Active Learning of Dynamics for Data-Driven Control Using Koopman Operators
Ian Abraham, Todd D. Murphey

TL;DR
This paper introduces an active learning approach for robotic control that leverages Koopman operator theory to efficiently learn system dynamics and improve control performance, demonstrated on quadcopters and real robots.
Contribution
It develops an active learning controller based on Koopman operators that accelerates system identification and control synthesis for nonlinear robotic systems.
Findings
Enhanced control performance with Koopman-based models
Active learning increases information gain about system dynamics
Successful implementation on quadcopters and real robots
Abstract
This paper presents an active learning strategy for robotic systems that takes into account task information, enables fast learning, and allows control to be readily synthesized by taking advantage of the Koopman operator representation. We first motivate the use of representing nonlinear systems as linear Koopman operator systems by illustrating the improved model-based control performance with an actuated Van der Pol system. Information-theoretic methods are then applied to the Koopman operator formulation of dynamical systems where we derive a controller for active learning of robot dynamics. The active learning controller is shown to increase the rate of information about the Koopman operator. In addition, our active learning controller can readily incorporate policies built on the Koopman dynamics, enabling the benefits of fast active learning and improved control. Results using a…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1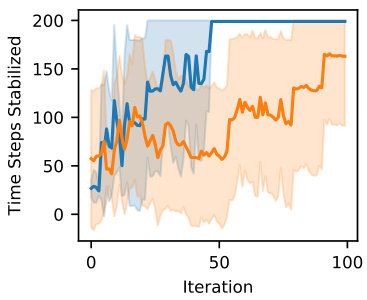 Figure 2
Figure 2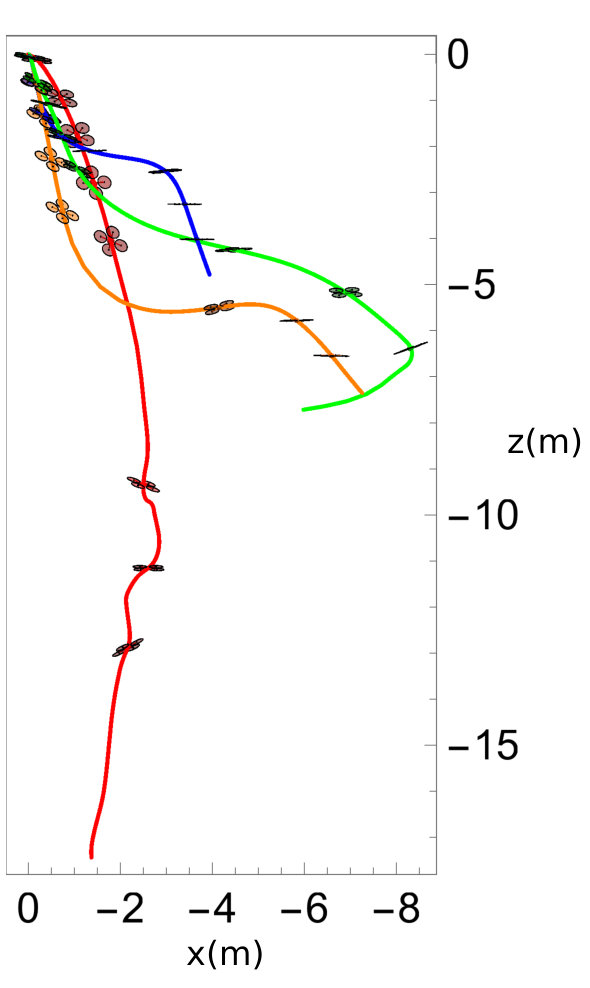 Figure 3
Figure 3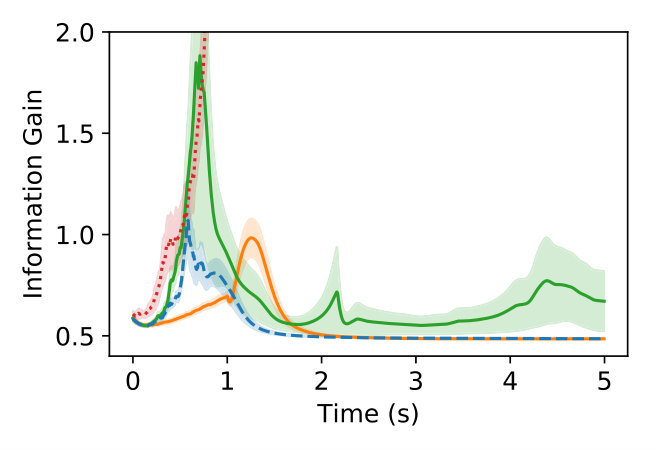 Figure 4
Figure 4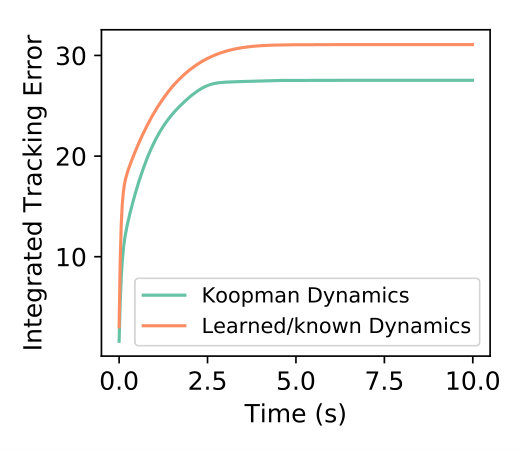 Figure 5
Figure 5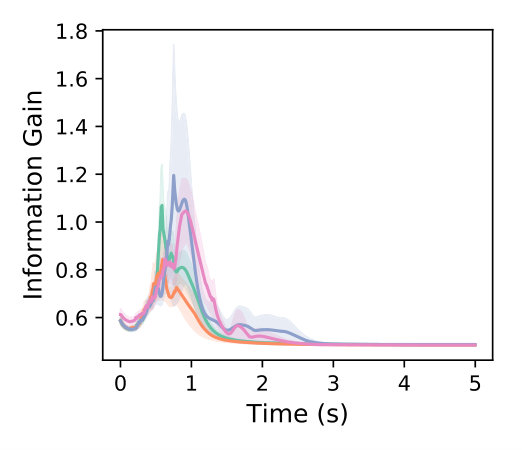 Figure 6
Figure 6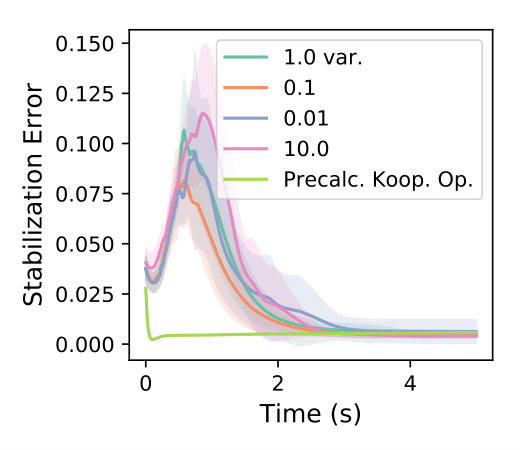 Figure 7
Figure 7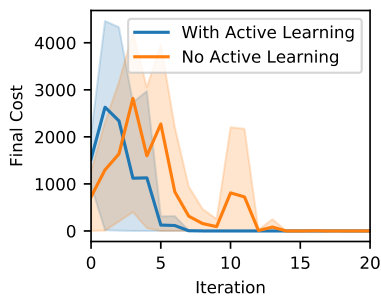 Figure 8
Figure 8 Figure 9
Figure 9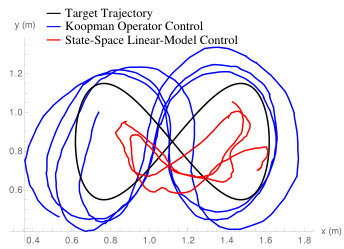 Figure 10
Figure 10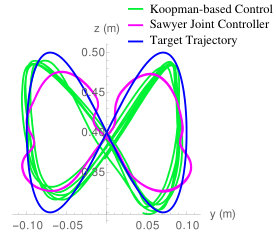 Figure 11
