Interpretable Few-Shot Learning via Linear Distillation
Arip Asadulaev, Igor Kuznetsov, Andrey Filchenkov

TL;DR
This paper introduces Linear Distillation Learning, a simple and interpretable method that enhances linear neural networks for few-shot learning tasks, demonstrating improved performance on MNIST and Omniglot datasets.
Contribution
It proposes a novel linear distillation approach that improves interpretability and performance of linear models in few-shot learning scenarios.
Findings
Outperforms classical Logistic Regression on MNIST and Omniglot
Provides a mathematically tractable and interpretable model
Effective in few-shot learning settings
Abstract
It is important to develop mathematically tractable models than can interpret knowledge extracted from the data and provide reasonable predictions. In this paper, we present a Linear Distillation Learning, a simple remedy to improve the performance of linear neural networks. Our approach is based on using a linear function for each class in a dataset, which is trained to simulate the output of a teacher linear network for each class separately. We tested our model on MNIST and Omniglot datasets in the Few-Shot learning manner. It showed better results than other interpretable models such as classical Logistic Regression.
Click any figure to enlarge with its caption.
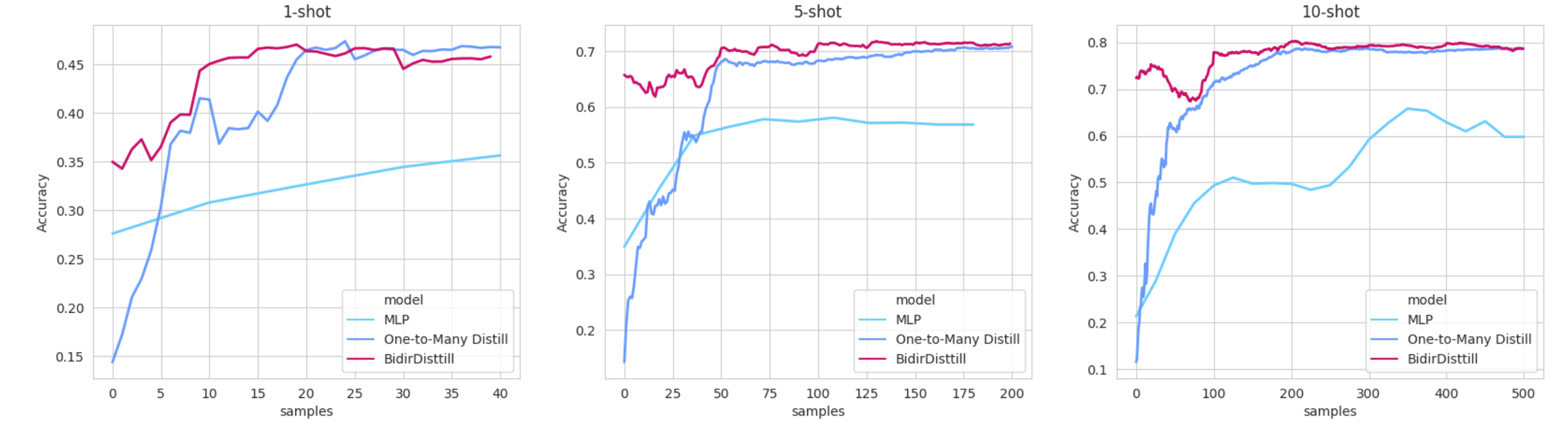 Figure 1
Figure 1 Figure 2
Figure 2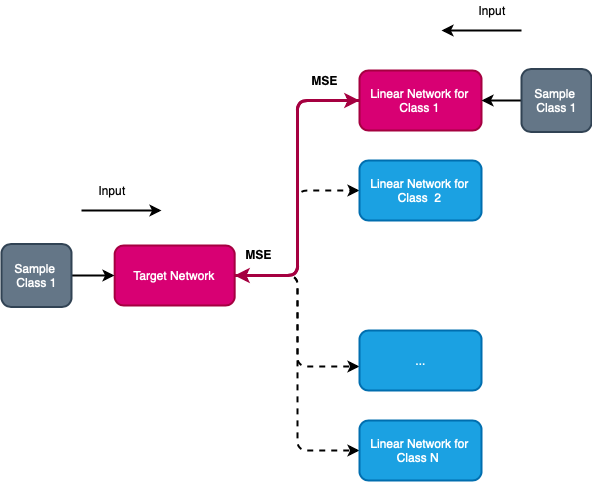 Figure 3
Figure 3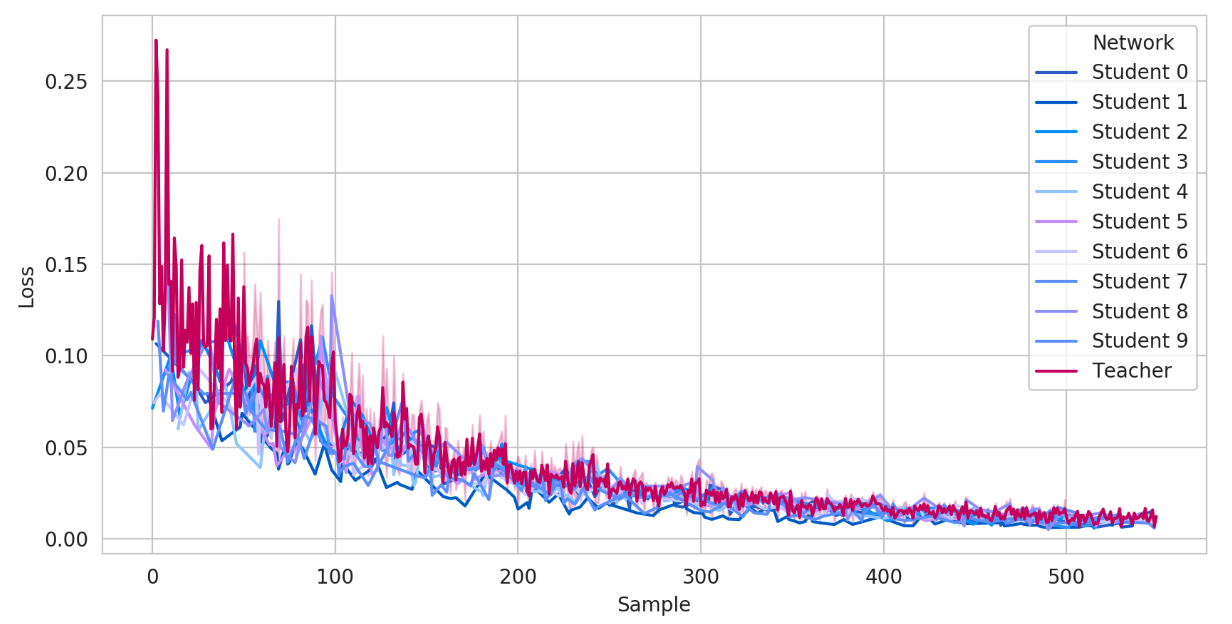 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6| Num | Naive | LR | MLP | O2MD | BD |
|---|---|---|---|---|---|
| 1 | 0.127 | 0.316 | 0.448 | 0.426 | 0.436 |
| 10 | 0.777 | 0.679 | 0.749 | 0.801 | 0.800 |
| 50 | 0.903 | 0.839 | 0.881 | 0.912 | 0.917 |
| 100 | 0.898 | 0.870 | 0.926 | 0.934 | 0.871 |
| 200 | 0.942 | 0.892 | 0.929 | 0.953 | 0.953 |
| way | shot | O2MD | BidirDistill | ||
|---|---|---|---|---|---|
| Output Size | Output Size | ||||
| 784 | 2000 | 784 | 2000 | ||
| 3 | 1 | 0.563 | 0.593 | 0.566 | 0.726 |
| 3 | 0.683 | 0.720 | 0.726 | 0.686 | |
| 5 | 0.800 | 0.803 | 0.773 | 0.760 | |
