Matrix Mittag--Leffler distributions and modeling heavy-tailed risks
Hansjoerg Albrecher, Martin Bladt, Mogens Bladt

TL;DR
This paper introduces matrix Mittag-Leffler distributions, a flexible family for modeling heavy-tailed risks, which can be interpreted through phase-type distributions or semi-Markov processes, and demonstrates their effectiveness on simulated and real insurance data.
Contribution
It defines matrix Mittag-Leffler distributions and shows their advantages over existing methods in modeling heavy-tailed risks, addressing threshold selection issues.
Findings
The class can be interpreted as inhomogeneous phase-type distributions with random scaling.
It effectively models heavy-tailed risks in insurance data.
Demonstrates advantages over traditional extreme value approaches.
Abstract
In this paper we define the class of matrix Mittag-Leffler distributions and study some of its properties. We show that it can be interpreted as a particular case of an inhomogeneous phase-type distribution with random scaling factor, and alternatively also as the absorption time of a semi-Markov process with Mittag-Leffler distributed interarrival times. We then identify this class and its power transforms as a remarkably parsimonious and versatile family for the modelling of heavy-tailed risks, which overcomes some disadvantages of other approaches like the problem of threshold selection in extreme value theory. We illustrate this point both on simulated data as well as on a set of real-life MTPL insurance data that were modeled differently in the past.
Click any figure to enlarge with its caption.
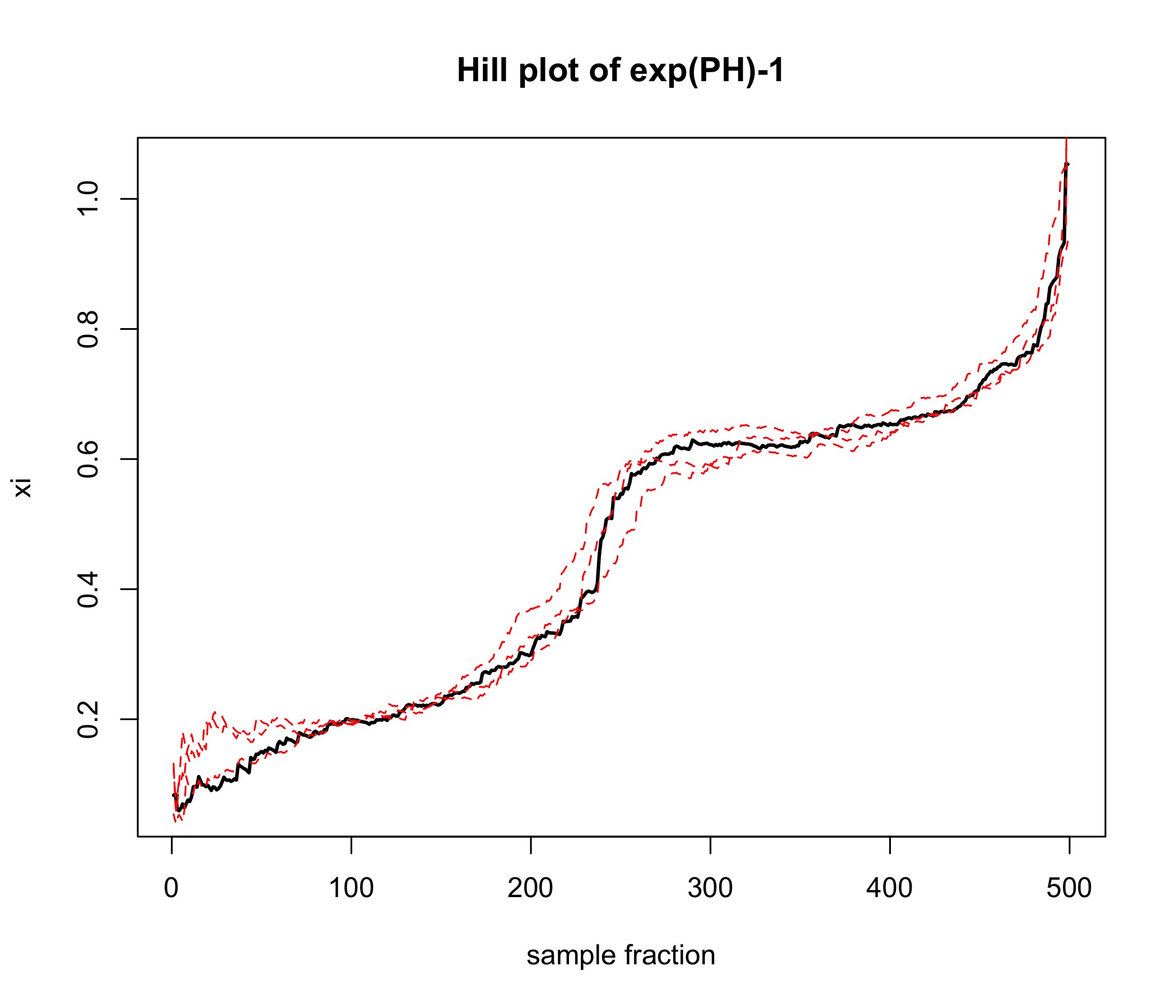 Figure 1
Figure 1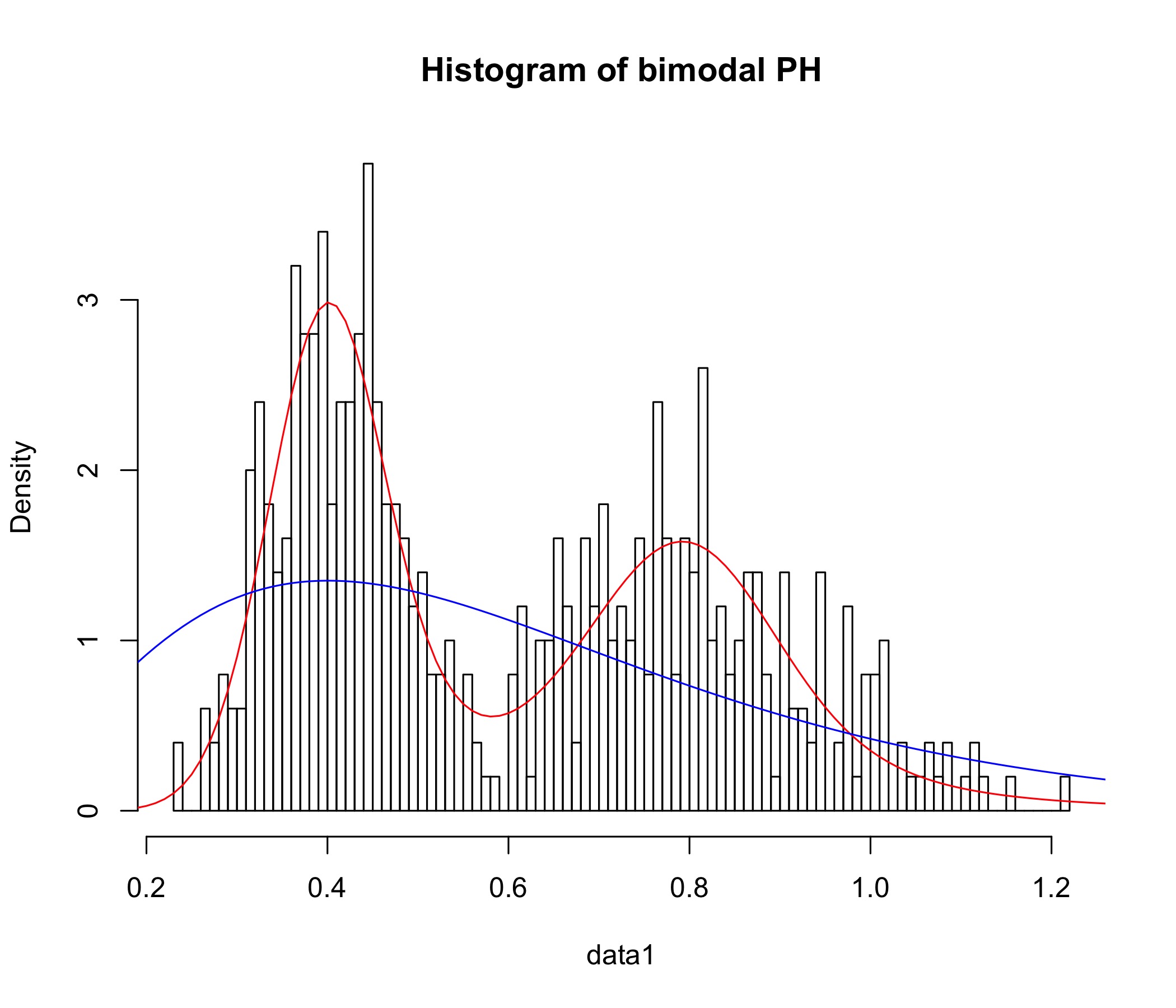 Figure 2
