Anti dependency distance minimization in short sequences. A graph theoretic approach
Ramon Ferrer-i-Cancho, Carlos G\'omez-Rodr\'iguez

TL;DR
This paper investigates the phenomenon where short sequences in language sometimes violate the dependency distance minimization principle, using a graph-theoretic approach and a binomial test to analyze syntactic structures across languages.
Contribution
It introduces a novel binomial test to detect anti-dependency distance minimization in short sequences and links this phenomenon to star tree structures in syntax.
Findings
Anti-DDm observed in some languages' short sequences
Star trees are associated with anti-DDm patterns
Method provides a new way to analyze syntactic dependency structures
Abstract
Dependency distance minimization (DDm) is a word order principle favouring the placement of syntactically related words close to each other in sentences. Massive evidence of the principle has been reported for more than a decade with the help of syntactic dependency treebanks where long sentences abound. However, it has been predicted theoretically that the principle is more likely to be beaten in short sequences by the principle of surprisal minimization (predictability maximization). Here we introduce a simple binomial test to verify such a hypothesis. In short sentences, we find anti-DDm for some languages from different families. Our analysis of the syntactic dependency structures suggests that anti-DDm is produced by star trees.
Click any figure to enlarge with its caption.
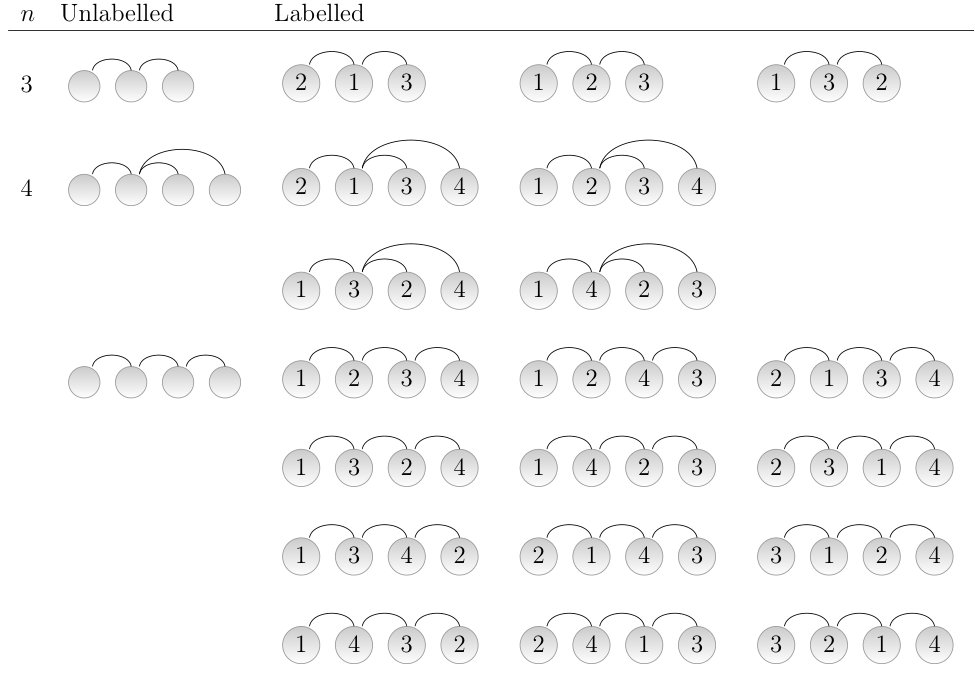 Figure 1
Figure 1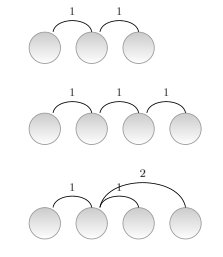 Figure 2
Figure 2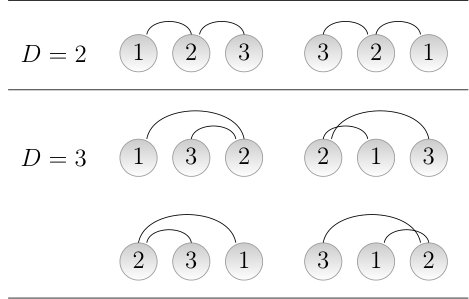 Figure 3
Figure 3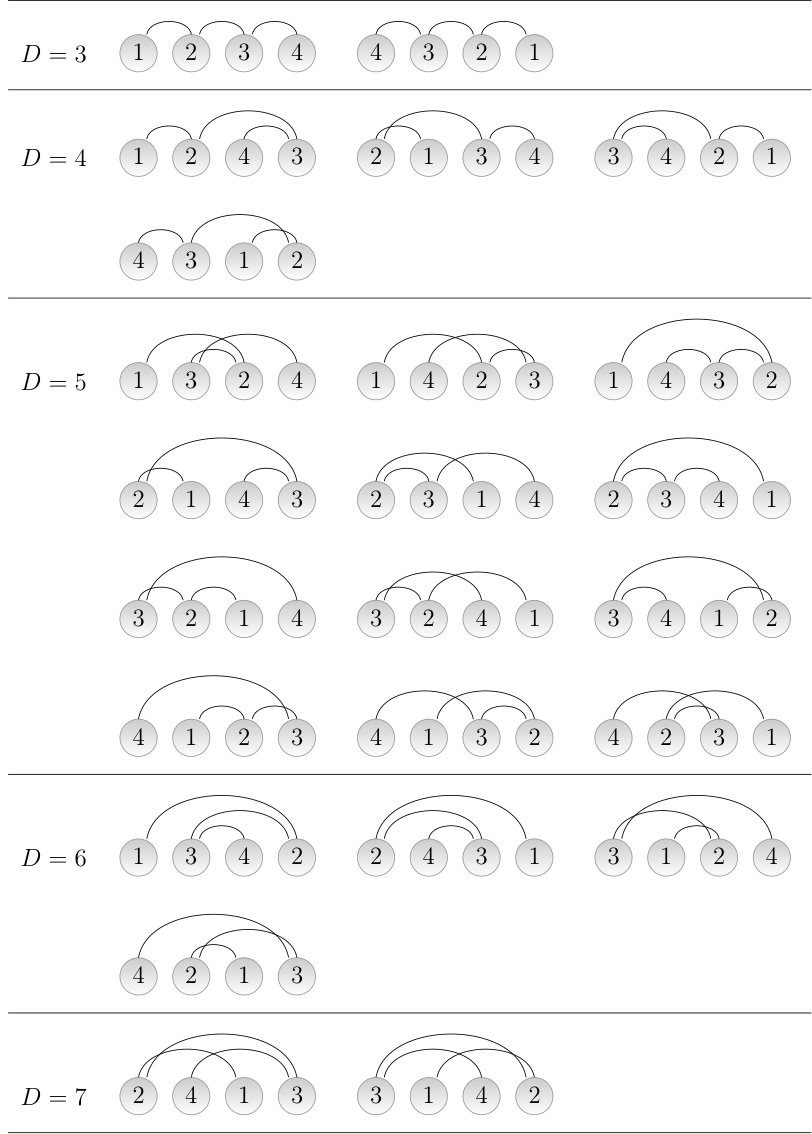 Figure 4
Figure 4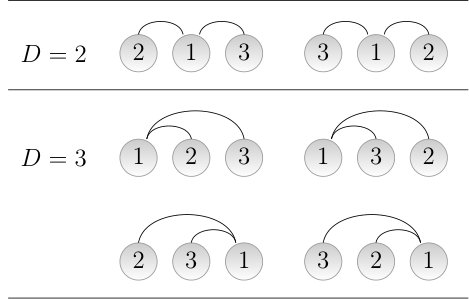 Figure 5
Figure 5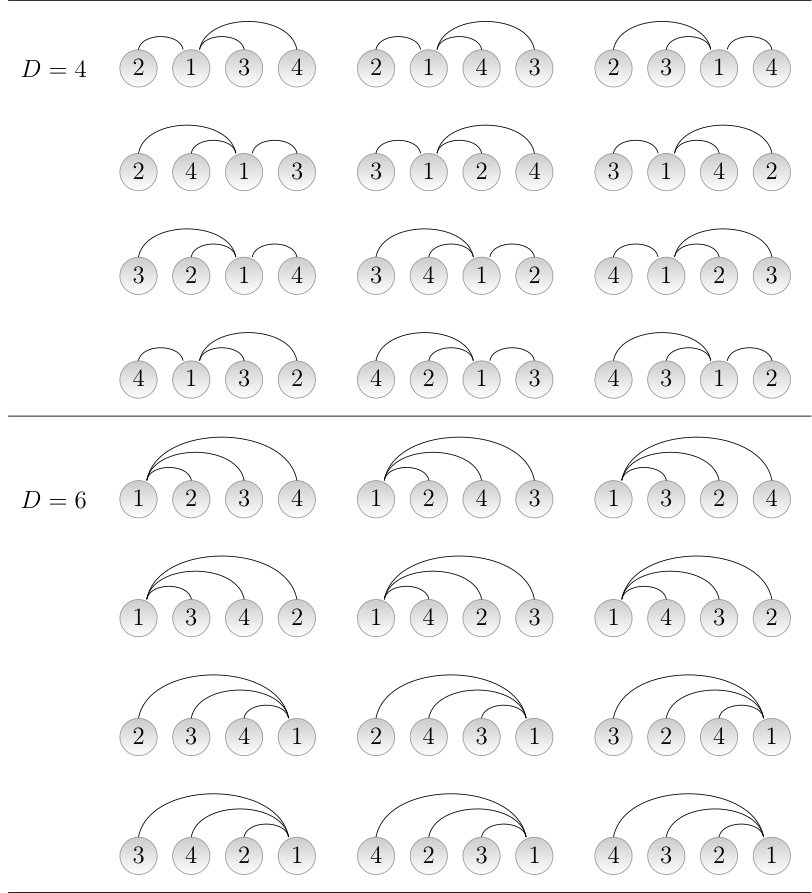 Figure 6
Figure 6| Collection | Family | Languages |
|---|---|---|
| UD (18, 76) | Afro-Asiatic (6) | Akkadian Amharic Arabic Coptic Hebrew Maltese |
| Altaic (3) | Kazakh Turkish Uyghur | |
| Austro-Asiatic (1) | Vietnamese | |
| Austronesian (2) | Indonesian Tagalog | |
| Basque (1) | Basque | |
| Dravidian (2) | Tamil Telugu | |
| Indo-European (44) | Afrikaans Ancient Greek Armenian Belarusian Breton Bulgarian Catalan Croatian Czech Danish Dutch English Faroese French Galician German Gothic Greek Hindi Hindi-English Irish Italian Kurmanji Latin Latvian Lithuanian Marathi Norwegian Old Church Slavonic Old French Persian Polish Portuguese Romanian Russian Sanskrit Serbian Slovak Slovenian Spanish Swedish Ukrainian Upper Sorbian Urdu | |
| Japanese (1) | Japanese | |
| Korean (1) | Korean | |
| Mande (1) | Bambara | |
| Mongolic (1) | Buryat | |
| Niger-Congo (1) | Yoruba | |
| Other (1) | Naija | |
| Pama-Nyungan (1) | Warlpiri | |
| Sign Language (1) | Swedish Sign Language | |
| Sino-Tibetan (2) | Cantonese Chinese | |
| Tai-Kadai (1) | Thai | |
| Uralic (6) | Erzya Estonian Finnish Hungarian Komi Zyrian North Sami | |
| Stanford (7, 30) | Afro-Asiatic (1) | Arabic |
| Altaic (1) | Turkish | |
| Basque (1) | Basque | |
| Dravidian (2) | Tamil Telugu | |
| Indo-European (21) | Ancient Greek Bengali Bulgarian Catalan Czech Danish Dutch English German Greek Hindi Italian Latin Persian Portuguese Romanian Russian Slovak Slovenian Spanish Swedish | |
| Japanese (1) | Japanese | |
| Uralic (3) | Estonian Finnish Hungarian | |
| Prague (7, 30) | Afro-Asiatic (1) | Arabic |
| Altaic (1) | Turkish | |
| Basque (1) | Basque | |
| Dravidian (2) | Tamil Telugu | |
| Indo-European (21) | Ancient Greek Bengali Bulgarian Catalan Czech Danish Dutch English German Greek Hindi Italian Latin Persian Portuguese Romanian Russian Slovak Slovenian Spanish Swedish | |
| Japanese (1) | Japanese | |
| Uralic (3) | Estonian Finnish Hungarian |
| Kind | |||
|---|---|---|---|
