Nonlinear System Identification via Tensor Completion
Nikos Kargas, Nicholas D. Sidiropoulos

TL;DR
This paper introduces a novel tensor completion approach for nonlinear system identification, offering an alternative to neural networks that handles multi-output and partial data scenarios effectively.
Contribution
The paper formulates nonlinear system identification as a tensor completion problem and extends it to multi-output and partially observed data cases, demonstrating its effectiveness.
Findings
Effective in standard regression benchmarks
Handles multi-output systems and partial data
Outperforms neural networks in certain scenarios
Abstract
Function approximation from input and output data pairs constitutes a fundamental problem in supervised learning. Deep neural networks are currently the most popular method for learning to mimic the input-output relationship of a general nonlinear system, as they have proven to be very effective in approximating complex highly nonlinear functions. In this work, we show that identifying a general nonlinear function from input-output examples can be formulated as a tensor completion problem and under certain conditions provably correct nonlinear system identification is possible. Specifically, we model the interactions between the input variables and the scalar output of a system by a single -way tensor, and setup a weighted low-rank tensor completion problem with smoothness regularization which we tackle using a block coordinate descent algorithm. We extend…
Click any figure to enlarge with its caption.
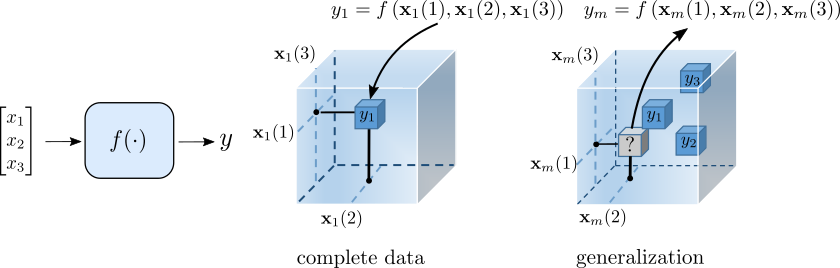 Figure 1
Figure 1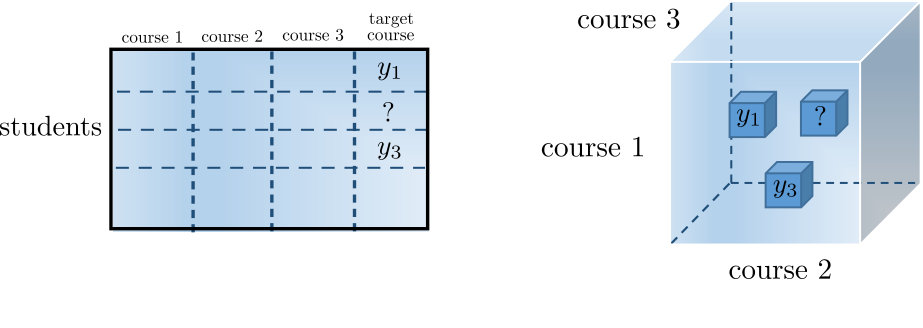 Figure 2
Figure 2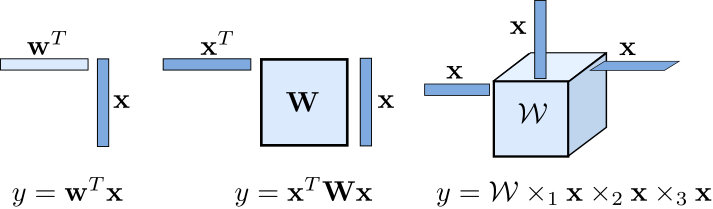 Figure 3
Figure 3| Dataset | RR | SVR (RBF) | SVR (polynomial) | DT | MLP (5 Layer) | CSID |
|---|---|---|---|---|---|---|
| Energy Eff. (1) | ||||||
| Energy Eff. (2) | ||||||
| C. Comp. Strength | ||||||
| SkillCraft Master Table | ||||||
| Abalone | ||||||
| Wine Quality | ||||||
| Parkinsons Tel. (1) | ||||||
| Parkinsons Tel. (2) | ||||||
| C. Cycle Power Plant | ||||||
| Bike Sharing (1) | ||||||
| Bike Sharing (2) | ||||||
| Phys. Prop. |
| Dataset | RR | SVR (RBF) | SVR (polynomial) | DT | MLP (5 Layer) | CSID |
|---|---|---|---|---|---|---|
| Energy Eff. (1) | ||||||
| Energy Eff. (2) | ||||||
| C. Comp. Strength | ||||||
| SkillCraft Master Table | ||||||
| Abalone | ||||||
| Wine Quality | ||||||
| Parkinsons Tel. (1) | ||||||
| Parkinsons Tel. (2) | ||||||
| C. Cycle Power Plant | ||||||
| Bike Sharing (1) | ||||||
| Bike Sharing (2) | ||||||
| Phys. Prop. |
| Dataset | RR | MLP (1 Layer) | MLP (3 Layer) | MLP (5 Layer) | DT | CSID |
|---|---|---|---|---|---|---|
| En. Eff. (2) | ||||||
| Park. Tel. (2) | ||||||
| B. Shar. (2) |
| Dataset | GPA | BMF | CSID |
|---|---|---|---|
| CSCI-1 | |||
| CSCI-2 | |||
| CSCI-3 | |||
| CSCI-4 | |||
| CSCI-5 | |||
| CSCI-6 | |||
| CSCI-7 | |||
| CSCI-8 | |||
| CSCI-9 | |||
| CSCI-10 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Nonlinear System Identification via Tensor Completion
Nikos Kargas 111Dedicated to John S. Baras. Nicholas D. Sidiropoulos
University of Minnesota University of Virginia
Abstract