| 10 | 0.797 | 0.830 | 0.780 | 0.880 | |
| 5 | 1 | 0.428 | 0.454 | 0.372 | 0.420 |
| 3 | 0.614 | 0.626 | 0.560 | 0.636 | |
| 5 | 0.666 | 0.674 | 0.632 | 0.672 | |
| 10 | 0.806 | 0.778 | 0.684 | 0.736 | |
| 10 | 1 | 0.305 | 0.342 | 0.301 | 0.343 |
| 3 | 0.480 | 0.536 | 0.457 | 0.491 | |
| 5 | 0.572 | 0.585 | 0.526 | 0.605 | |
| 10 | 0.685 | 0.689 | 0.663 | 0.697 | |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsDomain Adaptation and Few-Shot Learning · Machine Learning and Data Classification · Adversarial Robustness in Machine Learning
MethodsLogistic Regression
Interpretable Few-Shot Learning
via Linear Distillation
Arip Asadulaev
ITMO University
Saint-Petersburg, Russia
&Igor Kuznetsov
ITMO University
Saint-Petersburg, Russia
&Andrey Filchenkov
ITMO University
Saint-Petersburg, Russia
Abstract
It is important to develop mathematically tractable models than can interpret knowledge extracted from the data and provide reasonable predictions. In this paper, we present a Linear Distillation Learning, a simple remedy to improve the performance of linear neural networks. Our approach is based on using a linear function for each class in a dataset, which is trained to simulate the output of a teacher linear network for each class separately. We tested our model on MNIST and Omniglot datasets in the Few-Shot learning manner. It showed better results than other interpretable models such as classical Logistic Regression.
1 Introduction
One of the topical issues in the machine learning domain is the interpretability of models. For sophisticated models such as ensemble methods or deep neural networks (DNN), it is not easy to understand the rationale behind their predictions. The increasing adoption of machine learning in a variety of real-world systems contributes to the heightened into models understanding. Many papers proposing different techniques intended to improve model interpretability [5, 2] and measured the effect of different interpretability methods on user trust, ability to simulate models, and ability to detect mistakes [3]. A taxonomy for categorizing interpretability methods with different properties was presented in Lipton notes [4].
