A Look at the Effect of Sample Design on Generalization through the Lens of Spectral Analysis
Bhavya Kailkhura, Jayaraman J. Thiagarajan, Qunwei Li, Peer-Timo, Bremer

TL;DR
This paper introduces a spectral analysis framework to understand how sampling patterns influence the generalization error of machine learning models, linking geometric properties to spectral forms and providing error bounds.
Contribution
It develops a novel spectral analysis approach in Euclidean space that connects sampling geometry with generalization performance, offering insights for designing optimal sampling strategies.
Findings
Spectral properties of sampling patterns affect generalization error.
Error bounds and convergence rates are derived for various sampling methods.
Insights are provided that are independent of specific learning architectures.
Abstract
This paper provides a general framework to study the effect of sampling properties of training data on the generalization error of the learned machine learning (ML) models. Specifically, we propose a new spectral analysis of the generalization error, expressed in terms of the power spectra of the sampling pattern and the function involved. The framework is build in the Euclidean space using Fourier analysis and establishes a connection between some high dimensional geometric objects and optimal spectral form of different state-of-the-art sampling patterns. Subsequently, we estimate the expected error bounds and convergence rate of different state-of-the-art sampling patterns, as the number of samples and dimensions increase. We make several observations about generalization error which are valid irrespective of the approximation scheme (or learning architecture) and training (or…
