TL;DR
This paper introduces a spatio-temporal prior that leverages location and time data to improve fine-grained image classification, significantly enhancing accuracy by incorporating contextual cues often overlooked by traditional methods.
Contribution
It presents a novel, efficient prior model trained on presence-only data that jointly captures object categories, their distributions, and biases, integrating this with image classifiers for better performance.
Findings
Significant accuracy improvements when combining prior with classifiers
Effective modeling of object distributions and biases from presence-only data
Applicable across multiple challenging datasets
Abstract
Appearance information alone is often not sufficient to accurately differentiate between fine-grained visual categories. Human experts make use of additional cues such as where, and when, a given image was taken in order to inform their final decision. This contextual information is readily available in many online image collections but has been underutilized by existing image classifiers that focus solely on making predictions based on the image contents. We propose an efficient spatio-temporal prior, that when conditioned on a geographical location and time, estimates the probability that a given object category occurs at that location. Our prior is trained from presence-only observation data and jointly models object categories, their spatio-temporal distributions, and photographer biases. Experiments performed on multiple challenging image classification datasets show that…
Click any figure to enlarge with its caption.
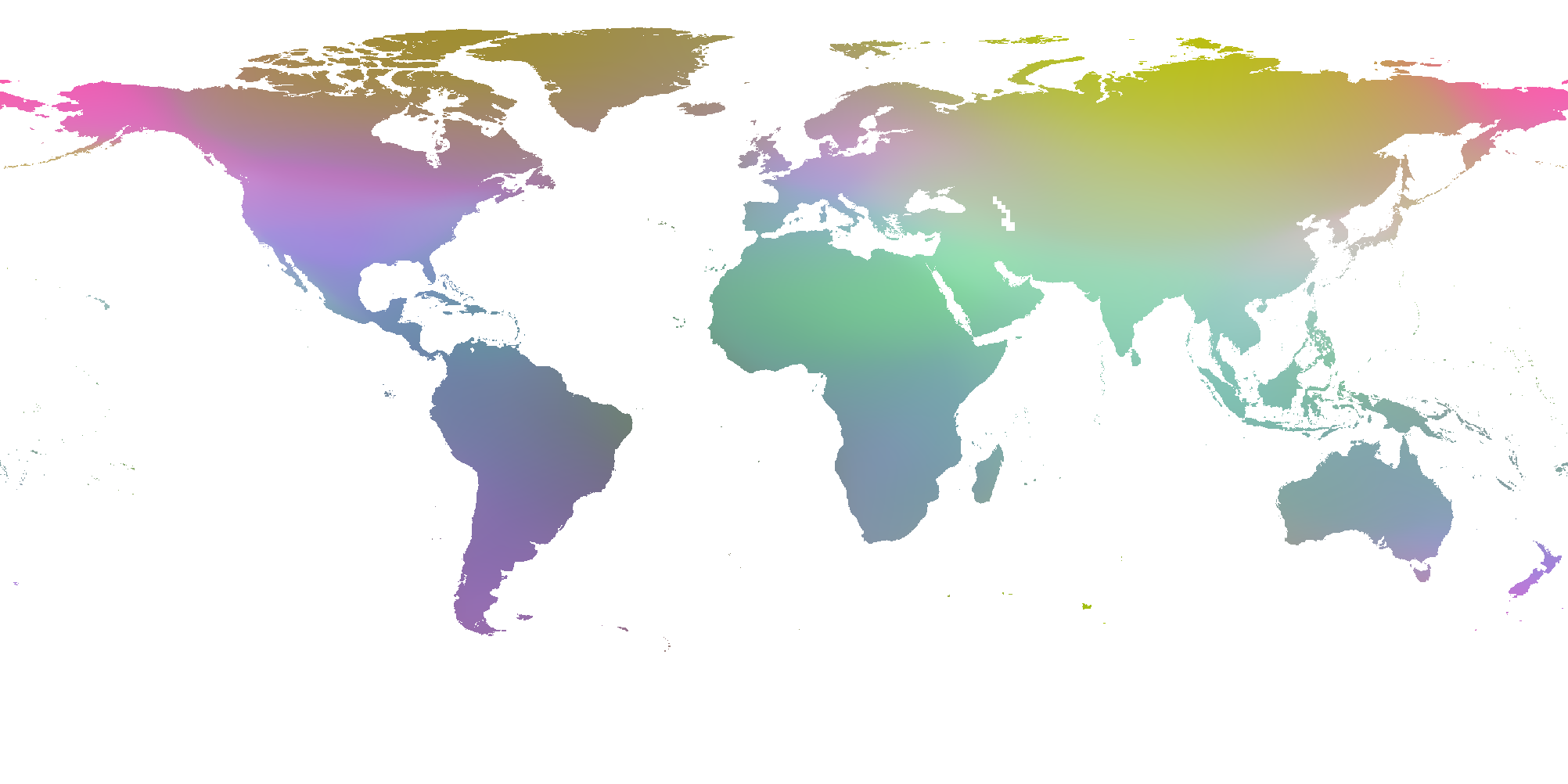 Figure 1
Figure 1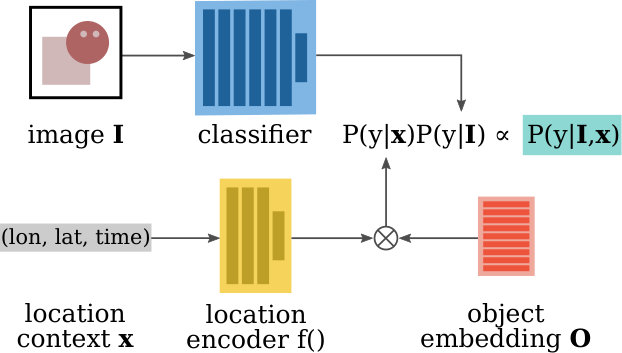 Figure 2
Figure 2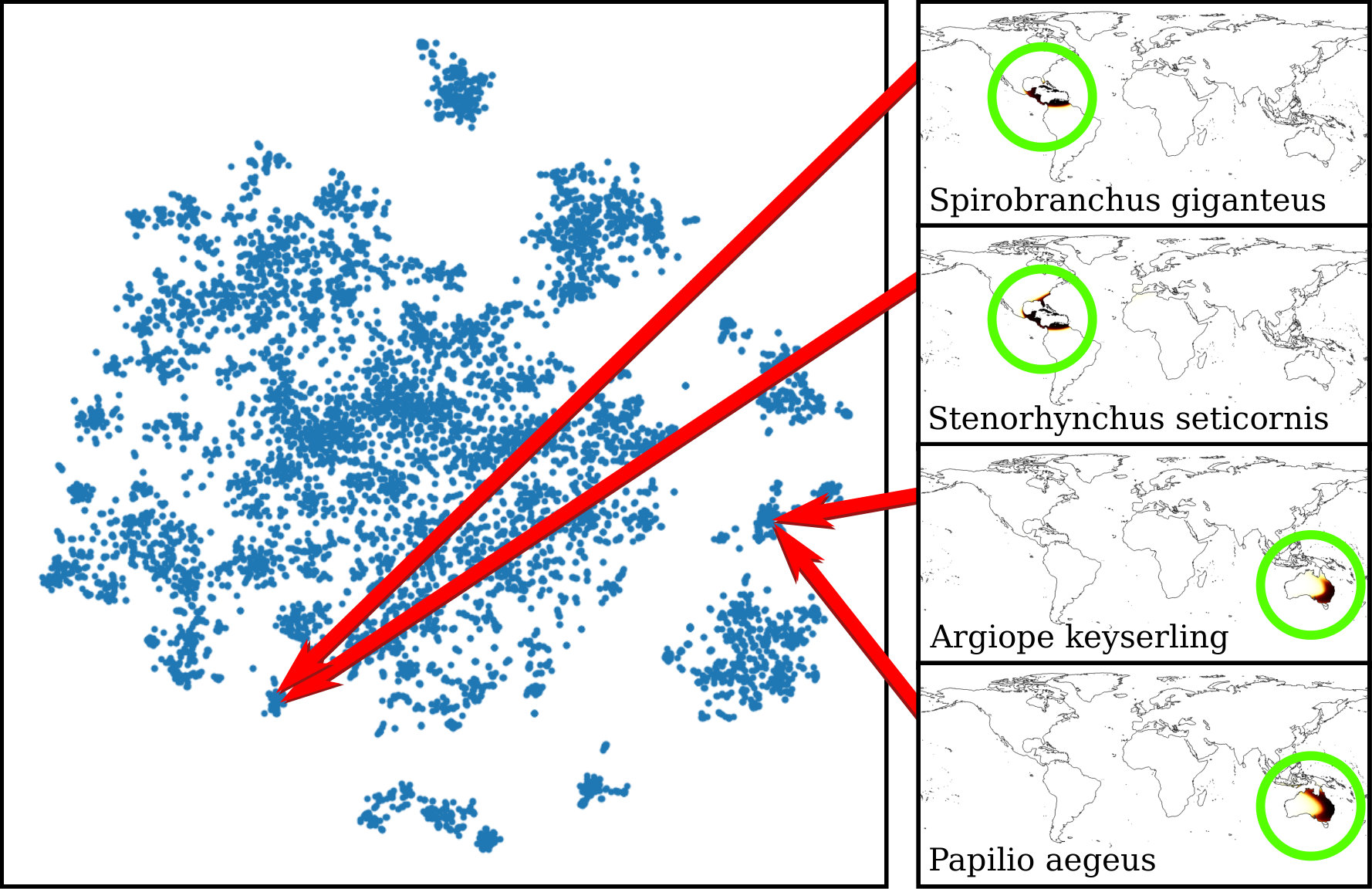 Figure 3
Figure 3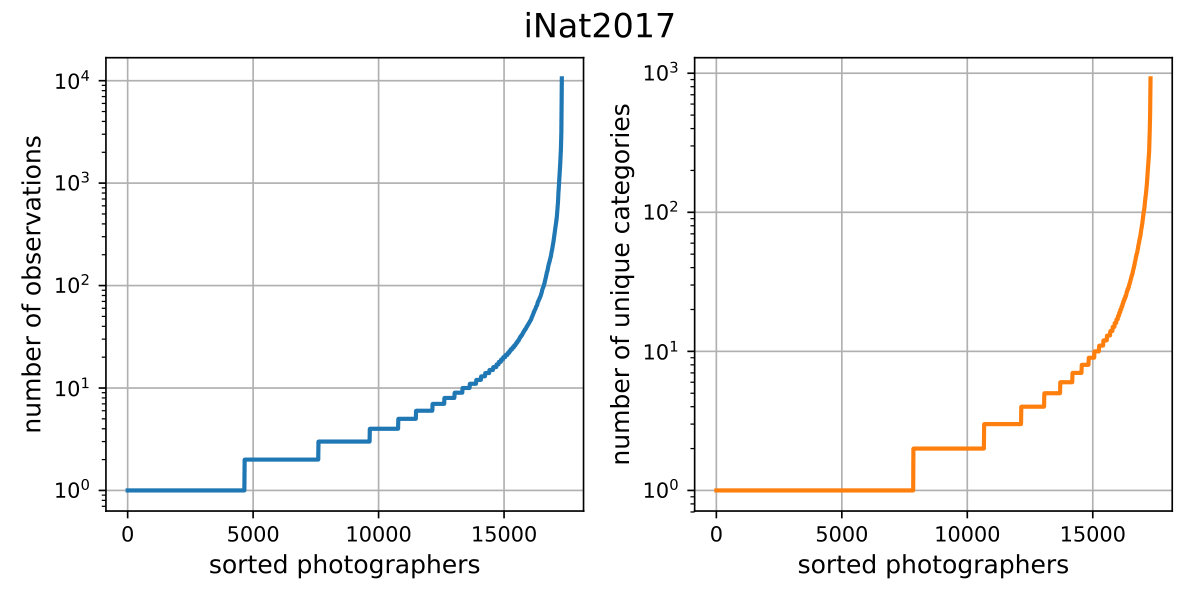 Figure 4
Figure 4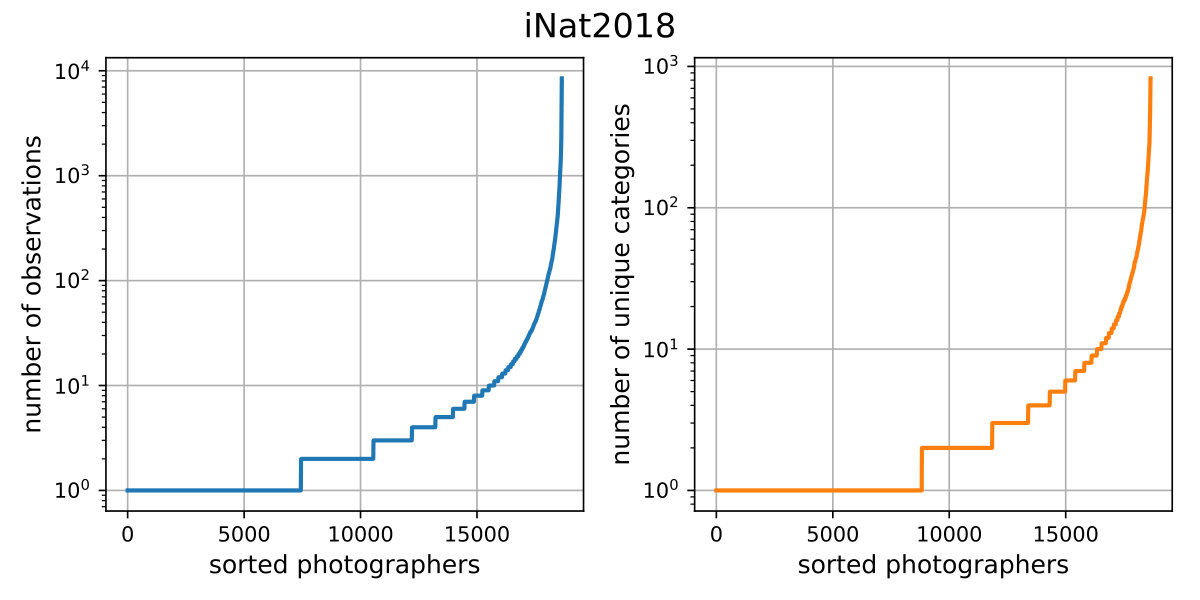 Figure 5
Figure 5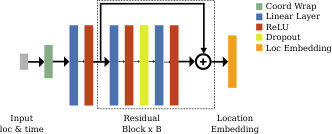 Figure 6
Figure 6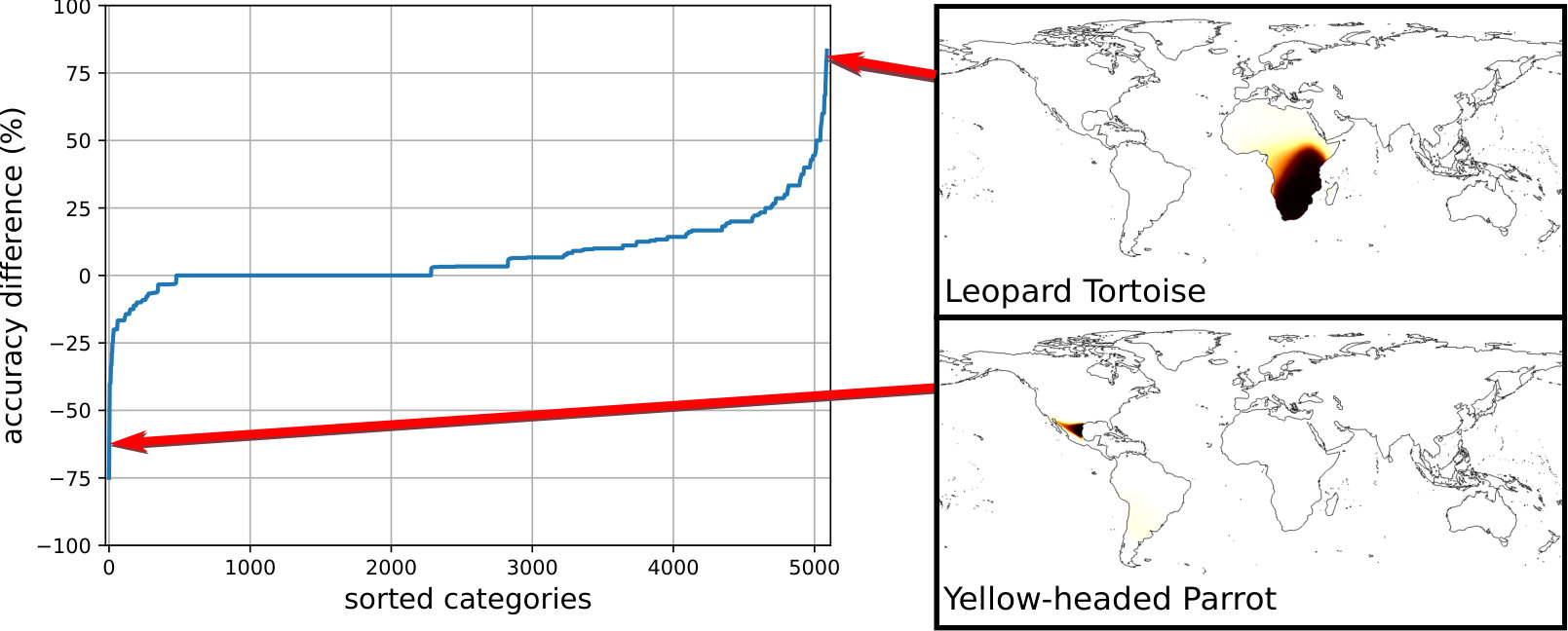 Figure 7
Figure 7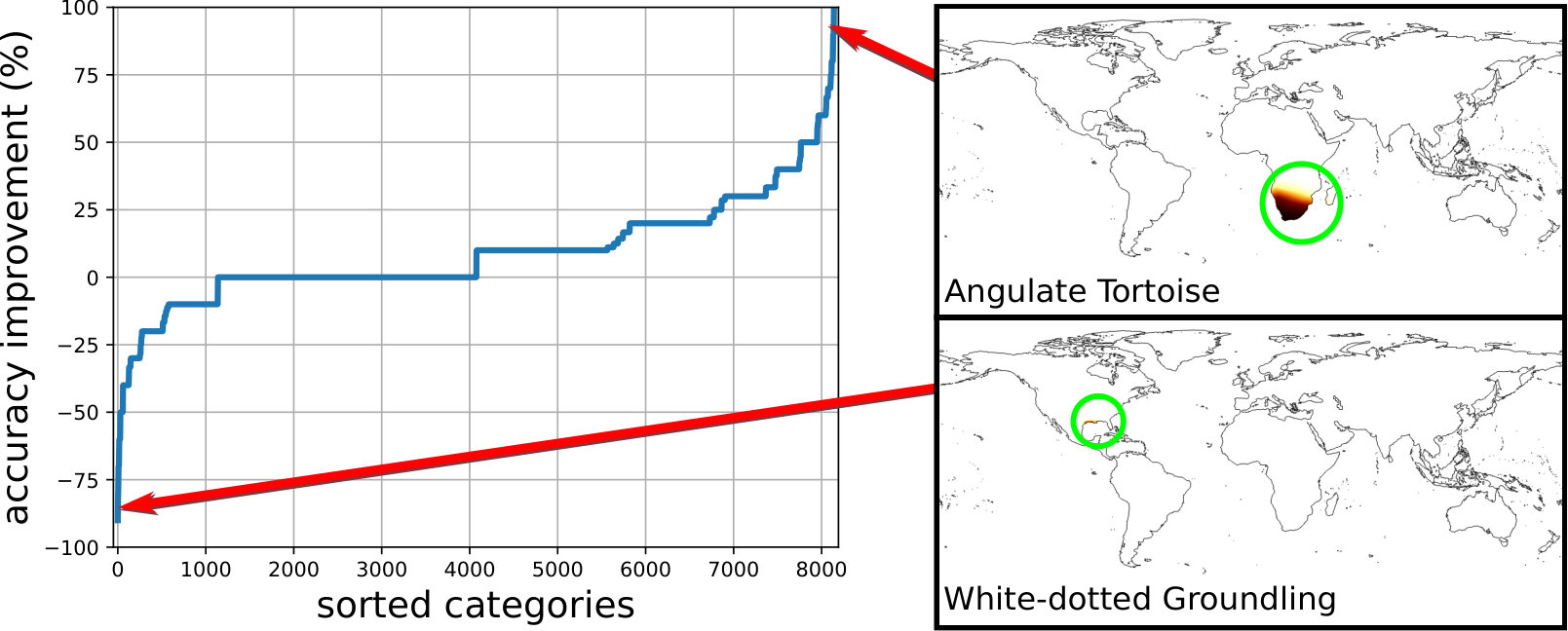 Figure 8
Figure 8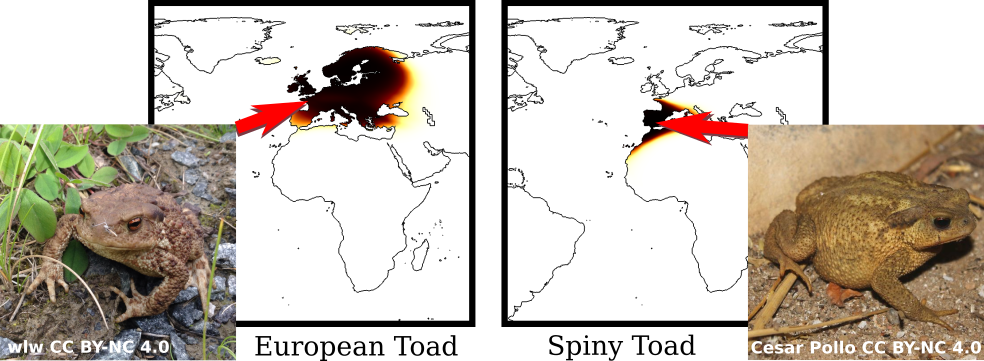 Figure 9
Figure 9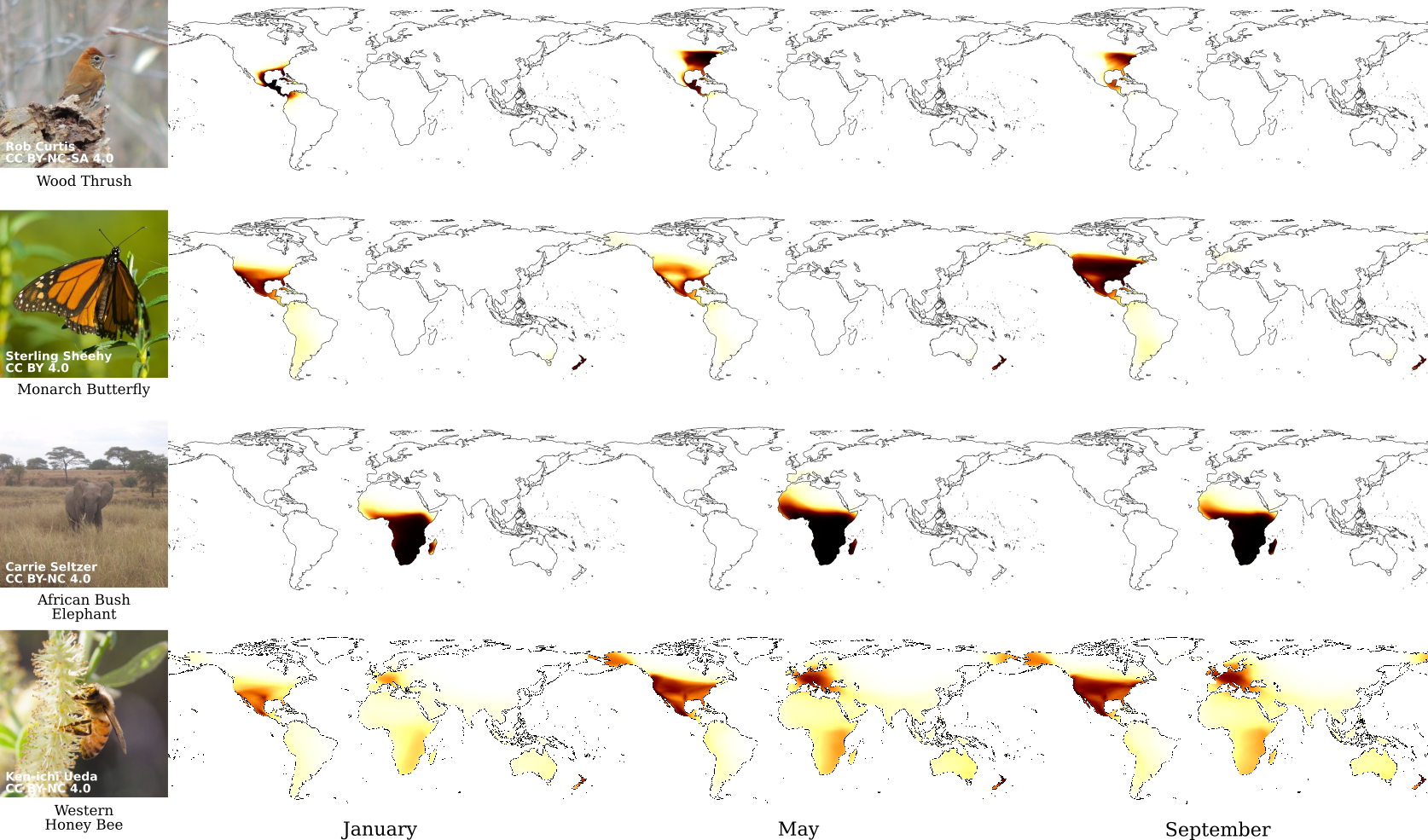 Figure 10
Figure 10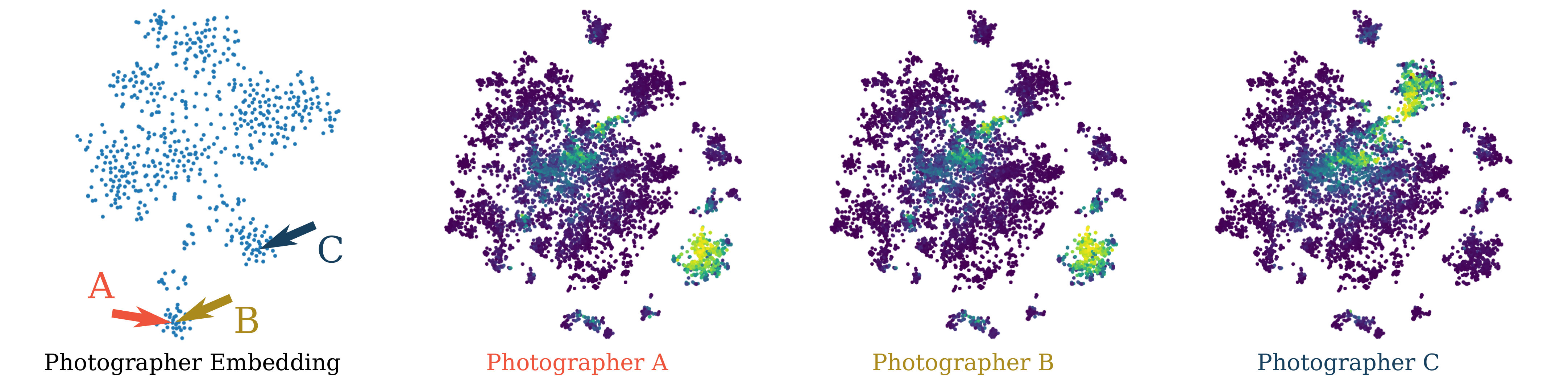 Figure 11
Figure 11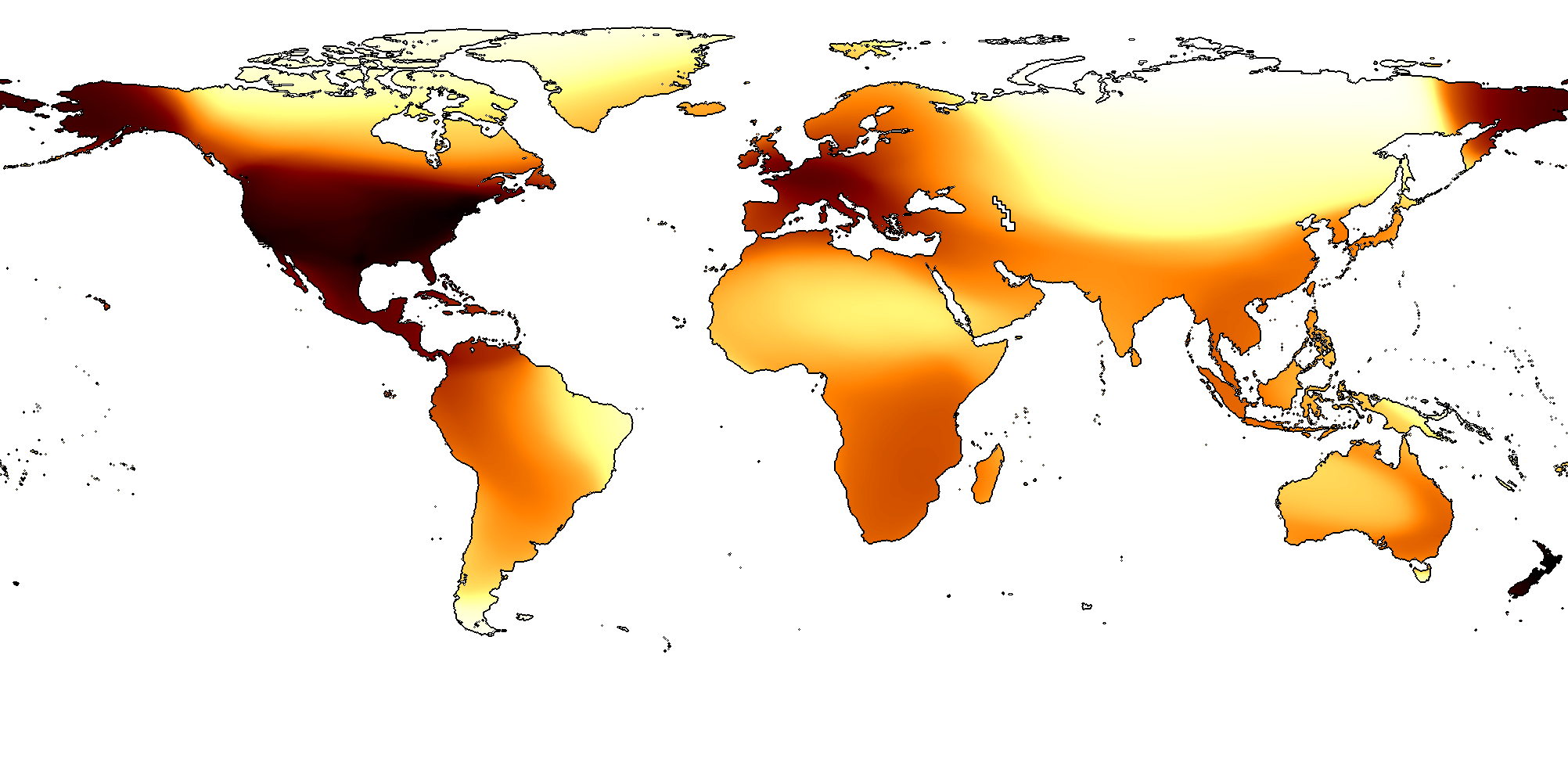 Figure 12
Figure 12| YFCC | BirdSnap | BirdSnap | NABirds | iNat2017 | iNat2018 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| - Prior Type | Test | Test | Test | Test | Val | Test Pu | Test Pr | Val | Test Pu | Test Pr |
