TL;DR
This paper introduces new activation functions derived from differential equations, demonstrating their effectiveness in classifying exoplanets with reduced tuning efforts compared to traditional functions.
Contribution
It presents novel activation functions based on differential equations and shows their advantages in exoplanet habitability classification with minimal tuning.
Findings
Proposed activation functions reduce tuning efforts.
Achieved comparable or better classification accuracy.
Established analytical relationships with existing activation functions.
Abstract
We present analytical exploration of novel activation functions as consequence of integration of several ideas leading to implementation and subsequent use in habitability classification of exoplanets. Neural networks, although a powerful engine in supervised methods, often require expensive tuning efforts for optimized performance. Habitability classes are hard to discriminate, especially when attributes used as hard markers of separation are removed from the data set. The solution is approached from the point of investigating analytical properties of the proposed activation functions. The theory of ordinary differential equations and fixed point are exploited to justify the "lack of tuning efforts" to achieve optimal performance compared to traditional activation functions. Additionally, the relationship between the proposed activation functions and the more popular ones is…
Click any figure to enlarge with its caption.
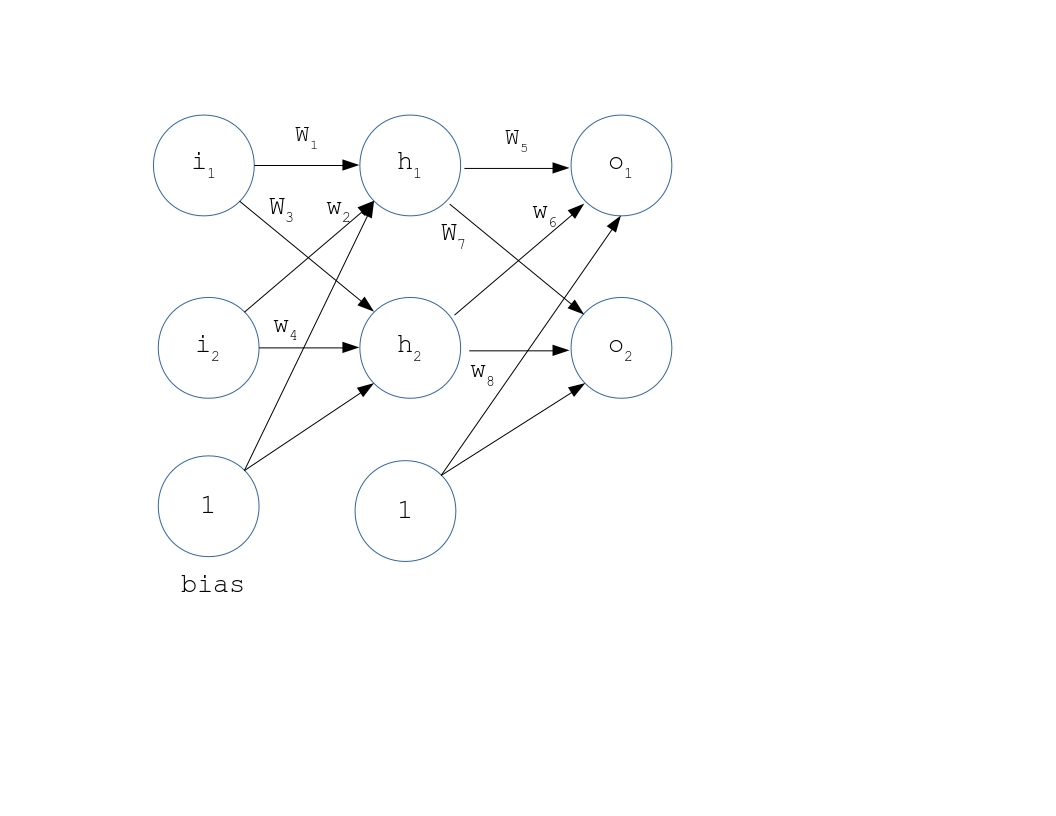 Figure 1
Figure 1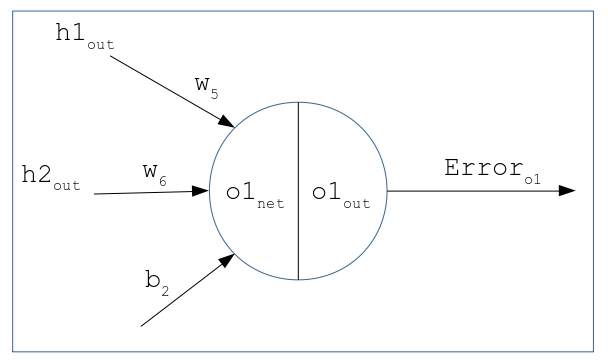 Figure 2
Figure 2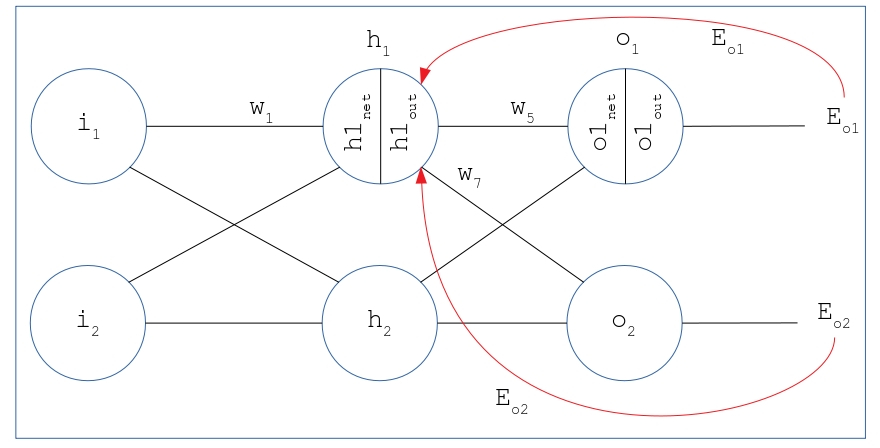 Figure 3
Figure 3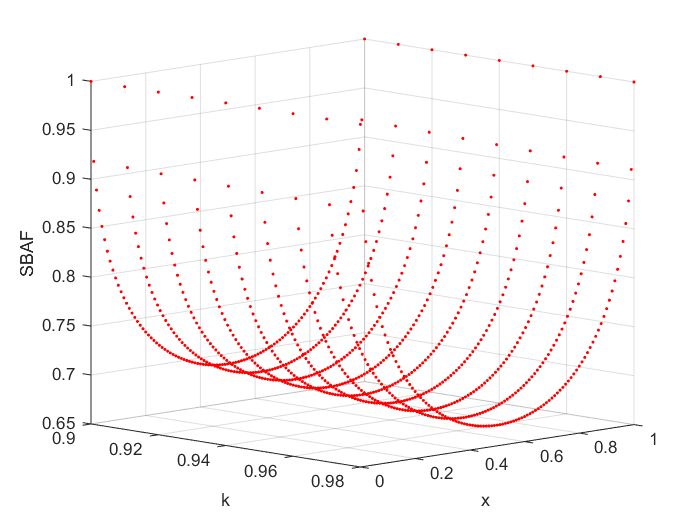 Figure 4
Figure 4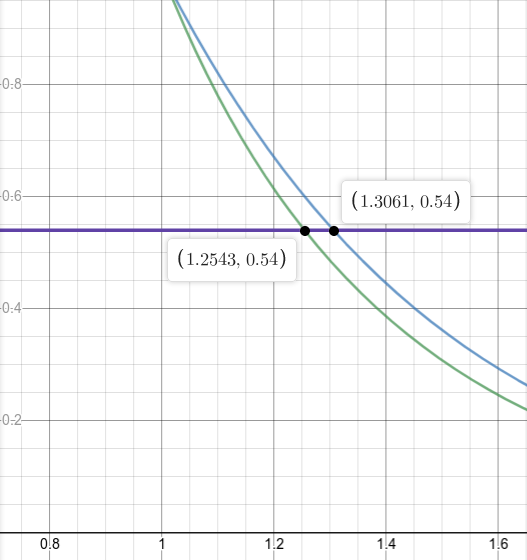 Figure 5
Figure 5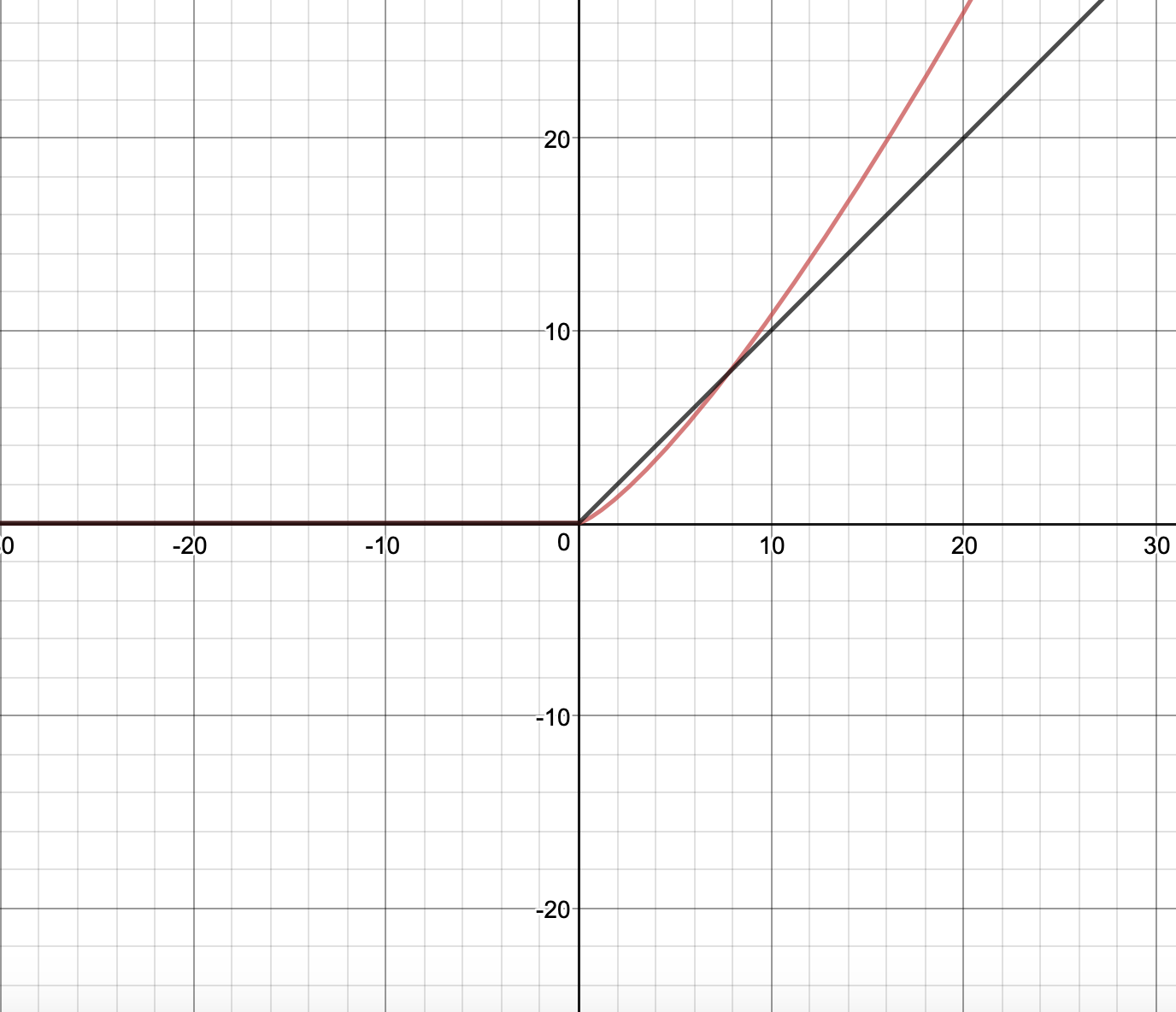 Figure 6
Figure 6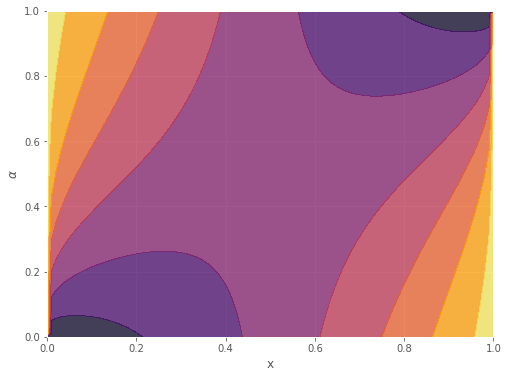 Figure 7
Figure 7 Figure 8
Figure 8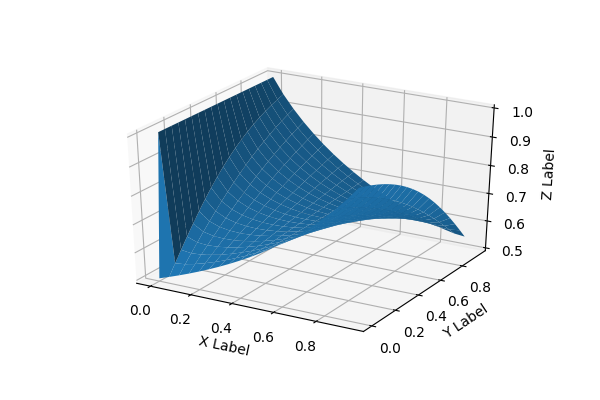 Figure 9
Figure 9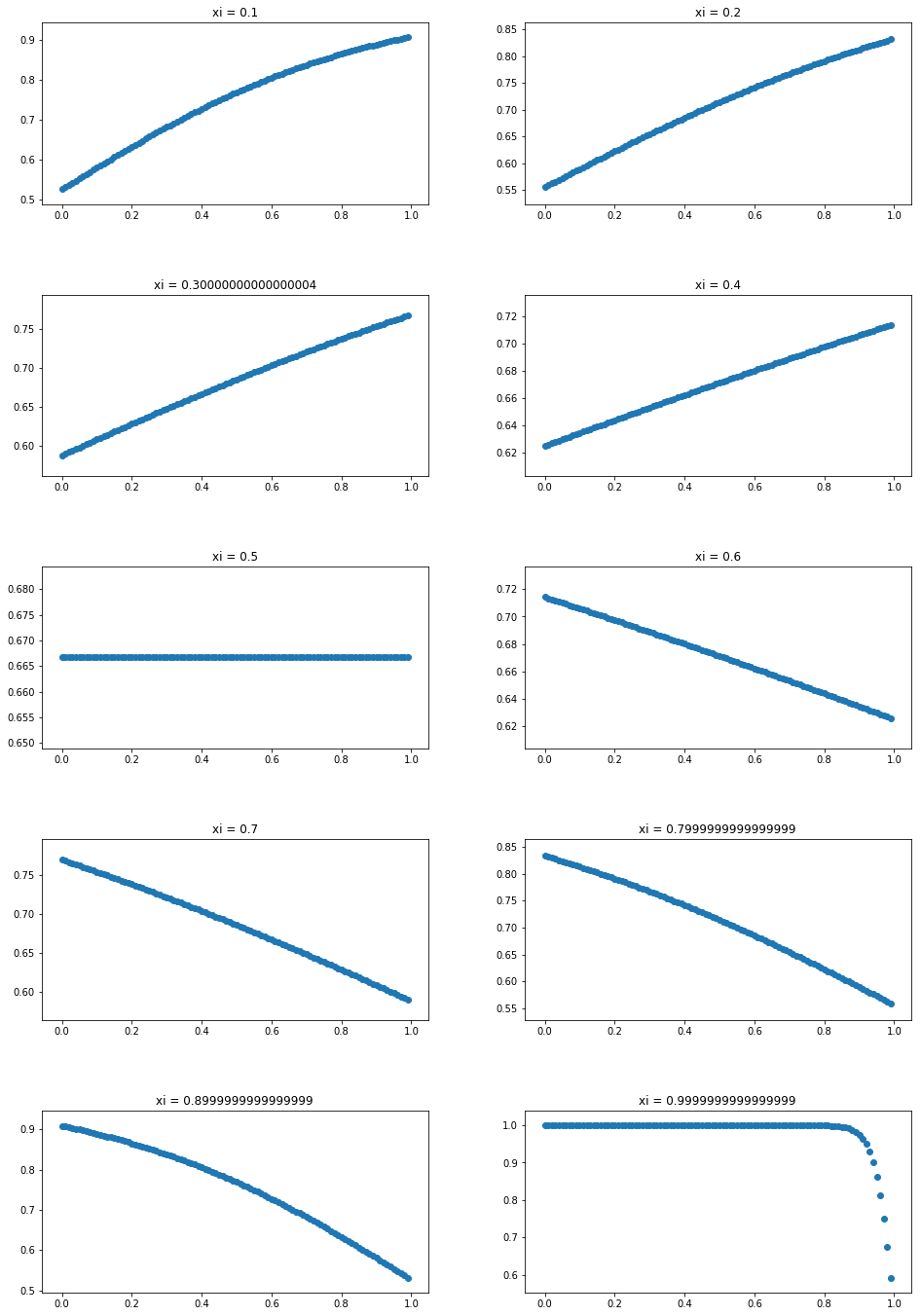 Figure 10
Figure 10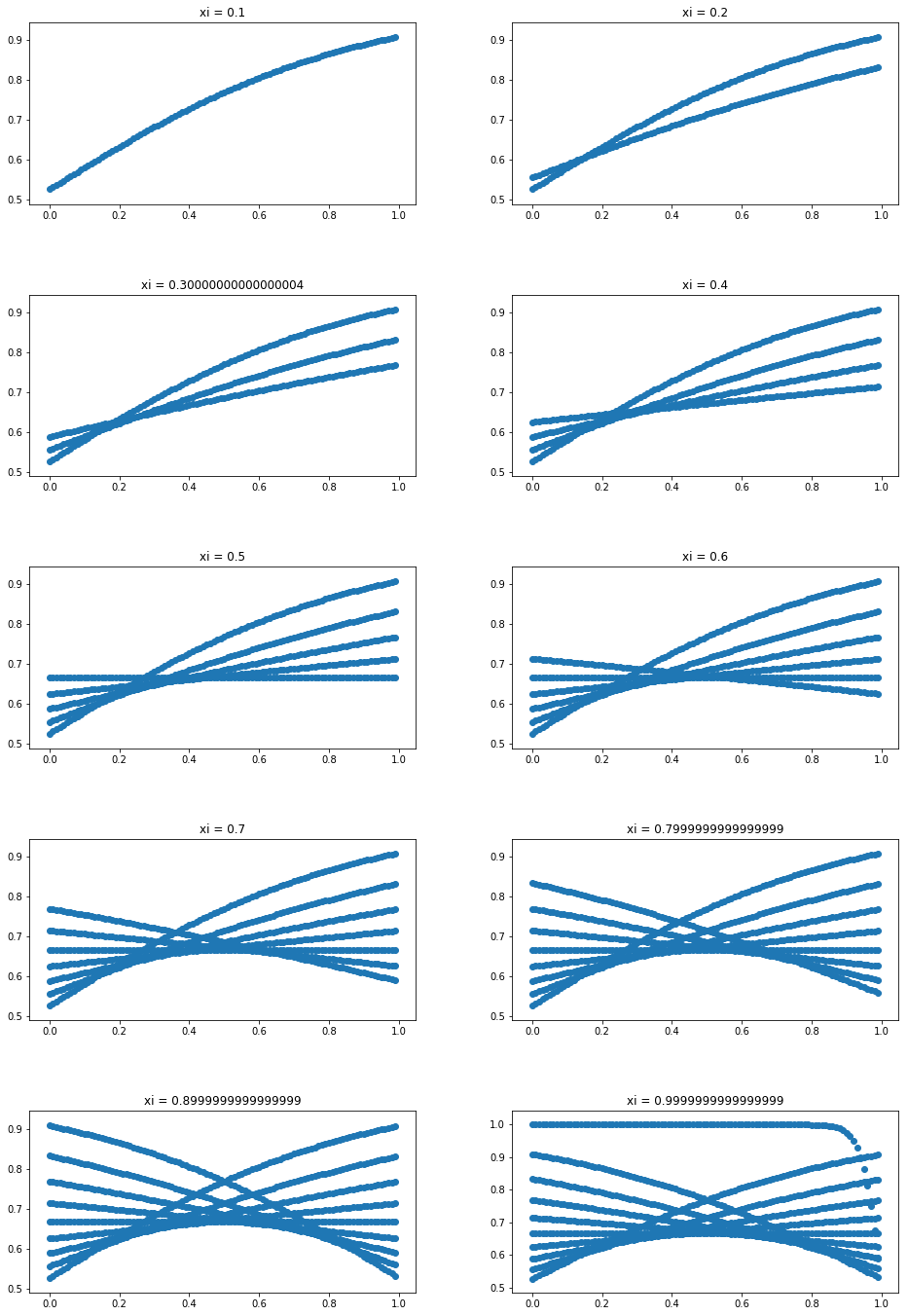 Figure 11
Figure 11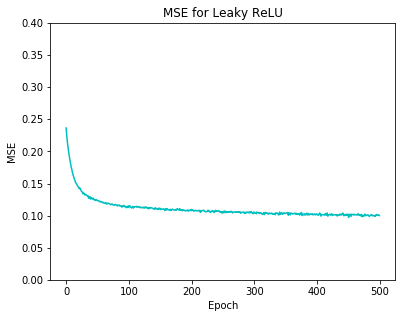 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16 Figure 17
Figure 17 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21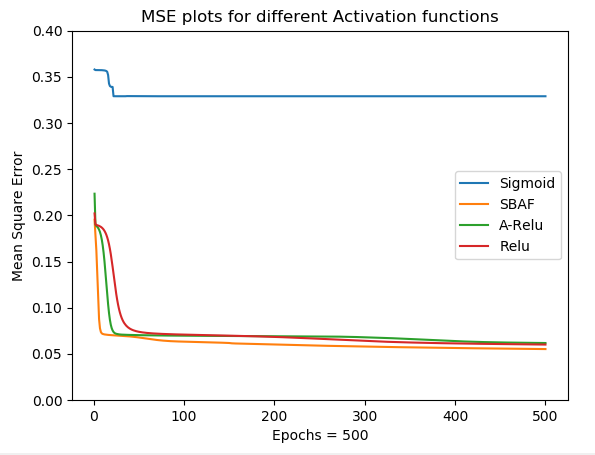 Figure 22
Figure 22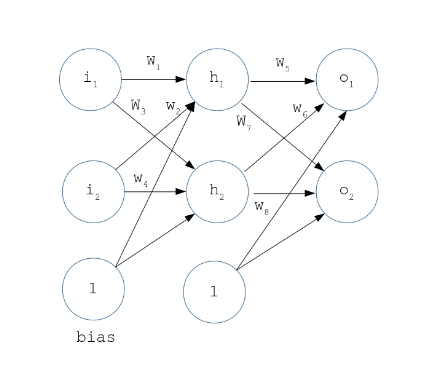 Figure 23
Figure 23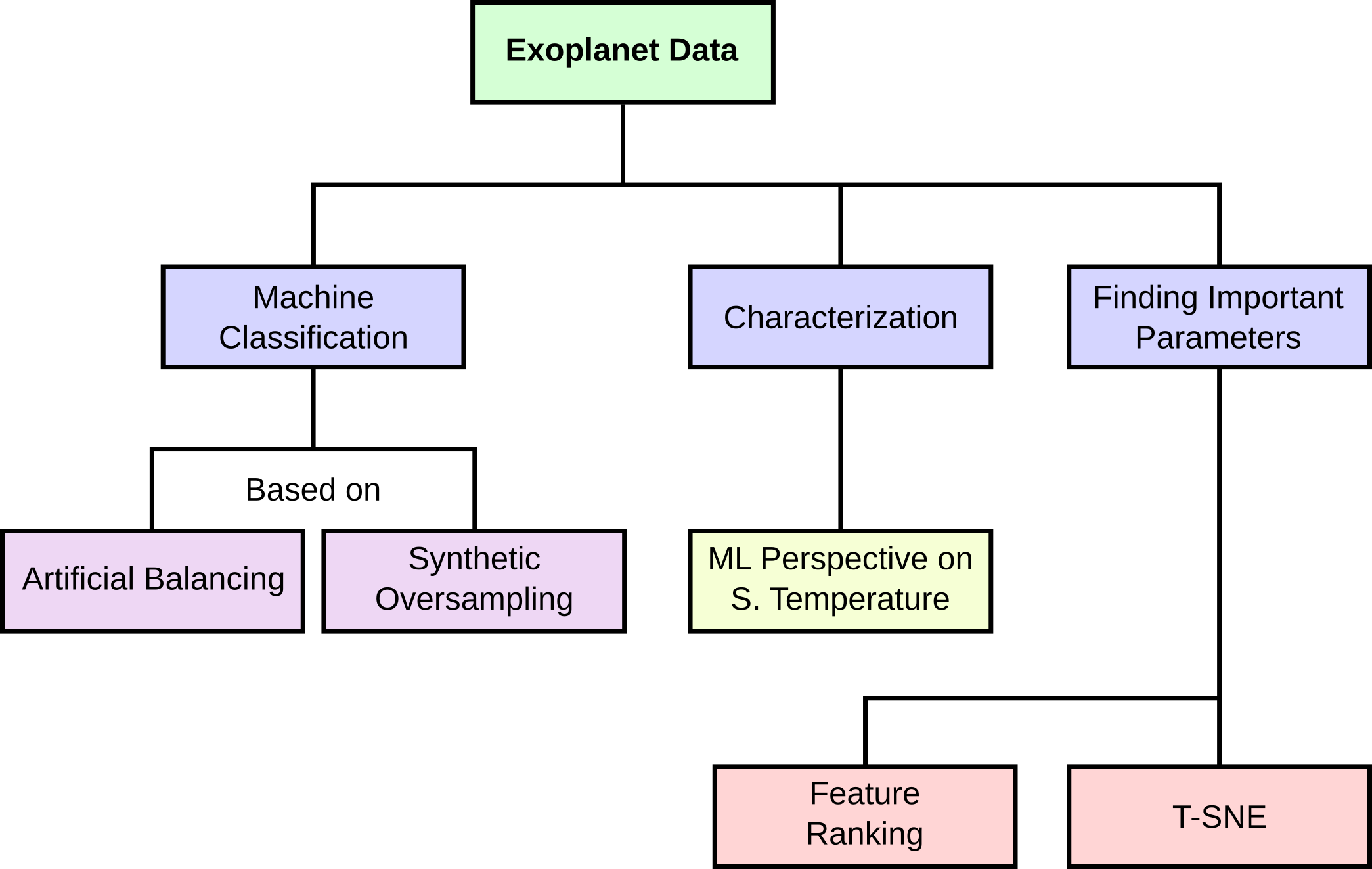 Figure 24
Figure 24 Figure 25
Figure 25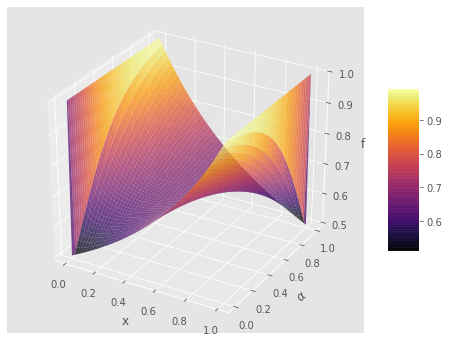 Figure 26
Figure 26 Figure 27
Figure 27| Predicted | |||||
| Non-Habitable | Mesoplanet | Psychroplanet | |||
| Actual | Non-habitable | 745 | 0 | 0 | |
| Mesoplanet | 0 | 5 | 4 | ||
| Psychroplanet | 0 | 0 | 1 | ||
| Different feature sets | Different Activation functions used in the study | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Performance | Sigmoid | SBAF | Approx. Relu | Relu | Leaky ReLU | |||||||||||