Click any figure to enlarge with its caption.
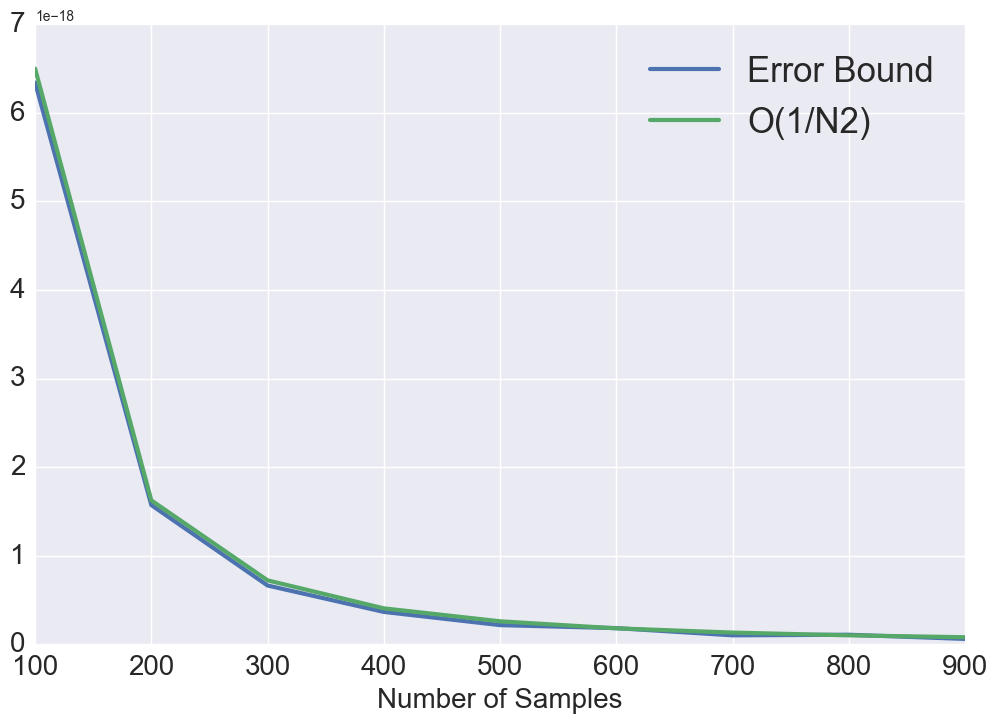 Figure 1
Figure 1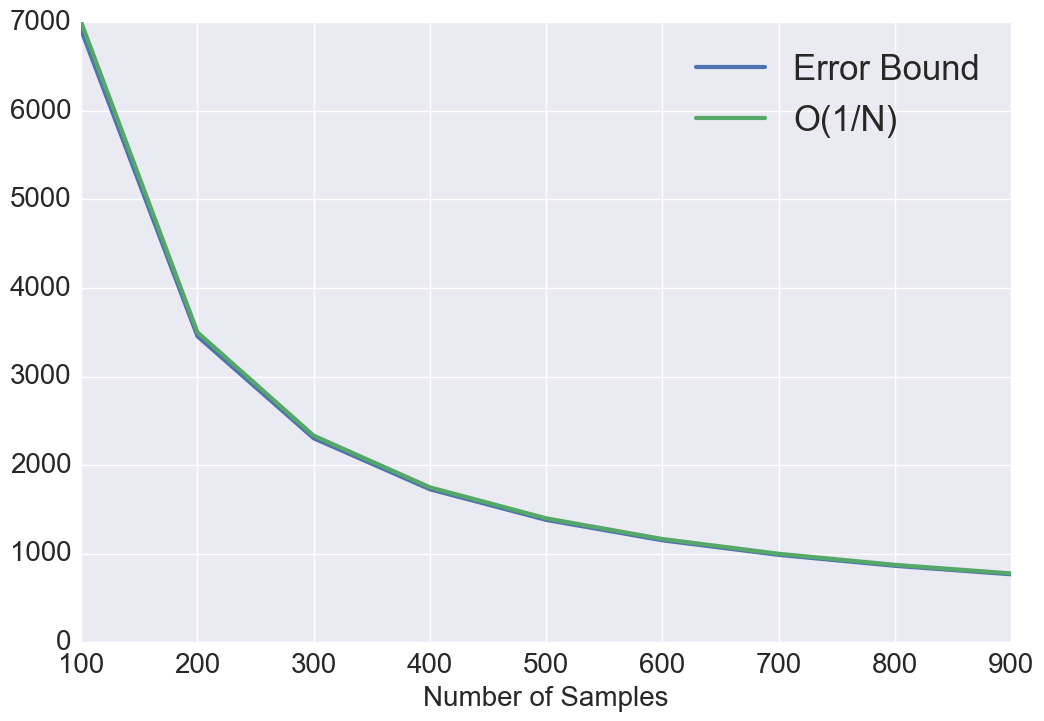 Figure 2
Figure 2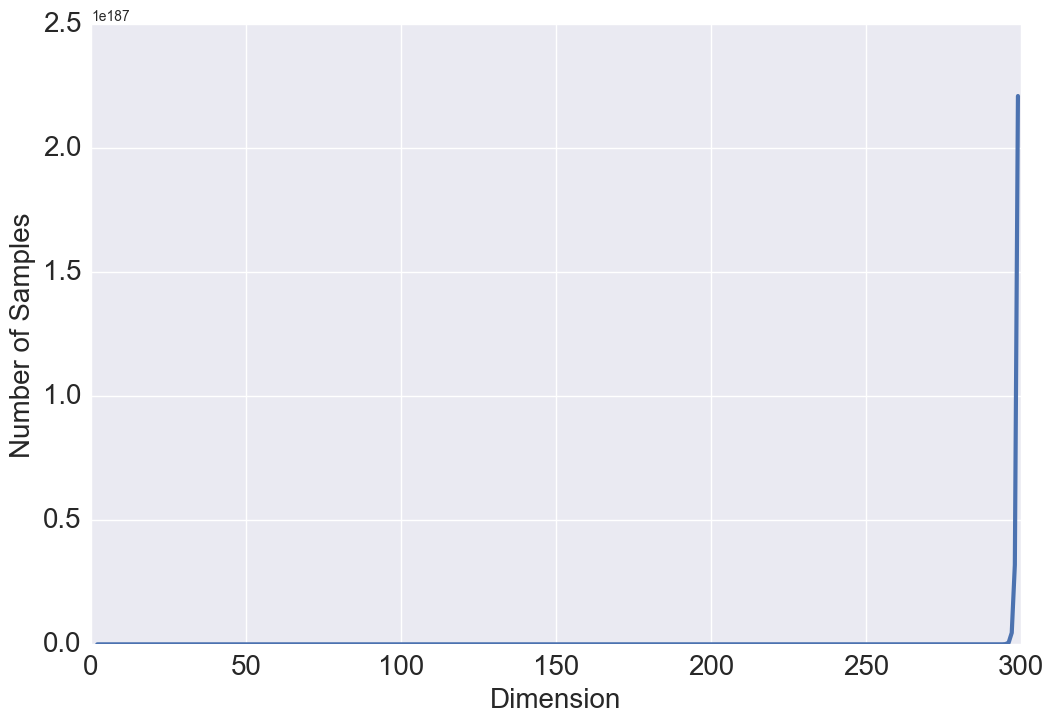 Figure 3
Figure 3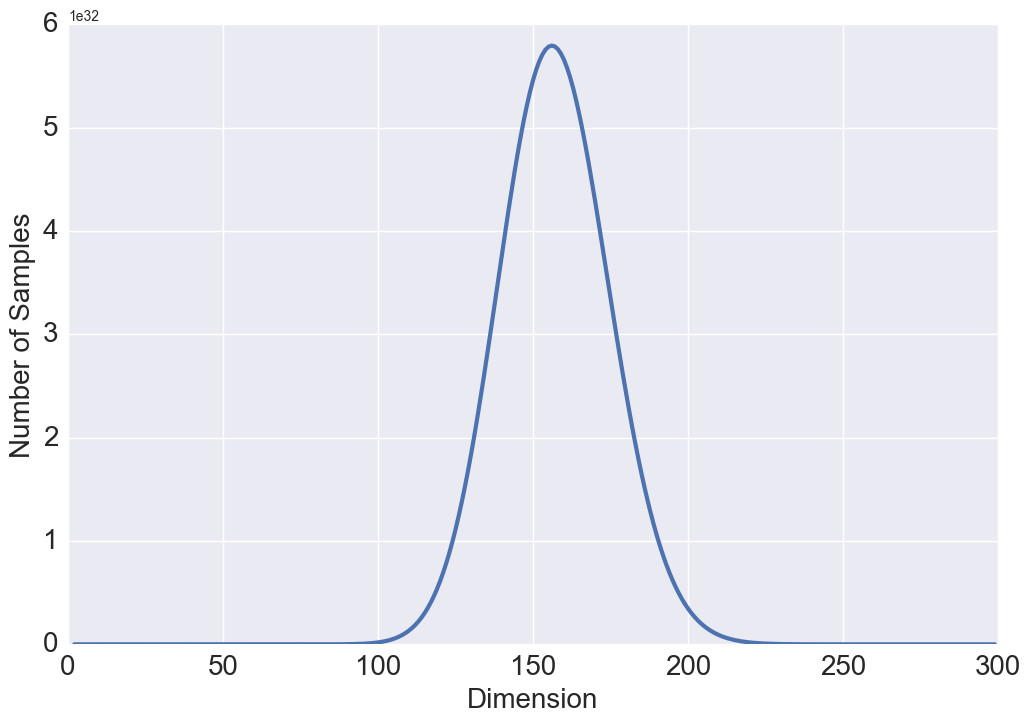 Figure 4
Figure 4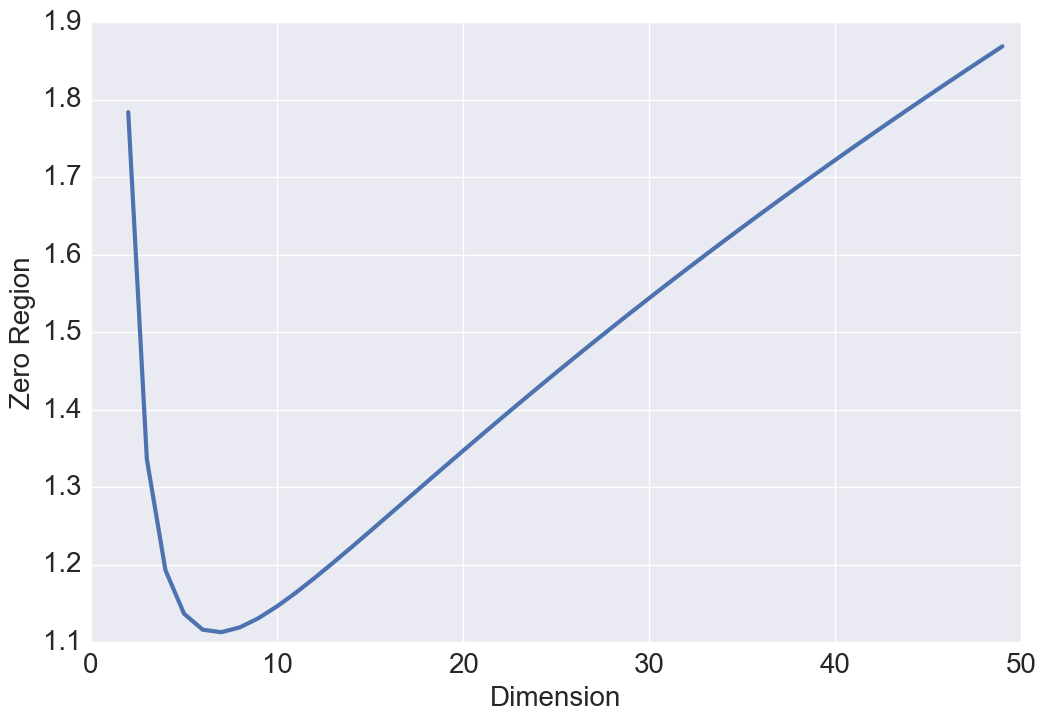 Figure 5
Figure 5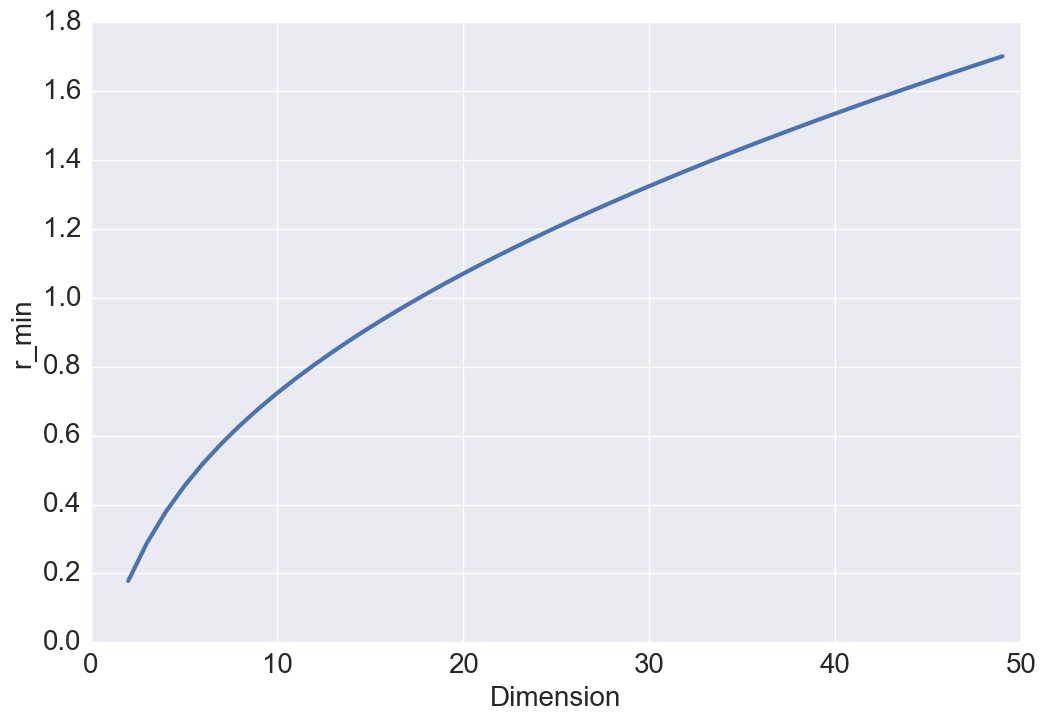 Figure 6
Figure 6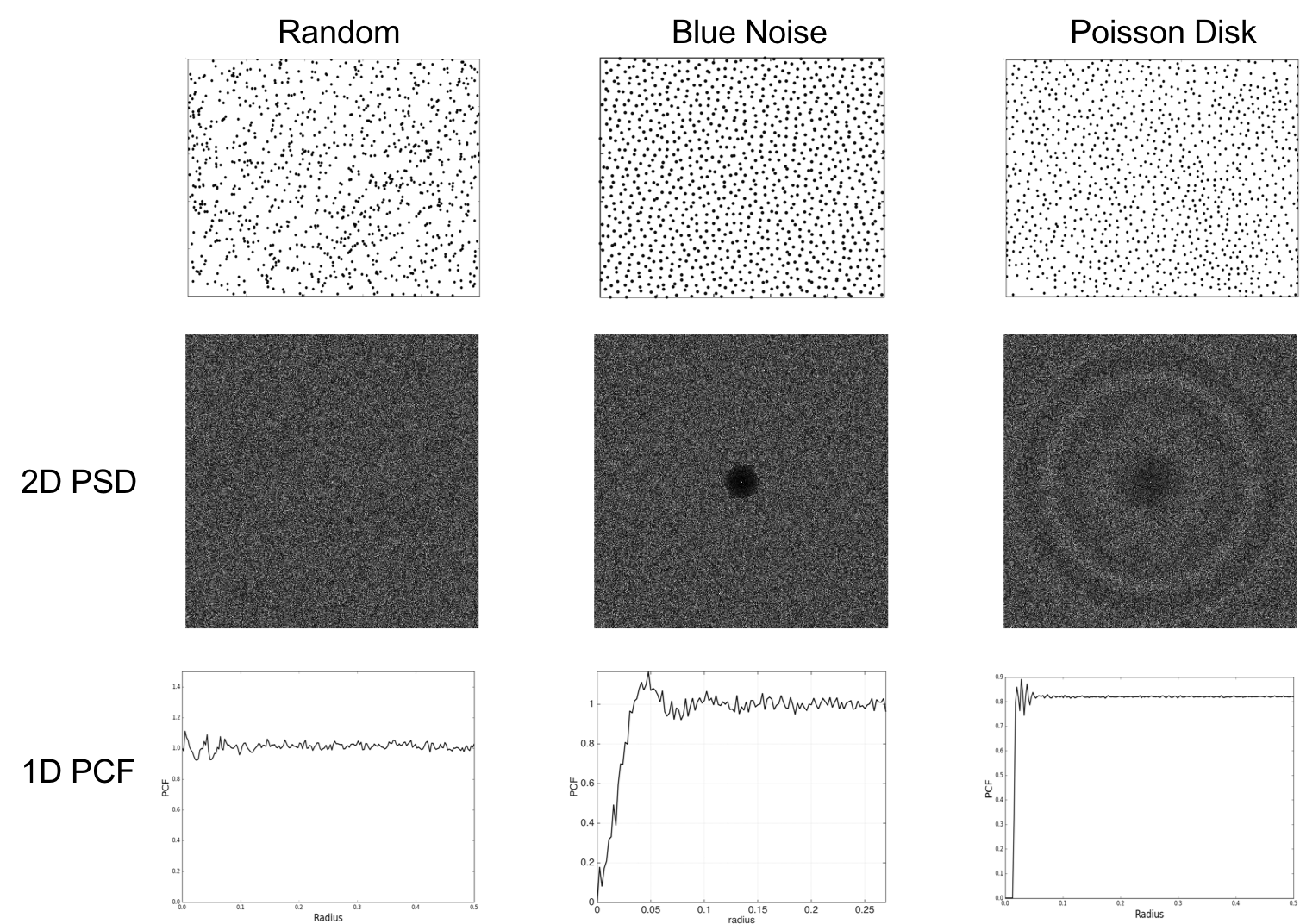 Figure 7
Figure 7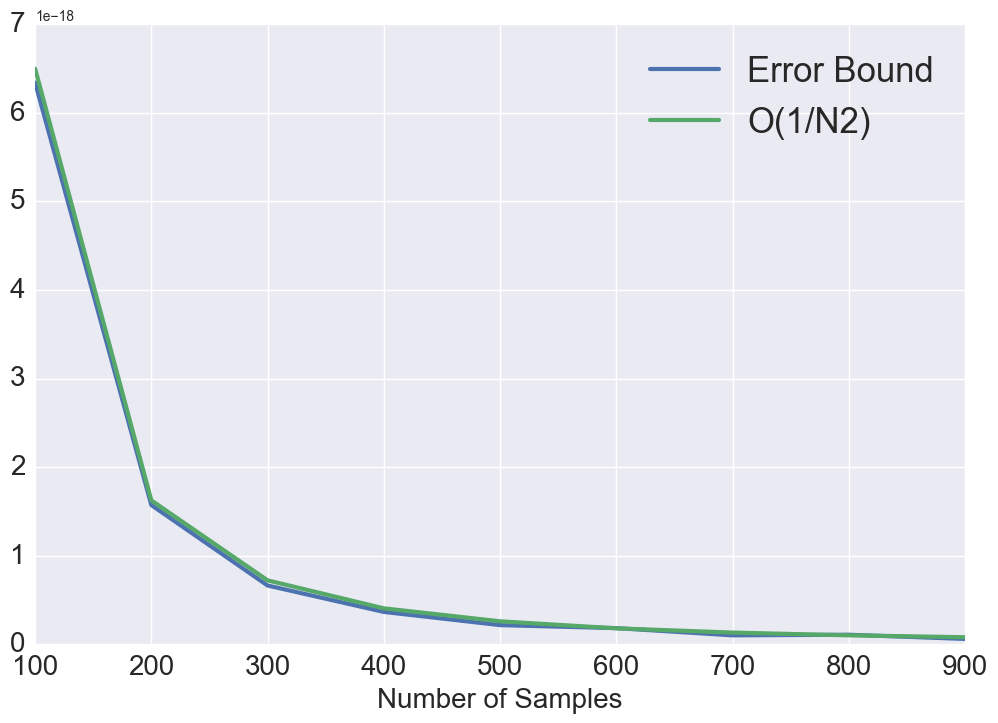 Figure 8
Figure 8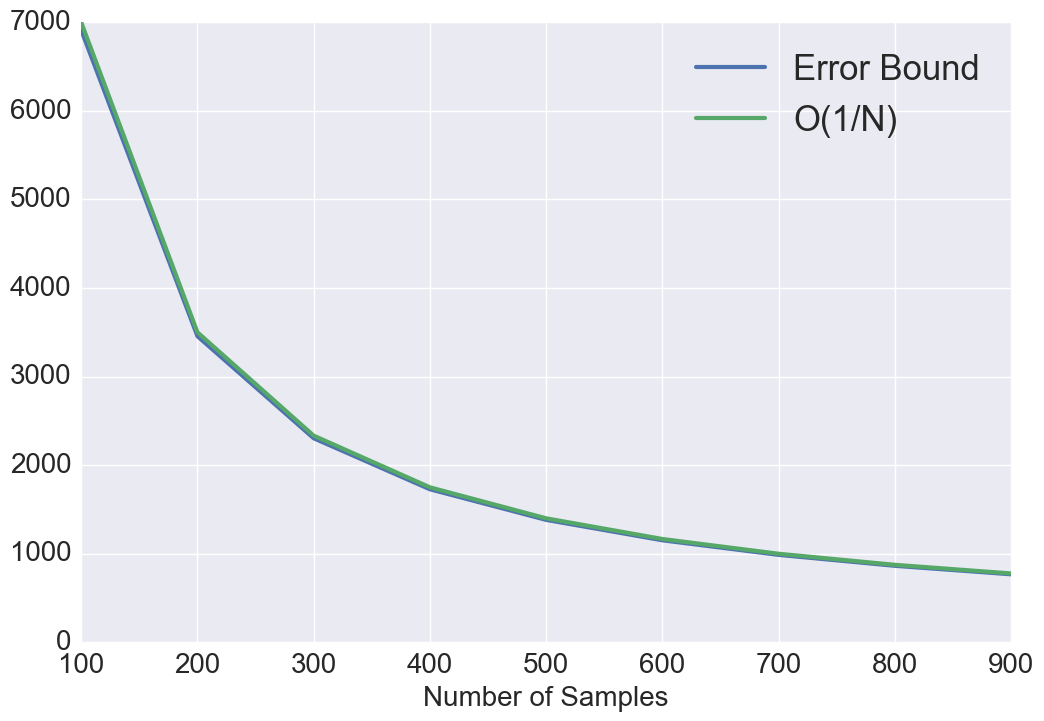 Figure 9
Figure 9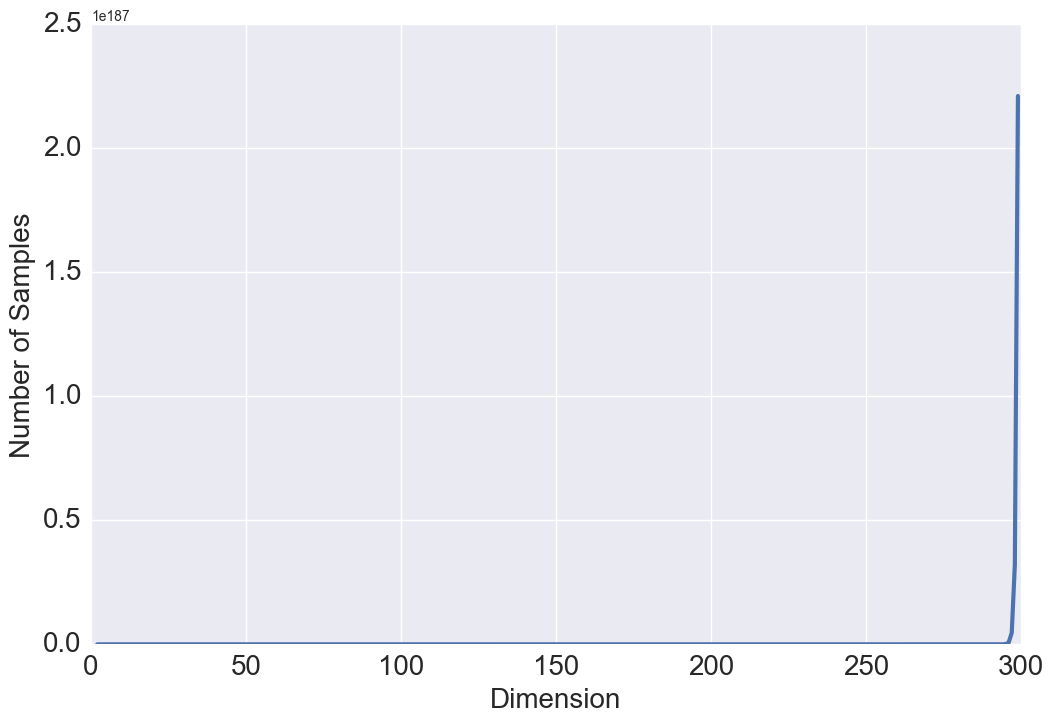 Figure 10
Figure 10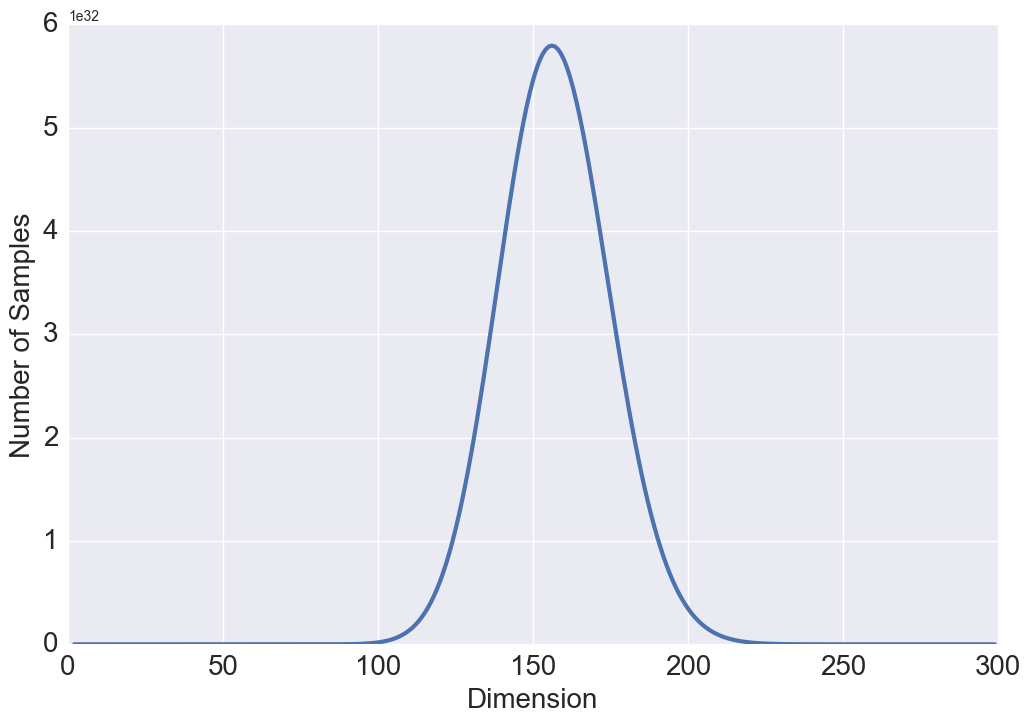 Figure 11
Figure 11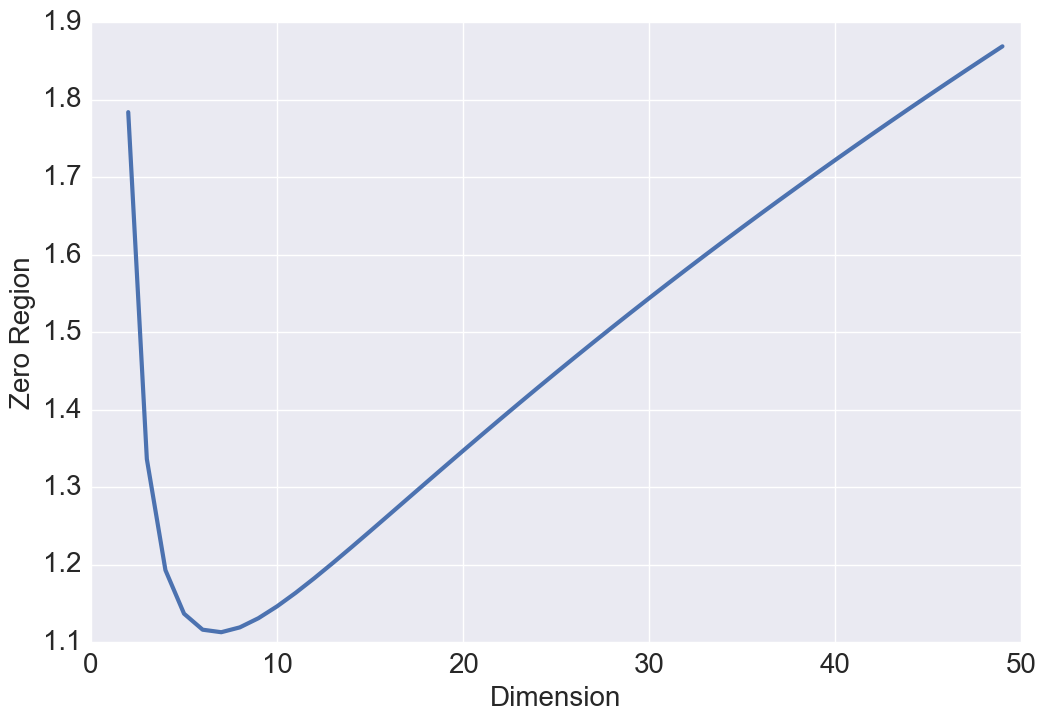 Figure 12
Figure 12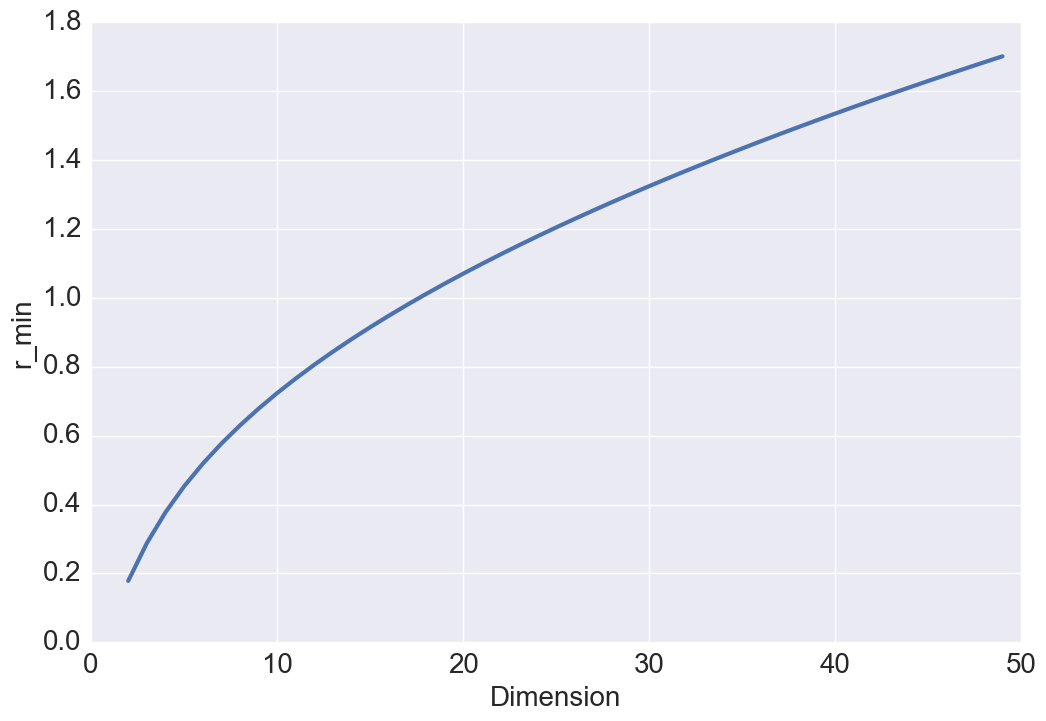 Figure 13
