TL;DR
This paper explores the analogy between deep learning and the renormalization group (RG) by comparing a trained RBM on the Ising model to RG transformations, revealing RG-like patterns in neural network correlations.
Contribution
It demonstrates that correlation functions in trained RBMs can exhibit RG-like coarse graining, providing a theoretical link between deep learning and RG.
Findings
Correlation functions show RG-like patterns in RBMs
Differences between RG and deep learning are identified
RBMs can mimic RG coarse graining processes
Abstract
Although there has been a rapid development of practical applications, theoretical explanations of deep learning are in their infancy. Deep learning performs a sophisticated coarse graining. Since coarse graining is a key ingredient of the renormalization group (RG), RG may provide a useful theoretical framework directly relevant to deep learning. In this study we pursue this possibility. A statistical mechanics model for a magnet, the Ising model, is used to train an unsupervised restricted Boltzmann machine (RBM). The patterns generated by the trained RBM are compared to the configurations generated through an RG treatment of the Ising model. Although we are motivated by the connection between deep learning and RG flow, in this study we focus mainly on comparing a single layer of a deep network to a single step in the RG flow. We argue that correlation functions between hidden and…
Click any figure to enlarge with its caption.
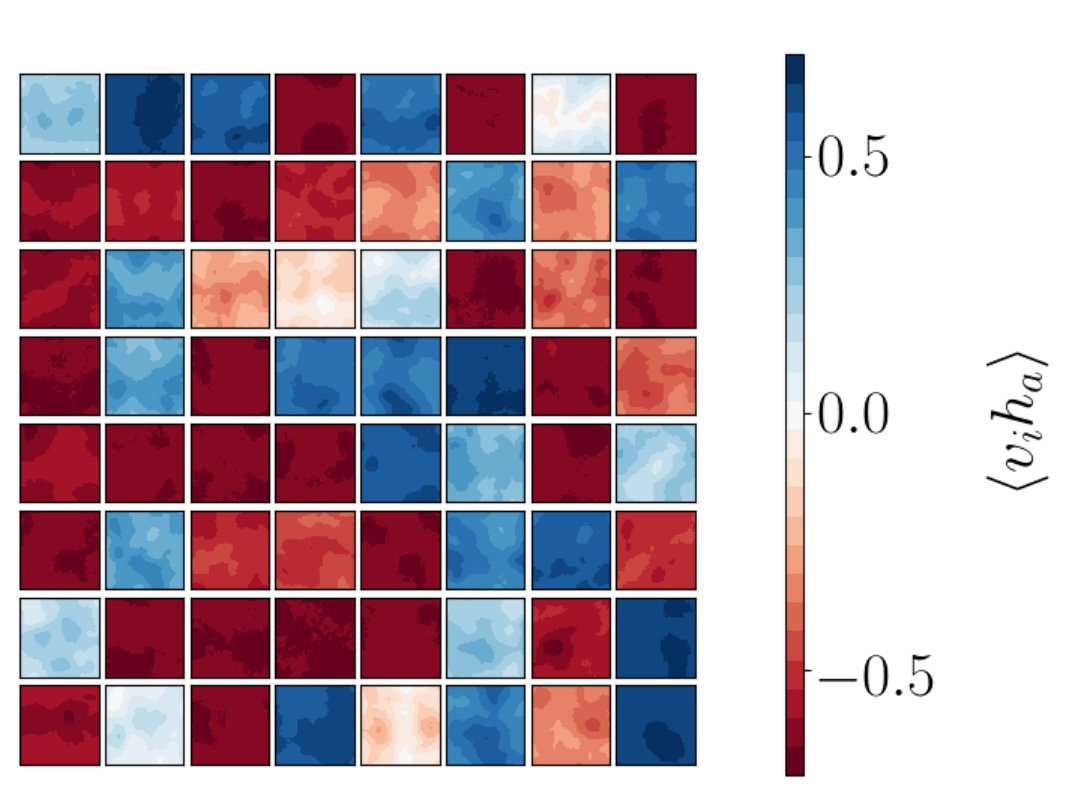 Figure 1
Figure 1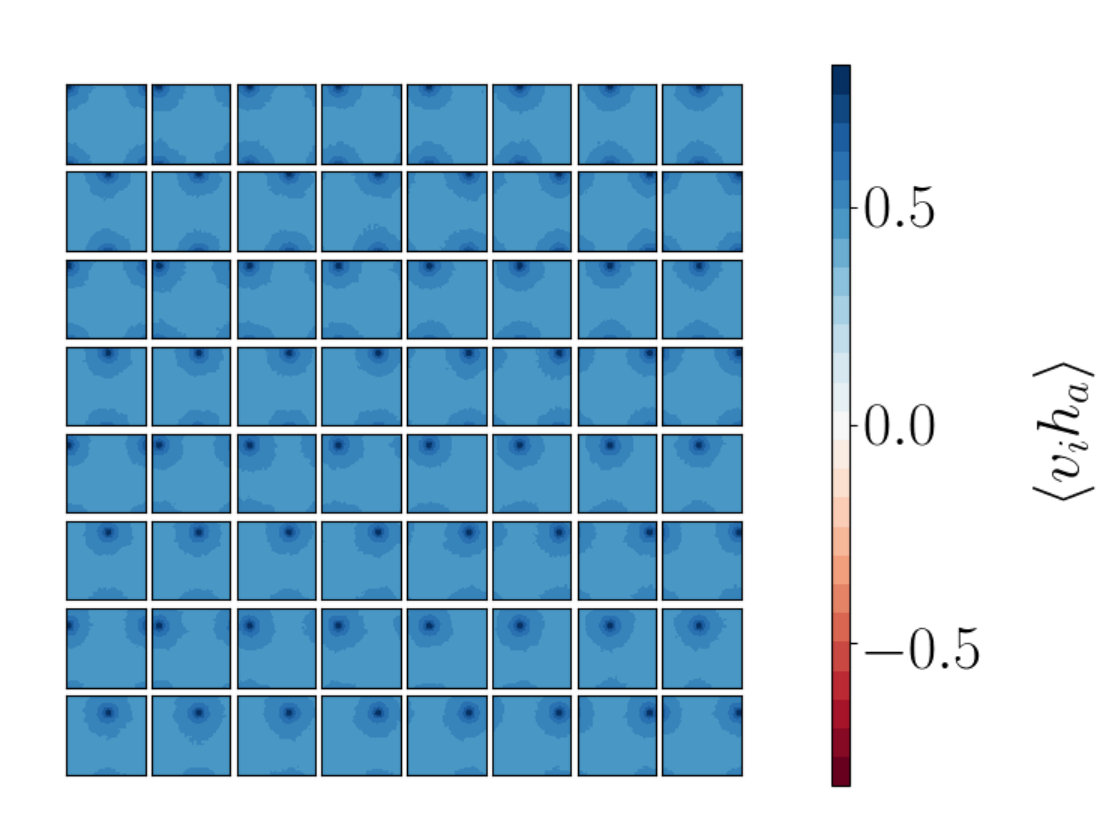 Figure 2
Figure 2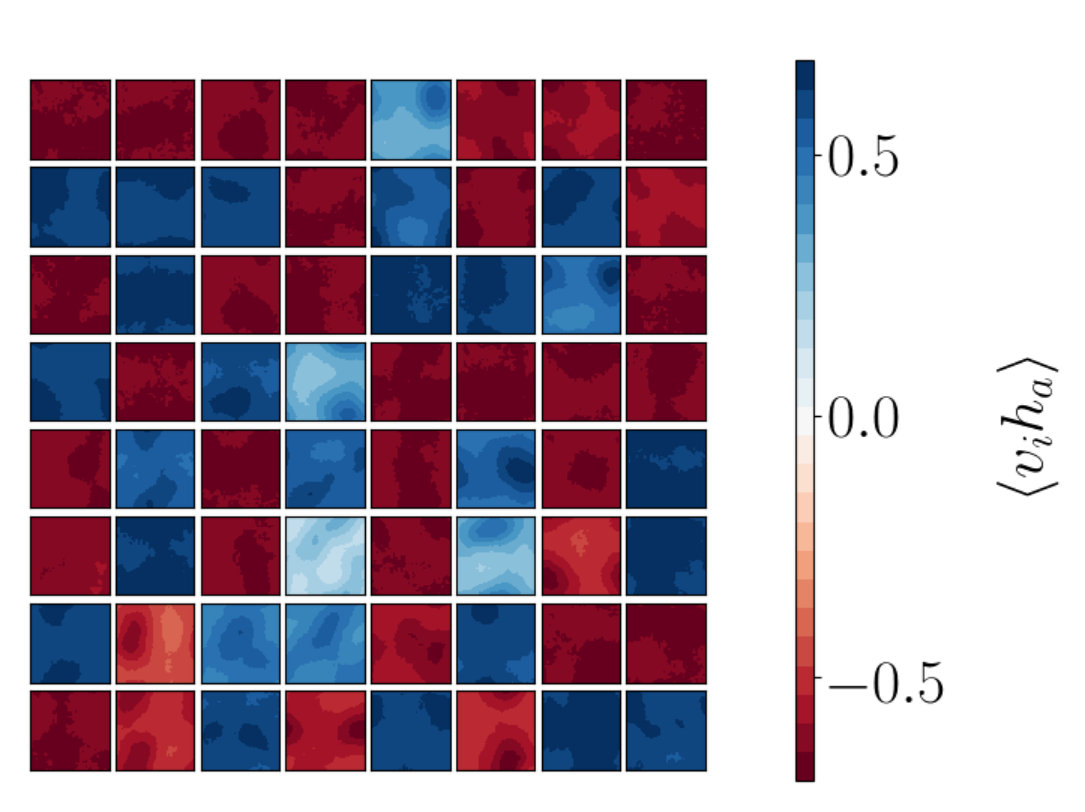 Figure 3
Figure 3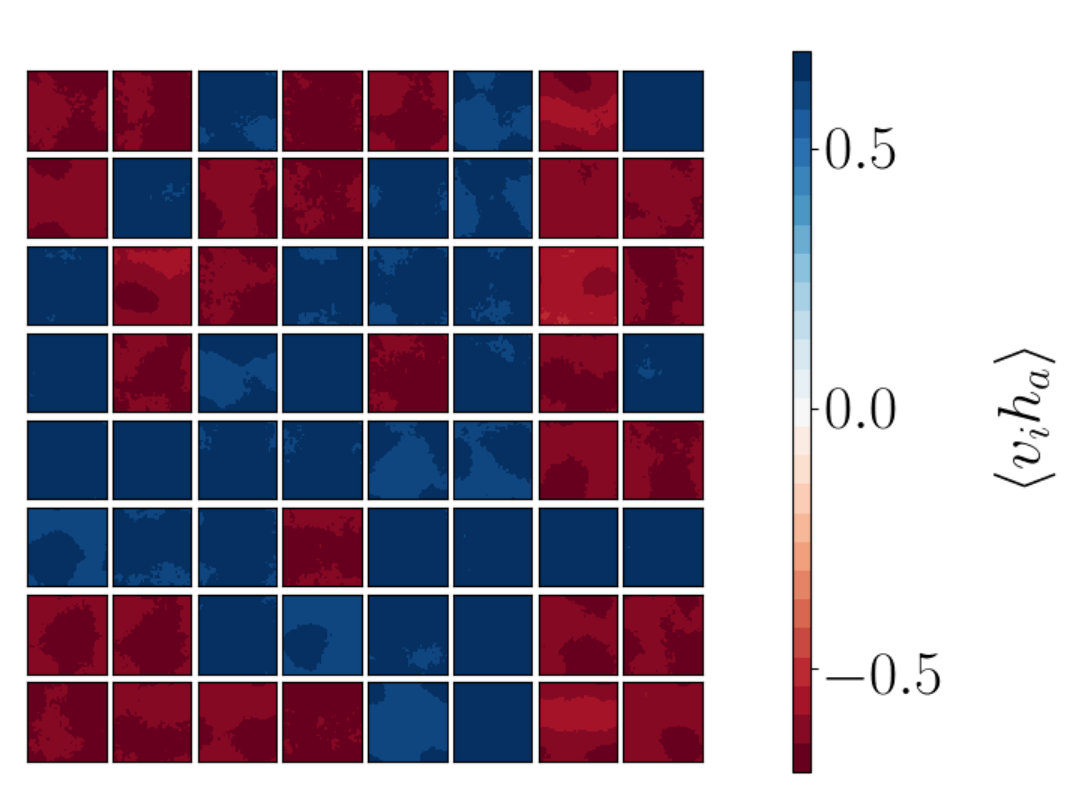 Figure 4
Figure 4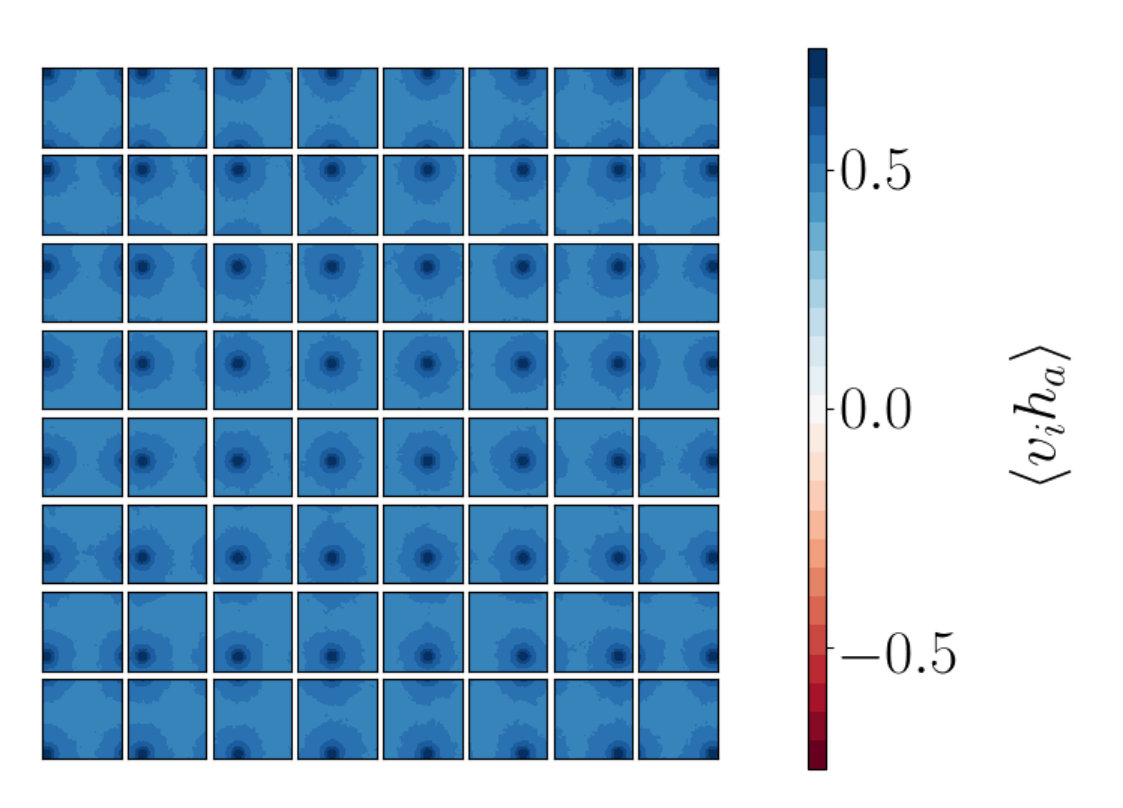 Figure 5
Figure 5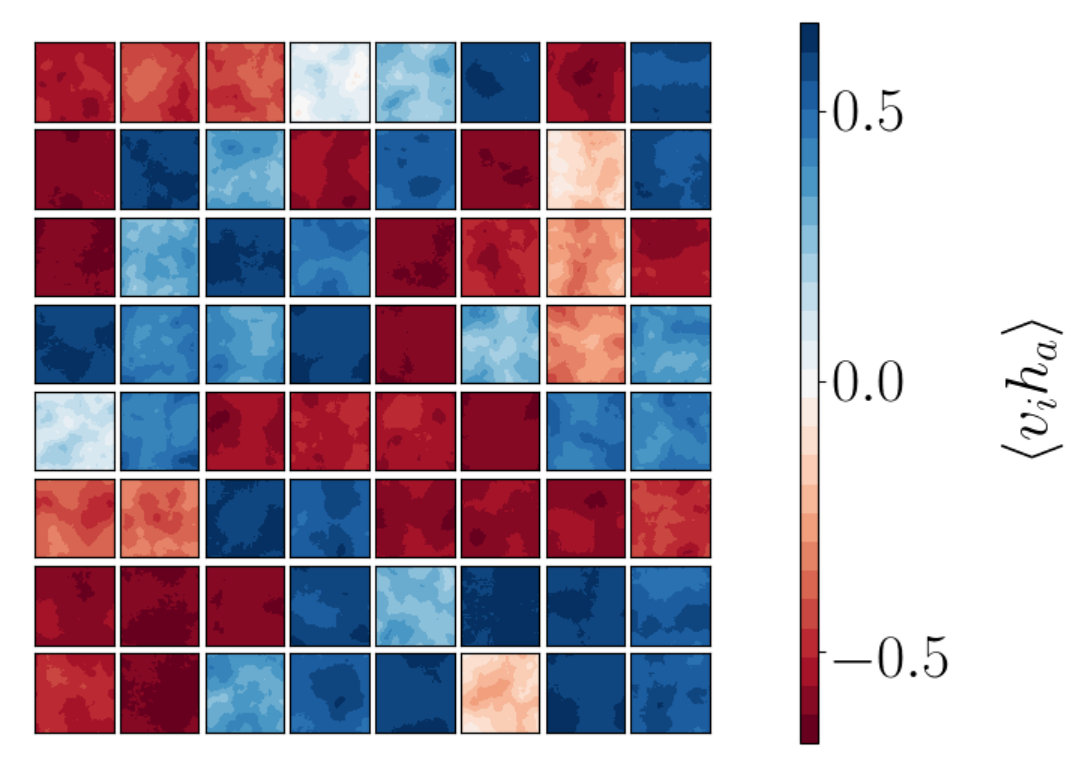 Figure 6
Figure 6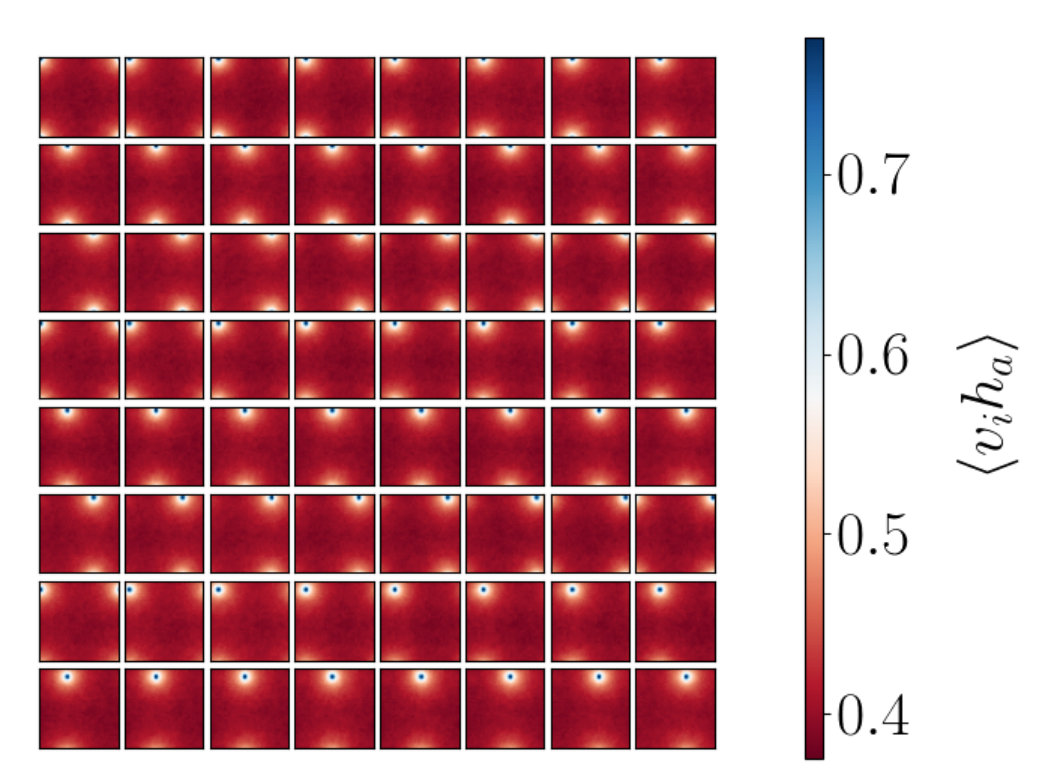 Figure 7
Figure 7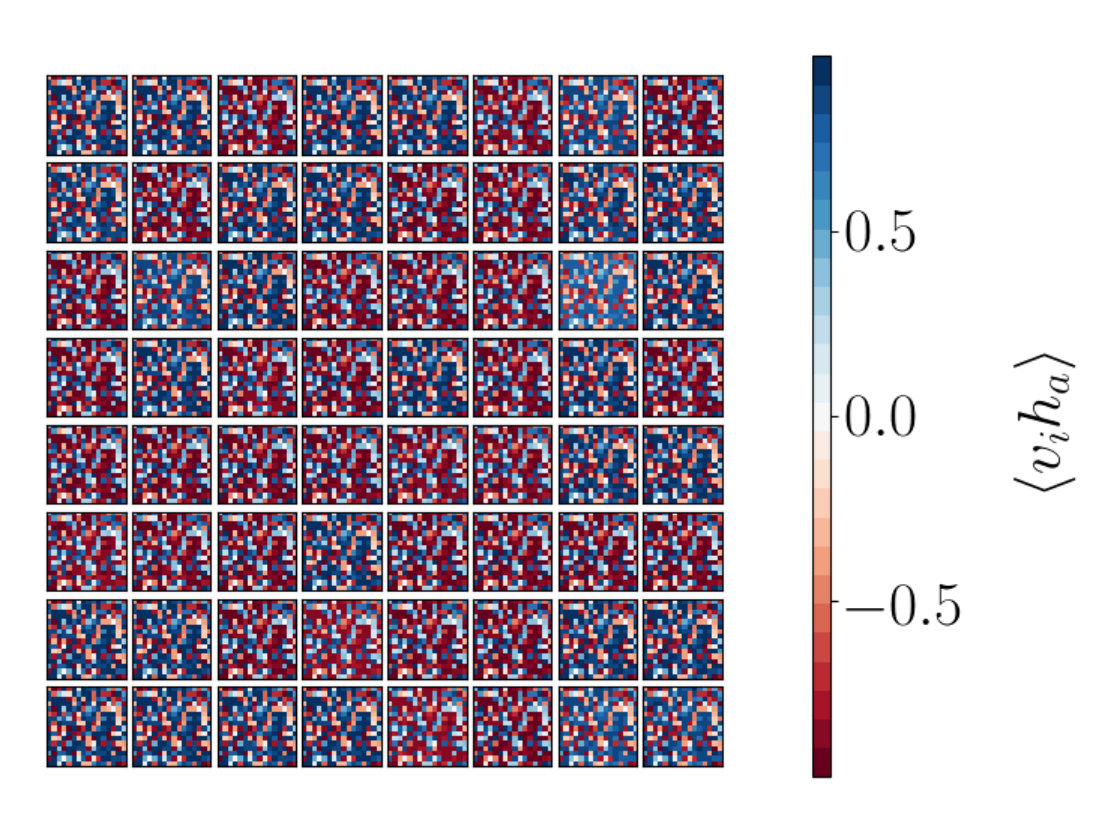 Figure 8
Figure 8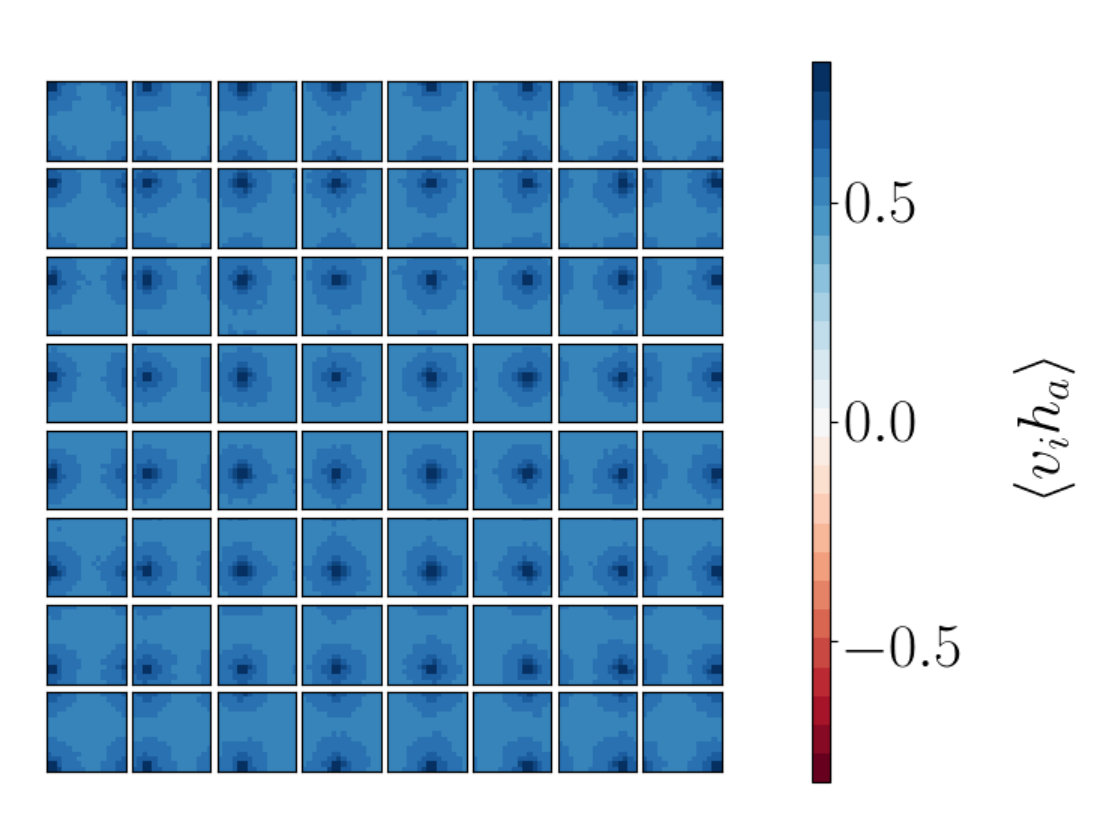 Figure 9
Figure 9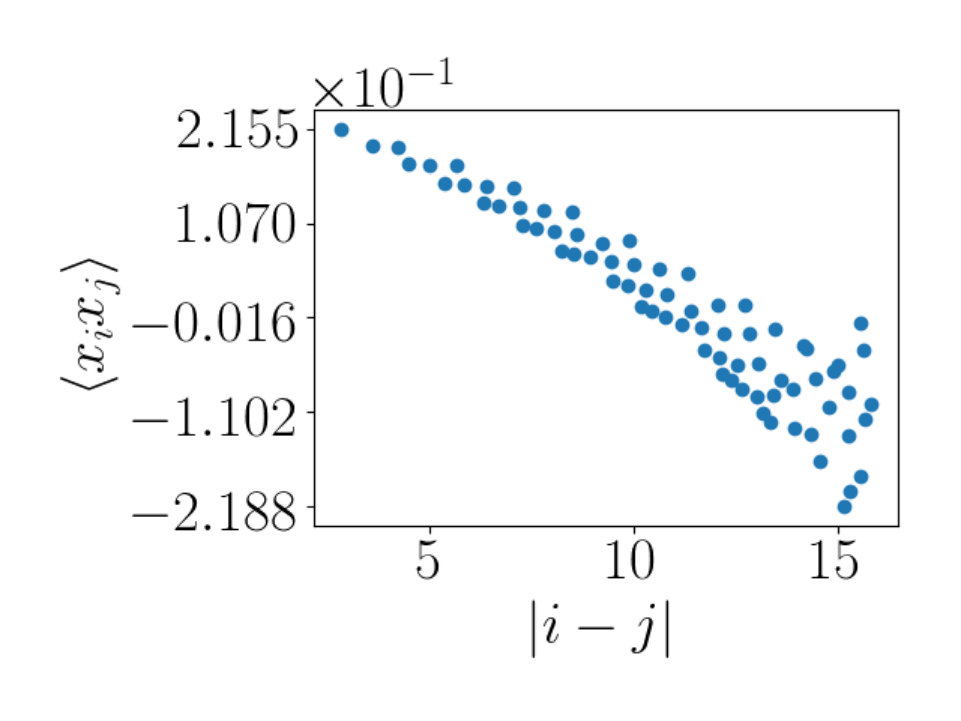 Figure 10
Figure 10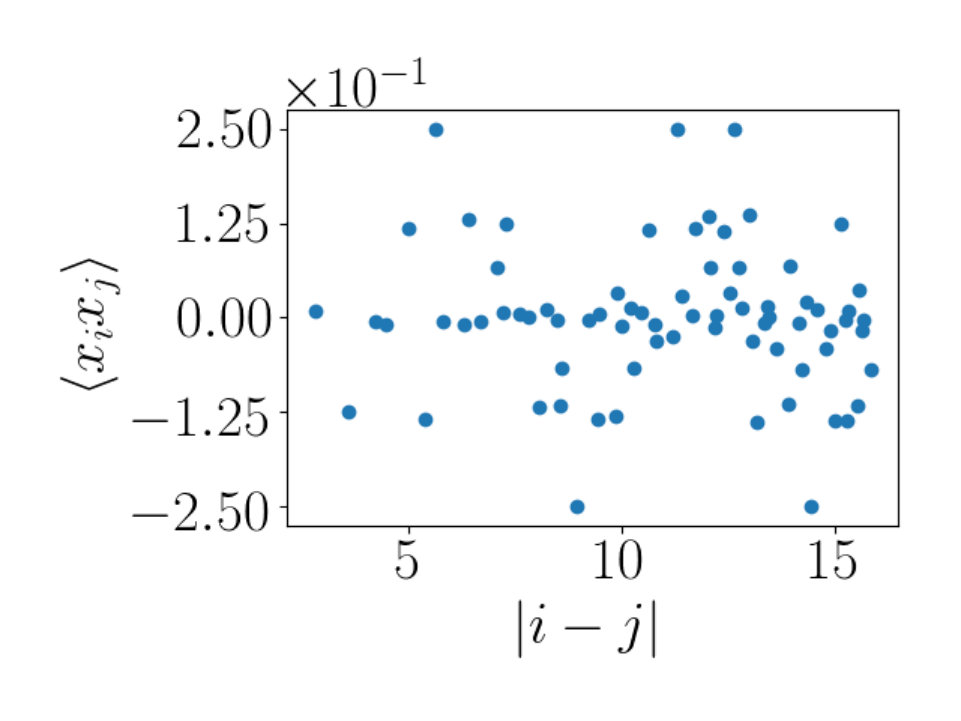 Figure 11
Figure 11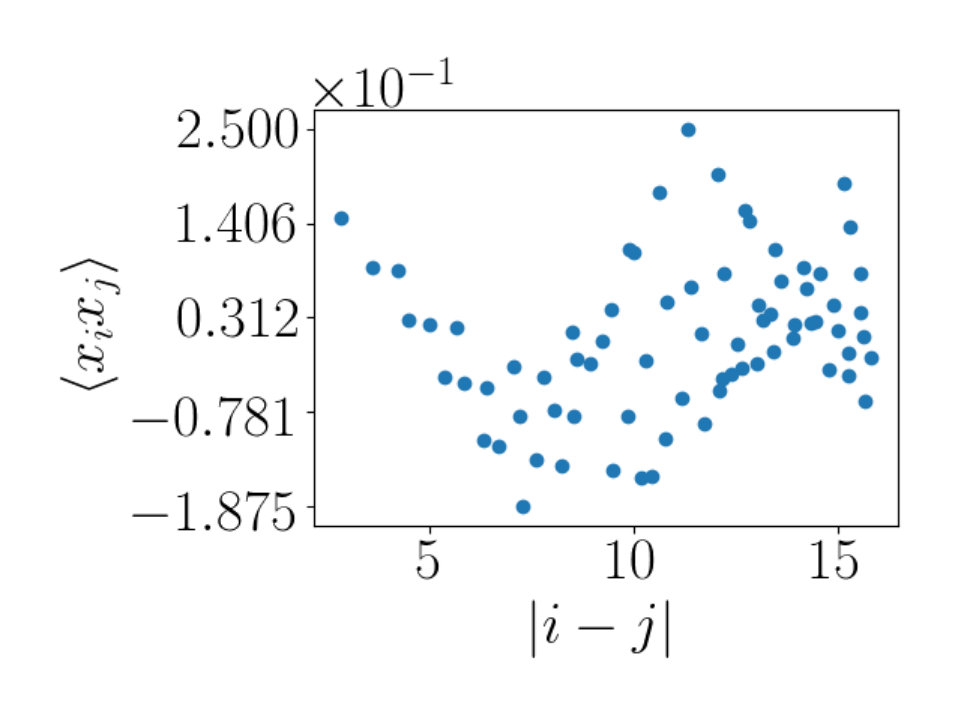 Figure 12
Figure 12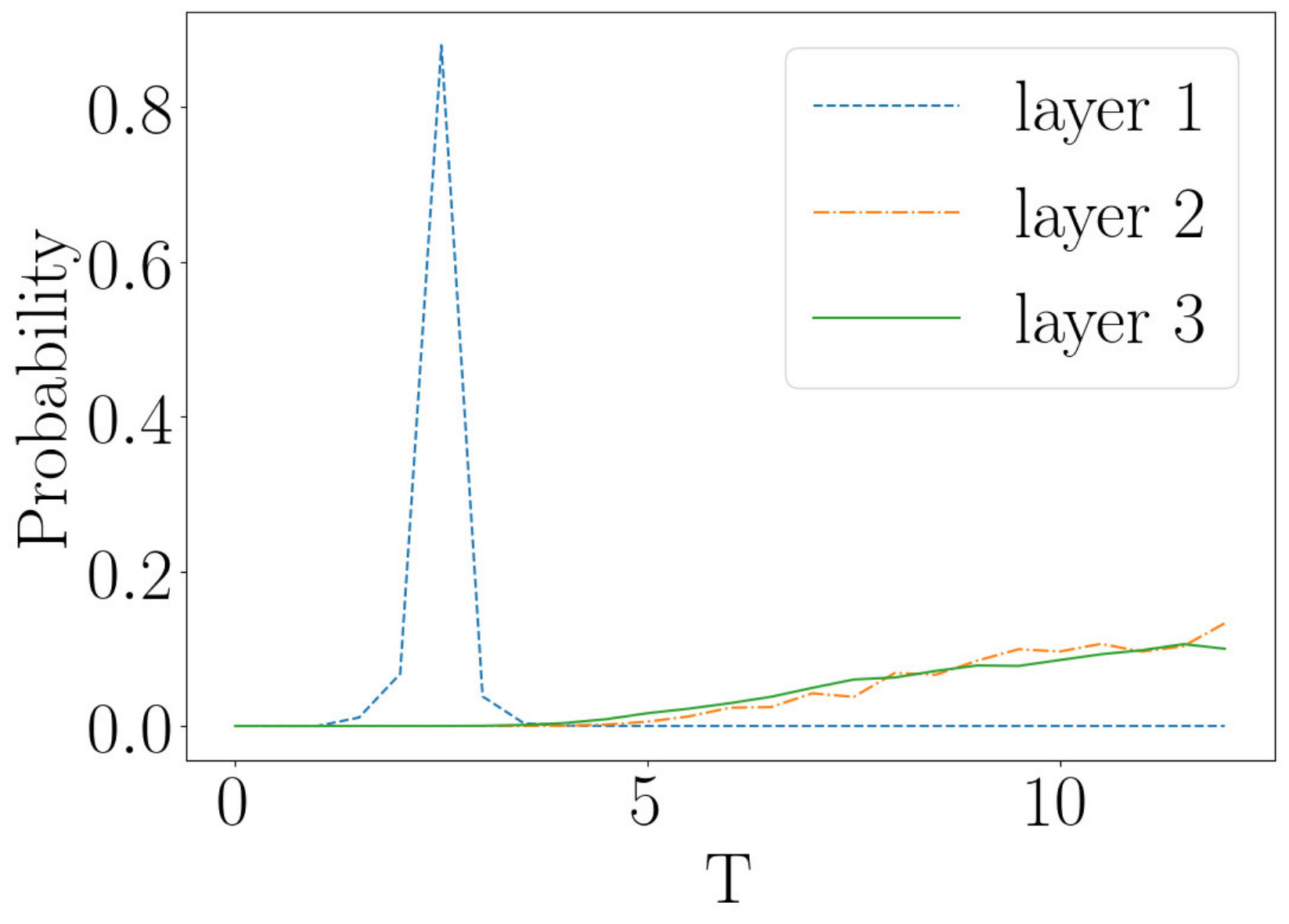 Figure 13
Figure 13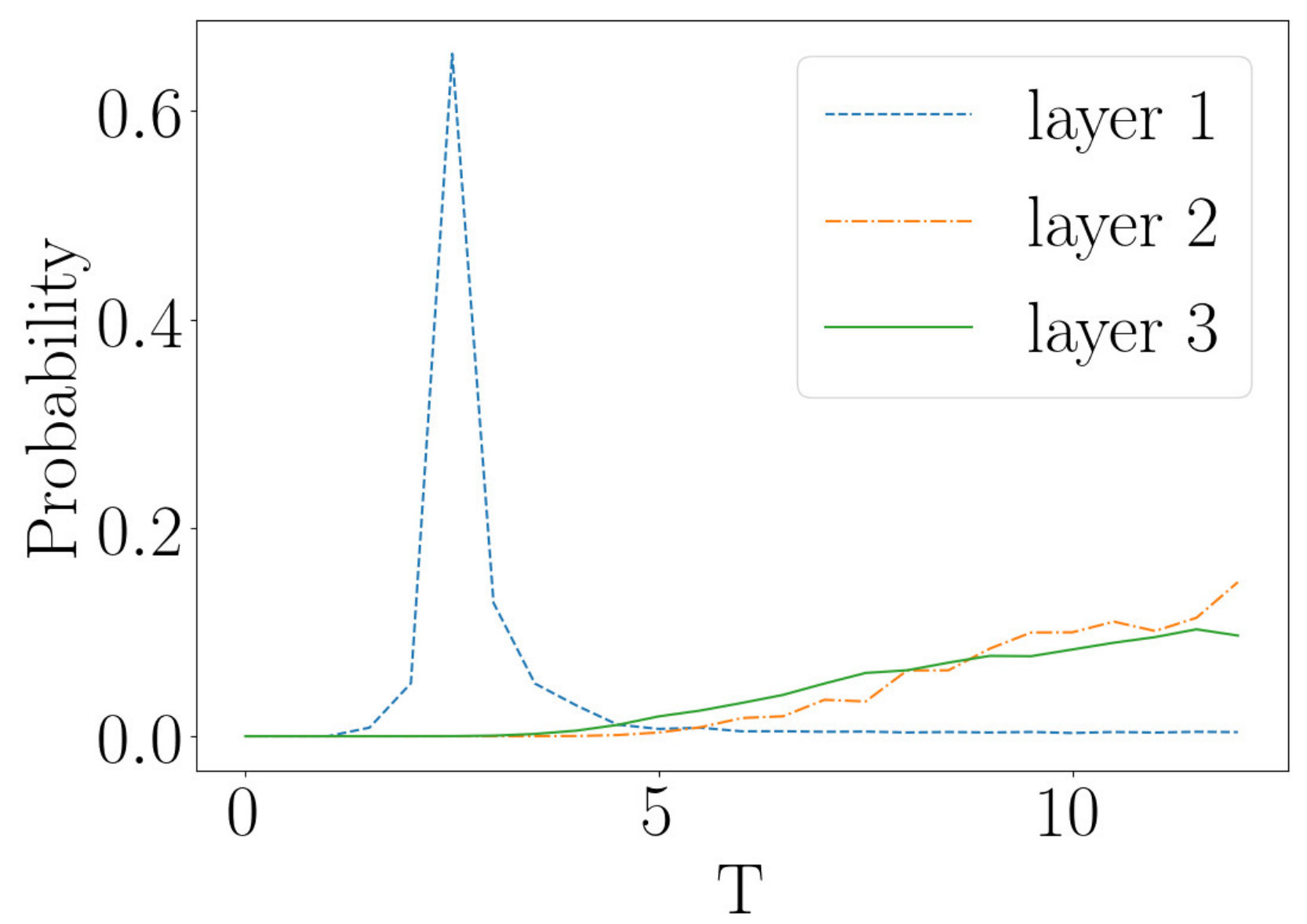 Figure 14
Figure 14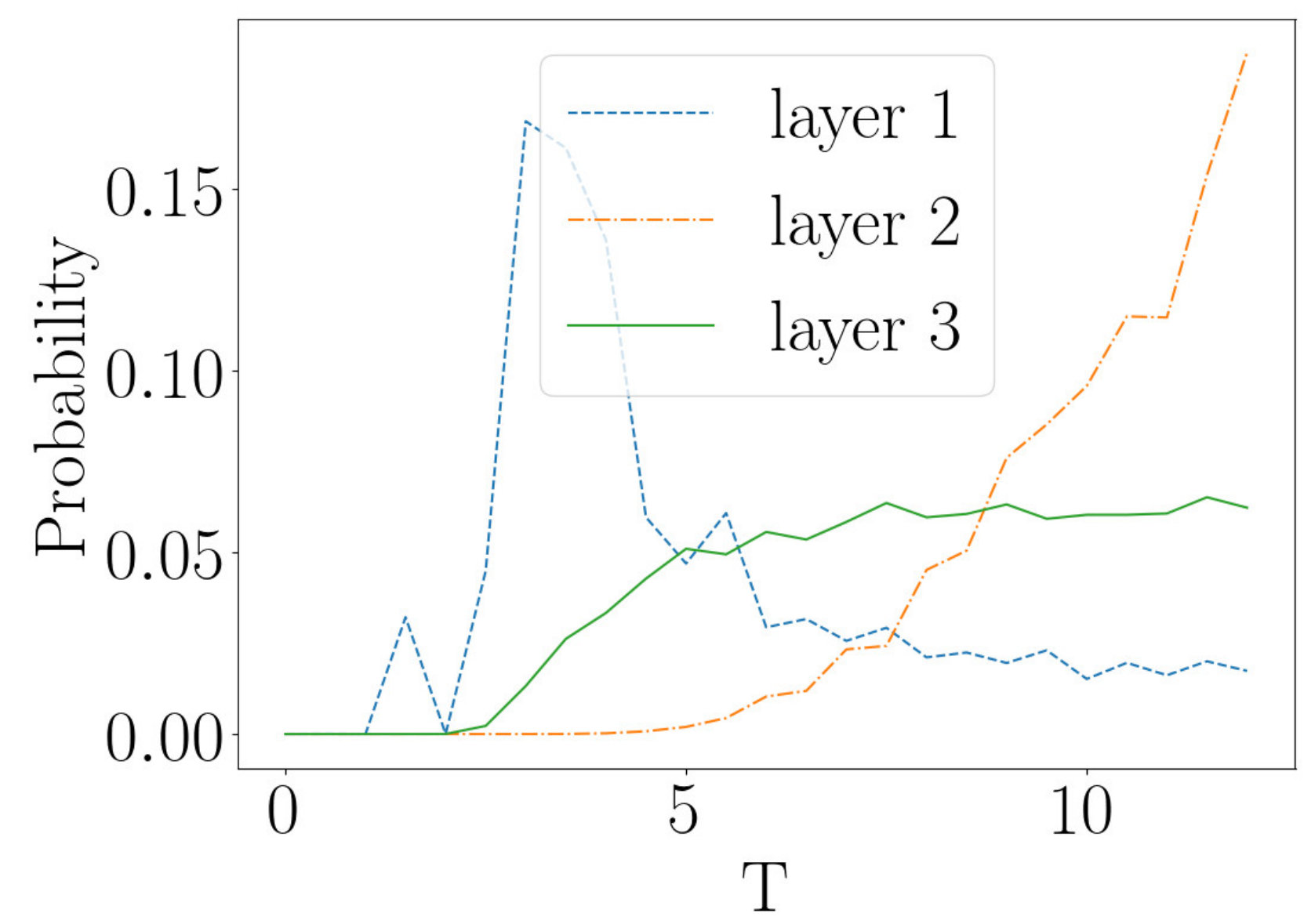 Figure 15
Figure 15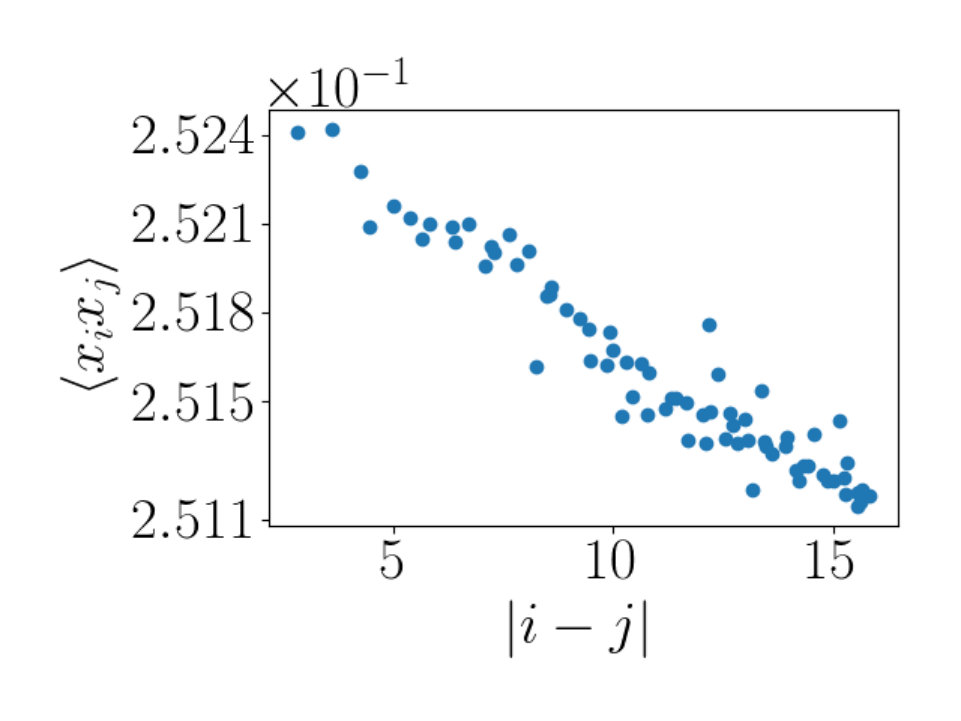 Figure 16
Figure 16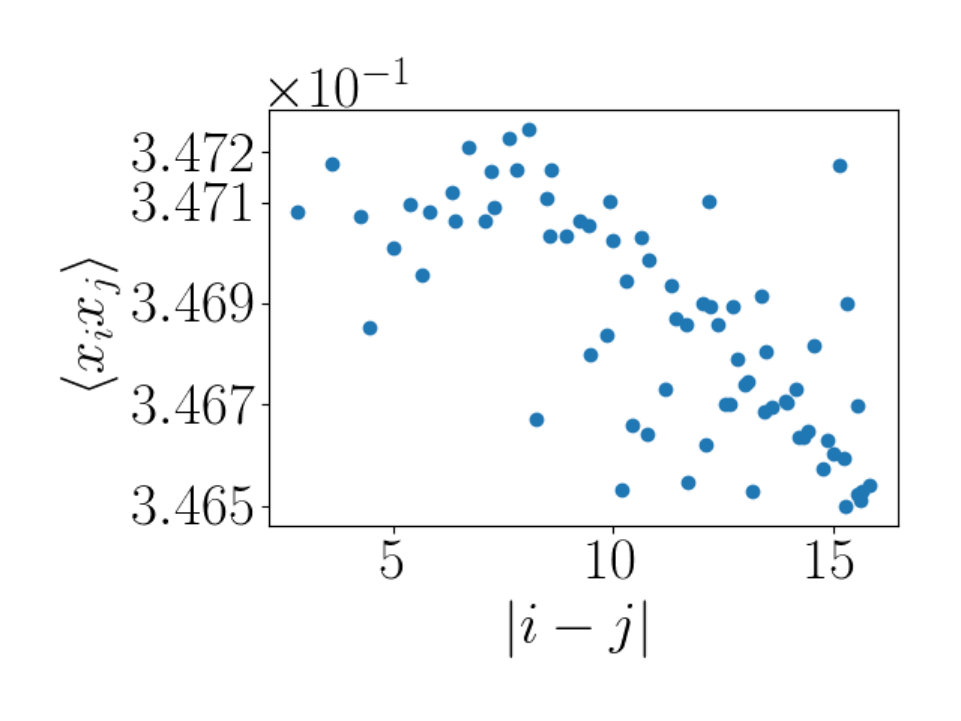 Figure 17
Figure 17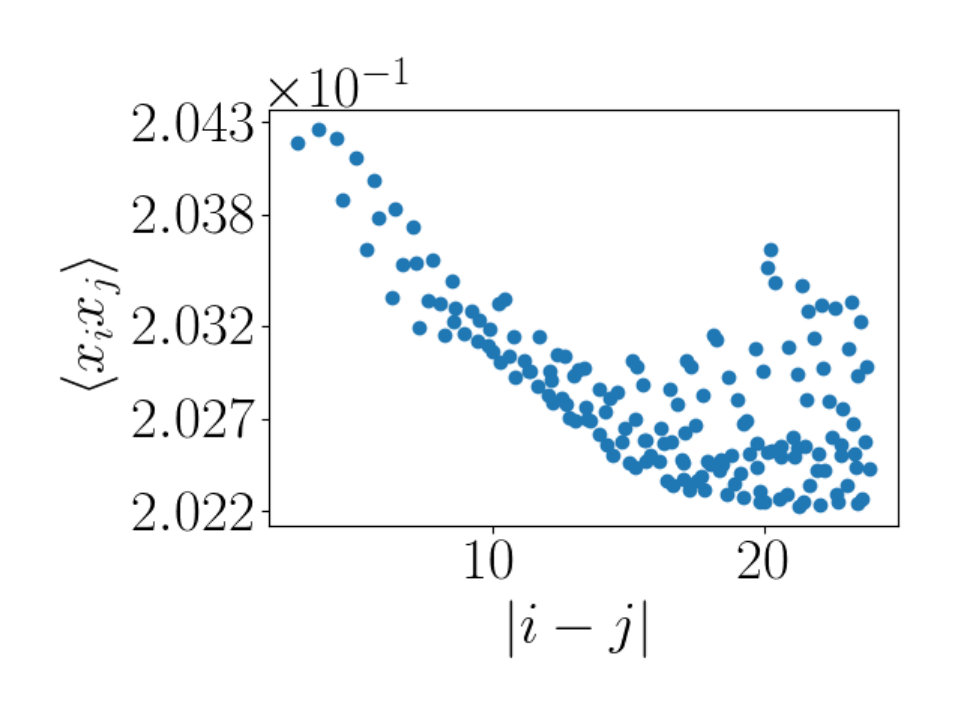 Figure 18
Figure 18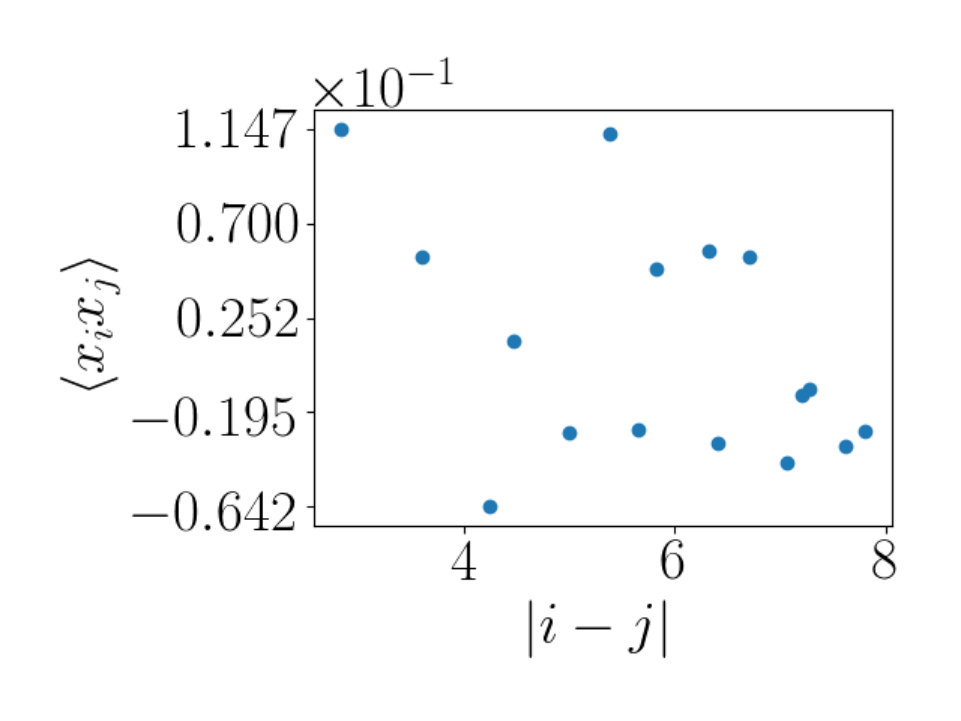 Figure 19
Figure 19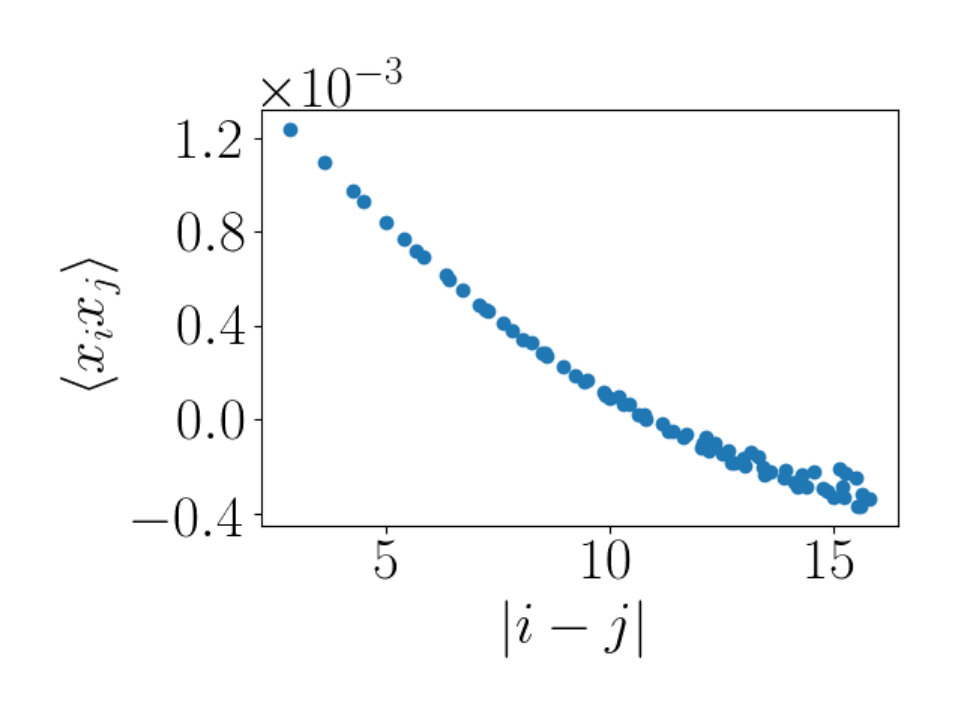 Figure 20
