Efficient, Lexicon-Free OCR using Deep Learning
Marcin Namysl, Iuliu Konya

TL;DR
This paper introduces a segmentation-free OCR system that leverages deep learning, synthetic data, and advanced augmentation to improve recognition of text in natural scenes with complex distortions and backgrounds.
Contribution
It presents a novel deep learning-based OCR approach that is segmentation-free and uses synthetic data generation with complex augmentation techniques.
Findings
Effective recognition of text in natural scenes.
Synthetic data and augmentation improve model robustness.
Deep learning models outperform traditional OCR methods.
Abstract
Contrary to popular belief, Optical Character Recognition (OCR) remains a challenging problem when text occurs in unconstrained environments, like natural scenes, due to geometrical distortions, complex backgrounds, and diverse fonts. In this paper, we present a segmentation-free OCR system that combines deep learning methods, synthetic training data generation, and data augmentation techniques. We render synthetic training data using large text corpora and over 2000 fonts. To simulate text occurring in complex natural scenes, we augment extracted samples with geometric distortions and with a proposed data augmentation technique - alpha-compositing with background textures. Our models employ a convolutional neural network encoder to extract features from text images. Inspired by the recent progress in neural machine translation and language modeling, we examine the capabilities of both…
Click any figure to enlarge with its caption.
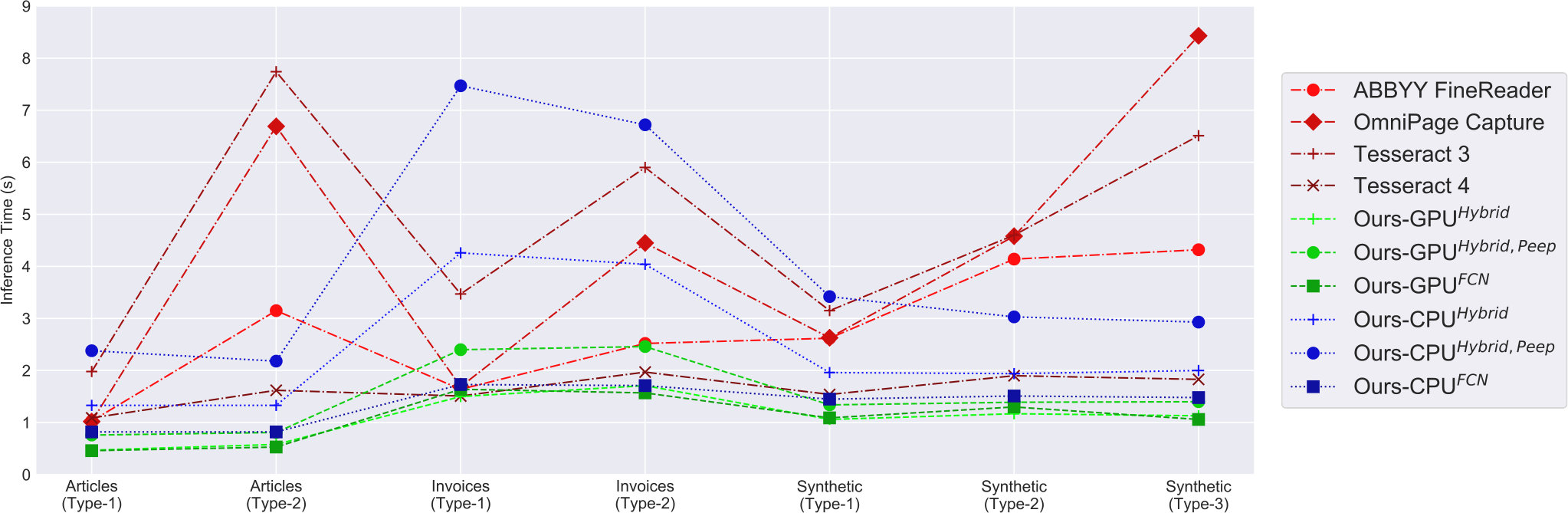 Figure 1
Figure 1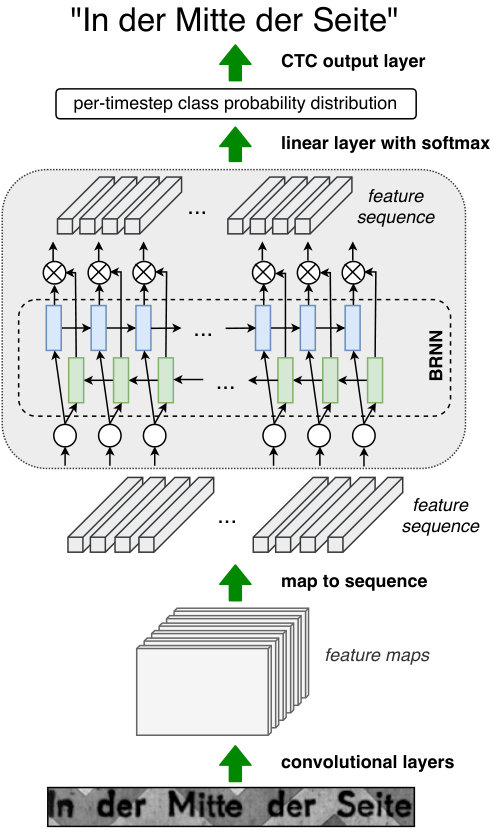 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9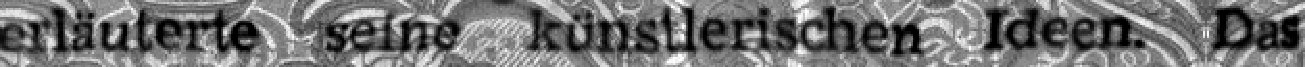 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14| Newspapers | Invoices | Synthetic documents | ||||
|---|---|---|---|---|---|---|
| Training | Test | Test | Training | Validation | Test | |
| Documents | ||||||
| Text lines | ||||||
| GT length | ||||||
| Operation | Output volume size |
|---|---|
| Conv2d (; stride: ) | |
| Max pooling (; stride: ) | |
| Conv2d (; stride: ) | |
| Max pooling (; stride: ) | |
| Map to sequence | |
| Dropout (50%) | — |
| Bidirectional RNN (units: ) | |
| Dropout (50%) | — |
| Linear mapping (units: num_classes) | |
| CTC output layer | output_sequence_length |
| Operation | Output volume size |
|---|---|
| Conv2d (; stride: ) | |
| Max pooling (; stride: ) | |
| Conv2d (; stride: ) | |
| Conv2d (, stride: ) | |
| Conv2d (, stride: ) | |
| Conv2d (, stride: ) | |
| Conv2d (, stride: ) | |
| Conv2d (, stride: ) | |
| Conv2d (, stride: ) | |
| Conv2d (, stride: ) | |
| Conv2d (, stride: ) | |