Figure 2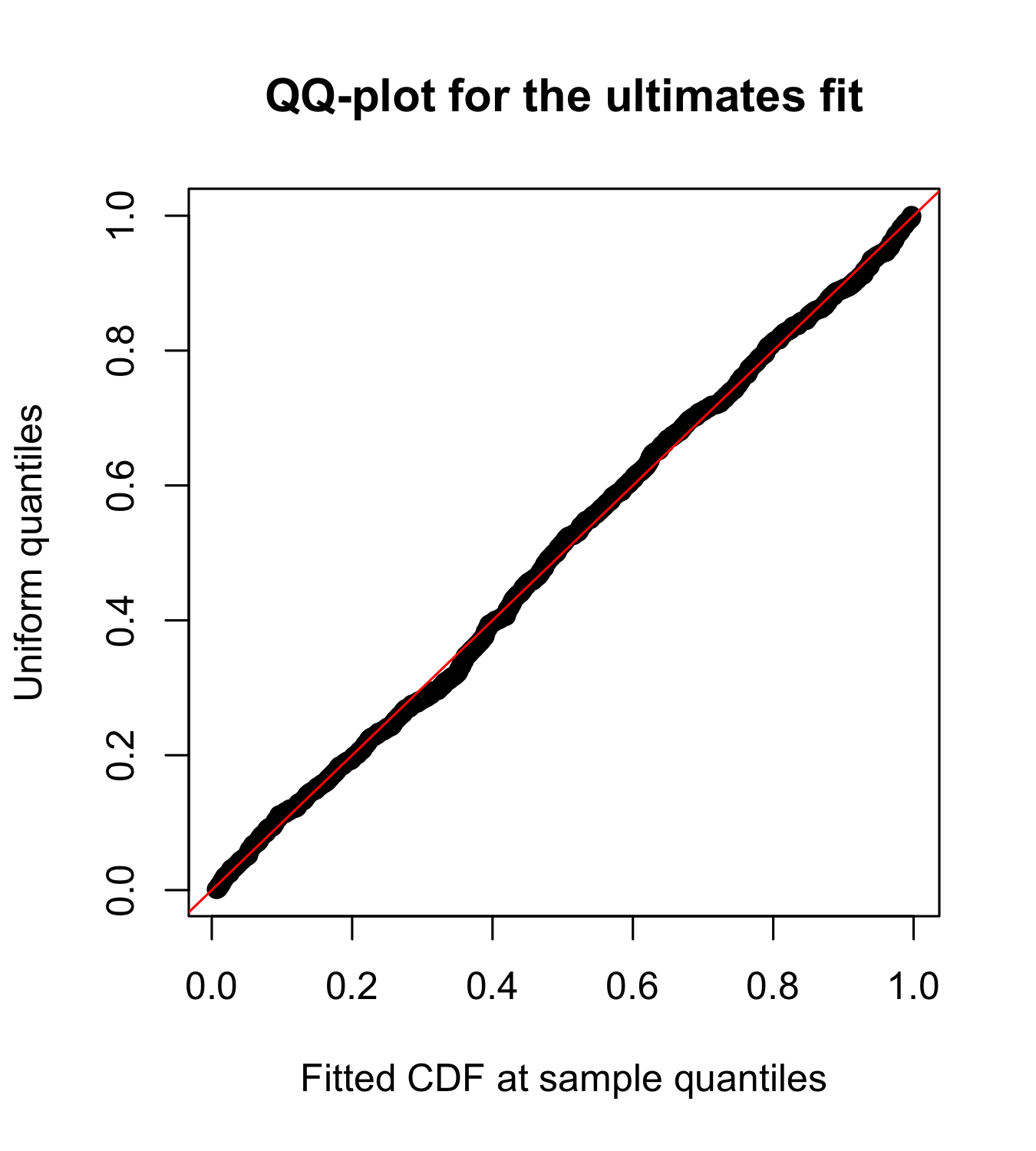 Figure 3
Figure 3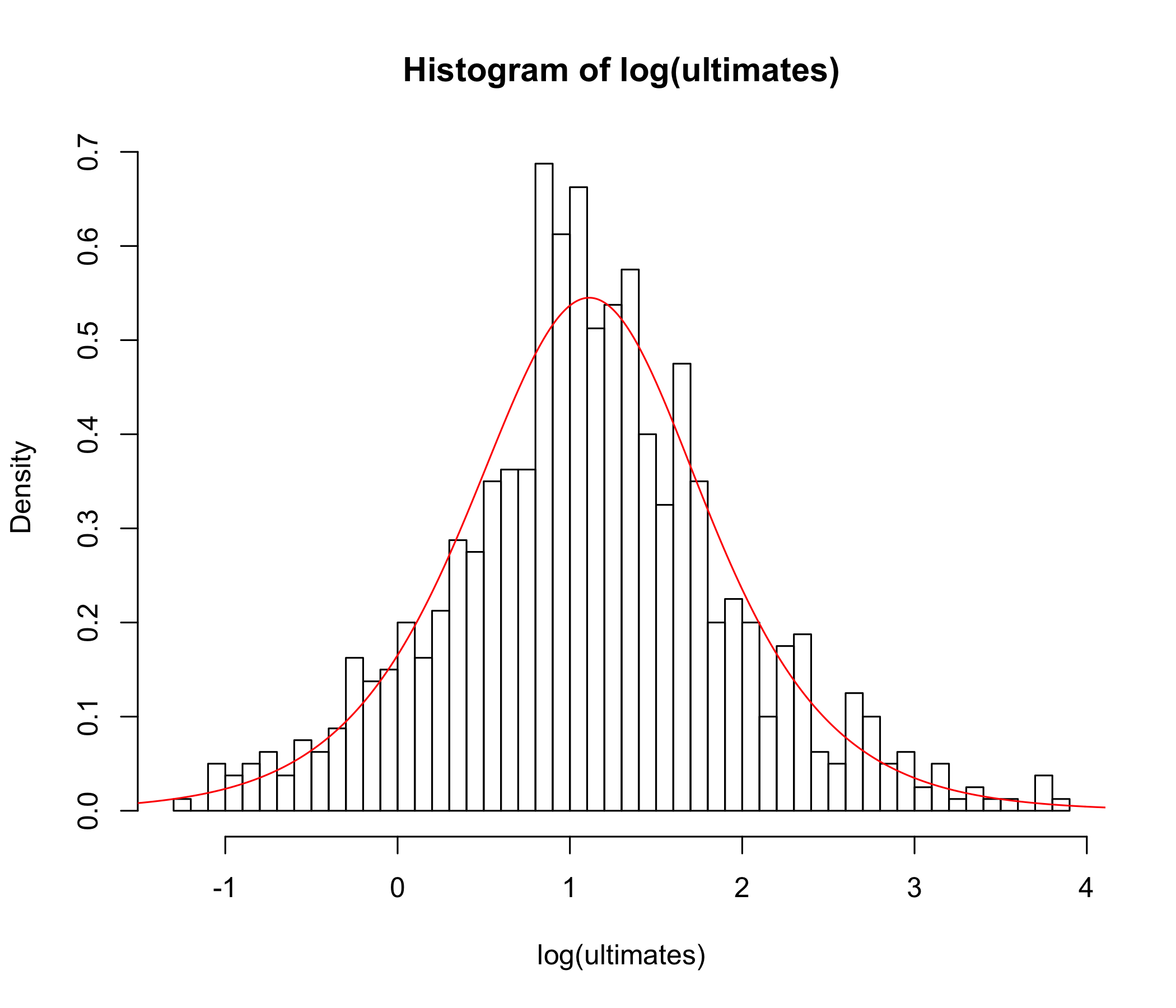 Figure 4
Figure 4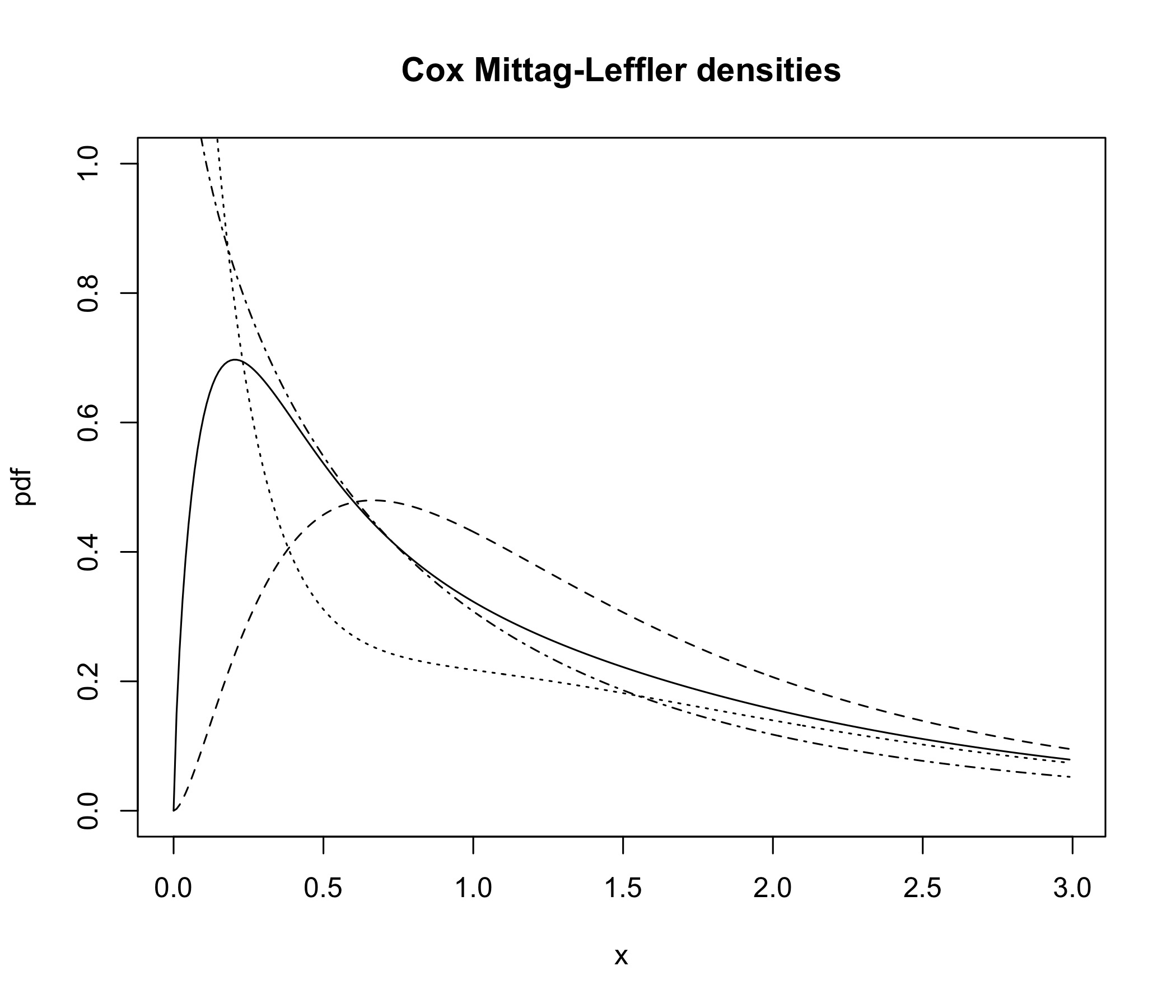 Figure 5
Figure 5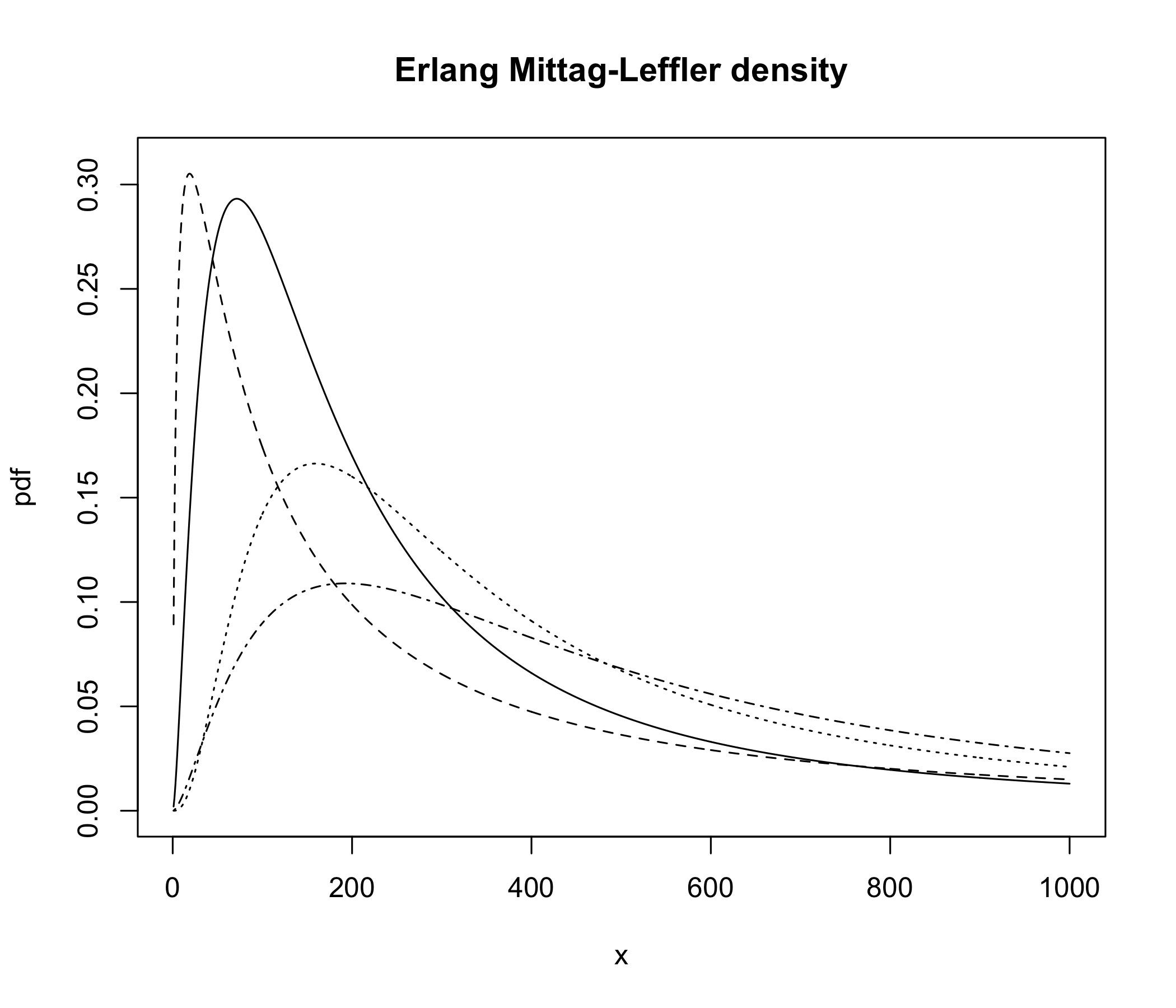 Figure 6
Figure 6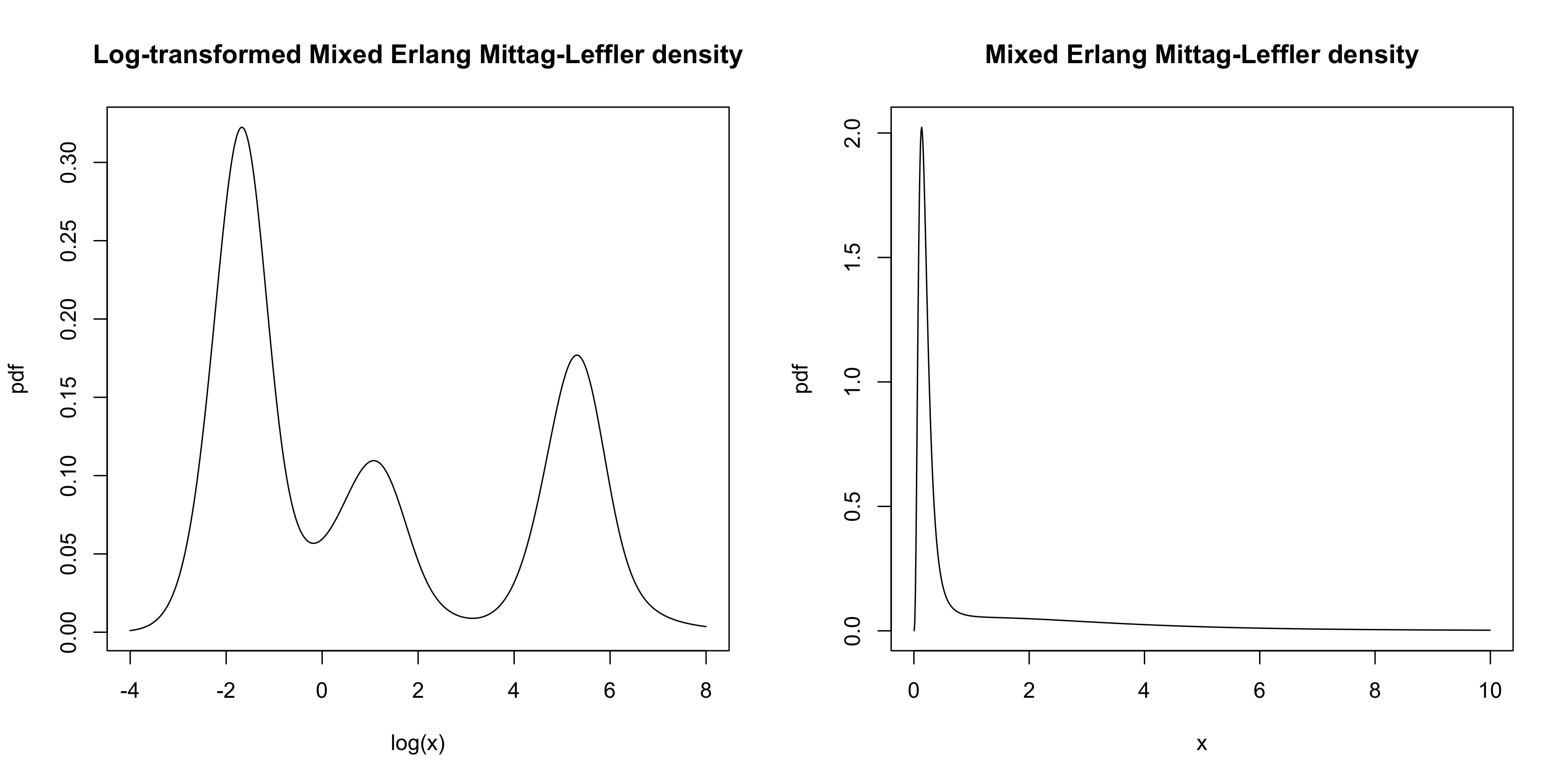 Figure 7
Figure 7_BimodalPH_hill.jpeg) Figure 8
Figure 8_BimodalPH_hist.jpeg) Figure 9
Figure 9_CompanyA_QQ.jpeg) Figure 10
Figure 10_CompanyA_hist.jpeg) Figure 11
Figure 11_CoxML.jpeg) Figure 12
Figure 12_ErlangML.jpeg) Figure 13
Figure 13_MixedErlangML.jpeg) Figure 14
Figure 14_Simulated_hill.jpeg) Figure 15
Figure 15_Simulated_hist.jpeg) Figure 16
Figure 16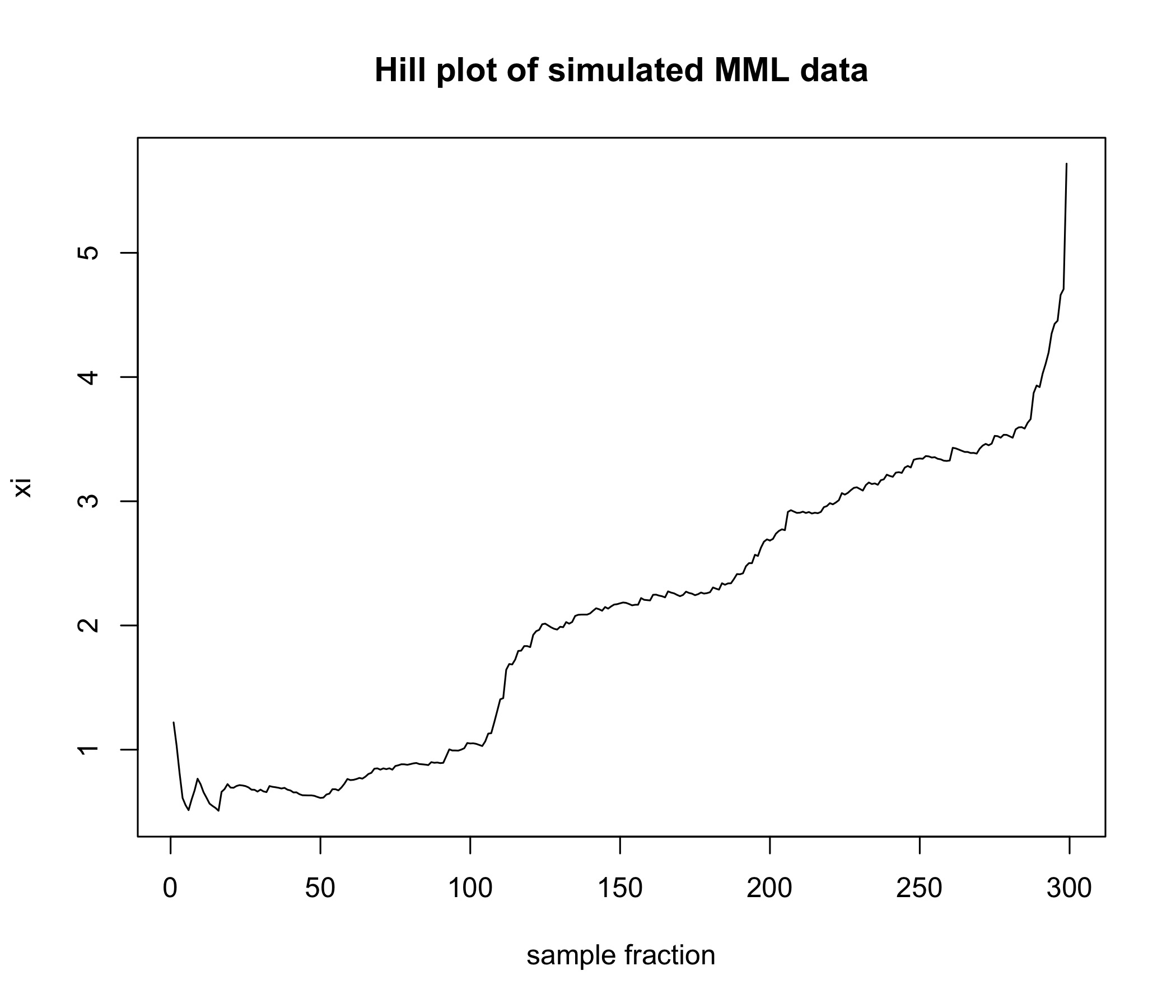 Figure 17
Figure 17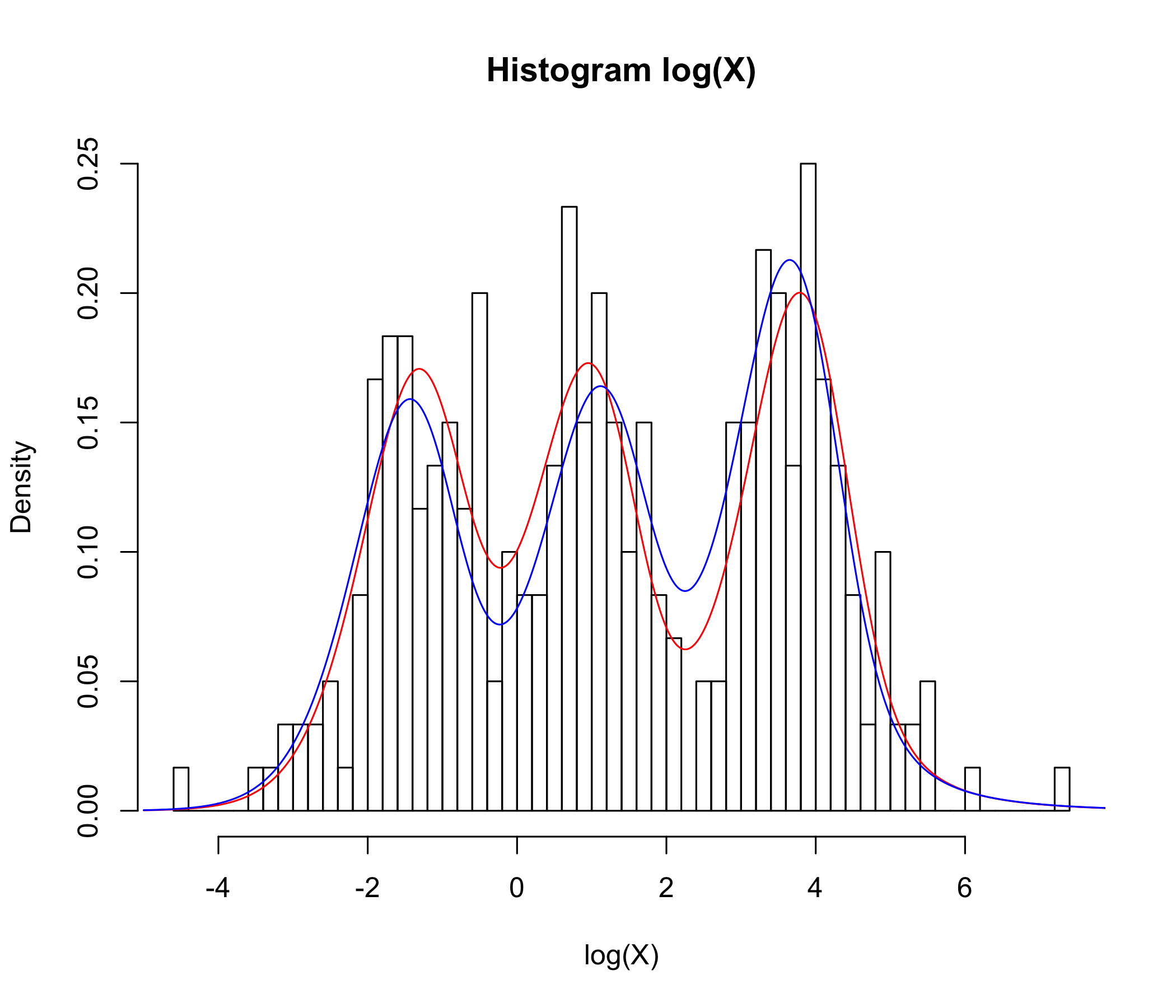 Figure 18
Figure 18Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Matrix Mittag–Leffler distributions and modeling heavy-tailed risks
Hansjörg Albrecher
Department of Actuarial Science, Faculty of Business and Economics and Swiss Finance Institute, University of Lausanne, CH-1015 Lausanne, Switzerland
,
Martin Bladt
Department of Actuarial Science, Faculty of Business and Economics, University of Lausanne, CH-1015 Lausanne, Switzerland
and
Mogens Bladt
Department of Mathematical Sciences, University of Copenhagen, Universitetsparken 5, DK-2100 Copenhagen Ø, Denmark
Abstract.
In this paper we define the class of matrix Mittag-Leffler distributions and study some of its properties. We show that it can be interpreted as a particular case of an inhomogeneous phase-type distribution with random scaling factor, and alternatively also as the absorption time of a semi-Markov process with Mittag-Leffler distributed interarrival times. We then identify this class and its power transforms as a remarkably parsimonious