Figure 13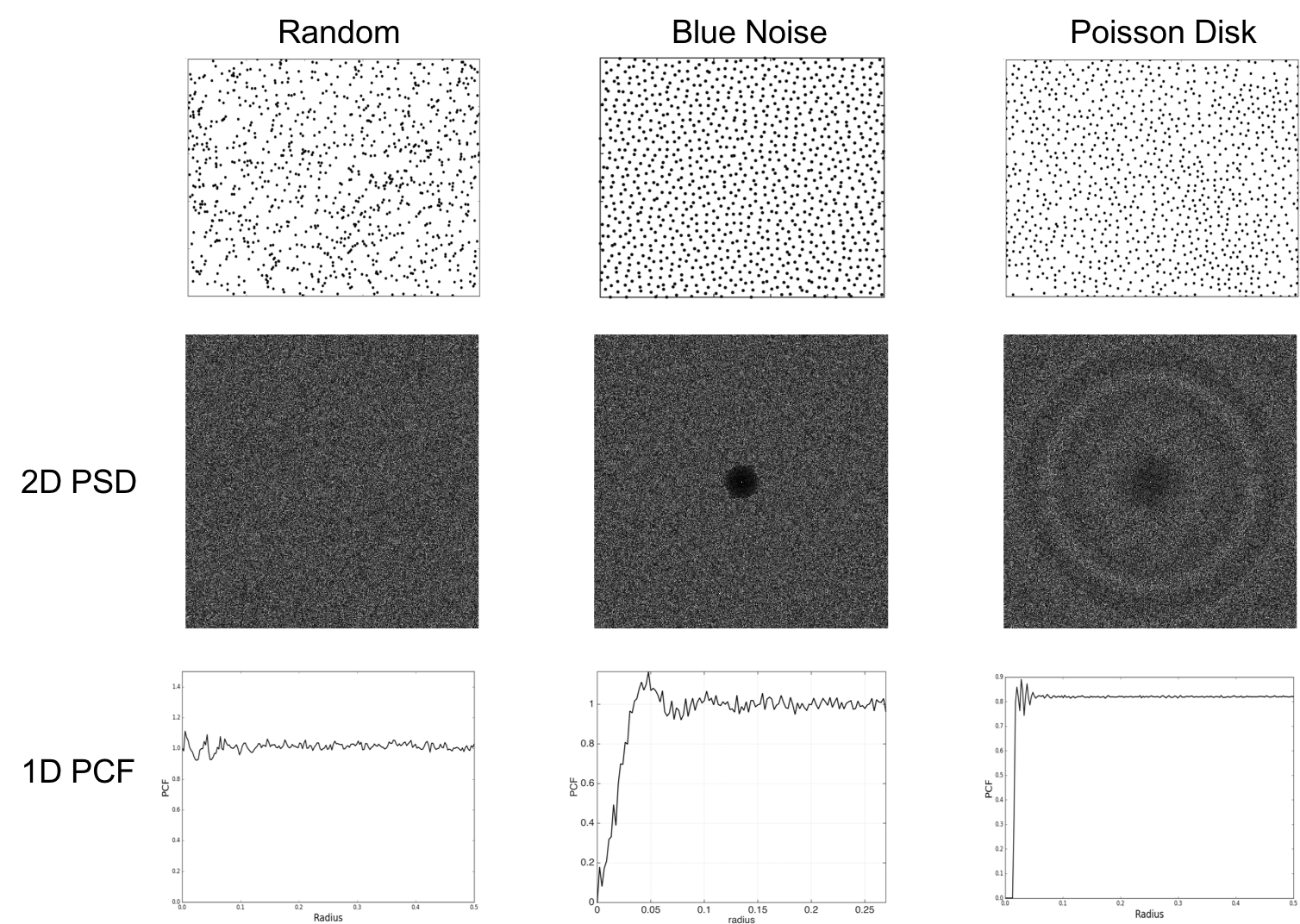 Figure 14
Figure 14Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMachine Learning and Algorithms · Sparse and Compressive Sensing Techniques · Neural Networks and Applications
A Look at the Effect of Sample Design on Generalization through the Lens of Spectral Analysis
Bhavya Kailkhura
Lawrence Livermore National Laboratories
Livermore, CA 15213
&Jayaraman J. Thiagarajan
Lawrence Livermore National Laboratories
Livermore, CA 15213
&Qunwei Li
Lawrence Livermore National Laboratories
Livermore, CA 15213
&Peer-Timo Bremer
Lawrence Livermore National Laboratories
Livermore, CA 15213
Abstract
This paper provides a general framework to study the effect of sampling properties of training data on the generalization error of the learned machine learning (ML) models. Specifically, we propose a new spectral analysis of the generalization error, expressed in terms of the power spectra of the sampling pattern and the function involved. The framework is build in the Euclidean space using Fourier analysis and establishes a connection between some high dimensional geometric objects and optimal spectral form of different state-of-the-art sampling patterns. Subsequently, we estimate the expected error bounds and convergence rate of different state-of-the-art sampling patterns, as the number of samples and dimensions increase. We make several observations about generalization error which are valid irrespective of the approximation scheme (or learning architecture) and training (or optimization) algorithms. Our result also sheds light on ways to formulate design principles for constructing optimal sampling methods for particular problems.
