Prediction of Workplace Injuries
Mehdi Sadeqi, Azin Asgarian, Ariel Sibilia

TL;DR
This paper presents a comprehensive approach to predicting workplace injuries by addressing data imbalance, transferring knowledge across organizations, and uncovering causal factors to improve injury prevention strategies.
Contribution
It introduces ensemble resampling methods, a novel transfer learning approach, and techniques for causal analysis in injury risk prediction, advancing the field significantly.
Findings
Ensemble resampling improves prediction accuracy on imbalanced datasets.
Transfer learning effectively generalizes injury risk models across organizations.
Causal analysis identifies key variables influencing injury risk.
Abstract
Workplace injuries result in substantial human and financial losses. As reported by the International Labour Organization (ILO), there are more than 374 million work-related injuries reported every year. In this study, we investigate the problem of injury risk prediction and prevention in a work environment. While injuries represent a significant number across all organizations, they are rare events within a single organization. Hence, collecting a sufficiently large dataset from a single organization is extremely difficult. In addition, the collected datasets are often highly imbalanced which increases the problem difficulty. Finally, risk predictions need to provide additional context for injuries to be prevented. We propose and evaluate the following for a complete solution: 1) several ensemble-based resampling methods to address the class imbalance issues, 2) a novel transfer…
Click any figure to enlarge with its caption.
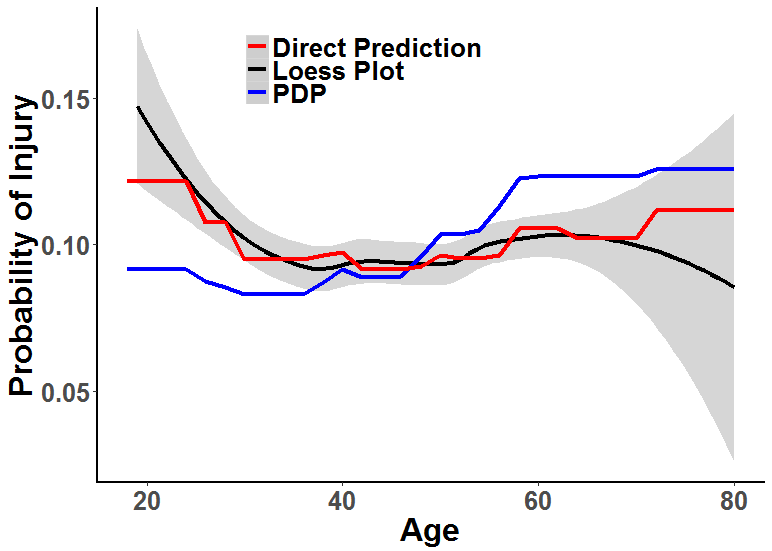 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3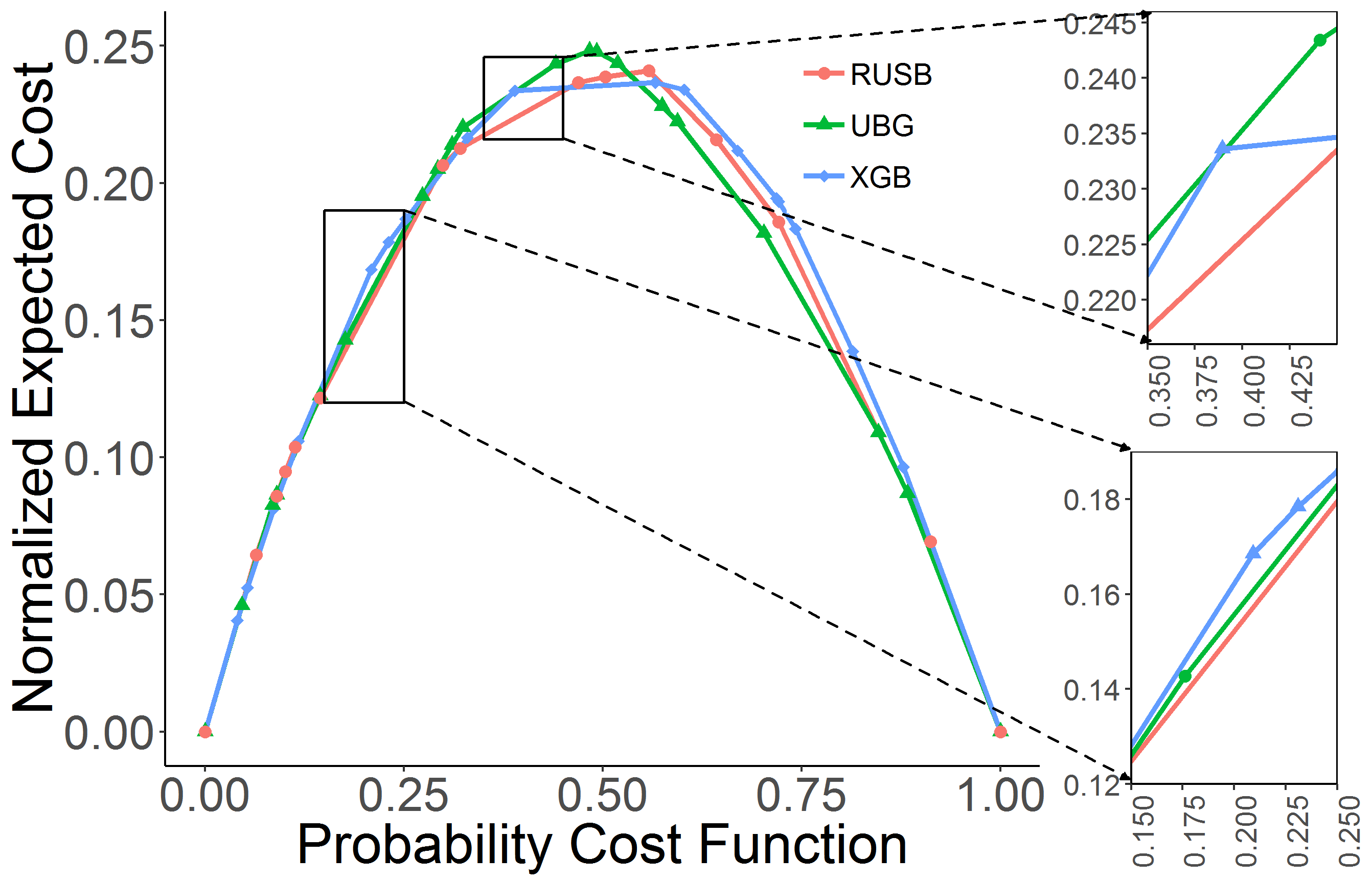 Figure 4
Figure 4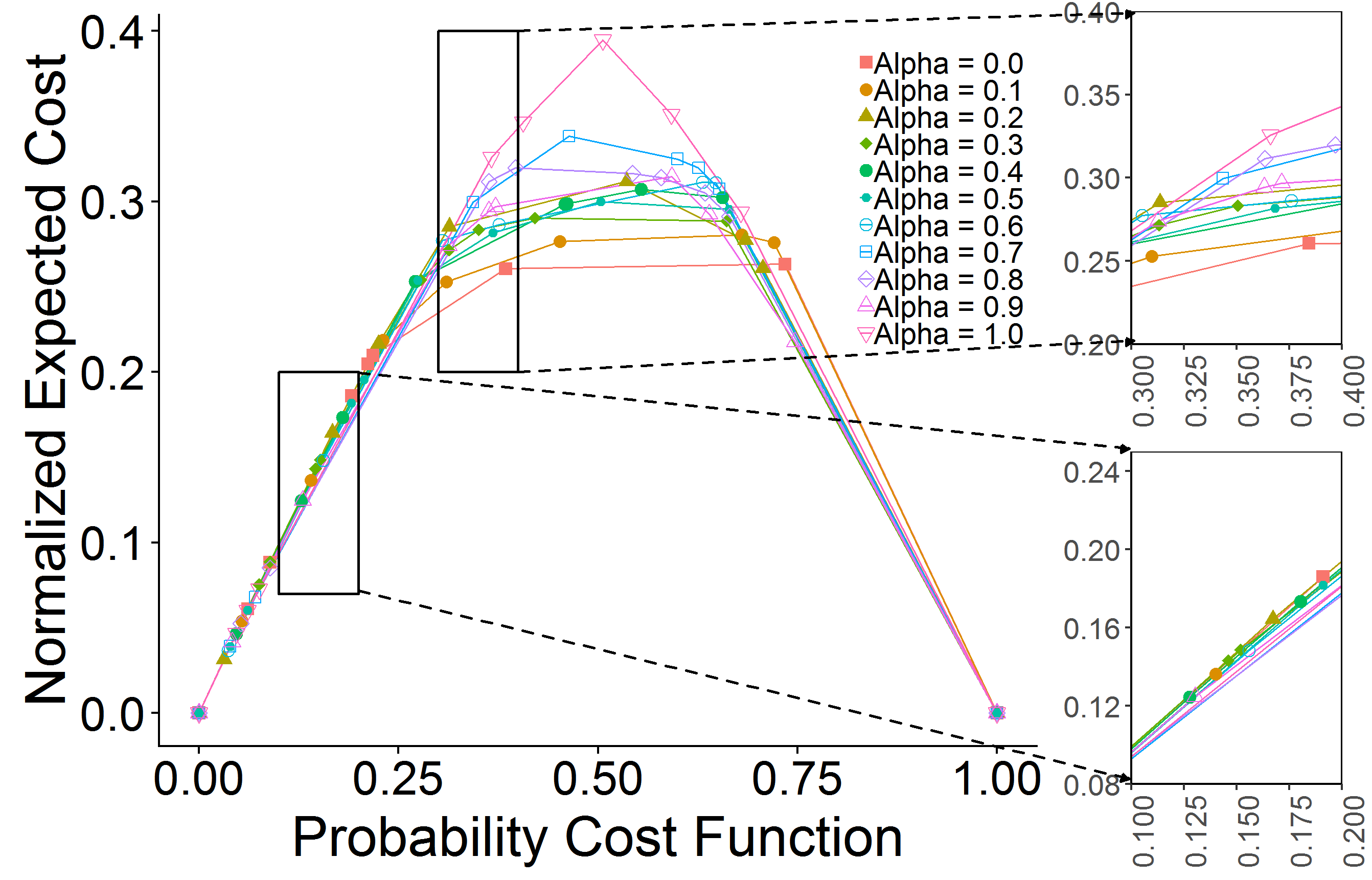 Figure 5
Figure 5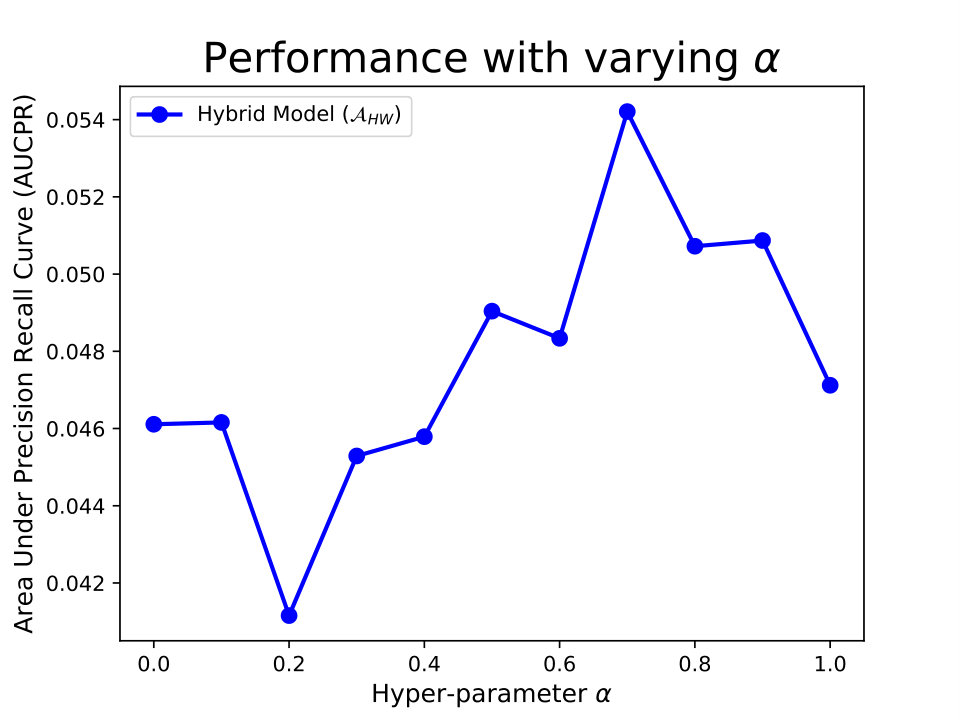 Figure 6
Figure 6 Figure 7
Figure 7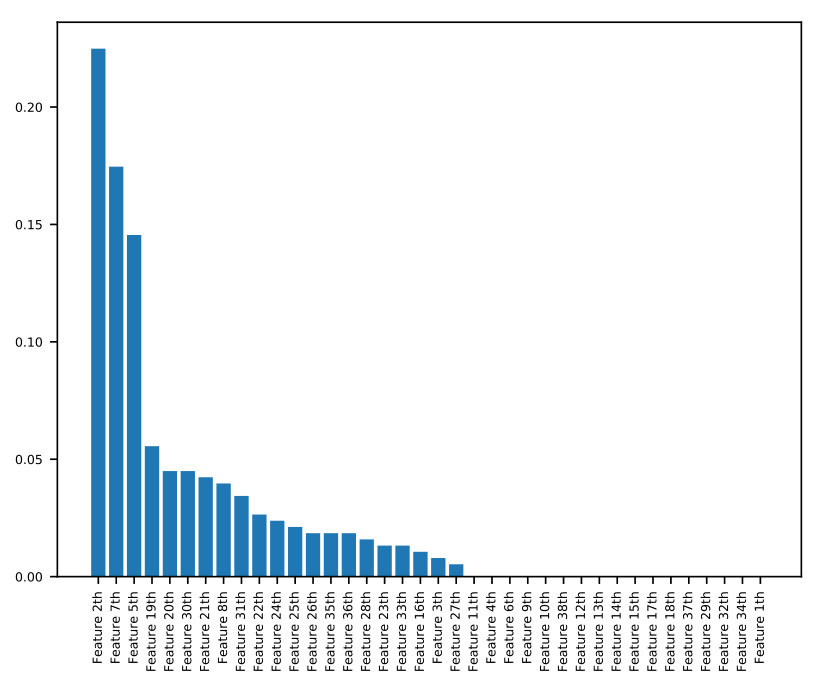 Figure 8
