TL;DR
This paper introduces MOPED, a method for setting informed weight priors in Bayesian deep neural networks using empirical Bayes, improving scalability and uncertainty quantification across various real-world tasks.
Contribution
The paper proposes a two-stage hierarchical approach, MOPED, that effectively sets weight priors in Bayesian DNNs, enabling scalable variational inference.
Findings
MOPED improves scalability of Bayesian DNNs.
Provides reliable uncertainty quantification.
Outperforms state-of-the-art Bayesian methods on multiple tasks.
Abstract
Stochastic variational inference for Bayesian deep neural network (DNN) requires specifying priors and approximate posterior distributions over neural network weights. Specifying meaningful weight priors is a challenging problem, particularly for scaling variational inference to deeper architectures involving high dimensional weight space. We propose MOdel Priors with Empirical Bayes using DNN (MOPED) method to choose informed weight priors in Bayesian neural networks. We formulate a two-stage hierarchical modeling, first find the maximum likelihood estimates of weights with DNN, and then set the weight priors using empirical Bayes approach to infer the posterior with variational inference. We empirically evaluate the proposed approach on real-world tasks including image classification, video activity recognition and audio classification with varying complex neural network…
Click any figure to enlarge with its caption.
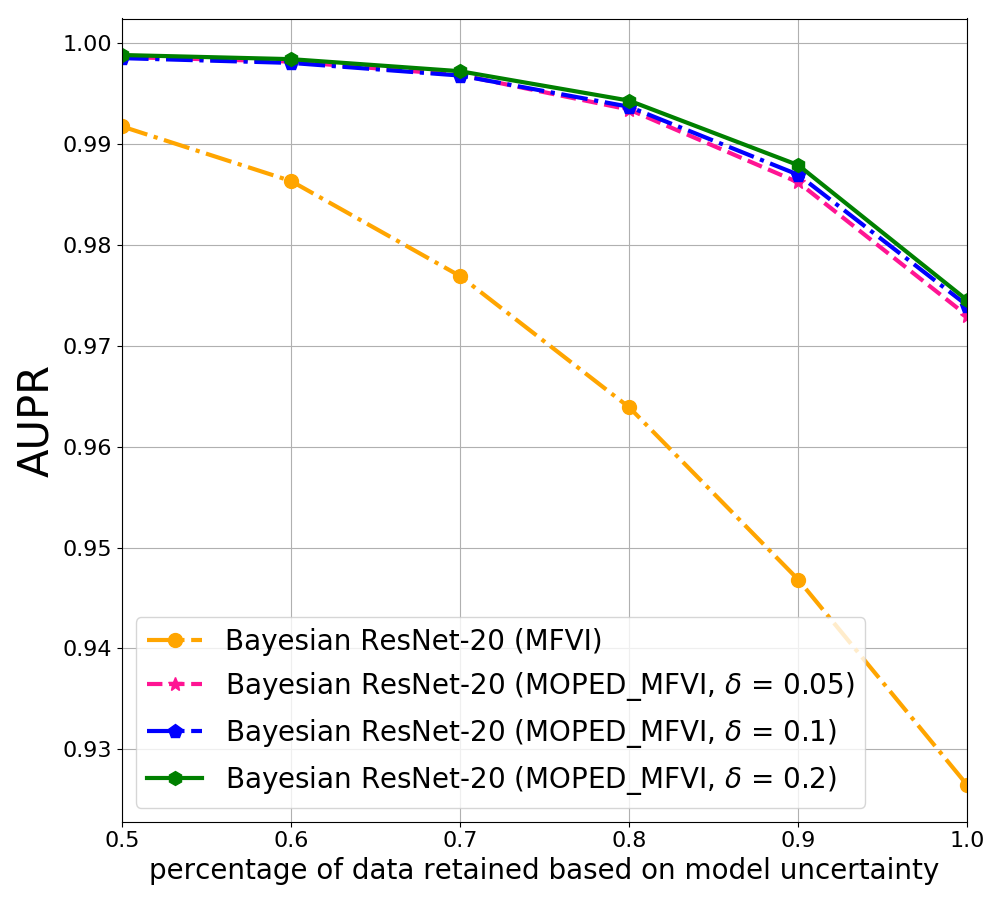 Figure 1
Figure 1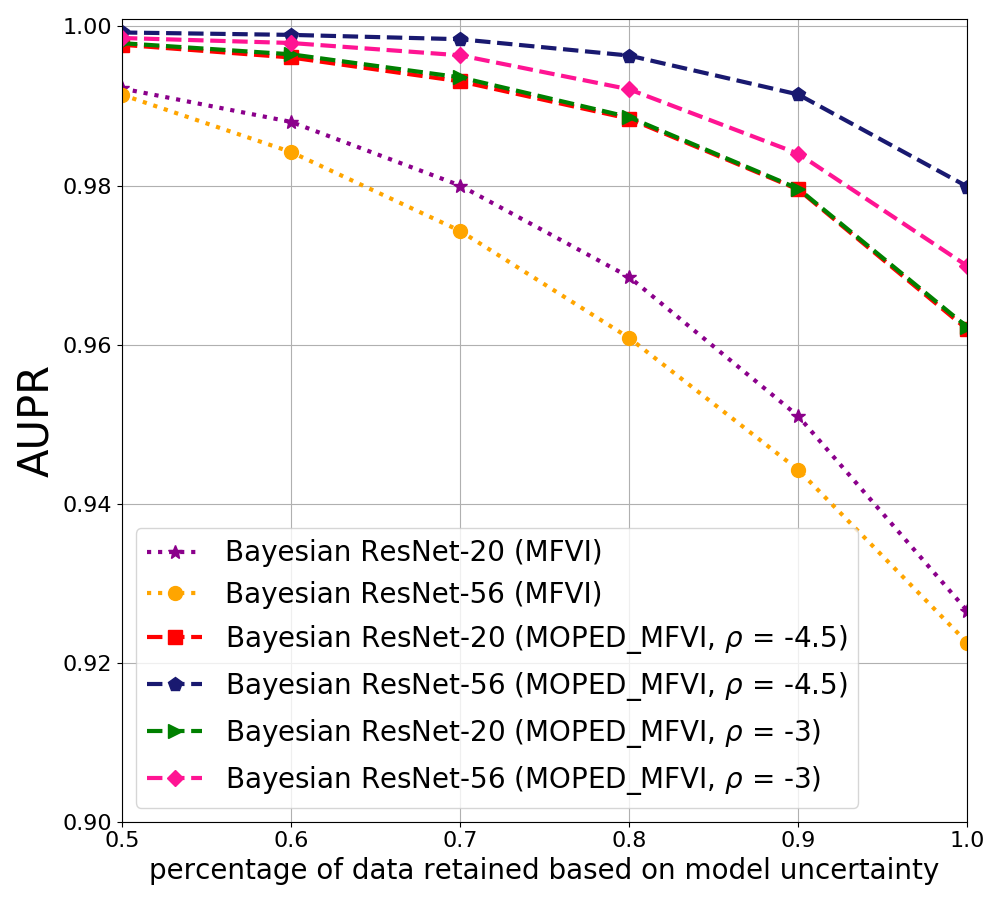 Figure 2
Figure 2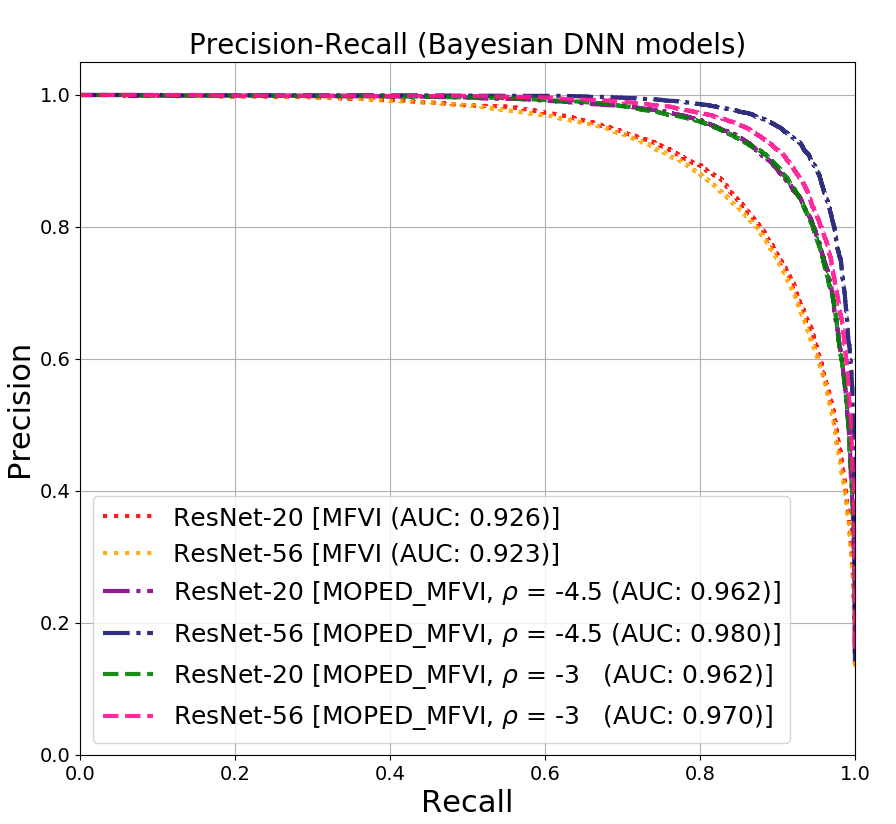 Figure 3