Some papers seek to discuss how machine learning researchers interpret models by measuring the interpretability of the model on a specific tasks [15].
In this paper, we approach the interpretability problem by creating a simple few-shot learning-based method using linear neural networks (LNNs) that are feedforward neural networks with no nonlinearities. Output of each layer is multiplication of its weights to its input and the output of such network can be computed by matrix multiplication of all weight matrices.
The main advantage of LNNs is that they are tractable and interpretable. Linear models learn monotonic relationships between the features and the target. They have been used for a long time by statisticians, computer scientists and widespread in academic fields such as medicine, sociology, psychology, and many more quantitative research fields. In these areas, it is important to not only predict, e.g., the clinical outcome of a patient but also to explain the model predictions. The linearity of the learned relationship makes the interpretation easy. The estimation procedure of linear model performance is straightforward and weights in the linear equations have an easy to understand interpretation. Despite LNNs are trivial from a representational perspective, the process of training such networks is in research focus. The study of linear networks loss dynamics is a source of novel research questions, helpful insights and brand new ways of looking at certain aspects of deep learning [14, 16, 27, 30, 31].
Deep neural networks tend to operate on raw features and learn rich representations that can be visualized, verbalized, or used for further processing. Increasing depth of LNN does not increase its expressive power, and in order to get comparable performance, linear models often must operate on heavily hand-engineered features.
In this paper, we were guided by a research question If one can improve linear network performance without harming its interpretability property? We claim that we found the positive answer to this question.