| Non-H | Meso | Psychro | Non-H | Meso | Psychro | Non-H | Meso | Psychro | Non-H | Meso | Psychro | Non-H | Meso | Psychro | ||
| Accuracy | 1. | 0.975 | 0.975 | 1.0 | 0.99 | 0.994 | 0.997 | 1. | 0.997 | 1.0 | 0.99 | 0.99 | 0.994 | 0.5 | 0.857 | |
| All features (45) | Precision | 1.0 | 0.943 | 0.932 | 1.0 | 1.0 | 0.2 | 1. | 1. | 0.987 | 0.988 | 0.998 | 1.0 | 0.25 | 0.857 | |
| (Case 1) | Recall | 1.0 | 0.895 | 0.965 | 1.0 | 0.55 | 1.0 | 0.997 | 1.0 | 1.0 | 0.998 | 0.991 | 0.991 | 0.994 | 0.5 | 0.857 |
| Restricted | Accuracy | 0.758 | 0.741 | 0.798 | 0.987 | 0.854 | 0.847 | 1.0 | 1.0 | 1.0 | 0.985 | 0.834 | 0.830 | 0.937 | 1.0 | 0.286 |
| Features (6) | Precision | 0.719 | 0.525 | 0.808 | 1. | 0.681 | 0.643 | 1.0 | 1.0 | 1.0 | 1.0 | 0.5 | 0.618 | 1.0 | 0.18 | 0.2 |
| (Case 2) | Recall | 0.864 | 0.583 | 0.384 | 0.978 | 0.223 | 0.943 | 1.0 | 1.0 | 1.0 | 0.974 | 0.149 | 0.925 | 0.937 | 1.0 | 0.286 |
| Without Surface | Accuracy | 0.998 | 0.998 | 0.997 | 0.997 | 0.924 | 0.927 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.98 | 1.0 | 0.67 |
| Temperature (44) | Precision | 0.994 | 0.995 | 1. | 1. | 0.484 | 0.783 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.5 | 0.33 |
| (Case 3) | Recall | 1. | 1. | 0.994 | 0.996 | 0.5 | 0.783 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.98 | 1.0 | 0.67 |
| Planet MinMass | Accuracy | 0.888 | 0.825 | 0.750 | 0.922 | 0.922 | 0.864 | 0.971 | 0.946 | 0.931 | 0.968 | 0.937 | 0.905 | 0.976 | 0.67 | 0.71 |
| Mass and | Precision | 0.974 | 0.534 | 0.547 | 1. | 0.3 | 0.456 | 1. | 0.619 | 0.673 | 0.996 | 1. | 0.567 | 0.997 | 0.25 | 0.56 |
| Radius (4) (Case 4) | Recall | 0.807 | 0.397 | 0.814 | 0.904 | 0.130 | 0.912 | 0.965 | 0.590 | 0.846 | 0.965 | 0.090 | 0.974 | 0.976 | 0.67 | 0.71 |
| Different feature sets | Different Activation functions used in the study | |||||||||||||||
| Performance | Sigmoid | SBAF | Approx. Relu | Relu | Leaky ReLU | |||||||||||
| Non-H | Meso | Psychro | Non-H | Meso | Psychro | Non-H | Meso | Psychro | Non-H | Meso | Psychro | Non-H | Meso | Psychro | ||
| Radius | Accuracy | 0.848 | 0.753 | 0.608 | 0.721 | 0.738 | 0.754 | 0.908 | 0.8311 | 0.807 | 0.890 | 0.861 | 0.795 | 0.813 | 0.5 | 0.57 |
| and other | Precision | 0.856 | 0.668 | 0.440 | 0.617 | 0.669 | 0.152 | 0.919 | 0.718 | 0.548 | 0.883 | 0.749 | 0.516 | 1 | 0.07 | 0.03 |
| Star features (Case 5) | Recall | 0.655 | 0.515 | 0.645 | 0.962 | 0.738 | 0.37 | 0.867 | 0.852 | 0.441 | 0.866 | 0.908 | 0.354 | 0.813 | 0.5 | 0.57 |
| Planet Mass | Accuracy | 0.846 | 0.706 | 0.58 | 0.859 | 0.868 | 0.881 | 0.997 | 1. | 0.997 | 0.877 | 0.899 | 0.902 | 0.837 | 0.71 | 0.5 |
| and other | Precision | 0.764 | 0.55 | 0.337 | 0.914 | 0.442 | 0.307 | 1. | 1. | 0.987 | 0.878 | 0.554 | 0.0 | 0.997 | 0.116 | 0.045 |