Figure 3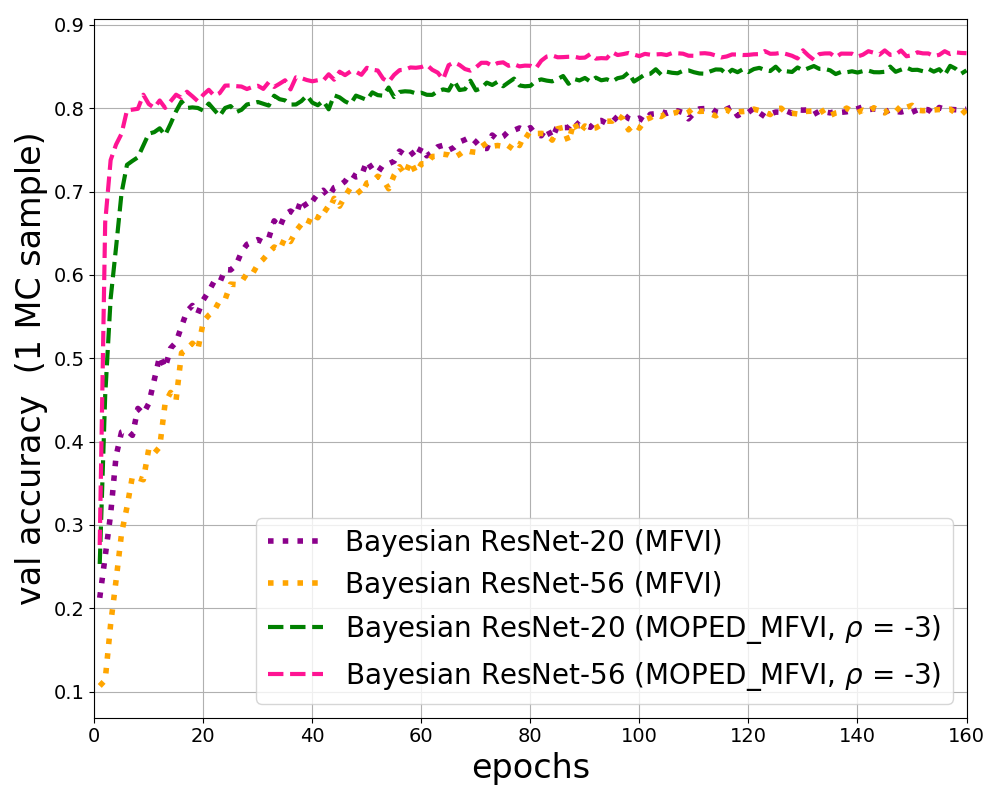 Figure 4
Figure 4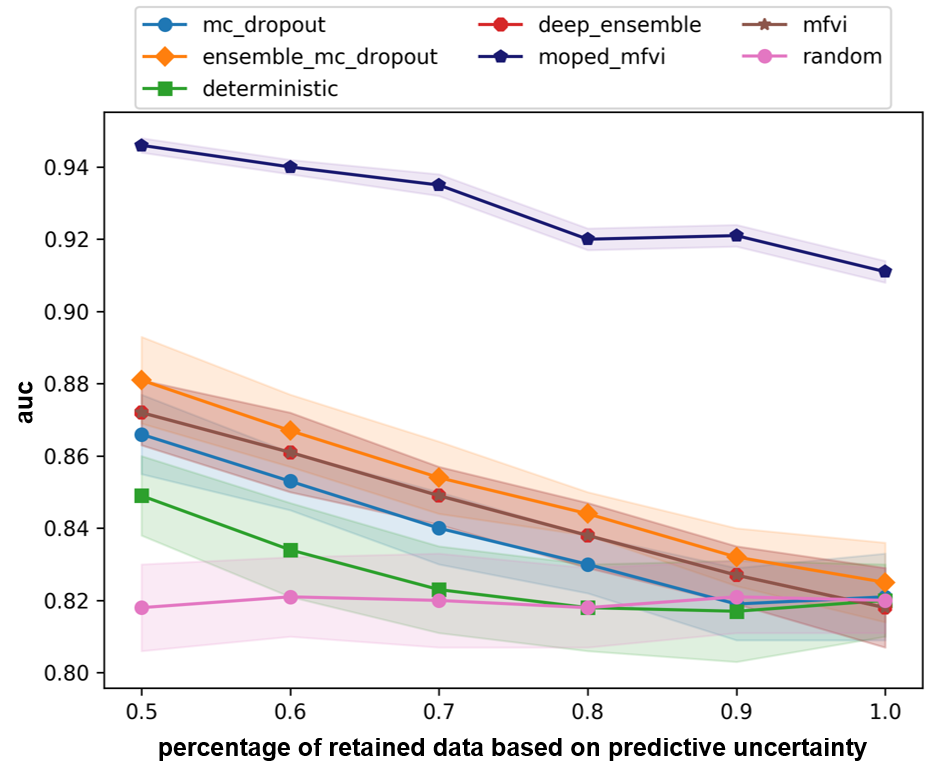 Figure 5
Figure 5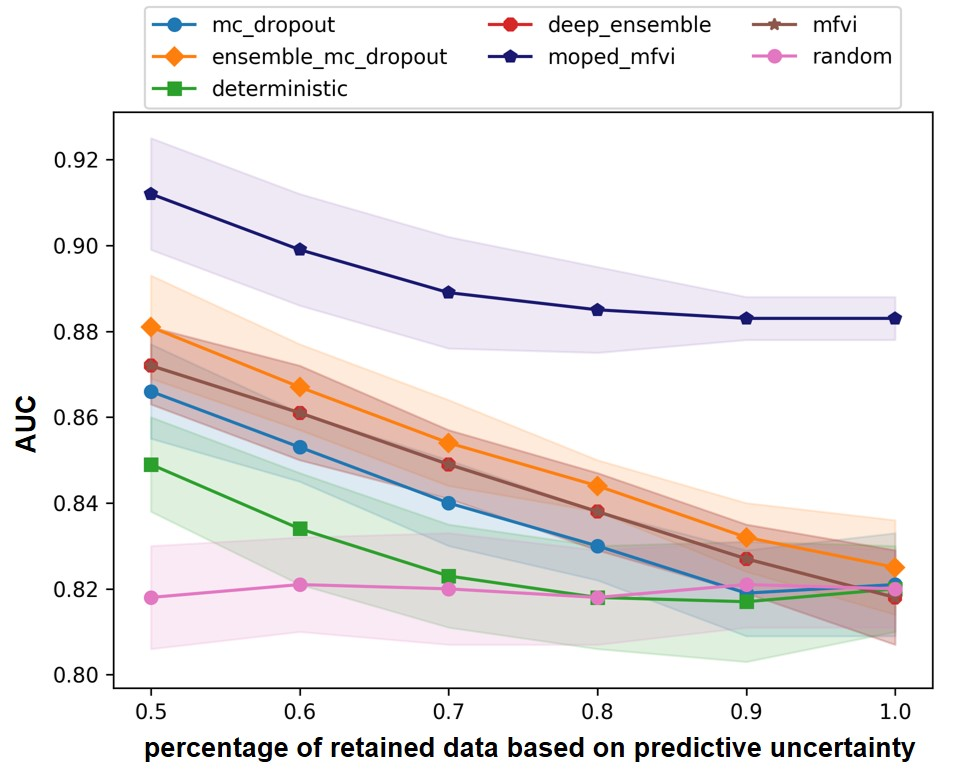 Figure 6
Figure 6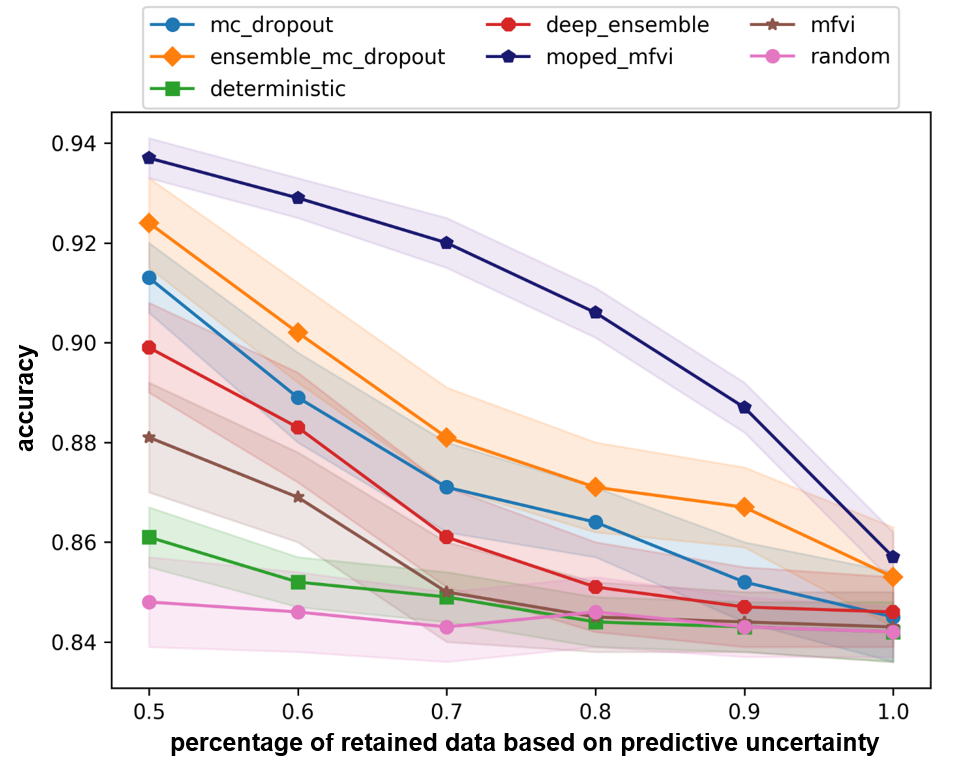 Figure 7
Figure 7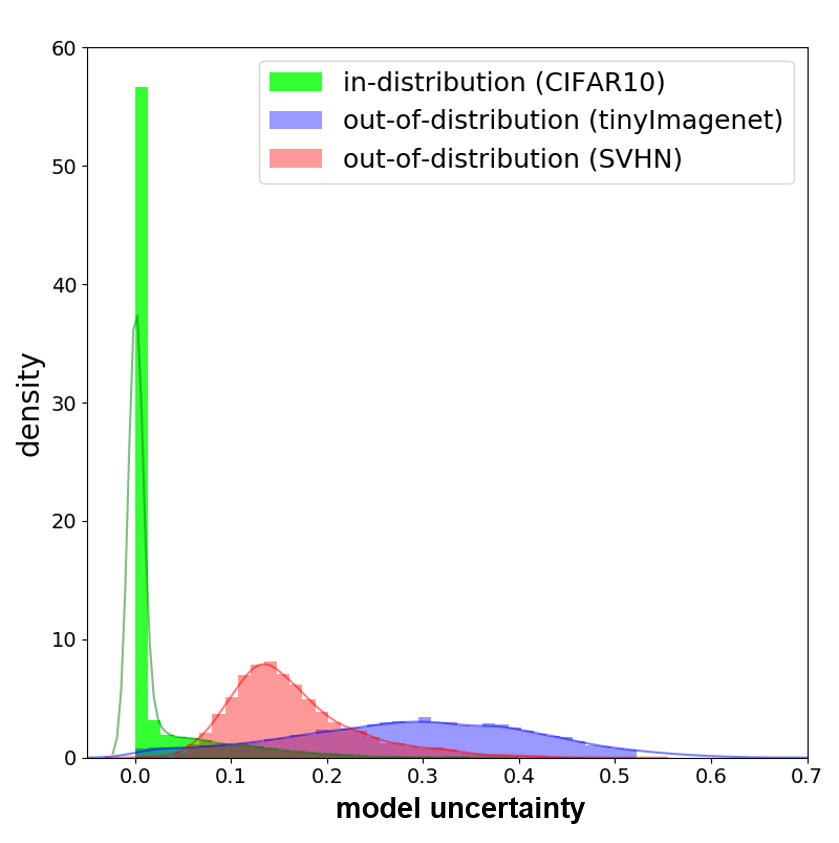 Figure 8
Figure 8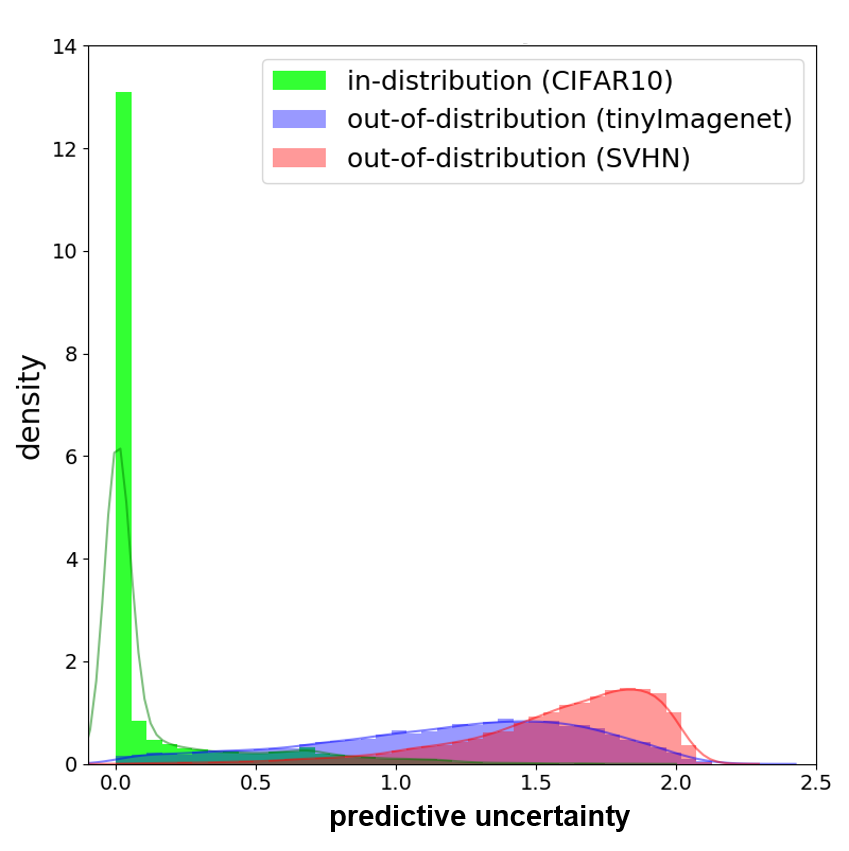 Figure 9
Figure 9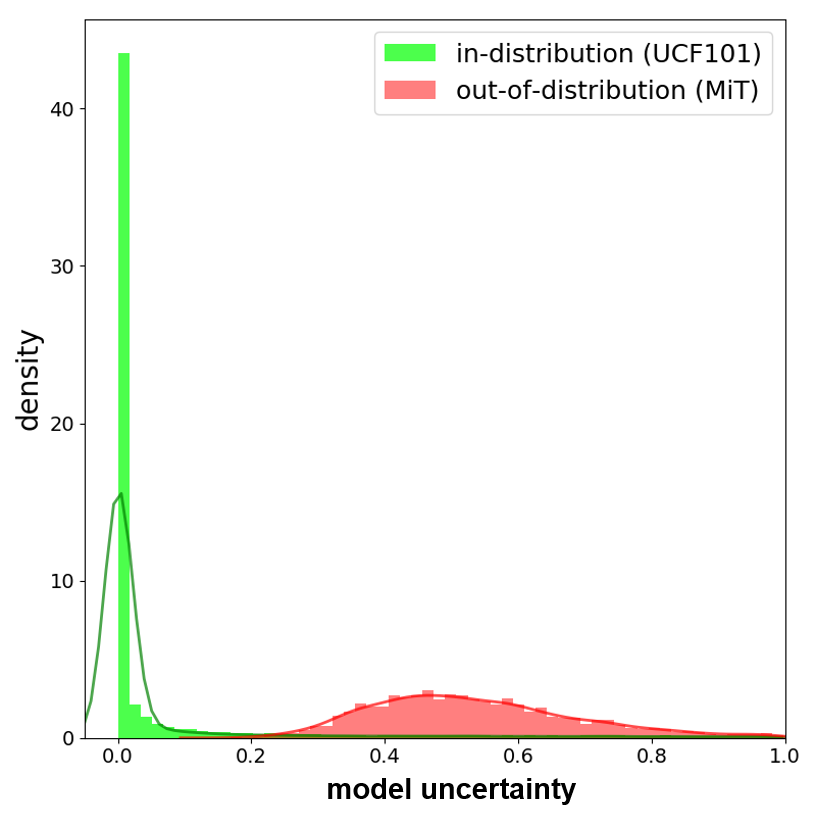 Figure 10
Figure 10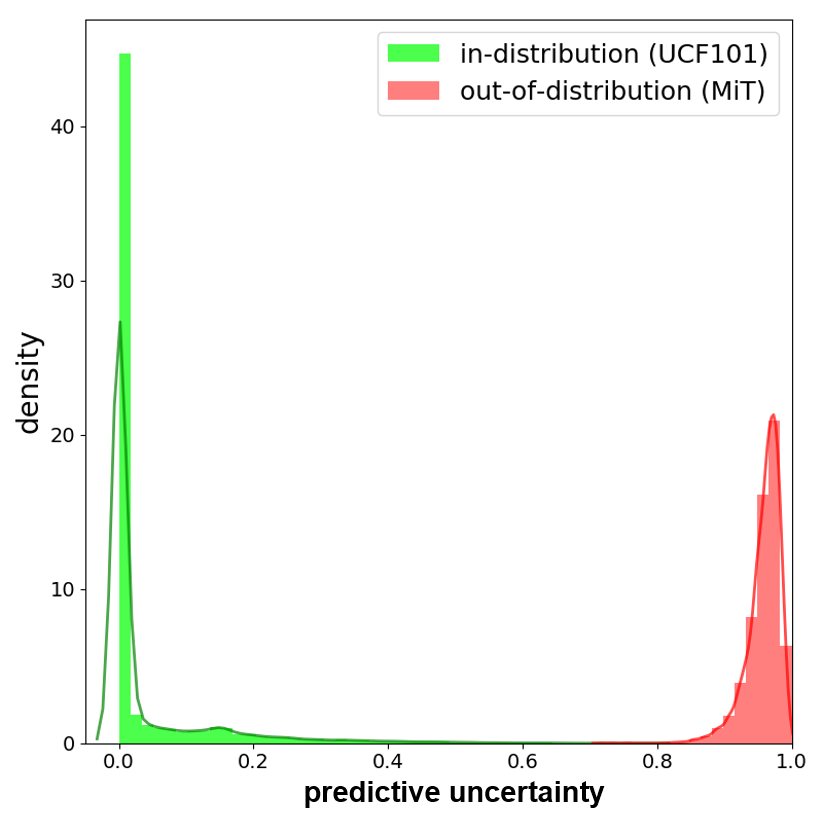 Figure 11
Figure 11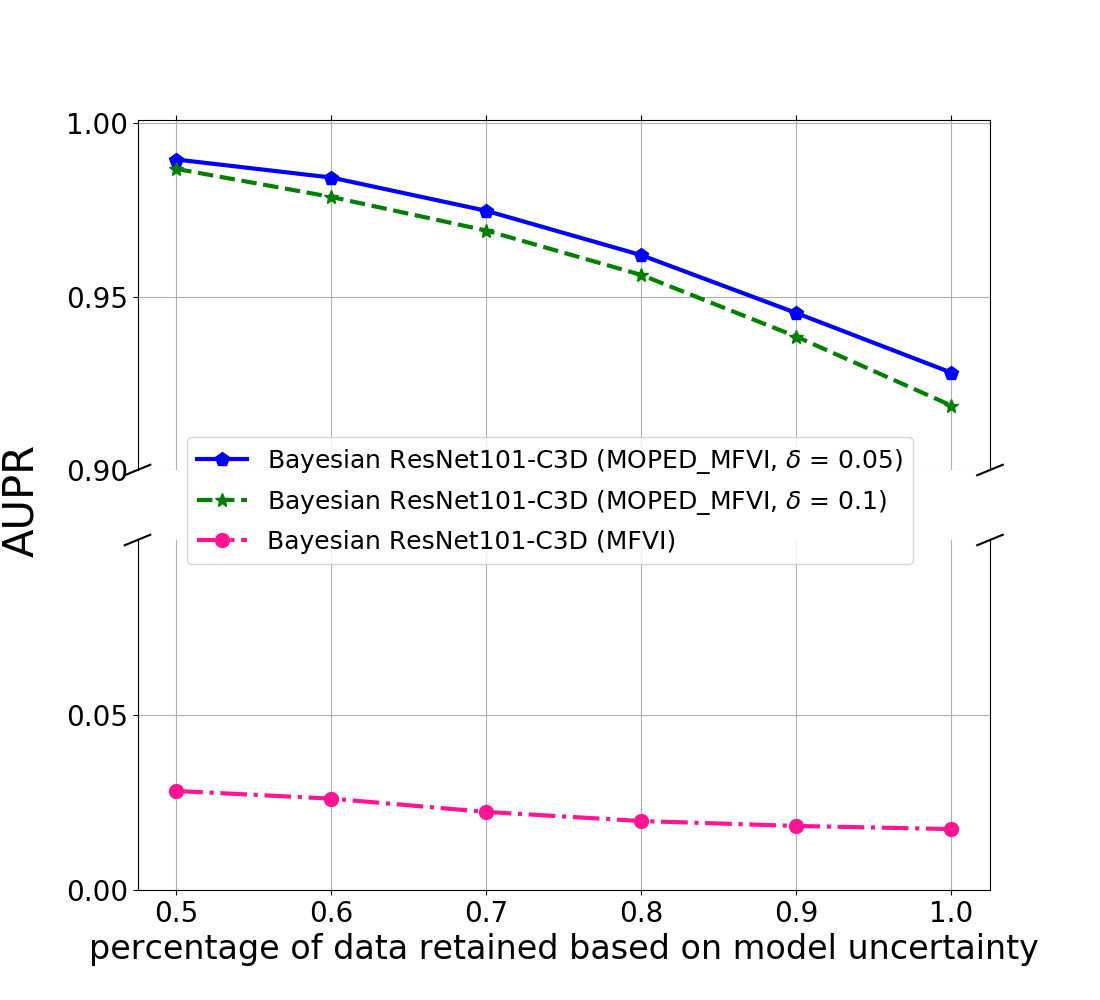 Figure 12
Figure 12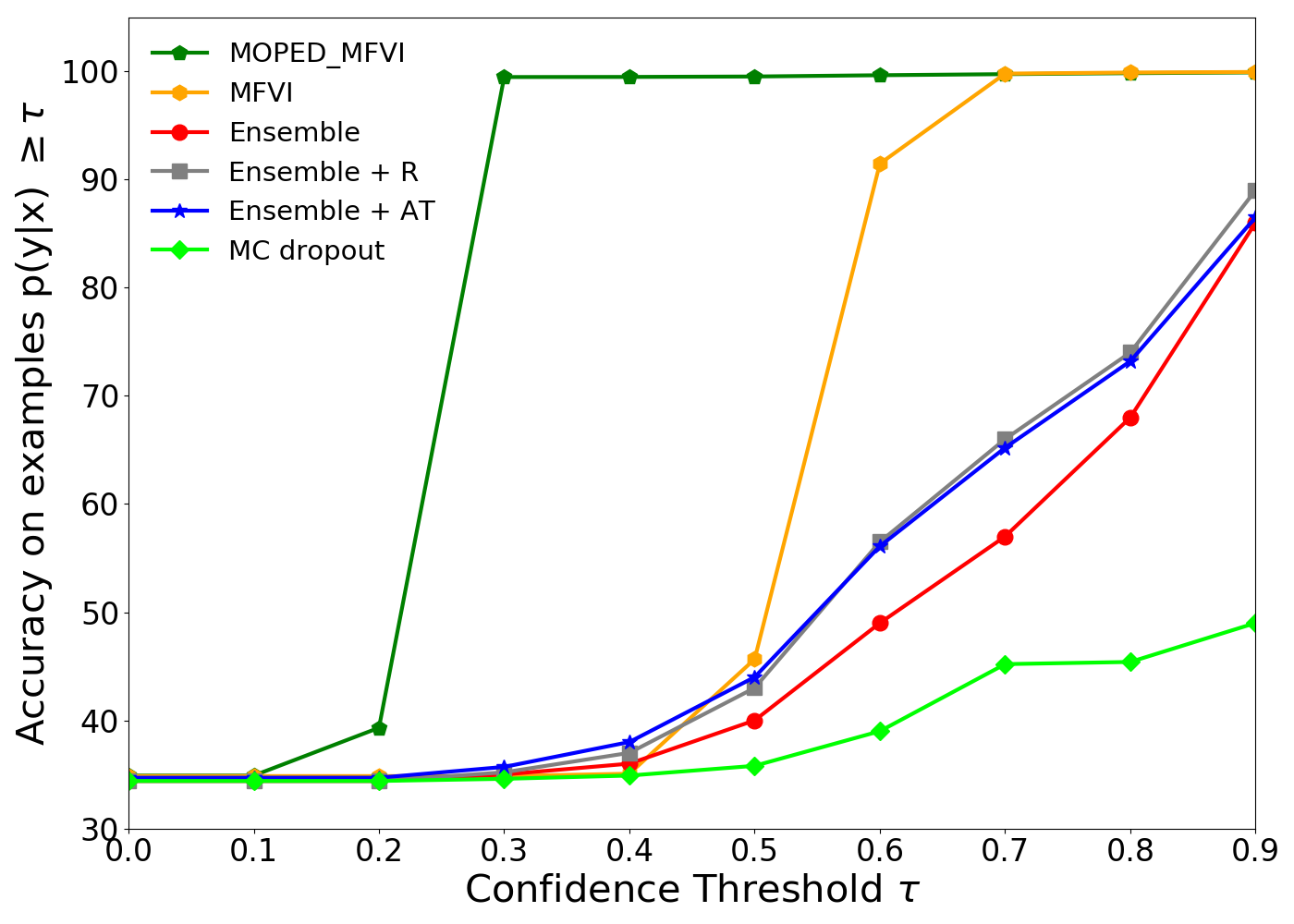 Figure 13
Figure 13| \hlineB 2.5 | Bayesian DNN | Validation Accuracy | ||||
| \clineB 5-72 | Complexity | Bayesian DNN | ||||
| Dataset | Modality | Architecture | (# parameters) | DNN | MFVI | MOPED_MFVI |
| \hlineB 2.5 UCF-101 | Video | ResNet-101 C3D | 170,838,181 | 0.851 | 0.029 | 0.867 |
| UrbanSound8K | Audio | VGGish | 144,274,890 | 0.817 | 0.143 | 0.819 |
| Diabetic Retinopathy | Images | VGG | 21,242,689 | 0.842 | 0.843 | 0.857 |
| CIFAR-10 | Images | Resnet-56 | 1,714,250 | 0.926 | 0.896 | 0.927 |
| Resnet-20 | 546,314 | 0.911 | 0.878 | 0.916 | ||
| MNIST | Images | LeNeT | 1,090,856 | 0.994 | 0.993 | 0.995 |
| Fashion-MNIST | Images | SCNN | 442,218 | 0.921 | 0.906 | 0.923 |
| \hlineB 2.5 | Bayesian DNN | AUPR | AUROC | |||
|---|---|---|---|---|---|---|
| \clineB 3-72 Dataset | Archiectures | MFVI | MOPED_MFVI | MFVI | MOPED_MFVI | |
| UCF-101 | ResNet-101 C3D | 0.0174 | 0.9186 | 0.6217 | 0.9967 | |
| Urban Sound 8K | VGGish | 0.1166 | 0.8972 | 0.551 | 0.9811 | |
| CIFAR-10 | ResNet-20 | 0.9265 | 0.9622 | 0.9877 | 0.9941 | |
| ResNet-56 | 0.9225 | 0.9799 | 0.987 | 0.9970 | ||
