A Latent Gaussian Process Model for Analyzing Intensive Longitudinal Data
Yunxiao Chen, Siliang Zhang

TL;DR
This paper introduces a Gaussian process-based latent curve model tailored for intensive longitudinal data, capturing individual dynamics with high temporal resolution and irregular observation times, advancing analysis in social sciences.
Contribution
The paper presents a semi-parametric Gaussian process model for latent curves, improving analysis of intensive longitudinal data over traditional models.
Findings
Model effectively captures individual-specific trajectories.
Simulation studies validate estimation procedures.
Application to real data demonstrates practical utility.
Abstract
Intensive longitudinal studies are becoming progressively more prevalent across many social science areas, especially in psychology. New technologies like smart-phones, fitness trackers, and the Internet of Things make it much easier than in the past for data collection in intensive longitudinal studies, providing an opportunity to look deep into the underlying characteristics of individuals under a high temporal resolution. In this paper, we introduce a new modeling framework for latent curve analysis that is more suitable for the analysis of intensive longitudinal data than existing latent curve models. Specifically, through the modeling of an individual-specific continuous-time latent process, some unique features of intensive longitudinal data are better captured, including intensive measurements in time and unequally spaced time points of observations. Technically, the…
Click any figure to enlarge with its caption.
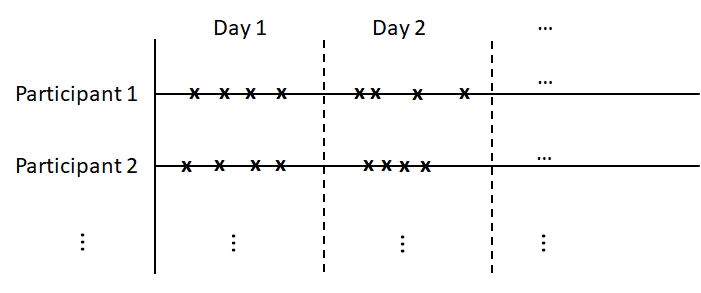 Figure 1
Figure 1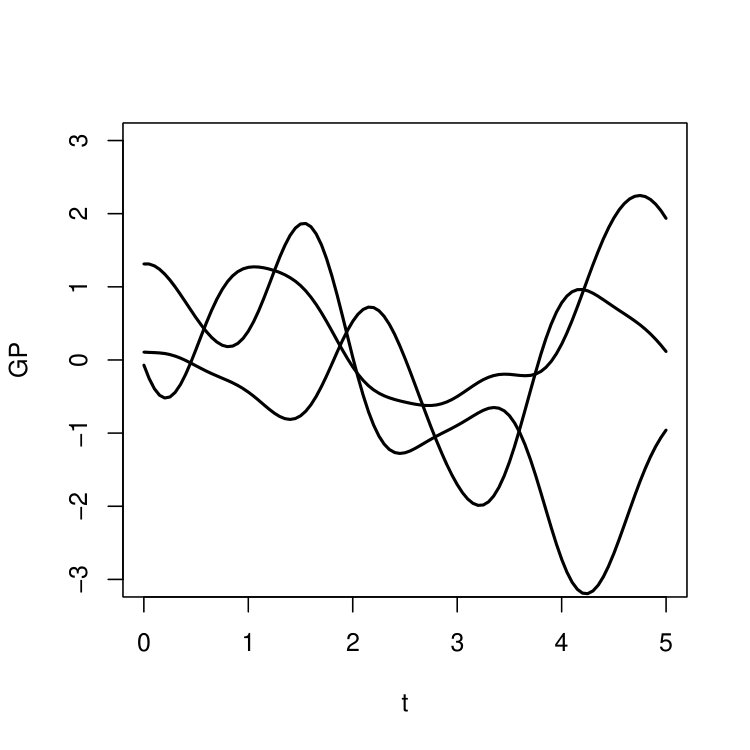 Figure 2
Figure 2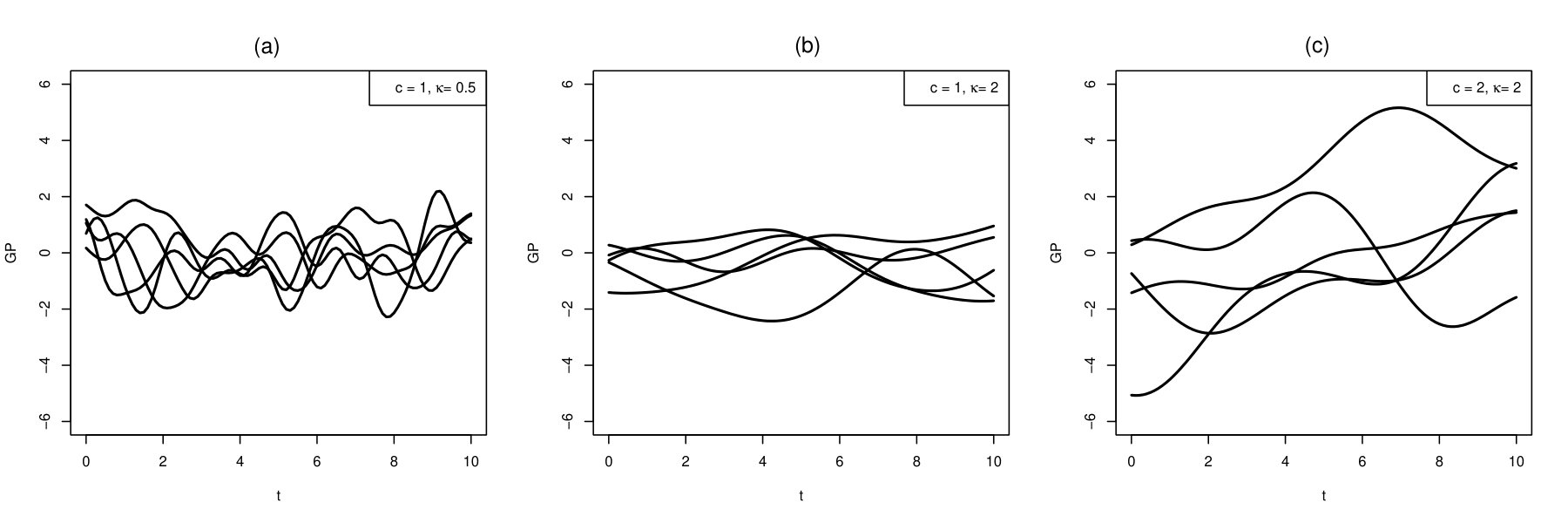 Figure 3
Figure 3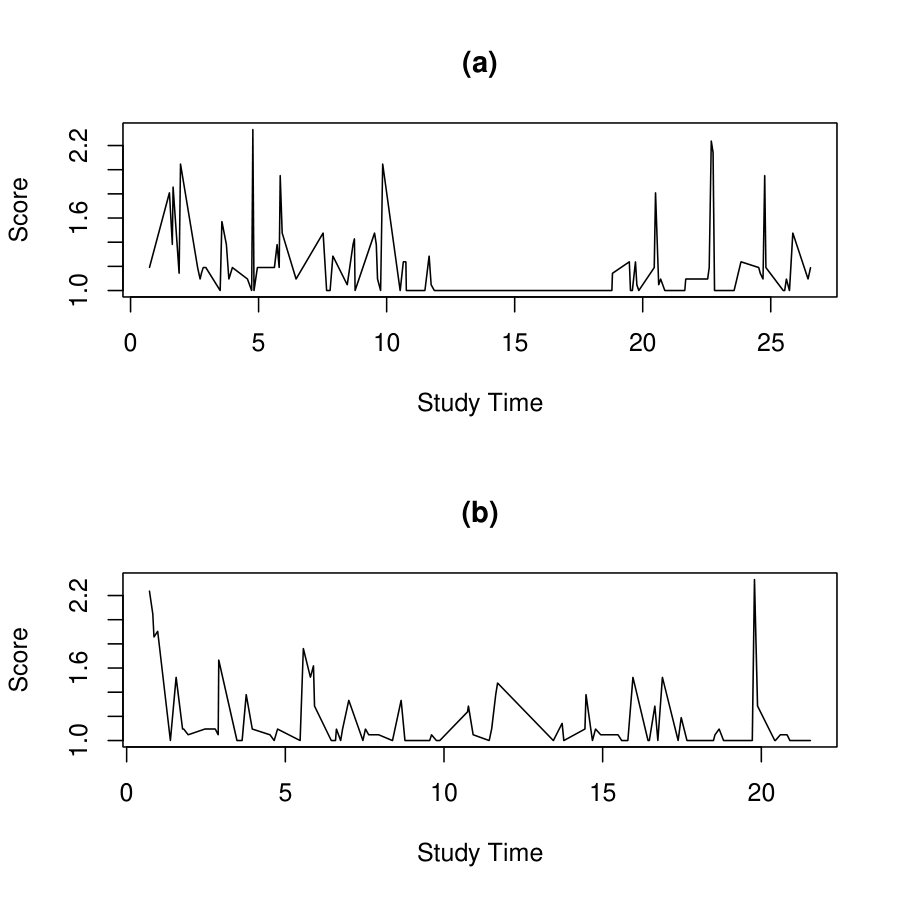 Figure 4
Figure 4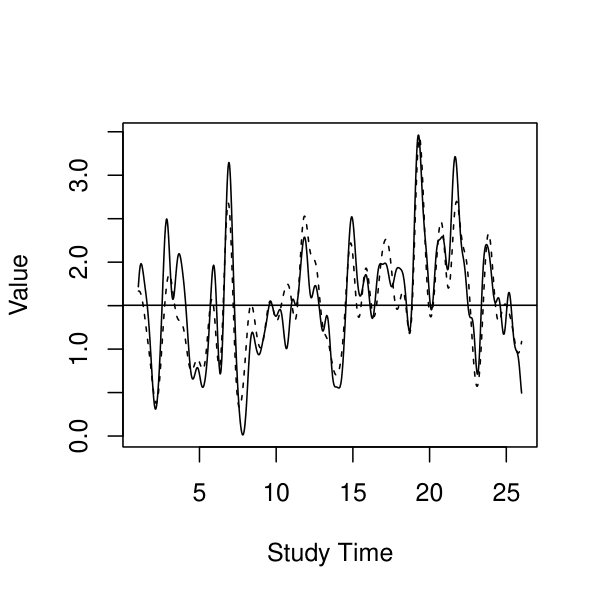 Figure 5
Figure 5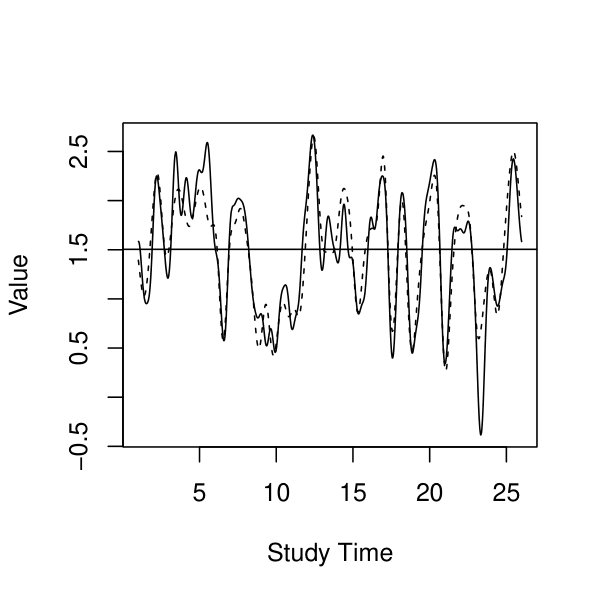 Figure 6
Figure 6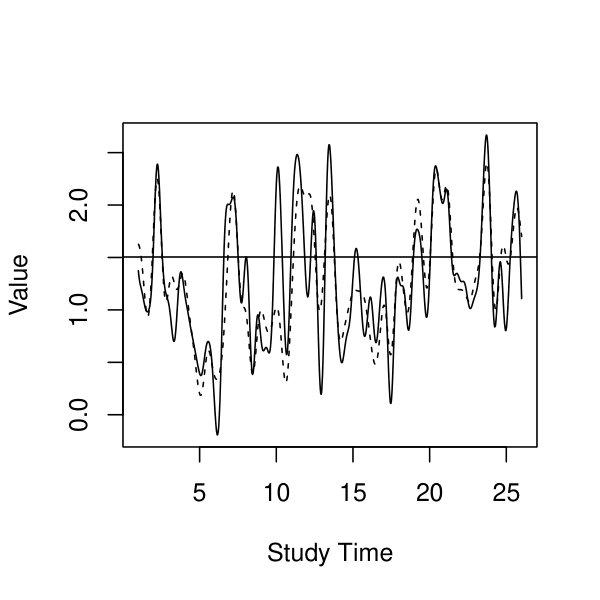 Figure 7
Figure 7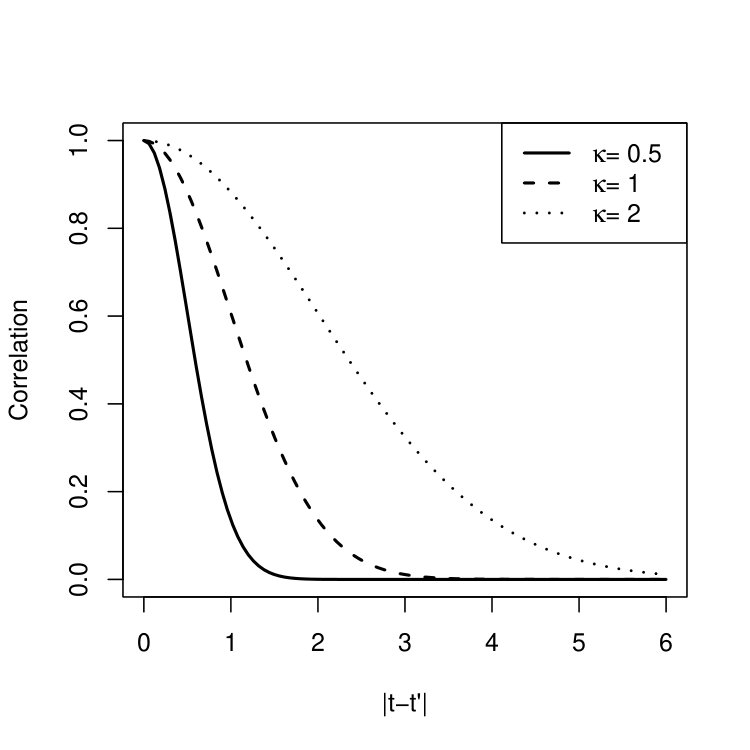 Figure 8
Figure 8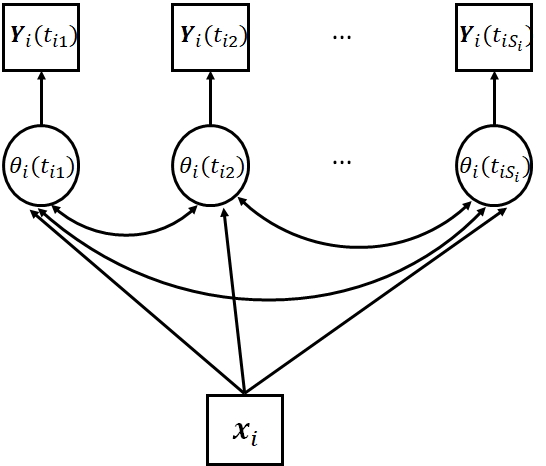 Figure 9
Figure 9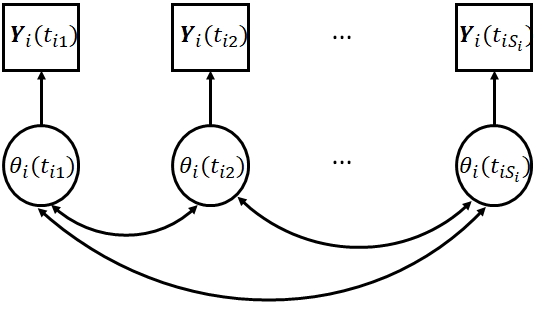 Figure 10
Figure 10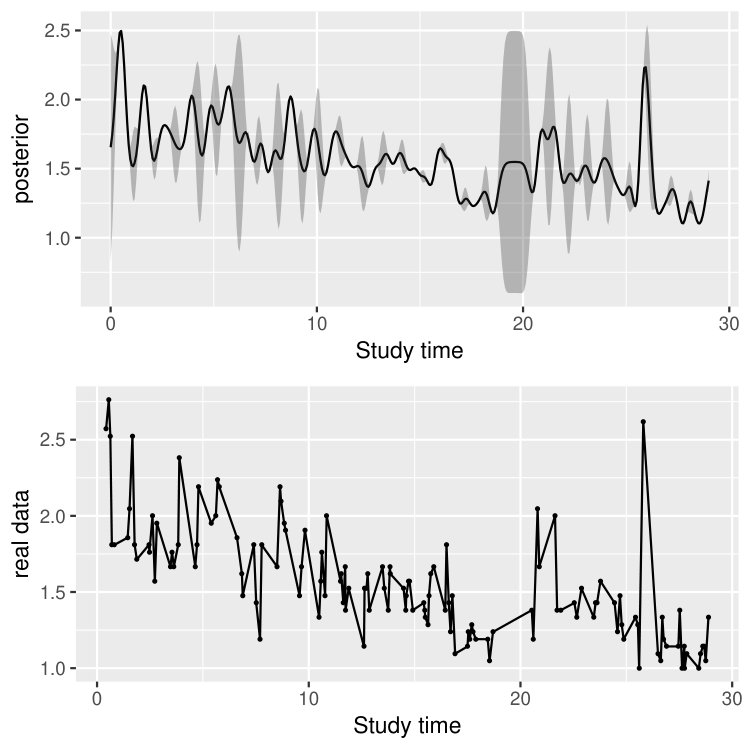 Figure 11
Figure 11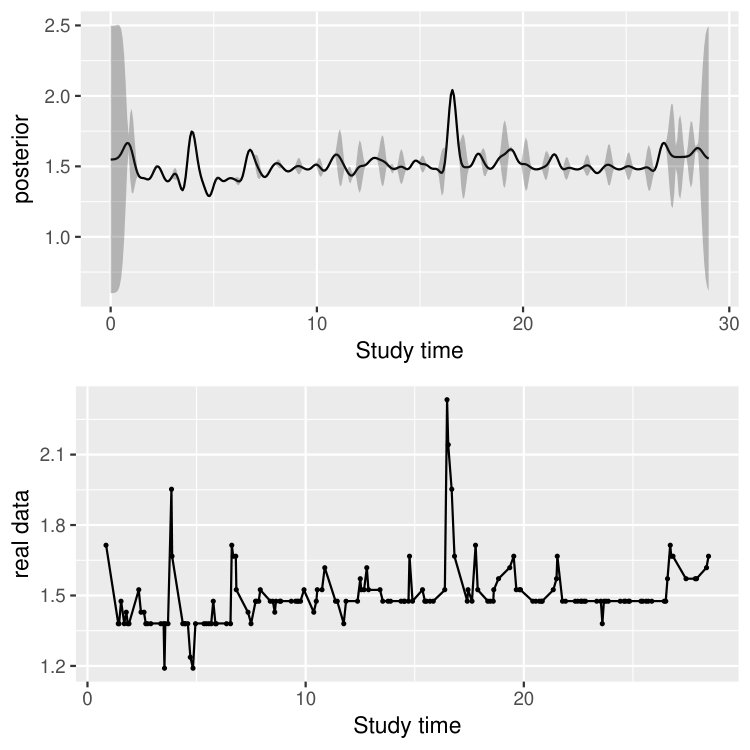 Figure 12
Figure 12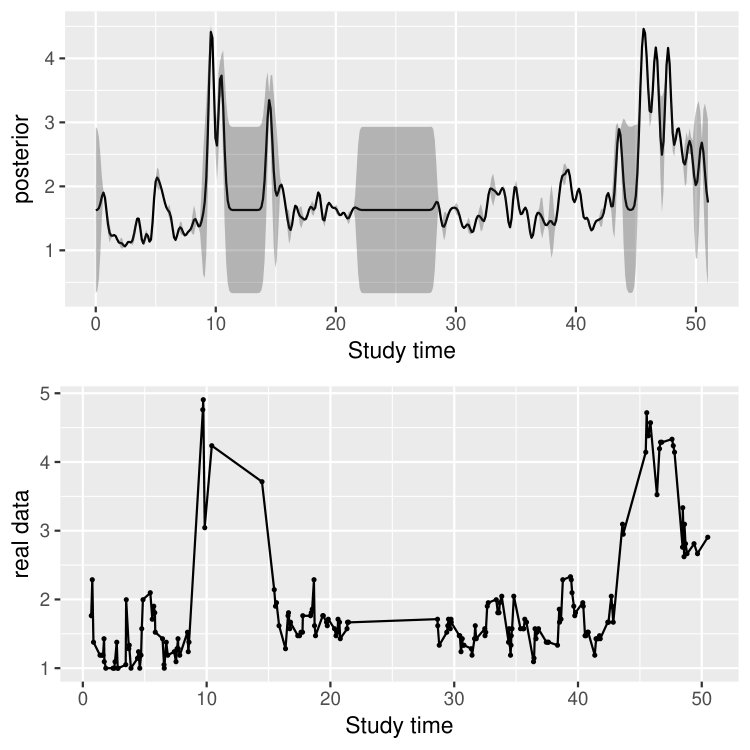 Figure 13
Figure 13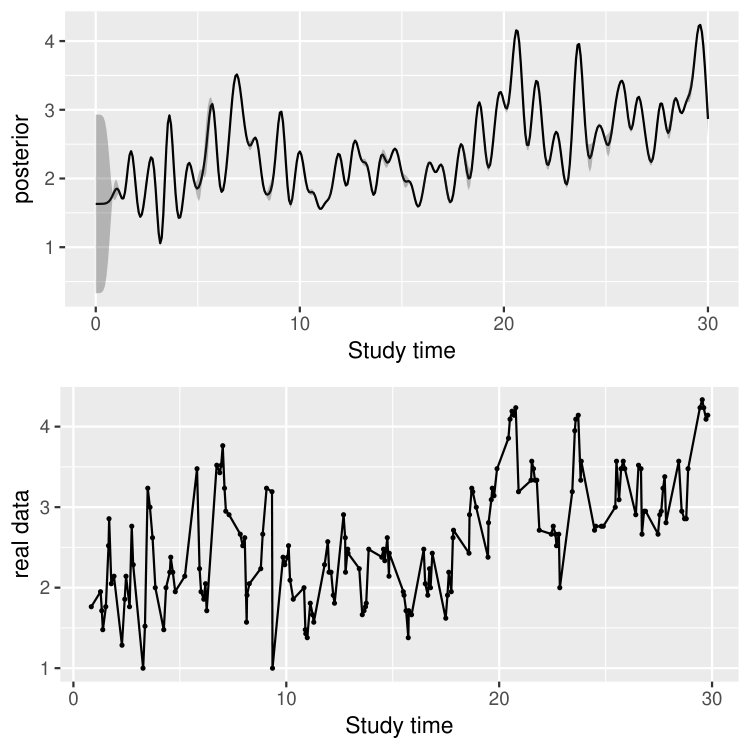 Figure 14
Figure 14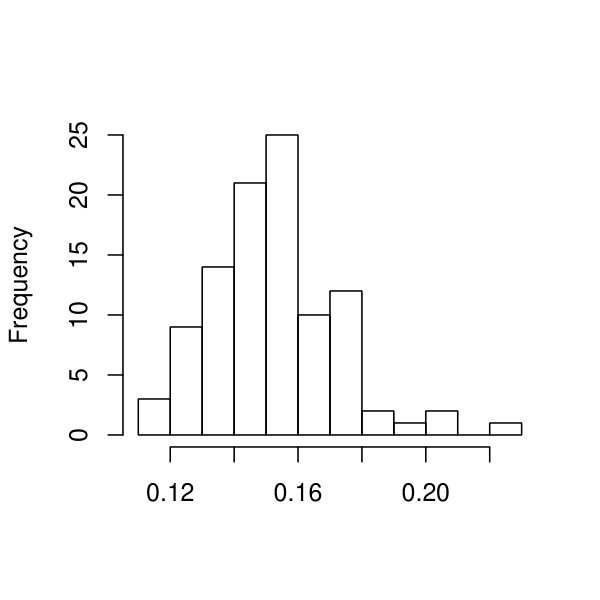 Figure 15
Figure 15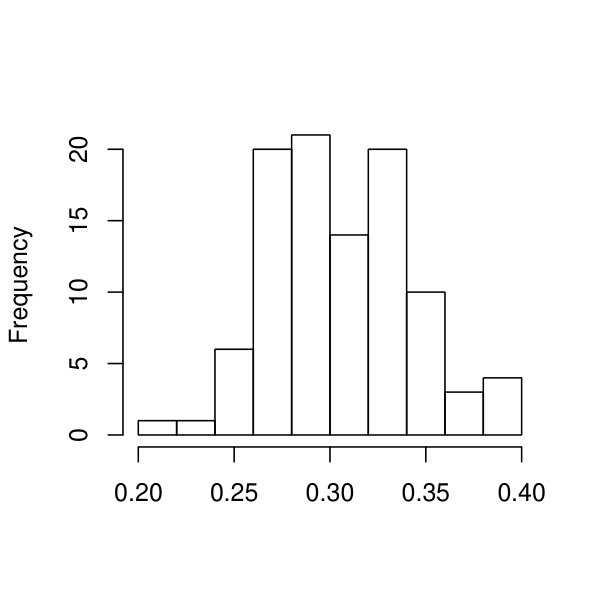 Figure 16
Figure 16| True | 1.5 | 0.4 | 0.3 | 0.1 |
|---|---|---|---|---|
| MSE() | ||||
| MSE() |
| True | 1.00 | 1.00 | 0.65 | 0.62 | 0.53 |
|---|---|---|---|---|---|
| MSE(N=50) | |||||
| MSE(N=100) | |||||
| True | 0.00 | 0.45 | -0.25 | -0.27 | 0.34 |
| MSE(N=50) | |||||
| MSE(N=100) | |||||
| True | 1.84 | 1.45 | 0.44 | 1.37 | 1.55 |
| MSE(N=50) | |||||
| MSE(N=100) | |||||
| True | -0.79 | 0.30 | 1.27 | ||
| MSE(N=50) | |||||
| MSE(N=100) |
| ID | Score | Group | Study Time | Calendar Time |
| 1 | 1.19 | 0 | 0.74 | 2005-03-18 17:40:00 |