| 3 | DLM | 3 | |
| anti-DLM | 8 | ||
| 4 | unlabelled | 4 | |
| labelled | 3 | ||
| star | 5 | ||
| linear | 3 |
| Collection | Kind | Family | Languages | |||||
|---|---|---|---|---|---|---|---|---|
| UD | 3 | all | 73 | 64 | 9 | 6 | Austronesian (1) | Tagalog1.5 |
| Dravidian (1) | Telugu1.8 | |||||||
| Indo-European (3) | English4.6 Old French7.2 Slovak6.2 | |||||||
| Japanese (1) | Japanese42.9 | |||||||
| 4 | all | 75 | 70 | 1 | 0 | — | — | |
| 4 | unlabelled | 75 | 70 | 1 | 1 | Pama-Nyungan (1) | Warlpiri2.4 | |
| 4 | labelled | 75 | 71 | 10 | 2 | Indo-European (1) | English1.9 | |
| Pama-Nyungan (1) | Warlpiri3.4 | |||||||
| 4 | star | 72 | 64 | 19 | 11 | Dravidian (1) | Telugu7 | |
| Indo-European (9) | Bulgarian5.1 Czech3.8 English4.2 Faroese2 French5.5 Old French17 Portuguese1.8 Russian2 Slovak5.7 | |||||||
| Mande (1) | Bambara1.3 | |||||||
| 4 | linear | 75 | 68 | 0 | 0 | — | — | |
| Stanford | 3 | all | 30 | 29 | 7 | 5 | Dravidian (1) | Telugu8.2 |
| Indo-European (3) | Czech4.2 German5.2 Slovak12 | |||||||
| Japanese (1) | Japanese25.5 | |||||||
| 4 | all | 30 | 29 | 1 | 0 | — | — | |
| 4 | unlabelled | 30 | 29 | 1 | 0 | — | — | |
| 4 | labelled | 30 | 30 | 5 | 3 | Dravidian (1) | Telugu2.5 | |
| Indo-European (2) | English2.1 Ancient Greek8.5 | |||||||
| 4 | star | 30 | 29 | 11 | 9 | Dravidian (1) | Telugu11.2 | |
| Indo-European (8) | Bengali3 Bulgarian1.5 Czech3 English3.7 Ancient Greek3.2 Latin1.8 Portuguese2.7 Slovak16.1 | |||||||
| 4 | linear | 30 | 29 | 0 | 0 | — | — | |
| Prague | 3 | all | 30 | 29 | 3 | 2 | Dravidian (1) | Telugu13.8 |
| Indo-European (1) | Persian14.7 | |||||||
| 4 | all | 30 | 29 | 3 | 2 | Dravidian (1) | Telugu2.7 | |
| Indo-European (1) | Ancient Greek2 | |||||||
| 4 | unlabelled | 30 | 29 | 2 | 2 | Dravidian (1) | Telugu4 | |
| Indo-European (1) | Ancient Greek2.4 | |||||||
| 4 | labelled | 30 | 30 | 3 | 2 | Dravidian (1) | Telugu9.8 | |
| Indo-European (1) | Ancient Greek10.1 | |||||||
| 4 | star | 30 | 28 | 5 | 4 | Dravidian (1) | Telugu22.8 | |
| Indo-European (3) | Bengali2.3 Ancient Greek6.4 Persian16.4 | |||||||
| 4 | linear | 30 | 29 | 0 | 0 | — | — |
| Collection | Kind | Families | |||||
|---|---|---|---|---|---|---|---|
| UD | 3 | all | 73 | 69 | 28 | 16 | Afro-Asiatic (3) Altaic (1) Basque (1) Indo-European (6) Mande (1) Sino-Tibetan (1) Uralic (3) |
| 4 | all | 75 | 70 | 60 | 50 | Afro-Asiatic (4) Altaic (3) Austro-Asiatic (1) Austronesian (1) Basque (1) Indo-European (29) Japanese (1) Korean (1) Mongolic (1) Other (1) Sino-Tibetan (2) Uralic (5) | |
| 4 | unlabelled | 75 | 70 | 59 | 49 | Afro-Asiatic (4) Altaic (3) Austro-Asiatic (1) Austronesian (1) Basque (1) Indo-European (28) Japanese (1) Korean (1) Mongolic (1) Other (1) Sino-Tibetan (2) Uralic (5) | |
| 4 | labelled | 75 | 71 | 61 | 59 | Afro-Asiatic (4) Altaic (3) Austro-Asiatic (1) Austronesian (1) Basque (1) Dravidian (1) Indo-European (35) Japanese (1) Korean (1) Mande (1) Mongolic (1) Other (1) Sign Language (1) Sino-Tibetan (2) Uralic (5) | |
| 4 | star | 72 | 64 | 21 | 15 | Afro-Asiatic (2) Altaic (1) Austro-Asiatic (1) Basque (1) Indo-European (5) Sino-Tibetan (2) Uralic (3) | |
| 4 | linear | 75 | 68 | 61 | 54 | Afro-Asiatic (4) Altaic (3) Austro-Asiatic (1) Austronesian (1) Basque (1) Dravidian (1) Indo-European (31) Japanese (1) Korean (1) Mande (1) Mongolic (1) Other (1) Sino-Tibetan (2) Uralic (5) | |
| Stanford | 3 | all | 30 | 30 | 8 | 6 | Altaic (1) Basque (1) Indo-European (3) Uralic (1) |
| 4 | all | 30 | 29 | 24 | 24 | Afro-Asiatic (1) Altaic (1) Basque (1) Indo-European (17) Japanese (1) Uralic (3) | |
| 4 | unlabelled | 30 | 29 | 24 | 24 | Afro-Asiatic (1) Altaic (1) Basque (1) Indo-European (17) Japanese (1) Uralic (3) | |
| 4 | labelled | 30 | 30 | 29 | 28 | Afro-Asiatic (1) Altaic (1) Basque (1) Dravidian (1) Indo-European (20) Japanese (1) Uralic (3) | |
