Cosmological constraints with deep learning from KiDS-450 weak lensing maps
Janis Fluri, Tomasz Kacprzak, Aurelien Lucchi, Alexandre Refregier,, Adam Amara, Thomas Hofmann, Aurel Schneider (ETH Zurich)

TL;DR
This paper demonstrates that convolutional neural networks applied to KiDS-450 weak lensing maps can improve cosmological parameter constraints by about 30% over traditional power spectrum methods, showing promise for future cosmological analyses.
Contribution
The study introduces a CNN-based analysis pipeline for weak lensing maps that outperforms traditional methods in constraining cosmological parameters, validated on real data with robustness tests.
Findings
CNN yields 30% tighter constraints than power spectrum analysis.
Robustness of CNN constraints tested against baryonic feedback and simulation uncertainties.
Constraints obtained: S8=0.777+/-0.037, A_IA=1.398+/-0.751.
Abstract
Convolutional Neural Networks (CNN) have recently been demonstrated on synthetic data to improve upon the precision of cosmological inference. In particular they have the potential to yield more precise cosmological constraints from weak lensing mass maps than the two-point functions. We present the cosmological results with a CNN from the KiDS-450 tomographic weak lensing dataset, constraining the total matter density , the fluctuation amplitude , and the intrinsic alignment amplitude . We use a grid of N-body simulations to generate a training set of tomographic weak lensing maps. We test the robustness of the expected constraints to various effects, such as baryonic feedback, simulation accuracy, different value of , or the lightcone projection technique. We train a set of ResNet-based CNNs with varying depths to analyze sets of tomographic KiDS…
Click any figure to enlarge with its caption.
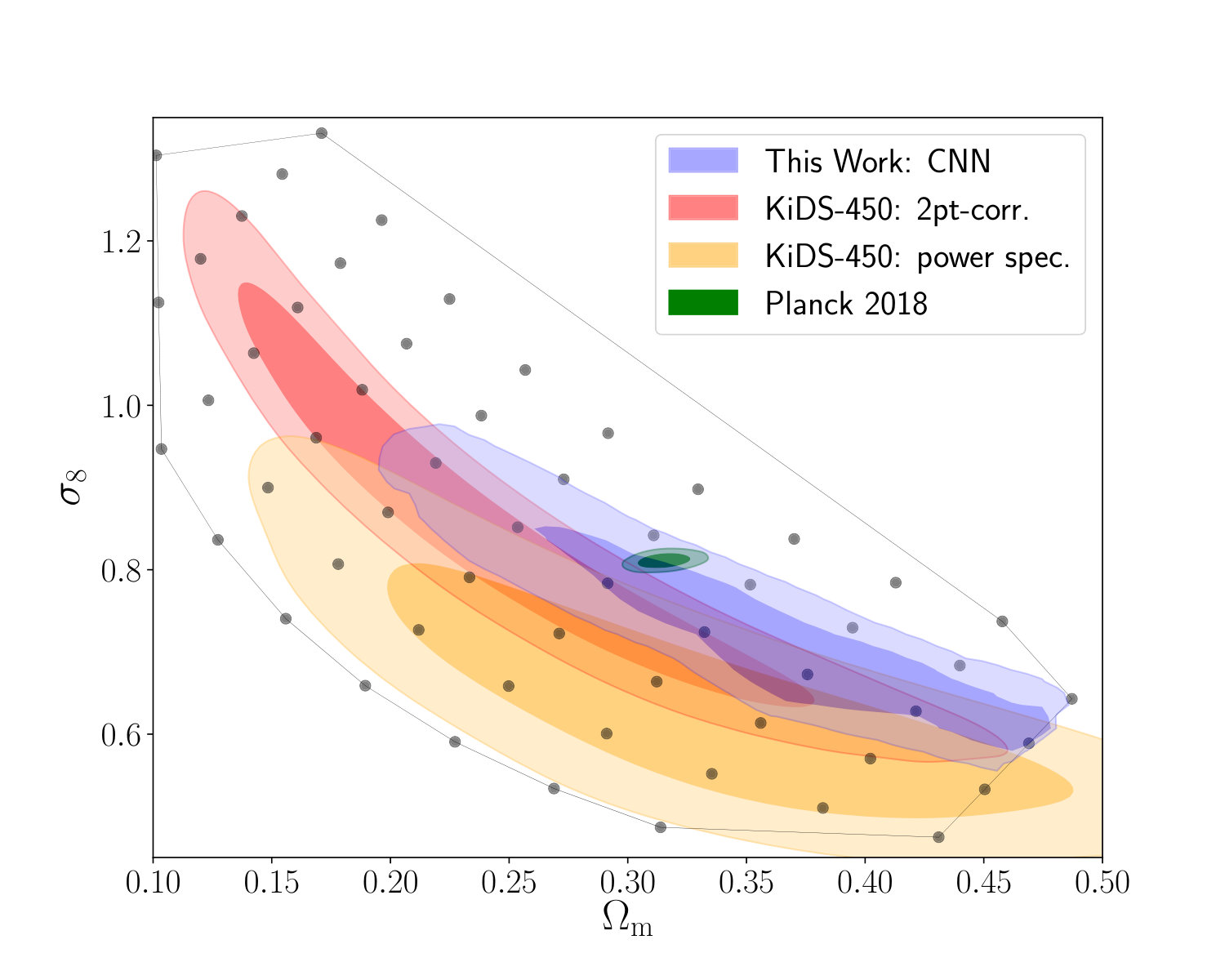 Figure 1
Figure 1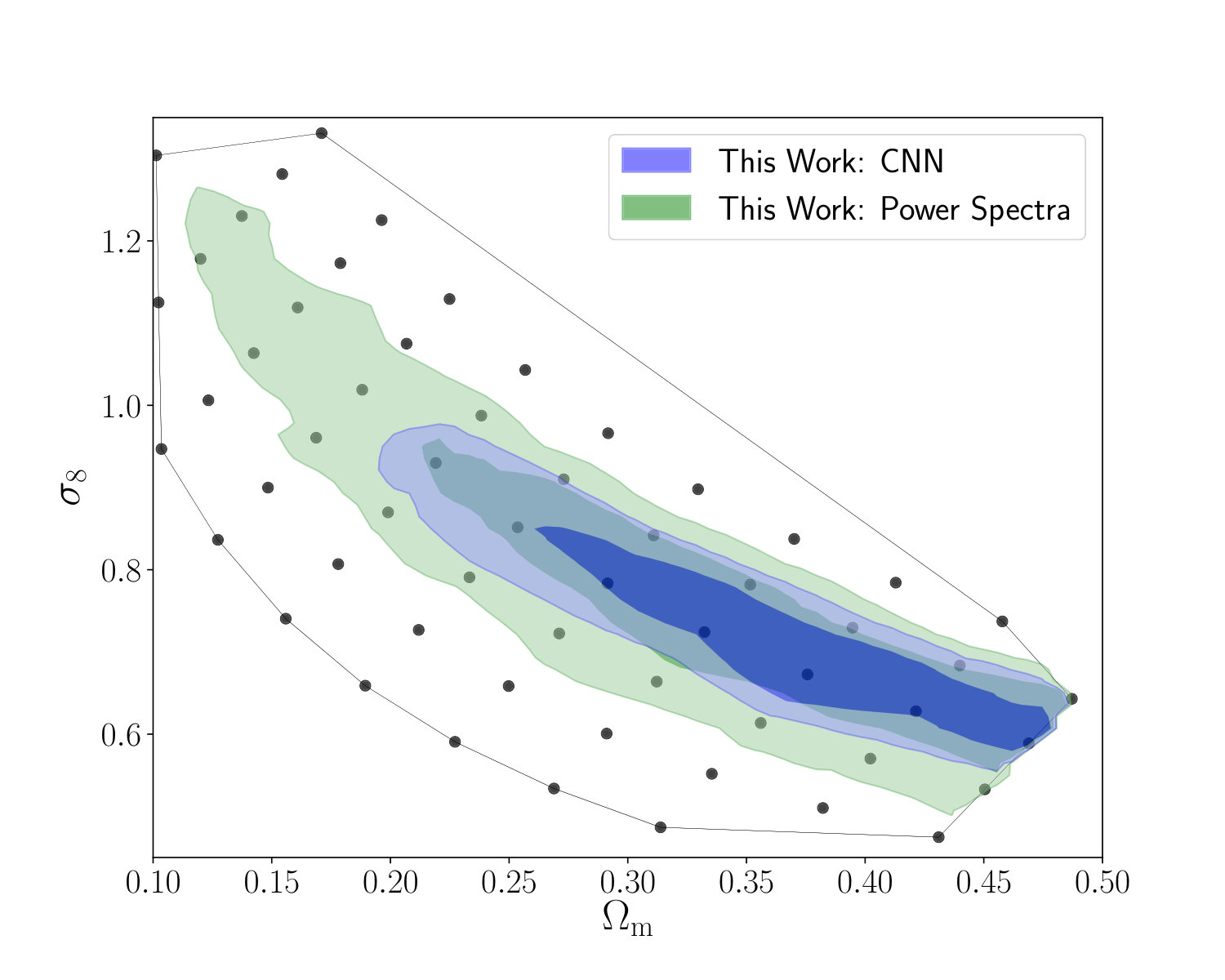 Figure 2
