TL;DR
This paper presents a novel neural style transfer model that uses a two-stage peer-regularization layer and cyclic losses to generate high-quality, stylized images without relying on pre-trained perceptual networks, enabling flexible and artistic image generation.
Contribution
The paper introduces a new two-stage peer-regularization layer and cyclic loss functions that allow end-to-end training of style transfer models without pre-trained perceptual networks.
Findings
Produces high-quality stylized images in zero-shot setting
Does not depend on pre-trained networks for perceptual loss
Achieves competitive results with a single model for multiple styles
Abstract
This paper introduces a neural style transfer model to generate a stylized image conditioning on a set of examples describing the desired style. The proposed solution produces high-quality images even in the zero-shot setting and allows for more freedom in changes to the content geometry. This is made possible by introducing a novel Two-Stage Peer-Regularization Layer that recombines style and content in latent space by means of a custom graph convolutional layer. Contrary to the vast majority of existing solutions, our model does not depend on any pre-trained networks for computing perceptual losses and can be trained fully end-to-end thanks to a new set of cyclic losses that operate directly in latent space and not on the RGB images. An extensive ablation study confirms the usefulness of the proposed losses and of the Two-Stage Peer-Regularization Layer, with qualitative results that…
Click any figure to enlarge with its caption.
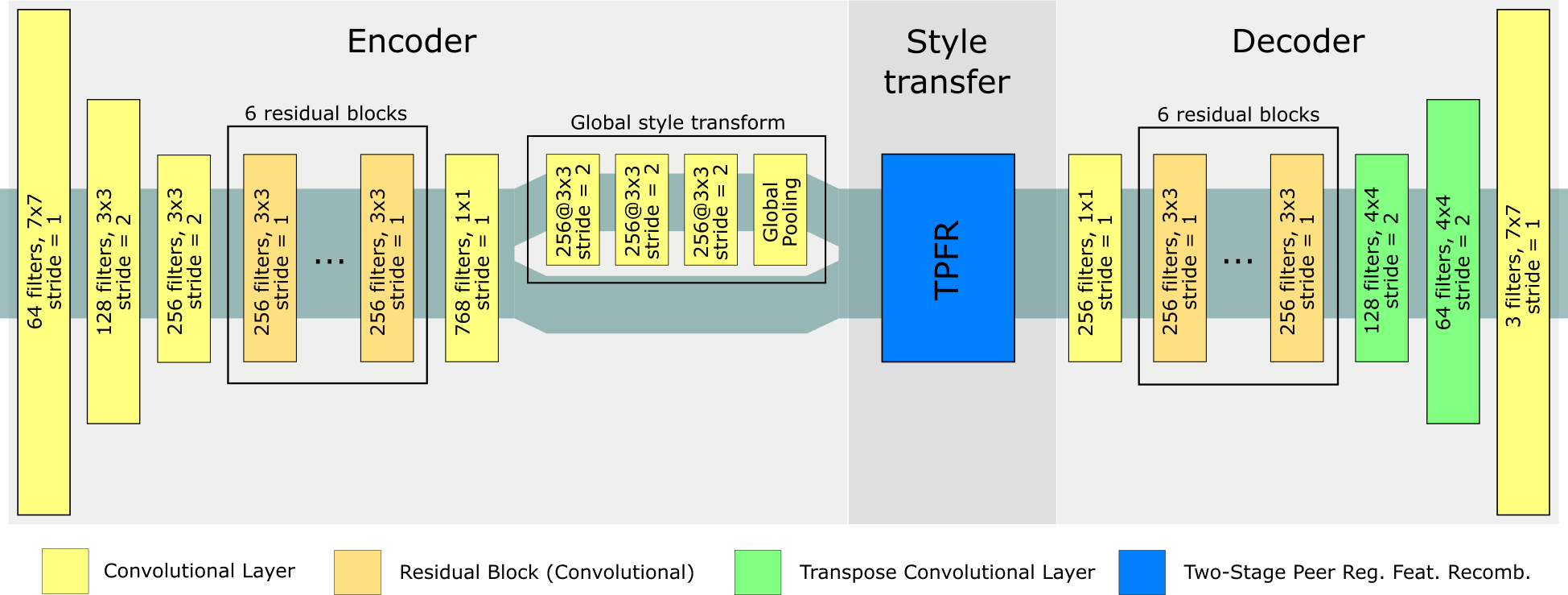 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8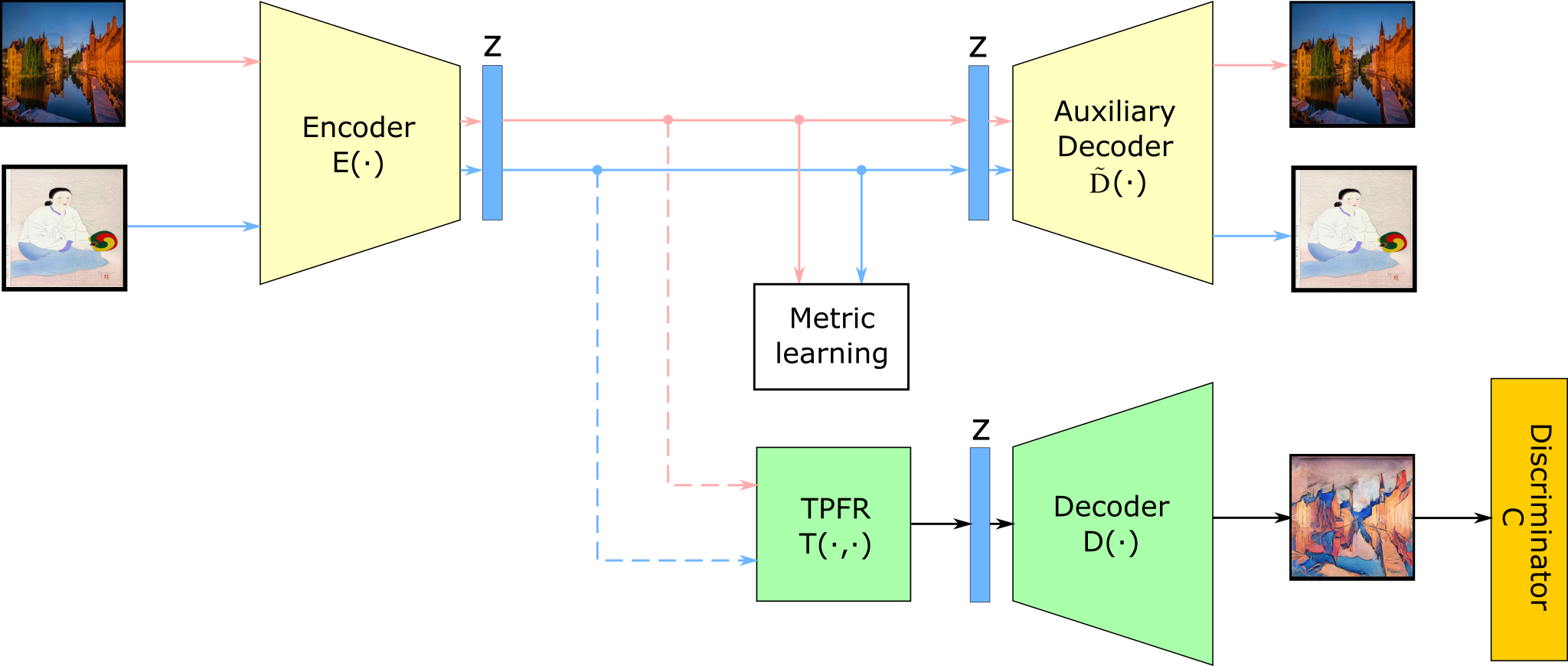 Figure 9
Figure 9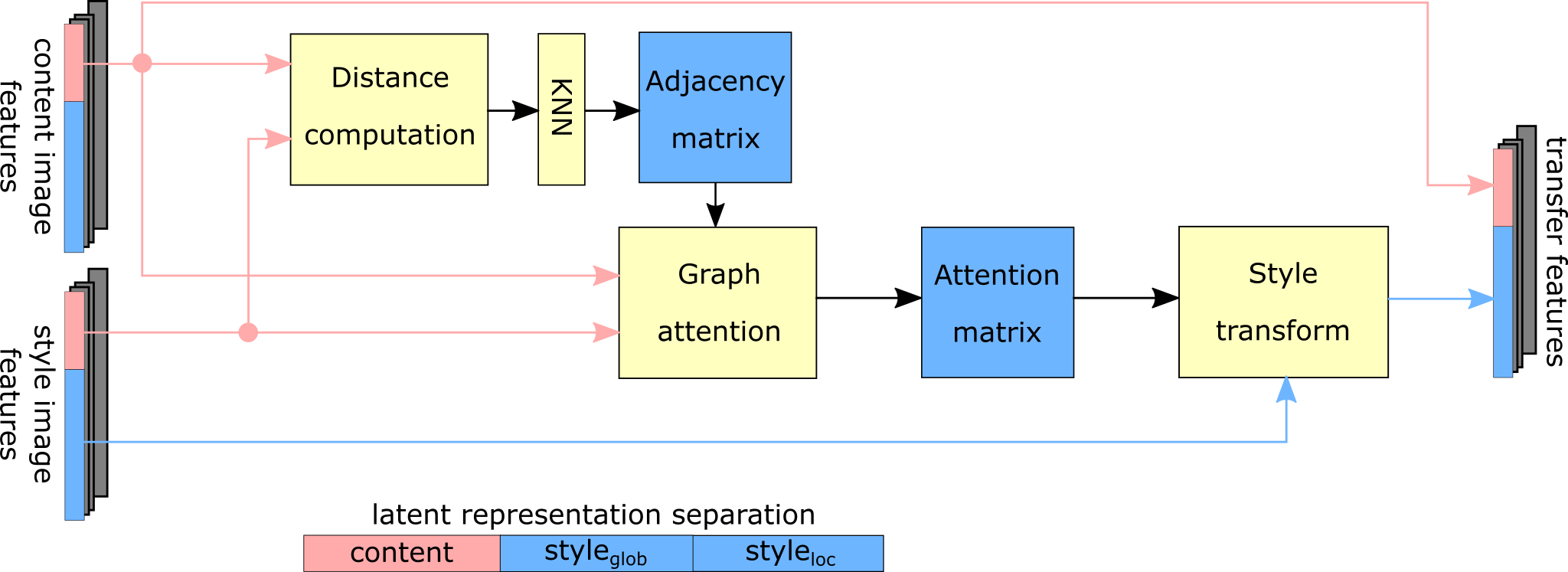 Figure 10
Figure 10 Figure 11
Figure 11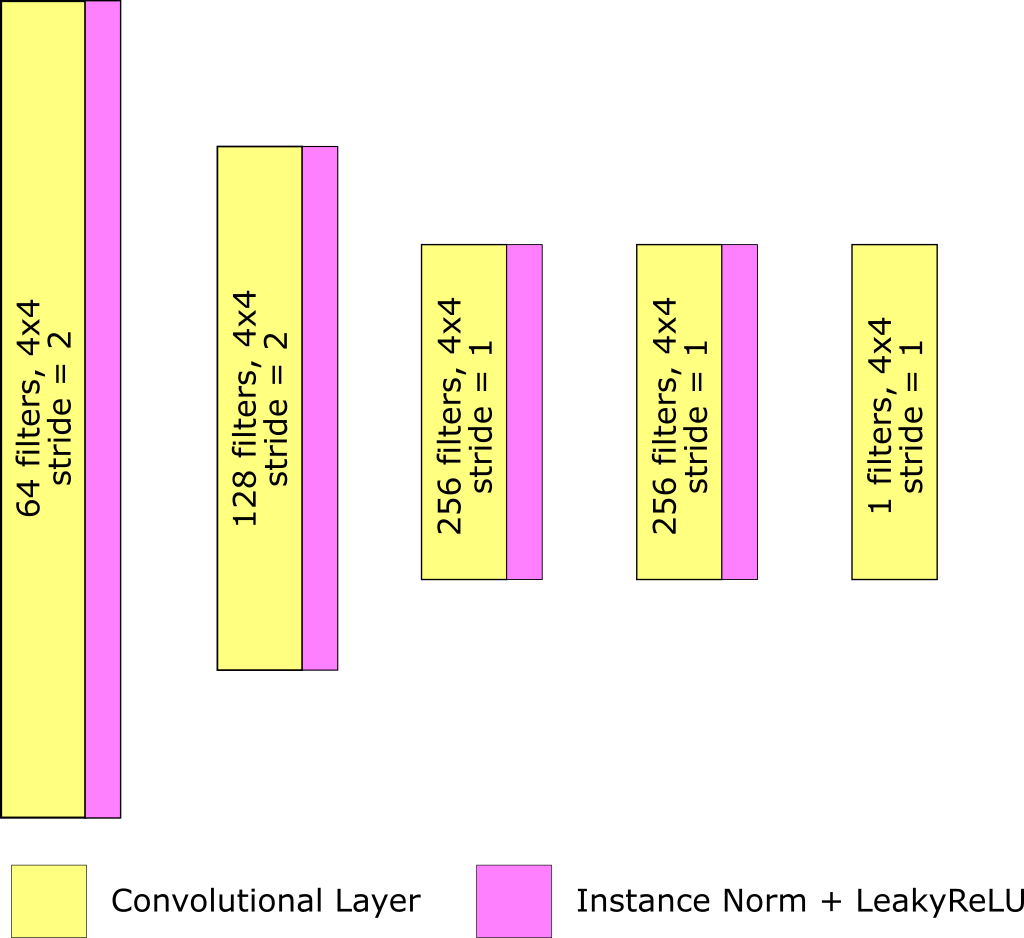 Figure 12
Figure 12Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
Two-Stage Peer-Regularized Feature Recombination for Arbitrary Image Style Transfer· youtube
Two-Stage Peer-Regularized Feature Recombination
for Arbitrary Image Style Transfer
Jan Svoboda1,2, Asha Anoosheh1, Christian Osendorfer1, Jonathan Masci1
1NNAISENSE, Switzerland 2Universita della Svizzera italiana, Switzerland
{jan.svoboda,asha.anoosheh,christian.osendorfer,jonathan.masci}@nnaisense.com
Abstract
This paper introduces a neural style transfer model to generate a stylized image conditioning on a set of examples describing the desired style. The proposed solution produces high-quality images even in the zero-shot setting and allows for more freedom in changes to the content geometry. This is made possible by introducing a novel Two-Stage Peer-Regularization Layer that recombines style and content in latent space by means of a custom graph convolutional layer. Contrary to the vast majority of existing solutions, our model does not depend on any pre-trained networks for computing perceptual losses and can be trained fully end-to-end thanks to a new set of cyclic losses that operate directly in latent space and not on the RGB images.
