Macro-action Multi-time scale Dynamic Programming for Energy Management in Buildings with Phase Change Materials
Zahra Rahimpour, Gregor Verbic, Archie C. Chapman

TL;DR
This paper introduces a novel macro-action multi-time scale dynamic programming approach for energy management in buildings with phase change materials, significantly reducing computational complexity while optimizing HVAC scheduling.
Contribution
It develops a new methodology combining macro actions and multi-time scale Markov decision processes to efficiently solve nonlinear energy management problems in buildings.
Findings
Achieves up to 12,900 times speed-up over traditional DP methods.
Effectively manages nonlinear and non-convex PCM characteristics.
Demonstrates practical applicability in residential building energy management.
Abstract
This paper focuses on energy management in buildings with phase change material (PCM), which is primarily used to improve thermal performance, but can also serve as an energy storage system. In this setting, optimal scheduling of an HVAC system is challenging because of the nonlinear and non-convex characteristics of the PCM, which makes solving the corresponding optimization problem using conventional optimization techniques impractical. Instead, we use dynamic programming (DP) to deal with the nonlinear nature of the PCM. To overcome DP's curse of dimensionality, this paper proposes a novel methodology to reduce the computational burden, while maintaining the quality of the solution. Specifically, the method incorporates approaches from sequential decision making in artificial intelligence, including macro actions and multi-time scale Markov decision processes, coupled with an…
Click any figure to enlarge with its caption.
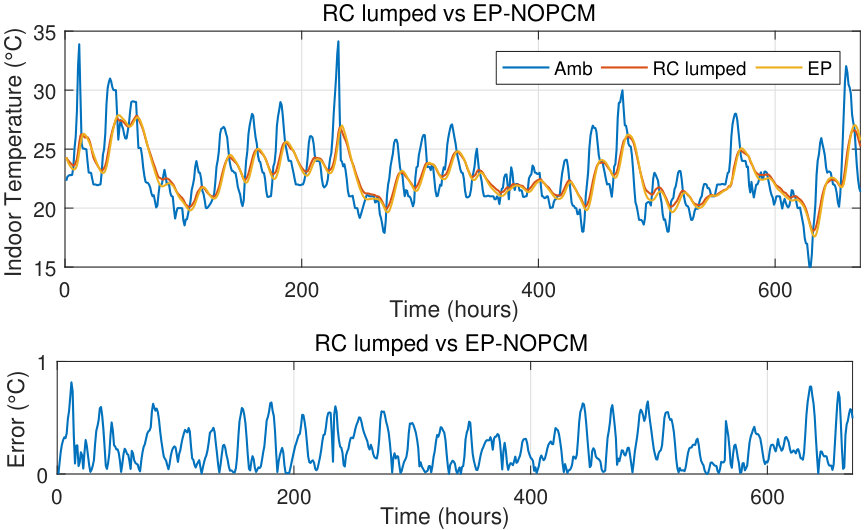 Figure 1
Figure 1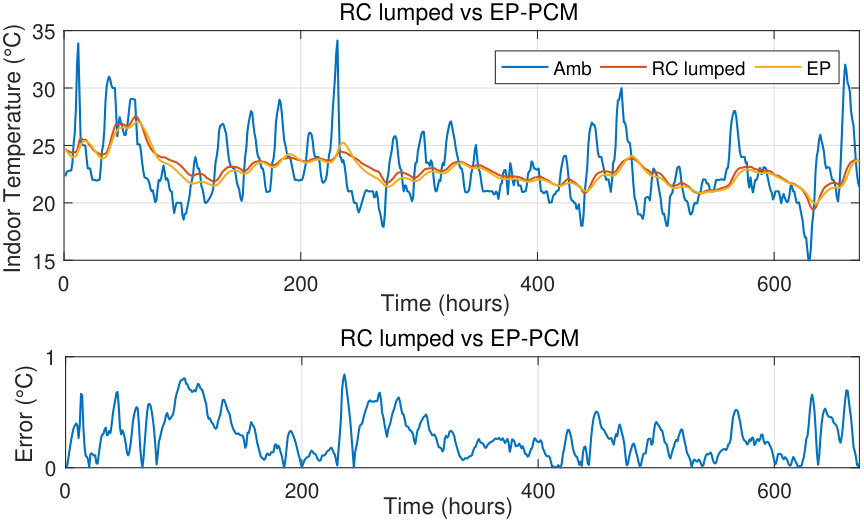 Figure 2
Figure 2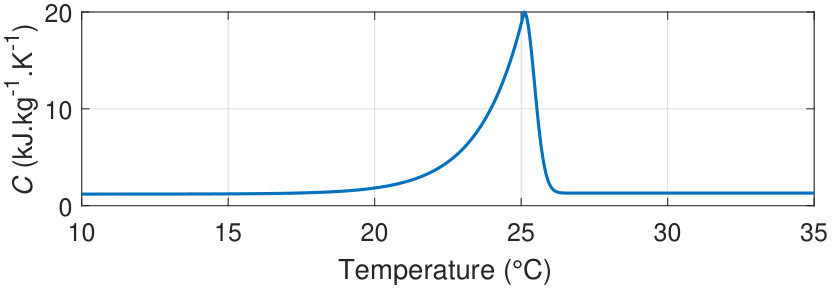 Figure 3
Figure 3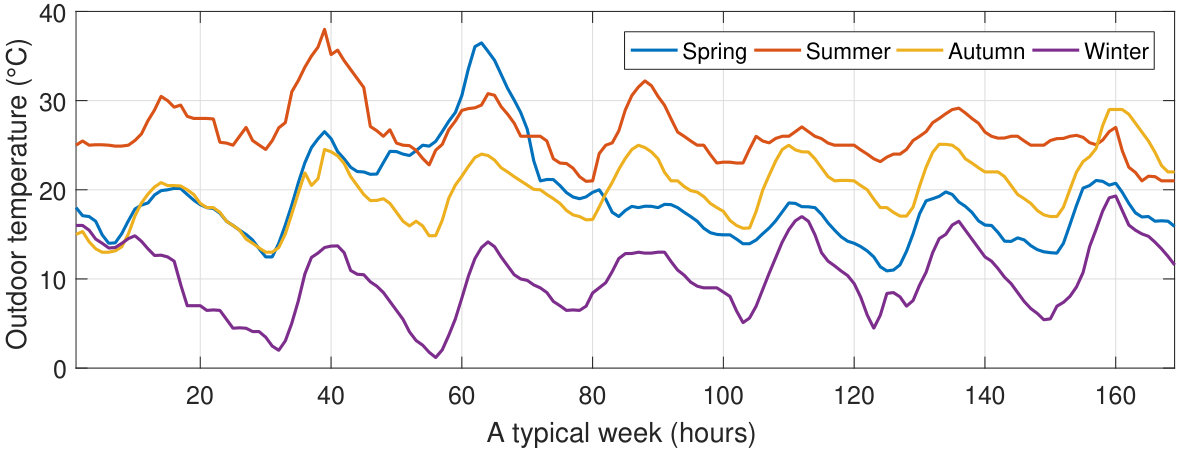 Figure 4
Figure 4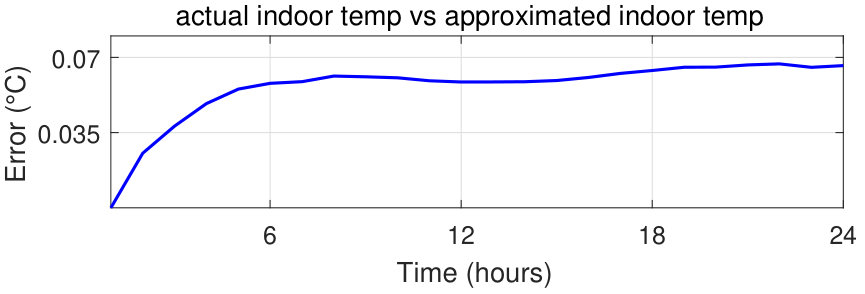 Figure 5
Figure 5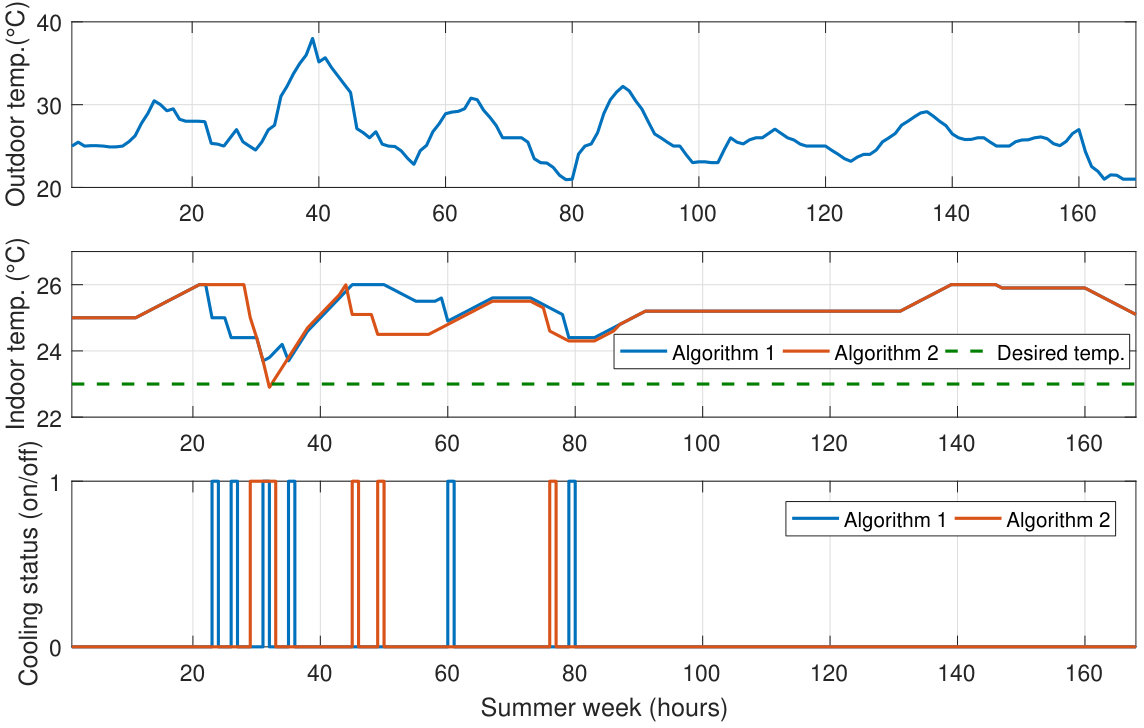 Figure 6
Figure 6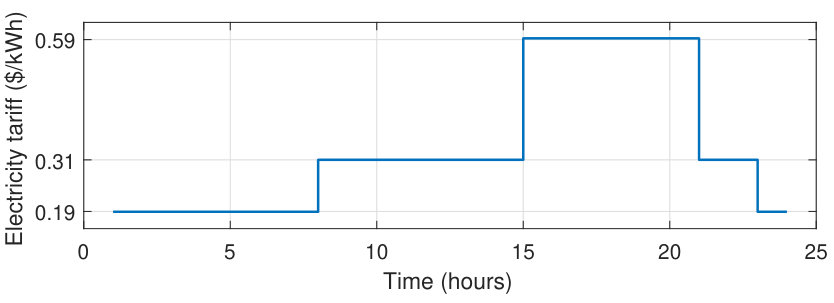 Figure 7
Figure 7_Figures_EMP3.jpg) Figure 8
Figure 8_Figures_EMP4.jpg) Figure 9
Figure 9_Figures_SH.jpg) Figure 10
Figure 10_Figures_fourseasons.jpg) Figure 11
Figure 11_Figures_rmse24n.jpg) Figure 12
Figure 12_Figures_sim1.jpg) Figure 13
Figure 13_Figures_tariff.jpg) Figure 14
Figure 14| Season | Spring | Summer | Autumn | Winter | |||||||