Figure 2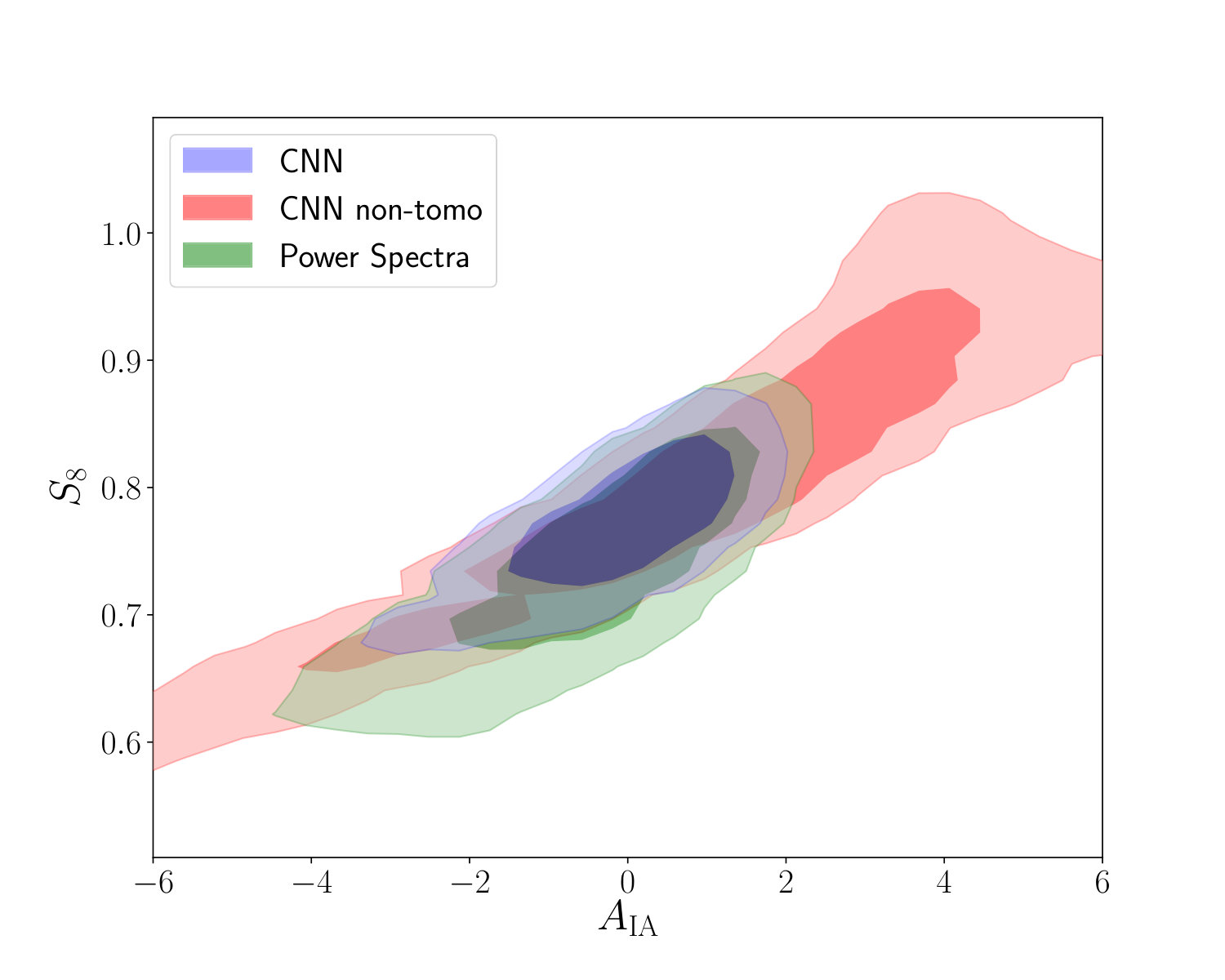 Figure 3
Figure 3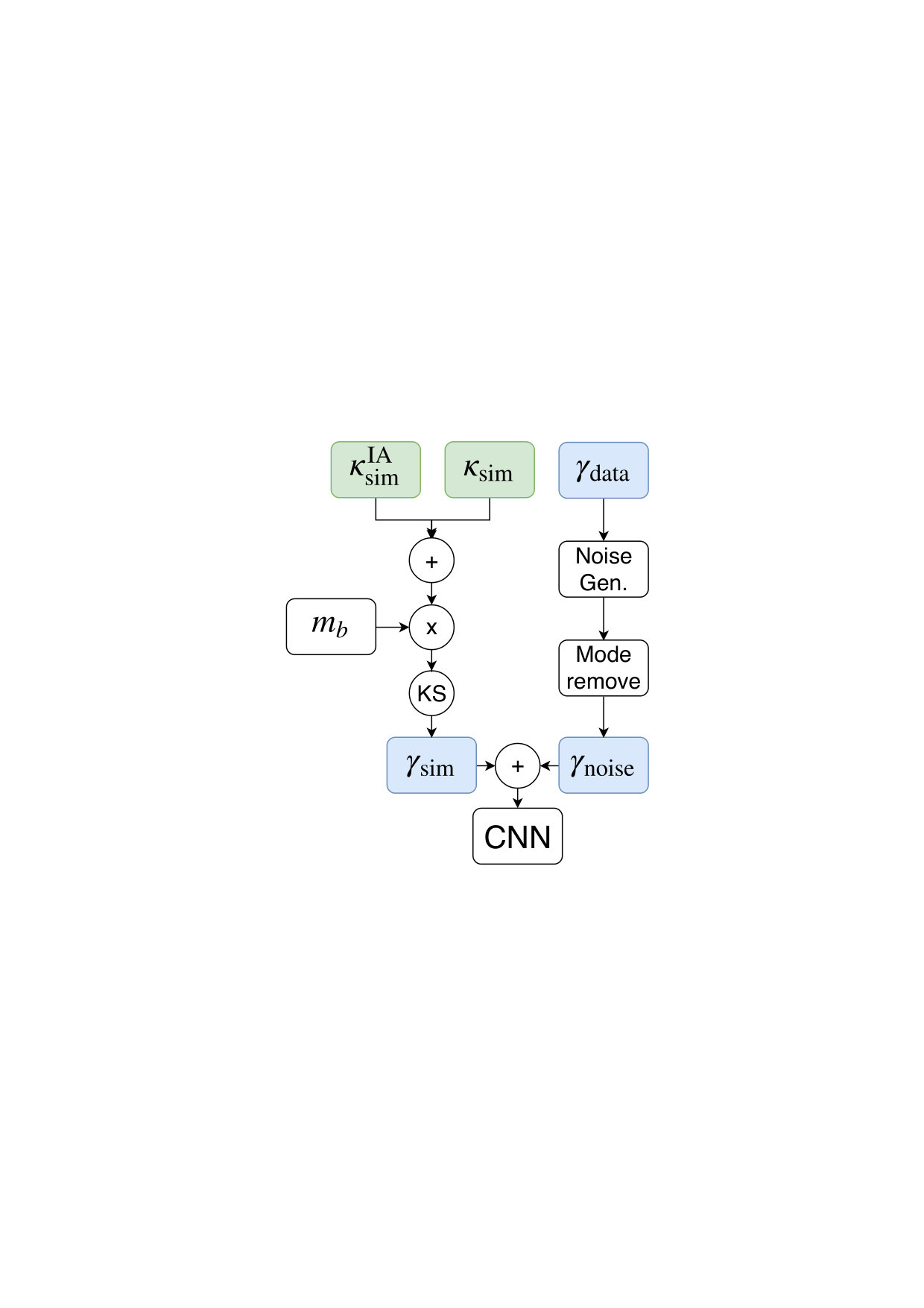 Figure 4
Figure 4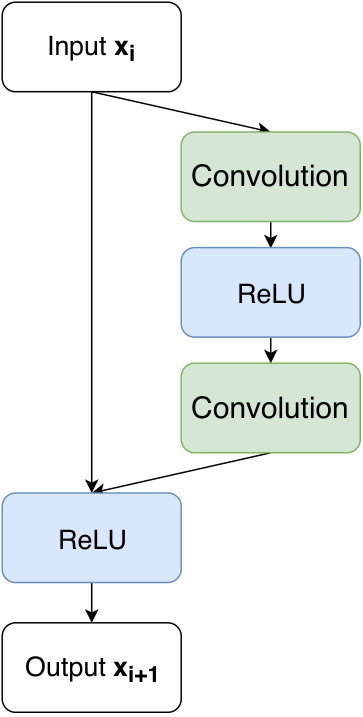 Figure 5
Figure 5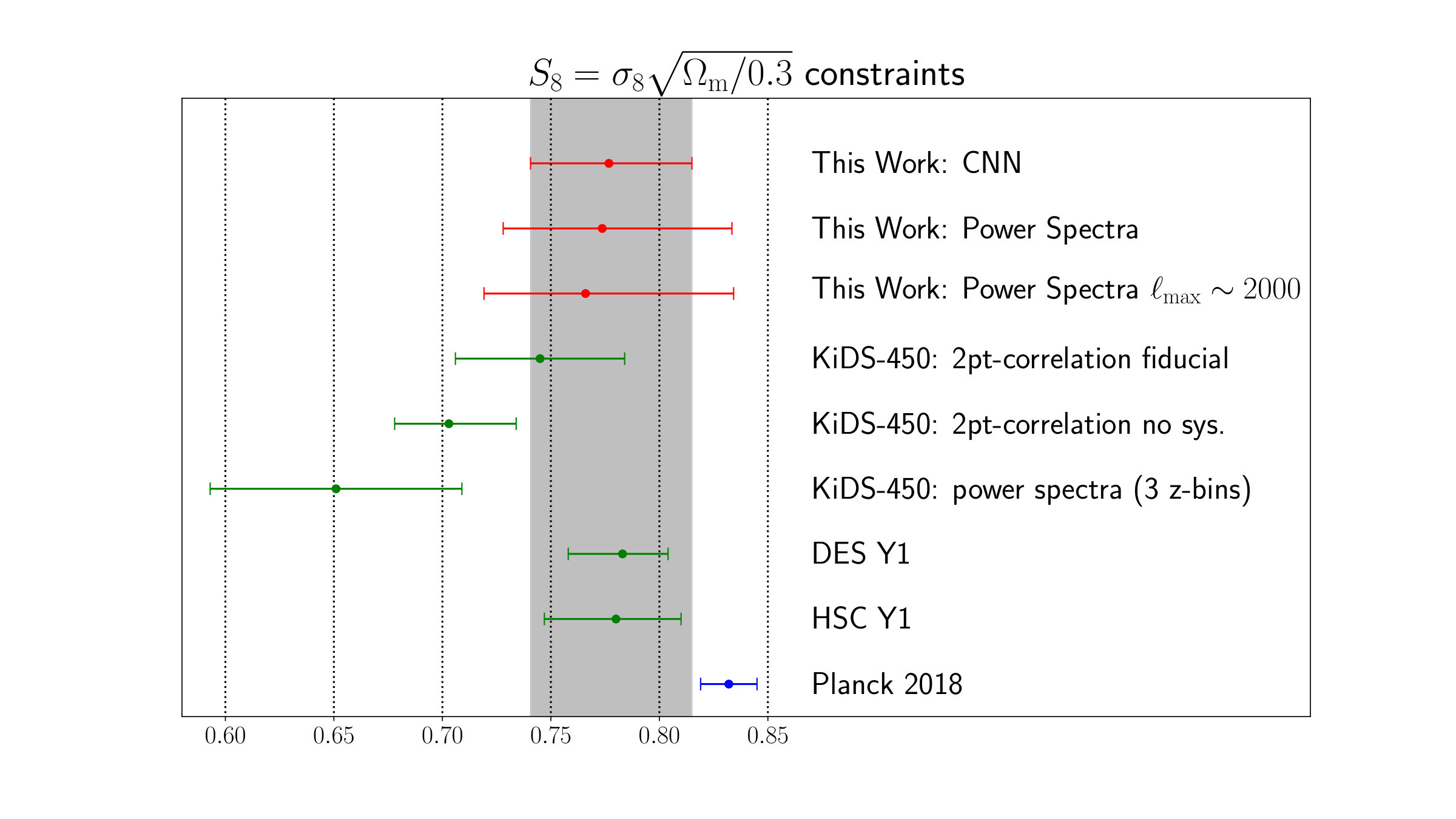 Figure 6
Figure 6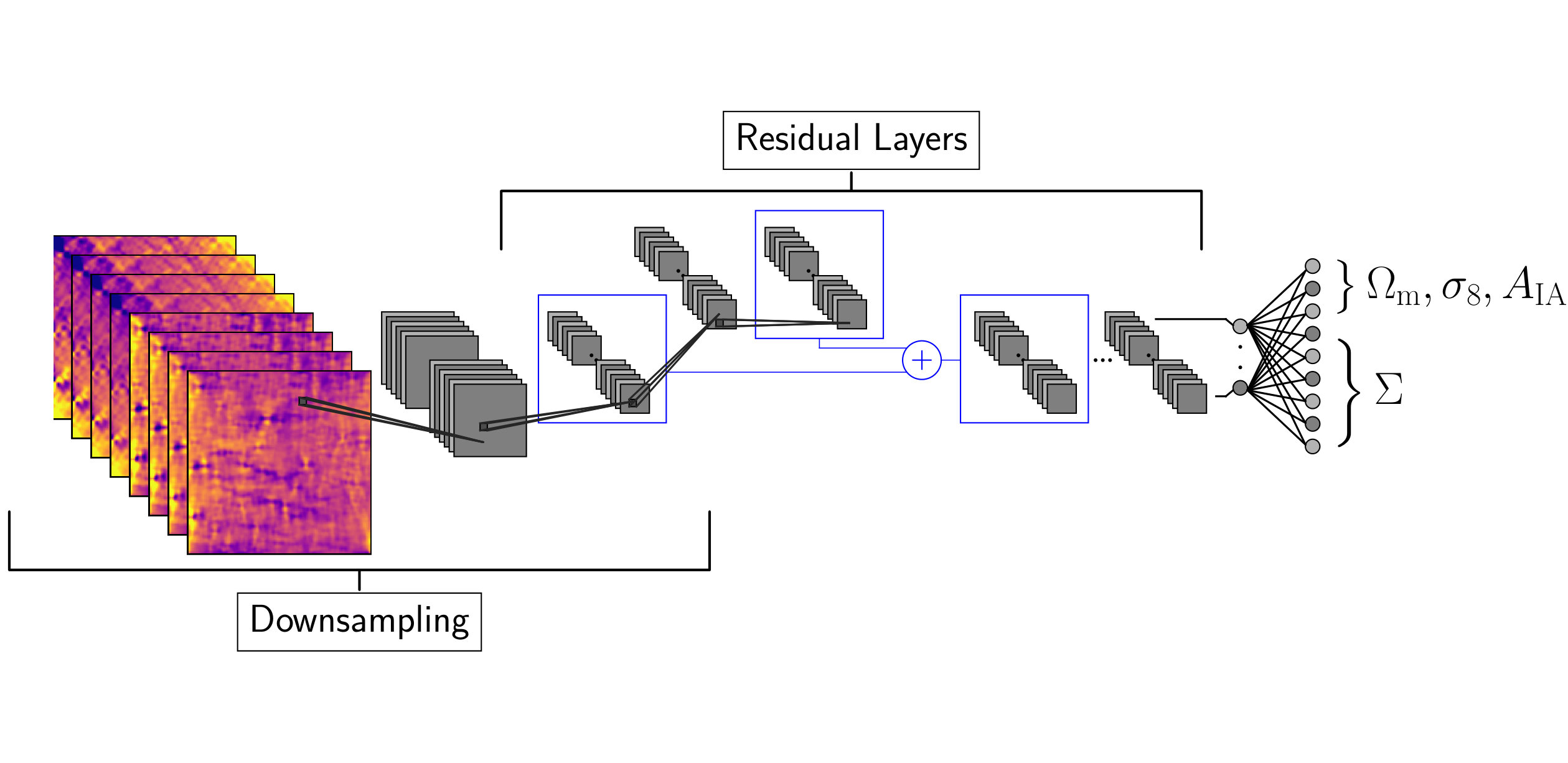 Figure 7
Figure 7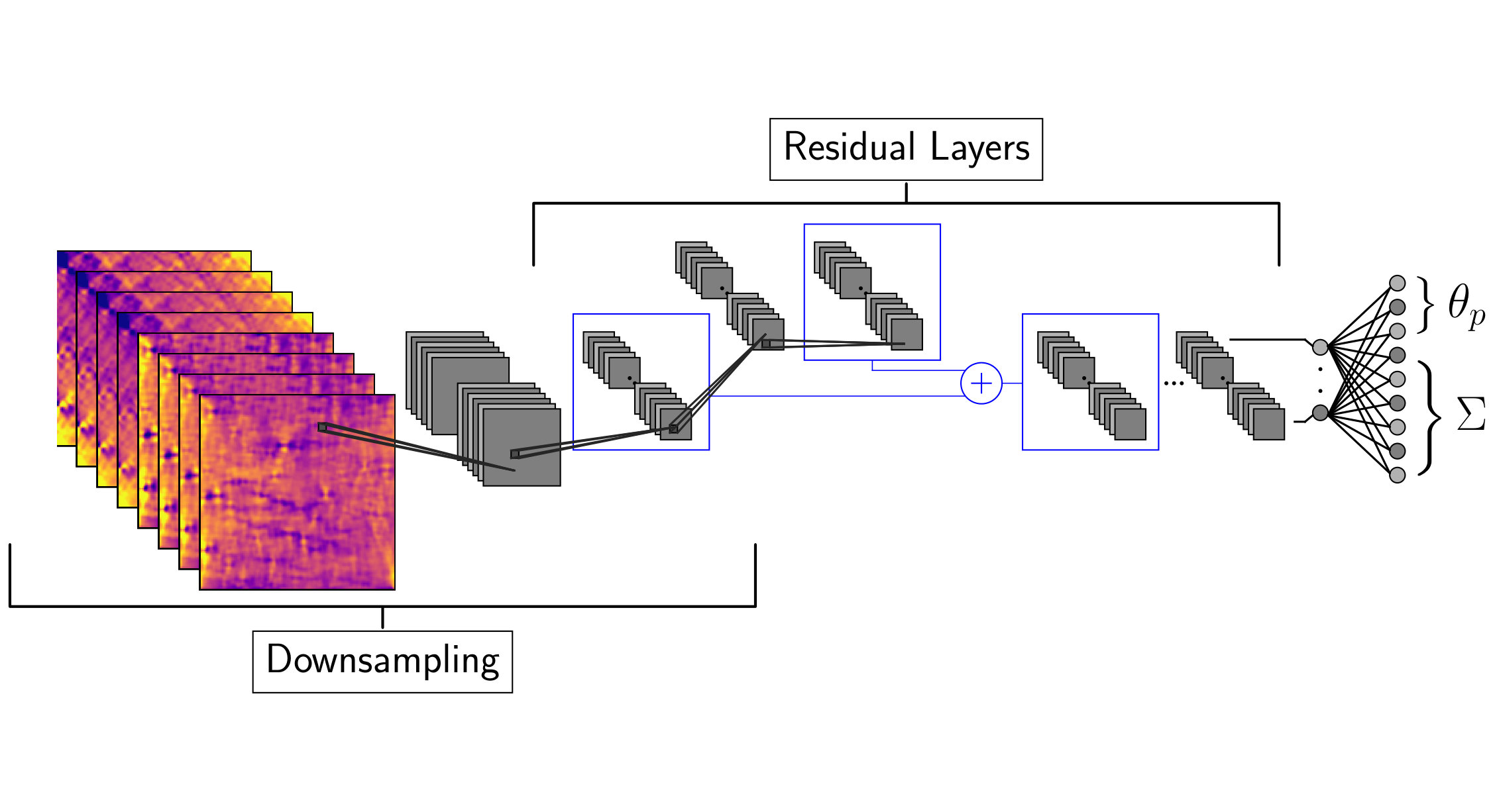 Figure 8
Figure 8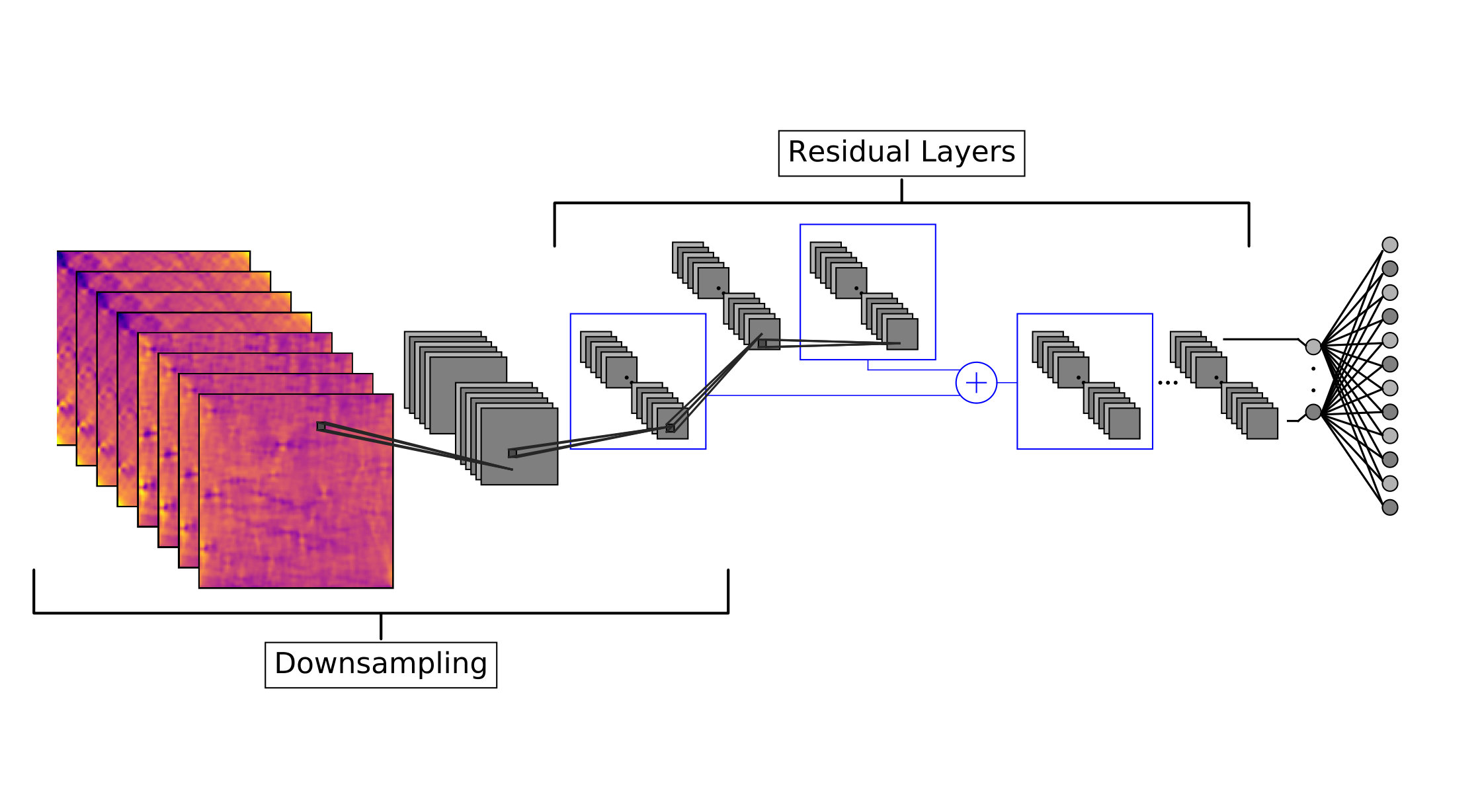 Figure 9
Figure 9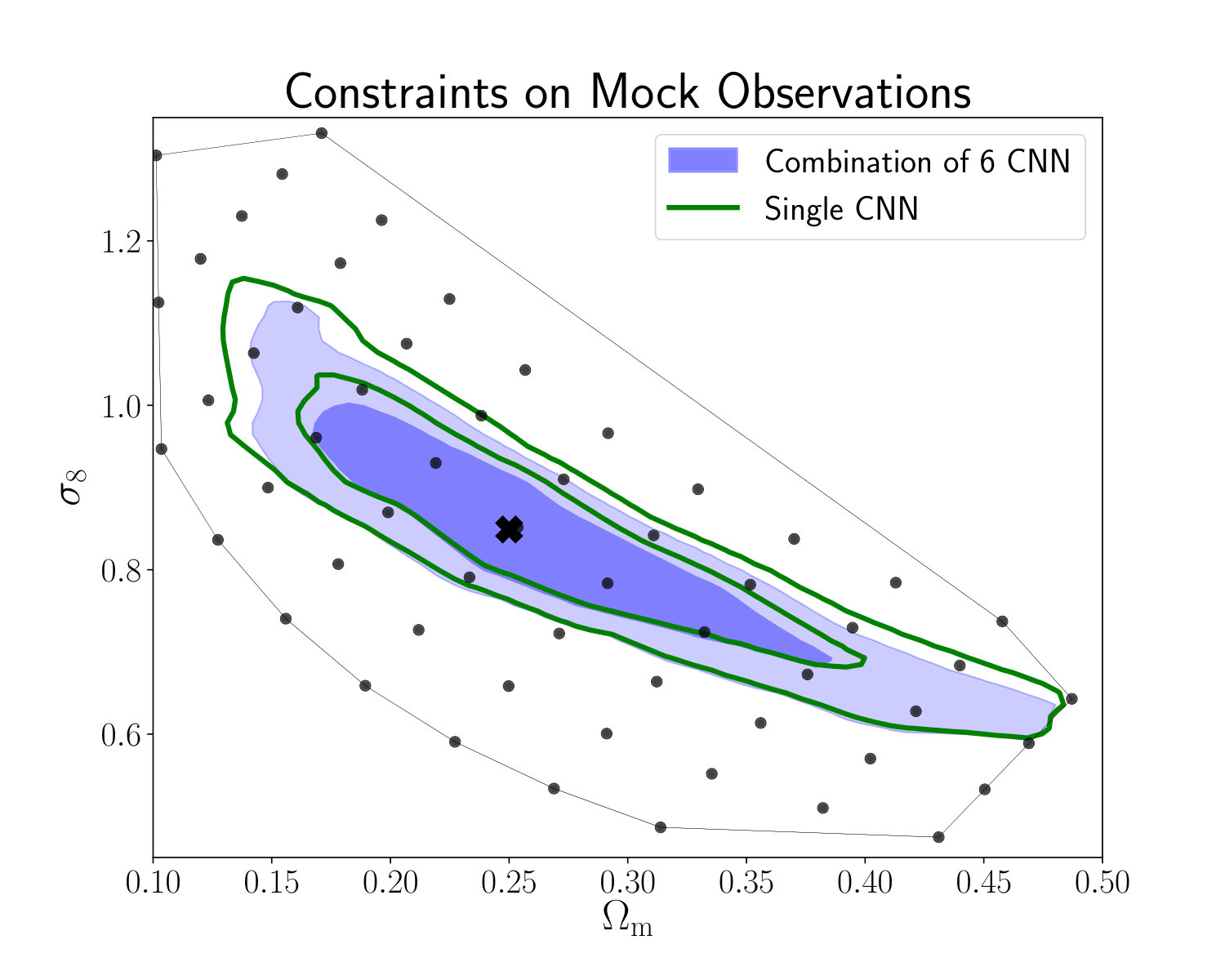 Figure 10
Figure 10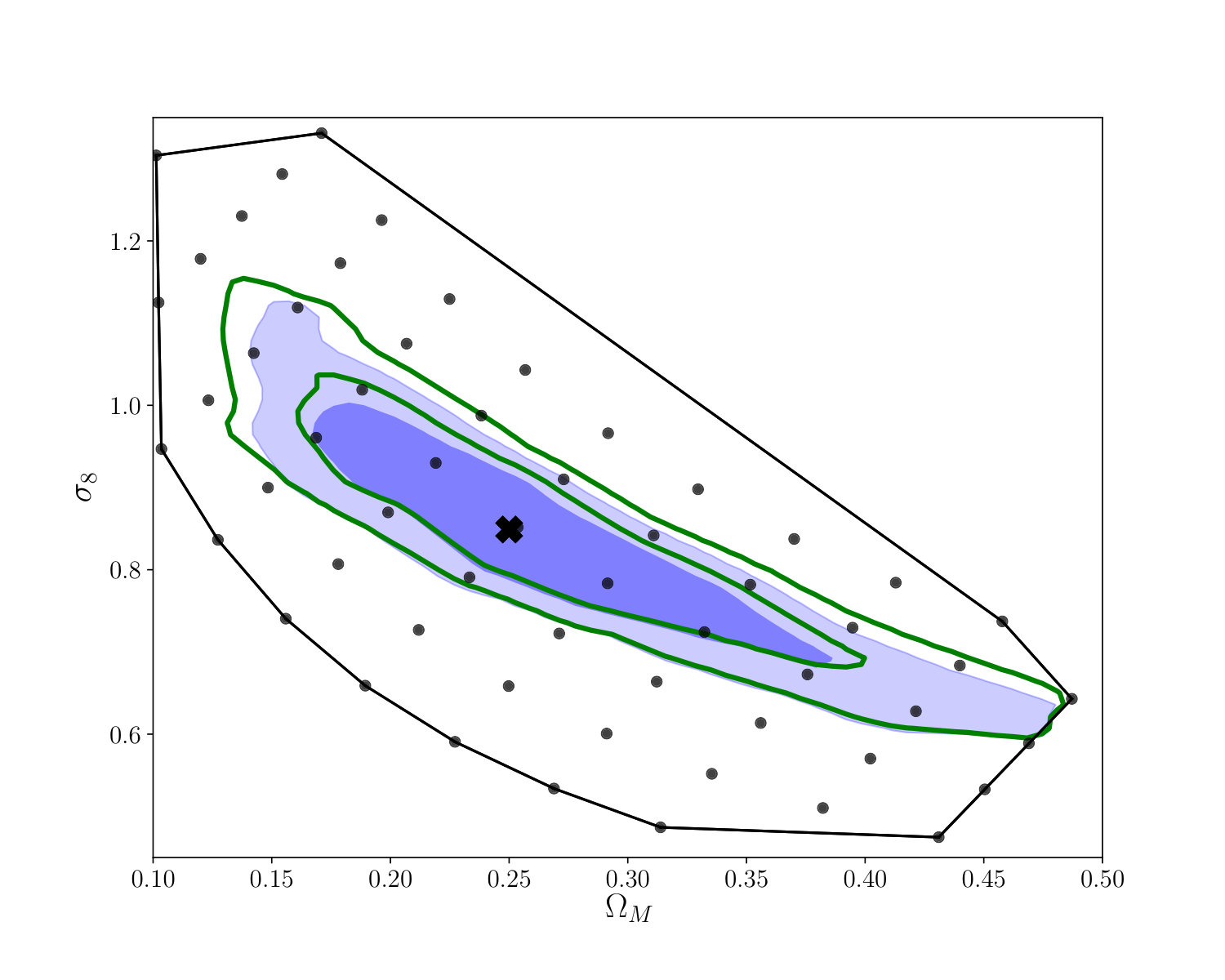 Figure 11
Figure 11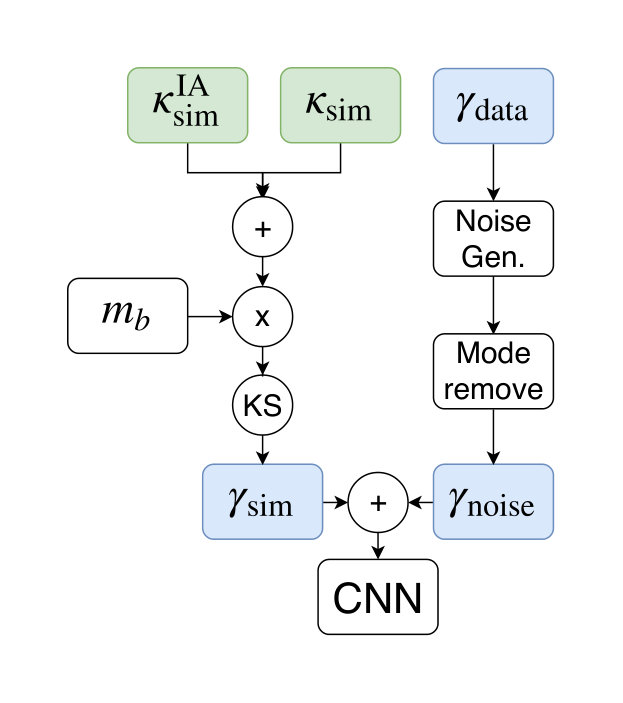 Figure 12
Figure 12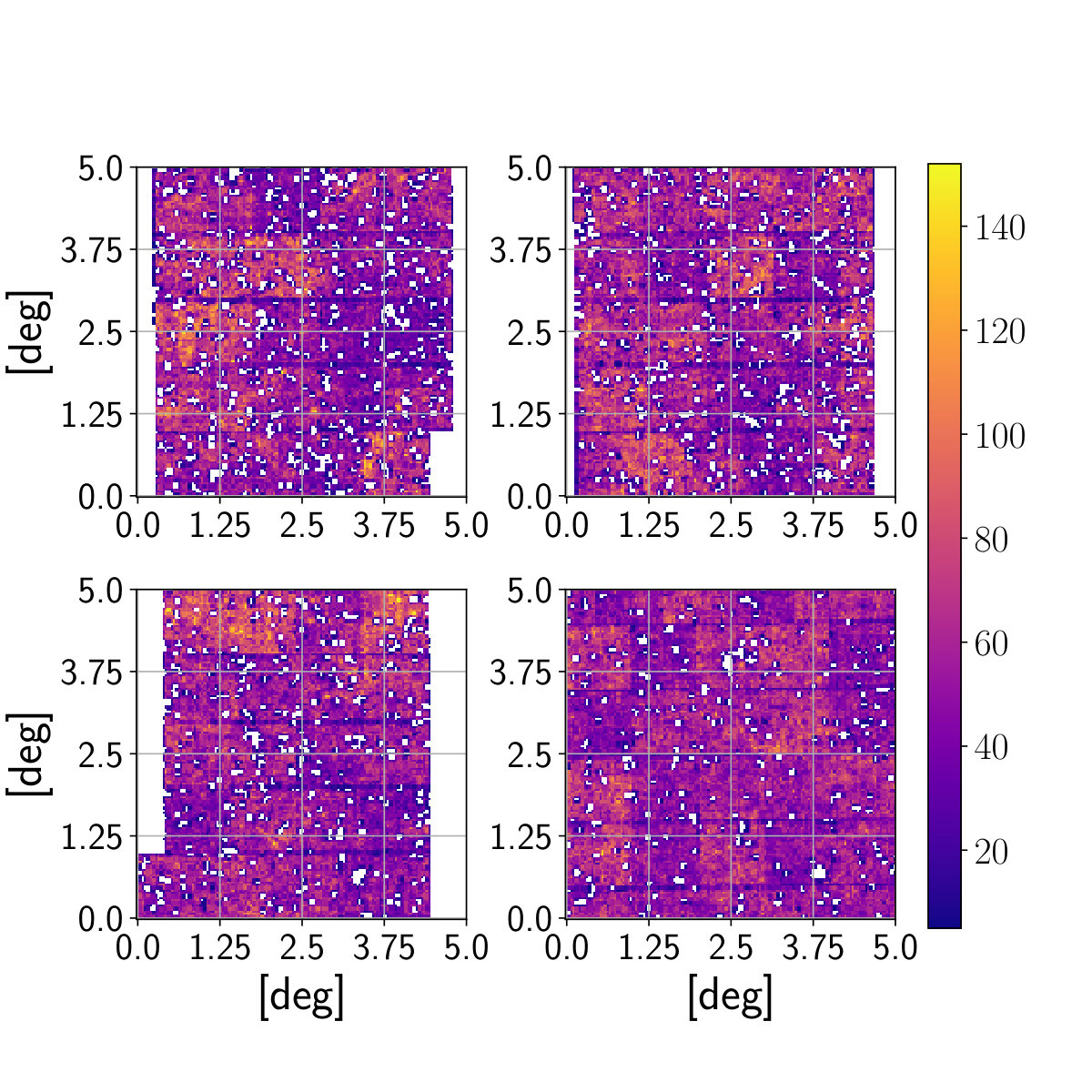 Figure 13
Figure 13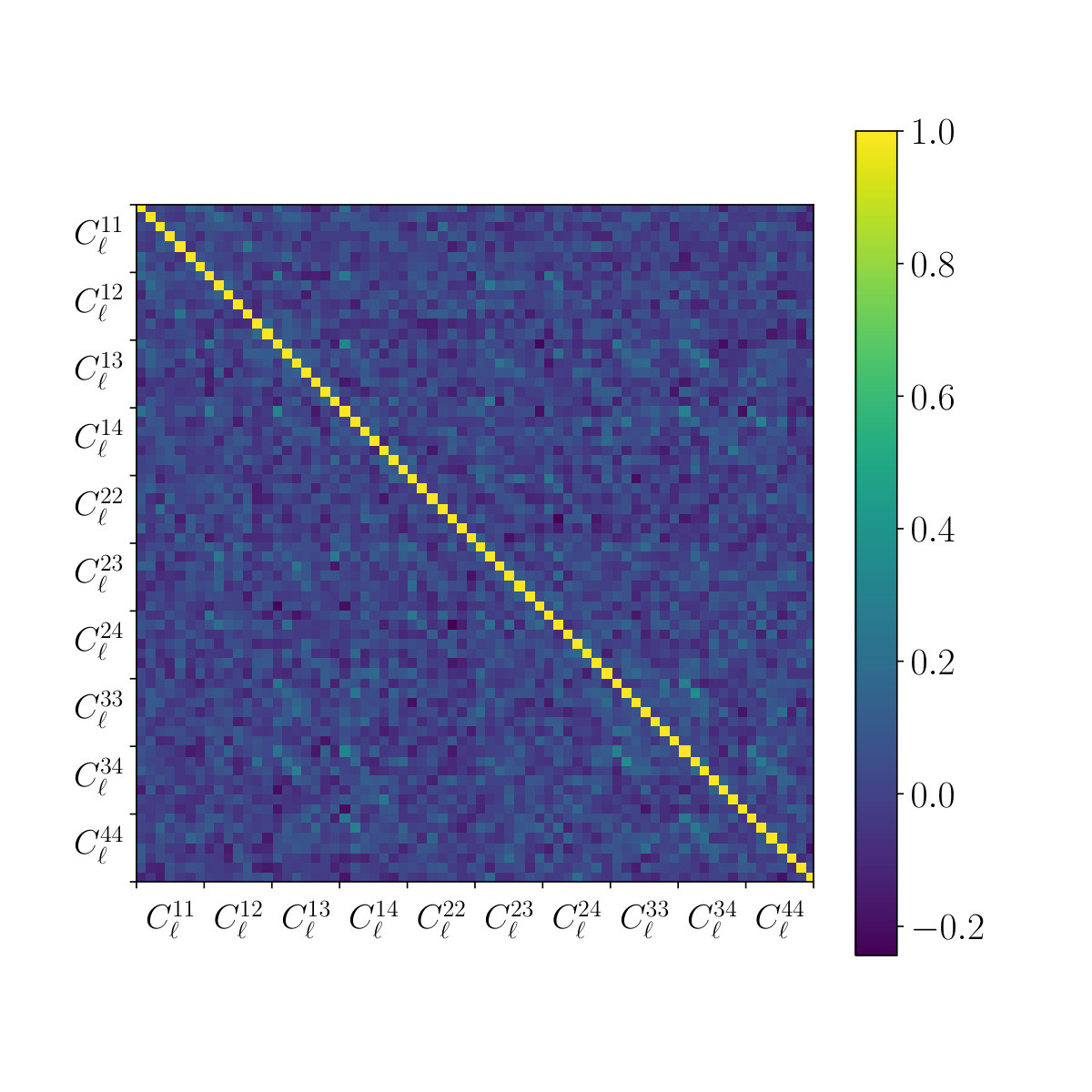 Figure 14
Figure 14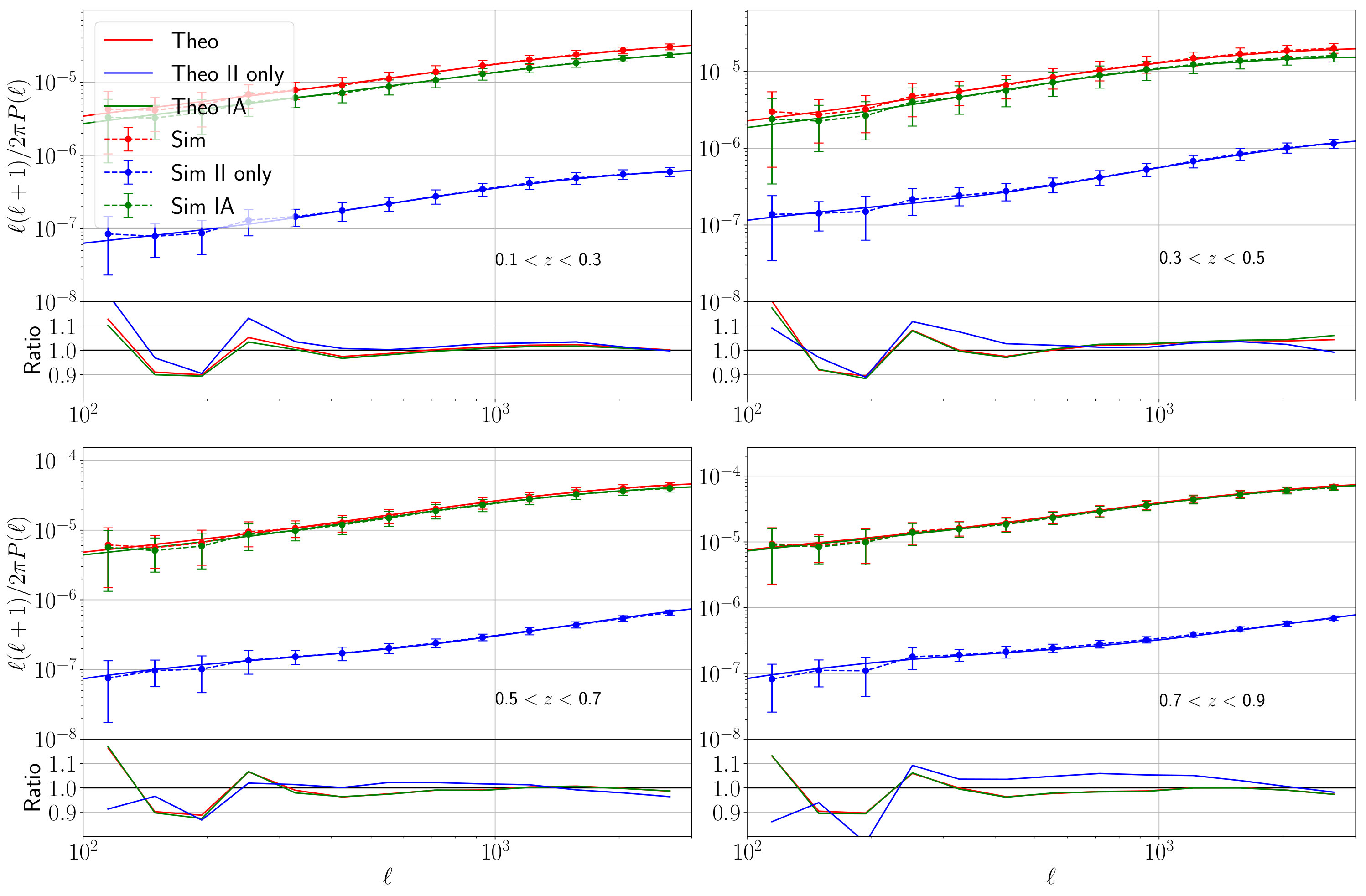 Figure 15
Figure 15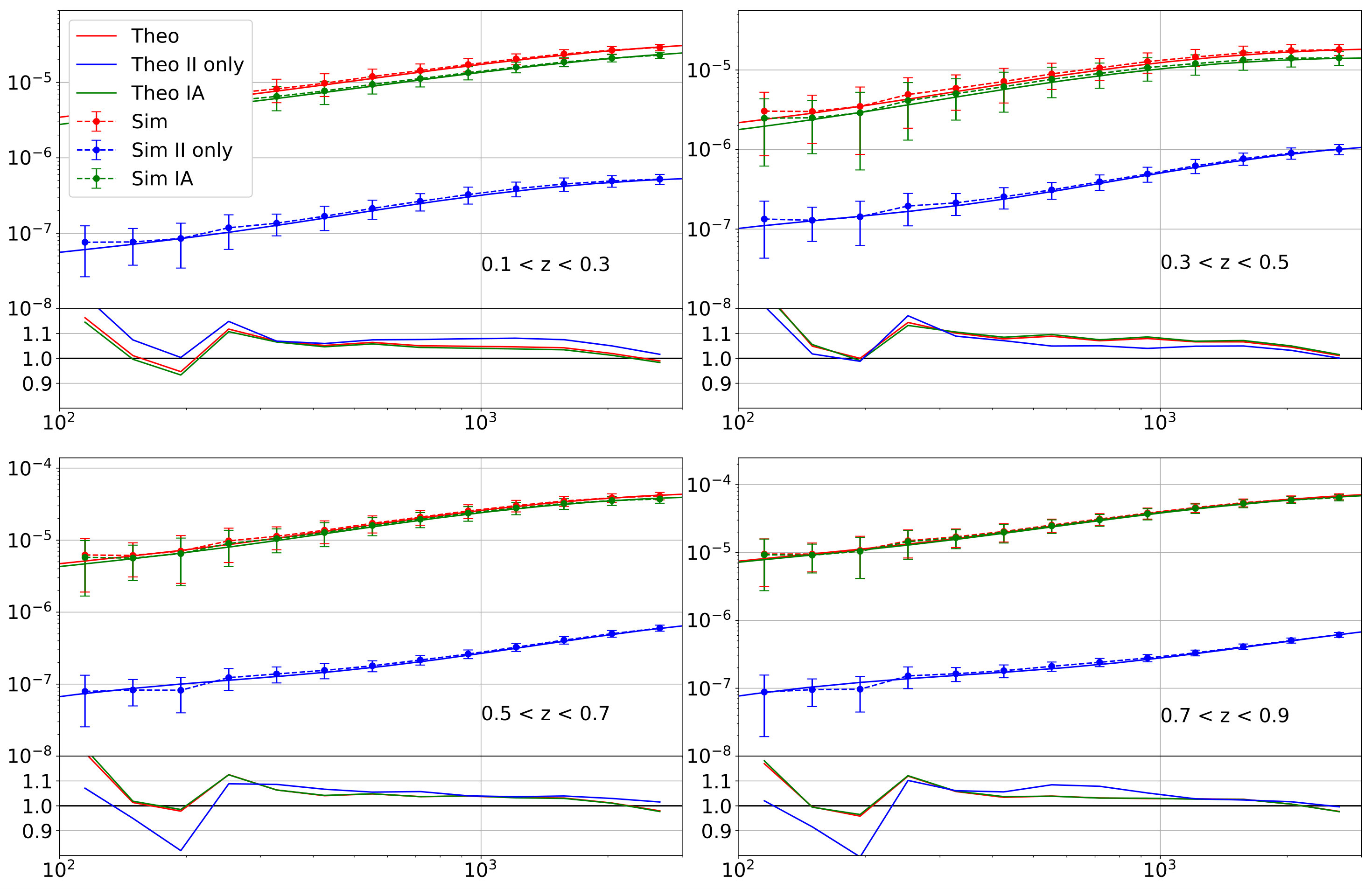 Figure 16
Figure 16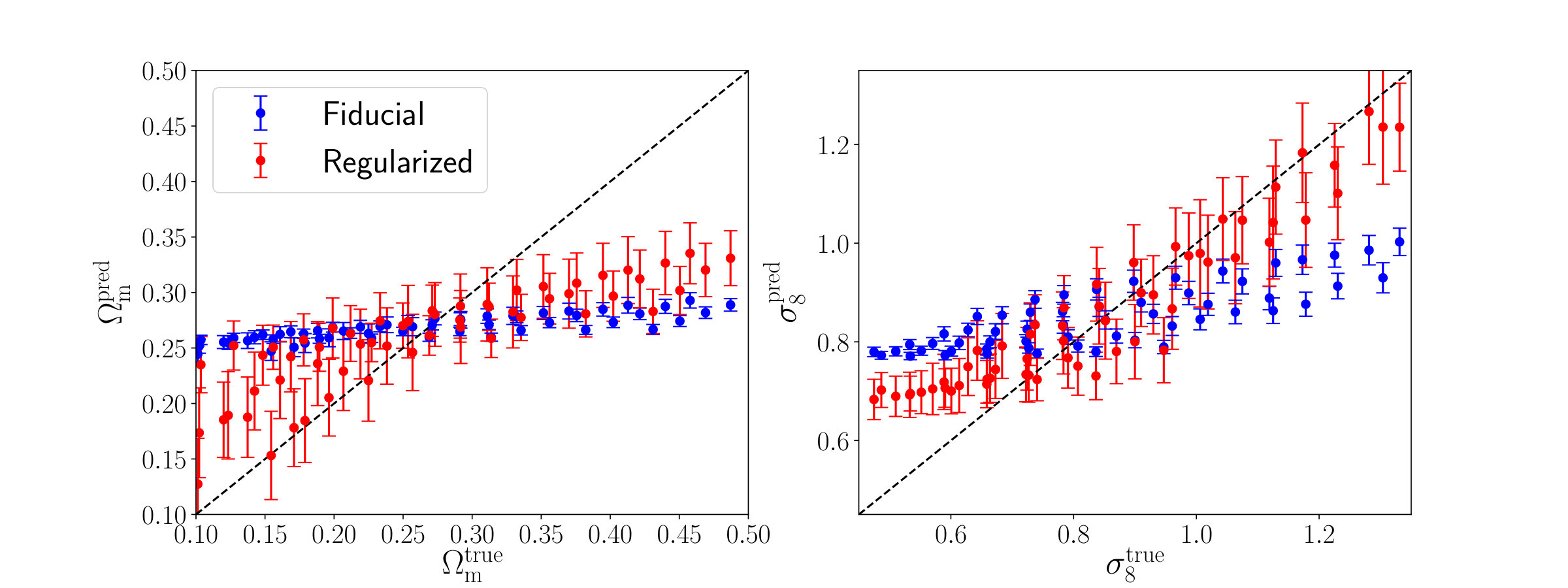 Figure 17
Figure 17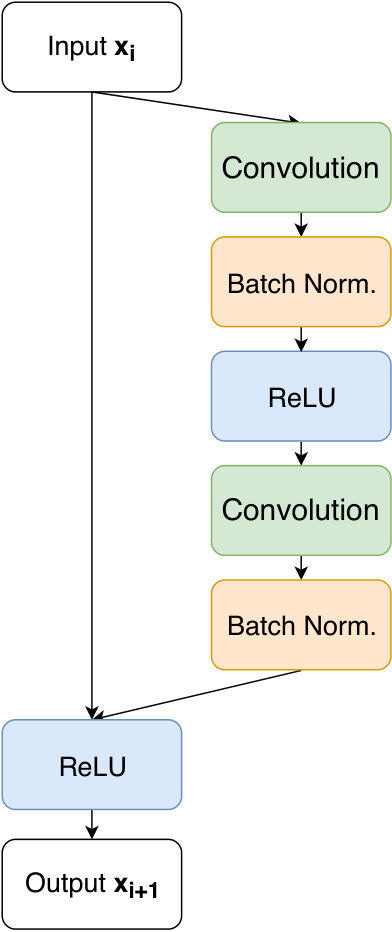 Figure 18