Figure 20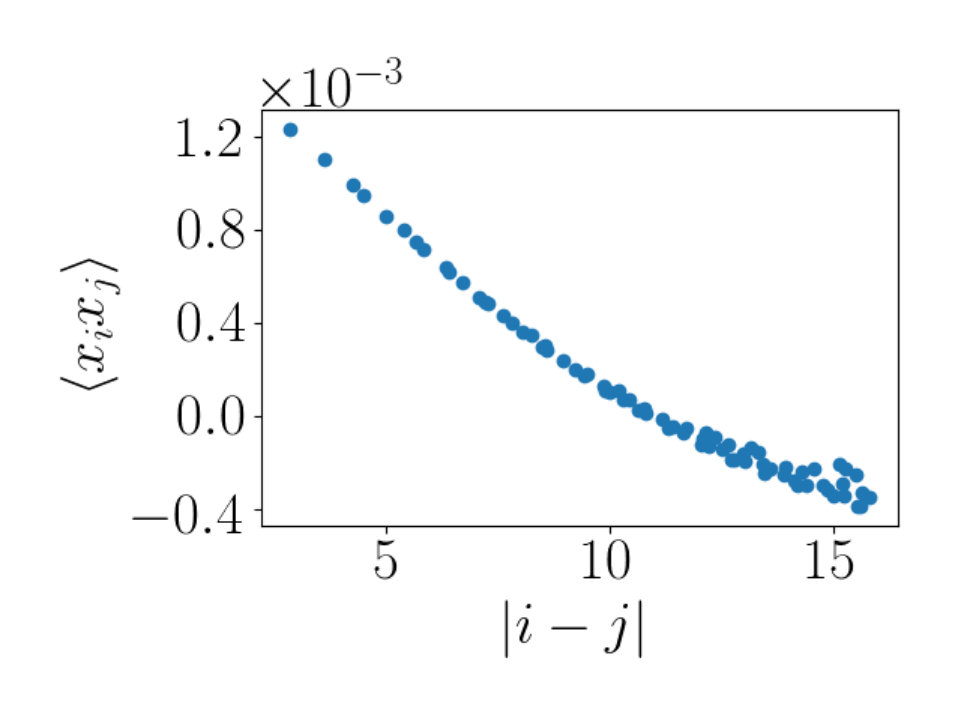 Figure 21
Figure 21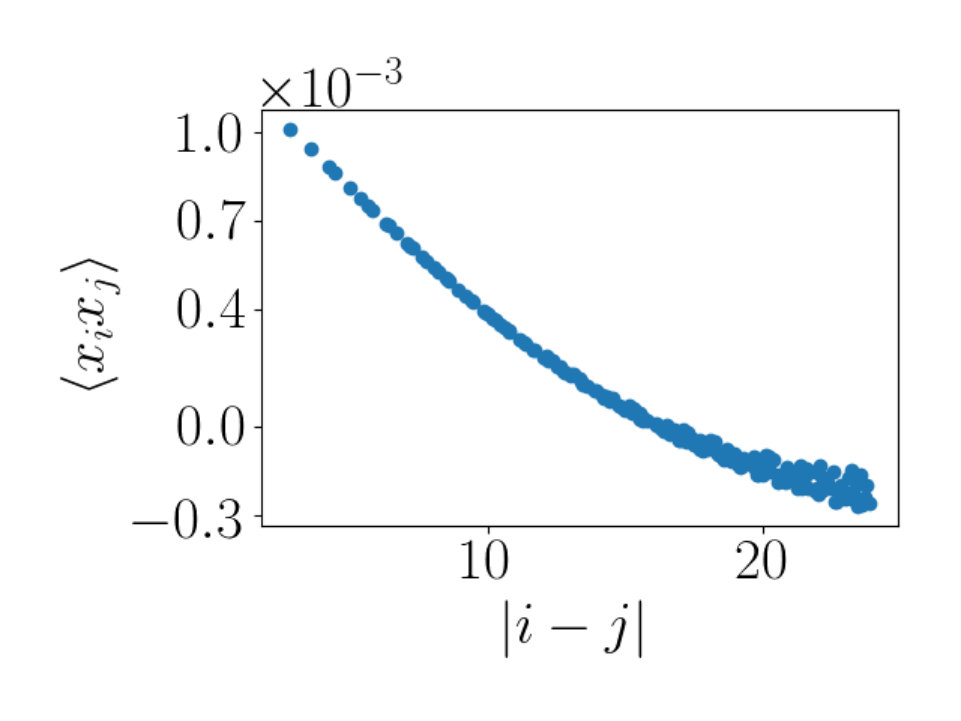 Figure 22
Figure 22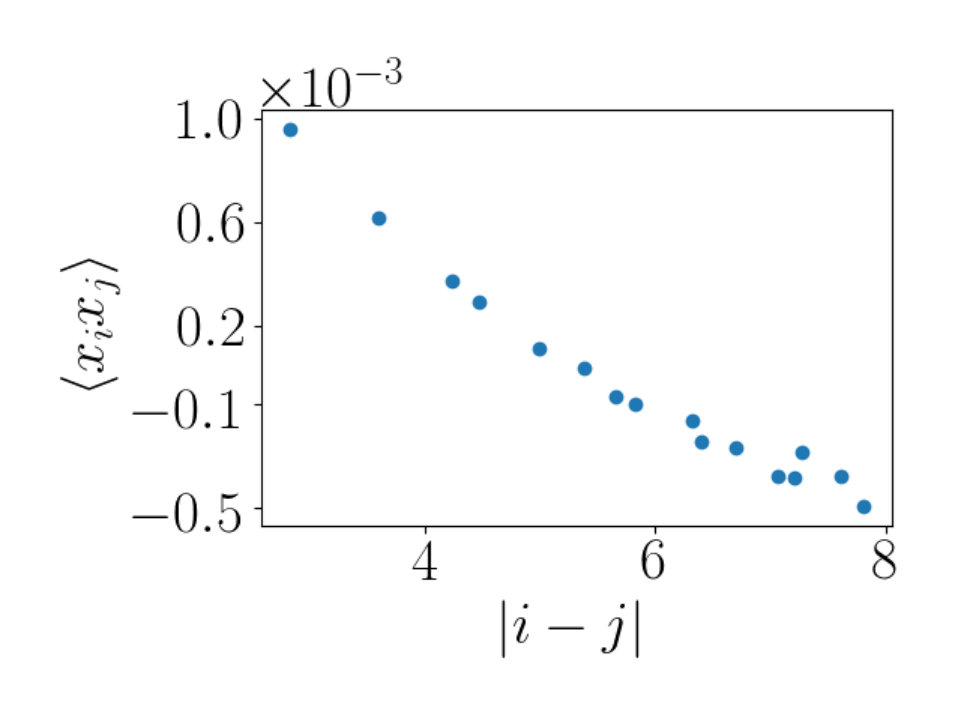 Figure 23
Figure 23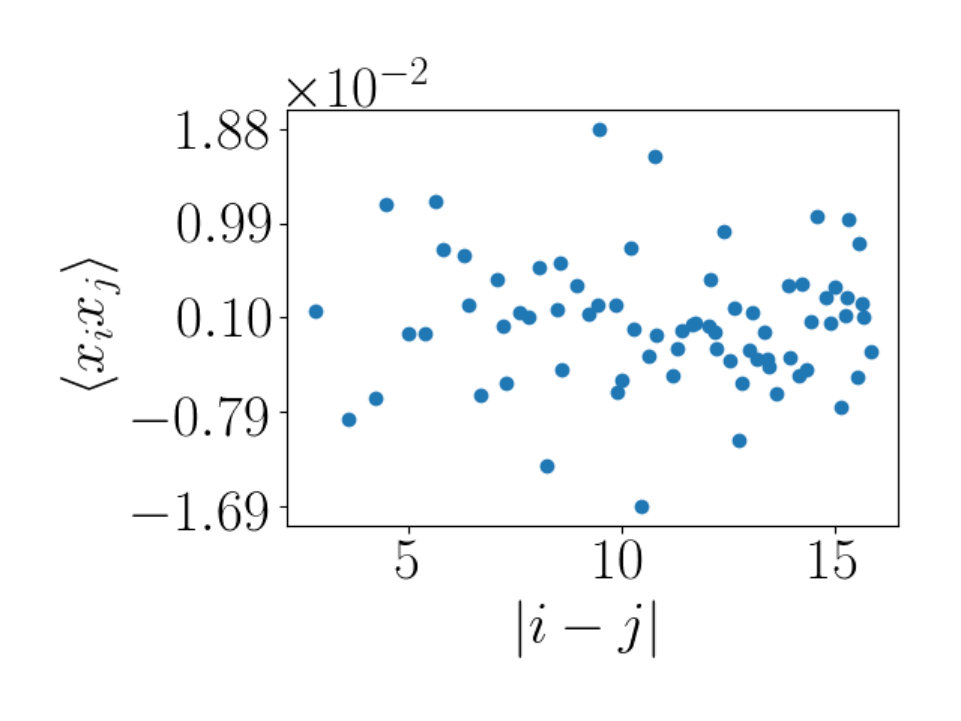 Figure 24
Figure 24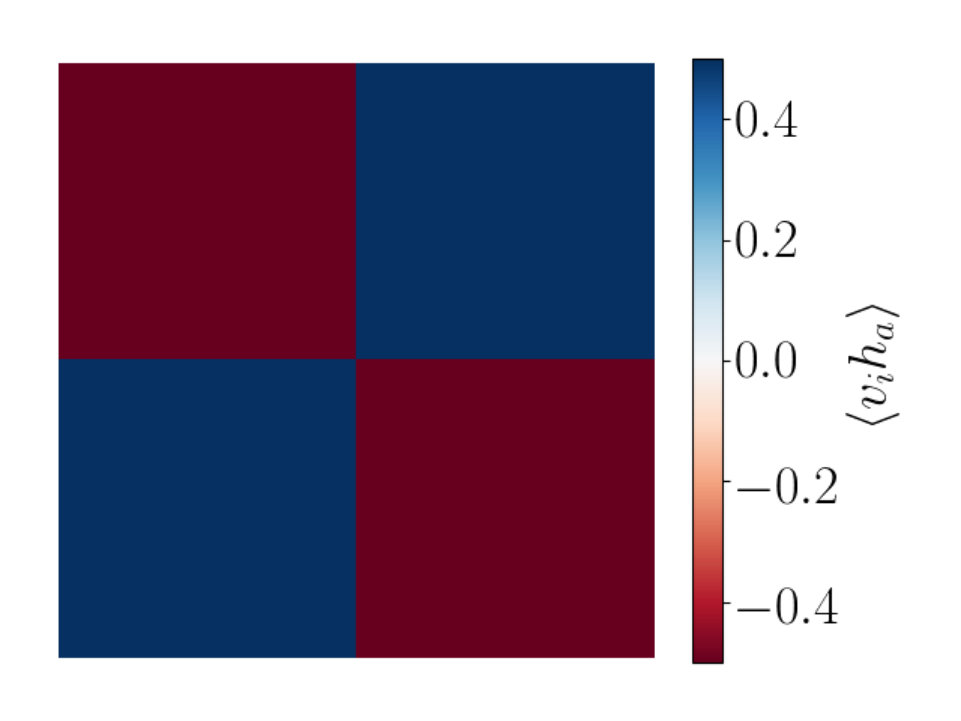 Figure 25
Figure 25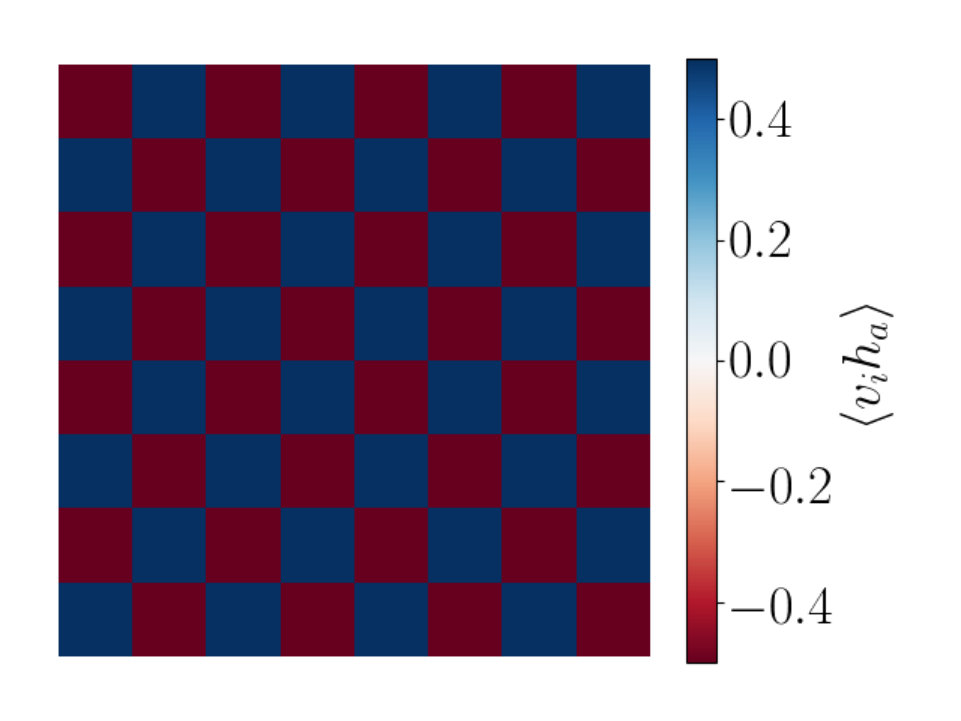 Figure 26
Figure 26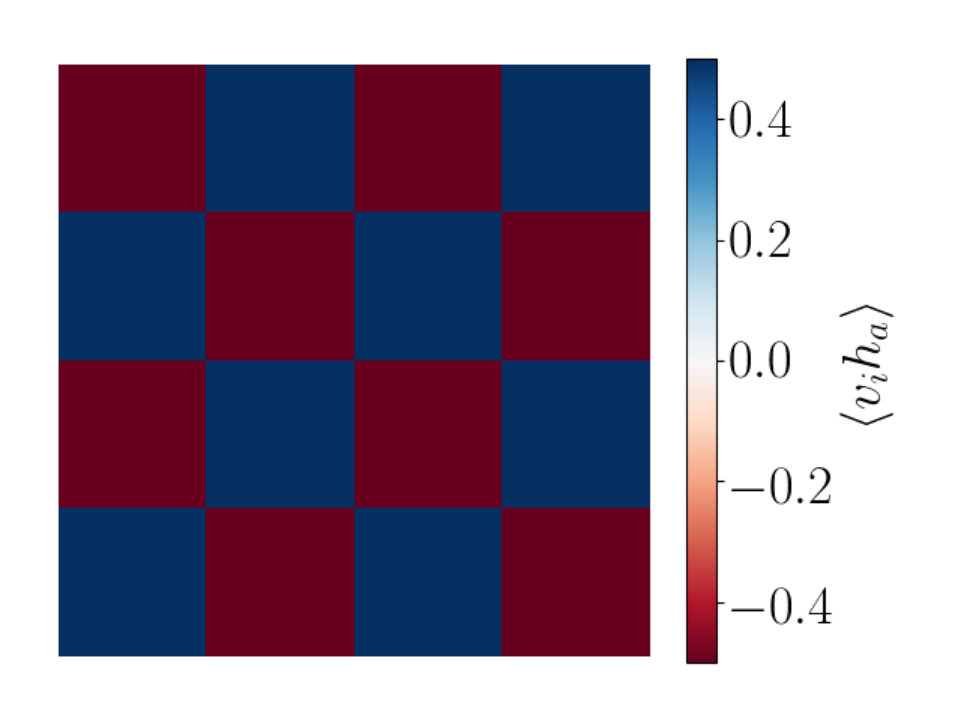 Figure 27
Figure 27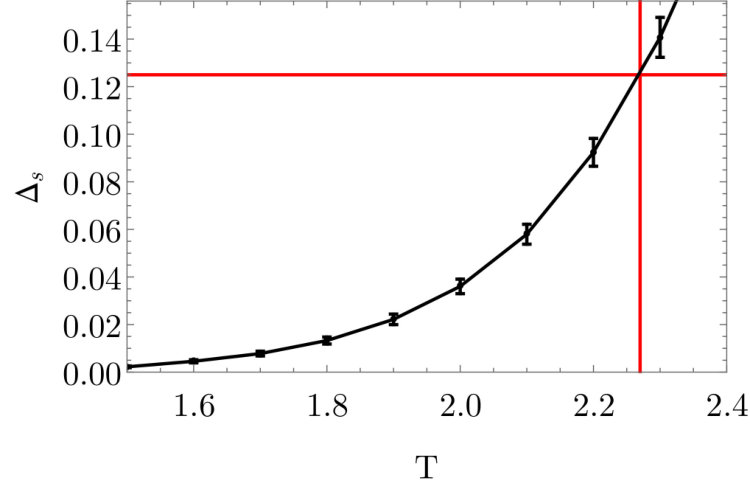 Figure 28
Figure 28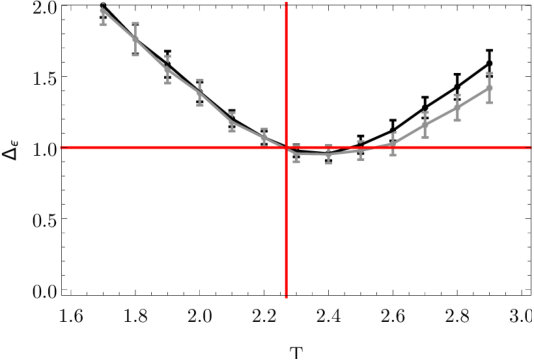 Figure 29
Figure 29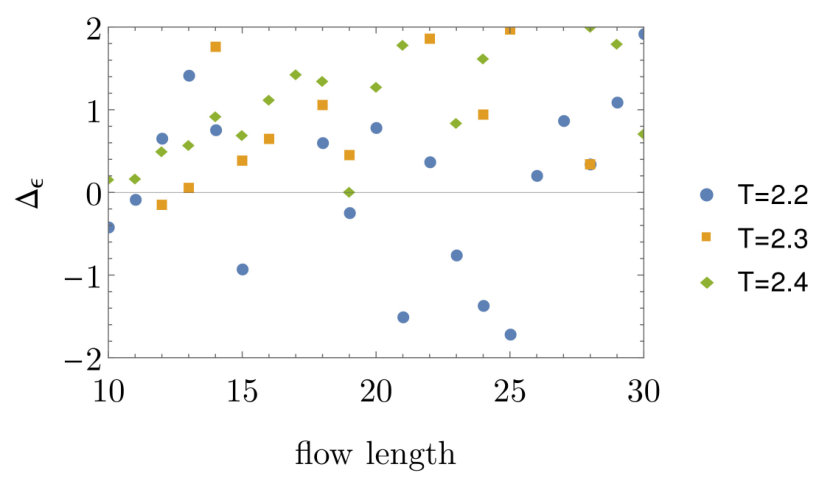 Figure 30
Figure 30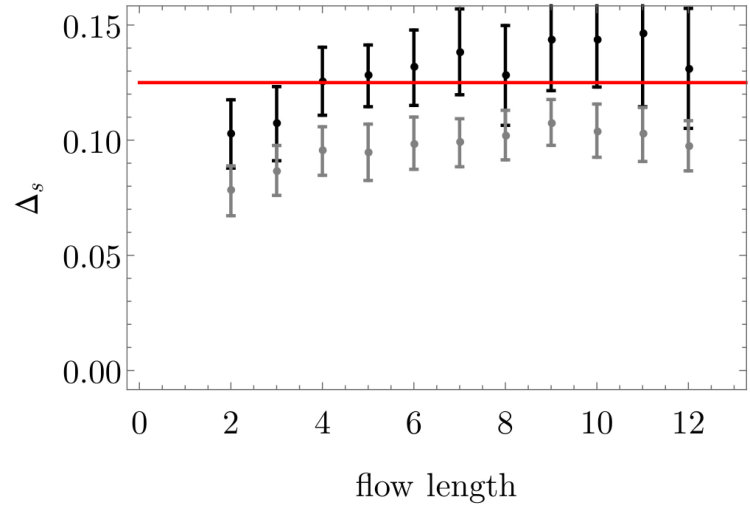 Figure 31
Figure 31 Figure 32
Figure 32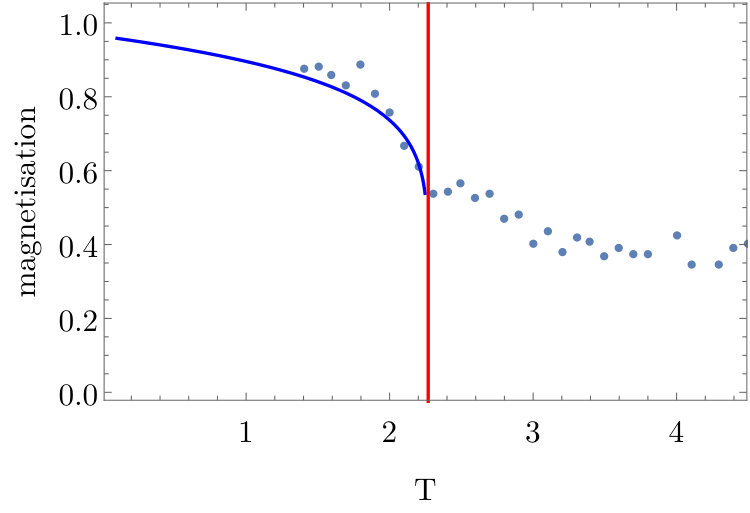 Figure 33
Figure 33 Figure 34
Figure 34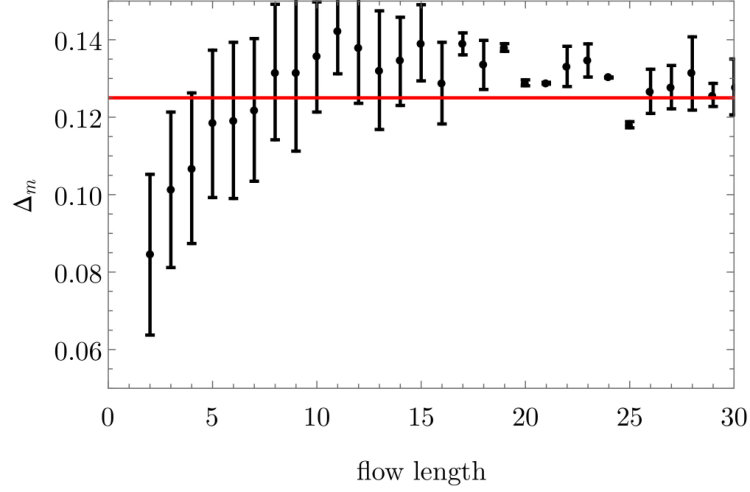 Figure 36
Figure 36 Figure 37
Figure 37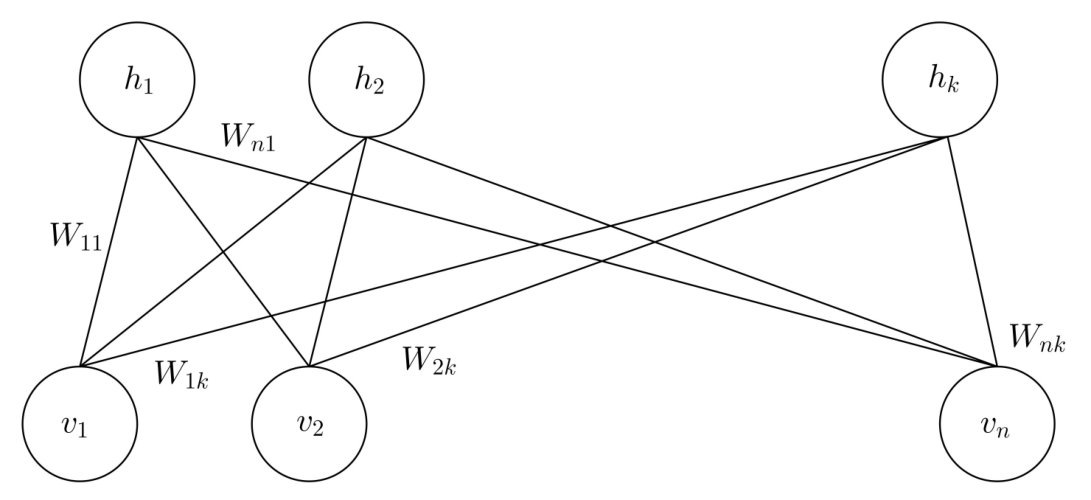 Figure 38
Figure 38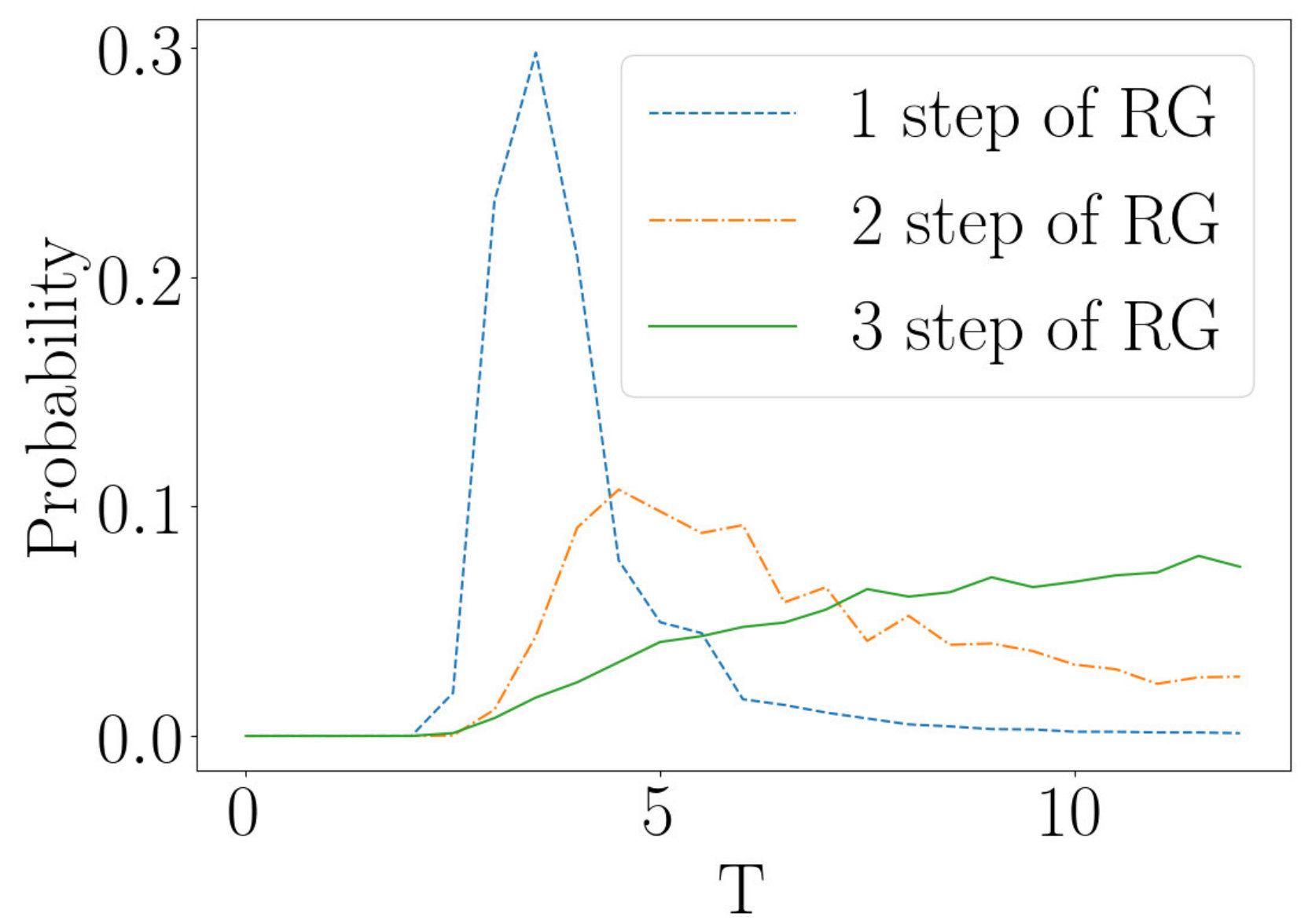 Figure 39
Figure 39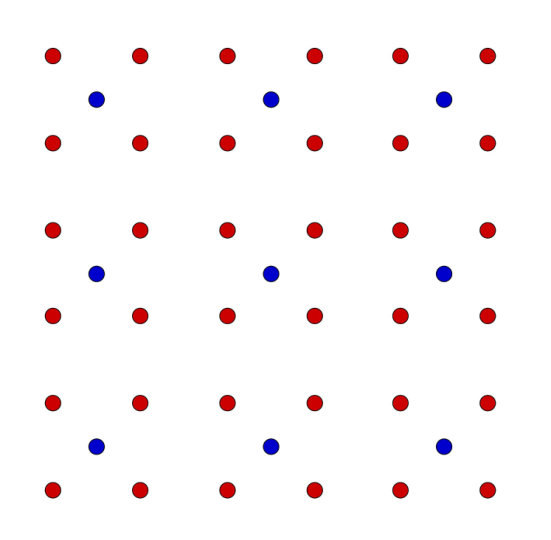 Figure 40
Figure 40Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
\history
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/ACCESS.2020.3000901, IEEE Access
\tfootnote
\corresp
Corresponding author: Robert de Mello Koch (e-mail: [email protected]).
Is Deep Learning a Renormalization Group Flow?
ELLEN DE MELLO KOCH1
