Model Order Reduction by Proper Orthogonal Decomposition
Carmen Gr\"a{\ss}le, Michael Hinze, Stefan Volkwein

TL;DR
This paper introduces Proper Orthogonal Decomposition (POD) for model order reduction, focusing on nonlinear parametric and time-dependent PDEs, with applications in PDE-constrained optimization and adaptive strategies.
Contribution
It provides a comprehensive overview of POD-MOR, including theoretical foundations, error estimation, adaptivity, and basis update strategies, with practical numerical demonstrations.
Findings
Effective reduction of nonlinear PDEs demonstrated
Error estimates enable reliable surrogate models
Adaptive basis updates improve control applications
Abstract
We provide an introduction to POD-MOR with focus on (nonlinear) parametric PDEs and (nonlinear) time-dependent PDEs, and PDE constrained optimization with POD surrogate models as application. We cover the relation of POD and SVD, POD from the infinite-dimensional perspective, reduction of nonlinearities, certification with a priori and a posteriori error estimates, spatial and temporal adaptivity, input dependency of the POD surrogate model, POD basis update strategies in optimal control with surrogate models, and sketch related algorithmic frameworks. The perspective of the method is demonstrated with several numerical examples.
Click any figure to enlarge with its caption.
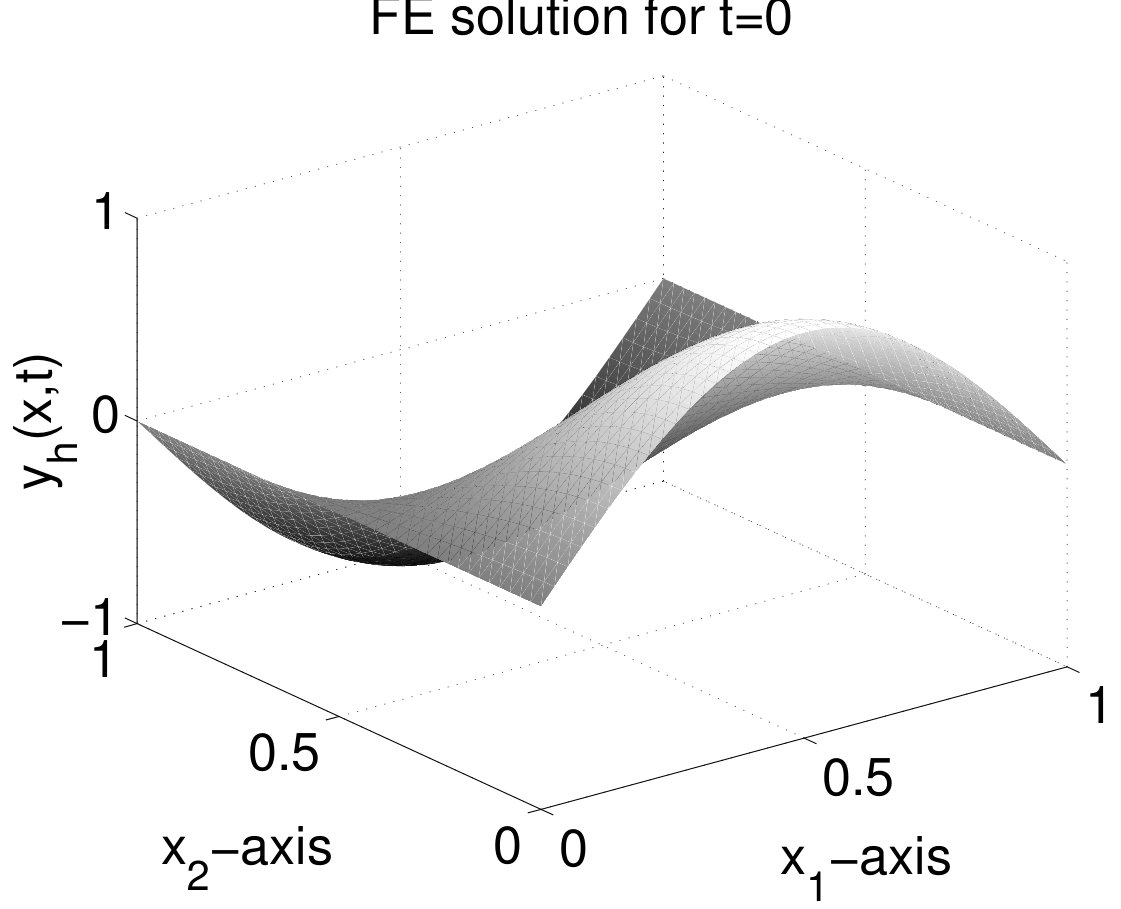 Figure 42
Figure 42 Figure 42
Figure 42 Figure 43
Figure 43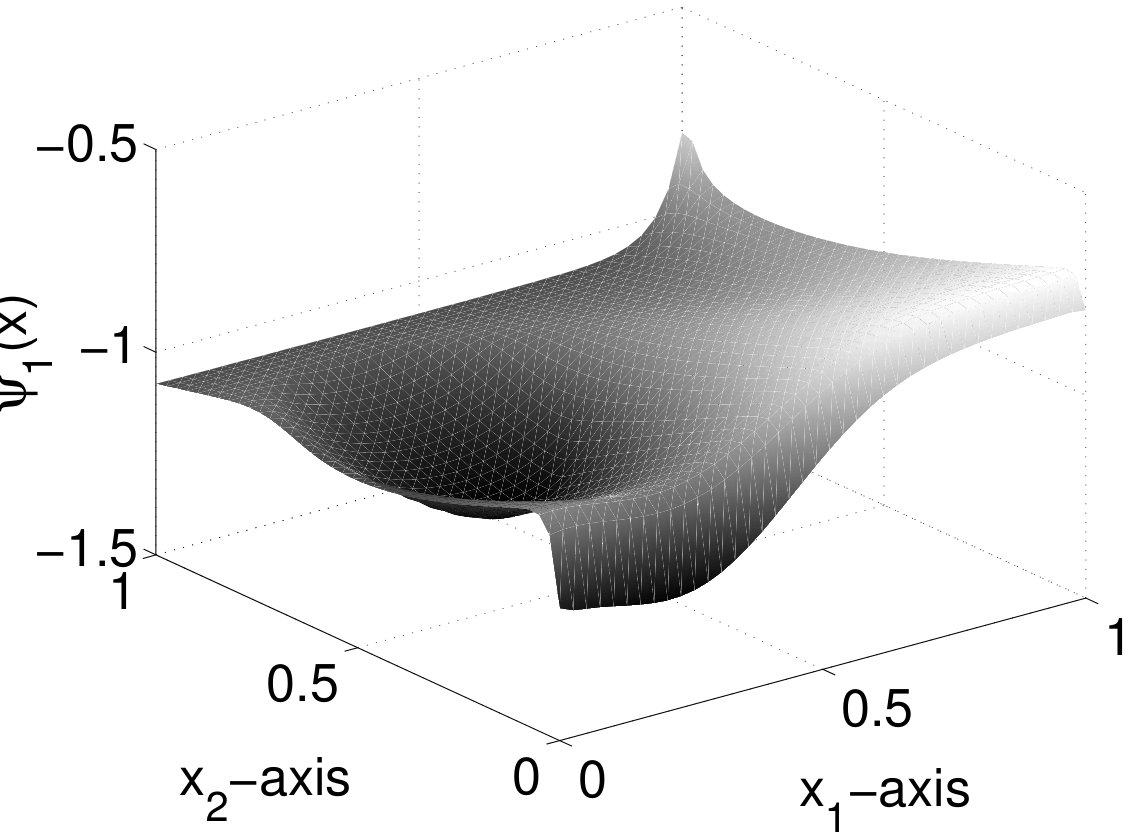 Figure 44
Figure 44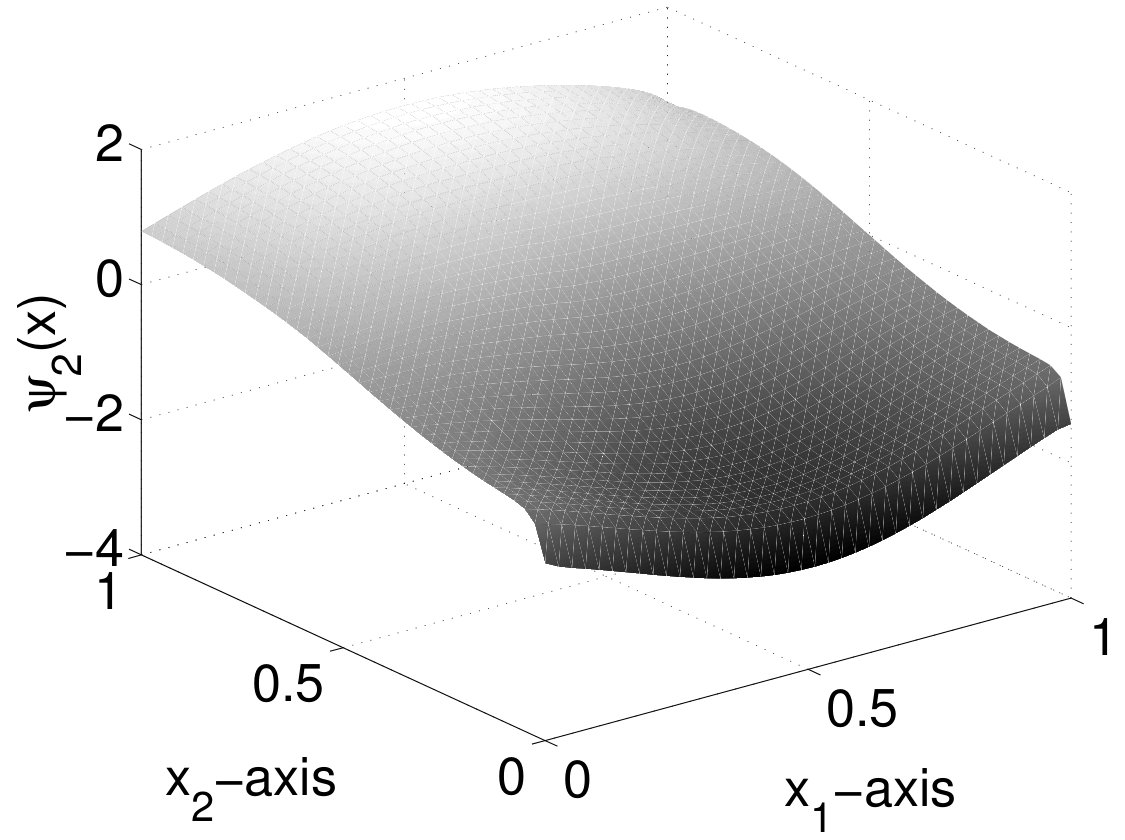 Figure 44
Figure 44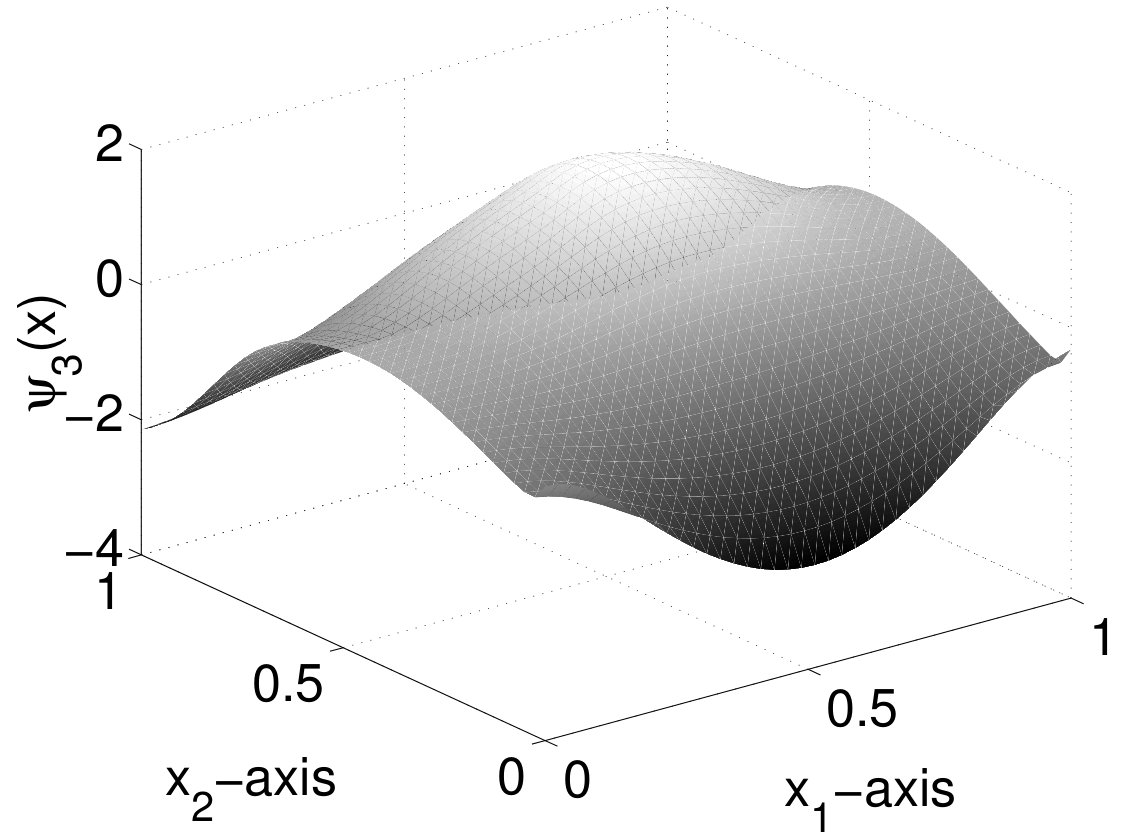 Figure 44
Figure 44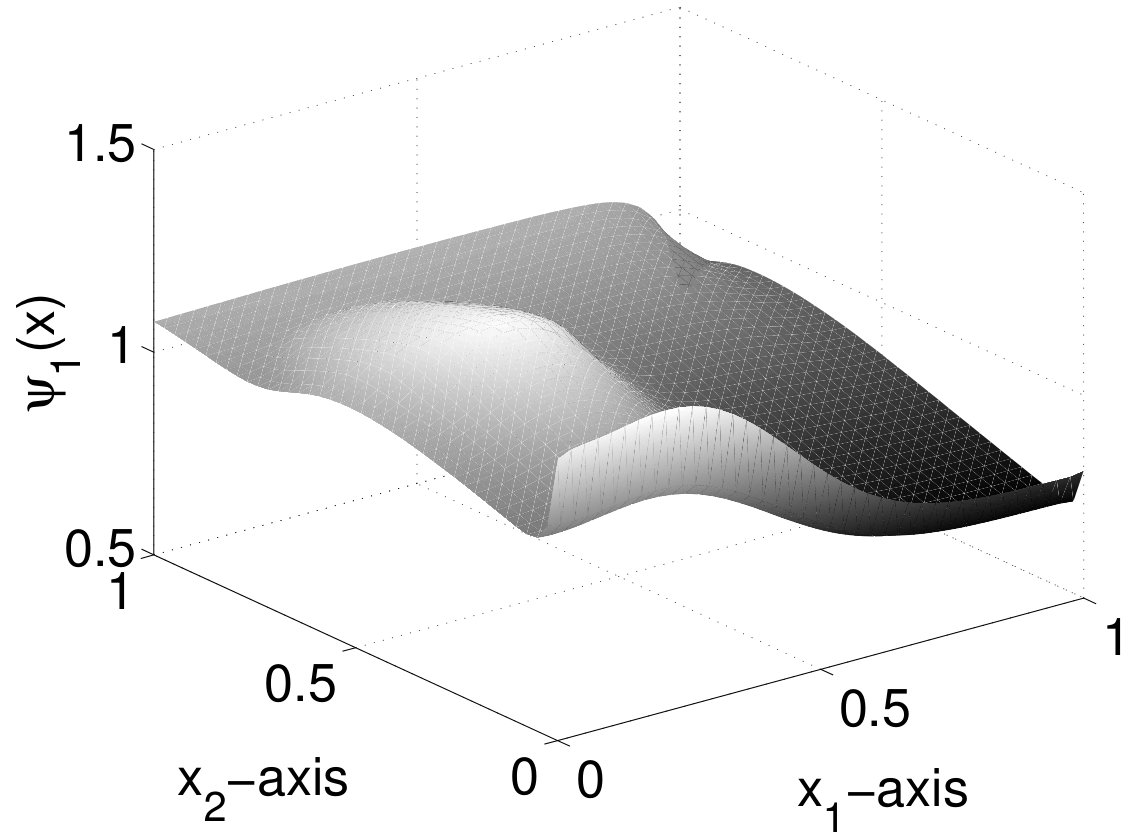 Figure 46
Figure 46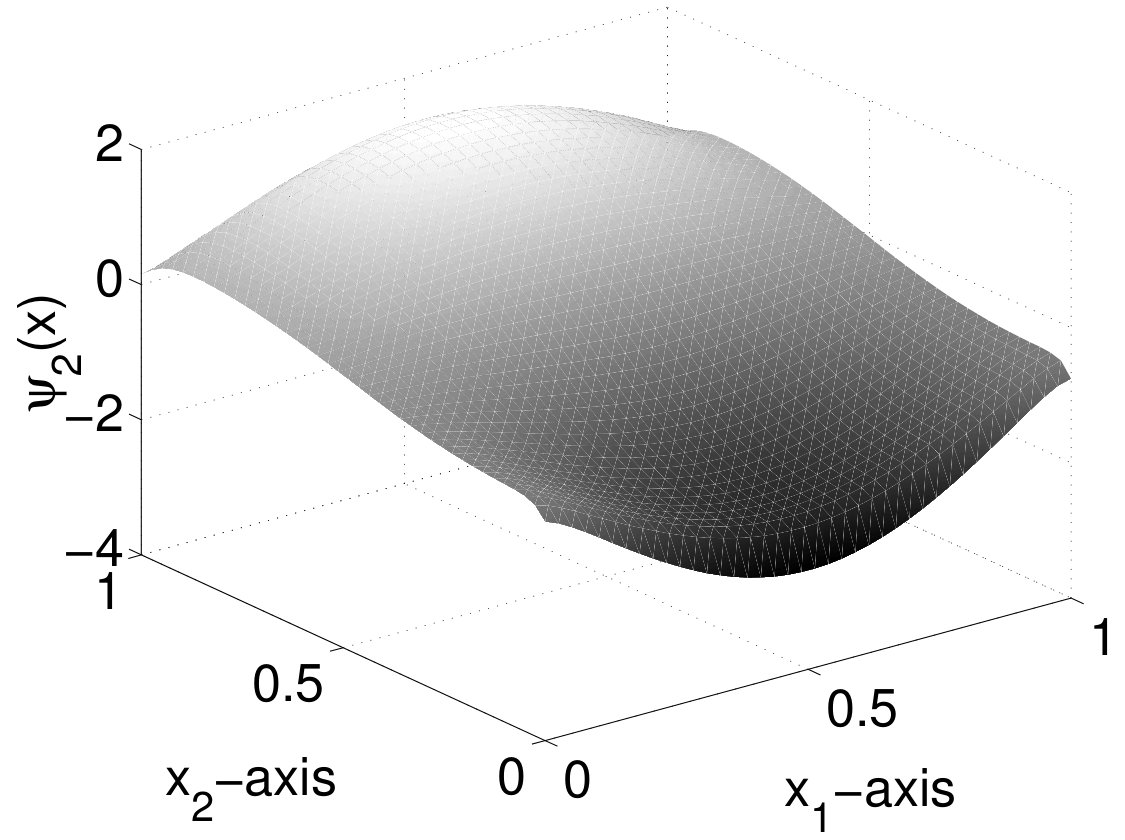 Figure 46
Figure 46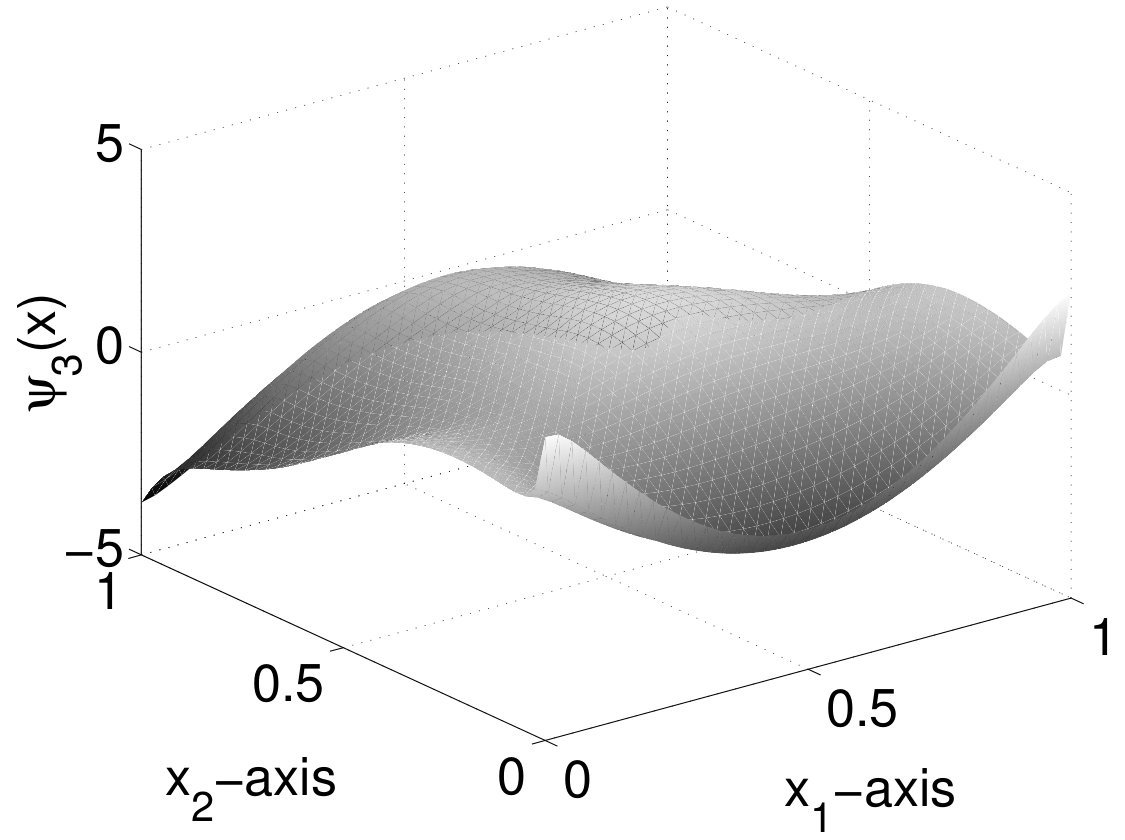 Figure 46
Figure 46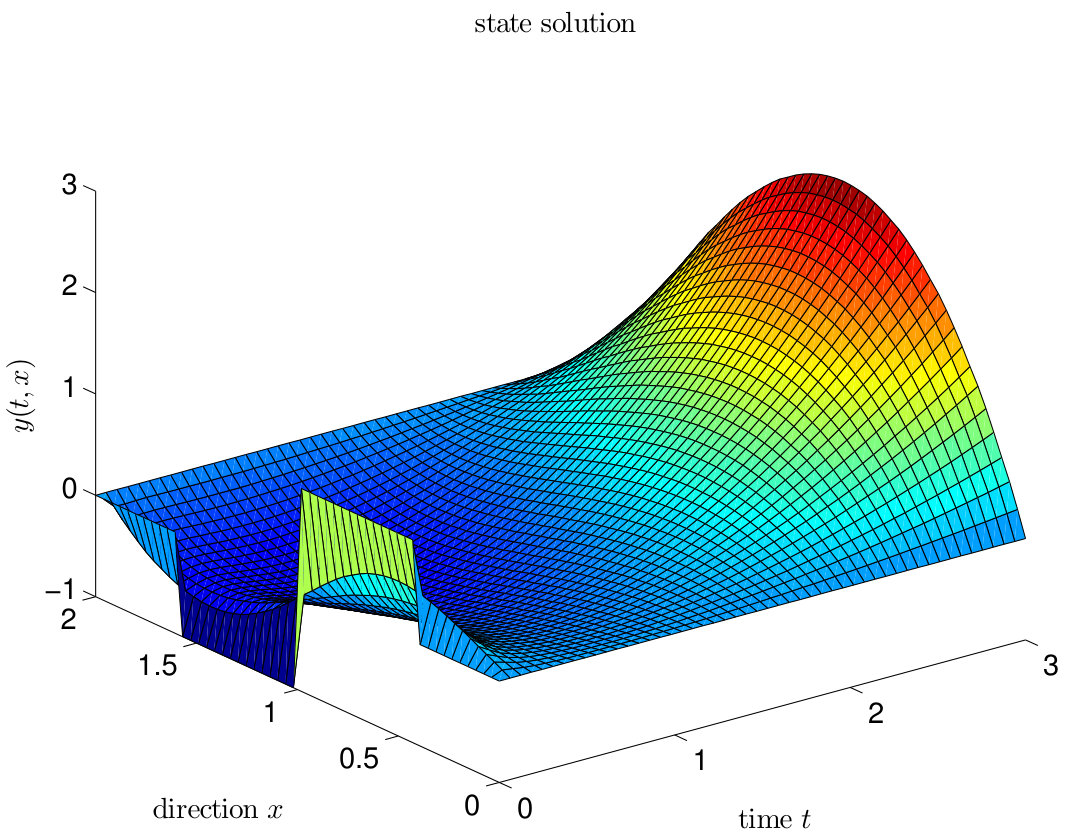 Figure 51
Figure 51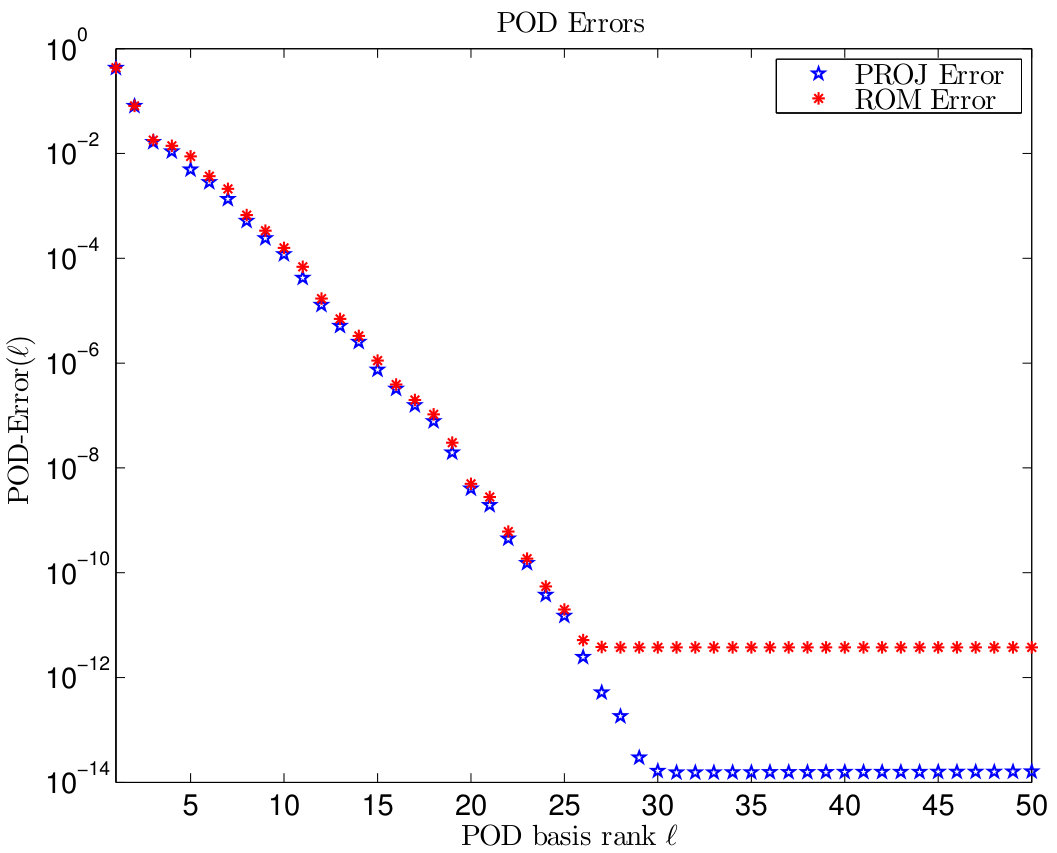 Figure 51
Figure 51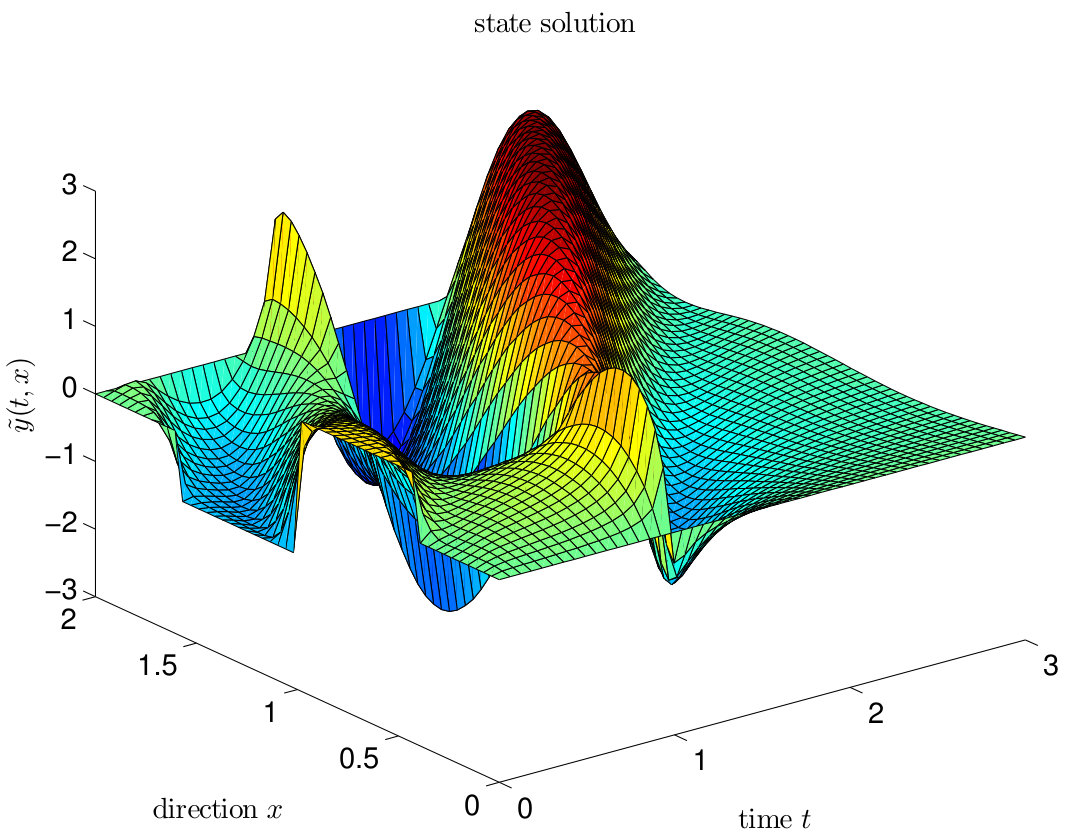 Figure 52
Figure 52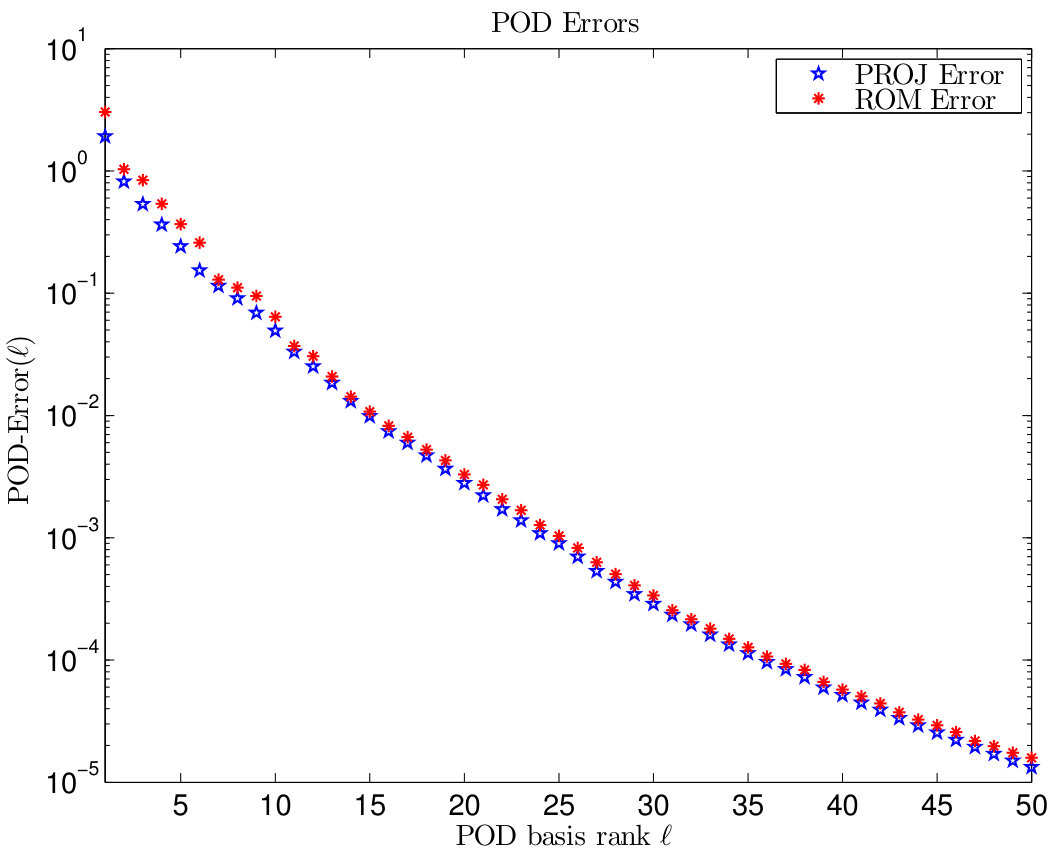 Figure 52
Figure 52 Figure 53
Figure 53 Figure 53
Figure 53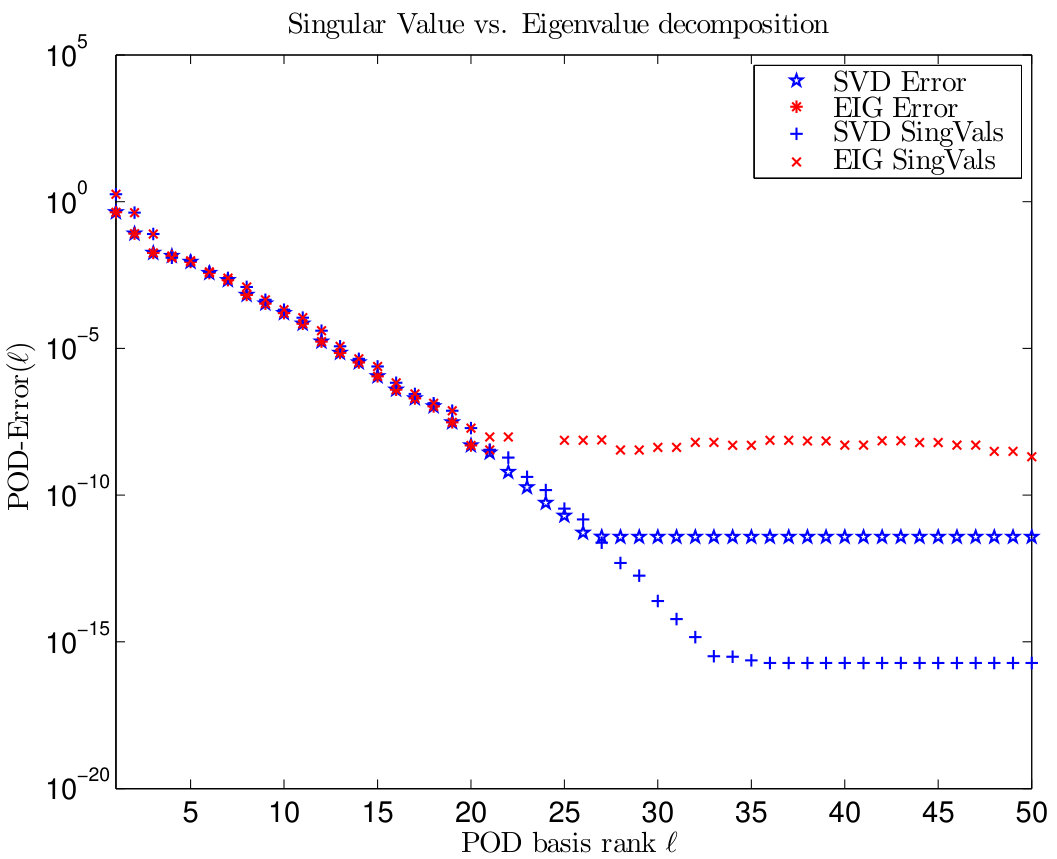 Figure 54
Figure 54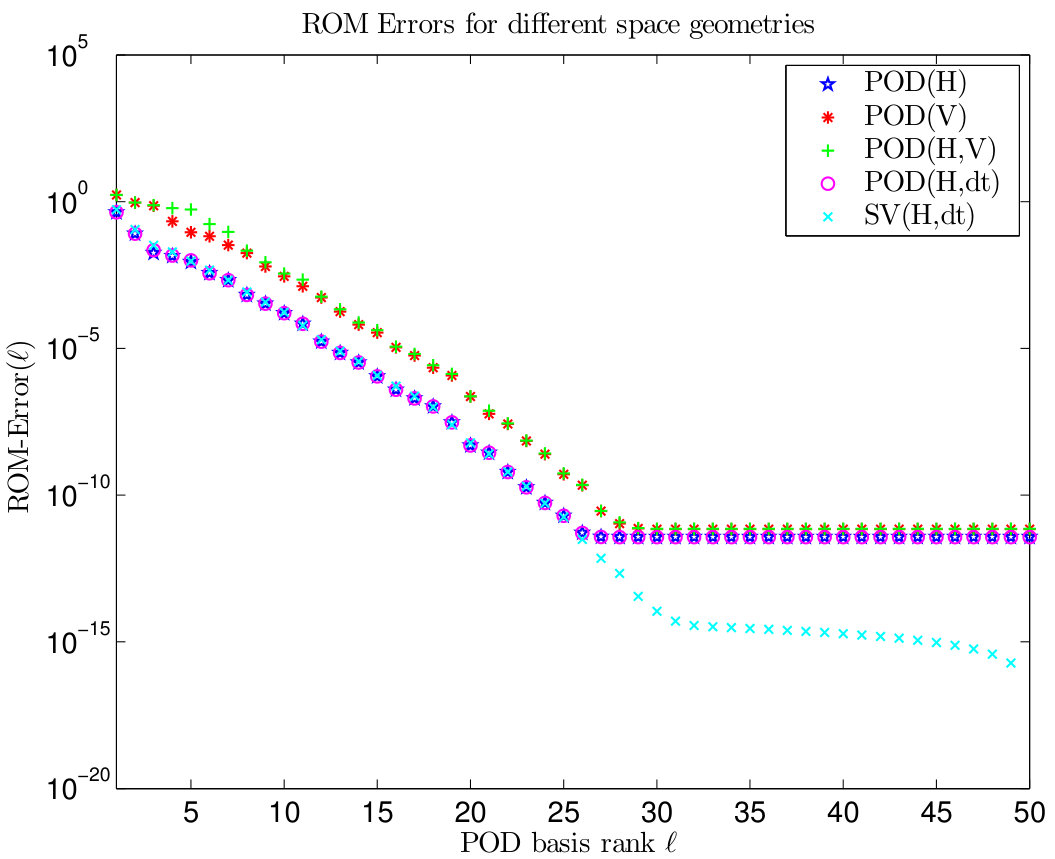 Figure 54
Figure 54 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21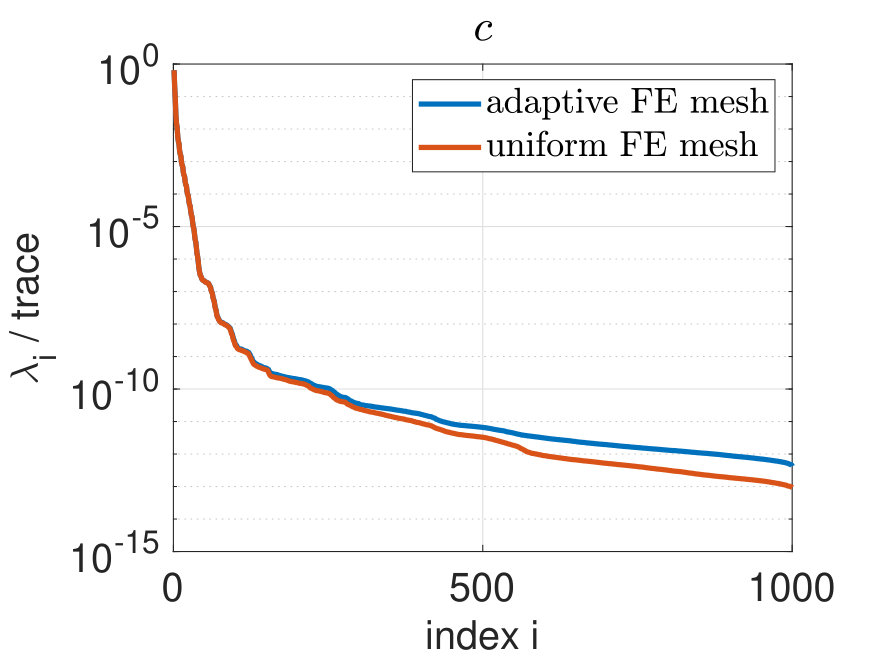 Figure 22
Figure 22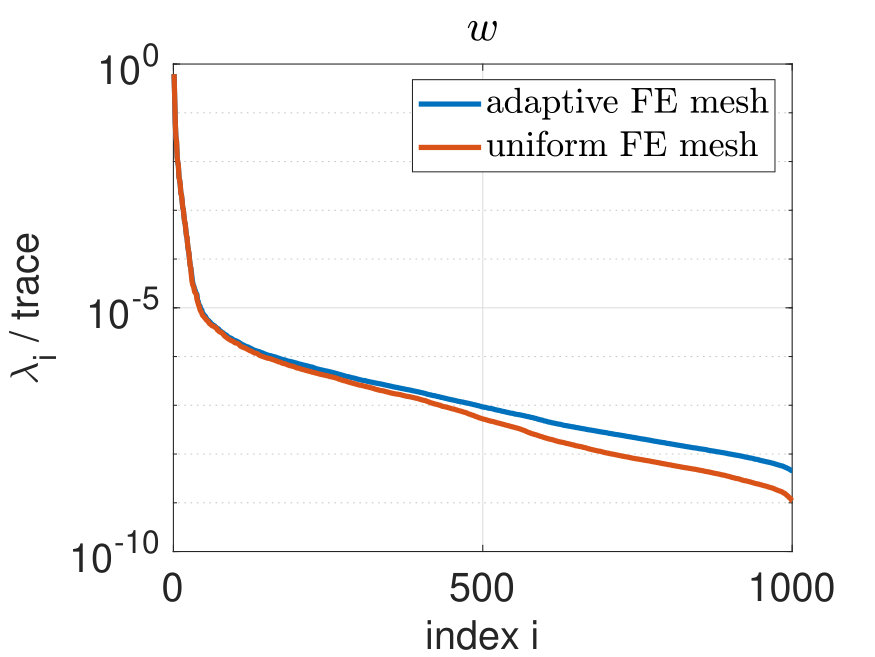 Figure 23
Figure 23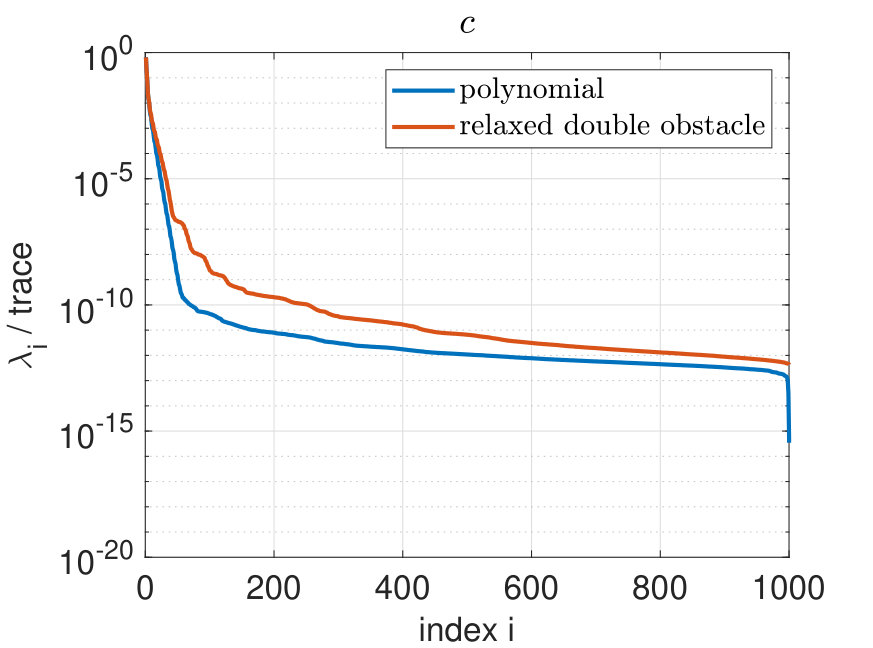 Figure 24
Figure 24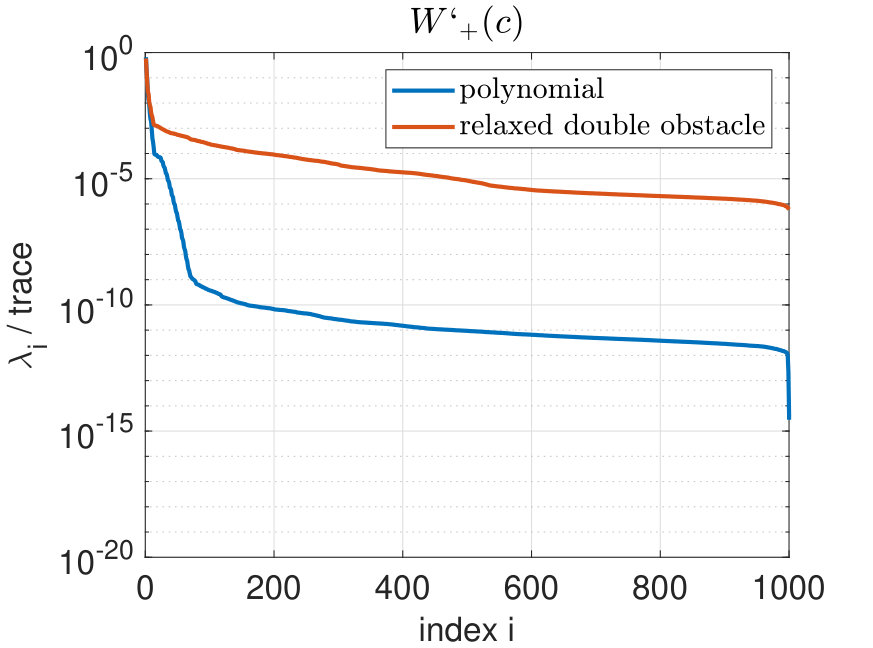 Figure 25
Figure 25 Figure 26
Figure 26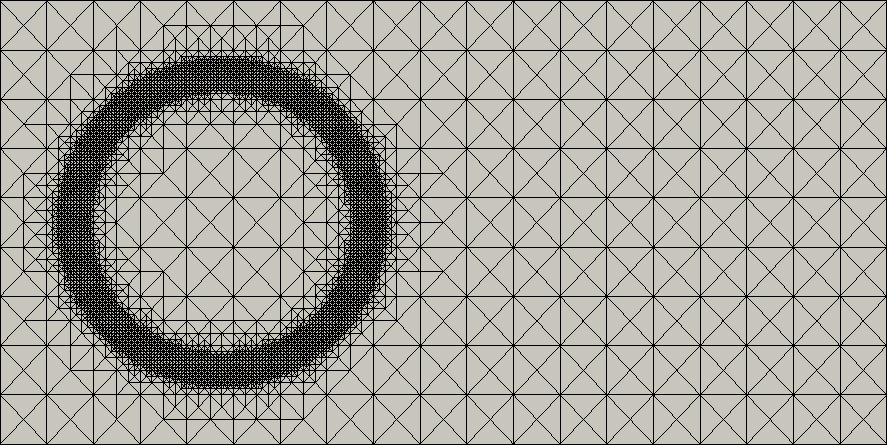 Figure 27
Figure 27 Figure 28
