Nonparametric volatility change detection
Maria Mohr, Natalie Neumeyer

TL;DR
This paper introduces nonparametric tests for detecting changes in the conditional variance of heteroscedastic time series, combining empirical process methods with classical CUSUM tests, and demonstrates their effectiveness through simulations and real data.
Contribution
It proposes new nonparametric change detection tests for variance functions that are consistent and asymptotically distribution-free in certain cases.
Findings
Tests are consistent against general alternatives.
Asymptotically distribution-free for univariate covariates.
Good performance demonstrated in simulations and exchange rate data.
Abstract
We consider a nonparametric heteroscedastic time series regression model and suggest testing procedures to detect changes in the conditional variance function. The tests are based on a sequential marked empirical process and thus combine classical CUSUM tests with marked empirical process approaches known from goodness-of-fit testing. The tests are consistent against general alternatives of a change in the conditional variance function, a feature that classical CUSUM tests are lacking. We derive a simple limiting distribution and in the case of univariate covariates even obtain asymptotically distribution-free tests. We demonstrate the good performance of the tests in a simulation study and consider exchange rate data as a real data application.
Click any figure to enlarge with its caption.
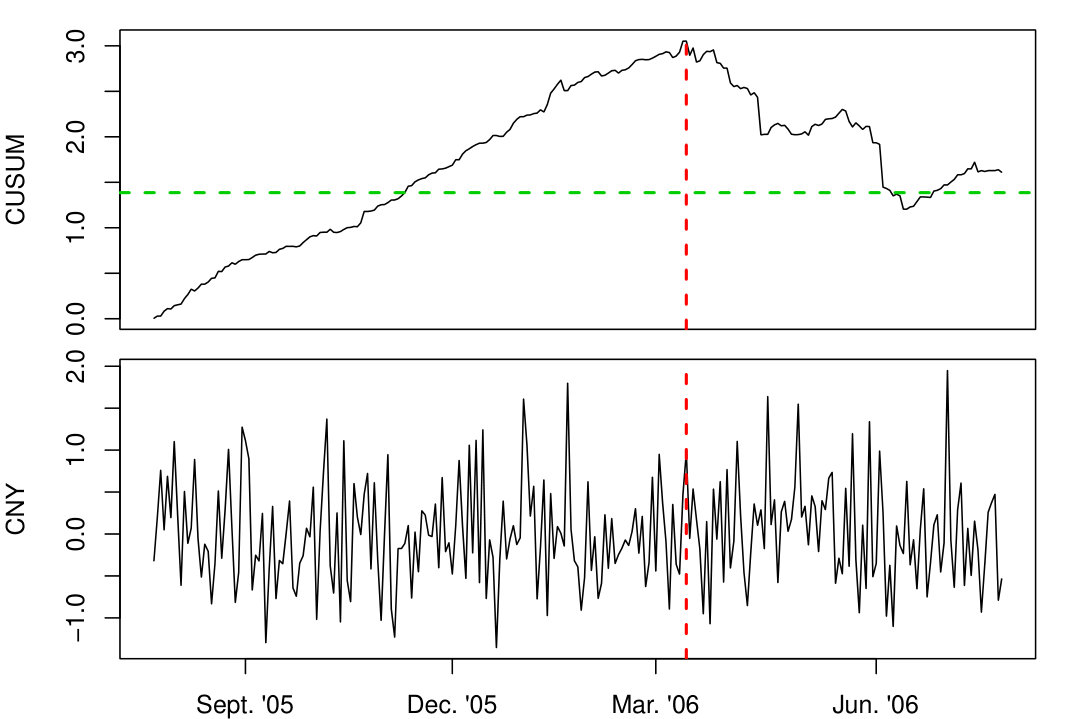 Figure 1
Figure 1| model 1 (a) | model 1 (b) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| model 2 (a) | model 2 (b) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Nonparametric volatility change detection
Maria Mohr and Natalie Neumeyer
Department of Mathematics, University of Hamburg
Abstract
We consider a nonparametric heteroscedastic time series regression model and suggest testing procedures to detect changes in the conditional variance function. The tests are based on a sequential marked empirical process and thus combine classical CUSUM tests with marked empirical process approaches known from goodness-of-fit testing. The tests are consistent against general alternatives of a change in the conditional variance function, a feature that classical CUSUM tests are lacking. We derive a simple limiting distribution and in the case of univariate covariates even obtain asymptotically distribution-free tests. We demonstrate the good performance of the tests in a simulation study and consider exchange rate data as a real data application.
