Sparse IDMA: A Joint Graph-Based Coding Scheme for Unsourced Random Access
Asit Pradhan, Vamsi Amalladinne, Avinash Vem, Krishna R. Narayanan,, and Jean-Francois Chamberland

TL;DR
This paper proposes a novel joint graph-based coding scheme called Sparse IDMA for unsourced random access, combining compressive sensing and multi-user coding to improve decoding efficiency and performance.
Contribution
It introduces a new coding framework that integrates compressive sensing with IDMA principles for unsourced multiple access, enabling low-complexity joint decoding.
Findings
Achieves performance comparable to existing low-complexity schemes.
Employs a graph-based approach to facilitate joint decoding.
Supported by numerical simulations demonstrating effectiveness.
Abstract
This article introduces a novel communication paradigm for the unsourced, uncoordinated Gaussian multiple access problem. The major components of the envisioned framework are as follows. The encoded bits of every message are partitioned into two groups. The first portion is transmitted using a compressive sensing scheme, whereas the second set of bits is conveyed using a multi-user coding scheme. The compressive sensing portion is key in sidestepping some of the challenges posed by the unsourced aspect of the problem. The information afforded by the compressive sensing is employed to create a sparse random multi-access graph conducive to joint decoding. This construction leverages the lessons learned from traditional IDMA into creating low-complexity schemes for the unsourced setting and its inherent randomness. Under joint message-passing decoding, the proposed scheme offers comparable…
Click any figure to enlarge with its caption.
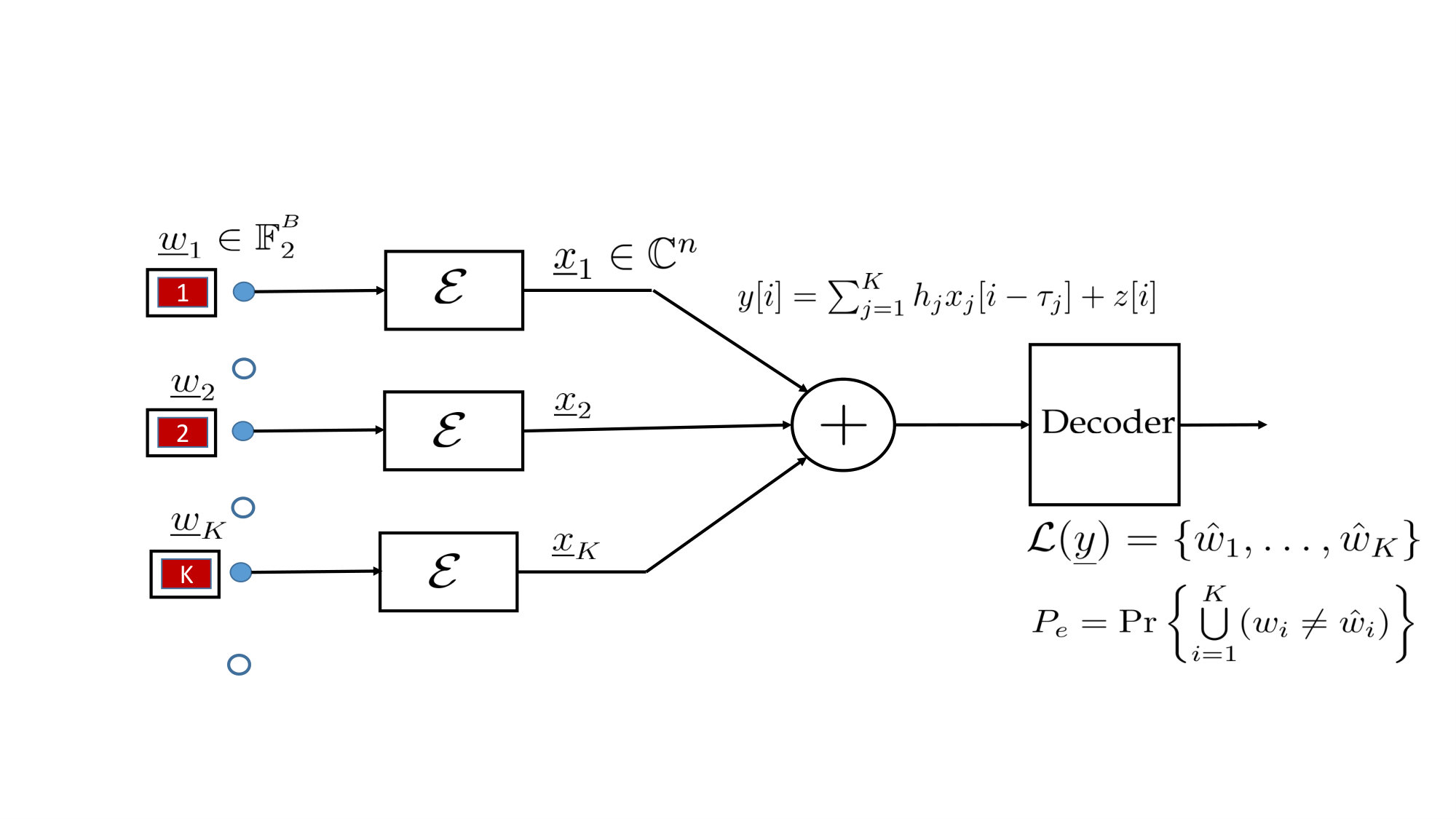 Figure 1
Figure 1| Number of Users | |||
|---|---|---|---|
| Rate |
| Number of Users | Repetition pattern | Rate |
|---|---|---|
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsIndoor and Outdoor Localization Technologies · Wireless Communication Security Techniques · Sparse and Compressive Sensing Techniques
Sparse IDMA: A Joint Graph-Based Coding Scheme for Unsourced Random Access
Asit Kumar Pradhan, Vamsi Amalladinne, Avinash Vem, Krishna R. Narayanan, and Jean-Francois Chamberland
Department of Electrical and Computer Engineering, Texas A&M University
This material is based, partly, upon work supported by the National Science Foundation (NSF) under Grant No. CCF-1619085. This work was presented in part at the IEEE Global Communications Conference, 2019.
Abstract