| HVAC system with deadband relay |
|
26 | 12 | 14 | 93 | ||||||
| Average cumulative cost | Electricity cost ($) | 14.62 | 11.14 | 7.69 | 57.24 | ||||||
| Discomfort () | 325.24 | 301.47 | 251.74 | 200.71 | |||||||
| Spring | Summer | Autumn | Winter | Spring | Summer | Autumn | Winter | ||||
| ALG 1 |
|
23 | 19 | 11 | 74 | 34 | 28 | 38 | 71 | ||
| Average cumulative cost | Electricity cost ($) | 11.53 | 8.20 | 4.48 | 40.89 | 21.64 | 22.86 | 19.20 | 46.21 | ||
| Discomfort () | 202.14 | 112.08 | 258.95 | 155.44 | 156.36 | 37.79 | 218.37 | 110.41 | |||
| Spring | Summer | Autumn | Winter | Spring | Summer | Autumn | Winter | ||||
| ALG 2 against ALG 1 | Max. MAE of indoor temp. of optimal policy () | 1.5 | 1.6 | 1.2 | 2.0 | 1.3 | 1.1 | 2.1 | 1.3 | ||
| MAE of the cumulative cost | Elect. cost error (%) | 7.89 | 6.71 | 14.95 | 6.11 | 2.86 | 1.88 | 20.83 | 0.84 | ||
| Discomfort error (%) | 7.14 | 13.94 | 5.48 | 10.63 | 6.38 | 15.85 | 2.93 | 19.95 | |||
|
1.39 | 0.49 | 0.66 | 0.95 | 0.61 | 0.54 | 3.59 | 0.96 | |||
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSmart Grid Energy Management · Microgrid Control and Optimization · Building Energy and Comfort Optimization
Macro-action Multi-time scale
Dynamic Programming for Energy Management
in Buildings with Phase Change Materials
Zahra Rahimpour1, Gregor Verbič1, Archie Chapman2
1School of Electrical and Information Engineering, University of Sydney, NSW, Australia
2School of Information Technology and Electrical Engineering, University of Queensland, QLD, Australia
Email:{zahra.rahimpour, gregor.verbic}@sydney.edu.au
Abstract
This paper focuses on energy management in buildings with phase change material (PCM), which is primarily used to improve thermal performance, but can also serve as an energy storage system. In this setting, optimal scheduling of an HVAC system is challenging because of the nonlinear and non-convex characteristics of the PCM, which makes solving the corresponding optimization problem using conventional optimization techniques impractical. Instead, we use dynamic programming (DP) to deal with the nonlinear nature of the PCM. To overcome DP’s curse of dimensionality, this paper proposes a novel methodology to reduce the computational burden, while maintaining the quality of the solution. Specifically, the method incorporates approaches from sequential decision making in artificial intelligence, including macro actions and multi-timescale Markov decision processes, coupled with an underlying