Marginalized Frailty-Based Illness-Death Model: Application to the UK-Biobank Survival Data
Malka Gorfine, Nir Keret, Asaf Ben Arie, David Zucker, Li Hsu

TL;DR
This paper introduces a novel semi-parametric illness-death model with shared frailty, tailored for UK Biobank data, to analyze genetic and environmental risk factors affecting disease and mortality, accounting for complex recruitment and data issues.
Contribution
It develops a new semi-parametric illness-death model with shared frailty that handles delayed entry, prevalent and incident cases, and age restrictions in UK Biobank data.
Findings
Effective estimation procedure for the new model
Handles delayed entry and prevalent cases
Applied to UK Biobank data for disease risk analysis
Abstract
The UK Biobank is a large-scale health resource comprising genetic, environmental and medical information on approximately 500,000 volunteer participants in the UK, recruited at ages 40--69 during the years 2006--2010. The project monitors the health and well-being of its participants. This work demonstrates how these data can be used to estimate in a semi-parametric fashion the effects of genetic and environmental risk factors on the hazard functions of various diseases, such as colorectal cancer. An illness-death model is adopted, which inherently is a semi-competing risks model, since death can censor the disease, but not vice versa. Using a shared-frailty approach to account for the dependence between time to disease diagnosis and time to death, we provide a new illness-death model that assumes Cox models for the marginal hazard functions. The recruitment procedure used in this…
Click any figure to enlarge with its caption.
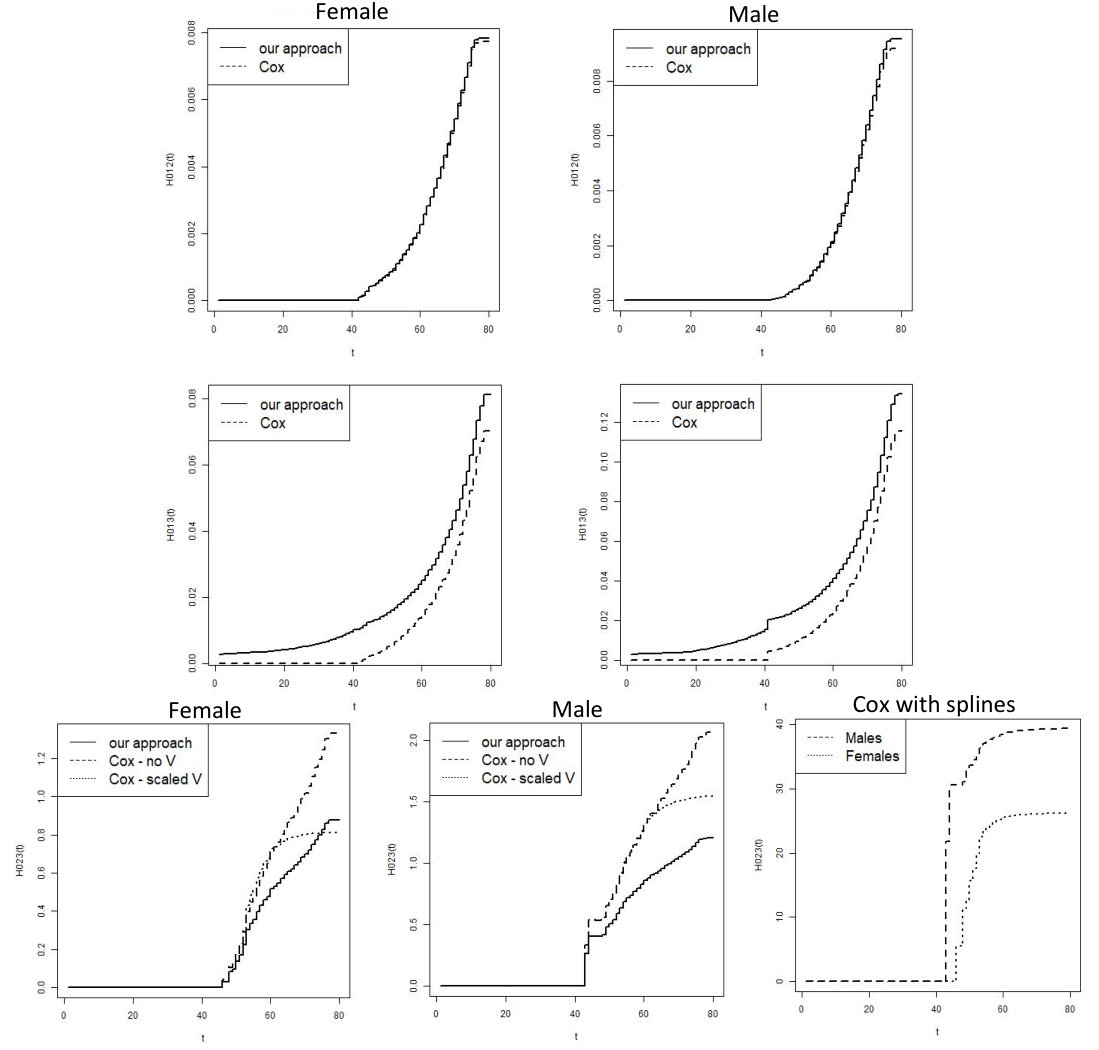 Figure 1
Figure 1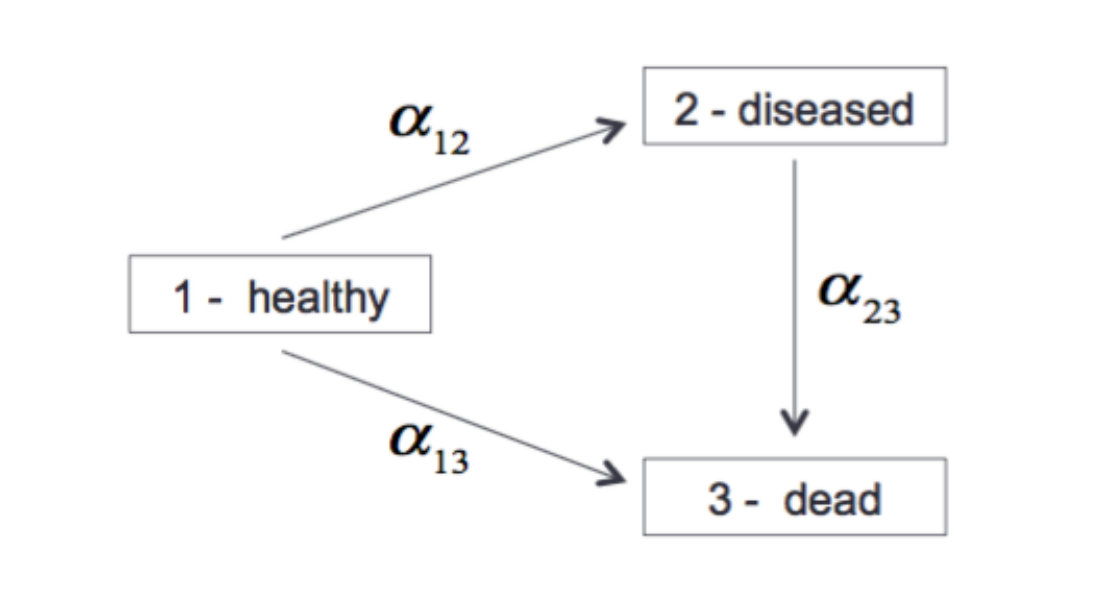 Figure 1
Figure 1| Cox I | Cox II | Cox III | Proposed (20K censored) | |
|---|---|---|---|---|
| 221,723 men; 1,603 CRC incident events; 7,752 deaths before CRC; | ||||
| out of the 2,945 with CRC (prevalent and incident) 668 died (out of them, 462 are incident cases) | ||||
| - | - | - | 1.957 (0.480) | |
| G-score 12 | 1.358 (0.091) | 1.358 (0.091) | 1.358 (0.091) | 1.333 (0.087) |
| E-score 12 | 0.743 (0.089) | 0.743 (0.089) | 0.743 (0.089) | 0.708 (0.095) |
| G-score 13 | 0.051 (0.039) | 0.051 (0.039) | 0.051 (0.039) | 0.048 (0.050) |
| E-score 13 | 0.785 (0.041) | 0.785 (0.041) | 0.785 (0.041) | 0.749 (0.050) |
| G-score 23 | -0.003 (0.139) | -0.072 (0.140) | -0.072 (0.139) | 0.421 (0.131) |
| Scaled | - | 1.439 (0.097) | 1.423 (0.219) | - |
| Spline | - | - | -0.251 (0.414) | - |
| Spline | - | - | 0.429 (1.536) | - |
| Spline | - | - | 0.004 (0.517) | - |
| 263,195 women; 1,189 CRC incident events; 5,015 deaths before CRC; | ||||
| out of the 2,186 with CRC (prevalent and incident) 372 died (out of them, 291 are incident cases) | ||||
| - | - | - | 2.297 (0.161) | |
| G-score 12 | 1.416 (0.106) | 1.416 (0.106) | 1.416 (0.106) | 1.404 (0.143) |
| E-score 12 | 0.260 (0.101) | 0.260 (0.101) | 0.260 (0.101) | 0.248 (0.105) |
| G-score 13 | -0.002 (0.049) | -0.002 (0.049) | -0.002 (0.049) | -0.008 (0.061) |
| E-score 13 | 0.650 (0.050) | 0.650 (0.050) | 0.650 (0.050) | 0.632 (0.058) |
| G-score 23 | -0.273 (0.184) | -0.399 (0.184) | -0.396 (0.184) | 0.208 (0.163) |
| Scaled | - | 2.065 (0.158) | 2.424 (0.466) | - |
| Spline | - | - | -0.594 (0.701) | - |
| Spline | - | - | 0.001 (0.707) | - |
| Spline | - | - | 0.535 (0.682) | - |
| Cox Corrected for LT | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| 0 | mean | - | 2.007 | 0.200 | 0.042 | 0.058 | 0.991 | 1.004 | 0.505 |
| empirical SD | - | 0.103 | 0.084 | 0.078 | 0.089 | 0.093 | 0.110 | 0.105 | |
| bootstrap SE | - | 0.093 | 0.088 | 0.087 | 0.097 | 0.092 | 0.120 | 0.107 | |
| coverage rate | - | 0.950 | 0.960 | 0.980 | 0.970 | 0.940 | 0.960 | 0.960 | |
| The Proposed Approach | |||||||||
| 0 | mean | 0.037 | 1.995 | 0.200 | 0.040 | 0.056 | 0.993 | 1.016 | 0.491 |
| empirical SD | 0.058 | 0.090 | 0.091 | 0.093 | 0.094 | 0.091 | 0.126 | 0.109 | |
| bootstrap SD | 0.057 | 0.095 | 0.088 | 0.088 | 0.098 | 0.093 | 0.122 | 0.105 | |
| coverage rate | 0.990 | 0.970 | 0.930 | 0.940 | 0.970 | 0.960 | 0.950 | 0.920 | |
| Cox Corrected for LT | |||||||||
| 1 | mean | - | 2.000 | 0.198 | 0.046 | 0.045 | 0.993 | 0.696 | 0.537 |
| empirical SD | - | 0.093 | 0.097 | 0.089 | 0.101 | 0.097 | 0.140 | 0.116 | |
| estimated SD | - | 0.092 | 0.088 | 0.086 | 0.097 | 0.092 | 0.139 | 0.127 | |
| coverage rate | - | 0.970 | 0.920 | 0.930 | 0.920 | 0.950 | 0.370 | 0.980 | |
| The Proposed Approach | |||||||||
| 1 | mean | 1.054 | 2.005 | 0.187 | 0.034 | 0.041 | 0.016 | 1.026 | 0.524 |
| empirical SD | 0.139 | 0.095 | 0.093 | 0.075 | 0.128 | 0.111 | 0.115 | 0.111 | |
| bootstrap SE | 0.123 | 0.090 | 0.080 | 0.079 | 0.118 | 0.105 | 0.123 | 0.108 | |
| coverage rate | 0.960 | 0.970 | 0.910 | 0.950 | 0.970 | 0.970 | 0.970 | 0.940 | |
| Cox Corrected for LT | |||||||||
| 2 | mean | - | 1.997 | 0.214 | 0.045 | 0.055 | 1.002 | 0.585 | 0.520 |
| empirical SD | - | 0.105 | 0.093 | 0.084 | 0.099 | 0.099 | 0.162 | 0.151 | |
| bootstrap SD | - | 0.093 | 0.088 | 0.087 | 0.097 | 0.092 | 0.160 | 0.146 | |
| coverage rate | - | 0.910 | 0.950 | 0.960 | 0.970 | 0.940 | 0.280 | 0.920 | |
| The Proposed Approach | |||||||||
| 2 | mean | 2.059 | 1.994 | 0.203 | 0.040 | 0.052 | 0.993 | 1.020 | 0.519 |
| empirical SD | 0.165 | 0.097 | 0.089 | 0.075 | 0.098 | 0.093 | 0.171 | 0.133 | |
| estimated SD | 0.170 | 0.096 | 0.083 | 0.080 | 0.097 | 0.088 | 0.153 | 0.128 | |
| coverage rate | 0.950 | 0.950 | 0.930 | 0.970 | 0.960 | 0.950 | 0.910 | 0.920 | |
| 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 0.6 | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 0.6 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Cox corrected for LT | The Proposed Approach | ||||||||||||
| 0 | 0.050 | 0.150 | 0.250 | 0.350 | 0.450 | 0.550 | 0.050 | 0.150 | 0.250 | 0.350 | 0.450 | 0.550 | |
| mean | 0.051 | 0.151 | 0.250 | 0.350 | 0.451 | 0.549 | 0.050 | 0.151 | 0.252 | 0.353 | 0.455 | 0.559 | |
| ESD | 0.007 | 0.013 | 0.019 | 0.027 | 0.038 | 0.046 | 0.006 | 0.014 | 0.023 | 0.030 | 0.037 | 0.049 | |
| CR | 0.980 | 0.990 | 0.990 | 0.960 | 0.950 | 0.940 | 0.940 | 0.950 | 0.930 | 0.960 | 0.970 | 0.930 | |