| MNIST | LeNet | 0.9996 | 0.9997 | 0.9999 | 0.9999 | |
| Fashion-MNIST | SCNN | 0.9722 | 0.9784 | 0.9962 | 0.9969 | |
| \hlineB 2.5 | 50% data retrained | 75% data retrained | 100% data retrained | |||||
| Method | AUC | Accuracy | AUC | Accuracy | AUC | Accuracy | ||
| MC Dropout | 0.878 | 0.913 | 0.852 | 0.871 | 0.821 | 0.845 | ||
| Mean-field VI | 0.866 | 0.881 | 0.84 | 0.850 | 0.821 | 0.843 | ||
| Deep Ensembles | 0.872 | 0.899 | 0.849 | 0.861 | 0.818 | 0.846 | ||
| Deterministic | 0.849 | 0.861 | 0.823 | 0.849 | 0.82 | 0.842 | ||
| Ensemble MC Dropout | 0.881 | 0.924 | 0.854 | 0.881 | 0.825 | 0.853 | ||
| MOPED Mean-field VI | 0.912 | 0.937 | 0.885 | 0.914 | 0.883 | 0.857 | ||
| Random Referral | 0. 818 | 0.848 | 0.820 | 0.843 | 0.820 | 0.842 | ||
| \hlineB 2.5 | ||||||||
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
\newfloatcommand
capbtabboxtable[][\FBwidth]
Specifying Weight Priors in Bayesian Deep Neural Networks with Empirical Bayes
Ranganath Krishnan
Intel Labs
&Mahesh Subedar11footnotemark: 1
Intel Labs
&Omesh Tickoo
Intel Labs
[email protected] Equal Contribution
Abstract
Stochastic variational inference for Bayesian deep neural network (DNN) requires specifying priors and approximate posterior distributions over neural network weights. Specifying meaningful weight priors is a challenging problem, particularly for scaling variational inference to deeper architectures involving high dimensional weight space. We propose MOdel Priors with Empirical Bayes using DNN (MOPED) method to choose informed weight priors in Bayesian neural networks. We formulate a two-stage hierarchical modeling, first find the maximum likelihood estimates of weights with