| 4 | star | 30 | 29 | 8 | 7 | Afro-Asiatic (1) Basque (1) Indo-European (4) Uralic (1) | |
| 4 | linear | 30 | 29 | 28 | 28 | Afro-Asiatic (1) Altaic (1) Basque (1) Dravidian (1) Indo-European (20) Japanese (1) Uralic (3) | |
| Prague | 3 | all | 30 | 30 | 20 | 19 | Afro-Asiatic (1) Altaic (1) Basque (1) Indo-European (13) Japanese (1) Uralic (2) |
| 4 | all | 30 | 29 | 23 | 23 | Afro-Asiatic (1) Altaic (1) Basque (1) Indo-European (16) Japanese (1) Uralic (3) | |
| 4 | unlabelled | 30 | 29 | 24 | 23 | Afro-Asiatic (1) Altaic (1) Basque (1) Indo-European (16) Japanese (1) Uralic (3) | |
| 4 | labelled | 30 | 30 | 26 | 25 | Afro-Asiatic (1) Altaic (1) Basque (1) Indo-European (18) Japanese (1) Uralic (3) | |
| 4 | star | 30 | 28 | 15 | 11 | Basque (1) Indo-European (8) Uralic (2) | |
| 4 | linear | 30 | 29 | 28 | 28 | Afro-Asiatic (1) Altaic (1) Basque (1) Dravidian (1) Indo-European (20) Japanese (1) Uralic (3) |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Anti dependency distance minimization in short sequences. A graph theoretic approach.
\nameRamon Ferrer-i-Canchoa and Carlos Gómez-Rodríguezb CONTACT Ramon Ferrer-i-Cancho. Email: [email protected] aComplexity and Quantitative Linguistics Lab, LARCA Research Group, Departament de Ciències de la Computació, Universitat Politècnica de Catalunya (UPC), Barcelona, Spain. ORCiD: 0000-0002-7820-923X; bUniversidade da Coruña, CITIC. FASTPARSE Lab, LyS Research Group, Departamento de Computación. Elviña, 15071 A Coruña, Spain. ORCiD: 0000-0003-0752-8812
Abstract
Dependency distance minimization (DDm) is a word order principle favouring the placement of syntactically related words close to each other in sentences. Massive evidence of the principle has been reported for more than a decade with the help of syntactic dependency treebanks where long sentences abound. However, it has been predicted theoretically that the principle is more likely to be beaten in short sequences by the principle of surprisal minimization (predictability maximization). Here we introduce a simple binomial test to verify such a hypothesis. In short sentences, we find anti-DDm for some languages from different families. Our analysis of the syntactic dependency structures suggests that anti-DDm is produced by star trees.
Keywords: dependency syntax; dependency distance minimization; word order; graph theory; treebanks
1 Introduction
Dependency distance minimization (DDm) is a word order principle favouring the placement of syntactically related words close to each other in sentences (Liu \BOthers., \APACyear2017). Massive evidence of the principle has been reported for more than a decade with the help of syntactic dependency treebanks where long sentences abound (Ferrer-i-Cancho, \APACyear2004; Liu, \APACyear2008; Ferrer-i-Cancho \BBA Liu, \APACyear2014; Futrell \BOthers., \APACyear2015). Sometimes short sentences are excluded from the analyses (e.g., Jiang \BBA Liu (\APACyear2015)). See Liu \BOthers. (\APACyear2017) for an overview of the cognitive origins of DDm.
It has been argued theoretically that the principle would be easier to beat by other word order principles in at least two conditions: short sequences (Ferrer-i-Cancho, \APACyear2014) and short words (Ferrer-i-Cancho, \APACyear2015), as dependency distances shorten and then the cognitive costs associated to them reduce, thus diminishing the pressure for DDm. The aim of this article is to verify empirically the prediction that DDm should be beaten in short sequences. DDm is also known as dependency length minimization (Futrell \BOthers., \APACyear2015), but the term distance allows one to see DDm as particular case of a general principle of distance minimization, crucial for the construction of a parsimonious theory of language and cognition in general (Ferrer-i-Cancho, \APACyear2017\APACexlab\BCnt4).