ROBERT DE MELLO KOCH2, AND LING CHENG.1
School of Electrical and Information Engineering, University of the Witwatersrand, Wits, 2050, South Africa
School of Physics and Telecommunication Engineering, South China Normal University, Guangzhou 510006, China and National Institute for Theoretical Physics and the School of Physics and Mandelstam Institute for Theoretical Physics, University of the Witwatersrand, Wits, 2050, South Africa.
Abstract
Although there has been a rapid development of practical applications, theoretical explanations of deep learning are in their infancy. Deep learning performs a sophisticated coarse graining. Since coarse graining is a key ingredient of the renormalization group (RG), RG may provide a useful theoretical framework directly relevant to deep learning. In this study we pursue this possibility. A statistical mechanics model for a magnet, the Ising model, is used to train an unsupervised restricted Boltzmann machine (RBM). The patterns generated by the trained RBM are compared to the configurations generated through an RG treatment of the Ising model. Although we are motivated by the connection between deep learning and RG flow, in this study we focus mainly on comparing a single layer of a deep network to a single step in the RG flow. We argue that correlation functions between hidden and visible neurons are capable of diagnosing RG-like coarse graining. Numerical experiments show the presence of RG-like patterns in correlators computed using the trained RBMs. The observables we consider are also able to exhibit important differences between RG and deep learning.
Index Terms:
restricted Boltzmann machines (RBMs), deep learning, deep neural networks, learning theory, renormalization group (RG).
doi:
10.1109/ACCESS.2020.3000901
I Introduction
The power of machine learning and artificial intelligence is established: these are powerful methods that already outperform humans in specific tasks [1, 2, 3, 4]. Much of the research carried out in machine learning is of an applied nature. It establishes the practical utility of the method but does not construct an understanding of how deep learning works or even if such an understanding is possible [5, 6, 7, 8, 9, 10]. Consequently, deep learning remains an impressive but mysterious black box. A possible starting point for a theoretical treatment suggests that deep learning is a form of coarse graining [3, 11, 12]. Since there are more input than output neurons this is almost certainly true. The real question is then if this is a useful observation, one that might shed light on how deep learning works. This is the question we take up in this paper.