1 Introduction
Analyzing the generalization error of a learning algorithm is essential for estimating how well the generated hypothesis will apply to unknown test data. Traditionally, generalization error is analyzed based on the complexity of the function class, such as, the Vapnik-Chervonenkis (VC) dimension and the Rademacher complexity [2], or properties of the learning algorithm, such as uniform stability [3], and upper bounds on the error are derived. Recently, the authors in [16] showed that the mutual information between the collection of empirical risks of the available hypotheses and the final output of the algorithm can be used to analyze the generalization error in learning problems. In a similar information-theoretic setup, the authors in [1] proposed to bound generalization error using the total-variation distance.
Here, we are interested in studying generalization from the viewpoint of the sampler generating the training data. Sample design has been a long-standing research area in statistics, and a plethora of sampling solutions exist in the literature with a wide-range of assumptions and statistical guarantees; see [7, 13] for a detailed review of related methods. The properties of the sampling distribution directly control the expected convergence behavior of the generalization error, as sample size grows asymptotically. Consequently, designing an optimal sampler for a learning algorithm requires quantifying how the properties of the sampling distribution affects the generalization error. Unfortunately, existing theoretical tools for analyzing generalization error are not applicable for our purpose as they do not provide a direct connection to the sample properties, i.e. uniformity, randomness, etc. In this context, this paper addresses two important challenges: identifying expressive metrics to quantify sample properties, and bounding generalization error in terms of those tractable sample properties.
Generically, a good sampling technique aims to cover the input space as uniformly as possible, in order to generate the so-called space-filling experiment designs [10]. Since it is challenging to qualitatively evaluate the space-filling property, simple scalar metrics such as discrepancy [5] or geometric distances (maximin or minimax distance of a sample design [17]) are utilized. However, recent studies have shown that these scalar metrics are not very descriptive, and when used as the design objective, often results in poor-quality samples [12]. Furthermore, existing sampling distributions are not designed to specifically improve generalization error of learning algorithms. This is due to the lack of a principled framework for connecting sampling properties to generalization error. To address this challenge, we develop a novel spectral analysis framework to study generalization error, expressed in terms of the power spectra of sampling patterns as well as the function to be recovered.
Contributions and Findings: First, we propose to adopt spectral analysis for characterizing the space-filling property of sampling patterns. More specifically, we use tools from statistical mechanics to connect the spectral properties of a sampling pattern with its spatial properties. Next, we develop an analysis framework for studying generalization error behavior of a learning algorithm through the lens of spectral properties of the sample design. Using this framework, for isotropic, homogeneous sampling patterns (i.e. we can use a radially averaged power spectrum), we derive best and worst-case generalization error bounds.
While majority of existing literature on generalization error characterization based on sampling [3] have focused on uniform random sampling, the proposed analysis framework allows us to study the behavior of a large class of sample designs. In particular, we consider the blue noise [11, 9] and the Poisson disk sampling (PDS) distributions and obtain sampler-specific bounds (see Figure 1 in the supplementary material for examples of the distributions used). We characterize the gain due to blue noise and PDS samples over random sampler in a closed-form. This analysis further helps us to formulate design principles to construct optimal sampling methods to specific ML problems. Finally, we make interesting (counter-intuitive) observations on the convergence behavior of generalization error with increasing dimensions, and hence develop novel spectral metrics to obtain meaningful convergence results for different sampling patterns (included in the supplementary material).
2 Preliminaries - Spectral Analysis for Sampling
Fourier analysis is a classical approach for studying properties of sampling distributions. For example, the power spectral density (PSD) can be used to assess the quality of sampling distributions. Alternately, analyzing spatial characteristics of samples can also provide crucial insights. While such a spatial analysis has been traditionally carried out using heuristic measures for uniformity of sampling patterns, we adopt a more descriptive characterization.
Power Spectral Density: For a finite set of samples, , in a region with unit volume, the radially-averaged power spectral density describes how the signal power is distributed over frequencies. It is formally defined as
[TABLE]
where denotes the spectral coefficients. For isotropic distributions, we have .
Pair Correlation Function: A PCF describes the joint probability of having samples at two locations at the same time. It can be more precisely defined in terms of the intensity and product density of a point process [14]. The intensity of is the average number of points in an infinitesimal volume around . For isotropic point processes, this is a constant. Let denote the set of infinitesimal spheres around the points, and denote the volume measures of . The product density . In the isotropic case, for a pair of points, depends only on the distance between the points, hence one can write and . The PCF is then defined as
Relating PCF and PSD via Fourier Transform: The PSD and PCF of a point distribution are related via the Fourier transform as follows:
[TABLE]
where denotes the -dimensional Fourier transform. Next, we establish a fundamental relationship between PSD and PCF for radially symmetric or isotropic distributions.
Theorem 1**.**
The pair correlation function and the power spectral density of radially symmetric function are related as follows:
[TABLE]
where is the Hankel transform.
Proof.
Please see supplementary material. ∎
Realizability: The two necessary mathematical conditions 111Whether or not these two conditions are not only necessary but also sufficient is still an open question (however, no counterexamples are known). that a sampling pattern must satisfy to be realizable are: (a) its PSD must be non-negative, i.e., , and (b) its pair correlation function must be non-negative, i.e., .
3 Risk Minimization using Monte Carlo Estimates
We consider the following general setup, which encompasses several supervised learning formulations. We consider two spaces of objects (toroidal unit cube ) and , and the goal is to learn a function (often called hypothesis) which outputs for a given . We assume access to training data comprised of samples drawn i.i.d. from an unknown distribution . Supervised learning attempts to infer a hypothesis that minimizes the population risk:
[TABLE]
where denotes the loss function.
Empirical Risk Minimization: In general, the joint distribution is unknown to the learning algorithm and hence the risk cannot be computed. However, we often use an approximation, referred as empirical risk, obtained by averaging the loss function on the training data:
[TABLE]
Note that the empirical risk is a Monte Carlo (MC) estimate of the population risk . It also has a continuous form
[TABLE]
where is the sampling domain, is the sampling function, i.e., a sampling pattern rewritten as a random signal composed of Dirac functions located at sample positions for .
Generalization Error: In ML and statistical learning theory, the performance of a supervised learning algorithm is measured by the generalization error, which measures how accurately an algorithm is able to predict outcome values for previously unseen data. More specifically, we adopt the following definition of generalization error:
[TABLE]
which is the expected difference between the population risk of the output hypothesis and its empirical risk on the training data. The generalization error also has an alternating form with a direct link to the statistical properties of the sampling pattern:
[TABLE]
We consider sampling patterns which are homogeneous, i.e. statistical properties of a sample are invariant to translation over the domain . Homogeneous sampling patterns are unbiased in nature, thus, the generalization error arises only from the variance. Note that the variance analysis of Monte-Carlo integration has been considered in the literature [6, 18, 15] and we build upon these methods. However, similar analysis is of generalization error in an ML context has not been carried out yet.
4 Connecting Generalization Error with Spectral Properties of Samples
In this section, we will express generalization error (or variance) in terms of the power spectra of both and . To this end, we use the Monte Carlo estimator of risk in the Fourier domain, and derive the variance in the Fourier domain by leveraging our homogeneity assumption on sampling patterns.
4.1 Monte Carlo Estimator of Risk in the Spectral domain
The MC estimator of the risk as given in equation (4) can be characterized in the Fourier domain using the fact that dot-product of functions (the integral of the product) is equivalent to the dot-product of their Fourier coefficients. This allows to us to build the MC estimator of the risk as follows:
[TABLE]
where , denote the Fourier transforms of the sampling function and the loss function .