Figure 28 Figure 29
Figure 29 Figure 30
Figure 30 Figure 31
Figure 31 Figure 32
Figure 32 Figure 33
Figure 33 Figure 34
Figure 34 Figure 35
Figure 35 Figure 36
Figure 36 Figure 37
Figure 37 Figure 38
Figure 38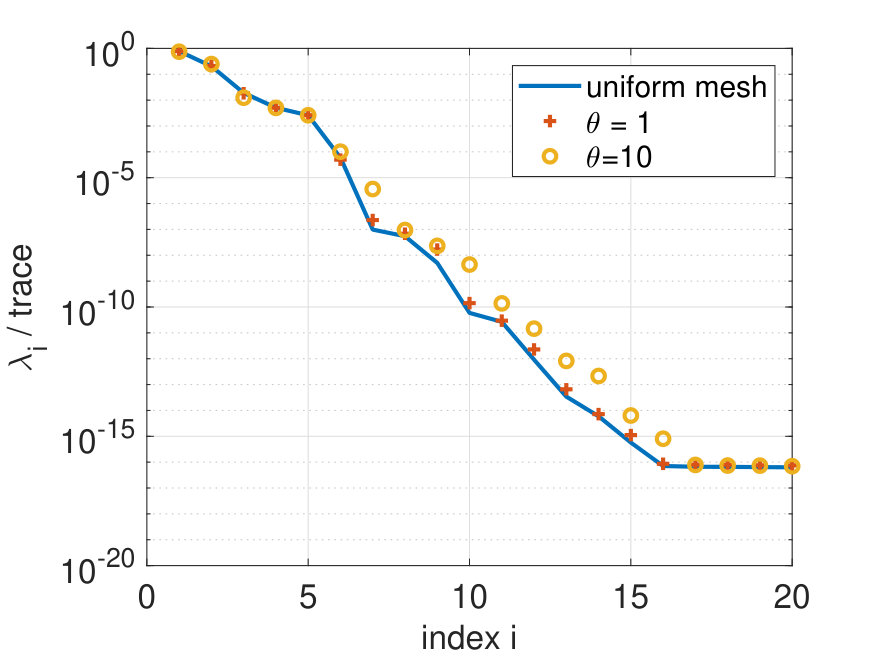 Figure 39
Figure 39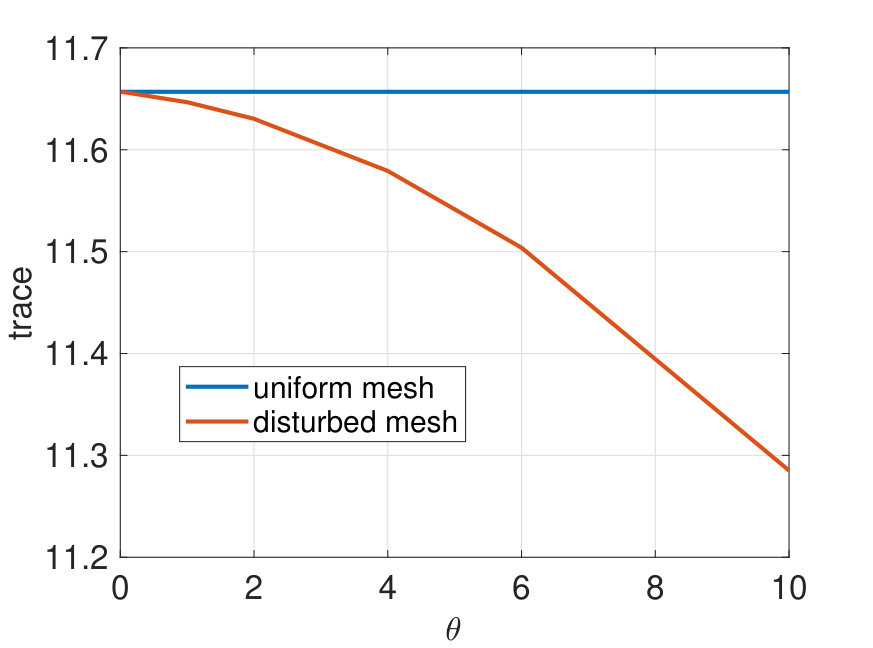 Figure 40
Figure 40| 3 | 4 | 3 | 4 | |||||
| 10 | 13 | 10 | 13 | |||||
| 19 | 26 | 19 | 25 | |||||
| 29 | 211 | 28 | 160 | |||||
| 37 | 644 | 37 | 419 |
| 1 | ||||
|---|---|---|---|---|
| 3 | ||||
| 5 | ||||
| 10 | ||||
| 20 | ||||
| 30 | ||||
| 50 | ||||
| 100 | ||||
| 150 |
| 1 | ||||
|---|---|---|---|---|
| 3 | ||||
| 5 | ||||
| 10 | ||||
| 20 | ||||
| 30 | ||||
| 50 | ||||
| 100 | ||||
| 150 |
| adaptive FE mesh | uniform FE mesh | speedup factor | |
| FE simulation | 944 sec | 8808 sec | 9.3 |
| POD offline computations | 264 sec | 1300 sec | 4.9 |
| POD simulation | 0.07 sec | – | |
| speedup factor | 13485 | 125828 | – |
| 3 | 4 | ||||
|---|---|---|---|---|---|
| 10 | 13 | ||||
| 19 | 26 | ||||
| 29 | 26 | ||||
| 37 | 26 | ||||
| 50 | 50 | ||||
| 65 | 26 | ||||
| 100 | 100 |
| FE | 1644 s | 3129 s | ||
| POD offline | 355 s | 355 s | 350 s | 349 s |
| DEIM offline | 8 s | 8 s | 9 s | 10 s |
| ROM | 183 s | 191 sec | 2616 s | 3388 s |
| ROM-DEIM | 0.05 s | 0.1 s | 0.04 s | no conv. |