Function approximation from input and output data pairs constitutes a fundamental problem in supervised learning. Deep neural networks are currently the most popular method for learning to mimic the input-output relationship of a general nonlinear system, as they have proven to be very effective in approximating complex highly nonlinear functions. In this work, we show that identifying a general nonlinear function from input-output examples can be formulated as a tensor completion problem and under certain conditions provably correct nonlinear system identification is possible. Specifically, we model the interactions between the input variables and the scalar output of a system by a single -way tensor, and setup a weighted low-rank tensor completion problem with smoothness regularization which we tackle using a block coordinate descent algorithm. We extend our method to the multi-output setting and the case of partially observed data, which cannot be readily handled by neural networks. Finally, we demonstrate the effectiveness of the approach using several regression tasks including some standard benchmarks and a challenging student grade prediction task.
The problem of identifying a nonlinear function from input-output examples is of paramount importance in machine learning, dynamical system identification and control, communications, and many other disciplines. In machine learning in particular, most of the supervised learning tasks are nonlinear system identification problems. For example, binary/multiclass classification, where the goal is to predict a discrete variable denoting the class label of each realization, and regression/prediction, where the goal is to predict real or complex valued variables. Algorithmic advancements, availability of vast amounts of data and increasing computational power have led to the development of state-of-the-art prediction models with unprecedented success in various domains such as image classification, speech recognition, and language processing. Kernel methods, random forests, neural networks and deep learning are powerful classes of machine learning models that can learn highly nonlinear functions and have been successfully applied in many supervised machine learning tasks Hastie et al. (2009). Each of the aforementioned methods can be well suited for a particular problem, but may perform badly for another. In general it is seldom known in advance which method will perform best for any given problem.
This paper presents a simple and elegant alternative for nonlinear system identification based on low-rank tensor decomposition. Tensor decomposition is a powerful tool for analyzing multi-way data and has had major successes in applications spanning machine learning, statistics, signal processing and data mining (Sidiropoulos et al., 2017). The Canonical Polyadic Decomposition (CPD) model is one of the most popular tensor models mainly due to its simplicity and its uniqueness properties. The CPD model has been applied in various machine learning applications, including recommender systems to model time-evolving relational data (Xiong et al., 2010), community detection and clustering to model user interactions across different networks (Papalexakis et al., 2013), knowledge base completion and link prediction for discovering unobserved subject-object interactions (Lacroix et al., 2018) and in latent variable models for parameter identification (Anandkumar et al., 2014). These works deal with relatively low-order tensors; however, high-order tensors also arise in practical scenarios – e.g., a joint probability mass function of categorical random variables can be naturally regarded as an -th order tensor and modeled using a CPD model (Kargas et al., 2018).