| Star features (Case 6) | Recall | 0.78 | 0.65 | 0.27 | 0.906 | 0.628 | 0.177 | 0.997 | 1. | 1. | 0.980 | 0.580 | 0.0 | 0.837 | 0.71 | 0.5 |
| Minimum | Accuracy | 0.85 | 0.683 | 0.7 | 0.850 | 0.8007 | 0.857 | 0.925 | 0.850 | 0.868 | 0.864 | 0.893 | 0.864 | 0.88 | 1 | 0 |
| Mass and other | Precision | 0.711 | 0.75 | 0.532 | 1.0 | 0.190 | 0.520 | 0.938 | 0.269 | 0.571 | 0.857 | 0.0 | 0.558 | 1 | 0.045 | 0 |
| Star features (Case 7) | Recall | 0.925 | 0.07 | 0.85 | 0.798 | 0.2666 | 0.8837 | 0.961 | 0.233 | 0.558 | 0.980 | 0.0 | 0.558 | 0.88 | 1 | 0 |
| Minimum Mass | Accuracy | 0.958 | 0.8 | 0.808 | 0.858 | 0.77 | 0.716 | 0.904 | 0.799 | 0.839 | 0.901 | 0.796 | 0.790 | 0.87 | 1 | 0 |
| P. Distance and | Precision | 1. | 0.785 | 0.649 | 0.911 | 0.35 | 0.38 | 0.894 | 0.506 | 0.666 | 0.893 | 0.000 | 0.478 | 1 | 0.05 | 0 |
| Star features (Case 8) | Recall | 0.875 | 0.55 | 0.925 | 0.846 | 0.106 | 0.746 | 0.958 | 0.636 | 0.349 | 0.9485 | 0.0 | 0.888 | 0.868 | 1 | 0 |
| Activation functions (Epochs =500) | |||||
| Sigmoid | SBAF | A-ReLU | ReLU | Leaky ReLU | |
| Learning rate, momentum | 0.01, 0.001 | 0.01, 0.01 | 0.01, 0.001 | 0.01, 0.01 | 0.01, 0.001 |
| Time(seconds) | 409.33 | 281.97 | 312.31 | 358.01 | 574.6 |
| CPU Utilization (%) | 54.6 | 53.6 | 42.8 | 48.4 | 41.81 |
| Memory Usage (MB) | 67.7 | 67.8 | 67.4 | 67.8 | 45.45 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Evolution of Novel Activation Functions in Neural Network Training with Applications to Classification of Exoplanets
Snehanshu Saha
PES University
Nithin Nagaraj
Consciousness Studies Programme
National Institute of Advanced Studies
Archana Mathur
Indian Statistical Institute Bangalore
Rahul Yedida
North Carolina State University
Abstract
We present analytical exploration of novel activation functions as consequence of integration of several ideas leading to implementation and subsequent use in habitability classification of exoplanets. Neural networks, although a powerful engine in supervised methods, often require expensive tuning efforts for optimized performance. Habitability classes are hard to discriminate, especially when attributes used as hard markers of separation are removed from the data set. The solution is approached from the point of investigating analytical properties of the proposed activation functions. The theory of ordinary differential equations and fixed point are exploited to justify the ”lack of tuning efforts” to achieve optimal performance compared to traditional activation functions. Additionally, the relationship between the proposed activation functions and the more popular ones is established through extensive analytical and empirical evidence. Finally, the activation functions have been implemented in plain vanilla feed-forward neural network to classify exoplanets.
keywords:
Machine Learning, Exoplanets, Activation Function, Information theory.