Key words: change point, conditional variance function, CUSUM, heteroscedasticity, kernel estimation, Kolmogorov-Smirnov test, marked empirical process, structural change
AMS 2010 Classification: Primary 62M10, Secondary 62G08, 62G10
1 Introduction
The paper is concerned with the investigation of structural stability of the conditional variance function (volatility function) in nonparametric heteroscedastic time series regression models. Those models have gained much attention over the last decades and contain as special cases nonparametric AR-ARCH models, which are also called nonparametric CHARN (conditional heteroscedastic autoregressive nonlinear) models; see Fan and Yao (2003) or Gao (2007) for overviews. They have been successfully applied to model econometric time series such as foreign exchange rates or stock market indices, see e.g. Yang et al. (1999) and Zhao and Wu (2008). Here tests for structural changes in the volatility function are of special importance.
A lot of research has been devoted to the parametric case, notably for ARCH and GARCH models. Among others, Kokoszka and Leipus (1999) suggested a CUSUM type test for parameter stability in ARCH models, while Kulperger and Yu (2005) considered partial sums of higher powers of residuals to test for a parameter change in GARCH models. Berkes et al. (2004) considered tests for parameter stability in GARCH models based on likelihood ratios. Kengne’s (2012) test, which is based on quasi likelihood estimators, is applicable to more general parametric causal time series models. Lee and Lee (2014) suggested a residual based CUSUM test for change points in parametric AR-GARCH models, while Lee and Song (2008) and Song and Kang (2018) considered ARMA-GARCH models. Very few results are available in the nonparametric framework. Chen et al. (2005) studied a nonparametric heteroscedastic time series model with a scale change in volatility. However, they assume a compact support of regressors, which is problematic when considering autoregression models. Tests for change points in the unconditional variance in time series models have been considered as well. Lee et al. (2003) considered parametric autoregression models, as well as fixed design nonparametric regression models with strongly mixing errors using a CUSUM testing procedure. Chen and Tian (2014) constructed a ratio test for change point detection in the variance in random design nonparametric regression models. However, their test does not allow for autoregressive effects, as a compact support of regressors is assumed. A related strand of the literature deals with change point detection in the error distribution of a time series regression model. In the parametric framework Koul (1996) considered non-linear regression models and Ling (1998) non-stationary AR models, to just mention a few, while Selk and Neumeyer (2013) considered nonparametric heteroscedastic autoregression models.
Recently, Mohr and Neumeyer (2019) suggested a test for change point in the regression function in nonparametric time series models. They combine traditional CUSUM tests as considered by Hidalgo (1995), Honda (1997) and Su and Xiao (2008) in the nonparametric context with the marked empirical process approach originally suggested by Stute (1997) and widely used in the goodness-of-fit literature. Compared with the CUSUM approach the new test shows better power properties, in theory as well as in finite sample simulations. In the paper at hand we will modify the CUSUM marked empirical process test in order to test for a change point in the conditional volatility function. We obtain tests with very simple limiting distributions, which are consistent against general fixed alternatives. In the case of univariate covariates one can even obtain tests that are asymptotically distribution-free.
The paper is organized as follows. In section 2 we define the process on which the test statistics are built. In section 3 we give the limiting distribution of the process under the null hypothesis of no change in the variance function. We further discuss consistency against fixed alternatives of one change point. In section 4 we describe a simulation study and discuss a real data example of currency exchange rates. Section 5 concludes the paper, whereas in the appendix we list the regularity assumptions and prove the asymptotic results.
2 The model and test statistic
Consider a strictly stationary and strongly mixing time series , , following the nonparametric model
[TABLE]
where a.s. for the sigma-field , and does not depend on . Further, let the following representation for the innovations hold,
[TABLE]
for some functions and an i.i.d. sequence , such that is independent of for all and fulfills , and . With these restrictions, is the variance function of , conditioned on , as
[TABLE]
The -dimensional absolutely continuous covariate may include finitely many lagged values of , for instance , such that the model includes nonparametric AR-ARCH models.
Our aim is to test whether the function is stable in time . Given observations the null hypothesis
[TABLE]
for some not further specified function (not depending on time ) will be considered.
