Distributionally Robust Partially Observable Markov Decision Process with Moment-based Ambiguity
Hideaki Nakao, Ruiwei Jiang, Siqian Shen

TL;DR
This paper introduces a distributionally robust POMDP framework using moment-based ambiguity sets, providing a method to derive robust policies that outperform traditional POMDPs under distribution misspecification.
Contribution
It develops a novel DR-POMDP model with moment-based ambiguity sets and proposes a heuristic value iteration method for policy computation.
Findings
DR-POMDP yields more robust policies than POMDP under distribution misspecification.
The approach is computationally efficient and insensitive to parameter variations.
Numerical tests on epidemic control demonstrate practical effectiveness.
Abstract
We consider a distributionally robust Partially Observable Markov Decision Process (DR-POMDP), where the distribution of the transition-observation probabilities is unknown at the beginning of each decision period, but their realizations can be inferred using side information at the end of each period after an action being taken. We build an ambiguity set of the joint distribution using bounded moments via conic constraints and seek an optimal policy to maximize the worst-case (minimum) reward for any distribution in the set. We show that the value function of DR-POMDP is piecewise linear convex with respect to the belief state and propose a heuristic search value iteration method for obtaining lower and upper bounds of the value function. We conduct numerical studies and demonstrate the computational performance of our approach via testing instances of a dynamic epidemic control…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1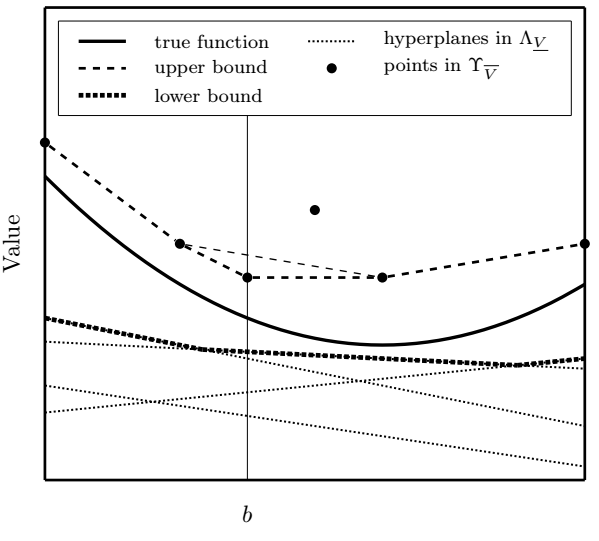 Figure 2
Figure 2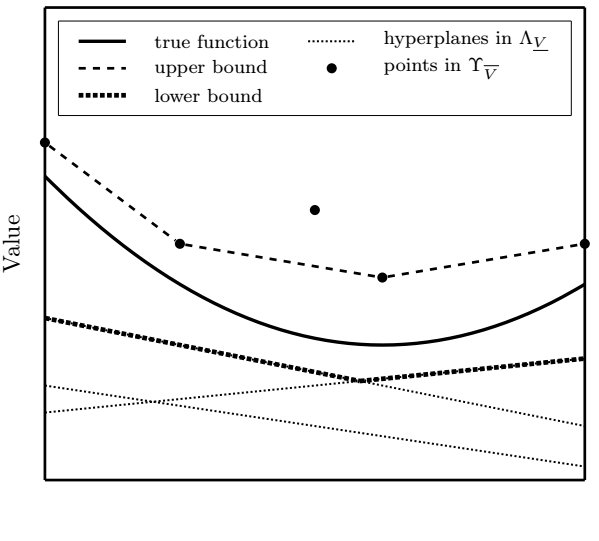 Figure 3
Figure 3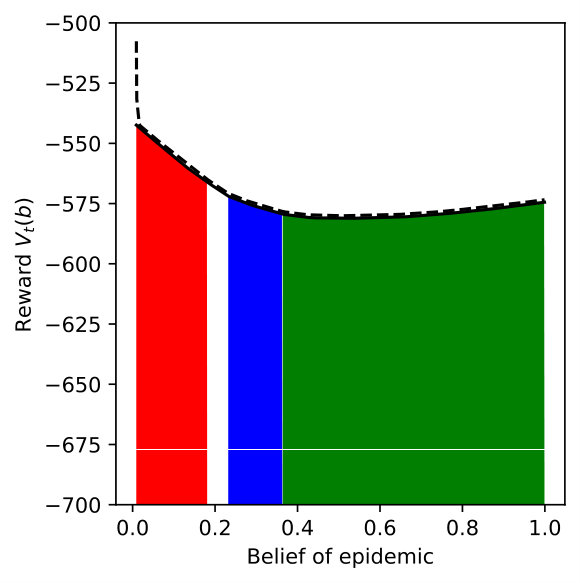 Figure 4
Figure 4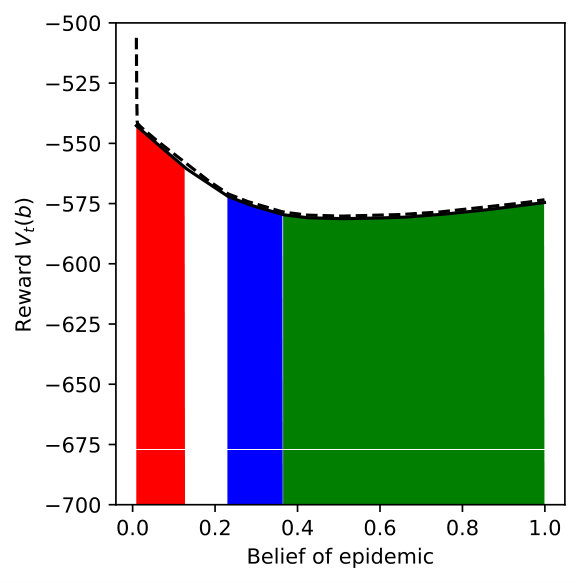 Figure 5
Figure 5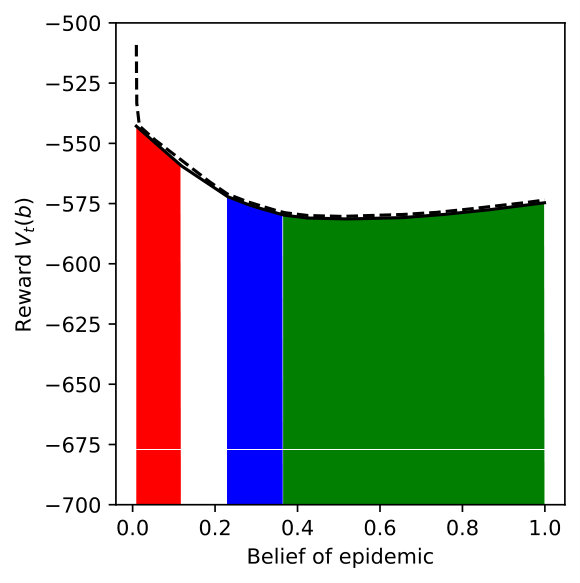 Figure 6
Figure 6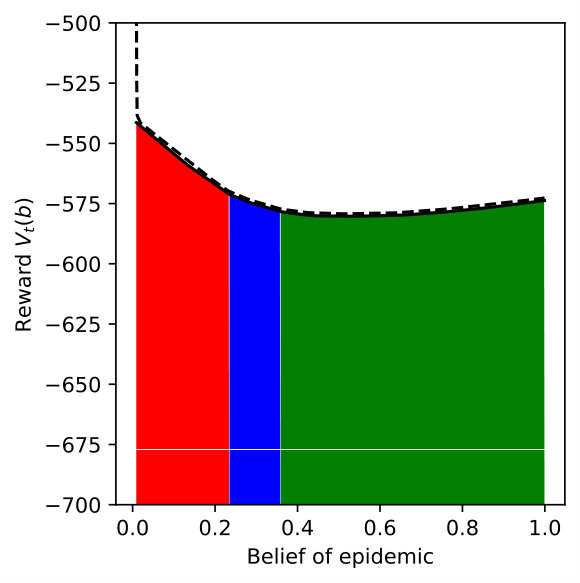 Figure 7
Figure 7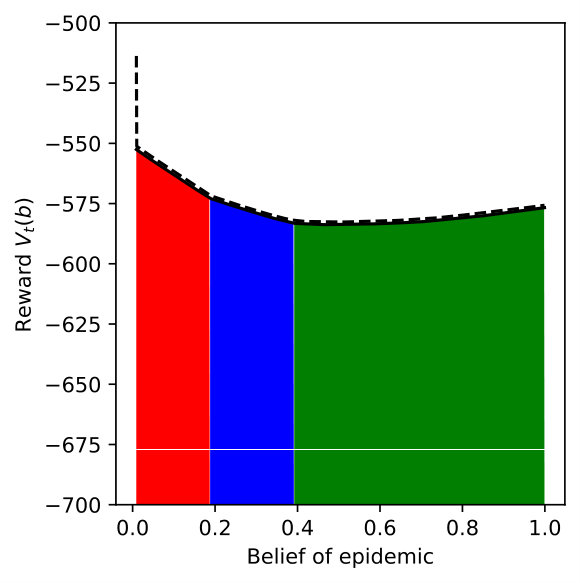 Figure 8
Figure 8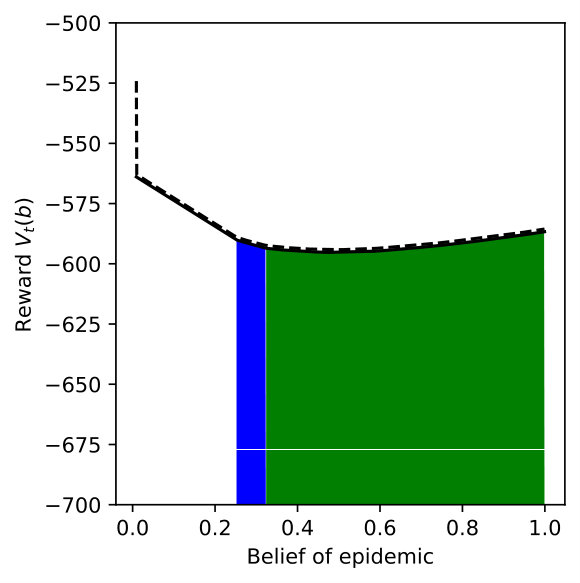 Figure 9
Figure 9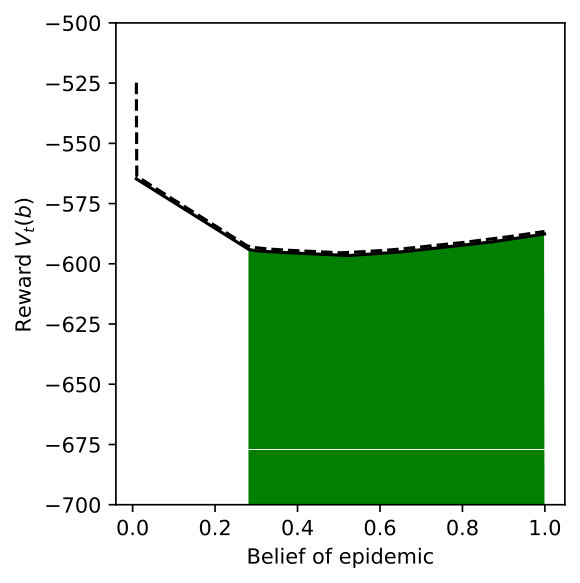 Figure 10
Figure 10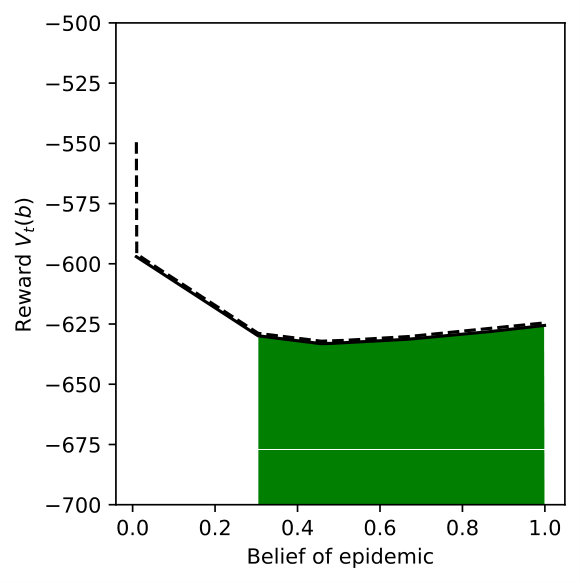 Figure 11
Figure 11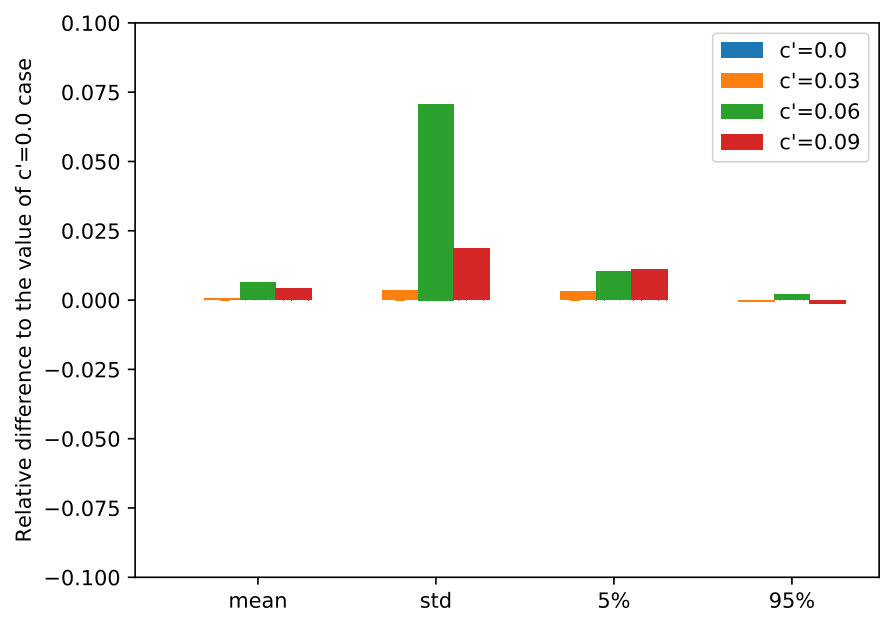 Figure 1
Figure 1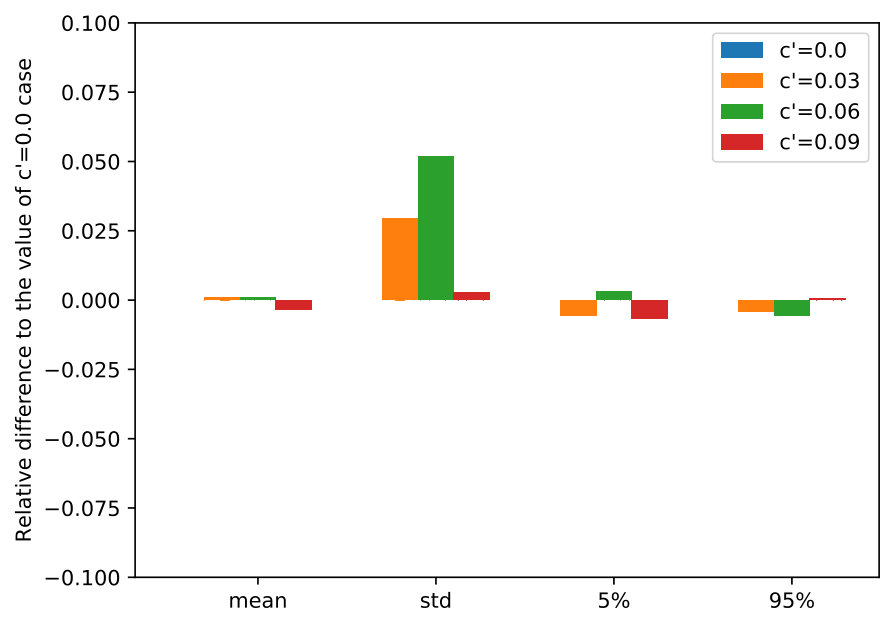 Figure 1
Figure 1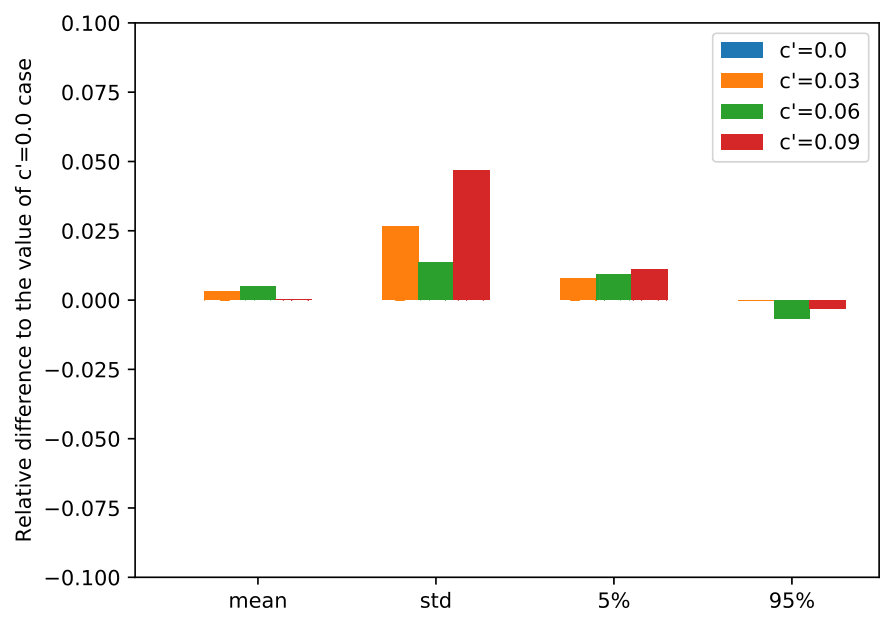 Figure 1
Figure 1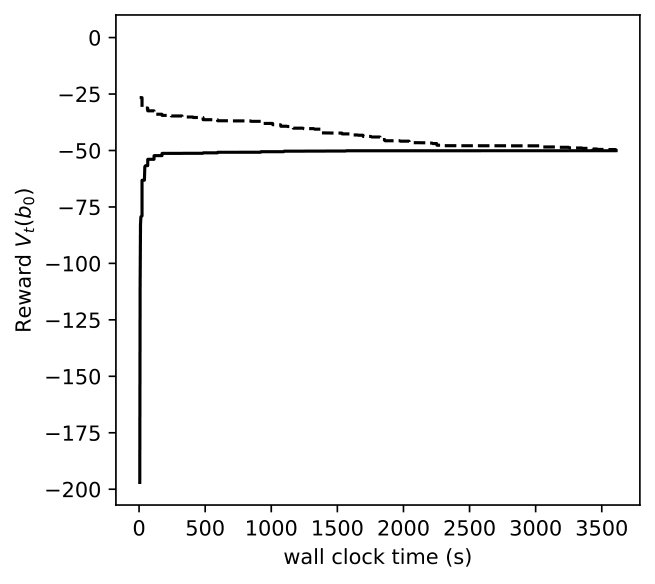 Figure 15
