Correlation bounds, mixing and m-dependence under random time-varying network distances with an application to Cox-Processes
Alexander Kreiss

TL;DR
This paper develops new correlation and mixing bounds for stochastic processes on dynamic networks, and applies these results to analyze a Cox-process model for bike-sharing data, demonstrating asymptotic properties of a goodness-of-fit test.
Contribution
It introduces novel correlation and mixing bounds for processes on time-varying networks and applies them to Cox-process models, advancing understanding of dependence in dynamic network data.
Findings
Established exponential inequalities for weak dependence on dynamic networks.
Proved asymptotic properties of a goodness-of-fit test in Cox-process models.
Applied the theoretical results to real bike-sharing data.
Abstract
We will consider multivariate stochastic processes indexed either by vertices or pairs of vertices of a dynamic network. Under a dynamic network we understand a network with a fixed vertex set and an edge set which changes randomly over time. We will assume that the spatial dependence-structure of the processes conditional on the network behaves in the following way: Close vertices (or pairs of vertices) are dependent, while we assume that the dependence decreases conditionally on that the distance in the network increases. We make this intuition mathematically precise by considering three concepts based on correlation, beta-mixing with time-varying beta-coefficients and conditional independence. These concepts allow proving weak-dependence results, e.g. an exponential inequality, which might be of independent interest. In order to demonstrate the use of these concepts in an application…
Click any figure to enlarge with its caption.
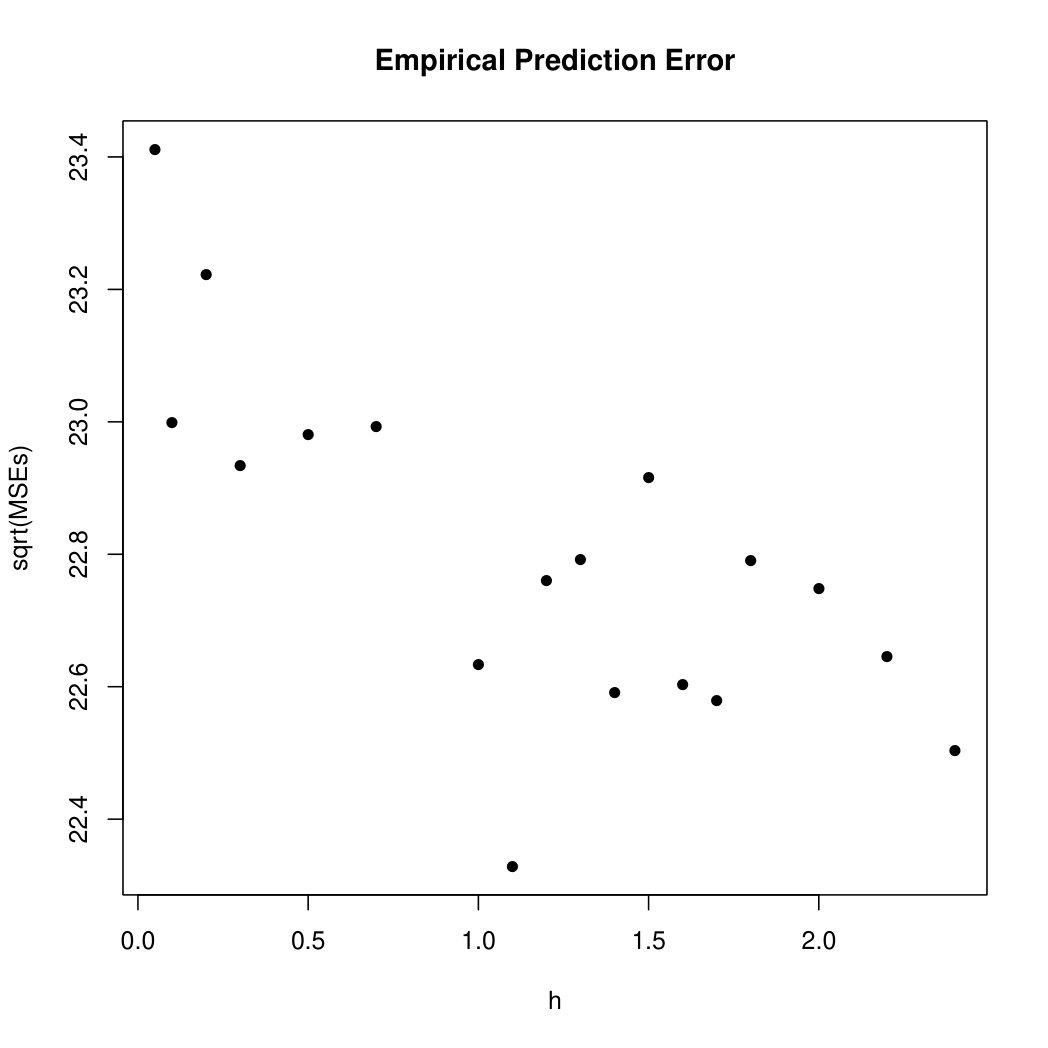 Figure 1
Figure 1 Figure 2
Figure 2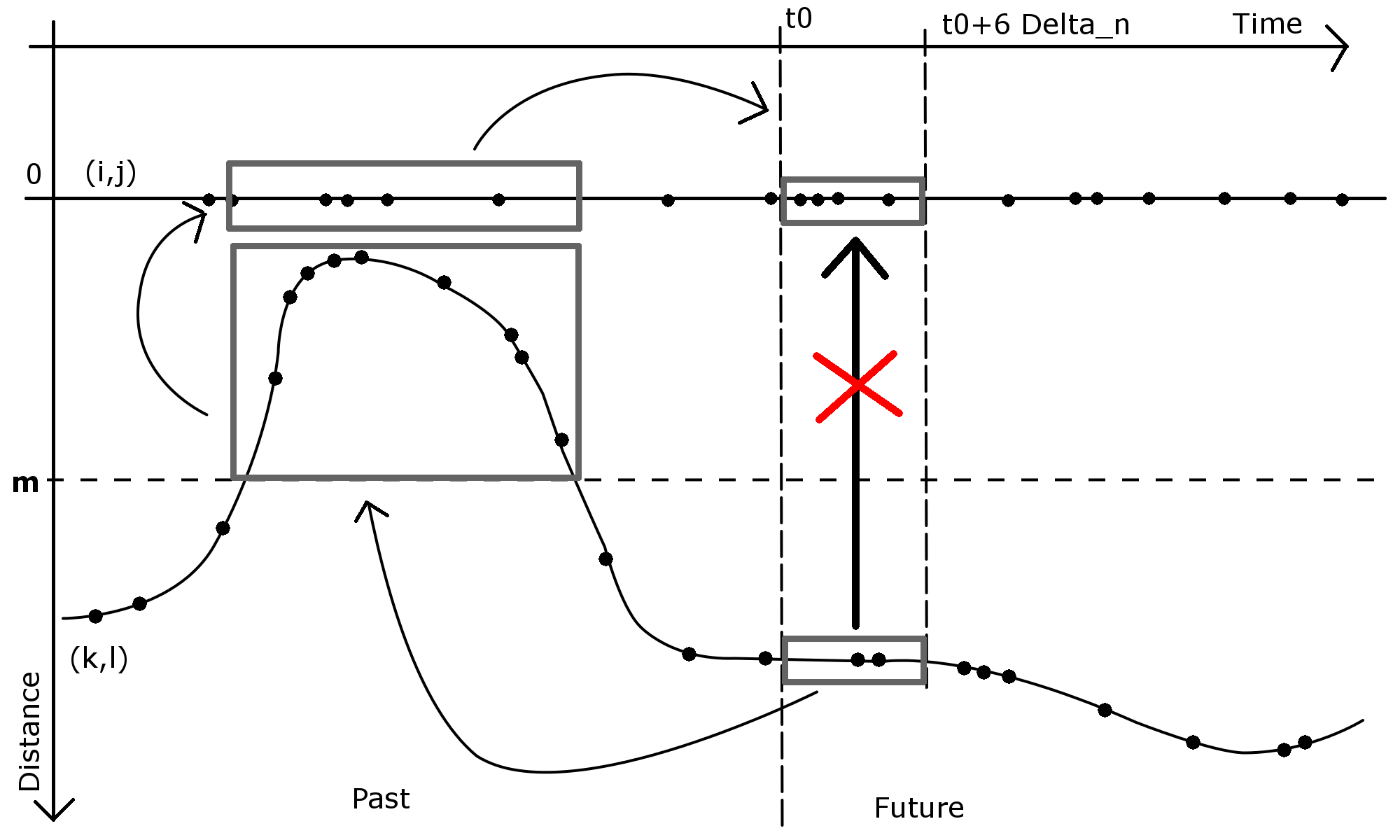 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStatistical Methods and Inference · Complex Network Analysis Techniques · Stochastic processes and statistical mechanics
Correlation bounds, mixing and -dependence under random time-varying network distances with an application to Cox-Processes
Alexander Kreiß
KU Leuven
ORSTAT KU Leuven
Naamsestraat 69
3000 Leuven
Belgium
We will consider multivariate stochastic processes indexed either by vertices or pairs of vertices of a dynamic network. Under a dynamic network we understand a network with a fixed vertex set and an edge set which changes randomly over time. We will assume that the spatial dependence-structure of the processes conditional on the network behaves in the following way: Close vertices (or pairs of vertices) are dependent, while we assume that the dependence decreases conditionally on that the distance in the network increases. We make this intuition mathematically precise by considering three concepts based on correlation, -mixing with time-varying -coefficients and conditional independence. These concepts allow proving weak-dependence results, e.g. an exponential inequality, which might be of independent interest. In order to demonstrate the use of these concepts in an application we study the asymptotics (for growing networks) of a goodness of fit test in a dynamic interaction network model based on a Cox-type model for counting processes. This model is then applied to bike-sharing data.
1 Introduction
Data indexed by vertices or pairs of vertices of networks has become popular in recent times (see e.g. Brownlees et al. [4], Demirer et al. [13], Butts [5] for recent applications) when also the availability of such data sets increases, see e.g. websites of SNAP (Stanford University) or KONECT (University of Koblenz-Landau). In order to illustrate the contribution of this paper, we consider the following example of network data: Suppose we observe on the interval a network with vertex set and random, dynamic adjacency matrix , i.e., for all we have a stochastic process , where means that and are connected by an edge at time . We consider the vertices to be actors who can interact with each other whenever they are connected by an edge. As an example, the actors could be users of a social media platform and an interaction is sending a private message. Then, we observe for all pairs a counting process which counts the interactions between and and a multivariate process which carries information about and , e.g. the number of interactions in the past or information about mutually shared interests. In this situation it is intuitive that the tuples cannot be modelled as independent. Instead, we adopt the following heuristic: For any two pairs and time points , we suppose that on a small neighbourhood around the dependence is influenced by the closeness of and where closeness is to be understood relative to the random adjacency matrix (we will be more precise later):
The processes and restricted to are dependent conditional on and being close at time in . 2. 2.
The processes and restricted to are almost independent conditional on and being far apart in .
Note that we implicitly allow that the dependence structure may randomly change over time by allowing that the adjacency matrix is a random function of time. In order to use this intuition we will have to assume that in large networks a given pair is at a given time most likely not close to too many other pairs.
The main contribution of this work is to make the above heuristic precise. We do this by formalizing time-varying spatial dependence concepts for multivariate processes indexed by pairs of vertices in a network. More precisely, we extend the concept of asymptotic uncorrelation which was used in the previous work Kreiß et al. [28] to momentary--dependence and -mixing on networks. In contrast to asymptotic uncorrelation the two new concepts take the random network structure into account. Thus, time-varying -Mixing coefficients will allow us to prove exponential inequalities. Moreover, by using Momentary--Dependence we can adapt a technique from Mammen and Nielsen [32] to networks in order to handle predictability problems related to counting processes which were also noted e.g. in Nielsen et al. [37]. In order to illustrate the necessity of these concepts in a specific situation we study a goodness of fit test in a counting process based network model. In the derivation of the asymptotic distribution of the test statistic under the null we require uniform control of the whole estimated parameter function. This cannot be handled by simple second order conditions (e.g. asymptotic uncorrelation as in Kreiß et al. [28]). However, more generally, these concepts can be used to provide interpretable conditions to transfer inference results for multivariate counting processes from the iid case (cf. Andersen and Gill [2]) to the case of random network data. Thus, Section 2 is of independent interest for the literature on multivariate (counting) processes on networks (see e.g. Butts [5], Perry and Wolfe [41], Fox et al. [15], Vu et al. [49] for such models).