| Map to sequence | |
| Linear layer (units: num_classes) | |
| CTC output layer | output_sequence_length |
| Newspapers | Invoices | Synthetic documents | ||||
| Type-1 | Type-2 | Type-1 | Type-2 | Type-1 | Type-2 | Type-3 |
| Newspapers | Invoices | Synthetic | |||||
| Type-1 | Type-2 | Type-1 | Type-2 | Type-1 | Type-2 | Type-3 | |
| ABBYY FineReader | |||||||
| OmniPage Capture | |||||||
| Tesseract 3 | |||||||
| Tesseract 4 | |||||||
| OursFCN | |||||||
| OursHybrid | |||||||
| OursHybrid,nG | |||||||
| OursHybrid,Peep | |||||||
| OursHybrd,E | |||||||
| OursHybrid,nA | |||||||
| OursHybrid,S | |||||||
| OursHybrid,S,E | |||||||
| FCN denotes the fully convolutional model. | |||||||
| Hybrid denotes the hybrid model. | |||||||
| nG denotes that no geometric normalization was used. | |||||||
| Peep denotes the use of peephole LSTM units. | |||||||
| E denotes training with elastic distortions. | |||||||
| nA denotes training without alpha compositing with background textures. | |||||||
| S denotes training exclusively with synthetic data. | |||||||
| Error type | % |
|---|---|
| Insertion of ’ ’ | |
| Substitution ’l’’i’ | |
| Substitution ’.’’,’ | |
| Insertion of ’.’ | |
| Substitution ’i’’l’ | |
| Insertion of ’_’ | |
| Substitution ’I’’l’ | |
| Insertion of ’t’ | |
| Substitution ’o’’a’ | |
| Substitution ’f’’t’ |
| Error type | % |
|---|---|
| Insertion of ’ ’ | |
| Substitution ’l’’i’ | |
| Substitution ’.’’,’ | |
| Insertion of ’.’ | |
| Substitution ’i’’l’ | |
| Insertion of ’_’ | |
| Substitution ’I’’l’ | |
| Insertion of ’t’ | |
| Substitution ’o’’a’ | |
| Substitution ’f’’t’ |
| Error type | % |
|---|---|
| Insertion of ’ ’ | |
| Substitution ’0’’O’ | |
| Deletion of ’.’ | |
| Substitution ’O’’Ö’ | |
| Deletion of ’_’ | |
| Deletion of ’-’ | |
| Substitution ’I’’l’ | |
| Substitution ’.’’,’ | |
| Insertion of ’r’ | |
| Substitution ’©’’O’ |
| Error type | % |
|---|---|
| Insertion of ’ ’ | |
| Insertion of ’.’ | |
| Substitution ’,’’.’ | |
| Insertion of ’i’ | |
| Insertion of ’r’ | |
| Deletion of ’e’ | |
| Substitution ’c’’e’ | |
| Insertion of ’l’ | |
| Insertion of ’n | |
| Insertion of ’t’ |
| Error type | % |
|---|---|
| Insertion of ’ ’ | |
| Insertion of ’i’ | |
| Insertion of ’e’ | |
| Insertion of ’t’ | |
| Insertion of ’r’ | |
| Insertion of ’.’ | |
| Insertion of ’l’ | |
| Insertion of ’-’ | |
| Insertion of ’n’ | |
| Insertion of ’a’ |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Efficient, Lexicon-Free OCR using Deep Learning
Marcin Namysl
Fraunhofer IAIS
53757 Sankt Augustin, Germany
Iuliu Konya
Fraunhofer IAIS
53757 Sankt Augustin, Germany
Abstract