| 1 | 1.81 | 0 | 1.52 | 2005-03-19 12:24:38 |
| 1 | 1.38 | 0 | 1.63 | 2005-03-19 15:06:36 |
| 1 | 1.86 | 0 | 1.66 | 2005-03-19 15:49:34 |
| Point estimate | 1.549 | 1.630 | 0.234 | 0.440 | 0.237 | 0.249 | 0.091 |
| 95% CI lower bound | 1.436 | 1.476 | 0.154 | 0.273 | 0.192 | 0.201 | 0.071 |
| 95% CI upper bound | 1.658 | 1.793 | 0.304 | 0.608 | 0.272 | 0.281 | 0.112 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsGaussian Processes and Bayesian Inference · Mental Health Research Topics · Statistical Methods and Bayesian Inference
A Latent Gaussian Process Model for Analyzing Intensive Longitudinal Data
Yunxiao Chen
Department of Statistics, London School of Economics and Political Science
Siliang Zhang
Shanghai Center for Mathematical Sciences, Fudan University
Abstract
Intensive longitudinal studies are becoming progressively more prevalent across many social science areas, especially in psychology. New technologies like smartphones, fitness trackers, and the Internet of Things make it much easier than in the past for data collection in intensive longitudinal studies, providing an opportunity to look deep into the underlying characteristics of individuals under a high temporal resolution. In this paper, we introduce a new modeling framework for latent curve analysis that is more suitable for the analysis of intensive longitudinal data than existing latent curve models. Specifically, through the modeling of an individual-specific continuous-time latent process, some unique features of intensive longitudinal data are better captured, including intensive measurements in time and unequally spaced time points of observations. Technically, the continuous-time latent process is modeled by a Gaussian process model. This model can be regarded as a semi-parametric extension of the classical latent curve models and falls under the framework of structural equation modeling. Procedures for parameter estimation and statistical inference are provided under an empirical Bayes framework and evaluated by simulation studies. We illustrate the use of the proposed model though the analysis of an ecological momentary assessment dataset.
KEY WORDS: Gaussian process, latent curve analysis, structural equation modeling, intensive longitudinal data, ecological momentary assessment, time-varying latent trait
1 Introduction
Intensive longitudinal data are becoming progressively more prevalent across many social science areas, especially in psychology, catalysed by technological advances (e.g., Chapter 1, Bolger \BBA Laurenceau, \APACyear2013). Such data usually involve many repeated measurements that reflect individual-specific change process in high resolution, enabling researchers to answer deeper research questions of human behavioral patterns. Due to the complex structure of intensive longitudinal data, statistical models play an important role in the analysis of such data.