| No Prior (i.e. uniform) | 50.15 | 70.07 | 70.07 | 76.08 | 63.27 | 64.16 | 63.63 | 60.20 | 50.17 | 50.33 |
| Nearest Neighbor (num) | 51.78 | 70.82 | 77.76 | 79.99 | 65.34 | 66.04 | 65.61 | 68.70 | 54.54 | 54.58 |
| Nearest Neighbor (spatial) | 51.21 | 71.57 | 77.98 | 80.79 | 65.85 | 67.02 | 66.41 | 67.55 | 53.67 | 53.81 |
| Discretized Grid | 51.06 | 71.09 | 77.19 | 79.58 | 65.49 | 66.62 | 66.07 | 67.27 | 53.13 | 53.16 |
| Adaptive Kernel [5] | 51.47 | 71.57 | 78.65 | 81.11 | 64.86 | 65.83 | 65.59 | 65.23 | 53.17 | 53.21 |
| Tang et al. [55] | 50.43 | 70.16 | 72.33 | 77.34 | 66.15 | 67.08 | 66.53 | 65.61 | 54.12 | 54.25 |
| Ours no date | 50.70 | 71.66 | 78.65 | 81.15 | 69.34 | 70.62 | 70.18 | 72.41 | 57.68 | 57.84 |
| Ours full | - | 71.84 | 79.58 | 81.50 | 69.60 | 70.83 | 70.51 | 72.68 | 58.44 | 58.59 |
| Top1 | Top3 | Top5 | |
| iNat2017 - InceptionV3 | |||
| No Prior (i.e. uniform) | 63.27 | 79.82 | 84.51 |
| Ours no wrap encode | 69.48 | 84.43 | 88.15 |
| Ours no photographer | 69.39 | 83.97 | 87.71 |
| Ours no date | 69.34 | 84.16 | 87.89 |
| Ours full | 69.60 | 84.41 | 88.07 |
| iNat2018 - InceptionV3 | |||
| No Prior (i.e. uniform) | 60.20 | 77.90 | 83.29 |
| Ours no wrap encode | 72.12 | 87.00 | 90.52 |
| Ours no photographer | 72.84 | 87.30 | 90.75 |
| Ours no date | 72.41 | 87.19 | 90.60 |