This article introduces a novel communication paradigm for the unsourced, uncoordinated Gaussian multiple access problem. The major components of the envisioned framework are as follows. The encoded bits of every message are partitioned into two groups. The first portion is transmitted using a compressive sensing scheme, whereas the second set of bits is conveyed using a multi-user coding scheme. The compressive sensing portion is key in sidestepping some of the challenges posed by the unsourced aspect of the problem. The information afforded by the compressive sensing is employed to create a sparse random multi-access graph conducive to joint decoding. This construction leverages the lessons learned from traditional IDMA into creating low-complexity schemes for the unsourced setting and its inherent randomness. Under joint message-passing decoding, the proposed scheme offers comparable performance to existing low-complexity alternatives. Findings are supported by numerical simulations.
Index Terms:
Communication, unsourced multiple access, joint-Tanner graph, belief propagation, compressive sensing.
I Introduction
Recently, there has been a lot of interest in the design of novel access paradigms for uplink data transfers in IoT scenarios [1, 2, 3, 4]. These contributions propose a network with a very large number of devices, among which only a small subset, whose typical size is on the order of hundreds, are active at any given point in time. In [1], Polyanskiy poses the unsourced multiple access channel (MAC) problem where each active device wishes to transmit a -bit message to a central base station and the base station is tasked with recovering the collection of -bit messages communicated by the active users, without regard to the identity of the senders. Therein, key finite block length (FBL) achievable bounds are derived for this setting. Since the publication of [1], there has been substantial interest in designing coding and decoding schemes with low complexity (polynomial in the number of message bits and the number of users) that perform close to the FBL bounds. In [5], Ordentlich and Polyanskiy report that traditional MAC coding schemes like ALOHA and treating interference as noise (TIN) exhibit performance far away from these FBL bounds. They then introduce the first low-complexity algorithm tailored to the unsourced MAC setting. In their scheme, the transmission period is divided into several slots, and each active user picks a random slot to transmit their message. Within each slot, a combination of compute-and-forward and forward error correction is employed for the -user Gaussian MAC. While their scheme provides insights into the design of practical coding schemes for unsourced MAC, there remains a significant gap between the performance of this scheme and the FBL benchmarks. Subsequently, several practical coding schemes have been proposed for the unsourced and uncoordinated MAC [6, 7, 8, 9]. Other related contributions, such as [10], present coding schemes for the uncoordinated random access channel which is closely related to the unsourced MAC.