In this work, we show that the CPD model offers an appealing solution for modeling and learning a general nonlinear system using a single high-order tensor. Tensors have been used to model low-order multivariate polynomial systems: a multivariate polynomial of order is represented by a tensor of order – e.g., a second-order polynomial is represented by a quadratic form involving a single matrix (Rendle, 2010). However, such an approach requires prior knowledge of polynomial order, and assuming that one deals with a polynomial of a given degree can be highly restrictive in practice.
Instead, what we advocate here is a simple and general approach: a nonlinear system having discrete inputs and a single output can be naturally represented as an -way tensor where the tuple of input variables can be viewed as a cell multi-index and the cell content is the response of the system . Given a new data point, the corresponding tensor cell is queried and the output is used as the predictor. Note that only a small fraction of the tensor entries are observed during training, and we are ultimately interested in answering queries for unobserved data points (Figure 1). This motivates the use of low-rank tensor models as a tool for capturing interactions between the predictors and imputing the missing data.
Both experimental (Tomasi and Bro, 2005) and theoretical studies (Krishnamurthy and Singh, 2013; Jain and Oh, 2014; Sorensen and De Lathauwer, 2019) have shown that exact tensor completion from limited samples is possible under certain conditions. The implication of our simple but profound modeling idea is very compelling, since:
- •
The CPD can model any nonlinearity (even of order) for high-enough rank – because every tensor admits a CPD of bounded rank; see (Sidiropoulos et al., 2017) and references therein. Even for low ranks, it can model highly nonlinear operators such as products or sums of the signs of the input variables.
- •
Provably correct nonlinear system identification is possible from limited samples. If the associated tensor describing the nonlinear operator is low rank, then it can be fully identified.
- •
In practice, tensors corresponding to real-world systems may not be low-rank; nevertheless even if a system is not exactly low rank, our approach will identify the principal components of the unknown nonlinear mapping, in a sense that will be clarified in the sequel.
Even though tensor recovery can be guaranteed under a low-rank assumption, tensor decomposition can often benefit from additional knowledge regarding the application by incorporating constraints such as non-negativity, sparsity or smoothness (Sidiropoulos et al., 2017). In our present context, smoothness is a desirable property for applications where we expect that small perturbations in the input will most probably cause small changes in the output of the system. Therefore, we propose augmenting the CPD tensor completion problem with smoothness regularization on the ordinal latent factors.
Contributions: We model a general nonlinear system using a single high-order tensor admitting a CPD model. Specifically, we formulate the problem as a smooth tensor decomposition problem with missing data. Although our method is naturally suited to handle discrete features, it can also be used for continuous valued features (Kargas and Sidiropoulos, 2019) and be enhanced using ensemble techniques. Additionally, leveraging the structure of the CPD model, we propose a simple yet effective approach to handle randomly missing input variables. Finally, we discuss how the approach can be extended to vector valued function prediction. The proposed approach requires little parameter tuning, and can model complex nonlinear functions. We propose an easy to implement Block Coordinate Descent (BCD) algorithm and demonstrate the performance in UCI machine learning datasets against competitive baselines as well as a challenging grade prediction task, using real student grade data.
1 Notation and Background
We use the symbols , , , for scalars, vectors, matrices, and tensors respectively. We use the notation , , to refer to a particular element of a vector, a column of a matrix and a slab of a tensor. Symbols , , , denote the outer, Kronecker, Hadamard and Khatri-Rao (column-wise Kronecker) product respectively.
An -way tensor is a multi-dimensional array whose entries are indexed by coordinates. A polyadic decomposition expresses as a sum of rank- components , where . If the number of rank- components is minimal then the decomposition is called the CPD of and is called the rank of (Sidiropoulos et al., 2017). By defining factor matrices , the elements of the tensor can be expressed as
[TABLE]
We adopt the common notation to denote the tensor synthesized from the CPD model using these factors. The mode- fibers of a tensor are the vectors obtained by fixing all the indices except for the -th index. We can represent tensor using a matrix called mode- matricization obtained by arranging the mode- fibers of the tensor as columns of the resulting matrix
[TABLE]
where The -mode product of a tensor with a matrix is denoted by and an entry of the resulting tensor is given by
[TABLE]
Furthermore, assuming that a tensor admits a CPD with rank , the -mode product can be expressed as
[TABLE]
CPD is a powerful tool for data analysis mainly due to its uniqueness properties. For a tensor of rank , we say that a decomposition is unique if the factors are unique up to a common permutation and scaling / counter-scaling of columns. Specifically, if there exists another decomposition , then, there exists a permutation matrix and diagonal scaling matrices such that and . Tensor decomposition is unique under mild rank conditions; see (Sidiropoulos et al., 2017) and references therein. In our context, uniqueness is a desirable property since it is necessary for model interpretability.
