8.3, our decoder flips the first erroneous row whose weight satisfies
[TABLE]
where the maximum weight is due to adding the additional bits of errors to the minimum weight . After the row flipping, there are number of erroneous columns having their weights reduced by 1. Among these erroneous columns, there is at least one column having its weight reduced from to while there are at most columns whose weights are larger than according to (E.2.2). Thus, we have
[TABLE]
where denotes the -th erroneous column after the row flipping operation. Since the -th column has weight , it can now be successfully decoded by the component code decoder. Therefore, at least one column is decodable.
After this step, the problem is reduced to solving a stall pattern. Based on Lemma 8.1, this stall pattern can be successfully solved by Step 4. Otherwise, when there is no stall pattern formed, the remaining errors can be directly corrected by the iterative hard-decision decoding in Algorithm 8.2.
E.2.3 Case 2
Next, we consider a detectable stall pattern. According to Step 3 of Algorithm 8.3, the decoder again first flips one erroneous row whose weight satisfying (E.4).
If , the flipped row can be decoded because the number of the remaining errors after row flipping is . For this case, the problem is reduced to solving the stall pattern of and thus it can be solved by applying all-flipping in Step 4 of Algorithm 8.3 according to Lemma 8.1.
Now consider the case such that and none of the erroneous columns can be decoded after Step 3 of Algorithm 8.3. Under this condition, the stall pattern has the property such that
[TABLE]
This indicates that after flipping the first row, all the column weights are still larger than and thus cannot be decoded by the component code decoder. The decoder then restores all the code blocks and perform all-flipping operation in Step 4 of Algorithm 8.3. This results in
[TABLE]
where denotes the -th erroneous column after the all-flipping operation. Since the -th column has maximum weight , it can now be successfully decoded by the component code decoder. Therefore, at least columns are decodable. Then, the problem is reduced to solving the stall pattern of . The decoder can successfully solve this stall pattern by repeating Step 4 of Algorithm 8.3 according to Lemma 8.1.
Therefore, our decoder is able to correct any detectable stall pattern with any .
E.2.4 Proof of Theorem 8.1-2
First, we prove that our decoder can solve any detectable stall pattern for any .
Since , the decoder first flips the first erroneous row. If the flipped row can be solved by the component code decoder, the stall pattern becomes and thus can be corrected after Step 4 of Algorithm 8.3 according Lemma 8.1. If at least one erroneous column can be decoded by the iterative hard-decision decoding, the stall pattern becomes which can be solved according to Theorem 8.1-1.
Now we consider the case such that none of the erroneous rows and columns are corrected after Step 3 of Algorithm 8.3. In other words, the row flipping does not result in any decodable rows and columns. The stall pattern thus has the property shown in (E.2.3) with and
[TABLE]
The decoder then restores all the code blocks and then proceeds to Step 4 of Algorithm 8.3. Similar to the case in Appendix E.2.3, this leads to (E.2.3) where after performing Step 4 of Algorithm 8.3. As a result, at least erroneous columns become decodable. The problem then becomes solving a stall pattern. Here, we note that for all component codes with . Thus, the resultant stall pattern can be corrected by repeating Step 4 of Algorithm 8.3 according to Lemma 8.1.
The proof for stall patterns can be done by swapping with in the above argument.
E.2.5 Proof of Theorem 8.1-3
In this subsection, we prove that our decoder can solve detectable stall patterns for some . The proof consists of three parts in the following.
E.2.6 Case 1
We first consider a stall pattern. For this case, we have the properties shown in (E.2.2)-(E.5) with . Similar to the case in Appendix E.2.2, the same conclusion can be drawn such that there is at least one erroneous column can be decoded. Thus the stall pattern becomes a stall pattern which can be corrected according to Theorem 8.1-2.
E.2.7 Case 2
We now consider a detectable stall pattern. This stall pattern has the following property:
[TABLE]
Here, the maximum row/column weight is strictly larger than because the average row/column weight is . If the flipped erroneous row has weight , then its weight becomes after row flipping. This row can now be corrected by the component code decoder. The stall pattern then becomes a stall pattern which can be solved according to Theorem 8.1-2.
If none of the erroneous columns and rows are corrected after Step 3 of Algorithm 8.3, the decoder again restores all the code blocks and proceeds to Step 4 of Algorithm 8.3. As a result, any erroneous row and column whose weights were greater than before all-flipping now have weight after all-flipping. Thus, at least one row and one column whose weights were larger than (E.2.7) can be decoded after Step 4 of Algorithm 8.3. The problem is reduced to solving a stall pattern which can be corrected based on Theorem 8.1-2.