Figure 18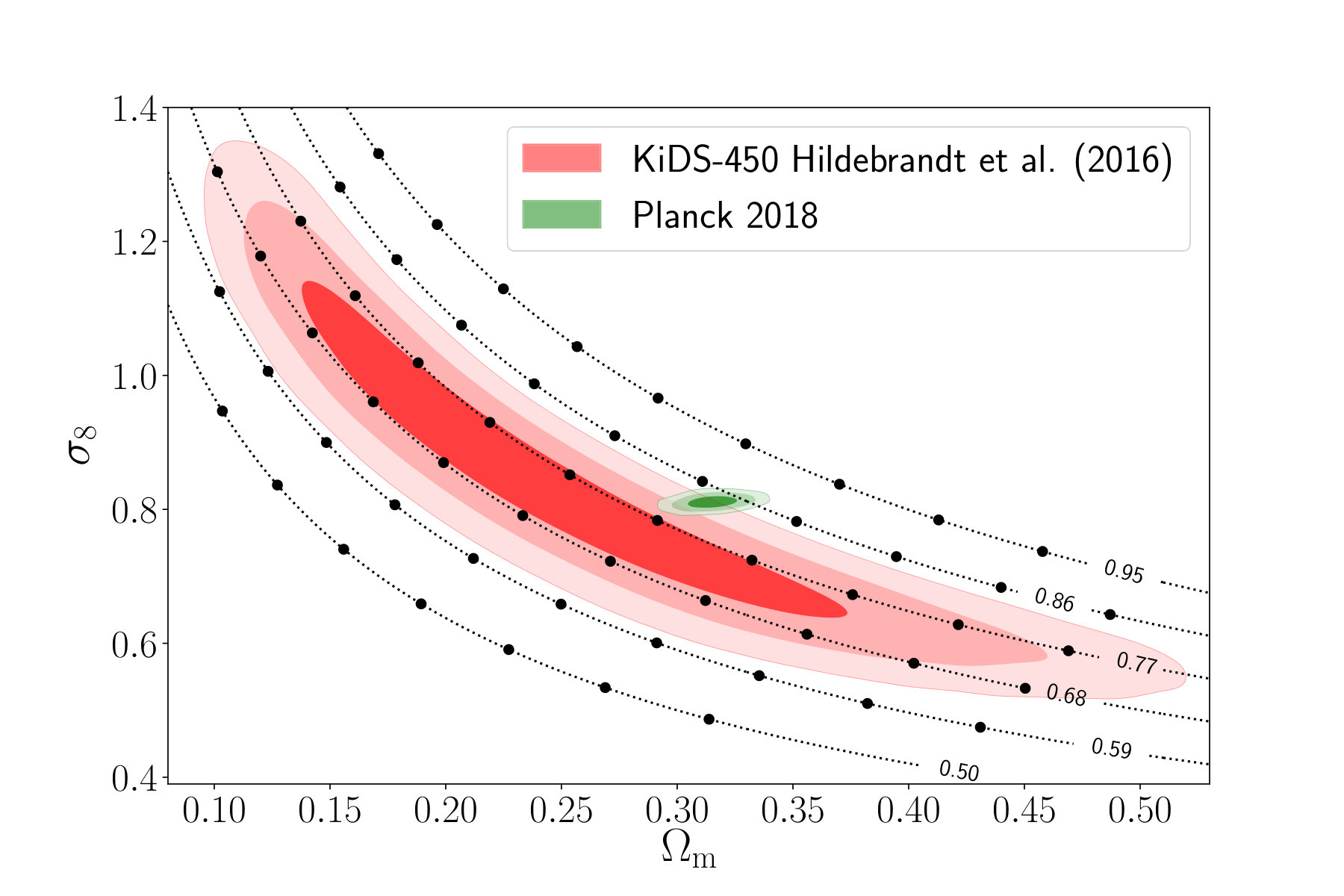 Figure 19
Figure 19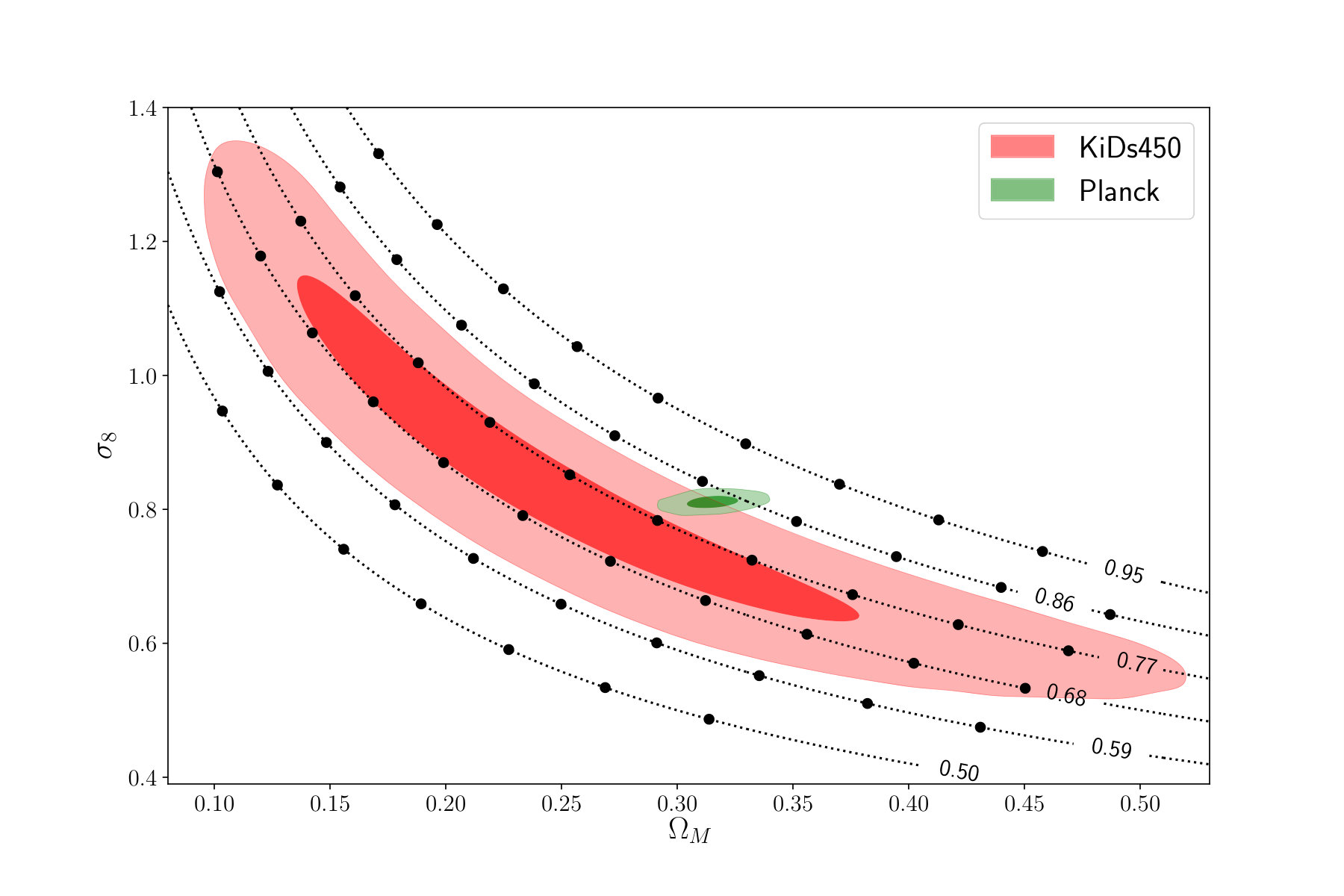 Figure 20
Figure 20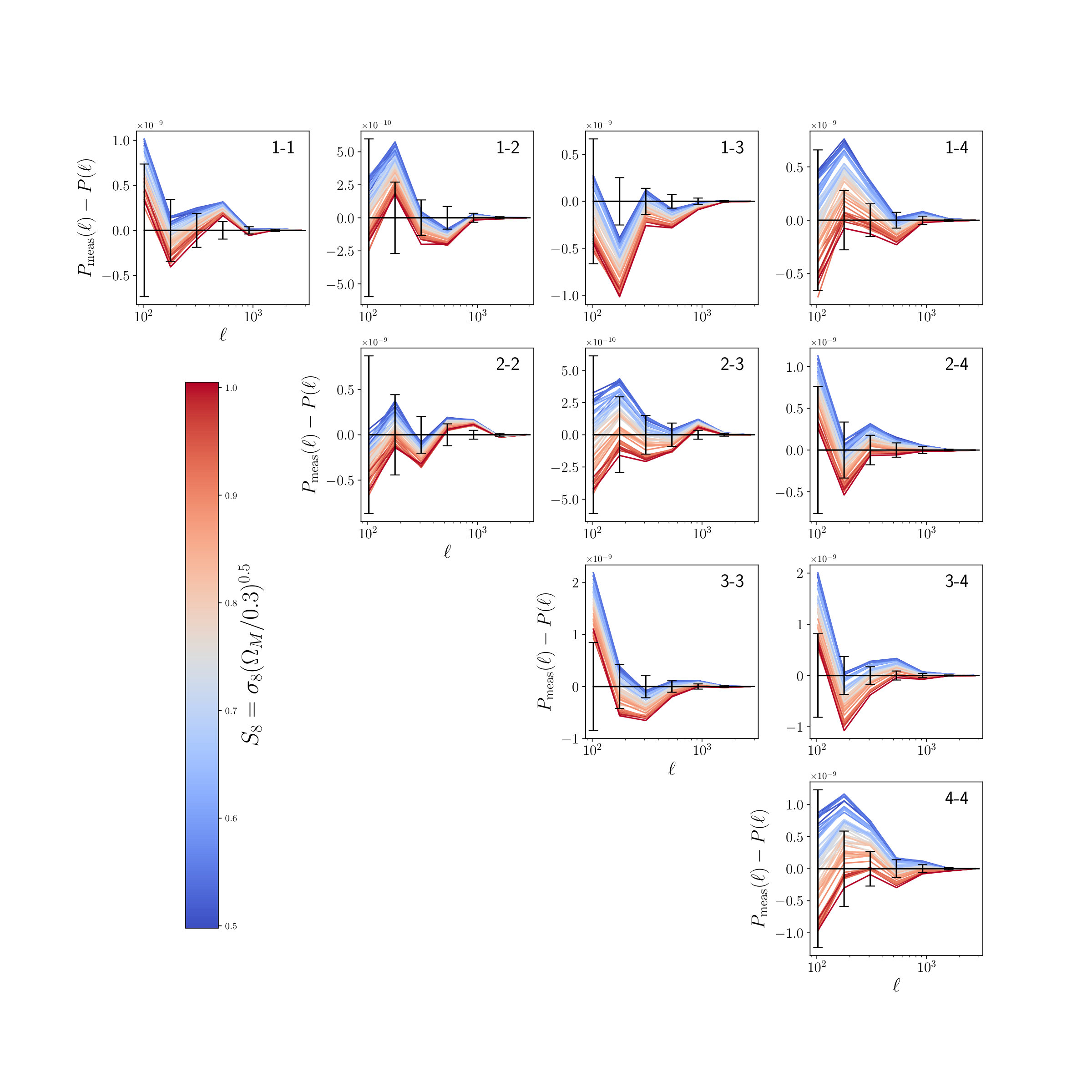 Figure 21
Figure 21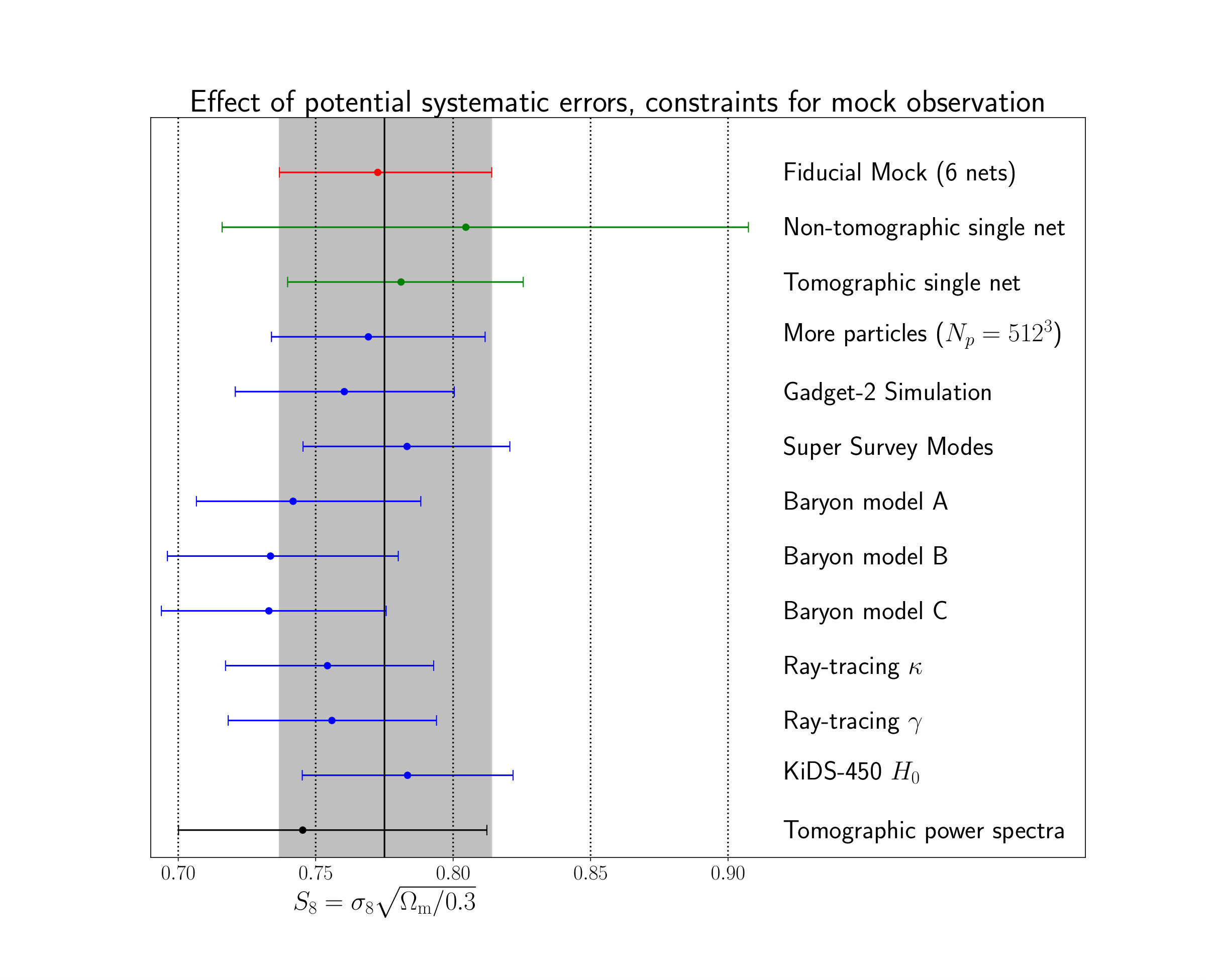 Figure 22
Figure 22 Figure 23
Figure 23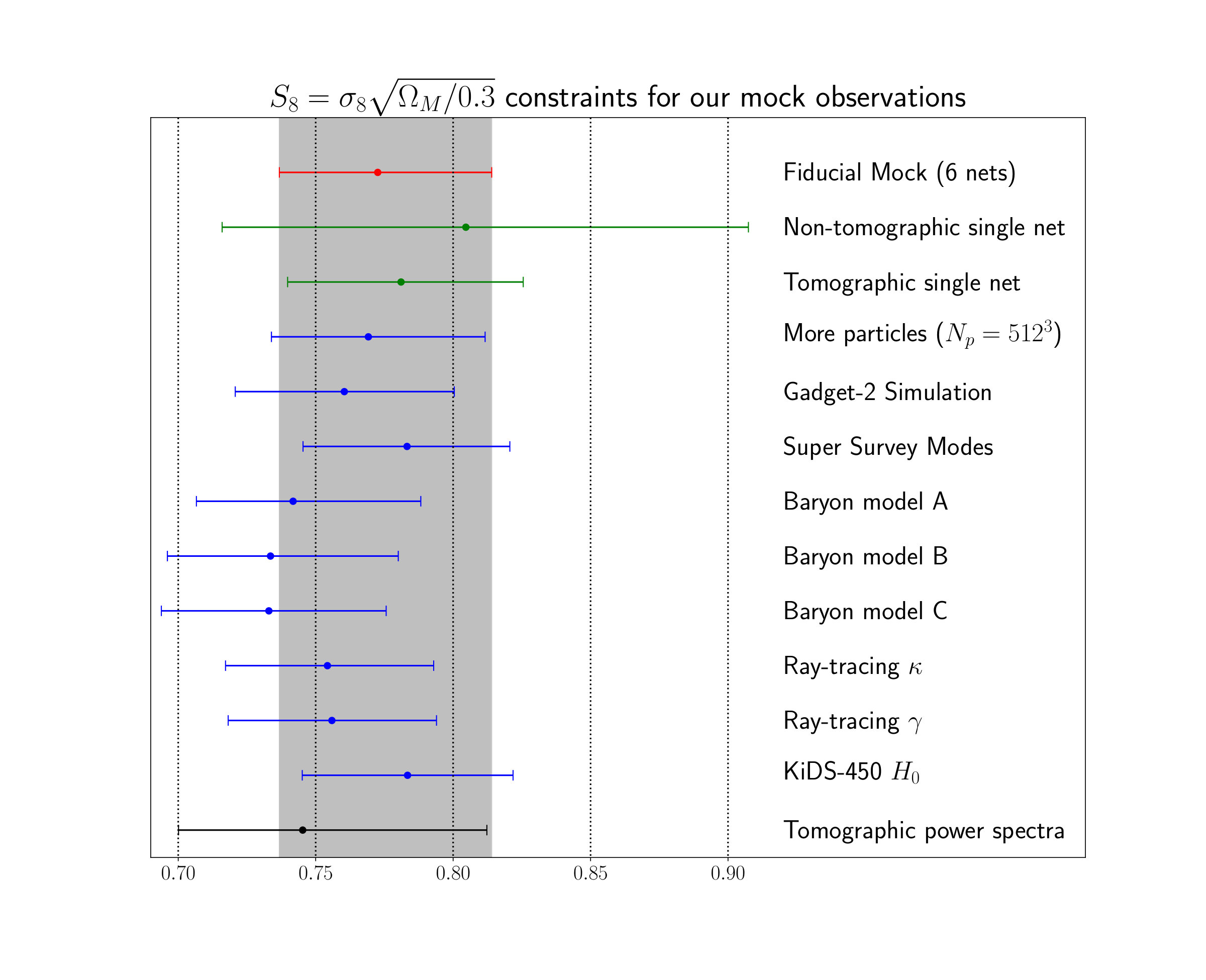 Figure 24
Figure 24 Figure 25
Figure 25 Figure 26
Figure 26| cuts | Number of Objects | After Projection |
|---|---|---|
| 3’879’822 | 3’268’559 | |
| 2’990’095 | 2’522’507 | |
| 2’970’569 | 2’501’016 | |
| 2’687’130 | 2’269’380 | |
| Total | 12’527’616 | 10’561’462 |
| Parameter | CNN | Power spectrum |
|---|---|---|
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsGalaxies: Formation, Evolution, Phenomena · Cosmology and Gravitation Theories · Astronomy and Astrophysical Research
Cosmological constraints with deep learning from KiDS-450 weak lensing maps
Janis Fluria
Tomasz Kacprzaka
Aurelien Lucchib
Alexandre Refregiera
Adam Amaraa
Thomas Hofmannb
Aurel Schneidera
aInstitute of Particle Physics and Astrophysics, Department of Physics, ETH Zurich, Switzerland
bData Analytics Lab, Department of Computer Science, ETH Zurich, Switzerland
Abstract
Convolutional Neural Networks (CNN) have recently been demonstrated on synthetic data to improve upon the precision of cosmological inference. In particular they have the potential to yield more precise cosmological constraints from weak lensing mass maps than the two-point functions. We present the cosmological results with a CNN from the KiDS-450 tomographic weak lensing dataset, constraining the total matter density , the fluctuation amplitude , and the intrinsic alignment amplitude . We use a grid of N-body simulations to generate a training set of tomographic weak lensing maps. We test the robustness of the expected constraints to various effects, such as baryonic feedback, simulation accuracy, different value of , or the lightcone projection technique.