In [6], Vem et al. devise a concatenated coding scheme with a slotted framework similar to [5] for the same problem. This latter approach is, in essence, a per-user repetition scheme whereby codewords are sent over several slots. The message corresponding to each active device is divided into two parts. The first part is used to pick an interleaver for a low-density parity-check (LDPC) code, which is employed to encode the second part of the message. The first part of the message is conveyed to the base station using compressive sensing (CS). The second part is decoded using a per-slot message-passing decoder designed to recover data in the presence of up to users (). The repetition pattern is a deterministic function of the user’s message sequence. A peeling decoder, which employs successive interference cancellation (SIC), works across slots to cancel the interference of successfully decoded messages. This scheme is shown to perform significantly better than the scheme in [5] and is only around dB away from the FBL bounds. In [11], Marshakov et al. propose using polar codes instead of LDPC codes to encode the second part of the message, which is decoded using a joint polar decoder. This further improves the error performance of the scheme in [6].
While the scheme in [11] uses time-division to sparsify active user’s collisions, in [12], Pradhan et al. use random spreading to alleviate multi-user interference. The payload corresponding to each active user is split into two parts. The first part acts as a preamble to choose a signature sequence from a codebook of sequences with good correlation properties. The second part is encoded using a polar code whose frozen bits are dictated by the preamble. The polar codeword is spread using the signature sequence picked by the first part of the message. The decoder first employs an energy detector that uses correlation properties of the signature sequences to detect the list of spreading sequences used. The preambles corresponding to active users are implicitly decoded in this step. This information is passed to an minimum mean square error (MMSE) estimator that produces log-likelihood ratios (LLRs) for the latter part of messages based on the spreading sequences. Finally, these LLRs are input to a single user polar list decoder that attempts to decode the latter part of messages treating interference as noise. The performance of the scheme is state-of-the-art when ; however, it does not scale well with the number of active users. Another drawback of this scheme is that the decoding complexity is .
In [7], Amalladinne et al. cast the unsourced MAC as a large compressive sensing problem. They then construct a divide-and-conquer approach to obtain a pragmatic, low-complexity solution. In their scheme, each active user’s message is divided into several fragments, and these fragments are enhanced with redundancy. The coded sub-blocks are then encoded using a sensing matrix designed to recover the sub-blocks in the presence of noise using the non-negative least squares decoding algorithm. The recovered sub-blocks are then stitched together using the redundancy introduced during the encoding process. In [8], Fengler et al. propose using approximate message passing (AMP) algorithm as the inner code in combination with the outer tree code in [7]. This scheme performs better than alternate schemes that preceded it. In [13], Amalladinne et al. further improved the error performance by passing information between AMP and the outer code. In addition, the work in [9] provides a very low complexity solution based on a chirp reconstruction algorithm. This complexity reduction, however, comes at the expense of error performance.
I-A Motivation and Contributions
In this paper, we describe a novel low-complexity solution inspired from the scheme in [6] based on SIC. The proposed coding scheme is based on decoding a joint Tanner graph for the unsourced MAC setting. Each active user’s message is divided into two parts. The first part is used to schedule the transmission policy and pick a repetition factor for the latter part of the message. Similar to the scheme in [6], this part of the message is conveyed to the decoder using a CS framework. The other part of the message is encoded using an LDPC code. Each bit of the LDPC codeword is then repeated a certain number of times, which is determined by the first part of the message.
We list below key features that distinguish our framework from prior art (details can be found in Section II).
- i.
In [6], messages are decoded on a per-slot basis, and copies are then peeled from other slots in the spirit of successive interference cancellation. In contrast, the approach we develop herein avoids the strategy of slotting-and-peeling altogether. A key contribution of this paper is to show that, when carefully designed, a single sparse joint Tanner graph that spans across all transmissions can provide substantial improvement in performance over the schemes in [6, 7, 8]. 2. ii.
The scheme in [6] relies on the existence of codes that achieve FBL capacity at the slot level. As the number of active users increases, the scheme in [6] warrants that the slot length decrease. Designing FBL capacity achieving multi-user LDPC codes for such short block lengths becomes very challenging. 3. iii.