Figure 11 Figure 12
Figure 12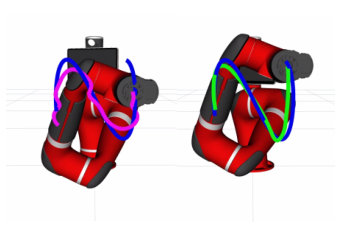 Figure 13
Figure 13 Figure 14
Figure 14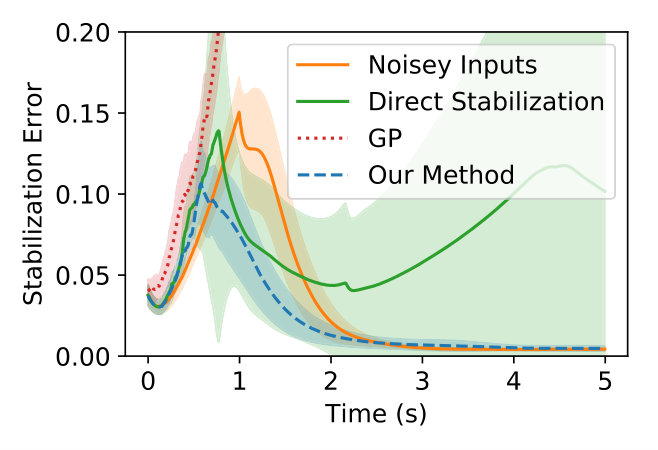 Figure 15
Figure 15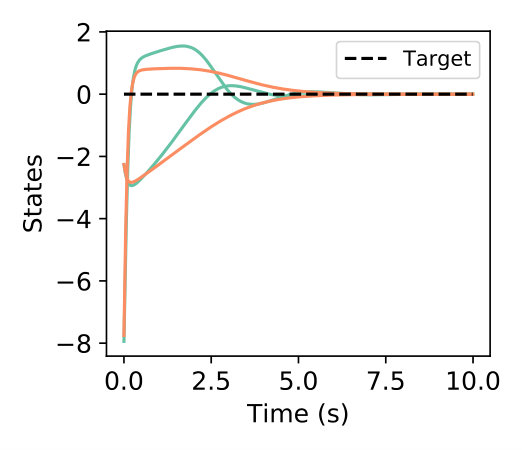 Figure 16
Figure 16| Method | RMSE | Correlation | Phase Lag (rad) |
|---|---|---|---|
| Koopman-based Control | 0.3010 | 0.4028 | 1.1262 |
| Controller in [32] | 0.3535 | 0.1034 | 1.4667 |
| Method | RMSE | Correlation | Phase Lag (rad) |
|---|---|---|---|
| Koopman-based Control | 0.0228 | 0.9777 | 0.2826 |
| Sawyer Joint Controller | 0.0443 | 0.6026 | 0.7041 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Active Learning of Dynamics for Data-Driven Control Using Koopman Operators
Ian Abraham and Todd D. Murphey Authors are with the Neuroscience and Robotics lab (NxR) at the Department of Mechanical Engineering, Northwestern University, 2145 Sheridan Road Evanston, IL, 60208. Videos of the experiments and sample code can be found at https://sites.google.com/view/active-learning-koopman-op . email: [email protected], [email protected]
Abstract
This paper presents an active learning strategy for robotic systems that takes into account task information, enables fast learning, and allows control to be readily synthesized by taking advantage of the Koopman operator representation. We first motivate the use of representing nonlinear systems as linear Koopman operator systems by illustrating the improved model-based control performance with an actuated Van der Pol system. Information-theoretic methods are then applied to the Koopman operator formulation of dynamical systems where we derive a controller for active learning of robot dynamics. The active learning controller is shown to increase the rate of information about the Koopman operator. In addition, our active learning controller can readily incorporate policies built on the Koopman dynamics, enabling the benefits of fast active learning and improved control. Results using a quadcopter illustrate single-execution active learning and stabilization capabilities during free-fall. The results for active learning are extended for automating Koopman observables and we implement our method on real robotic systems.