We train a set of ResNet-based CNNs with varying depths to analyze sets of tomographic KiDS mass maps divided into 20 flat regions, with applied Gaussian smoothing of arcmin. The uncertainties on shear calibration and error are marginalized in the likelihood pipeline. Following a blinding scheme, we derive constraints on with our CNN analysis, with . We compare this result to the power spectrum analysis on the same maps and likelihood pipeline and find an improvement of about for the CNN. We discuss how our results offer excellent prospects for the use of deep learning in future cosmological data analysis.
I Introduction
The current cosmological model used to describe the evolution of our universe suggests that we live in a spatially flat CDM cosmology. In this model, small initial fluctuations in the matter distribution collapsed through gravitational interactions and formed highly non-linear structures that can be observed today. In weak gravitational lensing (WL) (see e.g. Schneider (2005); Kilbinger (2015) for reviews) we aim to probe such structures directly through their interaction with the light from faint background galaxies. According to Einstein’s theory of general relativity, matter interacts with the space-time and deflects the incoming photons, thereby slightly distorting the original source image. WL surveys such as the Canada France Hawaii Telescope Lensing Survey (CFHTLenS)111cfhtlens.org Grocutt et al. (2013), the Kilo-Degree Survey (KiDS)222kids.strw.leidenuniv.nl Hildebrandt et al. (2018), the Dark Energy Survey (DES)333darkenergysurvey.org Troxel et al. (2018), and Subaru Hyper Suprime-Cam (HSC)444hsc.mtk.nao.ac.jp/ssp/survey Hikage et al. (2019a) have already successfully applied this method to constrain cosmological parameters. Future surveys like Euclid Laureijs et al. (2011) or LSST Chang et al. (2013) will be able to provide even more precise measurements.
Currently, the most common way to analyze the abundance of available data is the two-point correlation function (eg. Hildebrandt et al. (2018); Troxel et al. (2018)). The two-point correlation function is able to perfectly describe the statistics of Gaussian random fields. However, it lacks the capability of extracting non-Gaussian information that can significantly improve the constraints on the cosmological parameters, which lead to a search for new summary statistics. Approaches based on weak lensing peak statistics (e.g. Dietrich and Hartlap (2010); Kacprzak et al. (2016); Fluri et al. (2018); Liu et al. (2015); Shan et al. (2018); Martinet et al. (2018)) or the three-point correlations function (e.g. Semboloni et al. (2011a); Fu et al. (2014)) have been applied to obtain cosmological constraints. Recently, deep learning techniques have gained a lot of attention, due to their ability to automatically extract relevant features from image data, while being robust to noise.
A first demonstration of the ability of convolutional neural networks (CNN) to discriminate between different cosmologies directly from noisy weak lensing maps was done in Schmelzle et al. (2017). Afterwards, Gupta et al. (2018) showed that one can use CNNs to predict the total matter density and the fluctuation amplitude from a wide grid of different cosmologies using a parameter regression approach. In our previous work Fluri et al. (2018), we examined the performance of a CNN compared to the traditional power spectrum analysis in the case of noisy convergence maps. And recently Ribli et al. (2019) performed a similar analysis using noisy convergence maps where they bench-marked different architectures of CNNs and compared their results to a power spectrum and weak lensing peak analysis.
Deep learning has recently been applied to various other astrophysical problems, such as fast finding of strongly lensed systems (Lanusse et al., 2018), measuring parameters of early galaxies using the 21-cm signal (Gillet et al., 2019), fast Point Spread Function modeling Herbel et al. (2018), the introduction of Baryonic effects into dark matter N-body simulations Tröster et al. (2019), and other problems in cosmology (Merten et al., 2019; Ciuca and Hernández, 2019; Peel et al., 2018; Gheller et al., 2018; Lucie-Smith et al., 2018; Rodríguez et al., 2018). And recent work on information maximizing networks Charnock et al. (2018), neural density estimators, and the usage of networks to find optimal data compression Alsing et al. (2018, 2019); Alsing and Wandelt (2019) shows the potential of ML to improve the inference of cosmological parameters.
In this work, we perform a tomographic analysis of the KiDS-450 (Hildebrandt et al., 2016, hereafter HV16) data using a CNN to constrain , , and the intrinsic alignment amplitude . To our knowledge, this is the first time that a CNN was used to measure the cosmological parameters from observed weak lensing data. We train our CNNs on a large number of tomographic lensing mass maps that include realistic masks and noise maps. We apply a careful treatment of multiple systematic effects that can arise through astrophysical effects, measurement process, or during the construction of the simulations. We marginalize the photometric redshift error, the multiplicative and additive shear biases, and the intrinsic alignment amplitude. Further, we test if our inference pipeline is robust to other systematic effects such as the simulation algorithm, shear projection technique, or baryonic feedback Osato et al. (2015); Schneider et al. (2018). Following a blinding scheme, we derive constraints with a CNN in a number of configurations. We compare the constraints from the CNN with those we obtain with a power spectrum analysis on the same maps, as well as with previous measurements on the KiDS-450 dataset.
The paper is structured in the following way. In section II we present an overview of the data used in the analysis. In section III we explain our blinding scheme. The methodology is described in section IV. This section contains the detailed description of the used N-body simulations (section IV.1) and all our considered systematic effects (section IV.2). The examined networks are presented in section IV.3 and the inference procedure is described in section V. This is followed by the examination of the impact of the systematic effects in section VI and the results of the cosmological analysis in section VII. Appendix A describes how we combined the out of different networks. In appendices B and C we give further details regarding the training of the networks. Appendix D gives more insight about the constrained intrinsic alignment amplitude and appendix E shows additional plots of the power spectrum analysis.
II KiDS-450 data
In this work, we analyze the first 450 deg2 of the Kilo Degree Survey (KiDS). KiDS is an ESO public survey that will, after completion, cover 1350 deg2 in four bands (ugri). It uses the OmegaCAM CCD mosaic camera mounted at the Cassegrain focus of the VLT Survey Telescope (VST). This combination of telescope and camera was specifically designed for weak lensing measurements, having a well-behaved and almost round point spread function and a small camera shear. The shear of the observed objects was estimated using Lensfit Miller et al. (2013) and a detailed description of the procedure can be found in Fenech Conti et al. (2017). Lensfit uses a model of the point spread function at pixel level of individual exposures and extracts the ellipticities of galaxies by fitting a disc and bulge model via a likelihood-based method. This method enables it to provide weights for each object based on the likelihood of the fit. An estimate of the redshift of each object is obtained using the Bayesian photometric code BPZ from Benítez (2000); Hildebrandt et al. (2012). Further, HV16 examined three different calibration methods to obtain the effective redshift distribution of the observed objects.
We use the publicly available KiDS-450 data that contains the shapes of roughly 15 million galaxies and is divided into five patches de Jong, Jelte T. A. et al. (2017). The whole catalog has an effective galaxy number density of 8.53 galaxies/arcmin2 and an ellipticity dispersion of per shear component.
II.1 Data Preparation
We split the galaxies into the same four tomographic bins using the BPZ estimate of their redshift, in the same way as HV16.
The redshift bins have a width of and only galaxies with a BPZ redshift estimate between and were used. Detailed information about the redshift bins is listed in table 1. After these redshift cuts approximately million objects remained in the catalog. We decided to adopt a similar approach as in our previous work (Fluri et al., 2018) and projected the data onto smaller patches, to analyze the data with a CNN. One should note that there already exist a suitable neural network architecture working on spherical data Perraudin et al. (2018), which does not rely on smaller patches or the small angle approximation. While this approach may prove necessary for large area surveys, like DES, LSST or Euclid, the KiDS-450 area can still be conveniently analyzed by splitting the area into relatively small number of patches. This approach also reduces the computational costs of the necessary simulations to train the network. We split the data into 20 patches of deg2 with a resolution of 128 pixels ( arcmin) per side. Some of those patches are shown in figure 1. We used the gnomonic projection and the estimated shear value of each pixel was calculated with the Lensfit weights and the measured ellipticity of each galaxy
[TABLE]
where is the additive shear bias (section IV.2.2) of the corresponding redshift bin and projected patch. Due to the sparse distribution of the objects, it was not possible to fit the complete catalog inside the 20 patches and only million objects were used to create the shear maps. The generated shear maps were then fed into the CNN to predict the underlying cosmological parameters.
III Blinding
The data described in the previous sections was used to generate noise maps (see section IV.1.4), observation masks and the estimates of the additive and multiplicative shear biases (see section IV.2.2). However, to avoid confirmation bias, we calculated the cosmology constraints using the shear signal only after all the tests of the inference pipeline on simulations were completed and the design of the analysis was finalized (see section IV) and did not alter our cosmological analysis after this.
IV Methodology
The CNN-based analysis required a large and accurate set of simulations that include noise and various systematic effects.
A schematic diagram of the training pipeline is shown in figure 2. The simulated convergence maps (section IV.1) and intrinsic alignment maps (section IV.1.3) are combined with a random intrinsic alignment amplitude drawn from our prior. Furthermore, we model the multiplicative bias (section IV.2.2) and transform the resulting convergence maps into shear maps using the Kaiser Squires (KS) Kaiser and Squires (1993) inversion and mask them (section IV.1.5). The observed data is used to generate random noise realizations (section IV.1.4) that, after we apply a correction explained in section IV.1.5, are added to the simulated shear maps. These noisy shear maps are then used to train the CNN (section IV.3).
IV.1 Simulations
IV.1.1 N-body Simulations
To generate the convergence maps used to train the CNN, we ran N-body simulations using the PkdGrav3 code Stadel (2001). PkdGrav3 uses the fast multipole expansion to accurately compute the forces between the particles in linear time and can be run with GPU support, accelerating the computation even further. PkdGrav3 is considered to be one of the most accurate and efficient N-body simulation codes and has been run successfully with more than a trillion particles Potter et al. (2017). Assuming a flat CDM universe, we simulated a total of 57 different cosmologies in the plane. The whole simulation grid is shown in figure 3. We fixed the remaining cosmological parameters to , and which corresponds to the baseline results (CDM,TT,TE,EE+lowE+lensing) of Planck 2018 Planck Collaboration et al. (2018).
We chose the different cosmologies along the degeneracy parameter inside the prior ranges and , such that they cover the 3 confidence contours of the fiducial results of KiDS-450 (HV16) and Planck 2018 (Planck Collaboration et al., 2018). For each cosmology we ran a total of 12 simulations with 2563 particles in a volume of Mpc3. The initial conditions were generated at redshift using the initial condition generator Music Hahn and Abel (2011). All simulations were run with 500 time steps to redshift and we used the default accuracy parameters , and . These parameters set the tree opening radius for different redshifts. PkdGrav3 divides the force calculation into particle-particle and particle-cell interactions. A high value of a parameter results in a smaller tree opening radius and less particle-particle interactions are calculated, while a small value of results in more particle-particle interactions. For high redshifts with a homogeneous particle distribution, smaller values of are necessary to reach the desired accuracy, as the force is not dominated by the surrounding, close particles. The parameter was used for the redshift range between and , for the range between and and between and . Each simulation generated a total of 51 snapshots covering the redshift range of the KiDS-450 galaxies from to . For the early snapshots from to with less non-linear clustering we chose an output interval of . Afterwards, we reduced the output interval to down to redshift . One should note that the time steps of PkdGrav3 are solely determined by the number of steps and the cosmological parameters used for the simulation. It was therefore not possible to output snapshots at the exact redshifts described above. Due to this, we decided to output a snapshot each time PkdGrav3 crossed a redshift of interest for the first time. The redshift difference between two output redshifts was therefore not constant and also slightly varying across the different cosmologies.
IV.1.2 Convergence Maps
As in previous work Fluri et al. (2018), we used the Ufalcon package Sgier et al. (2019) to generate the convergence maps. Ufalcon follows the procedure described in the appendix of Teyssier, R. et al. (2009) and uses the Hierarchical Equal Area iso-Latitude Pixelization tool (Gorski et al., 2005) (HEALPix555Http://healpix.sourceforge.net.). However, instead of generating full sky convergence maps, in this work we used the pencil beam approach. Out of each snapshot at redshift we cut out a shell of particles with a thickness of , where is the redshift of the previous snapshot. If necessary, we made use of the periodic boundary conditions of the simulations to achieve a patch size of 5x5 deg2. Afterwards, the particles were projected onto a regular grid using the gnomonic projection. To increase the number of shells generated from one simulation, we repeated this process 1000 times for each snapshot. Each time we randomized the particle positions with random shifts, 90∘ rotations and parity flips. These shells were then used to generate convergence maps. A detailed description of the formalism can be found in Sgier et al. (2019); Fluri et al. (2018). The convergence of a given pixel can be calculated using the Born approximation in the following way
[TABLE]
where is the dimensionless comoving distance, is a unit vector pointing to the pixels center and is given by
[TABLE]
The sum runs over all redshift shells and is the thickness of shell . Each shell gets the additional weight which depends on the redshift distribution of the source galaxies. For a given source redshift distribution, the weight is calculated using
[TABLE]
with redshift boundaries and , covering the whole range of the KiDS-450 catalog. For each of the four redshift bins we used the effective source redshift distribution obtained with the weighted direct calibration (DIR), which is the default calibration method in HV16. This method was suggested by Lima et al. (2008) and first applied by Bonnett et al. (2016). It uses a k-nearest neighbor search to estimate the volume density of objects in the multi-dimensional magnitude space in photometric and spectroscopic catalogs. These estimates, together with a re-weighting scheme, are then used to infer the effective redshift distribution of the photometric catalog. A detailed description of the parameter choices can be found in HV16.
To check the accuracy of our simulations we compared the power spectrum of the convergence maps with theoretical predictions. The theoretical predictions were obtained using the Nicaea code Kilbinger et al. (2009). This comparison is shown in figure 4. We find that our simulations are able to accurately describe the matter distribution of the universe up to a multipole of . However, in order to reduce the impact of smaller scales in our analysis, smoothed maps that were fed into the CNN with a Gaussian kernel of width arcmin, which is equivalent to the pixel scale. The same smoothing was applied to the maps used for the power spectrum analysis.
With this approach, we generated 12’000 convergence maps for each of the simulated cosmologies. We used 10’000 maps generated with 10 independent simulations to train the CNN and reserved 2’000 as the test set. The test set was solely made out of maps created using simulation boxes that were not used to make the training set, as a precaution against the CNN learning features of the randomization procedure explained above.
IV.1.3 Intrinsic Alignment
Intrinsic galaxy alignment is one of the most important systematic effects in weak gravitational lensing. There are two types of intrinsic alignment: the intrinsic-intrinsic (‘II’) type is caused by massive objects that align the intrinsic ellipticities of galaxies around them, and gravitational-intrinsic (‘GI’) type concerns the correlations between the intrinsic ellipticity of a foreground galaxy and the shear of a background galaxy. To model the intrinsic alignment in our simulated convergence maps we used the model developed by Hirata and Seljak (2004); Bridle and King (2007); Joachimi et al. (2011). This model has also been used in the fiducial results of the KiDS-450 analysis (HV16) and many other weak lensing surveys. Originally, it was developed to predict the effects of intrinsic alignment on the power spectrum. It connects the intrinsic alignment power spectrum with the non-linear matter power spectrum
[TABLE]
where is a cosmology and redshift dependent term
[TABLE]
where the intrinsic alignment amplitude , and are the free parameters of this model, is a normalization constant, is the critical density at and normalized linear growth factor, so that . The parameters and are arbitrary pivot points to model the redshift and luminosity dependence. As in HV16 we fixed and did not consider the redshift and luminosity dependent terms.
We used equations (5) and (6) to implement the model on convergence map level, such that it reproduces the results for the power spectrum. Similar to equation (2) one can calculate the intrinsic alignment part of the convergence map
[TABLE]
where the weights are given by
[TABLE]
The accuracy of this model is shown in figure 4. For the intrinsic alignment amplitude we chose the same non-informative prior as in HV16. It is important to note that depends linearly on the intrinsic alignment amplitude . Due to this, it is only necessary to compute a single intrinsic alignment map for each corresponding convergence map. A convergence map with any intrinsic alignment amplitude can then be generated by simply adding the two maps with the appropriate factor.
