Efficient Full-Rank Spatial Covariance Estimation Using Independent Low-Rank Matrix Analysis for Blind Source Separation
Yuki Kubo, Norihiro Takamune, Daichi Kitamura, Hiroshi Saruwatari

TL;DR
This paper introduces an efficient algorithm that enhances blind source separation by estimating full-rank spatial covariance, improving separation of directional sources and diffuse noise with reduced computational cost.
Contribution
The paper presents a novel method that extends ILRMA to estimate full-rank spatial covariance, addressing limitations with diffuse noise separation.
Findings
Improved separation performance in BSS tasks.
Reduced computational cost compared to existing methods.
Effective estimation of diffuse noise spatial basis.
Abstract
In this paper, we propose a new algorithm that efficiently separates a directional source and diffuse background noise based on independent low-rank matrix analysis (ILRMA). ILRMA is one of the state-of-the-art techniques of blind source separation (BSS) and is based on a rank-1 spatial model. Although such a model does not hold for diffuse noise, ILRMA can accurately estimate the spatial parameters of the directional source. Motivated by this fact, we utilize these estimates to restore the lost spatial basis of diffuse noise, which can be considered as an efficient full-rank spatial covariance estimation. BSS experiments show the efficacy of the proposed method in terms of the computational cost and separation performance.
Click any figure to enlarge with its caption.
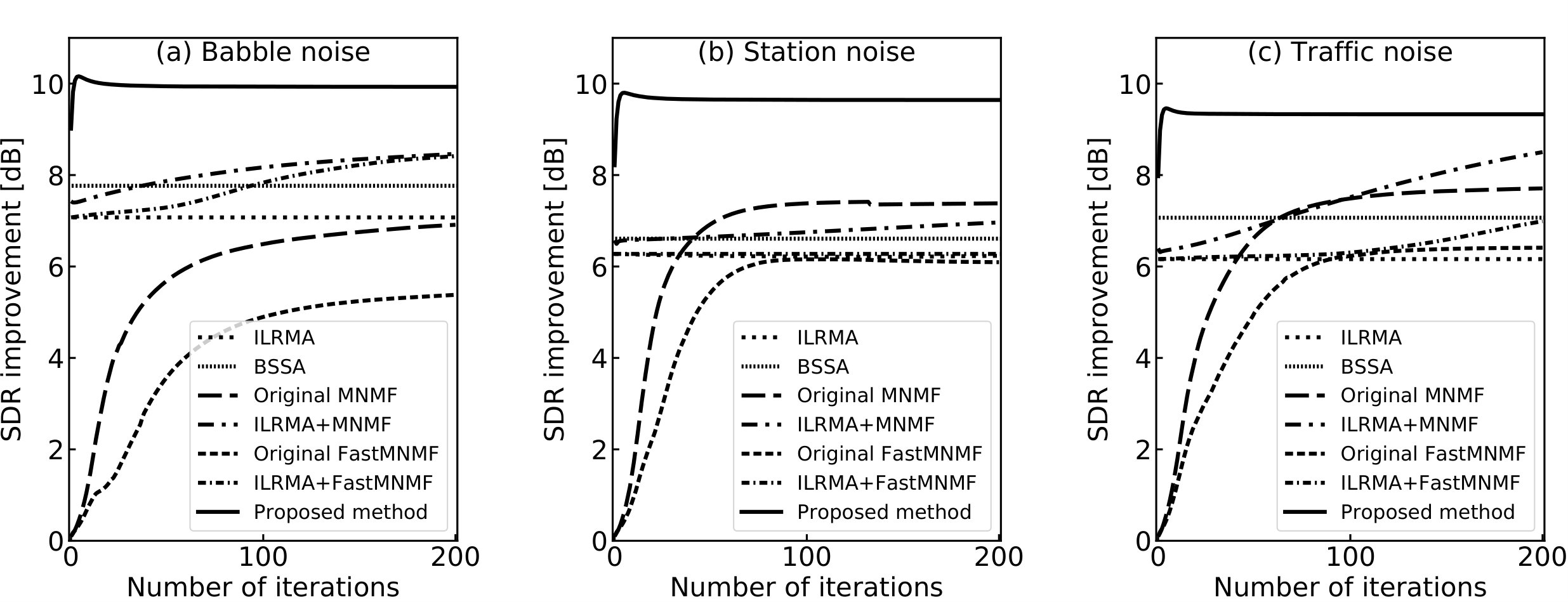 Figure 1
Figure 1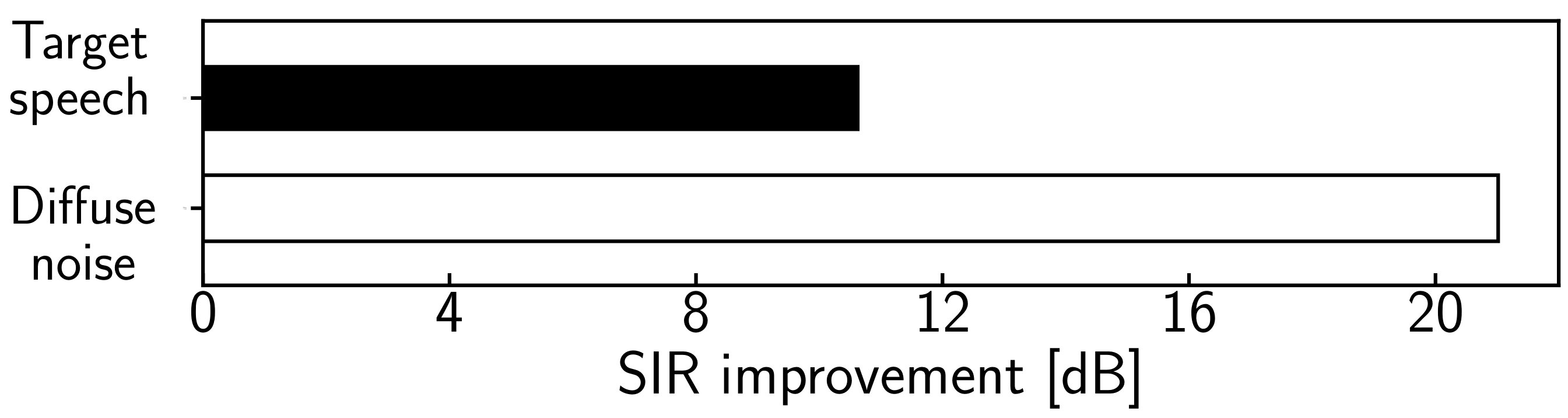 Figure 2
