TL;DR
This paper explores how adversarial attacks can undermine neural network explanations and proposes a novel regularization method to enhance model robustness and explanation fidelity, significantly advancing trustworthy AI in sensitive applications.
Contribution
Introduces a Lipschitz-inspired regularization technique that improves neural network robustness and explanation accuracy against adversarial attacks.
Findings
Achieved a 2.4x increase in Accuracy-Robustness Area on ImageNet
Demonstrated adversarial attacks can invalidate explanations of NN decisions
Leveraged attacks as more faithful explanations with robust networks
Abstract
For sensitive problems, such as medical imaging or fraud detection, Neural Network (NN) adoption has been slow due to concerns about their reliability, leading to a number of algorithms for explaining their decisions. NNs have also been found vulnerable to a class of imperceptible attacks, called adversarial examples, which arbitrarily alter the output of the network. Here we demonstrate both that these attacks can invalidate prior attempts to explain the decisions of NNs, and that with very robust networks, the attacks themselves may be leveraged as explanations with greater fidelity to the model. We show that the introduction of a novel regularization technique inspired by the Lipschitz constraint, alongside other proposed improvements, greatly improves an NN's resistance to adversarial examples. On the ImageNet classification task, we demonstrate a network with an Accuracy-Robustness…
Click any figure to enlarge with its caption.
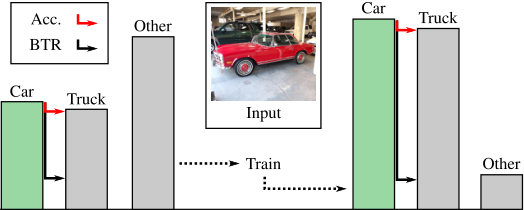 Figure 1
Figure 1 Figure 2
Figure 2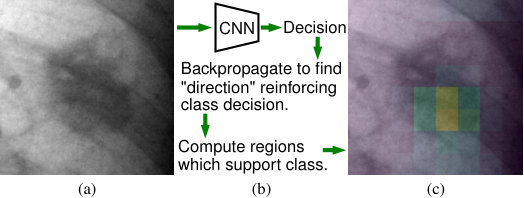 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6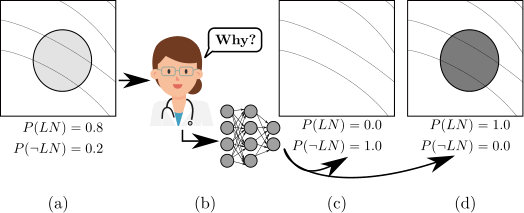 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10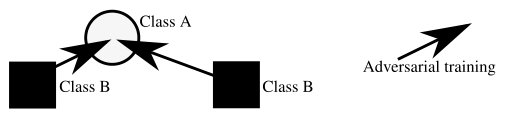 Figure 11
Figure 11 Figure 12
Figure 12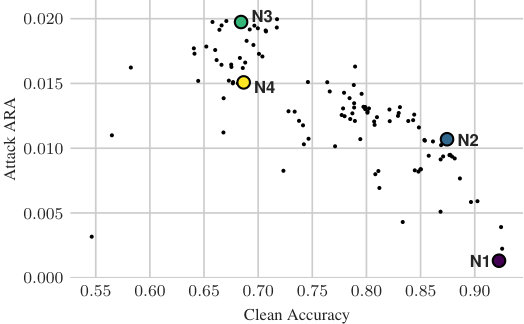 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16 Figure 17
Figure 17 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23 Figure 24
Figure 24 Figure 25
Figure 25 Figure 26
Figure 26 Figure 27
Figure 27 Figure 28
Figure 28 Figure 29
Figure 29 Figure 30
Figure 30 Figure 31
Figure 31 Figure 32
Figure 32 Figure 33
Figure 33 Figure 34
Figure 34 Figure 35
Figure 35 Figure 36
Figure 36 Figure 37
Figure 37 Figure 38
Figure 38 Figure 39
Figure 39 Figure 40
Figure 40Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
MethodsAccuracy-Robustness Area