We present a Linear Distillation Learning (LDL), a method that uses a linear function for each class in dataset, which is trained to simulate output of some teacher linear function for each class separately. After the model is trained, we can apply classification by novelty detection for each class in dataset. Our framework is distilling randomized prior functions for data. Due to our prior functions are linear, in couple with bootstrap methods it provides a Bayes posterior [18]. We tested our architectures on tasks with different amounts of data on MNIST and Omniglot datasets.
The remaining paper will be structured in the following way. In Section 2, we describe distillation learning techniques and their application. In Sections 3–5, we propose our method for linear network training and gradually describe the components of our architecture. In Section 3, we describe the teacher network, in Section 4 we describe the student network, in Section 5 we describe how to train them together. In Section 6, we present a description and results of empirical evaluations. In Section 7, we analyze the model performance and provide an interpretation of the results. Section 8 concludes the paper and outlines further research.
2 Distillation
Knowledge distillation (KD) is a method of transferring “knowledge” from one machine learning model called teacher to another one called student. The idea behind KD is that a teacher network is a high-capacity model with desired high performance and a student network is a more lightweight model [6, 25, 33]. A student cannot match the teacher, but the distillation process brings the student closer to the predictive power of the teacher. Distillation idea was brought to the neural network community by Hinton et. al. [12].
In distillation learning, knowledge is transferred by training a student model using a soft target distribution for comparison with the output layer. This distribution is produced by a cumbersome model with a high temperature in its output softmax
[TABLE]
with are logits and is temperature. Another scenario of knowledge distillation training is transferring knowledge from an ensemble of highly regularized models to a smaller model [12].
Distillation can also be applied for adversarial permutation [21], born-again neural networks [11] and Global Additive Explanations [32]. Furthermore, Sau and Balasubramanian [26] proposed to add random perturbations into soft labels for simulating learning from multiple teachers.
Surprisingly, the distillation method often allows smaller student network to be trained to mimic the larger and deeper models very accurately, while the student trained on the one-hot hard targets cannot achieve the same results. The clear reason for this awaits to be discovered.
Random Network Distillation [8] was used for exploration in environments with sparse rewards. In this setting, distillation allows an agent to determine whether states were visited or not, and therefore use curiosity for the exploitation. Let be a set of observable states. Predictor is a network that is trained to predict behavior of target during interaction with the environment using MSE for updating parameters . If the difference between the predictions of the random network and the predictor at some environment state is large, the agent receives a higher curiosity reward. This can be considered as a model of novelty detection [24], the training process of which is performed via distillation of a random network. An important claim is that can simulate the behavior of if their expressive powers are identical [8]. We conducted this property and downed the expressive of networks to the linear.
3 Class-Dependent Teacher Distillation
Consider a classification problem with object set and label set We are given a labelled dataset where and . Assume that the classification is performed by distance-based learning with some classifier that works with object representation is some -dimensional space. Consider also some target function which maps objects to this vector space, which is can be represented with a LNN or just a matrix.
Our idea is to create linear predictor for each class that would simulate behavior of the target function on this class. Each predictor is trained to map objects of class into representation .
Due to functions and are linear, we can denote them in a matrix form. For example, is can be considered as a matrix multiplication . During training, labels are used to activate one of the predictors . The process of training uses MSE:
[TABLE]
At the model evaluation step, we make prediction using the distance between and for each class : resulting label is chosen as
It is important to note, that despite each of is linear, the composition of their results cannot be expressed with a linear function. Nevertheless, on each step of learning process, both teacher and student are linear.
We replaced the classification problem with the problem of approximating a linear function with linear functions associated with classes and call this method One to Many Distillation (O2MD).
3.1 Bayesian Interpretation
Following the analogies in RND, our distillation framework can be presented as randomized prior functions for data . Osband et al.showed [18] that bootstrap approaches [29] and randomized prior functions provide a Bayes posterior in the linear case and allow for provides much cheap computing in comparison with Exact Bayes.