In an intensive longitudinal study, repeated measurements are made intensively over time. Such data may involve (1) a large number of time points, (2) individually-varying numbers of observations, (3) unequally spaced time points of observations, and (4) response data of various types (e.g., continuous, ordinal, etc.). For example, consider intensive longitudinal data from ecological momentary assessment (EMA) under a signal-contingent sampling scheme (see Chapter 5, Conner \BBA Lehman, \APACyear2012), which repeatedly measures individuals’ current behaviors and experiences in real time, in the individuals’ natural environments. Under this sampling scheme, participants are “beeped” at several (random) times a day to complete an electronic diary record on psychological variables, such as symptoms or well-being. The assessments can last for many days (e.g. a month). Such a design has been used to study, for example, borderline personality disorder (Trull \BOthers., \APACyear2008), adolescent smoking (Hedeker \BOthers., \APACyear2012), and others. We visualize this design in Figure 1, where the measurements happen at time points marked by “x”. Under such a design, each individual may receive hundreds of repeated measurements at irregularly spaced time points. Depending on the measurement scale, one or multiple indicators may be recorded at each observation time point and the indicators can be either continuous or categorical.
Latent curve models (e.g. Bollen \BBA Curran, \APACyear2006; Duncan \BOthers., \APACyear2013; Ram \BBA Grimm, \APACyear2015), also known as latent growth models or growth curve models, are an important family of psychometric models for the analysis of longitudinal measurements. These models characterize the growth or change in an individual through the modeling of an individual-specific time-varying latent trait, where the latent trait often has a substantive interpretation, such as a cognitive ability, a psychopathological trait, or subjective well-being. Such models are typically formulated under the structural equation modeling framework. In these models, each individual is represented by a latent curve , which represents a time-varying latent trait. At a given observation time , the individual’s response to a single or multiple items is assumed to be driven by his/her current latent trait level .
The classical latent curve models are developed for non-intensive longitudinal data (typically less than 10 times of measurement). Therefore, they often make strong assumptions on the functional form of . For example, a linear latent curve model assumes that , where and are the intercept and the slope of the curve, treated as individual specific latent variables. In other words, in this linear curve model, the latent curve is a random function, characterized by two random effects and that are often assumed to follow a bivariate normal distribution. Although can take slightly more complex forms (e.g., polynomial), the functional form of in the classical models is usually simple, which may not be suitable for analyzing individual change processes revealed by intensive longitudinal data, where the number of measurements may vary across different individuals.