Contrary to popular belief, Optical Character Recognition (OCR) remains a challenging problem when text occurs in unconstrained environments, like natural scenes, due to geometrical distortions, complex backgrounds, and diverse fonts. In this paper, we present a segmentation-free OCR system that combines deep learning methods, synthetic training data generation, and data augmentation techniques. We render synthetic training data using large text corpora and over 2 000 fonts. To simulate text occurring in complex natural scenes, we augment extracted samples with geometric distortions and with a proposed data augmentation technique – alpha-compositing with background textures. Our models employ a convolutional neural network encoder to extract features from text images. Inspired by the recent progress in neural machine translation and language modeling, we examine the capabilities of both recurrent and convolutional neural networks in modeling the interactions between input elements. The proposed OCR system surpasses the accuracy of leading commercial and open-source engines on distorted text samples.
Index Terms:
OCR, CNN, LSTM, CTC, synthetic data
I Introduction
Optical character recognition (OCR) is one of the most widely studied problems in the field of pattern recognition and computer vision. It is not limited to printed but also handwritten documents [1], as well as natural scene text [2]. The accuracy of various OCR methods has recently greatly improved due to advances in deep learning [3, 4, 5]. Moreover, many current open-source and commercial products reach a high recognition accuracy and good throughput for run-of-the-mill printed document images. While this has lead the research community to regard OCR as a largely solved problem, we show that even the most successful and widespread OCR solutions are neither able to robustly handle large font varieties, nor distorted texts, potentially superimposed on complex backgrounds. Such unconstrained environments for digital documents have already become predominant, due to the wide availability of mobile phones and various specialized video recording devices.
In contrast to popular OCR engines, methods used in scene text recognition [6, 7] exploit computationally expensive network models, aiming to achieve the best possible recognition rates on popular benchmarks. Such methods are tuned to deal with significantly smaller amounts of text per image and are often constrained to predefined lexicons. Commonly used evaluation protocols substantially limit the diversity of symbols to be recognized, e.g., by ignoring all non-alphanumeric characters, or neglecting case sensitivity [8]. Hence, models designed for scene text are generally inadequate for printed document OCR, whereas high throughput and support for great varieties of symbols are essential.