state-space approximation to reduce the state-space and action-space size. The performance of the method is demonstrated on an energy management problem for a typical residential building located in Sydney, Australia. The results demonstrate that the proposed method performs well with a computational speed-up of up to 12,900 times compared to the direct application of DP.
Index Terms:
Demand response, dynamic programming, home energy management, macro actions, multi-timescale Markov decision processes, thermal inertia, phase change materials.
I Introduction
The significant contribution of heating, ventilation, and air conditioning (HVAC) in building energy use (up to in certain countries) and the total contribution of buildings to the overall energy consumption (-), make space heating and cooling of growing importance in the area of demand response (DR)111Demand response refers to methods for influencing end-users to use available flexible resources to support network and system services such as load balancing, peak load shaving, and peak load shifting. [1]. A potential DR resource available to householders is to use their building’s thermal inertia as an energy storage system. However, lightweight buildings, which dominate the residential building stock in Australia and which are the focus of our paper, have low thermal inertia. A promising solution to increase their thermal inertia is to use materials with a high heat capacity, such as phase change materials (PCM). Storing or releasing the latent heat during the phase-change (from solid to liquid or vice versa) provides the building with sufficient thermal mass to smooth indoor temperature fluctuations.
However, to exploit the energy storage capacity of PCM cost-effectively, it needs to be either precooled or preheated (depending on the season) by the HVAC system during shoulder or off-peak hours. This task can be cast as an optimal HVAC scheduling problem, with an objective of minimizing electricity cost while maintaining the indoor temperature within the desired comfort range. In the existing literature, this type of optimization problem is classified as a home energy management (HEM) problem [2, 3, 4]. In spite of the ample literature on the use of PCM for improving thermal performance of buildings [5, 6, 7, 8, 9, 10, 11], there is a palpable lack of understanding on how to integrate PCM into HEM, where the non-linear nature of its energy storage can be be exploited using suitable scheduling methods.
