Indoor image representation by high-level semantic features
Chiranjibi Sitaula, Yong Xiang, Yushu Zhang, Xuequan Lu, and Sunil, Aryal

TL;DR
This paper introduces high-level semantic features for indoor image representation, improving classification performance by capturing semantic object relationships more effectively than traditional pixel-based methods.
Contribution
The paper proposes a novel high-level semantic feature extraction method that enhances indoor image classification accuracy and reduces feature dimensionality.
Findings
Outperforms state-of-the-art methods on MIT-67, Scene15, and NYU V1 datasets.
Achieves higher classification accuracy with lower-dimensional features.
Demonstrates the effectiveness of semantic features in capturing image semantics.
Abstract
Indoor image features extraction is a fundamental problem in multiple fields such as image processing, pattern recognition, robotics and so on. Nevertheless, most of the existing feature extraction methods, which extract features based on pixels, color, shape/object parts or objects on images, suffer from limited capabilities in describing semantic information (e.g., object association). These techniques, therefore, involve undesired classification performance. To tackle this issue, we propose the notion of high-level semantic features and design four steps to extract them. Specifically, we first construct the objects pattern dictionary through extracting raw objects in the images, and then retrieve and extract semantic objects from the objects pattern dictionary. We finally extract our high-level semantic features based on the calculated probability and delta parameter. Experiments on…
Click any figure to enlarge with its caption.
_block_diagram.jpg) Figure 1
Figure 1_block_diagram_revised1.png) Figure 2
Figure 2_combined_del1-eps-converted-to.jpg) Figure 3
Figure 3_combined_del1.jpg) Figure 4
Figure 4_first_paper_revised_diagram.jpg) Figure 5
Figure 5_keywords_extraction1.jpg) Figure 6
Figure 6_library.jpg) Figure 7
Figure 7_library_enhanced2.jpg) Figure 8
Figure 8_mit_scene.jpg) Figure 9