| Ours full | 72.68 | 87.26 | 90.79 |
| iNat2018 - InceptionV3 | |||
| No Prior (i.e. uniform) | 66.18 | 83.32 | 88.04 |
| Ours no wrap encode | 77.09 | 90.68 | 93.54 |
| Ours no photographer | 77.64 | 90.82 | 93.52 |
| Ours no date | 77.41 | 90.80 | 93.58 |
| Ours full | 77.49 | 90.85 | 93.57 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Presence-Only Geographical Priors for Fine-Grained Image Classification
Oisin Mac Aodha Elijah Cole Pietro Perona
Caltech
www.vision.caltech.edu/~macaodha/projects/geopriors
Abstract
Appearance information alone is often not sufficient to accurately differentiate between fine-grained visual categories. Human experts make use of additional cues such as where, and when, a given image was taken in order to inform their final decision. This contextual information is readily available in many online image collections but has been underutilized by existing image classifiers that focus solely on making predictions based on the image contents.
We propose an efficient spatio-temporal prior, that when conditioned on a geographical location and time, estimates the probability that a given object category occurs at that location. Our prior is trained from presence-only observation data and jointly models object categories, their spatio-temporal distributions, and photographer biases. Experiments performed on multiple challenging image classification datasets show that combining our prior with the predictions from image classifiers results in a large improvement in final classification performance.
1 Introduction
Correctly classifying objects into different fine-grained visual categories is a challenging problem. In contrast to generic object recognition, it can require knowledge of subtle features that are essential for differentiating between visually similar categories. However, without having access to additional information that may not be present in an image, many categories can be visually indistinguishable. For example, the two toad species in Fig. 1 are similar in appearance but tend to be found in very different locations in Europe. Knowing where a given image was taken can provide a strong prior for what objects it may contain.
Most images that are captured and shared online today also come with additional metadata in the form of where they were taken, when they were taken, and who captured them. This information not only offers the possibility of helping to resolve ambiguous cases for image classification, but can also enable us to generate predictions of where, and when, different objects are likely to be observed.
