Grounded Human-Object Interaction Hotspots from Video (Extended Abstract)
Tushar Nagarajan, Christoph Feichtenhofer, Kristen Grauman

TL;DR
This paper introduces a weakly supervised method to learn human-object interaction hotspots directly from video data, enabling the prediction of object manipulation points without extensive supervision, and generalizing to new object categories.
Contribution
It presents a novel approach that learns interaction hotspots from videos, reducing supervision needs and improving generalization to unseen objects.
Findings
Hotspot predictions are competitive with fully supervised methods.
The approach generalizes to novel object categories.
Grounded hotspots improve anticipation of object interactions.
Abstract
Learning how to interact with objects is an important step towards embodied visual intelligence, but existing techniques suffer from heavy supervision or sensing requirements. We propose an approach to learn human-object interaction "hotspots" directly from video. Rather than treat affordances as a manually supervised semantic segmentation task, our approach learns about interactions by watching videos of real human behavior and anticipating afforded actions. Given a novel image or video, our model infers a spatial hotspot map indicating how an object would be manipulated in a potential interaction, even if the object is currently at rest. Through results with both first and third person video, we show the value of grounding affordances in real human-object interactions. Not only are our weakly supervised hotspots competitive with strongly supervised affordance methods, but they can…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1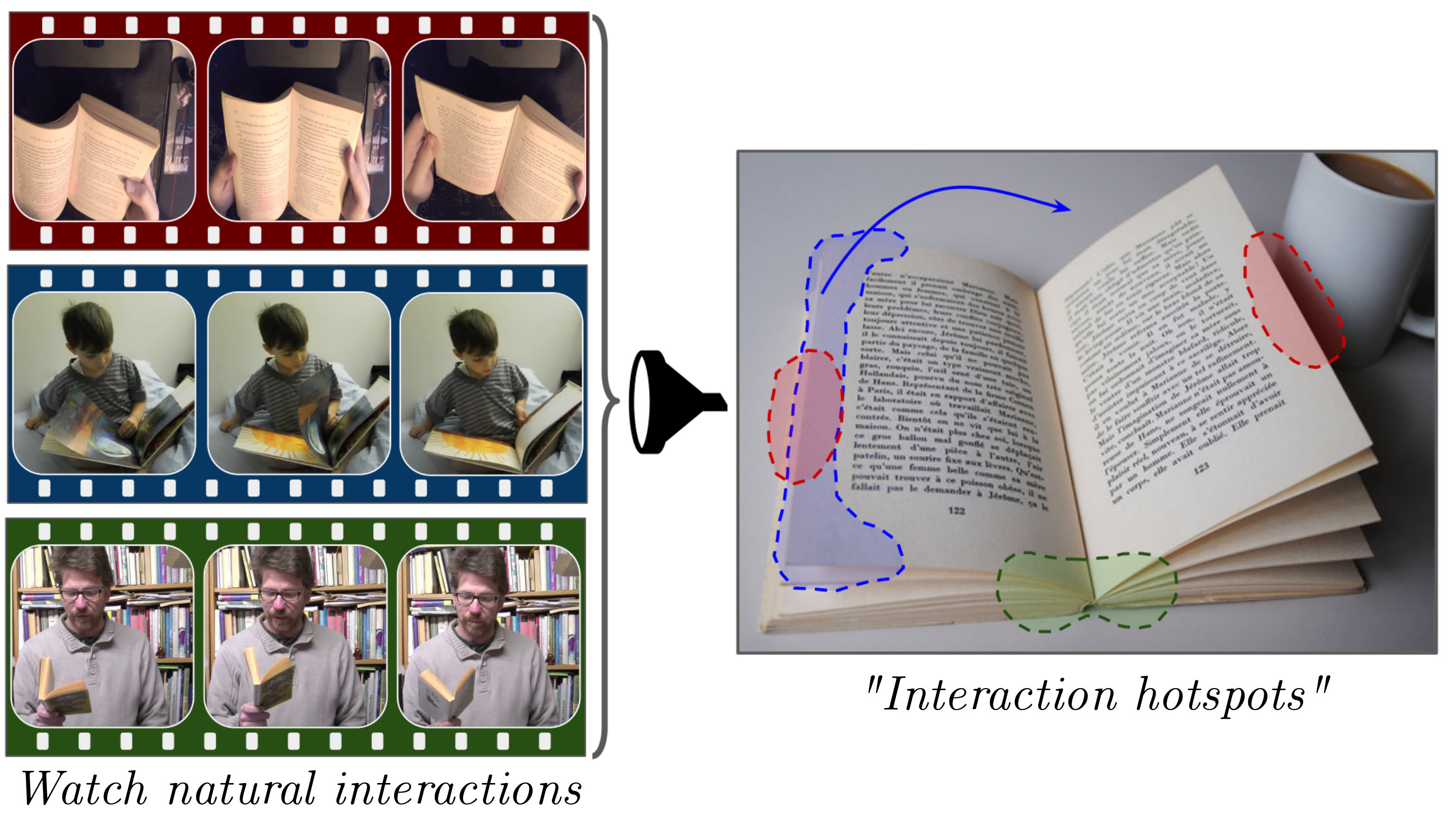 Figure 2