In this paper, we address the general OCR problem and try to overcome the limitations of both printed- and scene text recognition systems. To this end, we present a fast and robust deep learning multi-font OCR engine, which currently recognizes different character classes. Our models are trained almost exclusively using synthetically generated documents. We employ segmentation-free text recognition methods that require a much lower data labeling effort, making the resulting framework more readily extensible for new languages and scripts. Subsequently we propose a novel data augmentation technique that improves the robustness of neural models for text recognition. Several large and challenging datasets, consisting of both real and synthetically rendered documents, are used to evaluate all OCR methods. The comparison with leading established commercial (ABBYY FineReader 111https://www.abbyy.com/en-eu/ocr-sdk/, OmniPage Capture 222https://www.nuance.com/print-capture-and-pdf-solutions/optical-character-recognition/omnipage/omnipage-for-developers.html) and open-source engines (Tesseract 3 [9], Tesseract 4 333https://github.com/tesseract-ocr/tesseract/wiki/4.0-with-LSTM) shows that the proposed solutions obtain significantly better recognition results with comparable execution time.
The remaining part of this paper is organized as follows: in Section II, we highlight related research papers, while in Section III, we describe the datasets used in our experiments, as well as the data augmentation routines. In Section IV, we present the detailed system architecture, which is then evaluated and compared against several state-of-the-art OCR engines in Section V. Our conclusions, alongside a few worthwhile avenues for further investigations, are the subject of the final Section VI.
II Related work
In this section, we review related approaches for printed-, handwritten- and scene text recognition. These can be broadly categorized into segmentation-based and segmentation-free methods.
Segmentation-based OCR methods recognize individual character hypotheses, explicitly or implicitly generated by a character segmentation method. The output is a recognition lattice containing various segmentation and recognition alternatives weighted by the classifier. The lattice is then decoded, e.g., via a greedy or beam search method and the decoding process may also make use of an external language model or allow the incorporation of certain (lexicon) constraints.
The PhotoOCR system for text extraction from smartphone imagery, proposed by Bissacco et al.[10], is a representative example of a segmentation-based OCR method. They used a deep neural network trained on extracted histogram of oriented gradient (HOG) features for character classification and incorporated a character-level language model into the score function.
The accuracy of segmentation-based methods heavily suffers from segmentation errors and the lack of context information wider than a single cropped character-candidate image during classification. Improper incorporation of an external language model or lexicon constraints can degrade accuracy[11]. While offering a high flexibility in the choice of segmenters, classifiers, and decoders, segmentation-based approaches require a similarly high effort in order to tune optimally for specific application scenarios. Moreover, the precise weighting of all involved hypotheses must be re-computed from scratch as soon as one component is updated (e.g., the language model), whereas the process of data labeling (e.g., at the character/pixel level) is usually a painstaking endeavor, with a high cost in terms of human annotation labor.
Segmentation-free OCR methods eliminate the need for pre-segmented inputs. Cropped words or entire text lines are usually geometrically normalized (III-B) and then can be directly recognized. Previous works on segmentation-free OCR [12] employed Hidden Markov Models (HMMs) to avoid the difficulties of segmentation-based techniques. Most of the recently developed segmentation-free solutions employ recurrent and convolutional neural networks.
Multi-directional, multi-dimensional recurrent neural networks (MDRNNs) currently enjoy a high popularity among researchers in the field of handwriting recognition [1] because of their ability to attain state-of-the-art recognition rates. They generalize standard Recurrent Neural Networks (RNNs) by providing recurrent connections along all spatio-temporal dimensions, making them robust to local distortions along any combination of the respective input dimensions. Bidirectional RNNs, consisting of two hidden layers that traverse the input sequence in opposite spatial directions (i.e., left-to-right and right-to-left), connected to a single output layer, were found to be well-suited for both handwriting[13] and printed text recognition[14]. In order to mitigate the vanishing/exploding gradient problem, most RNNs use Long Short-Term Memory (LSTM) units (or variants thereof) as building blocks. A noteworthy extension to the LSTM cells are the ”peephole” LSTM units[15], where the multiplicative gates compute their activations at the current time step using in addition the activation of the memory cell from the previous time step.