A competitor of DDm is Sm, surprisal minimization, or PM, predictability maximization (Levy, \APACyear2008; Ferrer-i-Cancho, \APACyear2017\APACexlab\BCnt2). Surprisal minimization is a less technical name for the principle of entropy minimization (Ferrer-i-Cancho, \APACyear2017\APACexlab\BCnt2). Throughout this article we use m for minimization (as in Sm or DDm) and M for maximization (as in PM). A particular conflict between word order principles arises theoretically when deciding the placement of a head and its dependents. In single-head structures, the head should be put at the center according to the DDm principle whereas, according to the Sm or PM principles, the head should be put at one of the ends (Ferrer-i-Cancho, \APACyear2014, \APACyear2017\APACexlab\BCnt2). For simplicity, Sm and PM are considered to be equivalent in this article but some subtle differences have been discussed theoretically (Ferrer-i-Cancho, \APACyear2017\APACexlab\BCnt2).
Focusing on the ordering of the verb (head) and its dependents (subject and object), such a conflict has been linked to the diversity of word orders, the existence of languages lacking a dominant word order, word order reversions in evolution, alternative word orders with the head at the center and the preference for head last in simple sequences and its loss in more complex sequences (Ferrer-i-Cancho, \APACyear2014). As for the latter, the rationale is that DDm would be more likely to win in long sequences leading to central head placements while Sm (or PM) would be more likely to win in very short sequences leading to non-central head placements. A challenge for this argument is that DDm effects have also been found in short spans (such as noun phrases), casting doubts on the grounding of this effect in memory limitations (Gulordava \BOthers., \APACyear2015). Here we aim to verify the prediction that DDm is more likely to be beaten in short sequences with the help of real data with 75 languages from about 20 families.
Anti-DDm has been investigated in depth in the cognitive science or psycholinguistics community under the umbrella of anti-locality effects (Vasishth \BBA Lewis, \APACyear2006; Rajkumara \BOthers., \APACyear2016). However, such a research relies on psychological experiments suffering from a small set of languages and a limited range of set-ups or phenomena (Liu \BOthers., \APACyear2017) in addition to considering only some but not all dependency distances (Ferrer-i-Cancho, \APACyear2017\APACexlab\BCnt4). Here we adopt a big data (Liu \BOthers., \APACyear2017) and nomothetic (Roberts \BBA Winters, \APACyear2013) approach where set-ups and languages are only limited by the growing collection of syntactic dependency treebanks employed.
Following our hypothesis, we focus on sentences of words with small . is a critical sentence length for a theory of word order because of DDm (Ferrer-i-Cancho, \APACyear2008). When there is no word order problem at all. When , the distance between head and dependent is not affected by the order (Ferrer-i-Cancho, \APACyear2008, \APACyear2014). Therefore, is needed for the conflict between word orders above (Ferrer-i-Cancho, \APACyear2017\APACexlab\BCnt2). Here we focus on the two smallest values of where such a conflict exists: and . We exclude sentences of length from onwards for simplicity and also because DDm is more likely to manifest in longer sequences (Ferrer-i-Cancho, \APACyear2014).
Although syntactic dependency structures are directed graphs (Mel’čuk, \APACyear1988), here we consider them as undirected for two reasons: dependency direction is not relevant in the calculation of dependency distances and it simplifies the analysis of the kinds of syntactic dependency structures. When the only structures that are possible are linear and star trees. A linear tree is a tree where the maximum degree is 2 whereas a star tree is a tree where the maximum degree is , the maximum possible degree (Ferrer-i-Cancho, \APACyear2017\APACexlab\BCnt3). Fig. 1 shows some linear and star trees. When the tree is both a linear tree and a star tree. Star trees correspond to the single-head structures where a conflict between DDm and Sm (or PM) has been demonstrated theoretically. The sum of dependency distances is maximized when the hub (the vertex of degree ) is put at one of the ends of the linear arrangement, which coincides with the arrangement minimizing surprisal (or maximizing predictability) (Ferrer-i-Cancho, \APACyear2014, \APACyear2017\APACexlab\BCnt2).
If the theoretical arguments above are correct, one would expect to find dependencies that are farther than expected by chance when for two reasons. First, the abundance of star trees on which the theoretical conflict above holds (Ferrer-i-Cancho, \APACyear2014). Second, the smaller dependency distances that are expected as a side effect of the short length of the sentences (Ferrer-i-Cancho, \APACyear2014). In its current state of development, that theory has no specific predictions to make on linear trees.
We define chance with respect to some null models. Our core null model is a random linear arrangement of the vertices where the syntactic dependency structure of sentences remains constant (Ferrer-i-Cancho, \APACyear2004, \APACyear2019). When , the syntactic dependency structure is always the same (a tree that is both a linear tree and a star tree). As this does not happen when , we also consider an additional null model for where not only the order but also the syntactic dependency structure (a star tree or a linear tree) is chosen at random.
When trying to shed light on the origins of anti-DDm in languages, various complementary approaches are possible, e.g., psychological experiments or traditional linguistic analyses based on the properties of the vertices (e.g., their part-of-speech) or the type of the dependencies. Here we adopt a graph theoretic approach that abstracts away from these properties to allow one to maximize the generality and parsimony of potential explanations. Indeed, we will show that the kind of graph structure apparently determines the possibility that anti-DDm emerges in short sequences. Our graph theoretic approach is radical in the sense that we focus on aspects of the graph structure that can be analyzed independently from the linear ordering of the vertices. Common features in research on dependency syntax such as dependency distance, branching direction or adjacency (e.g., Jiang \BBA Liu (\APACyear2015)) depend on that ordering. Examples of features that do not depend on it are hubiness (Ferrer-i-Cancho, \APACyear2013; Ferrer-i-Cancho \BOthers., \APACyear2018), hierarchical distance (Jing \BBA Liu, \APACyear2015) or whether the syntactic dependency structure is a star tree or a linear tree (in this article).
When investigating DDm, many researchers have considered a stronger null model where, for instance, dependency crossings are not allowed. A popular example of this tradition is the recent work by Futrell \BOthers. (\APACyear2015). However, we have argued that this could shadow the very effects of DDm (Ferrer-i-Cancho \BBA Gómez-Rodríguez, \APACyear2016). It is crucial for our study to use a null model that does not introduce a bias for or against DDm. Thus, the only constraint of our null model for a given sentence is that all possible orderings are equally likely, as in the pioneering research of one of us (Ferrer-i-Cancho, \APACyear2004), and as expected from the maximum entropy principle without constraints (Kesavan, \APACyear2009).
The remainder of the article is organized as follows. Section 2 presents the syntactic dependency treebanks, i.e. collections of sentences with syntactic dependency annotations, that we used to investigate biases against DDm. By the conflict above, evidence of anti-DDM can be interpreted as Sm (or PM) beating DDm in star trees at least. Therefore, when we use the term anti-DDm we are not referring to a cognitive principle or a principle of word order but rather to a statistical phenomenon that can be attributed to the Sm (or PM) principle.