The idea is to base tests for on a sequential marked empirical process of residuals,
[TABLE]
indexed in and . Throughout denotes an indicator function. Further is a weight function with specified in assumption (J) in appendix A. The regression and volatility functions are estimated as
[TABLE]
and
[TABLE]
respectively, with kernel function and bandwidth as considered in the assumptions in appendix A. The null hypothesis of no change in the variance will be rejected for large values of, e.g., a Kolmogorov-Smirnov type test statistic
[TABLE]
due to the following motivation. Note that the volatility function from (2.2) can be viewed as regression function in a regression model
[TABLE]
with covariate , response variable and innovations , that satisfy and a.s. However, this is not a feasible model as is unobservable and has to be estimated. The term
[TABLE]
in the definition of the process can be seen as estimator for the innovation in the ‘non-feasible’ model above under the null hypothesis . Thus will vanish for under the null hypothesis. The limiting process of will be given in Corollary 3.2 below. From this result critical values for a test based on the Kolmogorov-Smirnov type test statistic can be approximated. The behavior of under fixed alternatives will be demonstrated in Remark 3.3 in order to motivate consistency of the test. The process is a consistent improvement of CUSUM tests analogous to the procedure in Mohr and Neumeyer (2019) developed for changes in the regression function.
Remark 2.1**.**
In model (2.1) we assume a regression function that is stable in time . For testing of a change in the variance function this assumption makes sense if beforehand one can test for a change in the regression function applying a testing procedure which only reacts sensitive to changes in the regression function, not to changes in the variance function. Mohr and Neumeyer (2019) provide such a bootstrap test, which can be applied in cases of unstable variances, but as desired only reacts sensitive to changes in the regression function. Consecutively applying the bootstrap test in Mohr and Neumeyer (2019) and, if it does not reject, the test in the paper at hand, gives the knowledge of whether a change occurs in the mean or the variance function.
3 Asymptotic results
Under the regularity assumptions in appendix A one can derive the following decomposition of the process defined in (2.3) in terms of the process
[TABLE]
as well as the weak convergence of .
Theorem 3.1**.**
Assume model (2.1), (2.2) under the null hypothesis and assumptions (G), (), (M), (J), (F1), (F2), (K), (B1) and (B2) from appendix A.
(i)* Then, uniformly in and .*
(ii)* The process converges weakly in to a centered Gaussian process with*
[TABLE]
where .
Here and throughout we define for . The proof of Theorem 3.1 is given in appendix B. An application of the continuous mapping theorem and Slutsky’s lemma give the following weak convergence result for the process .
Corollary 3.2**.**
Suppose that the assumptions of Theorem 3.1 and are satisfied. Then the process converges weakly in to a centered Gaussian process with
[TABLE]
The continuous mapping theorem then implies convergence in distribution of the Kolmogorov-Smirnov test statistic,
[TABLE]
In particular in the case using continuity of and the scaling property of the Brownian motion, it holds that converges in distribution to , where
[TABLE]
and is a Kiefer-Müller process. The constant can be consistently estimated as
[TABLE]
and the test statistic is asymptotically distribution-free. We reject at asymptotic level if is larger than the (known) -quantile of .
Remark 3.3**.**
To see that the test is consistent against simple fixed alternatives of one change in the volatility function,
[TABLE]
for some functions with , consider a triangular array
[TABLE]
with regression function stable in time and innovations such that and a.s. Further assume that the covariate is absolutely continuous with density function . Then will estimate the function
[TABLE]
Now assume that for each , the limit of exists and denote it by . Then will converge in probability to the integral
[TABLE]
which, under , does not vanish for at least one (provided that ). As , the test statistic will converge to infinity in probability and the test is consistent.
Remark 3.4**.**
A traditional CUSUM test statistic in our context would be defined as . With the same reasoning as in Remark 3.3, will converge in probability to
[TABLE]
which could be zero, even under the alternative . In such a case the CUSUM test is not consistent.
4 Finite sample properties
4.1 Simulations
A Monte Carlo study is conducted in order to compare the results for from section 2 and a Cramér-von Mises type test with those of the traditional CUSUM versions denoted by and . All simulations are carried out with a level of , replications and for sample sizes . For the nonparametric estimators and we use an Epanechnikov kernel and as a simple ad hoc bandwidth. Furthermore, we set for the weighting function. The data is simulated from the following models.