MDRNNs are computationally much more expensive than their basic 1-D variant, both during training and inference. Because of this, they have been less frequently explored in the field of printed document OCR. Instead, in order to overcome the issue of sensitivity to stroke variations along the vertical axis, researchers have proposed different solutions. For example, Breuel et al. [14] combined a standard 1-D LSTM network architecture with a text line normalization method for performing OCR of printed Latin and Fraktur scripts. In a similar manner, by normalizing the positions and baselines of letters, Yousefi et al. [16] achieved superior performance and faster convergence with a 1-D LSTM network over a 2-D variant for Arabic handwriting recognition.
An additional advantage of segmentation-free approaches is their inherent ability to work directly on grayscale or full-color images. This increases the robustness and accuracy of text recognition, as any information loss caused by a previously mandatory binarization step can be avoided. Asad et al. [17] applied the 1-D LSTM network directly to original, blurred document images and were able to obtain state-of-the-art recognition results.
The introduction of convolutional neural networks (CNNs) allowed for a further jump in the recognition rates. Since CNNs are able to extract latent representations of input images, thus increasing robustness to local distortions, they can be successfully employed as a substitute for MD-LSTM layers. Breuel et al. [18] proposed a model that combined CNNs and LSTMs for printed text recognition. Features extracted by CNNs were combined and fed into the LSTM network with a Connectionist Temporal Classification (CTC)[19] output layer. A few recent methods have completely forgone the use of the computationally expensive recurrent layers and rely purely on convolutional layers for modeling the local context. Borisyuk et al. [20] presented a scalable OCR system called Rosetta, which employs a fully convolutional network (FCN) model followed by the CTC layer in order to extract the text depicted on input images uploaded daily at Facebook.
In the current work, we build upon the previously mentioned techniques and propose an end-to-end segmentation-free OCR system. Our approach is purely data-driven and can be adapted with minimal manual effort to different languages and scripts. Feature extraction from text images is realized using convolutional layers. Using the extracted features, we analyze the ability to model local context with both recurrent and fully convolutional sequence-to-sequence architectures. The alignment of the extracted features with ground-truth transcripts is realized via a CTC layer. To the best of our knowledge, this is the first work that compares fully convolutional and recurrent models in the context of OCR.
III Datasets and data preparation
To train and evaluate our OCR system we prepared several datasets, consisting of both real and synthetic documents. This section describes each in detail, as well as the preparation of training, validation, and test samples, data augmentation techniques, and the geometric normalization procedure.
We collected pages of scanned historical and recent German-language newspapers as well as contemporary German invoices. All documents were deskewed and pre-processed via document layout analysis algorithms, providing us with the geometrical and logical document structure, including bounding boxes, baseline positions, and x-height values for each text line. The initial transcriptions obtained using the Tesseract [9] OCR engine were manually corrected.
Even without the need for the character- or word-level ground truth, the manual annotation process proved to be error-prone and time-consuming. Motivated by the work of Jaderberg et al. [21], we developed an automatic synthetic data generation process. Two large text corpora, namely the English and German Wikipedia dump files444https://dumps.wikimedia.org/, were used as training sources for generating sentences. For validation and test purposes, we used a corpus from the Leipzig Corpora Collection[22]. The texts were rendered using a set of over serif, sans serif, and monospace fonts555https://fonts.google.com/.
The generation process first selects a piece of text (up to characters) from the corpus and renders it on an image with a randomly chosen font. The associated attributes (i.e., bounding boxes, baseline positions, and x-height values) used for rendering are stored in the corresponding document layout structure. A counter for the number of occurrences of every individual character in the generated dataset is maintained and used to guide the text extraction mechanism to choose text pieces containing the less frequently represented symbols. Upon generating enough text line samples to fill an image of pre-specified dimensions (e.g., pixels), the image is saved on disk together with the associated layout information. The procedure described above is repeated until the number of occurrences of each symbol reaches a required minimum level (, and in our synthetic training, validation, and test set, respectively), which guarantees that even rare characters are sufficiently well represented in each of the generated datasets, or until all text files have been processed. By using sentences from real corpora we ensure that the sampled character and n-gram distribution is the same as that of natural language texts.
A summary of our data sources is presented in TABLE I. We train and recognize 132 different character classes, including basic lower and upper case Latin letters, whitespace character, German umlauts, ligature ß, digits, punctuation marks, subscripts, superscripts, as well as mathematical, currency and other commonly used symbols. The training data consists of about million characters, of which were synthetically generated.