Section 3 presents the statistical methods used, introducing a new binomial test that allows one to detect biases against or for DDm. To detect anti-DDm, the test examines the number of sentences where the sum of dependency distances is above the expected value in a random linear arrangement. If that number is significantly large, the test concludes that there is evidence of anti-DDm. Similarly, to detect DDm, the test examines the number of sentences where the sum of dependency distances is below the expected value in a random linear arrangement. If that number is significantly large, the test concludes that there is evidence of DDm. Section 3 shows that if dependency crossings were not allowed, the tests would lose statistical power (they would become more conservative) when (crossings for are impossible (Ferrer-i-Cancho, \APACyear2013)), shadowing either the effects of DDm or the effects of biases against DDm, supporting previous arguments for the case of DDm (Ferrer-i-Cancho \BBA Gómez-Rodríguez, \APACyear2016). Section 4 shows that some languages from different families exhibit an anti-DDm effect even after controlling for multiple comparisons. Interestingly, we find anti-locality in languages for which anti-locality effects have never been reported before based on traditional psychological experiments. Furthermore, our analysis of trees of four vertices suggests that anti-DDm is produced by star trees.
2 Data
In order to provide results on a wide range of languages of various families, while also controlling for the possible effects of differences in syntactic annotation criteria, we analyze two different collections of treebanks:
- •
Universal Dependencies (UD) 2.3 (Nivre \BOthers., \APACyear2018), the largest and most diverse dependency treebank collection that is currently available. It is comprised of 129 treebanks of 76 languages, annotated following the Universal Dependencies guidelines.
- •
HamleDT 2.0 (Rosa \BOthers., \APACyear2014), a collection of treebanks from 30 languages, each of them annotated with two different sets of guidelines: Universal Stanford dependencies (de Marneffe \BOthers., \APACyear2014) and Prague dependencies (Hajič \BOthers., \APACyear2006). In tables, we will simply write Prague and Stanford to refer to the HamleDT collection with Prague and Stanford annotation, respectively.
Universal Stanford dependencies are closely related to UD, as the latter evolved out of the former, which in turn are a multilingual adaptation of the Stanford Dependencies for English (de Marneffe \BBA Manning, \APACyear2008), based on lexical-functional grammar (Bresnan, \APACyear2000). However, Prague dependencies provide significantly different structural representations, based on the functional generative description (Sgall, \APACyear1969) of the Praguian linguistic tradition (Hajicova, \APACyear1995). In terms of tree structure, the most relevant differences are the annotation of conjunctions and adpositions (Passarotti, \APACyear2016).
Note that for many languages, there are UD and HamleDT treebanks with overlapping source material. Thus, our main goal in including HamleDT 2.0 is to provide results with different annotation formalisms, rather than to provide more data or languages with respect to using only UD. In this respect, it is also worth noting that, while a more recent version of HamleDT exists (3.0), it abandoned the dual annotation and adopted Universal Dependencies (version 1.1) as its only annotation style, so this newer version is not useful for our purposes.
For our analysis, punctuation tokens are removed from the treebanks, following common practice in research on statistical properties of dependency structures (Gomez2016a). Nodes that do not represent words, such as the null elements present in the Bengali, Hindi and Telugu HamleDT corpora and the empty nodes in various Universal Dependencies treebanks, are also removed. To preserve the integrity of dependency structures, non-deleted nodes whose head has been deleted are reattached as dependents of their nearest non-deleted ancestor.
Table 1 summarizes the linguistic diversity of our collections of treebanks. Bengali is the only language in the HamleDT collection that is not present in UD.
The UD collection contains sentences in 76 languages, belonging to 18 families. However, we exclude Yoruba from our analysis because its treebank does not contain any sentences of length 3 or 4. The remaining 75 languages belong to 17 families. Among these languages, there are a few special cases. One is Naija, an English-based pidgin language spoken in Nigeria, to which we assign the family Other. There is also a treebank of the Swedish Sign Language, which we associate with a family Sign Language for being the only non-vocal language in the sample. Finally, one of the corpora corresponds to a code-switching variety (Hindi-English), which belongs to the Indo-European family that is common to both languages.
The Prague and the Stanford HamleDT collections have 30 languages from 7 families.
Tables 3 and 4 show that the original number of languages (75) reduces to some number depending on the level of analysis in UD. When , the number of languages drops from 75 to 73 (there are two languages lacking sentences of length 3). When , the number of languages remains unchanged at the level of linear trees () while it drops from 75 to 72 at the level of star trees (there are three languages lacking star trees of 4 vertices). In the other collections, matches the original number (30) in all cases.
3 Methods
3.1 Graph theory
A leaf is a vertex of degree 1 and an internal vertex is a vertex of degree greater than 1. We use the term hub to refer to the vertex of a tree having the largest degree (Ferrer-i-Cancho, \APACyear2013). In a star tree, the are leaves and the only internal vertex is the hub.
When deciding when two trees are the same, standard theory provides two well-known criteria. One is when the vertices of a tree are labelled with distinct numbers, playing the role of vertex identifiers. In this case, the trees are said to be labelled. The other criterion is when the vertices are unlabelled (they have no identifier). Figure 2 shows the distinct trees for each of the two criteria. When there is only one possible unlabelled tree but three labelled trees. Each distinct labelled tree is defined by the label assigned to the internal vertex. By symmetry, exchanging the identifiers of the leaves does not produce another labelled tree. A distinct tree is only produced when the labels of a leaf and an internal vertex are exchanged. When , there are two unlabelled trees and 16 labelled trees. The unlabelled trees are a star tree and a linear tree. The unlabelled star tree yields 4 different labelled star trees that are determined by the label of the hub. As before, exchanging the labels of the leaves does not produce a new labelled tree. A distinct tree is only obtained swapping the label of the hub with that of another vertex. The unlabelled linear tree yields 12 different labelled linear trees that are determined by all the permutations of the four labels and the fact that each permutation and its reverse correspond to the same labelled linear tree, therefore there are distinct labelled linear trees.
Unlabelled trees are the most abstract criterion to define what a distinct tree is. Labelled trees define a level of abstraction that is intermediate between that of unlabelled trees and the linear arrangement of vertices. Notice that the labels of a labelled tree can be interpreted as vertex positions and thus define a linear arrangement of the vertices. However, the labellings in all the labelled trees of a given unlabelled tree do not cover all possible linear arrangements. For instance, Figure 2 shows that a star tree of 4 vertices has 4 different labelled trees but there are actually possible linear arrangements of a star tree. In particular, each labelled star tree of 4 vertices can be arranged linearly in different ways once the hub is placed in the position defined by its label.
In the context of trees whose vertices are assigned distinct positions in a linear arrangement (thus defining a particular labelled tree where labels indicate vertex positions), we define the distance of an edge as the distance in vertices between the linked vertices forming the edge: consecutive vertices are at distance 1, vertices separated by a vertex are at distance 2 and so on (Ferrer-i-Cancho, \APACyear2004). Suppose that is the sum of edge distances of a syntactic dependency tree (Ferrer-i-Cancho, \APACyear2016), i.e.
[TABLE]
where is the distance of the -th edge. In Fig. 1, the tree of 3 vertices has , the linear tree of 4 vertices has and the star tree of 4 vertices has .
There are linear arrangements of the vertices of the dependency tree. and , are the minimum and the maximum value of in a random linear arrangement. A uniformly random linear arrangement is one whose probability is . The expected value of in a uniformly random linear arrangement (rla) of a given graph is (Ferrer-i-Cancho, \APACyear2004, \APACyear2016)
[TABLE]
3.2 A simple binomial test
Suppose that is the number of sentences where exceeds . We wish to test if is larger than expected by chance. If that is the case then we conclude that there is evidence of anti-DDm.
We define Null hypothesis 1 as a two-fold null model on sentences of length from an individual treebank:
The syntactic dependency trees are the same as in the original treebank. 2. 2.
Although the tree structure of every sentence is the same as in the original dataset, vertices are ordered according to a uniformly random linear arrangement. Linear arrangements are independent.