An extensive ablation study confirms the usefulness of the proposed losses and of the Two-Stage Peer-Regularization Layer, with qualitative results that are competitive with respect to the current state of the art using a single model for all presented styles. This opens the door to more abstract and artistic neural image generation scenarios, along with simpler deployment of the model.
1 Introduction
Neural style transfer (NST), introduced by the seminal work of Gatys [8], is an area of research that focuses on models that transform the visual appearance of an input image (or video) to match the style of a desired target image. For example, a user may want to convert a given photo to appear as if Van Gogh had painted the scene.
NST has seen a tremendous growth within the deep learning community and spans a wide spectrum of applications e.g. converting time-of-day [44, 12], mapping among artwork and photos [1, 44, 12], transferring facial expressions [17], transforming animal species [44, 12], etc.
Despite their popularity and often-quality results, current NST approaches are not free from limitations. Firstly, the original formulation of Gatys et al. requires a new optimization process for each transfer performed, making it impractical for many real-world scenarios. In addition, the method relies heavily on pre-trained networks, usually borrowed from classification tasks, that are known to be sub-optimal and have recently been shown to be biased toward texture rather than structure [9]. To overcome this first limitation, deep neural networks have been proposed to approximate the lengthy optimization procedure in a single feed forward step thereby making the models amenable for real-time processing. Of notable mention in this regard are the works of Johnson et al. [15] and Ulyanov et al. [36].
Secondly, when a neural network is used to overcome the computational burden of [8], training of a model for every desired style image is required due to the limited-capacity of conventional models in encoding multiple styles into the weights of the network. This greatly narrows down the applicability of the method for use cases where the concept of style cannot be defined a-priori and needs to be inferred from examples. With respect to this second limitation, recent works attempted to separate style and content in feature space (latent space) to allow generalization to a style characterized by an additional input image, or set of images. The most widespread work in this family is AdaIN [11], a specific case of FiLM [31]. The current state of the art allows to control the amount of stylization applied, interpolating between different styles, and using masks to convert different regions of image into different styles [11, 33].
Beyond the study of new network architectures for improving NST, research has resulted in better suited loss functions to train the models. The perceptual loss [8, 15] with a pre-trained VGG19 classifier [34] is very commonly used in this task as it, supposedly, captures high-level features of the image. However, this assumption has been recently challenged in [9]. Cycle-GAN [44] proposed a new cycle consistent loss that does not require one-to-one correspondence between the input and the target images, thus lifting the heavy burden of data annotation.
The problem of image style transfer is challenging, because the style of an image is expressed by both local properties (e.g. typical shapes of objects, etc.) and global properties (e.g. textures, etc.). Of the many approaches for modelling the content and style of an image that have been proposed in the past, encoding of the information in a lower dimensional latent space has shown very promising results. We therefore advocate to model this hierarchy in latent space by local aggregation of pixel-wise features and by the use of metric learning to separate different styles. To the best of our knowledge, this has not been addressed by previous approaches explicitly.
In the presence of a well structured latent space where style and content are fully separated, transfer can be easily performed by exchanging the style information in latent space between the input and the conditioning style images, without the need to store the transformation in the decoder weights. Such an approach is independent with respect to feature normalization and further avoids the need for rather problematic pre-trained models.
However, the content and style of an image are not completely separable. The content of an image exhibits changes in geometry depending on what style it is painted with. Recently, Kotovenko et al. [20] has proposed a content transformer block in an adversarial setting, where the model is trained in two stages. First a style transfer network is optimized. Then it is fixed and content transformer block is optimized instead, learning to account for changes in geometry relevant to a given style. The style exchange therefore becomes two-stage. Modeling such dependence has been shown to improve the visual results dramatically.
This paper addresses the NST setting where style is externally defined by a set of input images to allow transfer from arbitrary domains and to tackle the challenging zero-shot style-transfer scenario by introducing a novel feature regularization layer capable of recombining global and local style content from the input style image. It is achieved by borrowing ideas from geometric deep learning (GDL) [2] and modelling pixel-wise graph of peers on the feature maps in the latent space. To the best of our knowledge, this is the first work that successfully leverages the power of GDL in the style transfer scenario. We successfully demonstrate this in a series of zero-shot style transfer experiments, whose generated result would not be possible if the style was not actually inferred from the respective input images.
This work addresses the aforementioned limitations of NST models by making the following contributions:
- •
A state-of-the-art approach for NST using a custom graph convolutional layer that recombines style and content in latent space;
- •
Novel combination of existing losses that allows end-to-end training without the need for any pre-trained model (e.g. VGG) to compute perceptual loss;
- •
Constructing a globally- and locally-combined latent space for content and style information and imposing structure on it by means of metric learning.