The batches containing the final training and validation samples are generated on the fly, as in the following. Text line images are randomly selected from the corresponding (training or validation) dataset and the associated layout information is used to normalize each sample. Note that the normalization step is optional (see also III-B), since especially in the case of scene text it may be too computationally expensive and error-prone to extract exact baselines and x-heights at inference time. All samples are re-scaled to a fixed height of pixels, while maintaining the aspect ratio. This particular choice for the sample height was determined experimentally. Larger sample heights did not improve recognition accuracy for skew-free text lines. However, if the targeted use case involves the recognition of relatively long, free-form text lines, the use of taller samples is warranted. Since text lines lengths vary greatly, the corresponding images must be (zero) padded appropriately to fit the widest element within the batch. We minimize the amount of padding by composing batches from text lines having similar widths. Subsequently, random data augmentation methods are dynamically applied to each sample (III-A).
III-A Data augmentation
We apply standard data augmentation methods, like Gaussian smoothing, perspective distortions, morphological filtering, downscaling, additive noise, and elastic distortions[23] during training and validation. Additionally, we propose a novel augmentation technique — alpha compositing[24] with background texture images. Each time a specific sample is presented to the network, it is alpha-composited with a randomly selected background texture image (Figure 1). By randomly altering backgrounds of training samples, the network is guided to focus on significant text features and learns to ignore background noise. The techniques mentioned above are applied dynamically both to training and validation samples. In contrast to the approach proposed by Jaderberg et al. [21], we render undistorted synthetic documents once, and then apply random data augmentations dynamically. This allows us to efficiently generate samples and eliminates the significant overhead caused by disk I/O operations.
III-B Geometric normalization
Breuel et al. [18] recommended that text line images should be geometrically normalized prior to recognition. We trained models with and without such normalization in order to verify this assumption. The normalization step is performed per text line, before feature extraction. During training, we use the saved text line attributes, whereas at inference time, the layout analysis algorithm provides the baseline position and the x-height values for each line. Using the baseline information, the skew of the text lines is corrected. The scale of each image is normalized, so that the distance between the baseline and the x-height line, as well as the heights of ascenders and descenders, are approximately constant.
For the unnormalized case, the normalization procedure is skipped entirely and each cropped text line sample is further passed on to the feature extractor. This case is especially relevant for scene text images, where normalization information is usually unavailable and expensive to compute separately.
IV System architecture
The architecture of our hybrid CNN-LSTM model is depicted in Figure 2 and is inspired by the CRNN [2] and Rosetta [20] systems. The bottom part consists of convolutional layers that extract high-level features of an image. Activation maps obtained by the last convolutional layer are transformed into a feature sequence with the map to sequence operation. Specifically, 3D maps are sliced along their width dimension into 2D maps and then each map is flattened into a vector. The resulting feature sequence is fed to a bidirectional recurrent neural network with hidden units in both directions. The output sequences from both layers are concatenated and fed to a linear layer with softmax activation function to produce per-timestep probability distribution over the set of available classes. The CTC output layer is employed to compute a loss between the network outputs and the ground truth transcriptions. During inference, CTC loss computation is replaced by greedy CTC decoding. TABLE II presents a detailed structure of our recurrent model.
In case of our fully convolutional model, feature sequences transformed by the map to sequence operation (see the previous paragraph) are directly fed to a linear layer, skipping the recurrent components entirely. TABLE III presents the detailed structure of our fully convolutional model.
All models were trained via minibatch stochastic gradient descent using the Adaptive Moment Estimation (Adam) optimization method[25]. The learning rate is decayed by a factor of every iterations and has an initial value of for the recurrent- and for the fully convolutional model. Batch normalization[3] is applied after every convolutional block to speed up the training. The hybrid models were trained for approximately epochs and the fully convolutional models for about epochs.
The Python interface of the Tensorflow [26] framework was used for training all models. The inference timings were done via Tensorflow’s C++ interface.
V Evaluation and discussion
We compare performance of our system with two established commercial OCR products: ABBYY FineReader 12 and OmniPage Capture SDK 20.2 and with a popular open-source OCR library – Tesseract versions 3 and 4. The latest Tesseract engine uses deep learning models similar to ours. Recognition is performed at the text line level. The ground truth layout structure is used to crop samples from document images.