Figure 9_nyu_scene.jpg) Figure 10
Figure 10_scene15_scene.jpg) Figure 11
Figure 11_slices_new_enhanced.jpg) Figure 12
Figure 12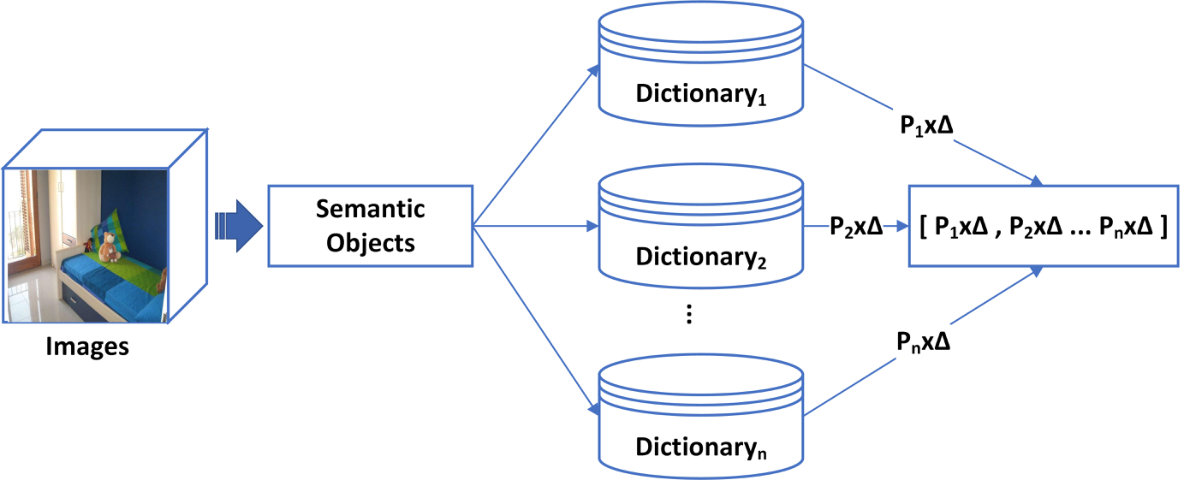 Figure 13
Figure 13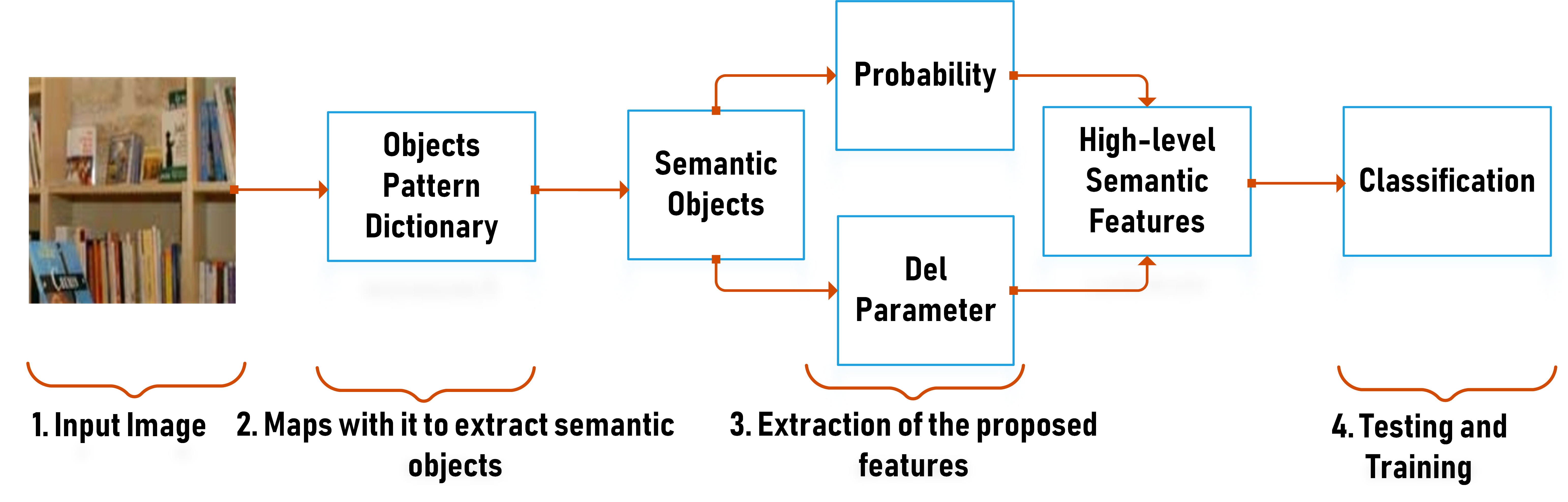 Figure 14
Figure 14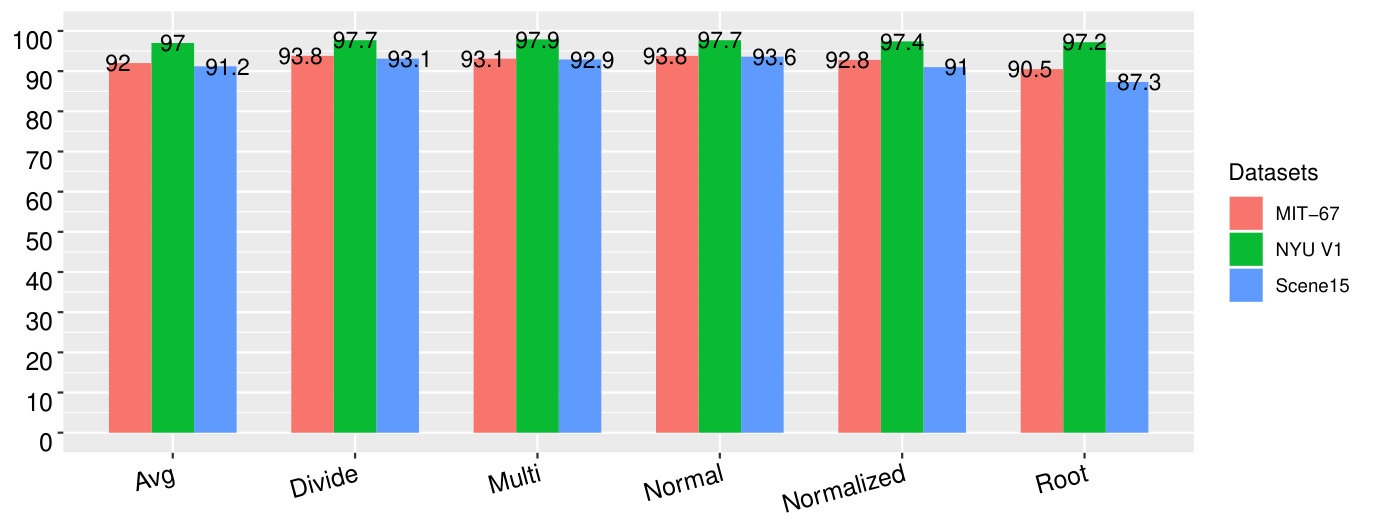 Figure 15
Figure 15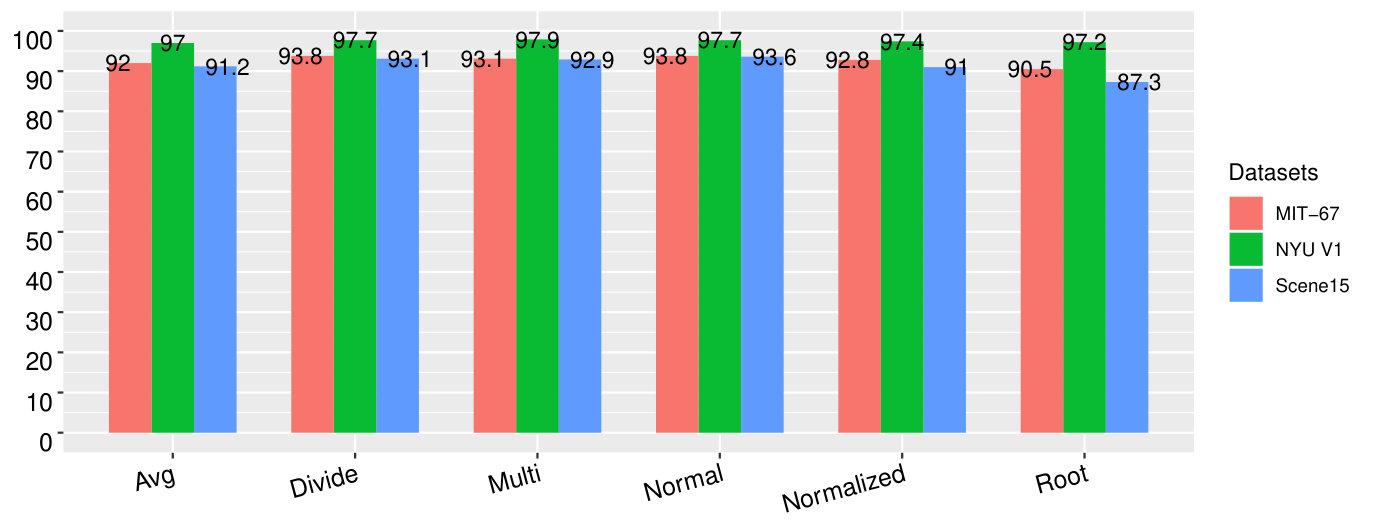 Figure 16
Figure 16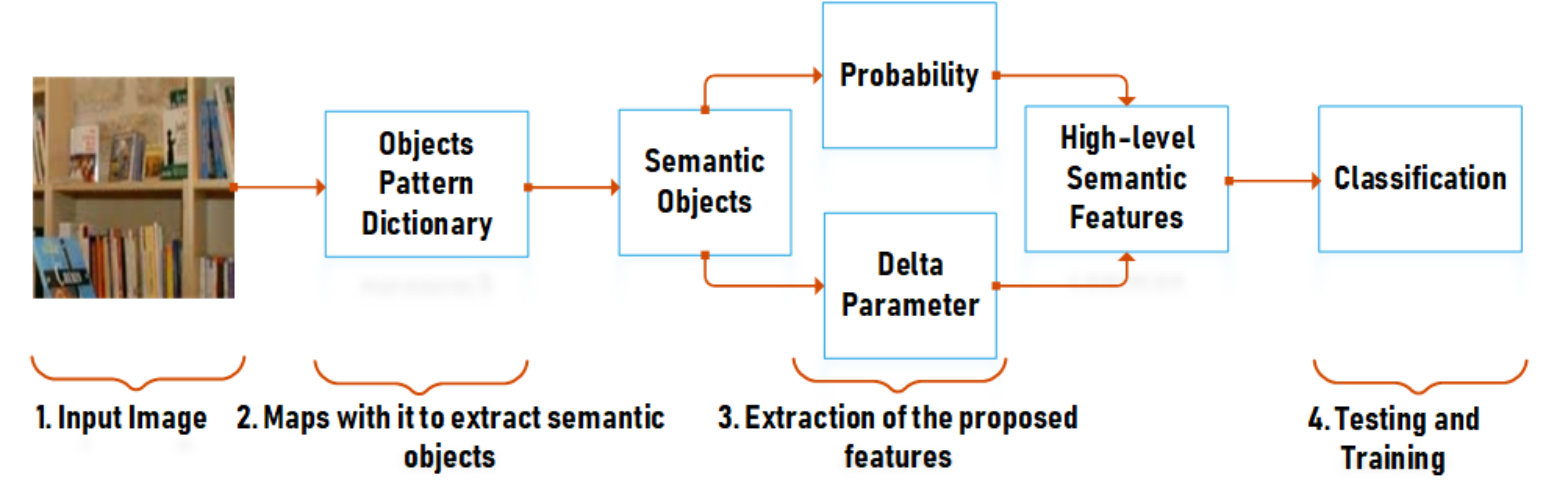 Figure 17
Figure 17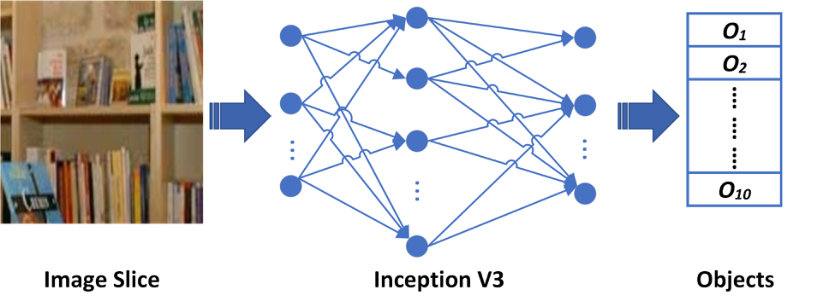 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23 Figure 24
Figure 24| Sample | MIT-67(%) | Scene15(%) | NYU V1(%) |
|---|---|---|---|
| 1 | 93.9 | 99.1 | 97.2 |
| 2 | 93.5 | 99.2 | 94.9 |
| 3 | 92.0 | 98.7 | 97.3 |
| 4 | 95.1 | 98.9 | 95.3 |
| 5 | 94.7 | 99.1 | 96.9 |
| 6 | 94.0 | 99.1 | 97.2 |
| 7 | 94.7 | 99.1 | 96.6 |
| 8 | 94.7 | 98.8 | 96.0 |
| 9 | 94.1 | 99.1 | 97.3 |
| 10 | 95.1 | 98.6 | 96.3 |
| Dictionary size | |||
| Sample | |||
| 9000 | 16000 | 25000 | |
| 1 | 93.6 | 94.1 | 93.3 |
| 2 | 94.7 | 94.0 | 93.8 |
| 3 | 94.0 | 93.7 | 93.6 |
| 4 | 94.3 | 94.2 | 93.5 |
| 5 | 93.2 | 93.3 | 92.8 |
| 6 | 92.9 | 93.2 | 91.4 |
| 7 | 92.4 | 94.1 | 93.5 |
| 8 | 92.8 | 94.1 | 93.1 |
| 9 | 92.9 | 93.6 | 93.4 |
| 10 | 93.5 | 92.3 | 92.0 |
| Average | 93.4 | 93.6 | 93.0 |
| Dictionary size | ||||
| Sample | Sub-images | |||
| 9000 | 16000 | 25000 | ||
| 9 (3*3) | 93.2 | 91.8 | 91.3 | |
| 1 | 16 (4*4) | 93.9 | 94.0 | 94.7 |
| 25 (5*5) | 93.2 | 92.2 | 92.3 | |
| 9 (3*3) | 93.5 | 91.9 | 91.4 | |
| 2 | 16 (4*4) | 93.5 | 93.3 | 93.2 |
| 25 (5*5) | 94.4 | 94.2 | 94.1 | |
| 9 (3*3) | 93.0 | 92.3 | 90.8 | |
| 3 | 16 (4*4) | 92.0 | 91.7 | 92.0 |
| 25 (5*5) | 92.7 | 93.0 | 93.2 | |
| 9 (3*3) | 92.9 | 92.2 | 91.5 | |
| 4 | 16 (4*4) | 95.1 | 92.8 | 93.3 |
| 25 (5*5) | 92.7 | 92.3 | 92.2 | |
| 9 (3*3) | 93.2 | 92.0 | 91.7 | |
| 5 | 16 (4*4) | 94.7 | 93.8 | 93.2 |
| 25 (5*5) | 93.8 | 93.2 | 93.5 | |
| 9 (3*3) | 92.8 | 90.5 | 90.8 | |
| 6 | 16 (4*4) | 94.0 | 94.7 | 94.0 |
| 25 (5*5) | 94.2 | 93.5 | 93.5 | |
| 9 (3*3) | 93.8 | 91.9 | 90.7 | |
| 7 | 16 (4*4) | 94.7 | 94.7 | 94.4 |
| 25 (5*5) | 95.0 | 94.1 | 93.8 | |