Index Terms:
Active Learning, Information Theoretic Control, Koopman Operators.
I Introduction
In order to enable active learning for robots, we need a control algorithm that readily incorporates task information, learns dynamic model representation, and is capable of incorporating policies for solving additional tasks during the learning process. In this work, we develop an active learning controller that enables a robot to learn an expressive representation of its dynamics using Koopman operators [1, 2, 3, 4]. Koopman operators represent a nonlinear dynamical system as a linear, infinite dimensional, system by evolving functions of the state (also known as function observables) in time [1, 2, 3, 4]. Often, these linear representations can capture the behavior of the dynamics globally while enabling the use of known linear quadratic control methods. As a result, the Koopman operator representation changes how we represent the dynamic constraints of the robotic systems, carrying more nonlinear dynamic information, and often improving control authority.
Koopman operator dynamics are typically found through data-driven methods that generate an approximation to the theoretical infinite-dimensional Koopman operator [2, 4, 5]. These data-driven methods require robotic systems to be actuated in order to collect data. The process for data collection in robotics is an active process that relies on control; therefore, learning the Koopman operator formulation, for robotics, is an active learning process.
In this paper, we use the Koopman operator representation for improving control authority of nonlinear robotic systems. Moreover, we address the problem of calculating the linear representation of the Koopman operator by exploiting an information-theoretic active learning strategy based on the structure of Koopman operators. As a result, are able to demonstrate active learning through data-driven control in real-time settings where only a single execution of the robotic system is possible. Thus, the contribution of this paper is a method for active learning of Koopman operator representations of nonlinear dynamical systems which exploits both information-theoretic measures and improved control authority based on Koopman operators.
I-A History and Related Work
Active learning in robotics has recently been a topic of interest [6, 7, 8, 9, 10]. Much work has been done in active learning for parameter identification [11, 12, 13, 14] as well as active learning for state-control mappings in reinforcement learning [9, 15, 16, 17, 18] and adaptive control [19, 20, 21]. In particular, much of the mentioned work refers to exciting a robot’s dynamics —using information theoretic measures [12, 13, 10], reward functions [9, 15, 17, 10] in reinforcement learning, and other methods [22, 23]—in order to obtain the “best” set of measurements that resolve a parameter or the “best-case” mapping (either of the state-control map or of the dynamics). This paper uses active learning to enable robots to learn Koopman operator representations of a robot’s own dynamic process.
Koopman operators were first proposed in 1931 in work by B.O. Koopman [1]. At the time, approximating the Koopman operator was computationally infeasible; the onset of computers enabled data-driven methods that approximate the Koopman operator [24, 4, 2]. Other research involves computation of Koopman eigenfunctions and Koopman-invariant subspaces that determine the size of the Koopman operator [25, 26, 27]. This allows for finite dimensional Koopman operators that captures nonlinear dynamics while compressing the overall state dimension used to represent the dynamical system.
Recent works, on combining model-based control methods and Koopman operators have suggested that control based on Koopman operators is a promising avenue for many fields including robotics [26, 3, 5, 28, 29, 30, 31, 32, 27, 33]. In particular, recent work from the authors implemented a controller using a Koopman operator representation of a robotic system in an experimental setting of a robot in sand [32]. Koopman operators are closely related to latent variable (embedded) dynamic models [34]. In embedded dynamic models, an autoencoder [35, 34] is used to compress the original state-space into a lower-dimensional representation. The embedded dynamics model then only evolves the states that are useful for predicting the overall dynamical systems behavior. Koopman operators represent the state of some dynamical system in a higher- or lower- dimensional representation where the evolution of the embedding is a linear dynamical systems. Thus, Koopman operators are a special case of an embedded dynamic model where the latent variable describes the nonlinearities of a dynamical system and are represented as a linear differential equation.
I-B Relation to Previous Work
We extend previous work in [32] with new examples of control with Koopman operator representations of robotic systems. In addition, we provide an example in Section III which gives further intuition for the use of Koopman operator dynamics. Moreover, we address design choices when generating a Koopman operator dynamic representation of a robotic systems and provide a methodology towards automating these design choices. Last, we introduce a method for enabling the robot to actively learn Koopman operator dynamics while taking advantage of linear quadratic (LQ) approaches for control. We note that there is no overlap with the results and the theoretical content that is presented in this paper with [32].
I-C Outline
The paper outline is as follows: Section II introduces the Koopman operator and data-driven methods to approximate the Koopman operator from data, including a recursively defined online approach for approximating the Koopman operator. Section III motivates using Koopman operator representations of dynamical systems for control. Section IV introduces a controller that enables robots to learn the Koopman operator dynamics. Simulated results for active learning using our method is provided with comparisons in Section V. Section VI discusses methods for automating the design specifications of the Koopman operator. Last, robot experiments are provided in Section VII and concluding remarks in Section VIII respectively.
II Koopman Operators
This section introduces the Koopman operator and formulates the Koopman operator for control of robotic systems.
II-A Infinite Dimensional Koopman Operator
Let us first define the continuous dynamical system whose state evolution is defined by
[TABLE]
where is the sampling time and is the sampling interval, is the state of the robot at time , is the applied actuation to the robot at time , is the unknown dynamics of the robot, and is the mapping which advances the state to . In addition, let us define an observation function where is the space of all observation functions. The Koopman operator is an infinite dimensional operator that directly acts on the elements of
[TABLE]
where are implicitly defined in such that
[TABLE]
In words, the Koopman operator takes any observation of state at time and time shifts the observations, subject to the control , to the next observable time . This formulation assumes equal time spacing .