Since it was shown that LSTMs learn an implicit language model[27], we evaluate our system without external language models or lexicons, although their use can likely further increase accuracy. By contrast, both examined commercial engines use language models and lexicons for English and German, and their settings have been chosen for best recognition accuracy. We use the fast integer Tesseract 4 models666https://github.com/tesseract-ocr/tessdata_fast because they demonstrate a comparable running time to the other examined methods.
Our data sources are summarized in TABLE I. We conduct experiments on the test documents with (Type-2, Type-3) and without (Type-1) additional distortions (III-A) applied prior to decoding. We explore two different scenarios for the degradations. In the first scenario, only geometrical transformations, morphological operations, blur, noise addition and downscaling are considered (Type-2). This scenario corresponds to the typical case of printed document scans of varying quality. In the second scenario, all extracted text line images are additionally alpha-composited with a random background texture (Type-3). Different texture sets are used for training and testing. Additionally, we randomly invert the image gray values. This scenario best corresponds to scene text recognition. Note that since the distortions are applied randomly, some images obtained by this procedure may end up nearly illegible, even for human readers.
We aggregate results from multiple experiments (every text line image is randomly distorted times) and report the average error values. TABLE IV summarizes our test datasets. We evaluate all methods on original and distorted text lines, containing and characters, respectively.
TABLE V compares error rates of all examined OCR engines. We use the Levenshtein edit distance metric[28] to measure the character error rate (CER). All of our models, unless otherwise stated, are fine-tuned with real data, use geometric text line normalization, and data augmentation methods (III-A) except elastic distortions. The results show that our system outperforms all other methods in terms of recognition accuracy in all scenarios. A substantial difference can be primarily observed on distorted documents alpha-composited with background textures, where Tesseract and both commercial engines exhibit a very poor recognition performance. Noisy backgrounds hinder their ability to perform an adequate character segmentation. Although Tesseract 4 was trained on augmented synthetic data, we observe that it cannot properly deal with significantly distorted inputs. The established solutions have problems recognizing subscript and superscript symbols. Both commercial engines have great difficulties in handling fonts with different, alternating styles located on the same page.
TABLE VI gives an insight into the most frequent errors (insertions, deletions, and substitutions) made by the best performing proposed and commercial methods on real versus synthetic data. All tested methods have the most difficulties in recognizing the exact number of whitespace characters due to non-uniform letter and word spacing (kerning, justified text) across documents. This problem is particularly visible on the manually corrected real documents, where a certain degree of ambiguity due to human judgment becomes apparent. The remaining errors for the hybrid models look reasonable and seem to be primarily focused on small or thin characters, which are indeed the ones most affected by distortions and background patterns. In contrast, ABBYY FineReader exhibits a clear tendency to insert spurious characters, especially for highly textured and distorted images.
Figure 3 presents the runtime comparison. Both commercial engines and Tesseract 3 work slowly for significantly distorted images. Apparently, they make use of certain computationally expensive image restoration techniques in order to be able to handle low-quality inputs. Unsurprisingly, the GPU-accelerated models are fastest across the board. We discuss the runtime on CPU in V-A. All experiments were conducted on a workstation equipped with an Nvidia GeForce GTX 745 graphics card and an Intel Core i7-6700 CPU.
V-A Ablation study
In this section, we analyze the impact of different model components on the recognition performance of our system.
V-A1 Fully convolutional vs. recurrent model
The fully convolutional model achieves a slightly lower accuracy than the best recurrent variant. However, its inference time is significantly lower on the CPU. This clearly shows that convolutional layers are much more amenable to parallelization than recurrent units.
V-A2 Peephole connections
The model that uses peephole LSTM cells and pools feature maps along the width dimension only once, exhibits a better recognition accuracy in the scene text scenario. This is not the case for typical document scans, where the peepholes do not seem to bring any additional accuracy gains compared to the vanilla LSTM model. The use of peephole connections does, however, add a significant runtime overhead in all cases.
V-A3 Alpha compositing with background textures (III-A)
We train one model without alpha compositing with background textures. The model exhibits significantly higher error rates, not only on samples with complicated backgrounds but also on those with significant distortions. This confirms our assumption that this augmentation technique has generally a positive effect on the robustness of neural OCR models.