2 Background
The key component of any NST system is the modeling and extraction of the ”style” from an image (though the term is partially subjective). As style is often related to texture, a natural way to model it is to use visual texture modeling methods [40]. Such methods can either exploit texture image statistics (e.g. Gram matrix) [8] or model textures using Markov Random Fields (MRFs) [6]. The following paragraphs provide an overview of the style transfer literature introduced by [14].
Image-Optimization-Based Online Neural Methods.
The method from Gatys et al. [8] may be the most representative of this category. While experimenting with representations from intermediate layers of the VGG-19 network, the authors observed that a deep convolutional network is able to extract image content from an arbitrary photograph, as well as some appearance information from works of art. The content is represented by a low-level layer of VGG-19, whereas the style is expressed by a combination of activations from several higher layers, whose statistics are described using the network features’ Gram matrix. Li [25] later pointed out that the Gram matrix representation can be generalized using a formulation based on Maximum Mean Discrepacy (MMD). Using MMD with a quadratic polynomial kernel gives results very similar to the Gram matrix-based approach, while being computationally more efficient. Other non-parametric approaches based on MRFs operating on patches were introduced by Li and Wand [21].
Model-Optimization-Based Offline Neural Methods.
These techniques can generally be divided into several sub-groups [14]. One-Style-Per-Model methods need to train a separate model for each new target style [15, 36, 22], rendering them rather impractical for dynamic and frequent use. A notable member of this family is the work by Ulyanov et al. [37] introducing Instance Normalization (IN), better suited for style-transfer applications than Batch Normalization (BN).
Multiple-Styles-Per-Model methods attempt to assign a small number of parameters to each style. Dumoulin [5] proposed an extension of IN called Conditional Instance Normalization (CIN), StyleBank [3] learns filtering kernels for different styles, and other works instead feed the style and content as two separate inputs [23, 41] similarly to our approach.
Arbitrary-Style-Per-Model methods either treat the style information in a non-parametric, i.e. as in StyleSwap [4], or parametric manner using summary statistics, such as in Adaptive Instance Normalization (AdaIN) [11]. AdaIN, instead of learning global normalization parameters during training, uses first moment statistics of the style image features as normalization parameters. Later, Li et al. [24] introduced a variant of AdaIN using Whitening and Coloring Transformations (WTC). Going towards zero-shot style transfer, ZM-Net [39] proposed a transformation network with dynamic instance normalization to tackle the zero-shot transfer problem. More recently, Avatar-Net [33] proposed the use of a ”style decorator” to re-create content features by semantically aligning input style features with those derived from the style image.
Other methods.
Cycle-GAN [44] introduced a cycle-consistency loss on the reconstructed images that delivers very appealing results without the need for aligned input and target pairs. However, it still requires one model per style. The approach was extended in Combo-GAN [1], which lifted this limitation and allowed for a practical multi-style transfer; however, also this method requires a decoder-per-style.
Sanakoyeu et al. [32] observed that the applying the cycle consistency loss in image space might be over-restricting the stylization process. They also show how to use a set of images, rather than a single one, to better express the style of an artwork. In order to provide more accurate style transfer with respect to an image content, Kotovenko et al. [20] designed the so called content transformer block, an additional sub-network that is supposed to finetune a trained style transfer model to a particular content. The strict consistency loss was later relaxed by MUNIT [12], a multi-modal extension of UNIT [26], which imposes it in latent space instead, providing more freedom to the image reconstruction process. Later, the same authors proposed FUNIT [27], a few-shot extension of MUNIT.
Towards exploring the disentanglement of different styles in the latent space, Kotovenko et al. [19] proposed a fixpoint triplet loss in order to perform metric learning in the style latent space, showing how to separate two different styles within a single model.
3 Method
The core idea of our work is a region-based mechanism that exchanges the style between input and target style images, similarly to StyleSwap [4], while preserving the semantic content. To successfully achieve this, style and content information must be well separated, disentangled. We advocate the use of metric learning to directly enforce separation among different styles, which has been experimentally shown to greatly reduce the amount of style dependent information retained in the decoder. Furthermore, in order to account for geometric changes in content that are bound to a certain style, we model the style transfer as a two-stage process, first performing style transfer, and then in the second step modifying the content geometry accordingly. This is done using the Two-stage Peer-regularized Feature Recombination (TPFR) module presented below.
3.1 Architecture and losses
The proposed system architecture is shown in Figure 2. To prevent the main decoder from encoding the stylization in its weights, auxiliary decoder [7] is used during training to optimize the parameters of the encoder and decoder independently. The yellow module in Figure 2 is trained as an autoencoder (AE) [29, 42, 28] to reconstruct the input. The green module, instead, is trained as a GAN[10] to generate the stylized version of the input using the encoder from the yellow module, with fixed parameters. The optimization of both modules is interleaved together with the discriminator. Additionally, following the analysis from Martineau et al. [16], the Relativistic Average GAN (RaGAN) is used as our adversarial loss formulation, which has shown to be more stable and to produce more natural-looking images than traditionally used GAN losses.