††journal: arXiv
1 Introduction
Neural networks [Lippmann, 1994] or Artificial Neural network (ANN) are systems of interconnected units called “Neurons” organized in layers (loosely inspired by the biological brain). ANN is a framework for many different machine learning algorithms to process complex input data (text, audio, video etc.) in order to “learn” to perform classification/regression tasks by considering examples and without the aid of task-specific programming rules. As of today, ANNs are found to yield state-of-the-art performance in a variety of tasks such as speech recognition, computer vision, board games and medical diagnosis [Xiao and Lu, 2015, Narayanan et al., 2004] and classification of exoplanets [Basak et al., 2018].
Every neuron in ANNs is followed by an activation function which defines the output of that neuron given its inputs. It is an abstraction representing the rate of action potential firing in the neuron. In most cases, it is a binary non-linear function - the neuron either fires or not. The celebrated sigmoidal activation function enables a feed-forward network with a single hidden layer containing a finite number of neurons to approximate a wide variety of linear and non-linear functions [Cybenko, 1989]. Recent works have shown that activation functions allow neural networks to perform complex tasks, including gene expression analysis [Narayanan et al., 2004] and solving nonlinear equations [Xiao and Lu, 2015]. The most popular activation functions are sigmoid, hyperbolic tangent (tanh) and ReLU (Rectified Linear Unit).
In this work, we explore novel activation functions as a consequence of integration of several ideas leading to implementation and subsequent use in habitability classification of exoplanets. The relationship between the proposed activation functions and the existing popular ones will be established through extensive analytical and empirical evidence.
1.1 Classification of Exoplanets
Astronomers and philosophers have been intrigued by the fact that the Earth is the only habitable planet within the solar system. There has been scant evidence or explorations in the direction of finding planets outside the solar system which may harbor life. Essentially, the mission to find ”Earth 2.0” gained momentum in recent times with NASA spearheading Kepler [Shallue and Vanderburg, 2018] and other missions. Initial missions exploring Earth’s neighbors, Mars and Venus, didn’t yield promising results. However, NASA’s missions in the past two decades led to discoveries of hundreds of exoplanets – planets that are outside our solar system, also known as extra-solar planets. The missions are carried out based on the inference that planets around stars are more frequent and the fact that actual number of planets far exceeds the number of stars in our galaxy. The mandate is to look for interesting samples from the pool of recently discovered exoplanet database [Méndez, 2018]. Additionally, finding ”Earth 2.0” based on similarity metric [Shallue and Vanderburg, 2018] [Bora et al., 2016] is not the only approach. In fact, the approach has its own limitations as astronomers argue that a distant “Earth-similar” planet may not be habitable and could be just statistical mirage [Mullally et al., 2018]. Therefore, a classification approach should be used to vet habitability scores of exoplanets in order to ascertain the probability of distant planets harboring life. This begets the need for sophisticated pipelines. Goal of such techniques would be to quickly and efficiently classify exoplanets based on habitability classes. This is equivalent to a supervised classification problem.
Neural networks, although a powerful engine, often require expensive “parameter-tuning” efforts. Classification of exoplanets is an intriguing problem and extremely hard, even for a neural network to solve, especially when clear markers for separation of habitability classes ( i.e. features such as surface temperature and features related to surface temperature) are removed from the feature set. To this end, a version of ANNs, replicated weight neural network (RWNN), in conjunction with sigmoid activation, has been applied to the task of classification of exoplanets [Basak et al., 2018]. However, the results turned out to be less than satisfactory. Add to that, the effort in parameter tuning [Saha et al., 2018b], the outcome is far from desired when applied to pruned feature sets used in this paper (please refer to the Data section).
The process of discovery of exoplanets involves very careful analysis of stellar signals and is a tedious and complicated process, as outlined by Bains et.al. [Bains and Schulze-Makuch, 2016], . This is due to the smaller size of exoplanets compared to other types of stellar objects such as stars, galaxies, quasars, etc. Radial velocity-based techniques and gravitational lensing are most popular methods to detect exoplanets. Given the rapid technological improvements and the accumulation of large amounts of data, it is pertinent to explore advanced methods of data analysis to rapidly classify planets into appropriate categories based on the physical characteristics.
The habitability problem has been tackled in different ways. Explicit Earth-similarity score computation [Bora et al., 2016] based on parameters mass, radius, surface temperature and escape velocity developed into Cobb-Douglas Habitability Score helped identify candidates with similar scores to Earth. However, using Earth-similarity alone [Agrawal et al., 2018] to address habitability is not sufficient unless model based evaluations [Saha et al., 2018c] are interpreted and equated with feature based classification [Basak et al., 2018]. However, when we tested methods in [Basak et al., 2018], it was found that the methods didn’t work well with pruned feature sets (features which clearly mark different habitability classes were removed). Therefore, new machine learning methods to classify exoplanets are a necessity.
To address this need for efficient classification of exoplanets, we embark on design of novel activation functions with sound mathematical foundations. We shall justify the need to go beyond Sigmoid, hyperbolic tangent and ReLU activation functions and demonstrate the superior performance of the proposed activation functions in habitability classification of exoplanets. Such a fundamental approach to solving a classification problem has obvious merits and the activation functions that we propose could be readily applied to problems in other areas as well.
One of the key reasons to classify exoplanets is the limitation of finding out habitability candidates by Earth similarity alone, as proposed by several metric based evaluations, namely the Earth Similarity Index, Biological Complexity Index [Irwin et al., 2014b], Planetary Habitability Index [Méndez, 2018] and Cobb-Douglas Habitability Score (CDHS) [Bora et al., 2016]. In Saha et al. [2018], an advanced tree-based classifier, Gradient Boosted Decision Tree was used to classify Proxima b and other planets in the TRAPPIST-1 system. The accuracy was near-perfect, providing a baseline for other machine classifiers. However, that paper considered surface temperature as one of the attributes/features, making the classification task significantly easier than the proposed one in the current manuscript.
2 Motivation and Contribution
Observing exoplanets is no easy task. In order to draw a complete picture of any exoplanet, observations from multiple missions are usually combined. For instance, the method of radial velocity can give us the minimum mass of the planet and the distance of the planet from its parent star, transit photometry can provide us with information on the radius of a planet, and the method of gravitational lensing can provide us the information regarding the mass. In contrast to this, stars are generally easier to observe and profile through various methods of spectrometry and photometry in different ranges of wavelengths of the electromagnetic spectrum. Hence, by the time a planet has been discovered around a star, we would possibly have fairly rich information about the parent star, and this includes information such as the luminosity, radius, temperature, etc. Therefore, the uniqueness of the approach is to classify exoplanets based on smaller sets of observables as features of the exoplanet along with multiple features of the parent star. We elaborate each case of carefully selected features in the Experiments section. We note, most of the sub-sets of features created from PHL-EC do not contain surface temperature. In fact, the most interesting result of the paper might be that some of the methods are unable to exactly reproduce the correct classification, given the strict dependence of the classification on a single feature, surface temperature namely. Surface temperature is a hard marker when it comes to classifying exoplanets. Removing this feature enhances the complexity of classification many folds. Our manuscript tackles the challenge by adopting a foundational approach to activation functions.
However a reasonable question arises. When there exists activation functions in literature with evidence of producing good performance, is there a need to define a new activation function? If indeed the necessity is argued, can the new activation function be related to existing ones? We are motivated by these questions and painstakingly address these in subsequent sections 4-9 in the manuscript. We show the activation functions proposed in the paper, SBAF and A-ReLU are indeed generalizations of popular activations, Sigmoid and ReLU respectively. Moreover, the theory of Banach spaces and contraction mapping have been exploited to show that SBAF can be interpreted as a solution to first order differential equation. Further, the theory of fixed point and stability has been used to explain the amount of effort saved in tuning parameters of the activation units. In fact, this is one of the hallmarks of the paper where we intend to show that our activation functions implemented to tackle the classification problem are “thrifty” in comparison to Sigmoid and ReLU. We demonstrate this by comparing system utilization metrics such as runtime, memory and CPU utilization. Additionally, we show that SBAF also satisfies the Universal Approximation Theorem and can be related to regression under uncertainty. We also demonstrate mathematically and otherwise that the approximation to ReLU, defined as A-ReLU is continuous and differentiable at ”knee-point” and establish the fact that A-ReLU doesn’t require much parameter tuning. Extensive experimentation shows conclusively, the insights gained from the mathematical theory are backed up by performance measures, beating Sigmoid and ReLU.
The remainder of the paper is organized as follows. A novel activation function to train an artificial neural network (ANN) is introduced. We discuss the theoretical nuances of such a function in section 5. We relate SBAF to binary logistic regression in section 6. The following section presnts a mathematical treatment of the evolution of SBAF from theory of differential equations. Next section introduces A-ReLU as an approximation exercise. We follow up with network architecture in the the next section, detailing the back propagation mechanism paving the foundation for ANN based classification of exoplanets. Consequently, the following section presents results on all data sets with performance comparison including system utilization. We conclude by discussing the efficacy of the proposed method.
3 Saha-Bora Activation Function (SBAF)
We shall introduce SBAF neuron to address the issues elicited in the previous sections. We begin with a brief description of mathematical concepts and definitions will be used throughout the remainder of the manuscript.
Definition of key terms:
Returns to Scale: For the objective function, feasible solution that maximizes the objective function exists, called an optimal solution under the constraints Returns to scale. When , it is called increasing returns to scale (IRS) and is known as decreasing returns to scale (DRS). is known as constant returns to scale and ensures proportional output, to inputs . is used to define production functions in Economics and the form is inspirational to designing the activation functions proposed in the manuscript. Note, we set in the activation function formulation ensuring CRS and therefore existence of global optima.
Absolute error is the magnitude of the difference between the exact value and the approximation.
Relative error is the absolute error divided by the magnitude of the exact value.
Banach Space: A complete normed vector space i.e. the Cauchy sequences have limits. A Banach space is a vector space.
Contraction Mapping: Let be a Banach space equipped with a distance function d. There exists a transformation, T such that is a contraction, if there is a guaranteed which squashes the distance between successive transformations (maps). In other words, . is called Lipschitz constant and determines speed of convergence of iterative methods.
Fixed point: A fixed point of a function is a value that is unchanged by repeated applications of the function, i.e., . Banach space endowed with a contraction mapping admits of a unique fixed point. Note, for any transformation on Turing Machines, there will always exist Turing Machines unchanged by the transformation.
Stability: Consider a continuously differentiable function with a fixed point , . The fixed point is defined to be stable if . If , then is defined as unstable.
First Return Map: Consider an iterative map on the set , . Starting from an initial value , we can iterate the map to yield a trajectory: , and so on. The first-return map is a plot of for integer .
Contour Plot: A contour plot is a 2-D representation of a 3-D surface. An alternative to surface plot, it provides valuable insights to changes in as input variables change.
This section defines SBAF, computes its derivative and focuses on estimation of parameters used in the function. We compute the derivative of SBAF for two reasons: to use the derivative in back-propagation and to show that SBAF possesses optima instead of saddle point (note, sigmoid has saddle point). SBAF, defined with parameters (these will be estimated in subsequent sections and no effort is spent on tuning these parameters while training) and input (Data in the input layer), produces output as follows:
[TABLE]
From the definition of the function, we have:
[TABLE]
[TABLE]
Figures 1 and 2 show various plots of the activation function. Figure 1 shows a surface plot by varying and . Figure 2 shows the contour plot. In both plots, we fixed . Note that the contour plot reveals a symmetry about . Further, as discussed in Section 6, the approximation of other activation functions using SBAF can be quite easily seen in the contour plot, by looking at the horizontal lines corresponding to and .