Figure 2 Figure 3
Figure 3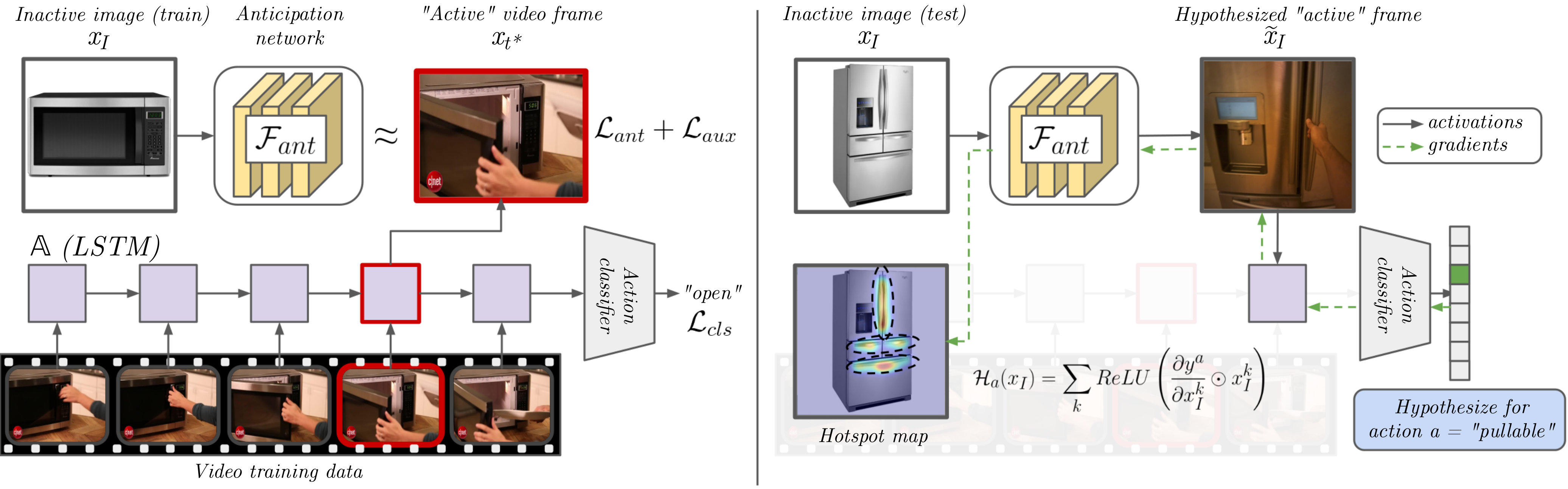 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6| OPRA | EPIC | OPRA | EPIC | |||||||||||
| KLD | SIM | AUC-J | KLD | SIM | AUC-J | KLD | SIM | AUC-J | KLD | SIM | AUC-J | |||
| center bias | 11.132 | 0.205 | 0.625 | 10.660 | 0.222 | 0.634 | 6.281 | 0.244 | 0.680 | 5.910 | 0.277 | 0.699 | ||
|
\ldelim[61mm[
WS |
lstm+grad-cam | 8.573 | 0.209 | 0.620 | 6.470 | 0.257 | 0.626 | 5.405 | 0.259 | 0.644 | 4.508 | 0.255 | 0.664 | |
| egogaze [13] | 2.428 | 0.245 | 0.646 | 2.241 | 0.273 | 0.614 | 2.083 | 0.278 | 0.694 | 1.974 | 0.298 | 0.673 | ||
| mlnet [3] | 4.022 | 0.284 | 0.763 | 6.116 | 0.318 | 0.746 | 2.458 | 0.316 | 0.778 | 3.221 | 0.361 | 0.799 | ||
| deepgazeII [15] | 1.897 | 0.296 | 0.720 | 1.352 | 0.394 | 0.751 | 1.757 | 0.318 | 0.742 | 1.297 | 0.400 | 0.793 | ||
| salgan [19] | 2.116 | 0.309 | 0.769 | 1.508 | 0.395 | 0.774 | 1.698 | 0.337 | 0.790 | 1.296 | 0.406 | 0.808 | ||
| ours | 1.427 | 0.362 | 0.806 | 1.258 | 0.404 | 0.785 | 1.381 | 0.374 | 0.826 | 1.249 | 0.405 | 0.817 | ||
|
\ldelim[21mm[
SS |
img2heatmap | 1.473 | 0.355 | 0.821 | 1.400 | 0.359 | 0.794 | 1.431 | 0.362 | 0.820 | 1.466 | 0.353 | 0.770 | |
| demo2vec [6] | 1.197 | 0.482 | 0.847 | – | – | – | – | – | – | – | – | – | ||
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMultimodal Machine Learning Applications · Human Pose and Action Recognition · Domain Adaptation and Few-Shot Learning
Grounded Human-Object Interaction Hotspots from Video
(Extended Abstract)
Tushar Nagarajan
UT Austin
[email protected] Work done during internship at Facebook AI Research.