Figure 8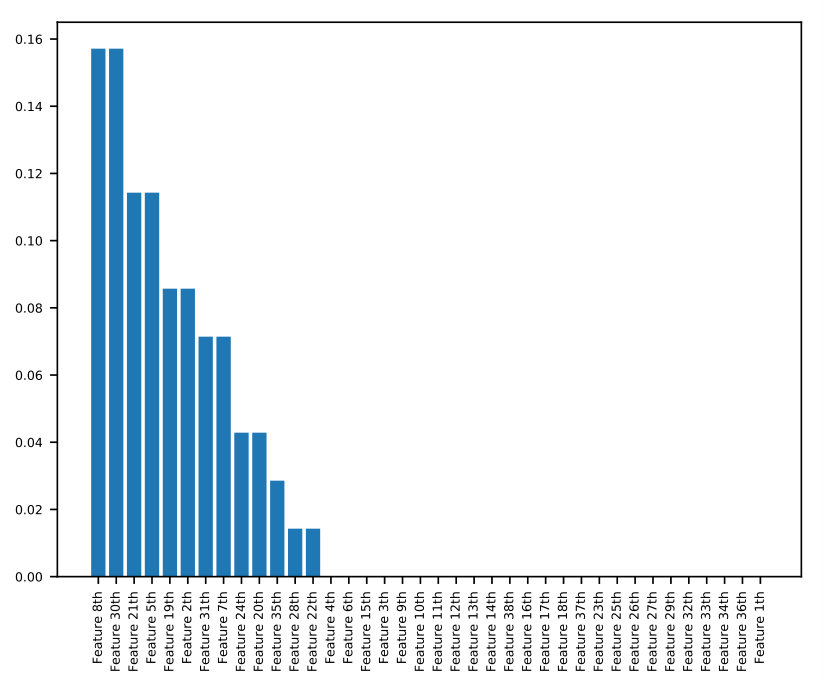 Figure 9
Figure 9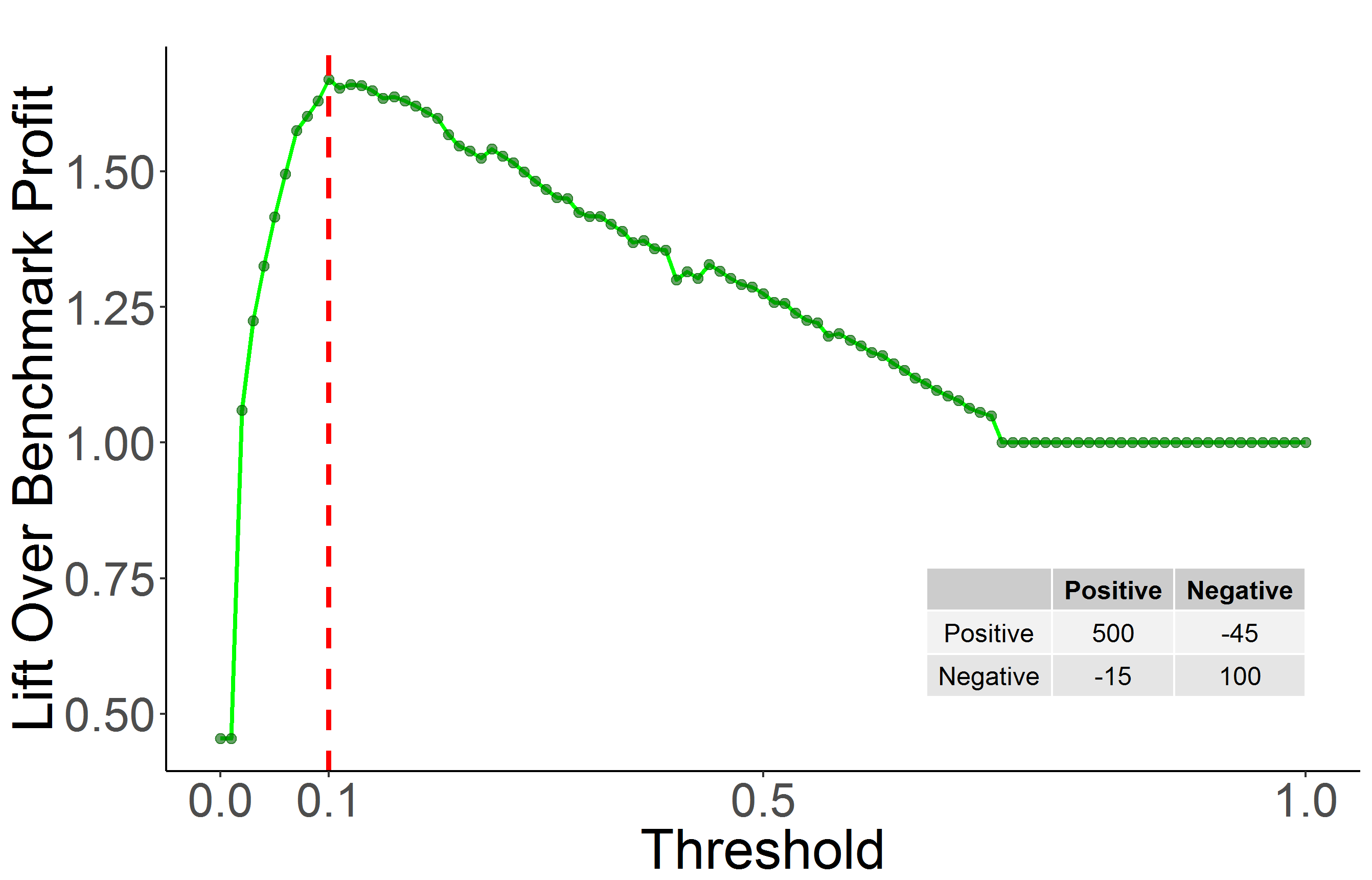 Figure 10
Figure 10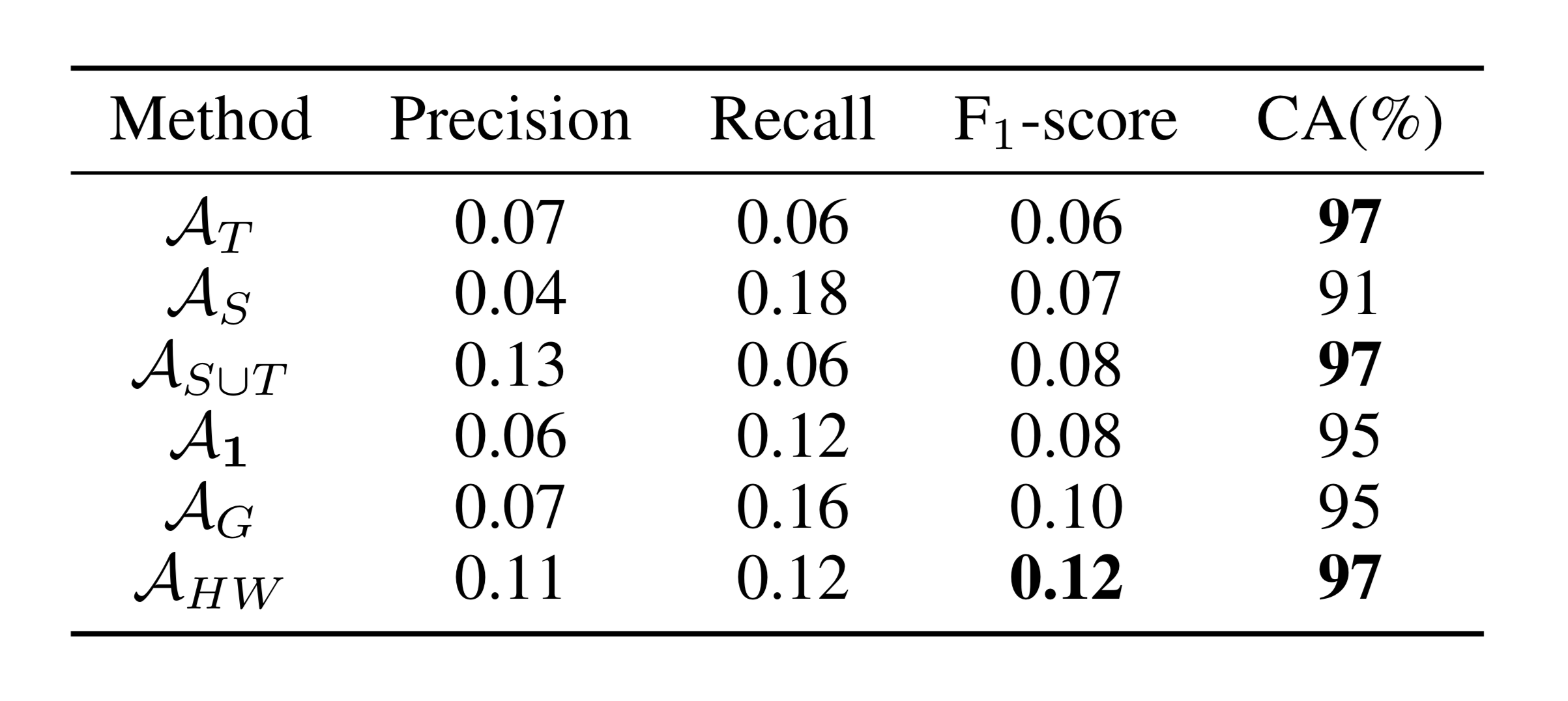 Figure 11
Figure 11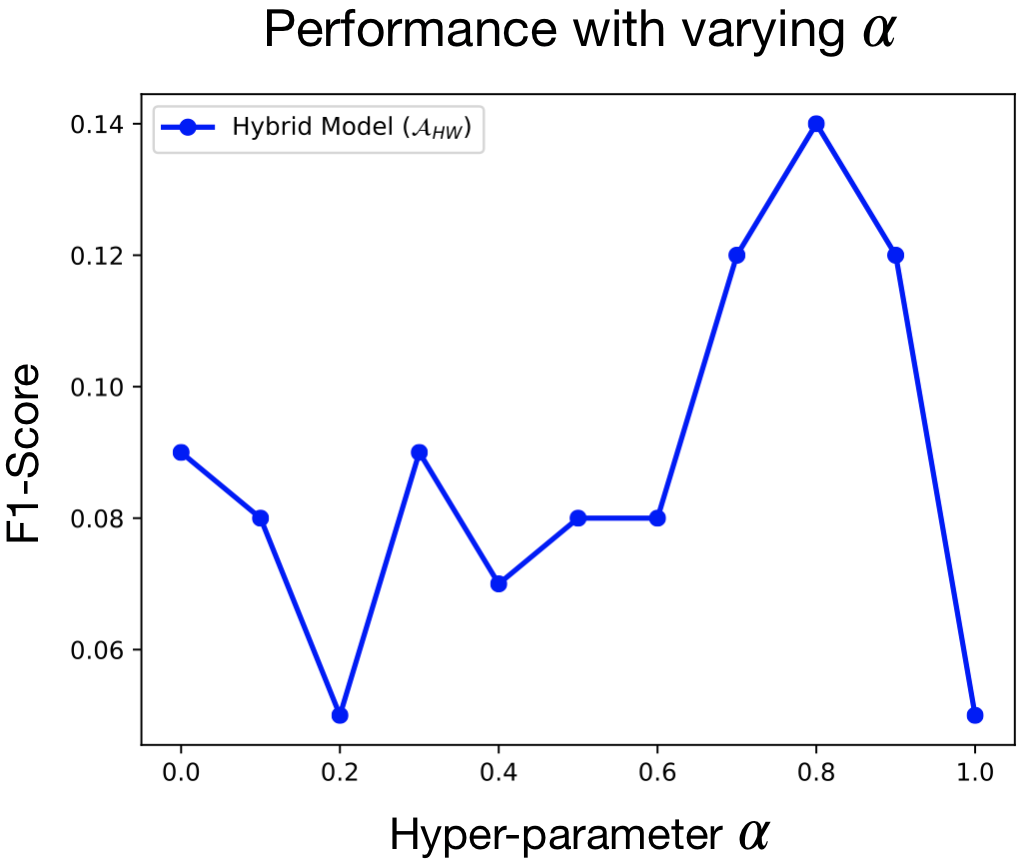 Figure 12
Figure 12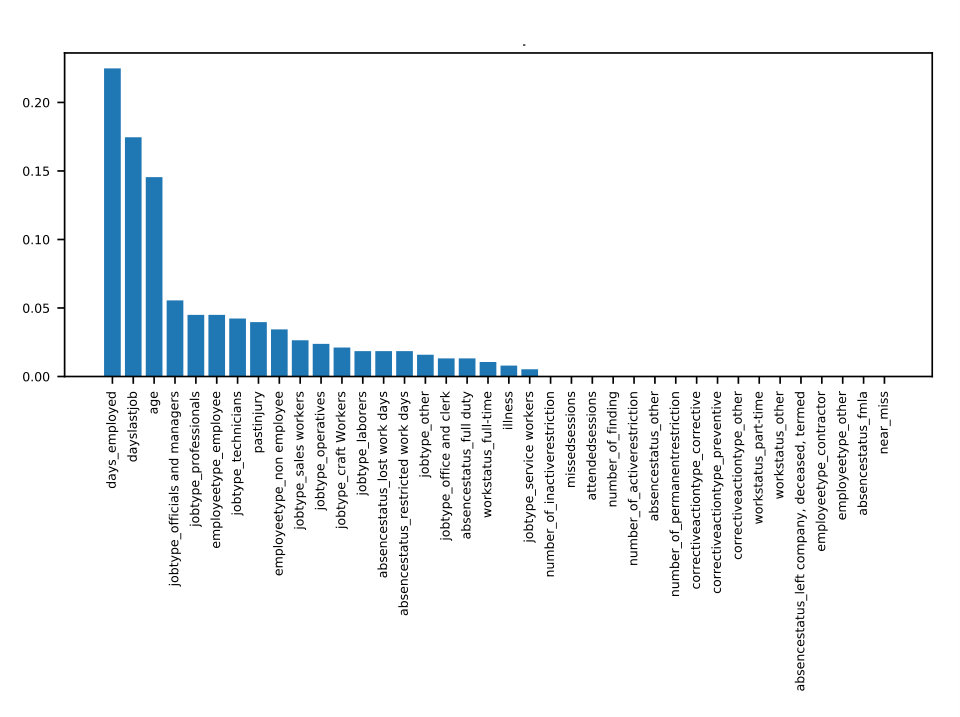 Figure 13
Figure 13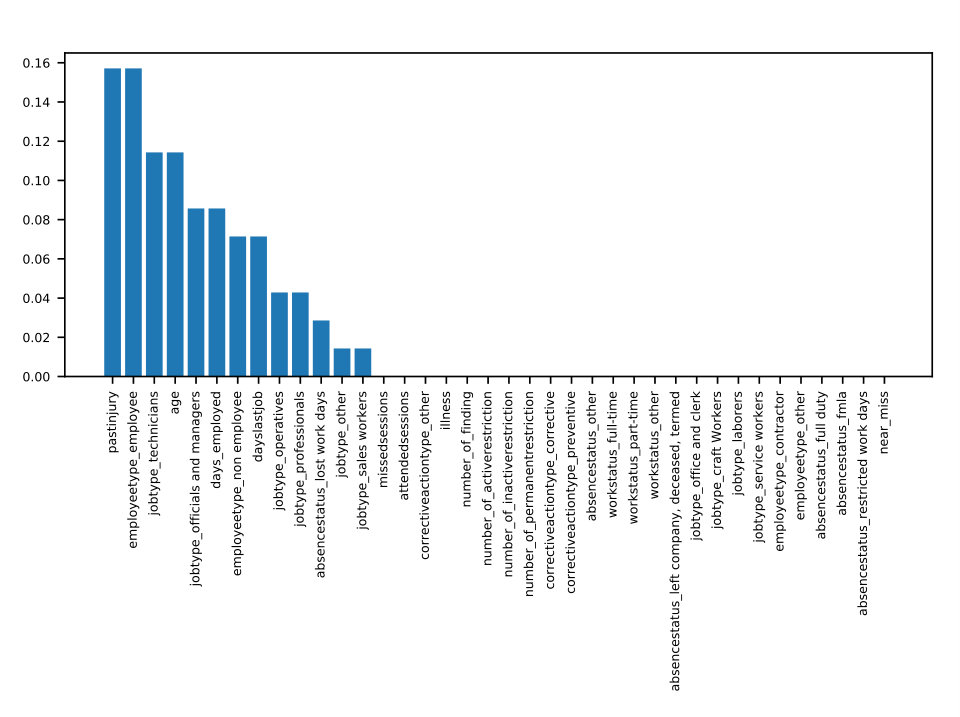 Figure 14
Figure 14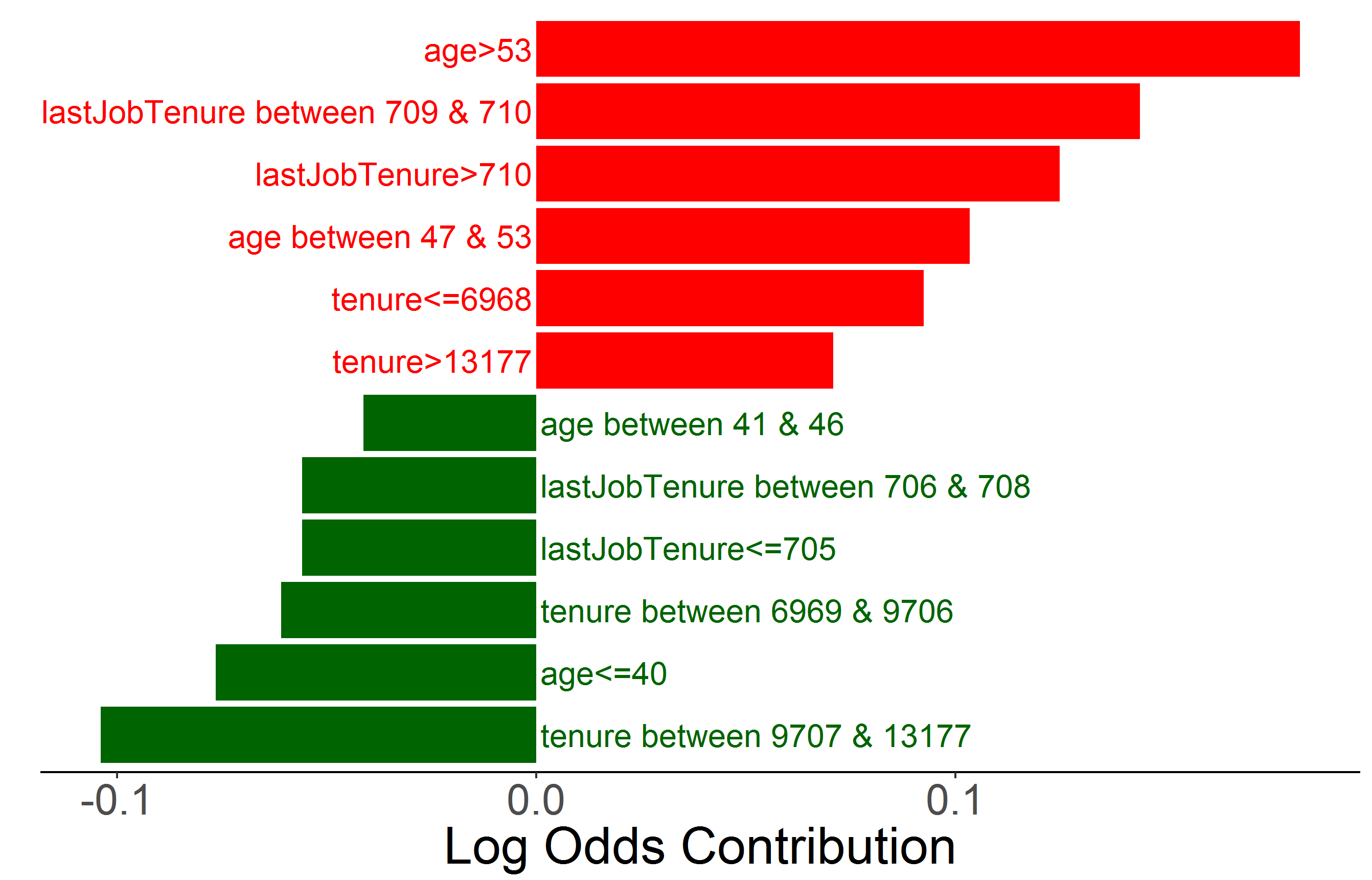 Figure 15
Figure 15 Figure 16
Figure 16 Figure 17
Figure 17| Method | Precision | Recall | AUCPR | |
|---|---|---|---|---|
| 0.07 | 0.06 | 0.06 | 0.0375 | |
| 0.04 | 0.18 | 0.07 | 0.0405 | |
| 0.13 | 0.06 | 0.08 | 0.0478 | |
| 0.06 | 0.12 | 0.08 | 0.0456 | |
| 0.07 | 0.16 | 0.10 | 0.0532 | |
| 0.11 | 0.12 | 0.12 | 0.0542 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsOccupational Health and Safety Research · Traffic and Road Safety · Anomaly Detection Techniques and Applications
Prediction of Workplace Injuries
Mehdi Sadeqi
Azin Asgarian
Ariel Sibilia
Abstract