and versatile family for the modelling of heavy-tailed risks, which overcomes some disadvantages of other approaches like the problem of threshold selection in extreme value theory. We illustrate this point both on simulated data as well as on a set of real-life MTPL insurance data that were modeled differently in the past.
1. Introduction
The modeling of heavy-tailed risks is a classical topic in probability, statistics and its applications to understand and interpret data, see e.g. Embrechts et al. [13], Beirlant et al. [5] and Klugman et al. [20]. The folklore heavy-tailed distributions like Pareto, (heavy-tailed) Weibull and lognormal distributions can often serve as very useful benchmark models, particularly when only a few data points are available. In addition, the Pareto distribution is simple to work with and has an intuitive justification in terms of limit properties of extremes. However, in situations with more (but not an abundance of) data points, one often empirically observes that a simple Pareto distribution does not serve as a good model across the entire range of the distribution. This is also the case for more general parametric families like Burr or Benktander distributions. Traditionally, and according to a main paradigm of the extreme value statistics approach, this is handled by only using the largest available data points to estimate the tail behavior, and model the bulk of the distribution separately by another distribution, finally splicing together the respective parts (see e.g. Albrecher et al. [1, Ch.4] for details). In insurance practice one often refers to this separate modeling as the modeling of attritional and large claims, and the resulting models are frequently referred to as