Our proposed scheme can be interpreted as a sparse version of IDMA [14] adapted to the uncoordinated and unsourced MAC by using an additional compressed sensing part. Unlike traditional IDMA, we carefully control the multi-user interference by keeping the transmissions sparse. Such sparsity is important in ensuring two key advantages: (a) the computational complexity of optimal soft-input soft-output demodulation is kept low, (b) the message passing decoding can perform efficiently for the large number of users and small message block lengths that are of interest in IoT. We derive the corresponding density evolution equations and optimize protograph based LDPC codes. In the simulation results section, we show that the proposed approach significantly outperforms traditional IDMA for a large number of users. 4. iv.
The performance of the proposed scheme is comparable to that of the scheme in [13] although the two schemes are entirely different. In some parameter regimes, the proposed scheme is less complex than the scheme in [13]. Our scheme is also substantially less complex than the polar coding based scheme in [12] while the performance of the polar coding scheme is better.
Throughout, we employ the following notation: denotes the set of integers from to , including end points; vectors are denoted by underlined symbols.
II System Model
Let and be the total number of users in the network and the number of active users, respectively. Every active user has bits of information (or, equivalently, one of indices) to be encoded and transmitted within a block of uses of the channel. Let be a random variable that represents the message index of the th user and let be a realization of this random variable. We assume that is uniformly distributed over and messages are independent from one another.
The observed signal vector at the receiver corresponding to the channel uses can be written as
[TABLE]
where is the signal transmitted by user , the additive noise is characterized by , and are the fading coefficients which are independent of and . The Boolean indicator is defined as if user is active and otherwise. We impose an average power constraint on the transmitted vectors when taken over all possible message indices, i.e., . The energy-per-bit of the system is defined as . The receiver produces an estimate of the list of messages. As in [1], the probability of error is defined by
[TABLE]
where denotes the Hamming weight. The objective is to design a low-complexity encoding and decoding scheme with the least possible such that , where is the target error probability.
III Description of Proposed Scheme
The overall schematic of the proposed scheme is illustrated in Fig. 1. The parameters of the encoding process in our unsourced setting are independent of the user identity. So, our description of the encoding process is solely based on the message index; the encoding process is identical for every active user.
III-A Encoder
The encoder contains two components: a sensing matrix for a -sparse robust compressed sensing (CS) problem, and a multi-user channel code for the binary-input real-adder multiple-access channel. The channel uses available for communication are split between these two components: channel uses for the compressed sensing part ( denotes preamble) and channel uses for the channel coding part. The bits to be transmitted are also split into two groups of and bits, respectively (). For convenience, we define and . Also, we denote the preamble and channel coding parts of the message index by and .
For the CS portion of the encoding process, we consider a sensing matrix of the form \mathbf{A}=\big{[}\underline{{a}}_{1}~{}\underline{{a}}_{2}~{}\cdots~{}\underline{{a}}_{M_{\mathrm{p}}}\big{]}\in\mathbb{R}^{N_{\mathrm{p}}\times M_{\mathrm{p}}} normalized to meet the power constraint, i.e. . An active user encodes its preamble message into the column of .
The channel coding part of the message index is first encoded into an -bit codeword of an LDPC code and modulated using binary phase shift keying (BPSK). The active user subsequently employs the many-to-one function to generate an integer based on , and the LDPC codeword is repeated times. The vector thus constructed takes the form
[TABLE]
Vector is then padded with zeros to generate the -length vector and normalized to satisfy the power constraint . At this stage, the preamble message is again used to pick an interleaver for the zero padded codeword .
Let be the codeword corresponding to message index . Then, is obtained by first permuting the zero-padded codeword employing the permutation and then inserting the th column of the sensing matrix at the beginning of the permuted codeword, i.e.,
[TABLE]
The key idea of the proposed construction is that zero-padding followed by interleaving the codeword ‘sparsifies’ the transmissions and reduces the interference in each use of the channel significantly, especially when . Specifically, the average channel as seen at each time index is (approximately) a -user Gaussian MAC rather than a -user Gaussian MAC, where denotes the fraction of users that employ repetition factor . This approach results in a superior performance, and it enables us to design a computationally efficient decoding algorithm.
III-B Decoder
The overall decoder has two components. The compressed sensing decoder recovers the preamble fragments, and concomitantly acquires the set of interleavers and repetition patterns picked by the active users. A low-complexity message passing decoder then recovers the codewords sent over the -user Gaussian multiple access channel.