We note, the motivation of SBAF is derived from using as discriminating function to optimize the width of the two separating hyperplanes in an SVM-like formulation. This is equivalent to the CDHS formulation when CD-HPF [Bora et al., 2016] is written as where , and is suitably assumed to be (CRS condition). The representation ensures global maxima (maximum width of the separating hyperplanes) under such constraints [Bora et al., 2016]. Please also note, when , CRS condition [Saha et al., 2018] is satisfied automatically and we obtain the form of the activation, SBAF.
Our activation function has an optima. From the visualization of the function below, we observe less flattening of the function, tackling the “vanishing gradient” problem. Moreover, since , we can approximate, to a first order polynomial. This helps us circumvent expensive floating point operations without compromising the precision.
3.1 Existence of Optima: Second order Differentiation of SBAF for Neural Network
From Equation 3 ,
[TABLE]
It’s easy to see,
[TABLE]
when ,
[TABLE]
Clearly, the first derivative vanishes when , and the derivative is positive when and is negative when (implying range of values for so that the function becomes increasing or decreasing). We need to determine the sign of the second derivative when to ascertain the condition of optima (corresponding to minima of gradient descent training ensuring optimal discrimination between habitability classes). Assuming , the condition of optimality, , by construction lies between . Hence, ensuring optima of .
3.2 Saddle points of sigmoid activation and a comparative note with SBAF
We note briefly that as opposed to the sigmoid activation function, SBAF has local minima and maxima. For example, for , a local minima occurs at . On the other hand, the sigmoid function has neither local minima nor maxima; it is easy to show that it only has a saddle point at :
Proof.
Note that if denotes the sigmoid function, then . Then, implies that . However, for both these values, the second derivative is 0. ∎
SBAF, however, has a critical point at .
3.3 Universal Approximation Theorem for SBAF
It is well known that a feed-forward network with a single hidden layer containing a finite number of neurons satisfies the universal approximation theorem. This is important since it guarantees that simple neural networks can represent a wide variety of interesting linear/non-linear functions (with appropriately chosen parameters). Cybenko [1989] proved one of the first versions of this theorem for sigmoid activation functions. We show that SBAF is also sigmoidal and hence satisfies the Universal Approximation Theorem.
Following Cybenko [1989], we shall define the following:
: -dimensional unit cube, .
- 2.
: Space of continuous functions defined on .
- 3.
: The space of finite, signed regular Borel measures on .
- 4.
: A univariate function is defined as being sigmoidal if
[TABLE]
- 5.
is defined to be discriminatory if for a measure ,
[TABLE]
and implies that .
Approximation Theorem (Cybenko, 1989): Let be any continuous discriminatory function. Then finite sums of the form
[TABLE]
are dense in . In other words, given any and , there is a sum, , of the above form, for which
[TABLE]
Proof.
Please refer to Cybenko (1989). ∎
Also, it should be noted that by Lemma 1 of Cybenko [1989], any continuous sigmoidal function is discriminatory. We can thus prove:
*Universal Approximation Theorem for SBAF: * The proposed function satisfies the universal approximation theorem.
Proof.
We observe that (for the choices and , see Section 6) is a continuous sigmoidal function and hence discriminatory. All the conditions of the approximation theorem are met. ∎
Thus SBAF can be used with a feed-forward network with a single hidden layer containing a finite number of neurons to approximate a wide variety of linear and non-linear functions.
3.4 SBAF is not a probability density function
Proof.
Let us compute the integral below: where I is the interval containing (). We know from earlier calculations, that
[TABLE]
&
[TABLE]
Using the above in the integral and readjusting the limits of integration, we observe that . Note, Therefore the integral of between 0 and 1 would also be less than or equal to 1. Equality will hold iff , but this is not possible for any . ∎
SBAF is sampled from a PDF. SBAF is not a PDF and we infer that it may oscillate. The next section contains a more pertinent insight, in clear agreement with the analysis, relating SBAF to regression under uncertainty.
4 Relating SBAF to Binary Logistic Regression: Regression under Uncertainty
Binary logistic regression builds a model to characterize the probability of (observed value of the binary response variable ) given the values of the explanatory variable in the following manner:
[TABLE]
where denotes the probability that the response variable given the value , and stands for the index of the observed sample. The LHS of equation 6 is known as logit() or log-odds. The above formulation leads to the celebrated sigmoid activation function:
[TABLE]
where the regression co-efficients and are to be determined.
Instead, if we formulate the logit as:
[TABLE]
where , constants and , then it leads to our proposed activation function:
[TABLE]
Equation 8 can be understood as follows. Firstly, think of as probabilities of the observed explanatory variable instead of the value itself. If is a binary discrete random variable, then the quantities and would be the self-information of these two outcomes (measured in bits if the base of the logarithm is 2). The convex combination of these two self-information quantities is like an average information quantity (Shannon entropy). In fact, the RHS is upper bounded by Shannon entropy (if then RHS is the entropy of ).
Proof.
Maximizing (9) is equivalent to minimizing its inverse. We ignore the constant term 1, and assume that is fixed. Then, the minima occurs where the derivative is 0:
[TABLE]
Clearly, the minima of this, and therefore the maxima of (9), occurs when . ∎
The quantity can be thought of as a bias term or the information content that is universally available (if we think of the RHS as average uncertainty instead of average information, then this quantity would be the irreducible uncertainty that is present in the environment, such as noise). Thus, under this scenario, the log-odds of classifying the binary response variable as 1 is a function of the average self-information of the observed explanatory variable.
This means that if the probability of observed explanatory variable was very close to zero, then would be close to zero and the RHS would also be close to zero giving the log-odds ratio (LHS) also close to zero. If the probability of the observed explanatory variable was close to 0.5, then RHS would be very high and the log-odds ratio (RHS) would be close to 1. Now, as the probability increases towards 1, the RHS starts to reduce and log-odds ratio (LHS) also starts to reduce. This means that we trust the observed variable only if it has probability between 0 and 0.5. We do not trust high values (above 0.5).
Another way to interpret this is that as the uncertainty increases, then the neuron fires (activates). The neuron in this case continuously increases the magnitude of its response as the uncertainty increases. The term is the ambient noise term, and the neuron can fire if this is high enough (greater than some preset threshold ). The task of regression here is to determine and such that it models the binary response variable as a function of the uncertainty of the observed variables (along with noise in the environment).
5 Functional Properties of SBAF
5.1 Existence of a fixed point
Let’s consider the first order differential equation
[TABLE]
which is a representation of the standard form:
[TABLE]
In order to prove the existence of a fixed point, we need to show that is a Lipschitz continuous function. On differentiating y w.r.t x we obtain y as:
[TABLE]
When , we observe that . Moreover, when , and when , . In our case, is a continuous and differentiable function over the interval [0,1]. This implies f is bounded in (0,1). This further implies that the function follows the mean value theorem. That is, for some ,
[TABLE]
On differentiating w.r.t we obtain the following equation
[TABLE]
Since we already know the representation of in terms of from (9), we can substitute the value of and we obtain the following representation for :
[TABLE]
Clearly, the right hand side is bounded between by some positive constant . Using the above constraint in the mean value theorem specified, we obtain the following:
[TABLE]
Since and , the above equation is of the form
[TABLE]
Therefore, is a Lipschitz continuous and by Picard’s theorem, the differential equation has a fixed point and a unique solution in the form of the activation function, to be used in neural networks for classification.
5.2 Lipschitz continuity, contraction map and unique fixed point
In this section, we show that the fixed point is unique in the interval, thus ensuring that the solution to the DE, SBAF, is unique in that interval. We exploit the Banach contraction mapping theorem to achieve this goal. We consider the following DE
[TABLE]
Assume to be continuous on . Then a solution in . This gives rise to the solution as the activation function, . Furthermore, if is Lipschitz continuous in D, or in a region smaller than D, the solution thus found is unique.
Proof.
(a) We first prove that is Lipschitz continuous. We write .
Now,
[TABLE]
Within , is bounded. The expression blows up at . Therefore,
[TABLE]
By construction, and are bounded by some positive constant . Therefore, the sum is bounded by and
This implies is Lipschitz continuous in . We may now proceed to establish the existence of a unique fixed point i.e unique solution (activation function) to the differential equation above.
(b) Let T be a contraction mapping, i.e. , where is a complete metric space. Then has a unique fixed point in [Rhoades, 1977]. Moreover, let , we define by setting an iterative map, . Let us fix . Then, by Lipschitz continuity
[TABLE]
Clearly, is a Cauchy sequence. Since is a complete metric space, . Thus,
[TABLE]
Thus, . But . Therefore, , i.e., . Suppose for .
[TABLE]
This is possible only if . This implies that the fixed point is unique. ∎
We use the following lemma to complete the missing piece. is continuous and Lipschitz w.r.t on the defined domain. Then, there exists a unique fixed point of in . The function (activation function) is the unique solution. We establish the fact that the activation function is unique in the interval (0,1).
5.3 Computation of the fixed point
Now that the existence of of the fixed point is established, we proceed to find it in the following manner. Let us consider the representation of y given by (1). By definition of fixed point we have at the fixed point, i.e.
[TABLE]
Assume . Hence, (15) becomes
[TABLE]
On applying log on both sides we obtain
[TABLE]
Thus, .
5.4 Visual Analysis of the fixed point
We use the formula from the above computation and visually represent the activation function, SBAF, the solution to the differential equation mentioned above. We observe that, for K=0.9 onward, we obtain a stable fixed point. SBAF used for training the neural net is able to classify PHL-EC data with remarkable accuracy when K is very close to 1. Existence of a stable fixed point thus is a measure of classification efficacy, in this case.
We explore the non-linear dynamics of SBAF. At a fixed point, as noted above, we have:
[TABLE]
In the above expression for the fixed point, for all real values of and when , the left-hand side is always negative if . Thus, there can’t be any fixed point for when . When , it is possible to have a fixed point . Below we plot the first return maps for the SBAF for a few cases with fixed and for different values of . We plot only the real values of (since we have complex dynamics as can become a complex number).
We can thus explicitly compute the values of for which there exists a stable fixed point when :
[TABLE]
which implies:
[TABLE]
where we seek the fixed point such that , , and we also require for stability: . There are infinite number of stable fixed points satisfying these conditions. Numerically, we found that can be any value in the range , and correspondingly, takes values: (lower the , higher the ). For example, if the stable fixed point is then . When the fixed point varies from 0 to 1, the value of varies from to (thus , making it a stable fixed point).
Note that We find it significant to mention that SBAF is inspired from a production function in economics [Saha et al., 2016] even though the adaptation is non-trivial and significantly more complex in structure than the Cobb-Douglas production function, CDPF. Since CDPF is a production function defined by and labor and capital inputs, a negative value of implies no quantity is produced, rather borrowing from market is necessary. This is important since it validates our choice of in neural net training from an econometric argument. This is consistent with our assertion that the choices of parameters for optimal classification performance are not accidental!
As noted above, stable fixed points exists for a range of values of depending on the value of and . When , we found that there is a stable fixed point for every . However, classification with SBAF works optimally at (corresponding ). This is again consistent with our hypothesis that a stable fixed point will facilitate classification while chaos might occur otherwise. We have proven from the first order ODE that a fixed point exists and computed the fixed point in terms of by fixing and verified the same via simulation. We have also observed (but not reported here) that altering values minimally within the stable fixed point range doesn’t alter classification performance greatly. This reaffirms the confidence in the range of values obtained from fixed point analysis. To sum up, SBAF is the analytical solution to the first order DE and has a fixed point! This fixed point analysis is computationally verified and applied in the classification task on the PHl-EC data, via a judicious choice of parameters.
5.5 Proof of global maxima for the activation
We now go back to an economics perspective of our activation function (or production function). In this section, we prove the existence of an optimum solution.