composite models [26]. A natural problem in this context is how to choose the threshold between the separate regions, often boiling down to the compromise of not leaving too few data points for the tail modeling. At the same time, the consequences of that choice can be considerable, for instance for the determination of solvency capital requirements in insurance (cf. [1, Ch.6] for illustrations). A considerable effort has therefore been made to develop techniques and criteria for an appropriate choice of such thresholds, see e.g. [5] for an overview and [7] for a recent contribution in that direction.
If the confidence in the relevance of available data points for the description of the (future) risk is sufficiently high, another possible approach is to use a tractable, but much larger family of distributions and identify a good fit. A particularly popular candidate for such an approach is the class of phase-type (PH) distributions, see e.g. Asmussen et al. [4]. The class of PH distributions is dense (in the sense of weak convergence) in the class of distributions on the positive real line, meaning that they can approximate any positive distribution arbitrarily well. They are, however, light-tailed, which may be a problem in applications which require a heavier tail and where the quantities of interest heavily depend on the tail behavior (as e.g. for ruin probabilities, cf. [3]). Fitting heavy-tailed distributions with a PH distribution can then lead to requiring many phases (rendering its use computationally cumbersome), and the resulting model will still not capture the tail behavior in a satisfactory manner. Two approaches to remedy this problem are Bladt & Rojas-Nandayapa [10] and Bladt et al. [9]. In Albrecher & Bladt [2] recently another direction was suggested, namely to transform time in the construction of PH distributions (as absorption times of Markov jump processes), leading to inhomogeneous phase-type (IPH) distributions. For suitable transformations, this approach allows to transport the versatility of PH distributions into the domain of heavy-tailed distributions, by introducing dense classes of genuinely heavy-tailed distributions. As a by-product, it was shown in [2] that a class of matrix-Pareto distributions can be identified, where the scalar parameter of a classical Pareto distribution is replaced by a matrix, providing an intuitive and somewhat natural extension of the Pareto distribution, much as the matrix-exponential distribution, which is a powerful extension of the classical exponential distribution, see e.g. Bladt & Nielsen [8].
In this paper we establish another matrix version of a distribution, namely the Mittag-Leffler distribution (first studied by Pillai [27]). While the identification of matrix versions of distributions is of mathematical interest in its own right, we will show that the resulting matrix Mittag-Leffler distributions (and its power transforms) have favorable properties for the modeling of heavy tails, and it can outperform some other modeling approaches in a remarkable way. Furthermore, we will identify this class of distributions as a particular extension of the IPH class, where the scaling is random. In addition, we will establish the matrix Mittag-Leffler distribution as the absorption time of a semi-Markov process with (scalar) Mittag-Leffler distributed inter-arrival times, extending the role of the exponential distribution for the inter-arrival in continuous-time Markov chains.