For an overview of statistical methods in network analysis we refer to the books Kolaczyk [26], Jackson [23] and Newman [35]. The general situation that the relational structure of network data is different from other dependent-data scenarios like time-series and spatial data analysis is for example mentioned in the beginning of Chapter 2 in Kolaczyk [27]. Classical results about dependent processes can e.g. be found in the books Doukhan [14] and Rio [43]. Some models which are used in the context of mixing, particularly in econometrics, are mentioned in Nze and Doukhan [38]. Further asymptotic normality results based on local dependence can be found in Chen and Shao [6] for random fields and in Schweinberger and Handcock [44], Kojevnikov et al. [25] for random, non-dynamic networks. Other approaches for modelling dependence in random networks are for example the extension of the concept of stationarity to random (but not time-changing) networks as in Vainora [46] or Bayesian networks (cf. Pearl [40] and Friedman et al. [16] for an extension to time series and Grzegorczyk et al. [19] for an application). In the application we will study a Cox-type proportional hazard model (cf. Andersen et al. [3], Martinussen and Scheike [33], Cox [8], Andersen and Gill [1]). Generalisations and variations of such models have been studied outside a network context e.g. in Nielsen et al. [37], Nielsen and Linton [36], Linton et al. [31, 30]. For network interactions, parameter estimation in models of this type has been considered e.g. in Butts [5] and Perry and Wolfe [41]. The goodness of fit test which we will consider is based on an -type test statistic as in Härdle and Mammen [21]. Particular references for smooth testing in survival analysis are Müller and Van Keilegom [34] (use the same type of test statistic) and Kauermann and Berger [24] (use a local likelihood approach), however, not within a network context.
After collecting some notation and briefly reviewing asymptotic uncorrelation in Sections 2.1 and 2.2, we introduce in the main part of Section 2 the concepts of momentary--dependence (Section 2.3) and -mixing on networks (Section 2.4). In the end of Section 2, in Section 2.5, we provide examples of data generating processes and motivate why they exhibit these properties. In Section 3 we apply the methods established in Section 2 to a goodness of fit test problem. The whole procedure is then illustrated on bike sharing data in Section 4. In the Appendix (Section 5) we collect missing proofs from the main part of the paper as well as some additional technical results. R-code which is used for the bike-data illustration is available on https://github.com/akreiss/Estimate-Event-Network.
2 Describing Dependence on Dynamic Networks
In this section we introduce the dependence concepts. For ease of exposition we stick to a model for relational event data which was also used e.g. in Butts [5], Perry and Wolfe [41], Kreiß et al. [28]. In Section 2.1 we will briefly review the basics of this framework and in Sections 2.2-2.4 we introduce the dependence concepts. Section 2.5 provides examples. We finish in Section 2.6 with a short note on processes indexed by vertices.
2.1 Preliminaries and Notation
We use the following notation from graph theory. We consider directed (undirected), dynamic, random networks for and which are comprised of a fixed vertex set and a random dynamic edge set , where is the set of all directed (undirected) pairs (we exclude loops). The adjacency matrix of at time is denoted by . Furthermore we denote by the number of directed (undirected) pairs of vertices.
We study stochastic processes with the following properties.
**Measurability
For all there is a filtration such that for all the processes are counting processes which are adapted to and such that for all the processes and are predictable with respect to . Moreover, the intensity function of is given by for some link function .**
Remark 2.1**.**
We choose here to index the processes with pairs of vertices. Similarly one could also index the processes with the vertices directly (cf. Section 2.6). We choose pairs here because we imagine observations to be driven by the interplay of two actors. 2. 2.
The processes are indicators which indicate whether the pair is currently active at time () or not (). Our understanding is that, for a given , the process is only interesting (i.e. useful for inference) on the set . 3. 3.
We are not too much concerned about the existence of a filtration as required in the above definition. One possibility would be to assume that and are continuous from the left and let be the filtration generated by the processes for all .
It is intuitively reasonable to assume that relabelling the vertices is not going to change the distribution of the processes. Hence, we will assume that
[TABLE]
holds for all permutations and all . This property is also called joint exchangeability of arrays (cf. Orbanz and Roy [39]). Note that for any two different pairs we can construct a permutation with and (recall that we consider networks without loops). Hence, and are identically distributed. This notion allows for the concept of hubs but every vertex has a priory the same potential of becoming a hub. Moreover, we assume that all possible interactions between vertices are observed. Therefore we do not have to worry about edge sampling issues as mentioned in Crane and Dempsey [10]. Note lastly that the permutations from above are deterministic and thus in particular they may not be chosen dependent on the actual observed network structure. This will be similar in Section 2.2 when discussing asymptotic uncorrelation. Thus, these two properties do not take the actually observed network into account. However, in Sections 2.3 and 2.4, when introducing Momentary--Dependence and -Mixing we condition on the observed network. Thus, in these concepts we consider the observations after making choices which are strongly dependent on the observed network.
One way of taking the network structure into account is through random distance functions on networks. A random distance function on networks is a collection of stochastic processes such that for any and , is almost surely a metric. For later reference we collect all the above in a single definition.
Definition 2.2**.**
The processes on together with the random distance function on networks is called structured interaction network process if for all
the above mentioned measurability properties hold, 2. 2.
the network process is exchangeable, i.e., (2.1) holds for all permutations , 3. 3.
* is predictable with respect to for all .*
In this case is well defined.
Remark 2.3**.**
- •
Later the interpretation of will be as follows: The distance reflects how strongly the pairs and are related conditionally on the observed network (short distance means strong relation, large distance means weak relation).
- •
From a modelling perspective, we emphasize that the distance function does not need to be known to the researcher. It is only necessary that it exists.
- •
In order to allow sparsity we explicitly allow that for .
2.2 Asymptotic Uncorrelation
We briefly review a stationarity type result which was similarly used for static networks in Vainora [46] and for dynamic networks in Kreiß et al. [28]. In this subsection we restrict to undirected networks (see also the paragraph below Corollary 2.4). Consider square integrable random variables with the following property: The are identically distributed. For let denote the number of common vertices of and . For the pairs and are identically distributed if .
We will later consider where takes real values and . The exchangeability assumption in Definition 2.2 guarantees the above property which in turn yields the following corollary:
Corollary 2.4**.**
For all , let be as above. Recall that is the number of undirected pairs. Then, for pairwise different vertices ,
[TABLE]
For the proof of this corollary we just need to think about the number of terms in each sum. It is a combinatorial exercise to find that their sizes are of the order and respectively. In order to have we hence require that and . We will call assumptions of this type asymptotic uncorrelation assumptions. This result naturally extends to directed networks by splitting the sum in all possible patterns which two directed pairs can have.
2.3 Momentarily m-Dependent Networks
We introduce momentary--dependence for processes . The aim is to mathematically formulate and use the following intuition: The processes and are dependent for any fixed choice of and . However, if we choose and such that they are far apart in the observed network (in terms of for some time ), then for real world actors it is likely that it takes some time for the pair to receive knowledge of interactions between and to process them before reacting by casting interactions themselves. Therefore, we assume: Provided that we know the network structure at time and that we know the past of all processes up to time and provided that we know that for two pairs the distance is large, then the processes and are conditionally independent given all information up to time for some (the factor six is chosen for later convenience). We illustrate this in Figure 1: The horizontal axis is time and the vertical axis is distance. The two lines correspond to two pairs and and the vertical distance between these two lines represents the distance between the pairs and . Dots on the lines indicate events between the respective vertices. The two gray rectangles in the future (next to the line at ) stand for the information of the processes of on the interval and the processes of on the interval . We suppose that these two are conditionally independent given the information up to time . So there is no direct information flow between these two areas. However, they are not unconditionally independent because we can infer from the gray rectangle in the future of on its past when and were possibly close, such that we can infer on the past of which is informative about its future. But if we already know the past, then additional knowledge of the future of is independent of the future of .
In mathematical terms this can be described as follows. For a set of pairs, let be the distance of to at time .
Definition 2.5**.**
A structured interaction network process with filtration and distance is said to be momentarily--dependent for , if
[TABLE]
In order to work with momentary--dependent networks, we introduce two augmentations of the filtration . Generally, when extending filtrations, we have more predictable processes and fewer martingales. In the following definition we introduce two extensions of , one of which is the exact right trade-off: Certain processes become predictable with respect to the extension while certain other processes remain martingales (see Lemma 2.7).
For two -fields and we denote by the -field which is generated by the union of and .
Definition 2.6**.**
Let be a structured interaction network with filtration and distance . For a subset define
[TABLE]
We call the long-sighted leave--out filtration. In contrast, the short-sighted leave--out filtration for is defined by
[TABLE]
Denote further for any pair , . Functions which are predictable with respect to will be called of leave--out type.
It holds that . We can now make the earlier mentioned property of the long-sighted leave--out filtration precise: The counting processes stay counting processes and in particular their martingales are still martingales. The proof of the result is a direct consequence of the definition and can be found in Appendix 5.5.
Lemma 2.7**.**
We consider a structured momentarily--dependent interaction network. For , the processes form a multivariate counting process with respective intensity functions with respect to . This means in particular that the counting process martingales remain martingales with respect to .
Remark 2.8**.**
Throughout we will use the notion of Stieltjes and Itô Integration interchangeably when possible. In particular, when is predictable, we will understand as an Itô Integral and use its martingale properties (since is a martingale). If is not predictable we can understand the same integral as Stieltjes Integral which is defined path-wise (no predictability required) but is itself no martingale (in contrast to the Itô Integral).
We can use momentary--dependence in order to extend a technique which Mammen and Nielsen [32] applied to iid observations in a non-network context: Approximate non-predictable integrands by processes which are predictable with respect to a larger filtration. The proof of the following result is along the lines of Mammen and Nielsen [32] and is given in Appendix 5.5.
Proposition 2.9**.**
Let be momentarily--dependent and let for be random functions (not necessarily predictable). Let furthermore for and be of leave--out type, i.e., predictable with respect to . Then, we have ( and mean the same as in Lemma 2.7)
[TABLE]
For our purposes we have to extend this technique even further: When studying kernel estimators we encounter integrals of the type
[TABLE]
where is a bandwidth and
[TABLE]
for some real-valued function . Hence, for a given the integrand in (2.2) is non-predictable. However, under momentary--dependence, by removing the correct terms from the sum in the definition of , we obtain processes which are partially predictable with respect to :
Definition 2.10**.**
Let be a real-valued stochastic process defined on . is called partially-predictable with respect to a filtration if for any filtration and any process which is adapted to the process
[TABLE]
is predictable with respect to . Note that with being adapted, being predictable (both with respect to ) and deterministic has this property.
Since the martingales and remain martingales under the correct long-sighted filtration, we can now use stochastic integral properties. For ease of notation, we use the convention for and we write sets without curly brackets, e.g. instead of , we simply write . The proof of the following result is given in Appendix 5.1.
Theorem 2.11**.**
Let be a structured interaction network with filtration and distance . Let for be random functions (possibly not predictable with respect to ). It holds that
[TABLE]
for , if
the processes are momentarily--dependent and 2. 2.
there exist random functions for all with which are partially predictable with respect to , respectively, and such that (the symbol means negation)
[TABLE]
2.4 Mixing Networks
In this section our interest lies in proving a Bernstein type exponential inequality e.g. for the following average
[TABLE]
where we will later have for a real-valued function . However, the following results do not depend on this specific functional form as long as the have the exchangeability property 2 in Definition 2.2. The difficulties here are two-fold: We usually have that when and hence the number of terms in the sum is random and, secondly, the terms are dependent. We argued in the discussion of Figure 1 that unconditional independence is not a good assumption. However, it is reasonable to assume that, conditionally on the network, far apart actors influence each other very weakly. We include this aspect in the model by imposing mixing assumptions with time-varying mixing coefficients. These mixing assumptions will be used in the proofs by applying the grouping technique for mixing random variables (cf. Rio [43], Doukhan [14], Viennet [48]): The idea is to group the random variables in blocks which have large distances between each other in the observed network. To this end, we define a partitioning of a network as follows (the existence of such partitions will be discussed in Section 2.5).
Definition 2.12**.**
Let , , and . We call the random sets a -partition of the network at time (note that we omit in the notation) if
, 2. 2.
For and : .
Intuitively speaking, the sets form random groups where two different groups of the same type are far apart in the random network. For the following definition we use the notion of -mixing coefficients. For any two -fields and denote the -mixing coefficient by (cf. e.g. Rio [43])
[TABLE]
where and denote measures on for which for all sets
[TABLE]
For two random variables we denote where and denote the -fields generated by and respectively.