Figure 2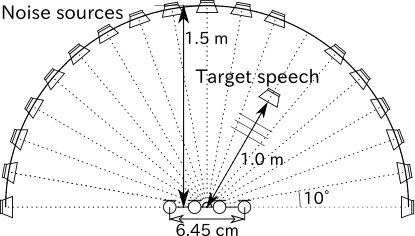 Figure 3
Figure 3| Sampling frequency | 16 kHz |
|---|---|
| STFT | 256-ms-long Hamming |
| window with 128 ms shift | |
| Number of NMF bases | 10 for source model |
| Number of iterations | 50 |
| in ILRMA | |
| Number of iterations | 200 |
| in methods except ILRMA | |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsBlind Source Separation Techniques · Speech and Audio Processing · Advanced Adaptive Filtering Techniques
Efficient Full-Rank Spatial Covariance Estimation Using Independent Low-Rank Matrix Analysis
for Blind Source Separation
Yuki Kubo2, Norihiro Takamune2, Daichi Kitamura3, Hiroshi Saruwatari2
2*The University of Tokyo, Graduate School of Information Science and Technology,
*7-3-1 Hongo, Bunkyo-ku, Tokyo 113-8656, Japan
3*National Institute of Technology, Kagawa College,
*355 Chokushi-cho, Takamatsu, Kagawa 761-8058, Japan
Abstract
In this paper, we propose a new algorithm that efficiently separates a directional source and diffuse background noise based on independent low-rank matrix analysis (ILRMA). ILRMA is one of the state-of-the-art techniques of blind source separation (BSS) and is based on a rank-1 spatial model. Although such a model does not hold for diffuse noise, ILRMA can accurately estimate the spatial parameters of the directional source. Motivated by this fact, we utilize these estimates to restore the lost spatial basis of diffuse noise, which can be considered as an efficient full-rank spatial covariance estimation. BSS experiments show the efficacy of the proposed method in terms of the computational cost and separation performance.