Figure 15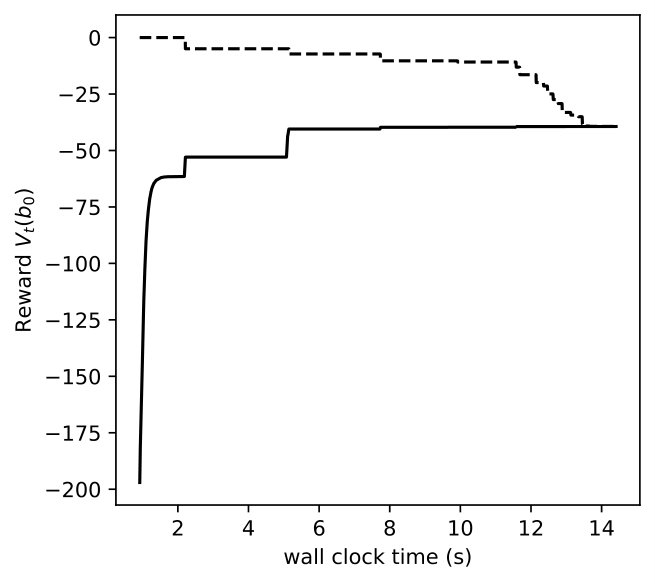 Figure 16
Figure 16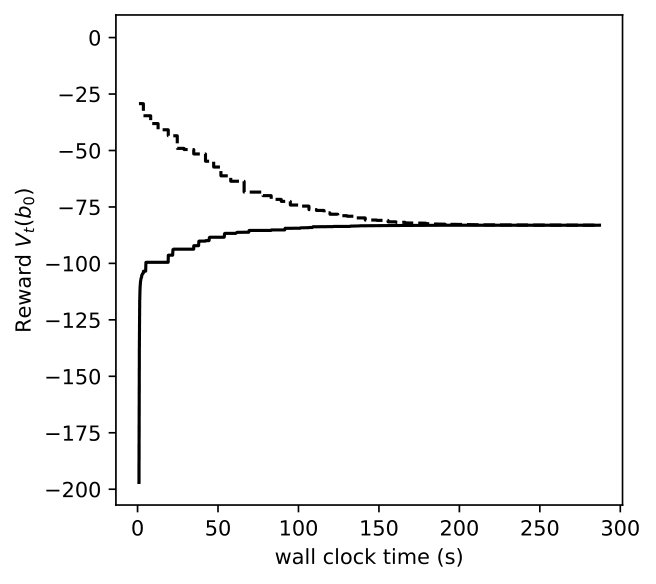 Figure 17
Figure 17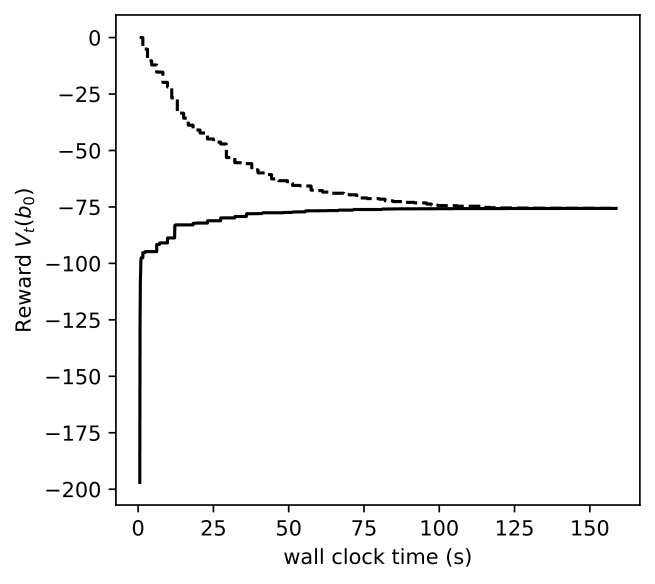 Figure 18
Figure 18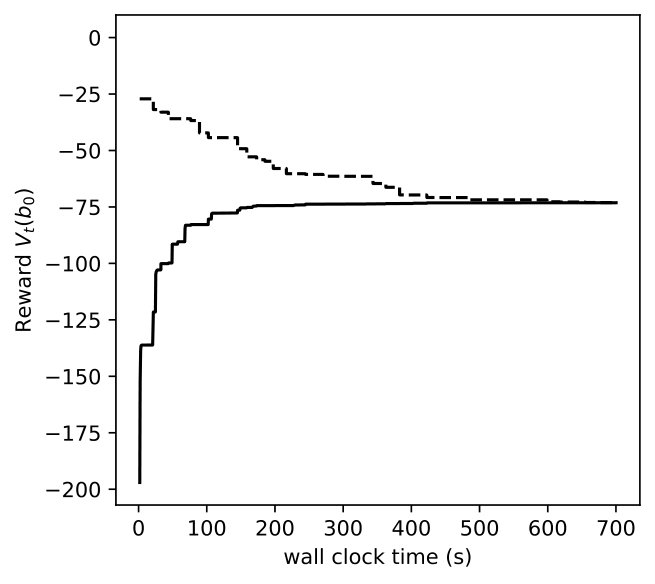 Figure 19
Figure 19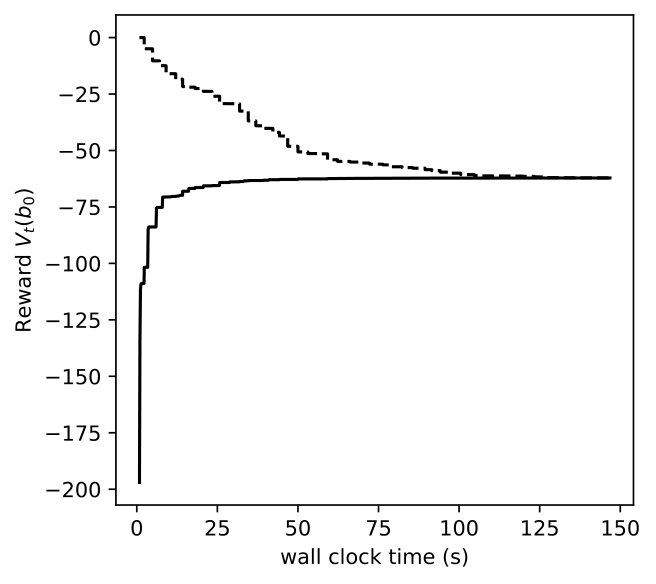 Figure 20
Figure 20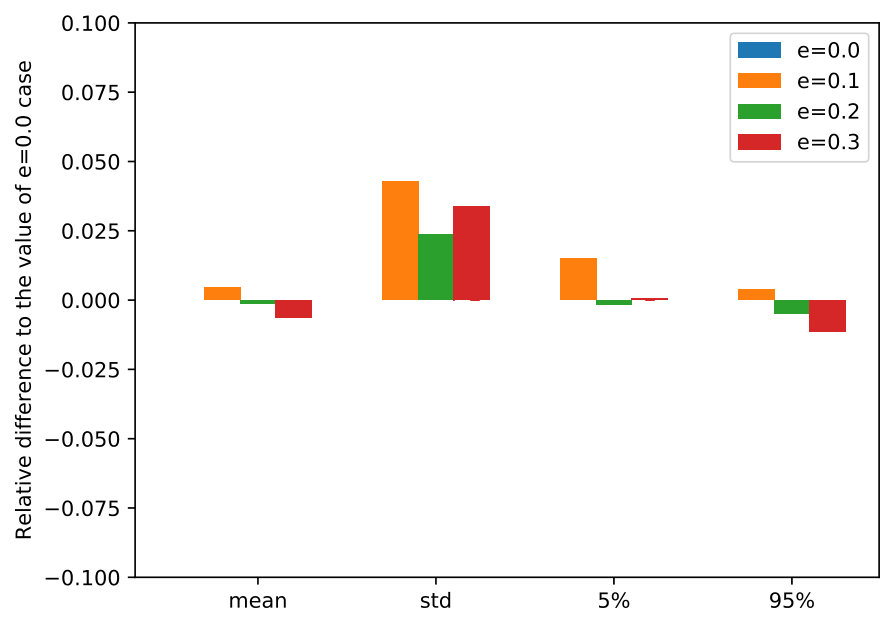 Figure 1
Figure 1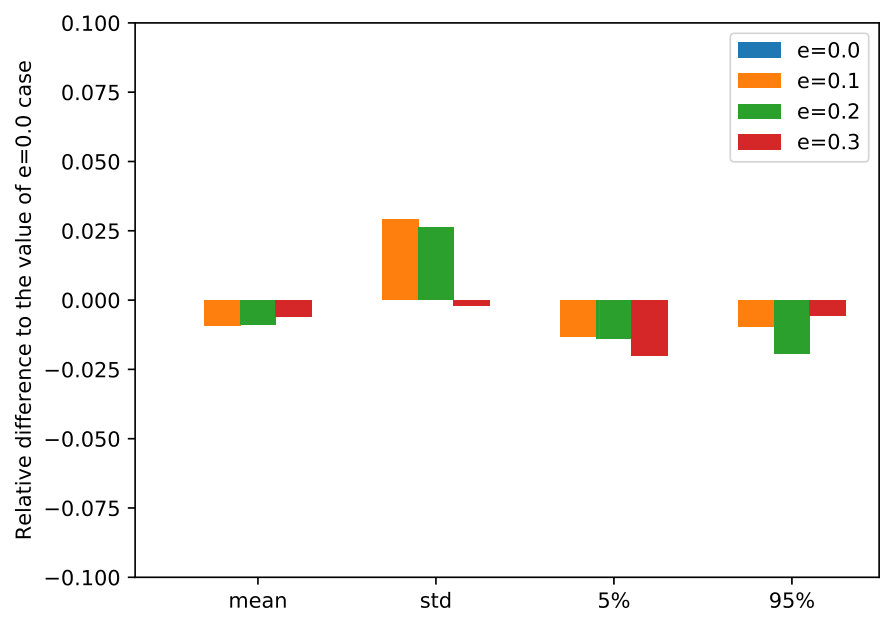 Figure 1
Figure 1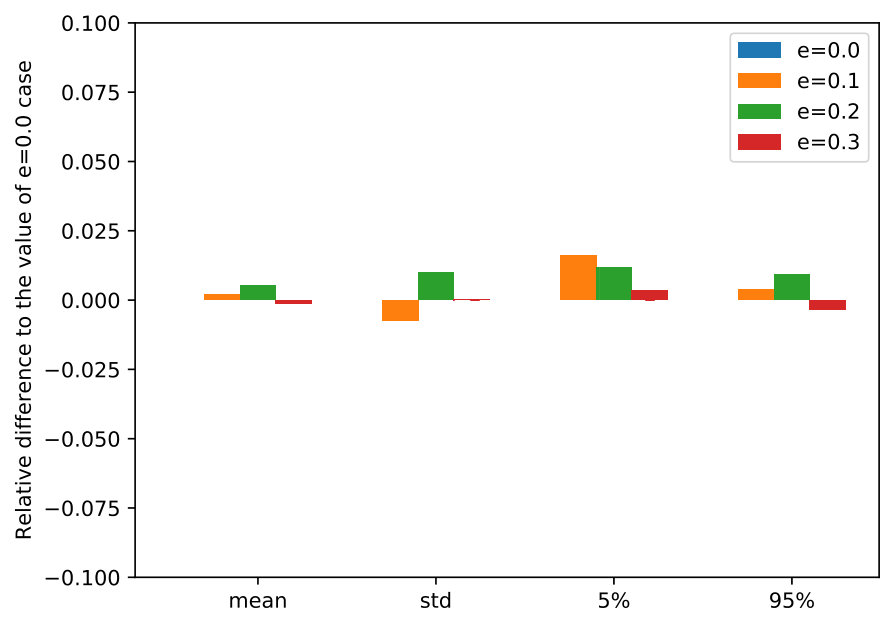 Figure 1
Figure 1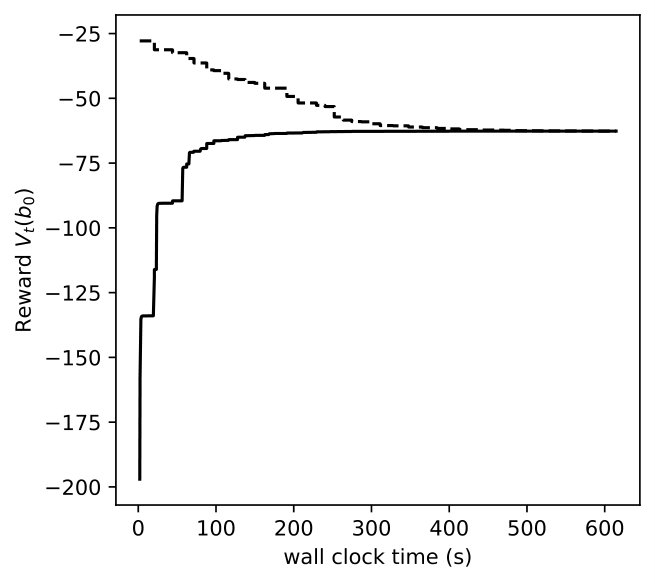 Figure 24
Figure 24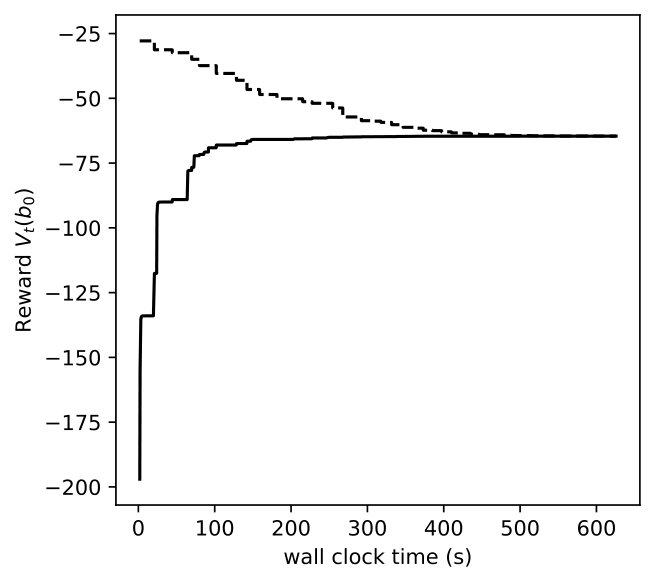 Figure 25
Figure 25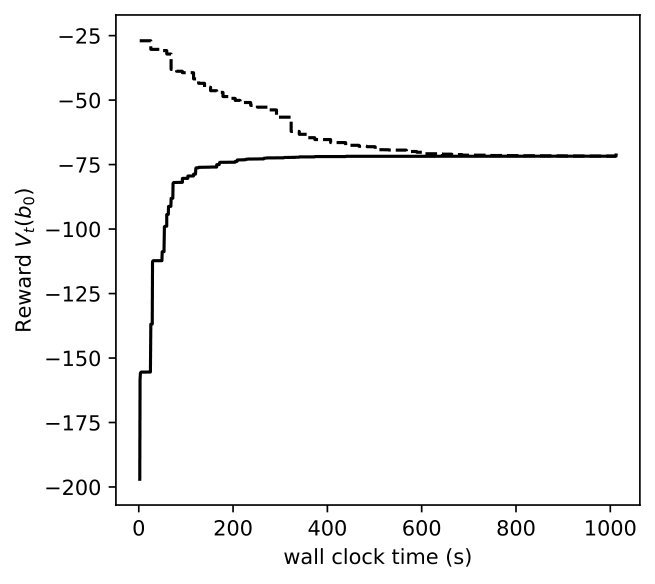 Figure 26
Figure 26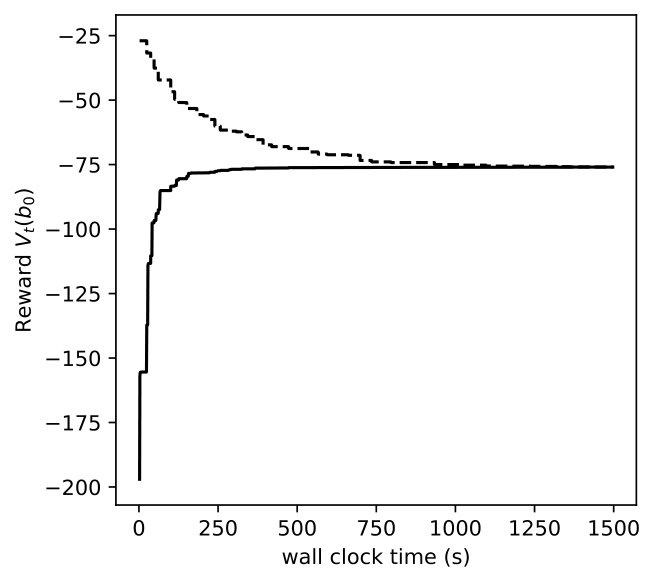 Figure 27
Figure 27| State/Action | Level 0 | Level 1 | Level 2 | Inspection |
|---|---|---|---|---|
| Epidemic | ||||
| Non-epidemic |
| Nature’s policy | |||
|---|---|---|---|
| DM’s policy | POMDP(std) | DR-POMDP(std) | Robust(std) |
| POMDP | |||
| DR-POMDP | |||
| Robust | |||
| Nature’s policy | |||
|---|---|---|---|
| DM’s policy | POMDP(std) | DR-POMDP(std) | Robust(std) |
| POMDP | |||
| DR-POMDP | |||
| Robust | |||
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsRisk and Portfolio Optimization · Bayesian Modeling and Causal Inference · Reinforcement Learning in Robotics
Distributionally Robust Partially Observable Markov Decision Process with Moment-based Ambiguity
Hideaki Nakao Ruiwei Jiang Siqian Shen Department of Industrial and Operations Engineering, University of Michigan at Ann Arbor, USA;Department of Industrial and Operations Engineering, University of Michigan at Ann Arbor, USA;Corresponding author; Department of Industrial and Operations Engineering, University of Michigan at Ann Arbor, USA. Email: [email protected].
Abstract
We consider a distributionally robust Partially Observable Markov Decision Process (DR-POMDP), where the distribution of the transition-observation probabilities is unknown at the beginning of each decision period, but their realizations can be inferred using side information at the end of each period after an action being taken. We build an ambiguity set of the joint distribution using bounded moments via conic constraints and seek an optimal policy to maximize the worst-case (minimum) reward for any distribution in the set. We show that the value function of DR-POMDP is piecewise linear convex with respect to the belief state and propose a heuristic search value iteration method for obtaining lower and upper bounds