Definition 2.13**.**
Let be a sequence of random variables, let and let be a -partition of the network as in Definition 2.12. For every time point and every pair , we define
[TABLE]
the indicator function which checks if belongs to the -th block of type at time . Group the based on the partition , i.e.,
[TABLE]
Then we define the -Mixing coefficient which depends on the graph partitioning (which we do not indicate in the notation) via:
[TABLE]
Remark 2.14**.**
In most (but not all) situations we have additionally to the properties of Definition 2.12 that
[TABLE]
where is the random edge set of the network. In case where for , i.e., if all relevant pairs are covered by the partition and it holds that
[TABLE]
In general, for our results to hold, we do not have to require (2.9). It will be sufficient to assume that (2.10) holds.
In applications, the random variables will depend on a time point . So it will be the case that for close to the -Mixing coefficients at time will be small while they might be large for far away from . The following result is the main result of this section (inspired by Doukhan [14]). The proof is deferred to Section 5.1.
Lemma 2.15**.**
Let be an array of random variables which fulfils (2.10) for a given and let . Suppose that for all there exist -partitions with block types and numbers for and as well as such that (cf. notation from Definition 2.13)
**
[TABLE] 2. 2.
for , it holds for all and all
[TABLE]
Then, for any and all ,
[TABLE]
Note that can be understood as the expected size of group of type and that can be understood as the largest expected group size of groups of type . Then, can be understood as the expected number of edges in the network at time , i.e., . Now the first part of condition 2 in Lemma 2.15 translates to assuming that the expected fraction of edges contained in all groups of type is non-negligible. The second part means that the largest single group cannot be too large. The first condition, the moment condition, will be discussed in the next lemma. We will also show that it suffices to assume the existence of a suitable partition as above with high probability. To this end we introduce an indicator function which ensures that we can partition the network suitably. Conditionally on that, we can use the previous mixing results. In order to obtain an unconditional result we need to assume that sufficiently often. This is reflected in the unusual condition on . The proof of the following result can be found in Appendix 5.1. In addition we will show in the Appendix (Lemma 5.22) a different result which provides an exponential inequality for (unbounded) martingales and also avoids the moment condition.
Lemma 2.16**.**
Let be random variables bounded by and let be the adjacency matrix of a random, undirected network at time . Let furthermore and be the indicators of a -partition with group types which fulfils (2.10) (cf. also Definition 2.13). Suppose there are numbers , such that for and
[TABLE]
there are constants and such that and that for pairwise different vertices
[TABLE]
Let denote the -mixing coefficients with respect to as in Definition 2.13. Then, for
[TABLE]
2.5 Examples
In the following we discuss the previous concepts on examples.
2.5.1 On -Partitions
For the exponential inequality to hold, we do not need to know the specific partition in practice: Knowledge of existence is sufficient. Nevertheless, we discuss under which circumstances a -partition with the properties of Lemma 2.16 can be expected to exist. Let be a given random, dynamic network with adjacency matrix . As a distance function we take the graph distance, i.e., denotes the length of the shortest path between the pairs and if (e.g. if and are adjacent, if there is one edge between and and so forth). Otherwise or if there is no path, we set . We begin by supposing that for a given point in time the network is a two-dimensional grid. In that situation we consider a chess-board like partitioning of the edges as illustrated in Figure 2 where the sides and corners of the blocks lie exactly on the vertices. For edges which lie on the sides of the blocks we take the convention that the bottom and left side belong to the respective block. Each block (square) is of side length and each block is assigned one of four types. In Figure 2 all blocks of the same type have been assigned the same number. It is clear that the distance between two points taken from two different blocks of the same type is at least . We assign numbers to all blocks of the same type such that we can speak of the -th block of type . Later we will choose and in Lemma 2.16 will be the expected size of the -th block of type . Above the -partition is made such that all edges are contained in exactly one set and we obtain as a consequence that by definition will equal the expected number of edges. Moreover, the blocks all have identical size . Thus . Also and hence for chosen large enough. These considerations can be directly transferred to higher dimensional grids. Hence, for networks which form a grid of any dimension, the assumption of the existence of a sequence of -partitions as required in Lemma 2.16 with is proven. In consideration of this, we conclude that for a network which roughly looks like a grid, the above construction still yields a valid partition.
In order to check the assumption for a general network, we assign to each pair of vertices random, -dimensional coordinates. Then, we plot these coordinates in the -dimensional plane and partition the edges by using a chess-board like partitioning as before. We suggest two example strategies for doing this.
Example 2.17**.**
Let be arbitrary pairs of vertices. For any and we call the coordinates of at time . Let for and comprise all pairs with coordinates lying in the -th block of type in a chess-board like grouping (similar to Figure 2 in the case ).
Note that above we construct the partition for each time point individually. Hence, the choice of the reference pairs may depend on time as well. Moreover, the pairs may be chosen randomly since -partitions are allowed to be random. That we produce indeed a -partition in the above example is ensured by the following Lemma.
Lemma 2.18**.**
Let be given. The sets defined in Example 2.17 form a -partition of the network in the sense of Definition 2.12.
Proof.
We consider the case (The proof for follows analogous arguments). and are disjoint for by construction. Let and denote by and their respective coordinates. Then we obtain by the triangle inequality
[TABLE]
which yields . Analogously, we obtain . The second condition in Definition 2.12 follows if we notice that by definition for , and implies either or . ∎
Additionally to Example 2.17, we provide another method of how to equip edges with -dimensional coordinates via multidimensional scaling.
Example 2.19**.**
Use Multidimensional Scaling (MDS) (cf. Cox and Cox [9]) to find for each coordinates in such that , where denotes the Euclidean distance in .
In general it is not possible to have equality above. So the method yields only an approximation. However, the resulting partition might still be valid for a different . In general we expect that for networks in which the vertices are already related to some position in (e.g. geographical positions) the assumption of the existence of such a -partition is not restrictive.
2.5.2 Example: Momentary--Dependence
This section provides an example of a data generating process which is momentarily--dependent and exchangeable. Consider the following over-simplistic model for the use of on-line communication: A population of people (e.g. employees of a company) is connected through a social network with adjacency matrix , i.e., people are in regular personal contact if . Now a new on-line communication tool is introduced. Consider a pair with . At a given point in time , the pair either has started to communicate via the on-line tool () or not (). We suppose that pairs with will also not connect via the communication tool and hence in these cases. So the processes have at most one jump in the period . Suppose we are interested in studying a statistic which depends on the array . Clearly it would not be justifiable to assume that all are independent because people who are connected will influence each other. However, assuming momentarily--dependence and exchangeability is less restrictive as we will motivate next.
In order to focus on the main ideas, we restrict to a time-constant network model. However, we can also apply dynamic network models and consider the distribution of a snapshot of the network at a given time of interest . As a network generating process we consider a stochastic block model (cf. Holland et al. [20]) with random group assignments. That is, we suppose that every vertex is randomly assigned to a group . While the number is fixed, the random variables for are assumed to be independent and identically distributed. Now we suppose that the random variables are independent conditionally on all and that for where contains the connection probabilities. Set for and . We suppose that all these random variables are measurable with respect to .
The model for the processes is as follows. We assume that the decision of a pair with to use the communication tool is influenced by how many neighbouring communication connections are established in the sense that the pair is more likely to use the tool if many others use it as well. In addition, we assume that it takes some time to process information such that if a pair uses the tool at time pair will be influenced by it not before time (let if or ). We allow that some pairs process information faster than others but we do not allow chains of arbitrary fast communication, i.e., we suppose there is and such that
[TABLE]
Let denote pair ’s perception of the new tool. We suppose that the are independent and identically distributed among all pairs. For any pair define moreover by the set of potential neighbours of . Using these preparations, we consider the following model for the process for given
[TABLE]
For simplicity of exposition, we choose here a model without covariates and consider only the process . Since the group assignments and the initial perceptions are iid, the process fulfils the exchangeability property (2.1).
Let denote the canonical filtration with respect to which all are adapted and and are measurable with respect to . Definition 2.5 reads in this situation as follows
[TABLE]
Note firstly that is measurable with respect to for all and thus may be treated as a constant. In order to see that the above holds for and we use the following notation: A sequence of pairs is called a path from to if , and and share at least one vertex. For such a path we denote by . Let be arbitrary and let . Let, moreover, be given with and let . By construction it is clear that depends only on those events of which happened before time (the is taken over all paths from to )
[TABLE]
since . Information about these is available in . Hence, the events of the processes on are non-influential to for on provided that is known. Therefore momentary--dependence holds.
2.5.3 Example: Mixing
In this section we will show that a simplified version of the process described in Section 2.5.2 is exchangeable and -mixing (see also Remark 2.20 at the end of this section). Let be a 2-dimensional discrete torus with a suitable number of vertices, i.e., the network has grid structure as in Figure 2 but the vertices on the left and on the right are identified, as well as the vertices on the bottom and the top. The random network is obtained by randomly assigning labels to the vertices of . As before denotes the adjacency matrix of . We consider processes where is a stochastic process which we specify now. Let be an arbitrary enumeration of the pairs of vertices and let . Denote by the random matrix with if and only if and the pairs and share exactly one vertex. Set . We suppose that follows the AR-model
[TABLE]
where and is (for simplicity) a vector of independent Brownian motions scaled by for . Then, for all and all . Since we assigned the vertex labels randomly, the processes and thus are exchangeable.
We prove now that the mixing coefficients at a given time decay exponentially fast. The -partition we consider is as follows: Fix a chess-board like partitioning as in Figure 2 with side-length on the deterministic network . The random blocks are formed based on the edges which lie in the corresponding square in . Fix and let for ease of notation and . The distance is defined as before. Then, if and . Denote and is defined analogously for . Note that by the symmetry of the network and the choice of the -partition the conditional distribution of given is actually the same for all realisations of . As a consequence for all adjacency matrices and all sets . In consideration of this, we can find the mixing coefficient as the supremum over all partitions of of (cf. Dedecker et al. [11])
[TABLE]
where is the sum over all adjacency matrices. On , the random variables and are deterministic functions of and , respectively. Thus, by Pinsker’s Inequality (e.g., Lemma 2.5 in Tsybakov [45])
[TABLE]
where denotes the Kullback-Leibler divergence (conditionally on ) and are independent with the same marginal distributions as . It follows from the properties of the normal-distribution that an exponential bound on implies a similar exponential bound on the Kullback-Leibler divergence and thus on (2.13). Details are given in Appendix 5.6. We prove now an exponential bound on the covariances for .
Note that all eigenvalues of can be bounded in absolute value by (since every edge has exactly six neighbours). Hence, and by the Neumann series representation
[TABLE]
Thus, conditionally on , all are normally distributed. Recall that gives the number of paths from to of exactly length . Hence, for all pairs we must have whenever because otherwise there would be a path of length shorter than which connects and via . Moreover, for all . Therefore we obtain by symmetry of that there is a constant (which depends only on ) such that
[TABLE]
Remark 2.20**.**
If depends on , we can write a more general version of (2.13) which requires two estimates: Firstly, the distribution of the sum over a single block may not depend too strongly on the specific network. In that sense, the main task of the -partition is to group pairs together such that similarly behaved blocks emerge. This is possibly also the case in the example from Section 2.5.2 if the -partition takes the original group structure into account. Once this holds, in a second step, it suffices to bound the conditional mixing coefficients for all fixed network realisations.
2.6 Processes Indexed by Vertices
The dependence concepts in Sections 2.3 and 2.4 have been introduced for processes which are indexed by pairs . The results also transfer to processes indexed by vertices. The results and definitions from Sections 2.3 and 2.4 can be obtained for this case by replacing all by , all indices of pairs of vertices by vertex indices and by replacing the set by . Moreover, has to be adopted.
3 Application
We apply the previously introduced dependence concepts to find the asymptotic null-distribution of an -type test statistic in the following situation. We consider a structured interaction network process (cf. Definition 2.2). In the measurability assumption in Section 2.1 we consider a Cox-type link function which depends on an unknown parameter function (recall that is the dimension of the covariate functions ), i.e., the intensity functions of the counting processes are given by
[TABLE]
Examples for choices of the covariate vector can be found in Butts [5], Perry and Wolfe [41] and Kreiß et al. [28]. Our interest lies in testing the hypothesis
[TABLE]
On , we denote the value of the constant parameter function also by . For setting up a test statistic, we compare a non-parametric estimator of with a parametric estimator which assumes that is constant. As non-parametric estimator we use the local maximum likelihood estimator as in Kreiß et al. [28] where is the localized-likelihood which is given by
[TABLE]
where is a kernel with kernel function and bandwidth . Note that when removing the kernel in (3.1) we end up with the regular likelihood for the case when is a constant (cf. Andersen et al. [3]). Denote finally by a parametric estimator for which assumes that the parameter function is constant (e.g. the maximum-likelihood estimator ). Similar as in Härdle and Mammen [21] we compare the non-parametric and parametric estimator above by means of the following test statistic
[TABLE]
where is a non-negative weight function with for and is the smoothed version of . In contrast to Härdle and Mammen [21], we know in advance that we test for a constant function. Therefore we can directly compare the parametric and non-parametric estimate and we do not require additional smoothing. For the statement of the following theorem define (note that under the following Assumption (A3, 1) the right hand side below does not depend on )
[TABLE]
with the abbreviation (on ) . The following theorem gives the asymptotic distribution of the test statistic on the hypothesis . The proof is given in Section 5.2 in the Appendix.