Index Terms:
Blind source separation, independent low-rank matrix analysis, full-rank spatial covariance model, diffuse noise
I Introduction
Blind source separation (BSS) is a technique for separating an observed multichannel signal, which is a mixture of multiple sources, into each source without any prior information about the sources or the mixing system. In a determined or overdetermined situation (number of sensors number of sources), frequency-domain independent component analysis (FDICA) [1, 2], independent vector analysis (IVA) [3, 4], and independent low-rank matrix analysis (ILRMA) [5, 6] have been proposed for audio BSS problems. In particular, ILRMA assumes low-rankness for the power spectrogram of each source using nonnegative matrix factorization (NMF) [7, 8] in addition to statistical independence between sources, and achieves efficient and accurate separation [5]. These methods assume a rank-1 spatial model; the frequency-wise acoustic path of each source can be represented by a single time-invariant spatial basis, which is often called a steering vector. Under this assumption, the determined BSS problem reduces to the estimation of a demixing matrix for each frequency. However, the assumption in the rank-1 spatial model becomes invalid in actual situations. For instance, when a target source (directional source) and diffuse noise that arrives from all directions are mixed, FDICA, IVA, and ILRMA cannot extract only the target source in principle [9], and the estimated target source includes residual diffuse noise.
Multichannel NMF (MNMF) [10, 11] is theoretically equivalent to ILRMA except for the mixing model, namely, MNMF employs a full-rank spatial covariance matrix [12]. This model can represent not only the acoustic path but also the spatial spread of each source or diffuse noise, while its optimization has a huge computational cost and lacks robustness against the initialization [5]. To accelerate the parameter estimation, FastMNMF has been proposed [13, 14]. It assumes a jointly diagonalizable spatial covariance matrix to greatly reduce the computational cost of the update algorithm, although its performance still depends on the initial values of parameters. To increase the stability of its performance, ILRMA-based initialization was utilized for MNMF in [15]. However, the improvement is still limited because of the complexity of optimization with a large number of parameters.
In this paper, we treat the BSS problem with one directional target source and diffuse background noise, where more than or equal to two microphones are available. In this case, the target source can be expressed using the rank-1 spatial covariance (one steering vector), but diffuse noise requires the full-rank spatial covariance because of its spatial spread. To achieve robust and computationally efficient BSS in this situation, we propose a new approach based on ILRMA: (a) rank-1 target covariance and rank- diffuse noise covariance matrices are simultaneously estimated by ILRMA, where is the number of microphones, (b) one lost spatial basis for diffuse noise is restored to obtain the rank- (full-rank) noise covariance via the expectation-maximization (EM) algorithm, and (c) a multichannel Wiener filter is applied to enhance only the target source. The efficacy of the proposed method is confirmed through BSS experiments using a mixture of speech and diffuse noise.
Regarding its relation to prior works, the proposed method is considered as a spatial model extension of FDICA, IVA, and ILRMA, which are the conventional independence-based BSS algorithms utilizing the rank-1 spatial model. Compared with conventional MNMF and FastMNMF based on the full-rank spatial model, the proposed method is regarded as a computationally efficient algorithm with higher separation accuracy.