| 9 (3*3) | 93.6 | 92.4 | 92.5 | |
| 8 | 16 (4*4) | 94.7 | 94.3 | 93.5 |
| 25 (5*5) | 93.8 | 93.3 | 93.8 | |
| 9 (3*3) | 93.8 | 92.4 | 91.4 | |
| 9 | 16 (4*4) | 94.1 | 93.0 | 93.3 |
| 25 (5*5) | 94.3 | 94.0 | 92.9 | |
| 9 (3*3) | 93.5 | 91.5 | 91.2 | |
| 10 | 16 (4*4) | 95.1 | 94.7 | 94.1 |
| 25 (5*5) | 93.1 | 92.2 | 92.2 | |
| Average | 93.7 | 92.9 | 92.6 | |
| Delta parameters | Avg | Divide | Multi | Normal | Normalized | Root |
| Accuracy | 93.4 | 94.8 | 94.6 | 95 | 93.7 | 91.6 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Indoor Image Representation by High-Level Semantic Features
Chiranjibi Sitaula, Yong Xiang , Yushu Zhang, Xuequan Lu and Sunil Aryal C. Sitaula, Y. Xiang, and Y. Zhang, X. Lu, and S. Aryal are with School of Information Technology, Deakin University, Victoria 3125, Australia.
Abstract
Indoor image features extraction is a fundamental problem in multiple fields such as image processing, pattern recognition, robotics and so on. Nevertheless, most of the existing feature extraction methods, which extract features based on pixels, color, shape/object parts or objects on images, suffer from limited capabilities in describing semantic information (e.g., object association). These techniques therefore involve undesired classification performance. To tackle this issue, we propose the notion of high-level semantic features and design four steps to extract them. Specifically, we first construct the objects pattern dictionary through extracting raw objects in the images, and then retrieve and extract semantic objects from the objects pattern dictionary. We finally extract our high-level semantic features based on the calculated probability and delta parameter. Experiments on three publicly available datasets (MIT-67, Scene15 and NYU V1) show that our feature extraction approach outperforms state-of-the-art feature extraction methods for indoor image classification, given a lower dimension of our features than those methods.
Index Terms:
Image classification, feature extraction, image representation, objects pattern dictionary, semantic objects.