[TABLE]
where is an exogenous variable following the AR(1) model with being i.i.d. .
[TABLE]
For both model 1 and 2 we consider and two different choices for the regression function, namely (case (a)) and (case (b)).
Model 1 is a heteroscedastic regression model with autoregressive covariables while model 2 is a heteroscedastic autoregression (AR-ARCH) model. In both cases is satisfied for and is satisfied for . Further, note that data generated from both models fulfill the stationarity and mixing assumptions when (see Remark A.1 in appendix A).
Table 1 shows the rejection frequencies for model 1. To summarize the performance of the tests it is to mention that all level simulations () show reasonably good results. The tests based on and show nice consistency properties (), rejecting the null more frequently with increasing sample sizes, where has larger power. The classical CUSUM tests, however, clearly fail in detecting the change, having a power that does not exceed for all cases (see Remark 3.4). All of the tests perform rather poorly when the sample size is small, i.e. for . Furthermore, we note that changes occurring at are easiest to detect.
The corresponding results in model 2 can be found in table 2. The level of is approximately hold for all tests, even in the case where the variance has a relatively large influence (). The power simulations suggest that our tests as well as the classical CUSUM tests result in reasonable rejection probabilities, detecting the change more often for increasing sample sizes. Again changes in are easiest to detect.
4.2 Data example
In this section we will apply our test to a financial data set that is concerned with exchange rates of currencies. Exchange rate regimes indicate how a country manages its currency with respect to other currencies, it can vary from ”fixed”, over ”pegged” to ”floating”. In the case of a fixed regime, the currency is more or less fixed to some other currency. Contrarily with a floating regime the currency is allowed to fluctuate freely by market forces. Pegged regimes are somehow in between, the currency then has limited flexibility when compared with other currencies. As Zeileis et al. (2010) point out, information on the exchange rate regime of a country is not always fully disclosed by the corresponding central bank. Hence, data driven methods such as linear regression became popular to classify the exchange rate regime in operation. Zeileis et al. (2010) suggest that a vanishing error variance can be interpreted as a fixed currency regime, while a small or large error variance can indicate a pegged or floating regime respectively. This is illustrating that the error variance is an important quantity when looking for changes in the exchange rate regime. As such changes are often caused by policy interventions, tests for sudden breaks (rather than smooth transitions) are of reasonable interest.
We consider the exchange rates of the Chinese Yuan Renminbi (CNY) regressed on the exchange rates of the US Dollar (USD). The reason to do so is that China decided to give up on a fixed exchange rate to the US dollar in 2005. More precisely, we consider 251 data points which are the daily log-difference returns from July 26nd, 2005 to July 25nd, 2006 of the CNY and USD each with respect to the Swiss franc (CHF) as numeraire currency. This is the first year of observations of a data set considered by Zeileis et al. (2010) as well as Kirch and Weber (2018). Both studies use a linear regression model and a basket of four currencies as regressors, namely the USD, Japanese yen (JPY), Euro (EUR) and the British Pound (GBP). However, the results of Zeileis et al. (2010) indicate nearly vanishing regression coefficients for the JPY, the EUR and the GBP over the whole investigated time period from July 26nd, 2005 to July 31st, 2009.
We first apply the bootstrap test by Mohr and Neumeyer (2019) to test for changes in the unknown regression function. With a p-value of it suggests a stable regression function.
Secondly, we apply our test based on using the -quantile of the limiting distribution as critical values. The test clearly rejects the null with a p-value smaller than , indicating a change in the conditional variance function. The possible change point can be estimated by and suggests a change of the exchange rate regime in March 3rd, 2006 which is consistent with the results of Zeileis et al. (2010). Figure 1 shows the cumulative sum, (top plot), as well as the exchange rates of the CNY plotted against the time (bottom plot). The green dashed line is indicating the critical value while the red dashed line corresponds to the estimated change point.
Note that applying the tests to the full data set, no change in the regression function is detected (p-value ), but a change in the variance is clearly detected (p-value smaller than ). However, as the data set is rather large and from the findings of Zeileis et al. (2010) we expect more than one change in the variance when looking at the full set of observations, which makes the estimation of possible changes more complicated (see also section 5).