The null model can be applied to a subset of the trees of length , e.g., all star trees of vertices.
Next subsections analyze the case of sentences of three words and four words ( and ), presenting derivations of binomial distributions from Null hypothesis 1 or a variant that can help one to find evidence of anti-DDm.
3.2.1
When , when the hub is put at the center and when it is not (Figure 3). Obviously, and . The probability that in a uniformly random linear arrangement is . To see it, notice that only two orderings have the hub at the center (the non-hub vertex that is put first gives the two orderings; Figure 3) and that there are possible orderings. Thus, . Then .
When , Eq. 1 gives . Thus, satisfying in a sentence is equivalent to satisfying . We define an indicator variable such that
[TABLE]
in a dependency tree of vertices. Interestingly, follows a Bernoulli distribution because with probability and with probability .
Suppose that is the number of syntactic dependency trees where and is the number of syntactic dependency trees where . Under Null hypothesis 1, it turns out that follows a binomial distribution with parameters and . Then, one can test if is significantly large, in favour of anti-DDm, with a binomial test (Conover, \APACyear1999).
We will check the probabilities above applying the general definition of , namely
[TABLE]
When , the general formula gives
[TABLE]
as expected by Eq. 1.
3.2.2
When , there is only one possible unlabelled tree, that is both a linear tree and a star tree (Figure 2). When , there are only two possible unlabelled trees: a star tree and a linear tree (Figure 2). We will investigate each kind of tree separately.
In a star tree with , there are only two possible values of : , when the hub is placed in one of the two central positions, and , when the hub is placed at one of the two ends (Fig. 4). Obviously, and . , the probability that in a uniformly random linear arrangement of a star tree, is . To see it, notice that there are six orderings where the hub is placed in the 1st central position, i.e., the 2nd position (permuting the positions of the non-hub vertices gives 6 configurations). There are six more orderings where the hub is placed in the 2nd central position, i.e., the 3rd position. Thus, . Then .
When , Eq. 1 gives . Thus, , the probability that exceeds in a random linear arrangement of a star tree with , matches . Applying the same arguments for the case , we obtain that, under Null hypothesis 1, follows a binomial distribution with parameters and , where is the number of star trees of 4 vertices.
We will check the probabilities above applying the general definition of in Eq. 2. For a star tree with , the general formula gives
[TABLE]
as expected by Eq. 1.
In a linear tree with , there are only five possible values of : 3, 4, 5, 6 and 7. Fig. 5 shows all the permutations giving each of the values of for a total of . Therefore, the probabilities of the values of in a linear tree are
- •
.
- •
.
- •
.
Applying the probabilities above to the general definition of in Eq. 2 one obtains
[TABLE]
as expected by Eq. 1. Thus, the probability that exceeds in a random linear arrangement of a linear tree with is
[TABLE]
Applying the same arguments for the case or for star trees, we obtain that, under Null hypothesis 1, , the number of linear arrangements of linear trees of 4 vertices, follows a binomial distribution with parameters and , where is the number of linear trees of 4 vertices and .
Above, we have distinguished linear trees from star trees. Now we consider an arbitrary tree, which leads to Null hypothesis 2, an additional three-fold null model (differences with respect to Null hypothesis 1 are marked in boldface):
The number of sentences of the target length is the same as in the original treebank. 2. 2.
**The tree structure of every sentence is chosen from a given statistical ensemble. Trees are independent. ** 3. 3.
The vertices of each sentence are ordered according to a uniformly random linear arrangement. Linear arrangements are independent.
Null hypothesis 2 becomes testable when a statistical ensemble is chosen.
We will consider three statistical ensembles: real trees, uniformly random labelled trees, i.e. all labelled trees with the same are equally likely, and uniformly random unlabelled trees, i.e. all unlabelled trees with the same are equally likely (Figure 2). The choice of uniformity for the two last ensembles can be justified based on the maximum entropy principle without constraints (Kesavan, \APACyear2009).
Under Null hypothesis 2, , the number of linear arrangements of arbitrary trees of 4 vertices where exceeds , follows a binomial distribution with parameters and . Suppose that is the probability that a tree of 4 vertices is a star tree and the same for a linear tree. As , can be derived noting that
[TABLE]
Recalling that and , Eq. 3 becomes
[TABLE]
is determined by the statistical ensemble for which Null hypothesis 2 is instantiated. When considering the statistical ensemble of real trees, is the proportion of star trees (with ) in a treebank. Knowing that there are only two possible unlabelled trees with , star trees and linear trees (Figure 2), we obtain for uniformly random labelled trees. Knowing that there are 16 labelled trees with , of which are star trees (Figure 2), we obtain for uniformly random labelled trees. Therefore, Eq. 4 gives for uniformly random unlabelled trees and for uniformly random labelled trees. The fact that allows one to predict that anti-DDm should surface more clearly with uniformly random labelled trees than with uniformly random unlabelled trees.
To sum up, the case of arbitrary trees with will be investigated with the help of various binomial tests, based on the fact that is binomially distributed with parameters and . The second parameter depends on the kind of random tree.
3.2.3 Simple binomial tests for DDm
Applying the same methodology, it is possible do derive binomial tests for the case of DDm. The distribution under the null model turns out to be the same as that of anti-DDm by symmetry except for . When , follows a binomial distribution with parameters and . When ,
- •
follows a binomial distribution with parameters and .
- •
follows a binomial distribution with parameters and .
- •
follows a binomial distribution with parameters and probability , that becomes in uniformly random labelled trees and in uniformly random unlabelled trees. This is easy to see noting that Eq. 3 gives
[TABLE]
by symmetry.
3.2.4 Minimum sample size
Here we aim to investigate when the sample size , namely the number of sentences involved in a certain binomial test, is too small to allow one to reject the null hypothesis. Suppose a random variable that follows a binomial distribution with parameters and . In our binomial tests, the p-value is the probability that equals or exceeds a certain value , i.e.
[TABLE]
As all the summands are positive, the smallest p-value is obtained when and then the p-value is . A necessary condition for significance is then
[TABLE]
Taking logarithms on both sides of the inequality (and noting this will change the sign of left and the right hand side because ), one obtains
[TABLE]
with
[TABLE]
Table 2 shows the value of for the different tests except for the case of real trees with , where depends on the proportion of star trees. When Eq. 6 is not satisfied, the binomial tests suffer from undersampling (Eq. 6 provides a necessary but not sufficient condition for sufficient sampling).
3.2.5 Summary
We have shown above that we can test DDm or dependency distance maximization (anti-DDm) with the help of one-tailed binomial tests (Conover, \APACyear1999). When , follows a binomial distribution with parameters and whereas follows a binomial distribution with parameters and . When ,
- •
and follow a binomial distribution with parameters and .
- •
and follow a binomial distribution with parameters and .
- •
and follow a binomial distribution with parameters and probability , that becomes in uniformly random labelled trees and in uniformly random unlabelled trees.
Given a treebank from a certain language, we consider six levels of application of the binomial test:
- •
All with , i.e. any tree with .
- •
All with , i.e. any tree with using real trees for reference ( is borrowed from real trees with ).
- •
Unlabelled, i.e. any tree with using random unlabelled trees with for reference ( is borrowed from random unlabelled trees with ).
- •
Labelled, i.e., any tree with using random labelled trees with for reference ( is borrowed from random labelled trees with ).
- •
Star trees with .
- •
Linear trees with .
The binomial tests were carried out with the function binom.test from the R programming language (R Core Team, \APACyear2018).