Theorem 3.1**.**
Under the Assumptions stated in the remainder of this section, on
[TABLE]
[TABLE]
Note that can be approximated by using a plug in estimator for and can be approximated by Lemma 5.2 in the Appendix.
In the following we firstly state an assumption and then discuss its meaning and the intuition behind it. All assumptions are formulated on , in particular, denotes the true value of the constant parameter function. We use the abbreviation
[TABLE]
such that denotes the true intensity function on .
(A1) Boundary Cut-Off
* is continuous, bounded and for some . *
(A2) Exhaustiveness of
There is an open and bounded set (denote the bound by ) such that .
Assumption (A1) allows to ignore convergence issues of the kernel estimator at the boundary and Assumption (A2) allows us to simplify some notation. Both assumptions are not very restrictive.
(A3) Modelling Assumptions **
The conditional distribution of given is independent of and . 2. 2.
For the estimator fulfils . 3. 3.
The covariates are almost surely bounded by a constant . Together with (A2) this implies that is almost surely bounded by a constant for all .
Assumption (A3, 1) is identical to Assumption (A1) in Kreiß et al. [28]. It is reflecting our intuition about the asymptotics of the network: For growing networks we assume that the number of actors to whom a fixed actor has active connections remains bounded over time. In our intuition, the distribution of the covariates and events on an active edge is therefore only influenced by this group which is not growing. In consideration of this, we regard Assumption (A3, 1) not restrictive. (A3, 2) holds for example for the maximum likelihood estimator as introduced in Chapter VI.1.2. in Andersen et al. [3]. However, for our theory here, it is not required that is the maximum likelihood estimator. For (A3, 3) we note that examples of covariates are the number of common friends, age difference, number of interactions in the past and so on. These quantities are naturally bounded e.g. if we believe that interactions and maintaining friendships requires time. More generally, we expect the intensity functions to be bounded if the actors have to invest time in the interactions (e.g. sending a message takes some time even though the actual event of sending is instantaneous). Because in this case, at least on average, actors will not cast arbitrarily many events in a given time frame.
(A4) Kernel and Bandwidth
For the bandwidth fulfils and . 2. 2.
The kernel is supported on and is Hoelder continuous with exponent and constant , i.e., . As a consequence it is bounded by a constant which we also denote by .
(A4, 1) holds for example when is the asymptotically optimal bandwidth choice in most one-dimensional regression contexts (e.g. Tsybakov [45]), so they are standard for this type of problem. The Hoelder continuity of the kernel in (A4, 2) is a mild assumption which avoids technical problems later. For most simple kernels like Epanechnikov or a triangular kernel it is true.
(A5) Invertibility of Fisher-Information
*The matrix (cf. (3.2)) is invertible for all and is continuously differentiable. Particularly, and is uniformly continuous on . *
In (A5) we assume that the Fisher Information is invertible. This is a classical assumption. The assumption that is smooth reflects our believe that the behaviour of the network is also changing smoothly over time. Note that is a conditional expectation conditional on , i.e., changes in the network itself (appearance or disappearance of edges) do not interfere with the smoothness of .
**(A6) Behaviour of
The quotient is bounded in and the function is Hoelder continuous with fixed exponent but the constant may vary like a power of .**
In this assumption we require that lies for a given always on the same scale. The convergence rate of the non-parametric estimator at a given point in time depends on . Hence, we actually assume here that the non-parametric estimator has the same rate at all points in time. Note, however, that is still allowed.
Before we can present the assumptions on the weak dependence structure, we introduce the concept of hubs. Informally speaking, a hub is a pair which is close to many other pairs.
Definition 3.2**.**
Let , and . For a subset of pairs we let
[TABLE]
be the maximal number of active edges being close to pairs in . A pair is called a hub on if .
Consider a collection for . Every random variable with
[TABLE]
is called hub-ability of the set . By we denote an upper bound on the number of possible hubs in the networks .
The definitions of and depend on the choice of . In order to avoid notation clutter, we do not indicate this in the notation. Note that denotes the size of the largest hub on . We think about hubs in the following way: Consider a social media setting where every edge represents the connection between two people. In the works Golder et al. [18], Huberman et al. [22] it is argued that in social media most of the friendships between users are actually inactive in the sense that they do not interchange messages. This underpins the very much believable idea that every actor has only close contact to a bounded number of people. Having close contact means in our formulas that their distance is less than . That means that most people interact with not more than, say people, regardless of the size of the network. Thus, if one edge exceeds the threshold of , we call it a hub. In the following assumptions (H1) and (H2) we have to balance the size and frequency of hubs. This is necessary because if there was one pair which strongly influences the entire network, inference would be impossible.
**(H1) Hub Predictability
For some and for , the random variables and are measurable with respect to . As a consequence also is measurable with respect to as well as .**
In this assumption we require that the fact whether a pair of vertices has the potential to become a hub is determined in the beginning of the observation period. Note that this does not require that every potential hub is a hub from the beginning. A pair can be close to few others in the beginning and then become a hub later. In addition, the maximal size of the hubs over time is assumed to be determined in the beginning as well (however it might be unknown). This latter assumption might be relaxed to an exponential growth condition.
**(H2) Hub size restriction
Let be as in (H1). The frequency of hubs is restricted to the following constraints:**
[TABLE]
The following assumptions refer to the dependence types we reviewed and introduced in Sections 2.2-2.4. For a discussion of them we refer to the respective section.
**(D1) Momentary--Dependence
Let be as in (H1). The processes are momentarily--dependent in the sense of Definition 2.5. Moreover, the conditions (2.4)-(2.8) of Theorem 2.11 are fulfilled for**
[TABLE]
where , () and
[TABLE]
*and . *
Proving the conditions (2.4)-(2.8) is very tedious. Therefore, we assume here that they hold and provide in Appendix 5.4 a list of technical but easy to believe assumptions under which they can be proven.
**(D2) Asymptotic Uncorrelation
It holds that**
[TABLE]
(D3) Mixing
For any , and there is a -partition with and many types such that for all
[TABLE]
and is measurable with respect to . Define
[TABLE]
where is either the kernel or and is defined analogously to . Suppose that for there is such that for
[TABLE]
it holds that vanishes exponentially fast. Also we suppose that there is a constant such that for all and either choice of
[TABLE]
Let denote the mixing coefficients as in Definition 2.13 of
[TABLE]
We suppose that for some . Let
[TABLE]
for any choice . Consider for each and each either
[TABLE]
Suppose that for either choice, there is such that for pairwise different vertices , all and all it holds that (use in the definition of for (3.9)-(3.11) and for (3.12))
[TABLE]
The assumptions have been mostly discussed in Sections 2.2-2.4. However, we would like to comment on and the measurability in Assumption (D3). The way is used ensures that the mixing property is only required if the partitioning of the network is reasonable. However, we also assume that the probability that the partitioning is reasonable is large. The inequality in (3.8) means that we assume that the percentage of the edges which are on average contained in the blocks of type is never negligible, i.e., that no block type is obsolete, a plausible assumption. We also tacitly assume that the number of block types is the same for all time points and does not change with . This assumption reflects the idea that the network geometry is staying the same while the network size is increasing. The measurability assumption is required because of Lemma 5.22 in the Appendix. In the proof of the lemma we see that measurability is essential because we have to apply martingale results. In practice this means that the -field contains the information which at the time inactive pairs (i.e., ) will possibly be active in the interval (i.e., ). Since there is in the condition in the beginning of (D3) the information is not required exactly: It is no problem if the partitioning contains a few pairs too many. When adding this information to the filtration we assume that the intensity process remains unaffected. This is plausible because we only add information about the future connectivity (not activity) of pairs which are currently known to be inactive (so they are known to not cast events among each other currently regardless of their future behaviour).
Denote for the next assumption
[TABLE]
The following set of assumptions looks very clumsy and difficult to check. However, the reader is politely asked to read the following assumptions by keeping in mind that Assumptions (AD, 3.14,3.15) are moment conditions which merely require a polynomial growth (but do not specify the exponent). Moreover, in (AD, 3.15) the integral is over an interval of length , so it is to be expected that this integral is small.
(AD) Additional Dependence
For any given we can choose such that
[TABLE]
For the next assumptions we use the notation . There is such that for all , it holds that
[TABLE]
Additionally suppose that
[TABLE]
Assumption (AD, 3.13) requires the network to concentrate around its expected size. It could be proven on the expense of other technical assumptions. In order to prove (3.13) we need an exponential inequality for averages of counting processes. Such an inequality can be shown by employing -mixing as in the proof of Lemma 2.15. However, instead of using the Bernstein inequality (see e.g. Proposition 5.25) we need a tail bound valid for independent sums of counting processes with bounded intensity functions. For our purposes it is sufficient to use a tail bound induced by using Chebyshev’s Inequality in its exponential form. The remaining assumptions (AD, 3.14)-(AD, 3.16) are moment growth conditions. Overall they appear to be weak because we only require that they do not grow super-polynomially. The main reason why we need these assumptions is that the martingales cannot be computed under the conditional probability.
**(AC) Additional Continuity
Recall the definition of in (D3). For every choice of entries there is such that**
[TABLE]
Instead of posing specific assumptions on the covariate processes , we choose to state the continuity which is required in the proofs directly. Assumption (AC, 3.18) could be replaced by assuming that the conditional expectation function is uniformly continuous. For Assumption (AC, 3.17) we could for example assume that the sample paths of the covariate processes are continuous and that the number of edges which change their status in a small time interval is very small.
4 Bike Data Illustration
In this section we apply the test from Section 3 to bike-sharing data from Washington D.C. The data is publicly available at https://www.capitalbikeshare.com/system-data. For this small application we use the same setting as in Section 3.2 in Kreiß et al. [28]. In particular we consider the bike stations as vertices. The bike stations and interact whenever there is a bike ride from station to station . In contrast to Kreiß et al. [28] we consider only bike rides which happened on May, 5th 2018 between 5am in the morning and 10pm in the evening. We consider a short time span because for a longer time span it would be obvious that the parameter function is not constant (e.g. on weekends and weekdays). Without additional detailed information about short term effects (e.g. street closures due to accidents or increased biking due to festivals), it is difficult to observe the true dynamic network. We therefore use a non-dynamic conservative network as described in Section 2.1 Kreiß et al. [28]: We consider two bike stations and connected by an edge if they are regularly used by which we mean that there were at least ten bike rides from to in April 2018 (that is, more than two rides per week). The true (but unobserved) time varying network is supposed to contain at each time more edges than the conservative network. But the above methodology could also be applied if we had a dynamic conservative network. Note finally that this small data application serves just as an illustration and is not meant to be and in-depth analysis of bike data which would particularly include a sensitivity analysis of the threshold for the network construction.
As covariates, we choose for this application the geographical distance between the bike stations. Let denote the logarithm of the distance (in minutes of bike time) between bike station and . Then, we consider the following covariate vector
[TABLE]
We suppose that the weak dependence concepts which we introduced in Sections 2.2-2.4 are applicable here because the bike stations have an underlying geographic structure and it is very plausible that bike connections which are geographically far away can be treated more or less independently. Therefore, we use a distance function which is related to the geographical distance (recall that we do not need the actual values of the distance function to apply the technique). To be more specific: If we observe the bike rides between two bike stations and during a short time-period , we can make inference about other bike rides between other stations and in the same time period only if these stations lie geographically close to each other. If there is e.g. a sudden traffic incident which affects the bike rides between and it is likely that the bike rides between and are also affected, if they lie in the same area. However, if they lie in a different part of the city, there is no influence. Therefore, we assume that asymptotic uncorrelation and -mixing are plausible assumptions. In order for the assumption of momentary--dependence to hold we need to assume that global events which effect the entire city, like big sport events, need to be included in the filtration as we condition on it. As a consequence special events should be included in the intensity function too. Since we restrict the data example to one day (May, 5th 2018) this is a plausible assumption too.