IV.1.4 Shape and Measurement Noise
In order to train the CNN with the right noise properties we used the positions and ellipticity magnitudes from the galaxy catalog. The noise was generated by randomly rotating each galaxy
[TABLE]
where the were drawn uniformly from . We implemented this procedure on GPUs to compensate the computational costs of this approach. This also allowed a “on the fly” generation of noise maps during the training of the CNN. This approach preserves the spatial variation of the number density of galaxies and the shape noise amplitude across the footprint.
IV.1.5 KS Inversion
The KS inversion Kaiser and Squires (1993) allows for transforming convergence maps into shear maps and vice-versa. We used it to generate shear maps from simulated convergence, as well as to generate convergence from shear maps, after having added the systematic effects. By making use of the small angle approximation and the fast Fourier transform (FFT) one can relate the shear and the convergence via the lensing potential , leading to the following relation in Fourier space
[TABLE]
where represents the Fourier-transformed real or imaginary part of the complex shear , is the Fourier transform of the convergence and the kernel is given by
[TABLE]
where is the 2D Fourier conjugate of the position in real space and . It is important to note that the kernels each vanish for certain values of . This issue can be alleviated for the transformation from shear maps to convergence maps by making use of the relation
[TABLE]
which was obtained by Kaiser (1992). Combining equations (11) and (13) one can express the Fourier transform of the convergence in the following way
[TABLE]
Afterwards one can simply perform an inverse FFT to obtain the actual convergence. However, for the transformation from convergence maps to shear maps, it is not possible to recover the modes missing due to the vanishing kernels. Since the examined CNN works on shear maps, it is important to address this issue. For the simulations used for the training of the CNN, some information is lost during the transformation from convergence to shear. However, this procedure would not be used for the survey data. We, therefore, removed these missing modes from the noise maps that were added to the simulated shear maps, as well as from the survey data before the final inference. This was done by performing a FFT on these maps and setting all modes, where the corresponding kernels vanish, to zero, and then transforming them back into real space. The FFT to remove the modes was performed on masked maps, while the KS inversion of the simulated convergence maps was done before the observational mask was applied. Therefore, this “mode removal” procedure could potentially introduce a bias in the inference pipeline. We examined this effect by using ray-traced simulations (see section IV.2.6). Ray-tracing allows for generating equivalent convergence and shear maps directly from the produced particle shells. The “mode removal” procedure can then be compared to the standard KS inversion of the convergence maps. The results of this comparison are shown in section VI.
Another common problem with the KS inversion is that the FFT assumes periodic boundary conditions. Using the KS inversion on non-periodic data can lead to boundary effects. Further, masking of the data can also lead to similar effects. To minimize these effects we applied zero-padding to with 64 pixels on each side before performing the FFT. This was done for each simulated convergence map that was transformed, as well as whenever the “mode removal” procedure was applied.
IV.2 Systematic Effects
In this section, we give an overview of all systematic effects considered in our analysis. The considered systematic effects include: shear multiplicative bias, photometric redshift error, baryon effects, super survey modes, simulations engine and resolution, and shear projection methods. The effects of the shear multiplicative bias and photometric errors are marginalized in the likelihood analysis. We test the impact on of the remaining effects by comparing the difference between the fiducial mock data with mock data that includes the systematic effect of interest. To isolate the desired effect, we kept the simulations seeds the same, wherever possible. The simulations that include the systematic effects were not used for training the network. The results of these tests are presented in section VI. Our fiducial mock observation was generated from a simulation with the values and , as measured from KiDS-450 by HV16.
IV.2.1 Photometric Redshift
We used the 1’000 publicly available bootstrapped ‘DIR’ redshift distributions to incorporate the uncertainty of the effective source redshift distribution in our analysis. However, due to memory limitations, it was not possible to generate each convergence map in the training and test sets with all of the 1’000 effective source redshift distributions. Therefore, the convergence maps used for training were generated with the mean ‘DIR’ distribution. The bootstrapped versions were then only used to obtain the summary statistics of the test set used for the inference (see section V), such that our likelihood analysis marginalized over this error.
IV.2.2 Multiplicative and Additive Shear Bias
As in HV16 we followed Heymans et al. (2006) and parametrized the shear bias as
[TABLE]
where is the multiplicative shear bias and the additive shear bias term. A detailed description of the calibration method of the KiDS-450 fiducial analysis HV16 can be found in Fenech Conti et al. (2017). Similar to HV16 we calibrated the additive shear bias directly from the observed data for each redshift bin and each of our 20 projected patches and neglect its uncertainty. This additive bias was corrected per shear component and averaged over all patches and both shear components we found -0.20, 4.53, 2.26, -0.36 for our four redshift bins. These values were then subtracted from each galaxy (see eq. (1)). Further, one should note that we obtained slightly different values than the KiDS-450 fiducial analysis HV16, since we were only using a subset of the whole catalog.
Further, we estimated the multiplicative shear bias per redshift bin using the publicly available, per-object estimates of the KiDS-450 observed data, by calculating their weighted average
[TABLE]
where the sum runs over all used galaxies in a given redshift bin and is the estimated multiplicative correction of the galaxy. The publicly available estimates were obtained using state-of-the-art simulations and the detailed procedure can be found in Fenech Conti et al. (2017). We found -0.015, -0.011, -0.01, -0.02] for our four redshift bins and, as in HV16, we assume a combined statistical and systematic uncertainty of for each value. These values are consistent with the method used in HV16, as it was shown in Fenech Conti et al. (2017). Further, since KiDS-450 power spectrum analysis Köhlinger et al. (2017) also followed Fenech Conti et al. (2017) to estimate the multiplicative bias, we expect them to be consistent as well.
The additive shear bias was removed from the observed data before generating the noise maps. The multiplicative correction was applied on the simulated convergence maps rather than on the observed data, by multiplying the simulated maps with the appropriate factor. A detailed description of how we applied this correction during the training and the inference is provided in sections IV.3 and V.
IV.2.3 Baryonic Effects
Baryonic effects can significantly change the weak lensing signal on small scales Semboloni et al. (2011b); Mohammed et al. (2014); Osato et al. (2015); Schneider et al. (2018). The main KiDS-450 analysis used the HMcode model Mead et al. (2015) with a prior of , where is the parameter regulating the strength of baryonic effects, with corresponding to no baryonic effects. For that analysis, marginalizing over this prior led to 20% increase in the size of the constraints.
Adding the effects of baryons to the dark matter only simulations is a challenging task, and only recently approaches have emerged to tackle this problem: Schneider et al. (2018) developed a method to modify the positions of particles using a parametric model, while (Tröster et al., 2019) used deep learning to paint the Baryon effects on the lensing maps based on hydrodynamic simulations. However, adding baryonic effects would result in several additional nuisance parameters making the problem substantially more complex. That is why we decided to neglect baryonic effects in our fiducial analysis configuration. We did, however, test the impact of baryons with the help of mock observations that include these effects on the map level. This was achieved by applying the baryon correction model Schneider and Teyssier (2015); Schneider et al. (2018), which is a method to modify the density field of gravity-only N-body simulations in order to mimic baryonic feedback effects. In more detail, the baryonic correction model displaces particles around N-body halos, in order to obtain more realistic halo profiles that include effects from star formation and AGN feedback. The halos were identified using the Amiga halo finder Gill et al. (2004); Knollmann and Knebe (2009). The baryonic correction model has been shown to be in good agreement with full hydrodynamical simulations Schneider et al. (2018).
In order to account for the inherent uncertainties related to the baryonic feedback processes, we created three mock observations with weak, best-guess, and strong baryonic corrections. These three models correspond to the average benchmark cases A, B and C described in table 2 of Schneider et al. (2018). They are motivated by observed X-ray gas fractions Sun et al. (2009); Vikhlinin et al. (2009); Gonzalez et al. (2013) including current uncertainties of the hydrostatic mass bias Eckert et al. (2016). The impact of these three benchmark models on the resulting weak-lensing constraints is described in section VI.
IV.2.4 Super Survey Modes and Finite Box Effects
The periodic boundary conditions used in N-body simulations can introduce a bias caused by finite box effects. The large-modes and their coupling to small-modes are usually not properly resolved which can lead to underestimated errors. To test that our pipeline is robust to this effect we generated a mock observation from a simulation where we doubled the box size to Mpc and the particle number .
IV.2.5 Simulation Settings
Our inference pipeline needs to be robust with respect to the simulation software used to generate the training data and an increased number of particles inside the simulations. To verify the robustness regarding the simulation software, we generated a mock observation with the TreePM-code Gadget-2 Springel (2005). One advantage of Gadget-2 is that it can output snapshots at specified redshifts. We, therefore, chose the redshifts described in section IV.1 and used the same initial conditions as for our fiducial mock observation.
The pipeline also needs to be robust to the number of particles used in the simulations. To test this, we generated a simulation equivalent to the one used for our fiducial mock observation, but with the number of particles increased to .
IV.2.6 The Born Approximation
The Born approximation we used to generate the convergence maps is a first-order approximation of the convergence. This approximation can have significant effects on the resulting constraints Petri et al. (2017). To test the sensitivity of our pipeline to this approximation, we created a mock observation that was fully ray-traced. This was done using the Lenstools package Petri (2016). Lenstools provides a multi-plane ray-trace algorithm that solves the lensing equation of the different mass shells in Fourier space. These mass shells should have a much higher resolution than the final convergence maps to avoid pixelization effects. We, therefore, used our simulation with an increased number of particles described above to generate mass shells with a resolution of 4096 pixels per side. Afterwards, we computed the shear of 2048 galaxies per side distributed according to the DIR redshift distributions to generate convergence and shear mock observations.
IV.3 Convolutional Neural Network
IV.3.1 Architecture
We examined three different architectures of convolutional neural networks. The implementation was done using Tensorflow Abadi et al. (2015). All of them were built out of residual layers He et al. (2015) shown in figure 6 and only the filter size and depth were different. A sketch of this type of architectures is shown in figure 5.
The first two layers of the networks are convolutional layers with a stride of two, a linear rectified unit (ReLU) activation function and no padding to down-sample the input. The first layer was set to increase the number of channels to 128, all other convolutional layers were set to conserve this channel dimension. We examined one network with a filter size of 55 and 10 residual layers as described in figure 6. Further, we examined two networks with a filter size of 33 using 15 and 25 residual blocks. The last layer is always a fully connected layer with no activation function to map the output of the last residual block to the desired output size. Similarly to Fluri et al. (2018); Perreault Levasseur et al. (2017), we used a negative log-likelihood loss function
[TABLE]
where represents the vector of predicted parameters, the predicted inverse covariance matrix and are the true parameters. The network was trained on the two cosmological parameters and , and the intrinsic alignment amplitude . To have all parameters in approximately the same dynamic range we divided the intrinsic alignment amplitude by a factor of ten, such that the network was trained on . Further, it is important that the network always predicts a valid covariance matrix. This was done by using the fact that every positive-definite symmetric matrix has a Cholesky decomposition of the form
[TABLE]
where is a lower triangular matrix. We, therefore, let the network predict the six free parameters of this lower triangular matrix instead of the covariance matrix directly. The inverse covariance matrix and its determinant were then built using this decomposition. Unlike in Fluri et al. (2018), we did not use the regularization term. The bias of the network prediction is handled in the likelihood function, as described in V.
IV.3.2 Input Pipeline
A schematic diagram of the input pipeline is shown in figure 2. For a single cosmology, the pipeline started by randomly selecting 204 (20 patches, 4 redshift bins) convergence maps and corresponding intrinsic alignment maps out of our training set. These maps were then added with an intrinsic alignment amplitude drawn from a uniform distribution according to our prior . Afterwards we implemented the multiplicative shear bias correction by multiplying all the maps from a given redshift bin with its corresponding bias term , where was drawn from a normal distribution with mean and standard deviation to model the uncertainty of our multiplicative shear bias estimate. The resulting maps were padded with 64 pixels of value zero on each side and transformed into shear maps using the KS inversion. We then masked each of the 208 (two shear maps per redshift bin) patches with the observational mask obtained from the survey data. Parallel to that process, we generated a random noise map from the observed data as explained in section IV.1.4. After applying our “mode removal” procedure (see IV.1.5) we added the generated noise maps to our simulated shear maps and smooth each map individually with a Gaussian smoothing kernel with arcmin, equivalent to the pixel size. At this point the input for a single cosmology had the dimension (20, 128, 128, 8), corresponding to the 20 projected patches, the 4 different redshift bins times the 2 shear components and the 128128 pixels of each map. However, we found the best results by additionally providing the network an estimate of the convergence. We, therefore, applied a second KS inversion and concatenated all maps to an input with dimensionality (20, 128, 128, 12). The last KS inversion was performed solely to improve the convergence of the network and we did not use any padding, because all considered systematic effects were already added to the maps. The network predicts a set of parameters , as well as the corresponding errors, for each of the 20 patches individually.
IV.3.3 Training
The training was performed with the Adam optimizer Kingma and Ba (2014) with first and second-moment exponential decay rates equal to 0.9 and 0.999 respectively and an the initial learning rate equal to . Further, we applied gradient clipping and normalized the length of the gradient of the weights to 100 if the global norm would exceed this value. To reduce the training time, we trained the networks asynchronously on 16 GPUs for 1’500’000 iterations where we fed the network maps from eight cosmological parameter combinations at each iteration. For the network architectures with 10 and 15 residual blocks, it was not necessary to slowly increase the smoothing scale and noise level as in our previous work Fluri et al. (2018). However, the network with 25 residual blocks did not converge when trained directly on noisy, smoothed maps. To address this, we pre-trained this network for 1’000’000 iterations on noise-free, smoothed maps, before training it on noisy maps.
In the asynchronous training approach, the weights of the network are governed by parameter servers and distributed to each GPU. Each GPU computes the gradients of a single mini-batch (input of eight cosmologies) and sends them back to the parameter server to update the weights. The 16 worker GPUs update the weights of the network asynchronously and as fast as possible. While being extremely efficient computationally, this approach can lead to slightly worse results than synchronous training on a single GPU. To alleviate this problem we trained each network for 100’000 iterations on a single GPU after the completion of the asynchronous training. However, we did not find a significant difference in the performance of the networks after the synchronous training.
We evaluated one batch of our test set every 250 iterations. An example of such a loss is shown in appendix B. We did not observe any signs of overfitting for the examined architectures.
V Inference
To generate cosmological constraints using the predictions of the networks we followed the same approach as in previous work Fluri et al. (2018). We used the predictions of our test set as summary statistics and perform a standard likelihood analysis. An example of the predictions of a single architecture is presented in appendix C. To perform this evaluations we randomly split the generated mass shells of our test set into 100 sets of 20 patches. For each set, we generated convergence maps with a randomly drawn redshift distribution from the 1’000 bootstrapped, publicly available ‘DIR’ redshift distributions to marginalize over the photometric redshift error. We then fed these maps into our inference pipeline with randomly drawn multiplicative shear bias error estimates and noise maps. The predictions of each set of 20 patches were then averaged to obtain the final prediction of a simulated survey. Afterwards, we repeated the process with new random seeds to obtain a total of 200 predictions of simulated surveys for each of our 57 cosmologies and for 25 linearly spaced intrinsic alignment amplitudes . Finally, we used these 200 predictions to calculate the mean and covariance matrix . These mean predictions and covariance matrices were then linearly interpolated across the grid to perform a likelihood analysis. We used the Gaussian likelihood described in Jeffrey and Abdalla (2018) that is based on Sellentin and Heavens (2015) and includes the uncertainty of the estimated means and covariance matrices. The likelihood of a given measurement , given a covariance matrix estimate that is obtained from simulations and an estimated mean from simulations is given by
[TABLE]
where
[TABLE]
and in our case we had .
V.1 Combining networks
While the results of a single network were already promising, we found that combining the prediction of the different architectures improved the results even further. We combined the different ResNet architectures by concatenating their predictions into a long data vector , where the are the predictions of , and of a single network after the asynchronous training is finished and the are the predictions of the different architectures after the synchronous training. This lead to an output vector of length 18 used in our fiducial analysis. The cosmological constraints from our fiducial mock observation obtained with the combination from the different architectures and from a single architecture with 10 residual blocks are shown in figure 10 in appendix A. The covariance matrix of this concatenated vector had a size of , taking into account all correlations between the output of the networks and is interpolated as described in section V. It is important to note that the linear interpolation used in our likelihood analysis is only valid inside the convex hull of our simulated cosmologies. This hull, therefore, defined our priors on the cosmological parameters. The combination of the different architectures reduces the area of the 95% confidence contours by approximately 14%. This improvement shows that a single network was not able to fully extract the information from the weak lensing maps and combining networks with different architectures can bring us closer to that goal. One reason for this is potentially the high noise levels which make it difficult for a single network to converge.