II-B Approximating the Data-Driven Koopman Operator
The Koopman operator is infeasible to compute in the infinite dimensional space. A finite subspace approximation to the operator acting on is used where we define a subset of function observables (or observations of state) . Each scalar valued and the span of all is the finite subspace . The operator acting on is then represented in discrete time as
[TABLE]
where is the residual function error. In principle, as , the residual error goes to zero [3, 4]; however, it is sometimes possible to find such that [26]. Equation (4) gives us the discrete time transition of observations of state in time. We overload the notation for the Koopman operator and write the differential equation for the observations of state as
[TABLE]
where the continuous time is acquired by taking the matrix logarithm as .
Provided a data set , we can compute the approximate Koopman operator using least-squares minimization over the parameters of :
[TABLE]
Since (6) is convex in , the solution is given by
[TABLE]
where denotes the Moore-Penrose pseudoinverse and
[TABLE]
The continuous time operator is then given by . Note that we can solve (6) using gradient descent methods [36] or other optimization methods. We write a recursive least-squares update [20, 37] which adaptively updates as more data is acquired.
II-C Koopman Operator for Control
The Koopman operator can include a predefined input that contributes to the evolution of . Consider the observable functions that includes the control input, where . The resulting computed Koopman operator can be divided into sub-matrices
[TABLE]
where and . Note that the term () in (9) refers to terms that evolve the observations on control which are ignored as there is no ambiguity in their evolution (they are determined by the controller). The Koopman operator dynamical system with control is then
[TABLE]
Note that the data set must now store in order to compute the Koopman operator matrix .
III Enhancing Control Authority with Koopman Operators
Koopman operators map dynamic constraints into a linear dynamical system in a modified state-space. The Koopman operator structure allows one to use linear quadratic (LQ) control methods to compute optimal controllers for nonlinear systems that can often outperform locally optimal LQ controllers obtained through linearizing the nonlinear dynamics model.
Let us consider control of the nonlinear forced Van der Pol oscillator, the dynamics of which are defined in Appendix A-A, as an example. We specify the control task as minimizing the following LQ objective
[TABLE]
where , , and . Choosing the set of function observable (Appendix A-A), we can compute a Koopman operator by repeated simulation of the Van der Pol oscillator subject to uniformly random control inputs for randomly sampled initial conditions.
Since the Van der Pol oscillator dynamics are nonlinear, a solution to the LQ control problem is to linearize the dynamics about the equilibrium state and form a linear quadratic control regulator (LQR). Using the Kooman operator formulation of the Van der Pol dynamics, we can compute a controller in a similar manner using the following objective
[TABLE]
where
[TABLE]
Setting and to only include the state observables allows us to compare the same control objective using the linearized dynamics against the Koopman operator dynamics where the first terms in the function observable is the state of the Van der Pol system itself.
Figure 1 illustrates the improvement in control performance when using the the Koopman operator dynamics for LQ control instead of linearizing the dynamics around a local region. We compare the control authority using a learned dynamics model in the original state-space using Bayesian optimization with the same functions used for the Koopman operator. This illustrates that the data used to compute the Koopman operator can learn a nonlinear model of the Van der Pol dynamics in the original state-space. The Koopman operator formulation of the Van der Pol approximates the dynamic constraints as a linear dynamical systems in a higher dimensional space that captures nonlinear dynamical behavior. As a result, the Koopman operator formulation coupled with LQ methods can be used to enhance the control the Van der Pol system as shown in Figure 1(b). Computing the resulting trajectory error (Figure 1(a)) shows that the trajectory taken from the Koopman operator controller results in less overall integrated error. This is due to formulating the LQ controller with additional information in the form of a dynamical systems that evolves functions of state.
While this example illustrates the possible benefits of utilizing the Koopman operator formulation, we ignored how the data was collected for the Van der Pol dynamical system. In fact, computing the Koopman operator used random inputs. For this example, such an approach works reasonably, but requires a significant amount of data to fully cover the state-space of the Van der Pol system. The following sections introduce a method that enables a robot to actively learn the Koopman operator.
IV Control Synthesis for Active Learning of Koopman Operator Dynamics
Active learning controllers need to consider existing polices that solve a task while generalizing to learning objectives. In this section, we formulate a controller for active learning that takes into account the Koopman operator dynamics as well as polices generated for solving tasks using the Koopman operator linear dynamics. We generate an active learning controller that takes into account existing policies by first deriving the mode insertion gradient [38, 39]. The mode insertion gradient calculates how an objective changes when switching from one control strategy to another. We then formulate an active learning controller by minimizing the mode insertion gradient while including policies that solve a specified task. 111During training, the policies derived from the Koopman operator dynamics will be inaccurate; however, over time and gathered experience, both the model and policy will converge. This is a common approach in most model-based reinforcement learning techniques [40]. The derived controller is then shown to increase the rate of change of the information measure, which guides the robot towards important regions of state-space, improving the data collection and the quality of the learned Koopman operator dynamics model.
IV-A Control Formulation
Active learning allows a robotic agent to self-excite the dynamical states in order to collect data that results in a Koopman operator that can be used describe system evolution. We formulate the active learning problem as a hybrid switching problem [41] where the goal is to switch between a policy for a task to an information maximizing controller that assists the dynamical system in collecting informative data.
Consider a general objective function of the form
[TABLE]
where is the value of the function observables at time subject to the Koopman dynamics in (10) starting from initial condition , is the running cost, is the terminal cost, and is a differentiable policy. In this work, the running cost is split into two parts:
[TABLE]
where is the information maximizing objective (learning task) and is the task objective for which the policy is a solution to (14) when .
Given equation (14), we want to synthesize a controller that is bounded to the policy , but also allows for improvement of an information measure for active learning. To do so, we examine in Proposition (1) how sensitive (14) is to switching between the policy to an arbitrary control vector at time for a time duration .
Proposition 1**.**
The sensitivity of switching from to for all for an infinitesimally small , (also known as the mode insertion gradient [38, 39]) is given by
[TABLE]
where is a solution to 10 with and , , , and
[TABLE]
subject to the terminal condition .
Proof.