Existing work that uses location information to improve classification performance either discretizes the input data into spatio-temporal volumes [5], store the entire training set in memory at inference time [64], or jointly train deep images classifiers along with corresponding location information [55]. Methods that discretize or store the raw training data do not scale well in terms of memory, and jointly training image classifiers with location information necessitates that location information is present at test time - which may not always be the case. We take inspiration from species distribution modeling (SDM) [20], and instead model a separate geographical prior that can be combined with the predictions of any image classifier. However, unlike many approaches to SDM that assume they have access to presence and absence information at training time (e.g. [56]), we make a more general assumption that only presence information is available i.e. we know where the categories have been observed, but have no explicit data regarding where they are not found.
In this work we make the following contributions: (1) An efficient spatio-temporal prior that jointly models the relationship between location, time of year, photographer, and the presence of multiple different object categories. (2) A novel presence-only training loss to capture these relationships. (3) Experiments that show that combining the probabilistic predictions of image classifiers with our prior significantly improves the test time performance on challenging fine-grained image datasets.
2 Related Work
Here we discuss work related to spatio-temporal models that encode the location of a set of discrete object categories. We do not address methods that explore other uses of location information such as inferring where an image was taken given only the raw pixels [29, 60], or methods that use location to disambiguate visually similar places for image localization [59, 68].
Fine-Grained Image Classification
Correctly determining which one of multiple possible fine-grained categories is present in an image requires understanding the relationship between subtle visual features and the corresponding image-level category label e.g. [61, 35, 66, 58]. Existing approaches have investigated the modeling of parts [41, 71, 9, 70, 32], higher order feature interactions [40, 23], attention mechanisms [65, 72, 62], noisy web data [37], novel training losses [14], and pairwise category information [17]. Orthogonal to those works, we propose a spatio-temporal prior that can be combined with the probabilistic predictions of any image classifier to improve the final classification performance.
Location and Classification
A small number of approaches have explored the use of location information to improve image classification at test time. Berg et al. [5] proposed a spatio-temporal prior that when combined with the output of an image classifier increased the accuracy of bird species classification. Their approach discretized location and time into spatio-temporal cubes and used an adaptive kernel density estimator to represent the distribution of each species independently. Also in the context of predicting the presence of different biological species, Wittich et al. [64] evaluated different nearest neighbor based lookup strategies for retrieving the most relevant instances from a training set of geo-tagged observations. These approaches are inefficient in terms their memory requirements as they necessitate storing either the entire training set or a discretized version of it. Existing repositories of citizen science data (e.g. [53, 2, 1]) can contain on the order of tens of millions of observations making them prohibitively large to store and retrieve on mobile devices. Choosing the correct discretization is challenging [48], and incorrect choices can significantly affect the final performance [38, 46]. A key benefit of our approach is that discretization is not required.
Tang et al. [55] explored different feature encodings for incorporating location information directly into deep neural networks at training time. This included raw location features (i.e. longitude and latitude), demographic information collected via a census, user provided hash-tags, and geographical map features (e.g. land use estimates). The disadvantage of their method is that it assumes that location information is present at test time and that all the required features can be computed for a given test location. Furthermore, they cannot use location information that does not have an associated image. They also need to retrain their entire model if new location data is collected. We instead propose an efficient spatio-temporal prior that jointly models the spatial distribution of multiple object categories that can be trained independently of the image classifier. Parallel to our work, [13] builds on [55] by exploring different ways to integrate location information into deep image classifiers.
Spatio-Temporal Distribution Modelling
Our goal is to estimate the spatio-temporal distribution of a set of object categories. Related to this, there is a rich literature exploring models for estimating the distribution of biological specimens across geographic space and time [31]. This is referred to as species distribution modelling or environmental niche modelling. Broadly, these methods can be divided into two groups, those that use presence-absence data and those that use presence-only data [28].
Making a presence-absence observation at a given location requires that every species from a predefined set of interest be confirmed as either present or absent for that sampling event. In practice, this kind of data is onerous to collect because it requires intense survey effort to confirm that a species is absent with a high degree of certainty [43]. However, once this data is collected it can be combined with standard supervised classification approaches such as logistic regression [28], probit regression [52], Gaussian processes [26], decision trees [20], and neural networks [67, 49, 45], among others [18, 47]. Presence-absence data is also compatible with traditional multi-label learning [34, 8, 69, 12, 63]. Recently deep models have been applied to this problem in order to jointly model the location preferences of different species [27, 11, 22, 56, 7] and human sampling biases [10].
In contrast, a presence-only (i.e. incidental) observation may be recorded wherever an object of interest is encountered - without requiring any absences to be verified. While presence-only data can be much easier to collect, the lack of absence information makes it more difficult to model. This limitation is typically dealt with in one of three different ways. The first approach is to generate ‘pseudo-negatives’ and then apply one of the presence-absence approaches from above. As no true negative information is available, these approaches randomly sample a set of locations and make the assumption that these locations are absences e.g. [19, 50, 3]. The second commonly used approach is to train a highly regularized model directly on the presence-only data e.g. by fitting a maximum entropy distribution [51] or a low-rank model [21], forcing the model to explain data where it has been observed and to be uncertain elsewhere. Finally, and most related to our work, there are approaches that use additional information such as the detectability of a given species and a photographer’s propensity to image them e.g. [44, 24].
Unlike many of the classic approaches for spatio-temporal distribution modelling, in this work we jointly learn a continuous spatio-temporal prior for each category of interest using a neural network to amortize the computation. In contrast to previous deep distribution models e.g. [27, 11, 56], we do not require presence-absence data or additional environmental features as input. We instead exploit the structure that exists in online image repositories, such as those collected by citizen scientists, to jointly model objects, their locations, and photographer biases.
3 Methods
Here we outline our spatio-temporal prior, which models the geographical and temporal distribution of a set of object categories and photographers. During training we assume that we have access to a set of tuples , where is an image, is the corresponding class label, represents the location (longitude and latitude) and time the image was taken, and is the individual, i.e. photographer, who captured the image. Note that the location does not need to be captured alongside the image. can be assembled from unrelated image and location datasets as long as both contain the same categories.
At test time, given an image and where and when it was taken we aim to estimate which category it contains i.e. . One approach is to model the joint distribution as in [55], but this necessitates that the location information is always available at test time. Instead, inspired by [5], we can incorporate location information as a Bayesian spatio-temporal prior. If we assume that and are conditionally independent given , then
[TABLE]
where we assume a uniform prior for . In reality an image may contain location information unrelated to the class label (e.g. the background), but we assume this factorization is valid. By factoring the distribution in this way we can represent the image classifier, , and spatio-temporal prior, , separately. Note that at test time we do not assume that we have any knowledge of the individual who captured the image. In this work we focus our attention on representing . For we can use any discriminative model that produces a probabilistic output e.g. a convolutional neural network.
Presence-Absence Loss
As we are modeling the spatio-temporal prior independently from the image classifier our training data is now of the form . In the ideal case we would have complete information consisting of where and when a given category has both been observed to be present and observed to be not present e.g. as in [11, 56]. Then instead of , each spatio-temporal location would be associated with a binary multi-label vector where each entry indicates whether or not category has been observed as being present at . This formulation results in a standard multi-label learning problem, enabling us to estimate the parameters of the spatio-temporal model by solving
[TABLE]
where we define and is parameterized by . However, as discussed previously, presence-absence information is both difficult and time consuming to acquire in real world settings.
Presence-Only Loss
In this work we explore the more challenging presence-only setting where each spatio-temporal location is associated with a single label indicating which category was observed. In essence, we have a label vector where there is only one affirmative entry, i.e. for some , and the remaining entries are unknown. In this setting, Eqn. 4 can be written as
[TABLE]
where represents a proxy absence term for the training example and is the corresponding observed category. Now the question becomes how to choose .