The bandwidth choice for the non-parametric estimator as defined above (3.1) is carried out in the same way as in Kreiß et al. [28] and for details about the procedure we refer to that paper: We compute firstly for different bandwidths a prediction of the bike rides per edge by using a locally-linear estimator with a one-sided kernel. The resulting prediction error is seen in Figure 3 for a discrete grid of choices of (we chose the grid for computational simplicity). It can be seen that the prediction error starts to flatten out roughly at and is minimal for . So we take that bandwidth and transfer it to the case of a regular kernel estimator by dividing by (see Kreiß et al. [28] for details). Hence, the bandwidth we use is . The non-parametric and parametric estimates in are shown in Figure 4(a). In this scenario the centred and scaled test statistic yields a value of above . At least asymptotically, we consider the centred and scaled test statistics to be distributed if the underlying data generating process has indeed a constant parameter function. So from this point of view, we have provided evidence that the model with the time-varying parameter function fits the data better. When looking at Figure 4(a) this result is at least intuitively not surprising. If we focus on a shorter time period, e.g. 4pm to 8pm, the result is not as extreme. In Figure 4(b) the corresponding estimators are shown. In this case the scaled and centred test statistic is about which results in a p-value of about which is usually not regarded as significant.
5 Appendix
5.1 Proofs of Section 2
Proof of Theorem 2.11.
The idea of the proof is to translate the convergence statement about to statements about . This will be useful because the latter are partially predictable with respect to the short sighted filtration. Since we have certain processes which are martingales with respect to the short sighted filtration (cf. Lemma 2.7) we can make use of martingale properties of the Itô Integral. For the first step, we see that the asymptotic behaviour of (2.3) is the same as the sum over the leave--out approximations, i.e.,
[TABLE]
and (5.1) converges to zero by (2.4). Hence, we only have to study (5.2). is partially-predictable with respect to the filtration and, by the assumption of Momentary -Dependence (c.f. Definition 2.5 and Lemma 2.7), is a martingale with respect to for all with . We will use this observation in order to prove that (5.2) converges to zero in probability by applying Markov’s Inequality:
[TABLE]
We will treat the terms (5.3)-(5.5) separately. Note, that in contrast to (2.3), all of the above expressions contain only the approximations with their predictability property. We will show in the following how this is useful.
(5.3) converges to zero by (2.5).
In order to see that (5.4) converges to zero, we note firstly that the two stochastic integrals in (5.4) (with respect to and ) are martingales with respect to the correct leave--out filtrations (namely and , respectively). Although these two filtrations are in general not the same, we can make use of the fact that the leave--out filtrations allow future knowledge. Define furthermore for Lebesgue sets
[TABLE]
Note that and are adapted with respect to all leave--out filtrations. Since is partially-predictable with respect to , we get that
[TABLE]
is predictable (cf. Definition 2.10) and as a consequence, is predictable as well with respect to .
With these definitions we have (if we define )
[TABLE]
We show that this is by considering the tree lines separately. Recall therefore that is the set of pairs which are further away than from at time .
For (5.6), we prove firstly that for each
[TABLE]
is measurable with respect to . This follows from the following intermediate results:
The integrators and in are only considered up to time at most and contains information up to and including time for processes which are at time at least of distance to . 2. 2.
We show that is measurable with respect to for all
- (a)
is partially-predictable with respect to by assumption. In particular, it is measurable with respect to for all . Thus requires two types of information: One on and up to time , and another type of information about the future (after ) on all processes which are away from . Both are contained in as we shall show in the following two steps. 2. (b)
The information about and for is well included in by the same arguments as in 1. 3. (c)
Let and , then
[TABLE]
is measurable with respect to because .
Together the above points imply that is predictable with respect to . Moreover, is a martingale with respect to by momentary -dependence. Hence,
[TABLE]
The last part is by (2.6).
In (5.7), we see that is predictable with respect to
. Thus, we conclude by using that is a martingale with respect to (with analogue arguments as in the first case): .
For (5.8), we note firstly that
[TABLE]
Now, we can play a similar game: This time, is a martingale with respect to . Furthermore, requires knowledge of , , and for which is included in as well as knowledge of for and , i.e., which is again included in . Hence, is predictable with respect to . Hence, the integrand of (5.8) is a martingale and we obtain . Thus, we have shown that .
Finally, we consider (5.5). Therefore note firstly that and are both partially-predictable with respect to . Moreover, , , and are all martingales with respect to . Hence,
[TABLE]
is also a predictable function in and
[TABLE]
is a martingale. The same holds when and are replaced by and . Hence, for
[TABLE]
For we will apply firstly a martingale result to compute the covariance of the two stochastic integrals (first equality below), in the second equality below we employ a similar technique as in the computations for (5.4): Note that is measurable with respect to , additionally and are martingales with respect to . Hence,
[TABLE]
So we may rewrite
[TABLE]
By (2.7) and (2.8) we conclude . Thus we have finally shown that and hence the proof is complete. ∎
Proof of Lemma 2.15.
The proof of (2.11) is an immediate consequence of the following Proposition 5.1 together with the assumptions:
[TABLE]
∎
Proposition 5.1**.**
Let be a set of random variables which fulfils (2.10) for a given . With the same notation as in Definition 2.13 assume that there is a -partition such that for all with and all and
[TABLE]
for some numbers and with . Then,
[TABLE]
Proof.
With the definitions as in Definition 2.13 we obtain by (2.10) that
[TABLE]
Hence,
[TABLE]
In order to reduce notation, we omit when talking about . By Lemma 5.24 we can construct sequences as follows: We assume that the -field is rich enough to allow for independent extra random variables which are uniformly distributed on and which are independent amongst each other and of everything else. The construction is the same for every , so we only construct the sequence , all other sequences for are constructed analogously. Define . For there is by Lemma 5.24 a function such that has the same distribution as , is independent of and
[TABLE]
To sum it up, we have sequences with
For any and any fixed , is a sequence of independent random variables. 2. 2.
and have the same distribution. 3. 3.
For all : .
Denote by the random number of blocks of type which exist, i.e., such that for we have . So we obtain by (5.9) for any and any sequence with and :
[TABLE]
For every the sequence is a sequence of independent random variables. Moreover, by definition . So, the assumptions of Proposition 5.25 are fulfilled with and . So we can estimate the first part of (5.10) by
[TABLE]
We chose and obtain by combining the equalities (5.10) and (5.11),
[TABLE]
∎
Proof of Lemma 2.16.
Define . Then,
[TABLE]
Line (5.15) is part of the statement, so we just leave it as it is. For line (5.14) we have
[TABLE]
Thus line (5.14) equals zero by choice of . For line (5.13) we can make a similar argument
[TABLE]
The last expression is a false statement and hence the first line cannot be true. Thus, . For line (5.12) we apply Lemma 2.15 to which is given in the statement of Lemma 2.16. We have
[TABLE]
In order to see that the conditions of Lemma 2.15 hold, let and greater or equal than two. Going on, we conclude for the grouping of by using the above estimation (recall that )
[TABLE]
Moreover, by assumption
[TABLE]
Thus the first requirement of Lemma 2.15 holds for the definitions in the statement of this Lemma and and . The first part of the second condition in Lemma 2.15 holds by assumption and the second part holds by definition of . Thus, we may apply Lemma 2.15 and obtain for (5.12)
[TABLE]
This yields the statement. ∎
5.2 Proof of Theorem 3.1
Recall that denotes the counting process martingale and decompose the likelihood as follows:
[TABLE]
Define moreover for and (we use the convention )
[TABLE]
We will also need the following functions defined for all
[TABLE]
where denotes the integral over the set . Most technical difficulties are contained in the proofs of the following Lemmas 5.2-5.7. Their proofs are presented in Appendix 5.3.
Lemma 5.2**.**
It holds that
[TABLE]
and
[TABLE]
The definition of is given in Theorem 3.1.
Lemma 5.3**.**
For any
[TABLE]
Lemma 5.4**.**
There is a sequence with , such that for all
[TABLE]
Lemma 5.5**.**
There is a sequence with such that for all and
[TABLE]
Lemma 5.6**.**
Denote by for the grid
[TABLE]
Then, for any there is such that
[TABLE]
Lemma 5.7**.**
Define for the grid
[TABLE]
Then, for any , there is such that
[TABLE]
The above lemmas hold under the assumptions in Theorem 3.1. Therefore, we can use all their statements in the following. We begin the proof of Theorem 3.1 by showing the following small lemmas.
Lemma 5.8**.**
Suppose (A4, 2) holds and that . Let . Then it holds for any and all that
[TABLE]
Suppose that, in addition, (A6) holds. Then,
[TABLE]
are uniformly bounded in and .
Proof.
The proof is just a direct calculation: Note that for and hence
[TABLE]
The second statement is now a direct consequence by noting that for
[TABLE]
The right hand side is uniformly bounded under (A6). The boundedness of is also a direct consequence of (A6). ∎
Lemma 5.9**.**
Suppose Assumption (A5) holds. There exist such that for all and all matrices with it holds that is invertible and .
Proof.
We begin by showing that
[TABLE]
Define and suppose the statement was wrong. Then, we find for all numbers and matrices such that but is not invertible. Since and is compact, there is a subsequence such that for . By continuity of in we conclude that
[TABLE]
and hence for . Note finally that the space of non-invertible matrices is given by . Since is continuous, the set of non-invertible matrices is closed. By construction is non-invertible and hence is non-invertible, too. This is a clear contradiction to (A5).
In order to find choose in (5.26) such that . This is possible because inverting a matrix is a continuous operation and by continuity of as in (A5). Let now and be as in (5.26). By using the fact that the spectral-norm of a matrix is sub-multiplicative, we find
[TABLE]
Hence, . ∎
Lemma 5.10**.**
Under (A3, 3), the functions and are twice differentiable with respect to and the derivatives can be computed by interchanging integral and differential.
Proof.
The integral with respect to can be split in an integral with respect to (which is a sum) and a regular Lebesgue integral. Therefore, the stochastic integration is not inducing additional difficulties and we can apply standard theory for Lebesgue integration. The integrands are clearly differentiable with respect to . Boundedness of the covariates guarantees that the derivatives can be bounded by an integrable function (which does not depend on ). Then the integral and derivative may be interchanged. ∎
Lemma 5.11**.**
Under Assumptions (A4, 2), (A5) and (A3, 3) and we have that for any and any the order of integration in the following integrals can be interchanged
[TABLE]
Proof.
Note that similar to the proof of Lemma 5.10, the integrals with respect to the martingales can be split into two integrals. The integral with respect to the counting process is a sum and hence it is clear that the order of integration can be interchanged. For the other (Lebesgue) integrals we can apply Fubini’s Theorem: We show that the iterated integrals exist even after taking the norm within the integral. For both iterated integrals we may apply Lemma 5.9 in order to remove from the consideration. Then, the innermost integral is in both cases an integral over the kernel, the weight function and in case of the first iterated integral of . All these functions are bounded (cf Assumptions (A1), (A4, 2) and Lemma 5.8) and hence the innermost integral can just be bounded by a constant. The outer integrals are now integrals over or , both of which are integrable by Assumption (A3, 3). ∎
Lemma 5.12**.**
Suppose that (A2) and (A3, 3) hold true. Then, there is such that for all and all , i.e., is Lipschitz continuous in for every fixed . Additionally,
[TABLE]
Proof.
The proof is immediate since the covariates are bounded by Assumption (A3, 3) and the parameter space is bounded by Assumption (A2). ∎
Lemma 5.13**.**
Suppose that (A1), (A3, 3), (A4), (A5) and (A6) hold. For , we have for
[TABLE]
Proof.
We use the bounds from (A1), (A3, 3) and Lemma 5.9 as well as the kernel properties (A4, 2) to obtain
[TABLE]
Using this estimate we can bound (denote )
[TABLE]
The statement follows now by using the properties of in (A6) and the bandwidth in (A4, 1). ∎
Lemma 5.14**.**
Suppose that (H2) holds. Then, we have for
[TABLE]
Proof.
Follows by applying (H2, 3.4). ∎
We continue with three more involved propositions. It is through these propositions how dependence structures enter the proof of Theorem 3.1.
Proposition 5.15**.**
Under the same assumptions as in Theorem 3.1 we have
[TABLE]
Proof.