The Mittag-Leffler function was first introduced in [24] and over the years turned out to be a crucial object in fractional calculus. It can be seen as playing the same role for fractional differential equations as the exponential function does for ordinary differential equations, see e.g. Gorenflo et al. [17] for a recent overview. A recent application of fractional calculus for a particular risk model in insurance can be found in Constantinescu et al. [12]. Mittag-Leffler functions with matrix argument were first introduced in Chikrii and Eidel’man [11] and play a prominent role for identifying solutions of systems of fractional differential equations, see e.g. Garrappa and Popolizio [16]. Here we will use them to define the class of matrix Mittag-Leffler (MML) distributions, which enjoy some attractive mathematical properties and are heavy-tailed with a regularly varying tail with index . While such extremely heavy tails with resulting infinite mean can be relevant in the modeling of operational risk [25] and possibly insurance losses due to natural catastrophes [1], in most applications of interest the tails are slightly less heavy. We therefore enlarge the class of matrix Mittag-Leffler distributions by also including its power transforms and estimate the corresponding power together with the other parameters from the data in the fitting procedure. The index of regular variation of this larger class of distributions can now be any positive number. Whereas the number of needed phases for a PH or IPH fit can be very large also due to multi–modality or other irregularities in the shape of the main body of the distribution, we will see that the class of matrix Mittag-Leffler distribution and its power transforms (which we call power matrix Mittag-Leffler (PMML) distributions) offers a significant reduction in the number of phases needed to obtaining adequate fits. For this reason, it can even be worthwhile to scale light-tailed data points to heavy-tailed ones first, then apply a matrix Mittag-Leffler fit to the latter and transform the fit back to the original light-tailed scaling. This procedure is to some extent the reverse direction of the philosophy that underlied the PH fitting of heavy-tailed distributions. We will illustrate the potential advantage of this alternative approach in the numerical section at the end of the paper.
The remainder of the paper is organized as follows. Section 2 recollects some useful definitions and properties of Mittag-Leffler functions, Mittag-Leffler distributions and PH distributions. Section 3 then defines matrix Mittag-Leffler distributions and derives a number of its properties. We also give three explicit examples. Section 4 establishes MML distributions as IPH distributions under a particular random scaling, which allows to intuitively understand the additional flexibility gained from using MML distributions for the modeling of heavy-tailed risks. We then also establish MML distributions as the absorption times of a semi-Markov process with ML distributed interarrival times, which is yet another perspective on the potential of the MML class as a modeling tool. Finally, Section 5 is devoted to the modeling of data using (power-transformed) MML distributions. We first illustrate the convincing performance of the numerical fitting procedure to something as involved as tri–modal data. Secondly, we consider an MTPL data set taken from [1] and already studied by various other means in the literature. We show that a plain maximum-likelihood fit to this data set gives a convincing fit to the entire range of the data with remarkably few parameters, and even identifies the tail index with striking accuracy when compared to recent extreme value techniques as in [7], without having to choose a threshold for the tail modeling at all. We then also provide an example where transforming light-tailed data into heavy-tailed ones, fitting with a PMML distribution and transforming back can lead to a much better fit for the same number of parameters than a classical phase-type distribution. We then also discuss the signature of MML distributions in the tail in terms of the behavior of the Hill plot, which allows to develop an intuitive guess as to when MML distributions are particularly adequate for a fitting procedure of heavy tails. Finally, Section 6 concludes.
2. Some relevant background
2.1. Mittag–Leffler functions
The Mittag–Leffler (ML) function is defined by
[TABLE]
where and . The ML function is an entire function if , and it satisfies (see e.g. Erdelyi et al. [14, p.210])
[TABLE]
This implies that (see [16, Prop.2])
[TABLE]
where
[TABLE]
For a matrix , we may define its ML function as
[TABLE]
If , one can then express the entire ML function of a matrix by Cauchy’s formula
[TABLE]
where is a simple path enclosing the eigenvalues of . If has a Jordan normal form with
[TABLE]
then we may equivalently express by
[TABLE]
where
[TABLE]
and is the dimension of .
In either case, we shall need to evaluate the derivatives of ML functions at the eigenvalues, which by (1) implies the evaluation of ML functions with possibly negative indices . This is not a problem, but it is important that initially to ensure that the ML function is entire and thereby the existence of the Cauchy integral formula is guaranteed.
For further properties on the ML function we refer e.g. to [14], [16], [22] and [18].
2.2. Mittag–Leffler distributions
A random variable having Mittag-Leffler (ML) distribution was defined in Pillai [27] through the cumulative distribution function and consequently density given by
[TABLE]
with Laplace transform
[TABLE]
A convenient representation, due to Kozubowski [21], for a ML random variable is
[TABLE]
where is standard exponential and has cumulative distribution function
[TABLE]
The tail behaviour of is equivalent to that of a Cauchy random variable, and hence is regularly varying with parameter in the tail (see e.g. [23, Prop.1.3.9]).
The following extension (for the case ) will also play a role in the sequel: a random variable is said to follow a generalized Mittag-Leffler (GML) distribution with parameters and , if its Laplace transform is given by
[TABLE]
The corresponding cumulative distribution function then is
[TABLE]
where is the Beta function (see Jose et al. [19]). The analogous representation for a GML variable is
[TABLE]
where is Gamma with scale parameter 1 and shape parameter , and is a random variable with Laplace transform given by
[TABLE]
2.3. Phase–type distributions
A random variable is said to be phase–type distributed with generator (or representation) , and we write , if it is the time until absorption of a (time–homogeneous) Markov jump process with state–space where states are transient and state is absorbing. The row vector is the initial distribution, , and where denotes the transition rates of jumps between transient states and . We assume that , i.e. cannot start in the absorbing state which would have caused an atom at zero. The intensity matrix for can be written as
[TABLE]
where is a column vector of exit rates, i.e. is the rate of transition from state to the absorbing state . We notice that , where is the –dimensional column vector of ones, since the row sums in must all be zero. Hence fully parametrises the Markov process.
The class of Phase–type distributions is dense in the class of distributions on the positive reals, meaning that they may approximate any positive distribution arbitrarily well. On the other hand, they constitute a class of probabilistically tractable distributions, which often allows for exact solutions to complex stochastic problems, and frequently in a closed form. The theory is well developed with numerous applications in insurance risk and queueing theory (see e.g. [8] and reference therein). Phase–type distributions are light-tailed (i.e., their tail has an exponential decay), which makes them inadequate for modelling certain phenomena like insurance risks with heavy-tailed claims. Recently, Albrecher & Bladt [2] proposed an extension of the PH construction principle to time–inhomogeneous Markov processes, in which case the absorption times can also be heavy-tailed with a wide spectrum of possible tail shapes.
If , then its density function is given by , its distribution function by and its Laplace transform by , where denotes the identity matrix. The (fractional) moments are . For further details on Phase–type distributions we refer to [8].
3. Matrix Mittag–Leffler distributions
Let us now derive a matrix version of the Mittag-Leffler distribution by defining its Laplace transform and identifying the distribution associated to it. To this end, in view of (2) consider the function
[TABLE]
where is a PH generator.
Theorem 3.1**.**
* is the Laplace transform of a probability distribution.*
Proof.
Let and
[TABLE]
Then . Now is a sub–intensity matrix for all and therefore is a non–negative matrix (Green matrix, see [8, p.134]). Thus
[TABLE]
which has sign . Concerning ,
[TABLE]
has sign . We shall employ Faá di Bruno’s formula,
[TABLE]
where the summation is over –tuples for which
[TABLE]
to determine the sign of . Notice that
[TABLE]
Hence all terms in the summation have the same sign , and we conclude that also the sum itself has sign , i.e. . Since , the result then follows with Bernstein’s theorem (see [15, p.439]). ∎
Remark 3.2**.**
Note that the proof does not rely on the special form of , and it follows that if is any function with and completely monotone, then
[TABLE]
is the Laplace transform of a probability distribution, which may also be useful in other contexts.
Theorem 3.3**.**
Let be a random variable with Laplace transform (4). Then the density function of is given by
[TABLE]
Proof.
We show that has the required Laplace transform. For sufficiently large one has
[TABLE]
The result for all then follows by analytic continuation. ∎
Definition 3.4**.**
Let be a PH generator and let . A random variable is said to have a matrix Mittag–Leffler distribution, if its Laplace transform is given by
[TABLE]
In this case we write .
Remark 3.5**.**
The proof Theorem 3.3 shows that for any triplet for which
[TABLE]
is a density function, the function is indeed a Laplace transform of a probability distribution. Distributions with density (5) are referred to as matrix–exponential distributions, and contain the class of phase–type distributions as a strict subset. We have stated the above definition in terms of a phase–type generator, but it is hence clear that the construction also applies to any matrix–exponential distribution. While most results in the following could be stated in terms of a matrix–exponential triplet, for the sake of simplicity and notation we restrict the parameters to phase–type generators only.
Corollary 3.6**.**
Let . Then the cumulative distribution function for is given by
[TABLE]
Proof.