Let us consider the activation function:
[TABLE]
+ =1 where 0 and
Let S = x and I = (1-x) and 1- =
For the constrained case of the above equation a critical point is defined in terms of the Lagrangian multiplier method. Suppose the constraint is
Let the Lagrangian function for the optimization problem be:
[TABLE]
[TABLE]
On partially differentiating equation (2) with respect to S,I and we obtain the following first order constraints
[TABLE]
On differentiate again we obtain the second order condition:
[TABLE]
For equation (1) to obtain a optimum max value it subject to the assumed constraint ,it must satisfy the condition 0 where M is the bordered hessian matrix
[TABLE]
= + + -
= +
the production function has global optima under CRS.
6 Approximating other activations
In this section, we show the values for which SBAF approximates other activation functions.
; SBAF becomes which is what we obtain in sigmoid when we restrict the Taylor series expansion at 0 of exp to first order!
- 2.
; SBAF becomes which upon binomial expansion (restricting to first order expansion assuming ) yields
As noted earlier, these approximations can be seen in Figure 2 along the top and bottom horizontal edges, which correspond to and respectively.
6.1 ReLU approximate in the positive half
Consider the function . We know that the ReLU activation function is . We need to approximate the values and such that approximates to the ReLU activation function over a fixed interval.
[TABLE]
Let the minimum tolerable error be
[TABLE]
Since approximates the positive half (i.e., when ) of the ReLU activation function, , the value of y when can be written as:
[TABLE]
Using this value in the error calculation we rewrite the error approximation as,
[TABLE]
The above is an optimization problem i.e. subject to the constraints . We obtain the following bounds on and :
[TABLE]
Therefore, we obtain the following continuous approximation of ReLU: when , otherwise . More precisely, the approximation to the order of is .
6.2 Error approximation and estimation of k and n
Define
[TABLE]
We need to minimize the least square error to approximate the function to the Relu activation function. This is a continuation in our efforts to find a continuous and differentiable approximation to ReLU.
Let us fix between some fixed interval, say . This choice is also justified by observing linear combinations of weights and inputs during the training where we observed the combination rarely surpassing +3 in the positive half plane. This means would be least likely. Starting with some fixed value of , say , we try to approximate the value of such that the error in approximation is minimum. Algorithm 1 shows a simple way to achieve this.
is minimum at or when . These are the parameter values used to train the network yielding better performance in classification, compared to ReLU.
6.3 Differentiability of f(x)
[TABLE]
We test for differentiability at . When , . When , . These derivatives are equal, and thus, the function is differentiable at . Moreover, the derivative is continuous.
6.4 Note about A-ReLU
On plotting the curve for the function, we obtain
[TABLE]
for different values of n and k, we have observed that the curve of f(x) for increases exponentially with increase in n. Since, the nature of the curve is non linear when , and , it is not meaningful to compute the absolute error for the entire range on the positive scale from 0 to . Hence, we have fixed the range of between 0 to on the positive scale and to 0 on the negative scale. In section 6.1 we have found the relative error is bounded by . In the chosen interval of , we find that the minimum absolute error is when or , and . This value is quite small compared to our chosen bound, 10. Hence, we can say that the function is a good approximation to the ReLU activation function. 111Please note, even if we don’t restrict the function in the specified range mentioned above, we can work with the function itself as another activation function with no discontinuity at . We choose the value of between 1 and 2 so that the derivative doesn’t explode!
For a continuous domain, the squared error changes from a sum to an integral. We take this integral over , for some that we choose later. To minimize this, we take the partial derivatives with respect to and , and set them to 0. This yields two equations, with two unknowns. can be thought of as the upper limit of the domain where the approximation is good.
[TABLE]
Because it is difficult to a solution to this system of equations analytically, we simply plot these equations, fixing . In the graph below, the y-axis is , and the x-axis is . Note that the intersection of the two equations yields the trivial solution ; however, this solution is not very interesting. Instead, we fix the value of , and find the intersections with the two curves above. Figure 7 shows this plot.
7 Network architecture
The architecture to explore the proposed activation functions is based on a multilayer perceptron that internally deploys back-propagation algorithm to train the network. Neurons are fully connected across all the layers and output of one layer is supplied as input to neurons of subsequent layer during the forward pass. Alternatively, the backward pass computes the error gradient and transmits it back into network in the form of weight-adjustments. Computation of gradients require calculating the derivatives of activation functions (SBAF and A-ReLU) which have been explained briefly in Algorithm 2 and 3.
The implementation of these algorithms is done in Python installed on an x64 based AMD E1-6010 processor with 4GB RAM. The github repository222https://github.com/mathurarchana77/A-RELUandSBAF stores the Python code for the SBAF and A-ReLU activations. The purpose of this exercise is to demonstrate the performance of the activation functions used on variety of data sets. The Python implementation of these activation functions is done from scratch. The whole architecture is implemented as a nested list, where the network is stored as a single outer list and multiple layers in the network are maintained as inner lists. A dictionary is used to store connection weights of the neurons, their outputs, the error gradients and other intermittent results obtained during back propagation of errors. The computations associated with the processing of neurons in the forward and backward pass are indicated in the algorithms below. The next sections explores the details involved in execution of these algorithms on different feature sets and investigates the performances by comparing them with the state-of-the-art activation functions.
8 Data
The PHL-EC (University of Puerto Rico’s Planetary Habitability Laboratory’s Exoplanet Catalog) dataset [Méndez, 2018, Schulze-Makuch et al., 2011] consists of a total of 68 features, 13 categorical and the remaining 55 are continuous. The catalog uses stellar data from the Hipparcos catalog [Méndez, 2011] and lists confirmed exoplanets (at the time of writing this paper), out of which are meso and psychroplanets and the remaining are non-habitable. The catalog includes important features like atmospheric type, mass, radius, surface temperature, escape velocity, Earth Similarity Index, flux, orbital velocity etc. The difference between The PHL-EC and other catalogs is that PHL-EC models some attributes when data are not available. This includes estimating surface temperature from equilibrium temperature as well as estimating stellar luminosity and pressure. The presence of observed and estimated attributes presents interesting challenges.
This paper uses the PHL-EC data set, of which an overwhelming majority are non-habitable samples. Primarily, PHL-EC class labels of exoplanets are non-habitable, mesoplanets, and psychroplanets Méndez [2018]. The class imbalance is observed in the ratio of thousands to one. Further, the potentially habitable planets (meso or psychroplanets) have their planetary attributes in a narrow band of values such that the margins between mesoplanets and psychroplanets are incredibly difficult to discern. This poses another challenge to the classification task.
The classes in the data are briefly described below:
Non-Habitable: Planets, mostly too hot or too cold, may be gaseous, with non-rocky surfaces. Such conditions don’t favor habitability. 2. 2.
Mesoplanet: Generally referred to as Earth-like planets, they have sizes between that of Ceres (the largest minor planet in our solar system) and Mercury. The average global surface temperature is usually between 0∘C and 50∘C. However, Earth-similarity is no guarantee of habitability. 3. 3.
Psychroplanet: These planets have mean global surface temperature between -50∘C to 0∘C. Temperatures of psychroplanets are colder than optimal for sustenance of terrestrial life, but some psychroplanets are still considered as potentially habitable candidates.
The data set also has other classes, though insignificant in number of samples for each class. These are thermoplanets, hypopsychroplanets and hyperthermoplanets. The tiny number of samples in each class makes it unsuitable for the classification task and these classes are therefore not considered for class prediction. Certain features such as the name of the host star and the year of discovery have been removed from the feature set as well. We filled the missing data by class-wise mean of the corresponding attribute. This is possible since the amount of missing data is about of all the data. The online data source for the current work is available at the university website 333http://phl.upr.edu/projects/habitable-exoplanets-catalog/data/database.
9 Experiments
The PHL-EC dataset has 3771 samples of planetary data for 3 classes of planets and 45 features (after pruning unnecessary features). As already mentioned, a Multi Layered Perceptron (MLP) is implemented at the core for classifying planets. The MLP internally utilizes gradient descent to update weights and biases during classification. The connection weights and biases are randomly initialized. The activation functions used in MLP are sigmoid, SBAF, A-ReLU and ReLU, and details for implementing SBAF and A-ReLU along with the computation of gradients in both cases is shared in the Appendix.
As a part of the experiments, different data sets are explicitly built by selecting certain combination of features from the original feature set. The idea behind doing this is to evaluate the performance of functions for a variety of feature sets. The following subsection illustrates various sets of data used on the activation functions and their results. In all these cases, the training set consists of 80% of samples and remaining 20% are used for testing. SBAF uses the hyper parameters, and , that are tuned during execution of code and best results were seen at = 0.5 and k = 0.91 (in agreement with the fixed point plots we observed, doesn’t alter classification performance). Similarly, for A-ReLU, and were set to 0.5 and 1.3 respectively (this is from the evidence by the approximation to ReLU-empirical observations match). This eliminates the need for parameter tuning.
The results of classification (Tables 2 and 3) are interesting. The accuracy, precision and recall is indicated for all classes of planets: Non habitable, Mesoplanet and Psychroplanet. As seen from the tables, A-ReLU has outperformed ReLU in almost all the cases under investigation and SBAF has performed significantly better than the parent function, Sigmoid.
9.1 Chosen feature sets
The different combination of features employed on the traditional and proposed activation functions is explored here. A case-by-case exploration of these feature sets with their performance comparison, is indicated in Tables 2 and 3. The first column of these tables reveal features, marked with their count and the case number. Remaining columns reflect class-wise accuracy, precision and recall of the 4 activation functions.
To begin with, all features are used as input to the neural network, thus leading to 45 input and 3 output neurons. Since the inherent characteristics of each activation function is different, each one uses a different number of neurons in the hidden layer to reach convergence. For sigmoid, 20 hidden neurons are used while SBAF, A-ReLU and ReLU used 11 neurons in the hidden layer. Sigmoid gives the best accuracy at learning rate of 0.015, momentum of 0.001 and at 500 epochs, while SBAF, A-ReLU and ReLU gives the best results at 100 epochs keeping the other parameters same. 2. 2.
A subset of features (restricted features) consisting of Planet Minimum Mass, Mass, Radius, SFlux Minimum, SFlux Mean, SFlux Maximum are used as input. All networks used 4 neurons in hidden layer to stabilize. Sigmoid converged at learning rate of 0.1 and momentum of 0.01. In parallel, SBAF A-ReLU and ReLU converged at learning rate of 0.08, momentum at 0.004 and number of epochs as 300. The performance of all the classifiers is reported in Table 2. It is evident from the table that the network is able to classify even the minority class samples (Mesoplanets and Psychroplanets) with fairly decent accuracy. 3. 3.
It has already being shown that Surface Temperatures (ST) can distinguish habitable planets from non-habitable ones with a large degree of precision. Therefore, it becomes essential to ascertain if the proposed activation functions (SBAF and A-ReLU) as well as the already established ones (sigmoid and ReLU), can perform classification when ST is removed from feature set. To achieve this, the next set of features are those from which ST is removed. Thus, exoplanet features used as input are Zone Class, Mass Class,Composition Class, Atmosphere Class,Min Mass, Mass, Radius, Density, Gravity, Esc Vel ,SFlux Min, SFlux Mean, SFlux Max, Teq Min (K) , Teq Mean (K),Teq Max (K), Surf Press, Mag, Appar Size, Period, Sem Major Axis, Eccentricity, Mean Distance , Inclination, Omega , HZD, HZC, HZA, HZI, ESI and Habitable. The features of parent Star that belong to feature set are Mass, Radius, Teff, Luminosity, Age, Appar Mag, Mag from Planet, Size from Planet, Hab Zone Min and Hab Zone Max. For SBAF and A-ReLU, the 44 featured data set is tuned at learning rate = 0.01, momentum = 0.001 and epochs = 300. The number of units in the hidden layer is 12 for all four activation functions. It is interesting to inspect that A-ReLU performs 100% classification for all three classes and this is at par with A-ReLU. However, sigmoid performs marginally better than SBAF. 4. 4.