We note firstly that existence of the derivative of is ensured by Lemma 5.10 and we can compute the derivative by taking the derivative under the integral sign. Let and recall the definition of the grid in (5.24). Denote by the corresponding projection on . Then and . Using this projection we can estimate for
[TABLE]
We have to prove that both (5.28) and (5.29) converge to zero. We start with (5.28). Denote therefore , then
[TABLE]
because . Then we get
[TABLE]
For (5.31) we apply Lenglart’s inequality (cf. Lemma 5.26 in the Appendix) to obtain for any choice of
[TABLE]
If we restrict to we obtain furthermore
[TABLE]
Since for any , , Lemma 5.8 implies that is Hoelder continuous with exponent and constant . Moreover, we have and Hoelder continuity of the kernel K by Assumption (A4, 2) (we denote the bound on the kernel also by ). Combining all these, we obtain for
[TABLE]
since by Lemma 5.8. So we get
[TABLE]
Since by definition of in Lemma 5.8, we have and the covariates are bounded by (A3, 3). Hence, we get that (5.33) is small, because we can choose such that for large enough the probability is small for all and then we can choose large enough such that the whole expression is small. Then, also (5.28) is small, for this good choice which we keep fixed from now on.
Let us now turn to (5.29). Here we take the supremum over a finite set and so we can estimate by applying union bound and Lemma 5.6 for large enough
[TABLE]
∎
Having established Proposition 5.15, we can quickly show the following result.
Lemma 5.16**.**
Under the same assumptions as in Theorem 3.1 we have
[TABLE]
Proof.
By Lemmas 5.4 and 5.5 we have that for any choice of
[TABLE]
where . Thus, we find by Proposition 5.15 that
[TABLE]
Hence, we can apply Kantorovich’s Theorem (cf. Theorem 5.29) for all with the same choice of and as above. Thus, there is such that for all
[TABLE]
∎
Corollary 5.17**.**
The probability of the event for all it holds that converges to one.
Proof.
By Assumption (A2) it holds and hence by Lemma 5.16 all estimates lie also in . ∎
Proposition 5.18**.**
*Under the same assumptions as in Theorem 3.1 for any choice of
(where for we denote by the connecting line between and ), define the matrix*
[TABLE]
where denotes for the -th row of the second derivative of with respect to . The matrix concentrates around (cf. (3.2)), i.e.,
[TABLE]
Furthermore, is invertible and
[TABLE]
Proof.
We begin by rewriting in terms of the second derivatives
[TABLE]
Since doesn’t vary in , it is enough to consider each term in the sum on the right hand side above separately. In order to reduce notation, we do not indicate which intermediate value we consider and write simply instead. Recall the definitions of , and in (5.19), (5.20) and (3.2), respectively. It holds that . Now, we can separate the problem as follows: Recall the abbreviation
[TABLE]
We note firstly that by definition of . Moreover, after taking the over all , the convergence rate of line (5.36) equals , because of the Lipschitz continuity of in Lemma 5.12 and Lemma 5.16 (recall that is an intermediate value between and in Taylor’s Formula). The expression in (5.37) can be handled by Assumption (A5) which states boundedness of together with a Taylor expansion in the time parameter:
[TABLE]
where we used in the last step that the kernel is supported on and hence . So (5.37) is of order .
To deal with the first expression, line (5.35), we let and and denote by the discrete grid covering as defined in (5.25). We apply the same splitting technique as in (5.28) and (5.29) and obtain
[TABLE]
In order to show that (5.39) converges to zero, we note that for . Note that by Lemma 5.12 and Assumption (A3, 3) is Hoelder continuous with exponent and random, time dependent constant which is uniformly bounded. Thus, we get by Hoelder continuity of the kernel (Assumption (A4, 2)) and of (Lemma 5.8)
[TABLE]
which converges to zero when is chosen large enough. (5.40) converges to zero by Statement 5.7. Thus we have shown the first part of the proposition. To prove that inversion preserves the rate, we denote . Since we have just shown above that converges in probability to we conclude by Lemma 5.9 that firstly is with probability converging to one invertible and . Thus, on this event,
[TABLE]
which concludes the proof of the proposition. ∎
Proposition 5.19**.**
Under Assumption (A3, 2)
[TABLE]
Proof.
To begin with, we use the Taylor expansion from equation (5.45) which is shown there without reference to this Proposition. By using also the Cauchy-Schwarz Inequality we get for every entry
[TABLE]
We show now that (5.41) and (5.42) are both . We begin with (5.41). Let be arbitrary, then for any
[TABLE]
In order to deal with the first part, we use Markov’s Inequality. The resulting expectation is written in terms of (5.30) and can be bounded by using the fact that the counting process martingales are uncorrelated and that everything is identically distributed. More precisely, we obtain for (cf. Assumption (A1))
[TABLE]
where is the bound on the kernel from (A4, 2), by (A1), the supremum is finite by Assumption (A3, 3) and by definition. By Proposition 5.18 and the assumptions on in (A4, 1) we find that for all and thus in particular it holds for large enough that
[TABLE]
Now, by using all previous considerations we may estimate by using (5.43) for large enough by
[TABLE]
Since were chosen arbitrarily, we have shown that .
We continue with (5.42). This is easier to handle because is deterministic and thus in particular predictable. It is therefore not necessary to separate first and second derivative as we did in (5.41). Let be arbitrary, then we find by applying Lemma 5.11 again for
[TABLE]
Since , this converges to zero by Assumption (A3, 3), Lemma 5.9 and using once again that . Thus, also . ∎
Proof of Theorem 3.1.
We note firstly that we may replace the estimator in the test statistic with because for it holds that
[TABLE]
By the Assumptions (A1), (A3, 2), Proposition 5.19 and the last two terms may be asymptotically neglected. Hence, the limiting distribution of can be found by studying .
By Corollary 5.17, with high probability. Since is differentiable by Lemma 5.10, we thus have on this event. As we are concerned with convergence in the distribution, we may restrict to this event. By a Taylor expansion there are which lie on the connecting line between and such that
[TABLE]
where is the -th component of the gradient (with respect to ) of and denotes the -th row of the Hessian Matrix of with respect to . Define
[TABLE]
By Proposition 5.18 and (A4, 1) we have that is uniformly close to . Hence, by Lemma 5.9 we find that with probability tending to one is invertible for all . Thus, (5.44) is equivalent to
[TABLE]
Using this expansion and by applying Propositions 5.15 and 5.18, we obtain (use also the properties of in (A1))
[TABLE]
Hence,
[TABLE]
where the part is by Assumption (A4, 1) on the bandwidth. Thus, for the asymptotic considerations, we have to investigate only the first part. By noting that for all we see that is maximal for and this holds for all and and all . Hence, defined in (5.16) has a local maximum at . By differentiability of (cf. Lemma 5.10) we conclude that for all . Using this together with the decomposition of the likelihood in (5.17) we obtain (the order of integration may be interchanged by Lemma 5.11)
[TABLE]
where was defined in (5.18). Note that . Then (in the second line we reorder integration by Lemma 5.11, and the third equality is not term-wise the same but for the whole sum),
[TABLE]
We will consider lines (5.47) and (5.48) separately. We start with line (5.47) and in there, we start with the second integral: Note that the martingales have jumps of height exactly one at those positions where the counting processes jump (this is because we assume a continuous integrated intensity process). Hence we have
[TABLE]
and furthermore
[TABLE]
Using the above equality, we obtain
[TABLE]
The first sum is a sum of uncorrelated martingales and so it will converge to zero in probability by an application of Markov’s inequality: Denote by a sequence of identically distributed, predictable functions, then in general and for
[TABLE]
So we get for any
[TABLE]
When letting , we have by Lemma 5.13 that the above converges to zero. Moreover, by definition
[TABLE]
Combining these considerations yields .
Next we consider (5.48). Firstly, we note, using an analogue of (5.49), that the second integral in (5.48) equals zero because the two martingales and never jump simultaneously because . To investigate the first integral we simplify notation by using the predictable functions defined in (5.21). Then
[TABLE]
is a martingale in . We intent to show convergence to a normal distribution by using Rebolledo’s martingale central limit theorem (Theorem 5.28). To this end, we need to prove the convergence of the variation towards a deterministic quantity and that the jump parts of the process converge to zero. We start with the quadratic variation (note that and are uncorrelated whenever ):
[TABLE]
by Lemma 5.2. Now the jump process (the process which contains all jumps of size greater than or equal to ) is given by (note that no two martingales jump at the same time)
[TABLE]
which converges to zero by Lemma 5.3. Hence, by Rebolledo’s martingale central limit theorem (see Theorem 5.28 in the Appendix)
[TABLE]
and the statement of the theorem is shown. ∎
5.3 Proof of Lemmas 5.2-5.7
Proof of Lemma 5.2.
Recall that for
[TABLE]
By substituting we obtain
[TABLE]
For ease of notation we denote
[TABLE]
Note firstly that is not random and secondly that for the above expression equals zero because we assume that the kernel is supported on (cf. Assumption (A4, 2)). So we obtain for :
[TABLE]
The integral in the above display is over a vector-valued integrand. Such integrals are always understood element-wise. We begin with proving (5.23). By using the representation of in (5.51) we obtain
[TABLE]
In order to study the behaviour of these integrals, we write the product of the two integrals as a sum. The equation from before continues (we can interchange the order of integration because the integrand after the second equality is non-negative and the martingales can be split into the counting process integral and a regular Lebesgue integral):
[TABLE]
Note that we do not need the indicator because and hence the martingales and will not jump simultaneously almost surely. We continue (for the second equality interchange the roles of and as well as the roles of and )
[TABLE]
here we have introduced the notation , where for any set of pairs ()
[TABLE]
The functions are partially predictable with respect to for because the integrand above has the product structure as mentioned in Definition 2.10 and summation and integration is preserving this property as it is a measurability property. In order to prove that (5.52) converges to zero we apply Theorem 2.11. To this end we have to prove that (2.4)-(2.8) with hold. This is either true by Assumption (D1) or Lemma 5.21. Thus, we may apply Theorem 2.11 and thus we can conclude that (5.23) holds.
To prove (5.22) in Lemma 5.2 we will apply very similar techniques as before. In fact, we can use almost exactly the same steps with we have taken in order to arrive at (5.52) with one exception: At some point we said that we can ignore the indicator function because , this is not true now and we need to take care of this. We obtain
[TABLE]
where we used the abbreviations and . We prove that (5.54) converges to zero in probability by applying similar techniques as before. We start by approximating by its measurable approximation :
[TABLE]
We now use again the approximation (5.69) and obtain by using martingale properties (recall that is measurable by Assumption (H1)) and Markov’s Inequality for any
[TABLE]
by Assumption (H2, 3.5).
For (5.57), we recall that is partially predictable with respect to (cf. remark after (5.53)) and thus we may apply Lemma 2.7. Together with (5.98) we get
[TABLE]
This converges to zero by conditioning on and Assumptions (AD, 3.13, 3.15).
We study now the convergence behaviour of (5.55). Note firstly that
[TABLE]
The first part, (5.58), converges to zero by an application of Proposition 2.9. We get by said Proposition with
[TABLE]
We apply estimates (5.69) and (5.98) to show that the three lines above converge to zero. We have by exchangeability of the network
[TABLE]
Convergence to zero of the above expression is implied by the fact that the third moment of exist by Assumption (AD, 3.16). We continue with (5.61) and (5.62) to get
[TABLE]
which converges to zero by conditioning and Assumptions (H2, 3.4) and (AD, 3.13, 3.14). Moreover,
[TABLE]
It can be shown that the above converges to zero by using martingale properties and the Assumptions (H2, 3.4), 5.27 and (D2, 3.7). And we conclude that (5.58) converges to zero.
So we have left to prove convergence of (5.59) which we do as follows: Denote by superscripts entries of vectors or matrices, i.e., refers to the square of the -th entry of and refers to the entry in row and column of the matrix . Then
[TABLE]
where for all
[TABLE]
We keep this in mind and prove now for all
[TABLE]
via exponential inequality techniques. Since the argument is the same for all indices, we omit in the notation. Let therefore denote a grid of with mesh (where is chosen later) and let be the projection of onto , i.e., . We obtain
[TABLE]
For (5.66) we define . Then, we find
[TABLE]
By the Assumptions (A1), (A5), (A6) and Lemma 5.8 we have that the functions , , and are all continuous on the compact interval . Therefore and are uniformly continuous on . Hence, we can choose large enough such that the first term converges to zero (recall also that the covariates are bounded by Assumption (A3, 3). The second and third term converge to zero by Assumptions (AC, 3.17, 3.18), respectively, after possibly increasing further. Keep this choice of fixed for the remainder of the proof.