We argue that understanding deep learning as a form of coarse graining is a useful observation, and make the case by adopting and adapting several ideas from theoretical physics. Specifically, in theoretical physics there is a sound framework to carry out coarse graining, known as the renormalization group (RG) [13]. RG provides a systematic way to construct a theory describing large scale features from an underlying microscopic description, which can be understood as recognizing sophisticated emergent patterns, a routine achievement of deep learning. Further, RG is applicable to field theories, that is, to systems with a large number of degrees of freedom so that it seems that RG is well positioned to deal with massive data sets. Finally, the way in which RG works is, in contrast to deep learning, well understood and can be described in precise mathematical language. These features suggest that RG may provide a useful framework in which to describe deep learning and attempts to argue that this is the case have been made in [14, 15, 16, 17]. We focus on unsupervised learning by a restricted Boltzmann machine (RBM).
Two distinct possible connections to RG have been attempted, both relevant to our study. The first [14] is an attempt to link deep learning to the RG flow. The RG flow is a smooth process during which degrees of freedom are continuously averaged out, so that we flow from the initial microscopic description to the final macroscopic description. In deep learning one stacks layers of networks to obtain a deep network. The proposed connection of [14] suggests that each layer in the stack performs a small step along the RG flow111For a critical discussion of this proposal, see [12, 18]. We contribute to this discussion by developing quantitative tools with which this proposal can be explored with precision. The basic objects that appear in our analysis are correlation functions between the visible and the hidden neurons. This allows us to decode the mechanics of the RBM’s pattern generation and to compare it to what the RG is doing. Although there are important differences, our results indicate remarkable similarities between how the RBM and RG achieve their results. The second approach [15, 16] builds an RBM flow using the weight matrix of the neural network after training is complete. The results of [15, 16] suggest that the RBM flow is closely related to the RG flow. We carry out a critical examination of this conclusion. The central tools we employ are correlation functions defined using the patterns generated by the RBM. We give a detailed and precise argument showing that the largest scale features of RG and RBM patterns are in complete agreement. The correlation functions involved are non-trivial probes of the statistics of the generated pattern222The studies carried out in [15, 16] used averages of the RBM pattern. Our correlation functions provide more sensitive probes into the structure of the pattern. so the conclusion we reach is compelling. We also find that if one probes smaller scale features there are important differences between the two patterns. We will comment further on the interpretation of these results in the conclusions.
At this point, a comment is in order. The word “deep” in “deep learning” indicates that many layers are stacked to produce the network. Each layer in our network is an unsupervised RBM. The word “flow” in “RG flow” indicates that many small steps of coarse graining are carried out. Each step performs a local averaging and one basic step is being repeated. In this study we are developing methods that allow a comparison between one step of the renormalization group flow to one layer of the deep network. Thus, although we spend much of our effort on comparing a single RBM layer to a single step in the RG flow, we are interested in understanding learning achieved through the composition of many layers as an RG flow. It is in this sense that although we study a single layer we nevertheless claim we are exploring the problem of deep learning.
The setting for our study is the two dimensional Ising model [19]. This is a simple model of a magnet, built for many individual “spins” each of which should be thought of as a microscopic bar magnet. Each spin can be aligned “up” or “down”. Spins align at low temperatures producing a magnet. At high temperatures, spins are aligned randomly and there is no net magnetic field. The spins themselves define a binary pattern (the two states are up or down) and it is these patterns that the RBM learns. An important motivation for this choice of model is that it is well understood. The theory exhibits a first order phase transition terminating at a critical point. The theory at the critical point enjoys a conformal symmetry so that it can be solved exactly. It exhibits many interesting observables which we use to explore how deep learning is working [20, 21]. For example, if a neural network generates a microstate of the model, we can ask what the corresponding temperature of the microstate is. At the critical point special observables known as primary operators, can be defined. Their correlation functions are power laws with powers that are known. These are the natural variables which encode, completely, the long scale features of the patterns. In this way, the Ising model gives a framework to explore deep learning both through the results of numerical experiments and using the complete understanding of the large scale features of the coarse grained system. To probe whether deep learning is a type of coarse graining, we will see that this knowledge of correlations on large length scales is a valuable tool.
Our study of an Ising magnet may seem rather far removed from more usual (and practical) applications, including for example image recognition and manipulation. However, one might be optimistic that lessons learned from the Ising model are applicable to these more familiar examples. Indeed, the energy function of the Ising model tries to align nearby spins with the result that nearby spins are correlated. This is not at all unlike an image for which the color of nearby pixels is likely to be correlated [22].
A description of deep learning in the RG framework would have important implications. RG explains how macroscopic physics emerges from microscopic physics. This understanding leads to an organization of the microscopic physics into features that are relevant or irrelevant, so that in the end the emergent patterns depend only on a small number of relevant parameters. Carried over to the deep learning context, a similar understanding will strive to explain what features of the data and which weights in the network are important for deep learning. Such an understanding would have implications for what architectures are optimal and how the learning process can be improved and made more efficient.
We now sketch the content of the paper and outline how it is organized. In Section II we give a quick review of RBMs, RG and the Ising model, providing the background needed to follow subsequent arguments. In Section III we consider the RBM flows defined using the matrix of weights learned by the network [15, 16]. By studying correlation functions of primary operators of the Ising conformal field theory, we argue that although the RBM and RG patterns agree remarkably well on the largest scales of the pattern they differ on the short scale structure. In Section IV we examine the possibility that deep learning reconstructs an RG flow, with each layer of the deep network performing one step of the flow. Our discussion begins with a critical look at the argument given in [14] that claims that deep learning is mapped onto the RG flow. The argument shows a system of equations that is obeyed by both the RBM and a variational realization of the RG flow. Our basic conclusion is that the argument of [14] only shows that aspects of the RBM learning are consistent with the structure of the RG transformation. Indeed, we explicitly construct examples that satisfy the equations derived by [14] that certainly do not perform an RG flow or arise from an RBM. Nevertheless, the arguments of [14] are compelling and we find the possible connection between deep learning and RG fascinating and deserving of further study. Towards this end we couch some of the qualitative observations of [14] as statements about the behavior of well chosen correlation functions. The form of these correlators, puts certain qualitative observations of Section IV.B. of [14] onto a firm quantitative footing. Finally we study the RG flow of the temperature. This turns out to be interesting as it reveals a further difference between the RBM patterns and RG. In the final Section of this paper, we discuss our results and suggest open directions that can be pursued.
II RBM, RG and Ising
In this section we introduce the background material used in our study. The first subsection reviews RBMs emphasizing both the structure of the network and its implementation. Following this, the RG is reviewed, with an emphasis on aspects relevant to deep learning. This section concludes with a review of the Ising model, motivating why the model is considered.
II-A Restricted Boltzmann Machines
RBMs perform unsupervised learning to extract features from a given data set [23, 24, 25]. They have a visible (input) and a hidden (output) layer. The visible layer is made up of visible nodes, with and the hidden layer is made up of hidden nodes, with as illustrated in Figure 1.
The visible nodes are set with values of and the trained network generates a corresponding pattern by setting the output nodes to . The values of the hidden neurons are obtained by evaluating a non-linear function on a linear combination of the visible neurons, perhaps offset by a constant bias. The nonlinear function we use here is the hyperbolic tangent which can be seen in equation (13). The specific linear combination of neurons is represented by connections between nodes, with a weight for each connection. For the RBM there are connections between every visible node and every hidden node, while nodes belonging to the same layer are not connected. The “unrestricted” Boltzmann machines allow connections between any two nodes in the network [26], but this generality comes at a cost: training algorithms are much less efficient [23, 24, 25]. The connection between visible node and hidden node is assigned a weight, , and visible (hidden) nodes are assigned a bias (). Using these ingredients we define a Hamiltonian for the RBM
[TABLE]
where . The RBM defines the probability distribution for obtaining configurations and of visible and hidden vectors by [27]
[TABLE]
where is the partition function, obtained by summing over all possible hidden and visible vectors
[TABLE]
As usual, to determine the marginal distribution of a visible vector, sum over the state space of hidden vectors
[TABLE]
Similarly, the marginal distribution of a hidden vector is
[TABLE]
The weights, and biases , are determined during training. Training strives to match the model distribution to the distribution defined by the data and it achieves this by minimizing the Kullback-Leibler (KL) divergence, which is given by
[TABLE]
The KL divergence is a measure of how much information is lost when approximating the actual distribution with the model distribution [28]. Training adjusts to minimize the KL divergence. Gradients of the KL divergence used to update the parameters of the RBM are computed as follows
[TABLE]
[TABLE]
[TABLE]
where the expectation values appearing above are easily derived using (2). They are given explicitly in Appendix A. The data set contains an enormous number of samples implying that the method just outlined is numerically intractable: the sum over the whole state space of visible and hidden vectors is too expensive. In this study we consider networks with in the range of to nodes and in the range of to nodes. The number of samples we sum over lies in the range of and . To make progress, we approximate the KL divergence by the contrastive divergence [25]. Rather than summing over the entire state space of visible and hidden vectors, one simply sets the states of the visible units to the training data [27]. This is an enormous simplification. Given a set of visible vectors, the hidden vectors are sampled by setting each to 1 with probability
[TABLE]
Likewise, given a set of , we are able to sample visible vectors by setting each to 1 with probability
[TABLE]
Expectation values for the data are computed using , generated using (11) and , provided by the training data set.
To determine model expectation values, determine a sample of visible vectors and a sample of the hidden vectors , using the equations (12) and (11) as we now explain. The set , is calculated using and equation (12). We then determine , using and equation (11). The equations for the vectors in the sets , and are thus
[TABLE]
[TABLE]
[TABLE]
Expectation values of the model are approximated using these sets. Again, summing these much smaller sets (and not the complete space of hidden and visible vectors) is an enormous simplification.
Using this approximation the expressions used to train the RBM are
[TABLE]
[TABLE]
[TABLE]
[TABLE]
[TABLE]
[TABLE]
where denotes samples in the training data set made up of samples. These approximations achieve a dramatic speed up in training. Although this method performs well in practice [1, 29, 30], it is difficult to understand when and why the approximations work [27, 31]. This approximation does not follow the gradient of any function [32].
II-B RG
RG is a tool used routinely in quantum field theory and statistical mechanics [13]. RG coarse grains by first organizing the theory according to length scales and then averaging over the short distance degrees of freedom. The result is an effective theory for the long distance degrees of freedom. RG thus gives a systematic procedure to determine the dynamical laws governing macroscopic physics of a system with given microscopic laws, and it achieves this by employing coarse graining. The analogy to deep learning should be evident: deep learning also extracts regularities from massive data sets.
At this point it is helpful to make a comment on what a field is. A field is a type of observable. A very simple example of a field could be the temperature inside a room. The measured value of the temperature depends on exactly where in the room you make the measurement333For example, there maybe an air conditioner in the room. Points closer to the air conditioner will be cooler. and when you make the measurement444Temperature measurements at midnight in the middle of winter will typically be lower than measurements at midday in the middle of summer.. Anything that can be measured everywhere and/or everywhen is an example of a field.
To illustrate RG consider the example provided by quantum field theory. To have a concrete example in mind, which is relevant to the discussion that follows, we might study a field describing the magnetization inside a magnet. The value of the field gives the value of the magnetization at position . can be manipulated as we would normally manipulate a function of . In particular, we can take derivatives of with respect to and we can take its Fourier transform to obtain . Observables are functions (usually polynomials) of the field and its derivatives. Examples of observables are the energy or momentum of the field. To calculate the expected value of observable , integrate (i.e. average) over all possible field configurations
[TABLE]
To make sense of this integral one can work on a lattice. Here we use the term “lattice” to denote an ordered array of points, and we imagine replacing the continuum of space with this discrete structure, so that the set of all possible positions in space is now a discrete set. The integral over all possible field configurations then becomes a product of ordinary integrals, with one integral over the allowed range of the field, at each lattice site. The range of the field is usually taken to be the real number field. The factor , which defines a probability measure on the space of fields, depends on the theory considered. is called the action of the theory and is also a polynomial in the field and its derivatives, with the coefficients of the polynomial providing the parameters of the theory, things like couplings and masses. A theory is defined by specifying .
To coarse grain, express the position space field in terms of momentum space components
[TABLE]
oscillates in position space with wavelength . High momentum (big ) components have small wavelengths and encode small distance structure. Low momentum components have huge wavelengths and describe large distance structure. Declare there is a smallest possible structure, implemented by cutting off the momentum modes at a large momentum as follows
[TABLE]
RG breaks the integration measure into high and low momentum components where
[TABLE]
The dimensionless parameter defines the split between the two sets of components. In the end we imagine taking as explained below. RG considers observables that depend only on large scale structure of the theory, i.e. observables that depend only on . In this case, when computing the expected value of we can pull out of the integral over and integrate over the high momentum components
[TABLE]
This procedure of splitting momentum components into two sets and integrating over the large momenta defines a new action . Repeating the procedure many times defines the RG flow under which changes continuously. To obtain a continuous flow we should take the limit , so that the procedure needs to be repeated an infinite number of times to flow to low momentum. The parameter should be thought of as a step size in a discrete flow. It is not a physical parameter and must be taken small enough that the results of computations are independent of . After the flow, one is left with an integral over the very long wavelength modes. This completes the coarse graining: we have a new theory defined by . The new theory uses only long wavelength components of the field and correctly reproduces the expected value of any observable depending only on long wavelength components. Values of the parameters of the theory, which appear in , change under this transformation. In general, many possible terms are generated and appear in . Each possible term defines a coupling of the theory. Each coupling can be classified as marginal (the size of the coupling is unchanged by the RG flow), relevant (the coupling grows under the flow) or irrelevant (the coupling goes to zero under the flow). It is a dramatic insight of Wilson that almost all couplings in any given quantum field theory are irrelevant and so the low energy theory is characterized by a handful of parameters. This is a dramatic (experimentally verified) simplicity hidden in the rather complicated quantum field theory. This simplicity explains why “simple large scale patterns” can emerge from “complicated short distance data”. The possibility that the same simplicity is at work in deep learning is a key motivation of this paper.
Although the equation (28) defines the relationship between and , the connection is rather abstract and a few clarifying remarks are in order. Consider the situation in which we started with an action and we have flowed to obtain some effective low energy dynamics . The action is the original action of the theory. In the case of a magnet, this would describe the dynamics of atomic spins, where the relevant length scale is m. The effective action would describe the dynamics of a classical magnet, where the relevant length scale may be m or even larger. The renormalization group is the coarse graining that constructs the classical macroscopic physics from the microscopic physics.
Conceptually, the coarse graining performed by RG is well defined. Computationally, it is almost impossible to carry out. To develop a useful calculation scheme, partition the momentum components into tiny sets (i.e. follow (26) with infinitesimal) and ask what happens when we average over a single tiny set. Two things happen: couplings change and the strength of the field changes . One can prove that all observables built using fields will obey the Callan-Symanzik equation [33]
[TABLE]
The parameter here defines the scale of the effective theory: the smallest wavelength in the effective theory is . This equation provides a remarkable and simple description of the RG coarse graining that captures the essential features of the long distance effective theory. In practice correlation functions are computed and then inserted into the Callan-Symanzik equation. The and functions are then read from the resulting equations.
If RG (or a variant of it) is relevant to understanding deep learning, it makes concrete suggestions for the resulting theory. For example, is there an analogue of the Callan-Symanzik equation? One might assign beta functions to the weights and biases . These would determine which parameters of the RBM are relevant, irrelevant or marginal.
The RG flow halts at a fixed point, described by a conformal field theory. This field theory enjoys additional symmetries including scale invariance. It is interesting to note that the possibility that scale invariance plays a role in deep learning has been raised in [12, 14, 15, 16, 17].
Although we have focused mainly on a physical model in this article, we should point out that there are many other applications of the renormalization group formalism. For example, RG has been used to understand the spread of forest fires [34], in the modeling of the spread of infectious diseases in epidemiology [35], for the prediction of earthquakes [35] and more generally, to any system with self organized criticality [36].
II-C Ising model
The Ising model is a model for a magnet. The two dimensional model has a discrete variable, called a spin, on each site of a rectangular lattice. The sites are labeled by a two dimensional vector , which has integer components. A state of the system is given by specifying a collection of spins, , one for each site in the lattice. To refer to a specific state of the spin system we use the notation . Spins on adjacent sites and interact with strength . Each spin will also interact with an external magnetic field , with strength . The energy of a given configuration of spins is determined by the Hamiltonian
[TABLE]
where the first sum is over adjacent pairs, indicated by . We simplify the model by setting the external field to zero , and by choosing the couplings in the most symmetric possible way . Since is an energy we can set it to 1 by choosing units appropriately. The probability of configuration of spins is given by the Boltzmann distribution, with inverse temperature
[TABLE]
where the constant , the partition function, is given by
[TABLE]
Averages of physical observables are defined by
[TABLE]
We study unsupervised learning of the Ising model by an RBM. The visible data that is used to train the network is generated using the probability measure (31). The lattices have a total of sites, with each site indexed by a position vector . We rearrange this array of spins into an dimensional vector by concatenating the rows of the given array. These components of these vectors are the training data input to the visible nodes of the RBM.