| 0.075 | 0.225 | 0.425 | 0.625 | 0.825 | 1.025 | 0.075 | 0.225 | 0.425 | 0.625 | 0.825 | 1.025 | ||
| mean | 0.051 | 0.201 | 0.401 | 0.602 | 0.803 | 1.003 | 0.078 | 0.228 | 0.429 | 0.630 | 0.828 | 1.027 | |
| ESD | 0.010 | 0.016 | 0.029 | 0.044 | 0.056 | 0.078 | 0.010 | 0.021 | 0.037 | 0.052 | 0.069 | 0.091 | |
| CR | 0.270 | 0.680 | 0.830 | 0.890 | 0.910 | 0.920 | 0.950 | 0.960 | 0.920 | 0.910 | 0.930 | 0.940 | |
| 0.000 | 0.080 | 0.180 | 0.280 | 0.380 | 0.480 | 0.000 | 0.080 | 0.180 | 0.280 | 0.380 | 0.480 | ||
| mean | - | 0.081 | 0.181 | 0.281 | 0.381 | 0.482 | - | 0.081 | 0.183 | 0.285 | 0.389 | 0.490 | |
| ESD | - | 0.010 | 0.020 | 0.028 | 0.037 | 0.047 | - | 0.010 | 0.021 | 0.032 | 0.043 | 0.056 | |
| CR | - | 0.900 | 0.930 | 0.940 | 0.930 | 0.940 | - | 0.960 | 0.920 | 0.910 | 0.900 | 0.890 | |
| 1 | 0.050 | 0.150 | 0.250 | 0.350 | 0.450 | 0.550 | 0.050 | 0.150 | 0.250 | 0.350 | 0.450 | 0.550 | |
| mean | 0.051 | 0.151 | 0.253 | 0.353 | 0.452 | 0.553 | 0.050 | 0.152 | 0.252 | 0.354 | 0.455 | 0.560 | |
| ESD | 0.009 | 0.017 | 0.025 | 0.034 | 0.042 | 0.052 | 0.007 | 0.018 | 0.027 | 0.038 | 0.047 | 0.059 | |
| CR | 0.930 | 0.900 | 0.930 | 0.930 | 0.930 | 0.950 | 0.930 | 0.960 | 0.950 | 0.950 | 0.960 | 0.960 | |
| 0.075 | 0.225 | 0.425 | 0.625 | 0.825 | 1.025 | 0.075 | 0.225 | 0.425 | 0.625 | 0.825 | 1.025 | ||
| mean | 0.050 | 0.203 | 0.404 | 0.606 | 0.807 | 1.009 | 0.080 | 0.233 | 0.435 | 0.639 | 0.844 | 1.040 | |
| ESD | 0.009 | 0.018 | 0.031 | 0.045 | 0.061 | 0.079 | 0.011 | 0.022 | 0.039 | 0.059 | 0.082 | 0.101 | |
| CR | 0.220 | 0.660 | 0.870 | 0.900 | 0.910 | 0.920 | 0.950 | 0.960 | 0.950 | 0.950 | 0.920 | 0.920 | |
| 0.000 | 0.080 | 0.180 | 0.280 | 0.380 | 0.480 | 0.000 | 0.080 | 0.180 | 0.280 | 0.380 | 0.480 | ||
| mean | - | 0.071 | 0.147 | 0.218 | 0.284 | 0.350 | - | 0.079 | 0.178 | 0.277 | 0.377 | 0.477 | |
| ESD | - | 0.011 | 0.021 | 0.030 | 0.037 | 0.044 | - | 0.009 | 0.017 | 0.026 | 0.036 | 0.045 | |
| CR | - | 0.740 | 0.550 | 0.390 | 0.240 | 0.180 | - | 0.940 | 0.930 | 0.980 | 0.980 | 0.980 | |
| 2 | 0.050 | 0.150 | 0.250 | 0.350 | 0.450 | 0.550 | 0.050 | 0.150 | 0.250 | 0.350 | 0.450 | 0.550 | |
| mean | 0.050 | 0.150 | 0.250 | 0.350 | 0.449 | 0.549 | 0.051 | 0.152 | 0.252 | 0.353 | 0.454 | 0.556 | |
| ESD | 0.007 | 0.014 | 0.022 | 0.031 | 0.039 | 0.047 | 0.007 | 0.013 | 0.021 | 0.028 | 0.036 | 0.045 | |
| CR | 0.940 | 0.960 | 0.930 | 0.930 | 0.930 | 0.960 | 0.970 | 0.960 | 0.950 | 0.960 | 0.950 | 0.970 | |
| 0.075 | 0.225 | 0.425 | 0.625 | 0.825 | 1.025 | 0.075 | 0.225 | 0.425 | 0.625 | 0.825 | 1.025 | ||
| mean | 0.049 | 0.200 | 0.400 | 0.601 | 0.801 | 0.999 | 0.077 | 0.229 | 0.431 | 0.633 | 0.836 | 1.038 | |
| ESD | 0.008 | 0.018 | 0.033 | 0.045 | 0.060 | 0.074 | 0.009 | 0.019 | 0.033 | 0.046 | 0.060 | 0.072 | |
| CR | 0.130 | 0.590 | 0.800 | 0.890 | 0.940 | 0.940 | 0.980 | 0.980 | 0.930 | 0.960 | 0.950 | 0.960 | |
| 0.000 | 0.080 | 0.180 | 0.280 | 0.380 | 0.480 | 0.000 | 0.080 | 0.180 | 0.280 | 0.380 | 0.480 | ||
| mean | - | 0.058 | 0.116 | 0.168 | 0.217 | 0.264 | - | 0.081 | 0.181 | 0.281 | 0.380 | 0.480 | |
| ESD | - | 0.010 | 0.017 | 0.023 | 0.030 | 0.034 | - | 0.013 | 0.027 | 0.039 | 0.052 | 0.063 | |
| CR | - | 0.330 | 0.090 | 0.020 | 0.000 | 0.000 | - | 0.920 | 0.920 | 0.940 | 0.950 | 0.940 | |
| Risk Factor | Coefficient | SE | Z-value | P-value |
|---|---|---|---|---|
| Family History (yes) | 0.271 | 0.063 | 4.267 | 0.000 |
| Height | 0.005 | 0.003 | 1.814 | 0.070 |
| BMI | 0.016 | 0.004 | 3.960 | 0.000 |
| smoking (yes) | 0.168 | 0.039 | 4.301 | 0.000 |
| Alcohol (reference - non or occasional): | ||||
| light frequent drinker | 0.034 | 0.053 | 0.635 | 0.525 |
| very frequent drinker | 0.093 | 0.048 | 1.949 | 0.051 |
| Physical activity (yes) | -0.010 | 0.041 | -0.255 | 0.799 |
| Education (reference - prefer not to answer): | ||||
| lower than high-school | -0.241 | 0.160 | -1.513 | 0.130 |
| high-school | -0.240 | 0.158 | -1.516 | 0.130 |
| higher vocational education | -0.243 | 0.163 | -1.490 | 0.136 |
| college or university graduate | -0.304 | 0.159 | -1.910 | 0.056 |
| Aspirin use | 0.066 | 0.050 | 1.324 | 0.186 |
| Ibuprofen drugs use (e.g. Nurofen) | -0.092 | 0.066 | -1.395 | 0.163 |
| Gender and Hormone use (reference - Male): | ||||
| Female, no hormones use | -0.307 | 0.063 | -4.881 | 0.000 |
| Female, hormone use | -0.354 | 0.064 | -5.532 | 0.000 |
| Quantile-transformed E-score: Mean (SD) | ||||
| Female diagnosed with CRC | 0.531 (0.289) | |||
| Female CRC free | 0.500 (0.289) | |||
| Male diagnosed with CRC | 0.588 (0.278) | |||
| Male CRC free | 0.500 (0.289) | |||
| Chromosome and SNP Names | RS Name | Position | Coefficient | SE | Z value | P-value |
|---|---|---|---|---|---|---|
| 1:22587728_T/C | rs72647484 | 22587728 | -0.151 | 0.050 | -3.012 | 0.003 |
| 1:183081194_A/C | rs10911251 | 183081194 | -0.091 | 0.027 | -3.353 | 0.001 |
| 1:222045446_G/T | rs6691170 | 222045446 | 0.068 | 0.028 | 2.464 | 0.014 |
| 2:192587204_T/C | rs11903757 | 192587204 | 0.008 | 0.036 | 0.224 | 0.823 |
| 2:219154781_G/A | rs992157 | 219154781 | 0.071 | 0.027 | 2.608 | 0.009 |
| 3:37034946_G/A | rs1800734 | 37034946 | 0.005 | 0.033 | 0.165 | 0.869 |
| 3:40924962_T/A | rs35360328 | 40924962 | 0.088 | 0.037 | 2.379 | 0.017 |
| 3:66442435_C/G | rs812481 | 66442435 | -0.033 | 0.027 | -1.240 | 0.215 |
| 3:169492101_C/T | rs10936599 | 169492101 | -0.035 | 0.031 | -1.116 | 0.264 |
| 3:169950156_T/C | rs185423955 | 169950156 | 1.363 | 0.502 | 2.717 | 0.007 |
| 4:94943383_C/T | rs1370821 | 94943383 | 0.074 | 0.027 | 2.713 | 0.007 |
| 4:149748994_T/C | rs60745952 | 149748994 | 0.000 | 0.038 | -0.005 | 0.996 |
| 4:163333405_T/A | rs35509282 | 163333405 | -0.022 | 0.043 | -0.507 | 0.612 |
| 5:1286516_C/A | rs2736100 | 1286516 | 0.017 | 0.038 | 0.439 | 0.661 |
| 5:1296486_A/G | rs2735940 | 1296486 | 0.085 | 0.038 | 2.234 | 0.026 |
| 5:40282106_G/C | rs1445012 | 40282106 | 0.128 | 0.029 | 4.406 | 0.000 |
| 5:96133795_G/A | rs142227741 | 96133795 | 0.049 | 0.170 | 0.286 | 0.775 |
| 5:112175211_T/A | rs1801155 | 112175211 | -0.142 | 0.627 | -0.227 | 0.820 |
| 5:134499092_C/A | rs647161 | 134499092 | 0.047 | 0.029 | 1.654 | 0.098 |
| 6:35528204_T/C | rs144037597 | 35528204 | -0.064 | 0.042 | -1.526 | 0.127 |
| 6:36622900_C/A | rs1321311 | 36622900 | 0.004 | 0.031 | 0.140 | 0.889 |