Lastly we need to discuss (5.67). To this end, we apply a standard union bound technique together with Lemma 2.16. We can estimate when noting the sup in (5.67) is actually only taken over that for every by (5.70)
[TABLE]
The two lines above work completely analogously and hence, we continue only with the first line. The proof of the second line is then identical, we just have to replace by . We will also replace now by for notational convenience, i.e., we show that
[TABLE]
To this end, we apply Lemma 2.16 to the array of random variables
[TABLE]
which is bounded by . Consider the sequence of -partitions as in Assumption (D3). Since , we have that fulfils (2.10) with respect to this -partitioning. The further requirements of Lemma 2.16 on the partitioning were required in (D3). The asymptotic uncorrelation condition of Lemma 2.16 holds by Assumption (D3, 3.9). Note that we show in the proof of Lemma 5.22 that . Thus, we may apply Lemma 2.16 with . We use that for some by Assumption (A6) and that is monotonically increasing to obtain
[TABLE]
The exponent of can be chosen arbitrarily small. By Assumption (D3) converges to zero exponentially fast and we can choose such that vanishes as fast as we want. Thus, also the product with converges to zero. This was the last piece for establishing (5.65).
We can now continue to compute (5.59) or equivalently (5.64). Note that by (5.70) it holds uniformly over all indices that
[TABLE]
as . Thus, the second line in (5.64) converges to zero. The limit of the first line of (5.64) is by using (5.65) the same as
[TABLE]
where we used continuity of from Assumption (A5) and where
[TABLE]
Thus we have proven (5.22) and the proof of Lemma 5.2 is complete. ∎
Lemma 5.20**.**
Suppose that (A1), (A3, 3), (A4, 2) and (A6) hold. Then, there is a constant such that for all and all with it holds for defined in (5.53) that
[TABLE]
where denotes the symmetric difference of and and and are to be understood with respect to .
Proof.
By Lemma 5.9, Assumptions (A1), (A4, (2)) and (A6) we find a constant such that for all and (note that then )
[TABLE]
By the assumption of bounded covariates (A3, 3), we get for any index sets and (i.e. ), that
[TABLE]
∎
Proof of Lemma 5.3.
Let be arbitrary. We have to show that a martingale evaluated at a certain time point converges to zero in probability. By Lenglart’s Inequality as in Corollary 5.27 it is sufficient to prove that the quadratic variation converges to zero in probability. Simply taking the yields for the quadratic variation
[TABLE]
Lemma 5.2 is stating that the second part is converging and hence it is sufficient to prove that the indicator function is converging to zero in probability which is equivalent of proving uniform convergence in probability (uniform in and ) of
[TABLE]
to zero. We are going to employ Lemma 5.22. To this end note firstly that has the following structure
[TABLE]
where is defined in (5.50) and can be written as
[TABLE]
We can simplify the expression by interchanging the integrals, taking the norm inside and using the boundedness properties from Assumption (A3, 3) and Lemma 5.9:
[TABLE]
Now, because the expression in (5.71) is the same as in but with replaced by . Moreover, all mixing properties valid for hold for as well and, of course, is also bounded. Thus, we may repeat the proof of Proposition 5.15 and all subsidiary results (which proofs do not require this Lemma) word by word and (5.71) converges to zero in probability. We also have that (5.72) is by the later proven equation (5.78). Hence, we have shown that
[TABLE]
and this finalizes the proof of the Lemma. ∎
Proof of Lemma 5.4.
Consider the following event
[TABLE]
where is the same as in Lemma 5.9 and suppose for the moment that . On , we find
[TABLE]
by Lemma 5.9. Hence, we conclude
[TABLE]
as required. In order to prove , we have to prove the uniform convergence of to . Denote therefore by a grid of with mesh for some and let for be be the projection of on , i.e., we have . Then we obtain
[TABLE]
The second in (5.73) is converging to zero for chosen large enough because as and by uniform continuity of (cf. Assumption (A5)). To prove that the first part of (5.73) is , we note that by the boundedness Assumption (A3, 3)
[TABLE]
Since and are Hoelder continuous by Assumption (A4, 2) and Lemma 5.8, respectively, the above converges to zero as after possibly increasing further. For this choice of , which we keep fixed from now on, . So finally, we have to prove that (5.74) is also . To this end, we firstly note that the is actually only taken over because we only consider . So we apply a standard union bound technique to get the out of the probability and we include : Let and recall the Definition of from the proof of Proposition 5.18. Then,
[TABLE]
The probability in line (5.76) equals zero for large enough because for we have by the definition of
[TABLE]
Finally, line (5.75) will be treated by applying Lemma 2.16. Note therefore firstly that we may work element-wise because we can estimate the norm from above by the 1-norm and consider each term separately (note that the dimension of the covariates is not increasing). Thus, we may pretend for the following that is a number rather than a matrix. Moreover, we can repeat the following proof word by word for and thus we may consider instead of . We apply Lemma 2.16 to
[TABLE]
is bounded by by (A3, 3). The assumptions on the partitions and asymptotic uncorrelation are fulfilled by Assumption (D3, 3.10) with . Then, the upper bound provided by Lemma 2.16 converges faster to zero than any power of because of the properties of the bandwidth in (A4, 1) and the properties of and the -mixing coefficients from Assumption (D3). This proves that (5.75) converges to zero for any choice of and thus and the proof of the Lemma is complete. ∎
Proof of Lemma 5.5.
We note firstly that by Assumption (A3, 3) for all and all we can estimate by a Taylor approximation
[TABLE]
Hence, we obtain for all and all
[TABLE]
Consequently, we can choose which is if
[TABLE]
So let us prove this. Denote therefore by a grid with mesh (where is chosen later) which covers . For a given time we denote by the closest element of to , i.e., . Now we split the over an uncountable set as usual in a over close elements and a over a finite set:
[TABLE]
We can apply the simple bound and use Hoelder continuity of and , cf. Assumption (A4, 2) and Lemma 5.8 respectively, to see that (5.79) converges to zero in probability. Next, we show that which concludes the proof of the Lemma. We begin, as usual, by taking the out of the probability (and recall that ):
[TABLE]
We will apply Lemma 2.16 to
[TABLE]
As before we use the -partitions as provided in Assumption (D3). Then, all requirements of Lemma 2.16 on the partitions are fulfilled and . Moreover is bounded by and the asymptotic uncorrelation holds also by Assumption (D3, 3.11). As a consequence we can apply Lemma 2.16 to obtain an upper bound on (5.81). Taking into account the assumptions on and the mixing coefficients in Assumption (D3), the upper bound on (5.81) provided by Lemma 2.16 converges faster to zero than any power of for . Therefore as . We conclude that . ∎
Proof of Lemma 5.6.
By employing Lemma 5.22 the proof of this result is fairly straight forward. Let be the constant such that for all where and denote the Euclidean- and the 1-Norm, respectively. We have
[TABLE]
Since
[TABLE]
we can directly apply Lemma 5.22 and obtain
[TABLE]
We see that for a chosen sufficiently large the first term decreases faster as . Moreover, by Assumption (D3), decreases fast enough too. Finally, decreases fast enough as well by the same assumption. ∎
Proof of Lemma 5.7.
Let . We begin with the standard union bound argument:
[TABLE]
The above probability can be shown by Lemma 2.16 to decrease faster than any power when is chosen large enough. As a matter of fact we argued already that Lemma 2.16 can be applied in this situation when we discussed (5.75). We just have to replace by an arbitrary . But this does not change the argument and all necessary assumptions were made in Assumption (D3). ∎
5.4 Primitive Assumptions for (D1)
In this section we provide additional assumptions under which the conditions (2.4)-(2.8) of Theorem 2.11 can be proven. These additional assumptions are in the spirit of the assumptions (H2) and (AD). Therefore, we present them here as extensions of them.
(H2) Hub size restriction
There is a deterministic sequence such that with
[TABLE]
The extension of (H2) requires a deterministic bound to the maximal hub-size. This seems restrictive but for large networks it is believable that even highly connected actors are only connected to a fraction of the whole network. Keep also in mind, that connected here really means active influence. So if we were to allow that there is one single pair who influences the entire network, then statistical inference is (at least intuitively) impossible.
Denote
[TABLE]
(AD) Additional Dependence
Let be arbitrary and consider the following choices for the pair
[TABLE]
where and are the Hoelder exponent and constant of , respectively. For any given we can choose such that for both choices above it holds that
[TABLE]
Moreover, there is such that for all , it holds that
[TABLE]
Assumption (AD, 5.84) is essentially stating that not too many jump at the same time. Note that (AD, 5.84) could be proven (similar as for (AD, 3.13)) by using other technical assumptions. In order to prove these assumptions we need an exponential inequality for averages of counting processes. Such an inequality can be shown by employing -mixing as in the proof of Lemma 2.15. However, instead of using the Bernstein inequality (see e.g. Proposition 5.25) we need a tail bound valid for independent sums of counting processes with bounded intensity functions. For our purposes it is sufficient to use a tail bound induced by using Chebyshev’s Inequality in its exponential form. For the remaining assumptions we emphasize that they are requiring a polynomial growth of certain moments. Since the power of the polynomial can be chosen arbitrarily, we regard these assumptions as easy to believe.
Lemma 5.21**.**
Suppose that the the assumptions (H2) and (AD) hold in their extended form as above. Then, the conditions (2.4)-(2.8) of Theorem 2.11 hold for as in (5.53) with .
Proof.
We begin with (2.4). Note that by Assumption (H1), is measurable with respect to for all and that by (A2, 3) is bounded by . Denote . We get by applying the estimate (5.69) from Lemma 5.20 for any and any
[TABLE]
We keep this in mind and make a similar estimation for (2.5): We use (5.69) in Lemma 5.20 in order to obtain (the step from (5.92) to (5.93) is unmotivated at this point, but will be useful later)
[TABLE]
A simple application of Markov’s Inequality is hence showing that implies that . To show the former we make the following definitions. Denote . Using that , we can calculate that
[TABLE]
Define and continue with the estimation:
[TABLE]
Define . By using Itô’s Lemma (cf. Theorem 5.30) for the semi-martingale in the first step we obtain for fixed constants
[TABLE]
Line (5.96) converges to zero by (5.27) and . Line (5.97) converges to zero by Lemma 5.23 and Assumption (AD, 5.85). For line (5.95) we use Lemma 5.23 together with Assumption (AD, 5.86) to show that it converges to zero for the correct choices of and . For line (5.94) we note that for
[TABLE]
is bounded by Assumptions (H2, 3.4), (AD, 5.87) and Lemma 5.23. Thus we have shown that (2.4) and (2.5) hold.
For showing condition (2.6) we define the random number of active edges as
[TABLE]
and use this to estimate for all , all and all
[TABLE]
In addition to the above estimate, we also observe that
[TABLE]
Using these two estimates together with the estimate in (5.69), we obtain
[TABLE]
Note that . Hence, we just saw in the proof of (2.5) (cf. (5.93)) that the first part above converges to zero. For the second part we employ similar techniques, i.e., we condition on the event that is bounded. So for any the second part above (without the square root) can be bounded by
[TABLE]
By the Assumptions (AD, 3.13, 5.90, 5.88) the expression above converges to zero and we have shown (2.6).
The indicator function in (2.7) is not significantly shortening the sum and hence we just ignore it. Moreover, we use the bound from (5.98) to obtain for any
[TABLE]
The expression above converges to zero by Assumptions (D2, 3.6), (AD, 3.13, 5.89). Hence, we have also that (2.7) holds.
For (2.8) we finally use that for every fixed choice of we get
[TABLE]
Thus, we obtain together with (5.98)
[TABLE]
The above converges to zero by conditioning on and the Assumptions (H2, 3.4) and (AD, 3.13, 3.14). Hence, we have shown that (2.8) holds as well. ∎
5.5 Further Proofs
Proof of Lemma 2.7.
Note that . Hence, is adapted with respect to and is predictable with respect to . So is a counting process for all . In order to check that is the intensity function, we need to check the martingale property: Let and , then by definition and assumption (recall )
[TABLE]
∎
Proof of Proposition 2.9.
The proof is almost exactly along the lines of Mammen and Nielsen [32] but it is not identical and we give it here for completeness. We see at first that
[TABLE]
We use now that and are both predictable with respect to and that and are uncorrelated martingales with respect to the same filtration (cf. Lemma 2.7). Hence, we obtain
[TABLE]
and the statement follows. ∎
The following result provides an exponential inequality for martingales. Note that the result is different from van de Geer [47] because the asymptotics in the motivation are different and in the following result we can avoid appearance of the higher order variation process in the probability.
Lemma 5.22**.**
Suppose that (A3, 3) and (A4, 2) hold. Recall the following definitions from (A3) and (A4): is the bound on the intensity function, the bound on the kernel and the bound on the covariates. Let be so large such that
[TABLE]
Suppose we have a -partition measurable with respect to (we write for ease of notation)
[TABLE]
for some and all . Define furthermore for arbitrary and ,
[TABLE]
Assume that there is such that for all
[TABLE]
Then it holds that
[TABLE]
where is the dimension of the covariate and is the constant for which for all and and are the Euclidean and -Norm respectively. The process can be replaced by any other predictable process which is bounded by .