The derivative of this function is
[TABLE]
which indeed coincides with the density. It remains to note that satisfies the boundary condition . ∎
One can now realize that the matrix ML distribution provides an extension of representation (3) in the following way:
Theorem 3.7**.**
Let . Then
[TABLE]
where , and is an independent (positive stable) random variable with Laplace transform given by .
Proof.
Simply note that
[TABLE]
∎
Corollary 3.8**.**
Let . The fractional moments of order are given by
[TABLE]
Proof.
It is known [28] that the fractional moments of a random variable with Laplace transform are given by
[TABLE]
From [8] we know that the th fractional moment of a random variable with PH() distribution is given by
[TABLE]
By Theorem 3.7, and setting , will have the th fractional moment given by
[TABLE]
∎
Remark 3.9**.**
Representation (6) is not only useful for establshing closed-form formulas, but it also suggests a simple and efficient simulation technique for . Simulation algorithms for PH and stable distributions are for instance available in the statistical software R via the packages actuar and stabledist, respectively.
Example 3.1**.**
Consider where is the PH representation of an Erlang distribution with () stages and intensity , i.e. and
[TABLE]
In this case
[TABLE]
so
[TABLE]
where is a simple path enclosing , and where in the last step we used the residue theorem. Note that this corresponds to the GML random variable given already for general shape parameter in (3) (although this explicit form of the density was not given in [19]). Figure 1 depicts the density for several choices of parameters. The parameter controls the heaviness of the tail (and more generally the deviation from exponentiality of the Mittag-Leffler function), the parameter determines the shape of the body of the distribution (since larger implies a more pronounced Erlang component), and is a scaling parameter.
∎
Example 3.2**.**
Mixture of Erlang distributions form the simplest sub–class of PH distributions which are dense in the class of distributions on the positive real line (in the sense of weak convergence). Let be the density
[TABLE]
where denotes the density of an Erlang distribution and are weights with . Then it follows immediately from Example 3.1 that the corresponding MML distribution has density
[TABLE]
In Figure 2, a trimodal distribution is considered, corresponding to , for a mixture of three Erlang PH components. The densities of and are both depicted. ∎
Example 3.3**.**
A Coxian phase–type distribution has a representation of the form
[TABLE]
where all , are distinct. In this case
[TABLE]
so
[TABLE]
In Figure 3 four such densities are plotted.
∎
4. Sample path respresentations
We now provide two different representations of the MML distribution as sample path properties of a stochastic process. The first one will be as an absorption time of a randomly scaled time-inhomogeneous Markov jump process, and the second one as an absorption time of a particular semi-Markov process (where random time scaling is not needed).
4.1. Random time-inhomogeneous phase–type distributions
We recall from Section 2.3 that a random variable is PH distributed if it is the time until absorption of a time–homogeneous Markov jump process on a finite state–space, where one state is absorbing and the remaining states are transient. In this section we show that a MML distribution can be interpreted as a time–inhomogeneous phase–type distribution with random intensity matrix.
Let us define a random time-inhomogeneous Markov jump process as a jump process with state space , where is an absorbing state, the remaining states being transient, and the intensity matrix given by
[TABLE]
where , , , ,
[TABLE]
and the independent, positive random variable is a random scaling factor. For the resulting absorption time
[TABLE]
we write . Note that the special case corresponds to the IPH class in [2].
If furthermore we can write , the intensity matrix (7) takes the form
[TABLE]
in which case we write . The following result is then immediate.
Theorem 4.1**.**
Let for a random variable with density . Then the density and distribution function of are given by
[TABLE]
Furthermore, if is a strictly positive function and we define by
[TABLE]
then
[TABLE]
where .
Combining Theorem 3.7 and Theorem 4.1, the matrix Mittag-Leffler random variable can hence be interpreted as a particular random scaling of a time-inhomogeneous phase-type distribution with (translating into ) and heavy-tailed random scaling factor . As we will illustrate in Section 5, this represents a particularly versatile yet simple class of random variables for fitting real data.
Remark 4.2**.**
For any random variable with cumulative distribution function , it is possible to write
[TABLE]
where is a unit mean exponential random variable. For modeling purposes, the rationale in [2] can be interpreted as approximating the transformation function before-hand by some function (in absence of the knowledge of ) and then replacing with a general PH distribution, providing flexibility for the fit with often explicit formulas for the resulting random variable. The matrix-Pareto distributions defined in [2] are then the special case and (up to a constant) in (8), which entails . The fitting in that case is particularly parsimonious for distributions ’close’ to a Pareto distribution (where the distance concept here is then inherited from the distance in the PH domain after the log-transform). The general representation (8), in contrast, allows to introduce a potential heavy-tail behavior also through the random scaling factor , providing more flexibility for the shape of the function (through the choice of ) in a fitting procedure while keeping the resulting expressions tractable.
Remark 4.3**.**
The form (8) may also suggest to consider – for modelling purposes – the somewhat simpler case of a PH variable multiplied by a standard Pareto variable with tail index , that is and , . For general it is straightforward to see that then
[TABLE]
where is the -th moment of , and is its -th moment distribution.
For this simplifies to
[TABLE]
where
[TABLE]
is the Whittaker M function and is the Pochhammer symbol. Inserting a matrix into the third argument of this function, one may now proceed again with the matrix version of Cauchy’s formula and by Jordan decomposition, potentially giving rise to a theory similar to the one for Mittag-Leffler distributions. However, this direction is not the focus of the present paper. In addition, a key difference between the above product construction and the MML distribution will be discussed in Section 4.2 below in the context of a non-random path representation, for which the fine properties of the ML distribution play a crucial role.
4.2. Semi–Markov framework
Let be a state space and let denote a transition matrix for some Markov chain defined on . We assume that for all . will serve as an embedded Markov chain in a Markov renewal process.
Let and . For let be i.i.d. random variables with a Mittag–Leffler distribution , where we use the parametrisation such that the density of a generic is given by
[TABLE]
An alternative common parametrisation is obtained in terms of the parameter that satisfies .
We now construct a semi–Markov process as follows. Let and
[TABLE]
Define
[TABLE]
Then changes states according to the Markov chain , denotes the time of the ’th jump, and the sojourn times in states are Mittag–Leffler distributed with paramters . The construction is illustrated in Figure 4.
Define the intensity matrix by
[TABLE]
and let
[TABLE]
Theorem 4.4**.**
We have
[TABLE]
Proof.
Conditioning on the time of the first jump, we get that
[TABLE]
Taking Laplace transforms, and using that
[TABLE]
together with , we get that
[TABLE]
or
[TABLE]
Now using , we get
[TABLE]
In matrix form this amounts to
[TABLE]
which has the solution
[TABLE]
The right-hand side is the Laplace transform of , establishing the result. ∎
Next we consider the case where and where the states are transient and state is absorbing (with respect to the Markov chain ). This means that has a transition matrix of the form
[TABLE]
and regarding the intensities we set . The matrix then is of the form
[TABLE]
We notice the following useful result.
Lemma 4.5**.**
[TABLE]
where (rows sum to zero).
Proof.
By definition,
[TABLE]
∎
Thus the restriction of to the transient states equals and is hence the sub–transition matrix between the transient states.
Theorem 4.6**.**
Let be a semi-Markov process, where the matrix has the form
[TABLE]
Let denote the time until absorption. Then has a MML() distribution, with cumulative distribution function given by
[TABLE]
Proof.
For , the events and coincide. Thus,
[TABLE]
∎
Remark 4.7**.**
The proofs above heavily depend on the form of the Laplace transform of the ML distribution, and its similarity with the exponential function. Note that the above construction naturally extends the definition of PH distributions as absorption times of continuous–time Markov chains, the latter being the limit case . In general, such a semi-Markov representation will hence not be available for other product distributions.
5. Statistical modeling using MML distributions
In this section we present some examples of MML distribution fitting to data. Let us start with an illustration of the maximum likelihood fitting performance to simulated data.
Example 5.1**.**
We simulate observations from , with a mixture of Erlang PH component, with parameters chosen in such a way that the log-data is trimodal. The corresponding maximum likelihood fit is depicted in Figure 5 (for visualization purposes the scale of the -axis is logarithmic). The true parameters are , , , , , whereas the maximum likelihood estimator is found to be
[TABLE]
The negative log-likelihood at the fitted parameters was , compared to at the true parameters (i.e., in the likelihood sense, the fitted model even outperforms the true model for the simulated data points). Note that the tri-modal shape of the underlying density is nicely identified here (which in pure PH fitting would typically not work as smoothly). We also provide a Hill plot of the simulated data, where the potentially heavy-tailed behavior can be clearly appreciated.