III-B1 Compressed Sensing Decoder
The first received symbols can be written in vector form as
[TABLE]
where is a -sparse vector whose support indicates the set of transmitted preamble messages and entries indicate the fading coefficients of the corresponding users. We first run a generic CS decoder , which yields estimate of . Yet, we emphasize that this does not guarantee an output signal of the required sparsity (as we know a priori from the structure of the problem). To address this issue, we sort the candidates and choose the list of the top indices () as the effective output from the CS decoder.
III-B2 Message Passing for Gaussian MAC
The compressed sensing decoder outputs a set of interleavers and corresponding fading coefficient estimates, which are used as input by the message passing decoder. The channel coding part of the received signal can be expressed as
[TABLE]
Note that the received signal includes contributions from interleavers that were not employed by any of the active users. The additional interleavers can be viewed as the ones employed by fictitious users, each of them transmitting a zero signal.
For ease of exposition, we describe the message passing rules for and . It can be generalized to larger values of , in a straightforward manner. Given the received signal the joint BP decoder proceeds iteratively passing messages along the edges of a Tanner graph that represents the coding scheme. Such a Tanner graph and the associated messages that are passed during the decoding are shown in Fig. 2. The nodes marked , and represent variable nodes, check nodes and MAC nodes, respectively. Throughout this section, we use superscript to distinguish between users and . The following messages are passed at every iteration along the edges of the Tanner graph.
- •
: Messages passed from bit node to check node along edge of user 1.
- •
: Messages passed from variable node to check node along edge of user 1.
- •
: Message passed from variable node of user to MAC node along edge .
- •
: Message passed from MAC node to variable node of user along edge .
The messages for user are defined similarly. The rules for message passing are somewhat standard.
Given an edge between a variable node and a check node, let and denote the variable node and check node connected to , respectively. Similarly, given an edge between a variable node and a MAC node, let and denote the variable node and MAC node connected to , respectively. Let be the set of edges connected to check node , and represent the set of edges that connect variable node to check nodes. Let denote the set of edges that connect the variable node to MAC nodes. Let be the set of edges connected to MAC node .
At the bit node, we have
[TABLE]
The LDPC check nodes implement
[TABLE]
As discussed earlier, the receiver sees a -user Gaussian MAC because of the sparse nature of transmissions, which enables the receiver to do optimal demodulation at MAC nodes. The message at the MAC node corresponding to the th use of the channel is updated by
[TABLE]
where is the neighboring edge of at a MAC node and . The function can be viewed as the log-likelihood of variable when , , the log-likelihood ratio of variable is known to be , and .
IV Density evolution and Code Construction
A protograph is a bipartite graph with the bipartition and called the set of variable and check nodes, respectively. The set of undirected edges specifies the connections between variable nodes in and check nodes in . The th variable node, check node and edge in the protograph are denoted, respectively, by , and . An example of a protograph appears in Fig. 3.
An LDPC code can be obtained from the protograph by copy-and-permute operation. Since the codes obtained form a multi-edge-type ensemble with edge types, density evolution proceeds with types of messages, one for each edge in the protograph [15].
Let denote the repetition degree distribution (d.d.), where represents the fraction of active users who repeat their codewords times. This structure induces a degree distribution on the MAC nodes given by , where is the fraction of time instants where users transmit. When the interleavers in (3) are chosen uniformly at random from the set of all possible interleavers of length , it can be seen that with . In the limit as grows large, converges to . The edge perspective MAC node degree distribution, denoted by , is given by .
Next, we introduce notations required to describe the density evolution (DE). Without loss of generality, we consider a coded bit whose value is +1. Under the assumption that messages (log-likelihood ratios) along edges are Gaussian with mean and variance , the mutual information (MI) between the message along an edge and the codeword bit associated with it is given by [16]
[TABLE]
Note that is the variance of the LLRs when the MI between the message and the corresponding variable is .
Consider the messages passed along the edges during the th iteration for a user who repeats its bits times. Let represent the MI between the message from variable node to check node along the edge type and the associated codeword bit. Similarly, define as the MI between the message along the edge type from check node to variable node and the associated codeword bit. Let denotes the MI between the message from variable node to the MAC node and the codeword bit associated with . Let denote the average MI between the message from MAC node to variable node and the associated codeword bit. Let denote the average MI between the message from variable nodes to MAC nodes and the codeword bits. Finally, let denote the mutual information between the posterior log-likelihood-ratio (LLR) evaluated at variable node and the associated codeword bit.