See Appendix B-A. ∎
We can write an unconstrained optimization problem for calculating over the interval that will minimize the mode insertion gradient. We can write this optimization problem using a secondary objective function
[TABLE]
where bounds the change of to , and \frac{\partial J}{\partial\lambda}\Big{|}_{\tau=t,\lambda=0} is evaluated at . Solving equation (17) with respect to can be viewed as a functional optimization over . Since equation (17) is quadratic in , we can compute a closed form solution for any application time .
Proposition 2**.**
Assuming that is differentiable, the control solution that minimizes (17) is
[TABLE]
Proof.
Since (17) is separable in time, we take the derivative of (17) with respect to at each point in which gives the following expression:
[TABLE]
Solving for in (IV-A) gives the control solution
[TABLE]
∎
Proposition (2) gives a formula for switching from to improve the objective (14). We can use equation (18) with (B-A) to show that our approach improves the active learning objective subject to bounds placed on arbitrary tasks included in (14).
Corollary 1**.**
Assume that the Koopman operator dynamics for a system are defined by the following control affine structure:
[TABLE]
where . 222This formulation assumes that we can recover from for computing . Moreover, assume that where is the control Hamiltonian for (14). Then
[TABLE]
for where is the control space.
Proof.
Inserting (18) into (B-A) gives
[TABLE]
which can be written as the norm
[TABLE]
∎
Because we define our objective to be reasonably general, we can add both stabilization terms as well as information measures that allow a robot to actively identify its own dynamics. The following subsection provides an overview of the Fisher information measure and information bounds based on our controller. We first describe the Fisher information matrix for the Koopman operator parameters and then generate an information measure. We then show that using (18) and Corollary 1, that we can approximately calculate to first order the gain in information.
IV-B Information Maximization
Using the controller defined in (18), we investigate information measures that we can use in (14) to enable the robot to actively learn the Koopman operator dynamics. In this work, we use the Fisher information [42, 43] to generate a information measure for active learning. The Fisher information is a way of measuring how much information a random variable has about a set of parameters. If we treat calculating the Koopman operator dynamics as a maximum likelihood estimation problem where the likelihood is given by , we can compute the Fisher information matrix over the parameters that compose of the Koopman operator . The Fisher information matrix is computed as
[TABLE]
where is the expectation operator, , and is the cardinality of the vector . Assuming that is a Gaussian distribution, (22) becomes
[TABLE]
where is the noise covariance matrix. Because the Fisher information defined here is positive semi-definite, we use the trace of the Fisher information matrix [44] in . This measure allows us to synthesize control actions that maximize the T-optimality measure of the Fisher information matrix [44].
Definition 1**.**
The T-optimality measure is given by the trace of the Fisher information matrix (22) and defined as
[TABLE]
In this work we incorporate (24) into (14) additively using , that is
[TABLE]
where is a small number to prevent singular solutions due to the positive semi-definite Fisher information matrix [45, 46, 47], and is computed using the evaluation of at time . By minimizing (14) we also minimize the inverse of the T-optimality (which maximizes the T-optimality).
Assumption 1**.**
Assume that implies where is an approximation to the Koopman operator computed from the data set that contains data up until the current sampling time .
Theorem 1**.**
Given Assumption 1 and dynamics (20), then the change in information 333With respect to the information acquired from applying only . subject to (18) is given to first order
[TABLE]
where , is the T-optimality measure (24) from applying the control and .
Proof.
See Appendix B-B. ∎
Theorem 1 shows that our controller increases the rate of information that a robot would have normally acquired if it had only used the control policy . Weighing the information measure against the task objective allows us to ensure that the relative information gain is positive when using the active learning controller. That is, the difference between the information from using the policy and the control will be positive. Other heuristics can be used such as a decaying weight on the information gain or setting the weight to 0 at a specific time so that the robot attempts the task. We provide a basic overview of the control procedure in Algorithm 1. Videos of the experiments and example code can be found at https://sites.google.com/view/active-learning-koopman-op.
The following sections use our derived controller to enable active-learning of Koopman operator dynamics.
V Single Execution Active Learning of Free-Falling Quadcopters
In this example, we illustrate the capabilities of combining the Koopman operator representation of a dynamical systems and active learning for single execution model learning of a free-falling quadcopter for stabilization. Additionally, we compare our approach to other common learning strategies such as active learning with Gaussian processes [48, 49, 50], online model adaptation through direct attempts at the tasks of stabilization (common online reinforcement learning and adaptive control approach [37, 19, 20, 51, 52]), and a two-stage noisy motor input (often referred to as “motor babble” [53, 54, 55]).
V-A Problem Statement
The task is as follows: The quadcopter, with dynamics described in Appendix A-B and [56], must learn a model within the first second of free-falling and then use the model to generate a stabilizing controller, preventing itself from falling any further. We define success of the quadcopter in the task when where is the desired target state defined by zero linear and angular velocity. The controllers are designed as linear quadratic regulators using the model that was learned and the LQ objectives provided in Section III. The parameters used for this example are defined in Appendix A-B and follows the same parameter choices as in Section III for fairness in terms of the learning methods against which we are comparing.
We compare the information gained (based on the T-optimality condition) and the stabilization error in time against various learning strategies. Each learning strategy is tested with the same 20 uniformly sampled initial velocities (and angular velocities) between and radians/meters per second. After each trial, the learned dynamics model is reset so that no information from the previous trials are used.
V-B Other Active Learning Strategies
We compare our method for active learning against common dynamic model learning strategies. Specifically, we compare three model learning approaches against our method, a two-stage noisy control input approach [53], a direct stabilization with adaptive model using least squares [37, 19], and an active learning strategy using a Gaussian process [57, 58]. Each of these strategies are generating a Koopman operator using the functions of state defined in Appendix A-B to generate a dynamic model of the quadcopter. The Gaussian process formulation is the only model where the functions map to the original state-space resulting in a nonlinear dynamics model.
Least Squares Adaptive Stabilization
The first strategy we compare to is to do the task of stabilization at the while updating the model of the dynamics recursively [37, 19]. This is often a strategy used in model-based reinforcement learning [54] and adaptive control [37].