5 Concluding remarks
This paper closes a gap in the change point testing theory for nonparametric time series models. Assume that one already has accepted that there is no change in the (nonparametric) regression function, but one suspects a change in the (nonparametric) volatility function. In such a case the new test gives a valid procedure. To the best knowledge of the authors the new test is the first that can be applied to (nonparametric) autoregressive models (no assumption of bounded support of the covariates) and is consistent against general alternatives of a change point in the variance function.
Under the assumption that only one change occurs, an estimator for the change point is given by . Asymptotic properties of this estimator will be considered in future research. If more than one change occurs it might be necessary to modify this estimator. For instance Fryzlewicz (2014) proposes a wild binary segmentation procedure for the estimation of multiple changes in a simple piecewise-constant signal model, which possibly can be adapted to our setting.
For our theoretical result Theorem 3.1 we need stationarity under the null. However, if there are no changes in both regression function and variance function , there still could be a change in the error distribution of . In this case, a bootstrap test similar to the wild bootstrap proposal of Mohr and Neumeyer (2019) can be conducted that is sensible to changes in the variance function but not to changes in the error distribution. If both tests of Mohr and Neumeyer (2019) and the bootstrap version of the test at hand do not indicate a change in the regression and variance function respectively, the procedure of Selk and Neumeyer (2013) can be used to detect changes in the error distribution.
Appendix A Assumptions
- (G)
Let be strictly stationary and -mixing with mixing coefficient such that for some . 2. ()
For let there exist some and some even such that , where , and a.s. for all , for some functions with for some and . 3. ()
For , from assumption () let for some . 4. (M)
For some let and let be absolutely continuous with density function that satisfies and . Let there exist some such that for all , where is the density function of . 5. (J)
Let be a positive sequence of real numbers satisfying and and let . 6. (F1)
For some and from assumption (J) let , where is from assumption (B1) and (B2) and let for all . Further, let for some and for all
[TABLE]
where and for . 7. (F2)
For from assumption (F1), from assumption (J) and from assumption (K), let for all with ,
[TABLE] 8. (K)
Let be symmetric in each component, times differentiable with and compact support . Additionally, let and for all with , where . For all let for all and for some and for all . (Here, and are from assumption (F1).) 9. (B1)
For and from assumption (F1) let
[TABLE]
and for some let
[TABLE] 10. (B2)
For from assumption (F1) and from assumption (B1) let
[TABLE]
and for with and from assumption ().
Remark A.1**.**
Assumption (G) is fulfilled by data following causal and stationary ARMA models as they have an MA() representation with coefficients that decay exponentially fast (see for instance Fan and Yao (2003) Subsection 2.6.1 (iii), p. 69). For more general nonlinear AR-ARCH processes both Lu (1998) and Liebscher (2005) give sufficient conditions on regression function, volatility function and the innovations under which the mixing condition in (G) holds. In the linear model
[TABLE]
where , the condition in Lu (1998) simplifies to .
Remark A.2**.**
In order to satisfy the first bandwidth assumption in (B2), a necessary condition is , hence for higher dimensional covariate , the existence of higher order partial derivatives of and is needed. In order to satisfy both the first and third bandwidth assumption in (B2) at the same time, depending on the dimension and the smoothness parameters and , the order of the kernel needs to be chosen such that holds. As a rule of thumb, one can choose for some and a kernel, such that . That choice satisfies the assumptions given negligible rates for and .
Further note that the last constraint in (B2) is merely a trade off between existence of moments of , dimension and smoothness parameters and . It is satisfied if (given negligible rates for and ).
Appendix B Proofs
Lemma B.1**.**
Under the assumptions of Theorem 3.1 and under the following rates of convergence can be obtained for the kernel estimators and ,
-
(i)
-
(a)
, 2. (b)
* for all ,* 3. (c)
* for all , * 2. (ii)
- (a)
, 2. (b)
* for all ,* 3. (c)
* for all . *
Note that the results for the Nadaraya-Watson estimator in (i) are also stated in Lemma A.1 in Mohr and Neumeyer (2019). The proof of Lemma B.1 is similar to the proof of Theorem 8 in Hansen (2008) and omitted for the sake of brevity.
Lemma B.2**.**
Under the assumptions of Theorem 3.1 and under we have uniformly in and
[TABLE]
Proof.