Christoph Feichtenhofer
Facebook AI Research
Kristen Grauman
Facebook AI Research
[email protected] On leave from UT Austin ([email protected]).
Abstract
Learning how to interact with objects is an important step towards embodied visual intelligence, but existing techniques suffer from heavy supervision or sensing requirements. We propose an approach to learn human-object interaction “hotspots” directly from video. Rather than treat affordances as a manually supervised semantic segmentation task, our approach learns about interactions by watching videos of real human behavior and anticipating afforded actions. Given a novel image or video, our model infers a spatial hotspot map indicating how an object would be manipulated in a potential interaction—even if the object is currently at rest. Through results with both first and third person video, we show the value of grounding affordances in real human-object interactions. Not only are our weakly supervised hotspots competitive with strongly supervised affordance methods, but they can also anticipate object interaction for novel object categories. Project page: http://vision.cs.utexas.edu/projects/interaction-hotspots/
1 Introduction
Today’s visual recognition systems know how objects look, but not how they work. Understanding how objects function is fundamental to moving beyond passive perceptual systems (e.g., those trained for image recognition) to active, embodied agents that are capable of both perceiving and interacting with their environment—whether to clear debris in a search and rescue operation, cook a meal in the kitchen, or even engage in a social event with people. Gibson’s theory of affordances [7] provides a way to reason about object function. It suggests that objects have “action possibilities” (e.g., a chair affords sitting, a broom affords cleaning), and has been studied extensively in computer vision and robotics in the context of action, scene, and object understanding [9].
However, the abstract notion of “what actions are possible?” is only half the story. For example, for an agent tasked with sweeping the floor with a broom, knowing that the broom handle affords holding and the broom affords sweeping is not enough. The agent also needs to know how to interact with different objects, including the best way to grasp the object, the specific points on the object that need to be manipulated for a successful interaction, how the object is used to achieve a goal, and even what it suggests about how to interact with other objects.
Learning how to interact with objects is challenging. Traditional methods face two key limitations. First, methods that consider affordances as properties of an object’s shape or appearance [16, 8, 11] fall short of modeling actual object use and manipulation. In particular, learning to segment specified object parts [17, 22, 16, 18] can capture annotators’ expectations of what is important, but is detached from real interactions, which are dynamic, multi-modal, and may only partially overlap with part regions (see Figure 1). Secondly, existing methods are limited by their heavy supervision and/or sensor requirements. They assume access to training images with manually drawn masks or keypoints [21, 5, 6] and some leverage additional sensors like depth [14, 24, 25] or force gloves [2], all of which restrict scalability. Such bottlenecks also deter generalization: exemplars are often captured in artificial lab tabletop environments [16, 14, 22] and labeling cost naturally restricts the scope to a narrow set of objects.
In light of these issues, we propose to learn affordances that are grounded in real human behavior directly from videos of people naturally interacting with objects, and without any keypoint or mask supervision. Specifically, we introduce an approach to infer an object’s interaction hotspots—the spatial regions most relevant to human-object interactions. Interaction hotspots link inactive objects at rest not only to the actions they afford, but also to how they afford them. By learning hotspots directly from video, we sidestep issues stemming from manual annotations, avoid imposing part labels detached from real interactions, and discover exactly how people interact with objects in the wild.