Two-Stage Motor Babble
The second strategy is a two stage approach using noisy motor input (motor babble) for the first second and then pure stabilization [53]. Rather than directly attempting to stabilize the dynamics, the priority is to simply try all possible motor inputs regardless of the model of the dynamics that is being constructed. The motor babble strategy allows us to bound the motor excitation which prevents the rotor from destabilizing once the learning stage is complete. As with the direct stabilization method, we use a recursive least squares to update the model of the Koopman operator.
Active Learning with Gaussian Process
The last strategy is an active Gaussian process strategy [57, 58]. In this active learning strategy, we build a model of the dynamics of the quadcopter by generating a Gaussian process dynamics model [57, 50]. Using the variance estimate [58], we uniformly sample points around the current state bounded by some constant and find the state which maximizes the variance. The sampled state with the largest variance is then used to generate a local LQ controller to guide the quadcopter dynamics to that state to collect the data. After the first second, the Gaussian process model is used to generate a stabilizing controller by linearizing the model about the final desired stabilization state. The kernel function used is computed using the functions of state provided in Appendix A-B for a fair comparison.
Note that for the two-stage, least squared adaptive, and our approach, we learn a Koopman operator dynamics model which we use to compute an LQ controller. The Gaussian process model is in in the original state-space as described in [50].
V-C Results
Figure 2 (a) illustrates the information (T-optimality of the Fisher information matrix) for each method. Our approach to active learning is shown to improve upon the information when compared to motor babble (the most basic method for active learning). The other methods outperform our approach in terms of the overall information gain by overly exciting the dynamics. The direct adaptive stabilization method utilizes the incorrect dynamics model to self-adjust and eventually stabilize the quadcopter (as shown in the variance). The active Gaussian process approach uses the covariance estimate to actuate the quadcopter towards uncertain regions. Collecting data in uncertain regions allows the active Gaussian process approach to actively select where the quadcopter should collect data next.
It is worth noting that these approaches will often lead the quadcopter towards unstable regions, making it difficult to stabilize the dynamics in time. Our approach actively synthesizes when it is best to learn and stabilize which assists in quickly stabilizing the quadcopter dynamics (see Figure 2 (b)). The addition of the Koopman operator dynamics further enhances the control authority of the quadcopter as shown with the direct adaptive stabilization, motor babble, and our approach to active learning. While the active Gaussian process model does at times succeed, the method relies on both the quality of data acquired and the local linear approximation to the dynamics. This results in a deficit of nonlinear information that is needed to successfully achieve the learning task in a single execution.
V-D Sensitivity to Initialization and Parameters
We further test our algorithm against sensitivities to initialization of the Koopman operator. Our algorithm requires an initial guess at the Koopman operator in order to boot-strap the active learning process. We accomplish this using the same experiment described in the previous section which used a zero mean, variance of normally distributed initialization of the Koopman operator. We vary the variance that initializes the Koopman operator parameters using a normal distribution with zero mean and a variance experiment set of .
In Fig. 3 we find that so long as the initialization of the Koopman operator is within a reasonable initialization (non-zero and within an order of magnitude), the performance is comparable to active learning described in Fig. 2. However, this may not be true for all autonomous systems and results may vary depending on the sampling frequency and the behavior of the underlying system. A benchmark is provided for stabilizing the quadcopter when the Koopman operator is precomputed in Fig 3 illustrating the performance of the control authority when using the Koopman operator-based controller.
The choices in the parameters of our algorithm can also effect its performance. Specifically, setting the value of the regularization term too large will prevent the robot from significantly exploring the states of the robot. In contrast, if the regularization term is set too low, the robot will widen its breath of exploration which can be harmful to the robot if the states are not bounded. A similar effect is achieved by adding a weight on the active learning objective.
Changes in the time horizon will also effect the performance of the algorithm. Generally, smaller will result in more reactive behaviors where larger tends to have more intent driven control responses. Choosing these values appropriately will be problem specific; however, the limited number of tunable parameters (not including choosing a task objective) provides the advantage of ease of implementation.
V-E Discussion
While the single execution capabilities of the Koopman operator with active learning is appealing, not all robotic systems will be capable of such drastic performance. In particular, this example relies on some prior knowledge of the underlying robotic system and the dynamics that govern the system. The functions of state are chosen such that they include nonlinear elements (e.g, cross product terms that we expect will help in stabilization). Thus, the approximate Koopman operator is predicting the evolution of nonlinear elements found in the original nonlinear dynamics. Often these underlying structures that we can exploit are not known or easily found in robotics. Choosing random polynomial or Fourier expansions as function observables can sometimes work (see Section VII), but often can lead to unstable eigenvalues in the Koopman operator dynamics which can make model-based control difficult to synthesize [26].
Recent work has attempted to address these issues using sparse optimization [59] or discovering invariances in the state-space [26]. A promising method is automating the discovery of the function observables by learning the functions from data [60]. By using current advances in neural networks and function representation, it is possible to automate the discovery of function observables. The following section further develops the work in automating the discovery of function observables for Koopman operators through the use of our approach for active learning.
VI Automating Discovery of Koopman operator Function Observables
As a solution to automating the choice of function observables, the use of deep neural networks [60] have been used to automatically discover the function observables. In this section, we illustrate that we can use these neural networks coupled with our approach for active learning to automatically discover the Koopman operator and the associated functions of state.
VI-A Including Automatic Function Discovery
Revisiting Equation 10, we can parameterize and using a multi-layer neural network with parameters . We denote the parameterization of as and where the subscript denotes the function observables are parameterized by the same set of parameters . Given the same data set that was defined previously, , the new optimization problem that is to be solved is
[TABLE]
where . Equation (26) can be solved using any of the current techniques for gradient descent (Adams method [61] is used in this work). The continuous time Koopman operator is obtained similarly using the matrix log of , resulting in the differential equation
[TABLE]
Because we are now optimizing over , we lose the sample efficiency of single execution learning that was illustrated in the example in Section V. Active learning can be used; however, adding the additional parameters to the information measure significantly increases the computational cost of calculating the Fisher information measure (22). As a result, we only compute the information measure with respect to in order to avoid the computational overhead of maximizing information with respect to .