2 Related Work
Tensors have been mostly used to model low-order multivariate polynomial systems. A multivariate polynomial of degree (order) can be represented by a tensor of order . For example, a second-order polynomial is represented by a quadratic form involving a single matrix i.e., while a third order polynomial is represented using a -way tensor i.e., (Figure 2). The number of parameters grows exponentially with the order of the approximation making this approach computationally demanding. One way to reduce the number of parameters is to assume that the coefficient tensor is low-rank.
Polynomial Networks (PN) and Factorization Machines (FM) utilize mainly third-order CPD models in order to parameterize the polynomial coefficients with applications in recommender systems and link prediction (Rendle, 2010; Blondel et al., 2016a, b). Such approaches require prior knowledge of polynomial order, and assuming that one deals with a polynomial of a given degree can be restrictive. Additionally, even when dealing with the simplest possible approximation model which is rank-, the number of parameters grows linearly with meaning that this approach cannot model high-degree polynomial functions. Similarly, another tensor model, known as the Tucker model, has also been used for parametrization of polynomial functions in a chemogenomics data prediction task (Perros et al., 2017). Finally, a tensor train model (Oseledets, 2011) has also been used in multivariate polynomial regression (Novikov et al., 2016). Unlike CPD, the model parameters of Tucker and tensor train models are not identifiable.
Output-only (‘blind’) identification of linear systems has also been considered from a tensor point of view. Specifically, identification of Finite Impulse Response (FIR) systems using only output examples has been shown in (Boussé et al., 2017; Van Eeghem et al., 2018).
Our work is radically different from existing approaches. We model a general nonlinear system using a single tensor of order equal to the number of inputs and propose using a high-order tensor completion approach for system identification. One of the earliest applications of tensor decomposition with smooth latent factors has been fluorescence data analysis (Bro, 1998; Fu et al., 2015). Recently, it is has been mostly proposed in the area of image processing. Specifically, CPD and Tucker models with smoothness constraints or regularization have been used for the recovery of incomplete 3- and 4-dimensional image data (Yokota et al., 2016; Imaizumi and Hayashi, 2017). To the best of our knowledge, tensor completion (with or without smooth latent factors) has not been considered yet as a tool for general nonlinear system identification.
3 Proposed Approach
3.1 Canonical System Identification (CSID)
We are given a training dataset of input-output pairs . Let us assume that all predictors are discrete and take values from a common alphabet . The scalar output is a nonlinear function of the input distorted by some unknown noise The nonlinear function can be modeled as an -way tensor where each input vector can be viewed as a cell multi-index and the cell content is the estimated response of the system . We are interested in building a model that minimizes the Mean Square Error (MSE) between the model predictions and the actual response. However, it is evident that it is impossible to infer the response of unobserved data without any assumptions on . To alleviate this problem we aim for the principal components of the nonlinear operator by minimizing the tensor rank. Assuming a low-rank CPD model, the problem of finding the rank- approximation which best fits our data can be formulated as
[TABLE]
where is a regularization parameter. It is convenient to express the problem in the following equivalent form
[TABLE]
where is a tensor containing the number of times a particular data point appears in the dataset and is a tensor containing the mean response of the corresponding data points. The equivalence between Problems (5), (6) is straightforward
[TABLE]
The set contains the indices the data point appears in the dataset. Oftentimes, datasets contain both categorical and ordinal predictors, the later, being either discrete or continuous. In the presence of ordinal predictors a desirable property of a regression model is having smooth prediction surfaces i.e., small variations in the input will cause small changes in the output. As an example consider the task of estimating students’ grades in future courses based on their grades in past courses, an important topic in educational data mining as it can facilitate the creation of personalized degree paths which will potentially lead to timely graduation (Polyzou and Karypis, 2016). The predictors correspond to the grades in past courses that a student has received and the the predicted response is the student’s grade in a future course. We are interested in building a model that maps an -dimensional discrete feature vector to the output response. Adding a smoothness constraint or regularization will guarantee that the model will produce similar outputs for two students that differ slightly in their past grades as they are likely to perform similarly in the future. Therefore, we propose augmenting the CPD tensor completion problem with smoothness regularization:
[TABLE]
where the matrix is a smoothness promoting matrix typically defined as with and or with , and . We set for categorical predictors and otherwise. Penalizing the difference of consecutive row elements of a factor guarantees that varying the -th dimension and keeping the remaining fixed will have a small impact on the predicted response. Another appealing feature of the proposed smoothness regularization is that it can potentially measure feature importance. Note that the effect a variable will have in the prediction is minimized if each column of the corresponding factor is a constant number. Irrelevant features are more likely to have factors that vary slightly. On the contrary, factors associated with predictive features will have more variations and induce a larger penalty cost.