I Introduction
Image recognition and classification has remained an active research field. It has a wide range of applications [1] such as robotics, object recognition, object localisation, video surveillance, and so on. To perform the task of image recognition and classification, we usually need to represent each image by a set of features. Generally, there are three categories of image features: low-level, middle-level, and high-level features.
Low-level features [2, 3, 4, 5, 6, 7, 8, 9, 10] are typically extracted using pixels, colour intensity or texture of the image. These features lack the spatial information on the image, thereby deteriorating the classification accuracy, especially for scene images (indoor/outdoor images). To improve the classification performance of low-level features, middle-level features were proposed. Middle-level features [11, 12, 13, 14] contain spatial information that yields features of certain parts or shapes on the image. Indoor images often involve one or multiple objects which can intuitively assist in recognising the categories of images. Thus, the object-level information for the objects on images could enhance the classification accuracy. The middle-level features are limited in depicting objects on images while high-level features [15, 16, 17] including objects can do so. High-level features are considered as the prominent features for the images, including objects on indoor/outdoor images [15, 16, 17]. In other words, high-level features can represent an image with the help of object details. Despite that high-level features are more powerful than middle-/low-level features, they still have limited performance for indoor images which often involve multiple objects with associations.
Domain-specific features are the specific types of features that are designed at the specific domain. In our work, the features representing semantic objects and their associations are domain-specific features. Domain-specific features are important to solve the specific classification problem. As an example, most of the low-level features, which are based on color or intensity as their features, have poor performance for indoor images involving multiple objects[2].
Indoor images are challenging because they usually include associated objects. For instance, two indoor categories library and kitchen may contain similar table and desk objects, but how can we differentiate the images? Similarly, we can hardly find the similarity using traditional features such as [2] if two images of the library category have different structures and the same types of objects (e.g., Fig. 1). As a result, it is difficult to classify indoor images. In addition, recent existing methods such as [18], [16] hardly solve the inter-class similarity and intra-class dissimilarity issues The recent work called objectness [17] considered objects and their associations to some extent for indoor images. However, their research yielded high dimensional features which creates burden in image classification.
Motivated by the above issues, we introduce the notion of semantic features that are calculated based on the semantic objects. General syntactic features may not solve these issues because the semantic meaning varies in different scenarios. The context, rather than objects, can define their separability in such cases. For example, the presence of books and tables in two different scenarios like kitchen and library would make machine “confused” in classification. While domain or context based objects (i.e., semantic) can help enhance classification in such cases. Semantic objects are the representative objects which are typically extracted from the object pattern dictionary of the corresponding category[17]. These objects are retrieved by mapping raw object tags of the input images with the co-occurrence pattern of raw object tags in the corresponding object pattern dictionary. Note that raw object tags are the deep tags which are extracted from the ImageNet pre-trained deep learning model. When retrieving the semantic objects for the raw objects through pattern dictionary, we can detect their co-occurrence patterns in the corresponding category with the help of rules we designed. Suppose we extract the semantic objects like books and chairs from the image, the co-occurrence of books and chairs will be higher in the library category than other categories. Similarly, the co-occurrence pattern of microwave and bread is higher in kitchen than other categories. The association information of objects can help extract meaningful features (i.e., semantic) on images. Also, the introduced semantic features can also alleviate inter-/intra-class (dis)similarity issues, because we can always extract meaningful information for whatever types of global layouts (similar or dissimilar).
To extract semantic features, we propose two main steps for our approach. We first design the object pattern dictionaries for each category, and then extract the semantic objects of each image according to their probabilities in the category. The rules are defined to exploit the co-occurrence patterns for the corresponding dictionaries. After the extraction of semantic objects with their probabilities in the corresponding category, we calculate semantic features by using the probability and delta parameters in various categories. This is based on the motivation that the importance of objects differs in different categories. For example, the importance of book and desk is higher in library than other categories such as restaurant.
The main contributions of this paper are summarised as follows.
We design the object pattern dictionary which encodes the associations of indoor raw objects for each category. With the help of this dictionary, the semantic objects of the candidate objects for each image are calculated by mapping the candidate objects of the image with the dictionary. Four propositions are proposed to handle this procedure. 2. 2.
We calculate the high-level semantic features with the help of semantic objects. The computed features usually have a low dimensional size. We perform a fusion of the probability and delta parameters to explore the prominent high-level semantic features. 3. 3.
The introduced high-level semantic features are tested on three different publicly available datasets (MIT-67[19], Scene15[20], and NYU V1[21]) for the task of classification. Experimental results show that our features are effective and outperform existing features in terms of classification accuracy.
II Related Work
Low-level features are extracted based on the pixels and color on the images. Some popular low-level features are Scale-Invariant Feature Transform (SIFT) [2], Generalized Search Trees (GIST) [3, 4], Histogram of Gradient (HOG) [5], CENsus TRansform hISTogram (CENTRIST) [6], multi-channel (mCENTRIST) [7] and OTC [9]. Since these features [2, 3, 4, 5, 6, 7, 9, 10] exploit the local information on the image, they provide neither the global structural information nor the object information. They may not work properly if the image feature extraction needs global structural details of the image. As a result, the classification accuracy of those features would also be low. The classification accuracy can be improved, especially for indoor/outdoor images, if we can represent an image in different way such as edges, shapes, and parts[22]. This leads to middle-level features.
Middle-level features are extracted from the intermediate layers of the deep learning model. They can also be extracted by the traditional methods using parts or regions [11, 12, 13, 14] on the image. Recent extraction methods of deep learning based middle-level features are bilinear [23], Deep Un-structured Convolutional Activations (DUCA) [24], Bag of Spatial Parts (BoSP) [18], Locally Supervised Deep Hybrid Model (LS-DHM) [25] and so on. In the bilinear approach, the middle-level features from two deep learning models were fused with the help of the outer product to extract the final features of the image. These features were used for the classification. Similarly, in DUCA, the features of the th layer of the deep learning model were used as the middle-level features which showed that the features have higher discriminability in the classification than the low-level features. The BoSP model considered the features of pooling layers (th and th layers) as the middle-level features. Last but not the least, another method called LS-DHM was proposed, which exploited a hybrid model for the extraction of the middle-level features with the help of th layer of deep learning model in a 7-layers AlexNet [26]. These features are extracted based on the lines, segments, shapes, and parts of the objects in the image. Thus, the classification accuracy using these features is higher than the low-level features because they are extracted in a higher level beyond the pixel and textural level. These features also provide certain semantic information of the objects in the image. Different hierarchical layers provides different types of features in deep learning. We obtain more semantic information related to objects of the image while extracting features from the intermediate layers[18, 25].