| ROM-proj | 0.008 s | 0.03 s | 0.01 s | 0.03 s |
| speedup FE-ROM | 8.9 | 8.6 | 1.1 | none |
| speedup FE-ROM-DEIM | 32880 | 16440 | 78225 | – |
| speedup FE-ROM-proj | 205500 | 54800 | 312900 | 104300 |
| rel error ROM | ||||
| rel error ROM-DEIM | – | |||
| rel error ROM-proj | ||||
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsModel Reduction and Neural Networks · Numerical methods for differential equations · Advanced Numerical Methods in Computational Mathematics
Model Order Reduction by
Proper Orthogonal Decomposition
Carmen Gräßle (Universität Hamburg),
Michael Hinze (Universität Koblenz-Landau),
Stefan Volkwein (Universität Konstanz)
Abstract. We provide an introduction to POD-MOR with focus on (nonlinear) parametric PDEs and (nonlinear) time-dependent PDEs, and PDE constrained optimization with POD surrogate models as application. We cover the relation of POD and SVD, POD from the infinite-dimensional perspective, reduction of nonlinearities, certification with a priori and a posteriori error estimates, spatial and temporal adaptivity, input dependency of the POD surrogate model, POD basis update strategies in optimal control with surrogate models, and sketch related algorithmic frameworks. The perspective of the method is demonstrated with several numerical examples.