Let us now describe the four main building blocks of our approach in detail111The full architecture details are found in the supplementary material.. We denote an input image, a target and fake image, respectively. Our model consists of an encoder generating the latent representations, an auxiliary decoder taking a single latent code as input, a main decoder taking one latent code as input, and TPFR module receiving two latent codes. Generated latent codes are denoted . We further denote the content and style part of the latent code, respectively.
The distance between two latent representations is defined as the smooth L1 norm [13] in order to stabilize training and to avoid exploding gradients:
[TABLE]
where , and are two different feature embeddings with channels and is the spatial dimension of each channel.
Encoder.
The encoder used to produce latent representation of all input images is composed of several strided-convolutional layers for downsampling followed by multiple ResNet blocks. The latent code is composed by two parts: the content part, , which holds information about the image content (e.g. objects, position, scale, etc.), and the style part, , which encodes the style that the content is presented in (e.g. level of detail, shapes, etc.). The style component of the latent code is further split equally into . Here, encodes local style information per pixel of each feature map, while undergoes further downsampling via a small sub-network to generate a single value per feature map.
Auxiliary decoder.
The Auxiliary decoder reconstructs an image from its latent representation and is used only during training to train the encoder module. It is composed of several ResNet blocks followed by fractionally-strided convolutional layers to reconstruct the original image. The loss is inspired by [32, 19] and is composed of the following parts. A content feature cycle loss that pulls together latent codes representing the same content:
[TABLE]
A metric learning loss, enforcing clustering of the style part of the latent representations:
[TABLE]
A classical reconstruction loss used in autoencoders, which forces the model to learn perfect reconstructions of its inputs:
[TABLE]
And a latent cycle loss enforcing the latent codes of the inputs to be the same as latent codes of the reconstructed images:
[TABLE]
which has experimentally shown to stabilize the training. The total auxiliary decoder loss , is then defined as:
[TABLE]
where is a hyperparameter weighting importance of the reconstruction loss with respect to the rest.
Main decoder.
This network replicates the architecture of the auxiliary decoder, and uses the output of the Two-stage Peer-regularized Feature Recombination module (see Section 3.2). During training of the main decoder the encoder is kept fixed, and the decoder is optimized using a loss function composed of the following parts. First, the decoder adversarial loss:
[TABLE]
where is the distribution of the real data and is the distribution of the generated (fake) data and is the discriminator.
In order to enforce the stylization preserve the content part of the latent codes while recombining the style part of the latent codes to represent the target style class, we use so called transfer latent cycle loss:
[TABLE]
Further, to make the main decoder learn to reconstruct the original inputs, we employ the classical reconstruction loss as we did for auxiliary decoder as well:
[TABLE]
The above put together composes the main decoder loss , where the reconstruction loss is weighted by the same hyperparameter used also in .
[TABLE]
Discriminator.
The discriminator is a convolutional network receiving two images concatenated over the channel dimension and producing an map of predictions. The first image is the one to discriminate, whereas the second one serves as conditioning for the style class. The output prediction is ideally if the two inputs come from the same style class and [math] otherwise. The discriminator loss is defined as:
[TABLE]
3.2 Two-stage Peer-regularized Feature Recombination (TPFR)
The TPFR module draws inspiration from PeerNets [35] and Graph Attention Layer (GAT) [38] to perform style transfer in latent space, taking advantage of the separation of content and style information (enforced by Equations 2 and 16). Peer-regularized feature recombination is done in two stages, as explained in the following paragraphs.
Style recombination.
It receives and as an input and computes the k-Nearest-Neighbors (k-NN) between and using the Euclidean distance to induce the graph of peers.
Attention coefficients over the graph nodes are computed and used to recombine the style portion of as convex combination of its nearest neighbors representations. The content portion of the latent code remains instead unchanged, resulting in: .
Given a pixel of feature map , its -NN graph in the space of -dimensional feature maps of all pixels of all peer feature maps is considered. The new value of the style part for the pixel is expressed as:
[TABLE]
[TABLE]
where denotes a fully connected layer mapping from -dimensional input to scalar output, and are attention scores measuring the importance of the th pixel of feature map to the output th pixel of feature map . The resulting style component of the input feature map is the weighted pixel-wise average of its peer pixel features defined over the style input image.
Content recombination.
Once the style latent code is recombined, an analogous process is repeated to transform the content latent code according to the new style information. In this case, it starts off with inputs and and the k-NN graph is computed given the style latent codes . This graph is used together with Equation 12 in order to compute the attention coefficients and recombine the content latent code as .
The output of the TPFR module therefore is a new latent code which recombines both style and content part of the latent code.
4 Experimental setup and Results
The proposed approach is compared against the state-of-the-art on extensive qualitative evaluations and, to support the choice of architecture and loss functions, ablation studies are performed to demonstrate roles of the various components and how they influence the final result. Only qualitative comparisons are provided as no standard quantitative evaluations are defined for NST algorithms.