The fact that MML distributions behave in a Pareto manner with parameter in the tail can be seen from (6). Since such a tail will be too heavy for most applications, we introduce a simple power transformation to gain flexibility for the tail behavior, which particularly allows lighter tails as well.
Definition 5.1**.**
Let . For , we define
[TABLE]
*and refer to it as the class of Power-MML (PMML) distributions. *
The density function of a distribution is given by
[TABLE]
which will be needed for the maximum likelihood procedure below.
Remark 5.2**.**
The introduction of the PMML class allows for an adaptive transformation of the data during the fitting procedure. The interpretation of is then as the power to which the data should be taken in order for the latter to be most adequately fit by a pure MML distribution. As the number of MML components grows, the product is expected to estimate the tail index. However, this estimate might be far off when the matrix is not large enough in order for the global fit to be adequate. In those cases, the power transform will tend to improve the fit of the body of the distribution, rather than the tail. When compared to the approach taken in [2] (fitting a PH density to log-transformed heavy tailed variables) one can consider the present procedure as adaptive selection of the transformation function, as opposed to fixing it to be the logarithm.
Example 5.2**.**
We consider a real-life motor third party liability (MTPL) insurance data set which was thoroughly studied in [1], mainly from a heavy-tailed perspective (referred to as ”Company A” there). The data set originally consists of observations, having the interpretation of claim sizes reported to the company during the time frame 1995-2010. The data are right-censored, and were analyzed recently in [6] using perturbed likelihood with censoring techniques. For the present purpose, we solely focus on the ultimates, which consists of imputing an expert prediction of the final claim amount for all claims which are still open, i.e. right-censored. We restrict our analysis here to the largest observations, since the inclusion of the 37 smallest claims lead to a sub-optimal fit, but are somehow irrelevant for modeling purposes. For convenience, we divided the claim sizes by .
The heavy-tailed nature of the data suggests that using MML distributions to model the claim sizes is appropriate. Recently, in [7], a tail index of was suggested through an automated threshold selection procedure, using a novel trimming approach for the Hill estimator. Since this (or also other much rougher pre-analysis techniques like Pareto QQ-plots) suggests a finite mean, we employ the PMML distributions for the present purpose. This is in fact advised as a general procedure, since in situations where a pure MML fit is appropriate, the fitting procedure will suggest a value for close to 1 anyway. The maximum likelihood procedure identifies here a surprisingly simple PMML distribution as adequate, namely with a PH component just being a simple exponential random variable:
[TABLE]
More complex PH components turn out to indeed numerically degenerate into this simple model again. The resulting model density is hence given by
[TABLE]
The adequate fit can be appreciated in Figure 6. Observe that the maximum likelihood approach is concerned not only with the tail behaviour but also with adequately fitting the body of the distribution. Nonetheless, the tail index of the PMML fit is given by , which is strikingly(!) close to the suggested in [7].
A previous approach to describe the entire data set by one model was given in [1, p.99], where a splicing point was suggested for this data set at around the th largest order statistic, based purely on expert opinion. A semi-automated approach in [7] suggested splicing at the th largest data point. Notice that not only does our model fit the data well and is much more parsimonious, but it also circumvents threshold or splicing point selection completely.
Phase-type distributions are weakly dense in the set of all probability distributions on the positive real line. However, often a very large dimension of the PH distribution is needed to get a decent fit to data. Here, we show an example of how the class of PMML distributions can be used to reduce the dimension of a PH fit, thanks to the increased flexibility that the randomization with an -stable distribution and the power function provide.
Example 5.3**.**
We consider simulated data points following a mixture of two Erlang(40) distributions. The PH representation is of dimension , with parameters
[TABLE]
Since the data is light-tailed, and PMML are heavy-tailed, we consider the transformed observations
[TABLE]
which are Pareto in the tail. We then proceed to fit a PMML distribution to the transformed data, but with a much lower matrix dimension. Concretely, we consider a mixture of two Erlang distributions of three phases each for the PH component of the PMML representation. In this way we are led to the maximum likelihood estimates
[TABLE]
The (back-transformed) fitted density is plotted in Figure 7, along with a histogram of the original PH data points. We also include a fitted density using a pure PH distribution of the same dimension and kind: a mixture of two Erlangs of three phases each. We observe how transforming the data into the heavy-tail domain, fitting a PMML and then back-transforming adds only two extra parameters and improves the estimation dramatically. Additionally, a Hill plot of the transformed data is provided, which shows that the tail index empirically could correspond to , such that it is necessary to use the PMML class, as opposed to only the MML. For reference, the resulting tail is , but here the quantification of the tail behaviour is not the main focus of the estimation, and used only qualitatively. In fact, a quick calculation shows that the true index is , and it is well-known that it is a hard task to estimate tail indices in the transition area between Fréchet and Gumbel domains of attraction. The additional Hill plots of simulated paths of the estimated model in Figure 7 show how the hump at the middle of the Hill plot is not a random fluctuation, but rather a systematic feature.
Notice that we took the exponential transformation (13) of the simulated data because in this case we know that their tail is exponential and hence the transforms will be regularly varying, in accordance with the PMML distribution. In general, the exponentiation of light-tailed data does not imply that the resulting underlying distribution is regularly varying in the tail. Hence, for real data, a preliminary assessment of the tail behavior and the one of their exponential transforms is recommended.
Remark 5.3**.**
When fitting a MML or PMML distribution to data, one has to decide upon the dimension of the underlying phase–type representation. This problem arises similarly when fitting phase–type distributions to light-tailed data, and there are no generally accepted and well established methods for model selection, since PH distributions may be well overparametrised so that penalized methods such AIC or BIC indices will not work in general. The order of the PMML (or phase–type distribution) is therefore usually chosen by fitting a range of models of different dimension and then comparing the fit and likelihood values (which, as opposed to information indices, are comparable).
6. Conclusion
In this paper we define the class of matrix Mittag-Leffler distributions and derive some of its properties. We identify this class as a particular case of inhomogeneous phase-type distributions under random scaling with a stable law, which together with its power transforms is surprisingly versatile for modeling purposes. In addition, the class is shown to correspond to absorption times of semi–Markov processes with Mittag–Leffler distributed interarrival times, providing a natural extension of the phase–type construction. We illustrate with several examples that this class can simultaneously fit the main body and the tail of a distribution with remarkable accuracy in a parsimonious manner. It turns out that the flexibility of this heavy-tailed class of distributions can even make it worthwhile to transform data into the heavy-tailed domain, fitting the resulting data points and then transforming them back. It will be an interesting direction for future research to further explore the potential of such fitting procedures, both from a theoretical and practical perspective.
Acknowledgement. H.A. acknowledges financial support from the Swiss National Science Foundation Project 200021_168993.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Hansjörg Albrecher, Jan Beirlant, and Jozef L. Teugels. Reinsurance: Actuarial and Statistical Aspects . John Wiley & Sons, 2017.
- 2[2] Hansjörg Albrecher and Mogens Bladt. Inhomogeneous phase–type distributions and heavy tails. Journal of Applied Probability , 56(4):to appear, 2019.
- 3[3] Søren Asmussen and Hansjörg Albrecher. Ruin probabilities . World Scientific, Hackensack, NJ, second edition, 2010.
- 4[4] Søren Asmussen, Olle Nerman, and Marita Olsson. Fitting phase-type distributions via the EM algorithm. Scandinavian Journal of Statistics , pages 419–441, 1996.
- 5[5] Jan Beirlant, Yuri Goegebeur, Johan Segers, and Jozef L Teugels. Statistics of extremes: theory and applications . John Wiley & Sons, Chichester, 2004.
- 6[6] Martin Bladt, Hansjörg Albrecher, and Jan Beirlant. Combined tail estimation using censored data and expert information. Preprint, University of Lausanne , 2019.
- 7[7] Martin Bladt, Hansjörg Albrecher, and Jan Beirlant. Trimming and threshold selection in extremes. ar Xiv Preprint ar Xiv:1903.07942 , 2019.
- 8[8] Mogens Bladt and Bo Friis Nielsen. Matrix-Exponential Distributions in Applied Probability . Springer, 2017.