Key words. POD model order reduction, (discrete) empirical interpolation, adaptivity, parametric PDEs, evolutionary PDEs, certification with error analysis.
Mathematics Subject Classification. 35B30, 37M99, 41A05, 65K99, 93A15, 93C05
1. Introduction
Proper orthogonal decomposition (POD) is a method which comprises the essential information contained in data sets. Data sets may have their origin in various sources, like, e.g., (uncertain) measurements of geophysical processes, numerical simulations of (parameter-dependent) complex physical problems, or (dynamical) imaging. In order to illustrate the POD idea of information extraction let denote a vector cloud (which here serves as our data set), where we suppose at least one of the vectors is nonzero. Let us collect the vectors in the data matrix
[TABLE]
Then we have . Our aim now is to find a vector with length one which carries as much information of this vector cloud as possible. Of course, we here have to specify what information in this context means. For this purpose we equip with some inner product and induced norm . We define the information content of vector with respect to some unit vector by the quantity . Then we determine the special vector by solving the maximization problem
[TABLE]
Notice that the solution to the maximization problem in (1) is not unique. If is a vector, where the maximum is attained, then is an optimal solution, too. Let us label the vector by . We now iterate this procedure; suppose that for we have already computed such orthonormal vectors , then seek a unit vector which is perpendicular to the -dimensional subspace
[TABLE]
and which carries as much information of our vector cloud as possible, i.e., satisfies
[TABLE]
It is now straightforward to see that the vectors are given by
[TABLE]
where the ’s solve the eigenvalue problem (cf. [42, 53])
[TABLE]
where with the symmetric, positive definite (weighting) matrix
[TABLE]
In (3) the vector denotes the -th unit vector in . The modes obtained in this way are called POD Modes or Principal Components of our data cloud. If now it is advantageous to consider the eigenvalue problem
[TABLE]
which admits the same eigenvalues as before. The modes and , , are related by singular value decomposition (SVD):
[TABLE]
and is the -th singular value of the weighted data matrix . Notice that in contrast to (2) the square root matrix is not required.
It is now clear that a vector cloud also could be replaced by a function cloud in some Hilbert space , where are parameters which may refer to, e.g., time instances of a dynamic process, or stochastic variables, and the concept of information extraction by the above maximization problems directly carries over to this situation. As it is shown in the next section we can even extend this concept to general Hilbert spaces. This will be formalized in Section 2.1 below. From the considerations above it also becomes clear that POD is closely related to SVD. This is outlined in Section 2.2. The POD method for abstract nonlinear evolution problems is explained in Section 2.3. The Hilbert space perspective also allows us to treat spatially discrete evolution equations, which include adaptive concepts for the spatial discretization. This is outlined in Section 2.4. The POD-Galerkin procedure is explained in Section 3, including a discussion of the treatment of nonlinearities. The certification of the POD method with a priori and a posteriori error bounds is outlined in Section 4. The POD approach heavily relies on the choice of the snapshots. Related approaches are discussed in Section 5. In Section 6 we briefly address the scope of the POD method in the context of optimal control of PDEs. Finally, in Section 7 we sketch further important research trends related to POD. Our analytical exposition is supported by several numerical experiments which give an impression of the power of the approach.
POD is one of the most successfully used model reduction techniques for nonlinear dynamical systems; see, e.g., [23, 42, 53, 75, 90] and the references therein. It is applied in a variety of fields including fluid dynamics, coherent structures [4, 9] and inverse problems [13]. Moreover in [11] POD is successfully applied to compute reduced-order controllers. The relationship between POD and balancing was considered in [61, 82, 101]. An error analysis for nonlinear dynamical systems in finite dimensions was carried out in [78] and a missing point estimation in models described by POD was studied in [10].
2. Proper Orthogonal Decomposition (POD)
In this section we introduce a discrete variant of the POD method, where we follow partially [42, Section 1.2.1]. For a continuous variant of the POD method and its relationship to the discrete one we refer the reader to [58] and [42, Sections 1.2.2 and 1.2.3].
2.1. The POD method
Suppose that are fixed natural numbers. Let the so-called snapshot ensembles be given for , where is a separable real Hilbert space. For POD in complex Hilbert spaces we refer the reader to [97]. We set . To avoid a trivial case we suppose that at least one of the ’s is nonzero. Then we introduce the finite dimensional, linear snapshot space
[TABLE]
with finite dimension . We distinguish two cases:
The separable Hilbert space has finite dimension : Then is isomorphic to ; see, e.g., [81, p. 47]. We define the finite index set . Clearly, we have . Especially in case of , the snapshots are vectors in for .
- 2)
is infinite-dimensional: Since is separable, each orthonormal basis of has countably many elements. In this case is isomorphic to the set of sequences of complex numbers which satisfy ; see [81, p. 47], for instance. The index set is now the countable, but infinite set .
The POD method consists in choosing a complete orthonormal basis in such that for every the information content of the given snapshots is maximized in the following sense:
[TABLE]
with positive weighting parameters , and . Here, the symbol denotes the Kronecker symbol satisfying and for .
An optimal solution to () is called a POD basis of rank . It is proved in [42, Theorem 1.8] that for every a solution to () is characterized by the eigenvalue problem
[TABLE]
where denote the largest eigenvalues of the linear, bounded, nonnegative and self-adjoint operator given as
[TABLE]
Moreover, the operator can be presented in the form
[TABLE]
with the mapping
[TABLE]
where denotes the Hilbert space adjoint of , whose action is given by
[TABLE]
The operator , then admits the same nonzero eigenvalues with corresponding eigenvectors , and its action is given by
[TABLE]
with the vector . For the eigensystems of and there holds the relation
[TABLE]
Furthermore, we obtain
[TABLE]
and for the POD projection error we get
[TABLE]
Thus, the decay rate of the positive eigenvalues plays an essential role for a successful application of the POD method. In general, one has to utilize a complete orthonormal basis to represent elements in the snapshot space by their Fourier sum. This leads to a high-dimensional or even infinite-dimensional approximation scheme. Nevertheless, if the term is sufficiently small for a not too large , elements in the subspace can be approximated by a linear combination of the few basis elements . This offers the chance to reduce the number of terms in the Fourier series using the POD basis of rank , as shown in the following examples. For this reason it is useful to define information content of the basis in by the quantity
[TABLE]
It can e.g. be utilized to determine a basis of length containing of the information contained in by requiring . Now it is shown in [42, Section 1.2.1] that
[TABLE]
holds true. This implies
[TABLE]
so that the quantity can be computed without knowing the eigenvalues .
2.2. Singular value decomposition and POD
To investigate the relationship between singular value decomposition (SVD) and POD let us discuss the POD method for the specific case . Then we define the matrices
[TABLE]
where we have introduced the weighting matrix in (3).
Remark 1**.**
Let us mention that holds true provided all are equal to one (i.e., is the identity matrix) and the inner product in is given by the Euclidean inner product (i.e., is the identity matrix).
Now (5) is equivalent to the eigenvalue problem
[TABLE]
with and the eigenvalue problem
[TABLE]
with . If holds, we solve (12). However, we have to solve the linear system for any in order to get the POD basis . Thus, if holds, we will compute the solution to (13) and get the POD basis by the formula . In that case we also have so that we do not have to compute the square root matrix . On the other hand, the diagonal matrix can be computed easily. The relationship between (12) and (13) is given by SVD: There exist real numbers and orthogonal matrices , with column vectors , , respectively, such that
[TABLE]
where and the zeros in (14) denote matrices of appropriate dimensions. Moreover, the vectors and are eigenvectors of and , respectively, with eigenvalues for . The vectors and (if respectively ) are eigenvectors of and with eigenvalue [math]. We summarize the computation of the POD basis in the pseudo code function [, ]= POD(, , , , flag).
function [, ]= POD(, , , , flag)
0: Snapshots matrix with rank , weighting matrices , , number of POD functions and flag for the solver;
1: if flag = 0 then
2: Set ;
3: Compute singular value decomposition ;
4: Define as the -th column of and for ;
5: Set and for ;
6: else if flag = 1 then
7: Compute eigenvalue decomposition ;
8: Define as the -th column of and for ;
9: Set for ;
10: else if flag = 2 then
11: Compute eigenvalue decomposition ;
12: Define as the -th column of and for ;
13: Set for ;
14: end if
15: return and ;
2.3. The POD method for nonlinear evolution problems
In this subsection we explain the POD method for abstract nonlinear evolution problems. We focus on the numerical realization. For detailed theoretical investigations we refer the reader to [42, 50, 51, 57, 58]; for instance.
2.3.1. The nonlinear evolution problems
Let us formulate the nonlinear evolution problem. For that purpose we suppose the following hypotheses.
Assumption 1**.**
Suppose that holds, where is the considered finite time horizon.
* and are real, separable Hilbert spaces and suppose that is dense in with compact embedding. By and we denote the inner products in and , respectively. We identify with its dual (Hilbert) space by the Riesz isomorphism so that we have the Gelfand triple*
[TABLE]
where each embedding is continuous and dense. The last embedding is understood as follows: For every element and , we also have by the embedding , so we can define . 2. 2)
For almost all we define a time-dependent bilinear form satisfying
[TABLE]
for time-independent constants , and where a.e. stands for almost everywhere. 3. 3)
Assume that , holds. Here we refer to [27, pp. 469-472] for vector-valued function spaces.
Recall the function space
[TABLE]
which is a Hilbert space endowed with the standard inner product; cf. [27, pp. 472-479]. Furthermore, we have
[TABLE]
in the sense of distributions in . Here, stands for the dual pairing between and its dual .
Now the evolution problem is given as follows: Find the state such that
[TABLE]
Throughout we assume that (16) admits a unique solution . Of course, this requires some properties for the nonlinear mapping which we will not specify here.
Example 1** (Semilinear heat equation).**
Let , be a bounded open domain with Lipschitz-continuous boundary and let be a fixed end time. We set and and . For a given forcing term and initial condition , we consider the semilinear heat equation with homogeneous Dirichlet boundary condition:
[TABLE]
The existence of a unique solution to (17) is proved in [83], for example. We can write (17) as an abstract evolution problem of type (16) by deriving a variational formulation for (17) with as the space of test functions, and integrating over the space . The bilinear form is introduced by
[TABLE]
and the operator is defined as for . For , the heat equation (17) is linear.
Example 2** (Cahn-Hilliard equations).**
Let , , and be defined as in Example 1. The Cahn-Hilliard system was proposed in [21] as a model for phase separation in binary alloys. Introducing the chemical potential , the Cahn-Hilliard equations can be formulated in the common setting as a coupled system for the phase field and the chemical potential :
[TABLE]
By we denote the outward normal on , is a constant mobility, denotes the surface tension and represents the interface parameter. Note that the convective term describes the transport with (constant) velocity . The transport term represents the coupling to the Navier-Stokes equations in the context of multiphase flow, see e.g. [52] and [2]. The phase field function describes the phase of a binary material with components and and takes the values in the pure -phase and in the pure -phase. The interfacial region is described by and admits a thickness of order , see e.g. Fig. 5, left column, where the binary phases are colored in blue and red, respectively, and the interfacial region is depicted in white. The function represents the free energy and is of double well-type. A typical choice for is the polynomial free energy function
[TABLE]
with two minima at , which describe the energetically favorable states. It is infinitely often differentiable. Another choice for is the relaxed double obstacle free energy
[TABLE]
with relaxation parameter , which is introduced in [43] as the Moreau-Yosida relaxation of the double obstacle free energy
[TABLE]
The energies and later will be used to compare the performance of POD on systems with smooth and less smooth nonlinearities. For more details on the choices for we refer to [1] and [19], for example. Concerning existence, uniqueness and regularity of a solution to (18), we refer to [19]. In order to derive a variational form of type (16), we rewrite (18) as a single fourth-order parabolic equation for by
[TABLE]
We choose equipped with the inner product , so that the dual space of is given by such that and denotes the duality pairing. We note that is a Hilbert space. We define the inner product for as where denotes the inverse of the negative Laplacian with zero Neumann boundary data. Note that . We introduce the bilinear form by
[TABLE]
and define the nonlinear operator by The evolution problem can be written in the form
[TABLE]
We note that this fits our abstract setting formulated in (16) with the Gelfand triple .
2.3.2. Temporal discretization and POD method
Let be a given time grid with step sizes for . Suppose that for any the element is an approximation of computed by applying a temporal integration method (e.g., the implicit Euler method) to (16). Then we consider the snapshot ensemble
[TABLE]
with and . In the context of () we choose and . Moreover, can be either or . For the weighting parameters we take the trapezoidal weights
[TABLE]
Of course, other quadrature weights are also possible. Now, instead of () we consider the minimization problem
[TABLE]
with either or .
Remark 2**.**
In [42, Sections 1.2.2 and 1.3.2] a continuous variant of the POD method is considered. In that case the trapezoidal approximation in (24) is replaced by integrals over the time interval . More precisely, we consider
[TABLE]
with either or . For the relationship between solutions to (24) and (25) we refer to [58] and [42, Section 1.2.3].
To compute the POD basis of rank we have to evaluate the inner products , where either or hold. In typical applications the space is usually infinite dimensional. Therefore, a discretization of is required in order to get a POD method that can be realized on a computer. This is the topic of the next subsection.
2.3.3. Galerkin discretization
We discretize the state equation by applying any spatial approximation scheme. Let us consider here a Galerkin scheme for (16). For this reason we are given linearly independent elements and define the -dimensional subspace
[TABLE]
endowed with the topology. Then a Galerkin scheme for (16) is given as follows: find satisfying
[TABLE]
Inserting the representation , , in (26) and choosing for we derive the following -dimensional initial value problem
[TABLE]
where we have used the matrices and vectors
[TABLE]
In the pseudo code function []= StateSol() we present a solution method for (27) using the implicit Euler method.
function []= StateSol()
0: Initial condition ;
1: Compute solving ;
2: for to do
3: Set and ;
4: Solve (e.g., by applying Newton’s method) for
\big{(}\mathrm{M}^{h}+\Delta t_{j}\mathrm{A}_{j}^{h}\big{)}\mathrm{y}^{h}_{j}+\Delta t_{j}\mathrm{N}^{h}(\mathrm{y}^{h}_{j})=\mathrm{M}^{h}\mathrm{y}_{j-1}^{h}+\Delta t_{j}\mathrm{F}^{h}_{j};
5: end for
6: return matrix ;
In the next subsection we discuss how a POD basis of rank can be computed from numerical approximations for the solution to (27).