Spatial units, extracted from their intermediate layers, are fundamental in feature maps of deep learning models. For instance, if we have a feature map of 77512 size extracted from the intermediate layers, the number of spatial units is 49, each with 512-D feature size. Although the intermediate layers provide more semantic information with the help of their spatial units on different feature maps, these features can hardly obtain full semantic information of the objects in the image. This demands the use of features in a higher level (i.e., high-level features).
We retrieve the high-level features from the top-layers (probability layers and -layers) of the deep learning model. Similarly, these features can also be extracted based on the traditional methods like Object Bank [15, 8] in which the features are extracted with the aid of object properties. Regarding indoor/outdoor images, objects-based features are very important because of the presence of objects and their associations in the image. It is very difficult to represent these associations by the help of low-level and middle-level features. Since high-level features are based on objects, we introduce prominent features related to the objects (i.e., high-level semantic features). Recent high-level features are GMS2F [16] and Objectness [17].
III Proposed Method
The proposed method comprises the following steps, namely: A) objects pattern dictionary construction, B) semantic objects extraction, C) probability and delta parameter calculation, and D) extraction of our high-level semantic features. For image classification, the high-level semantic features of the images are normalized in the attribute level before feeding them into the Support Vector Machine (SVM). Section III-A and III-B and III-C are the processing steps for the extraction of semantic objects and Section D is the feature extraction step.
III-A Objects Pattern Dictionary
We design a domain-specific dictionary (i.e., objects pattern dictionary) which helps to explore the pattern of the objects occurring in the indoor images. Quite different from the Natural Language Processing (NLP) dictionary [27, 28] and the sparse coding dictionary [29], our dictionary demonstrates the relationship of indoor objects in the indoor scenes. The objects pattern dictionary is to extract the semantically related objects on the image under the corresponding category of indoor scene images. To construct the objects pattern dictionary for each category, we select a fixed number of images per category and perform two steps: image slicing, and raw objects extraction and dictionary building.
III-A1 Image slicing
We slice each image into different sub-images to focus on the objects information. With the assistance of different sub-images, different objects and their frequencies are recorded. The occurrence of these frequencies of objects in the image help to reveal the semantic relationship of objects. Let be the image. Then, the sub-images of the image are represented by , where is the number of sub-images per image. The size of the dictionary depends on the number of sub-images per category. We construct three differing sizes of the dictionary to evaluate the robustness. For MIT-67 dataset, we randomly select 100 images per category and slice each into different numbers of sub-images, such as 9, 16, and 25. The number of sub-images per image determines the number of objects in the dictionary (i.e., dictionary size). The 9, 16 and 25 sub-images per image will yield the dictionary sizes of 9000, 16000 and 25000, respectively. We re-scale the original images into a suitable size before slicing. Fig. 2 demonstrates the slicing of the an image into 9 sub-images to extract the raw objects.
III-A2 Raw Objects Extraction and Dictionary building
After slicing every image into sub-images, each sub-image will be re-scaled to feed the pre-trained deep learning model, Inception V3 [30] for the extraction of the names of the involved objects. This pre-trained model was trained with the ImageNet [31] dataset that contains 1000 object categories. We choose Inception V3 because of three reasons: a) it has a deeper architecture than VGG-Net and AlexNet and has the capability to produce more semantic information on the image through its deeper layers, thereby helping to extract the more accurate names of objects. b) The computational complexity of this model is found to be lower than VGG-Net and other state-of-the-art deep architectures[30]. c) The error rate of this model is lower than the state-of-the-art deep learning models such as GoogleNet, VGG-Net, and Inception-V2 [30]. The output of the multinomial distribution of deep learning model is shown in (1).
[TABLE]
where is the multinomial probability which is extracted from the Softmax layer and is one among categories for the ImageNet based pre-trained deep learning models. Among the 1000 objects, we mainly consider the top ten raw objects with high probability scores in this work. The rest of the objects are ignored as they are less related to the images. Selecting the “best” objects from the image helps to exploit the distinguishable features. Fig. 3 shows the extraction of the top ten raw objects of the sub-images based on the pre-trained Inception V3 model. After the extraction of raw objects, our objective is to design the semantic dictionary, which is named objects pattern dictionary.
To design this dictionary, we construct a raw dictionary first to list the raw objects of the indoor images using concatenation operation.
Algorithm 1 shows how to design a raw dictionary using the objects of the sub-images extracted by the operation in Fig. 3. We denote the number of categories by th, the number of images by th and the number of objects by th . Similarly, represents the object for the category on the image, and is the raw dictionary of category. is extracted using sub-images of the image and its output order for each category. Here, the raw dictionary is defined as the list of ordered objects collected from some indoor images of the corresponding category. The raw dictionary is designed according to the objects’ output order of the Inception V3 model. The objects are concatenated exactly in the same order as obtained from Inception V3 model. This is helpful to show the relationship of the objects in the category.
While assembling those objects, the order shows certain associations among objects in the image. Furthermore, the list contains nine thousand objects in total if we consider one hundred images per category. The size of the dictionary is determined with the number of images available for different datasets. For instance, MIT-67 and Scene15 contain sufficient images to make dictionary using 100 images per category. It does not apply to NYU V1 dataset as some categories in NYU V1 dataset contain less than 100 images.
After the construction of the raw dictionary, we refine it further to design the objects pattern dictionary. The objects pattern dictionary is based on the semantic relatedness of the objects. To explore the semantic relatedness of the objects, we investigate the object co-occurrence pattern property for those images.
Object co-occurrence is the main component of the objects pattern dictionary. To detect the co-occurrence of the objects in the image, we study the adjacent object pairs and their co-occurrence in the image of the category. In order to solve the co-occurrence problem, we design Algorithm 2 to extract the frequency (i.e., the degree of relationship) of the adjacent pairs of objects. Here, and represent the raw dictionary and the objects pattern dictionary for the category, respectively. For each category, the objects pattern dictionary is designed based on the objects and orders of the raw dictionary. The objects are selected using forward and backward directions. Inspired by the 2-gram model [32] in Natural Language Processing, we utilize the adjacent pair of objects which co-occur in the image. If they have high-frequency pairs in the categories, higher degree of relationship exists between the objects. Unlike the 2-gram model that considers only the previous gram, we take the previous and next gram of the corresponding object as the semantic objects to design the objects pattern dictionary. For example, if we take an object , then its relationship can be shown with lower indexed object and higher indexed object . The general structure of the objects pattern dictionary () which shows the semantically related objects for the particular category is shown in (2).
[TABLE]
where , , … indicate the frequency of adjacent pairs obtained from the raw dictionary, . For example, where is the count of object pair in the raw dictionary (). The semantic relationship of objects and their occurrence are stored in the key-value pair format. We will apply our proposed propositions (Section III-B) on the objects pattern dictionary, which contains the order pattern of objects, to extract the semantic objects for the image. This domain-specific dictionary is to extract the semantically related objects for those types of images.