In this setting, we investigate a distribution over functions where parameters are specified by minimizing the expected prediction error with regularization [18]. In the formalism we propose, we have specific distribution for each class :
[TABLE]
Parameters are drawn from prior over the parameters of mapping After updating on the evidence we can extract from the posterior. In our case, if we set equal to [math] for every class, according to RND each distillation error is a quantification of uncertainty in predicting the constant zero function
[TABLE]
By default, we interpret our model as an unbiased ensemble with shared parameters, but in practice we can actually consider the model as ensemble of target-predictor networks for each class. In this settings, predictions and target in each ensemble are taken as the sum of target and predictor functions.
During bootstrapping with zero target, ensemble without priors has almost zero predictive uncertainty as becomes large and negative [19], which leads to to arbitrarily poor decisions [20].
4 Class-Dependent Students Distillation
In the previous Section, we have presented approach for learning linear predictors with linear target. In this Section, we present two approaches for selecting this target.
First, we will formulate desirable properties of target. Due to the predictors simulate target on corresponding classes, when we compare outputs, we can more clearly distinguish one of the predictor if dissimilarity with other classes is much larger. For example, if the target output for class is very different from the output for other classes, the trained predictor for this class will be closer to the target than other ones. It may be possible if the target outputs for each class are far from each other.
One of the way to choose that maps classes in distinct regions is to train it directly to do this. It can be done, for example, by updating our target parameters using distillation from some teacher.
In our case, we noticed an interesting feature of distillation: teacher does not have to be able to generalize data. It would be sufficient if teacher function just maps the train data classes in different regions of its output space. In contrast to the standard paradigm of distillation, our teacher is a set of random initialized linear functions for each class that map data in different spaces by default. At step we choose a linear neural network from corresponding to label and use its transformation as a target for our . Learning/optimization is performed by minimizing loss
[TABLE]
We call this method Many to One Random Distillation (M2ORD). The prediction accuracy of the model trained in this way is sub-optimal. It seems to be difficult to learn data distribution from the teachers’ outputs because the transformation the teachers apply to the data is not linear.
4.1 Orthonormal initialization
The idea of orthogonalization is to make functions orthogonal to each other to maintain distinct mapping for each class. We use the Gram–Schmidt process [13] to make teacher functions orthogonal. This method is used in linear algebra for orthonormalizing a set of vectors. We create for each class with size of and join them in single matrix size of , where .
We use singular vector decomposition (SVD) [9] to obtain an orthogonal matrix. SVD of a matrix is the factorization of into the product of three matrices: where is orthogonal. After obtaining results of SVD, we take and split it into matrices . Each such matrix consists of strings in corresponding to the objects of class . As a result, all rows of all teacher matrices are linearly independent and project points into subspaces that are orthogonal:
[TABLE]
[TABLE]
5 Bidirectional Distillation
In the previous two Section, we presented two ideas, namely, O2MD for learning linear predictor functions using distillation and M2ORD for learning linear target function using distillation. In this Section, we combine these two ideas in a method we call Bidirectional Distillation.
After initialization, our predictors are equal to , so at the first step we pretrain our function by in M2ORD and then distill this knowledge back into by O2MD training,
The learning procedure is presented in Figure 1. During Bidirectional Distillation, we alternate O2MD and M2ORD in different proportions, we consistently train them a certain number of iterations, allowing to be updated several times in each epoch.
6 Experiments and Results
In this Section, we describe the results of experiments, comparing One-To-Many and Bidirectional variants of a LDL model against a deep fully connected neural network, logistic regression and naïve linear model. In naïve settings, our predictors are trained without target. Each predictor is trained to produce output representation as close as possible to the original input. At the prediction stage, we only measure the distance between each predictor output and sample .