| 6:41692812_G/A | rs4711689 | 41692812 | 0.047 | 0.027 | 1.720 | 0.086 |
| 6:55714314_C/T | rs62404968 | 55714314 | -0.038 | 0.031 | -1.218 | 0.223 |
| 6:117822993_C/T | rs4946260 | 117822993 | 0.037 | 0.027 | 1.366 | 0.172 |
| 6:160840252_G/T | rs7758229 | 160840252 | 0.011 | 0.028 | 0.400 | 0.689 |
| 8:117624093_T/C | rs2450115 | 117624093 | -0.035 | 0.040 | -0.877 | 0.380 |
| 8:117630683_A/C | rs16892766 | 117630683 | 0.178 | 0.046 | 3.837 | 0.000 |
| 8:117647788_G/A | rs6469656 | 117647788 | -0.007 | 0.047 | -0.147 | 0.883 |
| 8:128413305_G/T | rs6983267 | 128413305 | -0.187 | 0.027 | -6.952 | 0.000 |
| 9:6365683_A/C | rs719725 | 6365683 | 0.033 | 0.028 | 1.216 | 0.224 |
| 10:8701219_G/A | rs10795668 | 8701219 | -0.127 | 0.029 | -4.346 | 0.000 |
| 10:16997266_G/T | rs10904849 | 16997266 | 0.008 | 0.029 | 0.284 | 0.776 |
| 10:52645424_C/T | rs10994860 | 52645424 | -0.085 | 0.036 | -2.362 | 0.018 |
| 10:80819132_A/G | rs704017 | 80819132 | 0.110 | 0.027 | 4.036 | 0.000 |
| 10:101345366_C/T | rs1035209 | 101345366 | 0.090 | 0.033 | 2.729 | 0.006 |
| 10:104595248_G/A | rs4919687 | 104595248 | 0.013 | 0.029 | 0.441 | 0.659 |
| 10:114280702_T/C | rs12241008 | 114280702 | 0.121 | 0.042 | 2.856 | 0.004 |
| 10:114726843_G/A | rs11196172 | 114726843 | 0.088 | 0.038 | 2.305 | 0.021 |
| 11:61552680_G/T | rs174537 | 61552680 | -0.034 | 0.028 | -1.190 | 0.234 |
| 11:61982418_G/A | rs60892987 | 61982418 | 0.009 | 0.033 | 0.265 | 0.791 |
| Chromosome and SNP Names | RS Name | Position | Coefficient | SE | Z value | P-value |
|---|---|---|---|---|---|---|
| 11:74345550_T/G | rs3824999 | 74345550 | 0.087 | 0.027 | 3.243 | 0.001 |
| 11:111171709_C/A | rs3802842 | 111171709 | -0.090 | 0.029 | -3.132 | 0.002 |
| 12:4368352_T/C | rs10774214 | 4368352 | -0.043 | 0.028 | -1.575 | 0.115 |
| 12:4388271_C/T | rs3217810 | 4388271 | 0.033 | 0.042 | 0.786 | 0.432 |
| 12:6385727_C/T | rs10849432 | 6385727 | 0.044 | 0.043 | 1.013 | 0.311 |
| 12:6982162_C/T | rs11064437 | 6982162 | -0.188 | 0.192 | -0.978 | 0.328 |
| 12:51155663_C/T | rs11169552 | 51155663 | -0.051 | 0.031 | -1.659 | 0.097 |
| 12:111884608_T/C | rs3184504 | 111884608 | 0.079 | 0.027 | 2.969 | 0.003 |
| 12:115888504_G/A | rs12822984 | 115888504 | 0.029 | 0.027 | 1.059 | 0.290 |
| 12:117747590_T/G | rs73208120 | 117747590 | 0.031 | 0.047 | 0.660 | 0.509 |
| 13:34093518_C/G | rs10161980 | 34093518 | -0.008 | 0.028 | -0.290 | 0.771 |
| 14:54410919_T/C | rs4444235 | 54410919 | 0.076 | 0.027 | 2.826 | 0.005 |
| 14:54560018_T/C | rs1957636 | 54560018 | -0.050 | 0.027 | -1.858 | 0.063 |
| 15:32993111_C/T | rs16969681 | 32993111 | 0.179 | 0.044 | 4.025 | 0.000 |
| 15:33004247_G/A | rs11632715 | 33004247 | 0.066 | 0.027 | 2.444 | 0.015 |
| 16:9297812_G/A | rs79900961 | 9297812 | -0.016 | 0.092 | -0.174 | 0.862 |
| 16:68820946_G/A | rs9929218 | 68820946 | -0.071 | 0.030 | -2.368 | 0.018 |
| 16:86340448_G/C | rs2696839 | 86340448 | -0.047 | 0.027 | -1.755 | 0.079 |
| 16:86695720_G/C | rs16941835 | 86695720 | 0.031 | 0.033 | 0.928 | 0.353 |
| 17:800593_T/C | rs12603526 | 800593 | 0.133 | 0.084 | 1.591 | 0.112 |
| 18:46450976_A/G | rs7229639 | 46450976 | 0.018 | 0.047 | 0.390 | 0.697 |
| 18:46453463_T/C | rs4939827 | 46453463 | -0.154 | 0.028 | -5.458 | 0.000 |
| 19:33532300_C/T | rs10411210 | 33532300 | -0.131 | 0.047 | -2.790 | 0.005 |
| 19:41860296_A/G | rs1800469 | 41860296 | 0.118 | 0.030 | 3.922 | 0.000 |
| 19:46321507_A/G | rs56848936 | 46321507 | -0.628 | 0.717 | -0.876 | 0.381 |
| 20:6404281_C/A | rs961253 | 6404281 | 0.026 | 0.028 | 0.934 | 0.350 |
| 20:6699595_T/G | rs4813802 | 6699595 | 0.084 | 0.028 | 3.030 | 0.002 |
| 20:7812350_T/C | rs2423279 | 7812350 | 0.098 | 0.031 | 3.218 | 0.001 |
| 20:33173883_C/T | rs2295444 | 33173883 | -0.030 | 0.027 | -1.104 | 0.270 |
| 20:47340117_A/G | rs6066825 | 47340117 | -0.178 | 0.029 | -6.250 | 0.000 |
| 20:49057488_C/T | rs1810502 | 49057488 | -0.094 | 0.027 | -3.468 | 0.001 |
| 20:60921044_T/C | rs4925386 | 60921044 | 0.114 | 0.029 | 3.910 | 0.000 |
| Quantile-transformed G-score: Mean (SD) | ||||||
| Female diagnosed with CRC | 0.603 (0.280) | |||||
| Female CRC free | 0.500 (0.289) | |||||
| Male diagnosed with CRC | 0.602 (0.280) | |||||
| Male CRC free | 0.500 (0.289) |
| Cox Corrected for LT | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| 0 | mean | - | 2.008 | 0.196 | 0.041 | 0.049 | 1.003 | 0.986 | 0.498 |
| empirical SD | - | 0.085 | 0.076 | 0.076 | 0.095 | 0.088 | 0.145 | 0.131 | |
| estimated SE | - | 0.088 | 0.083 | 0.082 | 0.092 | 0.089 | 0.140 | 0.125 | |
| coverage rate | - | 0.940 | 0.960 | 0.960 | 0.900 | 0.970 | 0.960 | 0.920 | |
| The Proposed Approach | |||||||||
| 0 | mean | 0.050 | 1.987 | 0.194 | 0.038 | 0.043 | 0.993 | 1.042 | 0.495 |
| empirical SD | 0.078 | 0.098 | 0.089 | 0.079 | 0.094 | 0.089 | 0.140 | 0.124 | |
| Cox Corrected for LT | |||||||||
| 1 | mean | - | 2.007 | 0.187 | 0.055 | 0.042 | 0.996 | 0.747 | 0.495 |
| empirical SD | - | 0.084 | 0.090 | 0.088 | 0.093 | 0.085 | 0.149 | 0.153 | |
| estimated SE | - | 0.088 | 0.083 | 0.082 | 0.092 | 0.089 | 0.163 | 0.148 | |
| coverage rate | - | 0.960 | 0.900 | 0.930 | 0.950 | 0.960 | 0.660 | 0.910 | |
| The Proposed Approach | |||||||||
| 1 | mean | 1.073 | 1.981 | 0.189 | 0.041 | 0.057 | 0.972 | 1.033 | 0.504 |
| empirical SD | 0.131 | 0.090 | 0.079 | 0.083 | 0.091 | 0.087 | 0.153 | 0.146 | |
| Cox Corrected for LT | |||||||||
| 2 | mean | - | 1.995 | 0.203 | 0.057 | 0.046 | 1.002 | 0.628 | 0.522 |
| empirical SD | - | 0.078 | 0.080 | 0.073 | 0.099 | 0.095 | 0.172 | 0.151 | |
| estimated SE | - | 0.088 | 0.083 | 0.082 | 0.092 | 0.089 | 0.187 | 0.171 | |
| coverage rate | - | 0.970 | 0.940 | 0.980 | 0.930 | 0.920 | 0.440 | 0.940 | |
| The Proposed Approach | |||||||||
| 2 | mean | 2.087 | 1.969 | 0.180 | 0.034 | 0.041 | 0.991 | 1.037 | 0.503 |
| empirical SD | 0.188 | 0.092 | 0.075 | 0.072 | 0.087 | 0.086 | 0.181 | 0.150 | |
| 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 0.6 | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 0.6 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Cox corrected for LT | The Proposed Approach | ||||||||||||
| 0 | 0.050 | 0.150 | 0.250 | 0.350 | 0.450 | 0.550 | 0.050 | 0.150 | 0.250 | 0.350 | 0.450 | 0.550 | |
| mean | 0.050 | 0.151 | 0.252 | 0.353 | 0.453 | 0.551 | 0.051 | 0.153 | 0.256 | 0.358 | 0.457 | 0.558 | |