DNN, and then set the weight priors using empirical Bayes approach to infer the posterior with variational inference. We empirically evaluate the proposed approach on real-world tasks including image classification, video activity recognition and audio classification with varying complex neural network architectures. We also evaluate our proposed approach on diabetic retinopathy diagnosis task and benchmark with the state-of-the-art Bayesian deep learning techniques. We demonstrate MOPED method enables scalable variational inference and provides reliable uncertainty quantification.
1 Introduction
Uncertainty estimation in deep neural network (DNN) predictions is essential for designing reliable and robust AI systems. Bayesian deep neural networks (?; ?) has allowed bridging deep learning and probabilistic Bayesian theory to quantify uncertainty by borrowing the strengths of both methodologies. Variational inference (VI) (?) is an analytical approximation technique to infer the posterior distribution of model parameters. VI methods formulate the Bayesian inference problem as an optimization-based approach which lends itself to the stochastic gradient descent based optimization used in training DNN models. VI with generalized formulations (?; ?) has renewed interest in Bayesian neural networks.
The recent research in Bayesian Deep Learning (BDL) is focused on scaling the VI to more complex models. The scalability of VI in Bayesian DNNs to practical applications involving deep models and large-scale datasets is an open problem. Hybrid Bayesian DNN architectures (?; ?) are used for complex computer vision tasks to balance complexity of the model while