4.2 Generalization Error via the Spectral Analysis
We now use the spectral domain version of empirical risk to define generalization error:
[TABLE]
where . Next, we provide an explicit closed-form relation of generalization error with the power spectra of both the sampling pattern and the loss function. To derive this relation, we first simplify (7) by restricting our analysis to homogeneous sampling patterns, which are unbiased.
Lemma 1**.**
The generalization error in terms of the power spectra of both the sampling pattern and the loss function in the toroidal domain can be obtained as:
[TABLE]
Proof.
Please see supplementary material. ∎
If homogeneous sampling is isotropic (i.e., the power spectrum is radially symmetric), then the error can be computed from the radial mean power spectrum of the loss and the sampling pattern .
Theorem 2**.**
The generalization error for isotropic homogeneous sampling patterns (in polar coordinates) is given by
[TABLE]
where is the Lebesgue measure of a -dimensional unit sphere in given by which is the surface area of the -dimensional unit sphere.
5 Best and Worst Case Generalization Error
Using the proposed spectral analysis framework to predict generalization error requires us to explicitly know the power spectra of the loss function, which is usually unknown. Thus, we restrict our analysis to a particular class of integrable functions of the form with smooth and a bounded domain with a smooth boundary ( is the characteristic function of ) [4]. We consider a best-case function and a worst-case function, both from this class of functions to derive the error convergence rates, as the number of samples and dimension grow. Note that the power spectra of sampling distributions are usually known in advance. We show that this information can be used in our framework to compute the generalization error bounds. Note, We perform our analysis following (9), where the error is characterized by the radial mean power spectra of both sampling pattern and loss function.
5.1 Best-Case Generalization Error
We define our best-case function directly in the spectral domain with the radial mean power spectrum profile which is a constant for , and zero elsewhere. The constant comes from the fact that the power spectrum is bounded. The best case error can be thus obtained from (9) as follows:
Lemma 2**.**
The best-case generalization error for isotropic homogeneous sampling patterns (in polar coordinate) is given by
[TABLE]
5.2 Worst-Case Generalization Error
For the worst-case, we consider our function to exhibit a radial mean power spectrum which is which is upper bounded by a constant for , and elsewhere, where and are non-zero positive constants. This spectral profile has a decay rate for .
Lemma 3**.**
The worst-case generalization error for isotropic homogeneous sampling patterns (in polar coordinate) is given by
[TABLE]
6 Sampler-Specific Generalization Error Bounds
In the previous section, we obtained the best and worst-case generalization error as a function of the sampling power spectrum . In this section, we study the effects of different sampling distributions on the generalization error.
Random (or Poisson) Sampler: This has a constant power spectrum since point samples are uncorrelated, i.e., . For this spectral profile, the best-case generalization error can be obtained as:
[TABLE]
and the worst-case generalization error can be bounded as:
[TABLE]
Blue Noise Sampler: Blue noise distributions are aimed at replacing visible aliasing artifacts with incoherent noise, and its properties are typically defined in the spectral domain. We consider the step blue noise pattern defined as follows: (a) the spectrum should be close to zero for low frequencies, which indicates the range of frequencies that can be recovered exactly; (b) the spectrum should be a constant one for high frequencies, i.e. represent uniform white noise, which reduces the risk of aliasing. The low frequency band with minimal energy is referred to as the zero region. Formally,
[TABLE]
The zero region indicates the range of frequencies that can be represented with no aliasing and the flat region guarantees that aliasing artifacts are mapped to broadband noise.
Lemma 4** ([11]).**
The pair correlation function of a Step blue noise sample of size in dimensions, for a given zero region is given by
[TABLE]
Using Lemma 4, we can pose an optimization problem for determining the maximum achievable zero region , that does not violate realizability conditions, for a given sample budget .
Lemma 5**.**
The maximum achievable zero region using Step blue noise samples in dimensions is equal to inverse of the -th root of the volume of a -dimensional hyper-sphere with radius ,
[TABLE]
where is the gamma function. Equivalently, we can determine the minimum number of samples needed to construct a step blue noise pattern, .
Proof.
Please refer to the supplementary material. ∎
For this spectral profile, the best-case generalization error can be obtained as:
[TABLE]
Note that, when the best-case generalization error , and when , we have
[TABLE]
The worst-case generalization error can be obtained as:
[TABLE]
Note that, when the worst-case generalization error , and when ,
[TABLE]
Poisson Disk Sampler: Without any prior knowledge of the function of interest, a reasonable objective for sampling is that the samples should be random to provide an equal chance of finding features of interest. However, to avoid sampling only parts of the parameter space, a second objective is required to cover the space in uniformly. Poisson Disk Sampling (PDS) pattern are designed to achieve these objectives. In particular, the step PCF sampling pattern is a set of samples that are distributed according to a uniform probability distribution (Objective 1: Randomness) but no two samples are closer than a given minimum distance (Objective 2: Coverage). Formally,
[TABLE]
The PDS can also be defined in the spectral domain as follows:
Lemma 6** ([12]).**
The power spectra of an ideal Poisson disk sampling pattern of size in dimensions, for a given is given by
[TABLE]
where is the Bessel function of order .
Similar to the previous case, we can determining the maximum achievable , that does not violate realizability conditions, for a given sample budget .
Lemma 7**.**
The maximum achievable using Step PCF samples in dimensions is equal to inverse of the -th root of the volume of a -dimensional hyper-sphere with radius ,
[TABLE]
where is the gamma function. Equivalently, we can also determine the minimum required to achieve a given , .
For PDS sampling, the best-case generalization error can be obtained as:
[TABLE]
The worst-case generalization error can be obtained as:
[TABLE]
These integrals are complicated to compute and it is non-trivial to get clean and general bounds. Further simplifications under certain simplistic assumptions are provided in the supplementary material.
7 Convergence Analysis of Generalization Error
Next, we analyze the convergence of error with blue noise and PDS sampling patterns with sample size . This analysis will shed light into design principles for constructing sampling patterns.
7.1 Analysis with Sample Size
For random sampling patterns, both the best and the worst case generalization errors converge as . For blue noise sampling, if best case functions/signals are bandwidth-limited with , then it can be perfectly recovered. However, when , the convergence is at the rate , which is the same as random sampling. For worst case functions, the error converges as when and as when . This provides a theoretical justification of designing a blue noise sampling pattern with a large zero-region for better performance. Note that the convergence rate analysis of Poisson disk sampling is not straightforward due to the involvement of Bessel functions under the integral in (26) and (27). Hence, we numerically analyze the convergence for PDS pattern. As showed in Fig. 1, We observe that the best case convergence rate approximately behaves as with and the worst case convergence behaves as .
7.2 Some Guidelines for Sample Design
Results from the convergence analysis suggest that an ideal sampling power spectrum must attain zero values in the low frequency regime. Note that the realizability conditions severely limit the range of realizable power spectra and hence in practice, this results in blue noise patterns with very small . Consequently, when the function is complex with , a blue noise sample design behaves similar to a random design, . On the other hand, Poisson disk samples have a better error convergence rate even for complex functions compared to blue noise patterns. However, when , blue noise pattern is ideal. This suggests that an ideal sampling pattern should trade-off the two paradigms by developing a sampling pattern that simultaneously carries the blue noise and PDS properties.
In many practical scenarios, it is possible to use information acquired from previous observations to improve the sampling process. As more samples are obtained, one can learn how to improve the sampling process by deciding where to sample next. These sampling feedback techniques are more generally known as adaptive sampling in the statistics literature. Our analysis provides a novel way to quantify the value of sample in terms of generalization error. A natural extension of our work is towards building importance sampling techniques, guided by spectral properties.