2.3.4. POD method for the fully discretized nonlinear evolution problem
Recall that we have introduced the temporal grid and set . Let be numerical approximations to the solution to (27) at time instances , . Then, a coefficient matrix is defined by the elements given by
[TABLE]
The -th column of (denoted by ) contains the Galerkin coefficients of the snapshot . We set and
[TABLE]
Due to we have for . Therefore, there exists a coefficient matrix that is defined by the elements satisfying
[TABLE]
where the -th column of the matrix consists of the Galerkin coefficients of the element . Notice that
[TABLE]
hold for , and for the symmetric, positive definite stiffness matrix
[TABLE]
Then, we have for
[TABLE]
and for
[TABLE]
Thus, we can apply the approach presented in Section 2.2 choosing for and for . Moreover, we set , and defined in (23). Now a POD basis of rank for (27) can be computed by the pseudo code function [,]= PODState(, , , , flag).
function [, ]= PODState(, , , , flag)
0: Initial condition , weighting matrices , , number of POD functions and flag for the solver;
1: Call []= StateSol();
2: Call [,]= POD(, , , , flag);
3: return and ;
In the next subsection we will discuss in detail how the POD method has to be applied in that case if we have – instead of – different spaces for each .
2.4. The POD method with snapshots generated by spatially adaptive finite element methods
In practical applications it often is desirable to provide POD models for time-dependent PDE systems, whose numerical treatment requires adaptive numerical techniques in space and/or time. Snapshots generated by those methods are not directly amenable to the POD procedure described in Section 2.3.4, since the application of spatial adaptivity means, that the snapshots at each time instance may have different lengths due to their different spatial resolutions. In fact, there is not one single discrete Galerkin space for all snapshots generated by the fully discrete evolution, but at every time instance the adaptive procedure generates a discrete Galerkin space , so that in this case . For this reason, no snapshot matrix can be formed with columns containing the basis coefficient vectors of the snapshots.
To obtain also a POD basis in this situation we inspect the operator of (8) and observe that its action can be computed if the inner products can be evaluated for all and .
Let us next demonstrate how to compute a POD basis for snapshots residing in arbitrary finite element (FE) spaces. To begin with we drop the superindex and set . For each time instant of our time discrete PDE system the snapshots are taken from different finite element spaces , where denotes a common (real) Hilbert space. Let . Then we have the expansions
[TABLE]
with coefficient vectors
[TABLE]
containing the finite element coefficients. The inner product of the associated functions can thus be computed as
[TABLE]
so that the evaluation of the action only relies on the evaluation of the inner products (, , ). In other words, once we are able to compute those inner products we are in the position to set up the eigensystem of from (8). The POD modes can then be computed according to (9) by
[TABLE]
Details on this procedure can be found in [62, 39].
To illustrate how this procedure can be implemented we summarize Examples 6.1-6.3 from [39], which deal with nested and non-nested meshes. All coding was done in C++ with using FEniCS [8, 66] for the solution of the differential equations and ALBERTA [87] for dealing with hierarchical meshes. The numerical tests were run on a compute server with 512 GB RAM.
Run 1** ([39, Example 6.1]).**
We consider the Example 1 with homogeneous Dirichlet boundary condition and vanishing nonlinearity, i.e. we set so that the equation becomes linear. The spatial domain is chosen as , the time interval is . Furthermore, we choose . For the temporal discretization we introduce the uniform time grid by
[TABLE]
with . For the spatial discretization we use -adapted piecewise linear, continuous finite elements on hierarchical and nested meshes. Snapshots of the analytical solution at three different time points are shown in Figure 1. Details on the construction of the analytical solution and the corresponding right hand side are given in [39, Example 6.1].
Due to the steep gradients in the neighborhood of the minimum and maximum, respectively, the use of an adaptive finite element discretization is justified. The resulting computational meshes as well as the corresponding finest mesh (reference mesh at the end of the simulation which is the union of all adaptive meshes generated during the simulation) are shown in Figure 2.
The number of nodes of the adaptive meshes varies between 3637 and 7071 points. The finest mesh has 18628 degrees of freedom. A uniform mesh with grid size of order of the diameter of the smallest triangles in the adaptive grids () would have 93025 degrees of freedom. This clearly reveals the benefit of using adaptive meshes for snapshot generation which is also well reflected in the comparison of the computational times needed for the snapshot generation on the adaptive mesh taking 944 seconds compared to 8808 seconds on the uniform mesh, see Table 4) for the speedup factors obtained by spatial adaptation. In Figure 3, the resulting normalized eigenspectrum of the correlation matrix is shown for snapshots obtained by uniform spatial discretization (“uniform FE mesh”), for snapshots obtained by interpolation on the finest mesh (“adaptive FE mesh”), and for snapshots without interpolation (“infPOD”), where is associated to the operator from (8), see also (30).
We observe that the eigenvalues for both adaptive approaches coincide. This numerically validates what we expect from theory: the information content which is contained in the matrix when we explicitly compute the entries without interpolation is the same as the information content contained within the eigenvalue problem which is formulated when using the finest mesh. No information is added or lost. Moreover, we recognize that about the first 28 eigenvalues computed corresponding to the adaptive simulation coincide with the simulation on a uniform mesh. From index 29 on, the methods deliver different results: for the uniform discretizations, the normalized eigenvalues fall below machine precision at around index 100 and stagnate. In contrary, the normalized eigenvalues for both adaptive approaches flatten in the order around . If the error tolerance for the spatial discretization error is chosen larger (or smaller), the stagnation of the eigenvalues in the adaptive method takes place at a higher (or lower) order (see Figure 3, right). Concerning dynamical systems, the magnitude of the eigenvalue corresponds to the characteristic properties of the underlying dynamical system: the larger the eigenvalue, the more information is contained in the corresponding eigenfunction. Since all adaptive meshes are contained in the uniform mesh, the difference in the amplitude of the eigenvalues is due to the interpolation errors during refinement and coarsening. This is the price we have to pay for faster snapshot generation using adaptive methods. A further aspect gained from the decay behavior of the eigenvalues in the adaptive case is the following; the adaptive approach filters out the noise in the system which is related to the modes corresponding to the singular values that are not matched by the eigenvalues of the adaptive approach. This in the language of frequencies means that the overtones in the systems which get lost in the adaptive computations live in the space which is neglected by the POD method based on adaptive finite element snapshots. From this point of view, adaptivity can be interpreted as a smoother.
The first, second and fifth POD modes of Run 1 obtained by the adaptive approach are depicted in Figure 4. We observe the classical appearance of the basis functions. The initial condition is reflected by the first POD basis function. The next basis functions admit a number of minima and maxima corresponding to the index in the basis: has two minima and two maxima etc. This behavior is similar to the increasing oscillations in higher frequencies in trigonometric approximations. The POD basis functions corresponding to the uniform spatial discretization have a similar appearance.
Run 2** ([39, Example 6.2]).**
(Cahn-Hilliard system.) We consider Example 2 in the form (18) with , , constant mobility , and constant surface tension . The interface parameter is set to , with resulting interface thickness . We use the relaxed double obstacle free energy from (20) with . As initial condition, we choose a circle with radius and center . The initial condition is transported horizontally with constant velocity . We set
[TABLE]
so that . The numerical computations are performed with the semi-implicit Euler scheme. For this purpose let and denote the time-discrete solution at and , respectively. Based on the variational formulation (22) we tackle the time discrete version of (18) in the form: given , find , solving
[TABLE]
for all and with . According to (22), here it is . Note that the free energy function is split into a convex part and a concave part , such that and is treated implicitly, whereas is treated explicitly with respect to time. This leads to an unconditionally energy stable time marching scheme, compare [33]. The system (29) is discretized in space using piecewise linear and continuous finite elements. The resulting nonlinear equation systems are solved using a semi-smooth Newton method.
Figure 5 shows the phase field (left) and the chemical potential (right) for the finite element simulation using adaptive meshes. The initial condition is transported horizontally with constant velocity.
The adaptive finite element meshes as well as the finest mesh which is generated during the adaptive finite element simulation are shown in Figure 6. The number of degrees of freedom in the adaptive meshes varies between 6113 and 8795. The finest mesh (overlay of all adaptive meshes) has 54108 degrees of freedom, whereas a uniform mesh with discretization fineness as small as the smallest triangle in the adaptive meshes has 88450 degrees of freedom.
Figure 7 shows the first, second and fifth POD mode for the phase field and the chemical potential . Analogously to Run 1, we observe a periodicity in the POD basis functions corresponding to their basis index numbers.
In the present example we only compare the POD procedure for two kinds of snapshot discretizations, namely the adaptive approach with using a finest mesh, and the uniform mesh approach, where the gridsize is chosen to be of the same size as the smallest triangle in the adaptive meshes. We choose and compute a separate POD basis for each of the variables and .
In Figure 8, a comparison is visualized concerning the normalized eigenspectrum for the phase field and the chemical potential using uniform and adaptive finite element discretization. We note for the phase field that about the first 180 eigenvalues computed corresponding to the adaptive simulation coincide with the eigenvalues of the simulation on the finest mesh. Then, the eigenvalues corresponding to the uniform simulation decay faster. Similar observations apply for the chemical potential .
We use the criterion (11) to determine the basis length which is required to represent a prescribed information content with the respective POD space. We will choose the POD basis length for the phase field and the number of POD modes for the chemical potential, such that
[TABLE]
for a given value representing the loss of information. Alternatively, the POD basis length could be chosen in alignment with the POD projection error (10) with the expected spatial and/or temporal discretization error, compare e.g. [39, Theorem 5.1]. Let us also refer, e.g., to the recent paper [12], where different adaptive POD basis extension techniques are discussed. Table 1 summarizes how to choose and in order to capture a desired amount of information. Moreover, it tabulates the POD projection error (10) depending on the POD basis length, where and denote the eigenvalues for the phase field and the chemical potential , respectively. The results in Table 1 agree with our expectations: the smaller the loss of information is, the more POD modes are needed and the smaller is the POD projection error.
Run 3** ([39, Example 6.3]).**
(Linear heat equation revisited). We again consider Example 1 with . The purpose of this example is to confirm that our POD approach also is applicable in the case of non-nested meshes like it appears in the case of -adaptivity, for example. We set up the matrix for snapshots generated on sequences of non-nested spatial discretizations. This requires the integration over cut elements, see [39]. We choose , , and we apply a uniform temporal discretization with time step size . The analytical solution in the present example is given by
[TABLE]
with , source term and the initial condition . The initial condition is discretized using piecewise linear and continuous finite elements on a uniform spatial mesh which is shown in Figure 9 (left). Then, at each time step, the mesh is disturbed by relocating each mesh node according to the assignment
[TABLE]
where is sufficiently small such that all coordinates of the interior nodes fulfill and . After relocating the mesh nodes, the heat equation is solved on this mesh for the next time instance. We use Lagrange interpolation to transfer the finite element solution of the previous time step onto the new mesh. The disturbed meshes at and as well as an overlap of two meshes are shown in Figure 9. To compute the matrix from (30) we have to evaluate the corresponding inner products of the snapshots, where we need to integrate over cut elements.
We compute the eigenvalue decomposition of the matrix representation of the operator (cf. (30)) for different values of and compare the results with a uniform mesh (i.e. ) in Figure 10. We note that the eigenvalues of the disturbed mesh are converging to the eigenvalues of the uniform mesh for . As expected, the eigenvalue spectrum depends only weakly on the underlying mesh given that the mesh size is sufficiently small.
Concerning the computational complexity of POD with non-nested meshes let us note that solving the heat equation takes 2.1 seconds on the disturbed meshes and 1.8 seconds on the uniform mesh. The computational time needed to compute each entry of the matrix is 0.022 seconds and computing the eigenvalue decomposition for takes 0.0056 seconds. Note that the cut element integration problem for each matrix entry takes a fraction of time required to solve the finite element problem.
3. The POD Galerkin procedure
Once the POD basis is generated it can be used to set up a POD-Galerkin approximation of the original dynamical system. This is discussed in the present section. In this context we recall that the space spanned by the POD basis is used with a Galerkin method to approximate the original system for e.g. other inputs and/or parameters than those used to generate the snapshots for constructing the POD basis. A typical application is given by PDE-constrained optimization, where the PDE system during the optimization is substituted by POD Galerkin surrogates, see Section 6 for more details.
3.1. The POD Galerkin procedure
Suppose that for given snapshots , , we have computed the symmetric matrix
[TABLE]
associated to the operator from (8) together with its eigensystem. Its largest eigenvalues are with corresponding eigenvectors . The POD basis is then given by (9), i.e.,
[TABLE]
This POD basis is utilized in order to compute a reduced-order model for (16) along the lines of Section 2.3.3, where the space is replaced by the space . More precisely we make the POD Galerkin ansatz
[TABLE]
as an approximation for , with the Fourier coefficients
[TABLE]
Inserting into (16) and choosing as the test space leads to the system
[TABLE]
for all and for almost all . The system (32) is called POD reduced-order model (POD-ROM). Using the ansatz (31), we can write (32) as an -dimensional ordinary differential equation system for the POD mode coefficients , , as follows:
[TABLE]
for . Note that if we choose in the context of Section 2.3. In a next step we rewrite this system using relation between and given in (9). This leads to
[TABLE]
for . In order to write (34) in a compact matrix-vector form, let us introduce the diagonal matrix
[TABLE]
From the first eigenvectors of we build the matrix
[TABLE]
Then, the system (34) can be written as the system
[TABLE]
for the vector-valued mapping , for the nonlinearity with
[TABLE]
and for the stiffness matrix given as
[TABLE]
Note that the right hand side and the initial condition are given by
[TABLE]
and
[TABLE]
for , respectively. Their calculation can be done explicitly for any arbitrary finite element discretization. For a given function (for example or ) with finite element discretization , nodal basis and appropriate mode coefficients we can compute
[TABLE]
for where denotes the -th snapshot. Again, for any and , the computation of the inner product can be done explicitly.