Workplace injuries result in substantial human and financial losses. As reported by the International Labour Organization (ILO), there are more than 374 million work-related injuries reported every year. In this study, we investigate the problem of injury risk prediction and prevention in a work environment. While injuries represent a significant number across all organizations, they are rare events within a single organization. Hence, collecting a sufficiently large dataset from a single organization is extremely difficult. In addition, the collected datasets are often highly imbalanced which increases the problem difficulty. Finally, risk predictions need to provide additional context for injuries to be prevented. We propose and evaluate the following for a complete solution: 1) several ensemble-based resampling methods to address the class imbalance issues, 2) a novel transfer learning approach to transfer the knowledge across organizations, and 3) various techniques to uncover the association and causal effect of different variables on injury risk, while controlling for relevant confounding factors.
Machine Learning, Causal Inference, Cost-Sensitive Learning, Transfer Learning, Imbalanced Data, Cost-Curves, Actionable Insights, Partial Dependence Plot
1 Introduction
Workplace injuries can affect workers’ lives and can cause substantial economic burden to employees, employers, and more generally to society (ILO, 2018; Sarkar et al., 2016). There are more than million work-related injuries reported every year, resulting in more than million deaths annually (ILO, 2018). The yearly cost to the global economy from work-related injuries alone is a staggering $3 trillion, estimated by ILO.
Predicting injuries and providing actionable insights on factors associated with injuries are critical for improving workplace safety. Recent research has focused on this problem in sports (Naglah et al., 2018; Rossi et al., 2018), construction (Tixier et al., 2016; Poh et al., 2018), and various workplace settings (Sánchez et al., 2011; Rivas et al., 2011; Sarkar et al., 2016). Despite introducing many interesting frameworks, these studies do not address some of the main challenges such as lack of labeled data and class imbalance issues. In addition, previous works do not investigate the causal relationships between different variables and injury incidents.
We propose a framework that employs ensemble-based resampling methods and a novel transfer learning approach to address class imbalance and data availability issues. We apply a method to predictive features of injuries to highlight their direct causal effect and we utilize a visualization technique that provides interpretability. We demonstrate the utility of our framework through experiments performed on real-world datasets. More specifically, we show that ensemble-based resampling and transfer learning techniques can increase the by 100% and area under precision recall curve by 44%, when compared to a model trained on a single organization dataset.