providing benefits of Bayesian inference. DNNs are shown to have structural benefits (?) which helps them in learning complex models on larger datasets. The convergence speed and performance (?) of DNN models heavily depend on the initialization of model weights and other hyper parameters. The transfer learning approaches (?) demonstrate the benefit of fine tuning the pretrained DNN models from adjacent domains in order to achieve faster convergence and better accuracies.
Variational inference for Bayesian DNN involves choosing prior distributions and approximate posterior distributions over neural network weights. In a pure Bayesian approach, prior distribution is specified before any data is observed. Specifying meaningful priors in large Bayesian DNN models with high dimensional weight space is an active area of research (?; ?; ?; ?), as it is practically difficult to have prior belief on millions of parameters. Empirical Bayes (?; ?) methods estimates prior distribution from the data. Based on Empirical Bayes and transfer learning approaches, we propose MOdel Priors with Empirical Bayes using DNN (MOPED) method to initialize the weight priors in Bayesian DNNs, which in our experiments have shown to achieve better training convergence for larger models.
Our main contributions include:
- •
We propose MOPED method to specify informed weight priors in Bayesian neural networks using Empirical Bayes framework. MOPED advances the current state-of-the-art by enabling scalable variational inference for large models applied to real-world tasks.
- •
We demonstrate with thorough empirical experiments on multiple real-world tasks that the MOPED method helps training convergence and provides better model performance, along with reliable uncertainty estimates. We also evaluate MOPED on diabetic retinopathy diagnosis task using BDL benchmarking framework (?) and demonstrate it outperforms state-of-the-art Bayesian deep learning methods.
The rest of the document is organized as below. We provide background material in Section 2. The details of proposed method for initializing the weight priors in Bayesian DNN models is presented in Section 3, and related work in Section 4. Followed by empirical experiments and results supporting the claims of proposed method in Section 5.
2 Background
2.1 Bayesian neural networks
Bayesian neural networks provide a probabilistic interpretation of deep learning models by placing distributions over the neural network weights (?). Given training dataset with inputs and their corresponding outputs , in parametric Bayesian setting we would like to infer a distribution over weights as a function that represents the neural network model. A prior distribution is assigned over the weights that captures our prior belief as to which parameters would have likely generated the outputs before observing any data. Given the evidence data , prior distribution and model likelihood , the goal is to infer the posterior distribution over the weights :
[TABLE]
Computing the posterior distribution is often intractable, some of the previously proposed techniques to achieve an analytically tractable inference include Markov Chain Monte Carlo (MCMC) sampling based probabilistic inference (?; ?), variational inference (?; ?; ?), expectation propagation (?) and Monte Carlo dropout approximate inference (?) .