of the value function. We conduct numerical studies and demonstrate the computational performance of our approach via testing instances of a dynamic epidemic control problem. Our results show that DR-POMDP can produce more robust policies under misspecified distributions of transition-observation probabilities as compared to POMDP, but has less costly solutions than robust POMDP. The DR-POMDP policies are also insensitive to varying parameter in the ambiguity set and to noise added to the true transition-observation probability values obtained at the end of each decision period.
**Keywords: ** Partially Observable Markov Decision Process (POMDP), distributionally robust optimization, moment-based ambiguity set, heuristic search value iteration (HSVI), epidemic control
1 Introduction
Partially Observable Markov Decision Processes (POMDPs) are useful for modeling sequential decision making problems, where a decision maker (DM) is only able to obtain partial information about the present state of a system of interest. Similar to the Markov Decision Processes (MDPs), the transition probabilities in between the states of the system depend on the current state and the action chosen by the DM. In addition, POMDPs are accompanied with a set of observation outcomes that are realized probabilistically given the DM’s action and the state into which the system has transitioned. Different from MDPs where the DM is able to directly observe the current state of the system, in POMDPs the DM can only view an observation instead of the true state. Applications of POMDPs include clinical decision making, inventory control, machine repair, epidemic intervention and many more Cassandra, (1998); Hauskrecht and Fraser, (2000); Treharne and Sox, (2002).
A general objective in sequential decision making is to devise a policy of taking dynamic actions to maximize (minimize) the expected value of the cumulative reward (cost). In MDPs, the DM gains a reward (or pays a cost) for each action made on a state of the system. In POMDPs, since the DM has no access to the true state, she is uncertain about the reward (cost) received. Instead, the DM retains her belief of the present state based on past actions and observations, and anticipates an expected value of the reward (or the expected cost) based on the belief. The DM’s belief is represented by a probability mass associated with each state of the system, which is a sufficient statistic of the history of past actions and observations (Kumar and Varaiya,, 2015, Chapter 6.6). Since a policy is a function of the past actions and observations, this property is useful to compactly represent an increasing sequence of information.