II Independent Low-Rank Matrix Analysis
II-A Formulation
Let us denote a multichannel observed signal as that is obtained via a short-time Fourier transform (STFT), where , , and are the indices of the frequency bins, time frames, and microphones, respectively, and denotes the transpose. Also, source signals (dry sources) are denoted as , where is the index of the sources and is the number of sources. If each source in can be represented by a time-invariant steering vector , the following mixing system holds:
[TABLE]
where is called a mixing matrix. If and is invertible, the separated signal can be obtained by estimating the demixing matrix as
[TABLE]
where denotes the Hermitian transpose.
II-B Generative Model and Update Rules
In ILRMA, as the generative model of source signals, the following complex Gaussian distribution is assumed:
[TABLE]
where is the time-frequency-varying variance (power spectrogram model of ). Also, is modeled by NMF [16] as , where and are the NMF variables, is the index of the NMF bases, and is the number of bases. From (1) and (3), the generative model of the observed signal becomes
[TABLE]
Since the mixing system (1) is assumed in ILRMA, the spatial covariance is represented by a rank-1 matrix as , which is called the rank-1 spatial model.
The cost function in ILRMA is defined as the negative log-likelihood function of (4) as
[TABLE]
where . Both the separation filter and the NMF variables and can be optimized in the maximum likelihood sense (minimization of (5)) by iterating the following iterative update rules [5]:
[TABLE]
where denotes the unit vector with the th element equal to unity. The update rules for are called the iterative projection [17], which promises convergence-guaranteed efficient optimization. Also, we can update and by minimizing the Itakura–Saito divergence between and (see [5] for details).
III Proposed Method
III-A Motivation and Strategy
In this paper, we deal with a mixture signal that includes one directional target source and diffuse background noise. Since diffuse noise cannot be expressed by the rank-1 spatial model (one steering vector), BSS based on a full-rank covariance model, such as MNMF, should be applied in this situation. However, estimation of the full-rank covariance has a huge computational cost, and its performance is always more unstable than ILRMA [5] because of the large number of spatial parameters, , which can be reduced to using the rank-1 spatial model (ILRMA).
For this reason, to achieve efficient and stable BSS, we propose a new ILRMA-based full-rank covariance estimation using more than or equal to two microphones. Although the sources are categorized into two groups (target and noise), we assume that one target source and noise components are mixed (). This assumption allows us to model the diffuse noise using spatial bases (rank- spatial covariance). The extraction of the target source in this manner is still difficult because noise components exist even in the same direction as the target source. However, FDICA or ILRMA can separate the diffuse noise with high accuracy even if one spatial basis for diffuse noise is lacking. Figure 1 shows an example of the separation performance (source-to-interference ratio (SIR) [18]) obtained by ILRMA, where directional speech and diffuse noise are mixed and the experimental conditions are described in Sect. IV. It can be seen that diffuse noise is accurately estimated (almost perfectly with more than 20 dB accuracy) rather than the target speech, where diffuse noise is modeled using the rank-() spatial covariance. This is because the demixing filters for the diffuse noise can precisely cancel the target speech, which is a point source [19], meaning that the steering vector of the directional source can be estimated by ILRMA with high accuracy, where denotes the index of the target source. This implies that we can fix some spatial parameters in the full-rank spatial model for diffuse noise by utilizing the estimates obtained by ILRMA in advance.
On the basis of the above motivation, we propose the following new estimation method for the full-rank spatial covariance of diffuse noise: (a) the rank-1 spatial covariance for the target source, , and rank- covariance for diffuse noise, , are estimated by ILRMA, (b) the lost spatial basis for diffuse noise is restored via the EM algorithm to estimate the noise components in the direction of the target source, and (c) a multichannel Wiener filter is applied to suppress the noise components remaining in the separated target source.
III-B Model of Target Source and Diffuse Noise
The observed signal is assumed to be the sum of two components, as
[TABLE]
where is the spatial image of the target source and is that of the diffuse noise. The target source is modeled as
[TABLE]
where , , and are the th steering vector , the dry source component, and the power spectrogram of the th source, respectively. As mentioned in Sect. III-A, can be accurately estimated by ILRMA. Thus, we hereafter consider as a given and fixed parameter in the following processes. In addition to (11), to improve the estimation performance, we introduce an a priori distribution for the variance using the inverse gamma distribution,
[TABLE]
where and are shape and scale parameters, respectively, and a large with a small induces the sparseness of .