Our approach works as follows. First, we use videos of people performing everyday activities to learn an action recognition model that can recognize the array of afforded actions when they are actively in progress in novel videos. Then, we introduce an anticipation model to distill the information from the video model, such that it can estimate how a static image of an inactive object transforms during an interaction. In this way, we learn to anticipate the plausible interactions for an object at rest (e.g., perceiving “cuttable” on the carrot, despite no hand or knife being in view). Finally, we propose an activation mapping technique tailored for fine-grained object interactions to derive interaction hotspots from the anticipation model. Thus, given a new image, we can hypothesize interaction hotspots for an object, even if it is not being actively manipulated.
We validate our model on two diverse video datasets: OPRA [6] and EPIC-Kitchens [4], spanning hundreds of object and action categories, with videos from both first and third person viewpoints. Our results show that with just weak action and object labels for training video clips, our interaction hotspots can predict object affordances more accurately than prior weakly supervised approaches, with relative improvements up to 25%. Furthermore, we show that our hotspot maps can anticipate object function for novel object classes that are never seen during training.
2 Approach
Our goal is to learn “interaction hotspots”: characteristic object regions that anticipate and explain human-object interactions, directly from video (see Figure 1). In particular, our approach learns to predict afforded actions across a span of objects, then translates the video cues to static images of an object at rest. In this way, without explicit region labels and without direct estimation of physical contact points, we learn to anticipate object use.
Learning Afforded Actions from Video. For a video with frames and afforded action class , we encode each frame using a ResNet [10] (up to conv5) resulting in features . These features are then spatially pooled and aggregated over time as follows:
[TABLE]
where denotes the L2-pooling operator and is an LSTM [12]. The afforded action is then predicted from the aggregated representation using a linear classifier trained with cross entropy . Once trained, this model can predict which action classes are observed in a video clip of arbitrary length. See Figure 2 (left) for the architecture.
Anticipation for Inactive Object Affordances. This video recognition model alone would focus on “active” cues directly related to the action being performed (e.g., hands approaching an object), but would not respond strongly to inactive instances—static images of objects that are at rest and not being interacted with. In fact, prior work demonstrates that these two incarnations are visually quite different [20].
To account for this, we introduce a distillation-based anticipation module that transforms the embedding of an inactive object , where no interaction is occurring, into its active state where it is being interacted with as . See Figure 2, top-left.
During training, the anticipation module is guided by the video action classifier, which selects the appropriate active state from a given video as the frame at which the LSTM is maximally confident of the true action. We then define a feature matching loss between (a) the anticipated active state for the inactive object and (b) the active state selected by the classifier network for the training sequence.
[TABLE]
Additionally, we make sure that the newly anticipated representation is predictive of the afforded action and compatible with our video classifier, using an auxiliary classification loss from a single step of the LSTM .
Overall, these components allow our model to estimate what a static inactive object may potentially look like—in feature space—if it were to be interacted with. They provide a crucial link between classic action recognition and affordance learning.
Interaction Hotspot Activation Mapping. Finally, we devise an activation mapping approach through to discover our hotspot maps. For a particular inactive image embedding and an action , we compute the gradient of the score for the action class with respect to each channel of the embedding. These gradients are used to weight individual spatial activations in each channel, acting as an attention mask over them. The positive components of the resulting tensor are retained and accumulated over all channels in the input embedding to give the final hotspot map for the action:
[TABLE]
where is the channel of the input frame embedding and is the element-wise multiplication operator.
We further enhance our hotspots by using dilated, unit stride convolutions in the last two residual stages, increasing our heatmap resolution () to capture finer details.
In summary, we jointly train our action recognition model and our anticipation model using the combined loss to learn features that can anticipate object use in a video (Figure 2, left). Once trained, we generate hotspots, on an inactive test image (Figure 2, right), by hypothesizing its active interaction embedding , and use it to predict the afforded action scores. Using Equation 4 we generate one heatmap over for each afforded action. This stack of heatmaps are the interaction hotspots.
3 Experiments
We evaluate our model on two datasets—OPRA [6], a product review dataset that comes with videos of people demonstrating product functionalities (e.g., pressing a button on a coffee machine), along with a paired catalog image of the product. The dataset spans 7 actions over 16k training instances; EPIC-Kitchens [4], a large scale egocentric video dataset of people performing daily activities in a kitchen environment. There are 40k training videos, spanning 352 objects and 125 actions.