To bridge this gap, and in contrast to much of the literature on HEM [2, 3, 4], we consider HEM that consists of an HVAC system as a controllable device and a PCM layer as an energy storage system. To date, most HEM optimization problems are solved using linear programming (LP) and mixed integer linear programming (MILP). However, these methods cannot be used to solve nonlinear optimization problems, which phase-change characteristics impart. Other methods that are widely used to solve the HEM problems are heuristic methods, such as particle swarm optimization (PSO) and genetic algorithms (GA). The downside of using these methods is that the solution may end up in a local optimum instead of the global optimum, which means the quality of the solution is uncertain [12]. More importantly, PSO and GA are black-box optimization routines, and in our specific problem they rely on the huge computational task of solving the initial value problems associated with the ordinary differential equations that govern the building’s thermal behavior. In this sense, they provide no benefit over using principled optimization methods like dynamic programming (DP) [13, 3].
In this paper, DP is used as the state-of-the-art algorithm for dealing with the nonlinear features of PCM. To solve our problem using DP, we first formulate it as a Markov decision process (MDP), where the objective is to minimize the accumulated instantaneous cost over a scheduling horizon. The main operator in DP is the value function, which is formed by summing the expected future costs of following a policy (in this problem specific on/off sequence of the HVAC system), given the state transition probabilities. Importantly, the objective is equivalent to computing the minimum value function of the problem. To do so, the value iteration (VI) algorithm is typically employed, which computes the minimum value function in a backward fashion using the Bellman optimality condition222An optimal policy has the property that whatever the initial state and initial decision are, the remaining decisions must constitute an optimal policy with regard to the state resulting from the first [13].. However, VI becomes intractable when the time-horizon of the problem, the number of state variables or the number of controllable devices grow. In the DP literature, this is known as the curse of dimensionality [13].
As such, in the HVAC-PCM HEM problem, as in many sequential decision problems in artificial intelligence (AI), large state-spaces and long time-horizons contribute to a considerable computational challenge. In response, the AI literature contains many methods and frameworks for dealing with such large or complex problems. Given this, in the next section, we present a brief review of three existing methods from AI that we use to build our computational methodology, namely state-space approximation, multi-timescale Markov decision processes and macro actions. It is worth noting that the cornerstone of all these methods is the concept of abstraction. In general, an abstraction is a compact representation of the original problem that is easier to work with than the ground representation. Each abstraction method we use works in a different way to reduce the complexity of the HVAC-PCM scheduling problem.
I-A Review of three abstraction approaches in AI
We now review the three abstraction methods: state-space approximations, multi-timescale MDPs, and macro actions.
State-space approximations — The foundation of our method is to discretize the continuous state-space, which is a standard approach to reducing its complexity [14]. However, we still left with a large state-space, so we build on this using the following two methods.
Multi-timescale Markov decision processes — The second abstraction approach to reducing the state-space size is to use a multi-timescale MDP, in which decisions are made at different discrete timescales [15]. Specifically, rather than solving the original MDP as one monolithic problem, we solve several smaller MDPs that are connected successively together to form the original MDP. The computation time of the resulting algorithm depends on the choice of each MDP’s length, and can be tuned for good performance. In our problem, using a multi-timescales model reduces computation time by up to 5,300 times.
Macro actions — The third approach is to use macro actions to reduce the action-space size [16]. This approach finds commonalities in the solutions across regions of the state-space to create macro actions, which result in significant computational savings over using the primitive action-space. In our methodology, we build on the multi-timescale MDP and treat nearly-identical policies as equivalent. This itself reduces the number of policies to consider by one third and speeds up the performance of the algorithm further by 2.4 times. However, the major limitation of applying macro actions is the quality of the solution. Certain policies cannot be captured since, in the macro-action MDP, the policies contain only macro actions. Therefore, the resulting policy may be suboptimal [17]; however, this results in poor performance only if the macro actions themselves are poorly selected [18].
I-B Contributions of the paper
The main technical contribution of this paper is to develop a computationally efficient algorithm for scheduling a controllable HVAC system in buildings with PCM. To our knowledge, this work is the first attempt to solve an optimization problem in buildings with PCM. Beyond this, the paper advances the state of the art in the following ways:
We derive a novel and computationally-efficient optimization method for online non-linear scheduling, which exploits several techniques from AI in one framework. 2. 2.
We demonstrate the method on a HVAC scheduling problem in a typical PCM-building, incorporating a non-linear RC lumped thermal model. 3. 3.
We evaluate the method on four different seasonal weather conditions, with results showing that the method has good accuracy over DP, and provides a considerable electricity cost saving over a deadband controller. 4. 4.
The proposed method gives substantial computational speed-ups, as much as 12,900 times faster than DP. 5. 5.
The method described in this paper can be implemented on current smart meters and IoT gateway devices, such as those built on Raspberry Pi boards.
I-C Outline of the paper
This paper progresses as follows: in Section II, a thermal model of a PCM-building is built in MATLAB, and validated by benchmarking it against an identical model in EnergyPlus333EnergyPlus is a software tool that is widely used for simulating the thermal behavior of buildings.. In Section III, the optimization problem of the PCM-building is formulated as an MDP, and the value iteration algorithm is used to solve it. Section IV contains the main technical contributions of this paper, where the proposed methodology of macro-action multi-timescale dynamic programming is derived. In Section V, the method is implemented on a typical PCM-building in Sydney, and its performance is evaluated over four seasonal weather conditions. Section VI concludes and outlines future directions of this work.