One common approach for representing is to generate ‘pseudo-negatives’ [3] by randomly sampling absence data from some parametric distribution. For instance, one might set
[TABLE]
where is a randomly selected spatio-temporal location with and . The implicit assumption is that each category (whether man-made or naturally occurring) occurs in a relatively small subset of , so the probability of a category occurring at a randomly chosen location is small as well. To the extent that this assumption holds, these pseudo-negatives are likely to be valid.
An alternative approach is to instead sample absences over locations and times where the presence data for other categories occurs. In this case we would set according to Eqn. 6 but sample negative locations from the positive occurrence locations i.e. . This biases the training towards regions that contain valid data.
3.1 Our Approach
In this section we outline how we model and train our spatio-temporal prior .
Location and Object Embedding
In many contexts, different objects do not occur independently at a given spatio-temporal location. Knowing that object A is present may provide information regarding the presence or absence of object B at the same place and time. Similarly, different spatio-temporal locations are not independent, and may share commonalities. We exploit this structure to encode low dimensional embeddings of objects and spatio-temporal locations.
Taking inspiration from [11], we model our spatio-temporal prior as . Here, is a multi-layered fully-connected neural network that maps a spatio-temporal location to a dimensional embedding vector. represents an object embedding matrix, where each column is a different category. The product results in a dimensional vector, where each element represents the affinity that a spatio-temporal location has for category . The intuition is that we are representing spatio-temporal locations and object categories in a shared embedding space where the inner product between the embedding of a location and an object is large if is likely to occur at location . Finally, is an entry-wise sigmoid operation to ensure that the resulting prediction are in the range .
Photographer Embedding
In online image collections we often have access to additional information at training time in the form of the photographer who captured the image. To see why this information is valuable, consider the following example. Suppose a photographer visits location and does not report object . If has never taken an image of an object like , then this non-report gives us little information. However, if has a history of reporting categories similar to object , then this constitutes weak evidence that might actually be absent at that location. Thus, we can interpret the same presence-only information in different ways depending on the individual who provides it.
To capture photographer biases, we embed photographers into the same shared embedding space as the objects and locations. This is achieved by learning a photographer embedding matrix at training time. Like different object categories, photographers may have affinities for particular locations and times, and share similarities in their spatio-temporal patterns with other photographers. This enables us to represent both a photographer’s preference for a given location , and a photographer’s affinity for a given object category . Once trained, the photographer embeddings are not required at test time, see Fig. 2.
Joint Embedding Loss
Our goal at training time is to estimate the set of parameters , where denotes the weights of the location embedding network , is the category embedding matrix, and is the photographer embedding matrix.
We start with the constraint that our model should be conservative i.e. if a category has been observed at the spatio-temporal location in the training set, then should be close to 1, otherwise it should be close to 0. Here, indicates the column of . We rely on the location embedding function to interpolate between presence locations. This is conservative in the sense that it assumes that an object is absent if it has not been observed. This is a very strong assumption, but it enables the spatio-temporal prior to be aggressive in down-weighting incorrect predictions from the image classifier.
Our first loss encourages the model to predict the presence of objects where they have been observed in the training set and downweight their likelihood where they have not been observed:
[TABLE]
is a hyperparameter used to weight the positive observations and is a uniformly random spatio-temporal datapoint. Next, we want the affinity between a photographer and a location be high if was present at , and low otherwise:
[TABLE]
We assume that a photographer has a low affinity for a category unless they have previously observed it:
[TABLE]
Finally, to estimate the parameters of our prior we maximize
[TABLE]
by iterating over each of the datapoints in the training set.
4 Experiments
We evaluate the effectiveness of our spatio-temporal prior by performing experiments on several image classification datasets that have location and time information. We choose image classification because for other domains (e.g. species distribution modeling) it is challenging to obtain accurate ground truth information regarding the true spatio-temporal distributions of the categories of interest.
4.1 Datasets
While location metadata is readily available for online image collections, many popular image classification datasets do not contain this information e.g. [61, 57, 16, 39]. Some datasets exist with location information, but for only a subset of the images e.g. [25]. However, datasets containing images of different species of plants and animals are available with location, time, and photographer information. To this end, we perform experiments on the iNaturalist 2017 and 2018 (iNat2017 and iNat2018) species classification datasets which contain images collected and annotated by citizen scientists [58]. They have 5,089 and 8,142 categories respectively. While [5] evaluated their location prior on the BirdSnap dataset, the images and location metadata used are not provided by the authors. We recollect the images and location data from the web using the original image URLs. Despite the dataset consisting of images of species commonly found in North America, when we recollected the images and locations we found that the original images are from all over the world and 40% were missing location. Like [5], we also simulate location metadata for BirdSnap [5] and another fine-grained dataset of birds, NABirds [57], by associating each image with a species observation from eBird [53]. Our train locations and photographers are sampled from eBird 2015, and the test set is from 2016. BirdSnap and NABirds contain images from 500 and 555 different species of North America birds. Finally, we also perform experiments on YFCC100M-GEO100 [55] (YFCC). YFCC contains 100 everyday object categories with associated locations, but no date or photographer information is provided. The train and test split used in [55] is not available and so we created a new one. Unlike the other datasets, many of the object categories in YFCC are not geographically distinct e.g. ‘band’, ‘ford’, or ‘ipod’.
4.2 Implementation Details
Our location encoder is a fully-connected neural network consisting of an input layer, followed by multiple residual layers [30], and a final output embedding layer. We jointly train the location encoder, along with the photographer and object embeddings using Adam [36] for 30 epochs with a batch size of 1024, using dropout to prevent overfitting. The dimensionality of the shared embedding space is set to . When weighting the positive instances during training we set to the number of categories. To counteract the heavily imbalanced nature of many of the datasets, we limit the maximum number of datapoints for each category per epoch. We set the maximum number of datapoints to 100, and for each epoch we randomly select a different subset for each category. The only exception is for YFCC, where capping the data hurt performance. Details of our network architecture are in the supplementary material.
Except where noted, at test time, our model takes three inputs – longitude, latitude, and day of the year, specifying where and when the image of interest was captured. For these three input features we explored different methods for ‘wrapping’ the coordinates i.e. an observation taken on December should result in a similar embedding to one captured on January . Similarly, we want geographical coordinates to wrap around the earth. To achieve this, for each input dimension of we perform the mapping , resulting in two numbers for each dimension. Here, we assume that each dimension of the input has been normalized to the range .
For the image classifiers we fine-tune a separate InceptionV3 [54] network for each of the datasets beginning with ImageNet initialized weights [16] with an image resolution of (unless otherwise noted).
4.3 Quantitative Evaluation
In Table 1 we evaluate how much our spatio-temporal prior improves image classification performance by comparing it to several baselines. We found that adding a uniform prior to the outputs of the nearest neighbor based baselines increases their performance. This adds robustness in cases where there are no objects from the training set present near the test locations. The lack of this uniform prior explains the poor results for nearest neighbor based approaches in [55]. For the comparison to Tang et al. [55], we jointly train a linear layer to embed the raw location information along with an output layer to combine the location embedding with the features from the last linear layer of the image classifier. The rest of the weights of the image classifier are not updated. For each of the baseline algorithms we select their hyperparameters (e.g. the number of neighbors) on a held out validation set for each dataset. When location information is not available at test time, we assume a uniform prior over the categories.