There are good reasons to focus on the Ising model. The model has a fixed point in its RG flow. The fixed point is described by a well known conformal field theory (CFT) [37]. This fixed point is an unstable fixed point meaning that generic flows move away from the fixed point. We must tune things carefully if we are to terminate on the fixed point. This tuning is necessary because there is a relevant operator present in the spectrum of the conformal field theory and it tends to push us away from the fixed point. We need to tune the temperature. If the temperature is slightly above the critical temperature, thermal fluctuations destroy the long range correlations that are forming, whilst if we are slightly below the critical temperature, the tendency of spins to align dominates and we find a state with all spins aligned and no fluctuations at all. It is only exactly at the critical temperature that the system exhibits the interesting long range correlations that are described by the CFT. The papers [15, 16] argue that the RBM flow always flows to the fixed point. This challenges conventional wisdom and it suggests a different kind of coarse graining to that employed by RG, is at work. A distinct proposal [14] claims that the RG flow arises by stacking RBMs to produce a classic deep learning scenario. Each layer of the deep network performs a step in the flow.
At the Ising model fixed point, detailed checks of both proposals are possible. There are CFT observables, known as primary operators, whose correlators are power laws of distances on the lattice. The powers entering these power laws are known, so that we have a rich and detailed data set that the RBM must reproduce if it is indeed performing an RG coarse graining. This is a compelling motivation for the model. Another advantage of the model is simplicity: it is a model of spins which take the values so it defines a simple model with discrete variables, well suited to numerical study and naturally accommodated in the RBM framework. Finally, the Ising model is not that far removed from real world applications: the Ising Hamiltonian favors configurations with aligned neighboring spins. Thus, at low enough temperatures “smooth” slowly varying configurations of spins are favored. This is similar to data defining images for example, where neighboring pixels are likely to have the same color. In slightly poetic language one could say that at low temperatures the Ising model favors pictures and not speckle.
We end this section with a summary of the most relevant features of the Ising model fixed point. At the critical temperature
[TABLE]
where is the interaction strength and is the Boltzmann constant, the Ising model undergoes a second order phase transition. The critical temperature is given by when . There are two competing phases: an ordered (low temperature) phase in which spins align producing a macroscopic magnetization, and a disordered (high temperature) phase in which spins fluctuate randomly and the magnetization averages to zero. At the critical point the Ising model develops a full conformal invariance and one can use the full power of conformal symmetry to tackle the problem. The field which takes values in the Ising model is a primary field, of dimension . The two and three point correlation functions of primary fields are determined by conformal invariance to be
[TABLE]
[TABLE]
where and are constants. Since we study the Ising model on a lattice, the positions , and appearing in the above correlation functions refer to sites in a lattice. There is also a primary operator in the Ising model (which we describe below) with a dimension . These correlation functions must be reproduced by the RBM if it is indeed flowing to the critical point of the Ising model.
III Flows derived from learned weights
In this section we consider the RBM flows introduced in [15, 16]. These flows use the weight matrix , and bias vectors and , obtained by training, to define a continuous flow from an initial spin configuration to a final spin configuration. The flow appears to exhibit a fascinating behavior: given any initial snapshot, the RBM flows towards the critical point of the Ising model. This is in contrast to the RG which flows away from the fixed point. In addition, the number of spins in the configuration is a constant along the RBM flow. In contrast to this, the number of spins in the configuration decreases along the RG flow, as high energy modes are averaged over to produce the coarse grained description. Despite these differences, the flow of [15, 16] appears to produce configurations ever closer to the critical temperature and these configurations yield impressively accurate predictions for the critical exponents of the Ising magnet. Our goal in this section is to further test if the RBM flow produces configurations at the critical point of the Ising model. We explore the spatial dependence of spin correlations in configurations produced by the flow. Our results prove that on large scales the Ising critical point configurations are correctly reproduced. However, we are also able to prove that as one starts to probe smaller scales there are definite quantifiable departures from the Ising predictions.
III-A RBM Flow
RBM flows [15, 16] are generated using equation (14) together with the trained weight matrix, , and bias vectors, and . Our data set is labeled by an index . For each value of , is a collection of spin values, one for each lattice site. The RBM flow is generated through a series of discrete steps, with each step producing a new data set of the same size as the original. Denote the data set produced after steps of flow by , and by convention we identify with the original training set. Apply equation (14) to and then apply (15) to carry out a single step of the RBM flow, with the result . The flow proceeds by repeatedly applying equations (14) and (15). Concretely, for a flow of length , we have
[TABLE]
where
[TABLE]
Note that the length of the vector is a constant of the flow and consequently there is not obviously any coarse graining implemented.
III-B Numerical results
This section considers statistical properties of configurations produced by the RBM flow. At the Ising critical point, the theory enjoys a conformal invariance. Using this symmetry a special class of operators with a definite scaling dimension can be identified. The utility of these operators is that their spatial two point correlation functions drop off as a known power of the distance between the two operators, as reviewed above in equation (35). These two point functions can be evaluated using the RBM flow configurations and, if these configurations are critical Ising states, they must reproduce the known correlation functions. This is one of the checks performed and it detects discrepancies with the Ising model predictions. There are two primary operators we consider. This first is the basic spin variable minus its average value . The prediction for the two point function is (35) with . This correlator falls off rather slowly, so that this two point function probes the large scale features of the RBM flow configurations. The RBM flow nicely reproduces this correlator and in fact, this is enough to reproduce the critical exponent for the Ising model consistent with the results of [16]. One should note however that our computation and those of [16] could very well have disagreed, since they probe different things. The critical exponent evaluated in [16] uses the magnetization computed from different flows generated by the RBM, at temperatures around the critical temperature. Magnetization measures the average of the spin in the lattice. It is blind to the spatial location of each spin. On the other hand, the two-point correlation function is entirely determined by the spatial location of spins in a single flow configuration. Thus, the two point correlation function uses data at a single temperature, but uses detailed spatial dependence of the lattice state. We also consider a second primary operator
[TABLE]
which has . We have again subtracted off the average value of the operator. This correlation function falls off much faster and is consequently a probe of shorter scale features of the RBM configurations. The RBM flow fails to reproduce this correlation function, indicating that the RBM configurations differ from those of the critical Ising model. They have the same long distance features, but differ on shorter length scales.
Consider an RBM network with visible nodes and hidden nodes. This corresponds to an input lattice of size and an output lattice of size . The number of visible and hidden nodes is chosen to match [16], so that we can compare our results to existing literature.
We would like to study a lattice that is as small as possible but large enough to detect the power law fall off of the correlation functions we study. The power law behavior is given in the scaling dimensions and . We demonstrate that when studying a lattice of size or larger we correctly determine the values for and using configurations generated from MC simulations. These results are shown in Figures 6a and 5b.
The network trains on data generated by Monte Carlo simulations which use the Boltzmann distribution given in equation (31) [38]. The training data set includes samples at each temperature, ranging from [math] to in increments of . This gives a total of configurations. Training uses iterations of contrastive divergence, performed with the update equations (13) to (21) which are derived from equations (8), (9) and (10) [39].
Once the flow configurations are generated, following [15, 16], a supervised network is used to measure the temperature of each flow.
The supervised network allows us to measure discrete temperatures of .
We train a network which consists of three layers, an input layer with 100 nodes, a hidden layer with 80 nodes and an output layer with 60 nodes which correspond to the 60 temperatures we want to measure. All nodes in the input layer are connected to all nodes in the hidden layer, and all nodes in the hidden layer are connected to all nodes in the output layer. No connections between nodes within the same layer exist.
The th sample of input data, is transformed by the hidden layer using the hyperbolic tangent function as follows
[TABLE]
The output layer then transforms into an output probability using the softmax function
[TABLE]
where the softmax function normalizes the output to sum to 1 as follows
[TABLE]
The output of the trained network can thus be interpreted as probabilities for the temperatures we measure. The highest probability in the output is taken as the temperature for the given input.
We make use of the Keras library [40] to train this network using the back-propagation algorithm [41]. The cost function used to train the network is the KL divergence as is used in [16]. We choose a learning rate of and train the network for 3000 epochs. In Figure 3 we show the validation and training loss versus the number of training epochs. The supervised network is trained using the same data set used to train the RBM as well as corresponding labels for each vector. These labels are one hot encoded vectors which correspond to the temperatures . Here we use a split of 40 % of the input data for validation and 60 % of the input data for training. Figure 3 shows that the supervised network has converged to a loss very close to zero after 3000 epochs.
To estimate using magnetization the study [16] selects flows at temperatures close to , where the average magnetization depends on temperature as
[TABLE]
In [16] the magnetization is expanded about the critical point to give values for and
[TABLE]
We denote obtained by this fitting as . The fit also determines . The value of is a known theoretical value for the 2D Ising model with coupling strength . The fit uses the magnetization computed at temperatures , and . A plot of versus flow length is given in Figure 2. The error bars shown in Figure 2 (and all subsequent plots) are determined using Mathematica’s NonlinearModelFit function. The error bars show the standard error obtained from the regression. Mathematica uses the Student’s t-distribution to calculate a confidence interval for the given parameters with a 90% confidence level.
Our results indicate that we converge to the correct critical value for flows of length 26. It is evident from Figure 2 that the flow converges to the theoretical value depicted by the red horizontal line. The convergence of the flow is also reflected as a decrease in the size of the error bars as the flow proceeds. In [16] the value for is found to be . The value of which we find after convergence is with a 90% confidence interval within of this value. Although the values we obtain for and are consistent with the results of [16], they have used a flow of length 9, at which point is correctly determined. As just described, we need longer flows for convergence. The fitting of and , for a flow length of 26, is shown in Figure 4.
We now shift our focus to consider spatial two point correlation functions computed using the configurations generated by the RBM flows. The correlators are calculated using the flow configuration and the result is then fitted to the function in equation (35) to estimate . We denote this estimate by as it is determined using spatial information. For RBM flows at the critical temperature, the prediction which is determined by theory is at , as explained above.
We expect that for temperatures below the critical temperature will be less than the theoretical value of . For temperatures that are above the critical temperature we expect that will be greater than . With a lattice of 10 by 10 spins, we find using Monte Carlo Ising model configurations. A plot showing this estimate can be seen in Figure 5b. The point of this exercise is to demonstrate that a lattice of size 10 by 10 is large enough to estimate the scaling dimension of interest and to verify the integrity of the data set used in the numerical simulations.
Figure 5a shows the scaling dimension versus the flow length, for RBM flows at temperatures of (in gray) and (in black). The red horizontal line indicates the scaling dimension at the critical point. The results are intuitively appealing. The gray points in Figure 5a show estimates of from flows slightly below the critical temperature, where the scaling dimension is slightly underestimated. Below the critical temperature spins are more likely to align and so the correlator should fall off more slowly than at the critical temperature. This is what our results show. The black points in Figure 5a show estimated using flows slightly above the critical temperature. The scaling dimension is over estimated, again as expected. Selecting flows at would determine the scaling dimension in between the values shown in Figure 5a. This gives a value very close to the theoretical value of .
The two point correlation functions for the spin variable establish that the critical Ising states and the states produced by the RBM flow share the same large scale spatial features. We will now consider the two point correlation function of the field, which probes spatial features on a smaller scale. Using critical Ising data generated using Monte Carlo, on a lattice of size 10 by 10 and 9 by 9, we estimate at various temperatures as shown in Figure 6a. We can estimate the error for the point we are interested in, at and which is depicted by the red vertical and horizontal lines shown in Figure 6a. The error bar of the estimate for the grey line ( lattice) is for an estimated value of being . For the black line ( lattice) we have an error bar of on an estimated value of for . This is determined using the average of the values as well as the errors on either side of the red vertical line at .
Figure 6a, demonstrates that a lattice of size is large enough to correctly determine the scaling dimension .
The intersection of the red horizontal and vertical lines cross the critical temperature and prediction . Interpolating the Ising data with a continuous curve, we would pass through the intersection point, as predicted. These numerical results again demonstrate that a lattice of size 10 by 10 is large enough for the questions we consider. The RBM flows are unable to confirm this prediction. Indeed, the RBM flows near are summarized in Figure 6b. None of the three temperatures shown have a value of that converges with flow length.
The fact that the RBM produces configurations that correctly reproduce the correlation function of the spin field but not of the implies that although the spatial correlations encoded into the RBM flow configurations agree with those of the critical Ising configurations at long length scales, the two start to differ on smaller length scales. This conclusion agrees with [16] which also finds differences between the RBM flow and RG. [16] considers and uses different arguments to reach the conclusion.
IV Flows derived from deep learning
The RBM flows of the previous section provide one possible link to RG. An independent line reasoning, developed in [14], claims a mapping between deep learning and RG. The idea is not that there is an analogy between deep learning and RG, but rather, that the two are to be identified. The argument for this identity starts from the energy function of the RBM, which is
[TABLE]
This energy determines the probability of obtaining configuration as
[TABLE]
where are the parameters of the RBM model which are tuned during training. Marginal distributions for hidden and visible spins are defined as follows
[TABLE]
The equations (48) are key equations of the RBM and [14] essentially uses these to characterize the RBM. The comparison to RG is made by employing a version of RG known as variational RG. This is an approximate method that can be used to perform the renormalization group transformation in practice. As explained in Appendix B, the variational RG uses an operator defined as follows
[TABLE]
In this formula, is the microscopic Hamiltonian describing the dynamics of the visible spins and is the coarse grained Hamiltonian describing the hidden spins where here defines the parameters of the variational RG. Block spin averaging is discussed in more detail in Appendix B-B. The operator is required to obey (see in equation (80))
[TABLE]
which obviously implies that
[TABLE]
Notice that (49) and (51) exactly match (48) as long as we identify
[TABLE]
This then implies that
[TABLE]
which is the central claim of [14].
The above argument proves an equivalence between deep learning and RG if and only if the equations (48) provide a unique characterization of the joint probability function . This is not the case: it is easy to construct functions that obey (48), but are nothing like either the RBM or RG joint probability functions. As an example, define
[TABLE]
where
[TABLE]
We clearly have which implies that
[TABLE]
obeys (48). It is quite clear that in there are no correlations between the hidden and visible spins
[TABLE]
so that we would reject it as a possible model of either the RG quantity
[TABLE]
or of the RBM quantity
[TABLE]
In addition to clarifying aspects of the argument of [14], the joint correlation functions between visible and hidden spins can be used to characterize the RG flow, as we now explain. The RG flow “coarse grains” in position space: a “block of spins” is replaced by an effective spin, whose magnitude is the average of the spins it replaces. Since correlations between microscopic spins fall off with distance, an RG coarse graining implies that because the hidden spin is a linear combination of nearby visible spins, the correlation function between hidden and visible spins reflects a correlation between a hidden spin and a cluster of visible spins. This produces distinctive correlation functions, some examples of which are plotted in Figure 7. We will search for this distinctive signal in the correlator, to find quantitative evidence that deep learning is indeed performing an RG coarse graining.
IV-A Numerical results
Our numerical study aims to do two things: First, we establish whether there are RG-like patterns present within the correlator , for correlators computed using the patterns generated by an RBM flow. If these patterns are indeed present, this constitutes strong evidence in favor of the connection between RG and deep learning.
The correlator is calculated using
[TABLE]
where with being the number of samples, labels the visible nodes within a visible vector and labels the nodes within a hidden vector.
For each hidden node we can produce a plot which shows how this hidden node is correlated to the visible nodes, . This gives us a total of plots. Each panel within the plot for shows the correlation values for . By arranging these panels according to the lattice sites of the visible spins we get a grid of values for the correlators , where a is fixed for the given plot and runs from 1 to .
By doing this we can determine if a given hidden node is correlated to a local patch of visible nodes which are neighbors on the original lattices produced from MC. This local information is not encoded inherently in the RBM so learning about the nearest neighbour interactions present in the 2D Ising model would show promise that RBMs are performing a coarse graining related to that of RG.
We find that RG-like patterns do indeed emerge.
Second, according to the proposal of [14], in a deep network each layer that is stacked to produce the depth of the network performs one step in the RG flow. With this interpretation in mind, it may be useful to compare how a network with multiple stacked RBMs learns as compared to a network with a single layer. This issue is explored below.
The training data is a set of configurations of Ising model 32 by 32 lattices, near the critical temperature . The dataset is generated using Monte Carlo simulations. An input lattice length of 32 allows a large enough final configuration even after two steps of RG, corresponding to stacking two RBMs. In each step of the RG, the number of lattice sites is reduced by a factor of 4. Thus, we flow from lattices with 1024 sites to lattices with 64 sites. We enforce periodic boundary conditions. To find signals of RG in the correlation functions the maximum distance between operators in a correlator must be large enough that the spin-spin correlation has dropped to zero. We have confirmed that our lattice is large enough, judged by this criterion.
Having described the conditions of our numerical experiment, we consider the correlators generated when the hidden neurons are generated from the visible neurons using RG. Our goal is to understand the patterns appearing in correlation functions, that are a signature of the RG. In Figure 7d the process of decimation used in our RG is explained. The red dots, representing the visible lattice, are averaged (coarse grained) to produce the blue dots which define the lattice after a single step of the RG. The four spin values located at the red dots surrounding each blue dot are averaged to obtain the value of the spin at the new (blue) lattice point. This process clearly reduces the number of lattice sites by a factor of four.
Using the visible data which populates a 32 by 32 lattice, we populate lattices of size 16 by 16 and 8 by 8 spins by applying the RG and then calculate the various possible correlations.
Figure 7a shows the correlation function that results from a single RG step. Each panel of the three Figures 7a, 7b and 7c, shows how a given hidden spin is correlated with the visible spins. We can clearly see a peak in correlation values around the spatial location of the hidden spin. This is the signal of RG coarse graining: small spatially localized collections of spins are replaced by their average value. We can go into a little more detail: the patches of large correlation in Figures 7b and 7c are larger in size than those of Figure 7a. This makes sense since each step of the RG implies ever larger spatial regions of the spins are being averaged to produce the coarse grained variables. The fact that the spins that are averaged are spatially localized is a direct consequence of the fact that the Ising model Hamiltonian is local in space so that spatially adjacent spins have similar behaviors. In more general big data settings it may be harder to decide if the coarse graining is RG-like or not, since it might not be clear what is meant by spatial locality.