Each dataset comes with a set of static, inactive images, labeled with heatmaps for where the interaction takes place, which we use for evaluation.111We crowd-source annotations for heatmaps on static images from EPIC, resulting in 1.8k annotated instances over 20 action and 31 objects We stress that (1) the annotated heatmap is used only for evaluation, and (2) the ground truth is well-aligned with our objective, since annotators were instructed to watch an interaction video clip to decide what regions to annotate for an object’s affordances.
We compare our method to several baselines and existing methods: (1) Center Bias: to account for any center bias in our data; (2) LSTM+Grad-CAM: Grad-CAM [23] derived heatmaps from a standard LSTM action recognition model; (3) Saliency: A set of recent, off-the-shelf models to estimate image saliency including egogaze [13], mlnet [3], deepgazeII [15] and salgan [19]; (4) Demo2Vec [6]: a supervised method trained using heatmaps and videos; (5) Img2Heatmap: a simplified supervised model that does not use videos. We report error as KL-Divergence, following [6], as well as other metrics (SIM, AUC-J) from the saliency literature [1].
Grounded Affordance Prediction. Table 1 (Left) summarizes the results. Our model outperforms all other weakly-supervised methods in all metrics across both datasets. On OPRA, our model achieves relative improvements of up to 25% (KLD) compared to the strongest baseline, and matches one of the strongly supervised baseline methods on two metrics. On EPIC, our model achieves relative improvements up to 7% (KLD).
The baselines have similar trends across datasets. The LSTM+Grad-CAM baseline in Table 1 demonstrates that simply training an action recognition model is clearly insufficient to learn affordances.
All saliency methods perform worse than our model— they produce a single “importance” heatmap, which cannot explain objects with multiple affordances. This can be seen in our qualitative results (Figure 3). Our model highlights multiple distinct affordances for an object (e.g., the knobs on the coffee machine as “rotatable” in column 1) after only watching videos of object interactions, while Saliency methods highlight all salient object parts in a single map, regardless of the interaction in question. img2heatmap and demo2vec generate better heatmaps, but at the cost of strong supervision. Our method approaches their accuracy without using any manual heatmaps for training.
Generalization to Novel Objects. Can interaction hotspots infer how novel object categories work? We divide our object categories into disjoints sets of familiar and unfamiliar objects, and only train on video clips with familiar objects. We test if our model can successfully infer heatmaps for novel, unfamiliar objects, implying that a general sense of object function is learned that is not strongly tied to object identity. Table 1 (Right) shows mostly similar trends as the previous section. On OPRA, our model outperforms all baselines in all metrics, and is able to infer the hotspot maps for unfamiliar object categories, despite never seeing them during training. On EPIC, our method remains the best weakly supervised method. Figure 4 illustrates that our model—which was never trained on some objects (e.g., cupboard, squash)—is able to anticipate characteristic spatial locations of interactions even before the interaction occurs.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Z. Bylinskii, T. Judd, A. Oliva, A. Torralba, and F. Durand. What do different evaluation metrics tell us about saliency models? TPAMI , 2018.
- 2[2] C. Castellini, T. Tommasi, N. Noceti, F. Odone, and B. Caputo. Using object affordances to improve object recognition. TAMD , 2011.
- 3[3] M. Cornia, L. Baraldi, G. Serra, and R. Cucchiara. A Deep Multi-Level Network for Saliency Prediction. In ICPR , 2016.
- 4[4] D. Damen, H. Doughty, G. M. Farinella, S. Fidler, A. Furnari, E. Kazakos, D. Moltisanti, J. Munro, T. Perrett, W. Price, et al. Scaling egocentric vision: The epic-kitchens dataset. ECCV , 2018.
- 5[5] T.-T. Do, A. Nguyen, I. Reid, D. G. Caldwell, and N. G. Tsagarakis. Affordancenet: An end-to-end deep learning approach for object affordance detection. ICRA , 2017.
- 6[6] K. Fang, T.-L. Wu, D. Yang, S. Savarese, and J. J. Lim. Demo 2vec: Reasoning object affordances from online videos. In CVPR , 2018.
- 7[7] J. J. Gibson. The ecological approach to visual perception: classic edition . Psychology Press, 1979.
- 8[8] H. Grabner, J. Gall, and L. Van Gool. What makes a chair a chair? In CVPR , 2011.