In POMDPs, a critical assumption is that the exact transition and observation probabilities are known to the DM for each action-state combination. In practice, there may exist estimation errors about either the transition or observation probability values, to handle which, Rasouli and Saghafian, (2018) builds an uncertainty set of probabilities and develops an exact algorithm for the problem of maximizing the expected reward in the worst-case realization of the unknown probabilities in POMDPs. We will numerically compare actions of robust POMDP (see Osogami, (2015)) with decision policies of DR-POMDP and POMDP in Section 6.
In this paper, using bounded moments, we construct an ambiguity set of the unknown joint distribution of the transition-observation probabilities, in which the true joint distribution lies with high probability. We consider a distributionally robust optimization framework of POMDPs (called DR-POMDP) to seek an optimal policy against the worst-case distribution in the ambiguity set, when realizations of the transition and observation probabilities in each decision period are generated from this distribution. Moreover, we allow transition-observation probabilities to vary in different decision periods, and assume that at the end of each period, the DM can gather side information to infer the true values of the transition-observation probabilities realized in that period, even these values were unknown to the DM when decisions were made. Admittedly, it is rather restrictive to have this assumption where the transition-observation probabilities can be observed retrospectively. However, there exist a wide range of applications where the underlying dynamics are understood and can be simulated to produce unknown parameters (i.e., transition-observation probabilities) once values of some exogenous parameters are gained after the decisions are made. For example, Mannor et al. Mannor et al., (2016) justify the electric power system as one case where the system performance can be reliably simulated when environmental factors, such as wind and solar radiation levels, are known. In Section 3, we provide a few examples to further illustrate and justify this assumption and in Section 6, we conduct numerical tests on dynamic epidemic control problem instances, which satisfy the assumption.