To better capture the temporal pattern in intensive longitudinal data, more flexible latent curve models have been proposed under the structural equation modeling framework. Depending on whether time is treated as discrete or continuous, these models can be classified into two categories. The discrete-time models are typically a hybrid of time series analysis models and the structural equation modeling framework. Specifically, the individual specific dynamic latent traits are modeled by a time series model, such as the autoregressive (AR) or vector autoregressive (VAR) models. Such models are usually known as the latent variable-autoregressive latent trajectory models (Bianconcini \BBA Bollen, \APACyear2018) or dynamic structural equation models (Asparouhov \BOthers., \APACyear2018). The continuous-time models typically assume that the dynamic latent traits follow a stochastic differential equation (SDE; Oud \BBA Jansen, \APACyear2000; Voelkle \BOthers., \APACyear2012; Lu \BOthers., \APACyear2015). For example, Lu \BOthers. (\APACyear2015) assume the dynamic latent trait to follow the Ornstein-Uhlenbeck Gaussian process (Uhlenbeck \BBA Ornstein, \APACyear1930), whose distribution is given by an SDE.
The above models have limitations. Discrete-time models may be over-simplified for intensive longitudinal data, for which measurement occurs in continuous time. In particular, when time points of measurements are irregularly spaced and different individuals have different numbers of measurements, it is difficult to organize intensive longitudinal data into the format of multivariate time-series data and then analyze using a discrete-time model. Arbitrarily transforming data into a multivariate time-series format is likely to introduce bias into the analysis, as time lags between measurements, which may vary substantially among individuals, are ignored in the discrete-time formatting. In theory, these issues with discrete-time models can be addressed by taking a continuous-time model. However, existing continuous-time models are typically not straightforward to specify, estimate, and make inference upon, as latent stochastic differential equations are not straightforward to deal with either analytically or numerically. Moreover, limited by the form of stochastic differential equations, the existing continuous-time models for insensitive longitudinal data may not be rich enough.
In this paper, we propose new continuous-time latent curve models for the analysis of intensive longitudinal data that do not suffer from the issues with the existing models and better capture the unique features of intensive longitudinal data mentioned previously. By imposing Gaussian process models (Rasmussen \BBA Williams, \APACyear2005) on the latent curves , a general framework for latent curve modeling is developed. We call it the Latent Gaussian Process (LGP) models. In contrast to discrete-time models, the proposed models retain the flexibility of continuous-time models in dealing with observations in a continuous time domain. In addition, this general framework contains models that are easier to specify and analyze than SDE-based models.