Proof.
We remark firstly that it is sufficient to consider univariate covariates, because (denote by the -th entry of for )
[TABLE]
Since is a covariate with the exact same properties as (in particular predictability with respect to and boundedness by , cf. Assumption (A3, 3), it is sufficient to assume (for simplicity of notation) that is univariate and to prove that
[TABLE]
The main idea of the proof is to apply Lemma 2.15 to the correct structured interaction network (in the sense of Definition 2.2). Define to this end
[TABLE]
Note that both, and , are predictable processes because they are deterministically equal to zero for and the sets are predictable with respect to . Hence, is a martingale. We are going to prove that fulfils the conditions of Lemma 2.15. Condition (2.10) is easy to check. Note that for we have and hence
[TABLE]
Thus, condition 2 of Lemma 2.15 holds simply by assumption and definition of . The main part of this proof is now to prove condition 1. Note therefore firstly that
[TABLE]
Hence, we need to show for
[TABLE]
We will show (5.102) for all and then it holds particularly in the case which is of primary interest to us. The idea of the proof is to prove a recursion inequality for the moments of stochastic integrals by applying Itô’s Formula and then using induction. Note that for . Therefore, (5.102) holds trivially for and it holds for when it holds for . Hence, we can restrict to the case .
For we have that the function is twice continuously differentiable and hence also is twice continuously differentiable. So by the multivariate Itô Formula for semi-martingales with jumps given in Theorem 5.30 and the fact that with probability one no two counting processes jump at the same time, we obtain for : Enumerate for the following computations the pairs in , i.e., such that . Then,
[TABLE]
and we can compute
[TABLE]
Note now that
[TABLE]
Hence, (*) contains a Taylor series expansion of around the point
[TABLE]
and we continue:
[TABLE]
where \Delta(s)\in\Big{[}0,\sum_{r\in L_{n}}F_{n,r}^{k,m}(s)\Delta N_{n,r}(s)\Big{]}. Since only one of the counting processes jumps at a time, we obtain with and continue by using again that no two processes jump at the same time:
[TABLE]
where we used in the last line that when . Now, the integrand is predictable and we can apply the expectation on both sides, to obtain a recursion formula: Use that for we have to get
[TABLE]
Define to summarize the previous inequality chain in the following recursion formula: For it holds almost surely
[TABLE]
By uniting the (countably many) exception sets of measure zero, these inequalities hold for all and all on the same set of measure one. Since both sides are continuous from the right (cf. Corollary 5.1.9 in Cohen and Elliott [7]), we also have it for all on the same set of measure one. Taking now limits from the left and repeating the same argument with continuity from the left, we obtain the same result for on the left hand side also on the same set of measure one.
We are going to prove now via induction that almost surely (on the same set of measure one)
[TABLE]
We begin with the induction start: For , (5.103) gives for all
[TABLE]
where the last inequality holds by choice of in (5.100) and because . Hence, the induction start is complete and we continue with the induction step. Assume that (5.104) holds for all powers and all and show that it holds for and all as well. We use first (5.103), then the binomial theorem and finally the induction hypothesis (5.104) for powers greater than one:
[TABLE]
Recall that for all and as well as for all , moreover is measurable with respect to . Hence, we may estimate
[TABLE]
Using this estimation we continue with the main inequality chain
[TABLE]
At this point, we see that we’re obviously done with the induction step if . Hence, we only need to show that the above is lesser than or equal to (5.104) on the event . This, in turn, we may conclude if the second part above is smaller than or equal to one (on the event ). This is the case because we have chosen appropriately and because and (and thus also ) on :
[TABLE]
and the induction is complete. To finalize the proof, we compute the expectation of . Note that on ,
[TABLE]
Taking expectations on both sides of (5.104) and together with the previous line, we obtain
[TABLE]
Hence, condition 1 of Lemma 2.15 is fulfilled and we can apply it to get
[TABLE]
∎
Lemma 5.23**.**
Let and be defined as in the proof of Lemma 5.2. For any there is and such that
[TABLE]
Proof.
The proof follows standard arguments. Let denote a discrete grid of with many elements such that for any with it holds that . Then,
[TABLE]
For the first probability we note that for the intervals and are overlapping on a length of at most and the area covered by only one interval is of length at most . We get for when using (recall that is bounded by )
[TABLE]
The last line is deterministic and converges faster to zero than by the Hoelder continuity of (cf. Assumption (A6)) and since grows moderately (cf. Assumption (H2, (5.83))). For the expressions in the first line, we note that in the end it comes down to evaluating expressions of the type where equals either or . In Assumption (AD, 5.84) we assume that in both cases the average behaves in such a way that the first probability in (5.106) converges to zero as fast as required if is chosen large enough. We keep this choice of fixed for the remainder of the proof.
For the second part of (5.106), we rewrite
[TABLE]
For both parts we have exponential inequalities available in Lemmas 5.22 and 2.16, respectively. So we just have to check that their conditions hold. Since is bounded by , we can divide by the bound and apply Lemma 5.22 with and . Note firstly that by Assumption (A6) we can replace the by when adding a multiplicative constant which we can compensate for by choosing appropriately. Moreover, by Assumption (D3) there are -partitions as required and the -mixing coefficients decay exponentially fast. Since , the mixing coefficients decay as fast as required. Moreover, by the same assumption, vanishes exponentially fast. Finally, by Assumption (H4, 5.83), the bound on behaves exactly such that also the leading term decays as fast we want if is chosen large enough. Therefore, the probability that the first part of (5.107) is larger than decreases to zero faster than any given power of for large enough .
The second term in (5.107) can be bounded by analogous arguments and Lemma 2.16. Denote . Then by Assumption (H2, 3.4) (note that is independent of and ). Keeping this in mind we obtain for the second term in (5.107) for small enough for all and
[TABLE]
Choose in the same way as in Lemma 5.22 with . Then and also is as defined in Lemma 5.22. Therefore all restrictions on the -partitioning are fulfilled by Assumption (D3) and the mixing coefficients vanish exponentially fast. Moreover vanishes exponentially fast. Lastly, by Assumption (D3, 3.12), the asymptotic uncorrelation conditions hold. Hence, we may apply Lemma 2.16 and obtain the desired results by the same arguments as for the first part of (5.107) by using again Assumption (H2, 5.83).
The proof of the concentration inequality for follows from similar arguments. ∎
5.6 Details for Example 2.5.3
Let and be two pairs of random variables with
[TABLE]
We suppose that all have the same dimension . The matrix contains the covariances of and . Let denote the determinant of a matrix and is the identity matrix. We can compute that (use formulas for the Kullback-Leibler divergence of two multivariate normals and for the determinant of block-matrices)
[TABLE]
Suppose that the entries of are small and that and are positive definite. In that case has small eigenvalues and is positive definite. With this we may continue the estimation by applying the bound and using the Neumann Series representation:
[TABLE]
Let every entry of be bounded in absolute value by . Then, there is such that each entry of is in absolute value bounded by . And by induction each entry of is bounded by . Then, we continue
[TABLE]
We have shown in (2.14) that . Moreover, . Recalling in addition that , we conclude overall that exponentially fast for .
5.7 Useful Results
For the convenience of the reader, we collect some result which are needed in the proofs.
We will consider the Grouping Lemma in the following form (Rio [43], Lemma 5.1 therein).
Lemma 5.24**.**
Let be a -field in and let be a random variable with values in a Polish space . Let be a random variable with uniform distribution over which is independent of the -field generated by and . Then, there exists a random variable which has the same law as and which is independent of , such that . Furthermore, is measurable with respect to the -field generated by and .
The Bernstein Inequality will be used in this form (cf. Giné and Nickl [17]).
Proposition 5.25**.**
Let , be a sequence of independent, centred random variables such that there are numbers and such that for all . Set , . Then, for all .
Lenglart’s Inequality shows how a martingale may be controlled by using the quadratic variation. We state in the following a slight adaptation of the original version as it is provided in Lenglart [29].
Lemma 5.26**.**
Let be a non-negative, right-continuous local sub-martingale and denote by its compensator. Then it holds for all finite stopping times and all that
[TABLE]
In this paper, we will apply Lenglart’s Inequality mostly in the following form which is close to Andersen et al. [3]. The following is an easy corollary to the previous lemma.
Corollary 5.27**.**
Let be a locally square integrable, right-continuous martingale and denote by it’s compensator.
For all we have
[TABLE] 2. 2.
For all it is true that
[TABLE]
The main tool for finding the asymptotic distributions in this paper is Rebolledo’s Martingale Central Limit Theorem. It is known that a Brownian Motion is the only continuous Gaussian process with a certain covariance structure. This is used to formulate a martingale central limit theorem in the following. We state here the version of the theorem as Theorem II.5.1 in Andersen et al. [3], the original work is Rebolledo [42].
Let be a vector of sequences of locally square integrable martingales on an interval . For we denote by a vector of locally square integrable martingales that contain all jumps of components of which are larger in absolute value than , i.e., is a local square integrable martingale for all and . Furthermore, we denote by the matrix of quadratic covariations. Moreover, we denote by a multivariate, continuous Gaussian martingale with , where is a continuous deterministic positive semi-definite matrix valued function on such that its increments are also positive semi-definite for , then is independent of . Given such a function , such a Gaussian process always exists. We can now formulate the central limit theorem for martingales.
Theorem 5.28**.**
Let . Assume that for all as
[TABLE]
Then
[TABLE]
as for all .
We remark that the predictable quadratic variation may be replaced by the optional quadratic variation. But we do not use that in this paper.
Finally, the theorem by Kantorovich gives a relation between the solution of an equation system and its derivative at the solution (see e.g. Deimling [12]):
Theorem 5.29**.**
(Newton-Kantorovich Theorem) Let be a system of equations where is a function defined on . Let be differentiable and denote by its first derivative. Assume that there is an such that all expressions in the following statements exist and such that the following statements are true
, 2. 2.
, 3. 3.
* for all ,* 4. 4.
* and .*
Then there is with and
[TABLE]
We also use Itô’s Formula for semi-martingales with jumps (Theorem 14.2.4 in Cohen and Elliott [7]). Here is to be understood as the cadlag modification of (cf. Corollary 5.1.9 in Cohen and Elliott [7]).
Theorem 5.30**.**
Let be a -dimensional vector of semi-martingales and let be a twice continuously differentiable function. Then,
[TABLE]
The above equality means that the processes to the left and to the right are indistinguishable and denotes the optional covariation of and (see below).
The optional quadratic variation of a cadlag square integrable local martingale is given by . The optional covariation for two such martingales and is given by .
Acknowledgement This work is part of my PhD Thesis which I have written under the supervision of Prof. Dr. Enno Mammen (Heidelberg University) and Prof. Dr. Wolfgang Polonik (UC Davis). I am thankful for many discussions and helpful remarks. My work was supported by Deutsche Forschungsgemeinschaft through the Research Training Group RTG 1953.
I am also very thankful for the comments of the associate editor and two referees, their suggestions significantly contributed to a great improvement the paper.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Andersen and Gill [1982 a] P. K. Andersen and R. D. Gill. Cox’s regression model for counting processes: A large sample study. Ann. Statist. , 10(4):1100–1120, 12 1982 a.
- 2Andersen and Gill [1982 b] P. K. Andersen and R. D. Gill. Cox’s regression model for counting processes: A large sample study. The Annals of Statistics , 10(4):1100–1120, 1982 b.
- 3Andersen et al. [1993] P. K. Andersen, O. Borgan, R. D. Gill, and N. Keiding. Statistical Models Based on Counting Processes . Springer, 1993.
- 4Brownlees et al. [2018] C. Brownlees, E. Nualart, and Y. Sun. Realized networks. Journal of Applied Econometrics , 33(7):986–1006, 2018.
- 5Butts [2008] C. T. Butts. A relational event framework for social action. Sociological Methodology , 38(1):155–200, 2008.
- 6Chen and Shao [2004] L. H. Y. Chen and Q.-M. Shao. Normal approximation under local dependence. Ann. Probab. , 32(3):1985–2028, 07 2004.
- 7Cohen and Elliott [2015] S. N. Cohen and R. J. Elliott. Stochastic Calculus and Applications . Birkhäuser, 2015.
- 8Cox [1972] D. R. Cox. Regression models and life-tables. Journal of the Royal Statistical Society. Series B (Methodological) , 34(2):187–220, 1972.