Predictive distribution is obtained through multiple stochastic forward passes on the network while sampling from the weight posteriors using Monte Carlo estimators. Equation 2 shows the predictive distribution of the output given new input :
[TABLE]
where, is number of Monte Carlo samples.
2.2 Variational inference
Variational inference approximates a complex probability distribution with a simpler distribution , parameterized by variational parameters while minimizing the Kullback-Leibler (KL) divergence. Minimizing the KL divergence is equivalent to maximizing the log evidence lower bound (ELBO) (?), as shown in Equation 3.
[TABLE]
In mean field variation inference, weights are modeled with fully factorized Gaussian distribution parameterized by variational parameters and .
[TABLE]
The variational distribution and its parameters and are learnt while optimizing the cost function ELBO with the stochastic gradient steps.
(?) proposed fully factorized Gaussian posteriors and a differentiable loss function. (?) proposed a Bayes by Backprop method which learns probability distribution on the weights of the neural network by minimizing loss function. (?) proposed a Flipout method to apply pseudo-independent weight perturbations to decorrelate the gradients within mini-batches.
2.3 Empirical Bayes
Empirical Bayes (EB) (?) methods lie in between frequestist and Bayesian statistical approaches as it attempts to leverage strengths from both methodologies. EB methods are considered as approximation to a fully Bayesian treatment of a hierarchical Bayes model. EB methods estimates prior distribution from the data, which is in contrast to typical Bayesian approach. The idea of Empirical Bayes is not new and the original formulation of Empirical Bayes dates back to 1950s (?), which is non-parametric EB. Since then, many parametric formulations has been proposed and used in wide variety of applications.We use parametric Empirical Bayes approach in our proposed method for mean field variational inference in Bayesian deep neural network, where weights are modeled with fully factorized Gaussian distribution.
Parametric EB specifies a family of prior distributions where is a hyper-parameter. Analogous to Equation 1, posterior distribution can be obtained with EB as given by Equation 5.
[TABLE]
2.4 Uncertainty Quantification
Uncertainty estimation is essential to build reliable and robust AI systems, which is pivotal to understand system’s confidence in predictions and decision-making. Bayesian DNNs enable to capture different types of uncertainties: “Aleatoric” and “Epistemic” (?). Aleatoric uncertainty captures noise inherent with observation. Epistemic uncertainty, also known as model uncertainty captures lack of knowledge in representing model parameters, specifically in the scenario of limited data.
We evaluate the model uncertainty using Bayesian active learning by disagreement (BALD) (?; ?), which quantifies mutual information between parameter posterior distribution and predictive distribution.
[TABLE]
where, is the predictive entropy as shown in Equation 7. Predictive entropy captures a combination of input uncertainty and model uncertainty.
[TABLE]
and is predictive mean probability of class from Monte Carlo samples, and is total number of output classes.
3 MOPED: informed weight priors
MOPED advances the current state-of-the-art in variational inference for Bayesian DNNs by providing a way for specifying meaningful prior and approximate posterior distributions over weights using Empirical Bayes framework. Empirical Bayes framework borrows strengths from both classical (frequentist) and Bayesian statistical methodologies.
We formulate a two-stage hierarchical modeling approach, first find the maximum likelihood estimates (MLE) of weights with DNN, and then set the weight priors using Empirical Bayes approach to infer the posterior with variational inference.
We illustrate our proposed approach on mean-field variational inference (MFVI). For MFVI in Bayesian DNNs, weights are modeled with fully factorized Gaussian distributions parameterized by variational parameters, i.e. each weight is independently sampled from the Gaussian distribution , where is mean and variance . In order to ensure non-negative variance, is expressed in terms of softplus function with unconstrained parameter . We propose to set the weight priors in Bayesian neural networks based on the MLE obtained from standard DNN of equivalent architecture. We set the prior with mean equals w_{\scalebox{0.7}{\scriptscriptstyle MLE}} and unit variance respectively, and initialize the variational parameters in approximate posteriors as given in Equation 8.
[TABLE]
where, w_{\scalebox{0.7}{\scriptscriptstyle MLE}} represents maximum likelihood estimates of weights obtained from deterministic DNN model, and (, ) are hyper parameters (mean and variance of Gaussian perturbation for ).
For Bayesian DNNs of complex architectures involving very high dimensional weight space (hundreds of millions of parameters), choice of can be sensitive as values of the weights can vary by large margin with each other.
So, we propose to initialize the variational parameters in approximate posteriors as given in Equation 9.
[TABLE]
where, is initial perturbation factor for the weight in terms of percentage of the pretrained deterministic weight values.
In the next section, we demonstrate the benefits of MOPED method for variational inference with extensive empirical experiments. We showcase the proposed MOPED method helps Bayesian DNN architectures to achieve better model performance along with reliable uncertainty estimates.
4 Related Work
Deterministic pretraining (?; ?) has been used to improve model training for variational probabilistic models. ? use a pretrained deterministic network for Sparse Variational Dropout method. ? use a warm-up method for variational-auto encoder by rescaling the KL-divergence term with a scalar term , which is increased linearly from 0 to 1 during the first N epochs of training. Whereas, in our method we use the point-estimates from pretrained standard DNN of the same architecture to set the informed priors and the model is optimized with MFVI using full-scale KL-divergence term in ELBO.
Choosing weight priors in Bayesian neural networks is an active area of research. ? propose implicit priors for variational inference in convolutional neural networks that exploit generative models. ? use prior with zero mean and unit variance, and initialize the optimizer at the mean of the MLE model and a very small initial variance for small-scale MNIST experiments. ? modify ELBO with a deterministic approximation of reconstruction term and use Empirical Bayes procedure for selecting variance of prior in KL term (with zero prior mean). The authors also caution about inherent scaling of their method could potentially limit its practical use for networks with large hidden size. All of these works have been demonstrated only on small-scale models and simple datasets like MNIST. In our method, we retain the stochastic property of the expected log-likelihood term in ELBO, and specify both mean and variance of weight priors based on pretrained DNN with Empirical Bayes. Further, we demonstrate our method on large-scale Bayesian DNN models with complex datasets on real-world tasks.
5 Experiments
We evaluate proposed method on real-world applications including image and audio classification, and video activity recognition. We consider multiple architectures with varying complexity to show the scalability of method in training deep Bayesian models. Our experiments include: (i) ResNet-101 C3D (?) for video activity classification on UCF-101(?) dataset, (ii) VGGish(?) for audio classification on UrbanSound8K (?) dataset, (iii) Modified version of VGG(?) for diabetic retinopathy detection (?), (iv) ResNet-20 and ResNet-56 (?) for CIFAR-10 (?), (v) LeNet architecture for MNIST (?) digit classification, and (vi) Simple convolutional neural network (SCNN) consisting of two convolutional layers followed by two dense layers for image classification on Fashion-MNIST (?) datasets.