III-B Semantic Objects Extraction
After the design of objects pattern dictionary for each category, the semantic objects extraction step needs to be conducted for each image under the corresponding category. In this step, we retrieve the semantic objects from the objects pattern dictionary of the corresponding candidate objects in the image. To extract the semantic objects of the image, we slice every image into different sub-images (such as 9, 16, and 25) to extract the raw objects. The highly frequent raw objects of the image from multiple sub-images are selected as the candidate objects to map the corresponding objects pattern dictionary. we propose four propositions to facilitate the extraction of the semantic objects. Each proposition is stated and proved.
III-B1 Proposition 1
If and are co-occurring in the multiple sub-images , then they can be used interchangeably.
Proof. If two objects are not co-occurring in the sub-images, we can say that these objects are unrelated to each other. For instance, if two objects and appear together, we say that one’s presence is related to others presence. If these objects are not co-occurring in the sub-image, we say that they are mutually exclusive (the presence of one object is not related to other objects presence). This claims that the co-occurring objects unveils their associations in the image.
III-B2 Proposition 2
If two pairs of objects (, ) and (, ) are co-occurring in the multiple sub-images , there exists the relationship between and .
Proof. If two objects and are co-occurring in the sub-images frequently, we can claim that they are correlated each other. Similarly, if the objects and are also co-occurring in the sub-images, then the associations between them can be claimed. Furthermore, from these two associations, we see that is correlated with both and . Hence, we can prove that and are related to each other.
III-B3 Proposition 3
If (, ) is co-occurring in the image sub-images and (, ) and (, ) are also occurring, it can be proved that and are related.
Proof. If two objects are co-occurring in the sub-images, the occurrence shows the relationship clearly between them which can be proved from the Proposition 1 that the usage of one in place of another makes no difference. In the above objects pair, the first pair shows that is related to and they can be used interchangeably. Similarly, in the second pair (, ), and are related. Furthermore, the pair (, ) also shows that and are also related. In this way, it can be proved that and are related to each other from Proposition 2.
III-B4 Proposition 4
If (, ) and (, ) are co-occurring in the image, it shows the relationship between and .
Proof. If (, ) show that the two objects are related to each other, they can be used interchangeably. It shows the relationship between these two objects. Similarly, the pair (, ) shows that there exists a relationship between these objects in the image. Looking in both pairs, there will be the occurrences of objects (, , and ) in the sub-images, which proves that and are related to each other.
In Algorithm 3, represents the mapping function of the selected raw objects with the objects pattern dictionary to produce semantic objects of the image. Mathematically, it is written as . This function applies the four propositions listed above. The function can be any proposition we proposed. In the function, represents the notation for the image, represents the objects pattern dictionary, and represents the extracted semantic objects. Similarly, is the list of semantic objects for the objects of under object pattern dictionary.
For explanation purposes, let the image contain two candidate objects in such as and which uses objects pattern dictionary . We search the related objects of in with the aid of the proposed propositions, and extract the co-occurring pairs. We select highly frequent co-occurred objects that are related to the candidate objects of the image under the corresponding category. For instance, let us consider a dictionary from Eq. (2) as an objects pattern dictionary.
[TABLE]
where we only select the unique objects that does not belong to the raw objects of the image. The extracted semantic objects are stored in . Here, is the semantic object. We use a number of candidate objects to extract the corresponding semantic objects in the image.
III-C Probability and Delta Parameter Calculation
After the extraction of semantic objects of the image, the probabilities and delta parameters of the semantic objects need to be calculated. The raw dictionary is used to calculate the probabilities. Denote each object by and the raw dictionary by i.
[TABLE]
[TABLE]
is the probability of the object () in a different dictionary (). Similarly, , and are the frequency of an object (), the total number of objects and the delta parameter value of the object, in the dictionary () The fusion of the probability and delta parameter is performed via Eq. (3). The delta parameter is the primary factor that helps distinguish the images having inter-class similarities. We design six different types of delta parameters in our experiments.
III-C1 Normal Delta Parameter
This is the normal delta parameter defined in Eq. (4). This is a normal probability function of the objects belonging to the category.
III-C2 Avg Delta Parameter
The average delta parameter measures the impact of normal probability with respect to the total probabilities of all semantic objects. It is shown in the Eq. (5).
[TABLE]
III-C3 Normalized Delta Parameter
Eq. (6) is the normalized delta parameter. To make probability non-zero and divide by zero exception handling, we add to all the frequency count operation if the dividing by zero exception occurs.
[TABLE]
III-C4 Multi-probability Delta Parameter
This delta parameter is the result of multiplying the normal probability value with the frequency of the objects in the corresponding category. The multi-probability delta parameter is defined in Eq. (7), where represents the frequency of an object, .
[TABLE]
III-C5 Root-based Delta Parameter
This type of delta parameter is obtained by taking the square root of the normal probability. The main objective of this delta parameter is to test the efficacy of increased normal probabilities. The square root of probability between 0 and 1 gives higher values. The root-based delta parameter is shown by the Eq. (8).
[TABLE]
III-C6 Decimal Scaling or Divide Delta Parameter
In this parameter, the probability score is made smaller than the original value. The number of decimal values increases with the help of this parameter. This type of delta parameter is to study the effect of lower probability scores. To perform the decimal scaling delta parameter, we use Eq. (9).
[TABLE]
III-D Extraction of High-level Semantic Features
The high-level semantic features are extracted by the help of Eq. (3), which is the product of the probability and delta parameter. Six different delta parameters (Eq. (4) - Eq. (9)) are tested one by one to choose the best delta parameter. Among these six delta parameters, we found that the normal delta parameter is better when designing the high-level semantic features. The resulting features have a higher classification accuracy of indoor images involving inter-/intra-class structural dissimilarities. The extraction of semantic objects and high-level semantic features extraction flow can be seen in Fig. 5.
IV Analysis of Proposed Method
We use the pre-trained deep learning model to extract the objects only as the first step of the research. Our method takes more time complexity in objects pattern dictionary construction and semantic objects extraction step. We study the time complexity of each operation while executing the proposed method. The time complexity of the raw dictionary module is approximately quadratic for categories, since it needs objects to form the dictionary from images of each category. As a result, the complexity is . In the objects pattern dictionary module, we need to find the adjacent objects occuring together. We need to track the adjacent objects and sort them. The worst complexity for dictionary construction is , and for sorting, the complexity does not exceed .