3.3 The risks of disallowing edge crossings
Here we will consider the effect of disallowing crossings for each of the six levels of application of the binomial tests. The ban does not have any impact for or star trees with , because crossings are impossible for star trees (Ferrer-i-Cancho, \APACyear2013). As for star trees with , Fig. 5 allows one to see that 8 out of 4! arrangements contain crossings: 6 permutations with crossings with and 2 permutations with crossings with . Then, the number of relevant linear arrangements drops from to non-crossing linear arrangements and , the expected value of in non-crossing linear arrangements, can be calculated as the average value of over these arrangements based on Fig. 5 as
[TABLE]
Accordingly,
[TABLE]
and
[TABLE]
When banning crossings,
- •
grows from to , implying that the test of anti-DDm for linear trees is more likely to make type II errors.
- •
grows from to , implying that the test of DDm for linear trees is also more likely to make type II errors.
At the level of , the application of and to Eq. 3 gives that the value of in non-crossing (nc) configurations is
[TABLE]
It is easy to see that and then the binomial tests of anti-DDm when crossings are banned are conservative also at the level of all trees with , labelled trees and unlabelled trees.
A similar conclusion is reached for the tests of DDm. The application of and to Eq. 5 gives
[TABLE]
It is easy to see that and then the binomial tests of DDm when crossings are banned are conservative also at the level of all trees, labelled trees and unlabelled trees with . We conclude that banning crossings precludes the detection of anti-DDm and also DDm when , consistent with previous arguments for the case of DDm in a general context (Ferrer-i-Cancho \BBA Gómez-Rodríguez, \APACyear2016).
3.4 Additional methods on top of the binomial test
For each level of analysis, we apply a binomial test to check anti-DDm and another to check DDm. To control for multiple comparisons within each level and target (anti-DDm or DDm), we apply a Holm correction, that does not assume independence between -values (Goeman \BBA Solari, \APACyear2014). This point is crucial in our case because languages in our sample are not independent, a well-known problem since Galton (Naroll, \APACyear1965). See (Goeman \BBA Solari, \APACyear2014) for a detailed analysis of the minimal assumptions of the correction and how to calculate it.
Notice that we are applying the correction globally, for all languages available for a certain level of analysis, and then checking if the null hypothesis is rejected in different families to fight against Galton’s problem. To control for the relatedness of languages, a simple, although conservative test is to run the analysis within each language family (Roberts \BBA Winters, \APACyear2013). Accordingly, we may also apply the correction within each family, but this would imply a less effective control for multiple comparisons. This is easy to see mathematically from the standpoint of the Bonferroni correction, the precursors of Holm’s correction (Goeman \BBA Solari, \APACyear2014). Bonferroni’s original correction consists of multiplying the p-value by , the number of languages. As is always smaller within a family, that means that applying the correction within family reduces the penalty for multiple comparisons.
4 Results
Table 3 summarizes the analysis of anti-DDm within each collection showing the number of languages for where the binomial test rejects the null hypothesis at a significance level of 0.05. The null hypothesis is impossible to reject due to undersampling only in a few languages (the difference between and is small, if any). After controlling for multiple comparisons, anti-DDm is found in some languages (as indicated by the value of in Table 3). For instance, at the level of with UD dependencies, anti-DDm is found in languages but after controlling for multiple comparisons it survives in languages. When , it turns out that anti-DDm is never found in linear trees but found in star trees. Star trees with are the level of analysis with the highest support for anti-DDm ( is the highest in each collection according to Table 3).
Two findings reduce the chance that the results are due to a common descent (Roberts \BBA Winters, \APACyear2013). First, the languages where anti-DDm is found belong to different families. Second, the anti-locality does not cover a whole family if the family is represented by more than one language a priori according to Table 1. For instance, at the level of with UD dependencies, the languages with evidence of anti-DDm are three Indo-European languages out of 44 (English, French and Slovak), one Austronesian language out of 2 (Tagalog), one Dravidian language out of 2 (Telugu) and one isolate (Japanese).
Table 3 confirms the prediction that anti-DDm should surface more clearly when the uniformly random trees are labelled trees instead of unlabelled trees (Figure 2) are used for reference. At the level of with UD dependencies, anti-DDm is found in languages before controlling for multiple comparisons and languages after controlling for that when random labelled trees are used for reference. In contrast, anti-DDm is found in only one language before and after controlling for multiple comparisons when random unlabelled trees are used for reference.
Given these findings, we aim to evaluate the scope of DDm using the same kind of binomial tests. Table 4 shows a broader support for DDm. The weakest support is found at the levels and star trees with according to the value of in Table 4. Indeed, Table 4 shows an opposite behavior with respect to Table 3: when , support for DDm is stronger in linear trees than star trees ( is greater in linear trees).
5 Discussion
We have confirmed the theoretical prediction that anti-DDm should be found in short sequences (Ferrer-i-Cancho, \APACyear2014): we have found evidence of anti-DDm in short sequences in languages from different families suggesting that anti-DDm is not lineage specific. The fact that anti-DDm is found in all annotation formalisms and that some languages show anti-DDm for more than one formalism (Telugu shows anti-DDm in all formalisms; in addition Ancient Greek shows anti-DDm in both Prague and Stanford dependencies) suggests that differences in annotation criteria cannot explain exclusively our findings. Interestingly, we have found anti-DDm in Telugu, Tagalog, French, Slovak in UD for (Table 3) that are languages for which anti-locality effects have never been reported before based on traditional psychological experiments as far as we know. Similar arguments can be made for . These discoveries illustrate the power of our statistical approach.
Following a classic view of memory, it could be argued that DDm is not activated in short sentences because they do not exhaust the capacity of short-term memory. Sentences of length 3 and 4 have a number of words that fits into the magical number 4 in short-term memory (Cowan, \APACyear2001). That memory limit has been has been argued to have been confirmed by the fact that mean dependency distance is below 4 (Jing \BBA Liu, \APACyear2015) but such a limit could be directly related to the breakpoint in the decay of the probability of dependency distance that is found at distance 4-5 (Ferrer-i-Cancho, \APACyear2004, \APACyear2017\APACexlab\BCnt1). Tentatively, if DDm were the only word order principle, one would expect an arbitrary ordering of words (a random ordering), but it has been shown that order in short sequences is lawful (e.g. Goldin-Meadow \BOthers. (\APACyear2008); Langus \BBA Nespor (\APACyear2010)). Such a lawfulness is confirmed by our finding of DDm and, to a lower degree, of anti-DDm. A reason for finding DDm even in short sentences could be some version of the Performance-Grammar Correspondence Hypothesis (PGCH): “grammars have conventionalized syntactic structures in proportion to their degree of preference in performance, as evidenced by patterns of selection in corpora and by ease of processing in psycholinguistic experiments” (Hawkins, \APACyear2004, 3). From an evolutionary standpoint, it could be that languages have undergone general adaptions consistent with DDm even in short sentences. But then, why should there be anti-DDm in short sequences as we have found? The conflict between Sm and DDm could explain it (short-term memory and DDm alone cannot): if short-term memory is not a problem any more, if would be easier for Sm to surface leading to a placement of the heads at one of the ends of the sequence (Ferrer-i-Cancho, \APACyear2017\APACexlab\BCnt2). It has been argued theoretically that pressure for DDm should be smaller in short sequences (Ferrer-i-Cancho, \APACyear2014), which could explain why the conflict between Sm and DDm (Ferrer-i-Cancho, \APACyear2017\APACexlab\BCnt2) is resolved in favour of DDm in short sentences (in the absence of general adaptations for DDm across all scales). Similar arguments can be used to shed light on experiments on unconventional gestural communication with short sequences where the head tends to be put at the end, against DDm (Ferrer-i-Cancho, \APACyear2017\APACexlab\BCnt2).