II Thermal RC lumped model of PCM-buildings
To formulate the HVAC-PCM optimization problem, we need a thermal model of the building that strikes the right balance between accuracy and computational efficiency. Therefore, we first build a thermal model of a PCM-building in MATLAB, which we then evaluate by benchmarking it against an identical model in the EnergyPlus software.
II-A *Thermal model of PCM-building *
A simple way of modeling the thermal performance of a building is using an RC representation of each building element, which is known as an RC lumped model[19, 20]. For simplicity, we use a 2RC model, where all elements of the wall, roof, and floor are lumped together into two lumped resistances and one lumped capacitance, as shown in Fig. 1. The circuit is thermally excited by the internal heat flow, including the HVAC system , and natural air infiltration , and the outside temperature . The building’s interior is simulated as a single capacitor , which captures the heat capacity of air. Elements like doors and windows have negligible thermal inertia, so they are modeled using resistance in parallel with the lumped model of the wall.
The dominant capacitance in the model is +, which captures the combined the thermal inertia of the envelope and the PCM layer. The building’s envelope is made up of three layers: rendered fibro-cement, a timber stud wall containing insulation batts, and plasterboard on the inside444The materials and configuration are chosen based on a common practice in lightweight building in Australia [21].. To improve the thermal inertia, PCM is added as a layer underneath the plasterboard. Therefore, two layers with significant amount of thermal mass (PCM layer and timber wall) are placed adjacent and can be lumped together as a single capacitance. The parameters are chosen so that the model represents a single-zone 8\text{\,}\mathrm{m}$\times$6\text{\,}\mathrm{m}$\times$2.7\text{\,}\mathrm{m} cuboid with a total floor area of . The detailed calculations of the resistances and capacitances of the model can be found in [22].
The specific heat capacity characteristic of the PCM used in this paper is shown Fig. 2. Observe that the phase change occurs over the range between and . The melting point is at , where the specific heat capacity is the largest. The PCM melting point is an important design parameter, chosen to reflect the occupants’ comfortable temperature range. The PCM specific heat capacity is given by:
[TABLE]
where is the melting point of the PCM. Finally, the thermal model of a PCM building consists of two first-order differential equations capturing the energy balance at the two nodes defined by, respectively, the indoor temperature and the surface temperature of the PCM layer :
[TABLE]
[TABLE]
Note that due to the discontinuity in (1a) and (1b), the PCM heat capacity curve needs to be fitted with a polynomial function before it can be used to numerically solve (2).
II-B Benchmarking thermal model against EnergyPlus
We now compare the performance of the RC lumped model implemented in MATLAB against an identical model in EnegyPlus, using the indoor temperature of the building for comparison. Simulations are performed for a typical summer month (1–28 February) in Sydney. We use the root-mean-square error (RMSE) as comparison metric. Observe in Figs. 3 and 4 that the models match well in both scenarios, with and without PCM, with the maximum RMSE value not exceeding ; this is acceptable with respect to the model uncertainty and human temperature sensitivity.
III Home energy management in PCM buildings
In this section, we present an MDP formulation of the HVAC-PCM optimization problem using differential equations (2) and (3) of the validated model as transition functions. Then we show how to use DP to solve the optimization problem.
An MDP comprises a state-space, , a decision-space, , transition functions and contribution functions. Let denote a time-step of one hour. A state variable, , contains the information that is necessary and sufficient to make the decisions and compute costs, rewards and transitions. The decision variable, , is an action that results in a transition from one state to another, in a sequence over the decision horizon. Finally, random effects are in general used to represent chance exogenous information, such as weather conditions or inhabitants’ behavioural patterns [2]. However, for simplicity and because we focus on the non-linear characteristics of PCM, in this work the problem is treated as deterministic, and as such, random effects are omitted and left for future work. Thus, the form of the HVAC-PCM MDP is given by
[TABLE]
where is a policy, i.e. a sequence of actions taken to move from each state to the next state over the whole time horizon. In this work, a policy is a sequence of on/off status of the HVAC system over a defined time horizon.
The function is the contribution function, which is the cost incurred at a given time-step that accumulates over time [2]. For our specific optimization problem, the cost consists of the electricity cost and the discomfort cost:
[TABLE]
To balance the two cost components, the contribution function includes a weighting factor , applied to the electricity cost, with () applied to the penalty for deviating from the desired HVAC set point . We assume a reverse-cycle HVAC system able to operate both in a heating and cooling mode. The setpoint for the two modes is assumed and , respectively. The electricity cost of the HVAC system is the electricity time-of-use tariff, (), multiplied by the energy used to run the HVAC system, .
Referring back to (III), let describe the state evolution from time step to the next time step, , where is the underlying mathematical model of the studied system [2]. In this problem, the system model is the thermal model of the building, so the MDP transition functions are given by (2) and (3).
Cost function (5), only considers the instantaneous cost that results from the decision that is taken at each time step. Building on this, DP solves the optimization problem by computing a value function , which is the expected future discounted cost of following policy starting in state . It is given by:
[TABLE]
where is the transition probability of landing on state from if we take action [2]. However, because the system model, is a deterministic function, we have
[TABLE]
making the calculation simpler than in the stochastic case.
The expression in (6) is a recursive reformulation of the objective function. Thus, in general, Bellman’s optimality condition states that the optimal value function is given by
[TABLE]
where is an optimal policy. To find , we need to solve (8) for each state.