V.2 Power spectrum Analysis
We performed a power spectrum (PS) analysis in a similar way to the CNN analysis in order to assess the advantage of the CNN in a tomographic setting. The likelihood for the PS analysis was constructed using our simulation test set as theoretical predictions, similar to our previous work Fluri et al. (2018). This was done by computing the auto- and cross-spectrum of all our patches in our test set. The prediction of a single simulated survey was then obtained by again averaging over our 20 patches. The auto- and cross-spectrum are calculated in seven logarithmic multi-pole bins in the range . The maps used for this analysis were identical to the ones used by the CNN, including the smoothing scale of arcmin. This smoothing scale reduces the power spectrum to 10% of its original values at . We did not interpolate the covariance matrices in our power spectrum analysis and use a fixed covariance matrix from our test set. The cosmological parameters of the covariance matrix were chosen such that they were close to the parameters of our mock observation and we set . We verified that the CNN and PS give consistent result on simulations. The generated constraints on the degeneracy parameter are shown in figure 7. More details of our power spectrum analysis can be found in appendix E.
VI Effects of the Systematic Errors
The results of our pipeline tests are shown in figure 7. All of the constraints were obtained by using the average prediction of all simulated surveys from a simulation in a given setting as a measurement vector . The number of simulated surveys was 40 for N-body simulations with 2563 particles and, because of the increased computational costs, 8 for mock observations generated from N-body simulations with 5123 particles. This was done to decrease the statistical error in the size and position of the constraints. All mock observations had an intrinsic alignment amplitude of . Wherever possible we used the same seeds to generate the initial conditions for the simulations.
The constraints from a single architecture are obtained with the parameters of the network with 10 residual blocks after the asynchronous training. For completeness, we also show the constraints generated from a non-tomographic analysis. Tomography improves the constraints on by almost 60%. This large improvement is mostly caused by the fact that a tomographic analysis is able to break the degeneracy of the intrinsic alignment amplitude and the cosmological parameters (see appendix D for more details).
The different simulations setting do not have a significant impact on the constraints. Increasing the number of particles leaves the results almost unchanged, while the Gadget-2 simulation prefers a slightly lower value.
The two versions of the ray-traced mock observation are consistent, meaning that a possible bias from our “model removal” procedure (see section IV.1.5) is negligible. The two mock observations were obtained using the multi-plane ray-trace algorithm, which made it possible to produce equivalent convergence and shear maps directly from the Jacobians and not relying on any inversion methods. The shear maps (“Ray-tracing ”) were fed into our inference pipeline exactly the same way as we handle the observed KiDS-450 data, while the convergence maps (“Ray-tracing ”) were fed into our inference pipeline in the same way as the training maps. However, it is evident that the ray-tracing itself leads to sightly smaller values of , meaning that the used Born approximation introduces a small systematic bias. We leave this bias to future work, as ray-tracing is computationally much more intensive than the Born approximation and usually also requires simulations with a higher particle number.
The three different baryon models from Schneider et al. (2018) have the biggest impact on the constraints. They shift the predicted values by approximately one standard deviation. There is only a small difference between the three baryon models, A, B, and C, corresponding to different values of the hydrostatic mass bias. In Schneider et al. (2018), they found that model A had the least impact on the power spectrum, and models B and C give larger deviation from the dark matter only case. Our results show a similar trend: the deviation is smallest for model A, and larger for models B and C. In the future analyses using CNNs, it may become necessary to include realistic baryon models in the simulations.
Changing the Hubble parameter of the mock observation does not introduce a significant shift to the constraints. We, therefore, conclude that our inference pipeline should not be affected by the discrepancy of the measured values from the KiDS-450 analysis HV16 and Planck 2018 Planck Collaboration et al. (2018).
VII Results
The constraints on the cosmological parameters and the intrinsic alignment amplitude are listed in table 2. The cosmological constraints in the plane obtained with our networks and the tomographic power spectrum analysis are shown in the left panel of figure 8 and a comparison of our constraints to previous work is shown in the right panel of figure 8. We constrain the degeneracy parameter to (68% CL) with our networks and to with our power spectrum analysis, which is also shown in figure 9.
The comparison of our power spectrum analysis to the networks clearly shows that the CNN is able to extract more information than the power spectrum. The area of the 95% confidence contours is smaller for the network analysis, while the constraints on the parameter improve by . These gains are consistent with the results from our mock observations and our previous work (Fluri et al., 2018). The CNN is able to better constrain the plane than the PS in the degeneracy direction, which is expected from a method exploiting the non-Gaussian features in the data.
Further, we performed another robustness test to check the impact of including the small scales on our constraints (shown in figure 9). These scales can be affected by simulation resolution effects, and as we do not use a hard cut on , but rather use a large range from previously smoothed maps. We performed another power spectrum analysis with only 6 bins, instead of 7 as in out fiducial analysis, by removing the highest -bin. The resulting constraints were consistent with our fiducial analysis and only slightly broader, which indicates that the constrains are not driven by the small scales. This is expected since the used pixel size, smoothing scale and the measurement noise should have already removed a lot of information from these scales.
In the comparison with the other constraints it is important to highlight the differences in the analysis of the KiDS-450 fiducial results from the two-point-correlation HV16, the KiDS-450 power spectrum analysis Köhlinger et al. (2017), and the constraints from our networks. The KiDS-450 power spectrum analysis used only three redshift bins and a multipole range of , while the KiDS-450 two-point-correlation function analysis used four redshift bins and angular separations from 0.5*′* to 72*′*. The two-point-correlation function had, therefore, access to much smaller scales, which explains the size difference of the corresponding contours. The relevant scales for our analysis are our pixel scale of 2.34 arcmin and the applied Gaussian smoothing kernel with arcmin, which lies between the smallest scales used in the two-point correlation function and the power spectrum analysis. Comparing the size of the 95% confidence contours from our tomographic power spectrum analysis to the other constraints shows the same trend: our constraints are narrower than the ones from the PS analysis (Köhlinger et al., 2017), but larger than HV16. In our work we use the same effective redshift distributions and similar multiplicative shear bias estimates, as well as their corresponding uncertainties. Our shear catalog was similar, with the exception of 2 million galaxies that lied outside the set of 20 flat patches we used.
It is important to note that both the KiDS-450 two-point-correlation function analysis HV16 and power spectrum analysis Köhlinger et al. (2017) used more cosmological and nuisance parameters, including baryon density , spectral index , Hubble parameter , and baryon feedback amplitude . Marginalizing over these parameters broadens the contours compared to the analysis that includes only , , and parameters; marginalization of baryon feedback alone leads to 20% degradation of the constraint. Our constraints are mostly consistent with the KiDS-450 fiducial analysis HV16, lying slightly above their fiducial result. Our obtained constraints are higher than the KiDS-450 power spectrum analysis Köhlinger et al. (2017). A possible reason for these apparent differences is the measured intrinsic alignment amplitude . The intrinsic alignment amplitude and the degeneracy parameter share a positive correlation, as can be seen in figure 13 in appendix D. With our CNN analysis, we measure the intrinsic alignment amplitude , which is slightly higher than the the KiDS-450 two-point-correlation function analysis HV16 , and much higher than the from the KiDS-450 power spectrum analysis of . We therefore suspect, this difference to be partial responsible for the differences in the constraints on . The difference in the measurement of between our PS analysis and the one in Köhlinger et al. (2017) could also potentially come from the different redshift bin configurations. We also notice a small shift towards higher , consistent with the uncertainties.
There are multiple possible explanations for the remaining small differences. Baryonic feedback could potentially shift our constraints by as much as . The additional cosmological parameters considered in the KiDS-450 fiducial analysis HV16 could potentially broaden and shift the constraints as well. And lastly, the chosen approach of projecting the shear catalog onto 20 independent patches using only a subset of the available galaxies could also have an impact.
VIII Conclusions
In this work we present the first cosmological constraints from weak lensing maps obtained using convolutional neural networks and the publicly available KiDS-450 dataset. To train the CNN we used state-of-the-art cosmological simulations generated with the PkdGrav3 code. We use the effective redshift distributions and multiplicative shear bias estimates to marginalize over these systematic effects. Furthermore, we implement the commonly used intrinsic alignment model by Hirata and Seljak (2004); Bridle and King (2007); Joachimi et al. (2011) on map level, enabling us to also constrain the intrinsic alignment amplitude .
We test the impact of other possible systematic effects that can affect the analysis. We consider baryon effects, simulation configurations and engines, projection method (Born approximation vs ray-tracing), and a different value for the Hubble parameter. We find a very small impact of these effects, except for baryon feedback, which can result in as much as shifts of the constraints. As implementations of baryon effects in N-body simulations is computationally challenging, we are not able to marginalize over the uncertainty on Baryons in this work, but this can potentially be implemented in the future.
We trained three different residual networks with 5, 10 and 25 residual blocks (see figure 6) and found the best constraints by combining their predictions. Following a blinding strategy, the CNN analysis gives and is consistent with the constraints generated from a power spectrum analysis performed on the same data-set. The CNNs shrink the area of the 95% confidence intervals on the plane by and constraints on the parameter by , compared to the power spectrum performed on the same maps. The improvement comes mostly from improved capacity of the CNN to break the degeneracy by extracting more non-Gaussian information from the lensing maps. Our analysis is broadly consistent with the original KiDS-450 fiducial analysis HV16, giving slightly higher value of , while constraining to be also slightly higher, on the level of . Higher measured intrinsic alignment parameter can also provide explanation for the difference between our CNN and PS results compared to the power spectrum analysis of (Köhlinger et al., 2017).
We show that generating cosmological constraints from pure forward-modeling simulations is computationally feasible for our chosen parameter set and consistent with constraints generated from theoretical predictions. Future work should include more nuisance and cosmological parameters. To do this, it is important to further improve the efficiency of the inference pipeline and to generate more N-body simulations. Recent work on cosmological emulators Knabenhans et al. (2019) and the release of new N-body simulations Heitmann et al. (2019) suggests that the simulation-driven inference of increasing number of cosmological parameters is becoming feasible.
Importantly, the simulation-level implementations of realistic baryon feedback models will most likely prove to be crucial for future analyses with deep learning. Approximate methods mimicking the effects of baryons on the density field or full hydrodynamical simulations have the potential to address this issue (Tröster et al., 2019; Schneider et al., 2018).
Further examinations of the scalability of the inference pipeline are also important to apply it to larger data-sets such as the Dark Energy Survey. The training of larger networks becomes possible through parallelized training strategies and the geometry of large survey can be taken into account with network architectures such as graph-based networks Perraudin et al. (2018). Finally, it would be interesting to compare and combine the constraints generated by the CNN with the power spectrum and higher order statistics.
Acknowledgements.
This work was supported by the Swiss Data Science Centre (SDSC), project sd01 - DLOC: Deep Learning for Observational Cosmology, and grant number 200021_169130 and PZ00P2_161363 from the Swiss National Science Foundation. We thank the KiDS collaboration for publishing their data products with a very good quality of documentation.
Appendix A Multiple CNN vs single CNN
As described in section V.1, a combination of separate CNNs results in improved constraints. The outputs of these networks was then concatenated and used in further likelihood analysis as a large data vector. In figure 10 we show the comparison between constraints from a single network and combination of multiple networks.
Appendix B Train and Validation Loss
An example of the training and validation loss of the network built out of 15 residual blocks is shown in figure 11. The two losses are almost identical over the whole training, which indicates that the network do not overfit to the training-set. The small difference in the loss for the asynchronous and synchronous training does not significantly affect the resulting cosmological constraints.
Appendix C Evaluation of the Test Set
The predictions on the test set for the network with 15 residual blocks are shown in figure 12. These predictions are heavily biased towards the center of the grid. However, this bias does not affect the resulting cosmological constraints, since we are using the predictions as summary statistics. The bias can be reduced by introducing a square loss over the average prediction of the 20 projected patches
[TABLE]
where is a constant chosen such that the loss is of the same order of magnitude as the negative log-likelihood loss of equation 17. The predictions of a network with 15 residual blocks, which is trained with the standard likelihood loss and the square loss with , are shown in figure 12. It can be seen that, while the bias is reduced, the variance of the predictions increases. We do not choose this combination loss in our fiducial analysis, since the resulting cosmological constraints are slightly worse.
Appendix D Intrinsic Alignment Amplitude
In figure 13 we show the constraints on the intrinsic alignment amplitude and the degeneracy parameter for different settings using our fiducial mock observation. One can clearly see the large degeneracy between the cosmological parameters and the intrinsic alignment amplitude in the non-tomographic case. Performing a tomographic analysis helps to break this degeneracy for the CNN and the power spectrum analysis.
Using our fiducial mock observation with we obtain the constraints , for our power spectrum analysis and for our non-tomographic analysis with a single network.
Appendix E Power spectrum: Cross-correlations and Covariance Matrix
We show a comparison of our measured power spectrum from the projected KiDS-450 data averaged over the 20 patches with the power spectrum from our simulations used for the inference in figure 14. Since we did average over all patches with different masks and applied Gaussian smoothing, it is difficult to disentangle the noise and the signal. The shown errorbars are obtained from the diagonal of the covariance matrix used for the inference. The correlation matrix (normalized covariance matrix) of the simulated surveys is shown in figure 15. Again, the matrix is difficult the interpret, as it contains noise, smoothing and the average over all 20 projected patches.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Schneider (2005) P. Schneider, ar Xiv e-prints , astro-ph/0509252 (2005), ar Xiv:astro-ph/0509252 [astro-ph] .
- 2Kilbinger (2015) M. Kilbinger, Reports on Progress in Physics 78 , 086901 (2015) , ar Xiv:1411.0115 [astro-ph.CO] . · doi ↗
- 3Note (1) cfhtlens.org .
- 4Grocutt et al. (2013) E. Grocutt, F. Simpson, C. Heymans, A. Heavens, T. D. Kitching, E. Semboloni, K. Kuijken, H. Hoekstra, M. Velander, L. Miller, M. L. Brown, J. Coupon, L. Fu, J. Harnois-Déraps, M. J. Hudson, B. Rowe, M. Kilbinger, Y. Mellier, J. Benjamin, L. Van Waerbeke, S. Vafaei, H. Hildebrandt, T. Erben, and T. Schrabback, Monthly Notices of the Royal Astronomical Society 432 , 2433 (2013) , http://oup.prod.sis.lan/mnras/article-pdf/432/3/2433/12627095/stt 601.pdf . · doi ↗
- 5Note (2) kids.strw.leidenuniv.nl .
- 6Hildebrandt et al. (2018) H. Hildebrandt, F. Köhlinger, J. L. van den Busch, B. Joachimi, C. Heymans, A. Kannawadi, A. H. Wright, M. Asgari, C. Blake, H. Hoekstra, S. Joudaki, K. Kuijken, L. Miller, C. B. Morrison, T. Tröster, A. Amon, M. Archidiacono, S. Brieden, A. Choi, J. T. A. de Jong, T. Erben, B. Giblin, A. Mead, J. A. Peacock, M. Radovich, P. Schneider, C. Sifón, and M. Tewes, ar Xiv e-prints , ar Xiv:1812.06076 (2018), ar Xiv:1812.06076 [astro-ph.CO] .
- 7Note (3) darkenergysurvey.org .
- 8Troxel et al. (2018) M. A. Troxel, N. Mac Crann, J. Zuntz, T. F. Eifler, E. Krause, S. Dodelson, D. Gruen, J. Blazek, O. Friedrich, S. Samuroff, J. Prat, L. F. Secco, C. Davis, A. Ferté, J. De Rose, A. Alarcon, A. Amara, E. Baxter, M. R. Becker, G. M. Bernstein, S. L. Bridle, R. Cawthon, C. Chang, A. Choi, J. De Vicente, A. Drlica-Wagner, J. Elvin-Poole, J. Frieman, M. Gatti, W. G. Hartley, K. Honscheid, B. Hoyle, E. M. Huff, D. Huterer, B. Jain, M. Jarvis, T. Kacprzak, D. Kirk, N. Kokron, C. · doi ↗