Our investigation of the effect of tree structure, linear tree versus star trees, is a further step into understanding lawfulness in short sequences. Indeed, our analysis of the case clarifies the nature of anti-DDm: anti-DDm is never found in linear trees but found in star trees (Table 3) whereas DDm is much stronger on linear trees than star trees (Table 4). This provides indirect empirical support for the theoretical conflict between DDm and Sm in the simple setup where it was proposed: one head and dependents, which implies star trees. When DDm wins the head should be put at the center; when Sm over heads wins, the head should be put last; when Sm over dependents wins, the head should be put first (Ferrer-i-Cancho, \APACyear2017\APACexlab\BCnt2). We hypothesize that anti-DDm is never found in linear trees with because the conflict between Sm and DDm reduces or disappears completely, namely the optima of DDm and Sm are closer or even coincide for linear trees. The fact that a star tree does not imply a single head with dependents (the root of the syntactic dependency structure may not be the hub, the most connected node) suggests that directed syntactic dependency structures should be the subject of future research. Here we have chosen undirected structures for simplicity as the first step of a new research line.
Another reason to not find anti-DDm in linear trees is that DDm may not be acting only at the level of the ordering of the words of the sentence but also at the level of the tree structures. The fact that , the minimum value of for a given tree, is minimized by linear trees (Ferrer-i-Cancho, \APACyear2013), where
[TABLE]
and maximized by star trees (Esteban \BOthers., \APACyear2016), where
[TABLE]
suggests that DDm could be favouring the choice of linear trees to ease the optimization problem.
It has been argued that nomothetic studies (statistical analyses of large-scale, cross-cultural data) like ours should be seen as hypothesis generating tools rather than as standalone studies due to the inter-connectedness of cultural traits (Roberts \BBA Winters, \APACyear2013). Ideally, hypotheses should be generated from theory (Roberts \BBA Winters, \APACyear2013). In our case, we have used cross-linguistic data to test a prior theoretical hypothesis on the competition between word order principles in short sequences. Based on our analysis of the origins of the findings, we would like to invite researchers to confirm by means of lab experiments that anti-locality effects are practically missing in linear trees while found in star trees.
Here we have investigated anti-DDm in short sentences. The same methodology could be applied to phrases or constituents that are also short (Gulordava \BOthers., \APACyear2015). This could help to find anti-DDm in more languages.
Acknowledgements
We are very grateful to G. Jäger for his hospitality and rich discussions from many perspectives. We also thank D. Celinska-Kopczynska for helpful discussions on the problem of multiple comparisons and many suggestions to improve the article. The manuscript has benefited enormously from the comments of an anonymous reviewer. RFC is supported by the grant TIN2017-89244-R from MINECO (Ministerio de Economia, Industria y Competitividad) and the recognition 2017SGR-856 (MACDA) from AGAUR (Generalitat de Catalunya). CGR has received funding from the European Research Council (ERC), under the European Union’s Horizon 2020 research and innovation programme (FASTPARSE, grant agreement No 714150), from the ANSWER-ASAP project (TIN2017-85160-C2-1-R) from MINECO, and from Xunta de Galicia (ED431B 2017/01, and a grant from Consellería de Cultura, Educación e Ordenación Universitaria to complement ERC grants).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Bresnan ( \APA Cyear 2000) \APA Cinsertmetastar Bresnan 00 {APA Crefauthors} Bresnan, J. \APA Cref Year 2000. \APA Crefbtitle Lexical-Functional Syntax Lexical-functional syntax. \APA Caddress Publisher Blackwell. \Print Back Refs \Current Bib
- 2Conover ( \APA Cyear 1999) \APA Cinsertmetastar Conover 1999 a {APA Crefauthors} Conover, W \BPBI J. \APA Cref Year 1999. \APA Crefbtitle Practical nonparametric statistics Practical nonparametric statistics. \APA Caddress Publisher New York Wiley. \APA Crefnote 3rd edition \Print Back Refs \Current Bib
- 3Cowan ( \APA Cyear 2001) \APA Cinsertmetastar Cowan 2001 a {APA Crefauthors} Cowan, N. \APA Cref Year Month Day 2001. \BBOQ \APA Crefatitle The magical number 4 in short-term memory: A reconsideration of mental storage capacity The magical number 4 in short-term memory: A reconsideration of mental storage capacity. \BBCQ \APA Cjournal Vol Num Pages Behavioral and Brain Sciences 2487-185. \Print Back Refs \Current Bib
- 4de Marneffe \B Others . ( \APA Cyear 2014) \APA Cinsertmetastar Universal Stanford {APA Crefauthors} de Marneffe, M \BHBI C., Dozat, T., Silveira, N., Haverinen, K., Ginter, F., Nivre, J. \BCBL \BBA Manning, C \BPBI D. \APA Cref Year Month Day 2014 may. \BBOQ \APA Crefatitle Universal Stanford Dependencies: a Cross-Linguistic Typology Universal Stanford dependencies: a cross-linguistic typology. \BBCQ \B In N \BPBI C \BPBI C. Chair) \B Others . ( \BEDS ), \APA Crefbtitle Proceedings of
- 5de Marneffe \BBA Manning ( \APA Cyear 2008) \APA Cinsertmetastar Stanford 2008 {APA Crefauthors} de Marneffe, M \BHBI C. \BCBT \BBA Manning, C \BPBI D. \APA Cref Year Month Day 2008. \BBOQ \APA Crefatitle The Stanford Typed Dependencies Representation The Stanford typed dependencies representation. \BBCQ \B In \APA Crefbtitle COLING 2008: Proceedings of the workshop on Cross-Framework and Cross-Domain Parser Evaluation COLING 2008: Proceedings of the workshop on cross-framework and
- 6Esteban \B Others . ( \APA Cyear 2016) \APA Cinsertmetastar Esteban 2016 a {APA Crefauthors} Esteban, J \BPBI L., Ferrer-i-Cancho, R. \BCBL \BBA Gómez-Rodríguez, C. \APA Cref Year Month Day 2016. \BBOQ \APA Crefatitle The scaling of the minimum sum of edge lengths in uniformly random trees The scaling of the minimum sum of edge lengths in uniformly random trees. \BBCQ \APA Cjournal Vol Num Pages Journal of Statistical Mechanics 063401. \Print Back Refs \Current Bib
- 7Ferrer-i-Cancho ( \APA Cyear 2004) \APA Cinsertmetastar Ferrer 2004 b {APA Crefauthors} Ferrer-i-Cancho, R. \APA Cref Year Month Day 2004. \BBOQ \APA Crefatitle Euclidean distance between syntactically linked words Euclidean distance between syntactically linked words. \BBCQ \APA Cjournal Vol Num Pages Physical Review E 70056135. \Print Back Refs \Current Bib
- 8Ferrer-i-Cancho ( \APA Cyear 2008) \APA Cinsertmetastar Ferrer 2008 e {APA Crefauthors} Ferrer-i-Cancho, R. \APA Cref Year Month Day 2008. \BBOQ \APA Crefatitle Some word order biases from limited brain resources. A mathematical approach Some word order biases from limited brain resources. A mathematical approach. \BBCQ \APA Cjournal Vol Num Pages Advances in Complex Systems 113393-414. \Print Back Refs \Current Bib