Obviously, for linear evolution equations the POD reduced-order model (35) can be set up and solved using snapshots with arbitrary finite element discretizations. The computation of the nonlinear component needs particular attention. In Section 3.3 we discuss the options to treat the nonlinearity.
3.2. Time-discrete reduced-order model
In order to solve the reduced-order system (32) numerically, we apply the implicit Euler method for time discretization and use for simplicity the same temporal grid as for the snapshots. It is also possible to use a different time grid, cf. [58]. The time-discrete reduced-order model reads
[TABLE]
for all and . Equivalently the following system holds for the coefficient vector (cf. (35)):
[TABLE]
with the inhomogeneity , , given as
[TABLE]
3.3. Discussion of the computation of the nonlinear term
Let us now consider the computation of the nonlinear term of the POD-ROM (35). It holds true
[TABLE]
for . It is well known that the evaluation of nonlinearities in the reduced-order modeling context is computationally expensive. To make this clear, let us assume, we are given a uniform finite element discretization with degrees of freedom. Then, in the fully discrete setting, the nonlinear term has the form
[TABLE]
where is the matrix in which the POD modes are stored columnwise and is a weighting matrix related to the utilized inner product (cf. (3)). Hence, the treatment of the nonlinearity requires the expansion of in the full space for a.e. Then the nonlinearity can be evaluated and finally the result is projected back to the POD space. Obviously, this means that the reduced-order model is not fully independent of the high-order dimension and efficient simulation cannot be guaranteed. Therefore, it is convenient to seek for hyper reduction, i.e., for a treatment of the nonlinearity, where the model evaluation cost is related to the low dimension . Common choices are empirical interpolation methods like, e.g., EIM ([14]), DEIM ([24]), and QDEIM ([31]). Another option is dynamic mode decomposition for nonlinear model order reduction, see e.g. [7]. Furthermore, in [99] nonlinear model reduction is realized by replacing the nonlinear term by its interpolation in the finite element space. An alternative approach for the treatment of the nonlinearity is missing point estimation [10], or best points interpolation [70].
Most of these methods need a common reference mesh for the computations. To overcome this restriction we propose different paths which allow for more general discrete settings like -adaptivity discussed in Run 3.
One option is to use EIM [14]. Alternatively, we can linearize and project the nonlinearity onto the POD space. For this approach, let us consider the linear reduced-order system for a fixed given state , which takes the form
[TABLE]
for all and for almost all . The linear evolution problem (38) can be set up and solved explicitly without spatial interpolation. In the numerical examples in Section 6, we take the finite element solution as given state in each time step, i.e., for .
Furthermore, the linearization of the reduced-order model (32) can be considered:
[TABLE]
for all and for almost all , where denotes the Fréchet derivative of the nonlinear operator . This linearized problem is of interest e.g. in the context of optimal control, where it occurs in each iteration level within sequential quadratic programming (SQP) methods; see [49], for example. Choosing the finite element solution as given state in each time instance and using (9) leads to
[TABLE]
for and . Finally, we approximate the nonlinearity in (37) by
[TABLE]
for and , which can be written as
[TABLE]
where
[TABLE]
and with , ,
[TABLE]
For weakly nonlinear systems this approximation may be sufficient, depending on the problem and its goal. A great advantage of linearizing the semilinear partial differential equation is that only linear equations need to be solved which leads to a further speedup, see Table 6. However, if a more precise approximation is desired or necessary, we can think of approximations including higher order terms, like quadratic approximation, see, e.g., [25] and [84], or Taylor expansions, see, e.g., [73, 74] and [35]. Nevertheless, the efficiency of higher order approximations is limited due to growing memory and computational costs.
3.4. Expressing the POD solution in the full spatial domain
Having determined the solution to (35), we can set up the reduced solution in a continuous framework:
[TABLE]
Now, let us turn to the fully discrete formulation of (40). For a time-discrete setting, we introduce for simplicity the same temporal grid as for the snapshots. The snapshots (28) admit the expansion
[TABLE]
Let denote an arbitrary set of grid points for the reduced system at time level . The fully discrete POD solution can be computed by evaluation:
[TABLE]
for and . This allows us to use any grid for expressing the POD solution in the full spatial domain. For example, we can use the same nodes at time level for the POD simulation as we have used for the snapshots, i.e., for it holds and for all . Another option can be to choose
[TABLE]
i.e., the common finest grid. Obviously, a special and probably the easiest case concerning the implementation is to choose snapshots which are expressed with respect to the same finite element basis functions and utilize the common finest grid for the simulation of the reduced-order system, which is proposed by [95]. After expressing the adaptively sampled snapshots with respect to a common finite element space, the subsequent steps coincide with the common approach of taking snapshots which are generated without adaptivity. Then, expression (41) simplifies to
[TABLE]
where are the nodes of the common finite element space.
Run 4** ([39, Example 6.1]).**
Let us revisit Run 1 and consider its POD Galerkin solutions. The POD solutions for and POD basis functions using spatial adaptive snapshots which are interpolated onto the finest mesh are shown in Figure 11. As expected, the more POD basis functions we use (until stagnation of the corresponding eigenvalues), the less oscillations appear in the POD solution and the better the approximation is.
Table 2 compares the approximation quality in the relative -norm of the POD solution using adaptively generated snapshots which are interpolated onto the finest mesh with snapshots of uniform spatial discretization depending on different POD basis lengths. Then, for we obtain a relative -error between the POD solution and the finite element solution of size , and a relative -error between the POD solution and the true solution of size .
We note that decays down to () and then stagnates if using a uniform mesh. This behavior is clear, since the more POD basis elements we include (up to stagnation of the corresponding eigenvalues), the better is the POD solution an approximation for the finite element solution. On the other hand, both and start to stagnate after in Table 2, columns 4 and 5. This is due to the fact that at this point the spatial (and temporal) discretization error dominates the modal error. This is in accordance with the decay of the eigenvalues shown in Figure 3 and is accounted for e.g. in the error estimation presented in [39, Theorem 5.1]. Similar observations hold true for the relative -error listed in Table 3 with the difference that the -error is larger than the respective -error.
The computational times for the full and the low order simulation using uniform finite element discretizations and adaptive finite element snapshots, which are interpolated onto the finest mesh, respectively, are listed in Table 4.
Once the POD basis is computed in the offline phase, the POD simulation corresponding to adaptive snapshots is 13485 times faster than the FE simulation using adaptive finite element meshes. This speedup factor is important when one considers e.g. optimal control problems with time-dependent PDEs, where the POD-ROM can be used as surrogate model in repeated solution of the underlying PDE model. In the POD offline phase, the most expensive task is to express the snapshots with respect to the common finite element space, which takes 226 seconds. Since (30) is symmetric, it suffices to calculate the entries on and above the diagonal, which are entries. Thus, the computation of each entry in the correlation matrix using a common finite element space takes around 0.00018 seconds. We note that in the approach explained in Sections 2.4 and 3, the computation of the matrix is expensive. For each entry the calculation time is around 0.03 seconds, which leads to a computation time of around 36997 seconds for the matrix . The same effort is needed to build . In this case, the offline phase takes therefore around 88271 seconds. For this reason, the approach to interpolate the adaptively generated snapshots onto the finest mesh is computationally more favorable. But since the computation of can be parallelized, the offline computation time can be reduced provided that the appropriate hardware is available.
Run 5** (Cahn-Hilliard equations).**
Now let us revisit Run 2, where we in the following run the numerical simulations for different combinations of numbers for and of Table 1. The approximation quality of the POD solution using adaptive meshes is compared to the use of a uniform mesh in Table 5. As expected, Table 5 shows that the error between the POD surrogate solution and the high-fidelity solution gets smaller for an increasing number of utilized POD basis functions. Moreover, a larger number of POD modes is needed for the chemical potential than for the phase field in order to get an error in the same order which is in accordance to the fact that the decay of the eigenvalues for is slower than for as seen in Figure 8.
We now discuss the treatment of the nonlinearity and also investigate the influence of non-smoothness of the model equations to the POD procedure. Using the convex-concave splitting for , we obtain for the Moreau-Yosida relaxed double obstacle free energy the concave part and the convex part . This means that the first derivative of the concave part is linear with respect to the phase field variable . The challenging part is the convex term with non-smooth first derivative. For a comparison, we consider the smooth polynomial free energy with concave part and convex part .
Figure 12 shows the decay of the normalized eigenspectrum for the phase field (left) and the first derivative of the convex part (right) for the polynomial and the relaxed double obstacle free energy. Obviously, in the non-smooth case more POD modes are needed for a good approximation than in the smooth case. This behavior is similar to the decay of the Fourier coefficients in the context of trigonometric approximation, where the decay of the Fourier coefficients depends on the smoothness of the approximated object.
Table 6 summarizes computational times for different finite element runs as well as reduced-order simulations using the polynomial and the relaxed double obstacle free energy, respectively. In addition, the approximation quality is compared. The computational times are rounded averages from various test runs. It turns out that the finite element simulation (row 1) using the smooth potential is around two times faster than using the non-smooth potential. This is due to the fact that in the smooth case, two to three Newton steps are needed for convergence in each time step, whereas in the non-smooth case six to eight iterations are needed in the semismooth Newton method.
Using the smooth polynomial free energy, the reduced-order simulation is 8-9 times faster than the finite element simulation, whereas using the relaxed double obstacle free energy only delivers a very small speedup. The inclusion of DEIM (we use ) in the reduced-order model leads to immense speedup factors for both free energy functions (row 8). This is due to the fact that the evaluation of the nonlinearity in the reduced-order model is still dependent on the full spatial dimension and hyper reduction methods are necessary for useful speedup factors. Note that the speedup factors are of particular interest in the context of optimal control problems. At the same time, the relative -error between the finite element solution and the ROM-DEIM solution is close to the quality of the reduced-order model solution (row 10-11).
However, in the case of the non-smooth free energy function using POD modes for the phase field and POD modes for the chemical potential, the inclusion of DEIM has the effect that the semismooth Newton method does not converge. For this reason, we treat the nonlinearity by applying the technique explained in Section 3.1, i.e. we project the finite element snapshots for (which are interpolated onto the finest mesh) onto the POD space. Since this leads to linear systems, the computational times are very small (row 6). The error between the finite element solution and the reduced-order solution using projection of the nonlinearity is of the magnitude . Depending on the motivation, this approximation quality might be sufficient. Nevertheless, we note that for large numbers of POD modes, using the projection of the nonlinearity onto the POD space leads to a large increase of the error.
To summarize, a POD reduced-order model construction approach is proposed which can be set up and solved for snapshots originating from arbitrary FE (and also other) spaces. The method is applicable for -, - and -adaptive finite elements. It is motivated from an infinite-dimensional perspective. Using the method of snapshots we are able to set up the correlation matrix from (30) by evaluating the inner products of snapshots which live in different FE spaces. For non-nested meshes, this requires the detection of cell collision and integration over cut finite elements. A numerical strategy how to implement this practically is elaborated and numerically tested. Using the eigenvalues and eigenvectors of this correlation matrix, we are able to set up and solve a POD surrogate model that does not need the expression of the snapshots with respect to the basis of a common FE space or the interpolation onto a common reference mesh. Moreover, an error bound for the error between the true solution and the solution to the POD-ROM using spatially adapted snapshots is available in [39, Theorem 5.1]. The numerical tests show that the POD projection error decreases if the number of utilized POD basis functions is increased. However, the error between the POD solution and the true solution stagnates when the spatial discretization error dominates. Moreover, the numerics show that using the correlation matrix calculated explicitly without interpolation in order to build a POD-ROM gives the same results as the approach where the snapshots are interpolated onto the finest mesh. From a computational point of view, sufficient hardware should be available in order to compute the correlation matrix in parallel and make the offline computational time competitive. For semilinear evolution problems, the nonlinearity is treated by linearization. This is of interest in view of optimal control problems, in which a linearized state equation has to be solved in each SQP iteration level. An appropriate treatment of the nonlinearity in our applications gains significant speedup of the ROM in computational times when compared to the full simulations. This makes POD-MOR with adaptive finite elements an ideal approach for the construction of surrogate models in e.g. optimal control with nonlinear PDE systems as they arise e.g. in the context of multi-phase flow control problems.
4. Certification with a priori and a posteriori error estimates
As we have seen in Section 3 POD provides a method for deriving low order models of dynamical systems. It can be thought of as a Galerkin approximation in the spatial variable, built from functions corresponding to the solution of the physical system at prespecified time instances. After carrying out a singular value decomposition the leading generalized eigenfunctions are chosen as the POD basis of rank . As soon as one uses POD, questions concerning the quality of the approximation properties, convergence, and rate of convergence become relevant. Let us refer, e.g., to the literature [22, 42, 56, 58, 57, 85, 88, 89, 80] for a priori error analysis for POD Galerkin approximations. It turns out that the error depends on the decay of the sum , the error (with an appropriate ) due to the used time integration method, the used Galerkin spaces and the choice or . In particular, best approximation properties hold provided the time differences (or the finite difference discretizations) are included in the snapshot ensembles; cf. [56, 58, 89].
Let us recall numerical test examples from [42, Section 1.5]. The programs are written in Matlab using the Partial Differential Equation Toolbox for the computation of the piecewise linear FE discretization. For the temporal integration the implicit Euler method is applied based on the equidistant time grid , and .
Run 6** (POD for the heat equation; cf. [42, Run 1]).**
We choose the final time , the spatial domain , the Hilbert spaces , , the source term for and the discontinuous initial value for , where, e.g., denotes the characteristic function on the subdomain , for and otherwise. We consider a discretization of the linear heat equation (compare (17) with )
[TABLE]
To obtain an accurate approximation of the exact solution we choose so that holds. For the FE discretization we choose spatial grid points and the equidistant mesh size . Thus, the FE error – measured in the -norm – is of the order . In the left graphic of Figure 13, the FE solution to the state equation (43) is visualized.