Remark: CPD can model any nonlinear operator for high-enough rank, but even for low ranks, it can model highly nonlinear operators such as
[TABLE]
Comparing these equations with Equation (1) we can verify that the former corresponds to a rank- CPD model, while the later to rank .
3.2 Tensor Completion: Identifiability
In this section we briefly review existing probabilistic and deterministic theoretical results on tensor recovery from a few samples. This is important because, using our approach of casting system identification as tensor completion, the results below directly yield new results on nonlinear multivariate system identification - even for systems of unbounded nonlinearity degree. Recovering a tensor from samples depends mainly on how the samples are generated – randomly or systematically, and if randomly from what distribution – as well as the operational . Practical experience suggests that the generic sample complexity for randomly drawn point samples is proportional to the degrees of freedom in the model. This has been proven for randomly drawn linear (generalized, aggregated) samples, but not yet for point samples (Bousse et al., 2018).
An adaptive sampling method with an estimation algorithm has been proposed by (Krishnamurthy and Singh, 2013) that provably recovers an -th order rank- tensor using samples where is a coherence bound on the factor matrices. Later, (Jain and Oh, 2014) proposed a method that can recover an -th order rank- tensor with orthogonal factor matrices and random sampling using samples. A necessary condition for these methods is that the rank needs to be less than the maximum outer dimension although a CPD model can be unique even if rank exceeds this bound. Probabilistic results on tensor completion have also been proven for incomplete tensors that have low mode- ranks under certain incoherence conditions, relying on minimization of the sum of nuclear norms of the tensor unfoldings (Gandy et al., 2011). For , the result in (Yuan and Zhang, 2016) can be used to show that for uniform random point samples, the sample complexity for our low-rank model is .
Deterministic conditions based on a specific sampling strategy, namely fiber sampling, have been given by (Sorensen and De Lathauwer, 2019). Necessary and sufficient conditions are provided which are dependent on the sampling pattern, assuming that the rank is low enough. The authors propose an eigenvalue decomposition algorithm and demonstrate exact recovery of low-rank incomplete tensors even when, less than one percent of the tensor entries are available. The authors have also extended the results in the case of not fully observed fibers. Finally, several regular sampling strategies are investigated and generic identifiability conditions are provided by (Kanatsoulis et al., 2019).
3.3 Algorithm
The work-horse of tensor decomposition is the so-called Alternating Least Squares (ALS) algorithm. ALS is a special type of BCD which offers two distinct advantages: monotonic decrease of the cost function, and no need for parameter tuning. In this section, we propose an ALS approach to tackle Problem 7.
Tensors despite being high-dimensional, are in general very sparse and optimized sparse tensor formats can offer huge memory and computational savings (Smith and Karypis, 2015). The idea of ALS is that we cyclically update variables while fixing the remaining variables at their last updated values. Assume that we fix estimates , we need to solve the following optimization problem
[TABLE]
where , with the square root computed element-wise. Equivalently, we have
[TABLE]
where , and . Note that we do not need to instantiate because only the non-zero elements of the sparse vector contribute to the cost function. The non-zero elements of correspond to the observed data points for which the -th variable takes the value and therefore we need to compute the corresponding rows of the Khatri-Rao product. Problem 9 can be optimally solved by finding the solution to a set of linear equations obtained after setting the gradient to zero e.g., using the conjugate Gradient descent algorithm (Bertsekas, 1997). Simpler updates can be obtained by fixing all variables except for a single row of the factor . Let us fix every parameter except for the -th row of
[TABLE]
The solution for is given by
[TABLE]
which results in very lightweight row-wise updates. BCD algorithms usually offer faster convergence in terms of the cost function compared to stochastic algorithms for small or moderate size problems. For large-scale problems on the other hand, Stochastic Gradient Descent (SGD) can attain moderate solution accuracy faster than BCD. The merits of both alternating optimization and stochastic optimization can be combined by considering block-stochastic updates (Xu and Yin, 2015). In this work, we propose an easy to implement ALS algorithm as our main goal is to present a fresh perspective on the nonlinear identification problem through low-rank tensor completion. Further algorithmic developments are underway, but beyond the scope of this first submission. Next, we show how the proposed approach can be extended to handle partially observed and multi-output regression tasks.