In the remainder of this paper, we first provide a brief overview of the problem and our machine learning framework in Section 2.1. We present the employed ensemble-based resampling techniques, our instance-based transfer learning method, and the approaches used to provide actionable insights in Sections 2.2, 2.3, and 2.4, respectively. Section 3 describes our results and Section 4 covers conclusions and future work.
2 Injury Prediction as Supervised Learning
2.1 Data and Problem Description
To conduct this study, we collected employees’ safety-related information from different organizations during years 2016-2017. We treat the learning problem as a binary classification task. Using the data collected during 2016, the objective is to predict whether an employee was injured or not in 2017. The collected datasets differ in size and distribution, however, they are all highly imbalanced (1-7% injury cases). In all datasets, the employee records are represented by 38 engineered features that capture two main groups of information: general employee information (e.g. age), and event-based information. Event-based information are either associated with the employee (e.g. number of absences) or with the employee’s site (e.g. the risk assessments scores).111The names of the organizations are masked due to confidentiality reasons. In this work, we use XGBoost (Friedman, 2001b) as our base predictive model.
2.2 Imbalanced Data
To address the problem of highly imbalanced data, several approaches are proposed in the literature. Among the most common ones are over-sampling and under-sampling methods (Chawla, 2003), neighbor-based techniques (Wilson, 1972; Tomek, 1976), Synthetic Minority Over-sampling TEchnique (SMOTE) (Chawla et al., 2002), adjusting class weights, boosting techniques, and anomaly detection methods. From these solutions, we are particularly interested in four methods that combine ensemble-based supervised learning algorithms with resampling methods (UnderBagging, SMOTEBagging, RUSBoost, and SMOTEBoost). We give a brief overview of these methods below.
UnderBagging and SMOTEBagging methods try to rebalance the class distribution in each bag of the bagging algorithms. UnderBagging uses random under-sampling while SMOTEBagging uses SMOTE or over-sampling to achieve this goal (Galar et al., 2012). Alternatively, RUSBoost (Seiffert et al., 2010) and SMOTEBoost (Chawla et al., 2003) combine AdaBoost.M2 (Freund & Schapire, 1997) boosting algorithms with resampling methods to address the class imbalance issues. Similar to UnderBagging and SMOTEBagging, in each iteration of training weak learners, these two algorithms respectively use random under-sampling (to reduce majority instances) and SMOTE (to increase minority instances). Moreover, these four approaches have the advantage of having very few number of hyper-parameters. We provide a comparison of these methods in Section 3.1.
2.3 Transfer Learning
To handle the data unavailability issues for a new organization (target domain), we leverage the knowledge learned from other organizations (source domain) by employing an instance-based transfer learning method. Given a set of target training samples
and a loss function
the goal of supervised learning is to find model
that minimizes the expected error, i.e.,
\mathcal{A}^{*}=\underset{\mathcal{A}\in\mathbb{A}}{\operatorname*{arg\,min}}\mathbb{E}_{x\sim P_{T}}\big{[}\mathcal{L}(\mathcal{A}(x),y)\big{]}.
Here is an arbitrary sample and
is the probability distribution of target samples. Following the idea of importance sampling (Liu, 2008; Asgarian et al., 2018) for transferring the knowledge from source domain (
) to target domain (
), we can express the expected error as
\alpha\mathbb{E}_{x\sim P_{T}}\Big{[}\epsilon(x)\Big{]}+(1-\alpha)\mathbb{E}_{x\sim P_{S}}[\epsilon(x)\tfrac{P_{T}(x)}{P_{S}(x)}]
. Here
shows the error for each sample and is a hyper-parameter that controls the overall relative importance between source and target samples. Source sample weights
play a major role in instance-based transfer learning methods, as they control the individual effect of source samples (Asgarian et al., 2017). We describe different weighting approaches including our five baselines models and our proposed weighting strategy in the following.
Baselines: Models
,
, and
trained respectively on source, target and the union of source and target, serve as minimum baselines that a transfer learning method must outperform. Our fourth baseline model is an instance-weighted model (
) with all the weights set to (i.e.,
). This is similar to
, except in this model we use to determine the relative overall importance between source and target samples. Our last baseline model
()
, assumes Gaussian distributions for target and source samples to evaluate the source sample weights .
Hybrid Weights: Previous methods evaluate the source sample weights solely based on their similarity to the target domain. We argue that it is also important to measure the relevance of source samples to the target task. Hence, we define weights , where measures the similarity of an arbitrary source sample to the target domain, while measures the importance of sample in the target task.
For evaluating , unlike the previous methods that employ generative approaches to estimate
and
, we directly approximate weights
with a discriminative classifier. More specifically, using
\{(x,l_{x})\ |x\in S\cup T\text{, and l_{x}=1x\in Sl_{x}=0 otherwise}\}
, we train a binary classifier (e.g., logistic regression (LR)) to differentiate source and target samples. Next, we use the learned weights of this classifier
( and )
to estimate source sample weights
.
To compute , we train an instance of our predictive model
(XGBoost)
using all samples from source and target with their corresponding injury labels. We then define to be the uncertainty of this model about sample . We define the uncertainty of a model about sample to be the distance of to the decision boundary. Note that this value could be negative (thus subtracting from ) when the decision is incorrect, or positive (thus adding to ) when the decision is correct. We denote this model as
.
2.4 Actionable Insights
To visualize the relationship between injuries and its predictors, we explore one method to show the straightforward association, and one to find causal relationship.222Please note that in order to infer meaningful and accurate causal relationships using this approach, we need adequately accurate models. The ensemble-based resampling methods and transfer learning are an attempt in this direction.
To measure the association between features and the target variable, we average the contribution of each feature’s possible values to the log-odds ratio of all samples which match that value. We bin every continuous variable, treating them as categorical, so that such matching is possible for all variables. We use the xgboost_explainer package in Python, which is inspired by (Foster, ), to find the average log-odds contribution of each feature to each sample. Next, for each discrete value of each feature, we average the sample-based contribution over all samples with matching values. This gives us a visualization of both the average impact and direction of each variable as seen in Figure 1. This is a unique approach for visualizing the association between safety-related variables and injuries and it also gives an interpretation of the model. However, it must be noted that each effect size measured here is an average over the population, not a deterministic effect.