All of our experiments are formulated within few-shot problem framework. Each model was provided with a set of labelled samples from classes. In the few-shot learning terminology, is traditionally called a way and is called a shot. The task is -class classification. Unlike traditional few-shot learning models, our approach does not imply knowledge transfer between episodes, being thus more similar to small-sample learning [28]. To avoid bias between small number of samples and reported results, each model was trained for 100 independent trials and average accuracy was reported. We ran experiments on two datasets with images of low resolutions, namely MNIST and Omniglot. Our experiments were conducted on a machine with two separate NVIDIA GeForce GTX 1080 Ti, 4 core Intel i5-6600K processors and 47.1 GB RAM memory. We used PyTorch 1.1 with CUDA 10 support for implementation of all models presented in the study. All datasets were uploaded into memory preliminary for faster computation.
6.1 MNIST
For experiments on the MNIST dataset, a small number of samples from each of the digits were given to the model, thus the way was always set to 10. After a model was trained on the given samples, we calculated accuracy on the whole official test part of the MNIST dataset for the easier comparison with well-known approaches. Models were trained on the shots of sizes 1, 10, 50, 200, 300. For testing the models, we performed no data preprocessing and image augmentation. As a result, a single sample was a flattened representation of the grayscale image. We also chose learning rates between , and values. We noticed that a large numbers of epochs were not sufficient for the linear setup and chose the total number epochs to be not greater than 10 for all training shots.
Linear distillation approaches were compared with logistic regression and fully connected network. Fully connected network was chosen between configurations of one and two hidden layers of sizes 64, 256 or 1024. The most promising results were reported for each of the shot value. Results comparing the One-To-Many and Bidirectional Distillation models for different number of shots are shown in Table 1. It is no surprise that the accuracy increased with the size of the training dataset, but it slowed down when the size of the dataset reached the size of about thousand samples.
An important property of our architecture is that it is learned fairly quickly on a small training epochs. The convergence of each student to the teacher is presented in Figure 3, where students are , and the teacher is network.
Training a Bidirectional Distillation model and a O2MD version has advantages over the classic deep fully connected network on a small amount of data. Bidirectional training allows much faster converging to an almost best capabilities of the model after the first epochs, because the target pre-trained on predictors simplifies training. An example of the training process comparing MLP with two hidden layers and the distillation models is depicted in Figure 4. The axis shows accuracy on the full test part of the dataset measured after each epoch/sample.
6.2 Omniglot
The Omniglot dataset consists of 1623 characters from 50 different alphabets, where each of the characters was drawn by 20 different people. Following the authors of Matching Networks [34], we augmented existing classes with rotations by multiples of 90 degrees and used 1200 characters from training and the remaining character classes for evaluation. We resized images to the size of pixels and obtained the very same model settings as for the previous dataset.
We experimented with different learning rates (, , ) and optimizer types (sgd, adam, adadelta) and reported results from most promising configurations. We tested our models on the way of sizes 3, 5 and 10 with shots of size 1, 3, 5, and 10. After training on the given samples, we measured the accuracy on the unseen samples from these classes (one sample per class). For the One-To-Many and Bidirectional setups, we provided results for 784 and 2000 networks’ output dimensions. To provide unbiased results, we averaged results over 100 independent runs. Results comparing studied models for different number of shots are shown in Table 2.
Our model showed acceptable results mainly on a small number of ways. It was sensitive to hyperparameter settings, but nevertheless, was able to learn classification with proper configuration.
7 Results Interpretation
Lipton notes [4] provide a definition of interpretability into two categories. The first relates to transparency, i.e., “How does the model work?” and post-hoc explanations, i.e., “What else can the model tell me?” Transparency connotes some sense of understanding the mechanism by which the model works. The post-hoc interpretation confer useful information for practitioners and end-users of machine learning model.
Our model meets these two requirements. In special cases, diagnostics of model predictions allows to fully understand model behavior, and propose hypotheses on how to improve the model performance. To demonstrate the interpretability of our model, we visualize the regions on which model is concentrated at different classes on MNIST dataset using LIME [35] technique that is a model interpretation technique based on attempting to understand a model by perturbing the input of data samples and observing how its predictions change. This test answering the questions “Why the model made this prediction?” and “Which variables influenced the prediction?” These relations are clearly shown in our model.