E.2.8 Case 3
Now consider a detectable stall pattern for some satisfying (8.2). This stall pattern has the following property:
[TABLE]
If none of the erroneous rows and columns are decoded after Step 3 of Algorithm 8.3, then the stall pattern satisfies the following condition
[TABLE]
This happens when the row flipping operation corrects 1 bit error in the erroneous column whose weight was . After Step 4 of Algorithm 8.3, the column weights of the stall pattern are
[TABLE]
No matter how many times of Step 3 and Step 4 of Algorithm 8.3 are performed on this stall pattern, none of the erroneous rows and columns are decodable by the component code decoder. For this case, the number of error bits in this stall pattern can be calculated by
[TABLE]
Substituting (E.11) into (E.2.8) results in . Therefore, our decoder can only guarantee to solve the stall pattern with and or .
E.2.9 Proof of Theorem 8.1-4
First, we prove that our decoder can solve any detectable stall pattern for any .
Since , the decoder first flips the first erroneous row. If at least one erroneous row can be decoded, then the stall pattern becomes and thus can be corrected by using Lemma 8.1. If at least one erroneous column can be decoded, the stall pattern becomes which can be solved according to Theorem 8.1-2.
Now we consider the case such that none of the erroneous rows and columns associated with the stall patterns are corrected after Step 3 of Algorithm 8.3. In this case, the stall pattern has the property shown in in (E.2.3) with and the flipped row whose weight satisfies
[TABLE]
Similar to the case in Appendix A.3.1, performing Step 4 of Algorithm 8.3 leads to (E.2.3) where . Same conclusion can be drawn such that there are at least erroneous columns can be decoded after Step 4 of Algorithm 8.3. The problem is then reduced to solving a stall pattern. Here, we note that for all component codes with . Thus, the resultant stall pattern can be solved according to Theorem 8.1-1.
The proof for stall patterns can be done by swapping with in the above argument.
E.2.10 Proof of Theorem 8.1-5
In this subsection, we first prove that our decoder can solve any detectable stall pattern. We first note that this stall has the following property
[TABLE]
After applying the row flipping operation in Step 3 of Algorithm 8.3 to this stall pattern, we have
[TABLE]
It can be seen that at least columns with weight can be successfully decoded after Step 3. The problem is then reduced to a stall pattern. We note that for . Thus, the resultant stall pattern can be successfully solved according to Theorem 8.1-2 and Theorem 8.1-4 when the underlying component code has . Note that for , the stall pattern is which may not be correctable according to Appendix E.2.8.
For the stall pattern with , it has the property shown in (E.2.2) with . According to (E.5), the number of decodable columns is after Step 3 of Algorithm 8.3. The problem is then reduced to solving a stall pattern. Here, we note that when . According to Appendix E.2.8, whether this stall pattern can be successfully decoded depends on . Since the knowledge of is not available to the decoder, this stall pattern may not be successfully decoded. However, we also note that when . This implies that the stall pattern can be solved according to Theorem 8.1-2 and Theorem 8.1-4 if one choose the component code has . Therefore, we only claim that our decoder is able to solve any detectable stall pattern when the underlying component code has .
The proof for stall pattern can be done by swapping with in the above argument.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] L. H. Ozarow and A. D. Wyner, “On the capacity of the Gaussian channel with a finite number of input levels,” IEEE Trans. Inf. Theory , vol. 36, no. 6, pp. 1426–1428, Nov. 1990.
- 2[2] G. D. Forney and L. F. Wei, “Multidimensional constellations. I. Introduction, figures of merit, and generalized cross constellations,” IEEE Trans. Inf. Theory , vol. 7, no. 6, pp. 877–892, May 1989.
- 3[3] Ericsson, “Ericsson mobility report,” TR, Jun. 2018. [Online]. Available: https://www.ericsson.com/assets/local/mobility-report/documents/2018/ericsson-mobility-report-june-2018.pdf
- 4[4] ITU-R, “ITU-R M.[IMT-2020.TECH PERF REQ] - minimum requirements related to technical performance for IMT-2020 radio interface(s),” ITU-R M.2410-0, TR, Nov. 2017. [Online]. Available: https://www.itu.int/dms˙pub/itu-r/opb/rep/R-REP-M.2410-2017-PDF-E.pdf
- 5[5] 3GPP, “Study on new radio (NR) access technology physical layer aspects,” 3rd Generation Partnership Project (3GPP), TR 38.802, Mar. 2017. [Online]. Available: https://portal.3gpp.org/desktopmodules/Specifications/Specification Details.aspx?specification Id=3066
- 6[6] V. W. S. Wong, R. Schober, D. W. K. Ng, and L. Wang, Key Technologies for 5G Wireless Systems . Cambridge, UK: Cambridge Univ. Press, 2017.
- 7[7] J. G. Andrews, S. Buzzi, W. Choi, S. V. Hanly, A. Lozano, A. C. K. Soong, and J. C. Zhang, “What will 5G be?” IEEE J. Sel. Areas Commun. , vol. 32, no. 6, pp. 1065–1082, Jun. 2014.
- 8[8] F. Boccardi, R. W. Heath, A. Lozano, T. L. Marzetta, and P. Popovski, “Five disruptive technology directions for 5G,” IEEE commun. Mag. , vol. 52, no. 2, pp. 74–80, Feb. 2014.