In distributionally robust optimization (DRO), we seek solutions to optimize the worst-case objective given by possible distributions contained in an ambiguity set. Compared with robust optimization that accounts for the worst-case objective outcome given by all possible realizations of uncertain parameters in an uncertainty set, optimal solutions to DRO models are less conservative and can be adjusted through the amount of data/information we have. Ref. Delage and Ye, (2010) develops a moment-based ambiguity set, considering a set of distributions with an ellipsoidal condition on the mean and a conic constraint on the second-order moment, to derive tractable reformulations of several distributionally robust convex programs. Standardization of ambiguity sets via conic representable sets is proposed by Wiesemann et al., (2014). Ref. Zymler et al., (2013) considers tractable reformulations of DR chance-constrained programs using moment-based ambiguity set. Other types of ambiguity sets used in DRO models bound the -divergence Ben-Tal et al., (2013); Jiang and Guan, (2016) or Wasserstein distance Esfahani and Kuhn, (2018); Gao and Kleywegt, (2016) in between possible distributions to a nominal distribution. In this paper, we also use a moment-based ambiguity set where the moment information is bounded via conic constraints. We establish the Bellman equation for DR-POMDP and prove the piecewise-linear-convex property of the value function, using which we further develop efficient computational algorithms and demonstrate the efficacy of the DR-POMDP model by testing epidemic control problem instances with diverse parameter settings.
The remainder of the paper is organized as follows. In Section 2, we review the most relevant POMDP, robust MDP/POMDP, and DRO literature. In Section 3, we formally present DR-POMDP and provide a few examples to show possible applications. In Section 4, we formulate the Bellman equation and show that the value function is piecewise linear convex under general moment-based ambiguity sets described in Yu and Xu, (2016). In Section 5, we develop an approximation algorithm for DR-POMDP based on a distributionally robust variant of the heuristic value search iteration algorithm. In Section 6, we demonstrate the computational results of solving DR-POMDP on randomly generated instances of a dynamic epidemic control problem, and compare it with POMDP and robust POMDP through different out-of-sample tests. Section 7 concludes the paper and presents future research directions.
2 Literature Review
Although strong modeling connections exist in between MDP and POMDP, techniques applied to solve MDP models where the states are discrete, are not directly applicable to solving POMDP since belief states are continuous. Ref. Smallwood and Sondik, (1973) shows that the value function of POMDP is piecewise linear convex (PWLC) with respect to the belief state, and derives an exact algorithm to find an optimal policy. The exact algorithm, which keeps a set of vectors for characterizing the value function, is intractable as the search space increases exponentially over periods. Ref. Pineau et al., (2003) proposes a point-based value iteration (PBVI) algorithm by only keeping characterizing vectors for a subset of belief states, and thus maintains a lower bound of the true value function that aims to maximize the reward. The PBVI algorithm is polynomial in the number of states, observations, and actions, and the error induced by taking a subset of belief states is shown to be convergent if the subset is sampled densely in the reachable set of belief states. Ref. Smith and Simmons, (2004) develops a heuristic search value iteration (HSVI) algorithm to derive an upper bound of the value function via finding the reachable set through simulation. Ref. Smith and Simmons, (2004) shows that HSVI is guaranteed to terminate after the gap between the upper and lower bounds converges within a certain threshold.
The research on robust MDP is motivated by possible estimation errors of transition matrices and how they may have a significant impact to the solution quality (see, e.g., Abbad and Filar, (1992); Abbad et al., (1990)). In Wiesemann et al., (2013), the authors show probabilistic guarantees for solutions to robust MDPs by building an uncertainty set using fully observable history. By construction, their robust policy achieves or exceeds its worst-case performance with a certain confidence. Ref. Nilim and El Ghaoui, (2005) considers robust control for a finite-state, finite-action MDP, where uncertainty on the transition matrices is described by particular uncertainty sets such as likelihood regions or entropy bounds, and the authors present a robust dynamic programming algorithm for solving the problem. Ref. Iyengar, (2005) analyzes a robust formulation for discrete-time dynamic programming where the transition probabilities are uncertain and ambiguously known, and shows that it is equivalent to stochastic zero-sum games with perfect information. Ref. Delage and Mannor, (2010) argues that robust MDP models may produce over-conservative solutions, as they do not incorporate the distributional information of uncertain parameters. Then Xu and Mannor, (2012) presents a distributionally robust MDP model, where the ambiguity set is characterized by a sequence of nested sets, each having a confidence level to guarantee that the true value is in the set with a certain probability. Ref. Yu and Xu, (2016) generalizes the distributionally robust MDP to include multi-modal distributions and the information of mean and variance. Ref. Yang, (2017) proposes a distributionally robust MDP model by building an ambiguity set of distributions on transition probability using a Wasserstein ball centered around a nominal distribution. The use of Wasserstein ball ambiguity set results in a Kantorovich-duality-based convex reformulation for distributionally robust MDP.
Ref. Saghafian, (2018) presents a modeling framework of ambiguous POMDP (called APOMDP), which generalizes the robust POMDP in Rasouli and Saghafian, (2018). APOMDP optimizes over the -maxmin expected utility, resulting in a policy that can achieve the intermediate performance of the worst case and the best case in the uncertainty set of parameters. Ref. Saghafian, (2018) describes conditions under which the value function of APOMDP is PWLC. Meanwhile, Rasouli and Saghafian, (2018) considers a general setting of robust POMDP, where the DM may not be able to obtain the exact transition-observation probabilities even after taking actions at the end of each period. In this case, the sufficient statistic is no longer a single belief state, but a collection of belief states, and the expected reward up to the current period must be taken into account to realize a policy that is robust in terms of the entire cumulative expected reward. The authors also derive an exact algorithm for robust POMDP where the uncertainty set is discrete. Here we note that robust POMDP with a continuous uncertainty set is computationally challenging even in a very simple setting. Moreover, Osogami, (2015) formulates a robust counterpart for POMDP, where the transition-observation matrix is assumed to lie in a fixed support within the probability simplex. The realized transition-observation probability values are assumed to be observable to the DM at the end of each decision period, similar to the setting in this paper. While the value function for the standard POMDP can be described by a PWLC function, the value function of the robust POMDP is not necessarily piecewise linear, as there are possibly infinitely many supporting hyperplanes. The authors derive an efficient algorithm based on PBVI to approximate the exact solution, and discusses a method to conduct a robust belief update.
3 Problem Description
Figure 1 depicts the sequence of events that occur during one decision period. In a distributionally robust setting, we consider another agent (the “nature”), who chooses a distribution of the transition-observation probabilities from a pre-assumed ambiguity set. The DM expects that the nature may access to the same information as the DM and acts adversarially against the DM’s action taken at the beginning of each period. Therefore, the distribution is expected to lead to the worst-case expected reward. Next, the joint transition-observation probability is realized from the distribution . The state makes a transition according to , and the observation outcome is shown. Finally, the DM obtains the values of and at the end of the period.
We denote as the set of states, as the set of actions, and as the set of observation outcomes. For all , we define as the probability of transitioning between and observing , given action . For , let be the reward for taking action at state . For all , we define a vector of probabilities and assume that the Cartesian product is a member of a set , where is a probability simplex of set . We denote and for all . We assume that follows a distribution , which is unknown but is included in an ambiguity set , where represents a set of all probability distributions with support . Furthermore, the set of distributions is rectangular with respect to the set of actions and the set of states , i.e., the overall ambiguity set is . This assumption is analogous to the -rectangularity in Wiesemann et al., (2013). The above conditions increase the conservativeness of the model in general. In the online supplement Nakao, Hideaki and Jiang, Ruiwei and Shen, Siqian, (2020) A, we discuss a relaxation of the -rectangularity assumption for DR-POMDP.
Below we describe several examples in which the above settings of DR-POMDP can be justified, and therefore our approach can be applied to optimize corresponding policies. The key is to justify whether the DM can obtain the true value of using side information at the end of each decision period. In Section 6, we also numerically show that our approach can produce quite stable reward in out-of-sample simulation tests even we add noise to the true -value obtained at the end of each period and thus the assumption is relatively weak.
First, consider dynamic epidemic surveillance and control. During a flu season, the number of weekly visits of patients who show influenza-like illness (ILI) symptoms is reported to the public. The number of ILI patients divided by the total population, called the ILI rate, is frequently used to estimate the prevalence of an epidemic. For example, Rath et al., (2003) studies a two-state MDP model (i.e., epidemic vs. non-epidemic) and shows that the ILI rate follows a Gaussian and an exponential distribution for the epidemic and non-epidemic state, respectively; Le Strat and Carrat, (1999) uses ILI rate to predict influenza epidemics through a hidden Markov model. The hidden states correspond to the current epidemic level, which is unobservable to the DM due to incubation period and patient arrival latency. Different epidemic levels also cause different probabilities of the population visiting healthcare providers, which will then be reflected in ILI rate.
Arguably, the transition probabilities and ILI rates are dependent on government control policies, such as restricting travels, stopping mass gatherings, and so on. These decisions often have to be made before knowing the true transition matrix and observation probabilities between ILI rate and the true epidemic state. The DR-POMDP seeks a policy to minimize the worst-case expected cost (e.g., the total infected count, death toll, etc.) and at the end of each decision period, side information such as humidity, antigenic evolution of the virus, and population travels in the past period can be used to infer the true transition and ILI-rate observation probabilities (see, e.g., Du et al.,, 2017). Note that the side information is not available at the beginning of each decision period when the DM takes an action, but can be collected at the end of each period.
Another example arises in clinical decision-making such as deciding prostate cancer treatment plans Zhang and Denton, (2018), where different treatment plans can probabilistically vary cancer conditions (i.e., states) of a patient. The true state of a cancer patient is hard to know but can be inferred probabilistically from belief states. Using DR-POMDP, a doctor’s objective is to provide treatment and inspection as needed in order to minimize the maximum expected quality-adjusted life years for each patient under ambiguously known transition-observation probabilities. According to Zhang and Denton, (2018), the detection of prostate-specific antigen (PSA), has a varying accuracy rate depending on the patient’s condition. After treatment in each period, the doctor can utilize the PSA information to infer the true transition and observation probabilities happening to the patient and update her belief to make treatment plans for the next period.
One can also consider planning production or maintaining inventory in highly seasonal industries such as agriculture Treharne and Sox, (2002), where system states correspond to market trends in each decision period. The trend makes a transition according to a probability mass function that is unknown to the DM and each trend is associated with a certain distribution of demand that the DM aims to satisfy. For a certain product, the market transition probability and the demand distribution are correlated with climate factors, such as temperature and precipitation, which are uncertain to the DM when she makes a production plan and thus using DR-POMDP, the goal is to minimize the maximum demand loss due to distributional ambiguity. After each period, the DM observes the realized temperature and precipitation and also the true demand, to identify the true value of .