Complex models such as ensemble methods or deep networks are not easy to understand. To interpret it, we must use a simpler model, which we set as any interpretable approximation of the original model. Dense embeddings are not interpretable, and applying LIME probably will not improve interpretability. In our case, the best explanation of the model is the model itself; it perfectly represents itself and is easy to understand, see Figure 4.
LDL outperforms other methods on small datasets since it is not that important how overfitted a single predictor is if other predictors are overfitted too. At the evaluation stage, we compare each predictor with others. After a few training samples, each predictor starts to recognize one class better than others, and it is enough to start classifier. The model performance is strongly correlated with the power of each predictor, if predictor’s power is imbalanced, the model will more often choose the prediction of a stronger predictor. To demonstrate this, we visualized model incorrect predictions in Figure 5.
As it seems, the model made an incorrect prediction, because of the imbalance between predictor for class ’2’and ’8’. Simply to avoid this problem, we trained predictor for class ’2’ in MNIST on one more epoch than all other predictors. As a result, after retaining our model made the correct prediction on this sample from the test dataset, see Figure 6.
8 Conclusion and Future Work
In this paper, we present an architecture based on several methods of random function distillation using linear neural networks. The first method is the training of a single network to simulate the behavior of another on a particular class. The second method is the training of a single network to predict the behavior of many other networks for each class in dataset. Our architecture can be considered through the Bayesian lens too. The motivation for our work was to create an architecture, which consists of linear functions capable of classifying on a small dataset. We tested our model on several datasets and showed results comparable to the results of nonlinear models on small amounts of data.
For the Omniglot dataset, we tested our architecture in the few-shot learning paradigm. Our model does not have the key concept of the paradigm to preserve knowledge in the learning process between sub-datasets (episodes). This is an important issue for future research, so one direction of the further studies can be usage of our method in the few-shot tasks on a higher level. There is abundant room for further progress in using distillation as a method of learning and explore open questions in this area.
9 Acknowledgments
We would like to thank Artem Zholus for productive discussions.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Guidotti, Riccardo, Monreale, Anna, Turini, Franco, Pedreschi, Dino, and Giannotti, Fosca. A Survey of Methods for Explain- ing Black Box Models. In ar Xiv:1802.01933 2018.
- 2[2] Guidotti, Riccardo, Monreale, Anna, Turini, Franco, Pedreschi, Dino, and Giannotti, Fosca. A Survey of Methods for Explaining Black Box Models. In ar Xiv:1802.01933 2018.
- 3[3] Poursabzi-Sangdeh, Forough, Goldstein, Daniel G., Hof- man, Jake M., Vaughan, Jennifer Wortman, and Wallach, Hanna. Manipulating and Measuring Model Interpretability. In ar Xiv:1802.07810 2018.
- 4[4] Lipton, Zachary Chase. The Mythos of Model Interpretability. In Proceedings of the ICML Workshop on Human Interpretability in Machine Learning pp. 96–100.2016.
- 5[5] Zhang Quan-shi and Zhu Song-chun. Visual interpretability for deep learning: a survey. In Frontiers of Information Technology and Electronic Engineering , 19(1):27–39, January 2018.
- 6[6] Jimmy Ba and Rich Caruana. Do deep nets really need to be deep? In Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, December 8-13 2014, Montreal, Quebec, Canada , pages 2654–2662, 2014.
- 7[7] Alberto Bernacchia, Máté Lengyel, and Guillaume Hennequin. Exact natural gradient in deep linear networks and its application to the nonlinear case. In Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, Neur IPS 2018, 3-8 December 2018, Montréal, Canada. , pages 5945–5954, 2018.
- 8[8] Yuri Burda, Harrison Edwards, Amos J. Storkey, and Oleg Klimov. Exploration by random network distillation. Co RR , abs/1810.12894, 2018.