| ESD | 0.004 | 0.012 | 0.020 | 0.027 | 0.038 | 0.045 | 0.006 | 0.017 | 0.028 | 0.037 | 0.047 | 0.056 | |
| CR | 0.980 | 0.980 | 0.980 | 0.970 | 0.950 | 0.970 | * | * | * | * | * | * | |
| 0.075 | 0.225 | 0.425 | 0.625 | 0.825 | 1.025 | 0.075 | 0.225 | 0.425 | 0.625 | 0.825 | 1.025 | ||
| mean | 0.075 | 0.225 | 0.426 | 0.626 | 0.822 | 1.021 | 0.075 | 0.227 | 0.429 | 0.633 | 0.835 | 1.042 | |
| ESD | 0.007 | 0.017 | 0.031 | 0.044 | 0.057 | 0.072 | 0.006 | 0.017 | 0.032 | 0.047 | 0.058 | 0.078 | |
| CR | 0.930 | 0.940 | 0.970 | 0.970 | 0.960 | 0.970 | * | * | * | * | * | * | |
| 0.000 | 0.080 | 0.180 | 0.280 | 0.380 | 0.480 | 0.000 | 0.080 | 0.180 | 0.280 | 0.380 | 0.480 | ||
| mean | - | 0.082 | 0.183 | 0.285 | 0.385 | 0.486 | - | 0.080 | 0.181 | 0.282 | 0.384 | 0.488 | |
| ESD | - | 0.012 | 0.023 | 0.036 | 0.047 | 0.059 | - | 0.011 | 0.020 | 0.032 | 0.042 | 0.055 | |
| CR | - | 0.920 | 0.940 | 0.950 | 0.940 | 0.930 | * | * | * | * | * | * | |
| 1 | 0.050 | 0.150 | 0.250 | 0.350 | 0.450 | 0.550 | 0.050 | 0.150 | 0.250 | 0.350 | 0.450 | 0.550 | |
| mean | 0.050 | 0.150 | 0.251 | 0.351 | 0.452 | 0.558 | 0.052 | 0.154 | 0.256 | 0.361 | 0.461 | 0.567 | |
| ESD | 0.004 | 0.012 | 0.019 | 0.026 | 0.038 | 0.048 | 0.006 | 0.015 | 0.024 | 0.035 | 0.048 | 0.062 | |
| CR | 0.980 | 0.970 | 0.950 | 0.970 | 0.960 | 0.970 | * | * | * | * | * | * | |
| 0.075 | 0.225 | 0.425 | 0.625 | 0.825 | 1.025 | 0.075 | 0.225 | 0.425 | 0.625 | 0.825 | 1.025 | ||
| mean | 0.076 | 0.227 | 0.430 | 0.632 | 0.837 | 1.033 | 0.076 | 0.228 | 0.431 | 0.633 | 0.836 | 1.038 | |
| ESD | 0.007 | 0.019 | 0.032 | 0.048 | 0.062 | 0.077 | 0.006 | 0.017 | 0.033 | 0.046 | 0.064 | 0.090 | |
| CR | 0.940 | 0.940 | 0.950 | 0.940 | 0.940 | 0.950 | * | * | * | * | * | * | |
| 0.000 | 0.080 | 0.180 | 0.280 | 0.380 | 0.480 | 0.000 | 0.080 | 0.180 | 0.280 | 0.380 | 0.480 | ||
| mean | - | 0.070 | 0.145 | 0.217 | 0.283 | 0.347 | - | 0.080 | 0.180 | 0.282 | 0.382 | 0.484 | |
| ESD | - | 0.010 | 0.020 | 0.028 | 0.036 | 0.044 | - | 0.012 | 0.024 | 0.035 | 0.047 | 0.060 | |
| CR | - | 0.770 | 0.600 | 0.400 | 0.250 | 0.170 | * | * | * | * | * | * | |
| 2 | 0.050 | 0.150 | 0.250 | 0.350 | 0.450 | 0.550 | 0.050 | 0.150 | 0.250 | 0.350 | 0.450 | 0.550 | |
| mean | 0.050 | 0.151 | 0.249 | 0.348 | 0.447 | 0.546 | 0.052 | 0.156 | 0.261 | 0.364 | 0.469 | 0.572 | |
| ESD | 0.004 | 0.011 | 0.018 | 0.028 | 0.036 | 0.048 | 0.004 | 0.013 | 0.021 | 0.029 | 0.036 | 0.049 | |
| CR | 1.000 | 1.000 | 1.000 | 0.980 | 0.950 | 0.950 | * | * | * | * | * | * | |
| 0.075 | 0.225 | 0.425 | 0.625 | 0.825 | 1.025 | 0.075 | 0.225 | 0.425 | 0.625 | 0.825 | 1.025 | ||
| mean | 0.075 | 0.225 | 0.427 | 0.630 | 0.825 | 1.029 | 0.076 | 0.228 | 0.432 | 0.638 | 0.842 | 1.038 | |
| ESD | 0.007 | 0.018 | 0.033 | 0.045 | 0.058 | 0.074 | 0.006 | 0.017 | 0.026 | 0.046 | 0.064 | 0.078 | |
| CR | 0.940 | 0.940 | 0.940 | 0.950 | 0.930 | 0.950 | * | * | * | * | * | * | |
| 0.000 | 0.080 | 0.180 | 0.280 | 0.380 | 0.480 | 0.000 | 0.080 | 0.180 | 0.280 | 0.380 | 0.480 | ||
| mean | - | 0.056 | 0.113 | 0.164 | 0.211 | 0.257 | - | 0.080 | 0.181 | 0.280 | 0.382 | 0.484 | |
| ESD | - | 0.010 | 0.019 | 0.026 | 0.033 | 0.039 | - | 0.013 | 0.027 | 0.042 | 0.056 | 0.072 | |
| CR | - | 0.320 | 0.100 | 0.020 | 0.020 | 0.010 | * | * | * | * | * | * | |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Marginalized Frailty-Based Illness-Death Model: Application to the UK-Biobank Survival Data
Malka Gorfine
Department of Statistics and Operations Research, Tel Aviv University, Israel
and
Nir Keret
Department of Statistics and Operations Research, Tel Aviv University, Israel
and
Asaf Ben Arie
Department of Statistics and Operations Research, Tel Aviv University, Israel
and
David Zucker
Departmet of Statistics, the Hebrew University, Jerusalem, Israel
and
Li Hsu
Fred Hutchinson Cancer Research Center, Seattle, USA
The authors gratefully acknowledge support from the NIH (R01CA189532), the U.S.-Israel Binational Science Foundation (BSF, 2016126), and the Israel Science Foundation (ISF, 1067/17) in carrying out this work
Abstract
The UK Biobank is a large-scale health resource comprising genetic, environmental and medical information on approximately 500,000 volunteer participants in the UK, recruited at ages 40–69 during the years 2006–2010. The project monitors the health and well-being of its participants. This work demonstrates how these data can be used to estimate in a semi-parametric fashion the effects of genetic and environmental risk factors on the hazard functions of various diseases, such as colorectal cancer. An illness-death model is adopted, which inherently is a semi-competing risks model, since death can censor the disease, but not vice versa. Using a shared-frailty approach to account for the dependence between time to disease diagnosis and time to death, we provide a new illness-death model that assumes Cox models for the marginal hazard functions. The recruitment procedure used in this study introduces delayed entry to the data. An additional challenge arising from the recruitment procedure is that information coming from both prevalent and incident cases must be aggregated. Lastly, we do not observe any deaths prior to the minimal recruitment age, 40. In this work we provide an estimation procedure for our new illness-death model that overcomes all the above challenges.
Keywords: Delayed entry; Frailty model; Left truncation; Random effect; Semi competing risks;
1 Introduction
The UK Biobank (UKB) is a large-scale health resource comprising genetic, medical and environmental information on approximately 500,000 volunteer participants in the UK, recruited at ages 40–69 during the years 2006–2010. The project monitors the health and well-being of its participants, thus providing a strong incentive for joining. The participants have undergone various measurements, provided blood, urine and saliva samples for future analysis, and have also provided detailed information about themselves. In using these data to study a given disease, the participants can be classified into three groups: those already diagnosed with the disease at the time of recuitment (”prevalent” cases), those in whom the disease is diagosed during follow-up (”incident” cases), and those not diagnosed with the disesase as of the end of follow-up.