Value iteration (VI) is the process of computing (8) for each state by backward induction; that is, starting at the end points of the MDP. The optimal policy is extracted from the optimal value function by selecting the minimum value action for each state. To describe this in a simple way, in VI, the desired state in step is set to the lower value while the undesired states and states that are out of comfort bounds are penalized by assigning higher values. Then, for all possible states at time , the VI algorithm moves backward in time and, in each time step, by solving the subproblem in (8), the minimum value function is computed for different states of each time step. In the final step of backward induction, corresponding to the initial starting point, all value function calculations converge to the optimal value function. Then, by tracing a minimum value-function path forward for a given time horizon, the optimal policy is found [2].
However, despite advancements in computation power, directly applying VI (or other exact DP algorithms) has an excessively high computational burden. Although we consider only one state-variable representing the indoor temperature of the building, the running time of the VI algorithm for a decision horizon of 24 hours with slot length of one hour is very long; in this problem, the running time is almost nine days on a high-performance computer cluster. The main reason behind this is that at each time step, the algorithm solves differential equations (2) and (3) for each action to update the MDP state, and this is repeated until the initial starting state is reached. Given this shortcoming, we now propose a method to overcome the computational burden of the DP algorithm.
IV Methodology
In this section, we describe our methodology in three steps, namely: state-space approximation, multi-time scale MDP, and macro-action abstraction.
IV-A State-space approximation
We now describe the state-space approximation used as a first step to deal with the computational burden of DP. However, before explaining the methodology, a few terms need to be defined. We call the MDP that uses equations (2) and (3) without any change, the exact model. The output of the exact model in each time-step is a state (indoor temperature), which we call the exact state. If we consider all the possible states over the decision horizon, we call that the exact state-space. The corresponding terms in the approximated methodology are called, respectively, the approximate model, approximated state and approximated state-space.
The proposed approximation involves rounding the output of differential equations (2) and (3) in each time step to the nearest multiple of 0.1. Given this, depending on the state trajectory of the exact model, an approximate state may cover more than one exact state, which improves the computational performance of the VI algorithm by reusing the computed state transitions and sub-problem solutions. In more detail, for the desired comfort range between and and assuming a penalty for out-of-bound temperatures, any state in the state-space is a value between and with a discretization. In other words, we can group the whole desired state-space into 61 groups. This approximation is acceptable as long as it does not affect the quality of the optimization solution. This is demonstrated in the first part of Section V, by defining metrics to measure the quality of the solution resulting from this state-space approximation. The approximated MDPs that are developed in this section, will be used as a ground MDP for the multi-time scale MDP and macro-action abstraction.
IV-B Multi-timescale Markov decision processes
Applying a multi-timescale abstraction significantly reduces the computational burden of energy management optimization problem. Building on the approximated state-space introduced above, we divide the time-horizon of the problem into blocks, each consisting of four time-steps (hours). We note that the performance of our methodology highly depends on the length of each block. Through the process of trial and error, we found that choosing four time-steps for each block strikes the right balance between the number of blocks and the length of each block, and results in the highest speed-up. For reference, we denote the multi-timescale method Algorithm 1 (Alg 1). We can formulate each block as a separate MDP; therefore, we solve a few successive block-MDPs using VI to find the optimal policy over the whole time-horizon.
As described in the pseudocode of Alg 1, first we apply VI algorithm on the last block-MDP (Lines 1-11). In more detail, we set the corresponding value functions in the last time step to zero for the states that have a value within the desired comfort range, and assign a high value for the states with the values out of the comfort range (Lines 5-9). To exploit the advantage of the approximated state-space, we run the VI algorithm for 61 (20:0.1:26) initial points (Lines 1 and 13) for each block-MDP except the first one. We save all the optimal value functions that correspond to each of the 61 initial points in look-up tables (Lines 10 and 23). Before running VI on the remaining block-MDPs, we update the initial value functions by replacing the corresponding value function of the current state. In more detail, we find the initial states that have the same value as the current state and replace the corresponding value functions as the initial value functions of the current block-MDP (Lines 18-19 and Lines 31-32). This process repeats until the first block-MDP. To find a solution for the optimization problem over a defined time-horizon, we need to fix either the initial or the final temperature. In this work, we provide the Alg 1 with a fixed initial temperature (Line 26). Therefore, we have only one VI to run for the first MDP.
Comparing the results of Alg 1 with a one-block MDP model shows that both methods converge to the exactly same solution. This corroborates with Sutton’s result that -block MDPs act exactly same as the corresponding one-block MDP [15]. The mathematical proof of this claim, tailored to our setting, is given in the online Appendix. Our simulations show that using Alg 1 reduces the computational burden of finding the optimal policy by a factor of 5,300.
IV-C Macro actions
Building on Alg 1, we now describe the macro-action abstraction. This is a widely-used method for reducing the size of a state-space. After running VI on each block-MDP for different initial points and observing the corresponding state-spaces, we define the macro actions. Specifically, the contribution function of the ground MDP (5) is modified to:
[TABLE]
where is a percentage of the HVAC system rated power used for the abstraction, and is the abstract state-space. To be clear, each ground MDP over four-time steps has possible policies consisting of primitive actions. These 16 policies are all the possible on/off permutations of the HVAC system over four-time steps. Under our defined macro actions, all 16 combinatorial arrangement of zero, one, two, three and four hours of operation of the HVAC system have the corresponding compact representations of no operation, or four hours operation of HVAC system at , , and rated power, respectively. This is illustrated in Fig. 5.