VI-B Examples
We illustrate the use of deep networks for automating the function observables for the Koopman operator for stabilizing a cart pendulum and controlling a 2-link robot arm to a target. A neural network is first initialized (see Appendix A-C for details) for the Koopman operator functions as well as an LQ controller for the task at hand. At each iteration, the robot attempts the task and learns the Koopman operator dynamics by minimizing (26). We compare against decaying additive control noise as well as our method for active learning where a weight on information measure is used which decays at each iteration according to where and is the iteration number. The data collected is then used to update the parameters and using (26) and the LQ controller is updated with the new parameters.
Figure 4 illustrates that we can automate the process of learning the function observables as well as the Koopman operator. With the addition of active learning, the process of learning the Koopman operator and the function observables is improved. In particular, stabilization of the cart pendulum is achieved in only iterations in comparison to additive noise which takes over iterations. Similarly, the 2-link robot can be controlled to the target configuration within iterations with our active learning approach.
VI-C Discussion
While this method is promising, there still exist significant issues that merit more investigation in future work. One of which is the trivial solution where . This issue often occurs with how the parameters were initialized. This trivial solution has been addressed in [62]; however, their approach requires significantly complicating how the regression (26) is formulated. We found that adding the state as part of the neural network output of was enough to overcome the trivial solution.
VII Robot Experiments
Our last set of examples test our active learning strategy with robot experiments. We use the robots depicted in Figure 5 to illustrate control and active learning with Koopman operators. The sphero SPRK robot (Figure 5(a)) is a differential drive robot inside of a clear outer ball. We test trajectory tracking of the SPRK robot in a sand terrain where the challenge is that the SPRK must be able to learn how to maneuver in sand. The Sawyer robot (Figure 5(b)) is a 7-link robot arm whose task is to track a trajectory defined at the end effector where the challenge is the high dimensionality of the robot. We refer the reader to the attached multimedia which has clips of the experiments.
VII-A Experiments: Granular Media and Sphero SPRK
Active learning is applied in an experimental setting using the Sphero SPRK robot (Fig. 5(a)) in sand. The interaction between sand and the SPRK robot makes physics-based models challenging.
The parameters for the experiment are defined in Appendix A-D. The experiment starts with seconds of active learning. After actively identifying the Koopman operator, the weight on information maximizing is set to zero at and the objective is switched to track the trajectory shown in Fig. I(b). In Fig. I(c), we show the average root mean squared error (RMSE) of the trajectory tracking, the average Pearson’s correlation using a two-sided hypothesis testing (values close to indicate responsive controllers), and the phase lag of the experimental results. Note that in contrast to previous work by the authors [32], the method of actively learning the Koopman operator improves the performance of the model-based controller. In particular, we find that the overall responsiveness and phase lag of the Koopman-based controller improved after active learning in sand.
VII-B Experiments: Trajectory Tracking of Rethink Sawyer Robot
In this experiment, we use active learning with the Koopman operator to model a DoF Sawyer robot arm from Rethink Robotics. The 7-DoF system is of interest because it is both high dimensional and inertial effects tend to dominate the dynamics of the system. We define the parameters used for this experiment in Appendix A-E.
Figure 7 illustrates a comparison of the embedded controller in the Sawyer robot and the data-driven Koopman operator controller. Here, we show the average root mean squared error of the tracking position, the Pearson’s correlation using a two-sided hypothesis testing (values close to indicate responsive controllers), and the phase lag of the trajectory tracking. The resulting controller using the Koopman operator is shown to be comparable to the built-in controller with the inclusion of the evolution of the nonlinearities on the Sawyer robot which improve overall trajectory tracking performance. The trajectories of the two methods are overlaid which illustrates the improvement in control from the Koopman operator after active learning has occurred. Since data is always being acquired online, the Koopman operator is continuously being updated as the robot is tracking the trajectory. The Koopman operator-based controller is able to capture dynamic effects of the individual joints from data. This is further reinforced by the improved results found Note that one can build a model to solve for similar, if not better, inverse dynamics of the Sawyer robot that can be computed for control. In particular, the Sawyer robot provides an implementation of inverse dynamics in the robot’s embedded controller. However, our approach provides high accuracy without needing such a model ahead of time and without linearizing the nonlinear dynamics.
VIII Conclusion
In this paper, we use Koopman operators as a method for enhancing control of robotic systems. In addition, we contribute a method for active learning of Koopman operator dynamics for robotic systems. The active learning controller enables the robots to learn their own dynamics quickly while taking into account the linear structure of the Koopman operator to enhance LQ control. We illustrate various examples of robot control with Koopman operators and provide examples for automating design choices for Koopman operators. Last, we show that our method is applicable to actual robotic systems.
Acknowledgment
The authors would like to thank Giorgos Mamakoukas for his insight and thorough review of this paper.
This material is based upon work supported by the National Science Foundation under awards NSF CPS 1837515. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation
Appendix A Parameters for Various Examples
A-A Control of forced van der pol oscillator
The nonlinear dynamics that govern the Van der Pol oscillator are given by the differential equations
[TABLE]
where and is the control input.
The Koopman operator functions used are defined as
[TABLE]
and . The same functions are used to compute a regression problem where the final equation is given by
[TABLE]
where and are both generated using linear regression.
The weight parameters for LQ control are
[TABLE]
where
[TABLE]
A-B Quadcopter Free-Falling
The quadcopter system dynamics are defined as
[TABLE]
where , the inputs to the system are , and
[TABLE]
(see [56] for more details on the dynamics and parameters used). Note that in this formulation of the quadcopter, the control vector has bidirectional thrust.
The measurements of the state of the quadcopter are given by
[TABLE]
where denotes the body-centered gravity vector and are the body angular and linear velocities respectively. The sampling rate for this system is Hz.