One concern in such a design is delayed entry, since subjects need to live at least up to the minimum recruitment age in order to participate in the study. Moreover, the existence of prevalent cases in the data requires special attention due to two reasons: (i) The delayed-entry correction for those observations must be different to that for the incident cases. (ii) The data are subject to recall bias – when participants are asked to provide information regarding their status at the time of disease diagnosis, it is likely that some information will be reported inaccurately, especially if a long time has passed since then. Death before the disease constitutes a competing risk to many studied phenotypes, and while death in general can censor the disease, the disease cannot censor death, hence these settings are termed “semi-competing risks”. The purpose of this work is to provide appropriate model and estimation procedure for estimating the survival distribution of a certain disease, such as colorectal cancer, that properly accommodate semi-competing risks and biased sampling due to delayed entry.
In this work we focus our attention on colorectal cancer data. Out of 484,918 participants with available genetic and environmental data, there is an overall number of 5,131 colorectal cancer cases in the UKB, of which 2,339 are prevalent and 2,792 are incident. The number of deaths before having the disease is 12,767, and the number of deaths after colorectal cancer diagnosis is 1,040. Over the years the number of incident cases will grow, while the number of prevalent cases will no longer change as recruitment is already complete.
Under semi-competing risks settings, three stochastic process are typically studied: the time until disease onset, time until death free of the disease, and time until death after disease onset. These three processes are sometimes measured on a sojourn time scale, namely, the disease-death process is not expressed as age of death after disease, but rather as the amount of time spent in diseased state until death. Since we wish to use a shared random effect to describe the dependence between the processes, it is easier to work only with the age-scale and avoid situations with negative dependence (e.g. between age at diagnosis and the sojourn time in diseased state until death).
Fine et al. (2001) considered a gamma frailty model defined on the upper wedge of the joint distribution of the events, and supplied a consistent estimator for the parameter of the gamma distribution, but did not incorporate covariates. Xu et al. (2010) proposed gamma-frailty illness-death conditional and marginal models, such that the conditional (on the frailty variate) model is a Cox-type model. If the marginal model is of primary interest, interpretation of the regression effects might become cumbersome as the marginal distribution does not take a simple form and also includes the frailty distribution parameter. Chen (2012) assumed a semi-parametric transformation model for the marginal regressions and a copula model for the joint distribution. However, it was assumed that occurrence of the non-terminal event does not alter the distribution of the terminal event, which is unrealistic in most illness-death scenarios. Extending the copula model in order to account for the change of distribution is not straightforward. Vakulenko-Lagun & Mandel (2016) considered an illness-death model with delayed entry and right-censored data, under a fully parametric regression framework. However, no dependence structure between the disease and death times was assumed beyond the observed covariates. Vakulenko-Lagun et al. (2017) describe a non-parametric inverse probability weighting (IPW) approach for estimating the joint distribution of disease and death times, subject to right censoring and delayed entry. This approach does not incorporate covariates. In addition, under the sampling scheme present in the UKB data, an IPW approach is inapplicable (as will be explained in Section 3.3). Zhou et al. (2016) described a simple pseudo-likelihood approach with copulas, aimed at estimating the marginal survival functions and the association parameter of the copula, but did not account for delayed entry and did not incorporate covariates. The approach of pseudo-values was presented by Andersen & Klein (2007), in order to directly estimate the covariate effects on the state probabilities, using a generalized estimating equations procedure. This approach requires the user to predetermine the time grid for the state probabilities. In addition, calculation of the pseudo-values for a dataset as big as the UKB poses a big computational burden.
In illness-death models, age at death after disease diagnosis is left truncated by the age at diagnosis. In most applications it is unrealistic to assume that the observed covariates contain all the sources of dependence between age at diagnosis and age at death. Limited literature exists on Cox regression with dependent left-truncation and right-censored data. A complete review can be found in Shen (2017). In Section 4.2 we analyze the UKB data also by including age at diagnosis as a covariate in the model of age at death after diagnosis, in the spirit of Mackenzie (2012) and Shen (2017). The troubling meaning of these analyses will be discussed.
None of the aforementioned approaches provides a satisfactory framework for the analysis of the UKB data. We are seeking a model that can accommodate delayed entry and a dependence structure between the three described processes. In addition, we want a model that is easy to interpret at the population level and can incorporate risk factors as covariates. Lastly, we would advise against using a fully parametric model, as these models require more assumptions and are typically less robust, but rather consider a semi-parametric framework.
The novelty of this work consists of several aspects: (i) Formulation of a new frailty-based illness-death model with Cox-type marginalized hazards. Under random sampling and right-censored data, the model parameters are consistently estimated. (ii) Adjusting the proposed estimators to accommodate delayed entry and the presence of both prevalent and incident cases, such as in the UKB data. R code for carrying out the data analysis and the simulations reported in this paper is available at the following Github site: https://github.com/nirkeret/frailty-LTRC.
The rest of the paper is organized as follows. Section 2 describes our proposed frailty-based illness-death model, and the pseudo-likelihood approach for estimating the regression coefficients and the baseline hazard functions for simple cohort studies with no delayed entry. The estimation procedure for delayed-entry data is outlined in Section 3. In Section 4 we present the analysis of colorectal cancer data in the UKB. Section 5 summarizes simulation results, with and without delayed entry. Final remarks are presented in Section 6.
2 Methods: right-censored data, no delayed entry
2.1 Models
Two types of hazard functions are considered: a conditional hazard given the unobserved frailty variate and the observed time-independent covariates, and a marginalized hazard function with respect to the frailty variate, namely, the hazard given the time-independent covariates. The main goal is estimating the illness-death marginalized hazards and survival functions. Xu et al. (2010) defined a frailty-based illness death model such that the conditional hazards follow Cox-type models multiplied by a frailty variate, while the marginalized hazards are functions of the frailty-distribution parameter (Xu et al., 2010, Eq.’s 19–20). In contrast, we adopt the approach of Glidden & Self (1999), and reformulate the frailty model so that the marginalized hazard functions obey a specified model, such as the Cox model, that is free of the frailty-distribution parameter. In the context of this work, it is preferable that the marginal model be free of the frailty parameter, as its interpretation as a model corresponding to a randomly selected individual from the population is facilitated this way. The frailty distribution parameter quantifies the degree of dependence between the different processes within the same person, so when it is present in a marginal model it obscures the interpretation of the regression coefficients.
Let and be age at diagnosis and age at death, respectively. Denote the unobserved frailty by a random variable with a known cumulative distribution function and an unknown parameter . Let be a vector of time-independent covariates. Based on the notation of Fig. 1, let the conditional hazards of transition from state 1 to either state or 3, given , be
[TABLE]
Let the conditional hazard function of leaving state 2, given , and given the transition to state 2 occurred at age be defined by
[TABLE]
The non-negative functions , , will be determined by the distribution of the frailty and the marginalized hazards presented below. The frailty distribution should be chosen such that the hazard models are identifiable.
The corresponding Cox marginalized hazards are defined by
[TABLE]
and
[TABLE]
where and , , are the regression coefficient vectors and unspecified baseline hazard functions, respectively. In , disease onset time is not included in the vector of covariates, but instead the dependence between the time to disease onset and the time from disease onset to death is captured by the frailty parameter . Our goal is estimating the regression coefficients , the hazards, , , and the dependence parameter .
If one is interested in estimating only and with , the standard partial likelihood approach can be applied, as in standard applications of Cox models with competing risks (Kalbfleisch & Prentice, 2011, Ch. 8). Estimation of and could be more involved since age of death is left-truncated by the age at disease diagnosis. Under the (unreasonable) assumption that and are conditionally independent given , and can be easily estimated using a standard partial likelihood approach and a Breslow estimator, with the usual risk-set correction for left-truncated data (see Section S8 of Supplementary Material). However, in most applications one cannot observe all the environmental and genetic effects that fully explain the dependence between and , and the above conditional independence assumption is violated. The standard approach yields biased estimators of and , as will be demonstrated in the simulation study (Seciton 4). Instead, we let represent the unobserved residual dependence, and assume that and are independent given . By this, we will be able to circumvent the dependent left-truncation problem. We provide a unified estimation procedure for all the parameters of interest, including the dependence parameter.
As a final step of our new illness-death model presentation, we derive the relationship between and , , for a given frailty distribution with differentiable inverse Laplace transform. Denote by the Laplace transform of , by its th derivative with respect to , by the inverse Laplace transform, by its th derivative, and by the inverse of . Also, let , , and , .
Lemma 1**.**
For , the relationships between and , , are given by
[TABLE]
and
[TABLE]
The proof of Lemma 1 is provided in Section S1 of the Supplementary Material.
Generally, a marginalized proportional-hazards model does not yield a conditional proportional hazards model. Importantly, are of the form
[TABLE]
where can be derived from the LT of the frailty distribution. For example, under the gamma-frailty model with expectation 1 and variance , , and thus
[TABLE]
and
[TABLE]
As will be shown in the following section, the representation provided by Eq. (1) plays an important role in our proposed estimation procedure.
2.2 Estimation Procedure
Suppose there are independent subjects. For the th subject, , denote by the censoring time. Let , , so that equals 1 if the subject was observed to have the disease before being censored or dying. Also let , so that equals 1 if the subject died before having the disease or being censored. Denote by the age at death or age at censoring after having the disease, and , which equals 1 if death after the disease was observed. Then, the observed data consists of , . The unobserved frailties , , are assumed to be independent random variables with cumulative distribution function , unknown parameter and LT such that and exist.
Let and . The regression coefficients will be estimated by maximizing a pseudo likelihood, while the cumulative hazard functions will be estimated with Breslow-type estimators. Since the likelihood contains , and the Breslow-type estimator in turn requires and , a circular dependence is created, which calls for an iterative algorithm. The proposed estimation procedure is an extension of Gorfine et al. (2006) for the standard shared-frailty models of correlated failure times. A discussion that compares the proposed method and that of Gorfine et al. (2006) is provided in Section S2 of the Supplementary Material.
It is assumed that conditional on and , the censoring times are independent of the failure times and non-informative for and all the other parameters in the models. In addition, the frailty variate is assumed to be independent of . Then, the likelihood function is proportional to , where
[TABLE]
, , , and
[TABLE]
A detailed explanation of Eq. (21) is provided in Section S3 of the Supplementary Material. Finally, for a given estimator of , denoted by , the pseudo maximum likelihood estimator of is defined to be the arguments which maximize .