Our model performs on par, or better, than the baselines across all datasets. The advantage of our approach is that it is computationally efficient at test time and does not require features from the image classifier during training. Compared to nearest neighbor based methods, it only requires a forward pass through a compact fully-connected neural network. In addition, it also captures structural information such as object and photographer biases. One failure case that is worth noting are the results on YFCC [55]. We observe that all methods perform similar to using no location information (No Prior). This can be explained by the relative lack of spatio-temporal structure in the object categories present in the dataset. Again, this is consistent with the findings in [55], where the authors had to use additional features to increase the performance.
4.3.1 Ablation Study
In Table 2 we compare the performance of different variants of our model on iNat2017 and iNat2018 [58]. Again, across all metrics there is a large increase in performance compared to the baseline uniform prior. In some cases, we even observe that there is an additional boost in performance when we explicitly model photographer biases.
Training fine-grained image classifiers with larger input images can significantly increase classification performance [15]. We observe that the benefit of our spatio-temporal prior is still apparent even when we use a more powerful classifier that has been training for longer with larger images. This increase in accuracy is also present when we evaluate performance using more lenient evaluation metrics i.e. top 5 vs. top 1 accuracy. This is significant because it highlights that for some datasets the performance boost provided by the spatio-temporal prior is orthogonal to improvements in the underlying image classifier.
4.4 Qualitative Evaluation
Our model captures the relationship between objects, locations, and photographers. In Fig. 3 (a) we can see the resulting embeddings for each input location from our model trained on iNat2018 [58]. By applying the embedding function to each location we can generate its dimensional embedding vector. We then use ICA [33] to project the embedded features to a three dimensional space and mask out the ocean for visualization. Perhaps as expected, there is low frequency structure in the resulting image i.e. nearby locations tend to support similar objects. One advantage of our approach is that we are not restricted to a fixed discretization. As a result we can generate embeddings for any location and time. In Fig. 4 we visualize our learned object embedding . Objects that have similar spatio-temporal distributions tend to result in similar embedding vectors.
Distinct from other work, our prior also models the relationship between photographers and locations, and photographers and object categories. In Fig. 3 (b) we plot the estimated affinity for each input location across all photographers i.e. . We only show results for photographers who provided at least 100 observations in the iNat2018 [58] training set, resulting in 634 individuals. In Fig. 5 we display the estimated affinity for each object category for a set of photographers i.e. . We observe that the embedding captures the similarity in object affinity held by different photographers.
Finally, in Fig. 6 we use our prior to generate spatio-temporal predictions for several different species from iNat2018 [58]. Each image is generated by querying every location on the surface of the earth, on a specified day of the year, to generate for the category of interest. In practice, we evaluate spatial locations for each time point (e.g. first day of the month). This step is very efficient as we can pre-compute for every location, independent of the category of interest. Again, for visualization we mask out the predictions over the ocean.
4.5 Limitations
We are limited by the quality of the provided location data e.g. it can be inaccurate or intentionally obfuscated. We also make strong assumptions about a photographer’s affinity for an individual object category. In reality, these interactions may be complex i.e. once a photographer captures an image of a particular category they may be less likely to take an image of the same object in the near future. There are also known spatial biases in the types of citizen science data we use [4, 10]. However, this may not be a major issue as we can assume that the distribution of test locations and dates is similarly biased. We currently only use location, time, and photographer ID during training. In practice, additional data such as environmental variables may be a valuable signal for specific object categories [6].
5 Conclusion
We introduce a spatio-temporal prior to help disambiguate fine-grained categories resulting in improved test time image classification performance. In addition to helping image classification, our model also naturally captures the relationships between locations and objects, objects and objects, photographers and objects, and photographers and locations in an interpretable manner. Importantly, our prior is efficient at test time, both in terms of model size and inference speed, and scales to large numbers of categories.
Acknowledgements This work was supported by a Google Focused Research Award and an NSF Graduate Research Fellowship (Grant No. DGE‐1745301). We thank Grant Van Horn and Serge Belongie for helpful discussions, along with NVIDIA and AWS for their kind donations.
Supplementary Material A Supplementary Results
In Fig. 7 we observe the per-category accuracy improvement on iNat2017 [58] when using our spatio-temporal prior compared to no prior i.e. the raw output of the classifier. On the right of the plot we see large improvements for many categories e.g. the ‘Leopard Tortoise’ which is predicted to be found in east and south Africa. Inspecting the errors before applying the spatio-temporal prior shows that the image classifier was confusing this category with the ‘Texas Tortoise’, commonly found in Mexico and Texas. Capturing this geographic specialization enables the prior to rule out instances of this category in other locations. On the left of the plot we see a small number of cases where the performance decreases after applying the prior e.g. the ‘Yellow-headed Parrot’. In this particular instance, the prior incorrectly biases the model by weighting the presence of the ‘Red-lored Parrot’ more highly. The ‘Red-lored Parrot’ has a very similar geographical range but with more observations in the training set (38 versus 18).
Supplementary Material B Training Details
In Fig. 8 we illustrate the architecture of our location encoder . As described in the main paper, each coordinate of the input spatio-temporal location vector is mapped to , resulting in two numbers for each input dimension. This is then passed through an initial fully connected layer, follower by a series of residual blocks, each consisting of two fully connected layers with a dropout layer in between. We set the number of hidden units in each fully connected layer and the output embedding to 256. In total we use four residual blocks (i.e. in Fig. 8).
Supplementary Material C Training Data Statistics
In Fig. 9 we display the total number of observations made by each photographer and the number of individual categories they observed for both iNat datasets. We only show data from the training set and exclude datapoints that do not have a corresponding valid location or photographer ID. This results in 569,465 observations (i.e. images) from 17,302 photographers for iNat2017 and 436,063 observations from 18,643 photographers for iNat2018.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] GBIF - www.gbif.org. 2019.
- 2[2] i Naturalist - www.inaturalist.org. 2019.
- 3[3] Morgane Barbet-Massin, Frédéric Jiguet, Cecile Helene Albert, and Wilfried Thuiller. Selecting pseudo-absences for species distribution models: how, where and how many? Methods in Ecology and Evolution , 2012.
- 4[4] Jan Beck, Marianne Böller, Andreas Erhardt, and Wolfgang Schwanghart. Spatial bias in the GBIF database and its effect on modeling species’ geographic distributions. Ecological Informatics , 2014.
- 5[5] Thomas Berg, Jiongxin Liu, Seung Woo Lee, Michelle L Alexander, David W Jacobs, and Peter N Belhumeur. Birdsnap: Large-scale fine-grained visual categorization of birds. In CVPR , 2014.
- 6[6] Christophe Botella, Pierre Bonnet, François Munoz, Pascal Monestiez, and Alexis Joly. Overview of Geo Life CLEF 2018: location-based species recommendation. 2018.
- 7[7] Christophe Botella, Alexis Joly, Pierre Bonnet, Pascal Monestiez, and François Munoz. A deep learning approach to species distribution modelling. In Multimedia Tools and Applications for Environmental & Biodiversity Informatics . 2018.
- 8[8] Matthew R. Boutell, Jiebo Luo, Xipeng Shen, and Christopher M. Brown. Learning multi-label scene classification. Pattern Recognition , 2004.