4.1 Training
A modification of the dataset collected by [32] is used for training the model. It is composed of a collection of thirteen different painters representing different target styles and selection of relevant classes from the Places365 dataset [43] providing the real photo images. This gives us 624,077 real photos and 4,430 paintings in total. Our network can be trained end-to-end alternating optimization steps for the auxiliary decoder, the main decoder, and the discriminator. The loss used for training is defined as:
[TABLE]
where is the discriminator, the main decoder, and is the auxiliary decoder (see Section 3.1). Using ADAM [18] as the optimization scheme, with an initial learning rate of and a batch size of 2, training is performed for a total of 200 epochs. After 50 epochs, the learning rate is decayed linearly to zero. Please note that choice of the batch size can be arbitrary, and we choose 2 only due to limited computing resources. In each epoch, we randomly visit of the real photos. The weighting of the reconstruction identity loss and the margin for the metric learning during all of our experiments. The training images are cropped and resized to resolution. Note that during testing, our method can operate on images of arbitrary size.
4.2 Style transfer
A set of test images from Sanakoyeu [32] is stylized and compared against competing methods in Figure 4 (inputs of size px) to demonstrate arbitrary stylization of a content image given several different styles. It is important to note that, as opposed to majority of the competing methods, our network does not require retraining for each style and allows therefore also for transfer of previously unseen styles, e.g. Pissarro in row 5 of Figure 4, which is a painter that has not been present in the training set.
Qualitative results222More results are shown in the supplementary material. that were done on color images of size , using previously unseen paintings from painters that are in the training set, are shown in Figure 5(b). It is worth noticing that our approach can deal also with very abstract painting styles, such as the one of Jackson Pollock (Figure 5(b), row 3, style 1). It motivates the claim that our model generalizes well to many different styles, allowing zero-shot style transfer.
Zero-shot style transfer.
In order to support our claims regarding zero-shot style transfer, we have collected samples of a few painters that were not seen during training. In particular, we collected paintings from Salvador Dali, Camille Pissarro, Henri Matisse, Katigawa Utamaro and Rembrandt. The evaluation presented in Figure 5(a) shows that our approach is able to account for fine details in painting style of Camille Pissarro (row 1, style 1), as well as create larger flat regions to recombine style that is own to Katigawa Utamaro (row 6, style 2). We find the results of zero-shot style transfer using the aforementioned painters very encouraging.
Ablation study.
There are several key components in our solution which make arbitrary style transfer with a single model and end-to-end training possible. The effect of suppressing each of them during the training is examined, and results for the various models are compared, highlighting the importance of each component in Figure 6. Clearly, the auxiliary decoder used during training is a centerpiece of the whole approach, as it prevents degenerate solutions. We observe that training encoder directly with the main decoder end-to-end does not work (Fig. 6 NoAux). Separation of the latent code into content and style part allows for the introduced two-stage style transfer and is important to account for changes in shape of the objects for styles like, e.g. Picasso (Fig. 6 NoSep). Two-stage recombination provides better generalization to variety of styles (Fig. 6 NoTS). Performing only exchange of style based on content features completely fails in some cases (e.g. row 1 in Fig. 6). Next, metric learning on the style latent space enforces its better clustering and enhances some important details in the stylized image (Fig. 6 NoML). Last but not least, the combined local and global style latent code is important in order to be able to account for changes in edges and brushstrokes appropriately (Fig. 6 NoGlob).
5 Conclusions
We propose a novel model for neural style transfer which mitigates various limitations of current state-of-the-art methods and that can be used also in the challenging zero-shot transfer setting. This is thanks to a Two-Stage Peer-Regularization Layer using graph convolutions to recombine the style component of the latent representation and with a metric learning loss enforcing separation of different styles combined with cycle consistency in feature space. An auxiliary decoder is also introduced to prevent degenerate solutions and to enforce enough variability of the generated samples. The result is a state-of-the-art method that can be trained end-to-end without the need of a pre-trained model to compute the perceptual loss, therefore lifting recent concerns regarding the reliability of such features for NST. More importantly the proposed method requires only a single encoder and a single decoder to perform transfer among arbitrary styles, contrary to many competing methods requiring a decoder (and possibly an encoder) for each input and target pair. This makes our method more applicable to real-world image generation scenarios where users define their own styles.
Appendix A Network architecture
This section describes our model in detail. We describe the encoder-decoder network and discriminator in separate sections below. We provide our code containing the implementation details 333Code is available at this link: http://nnaisense.com/conditional-style-transfer to assure full reproducibility of all the presented results.
A.1 Autoencoder
Detailed scheme of the architecture is depicted in Figure 8. Each of the convolutional layers (in yellow) is followed by Instance Normalization (IN) [37] and ReLU nonlinearity [30]. The TPFR module uses a variant of the Peer Regularization Layer [35] with Euclidean distance metric, k-NN with nearest neighbours and dropout on the attention weights of .