Estimation of will be done by applying the innovation theorem (Aalen, 1978, Theorem 3.4). We start with defining three counting processes. Let be the maximal follow-up time, and for any and define the counting processes
[TABLE]
A key assumption is that given the covariates and the frailty variate, and are independent. Each has intensity process
[TABLE]
where and . The -algebra generated by the observed history up to time , related to , denoted by , is defined by
[TABLE]
The -algebra related to consists of those observations that were diagnosed with the disease, namely, those with and , so it is defined by
[TABLE]
By the innovation theorem, the stochastic intensity process of , , with respect to , is given by
[TABLE]
where
[TABLE]
and . For subjects with and , the stochastic intensity process of , with respect to , is given by
[TABLE]
where
[TABLE]
and .
For example, under the gamma frailty model,
[TABLE]
and for subjects with and ,
[TABLE]
Then, the respective Breslow-type estimators of , , are defined as step functions with jumps at the respective observed failure times. That is,
[TABLE]
with
[TABLE]
and
[TABLE]
where in , , and in , , the unknown parameters are replaced by their estimators. A detailed description of , the estimators of , , is provided in Section S4 of the Supplementary Material.
The proposed estimation procedure is summarized as follows.
Step 1.
Use standard Cox regression software to obtain initial values of , and , by running three separate models, and take to a value near independence.
Step 2.
Use the current values of and estimate , , by Eq. (4)–(6).
Step 3.
Use the current estimate , , and estimate by maximizing .
Step 4.
Iterate between Steps 2 and 3 until convergence is reached.
Let , , , and , where the superscript denotes the respective true value. The following theorem summarizes the asymptotic properties of the proposed estimators. The required technical conditions and a sketch of the proof are provided in Section S5 of the Supplementary Material.
Theorem 1**.**
Under the assumptions listed in Appendix A.2, is a consistent estimator of , , , is asymptotically mean-zero multivariate normal, and , , converges to a Gaussian process.
2.3 Variance Estimation
Deriving the asymptotic or finite-sample variances of the proposed estimators analytically, is challenging, and is not attempted here. Instead, we advocate the use of the weighted bootstrap approach (Kosorok et al., 2004). Within each bootstrap sample, a random weight is assigned to each observation, from a standard exponential distribution. The estimators of each bootstrap sample are then derived based on , where is the weight for subject of the -th bootstrap repetition. Likewise, the -th bootstrap estimation of the baseline hazard function consists of
[TABLE]
and similarly for and . The weighted bootstrap approach is more suitable than regular bootstrap in this case, because in highly censored data, the regular bootstrap could produce samples with a low number of events.
2.4 Computational aspects
We analyze the large-scale UKB dataset. Taking CRC as an example, among the 221,723 men (263,195 women) there were 1,603 (1,189) CRC incident cases, 7,752 (5,015) died during the follow-up time before having CRC, and out of the 2945 (2,186) prevalent and incident CRC observations, 668 (372) died. Thus, 212,368 men and 256,991 women were censored. Our estimation procedure with such a big sample size, is time consuming. Thus, the following is a simple technique for reducing the sample size with only small efficiency loss, in the spirit of the basic ideas used in case-cohort designs (Cai & Zeng, 2004). In particular, the log-likelihood based on (21) can be written as
[TABLE]
where is given in (22). In the CRC UKB data, the last sum consists of more than 200,000 observations, within each sex, while most of the information is provided by the events. Let . Then, for big datasets with high censoring rates, we recommend taking a random sub-sample of size among the censored observations (i.e. those with ), denoted by , and the above log-likelihood function is replaced by
[TABLE]
Similarly, the denominators of the cumulative baseline hazard estimators of , , are replaced by
[TABLE]
There is no change in the estimator of since the sub-sampling step has no effect on the observations involved with this estimator. In summary, the sample consists of all the observations with at least one observed event and a random sub-sample from the censored data, where for each observation of the sub-sample a weight of is assigned; the rest are assigned with a weight of 1. Cai & Zeng (2004) studied the efficiency loss as a function of the failure and sampling rates for a simple case-cohort design. For example, with a failure rate of 0.01 and a sampling rate , the relative efficiency loss is less than 0.05. In the following UKB data analysis, .
3 Methods: right-censored data and delayed entry
3.1 Data and assumptions
In addition to the random variables defined previously, we assume that subject is recruited at age , , , and then followed prospectively until death or censoring, whichever comes first. In the UKB data, and . Thus, the data consist of independent observations, each with . Some participants had the disease before recruitment, namely , and these observations are referred to as prevalent, whereas those who develop the disease after being recruited, , are referred to as incident observations. Such a design, known also as length bias (or left truncation), suffers from sampling bias since only those individuals who live long enough are observed.
As there are no incident cases below the age of , one cannot directly estimate from the data any of the hazard functions below that age. In this work we focus on CRC. Since having CRC before age 40 is very rare (Ouakrim et al., 2015), we assume that the probability of having the disease before age is practically zero. Hence, the estimators of the hazard functions of types are only very slightly biased. Such an assumption should not be adopted for diseases such as breast cancer, where approximately 7% of diagnoses are before the age of 40 years (Anders et al., 2009). Thus, our proposed analysis is not directly applicable for such phenotypes and additional adjustment is required. Likewise, it is impossible to directly estimate the hazard functions of death before having the disease, and , based on the observed data.
For an illness-death model with delayed entry, there are three principal statistical methods for inference (Vakulenko-Lagun & Mandel, 2016, and references therein): (i) an unconditional approach where is considered as a random variable with a known distribution, and its distribution is included in the likelihood function; (ii) a conditional approach where the value of the recruitment age, , is conditioned upon; or (iii) a conditional approach where the entire observed history up to the recruitment age, , is conditioned upon. In practice, multivariate survival data with delayed entry are most often analyzed using approach (iii) (Andersen, 1988; Saarela et al., 2009). In an illness-death model with approach (iii), prevalent individuals are not considered for estimation prior to their entry time, so they only contribute for estimating the parameters related to transition from diseased state to death.
Since we have no knowledge or reasonable assumptions on the recruitment distribution (except for its support), approach (i) is inapplicable. While approach (ii) is more efficient than (iii) since it utilizes more information, it is more challenging computationally, as it requires an additional complicated numerical integration. In this section we propose an estimation procedure adapted for delayed entry, which is based on the procedure of Section 2, and applies approach (iii).
Our proposed estimation procedure for accommodating delayed entry consists of three modifications: (1) adjusting the likelihood; (2) leveraging external information to estimate the baseline hazard function of disease-free death, , at age ; and (3) adjusting the hazard functions estimators, , .
3.2 Adjusted likelihood
The likelihood function based on the observed data given the history up to entry age, , , is given by , where
[TABLE]
and . Also,
[TABLE]
where and . Details on the derivation of the above formulas are provided in Section S6 of the Supplementary Material.
3.3 Estimating for age
Estimation of the hazard functions under delayed entry is usually done in one of two approaches: risk-set correction or inverse probability weighting (IPW). In the risk-set correction approach, prevalent cases cannot contribute to the estimation of , , , , since only observations that satisfy the condition are included in the risk set; but they can nevertheless contribute to the estimation of and . By contrast, with the IPW approach, prevalent cases can contribute more in some settings. However, in our setting this approach is inapplicable. The IPW approach is based on the idea that observations with a small sampling probability are given more weight so as to rectify their under-representation in the data. Since in the UKB data only observations who die after the age of 40 can be included in the first place, those who died before that age have a sampling probability of 0, and the IPW cannot overcome it. Therefore, we use the risk-set correction approach.
We propose to estimate for by leveraging the external information on death rate in the general population, for example from life tables. We assumed that the marginal death distribution in the general population approximates sufficiently the marginal death distribution among individuals free of the disease (a reasonable assumption for diseases that are rare among individuals of age or less), and that there exists a reasonable comparability between the general population and the UKB population. The first step is to use general population data to estimate the marginal hazard for . For our analysis, we have used data published by the UK Office for National Statistics (https://www.ons.gov.uk).
Proceeding further, the marginal survival function of can be expressed as
[TABLE]
and, differentiating with respect to , the marginal density function is seen to be equal to
[TABLE]
Hence, the relationship between and is
[TABLE]
Assuming that in the cohort is representative of its distribution in the population, then, given an estimator for can be defined as
[TABLE]
where is estimated successively from 0 to at pre-specified equally-spaced grid of points of , and . If recruitment starts at age , the estimator of will be based on (9) up to age , and then will continue with the following estimator provided in Section 3.4.
For diseases where the probability of onset before is not negligible, such as breast cancer, a similar approach can be implemented upon the availability of similar disease incidence information in order to estimate and before .
3.4 The adjusted hazard function estimators
For estimating the cumulative hazard functions, the intensity processes above are used while correcting the risk-sets. Specifically, the respective Breslow-type estimators of , , are
[TABLE]
[TABLE]
and for ,
[TABLE]
To summarize, the following are the updated Steps 2 and 3 of the proposed estimation procedure for delayed-entry and right-censored data (Steps 1 and 4 are the same as before):
Step .
Use the current values of and estimate , , by Eq.’s (9) – (12).
Step .
Use the current estimate , , and estimate and by maximizing .
In order to estimate the estimators variance, we suggest using the weighted bootstrap, as described in Section 2.2.
4 Analysis of UKB Colorectal Cancer (CRC) Data
4.1 Data Processing
The failure time related to CRC, defined to be the age at first invasive colorectal cancer diagnosis, and death from colorectal cancer, were according to the ICD10 codes (C180, C182-C189, C19, and C20) or the ICD9 codes (1530–1534, 1536–1541). Cancer of the appendix or non-invasive (in situ) colorectal cancer cases were excluded, as well as cases of carcinoid or related tumors (8240–8249) or lymphomas (9590–9729).
To protect the participants’ anonymity, some information, such as exact birth dates, is suppressed from the dataset. Whenever we could calculate the exact recruitment ages, we did so, typically for observations who were diagnosed with cancer, or that have died. We were able to calculate those ages since exact dates of cancer diagnosis and death are provided in the data, in addition to the exact recruitment dates. Whenever we were unable to procure the exact recruitment ages, we arbitrarily set the birth dates of those observations to the 15-th of the month they were reported to be born in.
4.2 Anaylsis Results
We followed the analysis of Jeon et al. (2018), and generated an environmental risk score (E-score), for lifestyle and environmental risk factors. Specifically, a Cox model with a delayed-entry adjustment was fitted, with the age at diagnosis of CRC as the outcome and the recruitment age was used for the risk-set correction. The following well-known CRC risk factors were included as covariates: sex, height, body mass index, education, smoking status, alcohol consumption, ibuprofen use, drugs use, use of post-menopausal hormones (women only), and physical activity. Prevalent CRC cases were excluded. The results are provided in Table S1 of the Supplementary Material.