Having established the signal characteristic of the RG flow, we will now search for this signal in the correlators computed using the configurations generated from the RBM flow. We consider configurations generated by a stacked network with an RBM having 1024 visible nodes and 256 hidden nodes cascading into a second RBM having 256 visible nodes and 64 hidden nodes. We also consider configurations generated by a single RBM network with 1024 visible nodes and 64 hidden nodes. The factor of relating the number of visible to hidden nodes is chosen to mimic the decimation of lattice sites in each step of the RG. The networks are trained on the same data used as input for the RG considered above. Training is through steps of contrastive divergence [28].
Figures 8a-i to 8a-iii show plots for the stacked RBM and Figure 8b for the single RBM network. Figure 8a-iii shows the correlation functions between the visible vectors input to the first network in the stack and the final hidden vectors output from the stack and is to be compared to the corresponding RG result in Figure 7c. The two patterns are very similar suggesting that the trained RBM is indeed performing something like the RG coarse graining.
To quantitatively compare the patterns we observe in the correlators produced by RG to those produced by the RBM we make use of a two point correlation function. When we perform an RG coarse graining we average local nearby nodes from the input (visible lattice) to obtain the output (hidden lattice). This local averaging is encoded in the plots by bright spots. The bright spots correspond to a specific hidden node being highly correlated to a patch of local visible spins. In each plot, the hidden node we consider is fixed and we plot its correlation with all visible nodes. If we denote each value of by we calculate the two point correlator between values and summed over all hidden nodes
[TABLE]
By calculating this quantity, we learn about the size of the correlated patches in the plots. We can plot the value of versus the distance, . This quantity tells us important information about the size of the correlated patches. We average the values of where the distances are equal. The patches present in will thus be detected regardless of where they appear in the plot. If we do have local patches of high correlation, will be peaked at short distances and as distance increases, will decrease in value.
For RG, the plots seen in Figure 9 show a linear fall off in the correlator as distance increases. The fall off of these correlators is in the order of magnitude of . In Figure 10 the behavior of the RBM correlator is shown. Figures 10(a) and 10(c) show similar behavior to that seen for RG. There is a linear decrease in in the same order of magnitude of . A difference between these plots is that the RBM correlators are offset. We do not have an explanation for this offset.
We also study where the visible lattice is of size and the hidden lattice is of size . The correlators are determined using a visible set of 40000 lattices at and the hidden set produced by an application of RG and by applying a trained RBM (which is trained on this same visible data set). The results for are shown in Figure 11. For the RBM (Figure 11(d)) the fall off of the correlator again matches the behavior of RG (Figure 11(b)). For the RBM the fall off trend is clearer with these larger lattice sizes when compared to the RBMs of smaller lattice sizes. There is a slight increase in correlation in Figure 11(d) as the distance nears . This suggests that there are more than 1 local patches of correlation in the RBM plots. In Figure 11(c) we can see that some plots show some speckle with a few highly correlated spots in a single plot. We verify this observation by considering specific correlation patterns below.
To gain more understanding of the information encoded in the two point correlator we consider patterns of white noise in addition to a checkerboard shape with various sizes for the sub-blocks on the checkerboard. This allows us to explore the benefit of studying in probing patterns present in . We show an example of a single hidden node’s correlation with all visible nodes constructed using white noise in Figure 12(a). In Figure 12(b) we can see calculated from the values shown in Figure 12(a). We see different behavior to that observed in Figures 9 and 10. As expected, there is no clear relationship between the value of the two point correlator and the distance between values and .
We also study with a checkerboard pattern as shown in Figure 13. We explore various sub-block sizes within the checkerboard pattern. In Figures 13(a), 13(c) and 13(e) we show the plot with a checkerboard pattern on a lattice of size with sub-blocks of size 4 by 4, 8 by 8 and 16 by 16 respectively. The corresponding two point correlators are shown in Figures 13(b), 13(d) and 13(f). We can see from these plots that having many correlated patches in which are of size , produces a two point correlator which is peaked at a number of points. In the case of Figure 13(f), where the sub-block sizes equal we see similar behavior to that seen in the RBM and RG correlator plots. The additional peaks seen in Figures 13(b) and 13(d) are due to multiple patches in the image being correlated. This behavior is not characteristic of the RG local patches as a single highly correlated patch is present in the RG plots.
There is one more interesting comparison that can be carried out and it quantitatively tests the flow. The temperature is a relevant coupling so it grows as the flow proceeds. In the block spin RG that we are considering, the length of the lattice keeps halving. Thus, after 7 steps our unit of length is times larger than it was. To get some insight into the effect of this change of units, imagine we change units from centimeters to meters. In the new units, a length of cm is now 1m. Anything with the units of length will roughly halve with each step of the flow. In contrast to this, the temperature of the system, which in suitable units has a dimension of inverse length, will roughly double. There will be small departures from precise doubling due to interactions, but the temperature must increase by roughly a factor of 2 as each new layer is stacked. If the RBM is performing an RG-like coarse graining, the temperature should grow in a similar way as we pass through the layers of the deep network. Figure 14a plots the temperature of coarse grained lattices, generated by applying three steps of RG to an input lattice of size 64 by 64, at a temperature of . There is a clear increase in the measured temperature as the number of RG steps increase. The temperature of each layer is roughly , and for layers 1, 2 and 3 respectively, which is indeed consistent with the rough rule that the temperature doubles with each step.
Now consider a deep network made by stacking three RBMs. The first network has 4096 visible nodes and 1024 hidden nodes, the second 1024 visible nodes and 256 hidden nodes and the third 256 visible nodes and 64 hidden nodes. The network is trained on Ising data at the critical temperature, as described above. Figures 14b-i, 14b-ii and 14b-iii give the temperatures of the outputs of the layers of the RBM, given input lattices at temperatures of , and respectively. Temperatures of and lead to the same behavior for the temperature flow, as exhibited in Figures 14b-i and 14b-ii. The temperature jumps rapidly to a high temperature in the first step of the flow, and remains fixed when the second step is taken. This is an important difference that deserves to be understood better. It questions the identification of layers of a deep network with steps in an RG flow.
Figure 14b-iii shows different characteristics to those of 14b-i and 14b-ii. Here the temperature of the input is above at . Layer 1 is not as sharply peaked near as observed in Figures 14b-i and 14b-ii. In addition to this, layers 2 and 3 are not at the same temperature but rather layer 2 is at a higher temperature than layer 3. This differs to the RG flow, where temperature increases along the flow. Figure 14b-iii shows a decrease in temperature from layer 2 to layer 3 rather than an increase. These plots demonstrate that the flow defined by multiple layers in a “deep” network show important differences to the RG flow. The discrepancies we have uncovered are important and precise quantitative mismatches that may provide useful clues in understanding the relationship between unsupervised deep learning by an RBM and the RG flows.
The results above have shown that the correlator exhibits RG-like characteristics. This is evident from the comparison between the plots from RG, a stacked RBM network and a network with a single RBM. We can see RG-like patterns in the correlators produced by the two RBM networks. This is a promising result that demonstrates that a form of coarse graining is taking place when networks are stacked.
V Conclusions and Discussion
Our main goal has been to explore the possibility that RG provides a framework within which a theoretical understanding of deep learning can be pursued. We have focused on a single model, the Ising model, which is naturally related to RBMs. Thus, at best our conclusions and discussion can only suggest interesting avenues for further study. We are not able to draw general definite conclusions about the applicability of RG as a framework within which a theoretical understanding of deep learning can be achieved. Our data set contains the possible states of an Ising magnet, generated using Monte Carlo simulation. This is an interesting data set, since we know that there is a well defined theory for the magnet defined on large length scales. The existence of this long distance theory guarantees that there is some emergent order for the unsupervised learning to identify. Another point worth stressing is that the RG treatment of this system is well understood and is easily implemented numerically. It is therefore an ideal setting in which both deep learning and RG can be implemented and their results can be compared. At the critical temperature, where the system is on the verge of spontaneous magnetization, there is an interesting scale invariant theory which is well understood. By working at this critical point, we have managed to probe the patterns generated by the RBM at different length scales and to compare it to the expected results from an RG treatment.
Our first set of numerical results compare the RBM flow introduced in [15] and further pursued in [16]. From a theoretical point of view the RBM flow looks rather different to RG since the RBM flow appears to drive configurations towards the critical temperature. The RG would drive configurations to ever higher temperatures due to the fact that the temperature corresponds to a relevant perturbation. Another important difference between the RBM flow and RG is that the number of spins is a constant of the RBM flow, but decreases with the RG flow. Our numerical results confirm that the RBM flow does indeed generate RG-like Ising configurations and we have reproduced the scaling dimension of the spin variable from the spatial statistics of the patterns generated by the RBM. This is a remarkable result and it extends and supports results reported and discussed in [15, 16]. The spin variable has the smallest possible scaling dimensions and consequently probes the largest possible scales in the pattern. When considering correlation functions of the next primary operators we find that the RBM data does not reproduce the correct scaling dimension, proving that the spatial statistics of the patterns generated by the RBM flow and those generated by RG start to differ as smaller scales are tested. We therefore conclude that the RBM flow and RG are distinct, but they do agree on the largest scale structure of the generated patterns. This is a hint into the mechanism behind the RBM flow and it deserves an explanation.
Our second numerical study has explored the idea that deep learning is an RG flow with each stacked layer performing a step of RG. We have explained why correlation functions between the visible and hidden neurons, are capable of diagnosing RG-like coarse graining and we have computed these correlation functions using the patterns generated by the RBM. The basic signal of RG coarse graining is a “bright spot” in the correlation function, since this indicates that spins in a localized region were averaged to produce the coarse grained spin. The numerical results do indeed show a dark background with emerging bright spots. It would be interesting if the emergent patterns again guarantee agreement on the largest length scales, similar to what was found for the RBM flows, but we can not confidently make this assertion yet.
Our final numerical study considered the flow of the temperature, a relevant operator according to the RG. We find three distinct behaviors. Section III-B reviewed that RBM flows converge to the critical temperature. This is borne out in our results. The RG flows to ever higher temperatures, with (roughly) a doubling in temperature for each step. Again, this is precisely what we observe. Finally, for a deep network made by stacking three RBMs, the temperature appears to flow when moving between the first and second layers of a deep network, but is fixed when moving between the second and third layers. This is an important difference that deserves to be understood better. It questions the identification of layers of a deep network with steps in an RG flow.
Our results are encouraging. There are enough similarities between unsupervised learning by an RBM and the RG flow that the relationship between the two should be developed further. Regarding future studies, it maybe useful to explore models other than Ising. The Ising model has an unstable fixed point due to the presence of relevant operators. Consequently, finite flows starting near the critical point all terminate on different models. In this case its not easy to know if the RBM has flowed to the “right answer” because there are many possible right answers! The stable fixed point of the model is at infinite temperature and the configurations at this fixed point are random with correlators that have a correlation length of zero. This is hardly a promising answer to shoot for. It maybe more instructive to study models that have an attractive RG fixed point. In this case the minimum that the RBM is looking for would be unique and the connection between the two may be easier to recognize.
We have in mind systems that exhibit self organized criticality [36], including models constructed to understand the spread of forest fires [34] and models for the spread of infectious diseases [35].
By using Ising model data, generated by Monte Carlo simulation, starting from a local Hamiltonian we know how a coarse graining capable of identifying emergent patterns should proceed: spatially neighboring spins should be averaged. For more general data sets, this may not be the case. It is fascinating to ask what the rules determining the correct coarse graining are and in fact, with respect to this question, deep learning has the potential to shed light on RG.
Another interesting comparison worth mentioning is the similarity between an average pooling layer within a convolutional neural network (CNN) and the averaging performed in variational RG. CNNs are known for their excellent performance in image recognition and classification tasks [42, 43, 44]. CNNs have a number of layers which act on groups of nearby pixels in the image. One of these layers which is similar to the coarse graining performed in variational RG is called a pooling layer. The pooling layer performs a down-sampling on the data it receives from previous layers in the network [45, 46, 47]. The down-sampled data is more robust to changes in position of features and gives the network the property of local translation invariance. One way in which the pooling operation is implemented is by averaging all values in the given patch of data it acts on to obtain a new value to replace these values. Pooling usually averages blocks of data which are of size . This results in an input block of data being reduced by a factor of 2 in length and by a factor of 4 in the number of values which is the same factor of rescaling which occurs in variational RG.
In recent years a connection between the renormalization group and tensor networks [48] has been discovered, providing a connection to the field of quantum information. The discovered connection demonstrates that the multi-scale entanglement renormalization ansatz (MERA) tensor networks carry out a coarse graining that agrees in many ways with the coarse graining performed by the renormalization group [49] . This suggests that there maybe a link between tensor networks and deep learning. For related ideas see [50, 51]. Since tensor networks have been extensively studied for calculations the connection may prove to be useful for better understanding deep learning.
Apart from the exciting possibility that the link to RG might contribute towards a theoretical understanding of deep learning, one might also ask if the connection would have any practical applications. One possibility that we are currently pursuing, is a Callan-Symanzik like equation governing the learning process. Roughly speaking, one might mimic RG by dividing the weights to be learned into relevant, marginal and irrelevant parameters, depending on gross statistical properties of the training data. If this classification is itself not too expensive, one could pursue a more efficient approach towards training, since the classification of weights would provide an understanding of which weights are important, and which can simply be set to zero. We hope to report on this possibility in the future.
Acknowledgement
This work is supported by the South African Research Chairs Initiative of the Department of Science and Technology and National Research Foundation as well as funds received from the National Institute for Theoretical Physics (NITheP). We are grateful for useful discussions to Mitchell Cox and Dimitrios Giataganas.
Appendix A RBM expectation values
The expectation values quoted in equations (8), (9) and (10) are derived using (2). Data expectation values are evaluated by summing over all samples, in the training set. On the other hand model expectation values employ sums over the entire space of visible and hidden vectors. This is such an enormous sum that its numerically intractable. Consequently, the approximations described in Section II-A are used. The complete set of expectation values needed to describe the RBM are given by
[TABLE]
[TABLE]
[TABLE]
[TABLE]
[TABLE]
[TABLE]
with the th sample of the data set, .
Appendix B Two Versions of RG
In this section we review two versions of the RG that are needed in this article. The first of these, the variational renormalization group, was introduced by Kadanoff [52, 53, 54] as a method to approximately perform the renormalization group in practice.
B-A Variational RG
Consider a system of spins which each take the values . The partition function describing the system is given by
[TABLE]
Here the sum is over all possible configurations of the system of spins and the function , called the Hamiltonian, gives the energy of the system. This would include the energy of each individual spin as well as the energy associated to the fact that the collection of spins is interacting. The Hamiltonian can be an arbitrarily complicated function of the spins
[TABLE]
The RG flows maps the original Hamiltonian to a new Hamiltonian with a different set of coupling constants. The new Hamiltonian
[TABLE]
gives the energy for the coarse grained spins . After many RG iterations many coupling constants (the so called irrelevant terms) flow to zero. A much smaller number may remain constant (marginal terms) or even grow (relevant terms). To implement this conceptual framework a concrete RG mapping is needed. Variational RG provides a mapping which is not exact but can be implemented numerically. It does this by introducing an operator which is a function of a set of parameters . The Hamiltonian after a step of RG flow is
[TABLE]
The form of must be chosen cleverly, for each problem we consider. This is the tough step in variational RG and it is carried out using physical intuition, but essentially on a trial and error basis. Once a given has been chosen, we minimize the following quantity by choosing the parameters
[TABLE]
The minimum possible value for this quantity is zero. Notice that when
[TABLE]
(79) attains its minimum value of 0 and the RG transformation is called exact.
B-B Block Spin Averaging
Block spin averaging is a pedagogical version of RG. To illustrate the method, consider a rectangular lattice of interacting spins. Divide the lattice into blocks of squares. Block spin averaging describes the system in terms of block variables, which are variables describing the average behavior of each block. The “block spin” is literally the average of the four spins in the block. The plots shown in Figures 7a use block spin averaging. The block spins are each an average of four visible spins .
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Michael I Jordan and Tom M Mitchell. Machine learning: Trends, perspectives, and prospects. Science , 349(6245):255–260, 2015.
- 2[2] Li Deng, Dong Yu, et al. Deep learning: methods and applications. Foundations and Trends® in Signal Processing , 7(3–4):197–387, 2014.
- 3[3] Yoshua Bengio et al. Learning deep architectures for ai. Foundations and trends® in Machine Learning , 2(1):1–127, 2009.
- 4[4] Geoffrey E Hinton and Ruslan R Salakhutdinov. Reducing the dimensionality of data with neural networks. science , 313(5786):504–507, 2006.
- 5[5] Nicolas Le Roux and Yoshua Bengio. Deep belief networks are compact universal approximators. Neural computation , 22(8):2192–2207, 2010.
- 6[6] Nicolas Le Roux and Yoshua Bengio. Representational power of restricted boltzmann machines and deep belief networks. Neural computation , 20(6):1631–1649, 2008.
- 7[7] Yoshua Bengio, Yann Le Cun, et al. Scaling learning algorithms towards ai. Large-scale kernel machines , 34(5):1–41, 2007.
- 8[8] Arnab Paul and Suresh Venkatasubramanian. Why does deep learning work?-a perspective from group theory. ar Xiv preprint ar Xiv:1412.6621 , 2014.