Technically, the proposed modeling framework can be viewed as a hybrid of the latent Gaussian process model for functional data analysis (Hall \BOthers., \APACyear2008) and the generalized multilevel structural equation modeling framework for longitudinal measurement (e.g., Chapter 4, Skrondal \BBA Rabe-Hesketh, \APACyear2004). As will be shown in the sequel, many existing latent curve models, whether time is treated as continuous or discrete, can be viewed as special cases under the proposed general framework. By making use of mathematical characterizations of Gaussian processes, methods for the parametrization of LGP models are provided. In addition, parameter estimation and statistical inference are carried out under an empirical Bayes framework, using a Stochastic Expectation-Maximization (StEM) algorithm (Celeux \BBA Diebolt, \APACyear1985; Nielsen, \APACyear2000; Zhang \BOthers., \APACyear2018).
The rest of the paper is organized as follows. In Section 2, the classical latent curve models are reviewed under a unified framework of structural equation modeling and then a new latent Gaussian process modeling framework is introduced that substantially generalizes the traditional models. The parametrization of latent Gaussian process models is discussed. Estimation and statistical inference are discussed in Section 3, followed by the computational details in Section 4. Extension to the incorporation of covariates is discussed in Section 5. The proposed model is evaluated in Section 6 through simulation studies and further illustrated in Section 7 via a real data example. We end with concluding remarks in Section 8.
2 Latent Gaussian Process Model
2.1 A Unified Framework for Latent Curve Analysis
We first provide a unified framework for latent curve analysis. We consider participants being measured longitudinally within a time interval , where time is treated as continuous. For individual , let be the time that the th measurement occurs and be the total number of measurements received by individual . At each time , we observe a random vector \mbox{\mathbf{Y}}_{i}(t)=(Y_{i1}(t),...,Y_{iJ}(t))^{\top}, where can be either continuous or categorical, depending on the data type of the th indicator. In particular, the corresponding latent curve model is called a single-indicator model when and a multiple-indicator model when . We denote as a realization of \mbox{\mathbf{Y}}_{i}(t). Moreover, each individual is associated with a latent curve , which can be regarded as a time-varying latent trait. Note that the above setting is quite general that includes discrete-time longitudinal data as a special case, for which the observation time takes value in .
The latent curve model consists of two components: (1) a measurement model that specifies the conditional distribution of \{\mbox{\mathbf{Y}}_{i}(t):t=t_{i1},...,t_{iS_{i}}\} given , and (2) a structural model that specifies the distribution of the random function .
Measurement model.
The measurement model assumes that the distribution of \mbox{\mathbf{Y}}_{i}(t) only depends on , the latent trait level at the same time point, but does not depend on the latent trait levels or responses at any other time points. More precisely, it is assumed that
[TABLE]
where denotes the probability density/mass function of the conditional distribution of \mbox{\mathbf{Y}}_{i}(t_{i1}), …, \mbox{\mathbf{Y}}_{i}(t_{iS_{i}}) given the entire latent process and denotes the probability density/mass function of the conditional distribution of \mbox{\mathbf{Y}}_{i}(t_{i1}), …, \mbox{\mathbf{Y}}_{i}(t_{iS_{i}}) given . Equation (1) means that the latent trait level at any other time point is conditionally independent of the observed responses, given the latent trait levels at the corresponding time points of observation. As visualized in Figure 2, it is further assumed that the conditional distribution (1) has the following decomposition,
[TABLE]
where is the conditional probability density/mass function of \mbox{\mathbf{Y}}_{i}(t) given . The assumption in (2) is conceptually similar to the widely used local independence assumption in latent variable models (see Chapter 4, Skrondal \BBA Rabe-Hesketh, \APACyear2004). Finally, we assume local independence among multiple indicators at each time , i.e., , …, are conditionally independent given . That is
[TABLE]
where specifies the conditional distribution of the th indicator given . The choice of depends on the type of the th indicator. It is worth noting that the conditional distribution does not depend on time , implying that the measurement is assumed to be time-invariant. Although commonly adopted in latent curve models (e.g., Chapter 2, Bollen \BBA Curran, \APACyear2006), this assumption is quite strong and needs to be checked when applying such models to real data.
We provide several measurement model examples.
Linear factor model for continuous response:
[TABLE]
where , , and are model parameters. 2. 2.
Probit model for ordinal response ():
[TABLE]
where
[TABLE]
and are model parameters, and . When , degenerates to a binary response variable and the model (5) becomes the well-known two-parameter normal-ogive model in item response theory (Chapter 4, Embretson \BBA Reise, \APACyear2000).
Model (5) can be specified alternatively through the introduction of latent responses. That is, define latent response
[TABLE]
where is a noise term following a standard normal distribution. Then the observable response can be viewed as a truncated version of , obtained by
[TABLE]
When the multiple indicators contain a mixture of ordinal and continuous variables, the above models can be combined to model , since the measurement models for different items can be specified independently given the local independence assumption.
Structural model.
The structural model specifies the distribution of the random function . We list a few examples below and refer the readers to Bollen \BBA Curran (\APACyear2006) for a comprehensive review.
Linear trajectory model:
[TABLE]
where are individual specific random effects, following a bivariate normal distribution. 2. 2.
Quadratic trajectory model:
[TABLE]
where are individual specific random effects, following a trivariate normal distribution. 3. 3.
Exponential trajectory model:
[TABLE]
where are individual specific random effects, following a bivariate normal distribution and is a fixed effect parameter.
These models assume a simple functional form for . In particular, the realizations of are restricted to linear, quadratic, and exponential functions for models (6)-(8), respectively. Such models tend to be effective for non-intensive longitudinal data (typically less than 10 measurements), but may not be flexible enough when having intensive longitudinal measurements which provide information in a high temporal resolution. In the rest of the paper, a general modeling framework is proposed, based on which more flexible structural models can be constructed.
2.2 Gaussian Process Structural Model
In what follows, we introduce a new framework for modeling as a continuous-time stochastic process. A key component of this framework is the Gaussian process model.
Definition 1** (Gaussian Process)**
*A time continuous stochastic process on time interval is a Gaussian process if and only if for every finite set of time points , is multivariate normal. *
We remark that a Gaussian process can be defined more generally on a real line. In this paper, we focus on Gaussian process on a bounded interval , since real longitudinal data are collected within a certain time window. Many widely used stochastic processes, including the Brownian motion, the Brownian bridge, and the Ornstein-Uhlenbeck process, are special cases of Gaussian process. Thanks to the flexibility, nonlinearity, and inherent nonparametric structure, Gaussian processes have been widely used as a model for random functions for solving regression, classification, and dimension reduction problems (Chapter 4, Rasmussen \BBA Williams, \APACyear2005).
Thanks to the normality, a Gaussian process is completely characterized by two components: (1) a mean function , and (2) a kernel function for the covariance structure, where . We provide a definition of a kernel function below.
Definition 2** (Kernel Function)**
A bivariate function is called a kernel function if for every finite set of points , the matrix is positive semidefinite.
Note that since , the matrix has to be positive semidefinite, because it is the covariance matrix of . On the other hand, it can be shown that for any kernel function , there exists a Gaussian process whose covariance structure is given by the kernel (Chapter 4, Rasmussen \BBA Williams, \APACyear2005). As an illustrative example, Figure 3 shows three independent realizations from a Gaussian process, with a mean function and a squared exponential kernel function .
Definition 3** (Gaussian Process Structural Model)**
We say the structural component of a latent curve model follows a Gaussian process structural model, if are independent and identically distributed (i.i.d.) Gaussian processes for .
We remark that the Gaussian process structural model assumption in Definition 3 can be viewed as an extension of a commonly adopted assumption in unidimensional or multidimensional item response theory models where individual-specific latent trait or traits are assumed to be i.i.d. univariate or multivariate normal. The difference is that, rather than having a random variable or random vector for each individual, each individual in the proposed model is characterized by a random function, whose distribution is less straightforward to parameterize.
Combining a Gaussian process structural model and a measurement model as defined in Section 2.1, we obtain an LGP model. We point out that the examples (6)-(8) are all special cases of the LGP model. This is because, due to the multivariate normality of the random effects, for every finite set of time points , is multivariate normal. In addition, all the SDE based continuous-time latent curve models also fall into this framework, when the noise component of the SDE is assumed to be Gaussian. For example, Lu \BOthers. (\APACyear2015) assume the dynamic latent trait to follow the Ornstein-Uhlenbeck process (Uhlenbeck \BBA Ornstein, \APACyear1930). This process is a Gaussian process described by a stochastic differential equation with Gaussian noise. Furthermore, when the latent variables are assumed to be jointly normal, the latent variable-autoregressive latent trajectory models (see Bianconcini \BBA Bollen, \APACyear2018), which are discrete-time models, can also be viewed as special cases under the current framework.