A unique combination of planetary attributes like Minimum Mass, Mass, Radius and Composition class are taken as input. The essence of selecting these features is to know whether the activation functions can perform classification by solely using Mass and mass related features. It becomes a challenging machine learning problem since the discrimination of planets is not at all clear by features such as mass of planets. Interestingly, for this kind of problem, A-ReLU performs better than the parent function ReLU, and SBAF outpaces Sigmoid with substantial difference in accuracy. The networks are tuned at learning rate of 0.2 and momentum of 0.03 at 400 epochs. It uses 3 neurons in the hidden layer. 5. 5.
The following 4 cases (Cases 5-8) are set for an exclusive exploration, where exoplanets are classified using one feature from planets at a time alo ng with multiple features of the parent star. At first, the planet’s radius along with 6 star features (Mass, Radius, Teff, Luminosity, Hab Zone Min and Hab Zone Max) are fed as input to the four activation functions. With 4 neurons in the hidden layer, the learning rate and momentum for the network is tuned to 0.09 and 0.001. Results are achieved at 300 epochs, as shown in Table 3. The performance of A-ReLU is exceedingly better than the rest of the activation functions. 6. 6.
Continuing on the same line of work, another feature set bearing planet’s mass and previously used 6 star features are fed to the network. Hidden neurons are same in number as in the previous case. Here too, A-ReLU has performed better from its parent activation function, ReLU as well as from the other functions in terms of classification accuracy, precision and recall. 7. 7.
Table 3 shows the performance of classification using Minimum mass as planet’s feature and remaining parent star features as input keeping other arrangements same as the previous cases. Comparing accuracy in each activation function, A-ReLU has again performed better for all the 3 classes of planets. 8. 8.
A slightly different grouping of feature is attempted here. Two planet features, mass and minimum distance computed from parent star, and the remaining 6 star features are used as input. For this particular combination of features, A-ReLU and ReLU performs at par and sigmoid performs better classification in comparison with the rest. This is the only case where an irregularity is seen in the performance.
The performance metrics shown in Table 2 and 3 indicates that SBAF and A-ReLU outshine sigmoid and ReLU in almost all of the cases. Some more critical parameters in terms of training time, CPU utilization and memory requirements, for the execution of activation functions is reported in Table 4. SBAF and A-ReLU take the shortest time to reach convergence even though number of epochs are kept same. CPU utilization is minimum for A-ReLU followed by ReLU, SBAF and sigmoid. Memory consumption is balanced and almost equal for all the functions under study. It is worth mentioning that values reported in the table are obtained after taking the average of all 8 executions from above cases.
An investigation of the confusion matrix resulting from the execution of SBAF, is disclosed in Table 1. It is noted that, even though there are considerably large number of samples of non-habitable planets, SBAF is able to classify non-habitable and Psychroplanet unmistakably, with the accuracy of 1 and 0.994 for the respective classes. However, Mesoplanets are not flawlessly classified, (out of 9 samples, 5 were correctly labeled and rest of the 4 were mistakenly labeled to be of Psychroplanet), the reason can be attributed to the class distribution in the data set. The number of samples of non-habitable, Mesoplanet and Psychroplanet are 3724, 17 and 30 respectively. Evidently, Mesoplanet are lowest in number and thus, the number of samples were not sufficient to train the network. Nevertheless, this can be handled by generating synthetic data for balancing the class samples.
Even though our focus is not all on the performance of statistical machine learning or other learning algorithms on the PHL-EC data, we feel it’s necessary to report the performance of some of those briefly. This was a post-facto analysis (the realization dawned upon us much later) done to ascertain the efficacy of our methods compared to methods such as Gaussian Naive Bayes (GNB), Linear Discriminant Analysis (LDA), SVM, RBF-SVM, KNN, DT, RF and GBDT [Basak et al., 2018]. These methods didn’t precede the exploration into activation functions. We believe the readers should know and appreciate the complexity of the data and classification task at hand, in particular when hard markers (surface temperature and surface temperature related features which discriminate the habitability classes quite well). This also highlights the remarkable contribution of the proposed activation functions toward performance metrics. It is for this reason, we don’t tabulate the results in detail but just state that for the specific cases (Cases 2, 4, 5-8, ”six” out of the total ’eight” cases considered for our experiments) where ”hard marker” features were removed, none of the methods mentioned above reached over 75% accuracy class-wise and 68% overall. This augurs well for the strength of our analysis presented in the manuscript.
10 Discussion and Conclusion
The motivation of SBAF is derived from the idea of using to maximize the width of the two separating hyperplanes (similar to separating hyperplanes in the SVM as the kernel has a global optima) when . This is equivalent to the CDHS formulation when CD-HPF is written as where , is suitably assumed to be (CRS condition), and the representation ensures global maxima (maximum width of the separating hyperplanes) under such constraints [Bora et al., 2016, Saha et al., 2018]. The new activation function to be used for training a neural network for habitability classification boasts of an optima. Evidently, from the graphical simulations presented earlier, we observe less flattening of the function and therefore the formulation is able to tackle local oscillations more easily as compared to the more generally used sigmoid function. Moreover, since , the variable term in the denominator of SBAF, may be approximated to a first order polynomial. This may help us in circumventing expensive floating point operations without compromising the precision. We have seen evidence of these claims, theoretically and from implementation point of view, in the preceeding sections.
Habitability classification is a complex task. Even though the literature is replete with rich and sophisticated methods using both supervised [Zighed et al., 2010] and unsupervised learning methods, the soft margin between classes, namely psychroplanet and mesoplanet makes the task of discrimination incredibly difficult. A sequence of recent explorations by Saha et. al. expanding previous work by Bora et. al. on using Machine Learning algorithm to construct and test planetary habitability functions with exoplanet data raises important questions. The 2018 paper [Saha et al., 2018] analyzed the elasticity of the Cobb-Douglas Habitability Score (CDHS) and compared its performance with other machine learning algorithms. They demonstrated the robustness of their methods to identify potentially habitable planets [Saha et al., 2018a] from exoplanet data set. Given our little knowledge on exoplanets and habitability, these results and methods provide one important step toward automatically identifying objects of interest from large data sets by future ground and space observatories. The variable term in SBAF, is inspired from a history of modeling such terms as production functions and exploiting optimization principles in production economics, [Saha et al., 2016], [Ginde et al., 2016], [Ginde et al., 2015]. Complexities/bias in data may often necessitate devising classification methods to mitigate class imbalance, [Mohanchandra et al., 2015] to improve upon the original method, [Vapnik and Chervonenkis, 1964], [Cortes and Vapnik, 1995] or manipulate confidence intervals [Khaidem et al., 2016]. However, these improvisations led the authors to believe that, a general framework to train in forward and backward pass may turn out to be efficient. This is the primary reason to design a neural network with a novel activation function. We used the architecture to discriminate exoplanetary habitability [Schulze-Makuch and Bains, 2018], [Schulze-Makuch et al., 2011], [Irwin et al., 2014a], [Shallue and Vanderburg, 2018], [Méndez, 2011], [Méndez, 2018].
We had to consider the ramifications of the classification technique in astronomy. Hence, we try to classify exoplanets based on one feature of the exoplanet at a time along with multiple features of the parent star. Note, we did not consider surface temperature, which is hard marker. An example of this is as follows:
Attributes of a Sample Planet:
- (a)
Radius only
with attributes of the Parent Star such as Mass, Radius, Effective temperature, Luminosity, Inner edge of star’s habitable zone and Outer edge of star’s habitable zone with 2. 2.
Class Attributes:
- (a)
Thermal habitability classification label of the planet
Similarly, we present results of classification when we include the exoplanet’s mass, instead ofthe radius; and when we include the exoplanet’s minimum mass instead of the radius. Reiterating, we use only one planetary attribute in a classification run.
Machine classification on habitability is a very recent area. Therefore, the motivation for contemplating such a task is beyond doubt. However, instead of using ”black-box” methods for classification, we embarked upon understanding activation functions and their role in Artificial Neural Net based classification. Theoretically, there is evidence of optima and therefore absence of local oscillations. This is significant and helps classification efficacy, for certain. In comparison to gradient boosted classification of exoplanets, Basak et al. [2018], Saha et al. [2018], our method achieved more accuracy, a near perfect classification. This is encouraging for future explorations into this activation function, including studying the applicability of Q-deformation and maximum entropy principles. Even without habitability classification or absence of any motivation, further study of the activation function seems promising.
Our focus has shifted from presenting and compiling the accuracy of various machine learning and data balancing methods to developing a system for classification that has practical applications and could be used in the real world. The accuracy scores that we have been able to accomplish show that with a reasonably high accuracy, the classification of the exoplanets is being done correctly. The performance of the proposed activation functions on pruned features is simply remarkable for two reasons. The first being, the pruned feature set does not contain features which account for hard markers. This makes the job hard since one would expect a rapid degradation in performance when the hard markers such as surface temperature and all its related features are removed from the feature set before classification. We note, when an exoplanet is discovered, surface temperature is one of the features Astrophysicists use to label it. If surface temperature can’t be measure, it is estimated. Even if the surface temperature can’t be measured, our activation functions make strong enough classifiers to predict labels of exoplanet samples, dispensing away the need for estimating it. This implies that whenever an exoplanet is newly discovered, their thermal habitability classes can be estimated using our approach. This significant information could be useful for other missions based on methods that would try following up the initial observation. Hence, samples that are interesting from a habitability point of view could gain some traction quite early.
Future work could focus on using adaptive learning rates [Yedida and Saha, 2019] by fixing Lipschitz loss functions. This may help us investigate if faster convergence is achieved helping us fulfill the larger goal of parsimonious computing.
Acknowledgement
Funding: This work was supported by the Science and Engineering Re- search Board (SERB)-Department of Science and Technology (DST), Gov- ernment of India (project reference number SERB-EMR/ 2016/005687). The funding source was not involved in the study design, writing of the report, or in the decision to submit this article for publication.
References
- Agrawal et al. [2018]
Agrawal, S., Basak, S., Saha, S., Bora, K., Murthy, J., 2018.
A comparative analysis of the cobb-douglas habitability score (cdhs) with the earth similarity index (esi).
- Bains and Schulze-Makuch [2016]
Bains, W., Schulze-Makuch, D., 2016.
The cosmic zoo: The (near) inevitability of the evolution of complex, macroscopic life.
Life 6, 25.
doi:10.3390/life6030025.
- Basak et al. [2018]
Basak, S., Agrawal, S., Saha, S., Theophilus, A.J., Bora, K., Deshpande, G., Murthy, J., 2018.
Habitability classification of exoplanets: A machine learning insight.
- Bora et al. [2016]
Bora, K., Saha, S., Agrawal, S., Safonova, M., Routh, S., Narasimhamurthy, A., 2016.
Cd-hpf: New habitability score via data analytic modeling.
Astronomy and Computing 17, 129 -- 143.
doi:10.1016/j.ascom.2016.08.001.
- Cortes and Vapnik [1995]
Cortes, C., Vapnik, V., 1995.
Support-vector networks.
Machine Learning 20, 273--297.
- Cybenko [1989]
Cybenko, G., 1989.
Approximation by superpositions of a sigmoidal function.
Mathematics of control, signals and systems 2, 303--314.
- Ginde et al. [2015]
Ginde, G., Saha, S., Balasubramaniam, C., Harsha, R., Mathur, A., Dayasagar, B., Anand, M., 2015.
Mining massive databases for computation of scholastic indices: Model and quantify internationality and influence diffusion of peer-reviewed journals, in: Proceedings of the fourth national conference of Institute of Scientometrics, SIoT.
- Ginde et al. [2016]
Ginde, G., Saha, S., Mathur, A., Venkatagiri, S., Vadakkepat, S., Narasimhamurthy, A., Daya Sagar, B.S., 2016.
Scientobase: a framework and model for computing scholastic indicators of non-local influence of journals via native data acquisition algorithms.
Scientometrics 108, 1479--1529.
doi:10.1007/s11192-016-2006-2.