For some -times differentiable function define the norm
[TABLE]
and the function class with . The third bandwidth condition in (B2) implies
[TABLE]
and thus Lemma B.1 (i) implies that as holds for . It is then sufficient to consider for , and . Furthermore, using () and () it can be shown that for
[TABLE]
holds uniformly in and . Defining the function class and imposing , the assertion then follows if we show
[TABLE]
To this end let , and and let further partition in intervals of length such that . Furthermore, we use the bracketing numbers and , where is the supremum norm on . Let denote the brackets needed to cover . Let furthermore define the brackets needed to cover . It can be shown that and and further
[TABLE]
In what follows we only consider the first line on the right hand side, while the other ones can be treated similarly. We apply Theorem 2.1 of Liebscher (1996) to the random variable (for fixed)
[TABLE]
The mixing coefficient of can be bounded by the mixing coefficient of due to Bradley (1985), Section 2, remark (iv). Further, the variables are centered and have a bound of order . Applying Theorem 2.1 to yields for all and large enough
[TABLE]
where the first, second and last bandwidth constraint in (B2) were used in the last equality. Details are omitted for the sake of brevity.
∎
Lemma B.3**.**
Under the assumptions of Theorem 3.1 and under we have uniformly in and
[TABLE]
Note that the proof of Lemma B.3 is similar to the proof of Theorem 3.1 (i) in Mohr and Neumeyer (2019). It will only be sketched for the sake of brevity.
Proof.
Using under , it holds that
[TABLE]
By strict stationarity of and the moment constraints from () we deduce that uniformly in and
[TABLE]
Making use of the uniform convergence rates of stated in Lemma B.1 (ii) we furthermore obtain
[TABLE]
uniformly in and . Continuing by inserting the definition of , using and finally under , it holds that
[TABLE]
Concerning (B.1) and (B.2), it can be shown that
[TABLE]
and
[TABLE]
uniformly in respectively. Using the uniform rates of convergences of from Lemma B.1 (i) (a), which also hold on the slightly larger set , it can be shown that the term (B.3) is negligible uniformly in . Finally, using similar methods as for the proof of Lemma B.2, it can be shown that the term (B.4) is as well negligible uniformly in . Putting the results together, the assertion of the lemma follows.
∎
Proof of Theorem 3.1.
The assertion (i) follows by Lemma B.2 and Lemma B.3 and by Lemma B.1 (i) (a) together with the bandwidth constraints as
[TABLE]
For (ii) note that is strictly stationary and strongly mixing under and assumption (G). Denote by the marginal distribution of . The assertion then follows by an application of Corollary 2.7 in Mohr (2019) to the sequential empirical process indexed in the function class . The conditions that are needed for the asymptotic equicontinuity of the process are implied by assumptions (G) and (). The convergence of the finite dimensional distributions can be shown by applying Corollary 1 in Rio (1995), which is a central limit theorem for strongly mixing triangular arrays.
∎
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Berkes et al. (2004) Berkes, I., Horváth, L., and Kokoszka, P. (2004). Testing for parameter constancy in GARCH(p,q) models. Stat. Probab. Lett. , 70:182–195.
- 2Bradley (1985) Bradley, R. C. (1985). Basic properties of strong mixing conditions. In Eberlein, E. and Taqqu, M. S., editors, Dependence in Probability and Statistics , pages 165–192. Birkhäuser, Boston.
- 3Chen et al. (2005) Chen, G., Choi, Y. K., and Zhou, Y. (2005). Nonparametric estimation of structural change points in volatility models for time series. J. Econom. , 126:79–114.
- 4Chen and Tian (2014) Chen, Z. and Tian, Z. (2014). Ratio tests for variance change in nonparametric regression. Statistics , 48:1–16.
- 5Fan and Yao (2003) Fan, J. and Yao, Q. (2003). Nonlinear Time Series: Nonparametric and Parametric Methods . Springer, New York.
- 6Fryzlewicz (2014) Fryzlewicz, P. (2014). Wild binary segmentation for multiple change-point detection. Ann. Statist. , 42:2243–2281.
- 7Gao (2007) Gao, J. (2007). Nonlinear Time Series: Semiparametric and Nonparametric Methods . Chapman & Hall/CRC, Boca Raton.
- 8Hansen (2008) Hansen, B. E. (2008). Uniform convergence rates for kernel estimation with dependent data. Econom. Theory , 24:726–748.