Consider a MAC node with two users and BPSK modulation without additive noise. Let be the variance of a priori (incoming) LLRs at the MAC node. We assume that a MAC node performs soft interference cancellation and that the remaining interference at the MAC node is Gaussian. Let denote the minimum mean squared error in the estimate of a variable after soft interference cancellation. Then, is given by [17]
[TABLE]
For a user whose codeword is repeated times, we start the density evolution recursion by initializing to zero. Then,
[TABLE]
where is given by [17],
[TABLE]
We also have
[TABLE]
[TABLE]
[TABLE]
[TABLE]
where is the number the number of variable nodes in the protograph. Finally,
[TABLE]
[TABLE]
The density evolution threshold is defined as the minimum for which , as , for all and .
We use differential evolution [18] to optimize the protographs and by using the density evolution threshold as the cost function. We lift optimized protographs to codes using the progressive edge growth algorithm. Even though DE thresholds are meaningful benchmarks only for asymptotic lengths. Nevertheless, designing codes based on DE thresholds offers a principled way to optimize the performance of our system. Simulation results show that this approach is efficient even for short block lengths.
V Numerical Results
The parameters we select for our numerical study are: (i) Number of bits each user intends to transmit , (ii) Total number of channel uses , (iii) Total number of active users , (iv) Maximum per user error probability . These value are chosen to match the parameters employed in [5] for ease of comparison.
We fix and . The sensing matrix for the CS encoder is constructed as follows. We pick rows uniformly at random from the discrete Fourier transform (DFT) matrix of dimension . The real and imaginary parts of each row are then stacked to form a real sensing matrix ; entries are normalized to meet the power constraint. Matrices constructed this way satisfy restricted isometry property (RIP) with high probability and are a good choice for the sensing matrix in noisy compressed sensing [19]. This then yields the parameters for the channel coding part, with and .
For a fixed value of , computing the required SNR involves solving the optimization problem
[TABLE]
The proposed scheme is evaluated as follows. For each , we use the optimization procedure described in Section IV to optimize the protograph for the LDPC code and the repetition d.d. . The function is then chosen to induce this degree distribution. Although one needs to solve the optimization problem in (6) to achieve the optimal SNR, this task is computationally complex due to the parameter space being huge. Alternatively, using simulations, we found to be a suitable choice when , and thus we fix . With fixed, we sweep over all possible combinations of , in a two-dimensional grid of SNR values, with a resolution of 0.5 dB in each dimension, for the compressed sensing and the channel coding components. We emphasize that this only results in an approximate solution to the above optimization problem.
We perform full-blown simulations of the proposed scheme to account for preamble collision and missed detection of the CS decoder. The former event forces colliding users to pick the same parameters (interleaver and code rate) for the channel code; while the latter fails to provide information regarding the parameters of the channel code chosen by the active users whose preambles are not detected by the CS decoder. By choosing and as the approximate solutions to optimization problem (6), we ensure that these events occur with a low probability.
V-A *Selection of codes as a function of number of users *
The rate of the protograph LDPC code has a significant effect on the required for a fixed value of . For different rates, the minimum required to achieve a probability error of is plotted in Fig. 4 as a function of the number of users. It can be seen that the optimal rate changes with the number of active users . For example, for and , an of dB is required if a rate- LDPC code with is utilized, whereas an of dB is required if a rate- LDPC code with the same repetition pattern is employed. For a fixed number of users, we choose the rate through simulations to minimize the required to achieve a target probability of error.
V-B Comparison with existing schemes
The performance of the scheme developed herein is compared to the existing schemes in Fig. 5. Rates of LDPC codes used for each value of are given in Table I. In the simulation of proposed scheme, repetition pattern is used for all values of . The obtained simulation results show that the proposed scheme performs better than the schemes in [6, 7, 8, 9]. For example, at , the proposed scheme outperforms the scheme in [8] by dB. It can also be seen that the scheme in [12] outperforms the proposed scheme when . However, the polar coding based approach in [12] does not scale well with the number of active users. It is pertinent to note that performance of the proposed scheme can be further improved by using irregular repetition patterns across users.