4 Optimal Policy for DR-POMDP
We derive an optimal policy for DR-POMDP when the DM can obtain the value of transition-observation probability at the end of each decision period. In Section 4.1, we formulate DR-POMDP as an optimization problem and construct the Bellman equation to derive the optimal policy. In Section 4.2, we show that the value function satisfying the Bellman equation is PWLC. Finally, in Section 4.3, we consider the infinite-horizon case, and demonstrate that the value function converges under the Bellman update operation.
4.1 Distributionally Robust Bellman Equation
We formulate a dynamic game involving two players: The DM selects and then the nature selects from the ambiguity set to minimize the expected reward given the DM’s action . Let , , be the action, transition-observation probability outcome, and observation during decision period . We denote as the set of all possible histories up to period , and denote as a history in . The DM’s objective is to find an optimal policy of selecting an action based on the history from to , i.e., finding the best policy with . We denote the set of all such policies as , and define an extended history , on which the nature bases its decision for choosing . The nature’s objective is to find the best policy (from the nature’s perspective) , with to minimize the expected reward. Similarly, we denote the set of all the nature’s policies as .
Rasouli and Saghafian Rasouli and Saghafian, (2018) point out that the sufficient statistic for robust POMDP is no longer a single belief state, but a set of belief states. Moreover, they discuss that the set of belief states by itself cannot be used to construct an optimal policy since there exists uncertainty for the reward accumulated in the past, associated with each of the belief states. Because of the uncertainty in the expected reward, the DM must consider a belief state that achieves the smallest expected reward both in the past and the future, posing great challenge for optimization. We claim that a similar observation holds true for the distributionally robust case. However, when the DM can obtain the value of transition-observation probability at the end of each decision period, the ambiguity of the belief state, as well as the expected reward diminishes and the single belief state becomes a sufficient statistic for DR-POMDP, which can also be used to characterize the optimal policy.
Let the belief state in period be . Given action , transition-observation probability , and observation outcome , the sufficient statistic for the history , or the belief state in period is given by
[TABLE]
where represents a vector of ones having the length ; is a matrix of zeros and ones that projects the vector to a vector , whose entries correspond to the outcome . That is, . Note that the belief state cannot be updated using (1) and will not be a sufficient statistic of the history of past actions and observations if we do not have the true values of .
With slight abuse of notation, let be a policy that maps belief states to the actions, i.e., for all . Similarly, let for all . Note that the nature’s policy is dependent on the belief state since the nature acts adversarial to the DM.
Remark 1
Note that the deterministic policy is optimal since the nature is able to access to the same information as the DM, plus the action that the DM has performed. This does not hold true when the nature is not able to perfectly access to the DM’s immediate action.
Given the nature’s choice of distribution , the expected value of the instantaneous reward given belief state and action is denoted as , where “” expresses the relation between random variables and probability distributions. Let be a discount factor. The objective of the DM is to find a policy to maximize the minimum cumulative discounted expected reward given all possible policies (i.e., distributions of transition-observation probabilities) by the nature. That is, DR-POMDP aims to solve
[TABLE]
where the terminal reward is zero without loss of generality. The initial belief state is given as . Alternatively, we denote the problem (2) as
[TABLE]
Here we omit all the constraints in (2) for presentation simplicity.
To solve (2), we propose to use dynamic programming, and derive the Bellman equation below.
Proposition 1
Denote and as sequences of policies from to . Let and be the sets of all policies and , respectively. Consider the value function in period as
[TABLE]
Then,
[TABLE]
*Proof: * We first isolate the term associated with period inside the expectation of (4) as follows.
[TABLE]
Given , the probability of observing is
[TABLE]
Thus, we can calculate the expectation conditioned on the values of in the value function as:
[TABLE]
where the second equality is due to rearranging the terms and the fact that is an information state. Because policies beyond period do not affect , we have
[TABLE]
The final equality follows the definition of . This completes the proof. Following Proposition 1, the policies optimal to (3) can be determined by recursively solving (5) from period to .
Now define two functions:
[TABLE]
The solution to the Bellman equation provides the optimal action given belief state . That is, an optimal action for the DM in period is
[TABLE]
whereas the optimal distribution chosen by the nature, under belief state and the DM’s action , is
[TABLE]
4.2 Properties of Distributionally Robust Bellman Equation (5)
We consider an ambiguity set based on mean absolute deviation of transition-observation probabilities as described below. We refer the readers to the online supplement Nakao, Hideaki and Jiang, Ruiwei and Shen, Siqian, (2020) B for a more general ambiguity set that can also involve ambiguity in the reward, and the mean values are on an affine manifold with conic representable support. The same property here holds for DR-POMDP with the general ambiguity set and we omit the details for presentation simplicity.
Suppose that the expected value of the deviation of the transition-observation probability from its mean value is at most . Then for all and , the unknown distribution satisfies , which is reformulated as:
[TABLE]
Here, denotes a vector of auxiliary variables, and is a joint distribution of . This notation is introduced to differentiate from , which represents the true distribution of . The ambiguity set for distribution is therefore
[TABLE]
while the support for is given by
[TABLE]
For ambiguity sets and supports respectively defined in terms of (10) and (11), we show that the value function is convex with respect to the belief state for each decision period.
Theorem 1
For all and , let the ambiguity set and support be (10) and (11), respectively. For all , there exists a set of slopes such that the value function can be expressed as follows.
[TABLE]
A detailed proof of Theorem 1 is shown in the online supplement Nakao, Hideaki and Jiang, Ruiwei and Shen, Siqian, (2020) C. Following this result, having provided the values of and , the inner minimization in (43) can be solved efficiently using linear programming. The issue, however, is that there are possibly infinitely many elements in , and even if there are finitely many, the number of supporting hyperplanes inside increases exponentially as the value functions are calculated from period to . We describe in Section 5 a heuristic search value iteration (HSVI) algorithm for efficiently computing optimal policies in DR-POMDP.
4.3 Case of Infinite Horizon
We show that the PWLC property of the value function can be extended to the case with infinite horizon. We prove the result by following the Banach fixed point theorem (see, e.g., Puterman, (2014)), and show that by repeatedly updating the value function in (5), it converges to a unique function corresponding to the optimal value of the infinite-horizon DR-POMDP problem.
Theorem 2
The operator defined as
[TABLE]
is a contraction for .
We refer the readers to a detailed proof provided in C in the online supplement Nakao, Hideaki and Jiang, Ruiwei and Shen, Siqian, (2020). Theorem 2 suggests that by employing the exact algorithm discussed in the finite horizon case, starting from any initial value function, the value function converges to an optimal function with rate by iteratively performing the Bellman operator . Therefore, we can use the same solution approach to be discussed in Section 5 for handling both finite-horizon and infinite-horizon cases of DR-POMDP.
5 Solution Method
We present a variant of the HSVI algorithm proposed in Smith and Simmons, (2004) (originally for solving POMDP) for efficiently computing upper and lower bounds for DR-POMDP. We maintain a set of finite number of hyperplanes , where the resulting PWLC function bounds the true value function from below. We also maintain a set of points whose elements are , which is a combination of a belief and an upper bound of the true value function at the belief . Therefore, the resulting PWLC function bounds the value function from above. The upper bound corresponding to a belief is obtained through sampling. The sampling follows a greedy strategy to close the gap between the upper bound and the lower bound for the belief points that are reachable from the initial belief.
Algorithm 1 presents the main algorithmic steps in HSVI, where the details of Step 4 are later provided in Algorithm 2. During Step 4, one sample path of DM, the nature’s action and the observation outcomes are greedily selected, and then the bounds are updated using Bellman equations. Figure 2 demonstrates how the lower bound of the value function can be described as the maximum of the lower bounding hyperplanes, and the upper bound can be described as a convex hull of the upper bounding points. Figure 3 illustrates an example of how newly discovered bounding hyperplanes and points can be used to locally update the bounds.
In Section 5.1, we explain how the upper and lower bounds of the value function are initialized (i.e., the details for Step 2), and in Section 5.2, we present an exploration strategy to close the gap to a pre-determined tolerance level. Finally, in Section 5.3, we discuss how the value functions are updated given a belief state .
5.1 Initialization
Recall the ambiguity set and support defined in (10) and (11), respectively. In the initialization step, we compute the lower bound for the true value function by taking the best action for obtaining the worst-case expected reward in each decision period. That is, for each action , we solve
[TABLE]
In the case of mean absolute deviation based ambiguity set (10), the second minimization is trivial as is fixed. The minimum value for all is computed by enumeration. We then define an initial lower bounding hyperplane and set , where .
The upper bound for the true value function is obtained by considering full observability of the system and computing the MDP for the best-case scenario in the ambiguity set. Let be a value function for the distributionally-optimistic MDP. It satisfies
[TABLE]
To solve this, we take a linear programming approach by formulating
[TABLE]
In the case of ambiguity set (10), model (14) becomes
[TABLE]
After the optimal solution is discovered, we initialize , where is a column vector with 1 in the element corresponding to and zero elsewhere. Overall, the initialization step consists of solving a polynomial number of convex optimization problems.
To obtain , we solve
[TABLE]
by enumerating all the values of . To obtain , we consider a convex combination of points , and find a point so that is the smallest attainable value. That is, we let be a weight corresponding to a point and solve
[TABLE]
where denotes the set for some integer .
5.2 Forward Exploration Heuristics
The forward heuristics follow from the HSVI algorithm from Smith and Simmons, (2004), where the selection of a suboptimal action leads to lowering the upper bound of the value function, eventually being replaced by another action having higher upper bound. Then, the scenario of the observation is chosen such that the expected value of the gap is the highest in the child node. This process is repeated until the discounted value of the gap is smaller than a tolerance. The algorithmic steps described in this section are based on a greedy sampling strategy to close the gap between the upper and lower bounds of the value function. Samples in the simulation are branched by the DM’s actions , the nature’s distribution choices , and their outcomes and .
We consider the following function:
[TABLE]
We can obtain and by letting and , respectively.
First, we select the DM and nature’s decision pair . The gap between and at belief state is
[TABLE]
Here we describe a greedy strategy to select the branches. For a given action , we define . Then, we let . We therefore have
[TABLE]
This greedy strategy ensures that a suboptimal decision pair gets replaced by better ones as updating the value functions reduces the gap.