To this end, we implement our methodology in two phases, and call it Algorithm 2 (Alg 2). In the first phase, we implement Alg 1 on MDPs with macro actions. These solutions differ from those of Alg 1, which is applied to the MDP with primitive actions (Section IV-B). Then, in the second phase, we expand the optimal macro-policies for the next-executed block-MDP to their related primitive policies, as shown in Fig. 5. Sequentially expanding the optimal policy of these new MDPs gives the overall policy computed by Alg 2. Our simulation results in Section V show that policies produced by Alg 2 are close to those found with Alg 1, so they can be assumed near-optimal.
V Evaluation and discussion
We begin by evaluating the loss in the solution quality resulting from the state-space approximation. We then examine the quality of the policies computed using, respectively, Alg 1 and Alg 2, and compare their computational performance.
We define three measures of the solution quality, which we use in Section V-A. These are: (i) mean-absolute error (MAE) of the approximated state-space against the exact state-space (i.e. the temperature error), (ii) MAE of the final value function resulting from applying VI on the approximated state-space versus the final value function resulting from applying VI on the exact state-space without temperature discretization, and (iii) normalized calibration error between the optimal policy using DP on the approximated state-space compared to the optimal policy using DP on the exact state-space555Here we use the term calibration in the statistical sense, to measure the fit of the approximate DP method to exact DP.. In Section V-B, similar measures are used to compare the results of Alg 1 and Alg 2.
The simulations of the Section V-B were run in MATLAB using a computing platform with an Intel 2.7 GHz i7-7500U CPU, 64-bit operating system and 16 GB RAM, while for Section V-A, we used a high-performance computer cluster due to the excessive computational burden.
V-A Benefits of the state-space approximation
As mentioned in the previous section, the runtime of the exact VI for a time horizon of 24 hours is nine days. Thus, we consider the benefits of using state-space approximation, and calculate the performance metrics, for only one typical summer day in Sydney. To have a reasonable population to assess the approximation by the three criteria above, we generated both the approximated and the exact state-space for the 61 initial points between and with a discretization.
First, we calculate the MAE of the approximated state-space, which represents the indoor temperature versus the actual state-space over a time horizon of 24 hours. The maximum error is approximately , which is small and acceptable.
Second, as mentioned in Section III, the final value function (5) consists of two parts: the electricity cost and the discomfort cost. For each, the MAE is calculated separately. The results show that the MAE of the electricity cost for is 0.74 cents, relative to an average value of 8.08 cents. For the discomfort cost, the MAE is about relative to an average of . These results indicate that the error of the final value function is acceptable.
Third, the approximation is also verified further by examining the calibration error between the optimal policy of the exact and approximated models over a 24-hour horizon. To calculate the calibration error for each starting point, the difference in the number of on-cycles in the equivalent optimal policy is divided by a total number of time steps (24), and the results are averaged over the 61 starting points. Comparing the two cases shows that the difference in the number of on-cycles in the optimal policies is zero in 60 out of the total 61 studied cases. In the last case, the difference is one on-cycle, giving a calibration error of , which is acceptable.
Overall, these results demonstrate the efficacy of the state-space approximation, particularly in terms of model accuracy, which permits us to move on to Alg 1 and Alg 2.
V-B Evaluation of Algorithm 1 and Algorithm 2
We now evaluate the proposed methodology, Alg 2, and the approach using only the multiple timescales abstraction, Alg 1, in order to ascertain the benefits of the multi-timescale and macro-action abstractions. Moreover, to get a better sense of the benefits of using optimal HVAC scheduling in PCM-buildings, the algorithms are compared to a simple deadband relay for controlling the HVAC system. Furthermore, to demonstrate the ability of the two algorithms to capture the customer preferences in terms of electricity cost and comfort, the algorithms are run for two different weighting factors: (more weight on the electricity cost) and (more weight on the thermal discomfort). The results for four typical weeks, one for each season, are summarized in Table I. The temperature profiles of the four weeks are shown in Fig. 6.
V-B1 Deadband policy vs. Alg 1
To begin, we consider a conventional HVAC system operating with a deadband control. We simulate an identical home with an identical HVAC system. The only difference is that the HVAC system is controlled using a deadband controller as opposed to optimal scheduling used in Alg 1 and Alg 2. The deadband range is set between and for heating, and between and for cooling. The simulations are run for 61 initial points. We record the average number of HVAC operating hours and the average cumulative electricity cost, and compare the performance of the HVAC system with a deadband relay against Alg 1.
The results show considerable benefits from using optimization over simple deadband control. Specifically, using Alg 1 for a typical winter week with a weighting factor of reduces the number of HVAC operating hours by . Importantly, both cost function components see improvements: the electricity cost decreases by , while the number of discomfort hours also decreases by . In contrast, in summer, applying Alg 1 increases the number of HVAC operating hours by a factor of 2.3, which increases the electricity cost by a factor of two. The number of discomfort hours, on the other hand, reduces by , which is to be expected given that a much higher weight () is given to the comfort of the occupants. Putting more weight on the electricity cost () reduces the electricity cost by at the expense of a slightly lower reduction in the thermal discomfort (now ), which goes to show that the weighting factor has to be carefully tuned for optimal performance with respect to customers’ preferences.
The only season when doesn’t result in the reduction in both cost components is Autumn. However, the increase in discomfort is only while the reduction in electricity cost is significant (about ), which confirms the superiority of Alg 1 over the deadband control.
V-B2 Alg 1 vs. Alg 2
Finally, we evaluate Alg 2 with respect to Alg 1, using as a comparison metrics: (i) maximum MAE of the indoor temperature; (ii) MAE of the cumulative cost expressed as a percentage deviation from Alg 1; and, (iii) the normalized calibration error. We compute the first measure only for the optimal policy rather than for the whole state-space, because using macro actions in Alg 2, results in a different size of the state-space compared to Alg 1.