A Gaussian process is specified by a mean function and a kernel function , whose choices should be problem specific. We denote the distribution of such a stochastic process by . In what follows, we discuss the parametrization of Gaussian process structural models.
2.3 Parametrization of Gaussian Process Structural Model
Following the above discussion, we see that , where is Gaussian process with mean 0 and kernel . This allows us to discuss the modeling of and separately, while in the classical latent curve models (e.g., (6)-(8)) the mean and kernel are modeled simultaneously. In particular, the mean process can be viewed as the mean of , for individuals from a population of interest. Therefore, the mean function captures the mean level of the time-varying latent trait, possibly reflecting the trend and the periodicity of the dynamic latent trait at the population level. In addition, the mean zero Gaussian process can be viewed as the deviation from the mean process that is specific to individual .
Mean function.
We consider the parametrization of the mean function , which is typically assumed to have certain level of smoothness. Specifically, for the linear, the quadratic, and the exponential trajectory models mentioned in Section 2.1, the mean functions take linear, quadratic, and exponential forms.
Under the current framework, can be parameterized more flexibly. Specifically, we adopt a parametrization of using basis functions. That is,
[TABLE]
where , …, are pre-specified basis functions on . For example, when polynomial basis functions are used, , , where is the degree of the polynomial function. When cubic spline basis functions are used, , , , and , where , is the th spline knot that is pre-specified on , and when and 0 otherwise. Alternative basis functions may also be used, such as Fourier basis, wavelets, and other spline basis functions. We refer the readers to Chapter 3, Ramsay \BBA Silverman (\APACyear1997) for a review of different basis functions. We remark that the number of basis functions and the choices of basis function may be determined by data through model comparison.
We remark that if the dynamic trait is assume to be a stationary process (i.e., the joint distribution of does not change when the process is shifted in time), then the mean function does not depend on time . In that case, the mean function can only have an intercept parameter, .
Parameterizing kernel function.
One way to model the mean zero Gaussian process is by directly parameterizing the kernel function. In fact, different parametric kernel functions are available in the literature. We refer the readers to (Chapter 4, Rasmussen \BBA Williams, \APACyear2005) for a review. In what follows, we provide a few examples of kernel functions, with a focus on kernels that lead to stationary mean zero Gaussian processes. For such a kernel function , the value of only depends on the time lag , not the specific values of and . A stationary kernel should be used if the distribution of is believed to be invariant when the process is shifted in time.
Squared exponential (SE) kernel:
[TABLE]
where and are two model parameters, known as the scale and the length scale parameters, respectively. 2. 2.
Exponential kernel:
[TABLE]
where and are two model parameters that play similar roles as the ones in the SE kernel above. 3. 3.
Periodic kernel (MacKay, \APACyear1998):
[TABLE]
where and are two model parameters that play similar roles as the ones in the two kernels above and is known as the period parameter which determines the periodicity of the kernel function.
Mean zero Gaussian processes with different kernel functions have different properties. For example, the mean zero Gaussian processes with an SE kernel tend to have smooth pathes. In fact, a mean zero Gaussian process with the SE kernel is classified as one of the most smooth stochastic processes, according to the notion of mean square differentiability (Chapter 1, Adler, \APACyear1981), a classical quantification of the smoothness of stochastic processes. This kernel function is widely used in statistical applications of Gaussian process. It will be further discussed in the sequel and be used in the data analysis.
An alternative way of parameterizing the kernel is by directly modeling the mean zero Gaussian process, which can be done by using a linear basis function model. Specifically, let , …, be pre-specified basis functions on , such as spline basis, Fourier basis, or wavelet basis functions. The theory of functional principal component analysis provides an idea on choosing better basis functions (e.g., Hall \BOthers., \APACyear2008). Given the basis functions, the linear basis function model assumes that
[TABLE]
where , , are model parameters and , , are i.i.d. standard normal random variables. The model (13) yields
[TABLE]
For finite , this parametrization approach typically leads to a non-stationary kernel function. Making use of the theory of reproducing kernel Hilbert space, essentially any mean zero Gaussian process can be approximated by the form of (13) for sufficiently large .
Squared exponential kernel.
We further discuss on the properties of the SE kernel. According to (10), . *The scale parameter thus captures the overall variation of the Gaussian process in the long run. * Moreover, the length-scale parameter captures the short-term temporal dependence. More precisely, the correlation between and is given by
[TABLE]
As shown in Figure 4, for each value of , the correlation decays towards zero as the time lag increases. The decaying rate is determined by the value of . In particular, when the time lag , the correlation is smaller than . Moreover, for a given time lag, a smaller value of implies a smaller correlation. Figure 5 shows sample paths from three Gaussian processes with mean zero and SE kernels. Specifically, in panel (a), , in (b), , and in (c), . Panels (a) and (b) only differ by the values of the parameter and the paths in panel (a) are from a Gaussian process with a smaller value of . The paths in panel (a) are more wiggly (i.e., have more short-term variation) than those in panel (b), since the Gaussian process in panel (a) has less temporal dependence. Panels (b) and (c) only differ by the values of , due to which the paths in panel (c) have more variation in the long run.
Identifiability of the model parameters
Like many other structural equation models, constraints are needed to ensure model identifiability. In particular, two constraints are needed, one to fix the scale of the latent process and the other to avoid mean shift. For instance, we consider a model combining the mean function (9), the measurement model (4), and the SE kernel (10). To fix the scale in this model, we can either fix the scale parameter in (10) or the first loading parameter in (3). In addition, to avoid mean shift, we can set either in (9) or in (4).
3 Inference under LGP Model
The statistical inference under the proposed model can be classified into two levels, the population level and individual level. Both levels of inference may be of interest in the latent curve analysis. The population level inference considers the estimation of the parameters in both the measurement and structural models. The individual level inference focuses on the posterior distribution of given data from each individual when the measurement and the structural models are known (e.g. obtained from the population level inference).
Population level inference.
We use to denote all the model parameters, including parameters from both the measurement and structural models. As mentioned above, constraints may be imposed on to ensure model identifiability. Our likelihood function can be written as
[TABLE]
where is the density function of an -variate normal distribution with mean and covariance matrix . Note that this likelihood function is the marginal likelihood of data in which the latent curves are integrated out. The maximum likelihood estimator of is defined as , whose computation is discussed in Section 4. We then obtain the estimated mean and kernel functions by plugging in .
Individual level inference.
Similar to the classical latent curve analysis, the current modeling framework also allows for statistical inference on the latent curve of each individual. For ease of exposition, we assume both the measurement and the structural models are known when making individual level inference. In practice, we can first estimate the model parameters and then treat the estimated model as the true one in making the individual level inference. For individual , whether or not measurement occurs at time , one can infer on based on the posterior distribution of given . By sweeping over the entire interval , one obtains the posterior mean of as a function of , which serves as a point estimate of individual ’s latent curve. When calculated under the estimated model, we call the posterior mean of the Expected A Posteriori (EAP) estimate of individual ’s latent curve and denote it by . It mimics the EAP estimate of an individual’s latent trait level in item response theory (e.g. Embretson \BBA Reise, \APACyear2000).
4 Computation
In this section, we elaborate on the computational details.
4.1 Individual Level Inference
We first discuss computing the posterior distribution of given , for any time , when both the measurement and the structural models are given. We denote the density of this posterior distribution by . Following equation (1) of the measurement model, and (\mbox{\mathbf{Y}}_{i}(t_{i1}),...,\mbox{\mathbf{Y}}_{i}(t_{iS_{i}})) are conditionally independent given . Consequently,
[TABLE]
where denotes the conditional distribution of given and denotes the posterior distribution of given the observed responses. Specifically, since follows a multivariate normal distribution with mean and covariance matrix , is still normal, for which the mean and variance have analytic forms. Specifically,
[TABLE]
where , , , , and . Then the posterior mean of is given by
[TABLE]
In addition, the -level quantile of the posterior distribution is given by
[TABLE]
where is the -level quantile of a standard normal distribution.