The E-score of each participant, is then defined as a linear combination of all risk factors, each one weighted by its estimated regression coefficient. The E-scores were subsequently standardized by performing a quantile transformation based on the E-score empirical cumulative distribution function of the CRC-free observations. The transformed E-scores were then entered into the following illness-death model as a covariate. The bottom of Table S1 provides the means and standard deviations of the transformed E-scores, by CRC status and sex.
Similarly, a genetic risk score (G-score) was derived, based on 72 single-nucleotide polymorphisms (SNPs) that have been identified to be associated with CRC by GWAS (Jeon et al., 2018). Each SNP variable was coded as dosage, which is 0,1, or 2, based on the number of risk allele copies if the SNP is directly genotyped, and expected number of copies if it is imputed. The G-score was developed in a similar manner to the E-score. Specifically, a similar Cox regression model was fitted on the CRC onset age as the outcome, and the 72 SNPs as covariates. The G-score was constructed for each subject as the weighted sum of the 72 SNPs, with the estimated regression coefficients as weights. A quantile transformation was once again used, based on the G-score empirical cumulative distribution function of the CRC-free observations. The transformed G-scores were then entered into our proposed illness-death model as a covariate. A detailed description of the SNPs and the analysis results are provided in Tables S2–S3 of the Supplementary Material.
Women have a much lower risk of CRC. To allow more precise estimates of the baseline hazard functions, our proposed illness-death model with delayed-entry adjusted estimation procedure was applied separately to men and women. The regression coefficient vectors and included G-score and E-score, while included just the G-score. The E-score is not included in the transition model since this part of the model was estimated using both prevalent and incident data, and environmental data on the prevalent cases were expected to be subject to substantial recall bias. We compared our method with the following Cox models (in which the disease onset age was, in the spirit of Shen, 2017, included in the model for the transition ):
- Cox I:
Three separate Cox models were fitted. In particular, and are estimated based on CRC age at diagnosis as the outcome, age at recruitment is used for risk-set correction, and other events are treated as independent censoring; and are estimated based on age at death before CRC as the outcome, age at recruitment is used for risk-set correction, other events are treated as independent censoring; and are estimated based on age at death after CRC as the outcome, and age at CRC diagnosis and age at recruitment are used for risk-set correction. See Section S8 of the Supplementary Material, for the partial likelihoods.
- Cox II:
are estimated as in Cox I. In the standardized age at diagnosis is added as a time-independent covariate, for dealing with the fact that is a dependent left-truncation time (Shen, 2017).
- Cox III:
are estimated as in Cox I. The effect of age of CRC diagnosis is included using a linear truncated spline with three knots, at the 25%, 50%, and 75%.
The results are presented in Table 1 and Figure 2. As expected, the Cox and the proposed estimators of , are similar. Under Cox, the baseline hazard function equals 0 for , thus the Cox estimator of is smaller than the proposed estimator. There are substantial differences among the estimators of , with extreme results under Cox with linear truncated spline. The G-score and E-score coefficients are both significantly greater than zero for the healthy-diseased process. Additionally, it turns out that the G-score for CRC does not bear a significant effect on the healthy-death process, but the corresponding E-score does. This result seems plausible because many CRC-related risk factors such as smoking status and alcohol consumption, are known to be related to death in general, and not only to CRC. Also, it is well-known that women have lower risk for CRC, which might explain why the regression coefficient of the E-score for women in the healthy-diseased model is much smaller than that of men.
Under the Cox models, the effect of the G-score of the diseased-dead process is null for men, and negative for women. Namely, among the women, based on the Cox analysis, the G-score increases CRC risk, but decreases mortality after having the disease. This result is counter intuitive. In contrast, our proposed analysis suggests that the G-score also tends to increase the risk of death after having the disease. The dependence parameter among the event times is approximately 2 (corresponding to a Kendall tau value of approximately 0.5), in both men and women. The large standard error of among men (0.480) was driven by few outliers in the bootstrap sample, while the median absolute deviation was 0.204. As a result we can deduce that there is a non-negligible dependence between the processes which was not accounted for through the covariates. Moreover, under the Cox model, the assumption of independent left-truncated time for is most likely violated and thus yields biased estimates.
5 Simulation Study
5.1 Data Generation
An extensive simulation study was performed to demonstrate the finite-sample properties of the proposed estimation procedures, with and without delayed entry.
We assumed a gamma frailty model with expectation 1 and variance , and a covariate vector , each covariate generated independently from , and . Given a sample of frailty values and covariate vectors, the failure times and were generated based on the conditional models , . The marginalized baseline hazard functions were set to be
[TABLE]
The regression coefficients were chosen to be and . Three levels of dependence were studied, or 2, corresponding to Kendall tau values of approximately 0, 0.35 and 0.5, respectively. The motivation behind the independence configuration, , is for exploring whether using our procedure results in a substantial efficiency loss compared to the standard partial likelihood approach corrected for delayed entry.
Using the values of , and were generated by solving for the equation , where is a value generated from . For individuals that were diagnosed with the disease, the original values were discarded, and given , and , a new value was sampled from the respective truncated distribution, by solving for the equation Without delayed entry, all observations were followed since time 0. Under delayed entry settings, recruitment ages were randomly generated from . For each sample, a large dataset consisting of was first generated, and from those who were still alive at their recruitment age , observations were randomly sampled. Next, for each observation an independent censoring time was generated from an exponential distribution with a rate parameter of 2. In addition, an administrative censoring was imposed at time 0.61. For about 25% of observations are censored before disease onset or death, and among those who were diseased, about 65% are censored before death. For the corresponding numbers are about and .
5.2 Simulation Results
The following results are based on 100 repetitions for each configuration, and a sample size of 5000 individuals. The pseudo-likelihood function was maximized with the L-BFGS-B algorithm, as implemented in the optim function in R. Convergence of the algorithm was reached once the relative change in the pseudo-log-likelihood between two consecutive iterations went below 0.0001.
Under the cohort setting with no delayed entry (see Tables S4–S5 of the Supplementary Material), the proposed and the conventional Cox model yielded unbiased estimators for the parameters of and ; however, the conventional Cox model analysis yields biased parameter estimates in , whereas the proposed estimator is unbiased. For example, with , the corresponding estimates of by Cox and the proposed approach are 0.628 (SE=0.172) and 1.037 (SE=0.181). Also, the true values of at , are 0.08, 0.28 and 0.48, while the corresponding estimates of Cox are 0.056, 0.164 and 0.257 (SEs are 0.010, 0.026 and 0.039). The respective numbers based on the proposed approach are 0.080, 0.280 and 0.484 (SEs are 0.013, 0.042 and 0.072). Evidently, the proposed approach performs well in terms of bias, and under the efficiency loss is minimal, if any. These results highlight the importance of the independent assumption of left truncation, which is violated in the conventional Cox analysis.
Tables 2–3 summarize the empirical means and standard deviations of , the regression coefficients, and the baseline hazard functions at certain time points, under delayed entry. We contrast between Cox with delayed-entry adjustment by the risk-set approach, when relevant (see Section S8 of the Supplementary Material for more details) and the proposed methods. Biased results are displayed in bold.
Table 2 presents the biased Cox-model estimator of under . The estimator of is practically unbiased as its corresponding covariate is independent of all the other covariates in the model, while the corresponding covariate of is also affecting the disease age at onset. Table 3 presents the biased Cox-model results of under any value of , due to also ignoring the fact that no death can be observed before . Cox estimators of and are unbiased, as expected. In contrast, our proposed estimators perform well in terms of bias and coverage rates. In addition, we observe that applying our method under the independence scenario does not result in any substantial efficiency loss.
6 Discussion
We proposed a novel semi-parametric, shared-frailty based method for analysing time-to-event data, within the illness-death model framework. Our model accounts for delayed entry and possible dependence between the stochastic processes, and allows for covariates inclusion. The simulation study shows that the procedure works well in terms of bias and variance, and does not suffer from a substantial efficiency loss under the independence scenario.
An alternative estimation procedure, when there is no delayed entry, could be to estimate by a standard partial likelihood approach, estimating based on Eq. (6), and then plugging these estimates in the likelihood, Eq. (21), for estimating , which is a different pseudo likelihood approach. An iterative procedure is still required, between the estimates of and that of . Such a procedure might save some computation time but at the price of some efficiency loss. Under delayed entry, the estimator of would require a correction in the spirit of Section 3.2. In a future work, one can compare this approach with our proposed method. Consistency and asymptotic normality should be worked out from scratch.
There are a number of directions that this work can be further expanded to. The first direction is to try and develop a method that uses the prevalent cases for estimating and as well. In addition, instead of using the same frailty effect for all the three processes, a more flexible dependence structure can be considered.
1 Proof of Lemma 1
The following is the proof of Lemma 1. Let , . Then, for , the relationship between and , can be derived as follows. Denote by the event of transition from state to state . Then, for ,
[TABLE]
where , is the Laplace transform of , and is the th derivative with respect to . In addition,
[TABLE]
At the same time,
[TABLE]
where and . Then, based on the ratio of (13) and (14) we get the following equations,
[TABLE]
and
[TABLE]
From Eq.s (14) and (15) we get and
[TABLE]
where is the inverse Laplace transform, and . Also, taking the ratio of (16) and (17),
[TABLE]
Then, letting , and the above yields
[TABLE]
and
[TABLE]
Finally,
[TABLE]
and similarly,
[TABLE]
Now, for , the hazard of transition from disease to death is derived by
[TABLE]
and
[TABLE]
Then,
[TABLE]
where . Therefore,
[TABLE]
where is the inverse of , leading to
[TABLE]
Finally,
[TABLE]
2 A short comparison with Gorfine et al. (2006)
Our proposed estimation procedure for the setting of no delayed entry is an extension of Gorfine et al. (2006). It is useful to clarify the similarity and differences between Gorfine et al. (2006) and our current work:
- •
Gorfine et al. (2006) considered the standard shared-frailty model of clustered data (e.g. family data) in which the conditional hazard functions given are defined by Cox models times the frailty , with unspecified baseline hazards. In contrast, here we focus on the marginal hazard functions integrating over , and the conditional hazard functions, given , are dictated by the Cox models imposed on the marginal hazards and the frailty distribution.
- •
Gorfine et al. (2006) considered the standard shared-frailty model of clustered data (e.g. family data), in contrast to the illness-death model considered here. Thus, in the setting of Gorfine et al. the number of events within a cluster could be as large as the cluster size. In the current setting, the number of events within a cluster is at most two.
- •
Under the shared-frailty setting of Gorfine et al. (2006), the estimation procedure uses one algebra for the stochastic intensity processes. In our case, since death after having the disease can occur only after having the disease, two algebras are required.