- Irwin et al. [2014a]
Irwin, L., Méndez, A., Fairén, A., Schulze-Makuch, D., 2014a.
Assessing the possibility of biological complexity on other worlds, with an estimate of the occurrence of complex life in the milky way galaxy.
Challenges 5, 159--174.
- Irwin et al. [2014b]
Irwin, L.N., Méndez, A., Faiŕ, A.G., Schulze-Makuch, D., 2014b.
Assessing the possibility of biological complexity on other worlds, with an estimate of the occurrence of complex life in the milky way galaxy.
Challenges 5.
- Khaidem et al. [2016]
Khaidem, L., Saha, S., Basak, S., Dey, S.R., 2016.
Predicting the direction of stock market prices using random forest.
- Lippmann [1994]
Lippmann, R., 1994.
Book review: "neural networks, a comprehensive foundation", by simon haykin.
International Journal of Neural Systems 05, 363--364.
doi:10.1142/s0129065794000372.
- Méndez [2011]
Méndez, A., 2011.
The night sky of exoplanets URL: http://phl.upr.edu/library/notes/syntheticstars.
- Méndez [2018]
Méndez, A., 2018.
The habitable exoplanets catalog URL: http://phl.upr.edu/hec.
- Mohanchandra et al. [2015]
Mohanchandra, K., Saha, S., Murthy, K.S., Lingaraju, G., 2015.
Distinct adoption of k-nearest neighbour and support vector machine in classifying EEG signals of mental tasks.
International Journal of Intelligent Engineering Informatics 3, 313.
doi:10.1504/ijiei.2015.073064.
- Mullally et al. [2018]
Mullally, F., Thompson, S.E., Coughlin, J.L., Burke, C.J., Rowe, J.F., 2018.
Kepler’s earth-like planets should not be confirmed without independent detection: The case of kepler-452b arXiv:1803.11307.
- Narayanan et al. [2004]
Narayanan, A., Keedwell, E.C., Gamalielsson, J., Tatineni, S., 2004.
Single-layer artificial neural networks for gene expression analysis.
Neurocomputing 61, 217--240.
- Rhoades [1977]
Rhoades, B., 1977.
A comparison of various definition of contractive mappings.
Trans. Amer. Math. Soc. 226, 257--313.
- Saha et al. [2018]
Saha, S., Basak, S., Bora, K., Safonova, M., Agrawal, S., Sarkar, P., Murthy, J., 2018.
Theoretical validation of potential habitability via analytical and boosted tree methods: An optimistic study on recently discovered exoplanets.
Astronomy and Computing 23, 141--150.
- Saha et al. [2018a]
Saha, S., Bora, K., Basak, S., Srinivasa, G., Safonova, M., Murthy, J., Agrawal, S., 2018a.
Ebook-astroinformatics series machine learning in astronomy: A workman’s manual.
- Saha et al. [2018b]
Saha, S., Mathur, A., Bora, K., Agrawal, S., Basak, S., 2018b.
Sbaf: A new activation function for artificial neural net based habitability classification.
arXiv:10.13140/RG.2.2.21081.62565.
- Saha et al. [2016]
Saha, S., Sarkar, J., Dwivedi, A., Dwivedi, N., Narasimhamurthy, A.M., Roy, R., 2016.
A novel revenue optimization model to address the operation and maintenance cost of a data center.
Journal of Cloud Computing 5, 1--23.
doi:10.1186/s13677-015-0050-8.
- Saha et al. [2018c]
Saha, S., Sarkar, P., Mathur, A., Basak, S., 2018c.
Model visualization in understanding rapid growth of a journal in an emerging area.
- Schulze-Makuch and Bains [2018]
Schulze-Makuch, D., Bains, W., 2018.
Time to consider search strategies for complex life on exoplanets.
Nature Astronomy , 1--2doi:10.1038/s41550-018-0476-2.
- Schulze-Makuch et al. [2011]
Schulze-Makuch, D., Méndez, A., Fairén, A.G., von Paris, P., Turse, C., Boyer, G., Davila, A.F., de Sousa António, M.R., Catling, D., Irwin, L.N., 2011.
A two-tiered approach to assessing the habitability of exoplanets.
Astrobiology 11, 1041--1052.
- Shallue and Vanderburg [2018]
Shallue, C.J., Vanderburg, A., 2018.
Identifying exoplanets with deep learning: A five-planet resonant chain around kepler-80 and an eighth planet around kepler-90.
The Astronomical Journal 155, 94.
URL: http://stacks.iop.org/1538-3881/155/i=2/a=94.
- Vapnik and Chervonenkis [1964]
Vapnik, V.N., Chervonenkis, A.Y., 1964.
On a class of perceptrons.
Automation and Remote Control 1, 103--109.
- Xiao and Lu [2015]
Xiao, L., Lu, R., 2015.
Finite-time solution to nonlinear equation using recurrent neural dynamics with a specially-constructed activation function.
Neurocomputing 151, 246--251.
- Yedida and Saha [2019]
Yedida, R., Saha, S., 2019.
A novel adaptive learning rate scheduler for deep neural networks.
ArXiv e-prints arXiv:1902.07399.
- Zighed et al. [2010]
Zighed, D.A., Ritschard, G., Marcellin, S., 2010.
Asymmetric and Sample Size Sensitive Entropy Measures for Supervised Learning. Springer Berlin Heidelberg, Berlin, Heidelberg.
pp. 27--42.
doi:10.1007/978-3-642-05183-8_2.
11 Appendix
11.1 Neural Networks with SBAF and A-ReLU
A neural network is an interconnection of neurons arranged in hierarchy and predominantly used to perform predictions and classification on a dataset. Commonly, the input is given to the network over and over again to tune the network a little each time, so that when the new inputs are given, the network can predict its outcome. To explain how neural network works, we will run through a simple example of training a small network shown in figure below. Keeping its configuration simple, we have kept 2 nodes in input, hidden and output layer and have chosen SBAF and A-ReLU as activation functions to demonstrate the working of back propagation.
11.2 Basic Structure
Let us assume the nodes at input layer are , , at hidden layer , and at output layer , . To start off, we assign some initial random numbers to weights and biases and move on with a forward pass demonstrated in next subsection.
11.3 The Forward Pass using SBAF and A-ReLU
This section computes the activation of neurons at hidden and output layers by using SBAF and A-ReLU. We start with the first entry in the data set of two inputs and . The forward pass is a linear product of inputs and weights added with a bias. Calculating the total input at .
[TABLE]
[TABLE]
Use SBAF to calculate the activation’s of hidden neuron by the formula , .
[TABLE]
[TABLE]
In parallel, if we use A-ReLU to compute the activation’s of hidden neuron , the formula is if else , therefore
[TABLE]
[TABLE]
assuming and .
Repeat the process for neurons at output layer.
[TABLE]
[TABLE]
While using SBAF, the activation of neurons are
[TABLE]
[TABLE]
For A-ReLU, the activation are
[TABLE]
[TABLE]
assuming and .
Since we initialized the weights and biases randomly, the outputs at the neurons are off-target. Conclusively, we need to compute the difference and propagate it back to the network. The next subsection computes the error gradient by using back propagation and adjust the weights to improve the network. Calculating the errors,
[TABLE]
[TABLE]
[TABLE]
11.4 The Backward Pass for both SBAF and A-ReLU
This part deals with computing the error margins, the error resulted because the weights are randomly initialized. Therefore, the weights need adjustments so that the error can be decreased during predictions. Calculating the change of weights in done in two steps. The rate of change in error with respect to weights in computed in first step. In the second, the weights are updated by subtracting a portion of error gradient from weights. Similar to the forward pass, the backward pass is also computed layer-wise, but in the reverse mode.
11.4.1 At Output Layer
Moving backwards, lets consider weight that needs to be updated. To find the error gradient with respect to , i.e., we use the chain rule shown in the equation below. (Here is the total error at both neurons of output)
[TABLE]
Taking each component one at a time on the RHS of the equation, we first derive -
[TABLE]
Next we compute the derivative of the activation functions in terms of . We are using SBAF and A-ReLU, and dervatives of both the functions are available. First, while using SBAF -
[TABLE]
While using A-ReLU,
[TABLE]
Finally the third component of the chain rule (this is common for both SBAF and A-ReLU),
[TABLE]
The error gradient with respect to for SBAF is derivable by putting and and together in ,
[TABLE]
Likewise the other gradients are also computed as,
[TABLE]
[TABLE]
[TABLE]
Correspondingly, the error gradient with respect to for A-ReLU is derived by keeping (21)(23) and (24) together,
[TABLE]
Likewise the other gradients are also computed as,
[TABLE]
[TABLE]
[TABLE]
Both activation functions, the weights are adjusted as -
[TABLE]
where is the learning rate.
11.4.2 Hidden Layer
Continuing the backward pass, this part demonstrate the computation of error gradients with respect to weights that are connecting input and hidden layer. Once the gradients are found, the weights can be updated by the formula used previously. Thus, we need to derive and correspondingly the other gradients can be obtained.
We need to find .
Apparently, if is the total error at output layer, then
[TABLE]
Computing both the additive terms by using chain rule,
[TABLE]
[TABLE]
Finding the multiplicative terms of equation (Please note that this is with reference to SBAF. For A-ReLU, a similar procedure is followed.),
[TABLE]
Similarly, computing all the components of ,
[TABLE]
We already know the values of and . Similar calculations hold valid for computing gradient of A-ReLU.
Adding up everything,
[TABLE]
Adjusting the weight
[TABLE]
Likewise, the remaining error derivatives, , , , and can be computed in the similar manner for SBAF as well as for A-ReLU. Their corresponding weights are adjusted by using the same weight-update formula.
A Mind map of key ideas presented in the paper
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Agrawal et al. [2018] Agrawal, S., Basak, S., Saha, S., Bora, K., Murthy, J., 2018. A comparative analysis of the cobb-douglas habitability score (cdhs) with the earth similarity index (esi). ar Xiv:1804.11176 .
- 2Bains and Schulze-Makuch [2016] Bains, W., Schulze-Makuch, D., 2016. The cosmic zoo: The (near) inevitability of the evolution of complex, macroscopic life. Life 6, 25. doi: 10.3390/life 6030025 . · doi ↗
- 3Basak et al. [2018] Basak, S., Agrawal, S., Saha, S., Theophilus, A.J., Bora, K., Deshpande, G., Murthy, J., 2018. Habitability classification of exoplanets: A machine learning insight. ar Xiv:1805.08810 .
- 4Bora et al. [2016] Bora, K., Saha, S., Agrawal, S., Safonova, M., Routh, S., Narasimhamurthy, A., 2016. Cd-hpf: New habitability score via data analytic modeling. Astronomy and Computing 17, 129 -- 143. doi: 10.1016/j.ascom.2016.08.001 . · doi ↗
- 5Cortes and Vapnik [1995] Cortes, C., Vapnik, V., 1995. Support-vector networks. Machine Learning 20, 273--297. doi: 10.1023/A:1022627411411 . · doi ↗
- 6Cybenko [1989] Cybenko, G., 1989. Approximation by superpositions of a sigmoidal function. Mathematics of control, signals and systems 2, 303--314.
- 7Ginde et al. [2015] Ginde, G., Saha, S., Balasubramaniam, C., Harsha, R., Mathur, A., Dayasagar, B., Anand, M., 2015. Mining massive databases for computation of scholastic indices: Model and quantify internationality and influence diffusion of peer-reviewed journals, in: Proceedings of the fourth national conference of Institute of Scientometrics, S Io T.
- 8Ginde et al. [2016] Ginde, G., Saha, S., Mathur, A., Venkatagiri, S., Vadakkepat, S., Narasimhamurthy, A., Daya Sagar, B.S., 2016. Scientobase: a framework and model for computing scholastic indicators of non-local influence of journals via native data acquisition algorithms. Scientometrics 108, 1479--1529. doi: 10.1007/s 11192-016-2006-2 . · doi ↗