To achieve the gap at the initial state , the condition for the gap at depth level starting from the initial one is only , which can readily be seen from (17) and (18). We define the difference of the gap and the required condition as the excess uncertainty, which is
[TABLE]
Using (18) and applying the identity (17), we have
[TABLE]
Next, we greedily choose so that the quantity associated to the pair in right-hand side of (19) has the maximum expected value, i.e.,
[TABLE]
Note that because the worst-case distribution under ambiguity set (10) is a point mass distribution, obtaining is trivial. Algorithm 2 describes the detailed algorithmic steps. In the HSVI approach, Algorithm 2 is called recursively to make decisions on which branch to choose in the next depth level . After the simulation is terminated, the updates on the lower and upper bounds are made for the belief states that are discovered through the simulation.
5.3 Local Updates
In this section, we describe the details of and steps in Algorithm 2. We first illustrate how the lower bound is updated in . For each , we solve the two inner maximization problems in (42) provided and , where we set . The convex hull of is therefore,
[TABLE]
Thus, we combine the two inner maximization problems in (42) as
[TABLE]
We denote the optimal solutions to (22) using a superscript , and let the optimal dual solutions associated with constraints (22b) be . For each action , we can generate a lower bounding hyperplane
[TABLE]
where . We present the detailed algorithmic steps in Algorithm 3.
Next, we discuss how to update the upper bound and describe the algorithmic steps of in Algorithm 4. Combining (42) and the dual representation of (16), for each , we solve
[TABLE]
Here and are the dual variables associated with the two sets of constraints, , , respectively. The maximum objective value among all is added to .
Remark 2
The complexity of the related algorithm presented in Smith and Simmons, (2004) is based on the finiteness of the scenario tree up to a tolerance level . In the DR-HSVI algorithm, the scenario tree is not finite as the nature is able to choose from a continuous ambiguity set of distributions, and therefore the scenario tree has an infinite number of elements. Later we numerically demonstrate the convergence of the DR-HSVI algorithm in Section 6 for different combinations of parameter choices.
6 Numerical Studies
We test DR-POMDP policies for dynamic epidemic control (Sections 6.1 and 6.2), and compare the results of a two-state epidemic control problem with the ones given by POMDP and robust POMDP (Section 6.1.1). We vary parameter choices to test the robustness and sensitivity of DR-POMDP policies (i) under various types of ambiguity sets used in the in-sample tests (Sections 6.1.2, 6.1.3) and (ii) given certain noise added to the transition-observation probability value obtained at the end of each decision period in out-of-sample tests (Sections 6.1.4, 6.1.5). In Sections 6.2.1 and 6.2.2, we increase the sizes of the two-state influenza epidemic control instances in Section 6.1, demonstrate the algorithmic convergence, and present computational time results of using POMDP and DR-POMDP for solving larger-scale epidemic control instances.
6.1 Two-state Influenza Epidemic Control Problem
We study the problem of influenza epidemic control mentioned in Section 3. In the base setting, we consider two states, epidemic (E) and non-epidemic (N), and four actions as {Level 0, Level 1, Level 2, Inspection}. Here Level 0 corresponds to the minimum disease prevention and intervention plan, e.g., doing nothing, while Level 2 corresponds to the most restrictive strategy. The “Inspection” action refers to the same disease-control strategy as the Level 0 action, except that the DM pays extra cost to improve the observation of disease spread to obtain more accurate ILI rate.
For actions , the transition probability matrix is given by
[TABLE]
When (i.e., the DM does nothing), the above transition probabilities follow studies on influenza epidemics (see, e.g., Le Strat and Carrat, (1999)). The setting of the matrix (25) indicates that higher-level actions (i.e., more restrictive control strategies) will lead to greater chances that an epidemic state turns into non-epidemic and that a non-epidemic state remains itself. The transition probability for ‘Inspection’ (‘I’) is the same as the one for . The observation outcome is the ILI rate, calculated as the number of ILI patients per 1000 population. For actions , we follow Rath et al., (2003) and assume that the ILI rate follows a Gaussian distribution with mean value and variance for ‘Epidemic’ (‘E’), and with mean and variance for ‘Non-epidemic’ (‘N’). We discretize the observation outcome into five levels as . For ‘I’, the probabilities of observing the five outcomes are when ‘E’, and the ILI rate follows the same distribution as the one of if ‘N’, to model the situation where more careful inspection action can result in more ILI patients showing up. The rewards for each action-state combination are presented in Table 1, reflecting the negative number of total infections minus the effort paid for different actions in different states.
When implementing the HSVI algorithm in Section 5 for solving DR-POMDP, we set the discount factor and the gap tolerance . The computation is terminated when the gap between the upper and lower bounds is less than , at the initial states . We code the algorithm in Python and execute all the tests on a computer with Intel Core i5 CPU running at 2.9 GHz and 8 GB of RAM. We solve all the linear programming models using the Gurobi solver. Note that the complexity of computing the lower bound is linear in the number of elements in , and the complexity of computing the upper bound is polynomial in the size of set as we need to solve linear programs. Both and increase monotonically, but most elements in the two sets are dominated by others. We follow a heuristic to prune all the dominated elements whenever the number of elements increases by 10%.
6.1.1 Policy Comparison
We compare DR-POMDP policies with the ones by POMDP and robust POMDP via cross testing. We randomly generate ten samples of the transition probability for Level 2 action (i.e., ) and epidemic state (i.e., ‘E’), by keeping all the values the same as the base setting in (25) but letting the probability , where follows a standard Normal distribution. (We make sure that and re-sample if not.) For all three approaches, the mean value of the ten samples is used as the nominal transition probability. For robust POMDP, the maximum L1 norm from the mean defines an uncertainty set centered around the nominal probability. For DR-POMDP, we use the mean absolute deviation to define the ambiguity set.
We implement the DM’s optimal polices given by different approaches in out-of-sample environments where the nature follows the settings of POMDP, DR-POMDP, and robust POMDP to realize the transition probabilities in each period. The number of simulated instances is 5000 each. We report the estimated value of the median and the 5-percentile values of the reward in each case in Tables 2 and 3, respectively using Harrell-Davis quantile estimator Harrell and Davis, (1982). We also include the standard deviation of the estimator. Note that the 5-percentile of the reward is equivalent to the 95-percentile of the cost, indicating the tail (worse) performance of different policies. Therefore, Tables 2 and 3 indicate that POMDP has the smallest reward when the nature agrees with the DM to pick the nominal transition probabilities at each decision period, but it can lead to much worse reward (both in terms of the mean value and tail performance) if the transition probabilities are realized as the worst-case (in robust POMDP) or from the worst-case distribution (in DR-POMDP). On the other hand, the performance of DR-POMDP solutions is quite stable and robust under all out-of-sample circumstances but the tail performance is worse than the mean results. Lastly, the robust POMDP policy yields worse mean value and tail performance when the true environment is POMDP or DR-POMDP.
6.1.2 Results of Varying Ambiguity Set Sizes
We first only consider an ambiguity in the transition-observation probabilities of Level 0 action and epidemic state. We build the ambiguity set based on the mean absolute deviation such that for and ‘E’, where is the mean value of given probability samples and . We let be for some and vary the values of in our tests to vary the size of the ambiguity set.
We vary for DR-POMDP and also compute the POMDP policy using as the transition-observation probabilities for all and , which corresponds to a special case of DR-POMDP with . Figure 4 depicts the upper bound (dashed line) and the lower bound (solid line) of the value functions of POMDP and DR-POMDP, as well as optimal actions corresponding to different beliefs of the epidemic. The region of the belief in red (horizontal shade) corresponds to Level 0 action, blue (dotted shade) to Level 1 action, green (cross shade) to Level 2 action, and white (diagonal shade) to Inspection action. Because the ambiguity is in the transition-observation probabilities related to , in all the subfigures, as compared to POMDP, the DR-POMDP policy relies less on Level 0 action and replaces it with the ‘Inspection’ action when the belief of epidemic is relatively higher. When the belief increases further, both DR-POMDP and POMDP agree on implementing Level 1 or Level 2 action. As the ambiguity set size increases (i.e., increases), the DR-POMDP policy becomes more conservative and shifts to the ‘Inspection’ action earlier, even in relatively low belief of epidemic.
6.1.3 Results of Multiple Ambiguities
Next, we increase the number of action-state pairs that have distributional ambiguity in the transition-observation probabilities. We use for all ambiguity sets and vary the number of action-state pairs among . In Figure 5(a), action-state pairs (Level 0, E) and (Level 0, N) have ambiguous probability distributions and then we add pairs (Level 1, E), (Level 1, N), and (Level 2, E) one by one in the subsequent Figures 5(b), 5(c), 5(d).
We observe that the reward becomes smaller as we increase the number of action-state pairs with distributional ambiguity. This is because the worst-case scenario is considered jointly for all action-state pairs and the DR-POMDP policy aims to achieve a conservative reward outcome. Moreover, the belief range where Level 1 action is taken becomes smaller as we consider the distributional ambiguity in the transition-observation probabilities associated with . The ‘Inspection’ action also replaces the Level 0 action as we increase the number of ambiguity sources.
6.1.4 Solution Robustness under Different Ambiguity Sets
We simulate the DR-POMDP policies on instances with an initial state ‘E’ chosen with probability 50%. We use different sizes of ambiguity sets for the nature to choose the worst-case distributions in the in-sample computation. Specifically, we consider to compute DR-POMDP policies using the ambiguity setting in Section 6.1.2 and then vary to change the nature’s ambiguity set size for testing each DR-POMDP policy.
Figure 6 presents the statistics of the reward, including mean, standard deviation, 5-percentile and 95-percentile values, by implementing the DR-POMDP policies in in-sample tests when the nature uses different sizes of ambiguity sets to choose the worst-case distribution for the transition-observation probabilities. We observe that DR-POMDP policies are robust and not sensitive to the ambiguity set size change, especially in the mean, worst and best reward values.
6.1.5 Solution Sensitivity under Noise Added to the Realized Transition-Observation Probabilities
We argue that our assumption about the true transition-observation probabilities being accessible at the end of each decision period is relatively weak, by testing the DR-POMDP policies in out-of-sample scenarios while adding noise to the -value obtained at the end of each period. Specifically, when the DM takes Level 0 action, the transition probability of switching from an epidemic state to a non-epidemic state follows , where , and follows a standard Normal distribution. (We ensure that and re-sample if not.)