In Fig. 5, the red circles indicate the required when the optimized repetition d.d. given in Table II is used. A small improvement of about 0.2 dB results from using an irregular repetition d.d.
V-C Rayleigh fading channel
The proposed scheme also performs well over Rayleigh fading channel. The performance of the scheme is compared to the existing schemes in Fig. 6. The simulation results show that the proposed scheme’s performance is comparable to the scheme in [20], which assumes the existence of codes that achieve FBL capacity. The proposed scheme outperforms the scheme in [20] when it is simulated with LDPC codes in the regime .
V-D Comparison with IDMA
We now present a comparison of the proposed scheme with conventional IDMA. Prior work has shown that IDMA is very effective when the number of users is small (less than 25-30) and block lengths are reasonably large [14], [21]. Designing very low rate ( 1/300) iteratively-decodable multi-user codes with short block lengths for a large number of users is a significant challenge that renders conventional IDMA inefficient for the unsourced MAC formulation in this paper. It is known that for the single user channel, generalized LDPC codes with Hadamard codes as check nodes (GHLDPC codes) exhibit close-to-capacity performance at very low rates [22]. Motivated by this result, we attempted to design rate-1/300 GHLDPC protograph codes for a multi-user channel using differential evolution; however, the optimization procedure did not iterate beyond initial population and the density evolution thresholds were poor. A better rate-1/300 code for IDMA was obtained by repeating each coded bit of a rate-1/4 LDPC code times. The minimum required to achieve a probability error of for this code is plotted in Fig. 7. It can be seen that there is a significant gap between FBL bound and the performance of conventional IDMA, and that conventional IDMA scales very poorly with the number of users. Our proposed scheme circumvents this code design bottleneck by sparsifying the transmissions and controlling the interference. It provides significant performance improvement at low complexity for a large number of users. It is an interesting open problem to determine if there are other codes of rate-1/300 codes that could work well with conventional IDMA and without sparse repetition, even for a large number of users.
VI Conclusion
We proposed a CS and IDMA based scheme for the unsourced, uncoordinated Gaussian multiple access channel. The difficulty of designing low-rate LDPC codes for IDMA is circumvented by introducing a sparse version of IDMA. We developed the density evolution equations for sparse IDMA with Gaussian approximation and designed protograph-based LDPC codes for sparse IDMA. When decoded with a message passing algorithm, the proposed coding scheme performs comparably to the other existing schemes in the large number of users regime.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Y. Polyanskiy, “A perspective on massive random-access,” in Proc. Int. Symp. on Information Theory , pp. 2523–2527, 2017.
- 2[2] X. Chen, T.-Y. Chen, and D. Guo, “Capacity of Gaussian many-access channels,” IEEE Trans. Inform. Theory , vol. 63, no. 6, pp. 3516–3539, 2017.
- 3[3] G. Liva, “Graph-based analysis and optimization of contention resolution diversity slotted ALOHA,” IEEE Trans. on Commun. , vol. 59, no. 2, pp. 477–487, 2011.
- 4[4] E. Paolini, C. Stefanovic, G. Liva, and P. Popovski, “Coded random access: applying codes on graphs to design random access protocols,” IEEE Communications Magazine , vol. 53, no. 6, pp. 144–150, 2015.
- 5[5] O. Ordentlich and Y. Polyanskiy, “Low complexity schemes for the random access Gaussian channel,” in Proc. Int. Symp. on Information Theory , pp. 2528–2532, 2017.
- 6[6] A. Vem, K. R. Narayanan, J. Cheng, and J.-F. Chamberland, “A user-independent serial interference cancellation based coding scheme for the unsourced random access Gaussian channel,” in Proc. Information Theory Workshop (ITW), 2017 IEEE , pp. 121–125, IEEE, 2017.
- 7[7] V. K. Amalladinne, A. Vem, D. K. Soma, K. R. Narayanan, and J.-F. Chamberland, “A coupled compressive sensing scheme for uncoordinated multiple access,” ar Xiv preprint ar Xiv:1809.04745 , 2018.
- 8[8] A. Fengler, P. Jung, and G. Caire, “SPAR Cs for unsourced random access,” ar Xiv preprint ar Xiv:1809.04745 , 2018.