8 Conclusions
In this paper, we develop a framework to study the interplay between the sampling properties and the generalization error. We expressed generalization error in terms of power spectra of sampling pattern and the function of interest. We also analyzed the generalization error of some state-of-the-art sampling pattern and quantified their gain over random sampler in a closed-form. Finally, we provided some design guidelines for constructing optimal sampling patterns for a given problem. There are still many interesting questions that remain to be explored in the future work such as an analysis of the generalization error for cases where data comes from non-linear manifolds. Note that some analytical methodologies used in this paper are certainly exploitable for studying the effect of sample design on generalization error in different manifolds. Other questions such as PSD/PCF parameterizations for other variants of space-filling designs, adaptive and importance sampling, and optimization approaches to synthesize them can also be investigated.
9 Acknowledgments
This work was performed under the auspices of the U.S. Department of Energy by Lawrence Livermore National Laboratory under Contract DE-AC52-07NA27344.
10 Appendix
11 Description of Sampling Distribution Families
In this paper, we consider three different families of sampling patterns for our generalization error analysis, namely random, blue noise and Poisson disk sampling. Figure 2 illustrates the point distributions along with their spectral/spatial properties for and . Note that, we show the 2D PSD here, though our analysis assumes isotropic distributions and hence uses radially averaged 1D-PSD.
12 Proof for Lemma 1 from the main paper
The proof follows from [15] and provided here for completeness.
Let us denote the Fourier domain without the DC peak frequency as . Since homogeneous sampling patterns have statistical properties that are invariant to translation, it is equivalent to studying the error due to the translated version of each realization, with the average computed over all translations. Formally, we can treat the torus as the group of translations, so that denotes the translation of by an element . Then, averaging equation (7) over all translations of , we get:
[TABLE]
where the exponential arises from the translation of the sampling pattern by a vector in the Fourier domain. When , the integral of the exponential part equals zero, so that only the case contributes to the variance. Hence, we can remove one integral over and obtain
[TABLE]
Finally, denoting the power spectrum of the loss by and the power spectrum of the sampling pattern normalized by as , and leveraging the fact that ,
[TABLE]
This provides the expression for the generalization error in terms of the power spectra of both the sampling pattern and the loss function in the toroidal domain.
13 Proof of Theorem 1 from the main paper
We know that the PSD and PCF of a point distribution are related via the Fourier transform as follows:
[TABLE]
where denotes the -dimensional Fourier transform. Using symmetry of the Fourier transform, we have
[TABLE]
Next, we use polar coordinates with the axis along , so that where and . For radially symmetric PCF, we have and the above relationship can be rewritten as
[TABLE]
where is the area of unit sphere in dimension. Next, using the identity involving bessel function of order , i.e.,
[TABLE]
we obtain
[TABLE]
14 Proof of Lemma 5 from the main paper
Note that, for a Step blue noise configuration to be realizable, it is sufficient to show that the corresponding PCF is non-negative. Thus, we have
[TABLE]
In the last inequality, we have used the following approximation
[TABLE]
15 Generalization Error Bounds for Poisson Disk Sampling Patterns
Best Case
[TABLE]
The second inequality above is based on the series form of the hypergeometric function and the assumption that is a large number.
16 Convergence Analysis of Generalization Error with Dimensions
In this section, we report some interesting observations when analyzing generalization error with increasing dimensions. We study the limiting behavior of and as approaches infinity. We show that the analysis with conventional metrics to characterize the zero region, i.e., the range of frequencies that can be represented with no aliasing, provides some rather counter-intuitive results.
Lemma 8**.**
As the dimension approaches infinity, the maximum achievable zero region for blue noise sampling, with a fixed , goes to infinity, i.e., and, the minimum number of samples needed to achieve a zero region approaches zero, i.e.,
Intuitively, with gowing , one might expect and . To better understand this result, we study the relationship between these two quantities and the volume of a hyper-sphere. One of the surprising facts about a sphere in high dimensions is that as the dimension increases, the volume of the sphere goes to zero which justifies the above results. Our intuitions about space are formed in two or three dimensions and often do not hold in high dimensions. A more surprising fact is that and are not monotonic functions with respect to (see Figure 3 and 3). Either a steady increase or a steady decrease seems more plausible than having these two quantities grow for a while, then reach a peak at some finite value of , and thereafter decline. This behavior has also been observed in high dimensional geometry while analyzing the volume of a hypersphere, however, no physical interpretation or intuition currently exists for this open research problem [8].
Similarly, we study the asymptotic behavior of the maximum achievable for a fixed sample budget, and equivalently the minimum number of samples required to achieve a PDS with a given , as the dimension grows to infinity.
Lemma 9**.**
As the dimension approaches infinity, the maximum achievable for PDS sampling pattern, with a fixed number of samples, goes to infinity, i.e., and, the minimum number of samples needed to achieve a also approaches infinity, i.e.,
The results in the lemma above are reasonable, since the space is growing exponentially fast.
16.1 Analysis with Proposed Metrics
Analysis with the metrics and , which are based on the amplitude of the frequency vector, i.e., , to characterize the zero region, leads to inconsistent results in high dimensions. We argue that comparing and across different dimensions is not accurate, and these inconsistent results are a byproduct of the improper comparisons. Note that, each -dimensional space is comprised of a different range of frequency components, and comparing the magnitude of the frequency vector directly across dimensions is questionable. In particular, for a valid comparison of volumes across dimensions, we propose to measure them in terms of a standard volume in that dimension, i.e., unit hypercube or the measure polytope, which has a volume of in all dimensions. Further, as the dimension increases, the maximum possible distance between two points in a hypercube grows as . Consequently, to have same scale across dimensions, we normalize the radius of the hypersphere by the factor . In summary, we introduce the relative zero region, i.e., () for meaningful convergence analysis across dimensions.
Lemma 10**.**
As dimension approaches infinity, the maximum achievable relative converges to a constant, i.e.,
[TABLE]
and, the minimum number of blue noise samples needed to achieve goes to infinity.
Proof.
To prove the first identity, note that and invoke Stirling’s approximation, i.e., . Now, the required result can be obtained by letting approach infinity. The second identity can be proved in a similar manner. ∎
Similarly, we study the asymptotic behavior of for PDS sampling pattern.
Lemma 11**.**
As dimension approaches infinity, the maximum achievable relative converges to a constant, i.e.,
[TABLE]
and, the minimum number of PDS samples needed to achieve goes to infinity.
The results in Lemmas 10 and 11 show interesting limiting behaviors of both blue noise and PDS sampling distributions.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Alabdulmohsin [2015] I. M. Alabdulmohsin. Algorithmic stability and uniform generalization. In Advances in Neural Information Processing Systems , pages 19–27, 2015.
- 2Boucheron et al. [2005] S. Boucheron, O. Bousquet, and G. Lugosi. Theory of classification: A survey of some recent advances. ESAIM: probability and statistics , 9:323–375, 2005.
- 3Bousquet and Elisseeff [2002] O. Bousquet and A. Elisseeff. Stability and generalization. Journal of machine learning research , 2(Mar):499–526, 2002.
- 4Brandolini et al. [2001] L. Brandolini, L. Colzani, and A. Torlaschi. Mean square decay of fourier transforms in euclidean and non euclidean spaces. Tohoku Mathematical Journal, Second Series , 53(3):467–478, 2001.
- 5Caflisch [1998] R. E. Caflisch. Monte carlo and quasi-monte carlo methods. Acta Numerica , 7:1–49, 1998. doi: 10.1017/S 0962492900002804 .
- 6Durand [2011] F. Durand. A frequency analysis of monte-carlo and other numerical integration schemes. 2011.
- 7Garud et al. [2017] S. S. Garud, I. A. Karimi, and M. Kraft. Design of computer experiments: A review. Computers and Chemical Engineering , 106(Supplement C):71 – 95, 2017. ISSN 0098-1354. ESCAPE-26.
- 8Hayes [2011] B. Hayes. An adventure in the nth dimension. American Scientist. , 99(6):442–446, 2011.