The Tandem Duplication Distance is NP-hard
Manuel Lafond, Binhai Zhu, Peng Zou

TL;DR
This paper proves that computing the tandem duplication distance between two strings is NP-hard, even with all characters distinct, and explores the problem's complexity and fixed-parameter tractability in bioinformatics.
Contribution
It establishes the NP-hardness of the tandem duplication distance problem and introduces the Cost-Effective Subgraph problem with W[1]-hardness results, advancing understanding of computational complexity in bioinformatics.
Findings
Proved tandem duplication distance is NP-hard.
Demonstrated NP-hardness even for exemplar cases with distinct characters.
Showed fixed-parameter tractability for the exemplar TD distance.
Abstract
In computational biology, tandem duplication is an important biological phenomenon which can occur either at the genome or at the DNA level. A tandem duplication takes a copy of a genome segment and inserts it right after the segment - this can be represented as the string operation . For example, Tandem exon duplications have been found in many species such as human, fly or worm, and have been largely studied in computational biology. The Tandem Duplication (TD) distance problem we investigate in this paper is defined as follows: given two strings and over the same alphabet, compute the smallest sequence of tandem duplications required to convert to . The natural question of whether the TD distance can be computed in polynomial time was posed in 2004 by Leupold et al. and had remained open, despite the fact that tandem duplications have received…
Click any figure to enlarge with its caption.
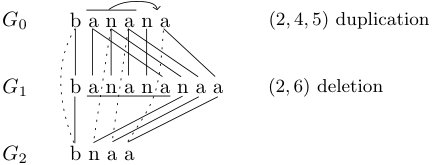 Figure 1
Figure 1 Figure 2
Figure 2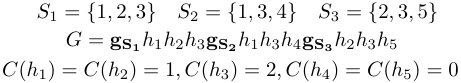 Figure 4
Figure 4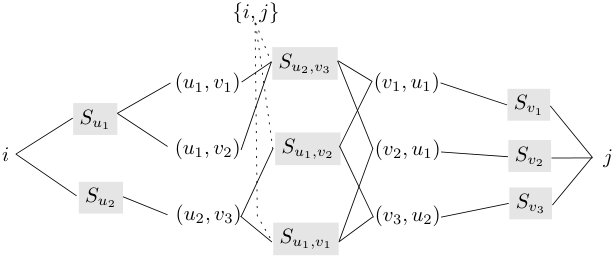 Figure 5
Figure 5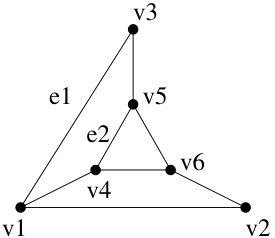 Figure 6
Figure 6Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.