The extraction of semantic objects is the most expensive, where we need to search the objects pattern dictionary in the backward or forward direction, depending on the situation. If the proposition is simple like Proposition 1, the complexity is . Here, is the number of candidate objects of the image for the extraction of semantic objects. We set a lower value of , so that the complexity does not go higher. For the worst case, we should find the semantic objects moving in both directions using Proposition 2, 3 or 4 and the complexity is . Similarly, for the delta parameters and probability calculation, the complexity is , where represents the extracted semantic objects. It is better to analyze the performance in terms of the worst cases because sometimes we need to perform expensive search operations of semantic objects. The overall time complexity of our approach is not greater than ++++. Here, is higher than other values, is a constant equal to 5 and is also a constant value which can be adjusted by users. Now the worst complexity of the algorithm becomes . The size of objects pattern dictionary is the main driving factor of the complexity. For training and testing using the SVM, the complexity is determined by the number of categories and dimension of the feature instances.
V Experiments and Analysis
V-A Datasets
We conduct experiments on three popular datasets: MIT-67 [19], Scene15 [20] and NYU V1 [21] datasets. Among these datasets, the MIT-67 and NYU V1 are indoor scenes datasets, whereas the Scene15 is a combination of indoor and outdoor scenes. As suggested in [33], we use the same number of images for the NYU V1 dataset. We extract the proposed features and performed classification using the given train/test split ratio of each dataset.
V-A1 MIT-67
MIT-67 includes images for classes (categories) in total. The MIT-67, the biggest dataset used in this work, has been used in many previous methods such as ROI with GIST [19], MM-Scene [34], Object Bank [15], RBoW [13], BOP [12], OTC [9], ISPR [11], CNN-MOP [35], DUCA [24], BoSP [18], Bilinear [23], G-MS2F [16], VSAD [36], Objectness [17] and so on. In the experiment, we design 10 sets of train/test dataset. For this, we select 100 images randomly from each category and split them into the ratio (train/test ratio) to use in the experiment. We repeated this technique 10 times to design 10 sets train/test data for the experiment.
V-A2 Scene15
This dataset includes categories, where some categories are outdoor. It contains images in total. The Scene15 dataset has been used in methods like GIST-color [4], SPM [14], CENTRIST [6], OTC [9], ISPR [11], G-MS2F [16], DUCA [24], Objectness [17] and so on. While selecting the training and testing images for the research, we choose 100 images randomly for training and remaining images for testing, which is a standard protocol for this dataset. We randomly design 10 sample sets for this dataset in this way for the research.
V-A3 NYU V1
It comprises of images and indoor categories. The NYU V1 dataset was used in works such as BoW with SIFT [21], RGB with LLC [33], RGB-LLC-RPSL [33] and DUCA [24]. For the experiments, we take as the train/test split ratio for each category. We randomly design sample sets for this dataset as well.
V-B Implementation Details
Firstly, the sub-images are generated by the image slicer library of the python programming language [37]. Each input image should be in 3-channel (RGB) format and feed into the pre-trained deep learning models. The images from two datasets (MIT-67 and NYU V1) are already in 3-channel format, while the images of Scene15 dataset are in grayscale format. We use keras [38] to convert grayscale images into the 3-channel format. Their algorithm repeats three times to get a 3-channel image for a grayscale image. The objects are then extracted by the Inception V3 model implemented on the popular keras [38] library in R [39]. These objects are processed to get semantic objects. The proposed feature extraction operations based on semantic objects are implemented using Python.
To evaluate the proposed features for classification, the SVM based on SMO [40] is used under Weka [41]. We employ a -fold cross-validation approach for training with the default parameter setting of the SVM algorithm available in Weka. The detailed flow is illustrated in Fig. 4. We also do the ablation study for three key elements: dictionary size, number of slices and delta parameters.
V-C Comparison With State-of-the-Art Features
The quantitative comparisons of the proposed features with previous features are listed in Tables I, II and III. Tables I, II and III represents the performance on the MIT-67, Scene15 and NYU V1, respectively. For fair comparisons, we utilize the same dataset and use the reported performance results for the previous approaches. To estimate the classification accuracy on each dataset, we design 10 samples, each of which has a train/test split. The average accuracy of samples on each dataset is used to compare with the state-of-the-art features. Compared with those existing features, we obtain noticeably higher classification accuracies on all datasets used in the research.
While observing in Table I, we see that our proposed features yield a substantially higher classification accuracy on MIT-67. At the very beginning of the research on this dataset, the GIST [19] approach with the traditional low-level feature representation by ROI gives only . Object Bank [15], RBoW[13], BOP [12], OTC [9] and ISPR [11] provided accuracies of , , , , and , respectively. The features based on traditional computer vision methods do not show promising results. These research works, focused on the handcrafted technology, have larger feature dimensions for the representation of the image. Their features simply rely on the low-level components such as colors or pixels of the image which may be not suitable for the images. The classification accuracy surged higher after adopting CNN-based techniques. The CNN-MOP[35] approach obtains an accuracy of , which is over twice of the accuracy produced by ROI with GIST. With the help of middle-level features based on deep features, the accuracy is improved drastically in classification because of the representation using parts of the objects in the image. The features extracted by DUCA [24] approach outperforms the normal CNN-MOP approach, which follows the proper step-wise operations of the feature extraction. This approach yields an accuracy of .
BoSP [18], which again considered middle-level features with spatial pooling layers, produces an accuracy of . These features have a lower dimensional size than the previous features. The middle-level features from Bilinear [23], high-level features G-MS2F [16] and Objectness [17] give , , and , respectively. This shows the effectiveness of high-level features on the MIT-67 dataset based on deep learning models. However, these features still suffer from a high dimensional cost for the image representation. By contrast, our high-level semantic features enable a lower feature size while a significantly improved accuracy ().
Similarly, we see the promising accuracy of our proposed features on the Scene15 dataset. The accuracies of all features are listed in Table II. The low accuracy is obtained by the GIST-based low-level features which have a higher dimension. The features extracted by the traditional methods such as SPM [14], CENTRIST [6] and OTC [9] yield accuracies of , and , respectively. Furthermore, middle-level features extracted by ISPR [11] show a promising result in terms of a classification accuracy of due to the part based representation of objects in the image. The accuracy is improved significantly with deep learning based features which involve hierarchical features of the image. The middle-level features from DUCA [24] approach provides an accuracy of . The high-level features extracted by G-MS2F [16] generates an accuracy of . Our proposed features yield an average accuracy of which is the highest among the state-of-the-art features.
Table III also shows that deep learning based features can produce promising results in image classification for the NYU V1 dataset. We noticed that the accuracy increases with the quality of the features set designed. The Bag of Visual Words (BoVW) approach with SIFT [21] features has a accuracy. The features based on deep learning yields a higher quality. Similarly, our proposed features outperforms all these existing features by achieving an average accuracy of .