Partial dependence plots (PDPs) (Friedman, 2001a) are an especially interesting and fairly natural way of adding interpretability to more complex models. PDPs show the average relationship between two variables over a population by marginalizing over the distribution of all other variables. For a trained model, this is approximated by summing over the training data, where, unlike the marginalized variables, the variables to be plotted are held constant (Friedman, 2001a). PDPs may also yield a causal interpretation of the effect of a variable on injuries (Zhao & Hastie, 2017). Zhao & Hastie showed that a partial dependence calculation that averages over a set of variables is equivalent to controlling for those variables using Pearl’s back-door adjustment formula (Pearl, 1993). For example, there are instances where the relationship between an input variable and injuries is reversed when doing a partial dependence calculation over another variable. In (Pearl, 2014), Pearl shows that instances of the Simpson’s paradox can be properly explained when using the back-door criterion to adjust for a variable.
In our example, we observe the effect of age on probability of injuries after adjusting for tenure. In our causal hypothesis, both age and tenure have a causal impact on injuries. However, neither are considered to directly cause each other. Nevertheless, they are strongly correlated, so we connect each of their exogenous variables in a causal graph. Intuitively, this can be described as both age and tenure being caused by the “passage of time”. In our causal path from age to injury there is one back-door path, which is blocked by tenure. Therefore, tenure satisfies the back-door criterion from age to injury. In Figure 2, we plot probability of injury versus age generated in three different ways. The direct prediction and loess (locally estimated scatterplot smoothing) plot both estimate the direct association between age and probability of injury. The partial dependence plot shows the same association, after adjusting for tenure.
3 Experiments
3.1 Imbalanced Data
For comparing the ensemble-based resampling methods to our benchmark XGBoost model, we adopted an effective visualization technique called cost-curves (Drummond & Holte, 2006). These curves allow us to evaluate a classifier in deployment conditions of two important factors–class distributions and misclassification costs–which are usually unknown or varying with time. Using cost-curves, we can visualize a classifier’s performance for the whole range of these unknown factors. Receiver operating characteristic (ROC) Curves are point/line dual with cost-curves and they convey the same information implicitly, but they are not visually as informative. Hence, we used cost-curves in addition to our other evaluation metrics. These curves also helps to find the conditions for which a classifier shows better performance compared to other classifiers and particularly to trivial classifiers (Drummond & Holte, 2006).
In all datasets, RUSBoost and UnderBagging showed a better performance than the XGBoost model in handling class imbalance (Figure 3). SMOTEBagging and SMOTEBoost, however, showed a lower performance compared to the XGBoost. To avoid a cluttered plot, they are not shown in Figure 3. That being said, this is a data-dependent behavior and one should test each of these algorithms to see which one best matches the data.
The cost-curve performance comparison and model selection is only needed if misclassification costs are unknown in advance or deployment class distribution is different from the test data class distribution. If this is not the case, we can find the optimum threshold that maximizes a profit function defined by a profit matrix. This threshold will be another hyper-parameter that should be optimized inside a cross-validation pipeline. In our XGBoost model, we used the profit function as the evaluation metric for early stopping for different thresholds. For simplicity, here we kept all other XGBoost parameters fixed and optimized only for threshold. Figure 4 shows the ratio of model profit to a benchmark profit as a function of threshold values. The profit matrix and the optimum threshold value are shown in this figure.
3.2 Transfer Learning
In our transfer learning framework, we considered Organization-1’s dataset as the target domain and Organization-2’s dataset as the source domain. For training, we used 58,271 samples from target (12,225) and source (46,046) training sets, and evaluated the models on 3,057 samples from target test set. Since the datasets were highly imbalanced (1-7 injury cases), we used precision, recall, (macro), and area under the precision-recall curve (AUCPR) as our four evaluation metrics. Results of our quantitative evaluation is shown in Table 1.
In Table 1, we see that model has a poor performance with equal to 0.06 and AUCPR of 0.0375. This is possibly due to data sparsity issue and lack of expressiveness of the model. On the other hand, has a higher and AUCPR, but the precision is diminished. Also model performs better in terms of and AUCPR compared to both models and . The best result is obtained with our model , which increases the and AUCPR considerably.
Figure 5 shows the AUCPR obtained with model as a function of hyper-parameter . We see that the best performance is achieved with equal to 0.7. However, increasing or decreasing results in lower AUCPR, as it enhances the influence of target or source samples respectively.
4 Conclusions And Future Work
In this paper, we investigate the problem of injury risk prediction in a supervised learning framework. To improve the performance in presence of highly imbalanced data, we employ ensemble-based resampling techniques. To address the lack of labeled data, we propose an instance-based transfer learning method. Additionally, we provide actionable insights to prevent injuries and show the effectiveness of our framework experimentally. In our future work, we focus further on discovering the causal relationships from observational data as it is a key element in injury prevention.
Acknowledgment
We would like to acknowledge Parinaz Sobhani, Madalin Mihailescu, Chang Liu, and Diego Huang for their invaluable assistance and insightful comments on the initial draft of this work. We are specially grateful to our management team at Georgian Partners and Cority including Madalin Mihailescu, Ji Chao Zhang, Stan Marsden, and David Vuong for encouraging and supporting our research activities, without which we were unable to complete this work. Finally, we would like to thank Babak Taati for his direction and guidance on this study.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1ILO (2018) Safety and health at work, 2018. URL http://www.ilo.org/global/topics/safety-and-health-at-work/lang--en/index.htm .
- 2Asgarian et al. (2017) Asgarian, A., Ashraf, A. B., Fleet, D., and Taati, B. Subspace selection to suppress confounding source domain information in aam transfer learning. In IEEE IJCB , 2017.
- 3Asgarian et al. (2018) Asgarian, A., Sobhani, P., Zhang, J. C., Mihailescu, M., Sibilia, A., Ashraf, A. B., and Taati, B. A hybrid instance-based transfer learning method. ar Xiv:1812.01063 , 2018.
- 4Chawla (2003) Chawla, N. V. C 4. 5 and imbalanced data sets: investigating the effect of sampling method, probabilistic estimate, and decision tree structure. In Proceedings of the ICML , 2003.
- 5Chawla et al. (2002) Chawla, N. V., Bowyer, K. W., Hall, L. O., and Kegelmeyer, W. P. Smote: Synthetic minority over-sampling technique. Journal of Artificial Intelligence Research , 2002.
- 6Chawla et al. (2003) Chawla, N. V., Lazarevic, A., Hall, L. O., and Bowyer, K. W. Smoteboost: Improving prediction of the minority class in boosting. In In Proceedings of the Principles of Knowledge Discovery in Databases (PKDD) , 2003.
- 7Drummond & Holte (2006) Drummond, C. and Holte, R. C. Cost curves: An improved method for visualizing classifier performance. Machine Learning , 2006.
- 8(8) Foster, D. xgboost Explainer: XG Boost Model Explainer . R package version 0.1.