3 Details of the likelihood function
It is assumed that conditional on and , the censoring times are independent of the failure times and non-informative for and all the other parameters in the models. In addition, the frailty variate is assumed to be independent of . Then, the likelihood function is proportional to , where
[TABLE]
, and
[TABLE]
The above likelihood consists of the fact that is defined on the restricted support , so the respective density function is a truncated density at .
4 Details of under gamma frailty
The estimators of , , under the gamma frailty settings, are derived in the following manner:
[TABLE]
where is the ordinal number of the largest observed failure time of the joined times and , which is still smaller than , and is the ’th ordered observed time of the joined times. Now, the function is constant between every pair of consecutive observed failure times, and the function is estimated by the slope of the line connecting two adjacent values of . As a result, the entire integrand within each interval is constant, so is practically calculated as a sum of constants, each multiplied by its respective interval length.
is estimated in a similar fashion, but only times are taken into account for the partitioning.
It should be noted that is estimable just up to the last observed failure time of type , denoted by , so that is estimated at time .
5 Assumptions and main steps of the proof of Theorem 1
The following are the required assumptions for Theorem 1.
The vectors , , are independent and identically distributed. 2. 2.
Given the time-independent vector of covariates and the frailty variate , the censoring is independent and non-informative of , and . In addition, is independent of . 3. 3.
There exists a finite maximum follow-up time such that for all and . 4. 4.
The covariates’ vector is bounded. 5. 5.
The parameter lies in a compact subset containing an open neighborhood of . 6. 6.
The baseline hazard functions , , are bounded over by some fixed constant. 7. 7.
The derivative of the frailty density function, with respect to the frailty parameter, is absolutely integrable. 8. 8.
For each subject, there is a positive probability of having the disease before death. 9. 9.
Let be the derivative of with respect to . The matrix is invertible with probability going to 1 and goes to infinity.
Our proposed estimation procedure for the setting of no ascertainment is an extension of Gorfine et al. (2006). The asymptotic theory of the estimators of Gorfine et al. (2006) is provided in details by Zucker et al. (2008). Hence the proof of Theorem 1 is based on Zucker et al. (2008).
To emphasize that the hazards’ estimators are functions of , we write also as , , when needed. Almost sure consistency of and , , is based on the following results and the consistency theorem of Foutz (1977):
- (i)
For , converge almost surely to some functions , uniformly in and .
- (ii)
The estimating function converges uniformly in to , where .
For the asymptotic normality of , write
[TABLE]
and study the right-side of (23). Specifically, can be written as a sum of independent identically distributed random vectors with mean zero. Then, the central limit theorem yields is asymptotically mean-zero multivariate normal.
The mean-zero asymptotic normality of is based on some algebra and the following steps:
- (1)
A Taylor expansion of about .
- (2)
Approximating , , by a martingale representation (See Eq. (26) of Zucker et al. (2008) and the relevant previous derivations for details).
- (3)
Plugging the martingale representation of (2) into the expansion of (1).
Taking the first order Taylor expansion of about gives
[TABLE]
where is the derivative of with respect to .
Combining the above, we conclude that is asymptotically zero-mean normally distributed. The asymptotic distributions of , , are based on writing
[TABLE]
The weak converges and tightness of is derived from the martingale representation mention in (2) above. Also, by a Taylor expansion we get
[TABLE]
where the limiting function of is Lipschitz in . Also, both terms of the right-hand side of Eq. (24) can be written as sums of independent and identically distributed random variables. Thus, by the central limit theorem we get asymptotic normality and tightness, and thus we conclude that , , converge to Gaussian processes.
6 The likelihood adjusted to delayed entry
The likelihood function based on the observed data given the history up to truncation times , is given by , where
[TABLE]
where and . Also,
[TABLE]
where and .
7 Additional simulation results - no delayed entry
Tables S7–S8 summarize the empirical means and standard deviations of , the regression coefficients, and the baseline hazard functions at certain time points, for the simple cohort setting in which observations are followed since birth (i.e. no delayed entry). To save computation time, estimated standard error and empirical coverage rates are not included in the setting of no delayed entry, but included in the setting with delayed entry, presented in the main text.
8 Illness-death model while and are independent given
The partial likelihoods for estimating , and while conditioning on the entire observed history up to the recruitment age are given by
[TABLE]
[TABLE]
and
[TABLE]
References
- Aalen (1978)
Aalen, O. (1978).
Nonparametric inference for a family of counting processes.
The Annals of Statistics , 701–726.
- Anders et al. (2009)
Anders, C. K., Johnson, R., Litton, J., Phillips, M. & Bleyer, A. (2009).
Breast cancer before age 40 years.
In Seminars in Oncology, vol. 36. Elsevier.
- Andersen (1988)
Andersen, P. K. (1988).
Multistate models in survival analysis: a study of nephropathy and mortality in diabetes.
Statistics in Medicine 7, 661–670.
- Andersen & Klein (2007)
Andersen, P. K. & Klein, J. P. (2007).
Regression analysis for multistate models based on a pseudo-value approach, with applications to bone marrow transplantation studies.
Scandinavian Journal of Statistics 34, 3–16.
- Cai & Zeng (2004)
Cai, J. & Zeng, D. (2004).
Sample size/power calculation for case–cohort studies.
Biometrics 60, 1015–1024.
- Chen (2012)
Chen, Y.-H. (2012).
Maximum likelihood analysis of semicompeting risks data with semiparametric regression models.
Lifetime Data Analysis 18, 36–57.
- Fine et al. (2001)
Fine, J. P., Jiang, H. & Chappell, R. (2001).
On semi-competing risks data.
Biometrika 88, 907–919.
- Foutz (1977)
Foutz, R. V. (1977).
On the unique consistent solution to the likelihood equations.
Journal of the American Statistical Association 72, 147–148.
- Glidden & Self (1999)
Glidden, D. V. & Self, S. (1999).
Semiparametric likelihood estimation in the clayton–oakes failure time model.
Scandinavian Journal of Statistics 26, 363–372.
- Gorfine et al. (2006)
Gorfine, M., Zucker, D. M. & Hsu, L. (2006).
Prospective survival analysis with a general semiparametric shared frailty model: A pseudo full likelihood approach.
Biometrika 93, 735–741.
- Jeon et al. (2018)
Jeon, J., Du, M., Schoen, R. E., Hoffmeister, M., Newcomb, P. A., Berndt, S. I., Caan, B., Campbell, P. T., Chan, A. T., Chang-Claude, J. et al. (2018).
Determining risk of colorectal cancer and starting age of screening based on lifestyle, environmental, and genetic factors.
Gastroenterology 154, 2152–2164.
- Kalbfleisch & Prentice (2011)
Kalbfleisch, J. D. & Prentice, R. L. (2011).
The statistical analysis of failure time data, vol. 2nd Ed.
John Wiley & Sons.
- Kosorok et al. (2004)
Kosorok, M. R., Lee, B. L., Fine, J. P. et al. (2004).
Robust inference for univariate proportional hazards frailty regression models.
The Annals of Statistics 32, 1448–1491.
- Mackenzie (2012)
Mackenzie, T. (2012).
Survival curve estimation with dependent left truncated data using cox’s model.
The International Journal of Biostatistics 8.
- Ouakrim et al. (2015)
Ouakrim, D. A., Pizot, C., Boniol, M., Malvezzi, M., Boniol, M., Negri, E., Bota, M., Jenkins, M. A., Bleiberg, H. & Autier, P. (2015).
Trends in colorectal cancer mortality in europe: retrospective analysis of the who mortality database.
BMJ 351, h4970.
- Saarela et al. (2009)
Saarela, O., Kulathinal, S. & Karvanen, J. (2009).
Joint analysis of prevalence and incidence data using conditional likelihood.
Biostatistics 10, 575–587.
- Shen (2017)
Shen, P.-S. (2017).
Semiparametric analysis of transformation models with dependently left-truncated and right-censored data.
Communications in Statistics – Simulation and Computation 46, 2474–2487.
- Vakulenko-Lagun & Mandel (2016)
Vakulenko-Lagun, B. & Mandel, M. (2016).
Comparing estimation approaches for the illness–death model under left truncation and right censoring.
Statistics in Medicine 35, 1533–1548.
- Vakulenko-Lagun et al. (2017)
Vakulenko-Lagun, B., Mandel, M. & Goldberg, Y. (2017).
Nonparametric estimation in the illness-death model using prevalent data.
Lifetime Data Analysis 23, 25–56.
- Xu et al. (2010)
Xu, J., Kalbfleisch, J. D. & Tai, B. (2010).
Statistical analysis of illness–death processes and semicompeting risks data.
Biometrics 66, 716–725.
- Zhou et al. (2016)
Zhou, R., Zhu, H., Bondy, M. & Ning, J. (2016).
Semiparametric model for semi-competing risks data with application to breast cancer study.
Lifetime Data Analysis 22, 456–471.
- Zucker et al. (2008)
Zucker, D. M., Gorfine, M. & Hsu, L. (2008).
Pseudo-full likelihood estimation for prospective survival analysis with a general semiparametric shared frailty model: Asymptotic theory.
Journal of Statistical Planning and Inference 138, 1998–2016.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Aalen (1978) Aalen, O. (1978). Nonparametric inference for a family of counting processes. The Annals of Statistics , 701–726.
- 2Anders et al. (2009) Anders, C. K. , Johnson, R. , Litton, J. , Phillips, M. & Bleyer, A. (2009). Breast cancer before age 40 years. In Seminars in Oncology , vol. 36. Elsevier.
- 3Andersen (1988) Andersen, P. K. (1988). Multistate models in survival analysis: a study of nephropathy and mortality in diabetes. Statistics in Medicine 7 , 661–670.
- 4Andersen & Klein (2007) Andersen, P. K. & Klein, J. P. (2007). Regression analysis for multistate models based on a pseudo-value approach, with applications to bone marrow transplantation studies. Scandinavian Journal of Statistics 34 , 3–16.
- 5Cai & Zeng (2004) Cai, J. & Zeng, D. (2004). Sample size/power calculation for case–cohort studies. Biometrics 60 , 1015–1024.
- 6Chen (2012) Chen, Y.-H. (2012). Maximum likelihood analysis of semicompeting risks data with semiparametric regression models. Lifetime Data Analysis 18 , 36–57.
- 7Fine et al. (2001) Fine, J. P. , Jiang, H. & Chappell, R. (2001). On semi-competing risks data. Biometrika 88 , 907–919.
- 8Foutz (1977) Foutz, R. V. (1977). On the unique consistent solution to the likelihood equations. Journal of the American Statistical Association 72 , 147–148.