To compute a POD basis of rank we utilize the multiple discrete snapshots for as well and , , i.e., we include the temporal difference quotients in the snapshot ensemble and , . We choose and utilize the (stable) SVD to determine the POD basis of rank ; compare Section 2.2. We address this issue in a more detail in Run 9. Since the snapshots are FE functions, the POD basis elements are also FE functions. In the right plot of Figure 13, the projection and reduced-order error given by
[TABLE]
are plotted for different POD basis ranks . The chosen trapezoidal weights have been introduced in (23). We observe that both errors decay rapidly and coincide until the accuracy , which is already significant smaller than the FE discretization error. These numerical results reflect the a priori error estimates presented in [42, Theorem 1.29].
Run 7** (POD for a convection dominated heat equation; cf. [42, Run 2]).**
Now we consider a more challenging example. We study a convection-reaction-diffusion equation with a source term which is close to being singular: Let , , , and be given as in Run 6. The parabolic problem reads as follows
[TABLE]
We choose the diffusivity , the velocity that determines the speed in which the initial profile is shifted to the boundary and the reaction rate . Finally, for , where restricts the image of on a bounded interval. In this situation, the state solution develops a jump at for ; see the left plot of Figure 14.
The right plot of Figure 14 demonstrates that in this case, the decay of the reconstruction residuals and the decay of the errors are much slower as in the right plot of Figure 13. The manifold dynamics of the state solution require an inconvenient large number of POD basis elements. Since the supports of these ansatz functions in general cover the whole domain , the corresponding system matrices of the reduced model are not sparse. This is different for the matrices arising in the FE Galerkin framework. Model order reduction is not effective for this example if a good accuracy of the solution function is required. Strategies to improve the accuracy and robustness of the POD-ROM in those situations are discussed in e.g. [18, 100]
Run 8** (True and exact approximation error; cf. [42, Run 3]).**
We consider the setting introduced in Run 6 again. The exact solution to (43) does not possess a representation by elementary functions. Hence, the presented reconstruction and reduction errors actually are the residuals with respect to a high-order FE solution . To compute an approximation of the exact solution we apply a Crank-Nicolson method (with Rannacher smoothing [77]) ensuring . In the context of model reduction, such a state is sometimes called the “true” solution. To compute the FE state we apply the Euler method. In the left plot of Figure 15 we compare the true solution with the associated POD approximation for different values of the time integration and for the spatial mesh size .
For the norm we apply a discrete -norm as in Run 6. Let us mention that we compute for every a corresponding FE solution . We observe that the residuals ignore the errors arising by the application of time and space discretization schemes for the full-order model. The errors decay below the discretization error . If these discretization errors are taken into account, the residuals stagnate at the level of the full-order model accuracy instead of decaying to zero; cf. right plot of Figure 15. Due to the implicit Euler method we have with the mesh-size . In particular, from it follows that . Therefore, the spatial error is dominated by the time error for all values of . We can observe that the exact residuals do not decay below a limit of the order . One can observe that for fixed POD basis rank , the residuals with respect to the true solution increase if the high-order accuracy is improved by enlarging , since the reduced-order model has to approximate a more complex system in this case, where the residuals with respect to the exact solution decrease due to the lower limit of stagnation .
Run 9** (Different strategies for a POD basis computation; cf. [42, Run 4]).**
As we have explained in Section 2.2, let denote the matrix of snapshots with rank , be the (sparse) spatial weighting matrix consisting of the elements (introduced Section 2.3.3) and be the diagonal matrix containing the nonnegative weighting parameters . As we have explained in Section 2.2, the POD basis of rank can be determined by providing an eigenvalue decomposition of the matrix , one of , or a singular value decomposition of . Since in Runs 6-8, the first variant is the cheapest one from a computational point of view. In case of multiple space dimensions or if a second-order time integration scheme such as some Crank-Nicolson technique is applied, the situation is converse. On the other hand, a singular value decomposition is more accurate and stable than an eigenvalue decomposition if the POD elements corresponding to eigenvalues/singular values which are close to zero are taken into account: Since holds for all eigenvalues and singular values , the singular values are able to decay to machine precision, where the eigenvalues stagnate significantly above. This is illustrated in the left graphic of Figure 16.
Indeed, for the EIG-ROM system matrices become singular due to the numerical errors in the eigenfunctions and the reduced-order system is ill-posed in this case while the SVD-ROM model remains stable. In the right plot of Figure 16 POD elements are constructed with respect to different scalar products and the resulting ROM errors are compared: -residuals for (denoted by POD(H)), -residuals for (denoted by POD(V)), -residuals for (denoted by POD(H,V)), which also works quite well, the consideration of time derivatives in the snapshot sample (denoted by POD(H,dt)) which allows to apply the a priori error estimate given in [42, Theorem 1.29-2)] and the corresponding sums of singular values (denoted by SV(H,dt)) corresponding to the unused eigenfunctions in the latter case which indeed nearly coincide with the ROM errors.
Notice that in many applications, the quality of the reduced-order model does not vary significantly if the weights matrix refers to the space or and if time derivatives of the used snapshots are taken into account or not. Especially, the ROM residual decays with the same order as the sum over the remaining singular values, independent of the chosen geometrical framework.
5. Optimal snapshot location for computing POD basis functions
The construction of reduced-order models for nonlinear dynamical systems using proper orthogonal decomposition (POD) is based on the information carried of the so-called snapshots. These provide the spatial distribution of the nonlinear system at discrete time instances. Thus, we are interested in optimizing the choice of these time instances in such a manner that the error between the POD-solution and the trajectory of the dynamical system is minimized. This approach was suggested in [59] and was extended in [64] to parametrized elliptic problems. Let us briefly mention some related issues of interest. In [26, 32] the situation of missing snapshot data is investigated and gappy POD is introduced for their reconstruction. An important alternative to POD model reduction is given by reduced basis approximations; we refer to [72] and references given there. In [37] a reduced model is constructed for a parameter dependent family of large scale problems by an iterative procedure that adds new basis variables on the basis of a greedy algorithm. In the Ph.D thesis [20] a model reduction is sought of a class for a family of models corresponding to different operating stages.
Suppose that we are given the snapshots . The goal is to determine additional snapshots at time instances with , . In [59] we propose to determine by solving the optimization problem
[TABLE]
where and are the solutions to (16) and its POD Galerkin approximation, respectively. Clearly, the definition of the operator given in (6) has to be modified as follows:
[TABLE]
with appropriately modified (trapezoidal) weights , . Consequently, (44) becomes an optimization problem subject to the equality constraints
[TABLE]
Note that no precautions are made in (44) to avoid multiple appearance of a snapshot. In fact, this would simply imply that a specific snapshot location should be given a higher weight than others. While the presented approach shows how to choose optimal snapshots in evolution equations, a similar strategy is applicable in the context of parameter dependent systems.
It turns out in our numerical tests carried out in [59] that the proposed criterion is sensitive with respect to the choice of the time instances. Moreover, the tests demonstrate the feasibility of the method in determining optimal snapshot locations for concrete diffusion equations.
Run 10** (cf. [59, Run 1]).**
For let and . For the FE triangulation we choose a uniform grid with mesh size , i.e., we have 900 degrees of freedom for the spatial discretization. Then, we consider
[TABLE]
where , ,
[TABLE]
and for (see Figure 17, left plot).
Furthermore, we have
[TABLE]
We utilize piecewise linear FE functions. The FE solutions for and are shown in Figure 17. Next we take snapshots on the fixed uniform time grid , , with and . The goal is to determine four additional time instances based on a FE approximation for (44). Since the behavior of the solution exhibits more change during the initial time interval than later on, we initialize our Quasi-Newton method by the starting value . The number of POD ansatz functions is fixed to be . The corresponding value of the ROM error is approximately . The optimal solution is given as , while the associated ROM error is approximately , which is a reduction of about 85 %. In Figure 18 we can see that the shapes of the three POD bases changes significantly from the initial time instances to the optimal ones .
6. Optimal control with POD surrogate models
Reduced-order models are used in PDE-constrained optimization in various ways; see, e.g., [50, 86] for a survey. In optimal control problems it is sometimes necessary to compute a feedback control law instead of a fixed optimal control. In the implementation of these feedback laws models of reduced-order can play an important, and very useful role, see [11, 40, 60, 65, 68, 79]. Another useful application is the use in optimization problems, where a PDE solver is part of the function evaluation. Obviously, thinking of a gradient evaluation or even a step-size rule in the optimization algorithm, an expensive function evaluation leads to an enormous amount of computing time. Here, the reduced-order model can replace the system given by a PDE in the objective function. It is quite common that a PDE can be replaced by a five- or ten-dimensional system of ordinary differential equations. This results computationally in a very fast method for optimization compared to the effort for the computation of a single solution of a PDE. There is a large amount of literature in engineering applications in this regard, we mention only the papers [67, 71]. Recent applications can also be found in finance using the reduced models generated with the reduced basis (RB) method [76] and the POD model [85, 88] in the context of calibration for models in option pricing.
We refer to the survey article [42], where a linear-quadratic optimal control problem in an abstract setting is considered. Error estimates for the POD Galerkin approximations of the optimal control are proved. This is achieved by combining techniques from [28, 29, 44] and [56, 58]. For nonlinear problems we refer the reader to [50, 75, 86]. However, unless the snapshots are generating a sufficiently rich state space or are computed from the exact (unknown) optimal controls, it is not a priorly clear how far the optimal solution of the POD problem is from the exact one. On the other hand, the POD method is a universal tool that is applicable also to problems with time-dependent coefficients or to nonlinear equations. Moreover, by generating snapshots from the real (large) model, a space is constructed that inhibits the main and relevant physical properties of the state system. This, and its ease of use makes POD very competitive in practical use, despite of a certain heuristic flavor. In this context results for a POD a posteriori analysis are important, see e.g., [94] and [41, 54, 55, 91, 93, 96, 98]. Using a fairly standard perturbation method it is deduced how far the suboptimal control, computed on the basis of the POD model, is from the (unknown) exact one. This idea turned out to be very efficient in our examples. It is able to compensate for the lack of a priori analysis for POD methods. Let us also refer to the papers [30, 36, 69], where a posteriori error bounds are computed for linear-quadratic optimal control problems approximated by the reduced basis method.
Data- and/or simulation-based POD models depend on the data (e.g. initial values, right hand sides, boundary conditions, oberservations, etc.) which is used to generate the snapshots. If those models are used as surrogates in e.g. optimization problems with PDE constraints the algorithmical framework has to account for this fact with providing mechanisms for accordingly updating the surrogate model during the solution process. Strategies proposed in this context for optimal flow control can be found in e.g. [3, 4, 9, 34, 17]. One of the most mature methods developed in this context is Trust-Region POD proposed in [9], which since then has successfully been applied in many applications. We also refer to the work [38], where strategies for updating the POD bases are compared.
The quality of the surrogate model highly depends on its information basis, which for snapshot-based methods is given by the snapshot set, compare Section 5. The location of snapshots and also the choice of the initial control in surrogate-based optimal control is discussed in [5]. There, techniques from time-adaptive schemes for optimality systems of parabolic optimal control problems are adjusted to compute optimal time locations for snapshots generation in POD surrogate modeling for parabolic optimal control problems.
Concepts for the construction and use of POD surrogate modeling in robust optimal control of electrical machines are presented in [63, 6]. Those problems are governed by nonlinear partial differential equations with uncertain parameters, so that robustness can be achieved by considering a worst case formulation. The resulting optimization problem then is of bilevel structure and POD reduced-order models in combination with a posteriori error estimators are used to speed up the numerical computations.
7. Miscellaneous
POD model order reduction can also be applied to provide surrogate models for high-fidelity components in networks. The general perspective is discussed in e.g. [48]. Related research for MOR of electrical networks is reported in e.g. [16, 46, 47]. The basic idea here consists in a decoupling of MOR approaches for the network and high-fidelity components which in general are modeled by PDE systems. For the latter, simulation-based POD MOR techniques are used to construct surrogate models which then are stamped back into the (reduced) electrical network. Details and performance tests are reported e.g. in [45, 47]. A short lecture series with related topics is presented under Hinze-Pilsen222https://slideslive.com/38894790/mathematical-aspects-of-proper-orthogonal-decomposition-pod-iii. Further contributions to this topic can be found in [15].
Recent trends in data-driven and nonlinear MOR methods are discussed within a YouTube lecture series under Carlberg-YouTube333https://www.youtube.com/watch?v=KOHxCIx04Dg.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] H. Abels. Diffuse Interface Models for Two-Phase flows of Viscous Incompressible Fluids. Max-Planck Institut für Mathematik in den Naturwissenschaften , Leipzig, Lecture Note, 36, 2007.
- 2[2] H. Abels, H. Garcke, and G. Grün. Thermodynamically consistent, frame indifferent diffuse interface models for incompressible two-phase flows with different densities. Mathematical Models and Methods in Applied Sciences , 22(3), 2012.
- 3[3] K. Afanasiev and M. Hinze. Adaptive control of a wake flow using proper orthogonal decomposition. Preprint No. 648/1999, Fachbereich Mathematik, TU Berlin, 1999.
- 4[4] K. Afanasiev and M. Hinze. Adaptive control of a wake flow using proper orthogonal decomposition. Lecture Notes in Pure and Applied Mathematics , 216:317-332, 2001.
- 5[5] A. Alla, C. Gräßle, M. Hinze. A-posteriori snapshot location for POD in optimal control of linear parabolic equations. ESAIM: Mathematical Modelling and Numerical Analysis (M 2AN), 52(5):1847-1873, 2018.
- 6[6] A. Alla, M. Hinze, P. Kolvenbach,O. Lass, S. Ulbrich. A certified model reduction approach for robust parameter optimization with PDE constraints. Adv. Comput. Math. , 45:1221-1250, 2019.
- 7[7] A. Alla and J. N. Kutz. Nonlinear model order reduction via dynamic mode decomposition. SIAM Journal on Scientific Computing , 39:B 778-B 796, 2017.
- 8[8] M.S. Alnaes, J. Blechta, J. Hake, A. Johansson, B. Kehlet, A. Logg, C. Richardson, J. Ring, M.E. Rognes, and G.N. Wells. The F Eni CS Project Version 1.5. Archive of Numerical Software , 100:9-23, 2015.