Figure 7 presents the statistics of the reward, including mean, standard deviation, 5-percentile and 95-percentile values, by implementing the DR-POMDP policies in out-of-sample scenarios under varying -values obtained at the end of each decision period. Similar to the previous section, we compare the reward statistics with the case when , i.e., the case when the DM can fully access the true -value at the end of each period. For different ambiguity sets (), the DR-POMDP solutions are not sensitive to the perturbation of -values obtained at the end of each period as we increase the noise. Moreover, all the statistics are within less than differences from the results of , indicating that our assumption about the necessity of using side information to obtain the true -value at the end of each period is not strong.
6.2 Large-scale Dynamic Epidemic Control Problem
We demonstrate the algorithmic convergence and compare the computational-time difference for larger-sized instances when applying the HSVI algorithm. We increase the problem size and instance diversity by extending the previous two-state model. Specifically, we consider people who are susceptible to infection and people who have recovered, so that we can model the variation and dynamics in the infection rate. We utilize the SIR compartmental model in epidemiology (see Hethcote,, 2000; Harko et al.,, 2014), where , , represent the susceptible, infected and recovered population ratios, respectively. These quantities can be modeled using differential equations:
[TABLE]
where is the rate of recovery, and is the average number of contacts per person per time. In this problem setting, we assume that these quantities can be controlled by the DM. We discretize the time horizon and consider discretized states , , . Furthermore, we take a first-order approximation and define the transition probabilities such that they satisfy
[TABLE]
We further assume that the states can only transition to its neighboring states, and the quantity of cannot increase. (Similarly, the quantity of cannot decrease.) We assume in the subsequent discussion.
The DM is able to make an imperfect observation of the state . The outcome of the observation is typically less than or equal to the true state , and the accuracy depends on the quality of the test. We assume that the observation outcome follows a Normal distribution with mean (with being a parameter that the DM can control) and standard deviation , and is further discretized by allocating the probability mass to the closest discrete observation outcome.
Moreover, the DM can implement certain epidemic control policies to vary and , and we fix . Choosing a low value of results in high cost due to its economic impact for a strict measure, and choosing a high value of results in high cost due to operating an expensive test process. We set the goal to minimize the number of infected people and preventing it from exceeding the treatment capacity, which is set as 0.2% of the overall population. Each percentage of population being infected will result in 10 units of cost, while 15 units of cost is incurred when the total infection is more than treatment capacity. Varying one unit of the - and -values costs 10 and 3 units, respectively. Additionally, when the total infection is more than 0.5% of the population, a reward will be given for performing the most strict measure in . Therefore,
[TABLE]
where and .
6.2.1 Computational Time for Varying Numbers of States
Let and , representing the ‘Non-epidemic’ state and ‘Epidemic’ state, respectively. We consider the following discretization schemes for the states : , , and .
In the numerical experiment, we only consider ambiguities in the action , corresponding to implementing the least strict control policy for reducing the infection rate. We set the radius of the ambiguity set as . Thus, the different problem sizes are , , and . We set the initial belief to be totally in the non-epidemic state, and allow a tolerance . The computational time limit is 3600 seconds.
In Figures 8, 9, 10, we depict how the upper bound and lower bound of POMDP () and DR-POMDP () policies converge as functions of time for the above three problem sizes, respectively. We observe that the computational time for POMDP does not correlate with the number of states. When the number of states are 4 and 8, the corresponding instances take about 150 seconds to converge, as compared to the instances having 16 states take about 14 seconds to converge. On the other hand, the computational time for DR-POMDP increases as the number of states and ambiguity sets increase. We also point out that the value function for DR-POMDP evaluated at is lower than that of POMDP, which is expected since DR-POMDP is more conservative.
6.2.2 Computation Time for Varying Uncertainty Sizes
We change the number of ambiguity sets and compare their solutions and computation time. The states are and , and actions are . We increase the number of actions that are associated with ambiguity sets from 1 to 4. Since there are 8 states in total, the number of ambiguity sets are 8, 16, 32, and 64, respectively. The results are shown in Figure 11. The solution time are 614, 625, 1012, 1497 seconds, respectively and increase as the number of ambiguity sets increases. The optimal objective values are , , , , respectively, and decrease monotonically.
7 Conclusion
In this paper, we developed new models and algorithms for POMDP when the transition probability and the observation probability are uncertain, and the probability distribution is not perfectly known. We presented a scalable approximation algorithm and numerically compared DR-POMDP optimal policies with the ones of the standard POMDP and robust POMDP, in both in-sample and out-of-sample tests. Although due to the more complicated model and problem settings, DR-POMDP is much harder to solve, it produces more conservative and robust results than POMDP. It is also not sensitive to the misspecified ambiguity set and true transition-observation probability values obtained at the end of each decision period.
In the future research, we aim to solve DR-POMDP when the outcomes of the transition-observation probabilities are not observable to the DM at the end of each time. In such a case, the value function is dependent on a set of belief states, where the characterization of the value function becomes much more challenging. We are also interested in designing randomized policy or time-dependent policy for DR-POMDP when we relax the condition that the nature is able to perfectly observe the DM’s action, or when the nature is not completely adversarial. We will compare the performance of different types of policies on diverse instances.
Acknowledgments
The authors thank the referees and the Associate Editor for their constructive comments and helpful suggestions. The authors gratefully acknowledge the support from the U.S. Department of Engineering (DoE) grant # DE-SC0018018 and National Science Foundation (NSF) grant # CMMI-1727618.
Appendix A Relaxation of -rectangularity
In this section, we investigate a variant of DR-POMDP where we relax the rectangularity condition of the ambiguity set in the actions. So far, we have only considered the setting where the ambiguity set is rectangular in terms of the states in and the actions in . This is known as -rectangular set in the literature of Wiesemann et al., (2013), who defined the term in the context of robust MDP. Ref. Wiesemann et al., (2013) also considered -rectangular set in robust POMDP, which is only rectangular in terms of the states . This setting has randomized policy as the optimal policy. We take a similar approach and formulate the Bellman equation:
[TABLE]
where is the probability for selecting action . We define the ambiguity set to be
[TABLE]
where is a vector of auxiliary variables, and
[TABLE]
Here, , , , , , , , and .
The value function is also convex in the form (12), since for ,
[TABLE]
where is a matrix of zeros and ones that maps to . For an exact algorithm, we solve the inner minimization problem for all , . The optimal objective is used for constructing the set , at each time step .
Appendix B General Ambiguity Set
In this section, we provide a general form of the ambiguity set where the mean values are on an affine manifold, and the supports are conic representable. For all and , we define a non-empty ambiguity set
[TABLE]
where is a vector of auxiliary variables, and a support with a non-empty relative interior
[TABLE]
Here, , , , , , , , and . The symbol represents a generalized inequality with respect to a proper cone . We denote the marginal distribution by , and also extend the definition to the ambiguity set so that . The auxiliary variables are used for “lifting” techniques, enabling the representation of nonlinear constraints to linear ones.
Appendix C Proofs of Theorems 1 and 2
First, we provide a detailed proof for Theorem 1 below. *Proof: * We show the result by induction. When , satisfies (12). For , the inner problem described in (7) becomes
[TABLE]
for all . Here is an indicator function, such that if event is true, it returns value 1 and 0 otherwise. Associating the dual variables and with constraints (35b) and (35c), respectively, we formulate the dual of (35) as
[TABLE]
Constraints (36b) are further equivalent to the following inequality with a minimization problem on the right-hand side (RHS).
[TABLE]
Substituting (12) for and (1) for , we obtain
[TABLE]
Since the objective of the maximization problem is linear in terms of , the optimal objective value does not change by taking the convex hull of , denoted as . Bringing the maximization to the front, we have
[TABLE]
The expression in the bracket is convex (linear) in for fixed , and concave (affine) in given fixed values of . Moreover, (37b)–(37e) and are convex sets. The minimax theorem (see, e.g., Osogami, (2015), Du and Pardalos, (2013)) ensures that the problem is equivalent to
[TABLE]
We take the dual of the inner minimization by associating dual variables , , with constraints (37b)–(37d), respectively. We thus have the following equivalence:
[TABLE]
Due to (37), we substitute in the objective function (36a) with (41). As a result, the value function (5) is equivalent to
[TABLE]
and after taking the dual of the most inner maximization problem, we have
[TABLE]
where
[TABLE]
Defining set as
[TABLE]
it follows that the above value function in (43) is of the form (12). Furthermore, by induction, this is true for all . This completes the proof.
The proof of Theorem 2 is given as follows. *Proof: * Consider two arbitrary value functions and . Given belief state , let
[TABLE]
for , and for all actions , denote
[TABLE]
for . First, suppose that . Then,
[TABLE]
The inequality follows that we replace the nature’s optimal decision for by , and replace the DM’s optimal solution for by . Then, by changing the difference between and to the absolute value of the difference, we have
[TABLE]
The second inequality follows that we take the supremum for all belief states , and the last equality is because .
The same result holds for the case where . Thus, for any belief state value , it follows that
[TABLE]
and therefore,
[TABLE]
yielding that is a contraction under . This completes the proof.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Abbad and Filar, (1992) Abbad, M. and Filar, J. A. (1992). Perturbation and stability theory for Markov control problems. IEEE Transactions on Automatic Control , 37(9):1415–1420.
- 2Abbad et al., (1990) Abbad, M., Filar, J. A., and Bielecki, T. R. (1990). Algorithms for singularly perturbed limiting average Markov control problems. In Decision and Control, 1990., Proceedings of the 29th IEEE Conference on , pages 1402–1407. IEEE.
- 3Ben-Tal et al., (2013) Ben-Tal, A., Den Hertog, D., De Waegenaere, A., Melenberg, B., and Rennen, G. (2013). Robust solutions of optimization problems affected by uncertain probabilities. Management Science , 59(2):341–357.
- 4Cassandra, (1998) Cassandra, A. R. (1998). A survey of POMDP applications. In Working notes of AAAI 1998 Fall Symposium on planning with partially observable Markov decision processes , pages 17–24.
- 5Delage and Mannor, (2010) Delage, E. and Mannor, S. (2010). Percentile optimization for Markov decision processes with parameter uncertainty. Operations Research , 58(1):203–213.
- 6Delage and Ye, (2010) Delage, E. and Ye, Y. (2010). Distributionally robust optimization under moment uncertainty with application to data-driven problems. Operations Research , 58(3):595–612.
- 7Du and Pardalos, (2013) Du, D.-Z. and Pardalos, P. M. (2013). Minimax and Applications , volume 4. Springer Science & Business Media.
- 8Du et al., (2017) Du, X., King, A. A., Woods, R. J., and Pascual, M. (2017). Evolution-informed forecasting of seasonal influenza a (h 3n 2). Science translational medicine , 9(413):eaan 5325.