We define the basis functions for this system as
[TABLE]
where are the chosen basis functions such that are elements of the body-centered angular and linear velocity respectively. The functions for control are
[TABLE]
The LQ control parameters for the stabilization problem are given as
[TABLE]
where the weight on the additional functions are set to zero as in (28) . The time horizon used in .
The active learning controller uses a weight on the information measure of and a regularization weight . Motor noise used in the two-stage method is given by uniform noise at of the control saturation.
A-C Neural Network Automatic Function Discovery Configuration
In this example, we use the Roboschool environments [65] for the robot simulations.
For the cart pendulum example, we use a three layer network with a single hidden layer for and with and nodes respectively for each layer making and . The exploration noise used on the control is given by additive zero mean noise with a variance of motor saturation decreasing at a rate of . The decay weight on the information measure is given by . The LQ weights are given by where the first non-zero weights correspond to the states of the cart pendulum. A time horizon of is used with a sampling rate of Hz. The regularization weight .
For the 2-link robot example, we use a similar three layer network with a single hidden layer for and with and nodes respectively for each layer making and . The exploration noise used on the control is given by additive zero mean noise with a variance of motor saturation decreasing at a rate of . The decay weight on the information measure is given by . The LQ weights are given by where the first non-zero weights correspond to the states of the cart pendulum. A time horizon of is used with a sampling rate of Hz. The regularization weight .
A-D SPRK Tracking in Sand
The SPRK robot is running a Hz sampling rate for control and state estimation. Control vectors are filtered using a low-pass filter to avoid noisy responses in the robot. The controller weights are defined as
[TABLE]
The control regularization is . A weight of is added to the information measure. A time horizon of is used to compute the controller.
We run the active learning controller for seconds and then set the weight of the information measure to zero and track the end effector trajectory given by
[TABLE]
In this example, the set of functions are chosen as a polynomial expansion of the velocity states to the order. The function observables are defined as
[TABLE]
and
[TABLE]
A-E Sawyer Control
The Sawyer robot was run on a sampling rate of Hz. Control vectors are filtered using a low-pass filter to avoid noisy responses in the robot. The controller weights are defined as
[TABLE]
The control regularization is . A weight of is added to the information measure. A time horizon of is used to compute the controller.
We run the active learning controller for seconds and then set the weight of the information measure to zero and track the end effector trajectory given by
[TABLE]
The functions of state using to compute the Koopman operator are defined as
[TABLE]
with as the torque input control of each individual joint and states containing the joint angles and joint velocities.
Appendix B Proofs
B-A Proof of Proposition 1
Proposition 1 : The sensitivity of switching from to at any time for an infinitesimally small , (also known as the mode insertion gradient [38, 39]) is given by
[TABLE]
where is a solution to 10 with and , , , and
[TABLE]
subject to the terminal condition .
Proof.
Consider the objective (14) evaluated at a trajectory generated from a dynamical system. Furthermore, assume that is generated by a policy and a controller where is the time of application of control and is the duration of the control. Formally, can be written as
[TABLE]
where is a mapping which describes the time evolution of the state .
Using (30) and (14), we compute the derivative of (14) with respect to the duration of control applied at any time :
[TABLE]
where
[TABLE]
such that , are boundary terms from applying Leibniz’s rule.
Because (32) is a linear convolution with initial condition, , we are able to rewrite the solution to using a state-transition matrix [66] with initial condition as
[TABLE]
Since the term is evaluated at time , we can write (31) as
[TABLE]
Taking the limit of (34) as gives us the sensitivity of (14) with respect to switching at any time . We can further define the adjoint (or co-state) variable
[TABLE]
which allows us to define the mode insertion gradient [39] as
[TABLE]
where
[TABLE]
subject to the terminal condition . ∎
B-B Proof of Theorem 1
Theorem 1 : Given Assumption 1 and dynamics (20), then the change in information 444With respect to the information acquired from applying only . subject to (18) is given to first order
[TABLE]
where , is the T-optimality measure (24) from applying the control and .
Proof.
First define (14) for a controller as
[TABLE]
where is a time duration, is subject to the controller , and is the measure of information from applying the control . If we consider the difference between and where is a controller that minimizes , then
[TABLE]
From Corollary 1 and that,
[TABLE]
we can show that
[TABLE]
which we rearrange (B-B) and insert (21) to get
[TABLE]
Setting in (B-B) and simplifying gives the relative information gain
[TABLE]
∎
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] B. O. Koopman, “Hamiltonian systems and transformation in Hilbert space,” Proceedings of the National Academy of Sciences , vol. 17, no. 5, pp. 315–318, 1931.
- 2[2] I. Mezić, “Analysis of fluid flows via spectral properties of the Koopman operator,” Annual Review of Fluid Mechanics , vol. 45, pp. 357–378, 2013.
- 3[3] ——, “On applications of the spectral theory of the Koopman operator in dynamical systems and control theory,” in IEEE Int. Conf. on Decision and Control (CDC) , 2015, pp. 7034–7041.
- 4[4] M. Budišić, R. Mohr, and I. Mezić, “Applied Koopmanism,” Chaos: An Interdisciplinary Journal of Nonlinear Science , vol. 22, no. 4, p. 047510, 2012.
- 5[5] M. Korda and I. Mezić, “Linear predictors for nonlinear dynamical systems: Koopman operator meets model predictive control,” ar Xiv preprint ar Xiv:1611.03537 , 2016.
- 6[6] N. Roy and A. Mc Callum, “Toward optimal active learning through monte carlo estimation of error reduction,” International Conference on Machine Learning , pp. 441–448, 2001.
- 7[7] A. Baranes and P.-Y. Oudeyer, “Active learning of inverse models with intrinsically motivated goal exploration in robots,” Robotics and Autonomous Systems , vol. 61, no. 1, pp. 49–73, 2013.
- 8[8] C. Dima, M. Hebert, and A. Stentz, “Enabling learning from large datasets: Applying active learning to mobile robotics,” in IEEE Int. Conf. on Robotics and Automation (ICRA) , vol. 1, 2004, pp. 108–114.