Three datasets involve various images which have impact in designing features, thereby affecting the classification performance. Some images from different categories are similar in nature, as shown in Fig. 6 for MIT-67 dataset. The cross-class similarity deteriorates the classification performance. Fig. 6 shows the images of four categories i.e., bookstore, library, restaurant and bakery. We see the structural similarity of bookstore and library images. However, the structural dissimilarity of the images within the category can be also seen. Furthermore, the Scene15 dataset (Fig. 7) has some challenging complex images having intra- and cross-class structural barriers. Similar to the MIT-67 dataset, this dataset also contains many images having such complexities.
We also see the intra-class structural dissimilarity of the images in Fig. 8 for the NYU V1 dataset. However, the images of this dataset contain fewer obstacles for the categories, compared to other datasets. Whatever types of datasets used in the experiments, each dataset has its own obstacles for the calculation of the proposed features. To generalize and ensure the quality of the proposed features under these obstacles, an intuitive way is to average the classification accuracy of more samples on each dataset. We conduct a more in-depth experiment on each sample of each dataset, to further evaluate the classification accuracy. The accuracies of each sample for different datasets are listed in Table IV. It shows the stability of the proposed features for each dataset. The average accuracies for 10 samples of MIT-67, Scene15 and NYU V1 dataset are , and , respectively.
V-D Ablative Analysis of Dictionary Size
The number of objects in the dictionary determines the size of the dictionary. We design three different sizes of dictionaries to evaluate the separability of the proposed features on the MIT-67 dataset. Three different sizes of dictionaries are , , and . These dictionaries are used to construct the objects pattern dictionaries. We extract semantic objects based on those object pattern dictionaries of the corresponding category and calculate the proposed features using those objects. Here, we use the corresponding numbers of sub-images for each dictionary in extracting the proposed features. For instance, on the -size, -size, -size dictionary, we use , , and sub-images per image, respectively. We design sample sets for the evaluation of the dictionary size. Table V enlists the classification accuracy of the proposed features under different dictionary sizes in the experiment.
While performing the individual dictionary size evaluation with the corresponding number of sub-images (3x3 sub-images for 9000-size dictionary, 4x4 sub-images for 16000-size dictionary, and 5x5 sub-images for 25000-size dictionary), we noticed that the -size dictionary obtains the best accuracy result in the classification.
V-E Ablative Analysis of the Number of Sub-images and Dictionary size
To analyze the effectiveness of the number of sub-images, we exploit the relationship between the number of sub-images and the dictionary size for the proposed features. The numbers of sub-images per image used are 9, 16 and 25, respectively. Firstly, the semantic objects of each image are extracted using the corresponding dictionary. For example, for the images with 9 sub-images, we extract semantic objects using the -size dictionary. The extracted semantic objects of each image are then utilized to respectively calculate the proposed features under three different dictionaries. Also, we design 10 sets of train/test data. The effectiveness of the number of sub-images is demonstrated in Table VI. The experiment reveals that the -size dictionary is suitable for the proposed features extraction of these images. All three sub-images (, and ) per image perform well on this -size dictionary for extracting the features for the classification. This finding between the number of sub-images and the dictionary size helps to explore highly separable features for such type of images during the feature extraction.
V-F Ablative Analysis of Delta Parameters
We designed six different types of delta parameters as the multiplier factors with the probability scores of the semantic objects in different categories. Since this parameter plays a crucial role in the design of the proposed features, we experiment them one by one on three datasets. We utilize the dictionary obtained from sub-images per image (e.g., for MIT-67 dataset) and corresponding semantic objects to evaluate the parameters. The details about these parameters are elaborated in Section III-C. We use sub-images per image to analyze the delta parameters. We design the features based on each delta parameter on three datasets. To test the robustness of the delta parameter, we design one set of data for each dataset by following the corresponding training and testing ratios. The accuracies are represented by the bar graph (Fig. 9).
While observing the individual classification accuracy in Fig. 9, the accuracy of the normal delta parameter is higher than other delta parameters on MIT-67, Scene15 and NYU V1. However, the accuracy of divide delta parameter was the same as the normal delta parameter in terms of classification accuracy on the MIT-67. The root-based delta parameter becomes worst for MIT-67 and Scene15 dataset. This result shows the robustness of the normal delta parameter.
Furthermore, we consider the average classification accuracy of each delta parameter on three datasets. The average accuracy of the proposed features that use a normal delta parameter on all three datasets is , which is the highest accuracy. The lowest accuracy reported is the root-based delta parameter which achieves only .
VI Conclusion
We have proposed the high-level semantic features concept and designed a set of steps to extract them for the representation of the indoor images. The proposed features outperform the state-of-the-art features, in terms of indoor image classification. Our features have a lower dimension and higher separability than the existing features, thereby achieving higher classification accuracies. It has demonstrated that the semantic objects are important clues for extracting the image features with high separability. We believe this work will arouse new insights in the future.
VII Acknowledgment
We would like to thank Mr. Rakesh K. Bachchan for helping us extract NYU V1 dataset from the repository.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] G. L. Foresti, C. Micheloni, L. Snidaro, P. Remagnino, and T. Ellis, “Active video-based surveillance system: the low-level image and video processing techniques needed for implementation,” IEEE Signal Process. Mag. , vol. 22, no. 2, pp. 25–37, Mar. 2005.
- 2[2] O. Zeglazi, A. Amine, and M. Rziza, “Sift descriptors modeling and application in texture image classification,” in Proc. 13th Int. Conf. Comput. Graphics, Imaging and Visualization (C Gi V) , Mar. 2016, pp. 265–268.
- 3[3] A. Oliva, “Gist of the scene,” in Neurobiology of Attention . Elsevier, 2005, pp. 251–256.
- 4[4] A. Oliva and A. Torralba, “Modeling the shape of the scene: a holistic representation of the spatial envelope,” Int. J. Comput. Vis. , vol. 42, no. 3, pp. 145–175, May. 2001.
- 5[5] N. Dalal and B. Triggs, “Histograms of oriented gradients for human detection,” in Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit. (CVPR) , 2005, pp. 886–893.
- 6[6] J. Wu and J. M. Rehg, “CENTRIST: A visual descriptor for scene categorization,” IEEE Trans. Pattern Anal. Mach. Intell. , vol. 33, no. 8, pp. 1489–1501, Aug. 2011.
- 7[7] Y. Xiao, J. Wu, and J. Yuan, “m CENTRIST: a multi-channel feature generation mechanism for scene categorization,” IEEE Trans. Image Process. , vol. 23, no. 2, pp. 823–836, Feb. 2014.
- 8[8] M. Song, C. Chen, S. Wang, and Y. Yang, “Low-level and high-level prior learning for visual saliency estimation,” Information Sciences , vol. 281, pp. 573–585, 2014.