Under the linear factor model (6), (\theta_{i}(t^{*}),\theta_{i}(t_{i1}),...,\theta_{i}(t_{iS_{i}}),\mbox{\mathbf{Y}}_{i}(t_{i1}),...,\mbox{\mathbf{Y}}_{i}(t_{iS_{i}})) are jointly normal. Consequently, (15)-(17) have analytical forms. Under other measurement models, (16) and (17) can be approximated by using Monte Carlo samples from the posterior distribution . Specifically, let be Monte Carlo samples. Then we approximate the mean and -level quantile of the posterior distribution of by
[TABLE]
Markov chain Monte Carlo (MCMC) methods can be used to obain Monte Carlo samples from the posterior distribution . For example, a Gibbs sampler is developed that efficiently samples from this posterior distribution under the probit model (5) for ordinal response data. This sampler, described as follows, makes use of the latent response formulation of the probit model (5).
- Step 1: For , , sample from a truncated normal distribution that truncates a normal distribution by interval , where is some initial value of .
- Step 2: For , given s, we update , by sampling from
[TABLE]
where and denotes the conditional distribution of given the ideal responses . It is worth noting that this conditional distribution is multivariate normal, because , …, , , …, are jointly normal. The observed data , …, are not conditioned upon, because , …, are conditionally independent of the observed data when given the latent responses , …, .
We point out that both steps can be efficiently computed, because step 1 only involves sampling from univariate truncated normal distributions and step 2 only involves sampling from multivariate normal distributions. Well-developed samplers exist for both steps.
4.2 Population Level Inference
We now discuss the computation for maximizing the likelihood function (14). Under the linear factor model (6), the Expectation-Maximization (EM) algorithm (Dempster \BOthers., \APACyear1977) is used to optimize (14), where the E-step is in a closed form due to the joint normality of data and latent variables. The implementation of this EM algorithm is standard and thus we omit the details here.
Under other measurement models, the classical EM algorithm is typically computationally infeasible when the number of time points is large, in which case the E-step of the algorithm involves a high-dimensional integral that does not have an analytical form. We adopt a stochastic EM (StEM) algorithm (Celeux \BBA Diebolt, \APACyear1985; Diebolt \BBA Ip, \APACyear1996; Zhang \BOthers., \APACyear2018) which avoids the numerical integration in the E-step of the standard EM algorithm (Dempster \BOthers., \APACyear1977; Bock \BBA Aitkin, \APACyear1981) by Monte Carlo simulations. The convergence properties of the StEM algorithm are established in Nielsen (\APACyear2000). Similar to the EM algorithm, the StEM algorithm iterates between two steps, the StE step and the M step. Let be the initial parameter values and be the initial values of person parameters. In each step (), the following StE step and M step are performed.
- StE step: For , sample from
[TABLE]
the conditional distribution of given under parameters . For the probit model (5), we use the Gibbs sampler described in Section 4.1 to sample from . 2. M step: Obtain parameter estimate
[TABLE]
where
[TABLE]
is the complete data log-likelihood of a single observation. Note that and are defined in (3) and (14), respectively, containing model parameters. In our implementation, the optimization is done using the L-BFGS-B algorithm (Liu \BBA Nocedal, \APACyear1989).
The final estimate of is given by the average of s from the last iterations, i.e.,
[TABLE]
As shown in Nielsen (\APACyear2000), can approximate the maximum likelihood estimator sufficiently accurately, when and are large enough.
5 Incorporation of Covariates
In practice, individual specific covariates are often collected and incorporated into the latent curve analysis. As visualized in the path diagram in Figure 6, covariates can be further added to the structural model to explain how the distribution of the latent curves depends on the covariates. A specific type of covariates of interest is group membership, such as experimental versus control and female versus male. Latent curve analysis that incorporates discrete group membership as covariates in the structural model is referred to as the analysis of groups (Chapter 6, Bollen \BBA Curran, \APACyear2006).
Covariates can be easily handled under the proposed framework. For example, when discrete group membership may affect the mean function of the latent curve, we let parameters in to be group-specific. Similarly, we may also allow parameters in to depend on the group membership. Quantitative covariates, such as age, can also be incorporated into the current model. The mean and kernel functions are denoted by and when they depend on the covariates. The tools for the inference and computation discussed above can be easily generalized.
6 Simulation
The proposed modeling framework and the estimation procedures are further evaluated by simulation studies.
6.1 Study I
We first evaluate the parameter recovery using the EM algorithm, under a setting similar to the real data example in Section 7, except that a single group is considered in this study. In particular, it is assumed that each participant is measured for 25 consecutive days, with four measurements per day. Such a design results in 100 times of measurement. The time points of the four measurements are randomly sampled within a day. And we consider a measurement model with a single indicator. More precisely, given the observation time, the model is specified as follows.
[TABLE]
where and . The true model parameters are specified in Table 1. Two sample sizes are considered, including and . The simulation under each sample size is repeated for 100 times, based on which the mean squared error (MSE) for parameter estimation is calculated. According to the MSE for parameter estimation presented Table 1, the parameter estimation is very accurate under the current simulation settings and the estimation accuracy improves as the sample size increases.
We further illustrate the performance of the individual level inference based on the distance between and its EAP estimate , where the distance is defined as
[TABLE]
In particular, quantifies the inaccuracy of estimating the latent curve by . The distance between and ,
[TABLE]
is used as a reference for that quantifies the inaccuracy of estimating by the estimate of the population mean . The ratio serves as a measure of inaccuracy in estimating the latent curve of individual , in which the difficulty in estimating the curve has been taken into account by the denominator . The smaller the ratio is, the more accurate the latent curve is estimated in a relative sense (relative to the overall difficulty in estimating measured by ).
In panel (a) of Figure 7, we show the histogram of the ratios for all individuals from a randomly selected dataset among all replications when the sample size . As we can see, is much smaller than , implying that estimates very accurately. Panels (b)-(d) of Figure 7 show , , as well as for three randomly selected individuals from the same dataset. According to these plots, the true latent curves are well approximated by their EAP estimates.
6.2 Study II
We now consider a simulation study whose setting is the same as Study I except for a different measurement model component. In particular, we consider ordinal response data generated by the probit model (5). Specifically, the measurement at each time point is assumed to be based on five polytomous items, each with three ordinal categories (i.e., ). The true model parameters are given in Table 2. Note that we fix and in both the true model and the estimation procedure for model identifiability.
The simulation under each sample size is repeated for 100 times. For each simulated dataset, the model parameters are estimated using the stochastic EM algorithm described in Section 4.2, based on a random initial value. The two tuning parameters and of the algorithm are set to be 100 and 200, respectively. The estimation accuracy measured by mean squared error is shown in Table 2, which indicates an accurate estimation result. The running time of the stochastic EM algorithm for one dataset with is around 10 minutes111The study is conducted on a personal computer with specifications: Processor 2.2 GHz Intel Core i7; Memory 8 GB 1600 MHz DDR3.. It can be further speeded up by parallel computing.
Finally, we examine the recovery of the individual latent curves, measured by the distance ratio defined in Study I. The EAP estimates of the individual curves are obtained by Monte Carlo approximation (18), where Monte Carlo samples are used. In particular, the histogram of , , is presented in Figure 8, for a randomly selected dataset among all replications under . According to the histogram, is much smaller than , though the ratios tend to be larger than those in Study I. It implies that, under the current setting, the EAP estimate is still substantially more accurate than the population mean in estimating all individuals’ latent curves.
7 Analysis of Negative Mood in BPD and MDD/DYS Patients
We analyze data from a study of the affective instability in borderline personality disorder (Trull \BOthers., \APACyear2008) that collected ecological momentary assessment data from psychiatric outpatients with borderline personality disorder (BPD) and with major depressive disorder (MDD) or dysthymic disorder (DYS). The participants were recruited from one of four community mental health outpatient clinics through flyers. The dataset has been analyzed in Jahng \BOthers. (\APACyear2008) and is downloaded from http://dx.doi.org/10.1037/a0014173.supp. The data contain 84 participants: 46 who met DSM-IV-TR (American Psychiatric Association, \APACyear2000) diagnostic criteria for BPD and who endorsed the diagnostic feature of affective instability; and 38 who met DSM-IV-TR diagnostic criteria for current MDD or DYS and did not report affective instability.
This dataset contains, for each time and each participant, a negative affect composite score based on 21 items from the Positive and Negative Affect Scales-Extended Version (Watson \BBA Clark, \APACyear1999). The participants were measured multiple times a day over approximately 4 weeks of consecutive days. As commonly encountered in EMA data, the number of days of assessments per person and the number of assessments per day differed (days per person: median = 29, interquartile range = 2; assessments per day: median = 5, interquartile range = 1). In total, the participants received 76 to 186 assessments (median = 153, interquartile range = 24) per person were conducted. Table 3 illustrates the data structure, where the five columns show the individual ID, the negative affect composite score, the group membership ( for the MDD/DYS group, for the BPD group), the study time, and the calendar time, respectively. In particular, the study time uses day as the time unit and sets 00:00 of the first day receiving measurement as time 0 for each individual. Figure 9 visualizes the data from a MDD/DYS patient and that from a BPD patient, where the individuals receive different numbers of measurement, at different and unequally spaced time points.