The results for the first metric show that the maximum MAE of the indoor temperature over four typical weeks for and , are and , respectively, which is about on average per hour. For the second metric, using macro-action abstraction in Alg 2 reduces the solution quality compared to Alg 1 by up to at most (electricity cost in Autumn and discomfort in Winter, both for ), but is otherwise mostly below . The third metric, the maximum calibration error, over four case studies is and for and , respectively. This implies that the optimal policies from Alg 2 and Alg 1 have a very similar number of on-cycles.
Overall, the results of these three metrics show that the performance of Alg 2 is comparable compared to Alg 1. Note that there is a trade-off between the superior runtime of Alg 2 and a better accuracy of Alg 1 in tracking the optimal policy. These errors may be mitigated by adding extra macro actions, but this will in turn reduce the computational efficiency of Alg 2.
To visually compare the performance of the two algorithms, Fig. 7 shows the indoor temperature and the HVAC schedule for the two algorithms for a typical summer week. Observe that the both temperature profiles are within the desired comfort range, with only a slight difference in the second day when the the on/off schedules of the HVAC system don’t match. It is worth mentioning that the indoor temperature for some hours such as 0-10 and 90-130, is constant, and this where phase change occurs. During this phase change, the PCM absorbs the heat from the building’s interior and keeps the indoor temperature of the building within the desired range.
We have also compared the runtime of both algorithms to be able to quantify the computational cost saving resulting from the use of macro-action and multi-timescale abstractions. We can observe a speedup of up to 12,900 times compared to the direct application of DP. The use of macro actions in Alg 2 results in a speedup of up to 2.4 times compared to Alg 1.
VI Conclusion
In this work, we have addressed the computational challenge of solving an optimization problem in buildings with PCM. We have developed a computationally efficient macro-action multi-timescale algorithm to deal with the computational burden of a large non-linear, non-convex HVAC scheduling problem. We demonstrated the efficacy of the proposed approach on a typical PCM-building over four typical weeks that are representative of four seasons in Sydney. The results demonstrate the superior computational performance of the proposed scheduling algorithm compared to a direct application of DP while maintaining an acceptable solution quality. The results also show that the weighting of the electricity and the discomfort costs in the objective function have to be selected carefully to ensure an optimal trade-off between electricity expenditure and thermal discomfort.
In future work, we will consider stochastic exogenous inputs, such as weather conditions and occupants’ behavior, which in this paper were considered deterministic.
Appendix A
Here we briefly explain the proof of the multi-timescale approach presented Section IV-B. The proof is based on a generalized Bellman equation [15]
[TABLE]
The model is valid if it satisfies (10) for any and , with , where is the number of the MDPs in the model. For any valid model, we can update the value function through lookahead or backup operation as follows:
[TABLE]
As long as the model is valid it converges to the same value function regardless of the number of steps:
[TABLE]
To prove that the solution of a multi-timescale MDP is the same as the solution of an one-step MDP, we need to prove that an -step model formulation satisfies the generalized Bellman equation (10).
Theorem @slowromancapvi.1@: A multi timescale or an -step model that has a general form (13) satisfies the generalized Bellman equation (10).
[TABLE]
where is the n-step truncated return starting from state .
Proof: We combine and and the initial value into a matrix :
[TABLE]
If the vector is also augmented by adding an initial component whose value is always , then the generalized Bellman equation (10), can be written as
[TABLE]
Same as before, we consider model to be valid if and only if it satisfies (14). For any valid model , the composed model is also valid because
[TABLE]
Note that has been constructed such that it is valid only if the corresponding and are valid. Therefore, (15) proves the validity of the -step model (13).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] L. Pérez-Lombard, J. Ortiz, and C. Pout, “A review on buildings energy consumption information,” Energy and Buildings , vol. 40, no. 3, pp. 394–398, 2008.
- 2[2] C. Keerthisinghe, G. Verbič, and A. C. Chapman, “A fast technique for smart home management: ADP with temporal difference learning,” IEEE Transactions on Smart Grid , vol. 9, no. 4, pp. 3291–3303, 2018.
- 3[3] H. Tischer and G. Verbič, “Towards a smart home energy management system - A dynamic programming approach,” in 2011 IEEE Innovative Smart Grid Technologies - Asia (ISGT-Asia) . IEEE, 2011.
- 4[4] M. Pipattanasomporn, M. Kuzlu, and S. Rahman, “An algorithm for intelligent home energy management and demand response analysis,” IEEE Transactions on Smart Grid , vol. 3, no. 4, pp. 2166–2173, 2012.
- 5[5] C. Castellón, A. Castell, M. Medrano, I. Martorell, and L. Cabeza, “Experimental study of PCM inclusion in different building envelopes,” Journal of Solar Energy Engineering , vol. 131, no. 4, 2009.
- 6[6] G. Evola, N. Papa, F. Sicurella, and E. Wurtz, “Simulation of the behaviour of phase change materials for the improvement of thermal comfort in lightweight buildings,” in 12th Conference of International Building Performance Simulation Association , 2011.
- 7[7] Y. Konuklu, M. Ostry, H. O. Paksoy, and P. Charvat, “Review on using microencapsulated phase change materials (PCM) in building applications,” Energy and Buildings , vol. 106, pp. 134–155, 2015.
- 8[8] Z. Rahimpour, A. Faccani, D. Azuatalam, A. C. Chapman, and G. Verbič, “Using thermal inertia of buildings with phase change material for demand response,” Energy Procedia , vol. 121, pp. 102–109, 2017.