The generated latent code are feature maps of size , where and are the input width and height respectively. First feature maps is the content latent representation, while the remaining is for the style. The style latent representation is further split into halves, having first feature maps left unchanged and the second feature maps are passed through the Global style transform block producing feature maps of size that hold the global part of the style latent representation.
The last convolutional block of the decoder is equipped with TanH nonlinearity and produces the reconstructed RGB image.
The auxiliary decoder copies the architecture of the main decoder, while omitting the Style transfer block (see Figure 8).
A.2 Discriminator
The discriminator architecture is shown in Figure 7. It takes two RGB images concatenated over the channel dimension as input and produces a map of predictions. Our implementation uses LS-GAN and therefore there is no Sigmoid activation at the output
To stabilize the discriminator training, we add random Gaussian noise to each input:
[TABLE]
where is a Gaussian distribution with mean and standard deviation .
Appendix B Style transfer results
This section provides more qualitative results of our style transfer approach that did not fit in the main text. Figure 9 are images generated with resolution and shows the generalization of our approach to different styles and ability of our approach to perform zero-shot style transfer. In particular, we have collected some paintings from Salvador Dali, Camille Pissarro, Henri Matisse, Katigawa Utamaro and Rembrandt.
In addition, images in Figure 10 were generated with resolution and show results of transfer taking a random painting from the dosjoint test set of thirteen painting styles that our model was trained with (Morisot, Munch, El Greco, Kirchner, Pollock, Monet, Roerich, Picasso, Cezzane, Gaugin, Van Gogh, Peploe and Kandinsky).
Appendix C Latent space structure
Our latent representation is split into two parts, and , content and style respectively. Metric learning loss is used on the style part in order to enforce a separation of different modalities in the style latent space.
[TABLE]
where , are style parts of latent representations of two different input images and , are style parts of latent representations of two different targets from the same target class. Parameter and it is the margin we are enforcing on the separation of the positive and negative scores.
C.1 Visualization in image space
Figure 11 visualizes the influence of the and parts of the latent representation after decoding back into the RGB image space. The TPFR module, which performs the style transfer, is executed first. The resulting latent code is then modified before feeding it to the decoder. Replacing the with [math] gives us some rough representation of the style with only approximate shapes. On the other hand, if we replace with [math] and we keep , a rather flat representation of the input with sharper is reconstructed. This demonstrates that represents the content, while holds most of the style-related information.
The fact that the latent code is passed through the TPFR module first means that the two-stage feature recombination is performed on the data we visualize. As a result, the decoded image slightly resembles the structure of the content image even if the is set to [math]. Likewise, in case of , the geometry of the objects is already slightly modified based on the resulting style.
Appendix D Computational overhead
Stylization of a single image of resolution using our method takes approximately ms on a single Titan-V100 GPU. Execution of the TPFR block takes approximately ms, which is of the whole runtime. Due to memory requirements, our method can currently process images of size up to pixels.
Appendix E Quantitative evaluation
We are aware of the recent efforts bringing in quantities such as deception score [32] or content and style distribution divergence [19]. However we decided not to use these metrics as they are all based on a VGG network trained to classify paintings. We argue that such evaluation may favor models that have used VGG perceptual losses for training. This concern is closely related to the work of [9].
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Asha Anoosheh, Eirikur Agustsson, Radu Timofte, and Luc Van Gool. Combogan: Unrestrained scalability for image domain translation. Co RR , abs/1712.06909, 2017.
- 2[2] M. M. Bronstein, J. Bruna, Y. Le Cun, A. Szlam, and P. Vandergheynst. Geometric deep learning: going beyond euclidean data. IEEE Signal Process. Mag. , 34(4):18–42, 2017.
- 3[3] Dongdong Chen, Lu Yuan, Jing Liao, Nenghai Yu, and Gang Hua. Stylebank: An explicit representation for neural image style transfer. Co RR , abs/1703.09210, 2017.
- 4[4] Tian Qi Chen and Mark Schmidt. Fast patch-based style transfer of arbitrary style. Co RR , abs/1612.04337, 2016.
- 5[5] Vincent Dumoulin, Jonathon Shlens, and Manjunath Kudlur. A learned representation for artistic style. Co RR , abs/1610.07629, 2016.
- 6[6] A. A. Efros and T. K. Leung. Texture synthesis by non-parametric sampling. In Proceedings of the Seventh IEEE International Conference on Computer Vision , volume 2, pages 1033–1038 vol.2, Sep. 1999.
- 7[7] Jeffrey De Fauw, Sander Dieleman, and Karen Simonyan. Hierarchical autoregressive image models with auxiliary decoders. Co RR , abs/1903.04933, 2019.
- 8[8] Leon A. Gatys, Alexander S. Ecker, and Matthias Bethge. A neural algorithm of artistic style. Co RR , abs/1508.06576, 2015.