Following the research question of Jahng \BOthers. (\APACyear2008), we investigate, by making use of the proposed latent Gaussian process model, whether the BPD group suffers from more temporal negative mood instability than the MDD/DYS group. We also investigate the mean of the negative mood of the two groups. To answer these questions under the latent Gaussian process modeling framework, we treat the negative affect composite score as a continuous variable and adopt a single-indicator linear factor measurement model. In addition, we assume the mean and the kernel functions of the latent Gaussian process are group specific. Specifically, the model is specified as follows.
[TABLE]
where , , , and . Under these assumptions, the Gaussian process for each group is stationary. According to the recruitment design of the study, the stationarity assumption seems reasonable.
The main results are shown in Table 4, including parameter estimates obtained from the EM algorithm and their bootstrap confidence interval (Chapter 6, Efron \BBA Tibshirani, \APACyear1993). The bootstrap results are obtained by resampling individuals with replacement. In particular, an estimate of the variance due to the measurement error is , which is much smaller than and , the overall variations of the two Gaussian processes. In addition, the two groups only significantly differ by the overall long-run variations, with a difference which has a corresponding 95% bootstrap confidence interval . That is, the BPD group has more variation in the long run than the MDD/DYS group, which is consistent with the existing knowledge these mental health disorders. Their overall mean scores are not significantly different, for which the difference is and a 95% confidence interval . Similarly, the two groups do not significantly differ in terms of the short-term temporal dependence, evidenced by and its 95% confidence interval .
In addition to the estimation of the model parameters, the proposed modeling framework allows us to make inference at the individual level. To demonstrate, in Figure 10, we show the posterior mean and the posterior and quantiles of , as well as the corresponding response process, of four participants, two of whom are from the MDD/DYS group and the other two from the BPD group. The calculation of the posterior mean and the posterior quantile for is described in Section 4. As we can see, the posterior mean of is quite smooth and captures the overall trend of the response process. In addition, the confidence band, given by the posterior and quantiles of , becomes wide when two subsequent measurements have a long time lag. For example, participant 35 from the BPD group did not have measurement from the 11th to the 13th day and from the 22nd to the 27th day. That is why the wide confidence bands are observed in panel (d) within the corresponding intervals. When there are multiple measurements occur around a single time point , the posterior variance at time can be close to 0 and consequently the corresponding posterior mean and posterior and quantiles are close to each other.
8 Concluding Remarks
In this paper, we introduce the latent Gaussian process model as a general family of continuous-time latent curve models. This new model complements the existing models for the analysis of intensive longitudinal data. The proposed model decomposes the latent curve analysis into a measurement model component and a structural model component. The measurement component captures the conditional distribution of an individual’s observed data given his/her latent curve in a continuous time domain and the structural component models the distribution of the latent curve. It is shown that many existing latent curve models are special cases of the proposed one.
In particular, a Gaussian process model is proposed for the modeling of latent curves in the structural model component. By making use of the mathematical properties of Gaussian processes, the modeling of the structural component is further decomposed into separate modeling of the mean function and the Kernel function of a Gaussian process. Estimation and statistical inference are further discussed under an empirical Bayes framework, where inference is considered at both population and individual levels.
The proposed model and methods are further illustrated through simulation studies and a real data example. In particular, our analysis of the negative mood of BPD and MDD/DYS patients reveals that the main difference between the two groups is due to the BPD group having significantly higher long-term variation, while the two groups are not significantly different in the mean negative affect levels and in the short-term temporal dependence.
The proposed framework leads to many new directions, which are left for future investigation. First, it is often of interest to measure multiple correlated dynamic latent traits, in which case becomes a vector at each time point . The current framework can be easily extended to that setting, by adopting a multidimensional measurement model (e.g., multidimensional item response theory model) and a multivariate Gaussian process model for the structural component. Second, many intensive longitudinal studies involve not only measurement but also interventions (e.g., treatment of mental health disorders). Interventions can be viewed as time-dependent covariates which can be incorporated into the structural component of the proposed model. By estimating the coefficients associated with the intervention covariates, the intervention effects can be evaluated dynamically. Finally, the psychometric properties of the proposed model remain to be studied, such as the detection of differential item functioning, the assessment of model goodness-of-fit, and the evaluation of measurement reliability.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Adler ( \APA Cyear 1981) \APA Cinsertmetastar adler 2010 geometry {APA Crefauthors} Adler, R \BPBI J. \APA Cref Year 1981. \APA Crefbtitle The Geometry of Random Fields The geometry of random fields. \APA Caddress Publisher New York, NY John Wiley & Sons. \Print Back Refs \Current Bib
- 2American Psychiatric Association ( \APA Cyear 2000) \APA Cinsertmetastar edition 2000 diagnostic {APA Crefauthors} American Psychiatric Association. \APA Cref Year 2000. \APA Crefbtitle Diagnostic and statistical manual of mental disorders 4th ed., revised Diagnostic and statistical manual of mental disorders 4th ed., revised. \APA Caddress Publisher Washington, DC American Psychiatric Association. \Print Back Refs \Current Bib
- 3Asparouhov \B Others . ( \APA Cyear 2018) \APA Cinsertmetastar asparouhov 2018 dynamic {APA Crefauthors} Asparouhov, T., Hamaker, E \BPBI L. \BCBL \BBA Muthén, B. \APA Cref Year Month Day 2018. \BBOQ \APA Crefatitle Dynamic structural equation models Dynamic structural equation models. \BBCQ \APA Cjournal Vol Num Pages Structural Equation Modeling: A Multidisciplinary Journal 25359–388. {APA Cref DOI} \doi 10.1080/10705511.2017.1406803 \Print Back Refs \Current Bib
- 4Bianconcini \BBA Bollen ( \APA Cyear 2018) \APA Cinsertmetastar bianconcini 2018 latent {APA Crefauthors} Bianconcini, S. \BCBT \BBA Bollen, K \BPBI A. \APA Cref Year Month Day 2018. \BBOQ \APA Crefatitle The Latent Variable-Autoregressive Latent Trajectory Model: A General Framework for Longitudinal Data Analysis The latent variable-autoregressive latent trajectory model: A general framework for longitudinal data analysis. \BBCQ \APA Cjournal Vol Num Pages Structural Equation Modeling:
- 5Bock \BBA Aitkin ( \APA Cyear 1981) \APA Cinsertmetastar bock 1981 marginal {APA Crefauthors} Bock, R \BPBI D. \BCBT \BBA Aitkin, M. \APA Cref Year Month Day 1981. \BBOQ \APA Crefatitle Marginal maximum likelihood estimation of item parameters: Application of an EM algorithm Marginal maximum likelihood estimation of item parameters: Application of an EM algorithm. \BBCQ \APA Cjournal Vol Num Pages Psychometrika 46443–459. {APA Cref DOI} \doi 10.1007/bf 02294168 \Print Back Refs \Curren
- 6Bolger \BBA Laurenceau ( \APA Cyear 2013) \APA Cinsertmetastar bolger 2013 intensive {APA Crefauthors} Bolger, N. \BCBT \BBA Laurenceau, J. \APA Cref Year 2013. \APA Crefbtitle Intensive Longitudinal Methods: An Introduction to Diary and Experience Sampling Research Intensive longitudinal methods: An introduction to diary and experience sampling research. \APA Caddress Publisher New York, NY Guilford Press. \Print Back Refs \Current Bib
- 7Bollen \BBA Curran ( \APA Cyear 2006) \APA Cinsertmetastar bollen 2006 latent {APA Crefauthors} Bollen, K. \BCBT \BBA Curran, P. \APA Cref Year 2006. \APA Crefbtitle Latent Curve Models: A Structural Equation Perspective Latent curve models: A structural equation perspective. \APA Caddress Publisher New York, NY John Wiley & Sons. \Print Back Refs \Current Bib
- 8Celeux \BBA Diebolt ( \APA Cyear 1985) \APA Cinsertmetastar celeux 1985 sem {APA Crefauthors} Celeux, G. \BCBT \BBA Diebolt, J. \APA Cref Year Month Day 1985. \BBOQ \APA Crefatitle The SEM algorithm: A probabilistic teacher algorithm derived from the EM algorithm for the mixture problem The SEM algorithm: A probabilistic teacher algorithm derived from the EM algorithm for the mixture problem. \BBCQ \APA Cjournal Vol Num Pages Computational Statistics Quarterly 273–82. \Print Back Refs \Cur