Since diffuse noise should have a full-rank spatial covariance, the generative model of is expressed by a multivariate complex Gaussian distribution as
[TABLE]
where and are the variance and spatial covariance for the diffuse noise, respectively. From the estimated demixing filter obtained by ILRMA, we can model the full-rank spatial covariance of the diffuse noise as follows:
[TABLE]
where is the unit eigenvector of that corresponds to the zero eigenvalue and is a scalar weight used to complement the lost spatial basis, namely, the direction of the target source. Note that (15) includes a back-projection operation to compensate the scales of the signals [20]. Since consists of noise estimates, its rank is . Therefore, to restore the lost spatial basis in , we must simultaneously estimate the eigenvalue , the variance of the target source , and the variance of the diffuse noise with and the rank- spatial covariance fixed. In summary, the number of spatial parameters to be estimated in the proposed method is (for ILRMA) (for ), i.e., , which is much less than that of MNMF () and FastMNMF ().
III-C Update Rules Based on EM Algorithm
The parameters , , and are optimized by a maximum a posteriori estimation based on the EM algorithm. A function is defined by the expected value of the complete-data log-likelihood w.r.t. as
[TABLE]
where includes the constant terms that do not depend on the parameters, is the set of parameters to be updated, is the set of up-to-date parameters, and and are the sufficient statistics obtained by the E-step. The update rules in the E-step are as follows:
[TABLE]
In the M-step, we employ a coordinate ascent algorithm to the function. The update rules are as follows:
[TABLE]
III-D Multichannel Wiener Filter
After the estimation of all the parameters, the following multichannel Wiener filter is employed:
[TABLE]
III-E Initialization of Source Variances
Since the EM algorithm strongly depends on the initial values of the parameters, we employ the ILRMA estimates to initialize the source variances and to avoid trapping at a poor local solution as follows:
[TABLE]
where and are the low-rank source model of the target source obtained by ILRMA, + denotes the pseudoinverse, and is the scale-fixed source image of diffuse noise obtained as . Also, is initialized by the minimum nonzero eigenvalue of .
IV Experiments
IV-A Experimental Conditions
To confirm the efficacy of the proposed method, we conducted a BSS experiment using a simulated mixture of a target speech source and diffuse noise. We compared seven methods, namely, ILRMA [5], BSSA [19], the original MNMF [11], MNMF initialized by ILRMA (ILRMA+MNMF) [5, 15], the original FastMNMF [14], FastMNMF initialized by ILRMA (ILRMA+FastMNMF), and the proposed method ( and were selected experimentally). In ILRMA, the observation was preprocessed via a sphering transformation using PCA. For BSSA, we replaced FDICA in [19] with ILRMA and set the oversubtraction and flooring parameters to 1.4 and 0, respectively. For ILRMA, the original MNMF, and the original FastMNMF, all the NMF variables were initialized by nonnegative random values. The demixing matrix in ILRMA and the spatial covariance matrix in the original MNMF and the original FastMNMF were initialized by the identity matrix . For ILRMA+MNMF and ILRMA+FastMNMF, the NMF variables were taken from ILRMA. Also, the spatial covariance matrix was initialized using for ILRMA+MNMF and for ILRMA+FastMNMF, where was estimated by ILRMA and was set to .
We used speech signals obtained from the JNAS speech corpus [21] to produce the target speech source and diffuse babble noise. The station and traffic noise signals were obtained from DEMAND [22]. These dry sources were convoluted with the impulse responses shown in Fig. 2 to simulate the mixture, where the target source was located at , , , or clockwise from the normal to a microphone array, the 18 loudspeakers used to simulate diffuse noise were arranged at intervals of except in the target source direction, the size of the recording room for these impulse responses was 3.9 m 3.9 m, and its reverberation time was about 200 ms. Note that the diffuse babble noise was produced by convoluting 18 independent speakers with each impulse response, and the diffuse station and traffic noises were produced by splitting the dry source into 18 short-time periods and convoluting them with each impulse response. The speech-to-noise ratio was set to 0 dB. The other conditions are shown in Table I.