V-A4 Geometric normalization (III-B)
The model using no geometric normalization exhibits a drop in accuracy especially for images showing stronger distortions. This indicates that geometric normalization is indeed beneficial, but not indispensable. Apparently, max pooling and strided convolution operations provide enough translational invariance.
V-A5 Training only on synthetic data
We train two models exclusively on synthetic training data. It obtains very competitive results, which indicates that using such a model together with proper data augmentation is sufficient for achieving a satisfactory recognition accuracy.
V-A6 Elastic distortions
We found that non-linear distortions can further reduce the error rate of models, particularly those trained exclusively on synthetic data. Hence, this augmentation method is beneficial, especially in cases where annotated real data is not available or simply too difficult to produce. We also observe that although most of our models were trained without elastic distortions applied to training data, they can nonetheless deal with test data augmented with non-linear distortions. We attribute this to the fact that we used a substantial amount of fonts to generate our synthetic training data, achieving an adequate variation of text styles.
VI Conclusions and future work
In this paper, we described our general and efficient OCR solution. Experiments under different scenarios, on both real and synthetically-generated data, showed that both proposed architectures outperform leading commercial and open-source engines. In particular, we demonstrated an outstanding recognition accuracy on severely degraded inputs.
The architecture of our system is universal, and can be used to recognize printed, handwritten or scene text. The training of models for other languages is straightforward. Via the proposed pipeline, deep neural network models can be trained using only text line-level annotations. This saves a considerable manual annotation effort, previously required for producing the character- or word level ground truth segmentations and the corresponding transcriptions.
A novel data augmentation technique, alpha compositing with background textures, is introduced and evaluated with respect to its effects on the overall recognition robustness. Our experiments showed that synthetic data is indeed a viable and scalable alternative to real data, provided that sufficiently diverse samples are generated by the data augmentation modules. The effect of different structural choices and data augmentation on recognition accuracy and inference time is experimentally investigated. Hybrid recognition architectures proved to be more accurate, but also considerably more computationally costly than purely convolutional approaches.
The importance of a solid data generation pipeline cannot be overstated. As such, future work will involve its continuous improvement and comparison with other notable efforts from the research community, e.g., [21]. We also plan to make the synthetic data used in our experiments publicly available. We feel that fully-convolutional approaches, in particular, offer great potential for future improvement. The incorporation of recent advances, such as residual connections [4] and squeeze-and-excitation blocks [5] into our general OCR architecture seems to be a promising direction.
Acknowledgment
This work was supported by the German Federal Ministry of Education and Research (BMBF) funded program KMU-innovativ in the project DeepER.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] A. Graves and J. Schmidhuber, “Offline handwriting recognition with multidimensional recurrent neural networks,” in Proceedings of the 21st International Conference on Neural Information Processing Systems , ser. NIPS’08. USA: Curran Associates Inc., 2008, pp. 545–552.
- 2[2] B. Shi, X. Bai, and C. Yao, “An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition,” IEEE Transactions on Pattern Analysis and Machine Intelligence , vol. 39, no. 11, pp. 2298–2304, Nov. 2017.
- 3[3] S. Ioffe and C. Szegedy, “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” ar Xiv preprint ar Xiv:1502.03167 , 2015.
- 4[4] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition (CVPR) , Jun. 2016, pp. 770–778.
- 5[5] J. Hu, L. Shen, and G. Sun, “Squeeze-and-excitation networks,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition (CVPR) , 2018, pp. 7132–7141.
- 6[6] P. Lyu, M. Liao, C. Yao, W. Wu, and X. Bai, “Mask textspotter: An end-to-end trainable neural network for spotting text with arbitrary shapes,” in Proc. European Conference on Computer Vision (ECCV) , September 2018.
- 7[7] M. Busta, L. Neumann, and J. Matas, “Deep textspotter: An end-to-end trainable scene text localization and recognition framework,” in Proc. IEEE International Conference on Computer Vision (ICCV) , 2017, pp. 2223–2231.
- 8[8] K. Wang, B. Babenko, and S. Belongie, “End-to-end scene text recognition,” in Proc. Int. Conf. Computer Vision , Nov. 2011, pp. 1457–1464.