3.4 Missing Data
It is quite common in general to have observations with missing values for one or more predictors. For example, in the grade prediction task described in the introduction, the predictions for a student rely on the student’s performance achieved in previously taken courses. Consider a student-grade matrix where our goal is to predict the -th course. The matrix will be in general sparse since each student enrolls in only few of the available courses, and the selected courses vary from student to student.
Common approaches for handling missing data include () removal of observations with any missing values, () imputing the missing values before training e.g., by replacing them with the mean, median, or the mode, and () directly handling the imputation by the algorithm. Let and denote the indices of the observed and missing entries of a single observation respectively. Instead of ignoring observations with missing entries we aim at computing the expectation of the nonlinear function conditioned on the observed variables i.e., we set
[TABLE]
Estimating the conditional probability is not possible since the number of parameters grows exponentially with the number of missing entries. Given the low-rank structure of the nonlinear function we propose modeling the Probability Mass Function (PMF) using a nonnegative CPD model which is a universal model for PMF estimation (Kargas et al., 2018). For the sake of simplicity, we adopt a simple rank-one joint PMF model estimated via the empirical first-order marginals (Huang and Sidiropoulos, 2017). Without loss of generality assume that the first predictors are known and the remaining missing, then, the expectation can be computed very efficiently
[TABLE]
In this case, we minimize the squared error between the target value and the conditional expectation of the function. The modification can be easily incorporated in the ALS algorithm. Rich dependencies between the variables can also be captured using a higher-order PMF model, but we defer this discussion to follow-up work due to space limitations.
3.5 Multi-Output Regression
The proposed framework is quite flexible and can easily be extended to vector-valued functions . When there is no correlation between the output variables of a system, one can build independent models, one for each output, and then use those models to independently predict each one of the outputs. However, it is likely that the output values related to the same input are themselves correlated and often a better way is to build a single model capable of predicting simultaneously all outputs. We can treat each different model as an -way tensor and stack them together to build an -way tensor. The new tensor model can be described by factors associated with the predictors and an additional mode of dimension , . The vector-valued prediction for is given by In matrix form we have
[TABLE]
No modification is needed for the ALS updates. Depending on the application one may or may not need to apply smoothness regularization on .
4 Experiments
We evaluate the proposed approach in single output regression tasks using several datasets obtained from the UCI machine learning repository (Lichman, 2013). Our proposed approach is implemented in MATLAB using the Tensor Toolbox (Bader and Kolda, 2007) for tensor operations. We then assess the ability of our model to handle missing predictors by hiding of the data as well as its ability to predict vector valued responses. For each experiment we split the dataset into two sets, used for training and for testing, and run Monte-Carlo simulations. Finally, we evaluate the performance of our approach in a challenging student grade prediction task using a real student grade dataset. For each method we tune the hyper-parameters using -fold cross-validation. We compare the performance of the different algorithms in terms of the Root Mean Square Error (RMSE).
4.1 UCI Datasets
We used four different machine learning algorithms as baselines, Ridge Regresion (RR), Support Vector Regression (SVR), Decision Tree (DT) and Multilayer Perceptrons (MLPs) using the implementation of scikit-learn (Pedregosa et al., 2011). For RR, SVR and MLP we standardize each ordinal feature such that it has zero mean and unit variance. Categorical features are transformed using one-hot encoding. For DT no preprocessing step is required. For our method, we fix the alphabet size to be and use Lloyd-Max scalar quantizer for discretization of continuous predictors. For the MLPs, we set the number of hidden layers to , or and varied the number of nodes per layer , and . We observed that in most cases the MLP with hidden layers performed better than the or layer MLP and that further increasing the number of layers did not improve the performance.