IV-B Results
Source-to-distortion ratio (SDR) [18] is used as a total evaluation score in terms of separation performance and sound distortion. The SDR behaviors for each of the methods, which are the averaged results over 10 parameter-initialization random seeds and four target directions, are shown in Fig. 3, where those of ILRMA-initialized methods are depicted except for their initializing iterations of ILRMA. The proposed method outperformed the other methods. In particular, the full-rank spatial model in the proposed method showed an improvement of more than 3 dB compared with the rank-1 spatial model in ILRMA, and the efficacy of the proposed spatial model extension was confirmed. Also, we reveal that, even with the assistance of ILRMA-based initialization, the SDRs of the conventional MNMFs and FastMNMFs with the full-rank spatial model cannot reach that of the proposed method.
As regards the optimization cost, the EM algorithm in the proposed method converged within five iterations, which was greatly reduced from the number of iterations required for MNMFs and FastMNMFs. In addition, the actual computational times of MNMF, FastMNMF, and the proposed EM algorithm for each iteration were 10.18 s, 0.87 s, and 0.005 s, respectively, further illustrating the advantageousness of the proposed method.
On the other hand, the unbiased sample standard deviations of SDR improvements just after 200 iterations of ILRMA, original MNMF, ILRMA+MNMF, original FastMNMF, ILRMA+FastMNMF, and the proposed method are 0.19, 2.37, 0.38, 5.75, 0.26, and 0.22, respectively. This means that the proposed method is a more stable algorithm than MNMF and FastMNMF in terms of initialization dependency.
V Conclusion
We proposed a new algorithm that accurately and efficiently extracts a directional target source in diffuse background noise. The proposed method is based on ILRMA and restores the lost spatial basis by using the EM algorithm to extend the spatial covariance of the noise from a rank-() matrix to the full-rank matrix. In an experiment, we confirmed that the proposed method outperforms the conventional methods in terms of accuracy and computational efficiency.
Acknowledgment
This work was partly supported by SECOM Science and Technology Foundation and JSPS KAKENHI Grant Numbers 17H06101, 19H01116, and 19K20306.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] P. Smaragdis, “Blind separation of convolved mixtures in the frequency domain,” Neurocomputing , vol. 22, no. 1, pp. 21–34, 1998.
- 2[2] H. Saruwatari et al., “Blind source separation based on a fast-convergence algorithm combining ICA and beamforming,” IEEE Trans. ASLP , vol. 14, no. 2, pp. 666–678, 2006.
- 3[3] A. Hiroe, “Solution of permutation problem in frequency domain ICA using multivariate probability density functions,” in Proc. ICA , 2006, pp. 601–608.
- 4[4] T. Kim et al., “Blind source separation exploiting higher-order frequency dependencies,” IEEE Trans. ASLP , vol. 15, no. 1, pp. 70–79, 2007.
- 5[5] D. Kitamura et al., “Determined blind source separation unifying independent vector analysis and nonnegative matrix factorization,” IEEE/ACM Trans. ASLP , vol. 24, no. 9, pp. 1626–1641, 2016.
- 6[6] D. Kitamura et al., “Determined blind source separation with independent low-rank matrix analysis,” in Audio Source Separation , S. Makino, Ed., pp. 125–155. Springer, Cham, 2018.
- 7[7] D. D. Lee, H. S. Seung, “Learning the parts of objects by non-negative matrix factorization,” Nature , vol. 401, no. 6755, pp. 788–791, 1999.
- 8[8] D. D. Lee, H. S. Seung, “Algorithms for non-negative matrix factorization,” in Proc. NIPS , 2000, pp. 556–562.