We implemented above Bayesian DNN models and trained them using Tensorflow and Tensorflow-Probability (?) frameworks. The variational layers are modeled using Flipout (?), an efficient method that decorrelates the gradients within a mini-batch by implicitly sampling pseudo-independent weight perturbations for each input. The MLE weights obtained from the pretrained DNN models are used in MOPED method to set the priors and initialize the variational parameters in approximate posteriors (Equation 8 and 9), as described in Section3.
During inference phase, predictive distributions are obtained by performing multiple stochastic forward passes over the network while sampling from posterior distribution of the weights (40 Monte Carlo samples in our experiments). We evaluate the model uncertainty and predictive uncertainty using Bayesian active learning by disagreement (BALD) (Equation 6) and predictive entropy (Equation 7), respectively. Quantitative comparison of uncertainty estimates are made by calculating area under the curve of precision-recall (AUPR) values by retaining different percentages (0.5 to 1.0) of most certain test samples (i.e. ignoring most uncertain predictions based on uncertainty estimates).
In Table 1, classification accuracies for architectures with various model complexity are presented. Bayesian DNNs with priors initialized with MOPED method achieves similar or better predictive accuracies as compared to equivalent DNN models. Bayesian DNNs with random initialization of Gaussian priors has difficulty in converging to optimal solution for larger models (ResNet-101 C3D and VGGish). It is evident from these results that MOPED method guarantees the training convergence even for the complex models.
In Figure 1, comparison of mean field variational inference with MOPED method (MOPED_MFVI) and mean field variational inference with random initialization of priors (MFVI) is shown for Bayesian ResNet-20 and ResNet-56 architectures trained on CIFAR-10 dataset. The AUPR plots capture the precision-recall AUC values as a function of retained data based on the model uncertainty estimates. Figure 1 (b) & (c) show that MOPED_MFVI provides better performance than MFVI. AUPR increases as most uncertain predictions are ignored based on the model uncertainty, indicating reliable uncertainty estimates. We show the results for different selection of values (as shown in Equation 8).
In Figure 2, we show AUPR plots for CIFAR-10 and UCF-101with different values as mentioned in Equation 9.
5.1 Benchmarking uncertainty estimates
Bayesian Deep Learning (BDL) benchmarks (?) is an open-source framework for evaluating deep probabilistic machine learning models and their application to real-world problems. BDL-benchmarks assess both the scalability and effectiveness of different techniques for uncertainty estimation. The proposed MOPED_MFVI method is compared with state-of-the-art baseline methods available in BDL-benchmarks suite on diabetic retinopathy detection task (?). The evaluation methodology assesses the techniques by their diagnostic accuracy and area under receiver-operating-characteristic (AUC-ROC) curve, as a function of percentage of retained data based on predictive uncertainty estimates. It is expected that the models with well-calibrated uncertainty improve their performance (detection accuracy and AUC-ROC) as most certain data is retrained.
We have followed the evaluation methodology presented in the BDL-benchmarks to compare the accuracy and uncertainty estimates obtained from our method. We used the same model architecture (VGG) and hyper-parameters as used by other baselines for evaluating MOPED_MFVI. The results for the BDL baseline methods are obtained from (?). In Table 3 and Figure 3, quantitative evaluation of AUC and accuracy values for BDL baseline methods and MOPED_MFVI are presented. The proposed MOPED_MFVI method outperforms other state-of-the-art BDL techniques.
5.2 Robustness to out-of-distribution data
We evaluate the uncertainty estimates obtained from MOPED_MFVI to detect out-of-distribution data. Out-of-distribution samples are data points which fall far off from the training data distribution. We evaluate two sets of out-of-distribution detection experiments. In the first set, we use CIFAR-10 as the in-distribution samples trained using ResNet-56 Bayesian DNN model. TinyImageNet (?) and SVHN (?) datasets are used as out-of-distribution samples which were not seen during the training phase. The density histograms (area under the histogram is normalized to one) for uncertainty estimates obtained from the Bayesian DNN models are plotted in Figure 5. The density histograms in Figure 5 (a) & (b) indicate higher uncertainty estimates for the out-of-distribution samples and lower uncertainty values for the in-distribution samples. A similar trend is observed in the second set using UCF-101 (?) and Moments-in-Time (MiT) (?) video activity recognition datasets as the in- and out-of-distribution data, respectively. These results confirm the uncertainty estimates obtained from proposed method are reliable and can identify out-of-distribution data.
In order to evaluate robustness of our method (MOPED_MFVI), we compare state-of-the-art probabilistic deep learning methods for prediction accuracy as a function of model confidence. Following the experiments in (?), we trained our model on MNIST training set and tested it on a mix of examples from MNIST and NotMNIST (out-of-distribution) test set. The accuracy as a function of confidence plots should increase monotonically, as higher accuracy is expected for more confident results. A robust model should provide low confidence for out-of-distribution samples while providing high confidence for correct prediction from in-distribution samples. The proposed variational inference method with MOPED priors provides more robust results as compared to the MC Dropout (?) and deep model ensembles (?) approaches (shown in Figure 4).
6 Conclusions
We proposed MOPED method that specifies informed weight priors in Bayesian deep neural networks with Empirical Bayes approach. We demonstrated with thorough empirical experiments that MOPED enables scalable variational inference for Bayesian DNNs.We demonstrated the proposed method outperforms state-of-the-art Bayesian deep learning techniques using BDL-benchmarks framework. We also showed the uncertainty estimates obtained from the proposed method are reliable to identify out-of-distribution data. The results support proposed approach provides better model performance and reliable uncertainty estimates on real-world tasks with large scale complex models.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[Atanov et al . 2019] Atanov, A.; Ashukha, A.; Struminsky, K.; Vetrov, D.; and Welling, M. 2019. The deep weight prior. In International Conference on Learning Representations .
- 2[Bengio, Courville, and Vincent 2013] Bengio, Y.; Courville, A.; and Vincent, P. 2013. Representation learning: A review and new perspectives. IEEE transactions on pattern analysis and machine intelligence 35(8):1798–1828.
- 3[Bishop 2006] Bishop, C. M. 2006. Pattern recognition and machine learning (information science and statistics) springer-verlag new york. Inc. Secaucus, NJ, USA .
- 4[Blei, Kucukelbir, and Mc Auliffe 2017] Blei, D. M.; Kucukelbir, A.; and Mc Auliffe, J. D. 2017. Variational inference: A review for statisticians. Journal of the American Statistical Association 112(518):859–877.
- 5[Blundell et al . 2015] Blundell, C.; Cornebise, J.; Kavukcuoglu, K.; and Wierstra, D. 2015. Weight uncertainty in neural networks. ar Xiv preprint ar Xiv:1505.05424 .
- 6[Casella 1992] Casella, G. 1992. Illustrating empirical bayes methods. Chemometrics and intelligent laboratory systems 16(2):107–125.
- 7[Dillon et al . 2017] Dillon, J. V.; Langmore, I.; Tran, D.; Brevdo, E.; Vasudevan, S.; Moore, D.; Patton, B.; Alemi, A.; Hoffman, M.; and Saurous, R. A. 2017. Tensorflow distributions. ar Xiv preprint ar Xiv:1711.10604 .
- 8[Filos et al . 2019] Filos, A.; Farquhar, S.; Gomez, A. N.; Rudner, T. G. J.; Kenton, Z.; Smith, L.; Alizadeh, M.; de Kroon, A.; and Gal, Y. 2019. Benchmarking bayesian deep learning with diabetic retinopathy diagnosis.