Table 1 shows the RMSE performance of the different methods when there are no missing predictors on the datasets. The number inside the square brackets denotes the number of nodes for each layer of MLP. We highlight the two best performing methods for each dataset. Our approach performs similarly or better than best baseline in most of the datasets. Note that both decision trees and our approach rely on discretization of continuous predictors however, adding the smooth regularization plays a significant role in boosting the RMSE performance for our method.
Next, we evaluate our approach on partially observed datasets. We randomly hide of the full dataset and repeat Monte-Carlo simulations. Before fitting the data to the baseline algorithms we replace each missing entry of an ordinal predictor with the mean and for each categorical predictor we use the most frequent value (mode). For our algorithm we use a rank- approximation of the joint PMF tensor estimated from the training data. Table 2 shows the performance of the different algorithms in this setting. Again, our approach similarly or better than best baseline.
Finally, we test our approach in predicting multi-output responses against RR, DT tree and MLPs. Table 3 contains the results for three datasets. Similarly to the single output setting our approach performs the same or slightly better compared to the baseline methods.
4.2 Grade Prediction Datasets
Finally we evaluate our method in a student grade prediction task on a real dataset obtained from the CS department of a university. The predictors corespond to the course grades the students have received. Specifically, we used the most frequent courses to build independent single output regression tasks each one of them having predictors. Grades take discrete values (-) and due to the natural ordering between the different values smoothness regularization was applied on all factors. We used the Grade Point Average (GPA) and Biased Matrix Factorization as our baselines. Low-rank matrix completion is considered a state-of-art method in student grade prediction (Polyzou and Karypis, 2016; Almutairi et al., 2017). Note that in the matrix case each course is represented by a column while in the proposed tensor approach, each course is represented by a tensor mode (Figure 3). Table 4 shows the results for the different algorithms. Our approach outperforms BMF in tasks, performs the same in and worse in .
5 Conclusion and Future work
In this paper, we considered the problem of nonlinear system identification. We formulated the problem as a smooth tensor completion problem with missing data and developed a lightweight BCD algorithm to tackle it. We have proposed a simple approach to handle randomly missing data and extended our model to vector valued function approximation. Experiments on several real data regression tasks showcased the effectiveness of the proposed approach.
6 Acknowledgements
The work of the authors was supported in part by NSFIIS-1447788, IIS-1704074.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Almutairi et al. (2017) F. M. Almutairi, N. D. Sidiropoulos, and G. Karypis. Context-aware recommendation-based learning analytics using tensor and coupled matrix factorization. IEEE Journal of Selected Topics in Signal Processing , 11(5):729–741, Aug 2017.
- 2Anandkumar et al. (2014) A. Anandkumar, R. Ge, D. Hsu, S. M. Kakade, and M. Telgarsky. Tensor decompositions for learning latent variable models. The Journal of Machine Learning Research , 15(1):2773–2832, 2014.
- 3Bader and Kolda (2007) B. W. Bader and T. G. Kolda. Efficient MATLAB computations with sparse and factored tensors. SIAM Journal on Scientific Computing , 30(1):205–231, December 2007.
- 4Bertsekas (1997) D. P. Bertsekas. Nonlinear programming. Journal of the Operational Research Society , 48(3):334–334, 1997.
- 5Blondel et al. (2016 a) M. Blondel, A. Fujino, N. Ueda, and M. Ishihata. Higher-order factorization machines. In Advances in Neural Information Processing Systems , pages 3351–3359, 2016 a.
- 6Blondel et al. (2016 b) M. Blondel, M. Ishihata, A. Fujino, and N. Ueda. Polynomial networks and factorization machines: New insights and efficient training algorithms. In International Conference on Machine Learning , pages 850–858, 2016 b.
- 7Boussé et al. (2017) M. Boussé, O. Debals, and L. De Lathauwer. Tensor-based large-scale blind system identification using segmentation. IEEE Transactions on Signal Processing , 65(21):5770–5784, 2017.
- 8Bousse et al. (2018) M. Bousse, N. Vervliet, I. Domanov, O. Debals, and L. De Lathauwer. Linear systems with a canonical polyadic decomposition constrained solution: Algorithms and applications. Numerical Linear Algebra with Applications , 25(6):e 2190, 2018.